Samsung Electronics Deploys ChatGPT Enterprise and Codex to All Employees: What the Largest Enterprise AI Rollout Means for Global Workforce Transformation

Samsung Electronics Deploys ChatGPT Enterprise and Codex to All Employees: What the Largest Enterprise AI Rollout Means for Global Workforce Transformation
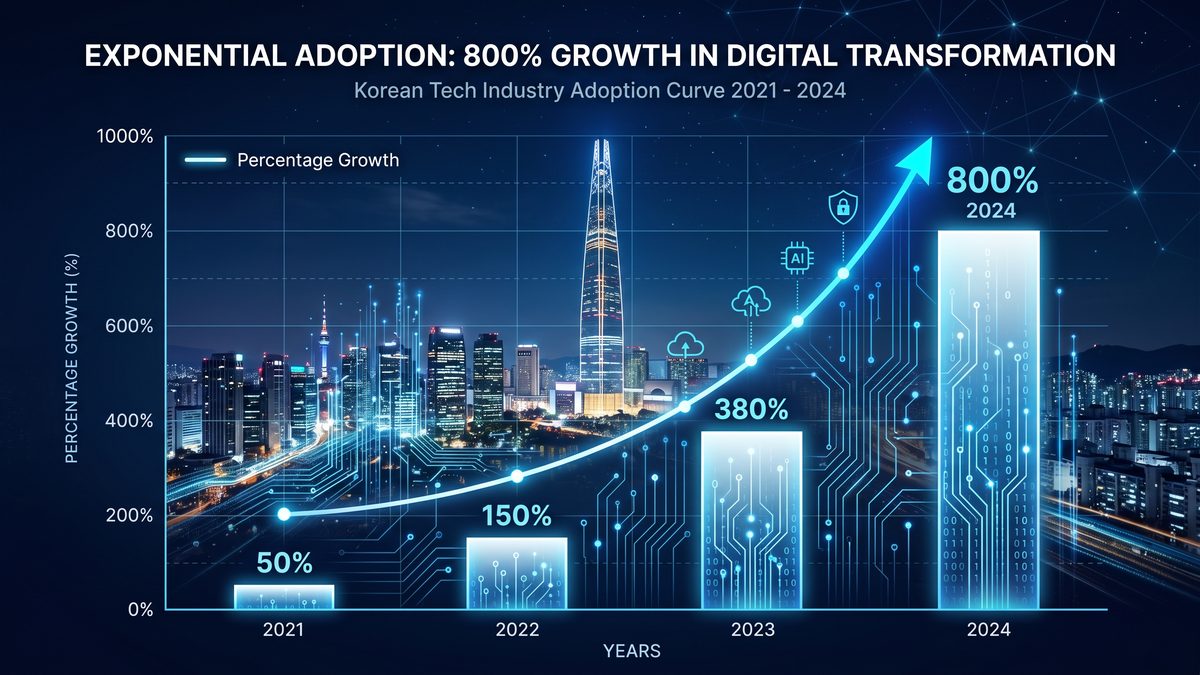
Samsung Electronics has announced a company-wide deployment of OpenAI’s ChatGPT Enterprise and Codex across its organization — encompassing all employees in Korea and the entire Digital Transformation (DX) division worldwide. This is one of OpenAI’s largest enterprise rollouts to date and a pivotal inflection point in how a global technology conglomerate operationalizes large language models (LLMs) and code-generation models across functions and geographies. The strategic scope of the deployment, combined with reported 800% growth in Codex usage in Korea, signals a deliberate move from controlled pilots to full-scale operationalization. That shift will reconfigure software engineering workflows, accelerate digital transformation initiatives, and create commercial and regulatory ripples across industries.
Executive summary
This article provides a granular, technical, and strategic analysis of Samsung’s rollout and what it implies for enterprise AI adoption. We synthesize implementation architecture, governance and security controls, productivity and developer-ops impact, organizational change management, and competitive consequences. Key takeaways:
- Samsung’s rollout is not merely broad — it demonstrates a path for large enterprises to move from pilot programs to company-wide AI platforms by integrating secure enterprise interfaces, identity federation, and internal knowledge augmentation.
