ChatGPT Ads Product Feeds: How Retail Brands Can Build AI-Native Shopping Campaigns with Inventory-Driven Targeting in 2026

ChatGPT Ads Product Feeds: How Retail Brands Can Build AI-Native Shopping Campaigns with Inventory-Driven Targeting in 2026
Table of Contents
- Introduction: The evolution of conversational commerce and ChatGPT Ads
- Unlocking Product Feed Campaigns: How to upload retail product catalogs directly to ChatGPT
- The Mechanics of Conversational Shopping: How ChatGPT matches user queries with live product inventory
- Advanced Targeting: Utilizing the newly released zip code targeting and geographic controls
- Writing Context Hints: Best practices for optimizing context signals for inventory-driven campaigns
- Measuring and Optimizing Conversational ROI: Analytics, attribution, and budget management
- Case Study & Playbook: Setting up a complete product feed campaign from scratch in 5 steps
- Conclusion and next steps
- Appendices: Example feed schema, API snippets, and validation checklist
Introduction: The evolution of conversational commerce and ChatGPT Ads
Conversational commerce has progressed from novelty chatbots and linear FAQ-style assistants to sophisticated, contextual, and commerce-enabled AI agents. By 2026, the integration of product feeds directly into conversational AI offers an unprecedented paradigm: AI-native shopping campaigns that use live inventory, geo-aware targeting, and context-driven prompts to produce high-intent shopping experiences. This article provides a comprehensive technical deep dive into the new ChatGPT Ads product feed campaign type and demonstrates how retail brands can build inventory-driven targeting strategies—especially focusing on the newly rolled-out zip code targeting and best practices for context hints optimization.
The goals of this article are:
- Explain the architecture and operational mechanics of product feed campaigns integrated into ChatGPT Ads.
- Walk through the technical requirements and methods for uploading and synchronizing retail catalogs with ChatGPT.
- Detail how the conversational agent performs semantic matching, availability checks, and ranking using live inventory signals.
- Provide an exhaustive guide to zip code and geographic targeting controls, with use cases such as store pickup, same-day delivery, and regional assortment.
- Deliver best practices for constructing context hints that steer the AI toward inventory-driven outcomes while preserving user-centered conversational quality.
- Outline measurement frameworks, attribution techniques, and optimization tactics for ROI in AI-native shopping campaigns.
This article is written for technical marketers, digital product managers, retail engineers, and ad operations teams who will be responsible for implementing and optimizing ChatGPT Ads product feed campaigns. Assumed knowledge includes basic familiarity with product feeds (CSV/JSON), retail inventory systems (PIM/ERP), and modern digital advertising concepts such as bid strategies and attribution windows.
Unlocking Product Feed Campaigns: How to upload retail product catalogs directly to ChatGPT
The ChatGPT Ads product feed campaign type streamlines the process of connecting an e-commerce catalog to conversational campaigns. Rather than redirecting users exclusively to landing pages, the AI references live catalog data to produce contextual product recommendations and transactional flows. Below are the mechanisms and technical patterns for successful feed ingestion, synchronization, and normalization.
Supported feed formats and schemas
ChatGPT Ads accepts several feed transport and serialization formats to accommodate diverse retail architectures. The supported formats typically include:
- CSV/TSV: Simple tabular exports from PIMs or e-commerce platforms.
- JSON Lines (NDJSON): For streaming and incremental updates.
- XML (with feed schemas similar to RSS/Atom or specific e-commerce namespaces).
- Direct API/Webhook ingestion: Real-time, authenticated feeds via REST endpoints or gRPC.
Regardless of format, a canonical internal schema is used to normalize product attributes. At minimum, ChatGPT Ads requires a unique product ID, a title, a description, price, currency, availability, fulfillment options (e.g., ship, pickup), location availability (store or node-level inventory), and canonical product metadata (GTIN/UPC, MPN, brand). Optional but strongly recommended fields include image URLs, category taxonomy (e.g., Google product category or retailer taxonomy), size/color variants, shipping lead times, and promotional prices/discount metadata.
Canonical feed schema example (JSON)
Below is a compact JSON example that reflects the canonical internal schema used during ingestion. This sample helps teams map their source fields to ChatGPT Ads required attributes. In production, feeds can be larger and contain nested arrays for variants and inventory nodes.
{
"product_id": "SKU-12345-RED-M",
"title": "Men's Performance T-Shirt - Red - Medium",
"description": "Breathable, quick-dry performance tee with reflective logo.",
"brand": "North Ridge",
"gtin": "0123456789012",
"mpn": "NR-TSHIRT-123",
"category": "Apparel > Tops > T-Shirts",
"price": {
"amount": 29.99,
"currency": "USD"
},
"availability": "in_stock",
"inventory": [
{
"location_id": "STORE-001",
"zipcode": "94107",
"quantity": 12,
"fulfillment_options": ["pickup", "ship"]
},
{
"location_id": "DC-1",
"zipcode": "94089",
"quantity": 250,
"fulfillment_options": ["ship"]
}
],
"images": ["https://cdn.example.com/products/sku12345_1.jpg"]
}Transport and synchronization patterns
There are three common approaches for integrating feeds, each appropriate for different scale and freshness requirements:
- Batch synchronization: Periodic uploads (e.g., nightly or hourly) using CSV/JSON exports. Suitable for low-velocity catalogs or when near-real-time accuracy is not essential.
