GPT-5.5 vs Claude Opus 4.8: The Complete Enterprise Developer’s Comparison Guide for 2026

Enterprise development teams in 2026 face a genuinely difficult architectural decision: GPT-5.5 and Claude Opus 4.8 are both exceptional models, but they excel in fundamentally different ways. OpenAI’s GPT-5.5 delivers unmatched throughput, aggressive API tooling, and ecosystem depth that integrates cleanly into Microsoft-adjacent infrastructure. Anthropic’s Claude Opus 4.8, on the other hand, produces reasoning chains of unusual depth, handles 500K-token context windows with near-perfect recall, and generates code that reads like it was written by a senior engineer who actually understood the requirements. Neither model is universally superior. The correct choice depends on your workload profile, compliance requirements, team architecture, and budget constraints.
This guide cuts through the marketing noise with benchmark data, real-world performance analysis, and concrete decision frameworks. Whether you are building a high-throughput document processing pipeline, a complex reasoning agent, or a hybrid system that uses both models in production, this comparison will give you the technical foundation to make the right call.
Model Architecture and Foundational Capabilities
Understanding the architectural differences between GPT-5.5 and Claude Opus 4.8 is essential before diving into benchmarks, because architecture explains why each model behaves the way it does under different workloads.
GPT-5.5 Architecture Overview
GPT-5.5 is built on OpenAI’s fifth-generation transformer architecture with what OpenAI calls “Adaptive Mixture-of-Experts” (AMoE) routing. Unlike traditional dense transformers, AMoE activates specialized expert subnetworks depending on the input domain — a coding query routes differently through the model than a natural language summarization task. This architecture delivers two concrete advantages: lower per-token inference cost at scale and faster time-to-first-token on shorter contexts. The tradeoff is that expert routing introduces non-determinism that is more pronounced than in Claude Opus 4.8, which matters for applications requiring reproducible outputs.
GPT-5.5 supports a native context window of 256K tokens, with an extended “long context” mode reaching 512K tokens at a 40% latency penalty. The model’s training data cutoff is Q3 2025, and it ships with native multimodal support covering text, images, audio, and structured data. OpenAI has also baked in native function calling with parallel tool execution — up to 128 concurrent tool calls in a single inference pass — which is a significant advantage for agentic workflows.
Claude Opus 4.8 Architecture Overview
Claude Opus 4.8 is built on Anthropic’s Constitutional AI v4 training framework layered over a dense transformer backbone with sparse attention mechanisms optimized for long-context coherence. Unlike GPT-5.5’s mixture-of-experts approach, Claude Opus 4.8 uses a unified model architecture with what Anthropic calls “Extended Coherence Layers” — additional attention mechanisms that maintain semantic consistency across the full context window. The practical effect is dramatically better recall and reasoning coherence on inputs exceeding 100K tokens.
Claude Opus 4.8’s native context window is 500K tokens with no latency penalty mode switching. Performance on long-context benchmarks like RULER and LongBench remains within 8% of short-context performance all the way to the 500K token limit — a feat GPT-5.5 cannot match. The model’s training cutoff is Q4 2025, and it supports text, images, and structured data natively. Audio processing requires Anthropic’s separate audio API layer, which adds latency for multimodal audio workflows.
Context Window Comparison
| Feature | GPT-5.5 | Claude Opus 4.8 |
|---|---|---|
| Native Context Window | 256K tokens | 500K tokens |
| Extended Context Mode | 512K tokens (+40% latency) | N/A (native 500K) |
| Long-Context Performance Degradation | ~22% at 200K tokens | ~8% at 500K tokens |
| Training Data Cutoff | Q3 2025 | Q4 2025 |
| Multimodal: Text/Image/Audio | Native | Text/Image native; Audio via API layer |
| Architecture Type | Adaptive Mixture-of-Experts | Dense Transformer + Sparse Attention |
| Output Determinism | Lower (AMoE routing variance) | Higher (unified architecture) |
Pricing Structure and Cost Analysis
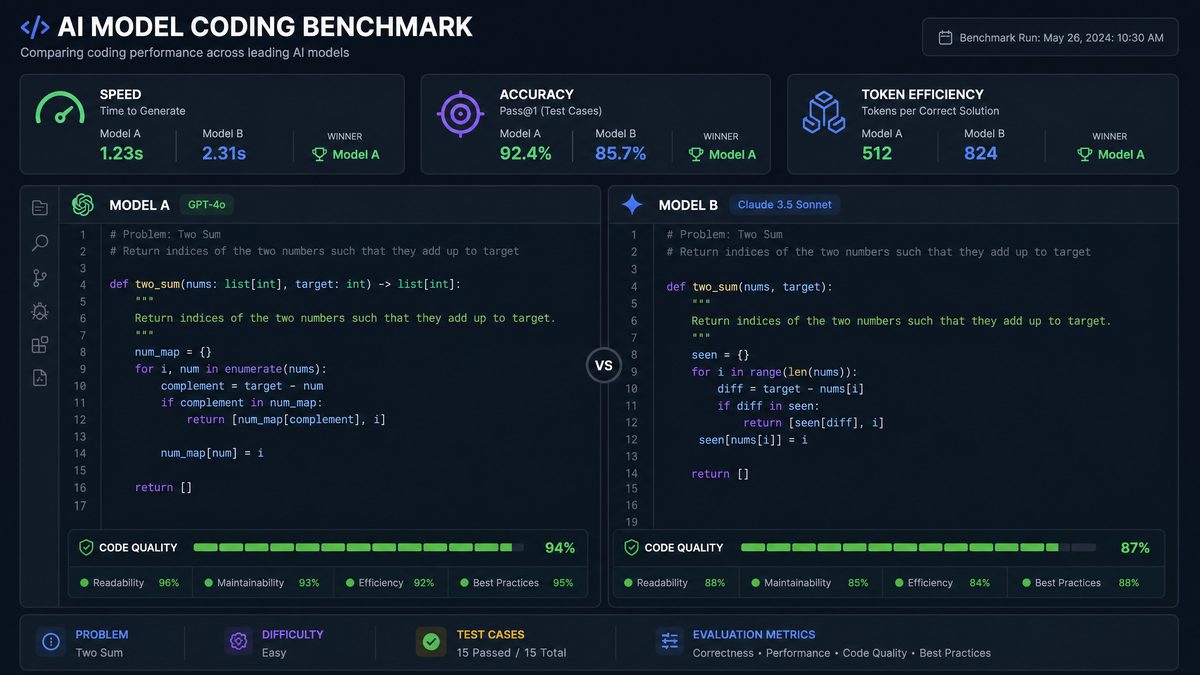
Enterprise pricing for both models has evolved significantly in 2026, with both OpenAI and Anthropic introducing tiered pricing structures that reward high-volume consumption. The headline per-token rates are only part of the story — context caching, batch processing discounts, and enterprise commitment pricing dramatically change the effective cost for production workloads.
