How to Build Production Kubernetes Agents with GPT-5.5 Structured Outputs: A Complete Implementation Guide

How to Build Production Kubernetes Agents with GPT-5.5 Structured Outputs: A Complete Implementation Guide
Kubernetes management at scale is one of the most operationally complex challenges in modern infrastructure engineering. The combination of declarative configuration, eventual consistency, and the sheer number of API primitives means that even experienced platform engineers make costly mistakes. GPT-5.5’s structured outputs capability fundamentally changes the calculus here: you can now build agents that parse natural language operational intent, validate it against strict schemas, and execute Kubernetes operations with machine-precision consistency. This guide walks through every layer of that system, from schema design to production deployment, with complete Python implementations you can adapt immediately.
The key insight driving this architecture is that structured outputs eliminate the ambiguity that makes LLM-driven infrastructure automation dangerous. When GPT-5.5 is constrained to return JSON that matches a predefined schema with 100% reliability, you can build validation pipelines that treat the model’s output as typed data rather than text that needs to be parsed and sanitized. This shifts the safety problem from “did the model generate valid JSON?” to “does this valid JSON represent a safe operation?” — a much more tractable engineering problem.
Why Structured Outputs Are Non-Negotiable for Infrastructure Automation
Traditional approaches to LLM-driven Kubernetes automation suffer from a fundamental reliability problem. When you prompt a model to generate a kubectl command or a YAML manifest, you get text that may or may not be syntactically valid, may or may not reference resources that exist, and may or may not express what the operator actually intended. The validation burden falls entirely on post-processing code that must anticipate every possible malformed output.
GPT-5.5 structured outputs with strict mode change this entirely. The model is constrained at the token generation level to produce output that conforms to a JSON Schema you define. This means you can define a KubernetesOperation schema with an enum of allowed operation types, required fields for namespace and resource name, and nested objects for operation-specific parameters. The model cannot produce output that violates this schema, not because of prompt engineering, but because of constrained decoding.
For infrastructure automation specifically, this matters in three concrete ways. First, your downstream validation code can use typed Python dataclasses or Pydantic models directly, with no try/except blocks around JSON parsing. Second, your audit log is structured by construction — every operation the agent considers is a valid JSON object you can store, query, and analyze. Third, your safety guardrails can be expressed as pure validation logic against typed objects, which is vastly easier to test than regex-based text sanitization.
