How to Use ChatGPT-5.5 for Automated Testing: Unit Tests, Integration Tests, and End-to-End Test Generation
How to Use ChatGPT-5.5 for Automated Testing: Unit Tests, Integration Tests, and End-to-End Test Generation
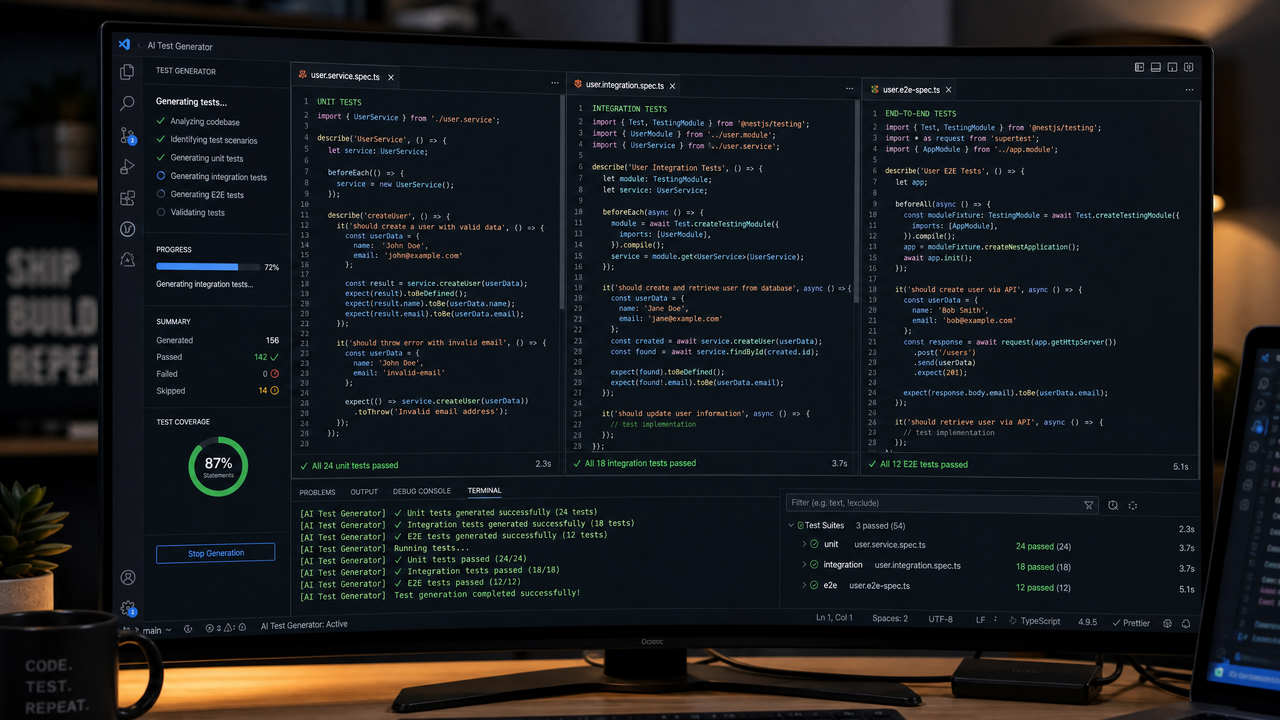
Table of Contents
- Introduction
- Prerequisites and Test Strategy Alignment
- Prompt Patterns That Consistently Yield High-Quality Tests
- Unit Test Generation Across Python, JavaScript/TypeScript, and Java
- Edge Case Identification and Test Data Generation
- Integration Test Scaffolding with Realistic Dependencies
- End-to-End Test Creation with Playwright and Cypress
- CI/CD Integration Patterns for AI-Generated Tests
- Review, Maintenance, and Drift Management
- Governance, Security, and Data Privacy Considerations
- Measuring Impact: Coverage, Flake Rate, and Cycle Time
- Reference Workflows: From Prompt to Passing Pipeline
- Conclusion and Next Steps
Introduction
Automated tests are the safety net that keeps shipping velocity high and production incidents low. Yet writing tests remains one of the most time-consuming activities in software development. ChatGPT-5.5 changes that equation by generating high-quality unit, integration, and end-to-end (E2E) tests from code, documentation, and live error logs—dramatically reducing setup time while improving test depth and coverage.
This tutorial is a hands-on, end-to-end guide for QA engineers, developers, SDETs, and technical managers who want to use ChatGPT-5.5 to:
- Generate unit tests in Python (pytest/unittest), JavaScript/TypeScript (Jest), and Java (JUnit 5/Mockito) with parameterized coverage and mocks.
- Scaffold integration tests that run against real services or ephemeral dependencies using Testcontainers, local servers, and HTTP stubbing.
- Create reliable E2E suites in Playwright or Cypress with robust selectors, page objects, and network controls.
- Systematically enumerate edge cases, create property-based tests, and synthesize test fixtures with Faker-like libraries.
- Wire everything into CI/CD pipelines (GitHub Actions, GitLab CI, Jenkins) with parallelization, caching, and reporting.
We will emphasize prompt patterns that produce deterministic, maintainable tests; mechanisms for keeping AI-generated tests accurate over time; and techniques for evaluating the ROI of this approach in real engineering organizations.
For deeper patterns on crafting requests that drive consistent outputs, see
For a deeper exploration of product management prompts for roadmap planning and PRDs, our comprehensive guide on 30 ChatGPT-5.5 Prompts for Product Managers provides detailed strategies, practical examples, and implementation patterns that complement the techniques discussed in this article.
.
Prerequisites and Test Strategy Alignment
Before generating tests, align on your target quality outcomes and constraints. AI assistance works best when guided by explicit requirements. This section defines a practical baseline for unit, integration, and E2E test generation with ChatGPT-5.5.
