ChatGPT Dreaming V3 Memory: How OpenAI’s New Background Memory Architecture Changes Enterprise AI Personalization
ChatGPT Dreaming V3 Memory: How OpenAI’s New Background Memory Architecture Changes Enterprise AI Personalization
By the ChatGPT AI Hub Editorial Team — Published June 2026
On June 4, 2026, OpenAI quietly shipped one of the most consequential architectural updates to ChatGPT since the introduction of GPT-4: a background memory system internally designated Dreaming V3. Unlike its predecessors, which stored discrete, retrievable facts about users in a structured knowledge base, Dreaming V3 synthesizes continuous behavioral signals across conversations into a unified, evolving user profile. The result is an AI that doesn’t just remember what you told it — it understands who you are, how you think, and what you’re likely to need before you ask. For enterprise teams deploying ChatGPT at scale, this architectural shift is not merely a feature update. It is a fundamental rethinking of what persistent AI memory means, and what governance, privacy, and customization obligations come with it.
This deep dive examines Dreaming V3’s architecture from the ground up: how it replaces discrete fact storage with continuous profile synthesis, how the system processes conversational signals in the background, what the enterprise API surface looks like, and what compliance and privacy teams must address before the new memory layer becomes a liability rather than an asset.
The Problem With Discrete Memory: Why OpenAI Rebuilt the Architecture
To appreciate the scope of what Dreaming V3 accomplishes, it helps to understand the limitations it was designed to overcome. ChatGPT’s original memory system, introduced in early 2024 and iterated through several versions, operated on a fundamentally transactional model. When the system identified a “memorable” piece of information — a user’s job title, a dietary preference, a recurring project name — it stored that fact as an explicit, human-readable record in a memory bank. Users could view, edit, and delete these records. Developers could query them via the API. The design was transparent by intent.
But transparency came at the cost of depth. Discrete fact storage is structurally incapable of capturing the richest signal in conversational data: behavioral patterns, cognitive preferences, communication style, the implicit logic behind repeated decisions. If a user consistently restructured every response the model gave them into bulleted hierarchies, the old system couldn’t infer “this person thinks in structured lists.” It could only store a fact if the user explicitly stated one, or if the model identified a sufficiently unambiguous declarative statement to log. Implicit behavioral intelligence — the kind human collaborators accumulate over months of working together — was simply inaccessible to the architecture.
OpenAI’s internal research teams documented this gap extensively. According to the technical notes accompanying the Dreaming V3 release, user satisfaction scores for “felt personalization” plateaued after approximately 30 conversations under the discrete memory model, regardless of how many facts were stored. Users reported that ChatGPT “remembers things I said but doesn’t actually know me” — a distinction that maps directly onto the difference between episodic fact retrieval and genuine behavioral modeling. Dreaming V3 was designed to close that gap.
The Cognitive Analogy Behind the Dreaming Name
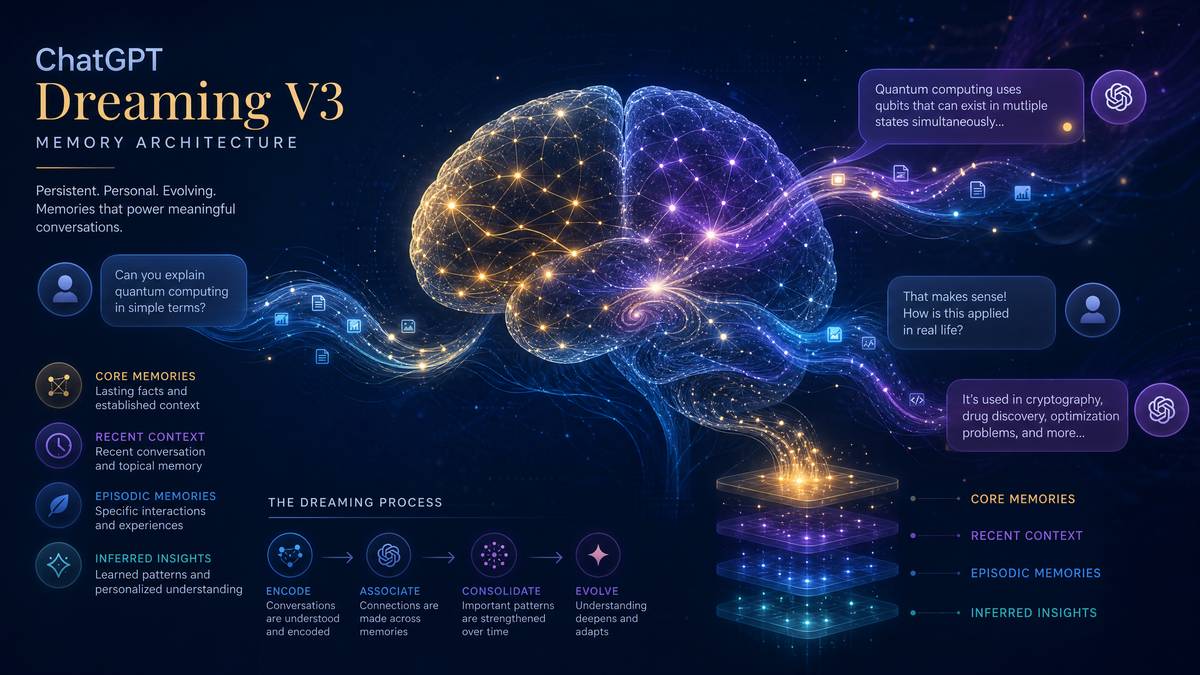
The “Dreaming” nomenclature is deliberate and technically meaningful. OpenAI’s documentation draws an explicit parallel to the neuroscientific theory of memory consolidation during sleep, specifically the role of rapid eye movement sleep in synthesizing episodic memories into semantic knowledge. During REM sleep, the brain doesn’t simply replay recorded events — it extracts patterns, discards noise, and encodes behavioral and emotional regularities into long-term schemas. Dreaming V3 performs an analogous function computationally: after each conversation concludes (and at scheduled intervals during long sessions), a background synthesis process ingests the raw conversational transcript, identifies behavioral signals, and updates the user’s profile representation in a high-dimensional embedding space rather than a discrete record store.