Consider the difference between receiving "kubectl scale deployment/api-server --replicas=50" as a string versus receiving {"operation": "scale", "resource_type": "deployment", "resource_name": "api-server", "namespace": "production", "parameters": {"replicas": 50}} as a validated object. The string requires parsing, validation, and interpretation. The object is immediately actionable, auditable, and constrainable. You can enforce replica limits, namespace allowlists, and resource quotas as simple comparisons before a single API call is made.
Designing the Agent Architecture
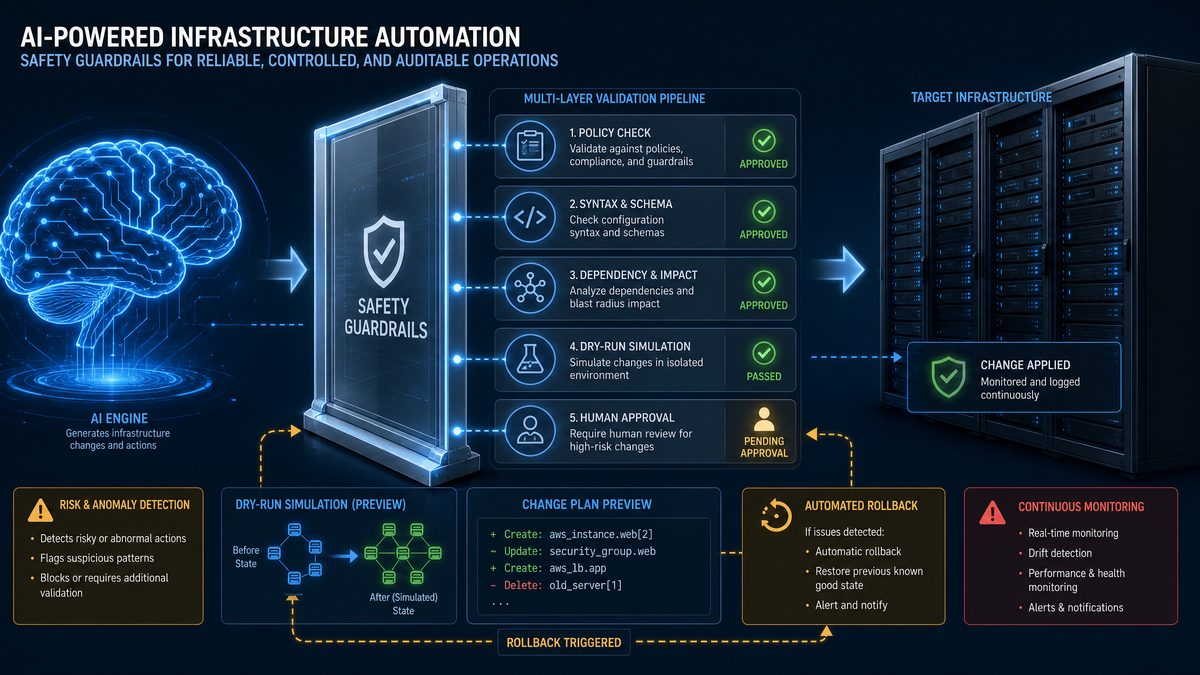
The production Kubernetes agent architecture consists of four distinct layers: intent parsing, validation, execution, and rollback. Each layer has a single responsibility and communicates with adjacent layers through typed interfaces. This separation is not just good software engineering — it is the mechanism by which you achieve safety. A bug in the intent parser cannot cause an unsafe execution because the validator will reject any operation that fails safety checks, regardless of how it was generated.
Intent Parsing Layer
The intent parser receives natural language input from operators and produces a structured KubernetesIntent object. This is where GPT-5.5 lives. The parser’s job is purely semantic: understand what the operator wants to do, not whether it is safe or feasible. Safety is the validator’s job. This separation means you can improve intent parsing independently of safety logic, and you can test safety logic against arbitrary intents without involving the model.
Validation Layer
The validator receives a KubernetesIntent and produces either a ValidationResult with a list of approved operations, or a ValidationError with a human-readable explanation of why the intent cannot be executed. The validator performs dry-run checks against the Kubernetes API, enforces resource limits, verifies namespace permissions, and checks for operations that would violate cluster policy. Critically, the validator is deterministic and has no LLM calls — it is pure Python logic against the Kubernetes API.
Execution Layer
The execution layer receives a validated list of operations and executes them in order, capturing the state of every affected resource before modification. This pre-execution snapshot is the foundation of the rollback system. The execution layer emits structured events for every operation it performs, which feed the observability system. It also implements retry logic with exponential backoff for transient API failures.
Rollback Layer
The rollback layer maintains a state store of pre-execution snapshots and can restore any resource to its pre-operation state. It exposes both automatic rollback (triggered by execution failures) and manual rollback (triggered by operator command). The rollback layer itself goes through the same validation pipeline as forward operations, preventing rollbacks that would violate current cluster policy.
Defining Strict JSON Schemas for Kubernetes Operations
The schema design is the most critical design decision in the entire system. Too permissive and you lose the safety benefits of structured outputs. Too restrictive and the agent cannot express legitimate operations. The right approach is to define schemas that are as specific as the operation requires, with explicit enums for all categorical fields and bounded integers for all numeric fields.