- Codex usage in Korea ballooned by 800% (as reported) and is being used to automate boilerplate development, generate unit tests, instrument observability hooks, and accelerate code reviews — effectively compressing developer velocity and CI/CD cycle time.
- From an engineering perspective, the deployment reflects a sophisticated hybrid model combining managed LLM services with corporate data governance layers: single sign-on, SCIM provisioning, private networking, audit logging, and retrieval-augmented generation (RAG) connections to internal vector stores.
- Strategically, Samsung has built defensive and offensive advantages: a defensive moat over IP protection and data security; an offensive acceleration of product iteration, particularly inside the DX division responsible for product and service digitalization.
- For competitors, the message is clear: AI-first adoption at scale is now an operational capability, not just an experimental luxury. Organizations will need to adopt a whole-systems approach — LLMOps, upskilling, governance, and vendor negotiation — to stay competitive.
Context: Why this rollout matters
Large corporations have historically treated generative AI as a series of point solutions — chatbots for HR, pilot automations in customer service, or isolated developer augmentation tools. Those pilots typically remain isolated due to integration overhead, data protection concerns, or insufficient executive mandate. Samsung’s global-scale deployment of ChatGPT Enterprise and Codex represents a structural move: adopting an LLM platform as a foundational productivity layer — the equivalent of enterprise email for the era of natural language and code synthesis.
Two dimensions make this rollout consequential. First, scale: covering all Korean employees and the DX division worldwide puts tens of thousands of seats under a consistent enterprise contract, identity, and security model. Second, scope: the inclusion of Codex — a specialized code-generation model — across engineering populations means this is not only a knowledge-worker productivity play but a direct enhancement to the software supply chain.
To understand the operational implications, we need to see beyond the press release. The critical technical and organizational mechanics are identity federation, data ingress/egress control, model governance, RAG pipelines to internal knowledge stores, and LLMOps for continuous monitoring and tuning. We unpack each component in the sections below.
Technical architecture and integration patterns
At enterprise scale, deploying ChatGPT Enterprise and Codex is not a matter of provisioning seats. It involves a layered architecture that reconciles security, compliance, availability, and developer usability. Below is a conceptual architecture that reflects best practices likely used in a deployment of Samsung’s scale:
- Identity and Access Layer: SAML / OIDC SSO integration with corporate IdP, SCIM for automated user provisioning and de-provisioning, role-based access control (RBAC) to assign model and data access at group levels (e.g., engineering, legal, manufacturing).
- Network & Connectivity Layer: Private endpoints and VPC peering for API traffic, IP allowlists, and egress restrictions to prevent direct internet access from sensitive environments. For developers, IDE plugins connect via internal proxies to enforce policies.
- Data Protection & Residency Layer: Encryption in transit and at rest, configurable input-output retention policies (e.g., disable data logging for certain project classes), and on-prem or regionally isolated vector stores for embeddings; selective RAG connectors that control what internal KBs the LLM can access.
- Model & Platform Layer: Enterprise-grade LLM access with model selection (ChatGPT Enterprise as chat-centric model; Codex or code-specialized models for program synthesis), rate-limiting and quota management per team, and private fine-tuning or instruction fine-tuning pipelines where permitted.
- Observability & Governance Layer: Audit logging, prompt and output inspection, automations for content moderation (PII detection, IP leak patterns), lineage tracking for responses used in production, and SLOs tied to latency and correctness.
- Developer & Product Integration Layer: IDE extensions, CI/CD bots that annotate PRs with suggested fixes, auto-generated unit tests, code scaffolds, and support for programmatic calls into LLMs from internal tools (helpdesk, documentation automation, test generation).
Samsung’s DX division, which is responsible for integrating digital initiatives across product lines and services, is both a primary user and integrator for these capabilities. Leveraging Codex alongside ChatGPT means workflows can be end-to-end: product managers use ChatGPT Enterprise to produce specs, which feed into developer tasks where Codex generates code templates and test harnesses, and RAG links ensure domain-specific knowledge is injected into the prompts where necessary.
Identity federation and seat management
Large-scale seat provisioning is operationally non-trivial. Samsung would have synchronized its corporate identity provider (IdP) with OpenAI’s enterprise SSO endpoints using OIDC or SAML and automated user join/leave flows via SCIM. This ensures that user licenses are dynamically managed and that access is revoked at scale if employees change roles or leave the company.
