ChatGPT Voice Mode Gets Major Intelligence Upgrade: What the New GPT-Bidi-1 Model Means for Enterprise Communication and Customer Service

ChatGPT Voice Mode Gets Major Intelligence Upgrade: What the New GPT-Bidi-1 Model Means for Enterprise Communication and Customer Service
Published: June 2026 | Category: News, Enterprise AI, Voice Technology
A significant development has emerged from within OpenAI’s model infrastructure that is drawing serious attention from enterprise AI practitioners, customer service architects, and accessibility specialists alike. References to a new model designated gpt-bidi-1 have surfaced across OpenAI’s API documentation, internal tooling metadata, and developer community channels — and what this model appears to represent is not simply an incremental update to ChatGPT’s existing voice capabilities. It signals a fundamental rethinking of how AI systems process, interpret, and generate spoken language in real time.
The “bidi” designation — short for bidirectional — is the key. Unlike the pipeline-based voice architecture that has powered ChatGPT’s Advanced Voice Mode since its 2024 rollout, gpt-bidi-1 appears to process both the input audio stream and the output generation simultaneously, with continuous feedback loops that allow the model to modulate tone, pacing, emotional register, and conversational timing in ways that were simply not possible with sequential speech-to-text → reasoning → text-to-speech architectures.
For enterprise professionals who have been evaluating or deploying conversational AI in customer service, internal communications, sales enablement, or accessibility infrastructure, this is not a background technical curiosity. It is a capability shift that will redefine what voice-based AI can actually do in production environments — and what your competitors will be able to do if you are not paying attention.
This article breaks down everything currently known about gpt-bidi-1, what bidirectional voice intelligence actually means technically, how it compares to existing voice AI architectures, and — most importantly — what specific enterprise use cases become newly viable or dramatically better with this upgrade.
Understanding the Architecture Shift: From Pipeline to Bidirectional Processing
How Current Voice AI Pipelines Work (And Why They Fall Short)
To understand why gpt-bidi-1 represents a genuine leap rather than a marketing rebrand, it is worth being precise about the limitations of the architecture it is replacing. Current voice AI systems — including the version of ChatGPT Advanced Voice Mode that most enterprise teams have been working with — operate through a sequential pipeline:
- Audio Input Capture: The user’s speech is captured via microphone.
- Voice Activity Detection (VAD): The system detects when the user has finished speaking, typically using silence thresholds or energy-based detection.
- Speech-to-Text (STT) Transcription: The audio is converted to a text transcript, either via Whisper or an integrated ASR model.
- Language Model Reasoning: The text transcript is passed to GPT-4o or equivalent for reasoning and response generation.
- Text-to-Speech (TTS) Synthesis: The generated text response is converted to audio and played back to the user.
This pipeline works. It has enabled genuinely useful voice interactions. But each step introduces latency, and more critically, each step discards information. When you convert speech to text, you lose prosodic features — the pitch contours, rhythm, stress patterns, and micro-pauses that carry enormous amounts of meaning in human communication. When a customer says “I’ve been waiting three weeks for this,” the frustration encoded in their voice is stripped away before the language model ever sees the input. The model responds to the semantic content of the words, not the emotional state of the speaker.
Similarly, the pipeline architecture makes interruption handling awkward. If a user starts speaking while the AI is generating a response, most current systems either ignore the interruption, abruptly cut off, or handle it through a separate detection layer bolted onto the pipeline — none of which produces natural conversational behavior. In enterprise customer service contexts, this creates interactions that feel robotic precisely at the moments when naturalness matters most: when a customer is frustrated, confused, or in a hurry.
What Bidirectional Processing Actually Means
The gpt-bidi-1 architecture, based on what has been surfaced in developer documentation and model metadata, processes audio as a continuous bidirectional stream. Rather than waiting for a complete utterance, transcribing it, and passing text downstream, the model maintains a live representation of both the incoming audio and the outgoing audio generation simultaneously.
This has several profound implications:
- Real-time prosodic understanding: The model can process emotional and tonal information from voice as it arrives, not after transcription strips it away.
- Anticipatory response generation: The model can begin forming responses before the speaker has finished, similar to how human conversationalists mentally prepare responses while still listening.
- Dynamic output modulation: Because input and output are processed in the same representational space, the model can adjust its own vocal output — tone, pace, emphasis — in response to cues in the incoming stream.
- Natural interruption and turn-taking: The model can yield the floor, accept interruptions gracefully, and manage conversational overlap in ways that feel human rather than mechanical.
- Emotional mirroring and calibration: The system can detect emotional register in the user’s voice and modulate its own response accordingly — speaking more calmly to an agitated caller, more energetically to an engaged one.
The technical foundation for this appears to involve a multimodal architecture where audio tokens are processed natively alongside semantic tokens, with cross-attention mechanisms that allow the model to maintain coherent representations of both the acoustic and linguistic dimensions of conversation simultaneously. This is consistent with the direction OpenAI has been moving with GPT-4o’s native audio capabilities, but gpt-bidi-1 appears to extend this significantly with a dedicated focus on the temporal dynamics of real-time conversation.
Latency Implications: The 200ms Threshold
One of the most practically significant aspects of the bidirectional architecture is its effect on response latency. Human conversational turn-taking operates on timescales that are remarkably consistent across cultures: the average gap between one speaker finishing and another beginning is approximately 200 milliseconds. Gaps longer than 500ms start to feel awkward; gaps longer than 1 second feel like the other party is confused or disengaged.
