How to Implement ChatGPT’s Dreaming Memory System in Enterprise Workflows: Architecture, Personalization Patterns, and Privacy Controls
How to Implement ChatGPT’s Dreaming Memory System in Enterprise Workflows: Architecture, Personalization Patterns, and Privacy Controls
This technical guide walks enterprise architects, platform engineers, and AI product teams through implementing a Dreaming V3-style memory system — a memory synthesis and retrieval architecture that condenses, enriches, and surfaces user-relevant facts from chat history across long-lived conversational contexts. This is not merely a storage layer; Dreaming V3 is an active memory synthesizer that turns fragmented interactions into structured, trustworthy, and privacy-conscious knowledge artifacts suitable for personalized workflows, automation triggers, and multi-tenant enterprise control.
The guide covers system architecture, data models, ingestion and synthesis pipelines, vector indexing and retrieval, personalization patterns (per-user, per-team, role-aware), robust privacy and compliance controls, and operational best practices for teams using shared workspaces. Along the way you’ll find step-by-step implementation patterns, JSON API payload examples, a table comparing Saved Memories vs Dreaming V1 vs Dreaming V3, and recommended monitoring and validation strategies for production-grade deployments.
Executive summary and core concepts
Dreaming V3 is best understood as a layered memory service that performs three main functions:
- Capture: ingest chat history, system messages, and structured signals (calendar events, CRM updates) in a normalized stream.
- Synthesize: apply summarization, entity extraction, canonicalization, and enrichment transforms to produce persistent memory artifacts (synthesized memories) optimized for retrieval and privacy policies.
- Surface: provide deterministic, latency-optimized retrieval to conversational agents and workflow automation systems using hybrid search (semantic + lexical + time decay) driven by embeddings and learned relevance signals.
Key properties enterprises require from a Dreaming V3 implementation:
- Privacy and consent controls at artifact and field level (redaction, access control, retention).
- Accuracy and provenance — each synthesized memory links back to evidence spans and source messages to support audit and correction.
- Scalable indexing and low-latency retrieval at multi-tenant scale.
- Personalization patterns that are predictable and controllable across users, teams, and roles.
- Operational visibility: metrics, drift detection, and human-in-the-loop review flows.
High-level architecture
Deploying Dreaming V3 requires integrating multiple components. The following diagram (conceptual) maps the primary functions of the system. Replace with your internal reference diagram as needed.
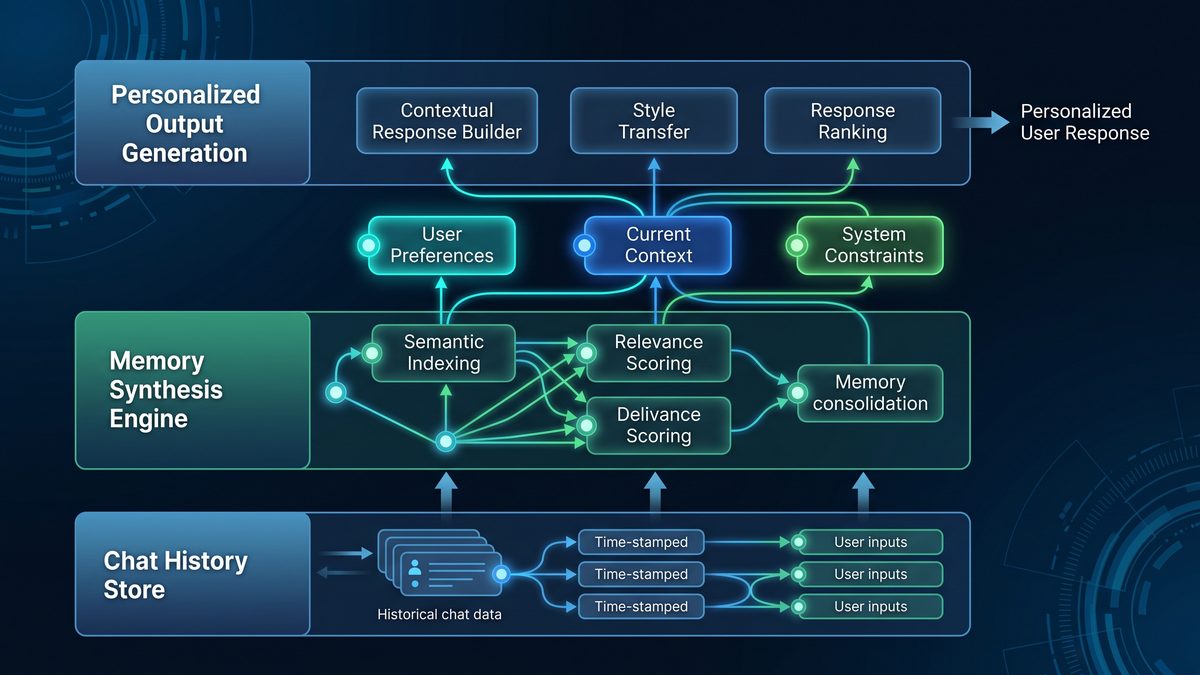
Architecture components explained:
- Event/Message Ingest Layer: Real-time stream or batch ingestion from chat systems, email, calendar, and external systems. Messages include structured metadata: sender, recipient(s), workspace id, thread id, timestamps, and message type.