from pydantic import BaseModel, Field, field_validator
from typing import Literal, Union, Optional
from enum import Enum
class ResourceType(str, Enum):
DEPLOYMENT = "deployment"
STATEFULSET = "statefulset"
DAEMONSET = "daemonset"
SERVICE = "service"
CONFIGMAP = "configmap"
SECRET = "secret"
INGRESS = "ingress"
HORIZONTALPODAUTOSCALER = "horizontalpodautoscaler"
NAMESPACE = "namespace"
JOB = "job"
CRONJOB = "cronjob"
class OperationType(str, Enum):
SCALE = "scale"
RESTART = "restart"
UPDATE_IMAGE = "update_image"
UPDATE_CONFIG = "update_config"
DELETE = "delete"
GET_STATUS = "get_status"
GET_LOGS = "get_logs"
APPLY_MANIFEST = "apply_manifest"
ROLLBACK = "rollback"
CORDON_NODE = "cordon_node"
DRAIN_NODE = "drain_node"
class ScaleParameters(BaseModel):
replicas: int = Field(ge=0, le=100, description="Target replica count")
class UpdateImageParameters(BaseModel):
container_name: str = Field(min_length=1, max_length=253)
image: str = Field(min_length=1, max_length=500)
tag: str = Field(min_length=1, max_length=128)
class UpdateConfigParameters(BaseModel):
configmap_name: str = Field(min_length=1, max_length=253)
key: str = Field(min_length=1, max_length=253)
value: str = Field(max_length=10000)
class GetLogsParameters(BaseModel):
container_name: Optional[str] = None
tail_lines: int = Field(default=100, ge=1, le=10000)
since_seconds: Optional[int] = Field(default=None, ge=1, le=86400)
class RollbackParameters(BaseModel):
revision: Optional[int] = Field(default=None, ge=1)
snapshot_id: Optional[str] = None
class KubernetesOperation(BaseModel):
operation_type: OperationType
resource_type: ResourceType
resource_name: str = Field(min_length=1, max_length=253)
namespace: str = Field(min_length=1, max_length=63)
parameters: Union[
ScaleParameters,
UpdateImageParameters,
UpdateConfigParameters,
GetLogsParameters,
RollbackParameters,
None
] = None
reason: str = Field(
min_length=10,
max_length=500,
description="Human-readable reason for this operation"
)
requires_confirmation: bool = Field(
default=True,
description="Whether this operation requires explicit operator confirmation"
)
class KubernetesIntent(BaseModel):
original_request: str = Field(max_length=2000)
operations: list[KubernetesOperation] = Field(min_length=1, max_length=10)
estimated_risk_level: Literal["low", "medium", "high", "critical"]
summary: str = Field(min_length=10, max_length=500)
@field_validator('operations')
@classmethod
def validate_no_cross_namespace_delete(cls, operations):
namespaces = {op.namespace for op in operations}
delete_ops = [op for op in operations if op.operation_type == OperationType.DELETE]
if len(namespaces) > 1 and delete_ops:
raise ValueError(
"Cross-namespace delete operations are not permitted in a single intent"
)
return operations
The bounded integer fields are particularly important. A replica count field with ge=0, le=100 means the model cannot, even in principle, generate an intent to scale a deployment to 10,000 replicas. The maximum is enforced at the schema level, before any application logic runs. Similarly, the OperationType enum means the model cannot generate an operation type that your execution layer does not handle — there is no code path for an unknown operation type to reach the Kubernetes API.
The reason field with a minimum length of 10 characters is a subtle but important safety feature. It forces the model to articulate why an operation is being performed, which serves two purposes: it provides audit trail context, and it forces the model to engage with the semantic meaning of the operation rather than mechanically translating syntax. In practice, models that must explain their reasoning make fewer semantic errors.
Building the Intent Classifier with GPT-5.5
The intent classifier is the component that calls GPT-5.5 with structured output constraints. The implementation uses the OpenAI Python SDK’s response format parameter with your Pydantic model, which handles schema generation and response parsing automatically.
import openai
from openai import OpenAI
from typing import Optional
import json
import logging
from datetime import datetime, timezone
logger = logging.getLogger(__name__)
class IntentClassifier:
def __init__(
self,
client: OpenAI,
model: str = "gpt-4.5-preview",
cluster_context: Optional[dict] = None
):
self.client = client
self.model = model
self.cluster_context = cluster_context or {}
def _build_system_prompt(self) -> str:
context_str = ""
if self.cluster_context:
context_str = f"""
Current cluster context:
- Cluster name: {self.cluster_context.get('cluster_name', 'unknown')}
- Available namespaces: {', '.join(self.cluster_context.get('namespaces', []))}
- Production namespaces: {', '.join(self.cluster_context.get('production_namespaces', []))}
- Current time (UTC): {datetime.now(timezone.utc).isoformat()}
"""
return f"""You are a Kubernetes operations assistant that translates natural language
requests into structured operation specifications.
{context_str}
Your responsibilities:
1. Parse the operator's intent accurately
2. Identify all required operations to fulfill the request
3. Assess risk level honestly:
- low: read-only operations, non-production namespaces
- medium: configuration changes in staging, scaling in production within normal bounds
- high: production deployments, image updates, scaling beyond 2x current
- critical: deletions in production, node operations, namespace-wide changes
4. Set requires_confirmation=true for any operation with risk level medium or higher
5. Always provide a clear reason for each operation
IMPORTANT CONSTRAINTS:
- Never generate operations for namespaces not in the available list
- Scale operations are bounded to 100 replicas maximum by schema
- Delete operations on production namespaces always require confirmation
- If the request is ambiguous, prefer the safer interpretation
Translate the following request into structured Kubernetes operations."""
def classify(self, request: str) -> KubernetesIntent:
logger.info(f"Classifying intent: {request[:100]}...")
try:
response = self.client.beta.chat.completions.parse(
model=self.model,
messages=[
{"role": "system", "content": self._build_system_prompt()},
{"role": "user", "content": request}
],
response_format=KubernetesIntent,
temperature=0.1,
max_tokens=2000
)
intent = response.choices[0].message.parsed
logger.info(
f"Intent classified: {len(intent.operations)} operations, "
f"risk={intent.estimated_risk_level}"
)
return intent
except openai.LengthFinishReasonError:
raise IntentParsingError(
"Request too complex to parse within token limits. "
"Please break it into smaller operations."