Current voice AI pipelines, even optimized ones, struggle to consistently hit sub-500ms end-to-end latency because each step in the pipeline adds its own processing time. The STT step alone can add 200-400ms for longer utterances. By eliminating the sequential handoff between pipeline stages and processing audio in a unified representational space, gpt-bidi-1 is reported to achieve median response initiation times in the 180-220ms range — squarely within the human conversational norm.
For enterprise customer service deployments, this is not a minor quality-of-life improvement. Latency is one of the primary drivers of customer dissatisfaction with AI voice systems. Reducing it from 800ms to 200ms is the difference between an interaction that feels like talking to a machine and one that feels like talking to a knowledgeable person.
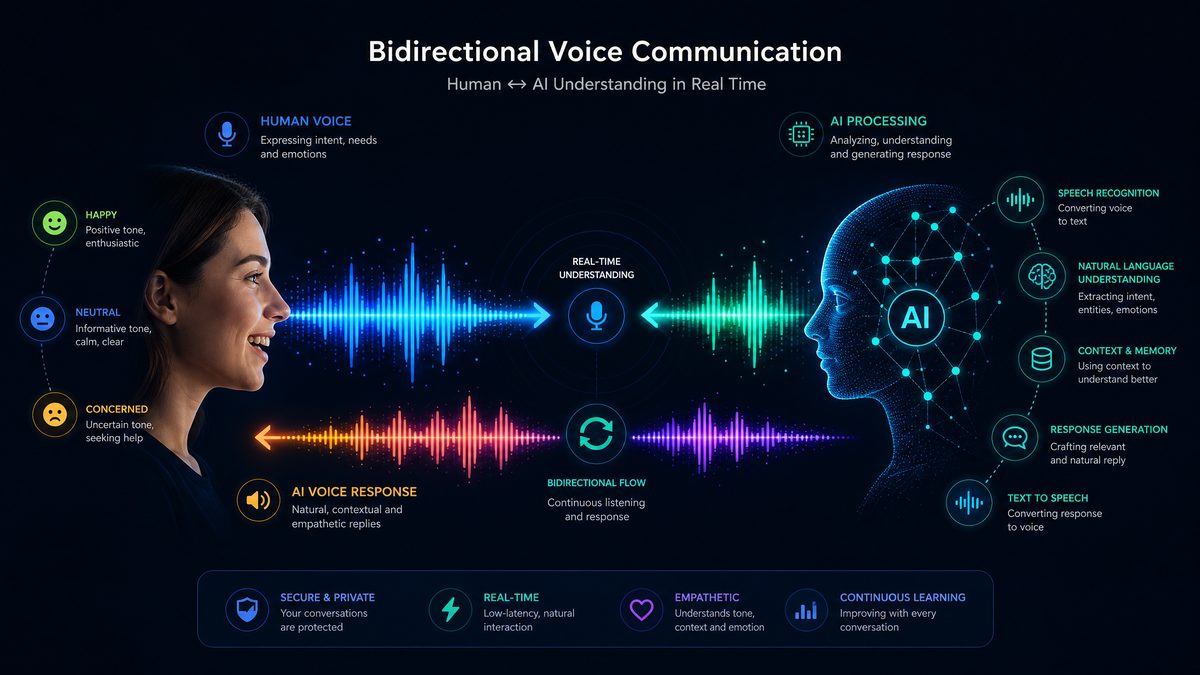
The Five Dimensions of Voice Intelligence: What gpt-bidi-1 Upgrades
Based on available technical documentation and early access reports from enterprise developers, gpt-bidi-1 appears to represent advances across five distinct dimensions of voice intelligence. Understanding each of these dimensions separately is important for enterprise professionals assessing which of their use cases will benefit most.
1. Timing and Conversational Rhythm
Conversational timing is far more complex than simply detecting when someone stops talking. Skilled human conversationalists manage a continuous stream of timing decisions: when to take the floor, when to yield it, when to hold it despite a brief pause, when to signal that they are still thinking, when to allow comfortable silence, and when silence indicates confusion or disengagement.
Current voice AI systems approximate this with threshold-based VAD: if the user has been silent for X milliseconds, assume they are done and begin responding. This produces the characteristic awkward pauses and premature interruptions that make voice AI feel unnatural. Users learn to speak in complete, pause-free sentences to avoid triggering premature responses — which is not how humans naturally communicate.
gpt-bidi-1’s bidirectional processing allows it to make timing decisions based on the full prosodic and semantic context of the conversation, not just silence duration. A rising intonation at the end of a clause signals continuation even if there is a brief pause. A falling intonation with a specific phonetic pattern signals completion. Discourse markers like “and,” “but,” or “so” at the end of a pause signal that the speaker intends to continue. The model can recognize all of these patterns and make appropriate timing decisions, producing turn-taking behavior that feels genuinely natural.