The V3 designation indicates this is the third generation of background synthesis architecture. V1, which never reached general availability, was a proof-of-concept that ran offline batch synthesis on anonymized aggregate data. V2 entered limited enterprise preview in late 2025 and introduced per-user synthesis but operated on a 24-hour delay. Dreaming V3 achieves near-real-time synthesis, with profile updates propagating within minutes of a conversation’s conclusion under normal infrastructure load.
Inside the Architecture: How Dreaming V3 Synthesizes User Profiles
The Dreaming V3 architecture operates across three distinct processing layers, each serving a specific function in the transformation from raw conversational data to actionable behavioral intelligence.
Layer One: Signal Extraction
The first layer runs during active conversations as a lightweight parallel process. Signal extraction does not generate user-visible outputs or alter the model’s responses in real time — it operates as a passive observer, tagging conversational turns with behavioral metadata. The system extracts signals across several dimensions:
- Communication style preferences: Formal versus informal register, preferred response length, tolerance for hedging and uncertainty language, use of technical jargon
- Cognitive scaffolding patterns: Whether the user prefers to see reasoning before conclusions or conclusions before reasoning, preference for examples versus abstract principles, comfort with ambiguity
- Task domain fingerprints: Recurring subject areas, tool ecosystems referenced, professional vocabulary clusters
- Feedback signals: Explicit corrections, regeneration requests, follow-up questions that indicate the prior response missed the mark, and positive engagement patterns like extended follow-on questions
- Temporal patterns: Session timing, conversation pacing, typical session depth
Signal extraction uses a dedicated lightweight model, distinct from the primary GPT-4o or o3 model handling the user’s actual requests. This separation is architecturally important for two reasons: it prevents the extraction task from consuming context window capacity or compute that would degrade response quality, and it creates a clean audit boundary between the response-generation system and the memory-synthesis system.
Layer Two: Profile Synthesis
After a conversation concludes, the accumulated signal tags are passed to the synthesis layer, which is where the “dreaming” computation actually occurs. The synthesis model receives the full signal log from the session alongside a compressed representation of the user’s existing profile vector. Its task is to produce an updated profile vector that integrates new behavioral evidence with historical patterns.
Critically, this process is not additive in the way discrete memory storage was. Older signals are not simply retained alongside newer ones — they are weighted, reconciled, and in some cases superseded. If a user who consistently preferred short responses suddenly spends three sessions requesting extended analysis, the synthesis model updates the communication preference dimension accordingly, rather than maintaining a contradictory historical record. This decay-and-update mechanism is mathematically analogous to an exponential moving average applied to behavioral dimensions, though the actual implementation uses a learned weighting function rather than a fixed decay constant.
The profile representation itself is stored as a dense vector in a high-dimensional embedding space, with dimensionality reported at 4,096 in OpenAI’s technical preview documentation. This is deliberately not interpretable as a list of human-readable facts. There is no field labeled “prefers bullet points: true.” Instead, behavioral tendencies are encoded in the geometry of the vector space, where similarity relationships between users with analogous preferences are preserved as proximity in embedding space.
Layer Three: Retrieval and Conditioning
At the start of each new conversation, the retrieval layer fetches the user’s current profile vector and uses it to condition the model’s initial context. This conditioning happens at the system-prompt level, but the mechanism is more sophisticated than simply prepending a text summary. Dreaming V3 uses a learned projection that maps the profile vector into a set of soft prompt tokens injected into the model’s context, influencing response generation without consuming visible context window tokens from the user’s perspective.
The conditioning is calibrated to be subtle in low-stakes contexts and more pronounced in contexts where behavioral alignment matters more. If a user asks a simple factual question, the conditioning has minimal effect. If the user is working through a complex multi-step problem where cognitive scaffolding preferences and communication style both matter significantly, the conditioning exerts stronger influence on how the model structures its response.
