OpenAI’s Jalapeno Chip: What In-House AI Silicon Means for Developers, API Pricing, and the Future of Inference

OpenAI’s Jalapeño Chip: What In-House AI Silicon Means for Developers, API Pricing, and the Future of Inference
In June 2026, OpenAI announced its first in-house AI inference chip—code-named “Jalapeño”—built in partnership with Broadcom. The move marks a strategic shift from reliance on general-purpose accelerators toward custom silicon optimized for large language model (LLM) inference. If executed well, Jalapeño will change the economics of serving multimodal AI, reshape developer-facing API pricing, and introduce new performance envelopes for products like ChatGPT and Codex.
This article unpacks what Jalapeño is and why OpenAI built it, explores the technical architecture as far as it is publicly known (and where details are still evolving), and analyzes the deeper implications: how custom silicon reduces the cost of inference, where it may outperform GPUs, expected effects on latency and throughput, and how developers can prepare for new operational realities. Along the way, we will compare Jalapeño to Nvidia’s H100/B200, Google TPU v5, and Amazon Trainium2; lay out a practical pricing model; and provide benchmark-ready code examples to measure latency and throughput as providers shift traffic to new backends.
Note on sources and uncertainty: as of the time of writing, not every specification for Jalapeño has been publicly disclosed. Where OpenAI has not provided specifics, we describe the most likely design patterns based on industry practice for inference accelerators and what can be inferred from partner ecosystems such as Broadcom’s packaging and interconnect capabilities. Treat “TBD,” “likely,” and “estimated” as placeholders subject to formal confirmation. This is intended to be a technical and economic guide, not a spec sheet.
Within this exploration, we will also connect to complementary topics for readers who want to dive deeper into particular areas such as server-side batching, price modeling, and latency benchmarking:
For a deeper exploration of related concepts, our comprehensive guide on GPT-5.1 vs Cursor: The 2026 Head-to-Head Comparison provides detailed strategies and practical frameworks that complement the approaches discussed in this section.
,
For a deeper exploration of related concepts, our comprehensive guide on 15 Best AI Coding Agents for Data Analysis (2026): Benchmarks, Pricing, and Use provides detailed strategies and practical frameworks that complement the approaches discussed in this section.
, and
For a deeper exploration of related concepts, our comprehensive guide on OpenAI’s GPT-5.5-Cyber: How a Specialized AI Model Is Redefining Cybersecu provides detailed strategies and practical frameworks that complement the approaches discussed in this section.
.
What Jalapeño Is and Why OpenAI Built It
The Jalapeño program is OpenAI’s first production-grade inference accelerator designed specifically for large-scale deployment across its inference fleet. Unlike general-purpose GPUs designed to serve a wide range of training and inference workloads, Jalapeño pursues a narrower, more efficient target: high-throughput, low-latency, cost-optimized inference for transformer-based models in text, code, and multimodal domains. The choice to focus on inference, not training, aligns with OpenAI’s present economic center of gravity—ChatGPT, API workloads, and integration partners—where service costs are dominated by serving models hundreds of millions to billions of times per day.
Why build a custom chip at all? Four forces converged to make this moment inevitable:
- Economics of scale: At OpenAI’s footprint, single-digit percentage improvements in cost per token translate to material reductions in the cost of goods sold (COGS). Custom silicon tuned for the actual instruction mix and memory behavior of inference can unlock double-digit savings relative to GPU baselines.
- Power and datacenter efficiency: Inference is increasingly constrained by memory bandwidth and power, not raw compute. Optimizing for perf/watt and memory movement at the silicon and package level is now the lever for both cost and sustainability.
- Supply chain independence: Nvidia’s dominance and high demand created persistent supply constraints. Owning part of the silicon stack gives OpenAI more predictable supply and a path to differentiated performance per dollar.
- Software co-design: Modern LLM serving stacks incorporate techniques like paged attention, KV-cache compression, dynamic batching, and speculative decoding. Hardware designed to accelerate exactly these patterns can outperform general-purpose designs, especially at scale.
Broadcom’s role in the collaboration centers on silicon design, interconnect IP, and packaging. While final foundry and node choices have not been fully disclosed publicly, it is typical for such chips to be fabricated at an advanced node (e.g., a cutting-edge TSMC process), and to be integrated into systems using high-bandwidth memory (HBM), chiplet partitioning, and high-speed interposers to achieve the data movement required by transformer inference.
OpenAI’s stated goal for Jalapeño is not to displace GPUs across the board, but to shift a meaningful fraction of high-traffic inference to a more efficient platform. Expect hybrid fleets to remain the norm: GPUs for complex multimodal and training-adjacent tasks; custom ASICs for bread-and-butter inference where cost and latency are paramount.