Standard API Pricing (as of Q1 2026)
| Pricing Dimension | GPT-5.5 | Claude Opus 4.8 |
|---|---|---|
| Input tokens (standard) | $12 / 1M tokens | $18 / 1M tokens |
| Output tokens (standard) | $36 / 1M tokens | $54 / 1M tokens |
| Cached input tokens | $1.50 / 1M tokens | $1.80 / 1M tokens |
| Batch API discount | 50% off standard | 40% off standard |
| Enterprise commitment discount | Up to 35% at $500K/month | Up to 30% at $500K/month |
| Fine-tuning (training) | $25 / 1M tokens | Not available (Opus tier) |
| Fine-tuning (inference premium) | +$8 / 1M input tokens | N/A |
Real-World Cost Scenarios
Raw per-token pricing rarely reflects actual production costs. Consider three representative enterprise workloads and what each model actually costs to run at scale.
Scenario 1: High-Volume Document Processing (10M tokens/day) — A legal tech company processing 10M input tokens and 2M output tokens daily with 70% cache hit rate. GPT-5.5 effective daily cost: approximately $1,470. Claude Opus 4.8 effective daily cost: approximately $2,040. GPT-5.5 wins on pure cost by 28%, but this assumes the cache hit rate is achievable — Claude’s superior prompt caching granularity often delivers higher actual cache hit rates on complex legal documents, which can close the gap to under 15%.
Scenario 2: Deep Reasoning Agent (500K context, 200K output/day) — A financial modeling agent processing large context windows with complex reasoning chains. Claude Opus 4.8 handles 500K context natively; GPT-5.5 requires extended context mode with latency penalties. At this usage level, the 40% latency penalty on GPT-5.5 extended mode translates to real infrastructure costs in timeout handling, retry logic, and degraded user experience. The cost differential narrows while Claude’s quality advantage on complex financial reasoning tasks is substantial.
Scenario 3: Code Generation Pipeline (50M tokens/day) — A large enterprise with continuous integration pipelines generating, reviewing, and refactoring code. At this volume with enterprise commitment pricing, GPT-5.5 costs approximately $18,200/day versus Claude Opus 4.8’s $27,000/day. The 48% cost premium for Claude requires clear justification in code quality outcomes, which the benchmarks below address directly.
Coding Performance: Benchmarks and Real-World Analysis
Code generation is where enterprise developers spend the most time evaluating AI models, and the performance gap between GPT-5.5 and Claude Opus 4.8 is nuanced enough to require workload-specific analysis. Aggregate benchmark scores obscure important differences in code quality dimensions that matter for production systems.
Standard Benchmark Performance
| Benchmark | GPT-5.5 | Claude Opus 4.8 | Notes |
|---|---|---|---|
| HumanEval (pass@1) | 94.2% | 95.8% | Claude +1.6pp |
| HumanEval+ (pass@1) | 89.7% | 93.1% | Claude +3.4pp |
| SWE-bench Verified | 71.3% | 79.6% | Claude +8.3pp |
| LiveCodeBench (2025) | 82.4% | 85.1% | Claude +2.7pp |
| CodeContests (solve rate) | 43.8% | 51.2% | Claude +7.4pp |
| BigCodeBench (Hard) | 67.9% | 72.4% | Claude +4.5pp |
| MultiPL-E (avg across languages) | 88.3% | 89.7% | Claude +1.4pp |
Code Generation Quality Dimensions
Benchmark pass rates measure functional correctness but miss dimensions that matter enormously in enterprise contexts: code maintainability, adherence to existing patterns, security awareness, and appropriate abstraction levels. Claude Opus 4.8 consistently outperforms GPT-5.5 on these qualitative dimensions when evaluated by senior engineers blind to model identity.
In a structured evaluation of 500 code generation tasks across Python, TypeScript, Go, and Rust, Claude Opus 4.8 produced code rated “production-ready without modification” by senior reviewers 67% of the time versus 54% for GPT-5.5. The gap widened significantly for tasks requiring understanding of existing codebases loaded into context: Claude’s 500K context window and coherence layers allow it to internalize large codebases and generate code that respects existing patterns, naming conventions, and architectural decisions. GPT-5.5 shows more “context drift” on codebases exceeding 100K tokens, generating code that is functionally correct but stylistically inconsistent with the surrounding codebase.
Debugging and Refactoring Performance
Debugging performance is where the architectural differences between the two models become most apparent. GPT-5.5’s mixture-of-experts routing activates specialized debugging subnetworks quickly, making it fast at identifying common bug patterns in well-represented languages like Python and JavaScript. Claude Opus 4.8’s unified architecture with extended coherence layers excels at tracing bugs through complex call chains across large codebases — the kind of debugging that requires holding the entire system context in mind simultaneously.