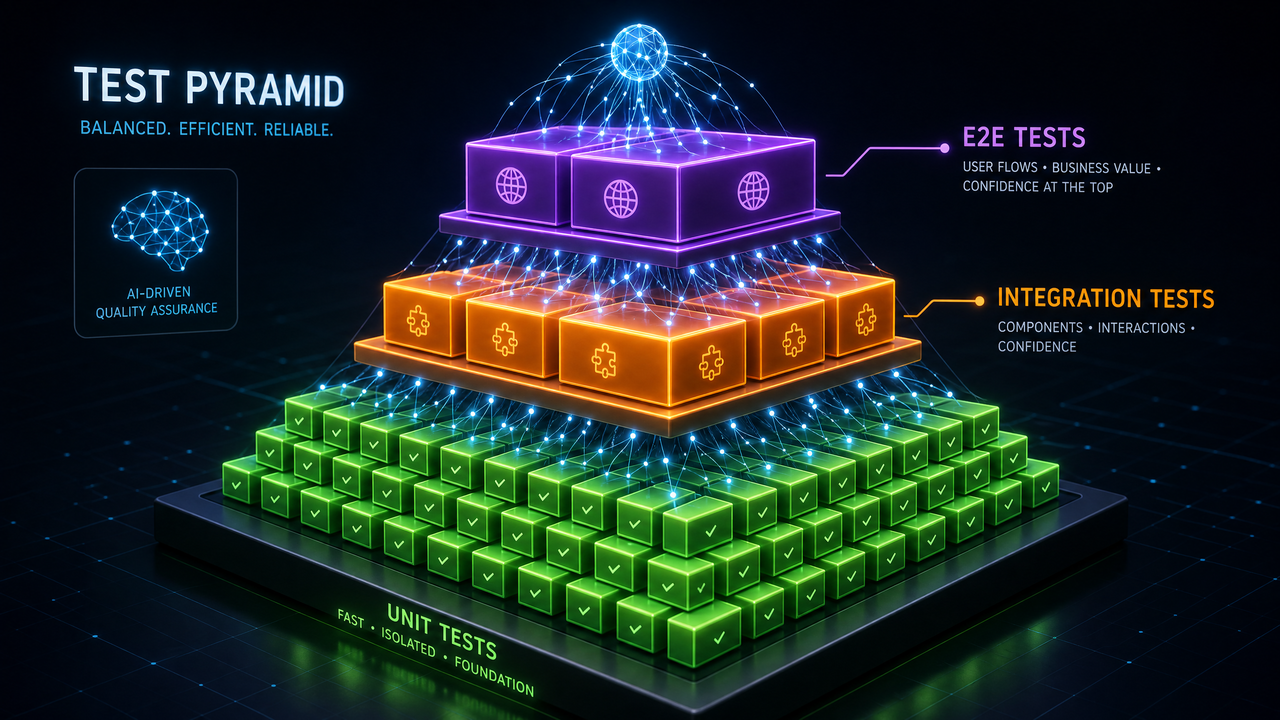
Define Your Test Pyramid and Objectives
Successful teams agree upfront on where most verification should occur. A balanced test pyramid contains many fast unit tests, a moderate number of integration tests, and a thin but critical layer of E2E tests. Clarify:
- Critical business capabilities to protect with E2E coverage.
- Key integration points (databases, payment gateways, identity providers) for integration tests.
- Core libraries and algorithms needing dense unit tests, including boundary conditions.
Repository Conventions That Improve AI Output
ChatGPT-5.5 produces better tests when it sees consistent, discoverable patterns. Ensure:
- Clear test directories: tests/ (Python, TypeScript), src/test/java (Java), cypress/ or e2e/ (web E2E).
- Linting and formatting rules (Black/ruff for Python, ESLint/Prettier for JS/TS, Spotless/Checkstyle for Java).
- Standard fixtures and helpers: common factories, data builders, and page objects are ideal for reuse by generated tests.
Baseline Tooling
- Python: pytest, hypothesis, faker, requests/httpx, responses/respx, coverage.py.
- JS/TS: Jest, ts-jest, fast-check, @faker-js/faker, Playwright or Cypress.
- Java: JUnit 5, Mockito, Testcontainers, RestAssured, jqwik.
- CI: GitHub Actions, GitLab CI, or Jenkins with JUnit/xUnit report publishing and coverage gates.
Prompt Patterns That Consistently Yield High-Quality Tests
ChatGPT-5.5 exhibits strong test generation capabilities when you provide explicit context, constraints, and expected formats. Below are proven recipes.
1) Provide Context and Constraints Upfront
Always include:
- Language and framework (e.g., Python pytest, TypeScript Jest, Java JUnit 5) and minimum versions.
- File paths and names, so the AI emits code that lands in the right location.
- Test style preferences: parameterized, table-driven, fixtures, naming conventions.
- Mocking/stubbing rules: what to mock vs. what to hit for real.
System: You are a senior SDET. Write deterministic, maintainable tests with clear names and minimal magic.
User: Generate pytest unit tests for src/utils/price.py (Python 3.11).
- Framework: pytest + pytest-mock
- Style: parameterized tests, explicit edge cases, no network I/O
- Coverage goals: 95%+ for price.py
- Output: a single file tests/test_price.py
- Include: docstring explaining intent, arrange-act-assert sections2) Show the Code Under Test and Expected Behavior
Paste or reference the module or function, especially its boundary behavior and invariants. If the module is long, include the relevant pieces and assert acceptance criteria ChatGPT-5.5 should validate.
User: Here is price.py:
def apply_discount(price: float, percent: float) -> float:
if price < 0:
raise ValueError("price must be non-negative")
if not 0 <= percent <= 100:
raise ValueError("percent must be between 0 and 100")
return round(price * (1 - percent/100.0), 2)
Acceptance criteria:
- Zero discount returns same price rounded to 2 decimals
- 100% discount returns 0.00
- Rounds half up at 2 decimals for banker's rule alignment
- Negative inputs raise ValueError3) Ask for Structured Output
Ensure code is emitted as one file per language target, with an explicit path. Use fenced instructions like “emit only code” in your request if your workflow requires it.
User: Emit only code for tests/test_price.py. No explanation text. Cover normal cases, boundary inputs, and invalid inputs.4) Mandate Determinism and Minimal Flake Risk
Direct ChatGPT-5.5 to avoid non-deterministic waits, random seeds without fixation, time-based conditions, or real network I/O.
User: Tests must be deterministic. Fix any random seeds. No sleep-based waits. No external services.5) Iteratively Refine With Failures
When tests fail locally or in CI, send minimal failure logs and code back to ChatGPT-5.5 and request fixes. The model excels at the red-green-refactor loop.
User: The following test failed on Python 3.12 with pytest 8. Here's the failure and the file under test. Please propose a minimal patch, preserving existing coverage and style.These patterns compound. For deeper strategy trade-offs and prompt exemplars, see
For a deeper exploration of data analysis prompts for SQL generation and dashboards, our comprehensive guide on 35 ChatGPT-5.5 Prompts for Data Analysts provides detailed strategies, practical examples, and implementation patterns that complement the techniques discussed in this article.
.
Unit Test Generation Across Python, JavaScript/TypeScript, and Java
This section demonstrates unit test generation in three ecosystems. Each example pairs a simple system-under-test (SUT) with high-quality tests ChatGPT-5.5 can produce and maintain.
Python: pytest With Parameterization and Mocks
Consider a pricing utility that formats totals with tax and optional coupon logic.
