Codex Credit Management and Rate Limit Optimization: The Complete Enterprise Cost Control Guide for 2026
Codex Credit Management and Rate Limit Optimization: The Complete Enterprise Cost Control Guide for 2026
By the ChatGPT AI Hub Editorial Team | Enterprise AI Infrastructure Series | Updated June 2026
As OpenAI’s Codex agent platform matures into a production-grade tool for enterprise software development, the economics of running high-volume agentic workloads have become as important as the technical capabilities themselves. Teams deploying Codex across dozens of engineers — or running autonomous agents that execute thousands of tasks per day — face a new operational challenge: understanding and optimizing the credit system that governs access, throughput, and cost. This guide breaks down every dimension of Codex credit management, from the mechanics of the rate limit reset savings feature to tiered plan comparisons, rollover strategies, and the architectural patterns that separate high-efficiency enterprise deployments from runaway cost centers.
Understanding the Codex Credit Architecture
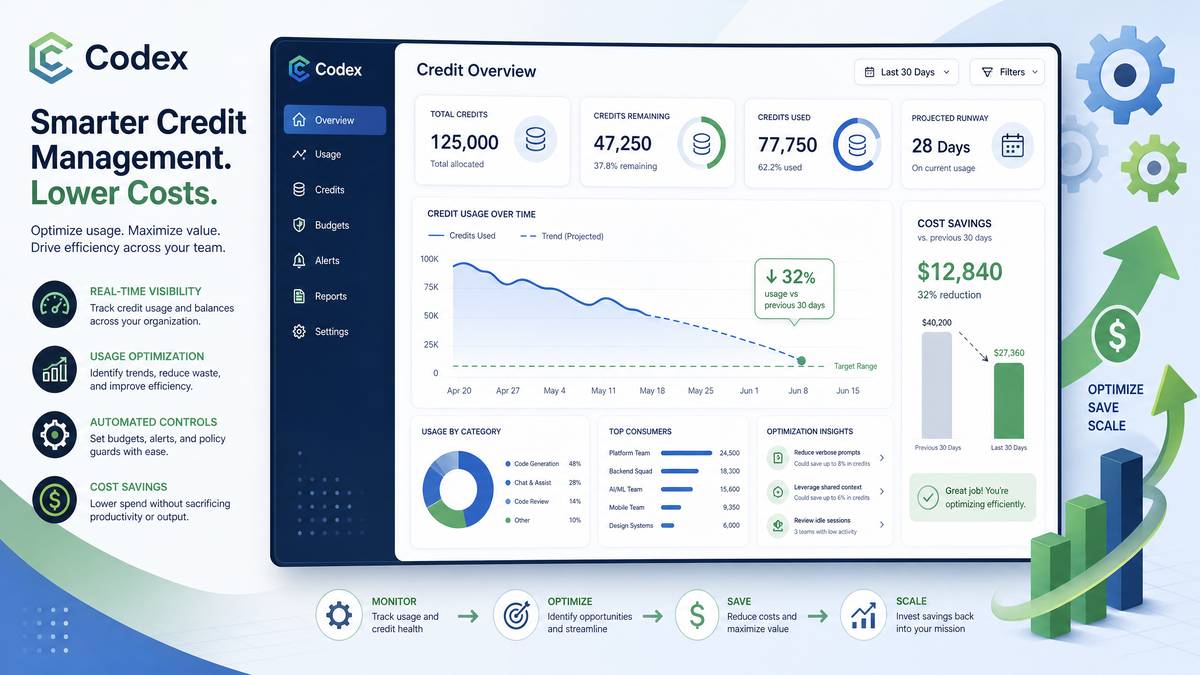
Codex operates on a fundamentally different billing model than the standard ChatGPT API. Rather than charging purely by token volume, the Codex platform uses a credit system that accounts for the full cost of agentic tasks — including background compute time, sandboxed execution environments, tool calls, file I/O operations, and the iterative reasoning loops that define autonomous coding workflows. This distinction matters enormously for budget planning, because a single Codex task that writes, runs, debugs, and documents a function may consume credits across five separate categories, none of which map cleanly to a simple tokens-in-tokens-out model.
The credit unit itself is denominated in Codex Compute Units (CCUs), an abstraction that OpenAI uses to normalize the wildly varying resource intensities of different task types. A straightforward code-completion request in a lightweight context might consume 0.2 CCUs, while a multi-step agent task that involves cloning a repository, running a test suite, patching failing tests, and generating a PR description could consume 15–40 CCUs depending on codebase size, execution time, and the number of tool invocations required.
Credit Consumption Categories
Enterprise teams need visibility into each consumption category to build accurate forecasting models. OpenAI currently segments credit usage across four primary dimensions:
| Consumption Category | CCU Weight | Primary Driver | Optimization Lever |
|---|---|---|---|
| Reasoning Tokens | High (0.8× multiplier) | Task complexity, context length | Task scoping, context pruning |
| Tool Executions | Medium (0.3× per call) | File reads, shell commands, tests | Batching, caching tool outputs |
| Sandbox Compute Time | Variable (0.1–2.0× per minute) | Test suite duration, build times | Parallelization, lightweight CI |
| Output Generation | Low (0.15× per 1K tokens) | Documentation, comments, PR text | Output templating, length limits |
Understanding this breakdown is the foundation of all downstream optimization. Most enterprise teams that come to us having overspent on Codex discover that sandbox compute time is the silent killer — a poorly scoped task that runs an entire integration test suite on every iteration can burn through credits an order of magnitude faster than an equivalent task bounded to unit tests only.