What Changes for End Users: The Experience Delta
For individual users, the most immediately perceptible change is that ChatGPT begins to feel adaptive in ways that transcend explicit instruction. Users who have historically needed to preface conversations with style instructions — “be concise,” “show your reasoning,” “use examples from software engineering” — find that those instructions become unnecessary over time. The system has internalized them as behavioral priors.
OpenAI’s public beta testing data, released alongside the Dreaming V3 announcement, reported a 34% reduction in explicit style correction requests after 10 sessions under Dreaming V3 compared to the previous memory architecture. Users also reported a 28% improvement in “response usefulness on first generation” scores, meaning fewer regeneration requests were needed. These are significant quality-of-life improvements for power users, but they take on considerably more strategic significance in enterprise deployment contexts.
The Personalization Depth Spectrum
Dreaming V3 introduces a concept OpenAI calls the personalization depth spectrum, which describes the degree to which behavioral conditioning influences responses across different task types. The spectrum has four bands:
| Depth Band | Trigger Context | Profile Influence Level | Example |
|---|---|---|---|
| Ambient | Simple factual or lookup queries | Minimal (<5% weight) | “What is the capital of France?” |
| Adaptive | Explanatory or instructional content | Moderate (20-40% weight) | “Explain how transformer attention works” |
| Contextual | Complex analysis, strategy, creative work | High (40-70% weight) | “Help me think through this architectural trade-off” |
| Immersive | Ongoing project work, extended sessions | Dominant (70%+ weight) | Multi-session coding project with established patterns |
Enterprise administrators have the ability to cap the maximum depth band permitted within their deployment, which is one of several governance controls explored in detail later in this article. An organization that needs strict, predictable response consistency for compliance reasons — a financial services firm generating client-facing reports, for instance — may choose to restrict all users to the Ambient band, effectively disabling behavioral conditioning while retaining discrete fact memory.
Dreaming V3 Versus Previous Memory Architectures: A Technical Comparison
Understanding how Dreaming V3 differs from its predecessors requires examining several key architectural dimensions side by side. The following comparison covers the three generations of ChatGPT memory available to enterprise customers.
| Dimension | Memory V1 (2024) | Memory V2 (2025) | Dreaming V3 (2026) |
|---|---|---|---|
| Storage Model | Discrete key-value facts | Discrete facts + basic behavior tags | High-dimensional profile embeddings |
| Synthesis Frequency | Per-conversation (fact detection) | 24-hour batch processing | Near-real-time (minutes post-session) |
| Human Readability | Fully readable, editable records | Readable facts, opaque behavior tags | Readable summary + opaque vector |
| Behavioral Learning | None | Limited (5 predefined dimensions) | Continuous (4,096-dimensional space) |
| Profile Decay | None (facts retained until deleted) | Manual expiration settings | Learned adaptive weighting |
| API Access | Full CRUD on memory records | Full CRUD on facts, read-only on tags | Read/write on facts, export-only on vectors |
| Cross-Platform Sync | ChatGPT only | ChatGPT + API | ChatGPT + API + enterprise integrations |
| Privacy Controls | On/off toggle, manual deletion | Granular category controls | Granular controls + admin policy layer |
The most strategically significant change in this comparison is the shift from human-readable discrete records to the combination of a readable summary layer and an opaque vector store. OpenAI made this architectural choice deliberately, and it has generated significant discussion in both the privacy and enterprise communities. The readable summary layer provides transparency and auditability; the opaque vector layer provides the behavioral depth that makes Dreaming V3 qualitatively different from its predecessors. The two layers coexist but serve different functions, and they have different governance implications.
The Enterprise API: What Developers Need to Know
For engineering teams building on the OpenAI API, Dreaming V3 introduces new endpoints, new configuration parameters, and new data structures that require deliberate integration decisions. The following section covers the key API surfaces available as of the June 4 release.
Profile Inspection Endpoint
Enterprise API customers with the memory.read scope can now retrieve a structured representation of a user’s memory state via the /v1/memory/profile endpoint. The response includes two components: the human-readable memory summary (equivalent to what the user sees in their ChatGPT settings) and a metadata object describing the profile vector’s recency, conversation count, and confidence scores across major behavioral dimensions.
GET /v1/memory/profile
Authorization: Bearer {api_key}
X-User-ID: {user_identifier}
Response:
{
"object": "memory.profile",
"user_id": "usr_abc123",
"version": "dreaming_v3",
"readable_summary": {
"facts": [
{
"id": "fact_001",
"content": "Works as a senior backend engineer at a fintech company",
"created_at": "2026-04-12T09:23:11Z",
"source": "explicit_statement",
"confidence": 0.97
},
{
"id": "fact_002",
"content": "Prefers Python and Go for systems work",
"created_at": "2026-05-01T14:44:32Z",
"source": "behavioral_inference",
"confidence": 0.89
}
],
"behavioral_summary": "User consistently prefers concise technical responses with
code examples. Shows strong preference for seeing trade-offs enumerated explicitly.