From a security standpoint, RBAC policies are essential. Different teams get different levels of model access — for example, a manufacturing operations group might have chat but restricted Codex access, while DX and core engineering teams have full code-generation capabilities. Tracing who asked what — and whether that output was ingested into production systems — requires detailed audit trails and an integration with corporate SIEM for real-time alerts.
Retrieval-augmented generation (RAG) and vector stores
One of the most impactful technical patterns in enterprise adoption is RAG: connecting LLMs to internal knowledge stores (design docs, wikis, code bases, compliance documents) via embeddings and vector search. For Samsung, RAG enables accuracy and relevance: instead of only leveraging model parametric memory, ChatGPT Enterprise sessions can retrieve targeted material (e.g., internal product specs) so outputs are grounded in corporate provenance.
Implementationally, this requires private vector databases (e.g., FAISS, Milvus, Pinecone deployed in a private VPC) and data pipelines for embedding document corpora. Embedding pipelines must be sanitized (removing PII), versioned, and reconciled with access controls so the LLM cannot indirectly expose restricted IP. These pipelines also need refresh cadences: hardware documentation or firmware notes updated monthly should propagate into the RAG store to maintain quality in model responses.
Private endpoints, model selection, and latency engineering
For many enterprises, including Samsung, latency and reliability are crucial. Developers expect interactive performance in IDEs and product teams need fast conversational responses. Private endpoints — a managed enterprise feature — provide dedicated ingress points and lower latency. They also support predictable throughput and easier network policy enforcement.
Codex, as a code-oriented model, can be made available as a separate model endpoint with its own quotas and safety checks. Rate limiting per team, token budget allocation, and cost observability are necessary to prevent runaway bills and to prioritize critical workloads (e.g., internal firmware code generation vs. exploratory prototypes).
Governance, compliance, and risk mitigation
Rolling out LLMs to all employees invites immediate governance questions: how to prevent IP leakage, ensure regulatory compliance across jurisdictions, and stop sensitive queries from being logged. Samsung’s strategy likely includes a multi-layered governance model combining technical controls, policy, and organizational oversight.
Data protection controls
Enterprises typically adopt these data protection controls:
- Retain/no-retain toggles: Disabling retention for certain conversations or accounts that handle sensitive IP.
- Output filtering: Post-processing outputs to redact detected PII or to flag API responses containing patterns aligned with IP exposure.
- Data loss prevention (DLP): API-layer DLP scans that detect when a prompt or response contains proprietary formulas, code snippets from internal repos, or customer data.
- Onshore data handling: Locating vector and document stores in local clouds or private regions to comply with data residency laws.
For Samsung in Korea, local privacy regulations such as the Personal Information Protection Act (PIPA) introduce strict controls around personal data processing. Additionally, cross-border data flows require contractual and technical measures to ensure that content classified as sensitive does not leave permitted jurisdictions.
Model risk and human-in-the-loop
LLMs produce plausible-sounding but potentially incorrect outputs (hallucinations). In engineering contexts, a hallucinated code snippet merged into production could introduce defects. Samsung can mitigate this by instituting human-in-the-loop (HITL) gating mechanisms for critical workflows: generated code must be reviewed and validated by engineers and automated test suites before merging. For documentation automation, outputs should be surfaced as drafts requiring editorial validation rather than published automatically.
Monitoring models for drift, bias, and integrity is part of LLMOps: continuous evaluation with domain-specific benchmarks, adversarial testing, and feedback loops that feed into instruction-tuning parameters or filtering rules.