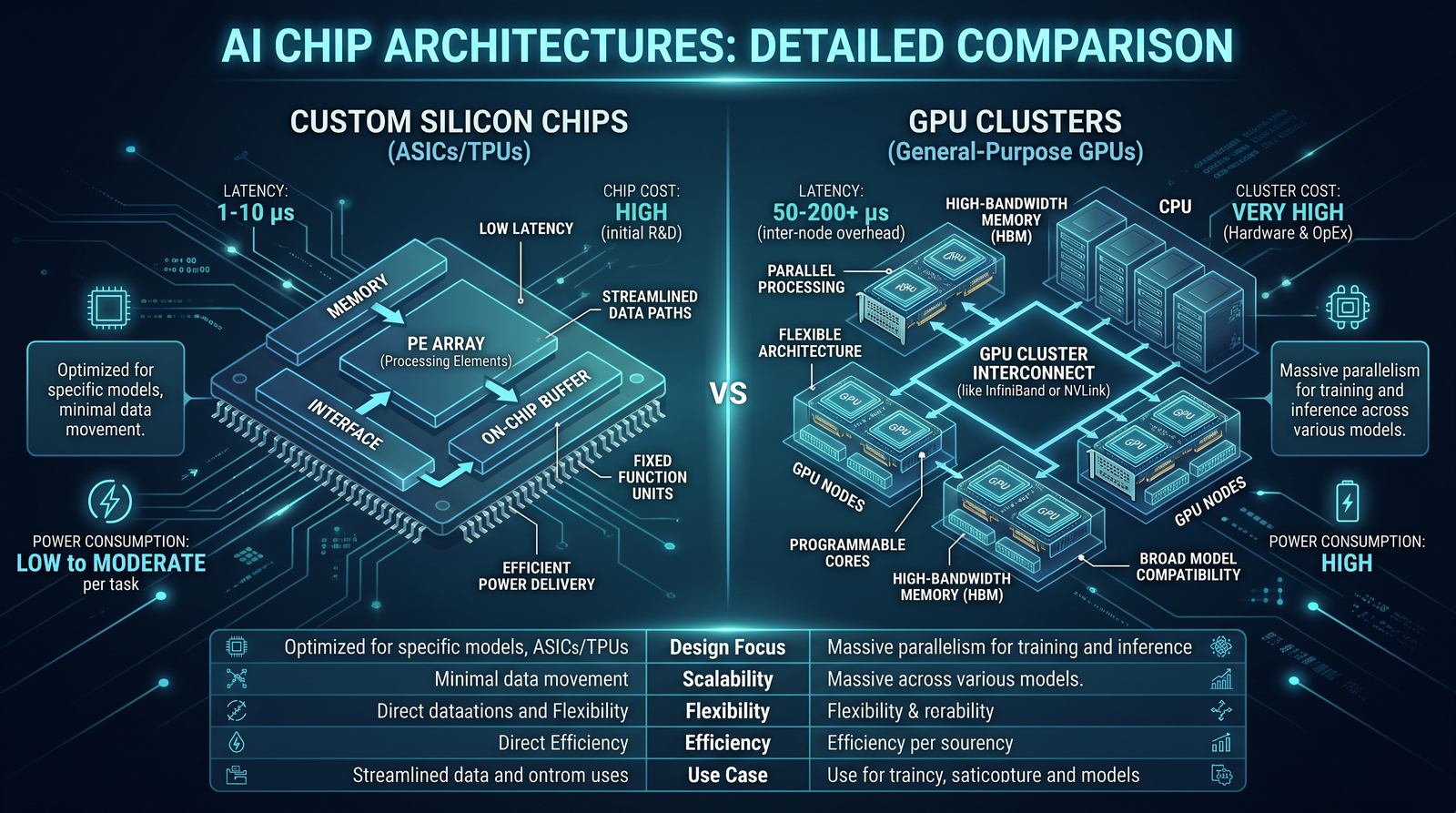
What We Know (and Can Safely Infer) About Jalapeño’s Architecture
OpenAI’s Jalapeño is purpose-built for transformer inference. While the exact microarchitecture is not fully public, an inference-optimized accelerator usually exhibits the following characteristics:
- Matrix/tensor cores optimized for low-precision inference: Support for INT8, FP8, and potentially even finer-grained formats (e.g., FP6 or 4-bit quantization schemes) with hardware dequantization/quantization units to minimize precision management overheads.
- Large on-die SRAM with hierarchical caches: Substantial on-chip SRAM designed to reduce KV-cache trips to HBM and support common attention patterns (paged attention, block-sparse attention, prefix caching) with consistent low latency.
- High HBM capacity and bandwidth: Multiple HBM stacks (HBM3 or later) to feed the memory-hungry attention and MLP layers of large models, potentially with hardware-accelerated gather/scatter patterns for attention score computation.
- Specialized decode-path optimizations: Dedicated units for sampling (top-k/top-p), logits softmax, and temperature scaling; hardware assistance for speculative decoding and tree-based decoding to accelerate next-token generation.
- Transformer-engine style kernels: Fused kernels for QKV projection, attention, MLP activation, and residual/bias addition to minimize kernel launches and maximize data locality.
- High-bandwidth interconnect: On-package or board-level links enabling multi-die scaling in a single accelerator module, and node-to-node connectivity for model sharding and tensor parallelism.
- Power-optimized scheduling: Micro-schedulers that keep tensor cores fed during variable-length sequences and ragged batches, plus backpressure signals friendly to dynamic server-side batching.
- Low-latency host interface: DMA engines and queue pairs designed to reduce host-device overhead, accelerate context uploads, and support streaming token output with minimal jitter.
Given Broadcom’s experience with custom silicon, it is reasonable to assume Jalapeño employs advanced packaging (e.g., 2.5D interposers with extremely wide links to HBM), carefully tuned SerDes, and possibly a chiplet architecture: separate dies for compute, memory I/O, and management, connected by a proprietary die-to-die interconnect. This approach de-risks yield, allows selective die binning, and improves scalability across product variants.
On the software side, the runtime would present as a backend class within OpenAI’s orchestration layer. Expect the serving platform to expose a uniform API to developers while routing requests to Jalapeño or GPU backends based on model, latency/SLA tier, and current load. That enables controlled rollouts and A/B testing without breaking application code.
How Custom Silicon Reduces Inference Costs
Inference cost is dominated by three factors: tokens processed per second per device (throughput), power consumed (perf/watt), and the amortized capital/operational expense of the hardware and datacenter (capex/opex). GPUs are incredibly capable, but their flexibility carries overhead: general-purpose schedulers, broader precision support, and a design centered on maximizing performance across training and inference simultaneously.
Custom inference ASICs can beat GPUs on cost per token by focusing on the realities of serving:
- Low-precision dominance: Most inference can run at FP8 or INT8 with negligible quality loss if quantization-aware methods are used. Hardware built from the ground up for these precisions yields gains in throughput and power efficiency.
- Memory-movement minimization: KV-cache and attention scores stress HBM bandwidth and host-device transfers. Architectures that keep hot data on-die or in tightly coupled SRAM reduce trips to HBM and DRAM.
- Fused operator pipelines: Serving-friendly instruction fusion reduces kernel launch synchronization and intermediate writes, a big win at the scale of millions of calls per hour.
- Scheduling for ragged batches: Production traffic is not uniform; sequences have different lengths. Schedulers that minimize tail latency and exploit dynamic batching improve effective utilization and reduce wasted cycles.
- Rack-level integration: Power supplies, cooling, and interconnect topologies tuned to inference patterns further trim cost and boost density.
The cumulative result is a better tokens-per-second-per-watt curve, and a higher sustained device occupancy under real-world, variable-length workloads. Over a quarterly or annual time horizon, even 20–40% gains translate to dramatic COGS shifts when extrapolated across tens of thousands of accelerators. Those savings can then be passed on to developers as lower API prices, or re-allocated to expand context windows and add features without raising cost.
From Silicon to API Pricing: A Practical Cost Model
API pricing ultimately maps to cost per token processed, plus margin. Providers convert device-level performance and datacenter efficiency into a unit price that’s simple enough for developers to budget against. To understand how Jalapeño could affect pricing, consider a simplified model:
- Let C be the blended hourly cost of an accelerator including amortized capex, power, cooling, and ops (C dollars/hour).
- Let T be the sustained tokens per second per device under a realistic workload mix (T tokens/second).
- Let U be the utilization factor (0–1), capturing idle time, headroom for bursts, and SLA commitments.