)
except openai.APIError as e:
logger.error(f"OpenAI API error during intent classification: {e}")
raise
class IntentParsingError(Exception):
pass
The temperature=0.1 setting is deliberate. Infrastructure operations require determinism, not creativity. A low temperature means the model will consistently choose the most likely interpretation of an ambiguous request rather than exploring alternatives. For edge cases where the request genuinely is ambiguous, the system prompt instructs the model to prefer the safer interpretation — and because the model must articulate its reasoning in the reason field, operators can immediately see if the interpretation was incorrect.
The cluster context injection into the system prompt is a critical safety mechanism. By providing the list of available namespaces, you prevent the model from generating operations for namespaces that do not exist or that the agent does not have access to. This is a defense-in-depth measure — the validation layer will catch these errors too — but preventing them at the intent parsing stage produces better error messages and avoids unnecessary API calls.
Practitioners seeking hands-on implementation guidance will benefit from our step-by-step tutorial. The comprehensive resource OpenAI Frontier Platform: The Complete Enterprise Guide to Building, Deploying, and Managing AI Agents at Scale walks through the exact configuration steps and deployment patterns that complement the strategies outlined above.
Access 40,000+ AI Prompts for ChatGPT, Claude & Codex — Free!
Subscribe to get instant access to our complete Notion Prompt Library — the largest curated collection of prompts for ChatGPT, Claude, OpenAI Codex, and other leading AI models. Optimized for real-world workflows across coding, research, content creation, and business.
Implementing Safety Guardrails
The validation layer is where operational safety is enforced. It has three distinct phases: static validation (checking the intent against known constraints without any API calls), dry-run validation (submitting operations to the Kubernetes API in dry-run mode), and policy validation (checking operations against cluster-specific policies).
from kubernetes import client as k8s_client, config as k8s_config
from kubernetes.client.rest import ApiException
from dataclasses import dataclass, field
from typing import Optional
import re
@dataclass
class ValidationResult:
is_valid: bool
approved_operations: list[KubernetesOperation] = field(default_factory=list)
rejected_operations: list[tuple[KubernetesOperation, str]] = field(default_factory=list)
warnings: list[str] = field(default_factory=list)
requires_confirmation: bool = False
class KubernetesOperationValidator:
PROTECTED_NAMESPACES = frozenset({
"kube-system", "kube-public", "kube-node-lease"
})
PRODUCTION_NAMESPACE_PATTERN = re.compile(
r'^(prod|production|live|prd)-?.*$', re.IGNORECASE
)
MAX_SCALE_FACTOR = 3.0
ABSOLUTE_MAX_REPLICAS = 50
def __init__(
self,
kubeconfig_path: Optional[str] = None,
allowed_namespaces: Optional[set[str]] = None,
dry_run: bool = True
):
if kubeconfig_path:
k8s_config.load_kube_config(config_file=kubeconfig_path)
else:
k8s_config.load_incluster_config()
self.apps_v1 = k8s_client.AppsV1Api()
self.core_v1 = k8s_client.CoreV1Api()
self.allowed_namespaces = allowed_namespaces
self.dry_run = dry_run
def validate_intent(self, intent: KubernetesIntent) -> ValidationResult:
result = ValidationResult(is_valid=True)
for operation in intent.operations:
op_result = self._validate_operation(operation, intent)
if op_result is None:
result.approved_operations.append(operation)
if operation.requires_confirmation:
result.requires_confirmation = True
else:
result.rejected_operations.append((operation, op_result))
result.is_valid = False
return result
def _validate_operation(
self,
operation: KubernetesOperation,
intent: KubernetesIntent
) -> Optional[str]:
# Static namespace validation
if operation.namespace in self.PROTECTED_NAMESPACES:
return (
f"Namespace '{operation.namespace}' is protected and cannot be modified. "
f"Operations in kube-system, kube-public, and kube-node-lease are blocked."