- Incremental feeds / Delta updates: Using JSON Lines or differential CSVs where only changed SKUs or changed attributes are sent. This reduces processing overhead and improves freshness for frequently changing inventory.
- Real-time API / Webhook sync: Pushing updates (inventory changes, price changes, availability) to ChatGPT Ads via authenticated API endpoints or webhooks. This is the best practice for high-velocity inventory (flash sales, limited stock) and for supporting accurate local pickup windows.
Authentication, security, and data governance
Feeds must be transmitted securely using TLS, and sensitive data such as cost structure or supplier details should be excluded or tokenized. Authentication options include API keys scoped to feed write-only permissions, OAuth 2.0 client credentials flow for enterprise integrations, and signed URLs for temporary S3/Cloud storage ingestion. Implement a least-privilege model, rotate keys frequently, and create detailed audit logs for feed uploads and processing. For retailers subject to privacy regulations, ensure that PII (e.g., customer IDs attached to inventory) is removed or hashed.
Validation and schema mapping
ChatGPT Ads provides schema validation feedback during ingestion. Validation checks include:
- Data type validation (price numeric, currency codes ISO-4217).
- Mandatory field presence.
- Cross-field consistency (e.g., if availability is “preorder”, estimated ship date must be present).
- Inventory node validation (matching location IDs to registered store services).
- Image validation: URL reachability, minimum resolution, aspect ratio constraints.
Validation is returned as a structured report listing errors and warnings with line-level indices for CSVs and JSON pointer references for JSON feeds. Errors must be corrected and re-uploaded; warnings can be deferred but should be addressed to optimize campaign performance.
Feed normalization and enrichment
ChatGPT Ads performs enrichment steps to improve retrieval quality:
- Tokenization and stemming of titles and descriptions for semantic search.
- Category mapping using both retailer taxonomy and industry taxonomies to allow multi-granular targeting.
- Image feature extraction (optional): extracting dominant color, detecting clothing vs electronics vs packaged goods to augment semantics.
- Embedding generation: Vector representations of titles and descriptions for semantic matching with user queries.
For best results, provide high-quality product descriptions (100–300 words where appropriate), structured attribute data (size, color, material), and canonical category labels. Use explicit synonyms and canonical variant relationships to assist the matching layer.
Operational considerations and scale
For enterprise retailers with millions of SKUs, consider the following:
- Sharding feeds by department or geographic region to parallelize ingestion.
- Using delta feeds for high-velocity SKUs while batching static SKUs.
- Implementing retries with exponential backoff for transient upload failures.
- Monitoring processing latency SLA—aim for under 5 minutes for delta updates in mission-critical use cases (e.g., limited-time promotions).
Implementing a robust feed pipeline is foundational for inventory-driven conversational campaigns; without accurate, timely catalog data, the AI cannot reliably surface purchasable options.
The Mechanics of Conversational Shopping: How ChatGPT matches user queries with live product inventory
Understanding the retrieval and ranking pipeline is crucial for designing product feed campaigns that reliably convert. ChatGPT Ads combines semantic retrieval (embeddings), attribute-based filtering (inventory status, shipping constraints, geo-availability), and a learning-to-rank model that optimizes for downstream business metrics like conversions and margin. The following subsections explain each stage and provide examples of how the system reconciles user intent with inventory constraints.
1) Query understanding and intent classification
When a user enters a query—explicit (“red running shoes size 10 near me”) or implicit (“I need a jacket for rainy weather”)—the system performs:
- Intent classification: predicts shopping intent signal (browse, compare, buy now, gift) and sub-intents (size search, color preference, price sensitivity).
- Slot extraction: extracts explicit slots such as color, size, brand, price range, timeline (e.g., “tomorrow”).
- Contextual signals: uses conversation history, user account preferences (if available and permitted), and session signals to refine intent.
Intent classification guides the retrieval strategy—e.g., prioritize “available for pickup today” items for same-day purchase intents.
2) Semantic retrieval via embeddings
ChatGPT Ads leverages vector embeddings for titles, descriptions, and enriched attributes. The retrieval pipeline typically follows a hybrid approach:
- Semantic nearest neighbor search using ANN (Approximate Nearest Neighbor) indices (e.g., HNSW or IVF+PQ) against a product embedding store.
- Filtering by structured attributes: after candidate retrieval, products are filtered by explicit constraints (availability, zipcode coverage, fulfillment options).
- Keyword boosting: for exact match queries (model decides), keywords and GTIN matches can yield higher ranking.
