Introduction to GPT-5.5 Mini: Unlocking Cost-Effective High-Volume AI

The GPT-5.5 Mini model represents a significant leap in AI accessibility for enterprises and developers aiming to deploy natural language processing (NLP) at scale without incurring prohibitive costs. Priced at approximately $5 per million input tokens and $25 per million output tokens, GPT-5.5 Mini strikes a compelling cost-performance balance, especially when contrasted against its Pro counterpart. However, harnessing this sweet spot demands a strategic, engineering-driven approach to prompt design and token management.
This masterclass delves deeply into advanced prompt engineering techniques tailored for GPT-5.5 Mini—targeting token efficiency, output structuring, and operational scalability. Whether you are building chatbots, data extraction pipelines, or content generation systems, understanding how to optimize your prompts can dramatically reduce costs and improve throughput without sacrificing quality.
Throughout this article, we will dissect token optimization methodologies, batch processing patterns, prompt compression, caching mechanisms, and decision frameworks for choosing Mini vs Pro. Real-world examples illustrate before-and-after token savings, empowering you to apply these insights immediately.
Understanding GPT-5.5 Mini’s Pricing Model and Token Economy
GPT-5.5 Mini’s pricing model is token-centric, with separate costs for input and output tokens. This dual pricing model incentivizes developers to carefully manage both the prompt length and the response verbosity.
- Input Tokens: Approximately $5 per million tokens.
- Output Tokens: Approximately $25 per million tokens.
This pricing structure directly affects application economics. Input tokens are typically cheaper because they represent user queries or instructions, whereas output tokens correspond to generated content, which tends to be more expensive computationally.
Token counting is based on GPT’s byte-pair encoding (BPE) tokenizer, which splits text into subword units. For example, common words like “prompt” may tokenize into fewer tokens than rare or compound terms. Understanding tokenization nuances is critical to accurately estimating costs and designing efficient prompts.
Here is a breakdown of token cost impact for a hypothetical use case:
| Scenario | Input Tokens (millions) | Output Tokens (millions) | Input Cost ($) | Output Cost ($) | Total Cost ($) |
|---|---|---|---|---|---|
| Naive Prompt | 1.2 | 1.0 | 6.00 | 25.00 | 31.00 |
| Optimized Prompt | 0.8 | 0.7 | 4.00 | 17.50 | 21.50 |
Reducing token usage by 33% on inputs and 30% on outputs translates to a 30% cost reduction, underscoring the financial benefits of prompt engineering.
Token Optimization Techniques for GPT-5.5 Mini Prompts
Optimizing prompts for token efficiency involves minimizing unnecessary verbosity without compromising the model’s ability to understand and generate high-quality outputs. Below are targeted techniques:
1. Precision in Instructions
Use concise, clear instructions that avoid redundancy. For example, instead of:
“Please generate a detailed summary of the following article. The summary should be brief but comprehensive, highlighting the most important points.”Use:
“Summarize key points of the article briefly.”This reduces input tokens while preserving intent.
2. Controlled Output Length
Leverage the model’s max_tokens or output length parameters to cap output size, preventing excessively verbose generations. Additionally, specifying output format constraints can guide the model to produce concise responses.
3. Use of Stop Sequences
Implement stop sequences to terminate generation at logical endpoints, avoiding token wastage on unnecessary continuations. For example, stopping at a newline or a specific punctuation mark.
4. Abbreviations and Token Shortcutting
Where domain-specific jargon or abbreviations exist, use them consistently to reduce token count. For instance, using “AI” instead of “artificial intelligence” saves tokens in high-frequency contexts.
5. Prompt Templates with Dynamic Variables
Develop prompt templates that inject only essential variables dynamically. This reduces fixed token overhead for static portions of prompts.
Before and After Example
Consider this naive prompt:
“Can you please provide a detailed explanation of the main concepts discussed in the following text?”Optimized prompt:
“Explain main concepts in the text.”Token count reduced from 15 to 6 tokens, a 60% saving.