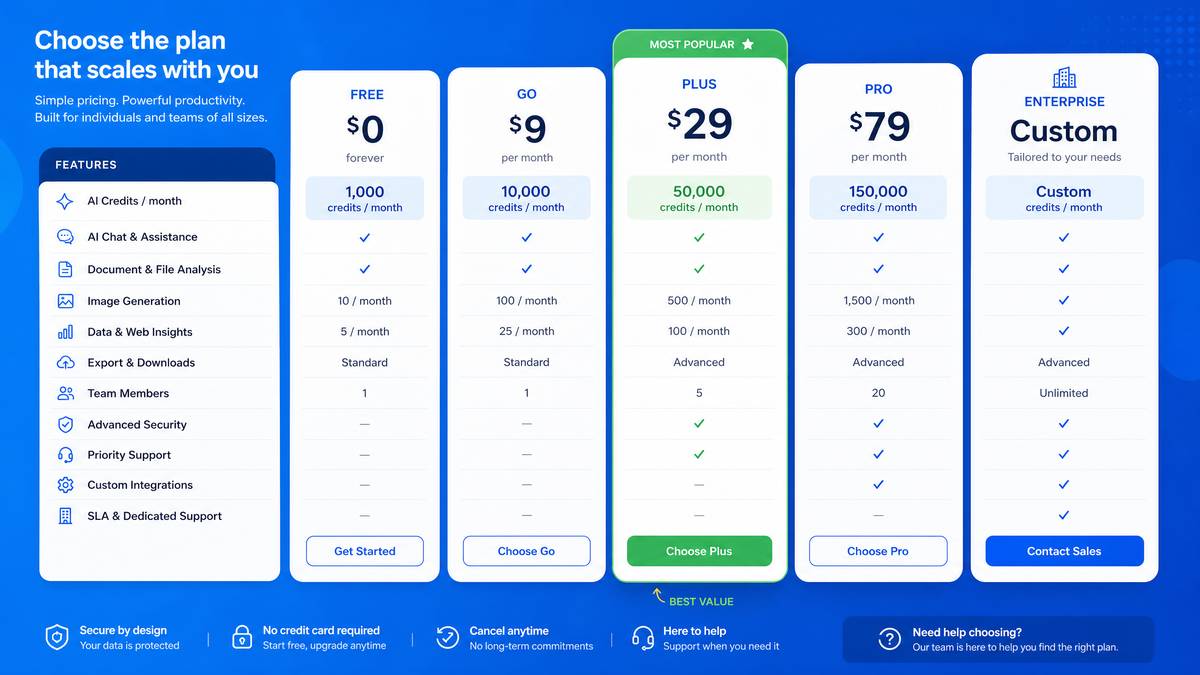
Tier Comparison: Free, Go, Plus, and Pro Plans
OpenAI’s tiered access structure for Codex reflects a deliberate positioning strategy: the free tier is genuinely useful for individual developers exploring agentic workflows, while the enterprise-grade Pro tier is engineered for teams running production CI/CD pipelines at scale. Here is a comprehensive breakdown of what each tier actually delivers in 2026.
| Feature | Free | Go ($9/mo) | Plus ($20/mo) | Pro ($200/mo) |
|---|---|---|---|---|
| Monthly CCU Allocation | 50 CCU | 500 CCU | 2,000 CCU | 10,000 CCU |
| Concurrent Agent Tasks | 1 | 3 | 5 | Unlimited (fair-use) |
| Rate Limit Reset Savings | No | No | Yes (partial) | Yes (full) |
| Credit Rollover | No | No | Up to 1 month | Up to 3 months |
| Sandbox Priority Queue | Standard | Standard | Elevated | Priority |
| API Access | No | Limited | Yes | Yes + dedicated endpoints |
| Team Seat Management | No | No | Up to 5 seats | Unlimited seats |
| Usage Analytics Dashboard | Basic | Basic | Advanced | Enterprise (export + alerts) |
| Custom System Prompts | No | Yes | Yes | Yes + shared org library |
| Overage Pricing (per CCU) | N/A | $0.025 | $0.018 | $0.012 |
Choosing the Right Tier for Your Team
The decision between Plus and Pro is rarely about the base credit allocation alone — it’s about the operational features that unlock at Pro. For teams running more than three or four active engineers who use Codex daily for substantial tasks, the mathematics shift decisively toward Pro even before accounting for the rate limit reset savings and rollover features. At a Pro overage rate of $0.012 per CCU versus Plus’s $0.018, a team burning 5,000 CCU in overage per month saves $30 in overage costs alone — representing 15% of the Pro subscription cost recovered purely through the rate differential.
The Go tier occupies an interesting middle position that works well for individual freelancers or small agencies running Codex for discrete, project-bounded work rather than continuous development cycles. The absence of rollover and rate limit savings features makes Go economically inefficient for any team with variable monthly workloads where credit utilization fluctuates significantly.
The Rate Limit Reset Savings Feature: A Deep Dive
Rate limit reset savings is arguably the most misunderstood feature in the Codex billing ecosystem — and among the most valuable for teams that learn to exploit it properly. The feature was introduced in the Q1 2026 platform update and represents OpenAI’s acknowledgment that the traditional hard-cutoff rate limiting model creates perverse incentives: developers who hit their rate ceiling have historically had no option but to wait, wasting valuable development time.