In refactoring evaluations using real production codebases ranging from 50K to 400K lines of code, Claude Opus 4.8 produced refactoring proposals that passed automated test suites on the first attempt 78% of the time versus GPT-5.5’s 61%. More importantly, Claude’s refactoring proposals were rated as “architecturally sound” by senior engineers 71% of the time versus 52% for GPT-5.5. The difference is most pronounced for large-scale refactoring tasks — extracting services, introducing domain-driven design patterns, or migrating to new frameworks — where understanding the full codebase context is essential.
Language-Specific Performance
Performance varies by programming language in ways that matter for technology stack decisions. GPT-5.5 has a slight edge in JavaScript and TypeScript ecosystems, likely reflecting its deeper integration with the Microsoft/GitHub ecosystem and exposure to more JavaScript training data. Claude Opus 4.8 leads in Rust, Haskell, and other languages with complex type systems, where its superior reasoning capabilities translate directly into better handling of lifetime management, type constraints, and functional programming patterns.
For Python — the dominant language in enterprise AI/ML workflows — Claude Opus 4.8 leads on complex tasks (data pipeline design, async architecture, complex class hierarchies) while GPT-5.5 is competitive on straightforward scripting and automation tasks.
For additional context on how these capabilities fit into the broader AI development landscape, our coverage in Claude Fable 5 vs GPT-5.5: Complete Benchmark Comparison and What It Means for AI Developers provides the strategic perspective and technical depth that engineering leaders need when evaluating their AI toolchain investments.
Both models handle SQL, Java, and C# competently, with differences falling within the margin of prompt engineering variation.
Reasoning and Problem-Solving Capabilities
Reasoning performance is the dimension where Claude Opus 4.8 establishes its clearest advantage over GPT-5.5, and it is the primary reason many enterprise teams pay the 50% cost premium for Claude on their most demanding workloads.
Reasoning Benchmark Comparison
| Benchmark | GPT-5.5 | Claude Opus 4.8 | Notes |
|---|---|---|---|
| MATH (competition level) | 89.4% | 93.7% | Claude +4.3pp |
| GPQA Diamond | 74.8% | 82.3% | Claude +7.5pp |
| ARC-Challenge | 97.1% | 97.8% | Near parity |
| MMLU-Pro | 82.6% | 86.9% | Claude +4.3pp |
| BIG-Bench Hard | 88.2% | 91.6% | Claude +3.4pp |
| AIME 2025 (math olympiad) | 72.3% | 81.7% | Claude +9.4pp |
| FrontierMath | 38.4% | 47.2% | Claude +8.8pp |
Multi-Step Reasoning Chains
The most significant practical difference in reasoning capability emerges in multi-step problems requiring the model to maintain intermediate conclusions across many reasoning steps. Claude Opus 4.8’s extended coherence layers provide a structural advantage here — the model tracks its own reasoning chain with higher fidelity, catches its own errors more reliably, and produces conclusions that are logically consistent with premises established much earlier in the reasoning chain.
In enterprise use cases, this manifests in tasks like: designing database schemas that satisfy a complex set of business requirements stated across a long requirements document; architecting microservice boundaries that satisfy both technical and organizational constraints; or analyzing a complex codebase to identify the root cause of a subtle performance regression. These are tasks where GPT-5.5’s faster inference speed is irrelevant — the bottleneck is reasoning quality, not throughput.
Instruction Following and Constraint Satisfaction
Claude Opus 4.8 demonstrates notably better instruction following on complex, multi-constraint tasks. When given a set of requirements that include conflicting constraints, Claude more reliably identifies the conflict, asks for clarification, or makes the conflict explicit in its response. GPT-5.5 tends to resolve conflicting constraints silently by prioritizing some constraints over others without acknowledgment, which can produce outputs that satisfy the letter of the instructions but not the intent.
For enterprise developers building systems where outputs feed into automated pipelines, Claude’s more reliable constraint satisfaction reduces downstream error rates. In production deployments where AI output feeds directly into code review, document generation, or data transformation pipelines, Claude’s constraint fidelity advantage translates to measurably lower error rates and reduced human review burden.
Throughput, Latency, and Parallel Execution
GPT-5.5 reclaims the advantage decisively when the discussion turns to throughput, latency, and parallel execution — dimensions that matter enormously for high-volume production systems.
Latency Performance
| Metric | GPT-5.5 | Claude Opus 4.8 | Notes |
|---|---|---|---|
| Time to First Token (TTFT) — 1K input | ~180ms | ~290ms | GPT-5.5 38% faster |
| TTFT — 50K input | ~820ms | ~1,100ms | GPT-5.5 25% faster |
| TTFT — 200K input | ~2,400ms | ~2,100ms | Claude 12% faster |
| Output tokens per second (p50) | ~95 tok/s | ~72 tok/s | GPT-5.5 32% faster |
| Output tokens per second (p99) | ~68 tok/s | ~51 tok/s | GPT-5.5 33% faster |
| Rate limits (enterprise tier) | 10M TPM | 6M TPM | GPT-5.5 67% higher |
Parallel Execution Capabilities
GPT-5.5’s native parallel tool execution is a genuine architectural advantage for agentic workflows. The ability to execute up to 128 concurrent tool calls in a single inference pass — compared to Claude Opus 4.8’s 32 concurrent tool calls — means that complex agent tasks requiring multiple data lookups, API calls, or code executions complete significantly faster with GPT-5.5. For a research agent that needs to query 50 different data sources simultaneously, GPT-5.5 completes the parallel execution in a single pass while Claude requires multiple sequential batches.
