Claude 4 Model Family 2026: An In-Depth Guide to Sonnet 4.6, Opus 4.6, and Opus 4.7
Author: Markos Symeonides

The rapid evolution of artificial intelligence language models over the past decade has fundamentally transformed the landscape of natural language processing (NLP), enabling machines to approach and, in some respects, even surpass human-level proficiency in understanding and generating language. Within this dynamic environment, the Claude 4 model family, introduced in 2026, stands out as a paradigm shift, integrating cutting-edge advances in architecture, reasoning, context management, and multimodal interaction. This family—comprising Sonnet 4.6, Opus 4.6, and Opus 4.7—embodies the culmination of years of research in transformer-based models, modular AI frameworks, and vision-language integration.
In this comprehensive guide, we undertake a meticulous examination of the Claude 4 family, dissecting its architectural innovations, benchmarking outcomes, and practical deployment scenarios. We elucidate the unique characteristics that distinguish each variant, from Sonnet 4.6’s balanced efficiency to Opus 4.7’s enhanced multimodal capabilities. Central to this discussion is the novel ‘Agent Skills’ modular framework, which empowers these models with unprecedented flexibility and task specialization. Additionally, we contextualize Claude 4’s advancements relative to competing models such as OpenAI’s ChatGPT series, providing actionable insights to inform strategic AI integration decisions.
Through detailed technical exposition and analytical commentary, this article aims to equip researchers, developers, and enterprise stakeholders with a deep understanding of the Claude 4 family’s potential, limitations, and optimal use cases, thereby facilitating informed adoption and innovation in AI-driven applications.
1. Overview of the Claude 4 Model Family: Architecture and Core Innovations
The Claude 4 family represents a milestone in the evolution of large language models (LLMs), synthesizing advances across multiple AI subfields into a cohesive and highly adaptable platform. Its development builds upon the foundational breakthroughs of earlier Claude models, themselves notable for their emphasis on ethical AI, robust contextual understanding, and modular extensibility. The 2026 series introduces a suite of architectural refinements and feature augmentations aimed at enhancing model robustness, interpretability, and scalability.
At the heart of the Claude 4 family is a transformer-based architecture that has been meticulously optimized for both depth and breadth of understanding. While the transformer paradigm has been the bedrock of NLP since its introduction, Claude 4 pushes the boundaries of this architecture by substantially increasing the model’s context window and introducing dynamic modularity through the Agent Skills framework. This balance between architectural sophistication and operational pragmatism enables Claude 4 models to excel in diverse applications, from conversational AI to domain-specific knowledge synthesis.
The family is composed of three principal variants, each engineered with nuanced design goals:
Sonnet 4.6 serves as the foundational model within the Claude 4 series. It emphasizes a harmonious balance between computational efficiency and linguistic capability, rendering it suitable for widespread deployment in enterprise systems where resource constraints and response latency are critical factors. Sonnet 4.6 is architected to deliver high-quality natural language understanding and generation, supporting tasks such as document summarization, semantic search, and conversational agents with moderate complexity requirements.
Opus 4.6
Opus 4.7
The architectural innovations that underpin these models are multifaceted. The extended context window, a hallmark feature of the Claude 4 family, expands the token capacity to over 120,000 tokens—an order of magnitude greater than many contemporary LLMs. This extension is achieved through a combination of memory-efficient attention mechanisms, hierarchical context encoding, and optimized positional embedding strategies, all designed to preserve information fidelity over long discourse spans.
Complementing this is the Agent Skills framework, which introduces a modular, plug-and-play approach to AI capability management. This paradigm shifts away from monolithic, one-size-fits-all models towards a dynamic ecosystem where specialized skill modules can be invoked on demand, tailored to task-specific requirements. The base model provides a generalist linguistic foundation, while Agent Skills extend its functional repertoire to encompass domain expertise, enhanced reasoning pathways, and multimodal sensory processing.
Collectively, these innovations position the Claude 4 family as a versatile and powerful toolset capable of addressing the increasingly complex demands of AI applications in 2026 and beyond.
