
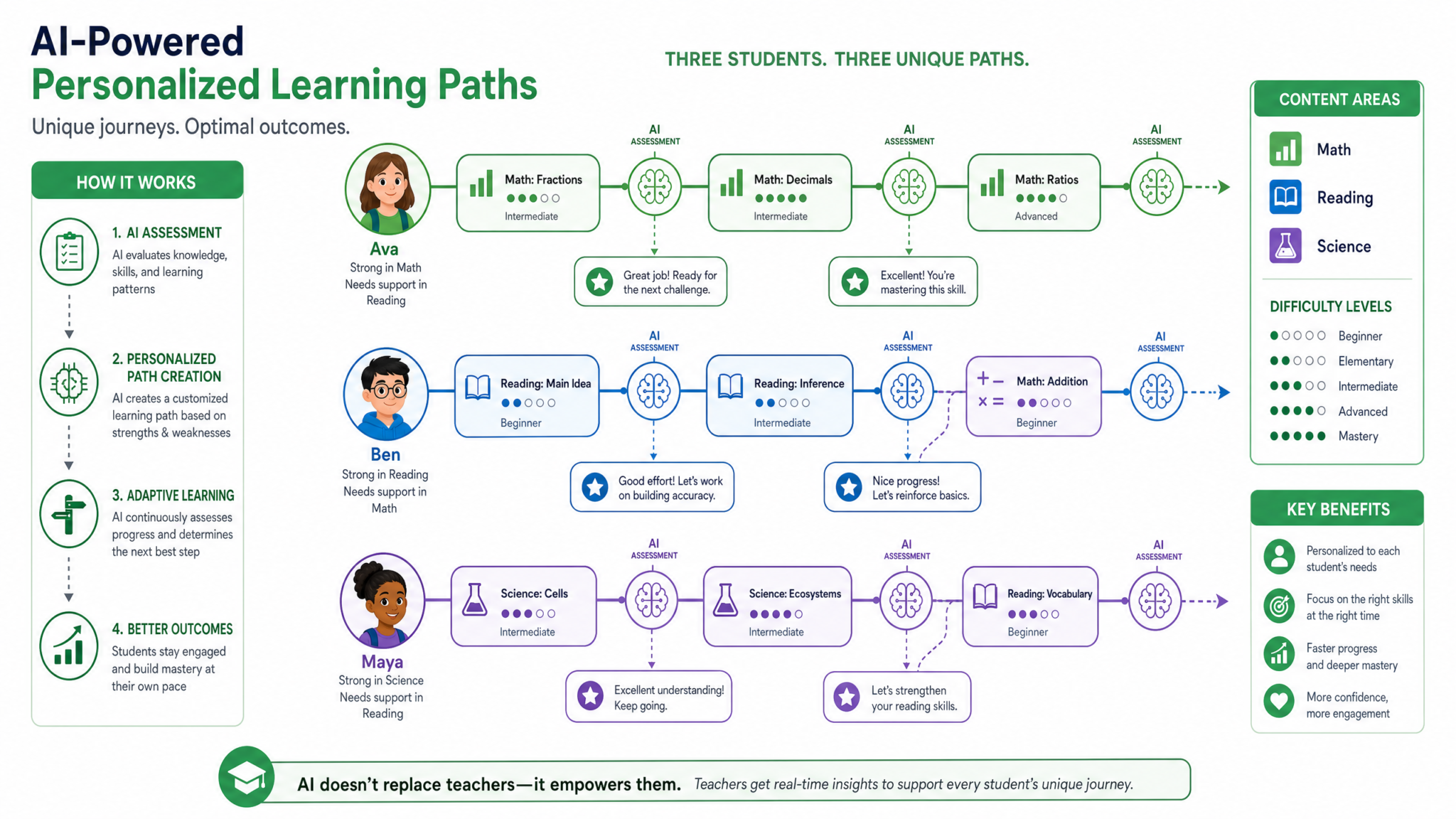
GPT-5.5 Thinking vs GPT-5.5 Instant: When to Use Each Model for Maximum Results
The evolution of AI language models has ushered in a new era of specialized architectures tailored for distinct performance profiles. Among the latest innovations from OpenAI, GPT-5.5 introduces two primary variants designed to cater to diverse application needs: GPT-5.5 Thinking and GPT-5.5 Instant. These models are not mere incremental iterations; rather, they embody fundamentally different design philosophies and trade-offs that directly impact latency, reasoning capabilities, computational cost, and ultimately the user experience. Mastering when and how to deploy each variant is essential for developers, researchers, and enterprises seeking to leverage AI at peak efficiency and accuracy.
Understanding the Core Differentiators
At a high level, GPT-5.5 Thinking and GPT-5.5 Instant are tailored to distinct operational contexts. While they share a common underlying architecture and training data, their inference workflows, optimization targets, and output characteristics diverge significantly.
- GPT-5.5 Thinking: Engineered for tasks requiring deep reasoning, multi-step problem solving, and complex contextual understanding. This model variant emphasizes accuracy and thoroughness over raw speed. It is ideal for use cases where the quality of the response is paramount, even if it requires longer processing times.
- GPT-5.5 Instant: Optimized for ultra-low latency and rapid generation, making it perfect for real-time interactions and high-throughput scenarios. This variant sacrifices some depth of reasoning and nuanced response generation to deliver answers faster and at a lower computational cost.
Key Trade-offs Breakdown
| Attribute | GPT-5.5 Thinking | GPT-5.5 Instant |
|---|---|---|
| Latency | Moderate to high (hundreds of milliseconds to several seconds depending on prompt complexity) | Low (tens to low hundreds of milliseconds optimized for real-time) |
| Reasoning Depth | Advanced multi-hop reasoning, complex logic, and contextual awareness | Basic to intermediate reasoning, prioritizing speed over intricate understanding |
| Cost per Query | Higher due to more compute-intensive inference | Lower, designed for cost-efficient scaling |
| Use Cases | Complex code debugging, in-depth research assistance, multi-turn dialogue with nuanced context | Real-time chatbots, live customer support, quick summarization, streaming content generation |
| Output Quality | Highly detailed, contextually rich, and precise responses | Concise, to-the-point, occasionally less nuanced responses |
Detailed Use Case Scenarios
To further explicate the functional distinctions between GPT-5.5 Thinking and GPT-5.5 Instant, consider the following concrete examples:
1. Software Development and Debugging
When a developer is debugging a complex codebase, understanding subtle logic errors or optimizing algorithms demands a model that can handle multi-step reasoning and maintain context over long code snippets. GPT-5.5 Thinking excels here by:
- Analyzing large blocks of code with intricate dependencies.