- Normalization and Tokenization: Preprocessing for language models: chunking long messages, extracting code blocks, tables, and attachments, normalizing date/time and language, and identifying sensitive tokens (PII) for masking according to policy.
- Memory Synthesizer (Dream Engine): A pipeline that executes a sequence of model-driven transforms — summarization, canonical entity extraction, relationship resolution, temporal consolidation, and confidence scoring. Outputs are “Synthesized Memories” with structured fields and provenance pointers to source messages.
- Vectorization + Indexing: Each synthesized memory is vectorized (multiple embedding vectors) and stored into a hybrid index: semantic vector index + inverted/lexical index + temporal index. Index supports weighted retrieval across multiple embedding models and a signals store for on-the-fly re-ranking.
- Policy & Access Control Layer: Enforces per-tenant, per-workspace, per-user access policies. Provides redaction, field-level encryption, retention enforcement, and opt-out semantics.
- Retrieval API + Orchestration: High-throughput read path that serves chat agents and workflow engines. Supports context-aware retrieval requests (query + conversation context + personalization hints) and returns ranked artifacts with provenance snippets and privacy tags.
- Review & Governance Console: Human-in-the-loop UI for reviewing synthesized memories flagged by heuristics (low confidence, sensitive content) or requested by users for correction/deletion. Maintains audit trails and consent records.
Data model: synthesized memory artifact
A Dreaming V3 synthesized memory is both a human-facing summary and a machine-friendly artifact. It should be compact, canonical, and deterministic across similar inputs to support downstream indexing and deduplication. Below is a canonical JSON schema blueprint; adjust types and fields to match your enterprise data model and compliance constraints.
{
"memory_id": "uuid-v3-0001",
"workspace_id": "workspace-123",
"created_by": "user:[email protected]",
"created_at": "2026-06-20T12:34:56Z",
"type": "preference | fact | relationship | task | event",
"title": "Alice prefers weekly status summaries on Fridays",
"summary": "Alice prefers to receive a weekly project status summary every Friday morning.",
"canonical_entities": [
{"entity_type": "person", "value": "Alice", "canonical_id": "user:[email protected]"},
{"entity_type": "schedule", "value": "weekly on Friday", "canonical_id": "schedule:friday-weekly"}
],
"source_references": [
{"message_id": "msg-987", "span": [12, 78], "source_type": "chat", "confidence": 0.98},
{"message_id": "email-34", "span": [120, 212], "source_type": "email", "confidence": 0.72}
],
"embedding_vectors": {
"semantic_v1": [0.00123, -0.0034, ...],
"semantic_v2": [0.1012, -0.2241, ...]