)
if self.allowed_namespaces and operation.namespace not in self.allowed_namespaces:
return (
f"Namespace '{operation.namespace}' is not in the allowed namespace list. "
f"Allowed: {', '.join(sorted(self.allowed_namespaces))}"
)
# Risk-specific validation
if operation.operation_type == OperationType.SCALE:
return self._validate_scale_operation(operation)
elif operation.operation_type == OperationType.DELETE:
return self._validate_delete_operation(operation)
elif operation.operation_type == OperationType.UPDATE_IMAGE:
return self._validate_image_update(operation)
elif operation.operation_type in (
OperationType.CORDON_NODE, OperationType.DRAIN_NODE
):
return self._validate_node_operation(operation, intent)
return None
def _validate_scale_operation(
self, operation: KubernetesOperation
) -> Optional[str]:
if not isinstance(operation.parameters, ScaleParameters):
return "Scale operation requires ScaleParameters"
target_replicas = operation.parameters.replicas
if target_replicas > self.ABSOLUTE_MAX_REPLICAS:
return (
f"Target replica count {target_replicas} exceeds absolute maximum "
f"{self.ABSOLUTE_MAX_REPLICAS}. Submit a manual override request "
f"for scaling beyond this limit."
)
# Check current replica count for scale factor validation
try:
if operation.resource_type == ResourceType.DEPLOYMENT:
deployment = self.apps_v1.read_namespaced_deployment(
name=operation.resource_name,
namespace=operation.namespace
)
current_replicas = deployment.spec.replicas or 1
elif operation.resource_type == ResourceType.STATEFULSET:
sts = self.apps_v1.read_namespaced_stateful_set(
name=operation.resource_name,
namespace=operation.namespace
)
current_replicas = sts.spec.replicas or 1
else:
return (
f"Scale operation not supported for resource type "
f"'{operation.resource_type}'"
)
scale_factor = target_replicas / max(current_replicas, 1)
if scale_factor > self.MAX_SCALE_FACTOR:
return (
f"Requested scale from {current_replicas} to {target_replicas} "
f"({scale_factor:.1f}x) exceeds maximum scale factor of "
f"{self.MAX_SCALE_FACTOR}x. This requires manual approval."
)
except ApiException as e:
if e.status == 404:
return (
f"Resource {operation.resource_type}/{operation.resource_name} "
f"not found in namespace {operation.namespace}"
)
raise
return None
def _validate_delete_operation(
self, operation: KubernetesOperation
) -> Optional[str]:
is_production = bool(
self.PRODUCTION_NAMESPACE_PATTERN.match(operation.namespace)
)
if is_production and not operation.requires_confirmation:
return (
f"Delete operations in production namespace '{operation.namespace}' "
f"must have requires_confirmation=true. This is an automatic safety block."
)
if operation.resource_type == ResourceType.NAMESPACE:
return (
"Namespace deletion is not permitted through the automated agent. "
"Use the manual deletion workflow with dual approval."
)
return None
def _validate_image_update(
self, operation: KubernetesOperation
) -> Optional[str]:
if not isinstance(operation.parameters, UpdateImageParameters):
return "Image update operation requires UpdateImageParameters"
image = operation.parameters.image
tag = operation.parameters.tag
# Block latest tag in production
is_production = bool(
self.PRODUCTION_NAMESPACE_PATTERN.match(operation.namespace)
)
if is_production and tag in ("latest", "main", "master"):
return (
f"Tag '{tag}' is not permitted in production namespace "
f"'{operation.namespace}'. Use an immutable tag (SHA digest or "
f"semantic version)."
)
# Block images from non-approved registries
approved_registries = [
"gcr.io/my-project/",
"us-docker.pkg.dev/my-project/",
"registry.k8s.io/"
]
if not any(image.startswith(reg) for reg in approved_registries):
return (
f"Image '{image}' is not from an approved registry. "
f"Approved registries: {', '.join(approved_registries)}"
)
return None
def _validate_node_operation(
self,
operation: KubernetesOperation,
intent: KubernetesIntent
) -> Optional[str]:
if intent.estimated_risk_level not in ("high", "critical"):
return (
"Node operations must be classified as high or critical risk. "
"Re-submit with appropriate risk assessment."