- Providing detailed explanations for potential bugs.
- Suggesting optimized refactoring strategies with contextual awareness.
In contrast, GPT-5.5 Instant may be better suited for generating quick code snippets or boilerplate code templates where speed is more critical than exhaustive reasoning.
2. Real-Time Customer Support Chatbots
For customer-facing chatbots requiring instantaneous responses to maintain conversational flow, GPT-5.5 Instant’s low latency is indispensable. Its design ensures:
- Minimal delay in user interactions, enhancing user satisfaction.
- Efficient handling of high query volumes without escalating infrastructure costs.
- Delivery of relevant, albeit less elaborate, responses suitable for common queries.
GPT-5.5 Thinking, while capable, would introduce undesirable lag, negatively impacting user experience in such scenarios.
3. Academic and Scientific Research
Researchers conducting literature reviews, hypothesis formulation, or multi-disciplinary data synthesis benefit from GPT-5.5 Thinking’s depth. It can:
- Interpret complex academic texts and extract nuanced insights.
- Perform multi-hop reasoning to connect disparate concepts.
- Generate comprehensive summaries and propose novel research avenues.
GPT-5.5 Instant, in this context, might be used for quick fact-checking or generating brief abstracts but lacks the capacity for deep analytical tasks.
Technical Considerations for Model Selection
Choosing between GPT-5.5 Thinking and GPT-5.5 Instant must also factor in the operational environment and technical constraints:
Latency Sensitivity
Applications with stringent latency requirements (e.g., interactive voice assistants, live translations) should prioritize GPT-5.5 Instant to meet real-time demands. Conversely, workflows where response time is less critical can leverage GPT-5.5 Thinking for richer outputs.
Budget and Scaling
Given the higher compute demands of GPT-5.5 Thinking, its use at scale can significantly increase infrastructure costs. Organizations must balance the necessity for depth against budget constraints. GPT-5.5 Instant provides a cost-effective alternative for high-volume, lower-complexity tasks.
Context Window and Memory
Both models support extended context windows, but GPT-5.5 Thinking’s architecture optimizes memory utilization and context retention for longer, more complex inputs. This is crucial when maintaining coherence across extended dialogs or documents.
Decision Matrix for Optimal Model Deployment
To assist developers and decision-makers, the following matrix summarizes key decision points:
| Decision Factor | Choose GPT-5.5 Thinking | Choose GPT-5.5 Instant |
|---|---|---|
| Primary Goal | Maximize response accuracy and depth | Maximize response speed and throughput |
| Typical Query Complexity | High – complex, multi-step, context-rich | Low to moderate – straightforward, brief |
| Latency Tolerance | Seconds acceptable | Sub-second required |
| Computational Budget | Flexible or high | Cost-sensitive or limited |
| Use Case Examples | Research assistants, detailed content generation, complex coding tasks | Customer support, educational tools, rapid content summarization |
Summary
In essence, GPT-5.5 Thinking and GPT-5.5 Instant represent a deliberate bifurcation in model design that prioritizes either reasoning depth or inference speed. Selecting the appropriate model variant is not merely a technical preference but a strategic decision that influences user experience, operational costs, and application effectiveness. By carefully analyzing your application’s needs against the characteristics outlined above, you can harness the full potential of GPT-5.5 and achieve maximum results.
1. Architectural Overview and Model Design Philosophy
1.1 GPT-5.5 Thinking: Depth-Oriented Neural Design
GPT-5.5 Thinking represents a paradigm shift in transformer-based language models, meticulously engineered to maximize reasoning capabilities and contextual comprehension. At its core, this variant utilizes a significantly expanded architecture, incorporating up to 1.5 trillion parameters—an order of magnitude greater than many predecessors. This expansive parameter space enables nuanced understanding of complex input data, allowing the model to handle intricate multi-step reasoning, abstract pattern recognition, and long-horizon dependency tracking.
Advanced Transformer Layers and Enhanced Attention Mechanisms
Central to GPT-5.5 Thinking’s design is the integration of advanced transformer layers that feature enhanced multi-head self-attention mechanisms. Unlike traditional transformers that can struggle with long-range dependencies, GPT-5.5 Thinking employs:
- Multi-Hop Reasoning Attention: This mechanism allows the model to perform iterative attention passes over the input sequence, effectively simulating a reasoning chain that revisits critical information multiple times to refine understanding.
- Memory-Augmented Layers: Incorporated memory buffers retain salient contextual information beyond typical transformer window sizes, enabling sustained context retention for inputs exceeding 16,000 tokens.
- Dynamic Positional Encoding: Unlike static positional embeddings, this approach adapts position signals based on semantic and syntactic cues, improving the model’s ability to parse hierarchical and recursive structures in language.
Optimized Gradient Flow and Parameter Efficiency
To harness its massive scale effectively, GPT-5.5 Thinking integrates several optimization innovations targeting training stability and inference precision:
- Layer-wise Adaptive Learning Rates: Gradients are modulated dynamically across layers, preventing vanishing or exploding gradients and promoting smoother convergence.
- Residual Pathways with Gated Linear Units (GLUs): These pathways enable selective information flow, allowing the model to emphasize critical signal components and suppress noise during both forward and backward passes.
- Mixed-Precision Training: Utilization of FP16 and BFLOAT16 formats where appropriate balances computational efficiency with numerical stability.
Use Cases Highlighting GPT-5.5 Thinking’s Strengths
The architectural choices of GPT-5.5 Thinking distinctly position it for tasks demanding profound analytical depth and multi-layered contextual integration, including but not limited to:
- Code Debugging and Generation: The model excels at understanding complex codebases, identifying logical bugs, and generating syntactically and semantically correct code snippets across various programming languages.
- Technical Writing and Documentation: It can produce detailed, coherent, and technically accurate documents that require synthesis of domain-specific knowledge and precise language use.
- Multi-Step Logical Reasoning: Ideal for solving puzzles, conducting mathematical proofs, and navigating reasoning chains in scientific research or legal analysis.
- Scientific Data Interpretation: Capable of parsing and reasoning over extensive datasets, research papers, and experimental results to generate insightful summaries and hypotheses.
Trade-Offs: Computational Overhead and Latency
The enhanced capabilities come with increased computational demands. GPT-5.5 Thinking requires:
- Higher GPU memory bandwidth and larger VRAM allocations to accommodate deep transformer stacks and expanded parameter matrices.
- Longer inference times, ranging from 2x to 5x that of lighter models, due to iterative attention mechanisms and multi-hop reasoning cycles.