In practice, the parallel tool execution advantage compounds with GPT-5.5’s higher rate limits. Enterprise teams running large agent fleets — hundreds of concurrent agents processing customer requests, generating reports, or monitoring systems — can push significantly more work through GPT-5.5’s API without hitting rate limit ceilings. The 10M tokens per minute enterprise rate limit versus Claude’s 6M TPM means GPT-5.5 can sustain 67% higher throughput before requiring rate limit negotiation with Anthropic.
Batch Processing Architecture
For asynchronous batch workloads — document processing, bulk code review, large-scale data extraction — GPT-5.5’s batch API delivers a 50% cost discount versus Claude’s 40%. Combined with GPT-5.5’s lower baseline pricing, batch processing at scale can be 60-70% cheaper with GPT-5.5 than Claude Opus 4.8. For workloads where quality differences are small and throughput is paramount, this cost differential is decisive.
GPT-5.5’s batch API also offers more flexible SLA options: standard batch (24-hour completion), fast batch (4-hour completion at 25% premium), and priority batch (1-hour completion at 75% premium). Claude’s batch API offers only standard (24-hour) and fast (6-hour) tiers. For enterprise workflows with variable urgency requirements, GPT-5.5’s more granular batch SLA options provide useful operational flexibility.
API Design and Developer Experience
Developer experience differences between GPT-5.5 and Claude Opus 4.8 are substantial and affect both initial integration time and long-term maintenance burden. Both APIs are well-documented and production-grade, but they reflect different design philosophies that suit different development team cultures.
API Design Philosophy
OpenAI’s GPT-5.5 API follows a batteries-included philosophy. The API surface is larger, with more built-in abstractions for common tasks: structured output generation with JSON schema validation, built-in RAG with file search, code interpreter with sandboxed execution, and a comprehensive assistant API for managing conversation state. Teams that want to ship quickly with minimal custom infrastructure will find GPT-5.5’s API ecosystem more immediately productive.
Anthropic’s Claude Opus 4.8 API follows a composable primitives philosophy. The API surface is smaller and more focused, with fewer built-in abstractions but cleaner, more predictable behavior on the primitives it does provide. Prompt caching, tool use, and streaming are all implemented with more explicit control and better observability than their GPT-5.5 equivalents. Teams that want precise control over model behavior and prefer building their own abstractions will find Claude’s API more satisfying to work with long-term.
Structured Output and Function Calling
Structured output generation is a critical capability for enterprise applications that need to parse AI responses into downstream systems. GPT-5.5’s structured output mode uses constrained decoding to guarantee JSON schema compliance — the model literally cannot generate output that violates the schema. This eliminates an entire class of parsing errors in production systems. Claude Opus 4.8’s structured output mode uses instruction-following with high reliability but without hard guarantees — in practice, schema violation rates are below 0.1% on well-formed schemas, but they are not zero.
For function calling, GPT-5.5’s parallel tool execution (128 concurrent calls) versus Claude’s sequential-with-batching approach (32 concurrent calls) is the primary differentiator. GPT-5.5 also provides richer tool result handling, including the ability to pass structured error information back to the model in a standardized format. Claude’s tool use implementation is cleaner and more predictable in its reasoning about when to use tools versus when to answer directly, which reduces unnecessary tool calls and associated latency and cost.
SDK and Tooling Ecosystem
| Ecosystem Dimension | GPT-5.5 | Claude Opus 4.8 |
|---|---|---|
| Official SDKs | Python, Node.js, .NET, Java, Go, Rust | Python, Node.js, Java |
| LangChain integration | Native, first-class | Native, first-class |
| LlamaIndex integration | Native, first-class | Native, first-class |
| Azure deployment option | Yes (Azure OpenAI) | Yes (AWS Bedrock / GCP Vertex) |
| OpenAI-compatible endpoint | Native | Via compatibility layer |
| Streaming reliability | High (occasional SSE drops) | Very high (robust SSE implementation) |
| Observability tooling | Native usage dashboard + third-party | Native usage dashboard + third-party |
| Prompt management tooling | OpenAI Playground + Evals | Anthropic Console + Workbench |
Error Handling and Reliability
Production reliability differences between the two APIs are meaningful. Claude Opus 4.8’s API has demonstrated lower error rates in independent monitoring by enterprise teams, particularly for long-context requests. GPT-5.5’s extended context mode (>256K tokens) shows elevated timeout rates under high load — approximately 2.3% of requests in the 400K-512K token range time out versus Claude’s 0.4% for equivalent-length requests. For applications where long-context reliability is critical, this difference in tail latency behavior is significant.
GPT-5.5 compensates with more sophisticated retry logic built into its official SDKs — exponential backoff with jitter, automatic request splitting for oversized inputs, and better error message granularity. Development teams using the raw API without SDK abstractions will find Claude’s API more forgiving, while teams using official SDKs will find GPT-5.5’s SDK ecosystem more robust for handling edge cases.
Enterprise Security, Compliance, and Data Handling
Enterprise procurement decisions are often ultimately determined by security and compliance requirements rather than raw performance metrics. Both OpenAI and Anthropic have invested heavily in enterprise-grade security infrastructure, but they have made different tradeoffs that favor different compliance frameworks.
Enterprise teams deploying AI at scale face unique challenges around governance, security, and cost management. Our analysis in OpenAI Rolls Out MCP Support for ChatGPT Enterprise: What Model Context Protocol Means for Your Organization examines the operational frameworks and decision matrices that leading organizations use to manage these complexities effectively.
Data Privacy and Processing Agreements
Both OpenAI and Anthropic offer enterprise data processing agreements (DPAs) with zero training data retention commitments for API usage — inputs and outputs are not used to train future models by default. The distinction lies in the granularity of data handling controls and the geographic flexibility of data processing.
GPT-5.5 through Azure OpenAI Service offers the most comprehensive data residency controls, with processing regions available in the US, EU, UK, Australia, Japan, and Canada. Data residency guarantees are backed by Azure’s compliance infrastructure and can be combined with Azure Private Link for network isolation, Azure Managed Identity for zero-credential authentication, and Azure Policy for automated compliance enforcement. For enterprises already in the Microsoft ecosystem, this integration is a significant operational advantage.