The reset savings mechanism works as follows: when a user or team exhausts their per-period rate limit (typically measured in requests-per-minute and CCU-per-hour), rather than receiving a hard block, the system draws from a “savings reserve” that accumulates during periods of under-utilization. Think of it as a token bucket algorithm operating at the billing level rather than the network level.
How the Savings Reserve Accumulates
Every hour in which your team’s CCU consumption falls below 70% of your tier’s pro-rated hourly allocation, the unused capacity flows into a savings reserve. The reserve has a cap — typically 4× your hourly allocation — and replenishment follows a sliding-window calculation that prevents gaming through deliberate artificial idle periods.
# Pseudocode for savings reserve calculation
# Run by OpenAI's billing system each hour
HOURLY_ALLOCATION = monthly_ccu / (30 * 24)
CONSUMPTION_THRESHOLD = HOURLY_ALLOCATION * 0.70
RESERVE_CAP = HOURLY_ALLOCATION * 4
if actual_consumption < CONSUMPTION_THRESHOLD:
unused_capacity = CONSUMPTION_THRESHOLD - actual_consumption
# Only 60% of unused capacity flows to reserve
reserve_contribution = unused_capacity * 0.60
savings_reserve = min(
savings_reserve + reserve_contribution,
RESERVE_CAP
)
# At rate limit breach:
if requested_ccu > remaining_period_allocation:
overage_needed = requested_ccu - remaining_period_allocation
if savings_reserve >= overage_needed:
savings_reserve -= overage_needed
# Request proceeds without rate limit error
return STATUS_OK
else:
return STATUS_RATE_LIMITED
The 60% efficiency factor in reserve accumulation is intentional — it prevents teams from strategically parking workloads off-peak purely to build reserve capacity for burst usage. OpenAI’s design philosophy here mirrors the approach used in cloud spot instance pricing: rewarding genuinely organic usage patterns rather than engineered arbitrage.
Practical Implications for Sprint Planning
For engineering teams operating on two-week sprint cycles, the rate limit reset savings feature creates a meaningful operational advantage during code review and release days. It’s common for Codex consumption to cluster heavily around PR review periods — typically days 4–5 and 13–14 of a sprint — while the middle days of a sprint see lower automated task volume as developers focus on implementation rather than code quality automation. Teams that build their Codex workflows with this rhythm in mind can accumulate substantial savings reserves during mid-sprint periods that buffer against the burst demand of review days.
A medium-sized engineering team of 20 developers on Pro plans, each consuming roughly 8 CCU per active day, will generate approximately 160 CCU/day on peak days and 40 CCU/day on light days. The savings reserve mechanism smooths this curve significantly, effectively giving the team a burst capacity of 320+ CCU on high-demand days without triggering overage charges.
Credit Rollover Strategies for Enterprise Teams
Credit rollover — the ability to carry unused monthly credits forward into subsequent billing periods — is one of the most financially impactful features available to Plus and Pro subscribers, and it is routinely underutilized because most teams don’t build explicit strategies around it. The mechanism is straightforward: unused credits at the end of a billing month roll forward with a cap of one month’s worth for Plus and three months for Pro. But the strategic implications extend well beyond simply “don’t waste credits.”
The Rollover Stacking Strategy
Pro subscribers can accumulate up to 30,000 CCU in rolled-over credits (3× the 10,000 CCU monthly allocation) on top of their standard monthly grant. Teams preparing for high-intensity development periods — major version releases, architecture migrations, AI-assisted codebase refactors — can deliberately throttle their Codex consumption in the 1–2 months prior to the project to build a substantial reserve. This is particularly valuable because rolled-over credits have no additional cost and are drawn before current-month credits, effectively extending the runway before any overage charges apply.
Consider a team planning a complete microservices decomposition project expected to consume 25,000 CCU over a single month. Without rollover strategy, they’d face 15,000 CCU in overage charges at $0.012 = $180 in additional costs. By deliberately reducing Codex usage in the two prior months — perhaps relying more on standard ChatGPT for lower-stakes tasks during that period — they can accumulate 8,000–12,000 CCU in rollover credits, cutting overage charges by 53–80%.
Multi-Seat Rollover Pool Management
Enterprise Pro accounts with multiple seats share a unified credit pool, which creates interesting optimization opportunities that don’t exist in individual accounts. The credit pool structure means that aggressive users don’t cannibalize other team members’ allocations — but it also means that team-level rollover accumulation is a collective resource requiring deliberate stewardship.