Embeddings capture paraphrase relationships—”sneakers” and “running shoes”—improving recall. For extremely precise queries (e.g., specific SKU search), the system falls back to exact-match heuristics.
3) Live inventory eligibility checks
Before surfacing any product as purchasable, ChatGPT Ads runs eligibility checks against live inventory signals. This process includes:
- Availability state mapping: the internal model maps inventory quantity and lead times to discrete states such as in_stock, low_stock, backorder, out_of_stock, and pre_order.
- Fulfillment feasibility: evaluate available fulfillment methods (ship, pickup, curbside) and lead times given the user’s location and requested timeline.
- Regional restrictions: some SKUs may not be sold in certain jurisdictions due to legal, logistic, or brand constraints.
- Reservation logic: if the retailer implements soft reservations for conversational checkouts, the system can tentatively reserve an item for a limited time.
Inventory checks are often executed against a cache updated by incremental feeds or real-time APIs. The system prioritizes freshness for products with volatile inventory.
4) Ranking: business objectives and user experience signals
Ranking balances commerce objectives (revenue, margin, speed of conversion) with user experience priorities (relevance, satisfaction). The ranking model ingests signals such as:
- Semantic match score (query-product embedding similarity).
- Availability and fulfillment desirability (stock level, delivery/pickup ETA).
- Price and promotional status (discounts and bundling opportunities).
- Historical performance (CTR, conversion rate) per SKU in conversational contexts.
- User personalization signals (past purchases, size preferences) when available and permitted.
Modern systems use a learning-to-rank framework trained with both online and offline labels. Offline labels include historical conversions and human relevance judgments. Online signals include immediate conversion events, add-to-cart, and session duration. Multi-objective optimization is common—e.g., maximize conversions within margin constraints—or apply policy constraints (inventory burn-down priorities, regional quotas).
5) Conversational response generation and cart flows
After ranked candidates are selected, the ChatGPT agent composes a conversational response that can include:
- Natural language product summarizations: short bullets, unique selling points, or product highlights.
- Interactive elements: quick reply buttons, product cards with image thumbnails, price, and buy/pickup options.
- Fulfillment options and ETA: “Available for pickup in 2 hours at San Francisco Flagship.”
- Checkout initiation: options for adding to cart, reserving stock, or proceeding to checkout on a website or within a conversational checkout flow.
Composing responses requires strict alignment with the product feed to avoid hallucinations. ChatGPT Ads uses templated and constraint-aware generation—assertions about inventory must be grounded in feed data returned by the retrieval system. This grounding prevents the agent from claiming availability that isn’t present.
6) Post-conversation state and transaction handling
Transaction flows must integrate with the retailer’s commerce backend. Common integration points:
- Cart API: add/remove items using product_id and inventory node information.
- Reservation API: temporary hold for inventory during checkout conversations.
- Order API: create orders with fulfillment instructions (ship, pickup) and capture payment tokens.
- Webhook events: notify ChatGPT Ads of order completion for conversion attribution and to update conversational state.
Implement end-to-end idempotency checks, error handling for partial fulfillment (e.g., multi-SKU orders with one item out of stock), and user-friendly fallbacks (suggest similar in-stock items).
Retrieval and ranking pipeline: example sequence
| Step | Operation | Systems Involved |
|---|---|---|
| 1 | Query intent & slot extraction | NLP model, session context store |
| 2 | ANN semantic retrieval (top N candidates) | Embedding store, ANN index |
| 3 | Structured filtering (availability, zip constraints) | Inventory cache/API, location service |
| 4 | Learning-to-rank scoring | Feature store (historical KPIs), R2L model |
| 5 | Response composition and UI generation | Generation engine, templating layer |
| 6 | Transaction orchestration (cart/order) | Cart API, payments, order management system (OMS) |
Each component should expose metrics and traces for observability. Latency budgets are critical—aim for sub-200ms retrieval and sub-1s full response time for a smooth conversational experience. Caching strategies (per-session, per-region) help meet these SLAs while keeping data fresh.