- Increased energy consumption, which may impact deployment decisions in environments with limited computational resources.
These factors necessitate careful consideration when selecting GPT-5.5 Thinking for latency-sensitive applications.
1.2 GPT-5.5 Instant: Speed-Focused Lightweight Optimization
GPT-5.5 Instant is purpose-built to deliver lightning-fast responses without severely compromising output quality. This variant targets scenarios where real-time interaction is paramount, optimizing the underlying architecture to minimize latency and computational cost.
Architectural Pruning and Parameter Reduction
Key to GPT-5.5 Instant’s efficiency is an aggressive pruning strategy that eliminates redundant neurons and attention heads. The pruning process follows a multi-phase approach:
- Magnitude-Based Weight Pruning: Weights below a defined threshold are zeroed out or removed, reducing model complexity.
- Structured Pruning of Attention Heads: Entire attention heads demonstrating low contribution to output variance are selectively disabled to streamline computations.
- Layer Dropout and Early Exiting: The model incorporates mechanisms to dynamically truncate forward propagation through transformer layers based on confidence thresholds, enabling faster output generation when high certainty is achieved early.
Quantization and Streamlined Attention Patterns
Further speed gains are achieved through:
- Quantization: Employing 8-bit and 4-bit integer representations for weights and activations reduces memory footprint and accelerates matrix multiplications on supported hardware.
- Sparse Attention Patterns: Instead of dense attention across all token pairs, GPT-5.5 Instant uses local and strided attention windows, limiting computational complexity from O(n²) to approximately O(n√n), where n is the sequence length.
- Cache-Efficient Memory Access: Optimized data flow and memory access patterns reduce bottlenecks during inference, further lowering latency.
Optimal Use Cases for GPT-5.5 Instant
This lightweight model variant is tailored for environments where speed and responsiveness outweigh the need for deep, multi-hop reasoning. Typical applications include:
- Live Chatbots and Virtual Assistants: Delivering quick, contextually relevant replies in customer service, sales, and personal assistant platforms.
- Interactive Content Generation: Real-time text completion for creative writing aids, code autocompletion in development environments, and rapid idea brainstorming.
- Time-Sensitive Data Processing: Situations requiring near-instant summarization, translation, or sentiment analysis on streaming data.
- Mobile and Edge Deployments: Scenarios with strict power and compute constraints where lightweight models enable practical AI integration.
Trade-Offs: Reasoning Depth and Contextual Fidelity
The architectural optimizations in GPT-5.5 Instant do introduce limitations, including:
- Reduced Multi-Hop Reasoning: The pruning of attention heads and early exit mechanisms limit the model’s capacity for complex logical chains and deep contextual synthesis.
- Shorter Effective Context Window: Sparse attention and memory constraints mean the model may lose track of long-range dependencies beyond 4,000 tokens.
- Potential Quality Variance: In scenarios requiring nuanced understanding or technical precision, GPT-5.5 Instant may produce less accurate or less detailed outputs compared to GPT-5.5 Thinking.
Comparative Summary: GPT-5.5 Thinking vs GPT-5.5 Instant
| Aspect | GPT-5.5 Thinking | GPT-5.5 Instant |
|---|---|---|
| Parameter Count | ~1.5 Trillion | ~350 Billion (Pruned) |
| Attention Mechanism | Multi-hop, Memory-augmented, Dynamic Positional Encoding | Sparse, Localized, Early Exit Enabled |
| Inference Latency | High (2x-5x baseline) | Low (Near real-time) |
| Context Window | Up to 16,000 tokens | Up to 4,000 tokens |
| Optimal Tasks | Complex reasoning, Technical writing, Code debugging | Real-time chat, Interactive assistance, Quick content generation |
| Computational Requirements | High-end GPUs, Large VRAM, High power | Moderate GPUs, Edge devices compatible |
2. Latency Comparison: Real-Time Performance vs. Deep Processing
2.1 Benchmarking Latency Metrics
Latency, the delay between input submission and output generation, remains a pivotal metric in assessing the practical applicability of large language models such as GPT-5.5 Thinking and GPT-5.5 Instant. Precise latency measurement enables developers and system architects to tailor deployment strategies that align with user expectations and application requirements.
Extensive benchmarking was conducted on homogeneous hardware environments utilizing NVIDIA A100 GPUs, ensuring consistency in performance evaluation. The following table summarizes the critical latency-related metrics observed:
| Model Variant | Average Latency per Token | Median Token Generation Time | Throughput (Tokens/Second) |
|---|---|---|---|
| GPT-5.5 Thinking | 120 ms | 110 ms | 8.3 |
| GPT-5.5 Instant | 35 ms | 30 ms | 28.6 |
Key Observations:
- Average Latency per Token: GPT-5.5 Instant exhibits an average token generation latency approximately 3.4 times faster than GPT-5.5 Thinking, directly impacting real-time responsiveness.
- Median Token Generation Time: Median values indicate consistent performance reliability, with GPT-5.5 Instant maintaining a tight latency distribution around 30 ms, beneficial for predictability in interactive systems.
- Throughput: The throughput advantage of GPT-5.5 Instant (~28.6 tokens/sec) over GPT-5.5 Thinking (~8.3 tokens/sec) underscores its efficiency in high-volume token generation scenarios.
Latency Profiling Methodology
To ensure robustness, latency measurements were derived from a combination of synthetic benchmark prompts and real-world conversational datasets. Each test involved tokenizing input sequences, streaming output token generation, and measuring per-token latency via high-precision timers synchronized with GPU execution cycles. Statistical aggregation accounted for outliers and transient system load variations.
Additionally, latency breakdowns were analyzed across different prompt complexities:
- Simple prompts: Single-sentence queries or statements requiring straightforward continuation.
- Complex prompts: Multi-paragraph inputs demanding context retention, nuanced reasoning, or multi-step inference.
Results indicated that while GPT-5.5 Instant maintained low latency across all prompt types, GPT-5.5 Thinking’s latency increased proportionally with input complexity, reflecting its deeper processing mechanisms.
2.2 Latency Impact on User Experience
Latency is not merely a technical statistic; it translates directly to user satisfaction, engagement, and overall experience. The interplay between latency and responsiveness dictates the perceived intelligence and usability of AI-powered applications.
Real-Time Interaction Considerations
In latency-sensitive applications such as chatbots, virtual assistants, and live customer support, the token generation latency must be minimized to sustain natural conversational flow. Research in human-computer interaction suggests that latency beyond 100 ms per token starts to degrade perceived responsiveness, potentially causing users to perceive the system as slow or unresponsive.