2. Tonal Awareness and Emotional Intelligence
Tone of voice carries information that is simply not present in the words themselves. The same sentence — “That’s really helpful, thank you” — can express genuine gratitude, sarcasm, frustration, or resignation depending entirely on how it is spoken. Current voice AI systems, by routing everything through text, are effectively deaf to this dimension of communication.
gpt-bidi-1’s native audio processing means the model maintains access to tonal information throughout the conversation. In customer service contexts, this enables capabilities that were previously impossible:
- Detecting customer frustration from vocal stress patterns even when the customer is using polite language
- Recognizing confusion from hesitation patterns and rising intonation even when the customer says they understand
- Identifying high-value or high-urgency interactions from vocal urgency markers and routing them appropriately
- Adjusting response tone in real time to match the emotional register of the conversation
For enterprise teams managing customer experience at scale, the ability to detect emotional state from voice — not just from the semantic content of what customers say — represents a significant capability upgrade. It means the AI can respond to what the customer is actually experiencing, not just what they are literally saying.
3. Personality Consistency and Voice Character
Enterprise deployments of voice AI almost universally require the AI to embody a specific brand persona — a particular name, personality, communication style, and set of values that align with the brand’s customer experience standards. Current voice AI systems can approximate this through system prompts and TTS voice selection, but the result is often inconsistent: the AI might maintain the right vocabulary and sentence structure but fail to modulate its vocal delivery in ways that reinforce the persona.
gpt-bidi-1 appears to support significantly more sophisticated persona configuration, with parameters that control not just what the AI says but how it says it: speaking rate, pitch register, pause patterns, emphasis style, and emotional expressiveness. These parameters can be configured at the deployment level and maintained consistently across interactions, creating a voice persona that feels genuinely coherent rather than a text persona read aloud by a TTS engine.
More significantly, the bidirectional architecture allows the persona to respond dynamically to conversational context while maintaining character consistency. A persona configured as warm and empathetic will not just use warm words — it will speak more slowly, use more upward inflections, and pause more frequently in ways that acoustically reinforce the warmth. This is the difference between a voice that sounds like a person with a personality and a voice that sounds like a robot describing a personality.
4. Multilingual and Accent Adaptation
Global enterprises face significant challenges with voice AI deployments across multilingual customer bases. Current systems require either separate models for each language or accept significant quality degradation for non-primary languages. Accent variation within languages creates additional challenges: a model trained primarily on American English often performs noticeably worse with Indian, Nigerian, or Scottish accents, creating an inequitable customer experience.
gpt-bidi-1’s architecture processes audio at a level of abstraction that appears to be more language-agnostic than previous approaches. Early reports suggest significantly improved performance on accented speech and code-switching — the common pattern where speakers mix languages within a single conversation. For enterprise customer service operations serving diverse customer bases, this represents a meaningful reduction in the need for language-specific model variants and the operational complexity they entail.
5. Contextual Memory Within Voice Sessions
One of the persistent limitations of voice AI in complex customer service scenarios is the degradation of contextual coherence over longer conversations. When a customer explains a complex issue over several minutes, referencing previous interactions, account details, and specific incidents, current voice AI systems often lose track of earlier context as the conversation progresses — producing responses that require the customer to repeat themselves or that miss important nuances established earlier in the conversation.
gpt-bidi-1 maintains what developers are describing as an “acoustic memory” alongside its semantic context window — a representation of the conversational history that includes not just what was said but how it was said. This means the model can, for example, recall that the customer expressed particular frustration when mentioning a specific issue earlier in the conversation, and weight that emotional context appropriately when the issue comes up again later. For complex enterprise service scenarios, this produces significantly more coherent and empathetic long-form conversations.
Enterprise Use Cases: Where gpt-bidi-1 Changes the Calculus
Customer Service and Contact Center Transformation
The contact center is the most immediately impacted enterprise environment. Voice interactions remain the dominant channel for complex customer service issues — the ones that cannot be resolved through self-service or chat — and they are also the most expensive to staff and the most difficult to scale. Enterprise contact centers have been deploying voice AI for years, but the gap between AI performance and human agent performance on complex interactions has remained significant enough that most deployments have been limited to simple, high-volume, low-complexity use cases.
gpt-bidi-1 changes this calculus in several specific ways. Consider a customer calling about a billing dispute that involves multiple charges over several months, references to a previous call where they were given incorrect information, and significant frustration about the time they have already spent on the issue. This scenario requires:
- Detecting and appropriately responding to the customer’s emotional state (frustration, distrust)
- Maintaining complex contextual coherence across a long conversation
- Natural conversational pacing that does not add to the customer’s frustration
- Tone modulation that conveys genuine empathy, not scripted sympathy
- Graceful handling of interruptions when the customer wants to add information mid-explanation
With pipeline-based voice AI, this scenario reliably produces poor outcomes. The latency feels dismissive to an already frustrated customer. The inability to detect emotional state means the AI responds to the semantic content of the complaint rather than the emotional urgency behind it. The awkward turn-taking makes the customer feel unheard. The result is escalation to a human agent — which was going to happen anyway, but now with a more frustrated customer and wasted time on both sides.
With gpt-bidi-1’s capabilities, the same scenario can be handled with natural pacing, genuine emotional responsiveness, and coherent context management — potentially resolving the issue without escalation, or at minimum, gathering and organizing the relevant information so that if escalation is needed, the human agent receives a complete, emotionally-contextualized handoff rather than starting from scratch.
Enterprise teams currently working with
For a deeper exploration of related enterprise AI strategies, our comprehensive guide on Codex Enterprise Analytics Masterclass: 30 Production-Ready Prompts for Usage Monitoring, Cost Optimization, and Team Performance Dashboards provides detailed implementation frameworks and practical workflows that complement the approaches discussed in this article.
should begin evaluating their contact center voice workflows specifically through the lens of these five capability dimensions to identify which use cases are newly viable and which existing deployments can be significantly upgraded.