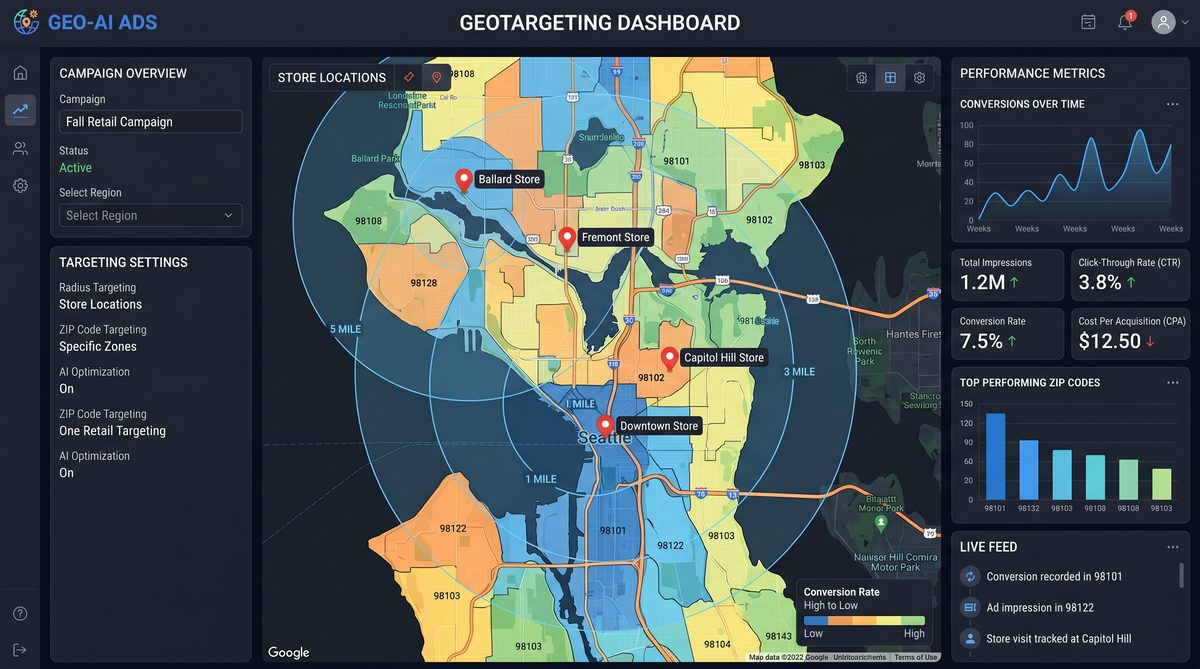
Advanced Targeting: Utilizing the newly released zip code targeting and geographic controls
The addition of zip code targeting to ChatGPT Ads introduces powerful localization capabilities. For retail brands, this enables highly granular inventory-aware targeting: combine product availability per store with ad delivery controls to prioritize users in zip codes where inventory is sufficient or where shipping costs are lower. Below we unpack how zip code targeting is implemented and how to operationalize it.
Why zip code targeting matters
Zip code-level controls allow advertisers to:
- Prioritize in-store pickup offers for nearby customers in ZIPs with stocked inventory.
- Optimize shipping promises by favoring audiences in zip codes serviced by faster distribution nodes.
- Manage regional promotions and avoid overselling in regions with constrained supply.
- Reduce logistic costs by targeting markets where last-mile costs are favorable.
Core capabilities of zip code targeting
Core controls provided by ChatGPT Ads include:
- Inclusion and exclusion lists of zip codes.
- Zip code radius targeting (e.g., 10-mile radius around a store ZIP).
- Dynamic eligibility mapping from feed inventory to zip code coverage—if a product is available at any location claiming coverage for a ZIP, that ZIP becomes eligible for that product.
- Priority scoring: ability to increase bid modifiers or delivery priority for ZIPs with higher inventory density or strategic value.
Data model for zip code coverage
When ingesting inventory, each inventory node must include the node’s ZIP code, service radius, and fulfillment options. A derived coverage map is computed that maps each ZIP to a set of eligible nodes and aggregated availability. The aggregate model includes:
- Aggregate inventory count by zip
- Average lead time for ship or pickup
- Maximum reservation capacity per zip (to avoid oversubscription)
This precomputed coverage map enables rapid eligibility checks during retrieval without requiring expensive multi-node queries for each incoming user request.
Creating zip-aware campaigns
Campaign configuration screens include options to:
- Upload target ZIP lists via CSV or select regions on a map.
- Define radius around one or more store ZIPs and set a default radius behavior (e.g., use shipping ETA or walking distance).
- Configure bid modifiers or delivery caps per ZIP or ZIP cluster (e.g., prioritizing metro areas during store hours).
- Assign SKU-level targeting overrides: e.g., only present product X in ZIPs A, B, C while product Y is nationwide.
Use cases and campaign strategies
Examples of strategic uses:
- Same-day pickup campaigns: Target ZIPs within 5–10 miles of stores with sufficient pickup inventory. Use higher bid modifiers during store hours and include context hints for pickup-specific messaging.
- Inventory burn-down: Promote slow-moving SKUs in ZIPs where they are overstocked with aggressive pricing and higher delivery frequency.
- Regional assortment and compliance: Use ZIP targeting to restrict SKU exposure to legally allowed regions (e.g., age-restricted items) or to match assortments by climate (e.g., winter vs summer products).
- Cost-optimized fulfillment: Limit campaigns to ZIPs that are cheaper to serve (avoiding high last-mile costs) or to ZIPs where the distribution center has surplus stock.
Implementation patterns for zip code targeting
Key implementation steps include:
- During feed ingestion, ensure each inventory node includes a normalized ZIP code and service radius.
- Precompute zip-to-node coverage maps on a periodic cadence (or compute incrementally on delta updates).
- Expose an API endpoint for campaign logic to query coverage and expected lead times by zip code for specific products.
- Design campaign rules that reference coverage map metrics (e.g., only target ZIPs with aggregated quantity > 10).