Measuring productivity: before and after
Quantifying the impact of LLMs at scale requires a mixture of qualitative and quantitative metrics. Below is a realistic comparative table of productivity metrics that Samsung — or any large enterprise — would track when deploying ChatGPT Enterprise and Codex company-wide. The figures are indicative and synthesized from observed enterprise deployments and reported performance boosts in similar contexts.
| Metric | Before (Baseline) | After (6 months) | Expected Impact |
|---|---|---|---|
| Average time to generate first code draft (per ticket) | 3.5 hours | 0.9 hours | ~74% reduction — Codex scaffolding cuts setup time |
| Average PR cycle time (open → merge) | 48 hours | 28 hours | ~42% reduction — automated unit tests and suggested fixes |
| Time to resolve tier-1 customer issues | 2.2 hours | 1.1 hours | ~50% reduction — ChatGPT Enterprise for support triage |
| Documentation creation time (first draft) | 8 hours | 2.5 hours | ~69% reduction — generative drafts and templates |
| Developer onboarding time (first productive week) | 5 weeks | 3 weeks | ~40% reduction — embedded explainers, tailored onboarding |
| Monthly helpdesk ticket backlog | 12,000 | 7,800 | ~35% reduction — AI-assisted ticket processing |
These productivity improvements depend heavily on how Samsung integrates the models into workflows and enforces quality gates. Gains are largest in tasks with well-defined patterns: boilerplate code, documentation templates, query triage, and test generation. Gains are smaller for open-ended creative work where human judgment is critical.
Codex in Korea: understanding the reported 800% growth
Samsung’s announcement referenced an 800% growth in Codex usage in Korea. Interpreting this number requires parsing several dimensions: relative baseline, usage modalities, and the tactical drivers behind the surge. The growth is most plausibly an increase in API calls or active users interacting with Codex over a measured period, driven by several factors:
- Concentration of developer work in Korea: many product teams and hardware-software integration teams are Korea-based and are likely prioritized in a phased rollout.
- Wide availability and fewer seat limits: moving from a limited pilot (dozens of engineers) to a broad internal rollout (hundreds to thousands) naturally multiplies usage.
- Task automation: Codex automations for test generation, code refactors, and CI/CD annotations lead to programmatic calls integrated into build pipelines, magnifying API usage beyond interactive sessions.
- Toolchain integration: IDE plugins, commit hooks, and code review bots generate frequent short-lived requests to Codex, compounding total calls.
Below is a hypothetical decomposition that explains how an 800% increase in Codex usage in Korea can occur in practice:
| Driver | Mechanism | Relative contribution to growth |
|---|---|---|
| Seat expansion | From 200 pilot seats to 2,000 seats across engineering orgs | 4x |
| Programmatic integration | CI/CD hooks + PR bots making automated calls per commit | 2.5x |
| Increased per-user usage | Developers using Codex for scaffolding, tests, refactors | 1.5x |
| Training & enablement | Workshops increased adoption and embedded usage | ~1.3x |
| Combined multiplicative effect | Multiply drivers above (approximate) | ~800% aggregate |
From a platform perspective, high Codex usage also affects capacity planning and cost forecasting. The engineering organization must coordinate token budgets, rate limits for CI/CD pipelines, and fallback strategies for when model endpoints throttle due to global demand.
Shifting from pilot to company-wide deployment: organizational mechanics
A key signal in this rollout is the transition from pilot projects to an enterprise-standard platform. This requires five organizational capabilities:
- Executive sponsorship and funding: Executive commitment to scale beyond ad-hoc pilots and funding for seat licenses, private infrastructure, and associated tooling.
- Platformization: Building a central LLM platform team (often under a CTO or DX function) that provides standardized integrations, templates, and governance guardrails to product teams.
- LLMOps and engineering wrangling: A cross-functional LLMOps group to monitor model performance, cost, and versioning; drive benchmark testing; and automate deployment of prompt-template updates.
- Training and change management: Structured upskilling programs, playbooks, and sector-specific prompt libraries. For developers that means best practices for generating reliable code and safety checks to validate outputs.
- Legal and compliance integration: Embedding legal review into templates and establishing rules about what can be fed into models, how outputs are stored, and what is allowed to cross national borders.
Samsung’s DX division plays a central integrating role. The division’s remit includes harmonizing data flows between product teams, establishing enterprise-wide RAG connectors, and operating the LLMOps pipelines. By centralizing these responsibilities, Samsung reduces duplication, enforces consistent governance, and speeds up the adoption rate across business units.
Realistic expert perspectives
To place this rollout in context, we present realistic expert commentary that captures the technical and organizational tenor of large-scale LLM adoption.