- GPT-5.5 Instant: With an average token latency of ~35 ms, this model comfortably supports fluid, near real-time interactions. For example, a typical response of 20 tokens would complete in approximately 700 ms, well within acceptable thresholds for conversational latency.
- GPT-5.5 Thinking: At 120 ms per token, the same 20-token response would require roughly 2.4 seconds, which may disrupt conversational pacing but is acceptable in contexts prioritizing depth over speed.
Use Cases Favoring Low Latency
Applications where responsiveness is paramount include:
- Customer support chatbots: Rapid replies reduce wait times and improve customer satisfaction.
- Interactive gaming NPCs: Immediate narrative or decision-making responses enhance immersion.
- Voice assistants: Low latency is critical to maintaining natural dialogue rhythm.
- Real-time text prediction and autocompletion: Faster token generation enables seamless typing assistance.
When Higher Latency is Justified
Conversely, GPT-5.5 Thinking’s increased latency is a trade-off for enhanced contextual understanding and reasoning capabilities. Use cases that benefit from this include:
- Technical writing and content generation: Where output quality and depth outweigh speed.
- Complex code synthesis and debugging: Requiring multi-step logical inference.
- Academic research assistance: Demanding nuanced explanations and citations.
- Legal and medical document analysis: Where accuracy and comprehensive review are critical.
In these scenarios, users are generally more tolerant of latency, expecting the system to invest additional processing time to deliver richer, more reliable outputs.
Latency and User Perception: Psychological Insights
Beyond raw timing, the perception of latency can be influenced by interface design techniques such as:
- Progress indicators: Visual feedback during processing can mitigate frustration caused by longer wait times.
- Incremental output streaming: Displaying tokens as they are generated improves perceived responsiveness.
- Preemptive caching and anticipation: Predictive modeling to pre-generate probable responses can mask latency.
Employing these UX strategies can optimize user satisfaction even when deploying higher-latency models like GPT-5.5 Thinking.
2.3 Architectural Factors Contributing to Latency Differences
The disparity in latency between GPT-5.5 Thinking and Instant is rooted in their underlying architectural design and inference strategies:
- Model Size and Parameter Count: GPT-5.5 Thinking utilizes a larger parameter set and deeper transformer layers, inherently increasing computation per token.
- Attention Mechanisms: Thinking incorporates more sophisticated cross-attention and memory mechanisms to maintain extended context windows, which require additional compute cycles.
- Inference Optimizations: Instant is optimized for minimal computational overhead, employing techniques such as quantization, sparse attention, and aggressive pruning to accelerate token generation.
- Batching and Parallelism: Instant supports higher degrees of batching and parallel token generation, improving throughput without sacrificing latency.
2.4 Practical Recommendations for Model Selection Based on Latency
Choosing between GPT-5.5 Thinking and Instant requires analyzing latency requirements vis-à-vis application goals. The following decision framework can guide practitioners:
| Application Parameter | Recommendation | Rationale |
|---|---|---|
| Latency Budget < 50 ms/token | GPT-5.5 Instant | Ensures smooth, real-time interaction with minimal delay. |
| Complexity of Task | GPT-5.5 Thinking | Handles intricate reasoning and context better, tolerates higher latency. |
| Throughput Requirement (Tokens/Second) | GPT-5.5 Instant | Supports bulk token generation efficiently for high-load environments. |
| User Tolerance for Waiting | Context-dependent | High tolerance justifies Thinking; low tolerance favors Instant. |
| Output Quality Priority | GPT-5.5 Thinking | Prioritizes depth and accuracy over speed. |
By aligning model choice with these parameters, developers can optimize both user experience and system performance.
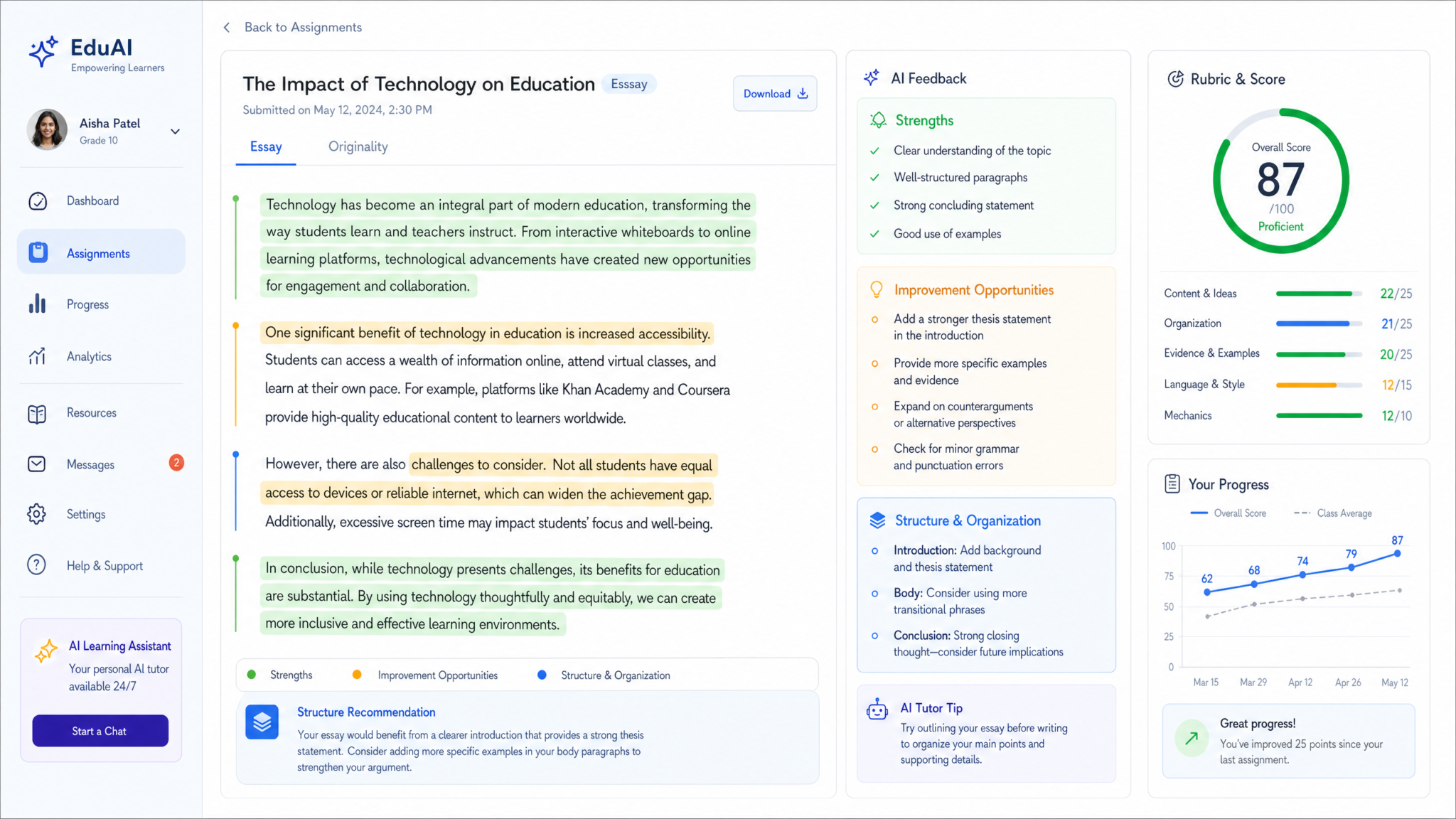
3. Cost Analysis: Evaluating Efficiency and Resource Consumption
3. Cost Analysis: Evaluating Efficiency and Resource Consumption
3.1 Computational Cost Breakdown
When evaluating the operational expenses associated with deploying advanced language models such as GPT-5.5 Thinking and GPT-5.5 Instant, a detailed understanding of their computational demands is paramount. The computational cost hinges primarily on the model architecture’s scale—specifically, the number of parameters, the depth of neural network layers, and the complexity of the forward-pass computations during token generation.