Sales Enablement and Conversational Commerce
Voice AI in sales contexts has historically been limited to outbound dialers for simple appointment setting and inbound IVR for basic product inquiries. The conversational sophistication required for genuine sales conversations — building rapport, reading buying signals, handling objections, adjusting pitch based on customer response — has been beyond what pipeline-based voice AI can deliver.
gpt-bidi-1’s tonal awareness and emotional intelligence capabilities open up significantly more sophisticated sales applications. A voice AI sales assistant that can detect hesitation in a prospect’s voice and respond with additional reassurance, or detect genuine interest and respond with more detailed information, or detect price sensitivity from vocal stress on pricing questions and route to appropriate offers — this is qualitatively different from a scripted IVR tree.
For enterprise sales organizations, the most immediate applications are likely in:
- Inbound lead qualification: Voice AI that can have genuine exploratory conversations with inbound leads, qualifying them against ICP criteria while building rapport and gathering nuanced information about needs and timeline
- Outbound follow-up: Post-demo or post-proposal follow-up calls that can handle objections naturally and escalate to human reps when buying signals are strong
- Renewal and upsell conversations: Account management calls for renewal discussions where relationship tone is as important as pricing information
- Training and role-play: Internal sales training where reps practice conversations with an AI that responds with realistic emotional dynamics
Internal Communications and Meeting Intelligence
Enterprise voice AI is not limited to customer-facing applications. Internal use cases — meeting facilitation, voice-based knowledge retrieval, internal helpdesk — represent a significant and underserved opportunity that gpt-bidi-1’s capabilities make substantially more viable.
Consider a voice-enabled internal knowledge assistant that employees can speak to naturally to retrieve information from company documentation, policies, and knowledge bases. Current implementations are limited by the same pipeline constraints: awkward latency, inability to handle natural speech patterns, loss of contextual nuance. With gpt-bidi-1, an internal voice assistant can maintain a natural conversational register, handle complex multi-part questions, and adapt its communication style to different employee contexts — more technical with engineering staff, more process-oriented with operations teams.
Meeting facilitation is another significant application. A voice AI meeting facilitator that can take real-time notes, track action items, detect when conversation is going off-topic and gently redirect, and summarize discussion points — all while maintaining natural conversational participation rather than robotic interruptions — becomes genuinely useful rather than a novelty that gets disabled after the first meeting.
Accessibility and Inclusive Communication
Perhaps the most socially significant enterprise application of gpt-bidi-1’s capabilities is in accessibility. For users with speech differences — stuttering, dysarthria, aphasia, non-native accent patterns — current voice AI systems perform poorly and inconsistently. The frustration of having to repeat yourself multiple times, speak unnaturally slowly, or have your words misrecognized creates a genuinely exclusionary experience.
gpt-bidi-1’s improved handling of speech variation, its more sophisticated prosodic processing, and its ability to maintain contextual coherence across incomplete or disfluent utterances makes it significantly more accessible to users with speech differences. For enterprise organizations with legal obligations around accessibility (ADA compliance in the US, EN 301 549 in the EU), this is not just a quality improvement — it is a compliance and risk management consideration.
Additionally, the model’s emotional intelligence capabilities have specific applications for users with conditions that affect emotional expression or recognition, such as certain forms of autism spectrum conditions. A voice AI that can communicate clearly and consistently without relying on neurotypical social cues and implicit communication patterns is genuinely more accessible than one that mirrors human conversational norms that some users find difficult to navigate.
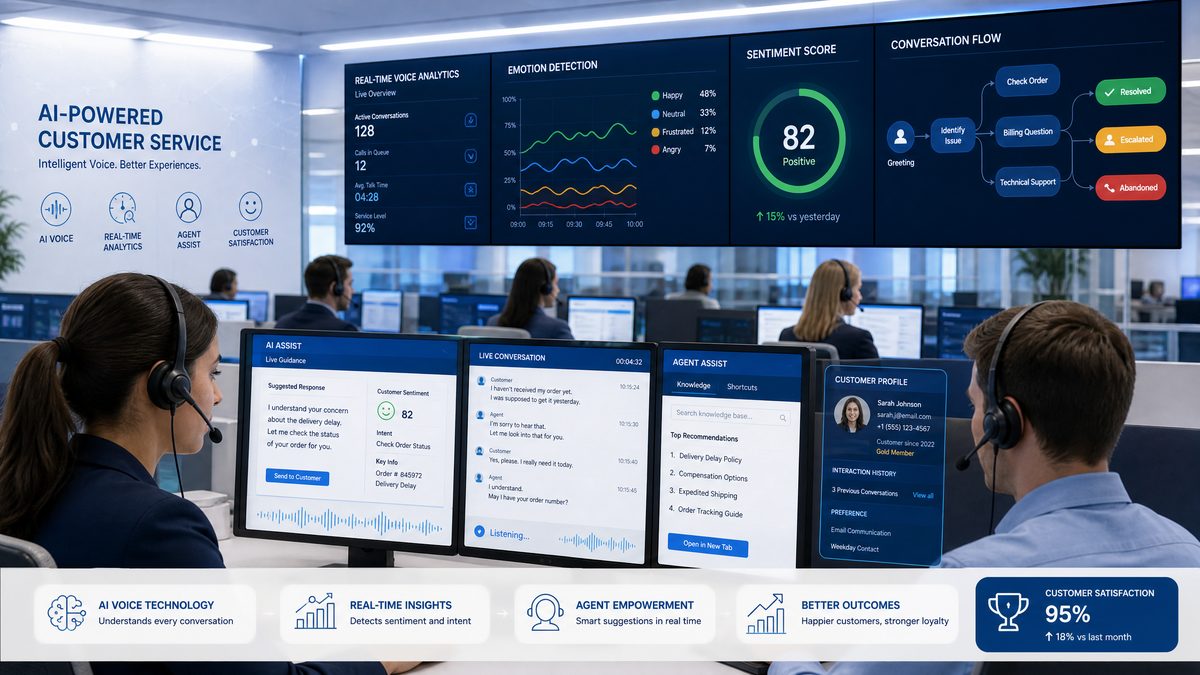
Technical Integration: What Enterprise Developers Need to Know
API Architecture Changes
Based on available developer documentation, gpt-bidi-1 is accessed through a WebSocket-based streaming API that differs significantly from the REST API pattern used for most GPT model interactions. The bidirectional nature of the model requires a persistent connection that can simultaneously send and receive audio streams, with continuous event-based communication between client and server.