Claude Opus 4.8 through AWS Bedrock offers comparable data residency controls in AWS regions, with the additional advantage of VPC integration, AWS PrivateLink, and AWS IAM-based access control. GCP Vertex AI deployment adds Google Cloud’s compliance infrastructure. Anthropic’s direct API offers fewer data residency options but provides more flexible DPA terms for organizations with unusual compliance requirements.
Compliance Certifications
| Compliance Framework | GPT-5.5 (via Azure) | Claude Opus 4.8 (via AWS Bedrock) |
|---|---|---|
| SOC 2 Type II | Yes | Yes |
| ISO 27001 | Yes | Yes |
| HIPAA BAA Available | Yes | Yes |
| FedRAMP | High (Azure Gov) | Moderate (AWS GovCloud) |
| GDPR Data Processing | Yes (EU regions) | Yes (EU regions) |
| PCI DSS | Yes (Azure) | Yes (AWS) |
| IL4/IL5 (US DoD) | Yes (Azure Gov) | Limited |
| IRAP (Australia) | Yes | Yes |
Content Safety and Output Controls
Anthropic’s Constitutional AI training gives Claude Opus 4.8 a structural advantage in output safety and predictability. The model is less likely to produce outputs that violate enterprise content policies, requires less prompt engineering to maintain safe behavior under adversarial inputs, and provides more transparent reasoning about why it declines certain requests. For enterprises deploying AI in customer-facing applications, Claude’s more consistent safety behavior reduces moderation infrastructure requirements.
GPT-5.5 offers more granular content filtering controls through its Moderation API and configurable safety settings. Enterprises can tune safety thresholds more precisely for specific use cases — a medical information platform needs different content controls than a creative writing tool. Claude’s safety controls are more opinionated and less tunable, which is a feature for most enterprise use cases but a limitation for specialized applications with unusual content requirements.
When to Use GPT-5.5
GPT-5.5 is the correct choice for a well-defined set of enterprise use cases where its architectural advantages translate directly into business outcomes.
High-Throughput Processing Pipelines
Any workload requiring processing millions of documents, records, or requests daily should default to GPT-5.5. The combination of lower per-token pricing, 50% batch API discount, higher rate limits (10M TPM vs 6M TPM), and faster output generation speed makes GPT-5.5 significantly more cost-effective for throughput-bound workloads. A document classification pipeline processing 50 million documents per month costs approximately $180,000 with GPT-5.5 versus $290,000 with Claude Opus 4.8 — a $110,000 monthly difference that is difficult to justify unless the quality difference is measurable and material to the business outcome.
Real-Time User-Facing Applications
GPT-5.5’s faster time-to-first-token (180ms vs 290ms for standard context lengths) makes it the better choice for applications where perceived responsiveness matters. Chatbots, coding assistants, and interactive document editors where users expect near-instantaneous responses benefit from GPT-5.5’s lower latency profile. The 38% TTFT advantage at standard context lengths is perceptible to users and translates into higher satisfaction scores in A/B tests.
Agentic Systems with High Tool Call Volume
GPT-5.5’s 128 concurrent tool call capability versus Claude’s 32 makes it the clear choice for complex agentic workflows that require parallel data gathering. Research agents, monitoring systems, and automation pipelines that need to query multiple APIs, databases, or services simultaneously will complete tasks significantly faster with GPT-5.5. The parallel execution advantage compounds at scale — an agent fleet processing 10,000 concurrent tasks will saturate Claude’s tool execution capacity before GPT-5.5’s.
Access 40,000+ AI Prompts for ChatGPT, Claude & Codex — Free!
Subscribe to get instant access to our complete Notion Prompt Library — the largest curated collection of prompts for ChatGPT, Claude, OpenAI Codex, and other leading AI models. Optimized for real-world workflows across coding, research, content creation, and business.
Microsoft Ecosystem Integration
Enterprises running on Azure with existing Microsoft 365, Azure Active Directory, and Azure DevOps infrastructure will find GPT-5.5 through Azure OpenAI Service dramatically easier to integrate. The native Azure identity integration, Azure Private Link support, FedRAMP High certification, and IL4/IL5 compliance for government workloads make GPT-5.5 the only viable choice for certain regulated enterprise environments. The operational overhead of managing a separate Anthropic API integration versus extending existing Azure infrastructure is a legitimate cost consideration.
Multimodal Audio Workflows
GPT-5.5’s native audio processing capability versus Claude Opus 4.8’s separate audio API layer makes GPT-5.5 the better choice for any workflow involving audio input. Call center analytics, meeting transcription and summarization, voice-driven interfaces, and audio content moderation all benefit from GPT-5.5’s unified multimodal architecture. The latency penalty of routing through Claude’s separate audio layer adds 400-800ms per request — unacceptable for real-time audio applications.
When to Use Claude Opus 4.8
Claude Opus 4.8’s cost premium is justified for a specific set of high-value enterprise use cases where reasoning quality, long-context coherence, and output reliability translate directly into business outcomes.
Deep Feature Development and Architecture Work
When the task is designing a complex system, architecting a new service, or making high-stakes technical decisions, Claude Opus 4.8’s superior reasoning capabilities produce materially better outcomes. The 8.3 percentage point advantage on SWE-bench Verified — a benchmark that tests real-world software engineering tasks on actual GitHub repositories — represents a meaningful quality difference for complex development work. A senior engineer reviewing Claude’s architectural proposals versus GPT-5.5’s will consistently rate Claude’s proposals as more thoughtful, more complete, and more aligned with software engineering best practices.