Then the effective cost per million output tokens is approximately:
(C / (T × 3600 × U)) × 1,000,000
As a rough example, suppose a Jalapeño-based node improves T by 35% and lowers power costs embedded in C by 15%, while allowing slightly higher U via better batching and scheduler behavior. A 35% improvement in T and a 15% decrease in C, compounded with a modest uplift in U (say 0.75 to 0.8), can yield a 40–55% reduction in cost per million tokens. While each production fleet is different, the direction is clear: modest gains at each layer multiply.
OpenAI can choose to pass those savings through as list price reductions, offer new discount tiers, or create performance-based SKUs where the same model is served by different backends with different latency/price characteristics. If OpenAI exposes a “compute class” parameter or an automatic tiered routing mode, developers might see options like Standard (GPU or mixed fleet), Efficient (Jalapeño-first routing), and Low-Latency (Jalapeño with higher per-request priority), each with different prices. This aligns with usage patterns many teams already have—cost-optimized background batch jobs versus latency-sensitive user flows. For more economic modeling details and historical patterns, see
For a deeper exploration of related concepts, our comprehensive guide on OpenAI Codex vs Gemini 3.1 Pro for Solo Developers: Which Should You Choose in 2 provides detailed strategies and practical frameworks that complement the approaches discussed in this section.
.
Comparison to Nvidia’s Dominance in AI Chips
Nvidia’s H100 and B200 families have set the state of the art in training and high-end inference. They offer immense compute, robust software ecosystems (CUDA/cuDNN/TensorRT), and deep integration with networking (NVLink, NVSwitch) and storage. GPUs remain the most versatile solution, and they excel where workloads are diverse or where training and inference share the same cluster.
However, for a company whose workloads skew heavily to inference with relatively stable model architectures, custom ASICs can take the lead on perf/watt and cost per token. The principal trade-offs are:
- Pros of custom inference ASICs: perf/watt, cost predictability, silicon-software co-design for specific attention patterns, supply diversification, and the ability to prioritize inference-friendly precisions.
- Cons: ecosystem maturity, risk of lock-in to a narrower instruction set, time-to-market challenges, and the need to maintain dual software paths (ASIC and GPU) for a long time.
Expect Nvidia to continue dominating training at scale, while targeted inference ASICs like Jalapeño pick off the highest-volume inference paths. The blended fleet approach benefits providers: GPUs handle the tail of complex, less predictable workloads, while ASICs shoulder the bulk of steady-state traffic with superior economics.
Technical Deep Dive: Inference Optimization, Batching, and Latency
Transformer inference performance is governed by a delicate interplay of compute, memory bandwidth, cache locality, network scheduling, and application-level streaming. Jalapeño’s value proposition hinges on raising the ceiling and the floor across these axes.
Precision and Quantization
Production LLMs increasingly adopt quantization for inference, e.g., migrating from BF16 to FP8 or INT8 weights and activations while preserving quality via techniques like per-channel scaling, smooth quant, and post-training calibration. Custom ASICs can accelerate these modes natively:
- Native FP8 tensor cores for MHA and MLP with minimal dequant overhead.
- INT8 dot-product units with accumulator widening and dequant in the data path.
- Microcode for outlier-aware quantization to mitigate degradation in sensitive layers.
Jalapeño likely supports mixed-precision pipelines, enabling critical layers (e.g., layer norm, logits) to run at higher precision without incurring context-switch penalties.
Memory Hierarchy and KV-Cache
In autoregressive decoding, the KV-cache dominates memory traffic after the prompt. Efficient handling of KV tensors is key to throughput. Serving stacks now use paged attention and memory arenas to avoid frequent reallocations and to enable sharing across requests with common prefixes. An inference ASIC can embed:
- On-die SRAM blocks sized for one or more layers of KV-cache for active tokens, minimizing HBM trips for hot keys and values.
- Hardware-accelerated gather/scatter primitives for attention score computation and head mixing.
- Compression modes (e.g., per-head quantization) with on-the-fly dequant for attention.
These approaches reduce the effective bytes/token and smooth out tail latencies on ragged batches, directly improving user-perceived responsiveness.
Server-Side Batching and Scheduling
Dynamic batching aggregates concurrent decode steps from multiple requests into large matmuls that keep tensor cores busy. The art lies in batching without blowing up latency. Jalapeño-aligned runtimes can support:
- Per-cycle micro-batching windows with backpressure: a 1–5 ms window to harvest concurrent decode steps without violating p95 latency budgets.
- Token-level priority queues: streaming-first tokens get ahead-of-line privileges to keep streams “hot.”
- Speculative decoding with verifier reuse: adding a lightweight predictor to issue multiple tokens per step, then verifying; ASIC hardware can accelerate both predictor and verifier efficiently.
When silicon and scheduler co-design, the result is higher sustained utilization with minimal p95/p99 penalties—ideal for products like ChatGPT that must feel instant while running at colossal scale.
Latency Reduction Techniques
Developers experience latency as prompt-to-first-token (TTFT) plus inter-token interval. Jalapeño-class optimizations to reduce these include:
- Fast path for context upload: reduced host-device round-trips and concurrent DMA for prompt and KV initialization.
- Fused attention-softmax-MLP kernels tailored to short-sequence, batch=dynamic scenarios.
- Streaming-friendly interrupts: tokens are emitted as soon as they’re available, with minimal buffering.
- Thermal and power headroom for bursts: better power delivery can keep clocks higher for short windows without throttling during demand spikes.
Impact on ChatGPT and Codex Performance
From a user perspective, the most visible changes will be in responsiveness and consistency. Expect the following trends as Jalapeño rolls out behind the scenes:
- Faster TTFT: Particularly on shorter prompts, where host-device transfer and scheduler latency dominate.
- Smoother streaming: More uniform token cadence in the 20–60 ms range per token for mainstream models, depending on output length and complexity, with fewer stalls.
- Higher concurrency: Spikes in usage are absorbed with fewer queueing delays, reducing error rates and the need for aggressive rate limits.
- Larger effective context: If KV-cache handling is cheaper, providers can push context windows higher with tolerable costs, enabling richer code completions and longer multi-document reasoning.
For Codex-style code generation, speculative decoding and batched next-token evaluation can lead to noticeably snappier completions, especially with high-temperature exploration modes. One caveat to monitor is determinism: when providers change backends or quantization levels, tokenization edges and logprob surfaces can shift subtly. Testing is essential any time a provider announces new backends or models.