Privacy, compliance, and fairness concerns
Zip code targeting raises privacy and fairness considerations:
- Zip codes can be granular proxies for socio-economic status. Avoid discriminatory optimization (e.g., deprioritizing essential health products in certain ZIPs).
- Ensure compliance with advertising regulations and local laws that may restrict targeted promotions in specific geographies.
- Document targeting logic and allow human review of ZIP-based exclusions to catch unintended bias.
Debugging and validation checklist
When troubleshooting ZIP-driven campaign behavior, verify:
- Inventory nodes have correct ZIP and service radius values.
- Coverage map was recomputed after the latest feed update.
- Exclusion rules are not unintentionally filtering target ZIPs.
- Bid modifiers per ZIP are applied correctly and not conflicting with budget caps.
Writing Context Hints: Best practices for optimizing context signals for inventory-driven campaigns
Context hints are structured signals provided to the ChatGPT Ads system that influence how the AI composes responses and which inventory to prioritize. They are not direct instructions to the end-user; instead they function as internal prompts that weigh intent, tone, and inventory constraints. Well-crafted context hints can dramatically improve conversion rates by ensuring the agent surfaces in-stock items with appropriate messaging and CTA placement.
Note: Context hints are distinct from user-visible content—they instruct the model without being displayed to the user. The following best practices draw on behavioral research, computational linguistics, and practical campaign optimizations.
Core components of a context hint
A robust context hint typically includes:
- Objective: What action should the user take? (e.g., “drive conversion for in-stock items in ZIP 94107”)
- Priority rules: Which attributes to prioritize (availability, price, margin, delivery speed)
- Tone and constraints: Natural language style, compliance constraints, maximum message length
- Fallback strategies: What to do when inventory is not available (e.g., suggest alternatives by category or initiate back-in-stock alerts)
Context hints are evaluated alongside query intent. They should be concise, precise, and machine-readable where possible (structured JSON wrapper) to enable validation and debugging.
Best practices: designing effective context hints
- Be explicit about inventory constraints: If the campaign’s objective is to drive same-day pickup, include explicit inventory states (e.g., require pickup availability within 2 hours). This avoids presenting items that are technically available for shipment but not for immediate pickup.
- Use prioritized attribute lists: Provide an ordered list—first prioritize availability in the user ZIP, second prioritize delivery ETA under 48 hours, third prioritize promotional price. The ranking layer uses these priorities to balance scoring.
- Include fallback preference order: When preferred SKUs are out of stock, specify fallback paths such as variant substitution (size/color), similar items within the same category, or back-in-stock notification with an explicit CTA.
- Limit hallucination risk: Require the model to cite grounded fields from the product feed for any definitive claims about availability, price, or time estimates.
- Use tokens for dynamic variables: Context hints can reference dynamic tokens (e.g., {{user_zip}}, {{session_intent}}) which are resolved at runtime to localize recommendations.
- A/B test context hint variants: Create controlled experiments to determine the best tradeoffs between urgency messaging (e.g., “only 2 left!”) and trust signals that might reduce cancellations.
Context hint examples
Below are three patterns of context hints suitable for different campaign objectives.
1) Same-day pickup priority (structured hint)
{
"objective": "promote_same_day_pickup",
"priority": ["pickup_availability_within_4h", "proximity_to_user_zip", "price_promo"],
"constraints": {
"must_be_in_stock": true,
"pickup_lead_time_hours": 4
},
"fallback": ["same_store_similar_skus", "reserve_and_notify"],
"tone": "concise, action-oriented"
}2) Margin-sensitive campaign (natural-language hint)
Natural-language hints are acceptable if translated into structured forms by the ingestion layer.
"Prioritize items with contribution margin > 30%. If multiple matches, break ties by highest conversion rate in the last 30 days. Avoid promoting clearance items unless stock > 50 units. Always present price and expected shipping time." 3) Friendly discovery experience (for browsing intent)
{
"objective": "help_user_discover",
"priority": ["semantic_relevance", "customer_reviews_score"],
"constraints": {
"avoid_as_promotional": true
},
"tone": "friendly, informative, exploratory"
}Dynamic context hint insertion and personalization
Context hints can and should be dynamically adjusted in real time based on session state or user profile. Examples:
- For a returning customer with size preference data, insert {{preferred_size}} into the hint so the model prefilters variants.
- When inventory for the initially recommended SKU is insufficient, dynamically escalate to the next hint variant that removes the “must be in stock” constraint but includes explicit reservation instructions.
Dynamic hints require a runtime layer that composes the hint prior to the model call. This layer should validate that tokens are resolved and that the final hint adheres to constraints (length, schema).
Measuring context hint effectiveness
To evaluate a context hint’s impact, instrument the following metrics at the hint-level:
- Conversion rate per impression when the hint is active.
- Add-to-cart rate and cart-to-purchase conversion.
- Average order value (AOV) and margin lift.
- User satisfaction signals: session length, explicit like/dislike actions, and NPS where available.