Domain focus: distributed systems, API design, financial data pipelines.",
"last_synthesized": "2026-06-04T07:12:44Z"
},
"vector_metadata": {
"dimensionality": 4096,
"conversation_count": 147,
"last_updated": "2026-06-04T07:12:44Z",
"behavioral_confidence_scores": {
"communication_style": 0.94,
"domain_expertise": 0.91,
"cognitive_preference": 0.88,
"task_pattern": 0.85
}
}
}
Note that the actual profile vector is not returned in this response. Vector export is available through a separate endpoint (/v1/memory/profile/export) that requires elevated permissions and generates a compliance audit log entry. This design reflects OpenAI’s deliberate separation between routine profile inspection (for debugging personalization issues or building transparency features) and full vector access (which carries more significant data portability and privacy implications).
Memory Configuration via the API
Enterprise administrators can set memory policies programmatically via the /v1/memory/config endpoint, which accepts organization-level and user-level configuration objects. The following example demonstrates setting a departmental memory policy that enables behavioral synthesis while restricting storage of certain data categories:
POST /v1/memory/config
Authorization: Bearer {admin_api_key}
{
"scope": "organization",
"organization_id": "org_xyz789",
"policy": {
"memory_enabled": true,
"synthesis_mode": "dreaming_v3",
"max_personalization_depth": "contextual",
"fact_storage": {
"enabled": true,
"excluded_categories": [
"health_information",
"financial_details",
"personal_relationships"
]
},
"behavioral_synthesis": {
"enabled": true,
"domains": ["communication_style", "cognitive_preference", "task_pattern"],
"excluded_domains": ["personal_sentiment", "emotional_state"],
"retention_days": 180,
"cross_session_synthesis": true
},
"user_override_permitted": false,
"audit_logging": {
"enabled": true,
"log_level": "full",
"export_destination": "s3://your-audit-bucket/chatgpt-memory-logs/"
}
}
}
The user_override_permitted flag is particularly significant for enterprise deployments. When set to false, individual users cannot modify their memory settings within the organization’s ChatGPT environment, which is appropriate for deployments where consistent AI behavior is a compliance requirement. When set to true, users retain personal control over their memory settings subject to the organization’s minimum policy floors. Understanding the right setting for your organization’s risk profile is one of the most consequential configuration decisions in a Dreaming V3 deployment.
For teams looking to expand their AI capabilities with proven prompt patterns, our comprehensive guide on 99+ ChatGPT Prompts for technical writers provides battle-tested templates that complement the strategies discussed in this article and can be immediately applied to production workflows.
Injecting Context Without Storing Memory
One API pattern that will be important for enterprise developers is the ability to inject session-specific behavioral context without triggering profile synthesis. This is valuable when building applications where you want to customize ChatGPT’s behavior for a specific use case without that use case’s behavioral patterns contaminating the user’s general profile. The mechanism uses the memory_exempt flag in the chat completions request:
POST /v1/chat/completions
Authorization: Bearer {api_key}
{
"model": "gpt-4o-2026",
"memory_settings": {
"read_profile": true,
"write_profile": false,
"memory_exempt": true,
"session_context": {
"role": "customer_support_agent",
"domain": "technical_billing_inquiries",
"style_override": {
"formality": "high",
"response_length": "concise",
"use_templates": true
}
}
},
"messages": [
{
"role": "system",
"content": "You are assisting a customer with billing inquiries..."
},
{
"role": "user",
"content": "I was charged twice for my subscription last month"
}
]
}
This pattern allows organizations to leverage the user’s existing profile knowledge (reading their communication preferences to inform tone) without allowing a specialized workflow to distort their general behavioral profile. It’s an important capability for organizations deploying ChatGPT across multiple distinct use cases — a customer who uses ChatGPT both as a personal productivity tool and as a customer support interface shouldn’t have those behavioral contexts bleed into each other.
Privacy Implications: The Dual-Layer Transparency Problem
Dreaming V3’s dual-layer architecture — readable facts plus opaque behavioral vectors — creates a novel privacy challenge that existing data governance frameworks are not fully equipped to address. The challenge is not that the system stores more data than before (though it does) but that it stores a category of data that has no direct precedent in traditional privacy regulation: inferred behavioral embeddings that are not interpretable by humans but nonetheless influence AI outputs in significant ways.
GDPR and the Right to Explanation
Under Article 22 of the General Data Protection Regulation, individuals subject to automated decision-making have the right to “obtain an explanation of the decision reached” and to “contest the decision.” Dreaming V3’s behavioral conditioning is not a “decision” in the narrow legal sense — it influences response generation rather than making determinations with legal or similarly significant effects. However, privacy counsel in the EU should carefully evaluate whether behavioral conditioning constitutes “profiling” under Article 4(4) of GDPR, which defines profiling as any form of automated processing of personal data to evaluate personal aspects related to a person. The behavioral dimensions captured by Dreaming V3 — cognitive preferences, communication patterns, professional domain signals — plausibly constitute personal aspects related to a natural person’s work performance, behavior, and preferences.