The Broader Trend: Custom AI Silicon
OpenAI joins a cohort of hyperscalers building their own accelerators: Google with TPU (now at v5 class), Amazon with Trainium/Inferentia, and Meta with MTIA. These efforts prioritize workload-appropriate designs: TPUs excel at large-scale training and serving within Google’s ecosystem; Trainium2 aims at cost-effective training and inference on AWS; MTIA targets Meta’s recommendation and ranking workloads as well as generative inference. Jalapeño aligns with this trend: own the inference-critical parts of the stack, and orchestrate fleets across ASICs and GPUs based on workload characteristics.
For developers, the existence of multiple high-performance backends competing on perf/watt is good news: lower prices over time, more stable supply, and differentiated performance tiers. The software abstraction layers—Kubernetes-style schedulers, inference servers, and provider APIs—will hide most of the complexity, but savvy teams will still want to measure and adapt to new latency and throughput patterns to optimize UX and spend.
Timeline and Availability
While OpenAI has announced Jalapeño in partnership with Broadcom, broader availability for API traffic is expected to roll out in controlled phases. Providers typically begin with internal products (e.g., subsets of ChatGPT traffic) and non-critical API paths to exercise the stack under load. Only then do they enable general routing for high-SLA enterprise customers. If you operate latency-sensitive production systems, monitor provider status pages and changelogs for signals like “improved latency for model X” or “new efficiency tier.” These are often correlated with backend shifts.
Expect 2026 to be a year of limited but growing deployment, with more meaningful developer-facing benefits arriving as production footprints expand and models are re-tuned to exploit hardware strengths. As always, predictions are contingent on manufacturing yields, packaging capacity, and datacenter integration. The safest position for developers: plan for a hybrid world where backends can change under the hood, and measure your real-world latency and quality continuously.
Comparison Table: Jalapeño vs Nvidia H100/B200 vs Google TPU v5 vs Amazon Trainium2
The following table summarizes key characteristics. Values are manufacturer-published or broadly reported where available and may vary by SKU and configuration. For Jalapeño, treat items as TBD or qualitative until OpenAI publishes specifics.
| Accelerator | Primary Orientation | Process Node | Memory (HBM) | Mem Bandwidth | Peak Low-Precision Compute | Interconnect | Software Stack | Notes | Availability |
|---|---|---|---|---|---|---|---|---|---|
| OpenAI Jalapeño | Inference (LLM-first) | TBD (advanced node) | TBD (multiple HBM stacks likely) | TBD (HBM3+ class likely) | TBD (FP8/INT8-optimized) | Proprietary die-to-die; DC fabric TBD | OpenAI runtime backend | Custom ASIC tuned for transformer inference | Phased rollout in 2026 |
| Nvidia H100 (SXM) | Training + inference | TSMC 4N | 80 GB HBM3 (common) | ~3 TB/s (approx.) | Up to ~2 PFLOPs FP8 (sparsity); ~1 PFLOP FP16 (sparsity, approx.) | NVLink/NVSwitch | CUDA, cuDNN, TensorRT | Industry-standard for LLM training | Shipping widely since 2023 |
| Nvidia B200 (Blackwell) | Training + inference | Advanced TSMC node | HBM3e (varies by SKU) | Higher than H100 (reported) | Substantially higher FP8/FP4 vs H100 (reported) | NVLink/NVSwitch (next-gen) | CUDA, cuDNN, TensorRT | Focus on training scale and inference efficiency | Announced 2024; ramping 2025–2026 |
| Google TPU v5p | Training + serving | Advanced TSMC node | Per-accelerator HBM (large; cluster-scale memory) | Very high (ICI mesh) | High BF16/FP8 throughput | Inter-Chip Interconnect (ICI) | XLA, JAX, TensorFlow | Large pod scale; internal + Vertex AI | Available via Google Cloud |
| Amazon Trainium2 | Training + inference (AWS) | Advanced node | HBM (varies) | High; optimized for AWS UltraClusters | Improved perf/watt vs Trainium1 (reported) | EFA Fabric | NeurON, PyTorch/XLA on AWS | Tied to AWS platform economics | Introduced 2023; ramping |
This table should not be read as a one-to-one face-off; Jalapeño is dedicated to inference, whereas many competitors target both training and inference. The key comparison for developers is cost per token, latency, and availability at API scale, not raw training FLOPs.
Practical Developer Guide: Benchmarking Latency and Throughput
As providers introduce Jalapeño-backed routes, you will often see improvements without any code changes. Yet for critical user flows, treat it like any backend change: measure. Below are practical, copy-pasteable scripts in Python to measure TTFT, per-token latency, and p50/p95 across concurrent requests. They are written to be agnostic of model names and backends, and are safe to run against most OpenAI-compatible APIs with minimal edits.
Single-Request Latency and Streaming Measurement
import os
import time
import json
import requests
from typing import Dict, Any, Optional, Tuple
API_BASE = os.getenv("OPENAI_API_BASE", "https://api.openai.com/v1")
API_KEY = os.getenv("OPENAI_API_KEY")
MODEL = os.getenv("OPENAI_MODEL", "gpt-4o-mini") # replace with your target model
def make_chat_completion(prompt: str,
stream: bool = True,
extra: Optional[Dict[str, Any]] = None) -> Tuple[float, float, int]:
"""
Returns: (ttft_seconds, total_seconds, tokens_out)
Measures prompt-to-first-token (TTFT) and total latency.
"""
headers = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json",
}
payload = {
"model": MODEL,
"messages": [{"role": "user", "content": prompt}],
"stream": stream,
# Add vendor-specific hints if exposed (hypothetical):
# "routing": {"preference": "efficient"}, # e.g., Jalapeño tier
}
if extra:
payload.update(extra)
url = f"{API_BASE}/chat/completions"
start = time.monotonic_ns()
ttft = None
tokens = 0
if stream:
with requests.post(url, headers=headers, data=json.dumps(payload), stream=True, timeout=120) as r:
r.raise_for_status()
for line in r.iter_lines(decode_unicode=True):
if not line or not line.startswith("data:"):
continue
data = line[len("data:"):].strip()
if data == "[DONE]":
break
try:
obj = json.loads(data)
except json.JSONDecodeError:
continue
if "choices" in obj and obj["choices"]:
delta = obj["choices"][0].get("delta", {})
# Count tokens roughly via chunks; for exact counts, request logprobs if supported
if delta.get("content"):
tokens += 1
if ttft is None:
ttft = (time.monotonic_ns() - start) / 1e9
end = time.monotonic_ns()
else:
r = requests.post(url, headers=headers, data=json.dumps(payload), timeout=120)
r.raise_for_status()
resp = r.json()
# Counting tokens from response usage if available:
usage = resp.get("usage", {})
tokens = usage.get("completion_tokens", 0)
ttft = (time.monotonic_ns() - start) / 1e9 # non-stream: treat total as ttft
end = time.monotonic_ns()
total = (end - start) / 1e9
return (ttft or total), total, tokens
if __name__ == "__main__":
prompt = "Explain the difference between throughput and latency in LLM inference in two paragraphs."