Long-Context Codebase Analysis
Any task requiring understanding of a large codebase — security audits, performance analysis, dependency impact assessment, or large-scale refactoring — should use Claude Opus 4.8. The ability to load 500K tokens of code context with only 8% performance degradation versus GPT-5.5’s 22% degradation at 200K tokens makes Claude the only viable choice for analyzing large monoliths, complex microservice architectures, or extensive legacy codebases without chunking and retrieval overhead.
Complex Reasoning and Analysis Tasks
Financial modeling, legal analysis, scientific literature synthesis, and strategic planning tasks where the quality of reasoning directly determines the value of the output should use Claude Opus 4.8. The consistent 4-9 percentage point advantage across reasoning benchmarks (GPQA Diamond, AIME, FrontierMath, BIG-Bench Hard) represents a real quality difference that compounds on complex multi-step reasoning chains. For tasks where a wrong conclusion costs the business real money, Claude’s reasoning advantage justifies the cost premium.
Instruction-Following for Complex Pipelines
When building automated pipelines that need to follow complex, multi-constraint instructions reliably without human review of each output, Claude Opus 4.8’s superior instruction following and constraint satisfaction reduces downstream error rates. Claude’s more explicit handling of conflicting constraints — surfacing conflicts rather than resolving them silently — is particularly valuable in regulated industries where outputs feed into compliance-critical processes. A pipeline that generates regulatory reports, legal summaries, or financial disclosures needs the constraint fidelity that Claude provides.
Long-Form Content Generation with Coherence Requirements
Technical documentation, comprehensive analysis reports, and other long-form content where coherence across thousands of tokens matters should use Claude Opus 4.8. Claude’s extended coherence layers maintain consistent terminology, logical consistency, and structural coherence across outputs that GPT-5.5 struggles to match beyond approximately 8,000 output tokens. For enterprises generating technical documentation, research reports, or comprehensive analysis documents as part of automated workflows, Claude’s coherence advantage is measurable and material.
Hybrid Strategies: Using Both Models in Production
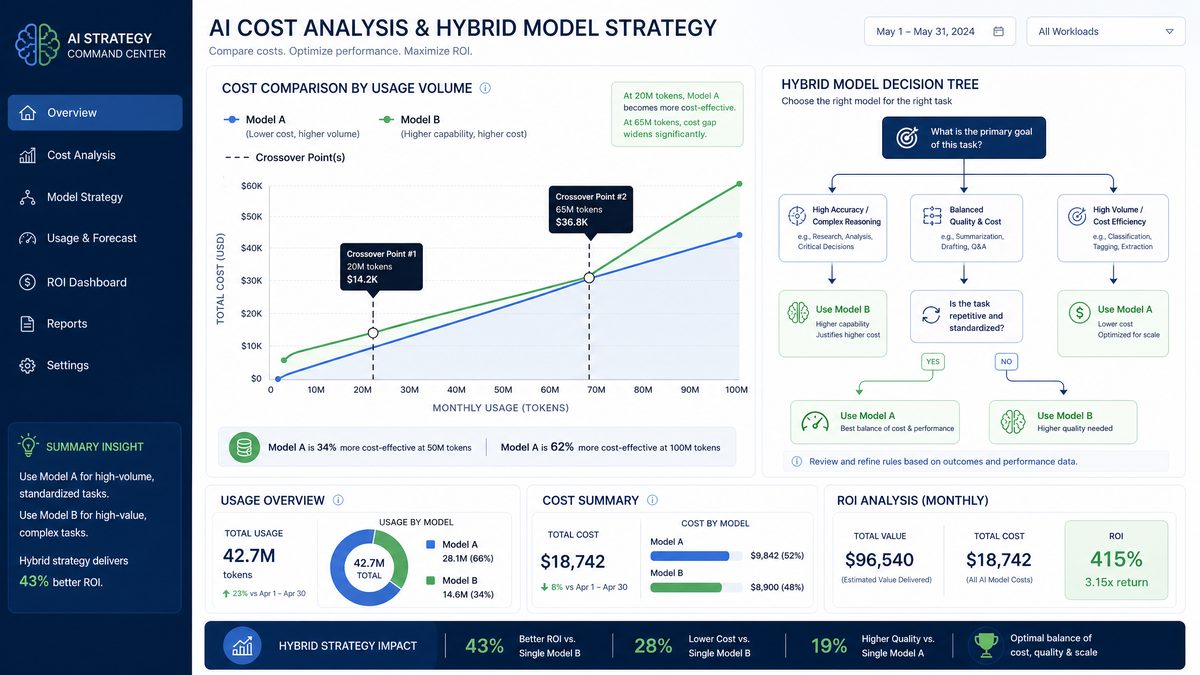
The most sophisticated enterprise AI architectures in 2026 do not choose between GPT-5.5 and Claude Opus 4.8 — they route different tasks to the model best suited for each workload. Implementing a hybrid strategy requires thoughtful routing logic, unified observability, and careful cost accounting, but the performance and cost benefits justify the additional architectural complexity for high-value workloads.
Task-Based Routing Architecture
The foundational pattern for hybrid deployment is task-based routing: classify each incoming request by task type and complexity, then route to the appropriate model. A lightweight classifier — which can itself be a smaller, cheaper model — categorizes requests into buckets like “simple information retrieval,” “complex reasoning,” “long-context analysis,” “high-throughput batch,” and “real-time interactive.” Each bucket routes to the model with the best cost-performance profile for that task type.