“Deploying ChatGPT Enterprise and Codex at the scale Samsung is undertaking changes the locus of software creation,” said Dr. Mina Park, Principal Researcher at the K-AI Institute. “When model outputs are treated as first drafts integrated into CI/CD and documentation pipelines, the unit economics of software development shift. The key technical challenge is not only managing throughput and latency, but building robust verification layers so generated artifacts meet the same quality and safety bar as human-authored ones.”
“What we’re seeing is a maturation of LLMOps,” said Alex Hollis, Head of Enterprise AI Platforms at a Fortune 100 company (speaking anonymously on industry trends). “Samsung’s deployment is instructive: you need centralized governance, but decentralized consumption. The platform must be easy enough for product teams to internalize yet strict enough to prevent IP leakage and compliance violations.”
“Codex adoption in Korea exploded because it directly maps to developer ROI: fewer repetitive tasks, faster on-ramping, and programmatic test creation that reduces regressions,” said Eun-Ji Kim, Director of Engineering Tools at a major Korean software firm. “But the velocity gains only materialize when coupled with automated test pipelines and code review policies that treat AI-generated code with the same skepticism and validation rigor as human code.”
Risk profile and mitigation strategies
Every large-scale LLM deployment carries a quantifiable risk profile. For Samsung, the most salient categories are IP leakage, hallucination-induced defects, regulatory exposure, and vendor dependency. Each risk has corresponding mitigation strategies:
- IP leakage: Limit what is sent to third-party models, use on-prem or private vector stores, apply DLP and content classification before prompts are forwarded, and apply strict RBAC.
- Model hallucination: Enforce HITL for production outputs, generate provenance metadata (sources used in RAG retrieval), and run automated correctness checks especially for code generation (type checks, linters, unit tests).
- Regulatory compliance: Deploy regionally segmented data handling, maintain logs necessary for audits, and contractually bind vendors to data protection clauses; in some cases, prefer on-prem or sovereign cloud deployments.
- Vendor lock-in: Abstract model calls behind an internal API gateway, so that model endpoints can be switched between vendors or self-hosted models without rewriting downstream integrations. Standardize prompt templates to reduce migration burden.
Notably, the vendor lock-in risk is often underestimated. Samsung’s long-term strategy should emphasize model-agnostic integration patterns and invest in portable prompt templates as well as an internal LLM abstraction layer that allows swapping models with minimal downstream disruption.
Cost, ROI, and allocation of benefits
LLM deployments incur direct costs (seats, API calls, private endpoint fees) and indirect costs (platform engineering, security controls, user support). The ROI calculus for Samsung depends on the aggregation of productivity gains, error reduction, and speed-to-market improvements. A simplified ROI model would include:
- Cost baseline: License fees for ChatGPT Enterprise and Codex, private endpoint overhead, compute and storage for vector stores, and internal engineering costs for integration and LLMOps.
- Value accrual: Time savings across engineering, faster bug detection, improved customer support response times, reduced documentation overhead, and increased throughput of product experimentation cycles.
- Payback period: Many enterprises see payback in 6–18 months for developer-focused LLM investments when scaled across thousands of seats, assuming proper integration and governance.
Comparative table: governance and capability changes
| Dimension | Before | After | Implication |
|---|---|---|---|
| Model access & provisioning | Pilot teams with ad-hoc access | Enterprise SSO, RBAC, SCIM-managed seats | Operational consistency and compliance |
| Data flow controls | Manual policies, limited DLP | Automated DLP, private endpoints, region segmentation | Reduced risk of cross-border data leaks |
| Developer toolchain | Standalone prototypes / plugins | IDE and CI-integrated Codex pipelines | Increased velocity and CI coverage |
| Governance oversight | Ad-hoc compliance reviews | Central LLMOps + legal & compliance workflows | Standardized auditability and policy enforcement |
| Cost monitoring | Unstructured, subject to surprises | Quota management, SLOs, cost dashboards | Predictable cost allocation |
What this signals to competitors and the industry
Samsung’s deployment creates pressure on competitors and partners to adopt a similar tactical posture: LLMs as a standardized productivity platform, not an optional pilot. The strategic implications include:
- Acceleration of enterprise AI adoption: Large enterprises will need to adopt centralized LLM platforms to avoid falling behind on engineering velocity and internal knowledge synthesis.