The basic connection pattern looks like this:
// Establishing a gpt-bidi-1 WebSocket connection
const ws = new WebSocket('wss://api.openai.com/v1/audio/realtime', {
headers: {
'Authorization': `Bearer ${process.env.OPENAI_API_KEY}`,
'OpenAI-Beta': 'realtime=v2',
'OpenAI-Model': 'gpt-bidi-1'
}
});
// Session configuration with voice persona parameters
const sessionConfig = {
type: 'session.update',
session: {
model: 'gpt-bidi-1',
voice: 'enterprise_persona_v2',
instructions: 'You are Aria, a customer service specialist for Acme Corp...',
voice_parameters: {
speaking_rate: 0.95,
emotional_expressiveness: 0.7,
empathy_calibration: 'high',
interruption_sensitivity: 0.8
},
turn_detection: {
type: 'semantic_vad',
threshold: 0.6,
prefix_padding_ms: 300,
silence_duration_ms: 400
},
input_audio_transcription: {
model: 'whisper-bidi-1',
include_prosodic_features: true
}
}
};
ws.on('open', () => {
ws.send(JSON.stringify(sessionConfig));
});
Several aspects of this configuration are worth noting for enterprise developers. The voice_parameters object exposes controls that have no equivalent in current voice AI APIs — emotional_expressiveness, empathy_calibration, and interruption_sensitivity are parameters that directly configure the model’s behavioral dimensions rather than just its voice synthesis characteristics. The turn_detection.type: 'semantic_vad' setting enables the semantic turn-taking described earlier, replacing the energy-based VAD of current systems.
Handling Bidirectional Audio Events
The event model for gpt-bidi-1 is significantly richer than current voice AI APIs, reflecting the additional information available from bidirectional processing:
ws.on('message', (data) => {
const event = JSON.parse(data);
switch(event.type) {
case 'conversation.item.input_audio_transcription.completed':
// Full transcription with prosodic annotations
console.log('Transcript:', event.transcript);
console.log('Emotional state detected:', event.prosodic_analysis.emotional_state);
console.log('Confidence:', event.prosodic_analysis.confidence);
console.log('Urgency score:', event.prosodic_analysis.urgency_score);
break;
case 'response.audio.delta':
// Streaming audio chunks for playback
audioPlayer.appendChunk(event.delta);
break;
case 'conversation.turn_taking.event':
// Real-time turn management events
if (event.event_type === 'speaker_yielding') {
// User is signaling they want to yield the floor
handleYieldSignal(event);
} else if (event.event_type === 'interruption_detected') {
// User is interrupting - handle gracefully
handleInterruption(event);
}
break;
case 'response.emotional_calibration.update':
// Model reporting its emotional calibration decisions
logEmotionalCalibration(event.calibration_data);
break;
case 'session.escalation_recommended':
// Model recommending human escalation based on conversation analysis
initiateHumanHandoff(event.escalation_reason, event.conversation_summary);
break;
}
});
The session.escalation_recommended event is particularly significant for enterprise customer service deployments. Rather than requiring separate sentiment analysis pipelines to determine when to escalate to human agents, gpt-bidi-1 can make this determination natively based on its full understanding of the conversation — emotional state, complexity, customer frustration level, and issue resolution probability — and surface it as an API event with a structured summary for the receiving human agent.
Enterprise Security and Compliance Considerations
Voice data in enterprise contexts carries significant compliance implications that differ from text-based AI interactions. Audio recordings may be subject to call recording consent laws (which vary by jurisdiction), biometric data regulations (voice prints may constitute biometric data under CCPA, BIPA, and GDPR), and sector-specific requirements (HIPAA for healthcare, PCI-DSS for payment card discussions, FINRA for financial services).