- Fallback rate: frequency the agent had to use a fallback strategy.
Use controlled experiments (A/B/n testing) where only the hint differs. Evaluate statistical significance using sequential testing frameworks to minimize risk in a live commerce environment.
Effective context hints are a powerful lever: they guide the AI’s retrieval and generation behaviors while preserving the flexibility and naturalness of conversational interactions.
Marketers building product feed campaigns should understand the broader ChatGPT advertising ecosystem before launching inventory-driven campaigns. Our comprehensive guide on measuring, optimizing, and scaling AI-native advertising campaigns in ChatGPT covers the foundational metrics, attribution models, and budget optimization strategies that apply directly to product feed campaign management.
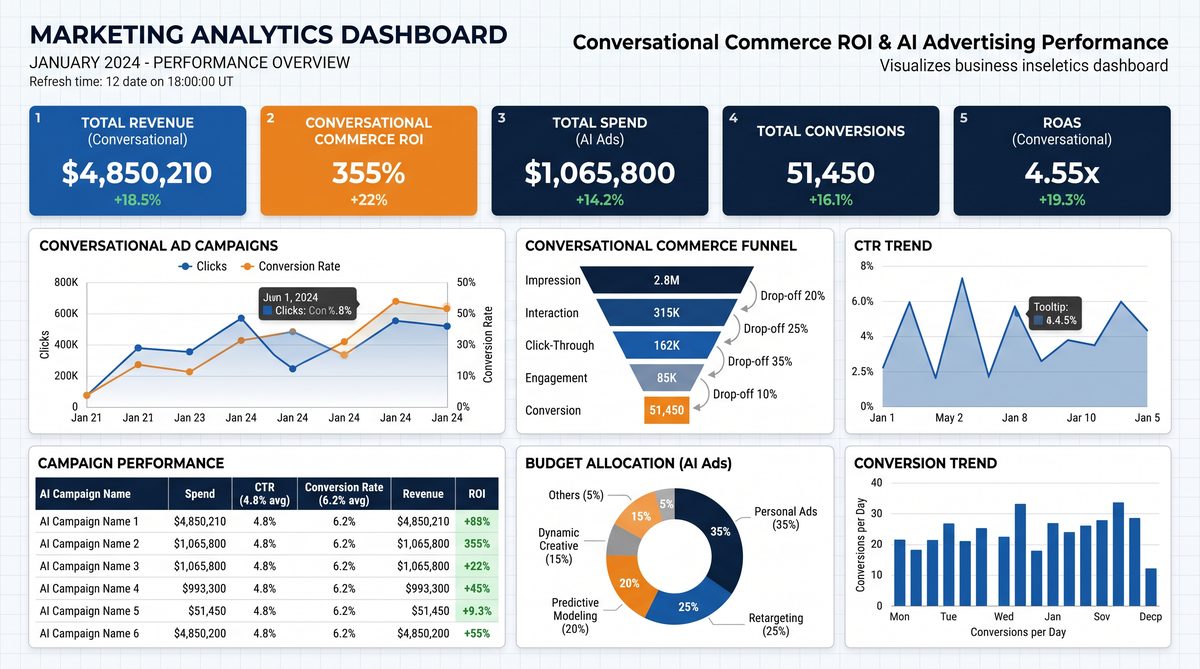
Measuring and Optimizing Conversational ROI: Analytics, attribution, and budget management
Measuring success for AI-native shopping campaigns requires rethinking metrics and attribution models that were designed for click-based channels. Conversational shopping introduces new event types (conversational adds, reservations, in-chat purchases) and requires hybrid attribution to account for deferred conversions and multichannel touchpoints. This section provides a practical analytics blueprint for retail teams.
Key performance indicators (KPIs)
Define KPIs aligned with business objectives. Common KPIs include:
- Conversational Conversion Rate: percentage of sessions that result in conversion (add-to-cart, reservation, or purchase).
- Time-to-purchase: median time from initial query to final order creation.
- Inventory Efficiency: ratio of units sold via conversational campaigns to units available in targeted ZIP codes.
- Return and Cancellation Rate: essential to evaluate the quality of conversationally-driven orders.
- Customer Lifetime Value (LTV) for customers acquired or reactivated through ChatGPT Ads.
- Cost per Acquisition (CPA) or Cost per Conversion—align with margin constraints.
Attribution strategies for conversational channels
Conversational attribution is a hybrid problem because interactions can be both in-session and cross-channel. Practical approaches include:
- Event-based multi-touch attribution: record every conversational event (impression, suggestion, add-to-cart, reservation) with unique IDs and map downstream conversions to these events using server-side logs.
- Time-decay windows: assign fractional credit to conversational events within a defined lookback window (e.g., 7–30 days) that recognizes the conversational channel’s role in discovery.
- Deterministic attribution via IDs: pass UTM-like parameters and session IDs through to checkout and order creation to ensure deterministic linking when the conversation leads to checkout on an owned channel.