If Dreaming V3 profiling falls within GDPR scope, organizations operating in the EU need a lawful basis for the processing. Legitimate interest may suffice for many enterprise deployments, but the balancing test requires documentation. Consent-based approaches are cleaner legally but practically difficult at enterprise scale. Data protection impact assessments (DPIAs) should be initiated for any EU-operating enterprise deployment before Dreaming V3 behavioral synthesis is enabled.
The Interpretability Gap and Right to Access Requests
Article 15 GDPR grants data subjects the right to obtain a copy of their personal data. For discrete memory facts, this right is straightforwardly satisfied: the readable summary can be exported and provided in response to a Subject Access Request (SAR). For the behavioral profile vector, the situation is more complex. The 4,096-dimensional vector is personal data about the data subject but is not interpretable without the proprietary model weights needed to decode it into behavioral semantics. OpenAI’s current position, outlined in their data processing agreement addendum for Dreaming V3, is that the behavioral_summary field in the readable summary layer constitutes a meaningful representation of the vector’s content for SAR purposes, with the full vector export available on request via the API.
Whether a behavioral_summary generated by the synthesis model itself satisfies the “copy of personal data” requirement is an open legal question that data protection authorities have not yet addressed specifically for AI behavioral embeddings. Privacy-forward enterprises should adopt the conservative position of offering full vector exports in response to SARs, even if that export is formatted as an opaque binary file that the user cannot independently interpret. The export exists as a compliance artifact and also enables the portability rights under Article 20.
Data Retention and the Decay Mechanism
One privacy-protective aspect of Dreaming V3’s architecture is that the adaptive decay weighting in the synthesis model means that old behavioral signals naturally attenuate over time. A user whose professional context changes significantly will find their old profile signals fading within weeks as new behavioral evidence accumulates. This is more privacy-respectful than traditional discrete memory, where old facts persist indefinitely unless explicitly deleted.
However, the decay mechanism does not constitute erasure, and the right to erasure under GDPR Article 17 still applies. Enterprise administrators must ensure that their Dreaming V3 deployment includes a compliant erasure workflow that deletes both the fact store and the behavioral embedding when a user exercises their erasure rights. OpenAI’s API provides the DELETE /v1/memory/profile/{user_id} endpoint for this purpose, which triggers immediate deletion of both layers and returns a compliance confirmation object that should be retained as evidence of erasure.
Enterprise Use Cases: Where Dreaming V3 Creates Measurable Value
Beyond the architectural and compliance dimensions, the practical question for enterprise decision-makers is where Dreaming V3 actually moves the needle on productivity, quality, and user satisfaction. The answer varies significantly by use case type, and organizations should calibrate their deployment expectations accordingly.
High-Value Use Cases
Knowledge Work and Analysis: For knowledge workers who use ChatGPT as an ongoing thinking partner — analysts, strategists, researchers, product managers — Dreaming V3’s behavioral conditioning creates compounding value over time. The system learns that a particular analyst prefers hypotheses stated as falsifiable claims, always wants to see confidence intervals when discussing quantitative estimates, and tends to work through problems by considering second-order effects first. These preferences, once learned, mean every subsequent analysis session starts closer to a useful output without requiring the user to re-explain their mental model.
Software Development: Developers using ChatGPT for code assistance benefit significantly from accumulated understanding of their codebase vocabulary, preferred patterns, and debugging approach. Dreaming V3 can learn that a particular engineer consistently prefers functional approaches over object-oriented ones, writes tests before implementation, and works in a TypeScript/PostgreSQL/Docker stack. The system doesn’t need to be told these things in each session — they emerge from behavioral synthesis. This is where the productivity delta versus discrete memory becomes most tangible.
For teams looking to expand their AI capabilities with proven prompt patterns, our comprehensive guide on 10 coding Prompts for Gemini 3.1 Pro u2014 Copy-Paste Ready for Production Workflows provides battle-tested templates that complement the strategies discussed in this article and can be immediately applied to production workflows.
Executive Communication Assistance: Senior leaders who use ChatGPT for drafting, reviewing, or preparing communications represent another high-value cohort. Communication style is one of the dimensions Dreaming V3 captures most reliably, and individual executive voice is highly consistent behavioral data. The synthesis model can learn that a particular executive writes in direct, active voice, never uses jargon without immediate definition, and structures arguments with the recommendation first and supporting evidence second. That learned voice profile makes ChatGPT a genuinely useful writing partner rather than a tool that produces outputs that always need heavy editing.
Lower-Value or Risk-Elevated Use Cases
Compliance-Critical Document Generation: For use cases where every user needs identical, policy-consistent outputs — compliance disclosures, regulated financial communications, healthcare information — behavioral personalization is a liability rather than an asset. The risk that Dreaming V3 adapts its communication style in ways that inadvertently alter the meaning or compliance-relevant framing of regulated content is real. These deployments should use the max_personalization_depth: “ambient” configuration to neutralize behavioral conditioning.
Access 40,000+ AI Prompts for ChatGPT, Claude & Codex — Free!