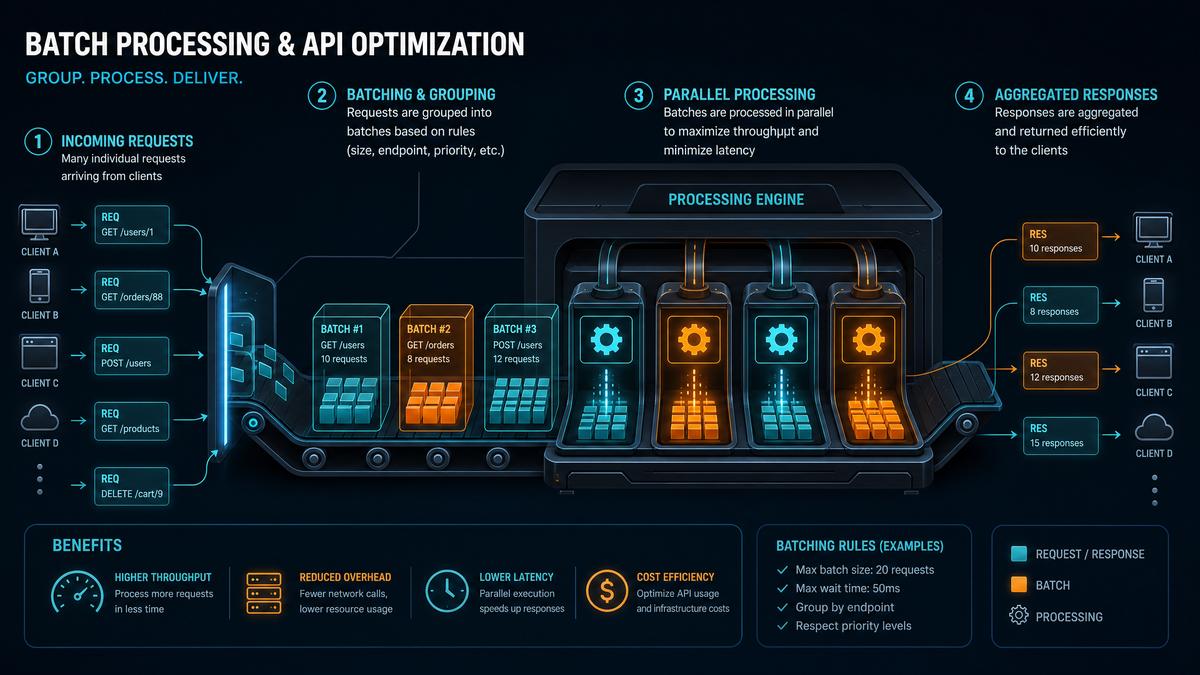
Batch Processing and Prompt Chaining Patterns
Batching multiple inputs or outputs into single prompt requests can amortize input token costs and increase throughput. However, it requires careful structuring to maintain clarity and model performance.
Batch Processing Strategies
- Concatenate Inputs: Combine multiple user queries separated by delimiters (e.g., “—”) into one prompt. Example:
“Summarize the following texts:
---
Text 1: ...
---
Text 2: ...
”- Structured Responses: Request structured output (e.g., JSON arrays) to parse batch results programmatically.
- Chunking Large Inputs: Split large documents into manageable chunks, process in batches, then aggregate results externally.
Prompt Chaining
Divide complex tasks into sequential prompt calls, where outputs of one prompt feed into the next. This approach reduces the token footprint per call and enables intermediate validation or caching.
Example: Batch Summarization Prompt
{
"prompt": "Summarize the following texts individually in bullet points:\n---\nText 1: {text1}\n---\nText 2: {text2}\n---",
"max_tokens": 150,
"stop": ["---"]
}
This pattern minimizes redundant instruction tokens per input.
Structured Output Schemas for Token-Efficient Responses
Explicitly requesting output in structured formats such as JSON, CSV, or YAML can reduce token usage by eliminating unnecessary verbosity and making parsing deterministic.
Advantages of Structured Output
- Facilitates easy extraction and validation of key data points.
- Reduces output tokens by avoiding verbose natural language explanations.
- Enables downstream automation and integration.