ttft, total, tokens = make_chat_completion(prompt, stream=True)
print(f"TTFT: {ttft:.3f}s, Total: {total:.3f}s, Tokens: {tokens}")
Concurrent Load Test with p50/p95 Latency
The following asyncio-based harness issues N concurrent requests and computes distribution metrics. It supports streaming and non-streaming modes.
import os
import time
import json
import asyncio
import aiohttp
import statistics
from typing import List, Dict, Any, Optional
API_BASE = os.getenv("OPENAI_API_BASE", "https://api.openai.com/v1")
API_KEY = os.getenv("OPENAI_API_KEY")
MODEL = os.getenv("OPENAI_MODEL", "gpt-4o-mini")
async def issue_request(session: aiohttp.ClientSession, prompt: str, stream: bool = True) -> Dict[str, Any]:
url = f"{API_BASE}/chat/completions"
headers = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json",
}
payload = {
"model": MODEL,
"messages": [{"role": "user", "content": prompt}],
"stream": stream,
# Hypothetical routing hint if provider supports it:
# "routing": {"preference": "efficient"},
}
start = time.monotonic_ns()
ttft = None
tokens = 0
if stream:
async with session.post(url, headers=headers, json=payload, timeout=120) as resp:
resp.raise_for_status()
async for raw_line in resp.content:
line = raw_line.decode("utf-8").strip()
if not line.startswith("data:"):
continue
data = line[5:].strip()
if data == "[DONE]":
break
try:
obj = json.loads(data)
except json.JSONDecodeError:
continue
if "choices" in obj and obj["choices"]:
delta = obj["choices"][0].get("delta", {})
if delta.get("content"):
tokens += 1
if ttft is None:
ttft = (time.monotonic_ns() - start) / 1e9
total = (time.monotonic_ns() - start) / 1e9
else:
async with session.post(url, headers=headers, json=payload, timeout=120) as resp:
resp.raise_for_status()
obj = await resp.json()
usage = obj.get("usage", {})
tokens = usage.get("completion_tokens", 0)
total = (time.monotonic_ns() - start) / 1e9
ttft = total
return {"ttft": ttft or total, "total": total, "tokens": tokens}
async def run_load(prompt: str, concurrency: int = 16, count: int = 64, stream: bool = True) -> None:
connector = aiohttp.TCPConnector(limit=concurrency)
timeout = aiohttp.ClientTimeout(total=180)
async with aiohttp.ClientSession(connector=connector, timeout=timeout) as session:
tasks = [asyncio.create_task(issue_request(session, prompt, stream=stream)) for _ in range(count)]
results = await asyncio.gather(*tasks)
ttfts = [r["ttft"] for r in results]
totals = [r["total"] for r in results]
tokens = [r["tokens"] for r in results]
def pct(ls: List[float], p: float) -> float:
return statistics.quantiles(ls, n=100)[int(p - 1)]
print(f"Requests: {count}, Concurrency: {concurrency}, Stream: {stream}")
print(f"TTFT p50: {statistics.median(ttfts):.3f}s, p95: {pct(ttfts, 95):.3f}s")
print(f"Total p50: {statistics.median(totals):.3f}s, p95: {pct(totals, 95):.3f}s")
if any(tokens):
tps = sum(tokens) / sum(totals)
print(f"Approx tokens/sec across batch: {tps:.2f} tok/s")
if __name__ == "__main__":
prompt = "Summarize the trade-offs between GPU and ASIC for LLM inference in 5 bullet points."
asyncio.run(run_load(prompt, concurrency=24, count=120, stream=True))
Batching Sensitivity Probe
Under Jalapeño, server-side batching windows and scheduler behavior may change. Your client batching strategy (if any) should harmonize, not compete. The following script explores latency as a function of small artificial client-side batches sent back-to-back, observing how the provider’s dynamic batching reacts.
import os
import time
import json
import requests
from typing import List, Tuple
API_BASE = os.getenv("OPENAI_API_BASE", "https://api.openai.com/v1")
API_KEY = os.getenv("OPENAI_API_KEY")
MODEL = os.getenv("OPENAI_MODEL", "gpt-4o-mini")
def send_non_stream(prompt: str) -> Tuple[float, int]:
headers = {"Authorization": f"Bearer {API_KEY}", "Content-Type": "application/json"}
payload = {"model": MODEL, "messages": [{"role": "user", "content": prompt}], "stream": False}
url = f"{API_BASE}/chat/completions"
start = time.monotonic_ns()
r = requests.post(url, headers=headers, data=json.dumps(payload), timeout=120)
r.raise_for_status()
total = (time.monotonic_ns() - start) / 1e9
obj = r.json()
usage = obj.get("usage", {})
return total, usage.get("completion_tokens", 0)
def probe_batch(batch_size: int, repeats: int = 5) -> None:
totals = []
toks = []
for _ in range(repeats):
start = time.monotonic_ns()
for i in range(batch_size):
total, t = send_non_stream(f"Provide a one-sentence fact number {i}.")
totals.append(total)
toks.append(t)
batch_total = (time.monotonic_ns() - start) / 1e9
print(f"Batch {batch_size} completed in {batch_total:.3f}s (avg req {sum(totals)/len(totals):.2f}s)")
print(f"Overall avg latency: {sum(totals)/len(totals):.3f}s; total tokens: {sum(toks)}")
if __name__ == "__main__":
for bs in [1, 2, 4, 8]:
probe_batch(bs, repeats=3)
A/B Testing Routing Hints (If/When Exposed)
Providers sometimes expose a routing hint or “compute class” header in responses to aid debugging. While speculative for Jalapeño, you can future-proof your telemetry by capturing any backend-related headers and including them in your logs.
import os
import time
import json
import requests
API_BASE = os.getenv("OPENAI_API_BASE", "https://api.openai.com/v1")
API_KEY = os.getenv("OPENAI_API_KEY")
MODEL = os.getenv("OPENAI_MODEL", "gpt-4o-mini")
def call_and_log(prompt: str):
headers = {"Authorization": f"Bearer {API_KEY}", "Content-Type": "application/json"}
payload = {"model": MODEL, "messages": [{"role": "user", "content": prompt}], "stream": False}
url = f"{API_BASE}/chat/completions"
start = time.monotonic_ns()
r = requests.post(url, headers=headers, data=json.dumps(payload), timeout=120)
r.raise_for_status()
total = (time.monotonic_ns() - start) / 1e9
backend = r.headers.get("X-Compute-Class") or r.headers.get("X-Model-Backend") or "unknown"
print(f"Latency: {total:.3f}s; backend: {backend}")
return total, backend
if __name__ == "__main__":
for _ in range(5):
call_and_log("One sentence on attention mechanisms.")