Subscribe to get instant access to our complete Notion Prompt Library — the largest curated collection of prompts for ChatGPT, Claude, OpenAI Codex, and other leading AI models. Optimized for real-world workflows across coding, research, content creation, and business.
Customer-Facing Applications: Organizations building ChatGPT-powered customer interfaces face a particular consideration: whose behavioral profile is being synthesized? In a customer support context, you likely want the AI to adapt to the customer’s communication preferences (beneficial personalization) but not to synthesize a behavioral profile that persists across support sessions in ways the customer hasn’t consented to (potential privacy issue). The session-exempt API pattern described earlier addresses this by reading communication preference signals in-session without persisting them to the behavioral profile.
The Memory Transparency Dashboard: New Controls for Users and Admins
Alongside the Dreaming V3 architecture, OpenAI shipped a substantially redesigned memory transparency dashboard available in both the ChatGPT web interface and the enterprise admin console. The redesign acknowledges that the dual-layer architecture requires dual-layer transparency tooling.
User-Facing Controls
Individual users (subject to their organization’s admin policy) now have access to the following controls in their ChatGPT settings:
- Memory Summary View: A human-readable overview combining stored facts and the behavioral_summary narrative, rendered in natural language. This is the primary transparency surface for non-technical users.
- Fact Management: Individual facts can be viewed, edited, or deleted. The source field on each fact (explicit_statement versus behavioral_inference) helps users understand how each fact entered their profile.
- Behavioral Dimension Controls: Users can toggle individual behavioral synthesis dimensions on or off. For instance, a user who wants ChatGPT to adapt to their communication style but not infer domain expertise signals can disable the domain_expertise synthesis dimension while keeping communication_style active.
- Profile Snapshot: Users can view a timestamp-indexed history of their behavioral_summary as it has evolved over time, providing a longitudinal view of how the system’s model of them has changed.
- Session Exemption: Users can mark individual conversations as memory-exempt before they begin, preventing the session’s signals from contributing to profile synthesis.
- Full Reset: A complete memory reset deletes all facts and reinitializes the behavioral vector. Users are warned that this action is irreversible and that behavioral personalization will degrade for several sessions while the system rebuilds from scratch.
Administrator Controls
Enterprise administrators in the admin console have access to a memory governance panel that provides organization-wide visibility and control:
- Policy Editor: A UI-based policy configuration tool that mirrors the API configuration options, enabling non-technical administrators to set memory policies without writing JSON.
- Aggregate Analytics: Anonymized, aggregate metrics on memory utilization across the organization, including average conversation counts before profile confidence reaches each threshold, distribution of personalization depth band usage, and fact category breakdowns.
- User Profile Audit: Administrators with appropriate permissions can view the readable summary layer (not the vector) for individual users, which is relevant for HR-adjacent use cases and compliance investigations.
- Bulk Erasure: For offboarding workflows, administrators can trigger bulk profile deletion for individual users or user groups, with compliance confirmation objects returned for each deletion.
- Data Residency Controls: New in the Dreaming V3 release, organizations can specify that behavioral profile vectors must be stored and processed within a specific geographic region, supporting data residency requirements in jurisdictions like the EU, Australia, and India.
Cross-Platform Profile Portability: A New Frontier for Enterprise AI
One of the less-discussed but strategically significant aspects of Dreaming V3 is its introduction of cross-platform profile portability through the export API. For the first time, enterprise customers can export a user’s behavioral profile representation and use it to pre-condition AI interactions in systems outside of ChatGPT. The immediate application is in enterprise environments where multiple AI tools are deployed alongside ChatGPT, and there is a desire for behavioral consistency across those tools.
The export format is an open specification that OpenAI is proposing as a contribution to the emerging AI Profile Interchange Standard (APIS) working group, which includes representatives from Microsoft, Anthropic, Google DeepMind, and several enterprise software vendors. The specification defines a portable profile representation that separates the readable semantic layer (which any AI system can consume via structured text) from the embedding layer (which requires compatible model architectures to use effectively).
In practice, this means that an organization can export a user’s ChatGPT behavioral profile and import it into a Microsoft 365 Copilot instance, where the readable semantic layer immediately improves Copilot’s personalization while the embedding layer provides additional conditioning for Copilot models that support the APIS vector format. This represents a meaningful step toward a world where behavioral AI personalization is a portable user asset rather than a proprietary lock-in mechanism.