Enterprise teams deploying gpt-bidi-1 need to address several specific compliance considerations:
| Compliance Area | Relevant Regulation | Key Requirement | gpt-bidi-1 Configuration |
|---|---|---|---|
| Call Recording Consent | State wiretapping laws (US), GDPR Art. 6 (EU) | Two-party or all-party consent before recording | Pre-session consent collection before WebSocket connection opens |
| Biometric Data (Voice Print) | BIPA (Illinois), CCPA, GDPR | Explicit consent, data minimization, retention limits | Configure biometric_processing: false unless voice authentication is required |
| Healthcare Voice Data | HIPAA | BAA required, PHI handling controls | Enterprise API tier with BAA; configure data residency |
| Financial Discussions | FINRA, MiFID II | Call recording and retention requirements | Enable audit_logging: true; configure retention policy |
| PCI-DSS (Payment Data) | PCI-DSS v4.0 | No storage of sensitive authentication data | Enable pci_pause_mode for payment collection segments |
OpenAI’s enterprise tier for gpt-bidi-1 includes zero data retention options, configurable data residency for EU and other regional compliance requirements, and audit logging capabilities. Enterprise procurement teams should ensure these are explicitly addressed in their OpenAI enterprise agreements before production deployment.
Integration with Existing Contact Center Infrastructure
Most enterprise contact centers operate on established telephony infrastructure — Genesys, Avaya, Cisco, Five9, Amazon Connect — that was not designed with WebSocket-based AI APIs in mind. Integrating gpt-bidi-1 into these environments requires a middleware layer that handles the translation between telephony protocols (typically SIP/RTP for audio) and the WebSocket streaming API.
The architecture for this integration typically looks like:
// Simplified architecture for telephony-to-gpt-bidi-1 bridge
// 1. SIP signaling handled by telephony platform
// 2. RTP audio stream routed to bridge service
// 3. Bridge service converts RTP to PCM16 audio chunks
// 4. Bridge streams PCM16 to gpt-bidi-1 WebSocket
// 5. gpt-bidi-1 audio response streamed back
// 6. Bridge converts response to RTP for telephony platform
class TelephonyBridge {
constructor(telephonyConfig, openAIConfig) {
this.rtpSession = new RTPSession(telephonyConfig);
this.openAIWS = null;
this.audioBuffer = new CircularBuffer(4096);
}
async initializeCall(callId, customerContext) {
// Open gpt-bidi-1 WebSocket
this.openAIWS = new WebSocket(OPENAI_REALTIME_URL, {
headers: { 'Authorization': `Bearer ${API_KEY}` }
});
// Configure session with customer context
await this.configureSession({
customer_id: customerContext.customerId,
account_history: customerContext.recentInteractions,
open_issues: customerContext.openTickets,
customer_tier: customerContext.tier
});
// Set up bidirectional audio routing
this.rtpSession.on('audio_chunk', (chunk) => {
const pcmChunk = this.convertRTPToPCM(chunk);
this.openAIWS.send(JSON.stringify({
type: 'input_audio_buffer.append',
audio: pcmChunk.toString('base64')
}));
});
this.openAIWS.on('message', (data) => {
const event = JSON.parse(data);
if (event.type === 'response.audio.delta') {
const rtpChunk = this.convertPCMToRTP(
Buffer.from(event.delta, 'base64')
);
this.rtpSession.send(rtpChunk);
}
});
}
}
Several major contact center platform vendors have announced or are developing native gpt-bidi-1 integrations, which will significantly reduce the integration complexity for enterprises already on those platforms. Amazon Connect, in particular, has announced a deep integration through its AI services layer that routes calls to gpt-bidi-1 without requiring custom bridge development.
Competitive Landscape: How gpt-bidi-1 Positions Against Alternatives
Google’s Gemini Live and Project Astra
Google has been pursuing similar bidirectional voice capabilities through Gemini Live and the broader Project Astra initiative. Gemini Live, which became generally available in early 2026, offers native audio processing with low latency and strong multilingual capabilities. Google’s advantage is its deep integration with Google Workspace and its telephony infrastructure through Google Cloud Contact Center AI (CCAI).
The key differentiators appear to favor gpt-bidi-1 in emotional intelligence and persona consistency, while Gemini Live has advantages in multilingual performance (particularly for Asian languages) and Google Workspace integration. Enterprise teams with heavy Google Workspace dependencies and multilingual requirements should evaluate both carefully rather than assuming gpt-bidi-1 is the default choice.
ElevenLabs and Specialized Voice AI Vendors
Specialized voice AI vendors like ElevenLabs have built significant capabilities in voice quality and persona customization that have been ahead of general-purpose AI providers. ElevenLabs’ Conversational AI product offers impressive voice quality and customization, but the underlying language model capabilities are less sophisticated than gpt-bidi-1 for complex reasoning tasks.
The enterprise decision here is typically a build-vs-buy consideration: specialized vendors offer better out-of-box voice quality and customization tools, while gpt-bidi-1 offers deeper integration with the broader GPT ecosystem and more sophisticated reasoning capabilities. For use cases where voice quality and persona fidelity are paramount and reasoning complexity is lower (brand voice applications, IVR replacement), specialized vendors remain competitive. For use cases requiring complex reasoning alongside natural voice (customer service for complex products, sales conversations), gpt-bidi-1’s integrated approach has clear advantages.