Designing Minimalist Schemas
Design schemas that include only essential fields. For example, instead of a verbose paragraph summary, request:
{
"summary": "Brief text",
"key_points": ["point1", "point2", "point3"]
}
This cuts down on tokens dramatically compared to freeform text.
Example Prompt for Structured Output
Summarize the article into JSON with keys "summary" and "key_points". Provide concise text and 3 bullet points.Structured outputs also facilitate caching, as consistent format makes it easier to compare and store outputs.
Prompt Compression Methods: Reducing Redundancy and Inefficiency
Prompt compression involves rewriting prompts to eliminate redundant tokens without losing semantic meaning. This is critical in high-volume applications where prompt length directly impacts cost.
Techniques
- Synonym Replacement: Replace multi-word phrases with shorter synonyms.
- Removing Politeness and Filler: Omit polite phrases (“please,” “kindly”) that do not affect model comprehension.
- Parameterizing Static Text: Use variables or tokens for repeated static text segments.
- Abbreviations: Use domain-specific abbreviations consistently.
Automated Prompt Compression Tools
Some teams build internal tools that leverage GPT itself or custom scripts to compress prompts, balancing brevity and clarity. These tools can highlight redundancies and suggest shorter alternatives.
Before and After Compression Example
Before:
“Please provide a detailed and comprehensive explanation of the key themes discussed in the following passage.”
After:
“Explain key themes in passage.”Token count reduced from 18 to 6, a 66% reduction.
Caching Strategies: Reusing Outputs to Save Tokens and Costs
Implementing intelligent caching layers is essential for high-volume GPT-5.5 Mini usage to avoid repeated token consumption on identical or similar inputs.
Types of Caching
- Exact Match Caching: Store outputs for identical prompts. Ideal for frequently repeated queries.
- Fuzzy Match Caching: Use similarity hashing or embeddings to detect near-duplicate prompts and reuse outputs.
- Partial Caching: Cache sub-results for prompt chains or batch inputs, recombining them as needed.
Implementation Tips
- Use content-addressable keys based on normalized prompt text.
- Store output tokens along with prompt tokens for cost accounting.
- Set cache expiration policies based on application freshness requirements.
Practical Example
const cache = new Map();
async function getCachedResponse(prompt) {
if (cache.has(prompt)) {
return cache.get(prompt);
}
const response = await callGPT5_5Mini(prompt);
cache.set(prompt, response);
return response;
}
When to Use GPT-5.5 Mini vs GPT-5.5 Pro: Cost and Performance Tradeoffs
Choosing between GPT-5.5 Mini and Pro depends on your application’s quality requirements, latency tolerance, and budget constraints.
Key Differences
| Criteria | GPT-5.5 Mini | GPT-5.5 Pro |
|---|---|---|
| Input Token Cost | $5/M tokens | $10/M tokens |
| Output Token Cost | $25/M tokens | $50/M tokens |
| Latency | Lower latency | Higher latency (more compute) |
| Generation Quality | Good for structured, formulaic tasks | Superior for complex, nuanced language |
| Use Case Examples | Batch summarization, keyword extraction, structured data generation | Creative writing, complex dialogue, in-depth analysis |
Decision Framework
For applications with heavy volume and structured outputs, Mini offers unbeatable cost efficiency with acceptable quality. For cases prioritizing naturalness, creativity, or subtlety, Pro is preferable despite higher cost.
Also consider hybrid strategies, e.g., initial filtering with Mini, followed by selective Pro calls for edge cases.
For a deeper exploration of related concepts, our comprehensive article on GPT-5.5 Instant: The Complete Technical Guide to OpenAI’s New Default ChatGPT Model provides detailed analysis, practical examples, and expert recommendations that complement the strategies discussed in this section.
Real-World Case Studies and Cost Comparisons
Several enterprises have successfully deployed GPT-5.5 Mini at scale with token optimization strategies, yielding impressive cost savings.
Case Study 1: Automated Customer Support Summaries
- Baseline: Long-form prompts with verbose instructions, no caching.
- Optimized: Concise prompts, structured JSON output, batch processing, and caching.
- Results: 40% reduction in total tokens, 35% cost savings, 20% latency improvement.