},
"privacy_tags": ["consent:granted", "sensitive:low", "retention:90d"],
"access_control": {
"visibility": "team", // "private" | "team" | "workspace" | "public"
"allowed_roles": ["manager", "assistant"],
"allowed_users": ["user:[email protected]", "user:[email protected]"]
},
"confidence": 0.91,
"ttl": "2026-09-20T12:34:56Z",
"provenance_hash": "sha256:abc123...",
"canonicalized": true,
"update_history": [
{"updated_at": "2026-06-21T08:00:00Z", "updated_by": "system:dreaming-v3", "change_summary": "merged with schedule:friday-weekly"}
],
"metadata": {
"tags": ["preference", "reporting"],
"automations": ["generate_weekly_summary"],
"notes": null
}
}Notes on critical fields:
- embedding_vectors: store multiple vector representations for model-agnostic retrieval and to support model upgrades without re-indexing all artifacts.
- privacy_tags/access_control: drives the enforcement layer responsible for masking and visibility. Put explicit retention TTLs to support automated deletion.
- source_references: every memory must include minimal provenance to enable audit and selective redaction.
- confidence: helps triage low-confidence memories into review queues.
Memory synthesis pipeline (step-by-step)
The synthesizer is the core differentiator for Dreaming V3. It does not simply copy messages into memory; it transforms message streams into stable facts and preferences. Below is a robust, production-grade pipeline design and implementation sequence.
- Ingest and materialize conversation snapshots
Collect conversation segments with granularity tuned to your application. For enterprise workflows, prefer thread-level snapshots with fixed sliding windows (e.g., last 30 messages or last 7 days). Persist raw snapshots to cold storage to support replay and provenance. Use event-sourcing to preserve immutability.
- Preprocess and tokenize
Normalize dates, currencies, and other structured tokens. Use rule-based extraction for high-confidence fields (emails, phone numbers, URLs), and mark them with sensitivity labels. Optionally apply NER and role resolution to map mentions to internal entity ids.
- Candidate extraction
Run lightweight extraction models to propose candidate memory types: preference, contact, milestone, decision, task, etc. Each candidate should include source spans and an initial confidence score.
- Canonicalization & deduplication
Resolve entities against a canonical index (directory, CRM, HR). Merge duplicate candidates using fuzzy matching and entity reconciliation rules. Create or link canonical ids.
- Summarization & consolidation
For overlapping candidates, run an aggregation transformation that consolidates evidence into a single synthesized memory. The synthesizer should be deterministic: given the same evidence set it should produce the same canonical summary. Use model prompting patterns that enforce structure (e.g., JSON schema completion) to ensure downstream parsing reliability.
- Enrichment
Enrich memories with derived attributes: likelihood scores for behavior, urgency, follow-up actions, and mapping to automation triggers. Add cross-links to other memories when relationships are detected.
- Privacy annotation & policy tagging
Apply policy rules to tag fields for redaction, field-level encryption, or restricted visibility. E.g., PII elements get “sensitive:high” and require higher entitlements to access.
- Vectorization & multi-indexing
Generate one or more embeddings for semantic retrieval and an inverted index for lexicon-based queries. Store embeddings with memory artifacts and push to vector DB. Keep a compact lexical summary in search index.
- Confidence gating & review
If confidence is below threshold or contains sensitive content, mark it for human review before making it visible. Provide UI for reviewers to accept, reject, or edit synthesized artifacts.
- Publishing
Publish the synthesized memory with associated metadata, provenance links, and TTL to the retrieval layer. Emit audit events and update change streams.
Algorithmic patterns for synthesis
Below are algorithmic strategies and prompt engineering patterns for key transforms in the Dreaming V3 pipeline. These are implementation-agnostic recipes to achieve robust synthesis behavior.
Summarization (structured, schema-constrained)
Use structured prompts designed to return JSON adhering to a schema. This preserves deterministic parsing and reduces hallucination. For example, in a chain-of-thought-less setting, prompt the model to produce only allowable keys with explicit types and examples. Optionally validate outputs with JSON schema validators; if invalid, re-run with the same backup model or fallback to rule-based summarizer.
Entity canonicalization
Combine a hybrid approach:
- Rule-based mapping for high-confidence fields (emails → user IDs, calendar IDs → canonical schedule records).
- Fuzzy matching for names with context-aware heuristics (role, workspace membership).
- Embedding similarity between newly extracted entity mentions and the global entity index for ambiguous cases.