// Example: Team credit allocation monitoring script
// Integrates with OpenAI Usage API
const OPENAI_USAGE_ENDPOINT = 'https://api.openai.com/v1/usage/codex';
const TEAM_MONTHLY_ALLOCATION = 10000; // Pro tier base CCUs
const ROLLOVER_CAP = 30000;
async function getCreditStatus() {
const response = await fetch(OPENAI_USAGE_ENDPOINT, {
headers: {
'Authorization': `Bearer ${process.env.OPENAI_API_KEY}`,
'Content-Type': 'application/json'
}
});
const data = await response.json();
return {
currentMonthUsed: data.current_period_ccu_consumed,
currentMonthRemaining: data.current_period_ccu_remaining,
rolloverBalance: data.rollover_ccu_balance,
projectedMonthEnd: projectMonthEndUsage(data),
rolloverForecast: calculateRolloverForecast(data)
};
}
function projectMonthEndUsage(data) {
const daysElapsed = data.billing_period_days_elapsed;
const daysTotal = data.billing_period_days_total;
const dailyRate = data.current_period_ccu_consumed / daysElapsed;
return dailyRate * daysTotal;
}
function calculateRolloverForecast(data) {
const projectedUsage = projectMonthEndUsage(data);
const unusedCredits = Math.max(0, TEAM_MONTHLY_ALLOCATION - projectedUsage);
const currentRollover = data.rollover_ccu_balance;
const newRollover = Math.min(
currentRollover + unusedCredits,
ROLLOVER_CAP
);
return {
creditsToRollover: unusedCredits,
projectedNewRolloverBalance: newRollover,
rolloverCapHeadroom: ROLLOVER_CAP - newRollover
};
}
Rolling Budget Cycles for Predictable Spend
Finance teams working with engineering leaders often struggle with the variable nature of AI tool costs. The rollover mechanism, combined with Pro’s overage pricing structure, enables a rolling budget approach that smooths costs over a longer planning horizon. By treating the combined credit pool (base allocation + rollover balance) as the true monthly budget rather than just the base allocation, finance teams can build more accurate quarterly forecasts. A team maintaining a consistent 15,000 CCU rollover balance is effectively operating with a 25,000 CCU effective monthly capacity — a budget line that can be planned and defended with confidence.
Enterprise Architecture Patterns for Cost-Efficient Codex Deployments
The most sophisticated Codex cost optimization happens not in the billing settings dashboard but in the architectural decisions that govern how agentic tasks are structured, batched, and routed. Teams that treat Codex as a simple chat interface for coding questions are dramatically overpaying relative to teams that have engineered their Codex integration around the credit model’s mechanics.
Task Decomposition and Scope Bounding
The single most impactful optimization available to any team is rigorous task scoping before dispatching work to Codex agents. Underbounded tasks — those described vaguely or with access to an entire large codebase — force the agent to perform extensive exploratory tool calls to establish context before it can begin productive work. Each of these exploratory file reads, directory listings, and test runs consumes credits without producing output value.
A well-designed task decomposition framework follows what we term the “three-bounds” approach: define the input boundary (exactly which files or modules the agent should consider), the output boundary (precisely what artifacts should be produced), and the execution boundary (which tools and test suites the agent is permitted to invoke).
# Poorly scoped task - high CCU waste
task_bad = {
"instruction": "Fix the authentication bug in the user service",
"repository": "full_repo_access",
"tools": ["all_tools"],
"tests": "full_test_suite"
}
# Expected CCU consumption: 12-25 CCU
# Exploratory tool calls: 20-40 (reading auth files, service files,
# middleware, DB schemas, tests, etc.)
# Well-scoped task - optimized CCU consumption
task_good = {
"instruction": """
Fix the JWT validation failure in src/auth/jwt_validator.py.
The bug causes tokens with valid expiry to fail validation when
the timezone offset is non-UTC.
Scope: Only modify src/auth/jwt_validator.py and its
corresponding test file tests/unit/test_jwt_validator.py.
Validation: Run only the jwt_validator test class, not the
full auth suite.
""",
"file_scope": [
"src/auth/jwt_validator.py",
"tests/unit/test_jwt_validator.py"
],
"tools": ["file_read", "file_write", "run_tests"],
"test_filter": "tests/unit/test_jwt_validator.py::TestJWTValidator"
}
# Expected CCU consumption: 1.5-3 CCU
# Exploratory tool calls: 2-4 (direct file reads only)
Intelligent Task Routing: Codex vs. Standard ChatGPT
Not every coding-adjacent task requires the full Codex agent stack. A significant percentage of tasks that teams route to Codex — documentation generation, code explanation, simple refactoring with no execution requirement — can be handled more cost-efficiently through the standard ChatGPT API or the code-focused GPT-4o endpoint.
Organizations implementing advanced Codex workflows will benefit from our detailed analysis in Codex Goal Mode and Multi-Agent Workflows: Everything New in the June 2026 Enterprise Update, which covers complementary techniques and architectural patterns that extend the concepts explored throughout this guide.
Building a routing layer that classifies incoming tasks and selects the appropriate endpoint is one of the highest-ROI infrastructure investments available to enterprise teams.
A simple routing decision tree might classify tasks as Codex-appropriate when they require: (1) actual code execution for validation, (2) multi-file edits with dependency tracking, (3) test generation with run-and-fix iteration, or (4) repository-level understanding that requires dynamic exploration. Tasks that require only text-based code generation, review, or explanation route to cheaper endpoints, reserving the Codex credit budget for work that genuinely requires the agentic execution environment.
Parallelization Strategy and Concurrency Limits
Pro tier’s “unlimited” concurrent agent tasks (subject to fair-use constraints) enables a parallelization strategy that can dramatically improve the effective throughput per CCU spent. When a large refactoring project can be decomposed into independent subtasks — for example, updating deprecated API calls across separate microservices — running 8–10 parallel agents completes the work in the same elapsed time as sequential execution while consuming roughly the same total CCU budget. The optimization comes from avoiding the sequential overhead of context re-establishment that occurs when a single long-running agent task handles multiple logically independent components.