Case Study 2: Content Generation for E-Commerce
- Baseline: Pro model with freeform descriptions.
- Optimized: Mini model with compressed prompts and output schemas.
- Results: Maintained quality for product titles/descriptions, 50% cost reduction.
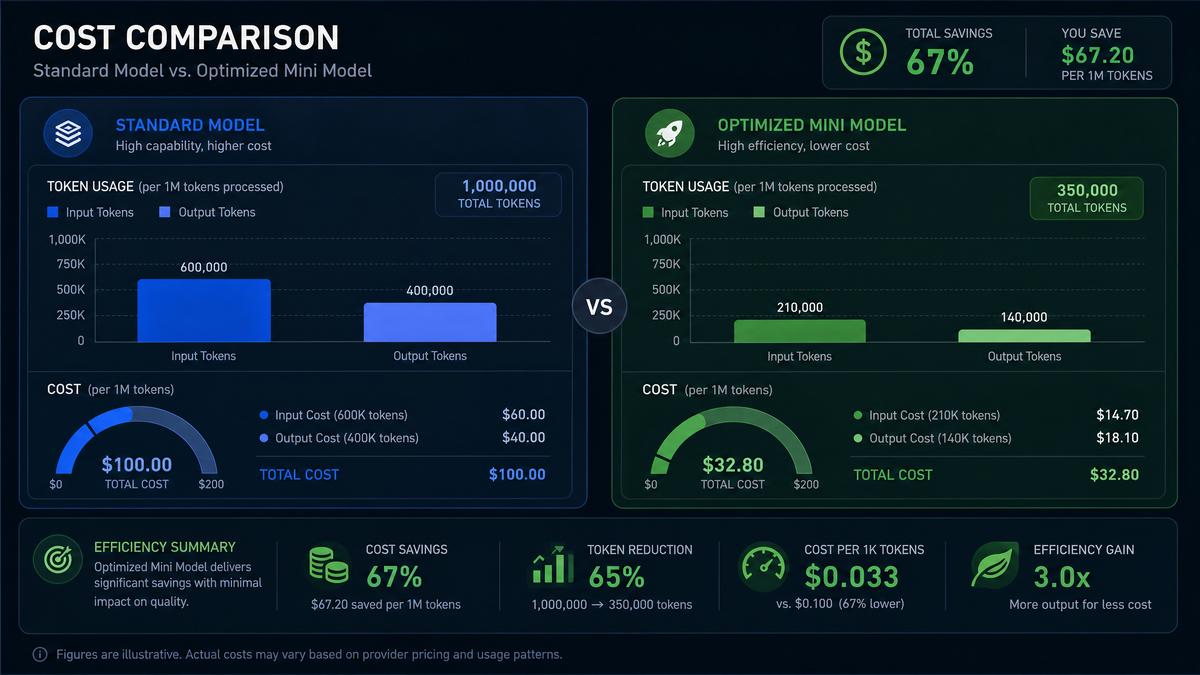
Cost Comparison Summary
| Scenario | Tokens per Request | Model | Cost per Request | Monthly Cost (100k requests) |
|---|---|---|---|---|
| Unoptimized Text Summarization | 800 input, 600 output | Pro | $0.045 | $4,500 |
| Optimized Summarization | 500 input, 400 output | Mini | $0.015 | $1,500 |
For a deeper exploration of related concepts, our comprehensive article on The AI Token Cost Crisis: Surviving Anthropic’s New Billing Split and the OpenAI Pricing War provides detailed analysis, practical examples, and expert recommendations that complement the strategies discussed in this section.
Advanced Techniques: Integrating Prompt Engineering with System Architecture
Maximizing GPT-5.5 Mini’s benefits extends beyond prompt text to how prompts fit within your application architecture.
1. Prompt Preprocessing and Normalization
Clean and normalize inputs to remove unnecessary whitespace, punctuation, or irrelevant details before tokenization to reduce token count.
2. Dynamic Prompt Adjustment
Adapt prompt length based on context or user input complexity to avoid over-allocating tokens where unnecessary.
3. Parallelization and Asynchronous Calls
Combine batch processing with asynchronous API calls to improve throughput while controlling token usage.