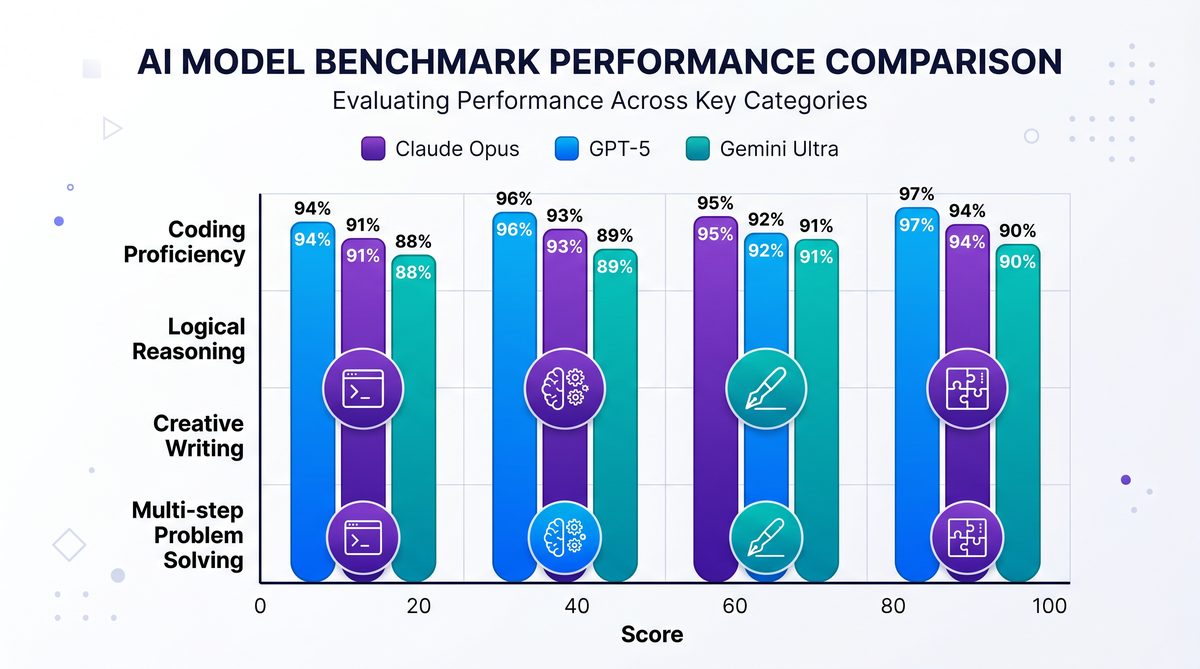
2. Benchmark Performance and Contextual Capabilities
Quantitative evaluation through rigorous benchmarking is essential for assessing the practical efficacy of large language models. The Claude 4 family has undergone extensive testing across multiple leading benchmarks to validate its performance claims, with particular attention to reasoning accuracy, language understanding, and contextual coherence.
Two benchmark suites—SWE-Bench and GPQA Diamond—serve as principal metrics in this evaluation. SWE-Bench is a comprehensive assessment platform designed to measure semantic understanding and sophisticated reasoning capacity across diverse linguistic and cognitive challenges. It encompasses tasks such as logical deduction, commonsense reasoning, multi-step problem solving, and semantic disambiguation. Claude 4’s achievement of an 87.6% score on SWE-Bench reflects a substantial leap relative to previous generation models, indicating a nuanced grasp of complex semantic relationships and the ability to maintain cognitive rigor over extended reasoning chains.
GPQA Diamond, on the other hand, focuses on general purpose question answering capabilities, evaluating model proficiency in accurately interpreting and responding to queries spanning a wide array of subject areas. The 91% score achieved by Claude 4 models on this benchmark positions them at the forefront of current AI question answering technology, demonstrating versatility and precision in handling both fact-based and inferential queries.
Central to these elevated benchmark outcomes is the Claude 4 family’s expansive context window. Traditional transformer models are constrained by token limits—often between 4,000 and 16,000 tokens—due to the quadratic scaling of attention mechanisms. Claude 4 circumvents this bottleneck through innovative memory architectures, such as segmented attention, recurrent memory layers, and sparse attention patterns that selectively prioritize relevant tokens. This enables the processing and retention of over 120,000 tokens in a single session, fostering sustained contextual awareness.
