Hugging Face’s story began in 2016 in New York, when a group of passionate machine learning enthusiasts – Clément Delangue, Julien Chaumond, and Thomas Wolf, set out to create a platform that would empower developers and users to build and deploy advanced AI models with ease. From its inception, the company had a clear and ambitious vision: to make AI more accessible, friendly, and collaborative, breaking down the barriers that often separate advanced technology from everyday users.
✓ Instant access✓ No spam✓ Unsubscribe anytime
Table of Contents
- Transformers library
- Datasets library
- Model Hub
- Flexible model selection and customization for personalized conversations
- What is an endpoint?
- HuggingChat models
- Additional key features
- Inference API
- Spaces
- MediAI
- Case study: Improving patient outcomes
- Feedback from the AI community
- How does Hugging Face plan to stay ahead in the AI landscape?
- What is BLOOM?
- Bias and fairness
- Privacy and Security
- Transparency and explainability
- Malicious code-execution models
- Safetensors conversion service vulnerability
- Response and mitigation
Although Hugging Face initially started as a chatbot application, it soon shifted to providing a platform and tools for machine learning development, particularly in natural language processing (NLP).
One of Hugging Face’s defining characteristics is its commitment to the open-source community. In a field that often faces criticism for its proprietary nature, Hugging Face has made their programming, models, and tools available to everyone for free. This approach has built a strong community of developers who share their skills, exchange ideas, and work together on new projects.
Their innovations range from developing the Transformers library to a Datasets library up to a collaborative Model Hub. Each of these components advances AI research and application, rendering AI more available and usable across sectors.
Transformers library
The Hugging Face Transformers library, launched in 2018, has become a foundation of the NLP community, providing access to thousands of pre-trained models for NLP, computer vision, audio tasks, and more. This open-source Python library hosts a wide array of models that can tackle diverse NLP tasks such as text classification, translation, summarization, and more. All these models serve the needs of the global tech community and provide solutions for all types of text-related work.

Python code example of how to use the library to perform a common NLP task. Surce: Huggin Face
Technically, Transformers leverage a self-attention mechanism, which allows models to focus on different parts of a sentence with varying degrees of importance, which is crucial for tasks like machine translation and question answering. For instance, in machine translation, understanding the context of each word within the sentence improves accuracy. In question answering, self-attention helps the model determine which parts of the context are relevant to the question.
The library is designed to easily integrate with the standard and most popular deep learning frameworks, such as TensorFlow and PyTorch. This adds further reach and flexibility to the library, enabling developers and researchers to very quickly implement new models into their projects. Parallel tasks of the transformer architecture, based on self-attention mechanisms for the input data of pre-trained models in the library, speed up and increase efficiency during the training and execution of models.
The Transformers library opened up access to powerful NLP tools, allowing developers and researchers with varying levels of expertise to easily tailor models for specific tasks. This has led to significant improvements in areas such as customer service chatbots, language translation, and sentiment analysis.
Real-world examples show the transformative impact of the Transformers library. Google Search, for instance, employs the BERT model to better understand user queries and deliver more relevant search results. In healthcare, BioBERT, a specialized variant of BERT trained on biomedical literature, aids in extracting crucial information from medical records and research papers, accelerating scientific discovery and potentially improving patient care.
Datasets library
Moreover, the Hugging Face Datasets library complements the Transformers library by providing a robust suite of ready-to-use datasets, which are essential for training, testing, and benchmarking machine learning models. It supports diverse data types, including text in various languages, images, and audio, and offers efficient data loading and preprocessing tools like tokenization, feature extraction, and audio format conversions.
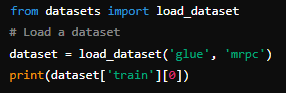
Example of how to load and preprocess datasets. Source: Hugging Face
This library simplifies access to diverse datasets and streamline the usually difficult process of preparing data. For example, the Datasets library allows researchers to load the popular GLUE dataset with a few lines of code, enabling quick and efficient access to data. This simplification accelerates the workflow by providing pre-processing tools like tokenization and feature extraction.
Model Hub
Get Free Access to 40,000+ AI Prompts
Join 40,000+ AI professionals. Get instant access to our curated Notion Prompt Library with prompts for ChatGPT, Claude, Codex, Gemini, and more — completely free.
Get Free Access Now →No spam. Instant access. Unsubscribe anytime.
Perhaps, one of the most innovative offerings from Hugging Face is the Model Hub, creating a collaboration space for AI development. It hosts thousands of models, sharing, discovering, and using machine learning models by researchers and developers.