The Portability API Pattern
// Export profile for portability
GET /v1/memory/profile/export?format=apis_v1&include_vector=true
Authorization: Bearer {api_key}
X-User-ID: {user_identifier}
Response:
{
"format": "apis_v1",
"spec_version": "1.0.0",
"export_timestamp": "2026-06-04T15:30:00Z",
"user_id_hash": "sha256:abc123...",
"semantic_layer": {
"facts": [...],
"behavioral_summary": "...",
"domain_tags": ["software_engineering", "distributed_systems"],
"communication_preferences": {
"formality": 0.72,
"conciseness": 0.85,
"example_affinity": 0.91,
"structure_preference": "hierarchical"
}
},
"embedding_layer": {
"model_family": "openai_dreaming_v3",
"dimensionality": 4096,
"vector": "[base64-encoded float32 array]",
"compatible_receivers": [
"openai_dreaming_v3",
"microsoft_copilot_profile_v2",
"apis_compatible_any"
]
},
"compliance": {
"data_subject_consent": "implicit_tos",
"export_logged": true,
"audit_id": "audit_xyz456"
}
}
Enterprise architects building multi-AI environments should evaluate this portability capability carefully during their Dreaming V3 deployment planning. Profile portability unlocks real productivity value but also introduces new governance questions: if a user’s behavioral profile is exported to a third-party system, who controls its subsequent use, retention, and deletion? The APIS specification includes provisions for consent tracking and deletion notification between systems, but implementation is the responsibility of the enterprise, not the AI vendors.
Security Considerations: Protecting Behavioral Profiles from Adversarial Exploitation
Behavioral profile data represents a new attack surface that security teams must account for in their AI governance frameworks. The high-dimensional vector representation of a user’s cognitive preferences and behavioral patterns is, in effect, a detailed psychological fingerprint. Several threat scenarios deserve specific consideration.
Profile Poisoning
An attacker who can inject signals into the synthesis pipeline — either by manipulating a user’s conversation inputs or by compromising the signal extraction layer — could gradually corrupt a user’s behavioral profile. This is analogous to data poisoning attacks on machine learning systems, but targeting a per-user model rather than a shared one. The practical implication is more subtle than dramatic: a poisoned profile might cause ChatGPT to consistently misalign with the genuine user’s preferences, degrading productivity rather than causing security breaches. However, in higher-stakes contexts where behavioral conditioning influences document generation or decision support, profile poisoning could have more significant consequences.
Mitigations include enabling the behavioral confidence score monitoring in the admin console, which flags anomalous or rapid changes to profile dimensions, and implementing the session-exempt flag for sensitive workflows where you don’t want adversarial signal injection to be possible.
Profile Inference Attacks
The behavioral_summary text field in the readable layer is generated by the synthesis model as a natural language description of the user’s behavioral profile. This summary is designed to be informative, which means it could leak sensitive information about the user if accessed by an unauthorized party. An attacker who gains access to a user’s memory profile (via API credential compromise or insider access) obtains not just stored facts but a synthesized behavioral model of the individual. Enterprise API access controls for the memory.read scope should be treated with the same sensitivity as access to HR records or medical information.
Cross-User Contamination in Shared Credentials
Organizations that have historically used shared API credentials or shared ChatGPT accounts (more common than it should be, particularly in smaller teams) face a specific risk with Dreaming V3: behavioral profiles are per-user-identifier, and if multiple humans share a single user identifier, their behavioral signals will be synthesized into a single contradictory profile that serves no one well. More importantly, an individual’s behavioral signals will be stored against a shared identifier that other people can access. Audit your user identifier architecture before enabling Dreaming V3 synthesis, and migrate shared accounts to individual user IDs with service account exceptions clearly documented.
Deployment Roadmap: Enterprise Readiness Checklist for Dreaming V3
For enterprise teams evaluating or actively deploying Dreaming V3, the following structured readiness assessment covers the key dimensions that should be addressed before full rollout.
Phase 1: Governance and Legal Readiness (Weeks 1-3)
- Conduct a data protection impact assessment (DPIA) for behavioral profile synthesis, particularly for EU/UK operations
- Review and update AI data processing agreements with OpenAI to confirm Dreaming V3 coverage
- Determine lawful basis for behavioral profiling under applicable privacy regulations
- Draft or update employee notices describing AI memory processing of work-related interactions
- Define data retention schedules for behavioral profiles, aligned with existing data governance policies
- Establish a subject access request workflow that can respond to requests for behavioral profile data
- Confirm data residency requirements and configure geographic processing restrictions via the admin console
Phase 2: Technical Configuration (Weeks 2-4)
- Audit existing user identifier architecture and eliminate shared credentials
- Implement organization-level memory policy via the admin console or API, starting with conservative settings
- Configure audit logging destination and confirm log format compatibility with your SIEM infrastructure
- Integrate profile deletion into user offboarding workflows
- Review API integrations for memory_exempt flag usage in customer-facing applications
- Implement API access controls for memory.read and memory.admin scopes
- Test the full erasure workflow and retain compliance confirmation objects
Phase 3: Change Management and User Communication (Weeks 3-5)
- Communicate Dreaming V3 capabilities and privacy controls to employees
- Provide training on the Memory Transparency Dashboard, including how to use session exemption
- Establish feedback channels for employees who experience personalization issues
- Document internal guidance on appropriate use cases for behavioral synthesis versus ambient-only deployments
- Define escalation path for profile-related issues (incorrect behavioral inferences, unexpected response changes)
Phase 4: Monitoring and Optimization (Ongoing)
- Monitor aggregate analytics in the admin console for personalization depth distribution and behavioral confidence trends
- Review anomalous profile change alerts in the security monitoring integration
- Conduct quarterly reviews of memory policy settings against evolving use cases and regulatory guidance
- Track user satisfaction scores for AI-assisted workflows where Dreaming V3 is active
- Evaluate cross-platform portability options as the APIS standard matures
What Comes After Dreaming V3: The Trajectory of AI Behavioral Memory
Dreaming V3 is best understood not as a destination but as an inflection point in a longer trajectory toward genuinely persistent, contextually aware AI collaboration. The architecture’s introduction of high-dimensional behavioral embeddings opens research and product directions that will define the next several years of AI assistant development.