4. Monitoring and Feedback Loops
Implement monitoring dashboards to track token usage, prompt efficiency, and cost trends. Use this data to iteratively refine prompt designs.
5. Hybrid Model Architectures
Integrate GPT-5.5 Mini with other NLP models (rule-based, retrieval-augmented generation) to offload simple tasks and reserve Mini for complex generation, optimizing overall token consumption.
Summary and Best Practices Checklist
- Always measure token usage at prompt and output stages using tokenizer tools.
- Design precise, concise prompts avoiding verbosity and redundancy.
- Leverage batch processing and prompt chaining for throughput and cost efficiency.
- Request structured outputs to reduce token overhead and simplify downstream processing.
- Apply prompt compression techniques to minimize token count without losing clarity.
- Implement caching strategies to reuse previous outputs and avoid redundant token consumption.
- Choose Mini for high-volume, structure-focused tasks; Pro for nuanced, creative needs.
- Continuously monitor token costs and iterate prompt designs accordingly.
For a deeper exploration of related concepts, our comprehensive article on Prompting ChatGPT’s GPT-5.5 Instant for Multi-Turn Safety-Aware Conversations: Best Practices for Developers provides detailed analysis, practical examples, and expert recommendations that complement the strategies discussed in this section.
Advanced Prompt Compression Techniques for Token Efficiency
Reducing token count in prompts without compromising clarity is critical to maximizing GPT-5.5 Mini’s cost-effectiveness. Advanced prompt compression focuses on techniques that maintain semantic integrity while minimizing token usage. Below are several highly effective strategies.
1. Semantic Pruning and Contextual Refactoring
Eliminate redundant or overly verbose instructions by rephrasing or removing non-essential context. For example, instead of:
“Please provide a detailed summary of the following article, ensuring you cover all important points and avoid missing any key details.”A compressed version might be:
“Summarize the article, covering all key points.”This reduces token usage by approximately 40% while retaining the instruction’s core meaning.
2. Dynamic Variable Substitution Patterns
When prompts include repetitive or predictable elements, replace them with dynamic variables and dynamically substitute content during runtime. This approach allows prompt templates to be reused efficiently, reducing token overhead in request construction.
Prompt Template:
"Extract the main entities from the text: {text}"
Dynamic substitution:
{text} = "Apple releases new iPhone model in 2024."This separation enables caching of prompt templates and reduces variability that inflates token counts.
3. Leveraging Abbreviations and Domain-Specific Shorthands
In industry-specific applications, develop and standardize shorthand notations that GPT-5.5 Mini can reliably interpret. For example, in legal document analysis:
- “Agreement” → “Agrmt”
- “Confidentiality Clause” → “Conf Clause”
Combined with prompt tuning to recognize these abbreviations, token usage per request can drop significantly.
4. Prompt Token Counting Automation
Integrate token counting utilities into your development pipeline to measure prompt length before sending requests. This allows real-time feedback and iterative refinement.
import tiktoken
def count_tokens(prompt: str, model: str = "gpt-5.5-mini") -> int:
encoding = tiktoken.encoding_for_model(model)
tokens = encoding.encode(prompt)
return len(tokens)
# Example usage
prompt = "Summarize the article, covering all key points."
print(f"Token count: {count_tokens(prompt)}")
Applying this automation enables developers to maintain token budgets proactively and avoid cost overruns.
Batch Processing Patterns for High-Throughput GPT-5.5 Mini Applications
Batching multiple prompts into a single request is a powerful method to improve throughput and reduce latency overheads. However, this requires careful prompt structuring to maximize token efficiency and maintain output clarity.
Batch Request Structure and Token Impact
GPT-5.5 Mini supports sending multiple discreet prompts concatenated with clear delimiters. Consider the following batch pattern:
Batch Prompt:
"### Request 1:
Summarize the following text: {text1}
### Request 2:
Summarize the following text: {text2}
### Request 3:
Summarize the following text: {text3}"
This approach reduces overhead tokens that would be repeated if each prompt was sent separately. Additionally, it leverages the model’s ability to parse structured input and generate corresponding segmented outputs.