Temporal consolidation
Implement time-decay and squashing heuristics for repeated mentions. For example, mark “Alice prefers weekly updates” as stable if observed across N distinct sessions within M days, and increase confidence accordingly. Conversely, for ephemeral facts (one-off decisions), keep them time-limited.
Confidence scoring and provenance attribution
Score synthesized memories using a blended metric: model confidence + count_of_evidence_points * weight + canonical_match_score. Normalize to [0,1], and retain the breakdown for auditing. Every synthesized memory must include references to the minimal set of evidence spans sufficient to justify the memory; include anchors to exact message ids and span offsets.
Retrieval and ranking: hybrid search at scale
Dreaming V3 retrieval must resolve queries with high precision and low latency. Avoid purely nearest-neighbor retrieval; prefer a hybrid architecture:
- Candidate generation: Use ANN (approx nearest neighbor) on semantic embeddings to get top-K candidates; simultaneously query lexical inverted index for exact term matches and temporal filters.
- Feature enrichment: For each candidate, compute features: semantic_similarity, exact_match_score, recency_score, confidence_score, access_penalty (based on ACL), and team_relevance_score.
- Re-ranking: Use a learned model or rule-based scoring function to combine features into a final rank. The re-ranker enforces policy constraints (e.g., do not show any memory with privacy tag requiring review).
- Snippet generation: Return a short summary with provenance spans that place the memory into context in the conversation.
Example re-ranking formula:
final_score = w1 * semantic_similarity
+ w2 * exact_match
+ w3 * log(1 + evidence_count)
+ w4 * confidence
+ w5 * recency_decay(timestamp)
- w6 * access_penaltyTune weights w1..w6 by A/B testing on relevance and safety metrics per workspace.
Personalization patterns for enterprise workflows
Dreaming V3 enables complex personalization patterns while maintaining control. Below are common enterprise use cases and recommended implementation patterns.
Per-user personal history
Store memories designated “private” that are scoped strictly to a user. Use client-side encryption for high-sensitivity personal data to ensure that only that user’s active client can decrypt. Provide users an interface to export and delete these memories. Authenticate reads with strong user tokens and require re-authentication for bulk exports.
Team-level personalization
Memories shared across a team (e.g., project-specific preferences, shared contacts) should be labeled with team_id and enforced via access_control.visibility=”team”. Implement role-aware view modes (manager vs contributor) and provide per-role redaction policies; for instance, salary-related memories may be visible only to HR roles.
Role-aware personalization
Map roles to capabilities in the memory service. Roles control derived features: whether a memory can be used to auto-trigger actions, whether it can be surfaced in summaries, or whether it requires approval before being acted upon. Keep role assignments in a central IAM service and fetch them at request time to evaluate visibility.
Ephemeral session memory
Not all memories belong in long-term storage. Use ephemeral memory for short-term personalization (e.g., within a support chat session). Implement TTLs under 24 hours and ensure these memories are never exported to long-term indices. Ephemeral memory speeds retrieval because it can remain in in-memory caches keyed per session.
Cross-user inference and anonymized aggregation
For analytic personalization, create aggregated, anonymized artifacts derived from many users. Use differential privacy techniques or k-anonymity thresholds before surfacing or modeling over this data. Store aggregated artifacts separately and mark them non-provenance-linked to prevent reconstruction of individual records.
Privacy, consent, and compliance controls
Dreaming V3 must be designed with privacy-first defaults. Below are industry best practices and technical controls to support enterprise compliance.
Field-level sensitivity and automatic redaction
Implement detection rules and models to label PII and other sensitive fields during normalization. For fields marked sensitive, apply redaction strategies:
- Nullify values when returning to callers without explicit permission.
- Use format-preserving pseudonymization for analytics.
- Encrypt fields at rest with dedicated KMS keys and require additional entitlements to decrypt.
Consent and opt-out management
Maintain consent records for users and provide APIs to update consent states. Consent affects visibility and retention. For example, a “no-memory” opt-out flag prevents memories originating from the user’s messages from being synthesized, or causes them to be withheld from long-term indices. Ensure the synthesizer consults consent at the candidate extraction step to avoid creating prohibited artifacts.