How Jalapeño Could Change API Pricing for Developers
OpenAI’s historical pricing reductions have tracked improvements in training and serving efficiency. Jalapeño offers a new lever focused on inference. Possible pricing strategies include:
- Across-the-board price cuts for popular models: e.g., 20–40% lower cost per million input/output tokens.
- New efficiency tiers: “Efficient” tier with slightly tighter rate limits but lower per-token price, ideal for batch workloads.
- Latency-optimized SKUs: Premium pricing for routes that guarantee lower TTFT and p95 via Jalapeño-first routing and capacity reservations.
- Context-based pricing changes: As context windows expand, input-token pricing may be adjusted downward due to more efficient prompt handling and KV-cache reuse.
Developers should consider pricing-aware routing in their clients to exploit these options. For instance, background summarization jobs might select an Efficient tier dynamically if the projected savings exceed a latency penalty threshold. Conversely, user-facing autocompletion should prioritize Low-Latency tiers. Implementing such logic can be as simple as a configuration file mapping tasks to SKUs, with automatic fallback if a route is degraded.
Server-Side Batching Improvements Under Jalapeño
Batching determines how well an accelerator’s compute units are utilized. With custom silicon, the scheduler can batch at finer granularity and with more predictable timing, especially when paired with fused kernels and SRAM-friendly attention data paths.
- Micro-batching windows: Rather than batching at request boundaries, decode steps from multiple requests arrive in small time slices, aggregated on-device with minimal overhead.
- Prefix-aware merging: Requests sharing large prompt prefixes can reuse KV-cache segments, cutting effective input cost and reducing TTFT for similar queries.
- Adaptive limits: The batching window flexes with load, shrinking during low-traffic periods to protect latency, and expanding under heavy load to keep utilization high.
These improvements matter most to the long tail of application latencies: fewer outliers, smoother p95/p99 behavior. Your SLA modeling should reflect this, and where possible, your UX should react to improved streaming cadence with faster incremental rendering.
Speculative Decoding and Verification Paths
Speculative decoding can double effective decoding throughput by allowing a lightweight “drafter” model to generate several candidate tokens that the main model verifies quickly. If Jalapeño accelerates both paths—e.g., by providing hardware-fast sampling and verification kernels—it can significantly reduce end-to-end latency for longer completions.
Developers do not control this mechanism directly in a managed API, but you can benefit by aligning your usage patterns: larger max_tokens may become less punitive, and temperature-based exploration might cost less latency than it once did. Care should be taken to test for shifts in distributional behavior (e.g., more diverse outputs) and to capture any small changes in tokenization edges that can occur across backends.
Reliability and SRE Considerations
A new backend class introduces new failure modes. Even with feature flags and canarying, systems evolve. Prepare your clients and services accordingly:
- Enable idempotent retries with jittered exponential backoff; propagate a request ID to correlate retries.
- Record p50/p95/p99 in your telemetry segmented by model and any backend hint headers; alert on regressions.
- Gracefully downgrade features when SLAs are violated (e.g., lower max_tokens, use concise modes).
- Implement fallback routes across models and providers where business-critical flows demand it.
Jalapeño’s promise is better reliability via less contention and more predictable scheduling. Still, plan for transition periods with mixed fleets and rolling updates.
Quality and Determinism Under Backend Shifts
When inference precision changes (e.g., FP8 vs BF16) or serving kernels are updated, minor output differences can appear. For code generation, a single token difference can change compilability; for RAG reasoning, small logprob shifts can alter cite/quote choices. To stay ahead:
- Snapshot-based validation: Keep a corpus of prompts and expected qualitative behaviors. Periodically test against staged and production APIs.
- Sensitivity thresholds: Accept minor output drift for non-critical tasks, but alert on structural failures (syntax errors, missing citations).
- Temperature/Top-p normalization: If outputs skew with a new backend, recalibrate sampling parameters to recover desired diversity.
This practice pairs well with continuous benchmarking as backends evolve. It’s especially important during major seasonal traffic events and after provider announcements.
Security and Isolation
Custom accelerators used by multiple tenants must uphold strict isolation. While implementation details are provider-internal, developers concerned with compliance should request updated SOC2/ISO documentation that reflects Jalapeño-backed clusters. From an application perspective, consistent token-level auditing, deterministic sampling modes for regulated workflows, and robust redaction pipelines remain essential regardless of backend.
Access 40,000+ AI Prompts for ChatGPT, Claude & Codex — Free!
Subscribe to get instant access to our complete Notion Prompt Library — the largest curated collection of prompts for ChatGPT, Claude, OpenAI Codex, and other leading AI models. Optimized for real-world workflows across coding, research, content creation, and business.
Workload Placement: When Jalapeño vs When GPU
Although routing is provider-managed, developers can conceptually categorize workloads:
- Likely Jalapeño-first: high-volume chat completions, code assist, summarization, translation, classification, tool-assisted reasoning with modest context.
- Likely GPU-first: very large multimodal inputs, training or fine-tuning jobs, research models with unusual attention mechanisms, and anything needing rare precisions.
This informs your performance expectations and your testing plan. It can also guide pricing-aware routing if providers expose SKUs aligned to these classes.
Rack-Level and Datacenter Considerations
The economic case for Jalapeño extends beyond die-level efficiency. Rack design, cooling, and power delivery tuned to inference can increase density and reduce operational cost:
- High-density racks: Optimized airflow and liquid cooling for sustained inference loads.
- Power distribution: Right-sized PSUs and conversion stages to reduce waste under bursty yet predictable decode cycles.
- Network topology: Shallow, low-latency fabrics for model-parallel shards rather than deep training fabrics.
All of this reduces amortized cost per token. Developers will not see these details, but they feel them in the form of lower prices and improved reliability.
Operator-Facing Metrics That Matter
Operators within providers will watch a familiar set of metrics, and you should mirror them where possible in your telemetry:
- TTFT p50/p95, Inter-token interval p50/p95
- Scheduler occupancy, batching window utilization
- KV-cache hit rate (internal provider metric)
- Error rate by class (timeouts, rate limits, backend unavailability)
- Cost per million tokens by route/SKU
When providers move production traffic to Jalapeño at scale, you can expect to see improvements in TTFT and inter-token cadence. Build dashboards that can show these shifts week-over-week.