)
if not operation.requires_confirmation:
return "Node operations always require explicit confirmation."
return None
Creating Tool Definitions for kubectl Operations
The execution layer translates validated KubernetesOperation objects into actual Kubernetes API calls. Each operation type maps to a specific executor function that captures pre-execution state, performs the operation, and emits structured events. The design uses the official Kubernetes Python client rather than shelling out to kubectl, which provides proper error handling, structured responses, and eliminates subprocess injection vulnerabilities.
import uuid
from datetime import datetime, timezone
from typing import Any
import json
@dataclass
class OperationSnapshot:
snapshot_id: str
operation: KubernetesOperation
pre_state: dict[str, Any]
captured_at: str
@dataclass
class ExecutionEvent:
event_id: str
operation: KubernetesOperation
status: Literal["started", "completed", "failed", "rolled_back"]
snapshot_id: Optional[str]
error: Optional[str]
duration_ms: Optional[float]
timestamp: str
class KubernetesExecutor:
def __init__(
self,
apps_v1: k8s_client.AppsV1Api,
core_v1: k8s_client.CoreV1Api,
state_store: "StateStore",
event_emitter: "EventEmitter",
dry_run: bool = False
):
self.apps_v1 = apps_v1
self.core_v1 = core_v1
self.state_store = state_store
self.event_emitter = event_emitter
self.dry_run = dry_run
self._executors = {
OperationType.SCALE: self._execute_scale,
OperationType.RESTART: self._execute_restart,
OperationType.UPDATE_IMAGE: self._execute_image_update,
OperationType.GET_STATUS: self._execute_get_status,
OperationType.GET_LOGS: self._execute_get_logs,
OperationType.ROLLBACK: self._execute_rollback,
}
def execute_operation(
self, operation: KubernetesOperation
) -> tuple[bool, Any, str]:
start_time = datetime.now(timezone.utc)
event_id = str(uuid.uuid4())
self.event_emitter.emit(ExecutionEvent(
event_id=event_id,
operation=operation,
status="started",
snapshot_id=None,
error=None,
duration_ms=None,
timestamp=start_time.isoformat()
))
# Capture pre-execution state for rollback
snapshot = self._capture_snapshot(operation)
if snapshot:
self.state_store.save_snapshot(snapshot)
executor_fn = self._executors.get(operation.operation_type)
if not executor_fn:
error = f"No executor for operation type: {operation.operation_type}"
self._emit_failure(event_id, operation, snapshot, error, start_time)
return False, None, error
try:
result = executor_fn(operation)
duration = (
datetime.now(timezone.utc) - start_time
).total_seconds() * 1000
self.event_emitter.emit(ExecutionEvent(
event_id=event_id,
operation=operation,
status="completed",
snapshot_id=snapshot.snapshot_id if snapshot else None,
error=None,
duration_ms=duration,
timestamp=datetime.now(timezone.utc).isoformat()
))
return True, result, ""
except ApiException as e:
error = f"Kubernetes API error: {e.status} {e.reason}: {e.body}"
self._emit_failure(event_id, operation, snapshot, error, start_time)
return False, None, error
def _capture_snapshot(
self, operation: KubernetesOperation
) -> Optional[OperationSnapshot]:
read_only_ops = {
OperationType.GET_STATUS, OperationType.GET_LOGS
}
if operation.operation_type in read_only_ops:
return None
try:
pre_state = self._get_resource_state(operation)
return OperationSnapshot(
snapshot_id=str(uuid.uuid4()),
operation=operation,
pre_state=pre_state,
captured_at=datetime.now(timezone.utc).isoformat()
)
except ApiException as e:
if e.status == 404:
return None
raise
def _get_resource_state(self, operation: KubernetesOperation) -> dict:
if operation.resource_type == ResourceType.DEPLOYMENT:
deployment = self.apps_v1.read_namespaced_deployment(
name=operation.resource_name,
namespace=operation.namespace
)
return {
"replicas": deployment.spec.replicas,
"image": {
c.name: c.image
for c in deployment.spec.template.spec.containers
},
"resource_version": deployment.metadata.resource_version,
"generation": deployment.metadata.generation
}
elif operation.resource_type == ResourceType.CONFIGMAP:
cm = self.core_v1.read_namespaced_config_map(
name=operation.resource_name,
namespace=operation.namespace
)
return {
"data": dict(cm.data or {}),
"resource_version": cm.metadata.resource_version
}
return {}
def _execute_scale(self, operation: KubernetesOperation) -> dict:
params = operation.parameters
assert isinstance(params, ScaleParameters)