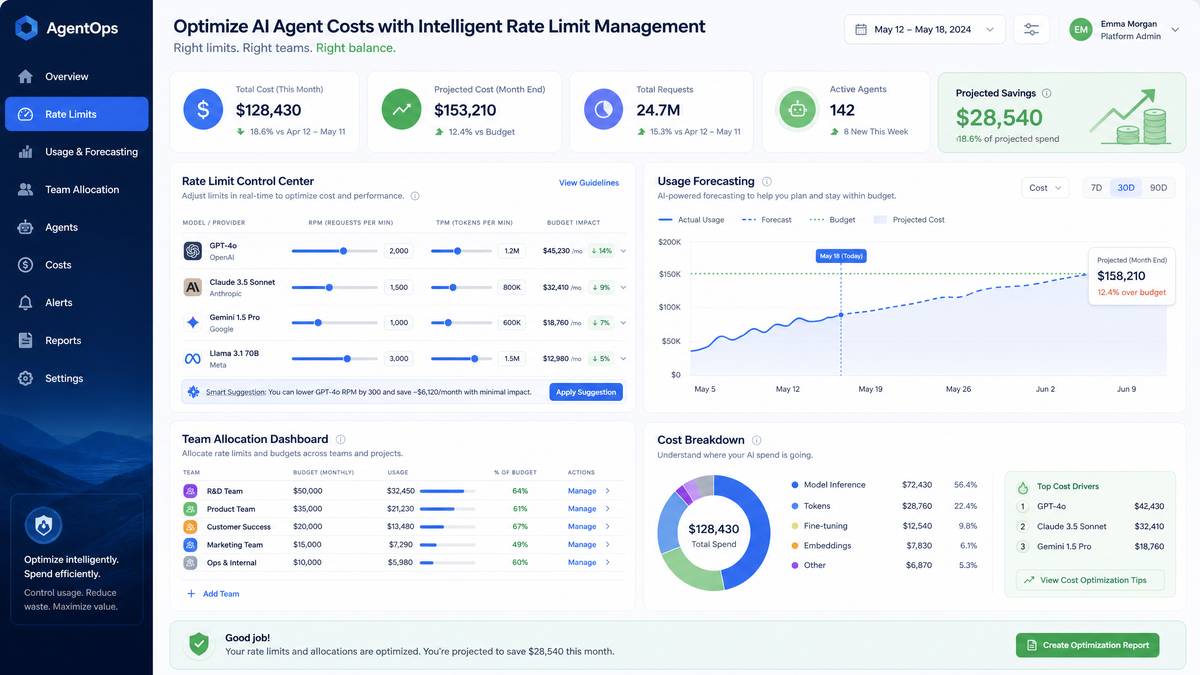
Monitoring, Alerting, and Cost Governance
Enterprise cost governance for Codex requires infrastructure beyond the standard OpenAI dashboard. Teams running Codex at scale need programmatic access to usage metrics, automated alerting on consumption anomalies, and chargeback mechanisms that attribute costs to specific teams, projects, or engineers.
Building a Usage Monitoring Stack
OpenAI’s Usage API provides the raw data necessary for enterprise cost dashboards. The key endpoints for a comprehensive monitoring implementation are:
# Comprehensive usage monitoring setup
import openai
import json
from datetime import datetime, timedelta
from dataclasses import dataclass
from typing import Optional
@dataclass
class CodexUsageReport:
period_start: str
period_end: str
total_ccu_consumed: float
ccu_by_task_type: dict
ccu_by_user: dict
ccu_by_project: dict
rate_limit_events: int
savings_reserve_used: float
rollover_consumed: float
estimated_overage_charges: float
def generate_usage_report(
api_key: str,
period_days: int = 7
) -> CodexUsageReport:
client = openai.OpenAI(api_key=api_key)
end_date = datetime.now()
start_date = end_date - timedelta(days=period_days)
# Fetch granular usage data
usage_data = client.usage.retrieve(
start_time=int(start_date.timestamp()),
end_time=int(end_date.timestamp()),
bucket_width="1d",
group_by=["user_id", "project_id", "task_type"],
product="codex"
)
# Aggregate by dimension
by_user = {}
by_project = {}
by_task_type = {}
total_ccu = 0
for bucket in usage_data.data:
for entry in bucket.results:
ccu = entry.compute_units_consumed
total_ccu += ccu
user = entry.metadata.get('user_id', 'unknown')
project = entry.metadata.get('project_id', 'unknown')
task_type = entry.metadata.get('task_type', 'unknown')
by_user[user] = by_user.get(user, 0) + ccu
by_project[project] = by_project.get(project, 0) + ccu
by_task_type[task_type] = by_task_type.get(task_type, 0) + ccu
# Fetch rate limit and savings reserve metrics
rate_metrics = client.usage.rate_limit_events(
start_time=int(start_date.timestamp()),
end_time=int(end_date.timestamp()),
product="codex"
)
# Calculate overage estimates
account_status = client.billing.subscription.retrieve()
monthly_allocation = account_status.codex_monthly_ccu
rollover_balance = account_status.codex_rollover_balance
overage_rate = account_status.codex_overage_rate
effective_budget = monthly_allocation + rollover_balance
period_fraction = period_days / 30
period_budget = effective_budget * period_fraction
estimated_overage = max(0, total_ccu - period_budget) * overage_rate
return CodexUsageReport(
period_start=start_date.isoformat(),
period_end=end_date.isoformat(),
total_ccu_consumed=total_ccu,
ccu_by_task_type=by_task_type,
ccu_by_user=by_user,
ccu_by_project=by_project,
rate_limit_events=rate_metrics.total_events,
savings_reserve_used=rate_metrics.reserve_ccu_consumed,
rollover_consumed=rate_metrics.rollover_ccu_consumed,
estimated_overage_charges=estimated_overage
)
Anomaly Detection and Budget Alerts
Runaway Codex tasks — agents caught in retry loops, tasks dispatched to the wrong scope, or tests that never terminate — are the most common cause of unexpected overage charges. Implementing automated anomaly detection against your usage stream is essential for any team spending more than a few hundred dollars per month on Codex.