Code example of how to download and use a model from the Model Hub. Source: Hugging Face
With many contributions, from academia and industry, the site covers hundreds of languages and various machine-learning tasks. For example, a developer working on a new language model can easily access and build upon pre-existing models shared by others, saving time and resources.
HuggingChat GUI
The HuggingChat Graphical User Interface (GUI) is built to be simple and easy for everyone to use. Its clean and intuitive interface allows users to interact with AI models without the need for coding knowledge, making advanced AI technologies accessible to a broader audience.

HuggingChat GUI. Source: Hugging Face
By leveraging JavaScript, HTML5, and CSS3, the GUI boasts a responsive design that adapts effortlessly to different screen sizes and resolutions, guaranteeing optimal usability on both desktop computers and mobile devices.
Flexible model selection and customization for personalized conversations
One of the key features of the HuggingChat GUI is the ability to easily switch between different pre-trained models. Users have the option of selecting a model from the available list for a straightforward chat experience. Simply start typing in the chat window, and the chosen model will respond in real time. Each pre-trained model comes with its unique strengths and personality, allowing users to find the perfect AI conversationalist for their needs.
Furthermore, for those who want more control and customization, HuggingChat allows you to combine multiple models to create a more personalized experience. This involves configuring an endpoint, which is essentially a set of instructions for how different models should be used together.
What is an endpoint?
In essence, an endpoint is a server-side configuration that defines how different models should be used together in a sequence to process user input and generate responses. It acts as a central hub for coordinating the interaction between multiple models, enabling complex workflows and tailored conversations.
Here’s a simplified explanation of how to configure an endpoint:
- Choose your models – Select the models you want to use from the HuggingChat library. You might choose one model for generating responses, another for summarizing text, and a third for handling specific tasks.
- Define the pipeline – Decide how you want the models to interact. For example, you might want one model to generate an initial response, another to refine it, and a third to add a touch of humor.
- Set the parameters – Adjust various parameters to fine-tune the behavior of each model. This includes things like temperature (which controls randomness) and top-p sampling (which influences the variety of responses).
- Save and test – Save your endpoint configuration and test it in the chat interface. You can experiment with different combinations of models and parameters to find the perfect setup for your needs.
By combining models, you can create chatbots that are more versatile and capable than any single model could be on its own.
HuggingChat models
Notable models that HuggingChat supports are Meta’s Llama 2 and Google’s Flan-T5.
Llama 2, a language model trained on a massive dataset of text and code, excels at generating creative dialogues, engaging in role-playing scenarios, and even composing poetry or song lyrics. Its training on diverse datasets, including text and code, enables it to understand and incorporate context effectively, making it suitable for applications that require a high creativity and expertise in the context.
Google’s Flan-T5, on the other hand, is a versatile model known for its impressive knowledge base and ability to answer complex questions with accuracy and clarity. It can summarize lengthy articles, explain scientific concepts, or even generate code snippets. This model is perfect for users seeking a chatbot that can provide informative and reliable responses.
Beyond these, HuggingChat supports a multitude of other models, each specializing in distinct areas. This extensive model range enables users to select the most suitable model for their specific needs and applications. Developers can explore various options to identify the model that best matches their desired chatbot behavior and functionality.
Additional key features
Inference API
The Hugging Face Inference API provides a scalable way to use pre-trained models for a variety of tasks such as text generation, classification, and translation. This API simplifies the integration of machine learning models into applications, enabling developers to focus on building features rather than managing infrastructure.
Spaces
Hugging Face Spaces offers a platform for users to create and share machine learning demos. Spaces supports various frameworks, including Gradio and Streamlit, allowing developers to showcase their models and create interactive experiences for the community.
User stories and testimonials
One notable application of Hugging Face’s technology is in the healthcare sector. A startup used the Transformers library to develop a tool for automating the analysis of medical literature, significantly reducing the time required for researchers to stay updated on the latest studies.
One notable application of Hugging Face’s technology is in the healthcare sector. A startup called MediAI used the Transformers library to develop a tool for automating the analysis of medical literature, reducing the time required for researchers to stay updated on the latest studies.
Traditionally, researchers and healthcare professionals spend countless hours sifting through vast amounts of medical journals, studies, and articles to stay informed about the latest advancements and research findings.
MediAI
MediAI’s tool uses pre-trained models from the Hugging Face Transformers library to automate and streamline this process. By using NLP capabilities, the tool can:
- Automatically categorize articles into relevant medical fields, such as cardiology, neurology, or oncology, making it easier for researchers to find pertinent information quickly.
- Generate concise summaries of lengthy articles, allowing researchers to understand the key points without reading through entire documents.