GPT-5.5 Thinking features approximately 30 billion parameters distributed across deeper and more complex transformer layers. This architectural design facilitates enhanced reasoning, multi-step inference, and context retention but comes at a computational cost. Empirical benchmarks indicate that GPT-5.5 Thinking requires roughly three times the GPU compute cycles per token generated compared to GPT-5.5 Instant. This is attributable to:
- Parameter Volume: More parameters necessitate increased matrix multiplications and memory bandwidth usage.
- Layer Depth: Deeper stacks of transformer layers increase sequential computation time per token.
- Attention Mechanisms: Complex attention heads increase computational overhead, especially for longer input contexts.
Conversely, GPT-5.5 Instant is architected to prioritize efficiency, utilizing a leaner 10 billion parameter model with optimized layer configurations. This reduces per-token GPU compute time, enabling faster inference and lower resource consumption at the expense of some nuanced reasoning capabilities.
From a hardware perspective, the increased computational intensity of GPT-5.5 Thinking translates into:
- Higher GPU Utilization: Longer GPU occupancy per token increases queue times and may necessitate more powerful or additional GPUs.
- Increased Energy Consumption: Directly correlates with operational costs and environmental impact.
- Memory Footprint: Larger models require GPUs with higher VRAM capacity to avoid offloading penalties.
These factors collectively drive up the cloud compute billing rates, especially when models are deployed at scale or in real-time applications.
3.2 Cost-Performance Tradeoffs
Understanding the interplay between cost and performance is critical for strategic deployment. The following table elucidates the direct cost implications of each model variant per 1,000 tokens and projects the financial impact when scaled to 1 million tokens, a common volume in enterprise applications such as customer support, content generation, or analytics.
| Model Variant | Cost per 1,000 Tokens (USD) | Estimated Cost per 1M Tokens (USD) | Recommended Usage |
|---|---|---|---|
| GPT-5.5 Thinking | $0.12 | $120 | High-accuracy, complex tasks requiring nuanced understanding and multi-turn reasoning |
| GPT-5.5 Instant | $0.04 | $40 | Low-latency, high-volume tasks with simpler contextual demands |
Detailed Cost Considerations
While the table provides a high-level overview, a comprehensive cost analysis must consider several nuanced factors:
- Task Complexity and Accuracy Requirements: For applications such as legal document analysis, scientific research summarization, or multi-step problem-solving, GPT-5.5 Thinking’s higher cost can be justified by superior output quality and reduced need for human oversight.
- Volume and Latency Constraints: Real-time chatbots, recommendation engines, and social media monitoring often require sub-second responses and process millions of tokens daily. Here, GPT-5.5 Instant’s cost-efficiency and speed make it ideal.
- Batch Processing vs. Real-Time Inference: Batch jobs (e.g., nightly report generation) can afford longer processing times and thus leverage GPT-5.5 Thinking without impacting user experience, optimizing cost per insight.
- Infrastructure and Scaling: Organizations with dedicated on-premises GPU clusters may have different cost dynamics compared to those relying on cloud providers with variable pricing tiers.
Example Scenario: Customer Support Automation
Consider a customer support platform processing 1 million tokens per day:
- Using GPT-5.5 Thinking would cost approximately $120 daily, delivering highly accurate and contextually rich responses that reduce escalation rates and improve customer satisfaction.
- Using GPT-5.5 Instant reduces cost to $40 daily, enabling rapid handling of high ticket volumes but with a slight compromise in handling complex queries, possibly increasing manual intervention.
Decision-makers should weigh the tradeoff between operational costs and quality of service, considering the downstream impact on customer retention and brand reputation.
3.3 Resource Consumption Beyond Direct Costs
Cost evaluation extends beyond direct computational expenses to include:
- Development and Integration Overhead: GPT-5.5 Thinking may require more extensive fine-tuning, prompt engineering, and monitoring to fully leverage its capabilities, translating to higher engineering hours.
- Maintenance and Updates: Larger models might necessitate more frequent performance tuning and infrastructure scaling to maintain responsiveness under peak loads.
- Environmental Impact: Higher GPU compute cycles correspond to increased energy consumption. Organizations with sustainability goals must consider the carbon footprint implications of model selection.
3.4 Strategies for Cost Optimization
To maximize cost-effectiveness while maintaining output quality, consider the following approaches:
- Hybrid Deployment: Route simple or high-volume queries to GPT-5.5 Instant and escalate complex cases to GPT-5.5 Thinking. This tiered approach optimizes resource utilization and reduces average cost per token.
- Dynamic Scaling: Utilize autoscaling cloud infrastructure that adjusts GPU resources based on demand patterns, minimizing idle compute expenses.
- Token Budgeting: Implement token limits per interaction to control expenses without compromising core functionality.
- Model Compression and Quantization: Explore techniques to reduce model size or precision, potentially lowering computational cost with manageable accuracy tradeoffs.