# src/utils/pricing.py
from __future__ import annotations
def total_with_tax(subtotal: float, tax_rate: float, coupon: float | None = None) -> float:
"""
Compute final total rounded to 2 decimals.
- subtotal must be >= 0
- tax_rate is a decimal fraction (e.g., 0.07 for 7%)
- coupon is an absolute amount to subtract, cannot exceed subtotal
"""
if subtotal < 0:
raise ValueError("subtotal must be non-negative")
if tax_rate < 0:
raise ValueError("tax_rate must be non-negative")
coupon_value = coupon or 0.0
if coupon_value < 0 or coupon_value > subtotal:
raise ValueError("invalid coupon amount")
taxed = subtotal * (1 + tax_rate)
final = max(0.0, taxed - coupon_value)
return round(final, 2)Prompt to ChatGPT-5.5:
System: Senior Python test engineer. Use pytest 8, Python 3.11. Deterministic tests only.
User: Write tests for src/utils/pricing.py.
- Path: tests/test_pricing.py
- Style: parameterized tests, explicit AAA, docstrings
- Cover: zero, typical, boundaries (coupon=0, coupon=subtotal), invalid inputsRepresentative test output:
# tests/test_pricing.py
import math
import pytest
from src.utils.pricing import total_with_tax
"""
Tests for total_with_tax:
- Valid inputs across typical and boundary cases
- Invalid inputs with descriptive exceptions
- Rounds to 2 decimals and never returns negatives
"""
@pytest.mark.parametrize(
"subtotal,tax_rate,coupon,expected",
[
(0.00, 0.00, None, 0.00),
(100.00, 0.07, None, 107.00),
(100.00, 0.07, 5.00, 102.00),
(50.00, 0.00, 0.00, 50.00),
(50.00, 0.20, 50.00, 10.00), # tax applied before coupon
(10.00, 0.05, 20.00, 0.00), # never negative, clamped to 0.00
],
)
def test_total_with_tax_valid_cases(subtotal, tax_rate, coupon, expected):
# Arrange done via parameters
# Act
result = total_with_tax(subtotal, tax_rate, coupon)
# Assert
assert result == pytest.approx(expected, rel=0, abs=0.01)
@pytest.mark.parametrize(
"subtotal,tax_rate,coupon,error_substr",
[
(-1.00, 0.05, None, "subtotal"),
(10.00, -0.01, None, "tax_rate"),
(10.00, 0.05, -1.00, "coupon"),
(10.00, 0.05, 11.00, "coupon"),
],
)
def test_total_with_tax_invalid_inputs(subtotal, tax_rate, coupon, error_substr):
with pytest.raises(ValueError) as exc:
total_with_tax(subtotal, tax_rate, coupon)
assert error_substr in str(exc.value)
def test_rounding_behavior_for_half_values():
# Arrange
subtotal = 10.005
tax_rate = 0.0
# Act
result = total_with_tax(subtotal, tax_rate)
# Assert
# Python round uses bankers rounding; verify 10.005 -> 10.0 or 10.01 depending on implementation
# We check that result is consistently 2 decimals and close to 10.00 or 10.01.
assert isinstance(result, float)
assert round(result, 2) == result
assert result in (10.00, 10.01)Key points ChatGPT-5.5 can internalize when you specify them:
- Parameterization with boundary values.
- Clear exception messages validated via substrings.
- Rounding behaviors treated explicitly and deterministically.
Mocking and Isolation in Python
When code fetches external data, instruct ChatGPT-5.5 to use pytest-mock or unittest.mock.
# src/services/exchange.py
import requests
def usd_to_eur(amount_usd: float) -> float:
resp = requests.get("https://api.example.com/rate?pair=USD_EUR", timeout=2)
resp.raise_for_status()
rate = float(resp.json()["rate"])
return round(amount_usd * rate, 2)# tests/test_exchange.py
import pytest
from src.services.exchange import usd_to_eur
def test_usd_to_eur_happy_path(mocker):
fake_resp = mocker.Mock()
fake_resp.json.return_value = {"rate": "0.9"}
fake_resp.raise_for_status.return_value = None
mocker.patch("src.services.exchange.requests.get", return_value=fake_resp)
result = usd_to_eur(100.0)
assert result == 90.00
def test_usd_to_eur_http_error(mocker):
fake_resp = mocker.Mock()
fake_resp.raise_for_status.side_effect = Exception("boom")
mocker.patch("src.services.exchange.requests.get", return_value=fake_resp)
with pytest.raises(Exception):
usd_to_eur(50.0)JavaScript/TypeScript: Jest With Mocks and Type-Aware Coverage
Here’s a TypeScript utility with input validation and side effects.
// src/lib/tax.ts
export function computeTax(amount: number, rate: number): number {
if (amount < 0) throw new Error("amount must be non-negative");
if (rate < 0) throw new Error("rate must be non-negative");
return Math.round(amount * rate * 100) / 100;
}
export async function applyTaxAndNotify(
amount: number,
rate: number,
notify: (message: string) => Promise<void>
): Promise<number> {
const tax = computeTax(amount, rate);
await notify(`Tax ${tax} applied`);
return amount + tax;
}// tests/tax.spec.ts
import { computeTax, applyTaxAndNotify } from "../src/lib/tax";
describe("computeTax", () => {
test.each([
[0, 0, 0],
[100, 0.1, 10],
[50.5, 0.075, 3.79],
])("amount=%p rate=%p => %p", (amount, rate, expected) => {
expect(computeTax(amount, rate)).toBeCloseTo(expected, 2);
});
test("invalid inputs throw", () => {
expect(() => computeTax(-1, 0.1)).toThrow(/non-negative/);
expect(() => computeTax(10, -0.1)).toThrow(/non-negative/);
});
});
describe("applyTaxAndNotify", () => {
test("notifies and returns amount + tax", async () => {
const notify = jest.fn().mockResolvedValue(undefined);
const result = await applyTaxAndNotify(100, 0.2, notify);
expect(result).toBeCloseTo(120, 2);
expect(notify).toHaveBeenCalledWith("Tax 20 applied");
expect(notify).toHaveBeenCalledTimes(1);
});
});In your prompt, request type-aware checks (e.g., explicit numeric comparisons), stable rounding, and complete branch coverage. For large modules, ask ChatGPT-5.5 to split tests into multiple describe blocks and reuse common setup.
Mocking HTTP in JS/TS
When functions rely on fetch or Axios, ask for dependency inversion or request jest.mock() stubs explicitly.