Retention, TTL, and automated deletion
Implement a retention engine that periodically enforces TTLs and enterprise retention policies. Deletions must be durable and include:
- Removal from vector/lexical indices (rebuild or tombstone semantics).
- Redaction of content in cold storage snapshots.
- Append-only audit record indicating deletion for compliance reporting.
Provable deletion
To satisfy regulatory requirements, provide provable deletion artifacts: a signed deletion receipt containing the memory id, deletion time, and cryptographic digest of prior state to prove the artifact was removed. Store deletion receipts in an immutable audit log (append-only ledger) with restricted access for compliance teams.
Access control and encryption
All transports must use TLS. For storage, apply layered encryption:
- Application-level encryption for highly sensitive fields (client or server-side depending on threat model).
- Envelope encryption using a KMS per tenant to support key rotation without mass re-encryption.
- Field-level access policies enforced server-side before decryption operations.
Audit logs and explainability
Every read and write must be logged with who accessed the artifact, the reason (API call metadata), and the returned redaction state. Provide “why this memory was retrieved” explanations by returning provenance spans and the re-ranking feature contributions to the client for transparency. This supports compliance and debugging.
Memory management APIs — example endpoints and payloads
Below are canonical API endpoints and JSON payload examples. Adapt endpoints and auth models to your enterprise API gateway and identity layer. These examples assume JSON/HTTP REST style with bearer tokens and role-based entitlements.
Create synthesized memory (system-generated)
POST /v1/workspaces/{workspace_id}/memories
Authorization: Bearer {SYSTEM_API_KEY}
Content-Type: application/json
{
"source_snapshots": ["snapshot-2026-06-20-1200"],
"type": "preference",
"requested_by": "system:dreaming-v3",
"privacy_hints": ["suppress-export"],
"publish": true
}Response:
200 OK
{
"memory_id": "uuid-v3-0001",
"status": "created",
"confidence": 0.88,
"visible_to": ["team:project-x"]
}Create memory (user-provided or corrected)
POST /v1/workspaces/{workspace_id}/users/{user_id}/memories
Authorization: Bearer {USER_TOKEN}
Content-Type: application/json
{
"title": "Prefer weekly status meeting on Fridays",
"summary": "I want weekly status meetings on Fridays at 10am.",
"type": "preference",
"privacy_tags": ["consent:granted"],
"access_control": {
"visibility": "team",
"allowed_roles": ["member"]
}
}Response:
201 Created
{
"memory_id": "uuid-manual-001",
"provenance_hash": "sha256:manual-abc",
"status": "published"
}Search memories (retrieval API)
POST /v1/workspaces/{workspace_id}/memories/search
Authorization: Bearer {CALLER_TOKEN}
Content-Type: application/json
{
"query": "What are Alice's preferences for reports?",
"context": {
"session_id": "sess-555",
"recent_messages": ["msg-1200", "msg-1201"],
"caller_user": "user:[email protected]",
"role": "assistant"
},
"filters": {
"types": ["preference", "task"],
"since": "2026-03-01T00:00:00Z"
},
"top_k": 10,
"re_rank": true
}Response (truncated):
200 OK
{
"results": [
{
"memory_id": "uuid-v3-0001",
"title": "Alice prefers weekly status summaries on Fridays",
"score": 0.94,
"provenance": [
{"message_id": "msg-987", "span": [12,78]}
],
"privacy_tags": ["consent:granted"]
}
],
"explain": {
"semantic_similarity": 0.87,
"exact_match": 0.6,
"confidence": 0.91
}
}Request deletion / right to be forgotten
DELETE /v1/workspaces/{workspace_id}/memories/{memory_id}
Authorization: Bearer {USER_OR_ADMIN_TOKEN}
Content-Type: application/json
{
"requested_by": "user:[email protected]",
"reason": "user_requested_deletion",
"provenance_required": true
}Response:
200 OK
{
"memory_id": "uuid-v3-0001",
"status": "deleted",
"deletion_receipt": {
"receipt_id": "del-rcpt-789",
"deleted_at": "2026-06-22T10:00:00Z",
"digest": "sha256:deleted-preimage",
"signature": "sig-..."