- Incrementality and lift testing: run randomized experiments (holdout groups) to measure the true causal impact of conversational campaigns on conversion lift, reducing bias from selection effects.
Instrumentation and data model
Essential instrumentation elements:
- Event taxonomy: standardize event names and payloads (impression, suggestion_shown, add_to_cart, reserve_item, checkout_initiated, purchase_completed).
- Session and conversation IDs: persistable across modalities (web, app, voice) and bound to persistent user IDs when privacy-permitted.
- Product-level metadata: include product_id, inventory_node_id, price, and discount at each event to support SKU-level analysis.
- Geographic context: record user_zip and node_zip to support zip-based attribution and supply-side analytics.
Dashboards and reporting
Build dashboards that integrate conversational campaign metrics with backend order and inventory systems. Recommended views:
- Real-time monitoring: impressions, response latency, reservation rates, and error rates.
- Performance by zip code: CPA, conversion rates, inventory sold, and stockouts.
- SKU-level cadence: top-performing SKUs, margin by SKU, and fallback frequency (how often an alternative was suggested).
- Customer journey visualizations: typical paths from first interaction to purchase including channel transfers.
Budgeting, pacing, and automated bid strategies
Conversational campaigns can operate with different bid strategies:
- Cost-per-conversation (CPC): pay per qualified conversational impression that results in an actionable engagement.
- Cost-per-acquisition (CPA): automated bidding targeting a CPA target based on historical conversion rates.
- Inventory-aware budget caps: budgeting rules that throttle delivery when projected inventory depletion in targeted ZIPs exceeds thresholds to avoid oversell.
- Time-of-day and store-hour pacing: increase delivery during store hours for pickup-focused campaigns, or adjust bidding around local peak delivery windows.
Use simulation and forecast tools to estimate the impact of different bid strategies on inventory consumption and marketing ROI. For example, estimate expected units sold in ZIPs with high inventory density under a target CPA to avoid depleting inventory needed for in-store customers.
Optimization loops and automated experiments
Optimization is continual. Effective loops include:
- A/B test context hint variants to find messaging that maximizes conversions while minimizing returns.
- Re-rank model retraining cadence: incorporate recent conversational signal features (e.g., conversion velocity) into the ranking model weekly or bi-weekly.
- Inventory-aware campaign tuning: automatically reduce bids in ZIPs where inventory drops below a threshold or increase bids for SKUs with high margin and low exposure.
- Operational playbooks: automated alerts and playbooks for cases like sudden stockouts or delivery disruptions to pause or reroute campaigns.
Case Study & Playbook: Setting up a complete product feed campaign from scratch in 5 steps
The following playbook illustrates a practical end-to-end setup for a mid-size retail brand launching its first ChatGPT Ads product feed campaign, targeting local pickup and optimizing for inventory-driven conversions in Q4 2026.
Campaign objective
Drive same-day in-store pickup conversions for a select holiday apparel collection in three metropolitan areas with high inventory across stores. Secondary objectives: reduce markdowns on overstocked SKUs and increase foot traffic for upsell.
Prerequisites
- Accessible product catalog in PIM with location-level inventory and store ZIP codes.
- Cart and reservation APIs for holding inventory during conversational sessions.
- Payment integration capable of checkout after conversation or redirect to site checkout with deterministic session linking.
- Analytics instrumentation with event schema defined.
5-step setup playbook
Step 1: Data mapping and feed preparation (Duration: 1 week)
Actions:
- Export product feed with SKU-level attributes and inventory nodes. Ensure each node includes:
- location_id
- zipcode
- quantity
- pickup_windows (e.g., store open hours)
- Map internal taxonomy to canonical categories expected by ChatGPT Ads; provide synonyms for search expansion (e.g., “puffer jacket” → “insulated jacket”).
- Validate images and descriptions; enhance product descriptions to support conversational summarization (3–5 bullets per product).
Step 2: Feed ingestion and validation (Duration: 2–3 days)
Actions:
- Upload initial feed via API or secure file upload. Address errors flagged by the validation report.
- Set up incremental delta feed process for inventory changes and price updates (hourly for this campaign).
- Verify coverage map accuracy for targeted ZIPs by sampling several SKUs and checking derived ZIP eligibility.
Step 3: Campaign configuration and context hint design (Duration: 3 days)
Actions:
- Create campaign targeting specific ZIP lists for three cities. Configure radius rules for each store cluster.
- Design context hints emphasizing same-day pickup and reservation capability. Example:
{
"objective": "promote_same_day_pickup",
"priority": ["pickup_availability_within_4h", "proximity_to_user_zip", "promotional_price"],
"constraints": {"must_be_in_stock": true},
"fallback": ["suggest_similar_in_store_items", "offer_reservation_for_next_day"],
"tone": "concise, friendly, trust-building"
}Step 4: Integration testing and live pilot (Duration: 1 week)
Actions:
- Conduct end-to-end tests: sample user queries across intents, verify retrieved items match expected inventory, test reservation and cart flows, and process test orders.