OpenAI’s public roadmap hints at several near-term extensions of the Dreaming architecture. One is multi-modal behavioral synthesis, which would extend signal extraction beyond text to include behavioral signals from image generation requests, voice interaction patterns, and document manipulation actions in Operator-connected tools. Another is collaborative profile synthesis for teams, where a group’s shared behavioral patterns — their collective communication norms, shared domain vocabulary, collaborative decision-making style — are modeled as a group profile that conditions team-oriented AI interactions without reducing to any individual’s personal profile.
The longer-term trajectory points toward what some AI researchers are calling relational AI memory: systems that model not just individual behavioral profiles but the relationships between users, the organizational contexts that shape those relationships, and the evolving norms of specific professional communities. This would enable AI assistants that understand not only how you work individually but how you work with your team, within your organization’s culture, and in the context of your industry’s practices. Dreaming V3 is the first architecture genuinely capable of scaling to that vision, because it abandons the discrete fact storage model that would make relational modeling computationally intractable.
The trajectory also implies a responsibility trajectory. As AI memory systems become more sophisticated in their behavioral modeling, the governance, transparency, and user control frameworks must scale commensurately. The controls OpenAI has shipped with Dreaming V3 — the dual-layer transparency dashboard, granular synthesis dimension controls, API-level policy management, and geographic data residency options — represent a significant improvement over what existed before. But they are foundational, not comprehensive. The enterprise AI community, regulators, and AI developers will need to continue co-evolving the governance frameworks as the technical capabilities advance.
The Competitive Landscape Response
OpenAI’s launch of Dreaming V3 is already prompting architectural responses from competitors. Anthropic’s Claude has shipped a behavioral memory preview feature in its Claude for Work product that uses a similar embedding-based approach but with a narrower initial scope focused on communication style and domain preference. Google’s Gemini Advanced has offered behavioral conditioning for several months through a different mechanism: explicit preference extraction that stores inferred preferences as structured preferences rather than continuous embeddings. Both approaches demonstrate that the industry has reached consensus on the limitations of discrete memory storage, even if the specific implementation choices differ.
For enterprise customers, this convergence is ultimately good news: it means the fundamental architectural shift toward behavioral synthesis is not a single-vendor bet but an industry direction. The governance frameworks and API patterns you develop for Dreaming V3 will be largely applicable to equivalent systems from other vendors, reducing lock-in risk. The APIS portability standard discussion, in which OpenAI is participating alongside competitors, is an early signal that behavioral profile portability may become a baseline expectation rather than a differentiator.
Conclusion: The Architecture of Understanding
Dreaming V3 represents OpenAI’s most ambitious answer to a question that has been implicit in the AI assistant market since the earliest ChatGPT release: can a machine learning system genuinely understand a person well enough to be a consistently useful collaborator, or will it always require users to re-explain themselves? The discrete memory model answered that question with a qualified yes, hedged by the fundamental limitation that fact storage is not behavioral understanding. Dreaming V3 answers it more ambitiously by treating understanding as an architectural problem: build the right synthesis mechanism, and the understanding emerges from the data rather than requiring explicit encoding.
Whether that ambition translates to value in your organization depends on the specifics of your use cases, your workforce’s comfort with AI behavioral modeling, and the maturity of your data governance infrastructure. The enterprise teams that extract the most value from Dreaming V3 will be those that treat the deployment as a governance and change management challenge as much as a technical one: investing in user education, building compliant data workflows, configuring appropriate policy guardrails, and establishing feedback mechanisms that surface personalization issues before they become compliance problems.
The architectural shift from discrete memory to continuous behavioral synthesis is not reversible. Having demonstrated that a richer form of AI memory produces measurably better outcomes for users who engage with it over time, the industry will not return to storing facts in key-value databases. Dreaming V3 is the first mature production implementation of what AI memory will look like going forward. For enterprise AI leaders, the time to build the governance foundation for this architecture is now, before deployment scale makes retrofitting controls exponentially more difficult.
OpenAI has provided, in Dreaming V3, the tools to do this responsibly: granular controls, transparent dual-layer architecture, compliant erasure workflows, and an API surface designed with enterprise governance requirements in mind. The synthesis capability is sophisticated. The governance capability is sufficient. The strategic question is whether your organization is ready to use both.
ChatGPT AI Hub covers enterprise AI deployment, OpenAI product updates, and AI governance strategy. This analysis is based on OpenAI’s technical documentation, the Dreaming V3 release notes, and API specifications published on June 4, 2026.