Case Study Modeling: Potential Cost Reduction Scenarios
Consider a mid-size SaaS product that spends $600,000/month on LLM inference. Tokens are roughly split 40% input and 60% output. Suppose OpenAI announces an “Efficient” tier powered by Jalapeño with a 35% lower list price on output tokens and 20% lower on input tokens, with slightly tighter p95 guarantees. If 70% of your traffic can use this tier, your monthly spend could drop by approximately:
- Output savings: 0.6 × 0.7 × 0.35 = 14.7%
- Input savings: 0.4 × 0.7 × 0.20 = 5.6%
- Total savings: ~20.3% → ~$122k/month
This back-of-the-envelope shows how even partial adoption yields material savings. If you further adopt task-specific models (e.g., a cheaper summarizer) or use system prompts to curb unnecessary verbosity, the compounded effect can exceed 25–30% without degrading UX.
Developer Playbook: Preparing for Jalapeño
To capitalize on Jalapeño-era improvements while avoiding pitfalls:
- Implement latency and cost telemetry across tasks, not just models, so you can align routes with business value.
- Build price- and latency-aware routing logic: map tasks to SKUs, with fallbacks and SLOs.
- Run A/B benchmarks periodically across time-of-day and load conditions; use the code above as a baseline.
- Validate quality stability under backend shifts; maintain golden datasets for regression checks.
- Budget for re-tuning sampling parameters if outputs change under new precisions.
Finally, document your assumptions (e.g., average TTFT, inter-token cadence) so future you can compare them against provider updates and justify migrations. This discipline pays for itself quickly when price changes and new tiers appear.
Architectural Patterns Likely Present in Jalapeño
While specific block diagrams remain proprietary, the following patterns are common to high-performance inference ASICs and are reasonable to expect in some form:
- Compute clusters: Dozens to hundreds of tensor-math tiles, each with local SRAM and tightly coupled DMA engines.
- On-die interconnect: Low-latency network-on-chip (NoC) supporting multicast of activations and reductions across tiles.
- Memory subsystem: Multi-stack HBM with ECC, prefetchers tuned to transformer layer strides, and SRAM-resident caches for hot KV pages.
- Instruction streams: Short VLIW- or micro-ops–like streams controlled by a hardware scheduler aware of ragged batch structure.
- I/O: Host interface tuned for concurrent prompt upload and token stream out, possibly over PCIe Gen5/Gen6 or CXL-based links with custom queues.
This architecture complements the serving runtime’s needs: low-latency scheduling, rapid context setup, and efficient small-matrix and vector operations mixed with very large matmuls.
Jalapeño and the Future of Multimodal Inference
Although designed foremost for text/code inference, Jalapeño-class accelerators will inevitably encounter multimodal flows: images as context, audio dictation to text, even video tags as prompt features. Efficient handling of these modalities can be achieved even without fully general-purpose GPU features:
- Edge pre-processing: Offload image/audio pre-processing to specialized blocks or nearby general-purpose CPUs before feeding embeddings to the LLM.
- Embedding accelerators: Provide efficient low-precision matrix ops for embedding models to minimize external GPU dependence.
- Unified caching: Treat multimodal embeddings like text prefixes in the cache and schedule decode accordingly.
For developers, the upshot is that multimodal endpoints should continue to speed up as providers rationalize the data path between modality-specific encoders and the core LLM, with ASICs handling the heavy decode path more efficiently.
Developer-Facing Interface Changes to Watch For
OpenAI may introduce routing or SKU indicators to allow explicit selection or at least transparent reporting of backend class. Examples (hypothetical; not currently standardized):
- A request parameter like “compute_class”: “efficient” or “low_latency”.
- Response headers indicating backend family for observability.
- Per-model variants suffixed with “-efficient” to imply Jalapeño-first routing.
Keep your client libraries tolerant of unknown parameters and headers, and surface them in logs. This is particularly useful when comparing
For a deeper exploration of related concepts, our comprehensive guide on The Complete Guide to ChatGPT-5.5 Memory and Personalization: How to Train Your provides detailed strategies and practical frameworks that complement the approaches discussed in this section.
across providers or tiers.
Economics Beyond Silicon: Software and Utilization
Even perfect silicon fails to deliver savings if software cannot maintain high utilization. Jalapeño’s success depends on the synergy between model kernels, runtime scheduling, and datacenter orchestration (autoscaling, bin-packing, and congestion control). Improvements you may notice indirectly:
- Lower rate-limiting: Fewer 429s during peak hours as utilization remains controlled without collapse.
- More granular SLAs: Provider can offer differentiated p95 commitments because tail latencies are more predictable.
- Faster cold starts: If context upload and warm-up paths are optimized, even rarely used tasks feel snappier.
Quantization-Aware Caveats for Application Developers
Deeper quantization often accompanies inference ASICs. Although generally safe, be mindful of tasks sensitive to small distributional changes:
- Syntax-critical generation: code, JSON, SQL; enable strict formats and validators.
- Numeric precision: instruct models explicitly to round or use fixed decimal places where necessary.
- RAG citations: maintain robust citation extraction/parsing to handle minor tokenization differences.
These are best-practice guardrails irrespective of backend, but transitions are a good time to harden them.
Observability: Tokenization, Logprobs, and Streaming Details
If your application consumes logprobs or relies on token-boundary semantics, capture and version these signals in your telemetry. Under backend changes, logprob calibration can drift slightly. Building dashboards that compare weekly averages (entropy, average logprob per token) can help detect shifts that warrant prompt or parameter adjustments.
A Practical Latency Budget Worksheet
As Jalapeño reduces backend-internal latency, your remaining bottlenecks may become network and application overhead. Create a simple budget for critical flows:
- DNS + TLS: 30–80 ms (amortized with keepalive)
- Request marshalling: 5–15 ms
- Provider ingress + auth: 5–20 ms
- TTFT (provider compute): e.g., 150–400 ms baseline shifting downward with Jalapeño
- Inter-token interval: 20–60 ms typical for medium models, trending lower
- Client render: 10–30 ms per chunk
Track this end-to-end and verify improvements map to user-perceived speed. Consider HTTP/2 or HTTP/3 streaming, efficient JSON parsing, and incremental rendering to exploit better cadence coming from the backend.