- Run a 48-hour live pilot in two pilot ZIP clusters with reduced spend to collect initial signals. Monitor errors, fallback rates, conversions, and reservation abandonment rates.
- Instrument UTM/session IDs to ensure deterministic attribution for any orders that move to site checkout.
Step 5: Scale, monitor, and iterate (Duration: ongoing)
Actions:
- Scale to all targeted ZIPs based on pilot success. Gradually increase budget and expand SKU coverage.
- Retrain ranking model incorporating pilot conversion data and adjust context hints based on learned behaviors.
- Implement inventory-aware pacing: automatic bid reduction when projected inventory burn in a ZIP crosses a threshold to avoid impacting in-store customers.
- Perform weekly incrementality tests with holdouts to maintain causal measurement of value.
Operational checklist and troubleshooting
| Area | Check | Remediation |
|---|---|---|
| Feed freshness | Inventory discrepancies between feed and store POS | Implement real-time inventory webhooks or increase delta feed cadence |
| Reservations | High reservation abandonment | Simplify checkout, reduce steps, follow-up via SMS/email, shorten reservation TTL |
| Zip targeting | Unexpected ZIP exclusions | Verify coverage map computation and radius settings per store |
| Measurement | Attribution mismatches | Ensure session IDs are propagated and server-side logging is capturing event linkage |
Expected outcomes and KPIs for the pilot
Projected performance targets for the pilot (example):
- Conversational conversion rate: 8–12%
- Reservation-to-purchase conversion: 75%
- Cost per pickup acquisition: within target CPA
- Inventory burn-down in targeted ZIPs: 18% reduction in overstocked SKUs over 8 weeks
Access 40,000+ AI Prompts for ChatGPT, Claude & Codex — Free!
Subscribe to get instant access to our complete Notion Prompt Library — the largest curated collection of prompts for ChatGPT, Claude, OpenAI Codex, and other leading AI models. Optimized for real-world workflows across coding, research, content creation, and business.
Conclusion and next steps
ChatGPT Ads product feed campaign type represents a step change for retail brands: it enables AI-native shopping experiences that are grounded in live inventory and localized at zip code level. Successful deployments rely on rigorous feed engineering, a robust retrieval and ranking architecture that respects inventory constraints, and careful use of context hints to guide the conversational agent. Measurement and attribution require new instrumentation and experimentation practices to quantify conversational impact.
Next steps for teams considering a rollout:
- Audit your catalog and inventory systems to ensure node-level data completeness.
- Design privacy-safe personalization and tokenization strategies for dynamic hints.
- Start with narrow pilots focusing on high-opportunity ZIP clusters and expand based on validated metrics.
- Adopt an iterative optimization cadence that integrates creative (context hints), ranking model updates, and inventory-aware pacing.
As AI-native shopping continues to mature, cross-functional collaboration across merchandising, engineering, analytics, and legal will be the differentiator between campaigns that drive revenue sustainably and those that inadvertently create fulfillment problems or reputational risk.
Beyond campaign management, marketing teams can leverage GPT-5.5 for the creative and strategic work that supports product feed campaigns. Our curated collection of battle-tested prompts specifically designed for marketers includes templates for writing compelling product descriptions, generating ad copy variations, and analyzing competitive positioning that directly enhance product feed campaign performance.
Appendices: Example feed schema, API snippets, and validation checklist
Appendix A — Minimal feed CSV header example
CSV header columns to include at minimum:
| Column | Description |
|---|---|
| product_id | Unique SKU identifier |
| title | Product title |
| description | Product description |
| price | Numeric price |
| currency | ISO-4217 currency code |
| availability | in_stock, out_of_stock, pre_order |
| location_id | Inventory node identifier (multiple lines per SKU allowed) |
| zipcode | Location ZIP code |
| quantity | Integer quantity available |
| fulfillment_options | pipe-separated: pickup|ship|curbside |
Appendix B — Example product feed API snippet (pseudo)
POST /feeds/upload
Headers:
Authorization: Bearer <API_KEY>
Content-Type: application/json
Body:
{
"feed_type": "product_catalog",
"transport": "s3",
"s3_url": "https://s3.example.com/feeds/q4_holiday_feed.jsonl",
"delta_mode": true,
"owner_id": "retailer_abc"
}Appendix C — Validation checklist
- Are all required attributes present and compliant with types?
- Is price expressed with consistent currency codes?
- Do inventory nodes include ZIP codes and fulfillment options?
- Have images been validated for resolution and accessibility?
- Are GTIN/MPN/brand values provided where available?
- Is the delta feed configured with proper change detection logic to avoid duplicative updates?
- Are PII and sensitive supplier details removed or hashed?
Successful adoption of ChatGPT Ads product feed campaigns requires both technical rigor and cross-functional readiness. By following the architectures, operational patterns, and best practices in this article, retail brands can deploy AI-native shopping campaigns that are inventory-aware, geographically precise, and optimized for conversational conversion.
End of Article