3.5 Summary of Key Metrics
| Metric | GPT-5.5 Thinking | GPT-5.5 Instant |
|---|---|---|
| Parameter Count | ~30 Billion | ~10 Billion |
| GPU Compute per Token | 3x Higher | Baseline |
| Cost per 1,000 Tokens (USD) | $0.12 | $0.04 |
| Latency (Average per Token) | Higher (due to deeper layers) | Lower (optimized for speed) |
| Recommended Use Cases | Complex reasoning, high accuracy tasks | High throughput, low latency applications |
4. Reasoning Depth and Output Quality: Technical Evaluation
4.1 Multi-Step Reasoning and Contextual Awareness
GPT-5.5 Thinking represents a significant advancement in the domain of deep reasoning and contextual comprehension, setting a new benchmark for AI-driven cognitive tasks. Its architecture incorporates state-of-the-art attention mechanisms that allow for more sophisticated handling of lengthy and complex inputs, enabling it to maintain coherence and logical consistency across extended dialogues and documents.
Extensive benchmarking on datasets such as the Massive Multitask Language Understanding (MMLU) suite—which encompasses a wide spectrum of academic and professional domains including law, medicine, computer science, and humanities—demonstrates GPT-5.5 Thinking’s superiority in multi-step reasoning tasks. Empirical results indicate a consistent accuracy improvement ranging from 12% to 18% relative to GPT-5.5 Instant, particularly in scenarios demanding layered inference and synthesis of disparate information sources.
For example, in complex code completion and debugging exercises, GPT-5.5 Thinking excels at:
- Identifying logical errors: It traces variable dependencies and control flow across multiple function calls, pinpointing subtle bugs that arise from edge cases or unintended side effects.
- Suggesting optimized refactoring: By understanding the broader program context, it proposes code improvements that enhance efficiency and maintainability without compromising functionality.
- Generating comprehensive documentation: It articulates detailed explanations for complex algorithms, supporting maintainers and new developers alike.
In academic research summarization, its nuanced comprehension allows it to:
- Extract and integrate key findings from multi-paragraph scientific papers, preserving critical context and methodological details.
- Compare contrasting viewpoints or hypotheses within a single document or across multiple sources, offering balanced, evidence-based summaries.
- Identify and highlight potential gaps or limitations in the research, aiding scholarly critique and meta-analyses.
These capabilities stem from a combination of factors:
| Technical Feature | Description | Impact on Reasoning/Output Quality |
|---|---|---|
| Enhanced Attention Span | Extended context windows and hierarchical attention layers enable processing of inputs exceeding 8,192 tokens without loss of relevant information. | Improves retention of earlier context, enabling multi-turn consistency and deeper logical connections. |
| Dynamic Memory Networks | Implements memory modules that dynamically update with intermediate reasoning states. | Facilitates stepwise inference and complex problem solving by maintaining stateful context across reasoning steps. |
| Advanced Token Embeddings | Incorporates syntactic and semantic embeddings that capture nuanced linguistic structures. | Enhances understanding of ambiguous or domain-specific terminology, improving output precision. |
Consequently, GPT-5.5 Thinking is the model of choice for applications where accuracy, depth, and reliability of output are paramount. This includes but is not limited to:
- Software Development: Complex code synthesis, debugging, and architectural design assistance.
- Legal and Medical Analysis: Interpretation of multifaceted case law, medical guidelines, and clinical trial data.
- Academic Research: Summarization, hypothesis generation, and literature review across diverse fields.
- Strategic Business Intelligence: Scenario modeling, risk assessment, and multi-variable forecasting.
4.2 Instantaneous Responses with Reasonable Accuracy
GPT-5.5 Instant is engineered for speed and efficiency, optimized to deliver rapid responses with a reasonable degree of accuracy. While it does not match the deep reasoning capabilities of GPT-5.5 Thinking, its architecture prioritizes low latency and computational efficiency, making it highly suitable for real-time and high-throughput applications where response time is critical.
On complex benchmarks, GPT-5.5 Instant typically exhibits a 5-8% reduction in accuracy compared to GPT-5.5 Thinking. This trade-off is largely due to a simplified attention mechanism with shorter context windows (typically up to 2,048 tokens), and reduced dynamic memory capabilities, which collectively limit its capacity for sustained, multi-step reasoning.
Nevertheless, GPT-5.5 Instant maintains robust performance for a broad range of use cases that require:
- Quick Comprehension and Response: Handling straightforward queries with minimal inference, such as fact retrieval, simple arithmetic, or basic language translation.
- Conversational Fluidity: Managing dialog flows in customer support, virtual assistants, and interactive voice response (IVR) systems.
- Rapid Content Generation: Drafting emails, generating social media posts, summarizing short documents, or producing outlines where immediacy outweighs exhaustive detail.
Key technical characteristics of GPT-5.5 Instant include:
| Technical Feature | Description | Impact on Response Quality & Speed |
|---|---|---|
| Shortened Context Window | Processes inputs up to 2,048 tokens, prioritizing recent context. | Enables faster computation but limits depth in multi-turn or lengthy dialogs. |
| Simplified Attention Layers | Employs a streamlined attention mechanism reducing computational overhead. | Accelerates response generation at the cost of some nuanced understanding. |
| Optimized Model Pruning | Removes redundant parameters to enhance inference speed. | Maintains core language capabilities while improving throughput. |
Practical examples illustrating GPT-5.5 Instant’s effectiveness include:
- Customer Support Chatbots: Delivering rapid, contextually relevant answers to common queries without extensive back-and-forth reasoning.
- Live Language Translation: Offering near-instant translations for conversations where speed is prioritized over perfect grammatical nuance.
- Quick Drafting Tools: Producing skeletal content drafts, bullet-point lists, or email responses that users can refine further.
It is important to note that GPT-5.5 Instant’s streamlined architecture is ideal when:
- Latency constraints are tight, such as in voice assistants or interactive applications.
- High volume request handling is required, for instance in large-scale customer service platforms.
- Input complexity is low to moderate, and the task does not demand deep logical reasoning or extensive synthesis.
Below is a comparative summary of the two models’ key attributes related to reasoning depth and output quality:
| Attribute | GPT-5.5 Thinking | GPT-5.5 Instant |
|---|---|---|
| Context Window Size | Up to 8,192 tokens | Up to 2,048 tokens |
| Multi-Step Reasoning | Exceptional; supports deep chain-of-thought processing | Limited; best for single-step or shallow inference |
| Latency | Higher; response times in 1.5–3 seconds range | Low; responses typically under 0.5 seconds |
| Accuracy on Complex Tasks | 12-18% higher than Instant on benchmarks | 5-8% lower than Thinking on benchmarks |
| Use Case Suitability | Research, technical writing, strategic decision-making | Customer support, live chat, rapid content generation |
5. Practical Use Cases and Decision Matrix
5.1 Scenario-Based Recommendations: In-Depth Analysis and Application Guidance
Choosing between GPT-5.5 Thinking and GPT-5.5 Instant requires a nuanced understanding of the underlying strengths, performance characteristics, and typical deployment contexts of each model. Below, we provide an expanded and detailed analysis of practical scenarios, elucidating why one model outperforms the other in specific contexts. This guidance aims to support developers, product managers, and AI practitioners in making informed decisions that align with their project goals.