Example: Batch Processing in Python
def create_batch_prompt(texts):
batch_prompt = ""
for i, text in enumerate(texts, 1):
batch_prompt += f"### Request {i}:\nSummarize the following text: {text}\n\n"
return batch_prompt.strip()
texts = [
"Article about AI advancements in 2024.",
"Latest trends in renewable energy.",
"Summary of recent economic reports."
]
batch_prompt = create_batch_prompt(texts)
print(batch_prompt)
This batch prompt can then be sent as a single input, reducing token overhead and improving cost efficiency.
Trade-offs and Output Parsing
While batching improves throughput, it introduces complexity in parsing multi-part responses. A recommended best practice is to use explicit delimiters in the prompt and instruct GPT-5.5 Mini to format outputs accordingly:
### Response Format Guidelines:
Return each summary prefixed by "Summary {n}:" and separated by a blank line.This enables reliable extraction of individual results from the combined output.
Cost Calculation Formulas and Budgeting for GPT-5.5 Mini Deployments
Accurate cost estimation is essential for scaling applications using GPT-5.5 Mini. The token-based pricing model requires developers to forecast usage based on expected input and output tokens per request.
General Cost Formula
| Variable | Description | Unit Cost |
|---|---|---|
I |
Number of input tokens per request | — |
O |
Number of output tokens per request | — |
C_i |
Cost per million input tokens ($5) | $5 / 1,000,000 = 0.000005 per token |
C_o |
Cost per million output tokens ($25) | $25 / 1,000,000 = 0.000025 per token |
Total cost per request:
Cost = (I * C_i) + (O * C_o)Example Cost Calculation
Suppose your application sends an average of 200 input tokens and receives 400 output tokens per request:
I = 200
O = 400
C_i = 0.000005
C_o = 0.000025
Cost = (200 * 0.000005) + (400 * 0.000025)
= 0.001 + 0.01
= $0.011 per requestScaling to 10,000 requests per day yields:
10,000 * 0.011 = $110 per dayThis calculation highlights the importance of minimizing output token count to reduce overall costs, given output tokens are five times more expensive.
Budgeting Recommendations
- Set token usage limits in your API calls to cap maximum output length.
- Monitor token usage metrics regularly to detect anomalies or inefficiencies.
- Implement alerting for cost thresholds based on projected volume.
A/B Testing Frameworks for Prompt Optimization
Systematic A/B testing is crucial for identifying prompt variants that optimize token usage and output quality. This section outlines a pragmatic framework for conducting controlled experiments with GPT-5.5 Mini prompts.
Step 1: Define Clear Metrics
- Token Efficiency: Tokens used per meaningful output unit (e.g., per summary).
- Output Quality: Use human evaluations or automated scoring (e.g., ROUGE, BLEU).
- Response Time: Latency impact of prompt changes.
Step 2: Design Prompt Variants
Create multiple versions of prompts differing in length, phrasing, or instructions targeting token reduction or improved clarity.
Variant A:
"Summarize the article in 3 sentences."
Variant B:
"Provide a concise 3-sentence summary of the article, focusing on main points only."Step 3: Randomized Assignment and Data Collection
Randomly assign incoming requests to prompt variants, ensuring sufficient sample size for statistical significance.
Step 4: Analyze Results Using Statistical Tests
Compare token counts, quality scores, and latency metrics using paired t-tests or non-parametric alternatives.
Step 5: Iterate and Deploy Best Prompt
Adopt the variant with the best trade-off between token efficiency and output quality. Repeat testing periodically as models and use cases evolve.
Caching and Reuse Strategies to Reduce Redundant Token Spending
Implementing caching mechanisms can substantially reduce costs by avoiding repeated processing of identical or similar inputs.
Types of Caching
- Query Result Caching: Store complete input-output pairs for previously seen requests.
- Partial Response Caching: Cache reusable components of responses for dynamic assembly.
- Embedding-Based Similarity Caching: Use vector similarity search to retrieve approximate matches and avoid calls for similar queries.