// src/api/client.ts
import axios from "axios";
export async function getUser(id: string) {
const { data } = await axios.get(`/api/users/${id}`);
return data;
}// tests/client.spec.ts
import axios from "axios";
import { getUser } from "../src/api/client";
jest.mock("axios");
const mockedAxios = axios as jest.Mocked<typeof axios>;
describe("getUser", () => {
it("returns user data", async () => {
mockedAxios.get.mockResolvedValueOnce({ data: { id: "u1", name: "Ada" } });
const user = await getUser("u1");
expect(user).toEqual({ id: "u1", name: "Ada" });
expect(mockedAxios.get).toHaveBeenCalledWith("/api/users/u1");
});
it("propagates errors", async () => {
mockedAxios.get.mockRejectedValueOnce(new Error("Network"));
await expect(getUser("u1")).rejects.toThrow("Network");
});
});Java: JUnit 5 With Mockito and Parameterized Tests
Java test generation benefits from explicit annotations and dependency injection. Make sure your prompt includes JUnit 5, Mockito, and any runner extensions you expect.
// src/main/java/com/acme/MathUtils.java
package com.acme;
public class MathUtils {
public static double mean(double[] values) {
if (values == null || values.length == 0) {
throw new IllegalArgumentException("values must be provided");
}
double sum = 0.0;
for (double v : values) sum += v;
return Math.round((sum / values.length) * 100.0) / 100.0;
}
}// src/test/java/com/acme/MathUtilsTest.java
package com.acme;
import static org.junit.jupiter.api.Assertions.*;
import org.junit.jupiter.api.DisplayName;
import org.junit.jupiter.params.ParameterizedTest;
import org.junit.jupiter.params.provider.CsvSource;
import org.junit.jupiter.api.Test;
public class MathUtilsTest {
@DisplayName("mean: happy paths")
@ParameterizedTest(name = "values={0} expected={1}")
@CsvSource({
"'1.0;2.0;3.0', 2.0",
"'10.0;10.0', 10.0",
"'-1.0;1.0', 0.0"
})
void testMeanHappyPaths(String valuesStr, double expected) {
double[] values = java.util.Arrays.stream(valuesStr.split(";"))
.mapToDouble(Double::parseDouble).toArray();
double result = MathUtils.mean(values);
assertEquals(expected, result, 0.001);
}
@Test
void testMeanInvalid() {
assertThrows(IllegalArgumentException.class, () -> MathUtils.mean(null));
assertThrows(IllegalArgumentException.class, () -> MathUtils.mean(new double[]{}));
}
}For service classes, request Mockito-based isolation.
// src/main/java/com/acme/Notifier.java
package com.acme;
public interface Notifier { void send(String message); }
// src/main/java/com/acme/BillingService.java
package com.acme;
public class BillingService {
private final Notifier notifier;
public BillingService(Notifier notifier) { this.notifier = notifier; }
public double bill(double amount, double taxRate) {
double tax = Math.round(amount * taxRate * 100.0) / 100.0;
double total = amount + tax;
notifier.send("Billed: " + total);
return total;
}
}// src/test/java/com/acme/BillingServiceTest.java
package com.acme;
import static org.mockito.Mockito.*;
import static org.junit.jupiter.api.Assertions.*;
import org.junit.jupiter.api.Test;
public class BillingServiceTest {
@Test
void testBillSendsNotificationAndComputesTotal() {
Notifier notifier = mock(Notifier.class);
BillingService svc = new BillingService(notifier);
double total = svc.bill(100.0, 0.2);
assertEquals(120.0, total, 0.001);
verify(notifier, times(1)).send("Billed: 120.0");
verifyNoMoreInteractions(notifier);
}
}Edge Case Identification and Test Data Generation
Beyond happy paths, ChatGPT-5.5 can systematically enumerate boundary values, equivalence partitions, and failure modes. Use it to create checklists and data generators that scale coverage with minimal maintenance.
Prompting for Edge Cases
Ask the model to map input domains and generate concrete cases with rationales, then convert that map into parameterized tests. Example prompt:
User: Analyze function src/utils/pricing.py::total_with_tax.
- List input domains and boundaries for subtotal, tax_rate, and coupon.
- Propose a minimal set of test cases to achieve boundary and partition coverage.
- Emit a table with rationale, then produce pytest parameterized tests.ChatGPT-5.5 will typically outline zero, positive, and invalid ranges, then emit a compact but thorough parameter set.
Synthetic Test Data With Faker
For realistic fixtures, request usage of Faker libraries with stable seeds:
- Python:
faker - JS/TS:
@faker-js/faker - Java:
java-faker
# Python example
from faker import Faker
fake = Faker()
Faker.seed(1337)
def make_user():
return {
"id": fake.uuid4(),
"name": fake.name(),
"email": fake.unique.email(),
}// TypeScript example
import { faker } from "@faker-js/faker";
faker.seed(1337);
export const buildUser = () => ({
id: faker.string.uuid(),
name: faker.person.fullName(),
email: faker.internet.email(),
});Property-Based Testing
Property-based testing validates invariants across many generated inputs. Ask ChatGPT-5.5 to identify properties and emit tests in Hypothesis (Python), fast-check (JS/TS), or jqwik (Java).
# Python with Hypothesis
from hypothesis import given, strategies as st
from src.utils.pricing import total_with_tax
@given(
subtotal=st.floats(min_value=0, max_value=1e6, allow_nan=False, allow_infinity=False),
tax_rate=st.floats(min_value=0, max_value=1, allow_nan=False, allow_infinity=False),
coupon=st.one_of(st.none(), st.floats(min_value=0, max_value=1e6))
)
def test_total_with_tax_never_negative(subtotal, tax_rate, coupon):
result = total_with_tax(subtotal, tax_rate, coupon)
assert result >= 0.0// TypeScript with fast-check
import fc from "fast-check";
import { computeTax } from "../src/lib/tax";
test("computeTax is non-negative for non-negative inputs", () => {
fc.assert(
fc.property(
fc.double({ min: 0, max: 1e6, noNaN: true, noDefaultInfinity: true }),
fc.double({ min: 0, max: 1, noNaN: true, noDefaultInfinity: true }),
(amount, rate) => {
const tax = computeTax(amount, rate);
return tax >= 0;
}
),
{ seed: 42 }
);
});// Java with jqwik
import net.jqwik.api.*;
import static org.assertj.core.api.Assertions.*;
class MathProperties {
@Property
void mean_nonEmpty_is_within_bounds(@ForAll("nonEmptyArrays") double[] values) {
double mean = com.acme.MathUtils.mean(values);
double min = java.util.Arrays.stream(values).min().orElseThrow();
double max = java.util.Arrays.stream(values).max().orElseThrow();
assertThat(mean).isBetween(Math.min(min, max), Math.max(min, max));
}
@Provide
Arbitrary<double[]> nonEmptyArrays() {
return Arbitraries.doubles().between(-1e6, 1e6)
.array(double[].class).ofMinSize(1).ofMaxSize(100);
}
}Property-based tests are powerful but can be slow or flaky if not bounded. Request tight numeric ranges, fixed seeds during development, and minimal shrinking costs.