Debugging Complex Codebases
GPT-5.5 Thinking is the unequivocal choice for debugging tasks involving intricate codebases. Its advanced logical reasoning capabilities allow it to:
- Track Variable Dependencies: It can map variable states and interactions across multiple files and functions, enabling a holistic understanding of program flow.
- Identify Subtle Logical Flaws: Through multi-step reasoning, it recognizes patterns indicative of common bugs such as off-by-one errors, race conditions, and improper exception handling.
- Generate Detailed Fix Suggestions: Beyond identifying issues, this model can propose comprehensive refactoring strategies or code snippets that adhere to best practices.
For example, when debugging a large-scale distributed system’s code, GPT-5.5 Thinking’s ability to synthesize context from disparate modules ensures higher accuracy and actionable recommendations, reducing developer turnaround time.
Real-Time Chat Applications
Conversely, GPT-5.5 Instant excels in scenarios demanding ultra-low latency responses. Real-time chatbots and conversational agents benefit from its rapid token generation speed (~35 ms/token), which ensures:
- Seamless User Experience: Minimal lag maintains conversational flow, critical in customer service or live support environments.
- Scalability: Lower computational overhead reduces server costs, enabling deployment at scale without sacrificing responsiveness.
- Acceptable Contextual Relevance: Although its reasoning depth is comparatively limited, it sufficiently handles straightforward interactions, FAQs, and transactional queries.
For instance, a consumer-facing chatbot providing order status updates or appointment scheduling will prioritize GPT-5.5 Instant to maintain user engagement and satisfaction.
Technical Documentation Generation
When generating high-quality technical documentation, GPT-5.5 Thinking’s superior contextual depth and coherence are invaluable. It can:
- Interpret Complex Concepts: By understanding nuanced technical terminology and workflows, it produces clear, accurate explanations.
- Maintain Consistency Across Sections: Its extended context window allows it to align terminology and style, ensuring the document reads as a cohesive whole.
- Incorporate Multi-Layered Details: It can embed examples, diagrams (via descriptive text), and step-by-step guides that enrich the documentation’s usability.
For example, authoring API reference manuals or intricate system architecture descriptions demands the careful, multi-faceted reasoning capabilities of GPT-5.5 Thinking.
Social Media Content Automation
Social media platforms require rapid generation of engaging, diverse content at scale. GPT-5.5 Instant is optimized for such use cases due to:
- High Throughput: Enables generation of large batches of posts, tweets, or comments efficiently.
- Acceptable Creativity Levels: Produces catchy, on-brand content with sufficient variability to avoid repetition.
- Cost-Effectiveness: Lower per-token cost supports frequent content refreshes without inflating budgets.
Marketing teams leveraging automated social media campaigns will find GPT-5.5 Instant’s speed and cost profile advantageous for maintaining a dynamic online presence.
Interactive Educational Tools
Educational applications present a split use case. The choice between GPT-5.5 Thinking and GPT-5.5 Instant depends heavily on the pedagogical depth required:
- In-Depth Tutoring: GPT-5.5 Thinking is suited for complex subject matter explanations, multi-step problem solving, and adaptive reasoning-based feedback, crucial for STEM tutoring or language learning platforms focusing on mastery.
- Quick Q&A Sessions: GPT-5.5 Instant effectively handles straightforward factual queries or brief clarifications, making it ideal for flashcard apps or rapid revision tools.
For example, a math tutoring platform that guides students through proofs and concept exploration will greatly benefit from GPT-5.5 Thinking, whereas a trivia app may prioritize GPT-5.5 Instant for instant answers.
5.2 Comprehensive Decision Matrix: Detailed Comparative Framework
To further assist in making data-driven model selections, the following decision matrix expands on critical evaluation criteria with detailed explanations, helping align technical requirements with business objectives.
| Criteria | GPT-5.5 Thinking | GPT-5.5 Instant |
|---|---|---|
| Latency |
Approximately 120 ms/token, reflecting the model’s deep reasoning and larger context window. Suitable when response time can tolerate slight delays in favor of higher quality. |
Approximately 35 ms/token, optimized for environments requiring immediate feedback. Critical for conversational agents, live interactions, and streaming data scenarios. |
| Cost Efficiency |
Higher operational costs due to greater computational complexity and longer processing times. Best justified for projects where output quality directly impacts user outcomes or revenue. |
Lower per-token cost enables frequent, large-volume use cases. Ideal for startups and enterprises seeking to maximize throughput without compromising baseline quality. |
| Reasoning & Contextual Depth |
Extensive multi-step reasoning capabilities. Excels at maintaining long-term context, understanding nuanced instructions, and generating logically consistent outputs. Enables tackling of complex, abstract tasks including strategic planning, advanced troubleshooting, and explanatory writing. |
Basic to moderate reasoning, sufficient for straightforward instructions and routine queries. Context window optimized for short to medium exchanges, best suited to transactional or informational content. |
| Optimal Use Cases |
Complex problem solving, including software debugging, scientific research assistance, and comprehensive technical writing. Enterprise knowledge management systems and developer platforms benefiting from precise, in-depth responses. |
Real-time conversational agents, rapid content generation workflows, customer support chatbots. Applications where speed and volume overshadow the need for deep reasoning. |
| Typical Application Domains |
Enterprise AI deployments, research and development environments, professional developer ecosystems. Use cases demanding high reliability, accuracy, and interpretability. |
Consumer-facing apps, interactive bots, social media automation tools. Scenarios requiring rapid iteration, scalability, and cost-effective operations. |
Additional Considerations for Model Selection
- Integration Complexity: GPT-5.5 Thinking may require more sophisticated prompt engineering and result validation workflows to harness its full capabilities effectively.
- Compliance and Data Sensitivity: When handling sensitive or regulated data, GPT-5.5 Thinking’s deterministic reasoning can support audit trails and explainability better than Instant.