Example: Measuring Tokens-Per-Second Under Streaming
import os
import time
import json
import requests
API_BASE = os.getenv("OPENAI_API_BASE", "https://api.openai.com/v1")
API_KEY = os.getenv("OPENAI_API_KEY")
MODEL = os.getenv("OPENAI_MODEL", "gpt-4o-mini")
def measure_stream_tps(prompt: str, trials: int = 5):
headers = {"Authorization": f"Bearer {API_KEY}", "Content-Type": "application/json"}
url = f"{API_BASE}/chat/completions"
payload = {"model": MODEL, "messages": [{"role": "user", "content": prompt}], "stream": True}
for i in range(trials):
start = time.monotonic_ns()
ttft = None
toks = 0
with requests.post(url, headers=headers, data=json.dumps(payload), stream=True, timeout=120) as r:
r.raise_for_status()
for line in r.iter_lines(decode_unicode=True):
if not line or not line.startswith("data:"):
continue
data = line[5:].strip()
if data == "[DONE]":
break
obj = json.loads(data)
if obj.get("choices"):
delta = obj["choices"][0].get("delta", {})
if delta.get("content"):
toks += 1
if ttft is None:
ttft = (time.monotonic_ns() - start) / 1e9
total = (time.monotonic_ns() - start) / 1e9
tps = toks / max(1e-6, total - (ttft or 0.0))
print(f"Trial {i+1}: TTFT={ttft:.3f}s, total={total:.3f}s, tokens={toks}, tokens/sec={tps:.2f}")
if __name__ == "__main__":
measure_stream_tps("List 50 short facts about GPUs and ASICs for LLM inference.")
SLA Tuning: Backoff and Fallback Example
Adopt a robust retry-and-fallback strategy to insulate your UX from rare backend issues during rollouts.
import os
import time
import json
import random
import requests
API_BASE = os.getenv("OPENAI_API_BASE", "https://api.openai.com/v1")
API_KEY = os.getenv("OPENAI_API_KEY")
PRIMARY_MODEL = os.getenv("OPENAI_MODEL", "gpt-4o-mini")
FALLBACK_MODEL = os.getenv("OPENAI_FALLBACK_MODEL", "gpt-4o-mini-extended")
def call_with_retry(prompt: str, model: str, attempts: int = 3, base_delay: float = 0.5):
headers = {"Authorization": f"Bearer {API_KEY}", "Content-Type": "application/json"}
url = f"{API_BASE}/chat/completions"
payload = {"model": model, "messages": [{"role": "user", "content": prompt}], "stream": False}
for i in range(attempts):
try:
r = requests.post(url, headers=headers, data=json.dumps(payload), timeout=60)
if r.status_code in (429, 503):
raise RuntimeError(f"Transient {r.status_code}")
r.raise_for_status()
return r.json()
except Exception as e:
delay = base_delay * (2 ** i) + random.uniform(0, 0.2)
time.sleep(delay)
raise RuntimeError("All attempts failed")
def robust_complete(prompt: str):
try:
return call_with_retry(prompt, PRIMARY_MODEL)
except Exception:
return call_with_retry(prompt, FALLBACK_MODEL)
if __name__ == "__main__":
resp = robust_complete("Explain speculative decoding in two bullets.")
print(resp.get("choices", [{}])[0])
Risk Factors and Reality Checks
Even the best silicon programs face risks:
- Manufacturing yield and packaging throughput: advanced HBM and interposers can bottleneck scale-up.
- Software maturity: kernel edges and scheduler bugs can surface only at massive scale under ragged traffic.
- Ecosystem inertia: developers expect stable behavior; any regression, however small, is magnified.
- Competitive responses: GPU vendors iterate rapidly; pricing and availability can shift unexpectedly.
None of these negate the case for Jalapeño; they simply argue for a measured rollout and strong telemetry. Prepare for a hybrid world where the best route for any given request is dynamic, and provider orchestration makes that decision on your behalf—most of the time.
Outlook: The Future of Inference
Inference is where AI meets users. Custom silicon like Jalapeño is a logical endpoint of scale: when the dominant workload is known (transformers), and the economics of power and memory bandwidth dominate, tailored chips win. The likely medium-term equilibrium:
- GPUs remain the gold standard for training and flexible inference, especially for cutting-edge research and complex multimodal tasks.
- Custom ASICs handle the bulk of steady-state inference, carving out growing territory as software stacks and models align.
- Developers benefit from more predictable pricing, lower latency, and larger contexts—provided they measure and adapt.
The intensity of competition between GPU vendors and hyperscaler ASICs will accelerate innovation in both camps. Developers can expect a cadence of API improvements even absent explicit model changes: faster streaming, cheaper tokens, and fewer rate limits. Your best response is operational excellence: observability, routing logic, and flexible UX.
FAQ for Practitioners
Will my code need changes to benefit from Jalapeño?
In most cases, no. Providers abstract backend details. You may see new SKU names or routing hints; your existing API calls should continue to work. To maximize benefits, add telemetry and consider price/latency-aware routing if exposed.
Will outputs change?
Small differences are possible when precision or kernels change. For code and structured outputs, use validators and sampling controls (e.g., temperature=0 for deterministic behaviors). Keep a regression suite.
Can I target Jalapeño explicitly?
Providers may offer hints or SKUs. Until then, treat backend selection as opaque and focus on measuring end-to-end behavior. If and when hints are supported, wire them through your config system and A/B test.
How big will the savings be?
It varies by model and task. A plausible range is 20–50% reduction in cost per token over time for workloads routed to Jalapeño-first tiers, though list pricing reflects strategic decisions beyond pure cost.
What about training?
Jalapeño is inference-focused. Training at the frontier scale will likely remain GPU/TPU-driven in the near term, with specialty accelerators filling niches as ecosystems mature.
Actionable Checklist
- Add latency distribution telemetry (TTFT, inter-token) per task and model today.
- Implement idempotent retries and backoff; capture backend-identifying headers if present.
- Introduce configuration for price/latency-aware routing; define fallbacks.
- Maintain a golden prompt corpus for regression testing across backend updates.
- Schedule regular benchmarks (weekly) and record results for trend analysis.
Conclusion
OpenAI’s Jalapeño chip is a milestone in AI infrastructure: a purpose-built inference accelerator co-designed with the serving stack it will power. For developers, the practical meaning is clear—lower latency, better streaming cadence, and the prospect of lower API prices, all without code changes. The deeper invitation is to become more sophisticated consumers of AI infrastructure: measure, adapt, and design your applications to thrive amid continual, mostly invisible improvements to the backend. In the competitive years ahead, operational excellence will be as important as model choice.
Keep an eye on provider announcements and your own dashboards. When the graph lines bend—latency dips, throughput increases, and cost per token trends down—you’ll know Jalapeño and its successors are moving into the critical path of your requests. Align your systems to take advantage, and your users, budgets, and roadmaps will all benefit.
Author: Markos Symeonides, ChatGPT AI Hub