- Identify and extract specific entities such as drug names, medical conditions, and treatment methods from the text, enabling detailed analysis.
- Evaluate the tone and feelings in articles to figure out the overall opinion on new treatments or medical discoveries.
Case study: Improving patient outcomes
Another impactful story comes from a large hospital network that integrated Hugging Face’s NLP models into their electronic health records (EHR) system. By employing these models, the hospital was able to:
- Automate the process of entering patient information, freeing up valuable time for doctors and nurses to focus on patient care.
- Use historical patient data to predict potential health issues and recommend preventative measures. For example, the model can identify patients at high risk of developing certain conditions based on their medical history and recommend early interventions.
- Provide doctors with real-time insights and recommendations during patient consultations, enhancing decision-making and improving patient outcomes.
Feedback from the AI community
Developers and researchers have also praised Hugging Face for its open-source model and collaborative environment. One AI developer at a leading tech company shared their experience:
“The Hugging Face community and tools have been instrumental in accelerating our NLP projects. The Transformers library, in particular, has allowed us to implement sophisticated models with ease, enabling us to deliver high-quality solutions to our clients faster than ever before.“
Hugging Face vs. ChatGPT
When comparing Hugging Face with another prominent platform, ChatGPT, it’s essential to consider their approaches to security and transparency:
- ChatGPT is built on OpenAI’s GPT-3.5 structure, while Hugging Face offers a range of LLMs, including models trained on more recent data.
- Hugging Face allows direct access to its platform and models without requiring account creation, making it more accessible to casual users. ChatGPT, on the other hand, requires user authentication, which can impact privacy expectations and user anonymity.
- ChatGPT’s source code remains closed-source, while Hugging Face embraces open-source principles, allowing users to access, modify, and contribute to model improvements.
- Hugging Face models are trained on more recent data, reflecting the latest linguistic trends and knowledge. ChatGPT, being restricted to older data, may face limitations in certain contexts that require up-to-date information.
- Hugging Face offers enhanced customization options, allowing users to fine-tune models for specific use cases. ChatGPT, being a closed-source platform, offers limited customization, impacting its adaptability to niche requirements.
- Hugging Face fosters a vibrant and collaborative community through its Hub, encouraging knowledge sharing.

Comparison table made with ChatGPT. Souce: ChatGPT
“ChatGPT feels more like a finished product, while Hugging Face is more like a toolkit. With ChatGPT, you get a seamless, polished experience, whereas Hugging Face gives you the freedom to build and customize, which is great for developers.” – AI Developer at a Gaming Studio
How does Hugging Face plan to stay ahead in the AI landscape?
Hugging Face continues to innovate by investing in research and development. They are committed to advancing the capabilities of their Transformers library and expanding their model offerings to include the latest architectures.
To the question: “How are you fighting your competition?” HuggingChat answered:
“Hugging Face is fighting AI competition by providing an open-source hosting platform for natural language processing (NLP) and other machine learning domains, making cutting-edge AI technologies accessible to everyone. Large language models are typically developed by large tech companies due to the high costs and processing power required. Hugging Face aims to empower small developers, scientists, and startups to compete with tech giants by providing $10 million in computing resources. Additionally, they have released their own pre-trained large language model, BLOOM, which has a similar architecture to OpenAI’s GPT-3, further enhancing competition in the AI space.”
By maintaining a strong focus on community engagement and collaboration, Hugging Face ensures they are at the forefront of AI advancements.
What is BLOOM?
BLOOM (BigScience Large Open-science Open-access Multilingual Language Model) is a large-scale language model developed by the BigScience research workshop and hosted by Hugging Face.
It stands out as one of the largest models ever built, with an impressive 176 billion parameters. This capacity allows BLOOM to process and generate text with more fluency and coherence.
A key feature of BLOOM is its multilingual capability. It is trained on a comprehensive dataset comprising 46 natural languages and 13 programming languages, enabling it to understand and produce text across different linguistic contexts.
Unlike many large language models created by major corporations, BLOOM is completely open-source. This openness means that anyone can access its code, architecture, and pre-trained weights for free.
Cybersecurity and ethical AI considerations at Hugging Face
As AI continues to integrate into various aspects of our lives, the importance of cybersecurity and ethical considerations in AI development cannot be overstated. Hugging Face recognizes these challenges and has implemented several measures to safeguard user data and maintain the integrity of its systems.
Bias and fairness
Hugging Face is committed to reducing bias in its AI models and datasets. They understand that AI can sometimes unintentionally reinforce existing societal biases. To prevent this, the company uses a variety of data and measures fairness to make sure outcomes are fair for everyone.