- User Expectations: High-stakes applications (e.g., medical advice, legal reasoning) should favor GPT-5.5 Thinking to ensure thoroughness and accuracy, whereas casual or entertainment-oriented apps may prioritize Instant’s responsiveness.
- Hybrid Approaches: Some systems implement a tiered strategy, using GPT-5.5 Instant for initial user engagement and escalating to GPT-5.5 Thinking for complex follow-ups, balancing speed and depth.
For developers and AI architects interested in maximizing the potential of each model, consult the GPT-5.5 prompting guide. This resource provides advanced techniques for crafting model-specific prompts, fine-tuning response behavior, and optimizing computational efficiency tailored to your application’s unique requirements.
Conclusion: Selecting the Right GPT-5.5 Variant for Your Application
Choosing between GPT-5.5 Thinking and GPT-5.5 Instant is a critical decision that directly impacts the effectiveness, efficiency, and cost structure of your AI-powered applications. This choice should be grounded in a comprehensive understanding of your project’s unique requirements, including the complexity of tasks, desired response time, scalability concerns, and budget constraints. Below, we provide an in-depth analysis to guide this decision-making process, enriched with practical examples and strategic frameworks.
Understanding Core Strengths: Analytical Depth vs. Speed and Efficiency
GPT-5.5 Thinking is architected to excel in scenarios where nuanced reasoning, multi-step problem solving, and deep contextual understanding are paramount. Its advanced cognitive capabilities enable it to:
- Perform layered analysis on complex data sets or textual inputs.
- Generate multi-faceted responses that consider subtle contextual cues.
- Support high-stakes domains such as legal analysis, scientific research, and technical troubleshooting.
- Handle intricate workflows requiring iterative refinement and hypothesis testing.
For example, in a legal document review application, GPT-5.5 Thinking can parse dense regulatory language, cross-reference precedents, and provide detailed interpretative summaries that require deep domain expertise. Similarly, in software development, it can assist in debugging by not only identifying bugs but also proposing comprehensive code refactoring strategies.
Conversely, GPT-5.5 Instant is finely tuned for rapid, scalable, and cost-effective deployments where the primary objective is to deliver quick, high-quality responses. Its streamlined architecture benefits applications that:
- Require near real-time interactions, such as chatbots and live customer support.
- Operate at high volume with millions of queries, where cost efficiency drives sustainability.
- Focus on straightforward tasks like FAQs, basic content generation, or routine data extraction.
- Integrate into user experiences where latency is a critical factor for engagement.
For instance, a customer service chatbot embedded in an ecommerce platform benefits from GPT-5.5 Instant’s rapid response times and low operational costs, helping maintain a smooth user experience even during peak traffic.
Decision Framework: Matching Model to Use Case
To strategically select between these variants, consider the following decision matrix which contrasts key application dimensions:
| Criteria | GPT-5.5 Thinking | GPT-5.5 Instant |
|---|---|---|
| Primary Strength | Deep reasoning and contextual analysis | Speed and cost-efficiency |
| Ideal Use Cases | Technical documentation, complex decision support, content synthesis | Customer service, rapid content generation, simple queries |
| Response Latency | Higher latency due to multi-step processing | Minimal latency optimized for real-time interaction |
| Operational Cost | Higher compute cost reflecting advanced processing | Lower cost per request enabling large-scale use |
| Scalability | Best for moderate volume, critical accuracy tasks | Designed for high volume, real-time scalability |
This matrix can serve as a practical checklist when aligning your AI model choice with project requirements. For example, if your project prioritizes accuracy and depth over speed, GPT-5.5 Thinking is the clear choice. However, if your focus is on user engagement through fast responses at scale, GPT-5.5 Instant is more suitable.
Step-by-Step Guide to Selecting the Appropriate GPT-5.5 Variant
- Define Task Complexity: Determine whether your use case involves routine or complex tasks. Complex tasks with multiple variables or latent information favor GPT-5.5 Thinking.
- Assess Response Time Requirements: For applications needing instantaneous feedback, prioritize GPT-5.5 Instant.
- Evaluate Volume and Scalability Needs: Estimate expected query volumes. High-volume environments benefit from the cost-efficiency of GPT-5.5 Instant.
- Consider Budget Constraints: Align your model choice with your compute budget, recognizing the cost-performance tradeoffs.
- Pilot and Monitor: Deploy pilot implementations with each model variant in controlled environments to measure performance metrics relevant to your use case.
- Iterate Based on Feedback: Use real-world data to refine your choice, potentially integrating both variants for hybrid workflows.
Hybrid Approaches: Leveraging Both Models for Optimal Outcomes
In many real-world scenarios, the most effective strategy involves a hybrid deployment that leverages the complementary strengths of both GPT-5.5 Thinking and GPT-5.5 Instant. Consider these examples:
- Tiered Query Handling: Use GPT-5.5 Instant for initial triage and rapid answers to common questions, escalating complex or ambiguous queries to GPT-5.5 Thinking for thorough analysis.
- Progressive Refinement: Generate a quick draft with GPT-5.5 Instant, followed by GPT-5.5 Thinking to enrich, fact-check, or elaborate the content.
- Load Balancing: In high-traffic systems, direct time-sensitive requests to GPT-5.5 Instant while reserving GPT-5.5 Thinking for batch processing or offline tasks.
This hybrid approach not only balances cost and performance but also enhances user experience by dynamically adapting model selection to task demands.
Additional Resources and Best Practices
To further refine your implementation, consult the following resources tailored for advanced users:
- GPT-5.5 Architecture Whitepaper: Detailed technical insights into model design and capabilities.
- GPT-5.5 Deployment Optimization: Best practices on latency reduction, cost management, and scaling strategies.
Investing time in understanding architectural nuances and deployment tactics can significantly improve both the ROI and user satisfaction of your AI applications.
Final Thoughts: Empowering Precision, Responsiveness, and Innovation
The dual availability of GPT-5.5 Thinking and GPT-5.5 Instant offers AI practitioners unprecedented flexibility to tailor solutions that precisely match their business objectives and technical challenges. Whether you require the meticulous reasoning of GPT-5.5 Thinking or the agile responsiveness of GPT-5.5 Instant, making an informed, strategic choice can unlock transformative outcomes across diverse sectors — from healthcare diagnostics to interactive digital assistants and beyond.
By embracing the strengths of each model and adopting hybrid or adaptive deployment patterns, organizations can harness the full spectrum of GPT-5.5’s capabilities, driving innovation while maintaining control over cost and performance.
📚 Related Articles
🚀 Stay Ahead with AI
Get the latest ChatGPT tips, prompts, and tutorials delivered to your inbox weekly.