A robust alerting strategy monitors three separate signals: per-task CCU consumption (alerting when any single task exceeds a configurable threshold), hourly burn rate (alerting when the current hour’s consumption exceeds 2× the rolling average), and daily-to-monthly projection (alerting when the current day’s usage, if sustained, would exhaust the monthly allocation before the billing period ends).
Team Credit Allocation and Chargeback Models
For organizations where multiple business units or product teams share a Codex enterprise account, implementing an internal chargeback or showback model transforms Codex from an opaque cost center into a transparent operational expense that can be attributed, budgeted, and optimized at the team level. OpenAI supports this use case through project-level credit allocation and per-user reporting.
Project-Scoped Budget Controls
The Pro enterprise tier enables administrators to create project workspaces with dedicated CCU budgets drawn from the organization’s master pool. This architecture allows engineering managers to set hard or soft limits on Codex consumption for a specific sprint, feature branch, or service domain. When a project approaches its allocated budget, the system can trigger alerts, request approval for additional allocation, or gracefully degrade to a lower-cost mode (such as disabling automatic test execution while preserving code generation capabilities).
| Budget Control Type | Behavior at Limit | Best Use Case | Override Mechanism |
|---|---|---|---|
| Hard Stop | All Codex requests return error | Contractor accounts, cost experiments | Admin re-allocation required |
| Soft Limit with Alert | Continue + notify budget owner | Team projects, sprint budgets | Budget owner approval |
| Degraded Mode | Disable sandbox execution, keep completion | Continuous development environments | Automatic on budget restore |
| Priority Queue Drop | New tasks queued, not rejected | Background automation pipelines | Budget restore or queue flush |
Engineering Cost Per Feature
One of the emerging best practices in AI-augmented development shops is calculating the “AI cost per feature” metric alongside traditional engineering velocity metrics. By tagging Codex tasks with feature or ticket identifiers, teams can calculate the total CCU investment per shipped feature — a metric that informs architecture decisions about where agentic assistance delivers strong ROI versus where traditional development workflows remain more economical.
Access 40,000+ AI Prompts for ChatGPT, Claude & Codex — Free!
Subscribe to get instant access to our complete Notion Prompt Library — the largest curated collection of prompts for ChatGPT, Claude, OpenAI Codex, and other leading AI models. Optimized for real-world workflows across coding, research, content creation, and business.
Early adopters of this metric consistently find that Codex delivers the highest CCU-per-value ratio on three categories: large-scale automated refactoring (migrating to new library versions across many files), test coverage generation for legacy code without existing tests, and boilerplate-heavy feature development in well-established architectural patterns. The metric also reveals where Codex is consistently over-deployed: exploratory research tasks, novel algorithm design, and complex system design decisions where the agent’s exploratory tool calls cost more than the output is worth.
Optimizing High-Volume Agent Workflows
Teams running Codex at the highest volumes — CI/CD-integrated automated review, scheduled technical debt reduction agents, or real-time code assistance platforms built on top of Codex — require optimization patterns that go beyond individual task design to encompass workflow orchestration at the system level.
The Defer-and-Batch Pattern
For workloads that are latency-tolerant, the defer-and-batch pattern can reduce CCU consumption by 20–40% compared to immediate task dispatch. The pattern works by accumulating similar tasks in a queue and dispatching them as a single multi-task context to the Codex agent, allowing the agent to build up shared context (repository structure, coding style, architecture patterns) once and amortize that cost across multiple output units.
# Defer-and-batch implementation
import asyncio
from collections import defaultdict
from datetime import datetime, timedelta
class CodexBatchQueue:
def __init__(
self,
batch_size: int = 5,
max_wait_seconds: int = 30,
similarity_threshold: float = 0.8
):
self.queue = defaultdict(list)
self.batch_size = batch_size
self.max_wait = max_wait_seconds
self.pending_batches = {}
async def enqueue_task(
self,
task: dict,
priority: str = "normal"
) -> str:
"""
Add task to batch queue. Returns task_id for status tracking.
Tasks are grouped by repository + task_type for context sharing.