}
}Re-synthesize / update memory
POST /v1/workspaces/{workspace_id}/memories/{memory_id}/resynthesize
Authorization: Bearer {SYSTEM_API_KEY}
Content-Type: application/json
{
"trigger": "evidence_added",
"new_source_snapshot": "snapshot-2026-06-21-0900",
"force_review": true
}Response:
202 Accepted
{
"job_id": "resynth-333",
"status": "in_progress"
}Schema for search response and provenance
Design your search response to include explainability data and provenance so client applications can trust or ask for review. Minimal required fields:
- memory_id
- title/summary
- score and feature breakdown
- privacy_tags and access level
- provenance list
Comparing Saved Memories vs Dreaming V1 vs Dreaming V3
| Dimension | Saved Memories | Dreaming V1 | Dreaming V3 |
|---|---|---|---|
| Primary focus | User-provided explicit facts and notes | Automated extraction from chat — basic summarization | Advanced synthesis, canonicalization, multi-embedding retrieval, and governance |
| Provenance | Direct link to saved note; limited evidence spans | Partial provenance (message links, poor span resolution) | Fine-grained evidence spans, provenance hashes, and audit trails |
| Privacy controls | User-visible, manual controls | Basic retention and visibility | Field-level redaction, consent enforcement, KMS-backed encryption, provable deletion |
| Personalization | Manual personalization via user edits | Heuristic personalization with limited role awareness | Role-aware, team-aware, ephemeral and persistent personalization with client- and server-side policies |
| Indexing & retrieval | Basic metadata search | Single embedding + lexical search | Multi-embedding, hybrid retrieval, learned re-ranking, temporal decay |
| Scaling | Works for single-user scale | Initial multi-user deployments; challenges at tenant scale | Designed for multi-tenant enterprise scale with per-tenant keys and indexing strategies |
| Human-in-loop | Manual edits only | Limited review flows | Integrated review queues, automated triage, and correction workflows |
Operational considerations and rollout strategy
Rolling Dreaming V3 into production requires careful staging. Use the following phased approach:
- Pilot with opt-in users: Start with a small set of teams that explicitly opt-in. Collect metrics: precision@k, recall for explicitly requested facts, false positive rate, privacy incidents, and user correction rates.
- Human review and calibration: Route low-confidence and sensitive memories to human reviewers and collect correction labels to refine extractor models and confidence thresholds.
- Progressive rollout: Expand to more teams with stricter opt-in rules for certain types of memories (e.g., HR or legal content requires explicit consent).
- Monitoring and alerting: Set alerts on anomalous spikes in deletion requests, memory generation rate, and low-quality metrics. Monitor drift in entity canonicalization accuracy and re-train or adjust heuristics quarterly.
- Governance and policy updates: Work with privacy and legal teams to codify memory types that are disallowed by default. Publish transparency reports and user-facing controls.
Best practices for teams using shared workspaces
Shared workspaces present subtle challenges. Follow these recommendations to minimize risk and maximize utility.
- Least privilege by default: Default visibility for synthesized memories should be “private” or “team-limited” rather than workspace-wide.
- Explicit publish step: Require users to explicitly publish sensitive memory artifacts to broader scopes with consent capture and a brief explanation prompt explaining usages.
- Workspace roles and entitlements: Mirror workspace roles in your memory ACLs and disallow privilege escalation through memory access alone.
- Shared artifact ownership: For artifacts created from multi-user conversations, record joint ownership and require consensus or opt-out mechanisms for deletion requests.
- Automations gating: Any automation that acts on memories (e.g., auto-summarize and send emails) should require a higher threshold of confidence and explicit automation opt-in per workspace.
- Onboarding and UX: Provide clear UI affordances that indicate when content may be captured into long-term memory and how to remove or change that behavior.
Evaluation, metrics, and validation
Define and track the following metrics for Dreaming V3 deployments:
- Precision@K for retrieval queries relative to labeled ground truth.
- False positive rate for synthesized memories (percentage of memories that users mark as incorrect).
- Average confidence score and distribution across memory types.
- Time-to-first-response for retrieval requests (latency SLO).
- Rate of deletion requests and origin (user vs compliance team).
- Human review throughput and average time in review queue.