The implications of this extended context window are profound. In practical terms, Claude 4 models can ingest and analyze entire books, legal contracts, or medical case files without resorting to artificial chunking or external memory systems. This holistic context understanding translates into more coherent and consistent outputs, with fewer instances of information loss or contradictory statements.
Use cases that benefit immensely from this capability include advanced document summarization, where the model synthesizes key insights from voluminous text; complex dialogue systems that require long-term memory of prior interactions; and multi-document synthesis tasks that amalgamate information from disparate sources. By eliminating the need for repeated context resets or manual information injection, Claude 4 streamlines workflows, reduces error rates, and enhances user trust.
Moreover, this large context capacity supports intricate reasoning structures, allowing the model to track dependencies across many discourse turns and interrelated concepts. This is particularly valuable in domains such as scientific research and legal analysis, where reasoning chains can span numerous pages and require rigorous logical consistency.
It is noteworthy that these context and benchmark performance enhancements are uniformly present in Sonnet 4.6 and Opus 4.6 models, ensuring a baseline of excellence across the family. Opus 4.7 builds upon this foundation by integrating vision capabilities, further enriching the model’s contextual comprehension through multimodal inputs.
Comparative Performance Analysis with Contemporary Models
In the competitive landscape of large language models, Claude 4’s performance merits detailed comparison with contemporaries such as OpenAI’s GPT-4 and its successors. While GPT-4 has been lauded for its robust natural language understanding and wide adoption, Claude 4 distinguishes itself through its strategic emphasis on context scale and modular extensibility.
Benchmark scores on SWE-Bench and GPQA Diamond reveal that Claude 4 models operate at or near the top echelons of accuracy and reasoning depth. Particularly in tasks requiring sustained inference over large textual inputs, Claude 4’s extended context window confers a decisive advantage, enabling more comprehensive and nuanced responses than models limited by smaller token capacities.
From a computational perspective, the Sonnet 4.6 model is optimized for low-latency inference, achieving faster response times suitable for interactive applications without substantial sacrifices in output quality. This contrasts with some larger, more complex models that incur higher computational costs due to increased parameter counts or more elaborate attention mechanisms.
The Opus variants prioritize enhanced reasoning and multimodal integration, which entail increased computational overhead and modest latency penalties. However, these trade-offs are offset by the enriched functional capabilities and improved accuracy in complex domains, making Opus models preferable for research, specialized enterprise applications, and multimodal AI systems.
In summary, Claude 4 models present a compelling value proposition: they offer superior contextual understanding and modular flexibility while maintaining operational efficiency. Their architecture enables unique use cases that remain challenging or infeasible for many competing models, particularly in knowledge-intensive and multimodal environments.
3. The ‘Agent Skills’ Framework: Modular Abilities On Demand
One of the most transformative innovations introduced by the Claude 4 family is the ‘Agent Skills’ framework—a modular system that revolutionizes how large language models extend and customize their capabilities. Traditionally, LLMs have been monolithic entities, with fixed parameters and capabilities baked into a single, static architecture. This approach, while effective, imposes limitations on scalability, specialization, and resource efficiency.
The Agent Skills framework reimagines this paradigm by enabling dynamic, on-demand loading of specialized modules—termed ‘skills’—that augment the base model’s functionality during runtime. Each skill encapsulates a distinct set of capabilities, fine-tuned to execute specific tasks or process particular data types. For example, dedicated skills might focus on advanced mathematical reasoning, domain-specific legal knowledge, code generation, data analytics, or, as in Opus 4.7, multimodal vision processing.
This modularity introduces several strategic advantages. Firstly, it promotes lean base models that avoid bloat by delegating specialized processing to discrete, purpose-built skill modules. This design reduces unnecessary computational load and accelerates inference for straightforward queries that do not require complex skills.
Secondly, Agent Skills afford unparalleled extensibility and adaptability. Organizations can develop proprietary skill modules tailored to their niche requirements, integrating them seamlessly into the Claude 4 ecosystem through well-defined APIs and interface protocols. This capability is especially valuable in sectors with stringent domain specificity—such as healthcare, where HIPAA-compliant medical knowledge skills can be integrated, or in finance, where regulatory compliance modules ensure adherence to evolving standards.