Hugging Face also provides tools and advice to help developers make AI models that are fair and unbiased. These efforts are designed to promote ethical AI practices and reduce discrimination, building trust and inclusion in AI applications.
Privacy and Security
To safeguard sensitive information, the company employs advanced encryption techniques, anonymization processes, and stringent security protocols. They regularly check their systems to strengthen them against potential attacks and support the principle of responsible disclosure to quickly fix any security weaknesses they find.
Transparency and explainability
The company provides comprehensive documentation, detailed model cards, and tools that explain how their AI models work, what kind of data was used to train them, and what their limitations are. This level of transparency is important because it helps users make well-informed decisions, actively consider ethical issues, and quickly find and fix any weaknesses in the models.
Addressing vulnerabilities and cybersecurity challenges
Despite its contributions to the AI community, Hugging Face has faced notable security challenges in recent years. Two major incidents in 2023 and 2024 highlighted the risks associated with open-source platforms and AI model deployment.
Malicious code-execution models
In late 2023, researchers uncovered approximately 100 machine learning models on the Hugging Face platform containing malicious code. These models were designed to exploit vulnerabilities, allowing attackers to execute arbitrary code on user machines. While some payloads were just examples to show what could be done, others were more harmful and raised serious concerns about possible misuse.
Breach details
In addition to the malicious models, a separate breach in late 2023 exposed over 1,600 valid API tokens on Hugging Face and GitHub. These tokens provided unauthorized access to numerous organizational accounts, including those of major companies like Meta, Microsoft, Google, and VMware. The exposed tokens, some with write permissions, represented a severe security threat by potentially allowing attackers to manipulate or steal AI models and sensitive data.
Safetensors conversion service vulnerability
In early 2024, a vulnerability was discovered in Hugging Face’s Safetensors conversion service. This service, which allows users to convert models between different formats, was found to be exposed to supply chain attacks. Attackers could exploit this flaw to inject malicious code into models during the conversion process, compromising their integrity and potentially affecting downstream applications.
Breach details
The vulnerability in the Safetensors conversion service allowed attackers to send malicious requests, manipulate model data, and possibly take control of the service’s container, putting the security of converted models at risk. This event showed the importance of strong security measures during all stages of AI model handling, from conversion to deployment.
Response and mitigation
Hugging Face’s commitment to open-source collaboration and community-driven development is evident in its approach to handling vulnerabilities. When malicious code-execution models and a vulnerability in the Safetensors conversion service were discovered in 2023 and 2024, respectively, Hugging Face responded swiftly and transparently.
In the case of the malicious models, Hugging Face acted promptly to remove the harmful content and revoke any exposed API tokens. A thorough security audit was conducted to identify and address any underlying vulnerabilities in the token management system. Additionally, stricter model vetting processes, improved anomaly detection mechanisms, and regular security assessments were implemented to prevent future issues.
The vulnerability in the Safetensors conversion service was similarly addressed promptly with a patch that closed the potential for supply chain attacks. Hugging Face also took a proactive approach by launching a security awareness campaign to educate users about best practices and partnering with external security experts to identify and address potential vulnerabilities.
Building trust and a secure future for AI conversations
Hugging Face’s transparent and proactive approach to addressing the security breaches garnered widespread commendation from both the AI community and the broader industry. The company’s willingness to openly acknowledge and communicate the details of the incidents, along with providing clear guidance on mitigating potential risks, served to build trust with its users and stakeholders.
This clear communication allowed for a quick reaction to the problems caused by the breaches. It also showed how important it is for the community to work together to handle cybersecurity issues in AI. The event proved that working together is key to keeping AI systems safe and secure. Hugging Face strongly supports teamwork by helping with community events like hackathons, webinars, and various group projects.
Looking ahead, Hugging Face is committed to further strengthening its platform and services. The company plans to enhance its Inference API and Spaces platform, providing more robust tools and resources for developers. Additionally, Hugging Face aims to further improve model transparency and explainability, making AI even more accessible and trustworthy.
🚀 Ready to Supercharge Your ChatGPT Skills?
Join 25,000+ professionals and get FREE access to our complete library of 40,000+ ChatGPT prompts across 41+ categories.
Access 40,000+ AI Prompts for ChatGPT, Claude & Codex — Free!
Subscribe to get instant access to our complete Notion Prompt Library — the largest curated collection of prompts for ChatGPT, Claude, OpenAI Codex, and other leading AI models. Optimized for real-world workflows across coding, research, content creation, and business.
🕐 Instant∞ Unlimited🎁 Free