- Security metrics — number of unauthorized access failures, key rotation events, and provable deletion verifications.
Establish continuous evaluation by sampling synthesized memories every hour and performing automated heuristics checks (consistency with source messages, schema validation) and quarterly human audits (random stratified sampling by memory type and privacy tag).
Common pitfalls and mitigations
Below are common failure modes and recommended mitigations.
- Over-zealous synthesis: The synthesizer creates too many memories, flooding indices and producing noise. Mitigation: increase confidence thresholds, require multiple evidence points, or require explicit user confirmation for certain types.
- Privacy leakage through embeddings: Embeddings sometimes encode PII. Mitigation: remove or redact high-sensitivity fields before vectorization; consider model-level differential privacy or use separate embedding models for sensitive data.
- Index staleness after deletion: Tombstones not propagated causing ghost results. Mitigation: implement tombstone markers in vector DB and periodic index compaction that physically removes deleted vectors.
- Conflicting memories: Two memories contradict each other (e.g., changed preferences). Mitigation: implement temporal precedence, version history, and explicit “current” flags with human review for conflicts.
Extensibility: automation and external integrations
Dreaming V3 is a natural integration point for automation workflows (e.g., task creation, meeting scheduling). Provide a secure automation API that evaluates memories against triggers. Example automation flow:
- Memory created: type = “task”, confidence > threshold, access_allowed -> emit automation event.
- Automation engine validates trigger conditions (roles, approvals).
- Action executed in target system (e.g., create Jira ticket) and automation result is recorded as metadata on the memory.
Always treat automation as a high-privilege operation. Log every automation action with evidence, action initiator, and precondition checks.
Tooling and developer ergonomics
Developer experience is key to adoption. Provide the following:
- SDKs in primary languages (Python, Java, Node) that wrap auth, pagination, and explainability fields.
- CLI tools to inspect memory artifacts and run local resynthesis for debugging.
- Simulated data generators to create synthetic but realistic conversations for testing the synthesizer and privacy enforcement.
- Replay tooling to re-run synthesis pipelines against archived snapshot material after model upgrades or policy changes.
Scaling and infrastructure patterns
For enterprise scale, adopt these infrastructure best practices:
- Use event-driven ingest with durable queues (Kafka or cloud equivalents) to smooth peaks and provide replay semantics.
- Partition indices by tenant/workspace and provide sharding strategies based on vector DB characteristics.
- Keep cold storage for raw snapshots to enable re-synthesis; compress and encrypt these snapshots.
- Run synthesis workers in autoscaling pools with GPU-backed nodes for heavy model operations. Use cheaper CPU-based models for preliminary extraction passes.
- Adopt async job orchestration for resynthesis and bulk deletion tasks (e.g., Celery, Temporal, or managed workflows).
Case study: implementing weekly status automation
A practical implementation pattern: generate a weekly status summary personalized for each manager by synthesizing preferences and extracting tasks across team conversations.
- Ingest all project-related threads tagged with “project-X”.
- Synthesize memories: extract tasks, decisions, owner assignments, and preferences (e.g., “send status on Friday”).
- Identify memories tagged “automation:weekly_status” and verify consent and access control.
- Use retrieval API to aggregate relevant items for each manager’s workspace and run a template-based generator to create the summary content.
- Queue the summary for approval if any item is low-confidence, otherwise auto-send through the enterprise email integration.
JSON payload example for automation request:
POST /v1/workspaces/{workspace_id}/automations/weekly-summary
Authorization: Bearer {SYSTEM_API_KEY}
Content-Type: application/json
{
"manager_id": "user:[email protected]",
"team_id": "team:project-x",
"period": {"from": "2026-06-14T00:00:00Z", "to": "2026-06-20T23:59:59Z"},
"filters": {"types": ["task", "decision", "milestone"]},
"require_approval_if": {"any_confidence_below": 0.8},
"delivery": {"channel": "email", "template_id": "weekly_status_v2"}
}Testing and validation: recommended test suites
Test the Dreaming V3 system across multiple axes:
- Unit tests for candidate extractors and canonicalization logic with edge cases for ambiguous names and dates.