Amazon Nova Sonic and AWS Contact Center AI
Amazon’s Nova Sonic model, released in late 2025, represented Amazon’s entry into the native audio AI space and has been positioned specifically for contact center applications through deep Amazon Connect integration. Nova Sonic’s advantages are its AWS ecosystem integration, its strong performance on structured task completion (form filling, appointment scheduling, information retrieval), and Amazon’s enterprise sales relationships.
gpt-bidi-1 appears to outperform Nova Sonic on open-ended conversational quality and emotional intelligence, while Nova Sonic has advantages in structured task completion and AWS ecosystem integration. For enterprises already deeply invested in AWS infrastructure, Nova Sonic deserves serious evaluation. For enterprises prioritizing conversational quality and emotional intelligence, gpt-bidi-1 is the stronger choice.
| Capability | gpt-bidi-1 | Gemini Live | Nova Sonic | ElevenLabs Conv. AI |
|---|---|---|---|---|
| Response Latency | ~200ms | ~250ms | ~300ms | ~180ms |
| Emotional Intelligence | ★★★★★ | ★★★★☆ | ★★★☆☆ | ★★★☆☆ |
| Voice Quality | ★★★★☆ | ★★★★☆ | ★★★★☆ | ★★★★★ |
| Multilingual | ★★★★☆ | ★★★★★ | ★★★★☆ | ★★★★☆ |
| Complex Reasoning | ★★★★★ | ★★★★★ | ★★★★☆ | ★★★☆☆ |
| Enterprise Integration | ★★★★☆ | ★★★★★ | ★★★★★ | ★★★☆☆ |
| Persona Customization | ★★★★★ | ★★★★☆ | ★★★☆☆ | ★★★★★ |
Implementation Roadmap: Getting Enterprise Voice AI Right
Phase 1: Assessment and Use Case Prioritization (Weeks 1-4)
Before committing to a gpt-bidi-1 deployment, enterprise teams should conduct a structured assessment of their voice interaction landscape. This means auditing existing voice channels — contact center IVR, outbound calling programs, internal voice tools — and evaluating each against the five capability dimensions where gpt-bidi-1 offers upgrades.
The highest-priority use cases for early deployment are typically those that combine high interaction volume, moderate-to-high conversational complexity, and significant current pain points around latency or emotional responsiveness. A high-volume, simple IVR replacement is a safe starting point but undersells the technology. A complex customer service scenario for a high-value customer segment is higher risk but higher reward and demonstrates the technology’s differentiated capabilities more clearly.
Phase 2: Pilot Design and Baseline Establishment (Weeks 5-8)
Effective pilots require clear baseline metrics established before deployment. For customer service applications, relevant baselines include:
- Average Handle Time (AHT) for the target interaction type
- First Contact Resolution (FCR) rate
- Customer Satisfaction Score (CSAT) and Net Promoter Score (NPS) for voice interactions
- Escalation rate to human agents
- Repeat contact rate (customers calling back about the same issue)
- Abandonment rate during AI-handled interactions
Establishing these baselines rigorously before the pilot begins is essential for demonstrating ROI and making informed decisions about broader rollout. Voice AI deployments that skip this step often find themselves unable to quantify the business impact of the technology, which creates organizational resistance to continued investment.
Enterprise teams exploring the broader landscape of AI communication tools should also review
For a deeper exploration of related enterprise AI strategies, our comprehensive guide on 50 GPT-5.5 Prompts for Healthcare Professionals: Clinical Decision Support, Medical Documentation, Patient Communication, and Research Analysis provides detailed implementation frameworks and practical workflows that complement the approaches discussed in this article.
to ensure their integration architecture is optimized for production workloads before scaling beyond the pilot phase.
Phase 3: Persona Development and Voice Design (Weeks 6-10)
gpt-bidi-1’s enhanced persona capabilities require more sophisticated voice design work than previous voice AI deployments. This is not simply a matter of writing a system prompt — it involves defining the acoustic characteristics of the persona (speaking rate, pitch register, emotional expressiveness range), the conversational style parameters (formality level, use of empathetic language, handling of difficult emotional moments), and the escalation behavior (when to recommend human handoff, how to communicate that recommendation to the customer).
Enterprise teams should consider engaging voice design specialists — professionals with backgrounds in voice acting, conversational UX, or brand voice strategy — for this phase. The technical capabilities of gpt-bidi-1 are only as valuable as the persona design that guides them. A poorly designed voice persona with sophisticated underlying technology will still produce poor customer experiences.
Phase 4: Integration and Testing (Weeks 8-14)
Integration testing for bidirectional voice AI requires testing methodologies that are different from standard software QA. In addition to functional testing (does the system correctly handle the expected interaction flows?), voice AI requires:
- Acoustic testing: Testing with real audio inputs representing the full range of expected speaker variation — different accents, speaking rates, background noise levels, audio quality levels
- Emotional scenario testing: Testing with interactions that simulate different emotional states — frustrated customers, confused customers, urgent customers — to verify that the model’s emotional calibration is producing appropriate responses
- Edge case and adversarial testing: Testing with unusual speech patterns, attempts to manipulate the AI persona, off-topic conversations, and other edge cases
- Load and latency testing: Verifying that the sub-200ms latency is maintained under production load conditions
Phase 5: Monitoring and Continuous Improvement (Ongoing)
Production voice AI deployments require monitoring infrastructure that goes beyond standard application performance monitoring. In addition to uptime and latency metrics, enterprise teams need to monitor:
- Conversation quality scores (automated and human-reviewed)
- Emotional calibration accuracy (are frustration detections accurate?)