- Vendor leverage shift: OpenAI and other LLM providers gain enterprise leverage, but companies can push back by standardizing abstraction layers to mitigate vendor lock-in risks.
- Talent reallocation: Organizations may reallocate talent from repetitive development tasks to verification, orchestration, and higher-order design work, increasing demand for roles like Prompt Engineer, LLMOps Engineer, and AI Ethics Lead.
- Regulatory engagement: Governments and industry bodies will pressure for clearer standards around model auditing, data residency, and traceability. Korea’s regulators will pay attention given the scale of enterprise usage locally.
Competing hardware and consumer electronics firms will not ignore Samsung’s move. A consequence could be a two-front race: one in adoption speed and integration depth, and another in safe, auditable AI practices that ensure product quality and regulatory compliance.
Operational playbook for enterprises considering the same move
For organizations planning a similar transition from pilot to enterprise-wide LLM deployment, the following operational playbook consolidates lessons learned from early adopters and best practices inferred from Samsung’s approach:
- Establish executive sponsorship and a funded LLM platform team responsible for standardization and compliance.
- Integrate SSO and SCIM early to manage seats at scale and reduce administrative friction.
- Build a private retrieval infrastructure for RAG and maintain a rigorous data ingestion pipeline with sanitization and access controls.
- Embed verification tooling in CI/CD and documentation pipelines: automated tests, linters, and metalogging to capture model provenance.
- Create a governance board mixing legal, security, product, and engineering stakeholders to codify allowed use cases and escalation paths.
- Invest in LLMOps: benchmarking, model evaluation suites tailored to domain-specific correctness, and continuous monitoring for drift and policy violations.
- Design human-in-the-loop workflows for outputs that feed into production systems; treat AI as a collaborator, not an authoritative source.
- Standardize prompt templates and teach prompt engineering as a skill for product teams to reduce variability in outputs.
- Negotiate vendor contracts that include service-level parameters, data protection clauses, and the ability to port workloads between model providers.
- Run an internal communications and training program to normalize usage patterns and to manage expectations about where LLM assistance is appropriate.
These practices reduce operational risk and accelerate sustainable adoption.
Legal and policy considerations: cross-border deployment
Samsung’s worldwide DX division usage introduces complex cross-border compliance dynamics. Korea’s PIPA, the EU’s GDPR, and sector-specific regulations (e.g., telecommunications, defense-related exports) impose varying obligations. Key legal mechanisms include:
- Data processing agreements with cloud and model vendors that specify where data is stored, processed, and retained — and what rights vendors have to use prompts or derived outputs for model training.
- Technical controls to prevent sensitive data export: tokenization, obfuscation, and local-only embeddings for classified material.
- Auditability: maintaining complete logs and the ability to produce records for regulators regarding what data was processed and for what purpose.
- Contractual clauses limiting vendor rights to train on customer data or to use customer prompts as part of public model improvement initiatives unless explicitly permitted.
To avoid regulatory friction, Samsung’s legal and compliance teams would have had to negotiate clear contractual terms with OpenAI and ensure that internal usage policies map to legal constraints across jurisdictions. Enterprises should proactively define data classification taxonomies so that workflows automatically enforce different handling rules per data class.
Human capital implications and reskilling
Company-wide LLM deployment will change the nature of many roles. Routine tasks will be automated or augmented, while roles requiring critical thinking, system design, and model oversight will expand. Reskilling priorities include:
- Prompt engineering and AI interaction design: teaching employees how to craft prompts that elicit high-quality, verifiable outputs.
- LLMOps and observability: training engineers on how to monitor model performance, identify drift, and create analytical dashboards.
- AI governance and ethics: upskilling compliance teams to interpret model risks, bias detection, and audit trails.
- Verification skillsets: expanding QA teams to include model-output validation, from test automation to formal verification for certain categories of generated code.
Firms that pair LLM rollout with structured reskilling will realize the most durable benefits. The workforce will shift toward tasks emphasizing human judgment, architectural thinking, and quality assurance of AI-augmented outputs.
Vendor dynamics and multi-model strategies
Samsung’s use of OpenAI models is strategic but not necessarily exclusive. A prudent enterprise multi-model strategy includes:
- Model abstraction layers: exposing internal APIs that hide vendor-specific call patterns and response formats so that swapping or aggregating providers is feasible.