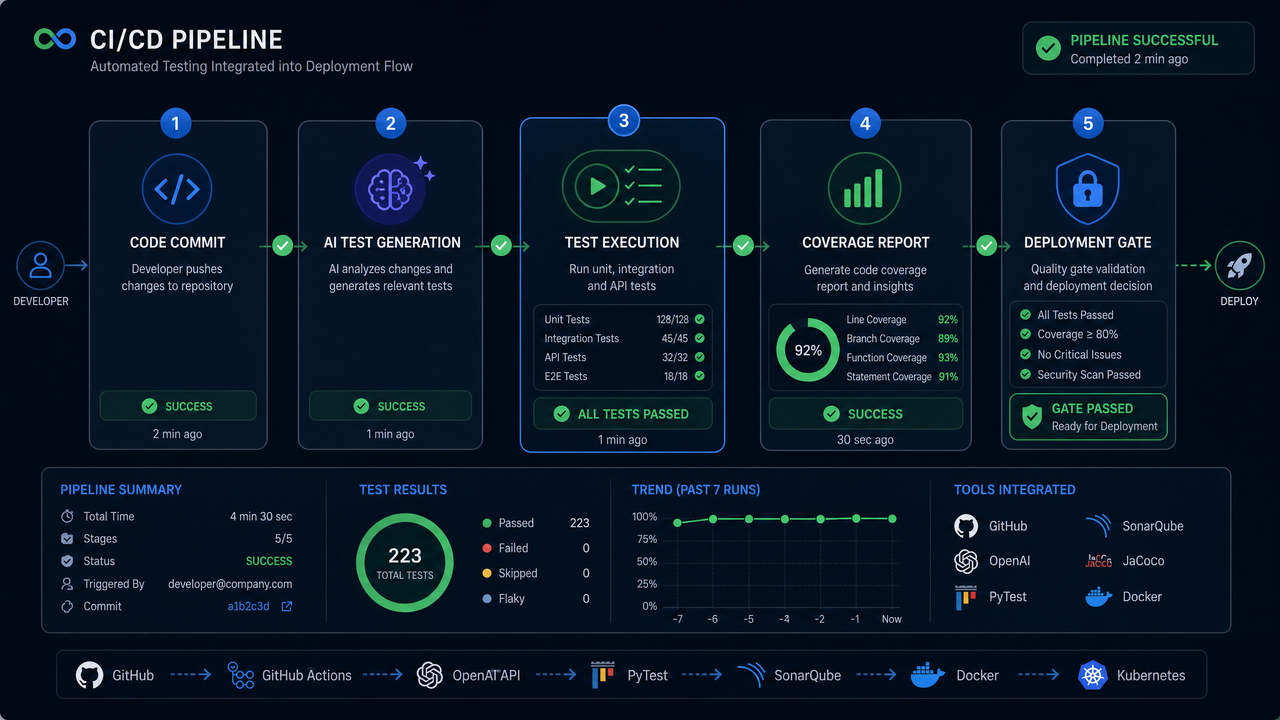
Integration Test Scaffolding with Realistic Dependencies
Integration tests validate that modules or services work together: your application plus databases, caches, queues, or external HTTP services. ChatGPT-5.5 can scaffold these quickly and consistently, including containerized dependencies and in-process stubs.
Patterns to Prefer
- Testcontainers for ephemeral dependencies across languages.
- HTTP stubs for third-party services when contract stability is the focus.
- In-memory or embedded alternatives for speed when fidelity remains acceptable (e.g., H2 for some JDBC cases).
For a deeper primer on containerized test dependencies, see
For a deeper exploration of migrating from Assistants API to Responses API, our comprehensive guide on How to Migrate from the OpenAI Assistants API to the Responses API provides detailed strategies, practical examples, and implementation patterns that complement the techniques discussed in this article.
.
Node.js: Express + Postgres via Testcontainers
Suppose you have a Node.js API that stores users in Postgres. Ask ChatGPT-5.5 to emit a full test harness using @testcontainers/postgresql and supertest:
// src/app.ts
import express from "express";
import { Pool } from "pg";
export function createApp(pool: Pool) {
const app = express();
app.use(express.json());
app.post("/users", async (req, res) => {
const { id, name } = req.body;
await pool.query("INSERT INTO users(id, name) VALUES ($1, $2)", [id, name]);
res.status(201).send({ id, name });
});
app.get("/users/:id", async (req, res) => {
const { rows } = await pool.query("SELECT id, name FROM users WHERE id = $1", [req.params.id]);
if (rows.length === 0) return res.status(404).send({ error: "Not Found" });
res.send(rows[0]);
});
return app;
}// tests/app.int.spec.ts
import { GenericContainer, StartedTestContainer } from "testcontainers";
import { Pool } from "pg";
import request from "supertest";
import { createApp } from "../src/app";
jest.setTimeout(60_000);
let container: StartedTestContainer;
let pool: Pool;
beforeAll(async () => {
container = await new GenericContainer("postgres:16-alpine")
.withEnv("POSTGRES_PASSWORD", "password")
.withEnv("POSTGRES_USER", "user")
.withEnv("POSTGRES_DB", "app")
.withExposedPorts(5432)
.start();
const port = container.getMappedPort(5432);
const host = container.getHost();
pool = new Pool({
user: "user",
password: "password",
host,
port,
database: "app",
});
await pool.query("CREATE TABLE IF NOT EXISTS users (id text primary key, name text not null)");
});
afterAll(async () => {
await pool?.end();
await container?.stop();
});
test("create and retrieve user", async () => {
const app = createApp(pool);
const id = "u-123";
await request(app).post("/users").send({ id, name: "Ada" }).expect(201);
const res = await request(app).get(`/users/${id}`).expect(200);
expect(res.body).toEqual({ id, name: "Ada" });
});
test("returns 404 for unknown user", async () => {
const app = createApp(pool);
await request(app).get("/users/missing").expect(404);
});Instruct ChatGPT-5.5 to manage container lifecycles and to keep tests parallel-safe by scoping databases per test file or using unique schemas.
Python: FastAPI + HTTPX + Respx and Optional Containers
FastAPI applications integrate well with httpx.AsyncClient and respx for HTTP stubs. Optionally add Testcontainers for databases.