Thirdly, the dynamic loading mechanism empowers real-time adaptability. Claude 4 models monitor the conversational context or task parameters to intelligently determine when to invoke particular skills. Upon detecting a relevant need—for instance, a request involving complex code synthesis or visual data interpretation—the model loads the corresponding skill module, executes the specialized processing, and unloads the skill upon task completion to conserve resources.
Technically, Agent Skills interface with the base model through rigorous API contracts that preserve state consistency and facilitate smooth data exchange. The framework supports both stateless skills, which operate independently per invocation, and stateful skills, which maintain context across multiple interactions to enable iterative reasoning and progressive refinement. This flexibility allows development of sophisticated multi-step workflows, where different skills collaborate seamlessly within a single session.
The implications for user experience are significant. End-users benefit from an AI system that intuitively adapts to their requests’ complexity and domain, providing precise, contextually rich responses without burdening the system with unnecessary overhead. Developers gain a modular architecture that simplifies maintenance, facilitates incremental upgrades, and encourages innovation through skill module development.
In the Opus 4.7 model, the Agent Skills framework has been expanded to encompass vision-related modules, enabling the model to process images, videos, and other visual data with high fidelity. These skills include image recognition, scene understanding, visual question answering, and multimodal data fusion, thereby extending Claude 4’s applicability into new frontiers of AI-assisted interaction.
Overall, the Agent Skills framework epitomizes a shift toward more adaptable, scalable, and maintainable AI architectures, aligning with broader trends in software engineering and system design toward modularity and composability.
4. Vision Improvements in Opus 4.7 and Choosing Between Claude 4 and ChatGPT
The Opus 4.7 variant encapsulates the Claude 4 family’s most advanced capabilities, primarily through its integration of sophisticated vision processing modules within the Agent Skills framework. This multimodal enhancement addresses a critical frontier in AI research—the seamless fusion of visual and textual information to support richer, more context-aware interactions.
Opus 4.7’s vision improvements span several key dimensions. Firstly, the model supports high-resolution image analysis, leveraging convolutional neural network (CNN) backbones and vision transformer (ViT) architectures fine-tuned for detailed object detection, scene parsing, and semantic segmentation. This enables the model not only to recognize discrete objects within an image but also to understand their relationships and contextual significance within complex scenes.
Secondly, the variant exhibits enhanced visual question answering (VQA) capabilities. By combining advanced attention mechanisms across modalities, Opus 4.7 can interpret user queries regarding images, diagrams, charts, and other visual stimuli, producing precise and contextually appropriate responses. The underlying training regimen incorporates large-scale multimodal datasets, such as image-caption pairs, video transcripts, and annotated visual reasoning corpora, which facilitate robust cross-modal alignment and generalization.
Thirdly, Opus 4.7 augments image generation assistance and editing workflows. While not primarily an image synthesis model like diffusion-based generators, it excels in generating detailed textual instructions and suggestions for visual content creation and modification. This capability supports creative professionals and designers by integrating textual and visual modalities into cohesive, iterative workflows.
The integration of vision capabilities within the Agent Skills framework ensures that these computationally intensive processes are invoked judiciously, maintaining efficiency during interactions that do not require visual processing. The modular nature of these skills also simplifies updates and extensions, allowing ongoing improvements in vision technologies to be incorporated without retraining the entire base model.
Choosing Between Claude 4 and ChatGPT: Complex Reasoning Versus Speed
In the contemporary AI ecosystem, Claude 4 models coexist alongside OpenAI’s ChatGPT variants, each offering distinct advantages and architectural philosophies. Selecting the appropriate model for a given application involves evaluating a nuanced trade-off between reasoning complexity, contextual depth, and operational speed.
Claude 4 models, particularly the Opus variants, excel in applications demanding deep, sustained reasoning over extensive context windows. Their benchmark-leading performance in semantic understanding and question answering reflects their ability to navigate intricate, multi-step reasoning processes and synthesize large bodies of knowledge. The Agent Skills framework further enhances this capability by enabling domain-specific expertise and multimodal integration, making Claude 4 exceptionally well-suited for research assistance, legal analysis, scientific exploration, and other knowledge-intensive tasks.