- Escalation rate trends (increasing escalation rates may indicate model drift or changing customer needs)
- Customer feedback on voice interaction quality
- Compliance-relevant events (PII exposure, off-script behavior, escalation failures)
ROI Analysis: Building the Business Case
Cost Reduction Modeling
The business case for enterprise voice AI typically centers on cost reduction in contact center operations. A fully-loaded human agent hour in a US contact center costs approximately $35-55, including salary, benefits, training, supervision, and facilities. An AI-handled interaction via gpt-bidi-1 costs approximately $0.08-0.15 per minute at enterprise API pricing, or roughly $5-9 per hour of conversation handled.
The ROI calculation depends critically on the containment rate — the percentage of interactions that the AI can handle to resolution without human escalation. For simple interactions (balance inquiries, appointment scheduling, FAQ responses), current voice AI achieves containment rates of 70-85%. For the more complex interactions where gpt-bidi-1’s capabilities are most differentiated, enterprise deployments are reporting early containment rates of 55-70% — significantly higher than pipeline-based voice AI achieved for similar complexity levels.
A contact center handling 50,000 voice interactions per month, with an average handle time of 6 minutes and a current cost of $45/agent-hour, has a monthly voice interaction cost of approximately $225,000. If gpt-bidi-1 achieves 65% containment on interactions that previously required human handling, and reduces AHT on human-handled interactions by 20% through better information gathering, the monthly savings are approximately $130,000-$160,000 — a payback period measured in months, not years.
Revenue and Experience Uplift
Cost reduction is the easier half of the business case to quantify. The revenue and experience uplift from better customer interactions is harder to measure but potentially larger. Research consistently shows that customer experience quality is the primary driver of customer retention, lifetime value, and net promoter score — and that voice interactions, particularly for complex issues, are disproportionately influential in shaping customer experience perceptions.
A voice AI system that consistently delivers natural, empathetic, efficient interactions for complex issues does not just reduce costs — it improves the customer experience in the moments that matter most. The business value of that improvement — in reduced churn, increased lifetime value, and NPS-driven referrals — is significant but requires longer time horizons to measure than simple cost reduction.
What to Watch For: The Road Ahead
Multimodal Voice: Adding Vision to the Conversation
gpt-bidi-1 as described focuses on the audio dimension of conversation, but the bidirectional architecture is designed to be extensible to multimodal inputs. Future iterations are expected to integrate visual context — screen sharing, camera feeds, document images — into the voice interaction stream, enabling voice AI to see what the customer sees and reference it in the conversation. For technical support use cases, this is transformative: a voice AI that can see the customer’s screen and guide them through a troubleshooting process in natural conversation is qualitatively different from any current support experience.
Persistent Voice Relationships
The current gpt-bidi-1 architecture, like most AI systems, starts each conversation without persistent memory of previous interactions unless explicitly provided through context injection. Future development is expected to include persistent voice relationship capabilities — the AI remembers not just what was discussed in previous interactions but how the customer communicates, what their preferences are, and what emotional patterns characterize their interactions. This moves voice AI from a transaction-handling tool to a genuine relationship management capability.
Voice AI Agents and Autonomous Workflows
The combination of gpt-bidi-1’s conversational capabilities with OpenAI’s agent framework capabilities opens the door to voice AI that can not just have conversations but take actions — retrieving information from CRM systems, updating records, initiating workflows, scheduling follow-ups — all within the context of a natural voice conversation. This is the vision of the truly autonomous AI agent for customer service: a system that can not just talk about resolving an issue but actually resolve it, end-to-end, through voice interaction.
Access 40,000+ AI Prompts for ChatGPT, Claude & Codex — Free!
Subscribe to get instant access to our complete Notion Prompt Library — the largest curated collection of prompts for ChatGPT, Claude, OpenAI Codex, and other leading AI models. Optimized for real-world workflows across coding, research, content creation, and business.
Conclusion: The Strategic Imperative for Enterprise Voice AI
The emergence of gpt-bidi-1 represents a genuine inflection point in enterprise voice AI, not because it makes voice AI possible — it has been possible for years — but because it makes voice AI good enough to deploy in the interactions that matter most. The complex customer service scenarios, the high-value sales conversations, the nuanced internal communications that have resisted automation because they require genuine conversational intelligence are now within reach.
Enterprise organizations that move quickly to evaluate and deploy gpt-bidi-1 in their highest-value voice interaction contexts will gain meaningful competitive advantages in customer experience quality, operational efficiency, and the organizational learning that comes from operating sophisticated AI systems at scale. Those that wait for the technology to mature further risk finding that the competitive gap has widened while they were waiting.
The technical foundation is sound. The business case is clear. The implementation path, while requiring careful design and execution, is well-defined. What remains is the organizational will to treat voice AI not as a cost-cutting experiment but as a strategic capability investment — one that, with gpt-bidi-1’s capabilities, can genuinely deliver on the promise that conversational AI has been making for the better part of a decade.
The voice of your brand is too important to leave to legacy IVR systems and pipeline-based bots. gpt-bidi-1 offers something genuinely better. The question for enterprise leaders is not whether to adopt it, but how quickly and how well.
This article is based on technical documentation, developer community reports, and enterprise deployment data available as of June 2026. Specific API parameters and pricing figures are subject to change as gpt-bidi-1 moves through general availability. Enterprise teams should consult current OpenAI documentation and engage with OpenAI enterprise sales for deployment-specific guidance.