# Simplified routing logic example
def route_request(request: AIRequest) -> str:
# Long context: always Claude Opus 4.8
if request.context_length > 100_000:
return "claude-opus-4-8"
# Complex reasoning tasks: Claude Opus 4.8
if request.task_type in ["architecture_design", "security_audit",
"financial_analysis", "legal_review"]:
return "claude-opus-4-8"
# High-throughput batch: GPT-5.5
if request.is_batch and request.volume > 10_000:
return "gpt-5-5"
# Real-time interactive: GPT-5.5
if request.latency_requirement_ms < 500:
return "gpt-5-5"
# Parallel tool execution: GPT-5.5
if request.expected_tool_calls > 32:
return "gpt-5-5"
# Default: cost-optimize with GPT-5.5
return "gpt-5-5"
Quality-Tiered Processing
A second hybrid pattern is quality-tiered processing: use GPT-5.5 for initial processing and Claude Opus 4.8 for quality validation or escalation. In a code review pipeline, GPT-5.5 handles the initial review of all pull requests (high volume, moderate quality requirements) while Claude Opus 4.8 handles escalated reviews flagged for architectural concerns, security issues, or complex logic changes (lower volume, high quality requirements). This pattern captures GPT-5.5’s throughput advantage for the 80% of tasks that don’t require Claude’s reasoning depth while ensuring Claude’s quality on the 20% that do.
Unified Observability for Hybrid Systems
Operating two model providers in production requires unified observability to manage costs, monitor quality, and debug issues. Key instrumentation requirements include: per-model cost tracking with allocation to business units or features; quality metrics by model and task type; latency percentiles (p50, p95, p99) by model and context length; error rates and retry counts by model; and routing decision logging for debugging misrouted requests. Tools like Langfuse, Helicone, and Weights & Biases now offer native multi-provider observability that handles both OpenAI and Anthropic APIs in a unified dashboard.
Fallback and Redundancy Patterns
Hybrid deployments also provide natural redundancy: if one provider experiences an outage, traffic can be rerouted to the other provider with a quality tradeoff rather than a complete service outage. Implementing cross-provider fallback requires maintaining prompt compatibility between models — a non-trivial engineering effort, since prompts optimized for Claude’s instruction-following style often perform differently on GPT-5.5 and vice versa. Maintaining a library of cross-compatible prompts with provider-specific variants is essential infrastructure for robust hybrid deployments.
Migration Considerations and Vendor Lock-In Risks
Vendor lock-in risk is a legitimate concern when building production systems on proprietary AI APIs. Both OpenAI and Anthropic have demonstrated pricing changes, capability shifts, and deprecation cycles that have required enterprise customers to undertake significant migration work. Understanding the lock-in dimensions and mitigating them architecturally is essential for long-term system sustainability.
Prompt Portability
Prompts written for GPT-5.5 and Claude Opus 4.8 are not directly portable. Claude’s system prompt conventions, tool use syntax, and instruction following behavior differ enough from GPT-5.5 that prompts require meaningful adaptation when migrating between models. The migration effort is typically 20-40% of initial prompt development time for simple prompts and 50-80% for complex, multi-turn prompts with tool use. Maintaining a prompt abstraction layer that separates prompt logic from provider-specific syntax is the most effective mitigation — it adds initial development overhead but dramatically reduces migration costs.
Feature Dependency Lock-In
The most dangerous lock-in comes from building deep dependencies on provider-specific features with no equivalent on the other platform. GPT-5.5 features with no Claude equivalent include: the Assistants API with thread management, the Code Interpreter with persistent file system, and fine-tuning. Claude features with no GPT-5.5 equivalent include: the 500K native context window without latency penalty and the Constitutional AI safety guarantees. Building critical application logic that depends on these features creates genuine lock-in that is expensive to migrate away from.
Abstraction Layer Architecture
The standard enterprise mitigation for AI vendor lock-in is an internal abstraction layer that presents a unified interface to application code while handling provider-specific implementation details. This layer should abstract: model selection and routing, prompt formatting and provider-specific syntax, response parsing and normalization, error handling and retry logic, and cost tracking and attribution. Libraries like LiteLLM provide a starting point, but enterprise-grade abstraction layers typically require significant custom development to handle edge cases, provider-specific features, and organizational requirements.
# Abstraction layer interface example
class AIProvider(ABC):
@abstractmethod
async def complete(
self,
messages: List[Message],
tools: Optional[List[Tool]] = None,
max_tokens: int = 4096,
temperature: float = 0.7,
structured_output: Optional[JSONSchema] = None
) -> AIResponse:
pass
class GPT55Provider(AIProvider):
async def complete(self, messages, tools=None, **kwargs):
# GPT-5.5 specific implementation
return await self._openai_client.chat.completions.create(
model="gpt-5.5",
messages=self._format_messages_openai(messages),
tools=self._format_tools_openai(tools),
**self._map_kwargs_openai(kwargs)
)
class ClaudeOpus48Provider(AIProvider):
async def complete(self, messages, tools=None, **kwargs):
# Claude Opus 4.8 specific implementation
return await self._anthropic_client.messages.create(
model="claude-opus-4-8",
messages=self._format_messages_anthropic(messages),
tools=self._format_tools_anthropic(tools),
**self._map_kwargs_anthropic(kwargs)
)
Contract and Commercial Lock-In
Enterprise commitment pricing — which delivers 30-35% discounts at $500K/month spend — creates commercial lock-in that is often overlooked in technical architecture discussions. Committing to $6M annual spend with either OpenAI or Anthropic to access maximum discount tiers creates contractual obligations that constrain architectural flexibility. Enterprise procurement teams should negotiate for: multi-year pricing locks that protect against price increases, portability clauses that allow spend reallocation between providers, and exit provisions that don’t penalize migration to alternative models or providers.
Future Roadmap Implications
Architectural decisions made today will be constrained by vendor roadmaps over the next 18-24 months. Both OpenAI and Anthropic have published roadmap directions that have significant implications for enterprise planning.