dry_run_param = ["All"] if self.dry_run else None
if operation.resource_type == ResourceType.DEPLOYMENT:
patch = {"spec": {"replicas": params.replicas}}
result = self.apps_v1.patch_namespaced_deployment_scale(
name=operation.resource_name,
namespace=operation.namespace,
body=patch,
dry_run=dry_run_param
)
return {
"resource": f"deployment/{operation.resource_name}",
"namespace": operation.namespace,
"target_replicas": params.replicas,
"dry_run": self.dry_run
}
raise ValueError(
f"Scale not implemented for {operation.resource_type}"
)
def _execute_restart(self, operation: KubernetesOperation) -> dict:
import json
from datetime import datetime, timezone
restart_annotation = {
"kubectl.kubernetes.io/restartedAt":
datetime.now(timezone.utc).isoformat()
}
patch = {
"spec": {
"template": {
"metadata": {
"annotations": restart_annotation
}
}
}
}
dry_run_param = ["All"] if self.dry_run else None
if operation.resource_type == ResourceType.DEPLOYMENT:
self.apps_v1.patch_namespaced_deployment(
name=operation.resource_name,
namespace=operation.namespace,
body=patch,
dry_run=dry_run_param
)
return {
"resource": f"deployment/{operation.resource_name}",
"namespace": operation.namespace,
"restarted_at": restart_annotation[
"kubectl.kubernetes.io/restartedAt"
],
"dry_run": self.dry_run
}
def _execute_image_update(self, operation: KubernetesOperation) -> dict:
params = operation.parameters
assert isinstance(params, UpdateImageParameters)
full_image = f"{params.image}:{params.tag}"
dry_run_param = ["All"] if self.dry_run else None
if operation.resource_type == ResourceType.DEPLOYMENT:
deployment = self.apps_v1.read_namespaced_deployment(
name=operation.resource_name,
namespace=operation.namespace
)
containers = deployment.spec.template.spec.containers
container = next(
(c for c in containers if c.name == params.container_name),
None
)
if not container:
available = [c.name for c in containers]
raise ValueError(
f"Container '{params.container_name}' not found. "
f"Available: {available}"
)
patch = {
"spec": {
"template": {
"spec": {
"containers": [{
"name": params.container_name,
"image": full_image
}]
}
}
}
}
self.apps_v1.patch_namespaced_deployment(
name=operation.resource_name,
namespace=operation.namespace,
body=patch,
dry_run=dry_run_param
)
return {
"resource": f"deployment/{operation.resource_name}",
"container": params.container_name,
"new_image": full_image,
"dry_run": self.dry_run
}
def _emit_failure(self, event_id, operation, snapshot, error, start_time):
duration = (
datetime.now(timezone.utc) - start_time
).total_seconds() * 1000
self.event_emitter.emit(ExecutionEvent(
event_id=event_id,
operation=operation,
status="failed",
snapshot_id=snapshot.snapshot_id if snapshot else None,
error=error,
duration_ms=duration,
timestamp=datetime.now(timezone.utc).isoformat()
))
Implementing Rollback Logic and State Tracking
The rollback system is the safety net that makes aggressive automation acceptable in production. Every mutating operation captures a snapshot of the resource’s pre-execution state, stored with a UUID that is included in the execution event. This creates a complete audit trail: for any operation in the event log, you can retrieve the corresponding snapshot and restore the resource to its exact pre-operation state.
import sqlite3
import json
from pathlib import Path
class StateStore:
"""
SQLite-backed state store for operation snapshots.
In production, replace with a distributed store (Redis, PostgreSQL)
with proper backup and replication.
"""
def __init__(self, db_path: str = "/var/lib/k8s-agent/state.db"):
Path(db_path).parent.mkdir(parents=True, exist_ok=True)
self.conn = sqlite3.connect(db_path, check_same_thread=False)
self._init_schema()
def _init_schema(self):
self.conn.execute("""
CREATE TABLE IF NOT EXISTS snapshots (
snapshot_id TEXT PRIMARY KEY,
operation_type TEXT NOT NULL,
resource_type TEXT NOT NULL,
resource_name TEXT NOT NULL,
namespace TEXT NOT NULL,
pre_state TEXT NOT NULL,
captured_at TEXT NOT NULL,
restored_at TEXT,
is_active INTEGER DEFAULT 1
)
""")
self.conn.execute("""
CREATE INDEX IF NOT EXISTS idx_namespace_resource
ON snapshots(namespace, resource_name, resource_type)
""")
self.conn.commit()
def save_snapshot(self, snapshot: OperationSnapshot):
self.conn.execute("""
ADD INTO snapshots
(snapshot_id, operation_type, resource_type, resource_name,
namespace, pre_state, captured_at)
VALUES (?, ?, ?, ?, ?, ?, ?)