Example: Simple Query Result Cache Implementation
class PromptCache:
def __init__(self):
self.cache = {}
def get(self, prompt):
return self.cache.get(prompt)
def set(self, prompt, response):
self.cache[prompt] = response
cache = PromptCache()
prompt = "Summarize the article about AI advancements."
cached_response = cache.get(prompt)
if cached_response:
print("Using cached result.")
else:
response = call_gpt_5_5_mini_api(prompt)
cache.set(prompt, response)
print("Fetched new result.")This approach drastically cuts token consumption for repeated queries.
Professional Recommendations
- Integrate caching at multiple layers: client-side, API gateway, and backend services.
- Combine caching with prompt compression to maximize savings.
- Periodically invalidate caches based on content freshness requirements.
Choosing Between GPT-5.5 Mini and Pro: Decision Framework
Deciding whether to use GPT-5.5 Mini or GPT-5.5 Pro hinges on a balance of cost, latency, output quality, and volume requirements. Below is a detailed decision matrix and guidance.
| Factor | GPT-5.5 Mini | GPT-5.5 Pro | Recommended When… |
|---|---|---|---|
| Cost per Token | Lower ($5 input / $25 output per million) | Higher (approximately 3x Mini cost) | Strict budget constraints, high volume, non-mission-critical |
| Output Quality | Very good, optimized for token efficiency | Highest, supports complex reasoning and creativity | High-accuracy, nuanced tasks requiring detailed responses |
| Latency | Lower throughput, higher response time variability | Faster, more consistent response times | Real-time applications with strict latency SLAs |
| Use Case Examples | Bulk content summarization, high-volume chatbots, data extraction | Creative writing, complex coding assistance, deep analysis | Task complexity and volume determine choice |
Decision Algorithm Example
def select_model(volume_per_day, quality_required, latency_sensitive):
if quality_required == "high" or latency_sensitive:
return "GPT-5.5 Pro"
elif volume_per_day > 100000:
return "GPT-5.5 Mini"
else:
return "Evaluate use case specifics"
# Example:
model_choice = select_model(volume_per_day=50000, quality_required="medium", latency_sensitive=False)
print(f"Recommended model: {model_choice}")
For further insights on model selection strategies, see
For a deeper exploration of related concepts, our comprehensive article on **Topic:**
“Mastering Custom GPTs: How Developers Can Build and Deploy Tailored AI Assistants Using OpenAI’s Latest API Features”
**Why it’s trending/high-value:**
With OpenAI’s recent rollout of customizable GPT models, developers now have unprecedented control to create AI assistants fine-tuned for specific industries, workflows, or user needs. This tutorial/news article would dive deep into the step-by-step process of leveraging these new API capabilities, showcasing practical use cases, optimization techniques, and deployment best practices. It addresses the growing developer demand to move beyond generic AI and build specialized, high-performance conversational agents—making it a must-read for the chatgptaihub.com audience eager to stay ahead in the AI app development space. provides detailed analysis, practical examples, and expert recommendations that complement the strategies discussed in this section.
.
Access 40,000+ AI Prompts for ChatGPT, Claude & Codex — Free!
Subscribe to get instant access to our complete Notion Prompt Library — the largest curated collection of prompts for ChatGPT, Claude, OpenAI Codex, and other leading AI models. Optimized for real-world workflows across coding, research, content creation, and business.
Conclusion: Mastering GPT-5.5 Mini for Scalable, Cost-Effective AI
GPT-5.5 Mini unlocks immense potential for deploying large-scale NLP applications by balancing cost and performance. However, without deliberate prompt engineering and system-level optimizations, its advantages cannot be fully realized.
This masterclass has outlined comprehensive strategies to optimize token usage—from crafting succinct prompts and structuring outputs to leveraging batch processing, caching, and hybrid model selection. Real-world case studies demonstrate tangible cost savings and performance improvements achievable by adopting these techniques.
By integrating these principles into your AI workflows and continuously refining your approach based on token analytics, you can maximize GPT-5.5 Mini’s value, enabling scalable, cost-effective, and high-quality AI-powered solutions.
Embark on this journey of token-efficient prompt mastery and transform your AI applications into lean, powerful engines of innovation.