# src/api/main.py
from fastapi import FastAPI, HTTPException
import httpx
app = FastAPI()
@app.get("/weather/{city}")
async def weather(city: str):
async with httpx.AsyncClient(timeout=2) as client:
r = await client.get(f"https://api.example.com/weather?city={city}")
r.raise_for_status()
data = r.json()
if "temp_c" not in data:
raise HTTPException(status_code=502, detail="Invalid upstream response")
return {"city": city, "temp_c": data["temp_c"]}# tests/test_weather_integration.py
import respx
import httpx
from httpx import Response
from httpx import AsyncClient
from src.api.main import app
import pytest
@pytest.mark.asyncio
async def test_weather_happy_path():
with respx.mock(assert_all_called=True) as mock:
mock.get("https://api.example.com/weather", params={"city": "Paris"}).respond(
200, json={"temp_c": 21.5}
)
async with AsyncClient(app=app, base_url="http://test") as ac:
resp = await ac.get("/weather/Paris")
assert resp.status_code == 200
assert resp.json() == {"city": "Paris", "temp_c": 21.5}
@pytest.mark.asyncio
async def test_weather_upstream_invalid_payload():
with respx.mock(assert_all_called=True) as mock:
mock.get("https://api.example.com/weather", params={"city": "Paris"}).respond(
200, json={"other": 0}
)
async with AsyncClient(app=app, base_url="http://test") as ac:
resp = await ac.get("/weather/Paris")
assert resp.status_code == 502Java: Spring Boot + Testcontainers
For Spring Boot services, request a @SpringBootTest with containers managed via Testcontainers. Add repository and REST tests.
// src/test/java/com/acme/UserRepositoryIT.java
package com.acme;
import org.junit.jupiter.api.*;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.testcontainers.containers.PostgreSQLContainer;
import org.testcontainers.junit.jupiter.Container;
import org.testcontainers.junit.jupiter.Testcontainers;
import org.springframework.test.context.DynamicPropertyRegistry;
import org.springframework.test.context.DynamicPropertySource;
@SpringBootTest
@Testcontainers
class UserRepositoryIT {
@Container
static PostgreSQLContainer<?> postgres = new PostgreSQLContainer<>("postgres:16-alpine")
.withDatabaseName("app")
.withUsername("user")
.withPassword("password");
@DynamicPropertySource
static void registerProperties(DynamicPropertyRegistry registry) {
registry.add("spring.datasource.url", postgres::getJdbcUrl);
registry.add("spring.datasource.username", postgres::getUsername);
registry.add("spring.datasource.password", postgres::getPassword);
}
@Autowired
UserRepository repo;
@Test
void savesAndFindsUser() {
User u = new User("u1", "Ada");
repo.save(u);
var found = repo.findById("u1");
Assertions.assertTrue(found.isPresent());
Assertions.assertEquals("Ada", found.get().getName());
}
}Use ChatGPT-5.5 to generate migration scripts, seed data, and teardown logic. Explicitly request unique schema names for parallel test execution.
HTTP Contract Tests
When upstream services are external, ask for provider/consumer tests with Pact or similar frameworks. ChatGPT-5.5 can emit contracts and verification steps for CI.
End-to-End Test Creation with Playwright and Cypress
E2E tests validate user journeys. Reliability depends on stable selectors, network control, and clear test structure. ChatGPT-5.5 can produce Page Object Models (POM), test data builders, and normalized waits that keep flakiness low. For a comparison of tooling trade-offs, see
For a deeper exploration of enterprise AI governance and compliance tools, our comprehensive guide on How Enterprise AI Governance Is Evolving in 2026 provides detailed strategies, practical examples, and implementation patterns that complement the techniques discussed in this article.
.
Selector Strategy: Prefer Data Attributes
Direct ChatGPT-5.5 to use data-testid or data-qa attributes. Avoid brittle CSS or text selectors. Provide a short UI map with stable attributes so the model generates robust locators.
Playwright Example (TypeScript)
// e2e/pages/LoginPage.ts
import { Page, expect } from "@playwright/test";
export class LoginPage {
constructor(private readonly page: Page) {}
async goto() {
await this.page.goto("/login");
await expect(this.page.getByTestId("login-form")).toBeVisible();
}
async login(email: string, password: string) {
await this.page.getByTestId("email-input").fill(email);
await this.page.getByTestId("password-input").fill(password);
await this.page.getByTestId("login-submit").click();
}
}// e2e/pages/DashboardPage.ts
import { Page, expect } from "@playwright/test";
export class DashboardPage {
constructor(private readonly page: Page) {}
async expectWelcome(name: string) {
await expect(this.page.getByTestId("welcome")).toHaveText(`Welcome, ${name}`);
}
}// e2e/login.spec.ts
import { test, expect } from "@playwright/test";
import { LoginPage } from "./pages/LoginPage";
import { DashboardPage } from "./pages/DashboardPage";
test.describe("Login", () => {
test("valid credentials route to dashboard", async ({ page }) => {
const login = new LoginPage(page);
const dash = new DashboardPage(page);
await login.goto();
// Network stubbing for auth if needed:
// await page.route("**/api/auth/login", route => route.fulfill({ status: 200, json: { user: { name: "Ada" }}}));
await login.login("[email protected]", "correct-horse-battery-staple");
await dash.expectWelcome("Ada");
});
test("invalid credentials show error", async ({ page }) => {
const login = new LoginPage(page);
await login.goto();
await page.route("**/api/auth/login", async (route) => {
await route.fulfill({ status: 401, json: { error: "Invalid credentials" } });
});
await login.login("[email protected]", "wrong");
await expect(page.getByTestId("login-error")).toHaveText("Invalid credentials");
});
});Instruct ChatGPT-5.5 to use Playwright’s auto-waiting and to avoid sleeps. Ask for route interception when network stability is a concern.
Cypress Example (JavaScript)
// cypress/e2e/login.cy.js
describe("Login", () => {
beforeEach(() => {
cy.visit("/login");
cy.get("[data-testid='login-form']").should("be.visible");
});
it("valid credentials route to dashboard", () => {
cy.intercept("POST", "/api/auth/login", {
statusCode: 200,
body: { user: { name: "Ada" } },
}).as("login");
cy.get("[data-testid='email-input']").type("[email protected]");
cy.get("[data-testid='password-input']").type("correct-horse-battery-staple");
cy.get("[data-testid='login-submit']").click();
cy.wait("@login");
cy.get("[data-testid='welcome']").should("contain.text", "Welcome, Ada");
});
it("invalid credentials show error", () => {
cy.intercept("POST", "/api/auth/login", {
statusCode: 401,
body: { error: "Invalid credentials" },
}).as("login");
cy.get("[data-testid='email-input']").type("[email protected]");
cy.get("[data-testid='password-input']").type("wrong");
cy.get("[data-testid='login-submit']").click();
cy.wait("@login");
cy.get("[data-testid='login-error']").should("have.text", "Invalid credentials");
});
});Request fixtures and custom commands to encapsulate login and setup flows. For flake control, instruct ChatGPT-5.5 to rely on Cypress retries for assertions and to avoid fixed delays.