However, these strengths come with certain operational considerations. The invocation of specialized skills and processing of large multimodal inputs incur higher computational costs, resulting in increased latency compared to more streamlined models. Therefore, in scenarios where rapid response times and high throughput are paramount—such as customer service chatbots, real-time interactive assistants, or latency-sensitive applications—ChatGPT models, especially the GPT-4 Turbo variant, often provide a more expedient solution.
ChatGPT’s architecture is optimized for efficient inference, achieving a balance between conversational fluency and speed that supports dynamic, low-latency interactions. While its context window and reasoning capabilities have improved over successive iterations, they generally remain more modest than Claude 4’s expansive context and modular flexibility. Nonetheless, ChatGPT’s robust generalist performance and optimized infrastructure make it a practical choice for many real-world deployments.
Ultimately, the choice between Claude 4 and ChatGPT should be informed by the specific parameters of the intended application. For complex, knowledge-rich workflows requiring deep contextual understanding and domain-specialized reasoning, Claude 4’s architectural innovations provide a decisive edge. Conversely, for applications prioritizing rapid, scalable conversational engagement with moderate reasoning demands, ChatGPT remains a highly effective and accessible option.
Many organizations may also find value in hybrid deployment strategies, leveraging the complementary strengths of both model families. For instance, ChatGPT can serve as a front-line conversational interface, handling routine queries and swift interactions, while Claude 4 can be engaged for more demanding analytical tasks or multimodal processing. Such hybrid architectures maximize the overall efficacy of AI systems by tailoring model usage to task complexity and latency requirements.
Useful Links
- Transformer Architectures in AI – Arxiv
- OpenAI Research Publications
- SWE-Bench Benchmark Suite
- GPQA Diamond Benchmark Details
- Modular Large Language Models – Hugging Face Blog
Conclusion
The Claude 4 model family, epitomized by Sonnet 4.6, Opus 4.6, and Opus 4.7, represents a significant milestone in the evolution of artificial intelligence language models. By integrating an expansive context window, a pioneering modular ‘Agent Skills’ framework, and advanced vision capabilities, this family delivers unparalleled proficiency in complex reasoning, domain-specific application, and multimodal interaction. Its benchmark performance validates its standing as a formidable tool for knowledge-intensive workflows and cutting-edge AI deployments.
When positioned alongside contemporaries such as ChatGPT, Claude 4 offers distinct advantages in reasoning depth and contextual breadth, balanced against considerations of computational latency and operational speed. This nuanced trade-off necessitates careful evaluation of use case requirements to ensure optimal model selection and deployment strategy.
Looking forward, the modular and extensible design principles exemplified by Claude 4 provide a promising blueprint for the next generation of scalable, adaptable AI systems. By enabling dynamic capability augmentation and seamless integration of multimodal inputs, Claude 4 lays the groundwork for increasingly sophisticated and human-aligned AI assistants.
Practitioners, developers, and decision-makers are encouraged to explore the linked internal resources for deeper insights into transformer architectures, modular AI system design, and the expanding frontier of multimodal AI advances. Through such engagement, the AI community can continue to push the boundaries of what intelligent systems can achieve, fostering innovations that enhance productivity, creativity, and understanding across diverse domains.
For further exploration of related technologies and benchmarks, readers may consult the internal resources linked throughout this article, including
The convergence of multiple AI models into coordinated agent systems is transforming how enterprises approach automation. Our analysis of how multi-model AI agents are reshaping enterprise operations examines the architectural patterns and real-world deployments driving this shift toward autonomous, multi-step business workflows.
,
The discipline of prompt engineering has evolved significantly with the emergence of agentic coding tools. Our detailed tutorial on advanced prompt engineering for AI coding agents covers the latest techniques for crafting precise, context-rich instructions that guide AI models through complex multi-file development tasks.
, and
The ability to control Codex remotely opens new possibilities for developers who need to manage coding tasks on the go. Our tutorial on using OpenAI Codex from mobile devices via remote SSH, hooks, and mobile steering provides step-by-step instructions for configuring remote access and managing Codex sessions from iPhone and iPad.
.
Access 40,000+ AI Prompts for ChatGPT, Claude & Codex — Free!
Subscribe to get instant access to our complete Notion Prompt Library — the largest curated collection of prompts for ChatGPT, Claude, OpenAI Codex, and other leading AI models. Optimized for real-world workflows across coding, research, content creation, and business.