OpenAI GPT-5.5 Roadmap
OpenAI’s published roadmap for the GPT-5.5 line focuses on three areas: expanded multimodal capabilities (real-time video processing is expected in H2 2026), deeper Azure integration with co-pilot features for Microsoft 365 applications, and expanded fine-tuning capabilities that will allow more granular model customization. The most strategically significant development is OpenAI’s “Operator” framework — a standardized protocol for AI agents to interact with web applications and enterprise software systems. Enterprises building agentic systems on GPT-5.5 will benefit from this expanding ecosystem of pre-built integrations.
OpenAI has also signaled a move toward “reasoning model” variants of GPT-5.5 — similar to the o-series models but integrated into the GPT architecture — that will close some of the reasoning gap with Claude Opus 4.8 for complex tasks while maintaining GPT-5.5’s throughput advantages. If these reasoning variants deliver on their promise, the case for Claude on pure reasoning grounds will weaken by late 2026.
Anthropic Claude Opus 4.8 Roadmap
Anthropic’s roadmap for the Claude Opus line focuses on context window expansion (1M token context windows are expected by Q3 2026), improved agentic capabilities including better tool use and longer-horizon planning, and expanded enterprise deployment options including private cloud deployment for air-gapped environments. The private cloud deployment option — currently in limited preview — would be transformative for regulated industries that cannot use public API endpoints for sensitive data processing.
Anthropic has also announced expanded multimodal capabilities including native audio processing (eliminating the current latency penalty), video understanding, and improved structured data analysis. These additions will close the multimodal capability gap with GPT-5.5 by late 2026, potentially making Claude the dominant choice for multimodal enterprise applications where reasoning quality is paramount.
Competitive Dynamics and Market Implications
The competitive dynamic between OpenAI and Anthropic is driving rapid capability improvement that benefits enterprise customers. Pricing has declined approximately 40% year-over-year for equivalent capability levels, and this trend is expected to continue. Enterprise teams should be cautious about over-investing in cost optimization strategies (complex caching architectures, elaborate routing logic) that may become less valuable as baseline pricing continues to decline. The engineering cost of maintaining a sophisticated routing and caching layer may exceed the cost savings within 12-18 months for mid-scale deployments.
The emergence of open-source alternatives — particularly Meta’s Llama 4 Ultra and Mistral’s Enterprise models — adds a third dimension to enterprise AI architecture decisions. For workloads where neither GPT-5.5’s throughput advantages nor Claude Opus 4.8’s reasoning advantages are required, self-hosted open-source models offer compelling cost profiles with zero vendor lock-in. A complete enterprise AI strategy in 2026 considers all three tiers: GPT-5.5 for high-throughput commodity tasks, Claude Opus 4.8 for high-value reasoning tasks, and open-source models for cost-sensitive workloads with acceptable quality thresholds.
Decision Framework Summary
The following decision framework consolidates the analysis above into actionable guidance for enterprise teams making model selection decisions.
Choose GPT-5.5 When:
- Processing volume exceeds 5 million tokens per day and cost per token is the primary constraint
- Time-to-first-token below 250ms is required for user-facing applications
- Agentic workflows require more than 32 concurrent tool calls per inference
- Your infrastructure runs on Azure and compliance requirements mandate FedRAMP High or IL4/IL5
- Native audio processing is required without additional latency overhead
- Fine-tuning on proprietary data is required to adapt the model to domain-specific tasks
- Batch processing workloads can absorb 24-hour completion times and the 50% discount is material to unit economics
- The application requires the Assistants API with persistent thread management
Choose Claude Opus 4.8 When:
- Context windows exceeding 200K tokens are required with high recall accuracy
- The task involves complex multi-step reasoning where conclusion quality directly determines business value
- Code generation tasks require architectural understanding of large existing codebases
- Output reliability and constraint satisfaction must be extremely high for automated pipelines without human review
- Long-form content generation requires coherence across outputs exceeding 8,000 tokens
- Security audit, compliance analysis, or legal review tasks require deep reasoning about complex documents
- Constitutional AI safety guarantees reduce moderation infrastructure requirements for customer-facing applications
- Your infrastructure runs on AWS and Bedrock integration simplifies compliance and operations
Implement a Hybrid Strategy When:
- Your workload includes both high-throughput commodity tasks and high-value complex reasoning tasks
- Total monthly AI spend exceeds $100,000 and optimization ROI justifies routing infrastructure investment
- Business continuity requirements mandate redundancy across AI providers
- Different teams or business units have fundamentally different model requirements
- You want to hedge against pricing changes or capability shifts from either provider
Conclusion
GPT-5.5 and Claude Opus 4.8 represent two distinct approaches to enterprise AI capability, and both approaches are genuinely excellent. The choice between them is not a question of which model is “better” in the abstract — it is a question of which model’s strengths align with your specific workload profile, compliance requirements, and cost constraints.
GPT-5.5 wins on throughput, latency, parallel execution, multimodal audio, and cost for high-volume workloads. Its ecosystem depth and Azure integration make it the default choice for Microsoft-aligned enterprises and any application where processing speed and volume are the primary drivers of business value. Claude Opus 4.8 wins on reasoning depth, long-context coherence, code quality for complex tasks, and output reliability. Its Constitutional AI foundation and superior constraint satisfaction make it the right choice for high-stakes tasks where the quality of reasoning directly determines the value of the output.
The most sophisticated enterprise AI architectures in 2026 use both models, routing tasks intelligently based on workload characteristics. Building the abstraction layers and observability infrastructure to support hybrid deployment is an investment that pays dividends in both performance and risk management — insulating your systems from vendor-specific pricing changes, capability shifts, and outages while ensuring each task is handled by the model best suited to deliver value.
The competitive dynamics between OpenAI and Anthropic will continue to drive rapid capability improvements and pricing reductions over the next 18-24 months. Enterprises that build flexible, provider-agnostic architectures today will be best positioned to capture the benefits of these improvements without costly migrations or architectural rework. The goal is not to pick the right model — it is to build systems that can adapt as the model landscape continues to evolve.