- Integration tests for the full pipeline with synthetic conversation scenarios covering multi-party mentions, corrections, and nested replies.
- Privacy tests verifying that opt-out flags prevent memory creation and that field-level encryption keys prevent unauthorized decryption.
- Load tests for ingestion and retrieval to validate SLOs and auto-scaling behavior.
- Adversarial tests that attempt to inject PII or malicious content to validate redaction rules and model behavior under prompt injections.
Governance: policy templates and SOPs
Provide standardized policies and playbooks for administrators:
- Memory retention policy per data classification.
- Incident response playbook for privacy breaches involving memory artifacts.
- Review cadence — quarterly audits of memory types and consent logs.
- User-facing policies and disclosure language for how memories are generated and used.
Recommended SOP for responding to deletion requests:
ol
Note: ensure your legal and compliance teams sign off on SOPs for regulated industries.
Future-proofing and model upgrades
Design the system for model-agnostic upgrades:
- Store multiple embeddings to avoid a full reindex on model change. When upgrading, compute new embeddings incrementally for high-value artifacts first.
- Version your synthesized memory schema to support backward-compatible changes. Include a “schema_version” field.
- Keep an immutable raw snapshot to re-run synthesis when you improve models or policy rules.
Conclusion: operationalizing Dreaming V3 safely
Dreaming V3 represents a leap from passive note storage to a proactive knowledge fabric that augments enterprise workflows with synthesized, actionable artifacts. The differentiators are: rigorous provenance, multi-model retrieval, privacy-first enforcement, and integrated human controls. Implementing such a system requires combining state-of-the-art NLP techniques with classical data engineering practices and enterprise governance.
To summarize the most important takeaways:
- Prioritize determinism and provenance in synthesis — it makes results auditable and fixable.
- Use hybrid retrieval (semantic + lexical + temporal) with a re-ranker that enforces policy decisions.
- Apply strict privacy and consent controls, including field-level encryption and provable deletion receipts.
- Start small with opt-in pilots, iterate with human review, and expand with clear governance.
- Provide strong developer tooling and SDKs to simplify adoption and experimentation.
Implementing these patterns will enable your teams to surface relevant memories in context-sensitive ways — driving efficiency and personalization — while maintaining enterprise-grade privacy and compliance. If you need a checklist to start planning, below is a concise implementation roadmap.
Access 40,000+ AI Prompts for ChatGPT, Claude & Codex — Free!
Subscribe to get instant access to our complete Notion Prompt Library — the largest curated collection of prompts for ChatGPT, Claude, OpenAI Codex, and other leading AI models. Optimized for real-world workflows across coding, research, content creation, and business.
Implementation roadmap (concise checklist)
- Define memory taxonomy and schema_version 1.0.
- Implement message ingest and raw snapshot storage with encryption.
- Build initial candidate extraction and canonicalization modules.
- Create the memory synthesizer pipeline and low-confidence review UI.
- Provision vector DB and lexical indices; implement retrieval API.
- Integrate policy engine and access control hooks.
- Run pilot with a small set of teams and iterate on metrics.
- Document SOPs, audit processes, and user-facing consent controls.
- Plan for model upgrades and re-synthesis tooling.

Two internal resources you may want to consult within your organization for alignment and references:
The Dreaming V3 memory system builds upon the foundational capabilities introduced with GPT-5.5, leveraging its enhanced reasoning and personalization architecture. For a deeper exploration of this topic, see our comprehensive guide on Setting Up GPT-5.4 for Production Workflows u2014 Complete Developer Walkthrough, which provides actionable frameworks and implementation strategies for enterprise teams.
and
Enterprise teams implementing memory-driven workflows should also consider how workspace agents can complement personalized AI interactions. For a deeper exploration of this topic, see our comprehensive guide on How to Use Chain-of-Thought to Improve AI Output Quality by 7%, which provides actionable frameworks and implementation strategies for enterprise teams.
.
End-to-end, Dreaming V3 is less about a single model and more about an orchestration of model-driven transforms, deterministic engineering practices, and strong governance. With the patterns and examples provided here, engineering teams can design a memory system that is trustworthy, scalable, and privacy-compliant — a true enterprise-grade memory architecture for conversational AI.