"""
batch_key = f"{task['repository']}:{task['task_type']}"
task_id = f"task_{datetime.now().timestamp()}_{id(task)}"
self.queue[batch_key].append({
"id": task_id,
"task": task,
"enqueued_at": datetime.now(),
"priority": priority
})
# Check if batch is ready to dispatch
if len(self.queue[batch_key]) >= self.batch_size:
await self._dispatch_batch(batch_key)
elif batch_key not in self.pending_batches:
# Set timer for max_wait dispatch
self.pending_batches[batch_key] = asyncio.create_task(
self._delayed_dispatch(batch_key)
)
return task_id
async def _delayed_dispatch(self, batch_key: str):
await asyncio.sleep(self.max_wait)
if self.queue[batch_key]:
await self._dispatch_batch(batch_key)
async def _dispatch_batch(self, batch_key: str):
tasks = self.queue.pop(batch_key, [])
if not tasks:
return
# Construct multi-task prompt with shared context
repo = tasks[0]['task']['repository']
combined_instruction = self._build_batch_instruction(tasks)
# Single Codex API call for all batched tasks
# Context is loaded once, amortized across all tasks
result = await dispatch_to_codex({
"repository": repo,
"instruction": combined_instruction,
"output_format": "structured_per_task",
"task_ids": [t['id'] for t in tasks]
})
await self._distribute_results(result, tasks)
def _build_batch_instruction(self, tasks: list) -> str:
instructions = []
for i, task_item in enumerate(tasks, 1):
instructions.append(
f"Task {i} (ID: {task_item['id']}):\n"
f"{task_item['task']['instruction']}"
)
return "\n\n---\n\n".join(instructions)
Context Caching for Repeated Repository Access
One of the most significant CCU savings opportunities for teams running frequent Codex tasks against the same repositories is context caching. When Codex processes the same repository structure, coding conventions file, or architecture documentation repeatedly across independent tasks, it pays the token and computation cost each time. OpenAI’s context caching feature for enterprise accounts allows frequently accessed reference content to be cached at the API level, reducing the CCU cost of context establishment by 60–75% for cached content.
The most valuable content to cache includes: CONTRIBUTING.md and coding style guides, architecture decision records (ADRs), test fixture boilerplate, shared utility modules that many features depend on, and database schema files. Teams managing their cache strategically can achieve substantial efficiency gains, particularly in large codebases where establishing context from scratch is expensive.
Automated Quality Gates to Prevent Runaway Tasks
Implementing quality gates at the task dispatch layer prevents the most common source of unexpected CCU overruns: tasks that enter problematic execution patterns. The key failure modes to guard against are:
Test-Fix Loop Explosion: An agent tasked with fixing failing tests that keeps generating new implementations, running tests, finding failures, and iterating without converging. Setting a maximum iteration count (typically 3–5 for well-scoped tasks) prevents a single task from consuming the equivalent of dozens of properly scoped tasks.
Context Scope Creep: An agent that starts with a narrowly defined task but expands its file access scope as it discovers related code. Implementing hard file access limits through the API’s tool configuration prevents this pattern from multiplying exploration costs.
Silent Sandbox Timeouts: Tasks whose test execution hangs rather than failing cleanly, causing the sandbox compute cost to accrue indefinitely. A timeout configuration at the task level — distinct from the API’s own timeout — ensures hanging tests terminate at a cost-controlled threshold.
The Economics of Codex at Scale: ROI Calculation Framework
Justifying Codex investment at the enterprise level requires a structured ROI framework that connects credit costs to engineering velocity outcomes. The key metrics to track are developer-hours saved per CCU spent, defect rates in Codex-assisted versus manually written code, time-to-PR for Codex-assisted features, and test coverage improvement rates from automated test generation.
Teams seeking additional context on related developments will find valuable insights in our coverage of 5 Best AI Research Tools for automation Compared u2014 Features, Pricing, Use Cases, which explores interconnected themes and practical applications that build upon the foundations established in this article.
A mature Codex deployment at a 50-person engineering organization typically shows a payback period of 4–8 weeks on the Pro subscription cost when these metrics are calculated rigorously.
Building the Business Case
| ROI Metric | Baseline (No Codex) | With Optimized Codex | Value Calculation |
|---|---|---|---|
| Test writing time per feature | 4 hours average | 1.2 hours average | 2.8h × $85/h × features/mo |
| Code review turnaround | 18 hours average | 6 hours average | 12h × $85/h × PRs/mo |
| Refactoring throughput | 1 service/week | 4 services/week | 3× velocity on scheduled tech debt |
| Documentation coverage | 35% of new code | 88% of new code | Reduced onboarding time by ~30% |
| Regression detection | 62% caught in CI | 81% caught in CI | Fewer production incidents per quarter |
Calculating Your Break-Even CCU Rate
The break-even analysis for Codex investment requires expressing both the cost and the value in comparable units. If an engineering hour costs $85 fully burdened and a Pro subscription seat costs $200/month with 10,000 CCU, the team needs to generate at least 2.35 engineering hours of saved work per 1,000 CCU consumed to justify the base subscription cost — before considering the overage efficiency gains. In practice, well-optimized Codex deployments deliver 8–15 engineering hours of equivalent work per 1,000 CCU, making the ROI case straightforward for most enterprise environments.
Security, Compliance, and Cost Governance Integration
Enterprise Codex deployments must integrate cost governance with security controls — the same mechanisms that restrict which code the agent can access also determine which tasks are permissible, which directly affects credit consumption patterns. Organizations in regulated industries have an additional compliance layer that can either increase or decrease CCU costs depending on how it’s implemented.