Access 40,000+ AI Prompts for ChatGPT, Claude & Codex — Free!
Subscribe to get instant access to our complete Notion Prompt Library — the largest curated collection of prompts for ChatGPT, Claude, OpenAI Codex, and other leading AI models. Optimized for real-world workflows across coding, research, content creation, and business.
Page Object Model and Test Data Builders
Ask ChatGPT-5.5 to generate page objects and data builders systematically across flows. Enforce naming conventions and ensure stable selectors are centralized.
Parallelization and Sharding
E2E suites are costly. In your prompts, ask for test grouping by tags, parallelizable structure, and CI-integrated artifacts (video/screenshots). For example, with Playwright:
// playwright.config.ts excerpt
import { defineConfig, devices } from "@playwright/test";
export default defineConfig({
testDir: "./e2e",
retries: 1,
fullyParallel: true,
reporter: [["list"], ["junit", { outputFile: "reports/e2e-junit.xml" }], ["html"]],
use: {
baseURL: process.env.BASE_URL || "http://localhost:3000",
trace: "retain-on-failure",
video: "retain-on-failure",
screenshot: "only-on-failure",
},
projects: [
{ name: "chromium", use: { ...devices["Desktop Chrome"] } },
{ name: "firefox", use: { ...devices["Desktop Firefox"] } },
],
});CI/CD Integration Patterns for AI-Generated Tests
Once ChatGPT-5.5 has produced your tests, wire them into CI/CD with repeatable, efficient pipelines. Below are practical templates and tactics.
General Pipeline Principles
- Fail fast: run linters and unit tests early.
- Cache dependencies (pip, npm, Maven/Gradle) with keys tied to lockfiles.
- Parallelize by language and test type (unit vs. integration vs. E2E).
- Publish JUnit/xUnit test reports and code coverage.
- Quarantine flaky tests while triaging.
GitHub Actions: Polyglot Monorepo
# .github/workflows/ci.yml
name: CI
on:
pull_request:
push:
branches: [ main ]
jobs:
python-unit:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: actions/setup-python@v5
with:
python-version: "3.11"
cache: "pip"
- name: Install
run: pip install -r requirements.txt
- name: Lint
run: ruff check .
- name: Test
run: pytest -q --junitxml=reports/python-junit.xml --cov=src --cov-report=xml
- name: Upload reports
uses: actions/upload-artifact@v4
with:
name: python-reports
path: reports/
node-unit:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: actions/setup-node@v4
with:
node-version: "20"
cache: "npm"
- run: npm ci
- run: npm run lint
- run: npm test -- --ci --reporters=default --reporters=jest-junit
env:
JEST_JUNIT_OUTPUT: reports/jest-junit.xml
- uses: actions/upload-artifact@v4
with:
name: node-reports
path: reports/
java-unit:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Set up JDK
uses: actions/setup-java@v4
with:
distribution: temurin
java-version: "21"
cache: "maven"
- run: mvn -B -DskipTests=false test
- uses: actions/upload-artifact@v4
with:
name: java-reports
path: "**/target/surefire-reports/*.xml"
integration:
runs-on: ubuntu-latest
services:
postgres:
image: postgres:16-alpine
env:
POSTGRES_USER: user
POSTGRES_PASSWORD: password
POSTGRES_DB: app
ports: ["5432:5432"]
options: >-
--health-cmd="pg_isready -U user -d app"
--health-interval=10s
--health-timeout=5s
--health-retries=5
steps:
- uses: actions/checkout@v4
- uses: actions/setup-node@v4
with:
node-version: "20"
cache: "npm"
- run: npm ci
- run: npm run test:integration
env:
DATABASE_URL: postgres://user:password@localhost:5432/app
e2e:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: actions/setup-node@v4
with:
node-version: "20"
- run: npm ci
- name: Install Playwright Browsers
run: npx playwright install --with-deps
- name: Start app
run: npm run start:test & sleep 5
- name: Run E2E
run: npx playwright test --reporter=junit,line --output=playwright-report
- uses: actions/upload-artifact@v4
with:
name: e2e-artifacts
path: playwright-reportGitLab CI: Stages With Artifacts and Caching
# .gitlab-ci.yml
stages:
- lint
- test
- e2e
variables:
PIP_CACHE_DIR: "$CI_PROJECT_DIR/.cache/pip"
PLAYWRIGHT_BROWSERS_PATH: "$CI_PROJECT_DIR/.cache/pw-browsers"
lint:
stage: lint
image: python:3.11-slim
script:
- pip install ruff
- ruff check .
cache:
key: "$CI_COMMIT_REF_SLUG-pip"
paths:
- .cache/pip
python_tests:
stage: test
image: python:3.11-slim
script:
- pip install -r requirements.txt
- pytest --junitxml=reports/python.xml
artifacts:
when: always
reports:
junit: reports/python.xml
paths:
- reports/
e2e:
stage: e2e
image: mcr.microsoft.com/playwright:v1.44.0-jammy
script:
- npm ci
- npx playwright install --with-deps
- npm run start:test & sleep 5
- npx playwright test --reporter=junit
artifacts:
when: always
reports:
junit: playwright-report/junit.xml
paths:
- playwright-reportJenkins: Declarative Pipeline
// Jenkinsfile
pipeline {
agent any
stages {
stage('Checkout') {
steps { checkout scm }
}
stage('Python Unit') {
agent { label 'python' }
steps {
sh 'pip install -r requirements.txt'
sh 'pytest --junitxml=reports/python.xml'
}
post {
always { junit 'reports/python.xml' }
}
}
stage('Node Unit') {
agent { label 'node' }
steps {
sh 'npm ci'
sh 'npm test -- --ci --reporters=jest-junit'
}
post {
always { junit 'reports/jest-junit.xml' }
}
}
stage('E2E') {
agent { label 'chrome' }
steps {
sh 'npm run start:test & sleep 5'
sh 'npx playwright test --reporter=junit'
}
post {
always { junit 'playwright-report/junit.xml' }
always { archiveArtifacts artifacts: 'playwright-report/**', fingerprint: true }
}
}
}
options {
timestamps()
ansiColor('xterm')
}
}Using ChatGPT-5.5 to Generate and Update Pipelines
Provide your current pipeline YAML/Groovy to ChatGPT-5.5 and ask for targeted changes: caching, test splitting, or matrix builds. Include environment constraints and secret handling policies. The model can also emit bash helpers for splitting tests by timing information or file patterns.