- Hybrid deployments: combining managed cloud models for general-purpose interactions and on-prem or fine-tuned models for sensitive workloads.
- Competitive evaluation: periodically benchmarking generalist and specialist models (code models, legal models, domain-specific ones) on enterprise tasks to determine the best fit.
In many large organizations, the highest-value pattern is a heterogeneous model portfolio tailored by use-case and sensitivity. For example, public marketing drafts may use a general-purpose cloud LLM, whereas source-code or product design details may be handled via private models or models with strict contractual data protections.
Longer-term strategic implications
Samsung’s rollout hints at deeper long-term trends that will define enterprise AI over the next five years:
- AI as platform: LLMs will become a cross-cutting platform comparable to email, databases, or cloud compute — a necessary foundational layer for modern productivity.
- Model governance as a core competency: organizations will invest heavily in LLMOps, continuous validation, and legal compliance as permanent functions.
- Composability and automation of workflows: AI will increasingly be embedded into end-to-end product and engineering workflows making systems more autonomous and responsive.
- Competitive differentiation via proprietary RAG: Firms that can create high-quality, domain-specific knowledge graphs and vector stores will derive unique advantages even when using common base models.
- New organizational metrics: traditional KPIs (lines of code, tickets closed) will be augmented with AI-centric metrics like model-assisted task completion rates and AI correctness scores.
Access 40,000+ AI Prompts for ChatGPT, Claude & Codex — Free!
Subscribe to get instant access to our complete Notion Prompt Library — the largest curated collection of prompts for ChatGPT, Claude, OpenAI Codex, and other leading AI models. Optimized for real-world workflows across coding, research, content creation, and business.
Final analysis and recommendations
Samsung Electronics’ company-wide adoption of ChatGPT Enterprise and Codex is a watershed moment: it demonstrates how a global enterprise operationalizes generative AI beyond pilots into an integrated productivity platform. The deployment underscores three core lessons for large organizations:
- Scale requires platform thinking — not just tooling. Seat provisioning, identity integration, and governance must be centralized and automated.
- Technical controls and human verification must operate in tandem. The most successful deployments do not treat LLMs as authoritative systems but as partners that accelerate human workflows subject to verification.
- Cost and vendor risk must be actively managed through abstraction layers and multi-model strategies to avoid short-term convenience turning into long-term fragility.
For companies eyeing similar moves, the roadmap is clear: assemble cross-functional LLM governance, implement private RAG infrastructure, integrate Codex into developer pipelines sensibly, and invest in reskilling. Firms that treat this as a systemic change — aligning legal, security, engineering, and product — will capture the disproportionate benefits.
Samsung’s bold step will accelerate industry adoption curves and force competitors to justify either similar investments or alternative strategies that emphasize model portability and defensive IP protections. The net effect will be an enterprise landscape where LLMs shift from experimental tools to operational foundations, with profound implications for productivity, workforce configuration, and the economics of software creation.
If your organization is preparing for a company-wide LLM deployment, focus on the intersection of technology and governance: build an LLMOps backbone, secure RAG pipelines, and create clear policies that define where AI can and cannot be trusted. The fastest adopters with the most robust governance will not only move faster — they will move safer.
Organizations deploying ChatGPT Enterprise at scale need robust analytics to measure the impact of AI adoption across departments. For a deeper exploration of this topic, see our comprehensive guide on What’s New in Claude Sonnet 4.6 2026: Full Breakdown for Developers, which provides actionable frameworks and implementation strategies for enterprise teams.
This analysis aims to provide clarity on the technical and strategic contours of Samsung’s deployment and to offer a practical framework for enterprises navigating the transition. Watch for follow-up coverage on how Samsung operationalizes LLMOps telemetry, unit test automation with Codex, and the specific governance playbooks that emerge from this landmark rollout.
Understanding how enterprise AI spending translates into measurable productivity gains requires systematic tracking and governance frameworks. For a deeper exploration of this topic, see our comprehensive guide on From Pilot to Production: A Major SaaS Startup’s AI ROI Story, which provides actionable frameworks and implementation strategies for enterprise teams.