Zero-Trust Task Authorization
Implementing a zero-trust authorization model for Codex tasks means every task request is evaluated against a policy engine before dispatch. This adds a small latency overhead but prevents the most costly compliance failures: agents accidentally accessing sensitive data repositories, generating code that violates security policies, or running in environments they’re not cleared to operate in. From a credit perspective, tasks that are blocked before dispatch cost zero CCUs — making front-end policy enforcement far cheaper than detecting policy violations after a task has run.
Audit Trail and Regulatory Compliance
Pro enterprise accounts maintain a full audit log of every Codex task — including the instruction sent, the files accessed, the tools invoked, and the CCU consumed — with a configurable retention period of up to 24 months. For SOC 2 Type II compliance, this audit trail is essential evidence of controlled AI usage. For GDPR-regulated environments, the audit log also enables data access reporting: demonstrating exactly which code repositories (and by extension, which personal data implementations) the Codex agent accessed, when, and under whose authorization.
Looking Ahead: Predicted Changes to the Credit Model in Late 2026
Based on OpenAI’s published roadmap and the directional signals from their pricing announcements, several significant changes to the Codex credit model are expected before the end of 2026. Understanding these shifts now allows enterprise teams to architect their workflows for forward compatibility and avoid optimization investments that will be disrupted.
Dynamic Pricing for Off-Peak Execution
OpenAI has telegraphed the introduction of time-of-day dynamic pricing for Codex sandbox compute — a model where tasks dispatched during low-demand periods (typically late night in US Eastern time, roughly 2–7 AM) receive a 30–50% CCU discount. Teams running batch workloads — automated code quality sweeps, overnight refactoring agents, scheduled documentation generation — can achieve significant cost reductions by shifting these workloads to off-peak windows. Building task dispatch infrastructure that supports scheduled execution is therefore a forward-looking optimization that will pay dividends when dynamic pricing launches.
Model-Tier Selection within Codex
A model-selection layer within the Codex API is expected, allowing tasks to route to lighter-weight reasoning models for simpler tasks at a lower CCU rate, with the full Codex model available for complex agentic work. This will require teams to implement task complexity classification at dispatch time — a capability that pairs naturally with the routing layer described earlier — but will dramatically improve the cost efficiency of the long tail of simpler tasks that currently route to the full Codex stack by default.
Credit Pools for Agent Networks
OpenAI’s multi-agent orchestration ambitions suggest that a shared credit pool mechanism for agent networks is coming — allowing a primary orchestrator agent and its spawned sub-agents to share a unified CCU budget rather than each consuming from separate allocations. This architectural change will require updates to monitoring and alerting infrastructure but will simplify budget management for teams already running multi-agent workflows.
Implementation Checklist for Enterprise Codex Cost Optimization
For teams looking to implement the practices covered in this guide, the following prioritized checklist provides a structured implementation path. Items are ordered by impact-to-effort ratio, with the highest-ROI changes first.
| Priority | Action Item | Estimated CCU Savings | Implementation Effort |
|---|---|---|---|
| 1 | Implement task scoping standards (three-bounds framework) | 40–60% reduction | Low (documentation + training) |
| 2 | Deploy usage monitoring with anomaly alerts | 10–25% via runaway task prevention | Medium (API integration) |
| 3 | Build task routing layer (Codex vs. standard API) | 15–30% of total AI spend | Medium (classification logic) |
| 4 | Implement rollover strategy for high-intensity periods | Avoids 50–80% of projected overage | Low (planning discipline) |
| 5 | Enable context caching for shared reference content | 20–35% on repeated context | Low-Medium (API configuration) |
| 6 | Deploy defer-and-batch for latency-tolerant workloads | 20–40% on batch workloads | High (queue infrastructure) |
| 7 | Implement per-project budget controls | Prevents budget overruns | Medium (admin configuration) |
| 8 | Calculate cost-per-feature metric | Enables targeted optimization | Medium (analytics build) |
Conclusion: Making Codex Economics Work for Your Organization
The Codex credit system is more nuanced than any other billing model in the enterprise AI tools landscape, and that nuance creates both risk and opportunity. Teams that deploy Codex without intentional cost governance will encounter unpredictable bills, frustrated engineers hitting rate limits at critical moments, and difficulty building the business cases needed to sustain and grow their AI investment. Teams that master the credit architecture — understanding how savings reserves accumulate, how rollover buffers against seasonal usage spikes, how task scoping multiplies the value per CCU spent, and how monitoring infrastructure catches problems before they become expensive — will find that Codex delivers a return on investment that justifies aggressive expansion of its role in their development workflow.
The technical patterns covered in this guide — from the task decomposition framework to the batch queue implementation, from usage monitoring code to rollover stacking strategy — represent the accumulated best practices of enterprise teams that have moved through the painful early phase of unbounded Codex usage and emerged with optimized, financially sustainable deployments. The investment in building these controls compounds over time: each CCU saved is a CCU available for additional productive work, and the teams that operate Codex most efficiently are those with the headroom to push the boundaries of what agentic coding workflows can accomplish.
As OpenAI’s pricing model evolves through 2026 with dynamic pricing and model-tier selection, the organizations with mature cost governance infrastructure will adapt quickly — their monitoring systems will detect and exploit new savings opportunities, their routing layers will incorporate new pricing signals, and their rollover strategies will remain effective in the new pricing environment. Building that infrastructure today is the foundation for sustainable AI-augmented development at enterprise scale.