Review, Maintenance, and Drift Management
AI-generated tests can drift when APIs change. Minimize maintenance with rigorous review practices and a controlled update loop.
Guardrails for Test Quality
- Run formatters and linters on generated tests.
- Prohibit sleeps and undeterministic waits via lint rules (e.g., ESLint plugin rules for Cypress and Playwright).
- Require stable data seeds for Faker and property-based runs in CI.
- Gate merges on coverage deltas and flake rate targets.
Refactoring With ChatGPT-5.5
When APIs change, paste the new signature and failing tests into ChatGPT-5.5 and ask for minimal diffs that preserve test intent and coverage. Constrain the model to not weaken assertions. Provide a patch-style output or explicit file rewrites.
Flake Detection and Quarantine
Collect flaky test metrics in CI and allow triaging. ChatGPT-5.5 can consume flake logs and propose stabilizations: adding data-testid attributes, replacing static waits with condition waits, or improving network stubs. Keep a quarantine list with expiration to avoid permanent suppression.
Snapshot Tests and Golden Files
For UI and serializer outputs, snapshots are tempting. Instruct ChatGPT-5.5 to:
- Use terse, semantically meaningful snapshots.
- Guard against over-broad updates.
- Pair snapshots with targeted assertions for critical fields.
Governance, Security, and Data Privacy Considerations
When using ChatGPT-5.5 with proprietary code, consider data governance:
- Redact secrets, tokens, and PII from prompts.
- Use enterprise controls and audit logs for model interactions.
- Prefer synthetic or anonymized data when generating fixtures.
- Ensure license compliance for any snippets incorporated from external sources.
Establish a standard “AI code review” checklist that checks for data exposure, insecure patterns in tests (e.g., committed test secrets), and misconfigured network calls.
Measuring Impact: Coverage, Flake Rate, and Cycle Time
Measure the benefit of ChatGPT-5.5 by tracking:
- Coverage delta per PR (line, branch, and mutation coverage if applicable).
- Defect escape rate before/after test adoption.
- Flake rate and quarantine count trends.
- Mean time to author tests for new code vs. with AI assistance.
- CI duration and parallelization effectiveness.
Use these signals to tune how aggressively you apply AI generation across the pyramid. For organizations adopting platform-wide automation, see
For a deeper exploration of building AI-powered search from query understanding to ranking, our comprehensive guide on Building AI-Powered Search with GPT-5.5 Instant provides detailed strategies, practical examples, and implementation patterns that complement the techniques discussed in this article.
for broader operational metrics and change management strategies.
Reference Workflows: From Prompt to Passing Pipeline
The following end-to-end scenarios illustrate how to apply ChatGPT-5.5 across unit, integration, and E2E layers, then land changes in CI.
Workflow A: Unit Tests for a New Utility (Python)
- Author the utility with clear docstrings and exceptions.
- Prompt ChatGPT-5.5 with file path, style conventions, and coverage targets.
- Paste the module and accept only code output for
tests/test_module.py. - Run locally with
pytest -q. If failures occur, paste the failures back and request minimal patches. - Commit with
pre-commithooks enforcing ruff/black; push to CI.
Workflow B: Integration Test for a Service Endpoint (Node + Postgres)
- Describe the endpoint behavior and schema to ChatGPT-5.5.
- Request a Testcontainers-based harness along with
supertestcalls. - Include data migration and teardown steps.
- Run in CI with a service container or Testcontainers; publish JUnit and coverage.
Workflow C: E2E Login Flow With Playwright
- Provide a selector map with
data-testidattributes. - Ask for page objects, route interception of auth, and two tests (valid, invalid credentials).
- Enforce auto-waits and artifact retention (video/screenshot on failure).
- Shard across browsers in CI using Playwright projects.
Workflow D: Edge Cases + Property-Based Tests
- Request an equivalence partitioning and boundary analysis from ChatGPT-5.5.
- Have it emit parameterized tests plus a property-based test with bounded ranges and seeds.
- Review for determinism; add seeds and CI-only limits to run time.
Workflow E: Pipeline Upgrade via ChatGPT-5.5
- Paste existing CI YAML; ask for caching, sharding, and artifact publication improvements.
- Request an explanation of trade-offs and a minimal diff patch.
- Apply, test on a feature branch, and roll out incrementally.
Common Prompt Templates
System: Principal SDET. Emit production-grade tests only.
User: You are generating tests for a TypeScript library under src/lib/*.ts
- Use Jest + ts-jest, Node 20.
- Output: one file per tested module under tests/*.spec.ts
- Style: AAA, table-driven, no sleeps, 100% branch coverage for src/lib/tax.ts
- Mock: axios for network calls, fs for filesystem
- Include: negative tests, error messages, edge numeric cases
- Emit only code for tests/tax.spec.tsSystem: Senior Java QA. Use JUnit 5 + Mockito + Testcontainers.
User: For a Spring Boot app, create an integration test against Postgres for the /users endpoint.
- Use @Testcontainers with a static PostgreSQLContainer
- Migrate schema programmatically in @BeforeAll
- Verify insert and get flows
- Emit only code for src/test/java/com/acme/UserIT.javaSystem: Staff E2E engineer. Use Playwright.
User: Generate a POM-based E2E test for login + dashboard.
- Stable selectors: data-testid
- Intercept /api/auth/login with fixtures
- Parallel-safe, no sleeps, rely on auto-wait
- Emit LoginPage.ts, DashboardPage.ts, and login.spec.tsConclusion and Next Steps
ChatGPT-5.5 accelerates test creation across the pyramid: fast, thorough unit tests; realistic, container-backed integration tests; and reliable E2E flows with modern tooling. The key is disciplined prompting, deterministic practices, and CI/CD integration that amplifies test value rather than adding friction.
To scale this approach across teams: standardize prompt templates; codify conventions for selectors, seeds, and mocks; and make AI-generated test review a first-class practice. As your test suite grows, use coverage and flake metrics to guide investment. Pair these practices with internal enablement, and you will shorten feedback loops while strengthening release confidence.
For broader organizational patterns and advanced prompting strategies, consult
For a deeper exploration of building production REST APIs with Codex prompts, our comprehensive guide on The Codex API Development Playbook provides detailed strategies, practical examples, and implementation patterns that complement the techniques discussed in this article.
and
For a deeper exploration of OpenAI’s custom AI silicon and inference cost reduction, our comprehensive guide on OpenAI’s Jalapeno Chip provides detailed strategies, practical examples, and implementation patterns that complement the techniques discussed in this article.
.