""", (
snapshot.snapshot_id,
snapshot.operation.operation_type.value,
snapshot.operation.resource_type.value,
snapshot.operation.resource_name,
snapshot.operation.namespace,
json.dumps(snapshot.pre_state),
snapshot.captured_at
))
self.conn.commit()
def get_snapshot(self, snapshot_id: str) -> Optional[OperationSnapshot]:
cursor = self.conn.execute(
"SELECT * FROM snapshots WHERE snapshot_id = ? AND is_active = 1",
(snapshot_id,)
)
row = cursor.fetchone()
if not row:
return None
# Reconstruct operation from stored data
operation = KubernetesOperation(
operation_type=OperationType(row[1]),
resource_type=ResourceType(row[2]),
resource_name=row[3],
namespace=row[4],
reason=f"Snapshot captured at {row[6]}",
requires_confirmation=False
)
return OperationSnapshot(
snapshot_id=row[0],
operation=operation,
pre_state=json.loads(row[5]),
captured_at=row[6]
)
def get_latest_snapshot_for_resource(
self,
namespace: str,
resource_type: str,
resource_name: str
) -> Optional[OperationSnapshot]:
cursor = self.conn.execute("""
SELECT * FROM snapshots
WHERE namespace = ? AND resource_type = ? AND resource_name = ?
AND is_active = 1
ORDER BY captured_at DESC LIMIT 1
""", (namespace, resource_type, resource_name))
row = cursor.fetchone()
if not row:
return None
return self.get_snapshot(row[0])
class RollbackEngine:
def __init__(
self,
executor: KubernetesExecutor,
state_store: StateStore,
apps_v1: k8s_client.AppsV1Api,
core_v1: k8s_client.CoreV1Api
):
self.executor = executor
self.state_store = state_store
self.apps_v1 = apps_v1
self.core_v1 = core_v1
def rollback_by_snapshot(self, snapshot_id: str) -> tuple[bool, str]:
snapshot = self.state_store.get_snapshot(snapshot_id)
if not snapshot:
return False, f"Snapshot {snapshot_id} not found or already consumed"
return self._apply_snapshot(snapshot)
def rollback_resource(
self,
namespace: str,
resource_type: ResourceType,
resource_name: str
) -> tuple[bool, str]:
snapshot = self.state_store.get_latest_snapshot_for_resource(
namespace=namespace,
resource_type=resource_type.value,
resource_name=resource_name
)
if not snapshot:
return False, (
f"No snapshot found for {resource_type}/{resource_name} "
f"in namespace {namespace}"
)
return self._apply_snapshot(snapshot)
def _apply_snapshot(
self, snapshot: OperationSnapshot
) -> tuple[bool, str]:
op = snapshot.operation
pre_state = snapshot.pre_state
try:
if op.resource_type == ResourceType.DEPLOYMENT:
# Restore replicas
if "replicas" in pre_state:
patch = {"spec": {"replicas": pre_state["replicas"]}}
self.apps_v1.patch_namespaced_deployment_scale(
name=op.resource_name,
namespace=op.namespace,
body=patch
)
# Restore images
if "image" in pre_state:
container_patches = [
{"name": name, "image": image}
for name, image in pre_state["image"].items()
]
patch = {
"spec": {
"template": {
"spec": {
"containers": container_patches
}
}
}
}
self.apps_v1.patch_namespaced_deployment(
name=op.resource_name,
namespace=op.namespace,
body=patch
)
elif op.resource_type == ResourceType.CONFIGMAP:
if "data" in pre_state:
patch = {"data": pre_state["data"]}
self.core_v1.patch_namespaced_config_map(
name=op.resource_name,
namespace=op.namespace,
body=patch
)
# Mark snapshot as consumed
self.state_store.conn.execute(
"UPDATE snapshots SET is_active = 0, restored_at = ? "
"WHERE snapshot_id = ?",
(datetime.now(timezone.utc).isoformat(), snapshot.snapshot_id)
)
self.state_store.conn.commit()
return True, (
f"Successfully rolled back {op.resource_type}/{op.resource_name} "
f"in {op.namespace} using snapshot {snapshot.snapshot_id}"
)
except ApiException as e:
return False, f"Rollback failed: {e.status} {e.reason}: {e.body}"
Testing Strategies
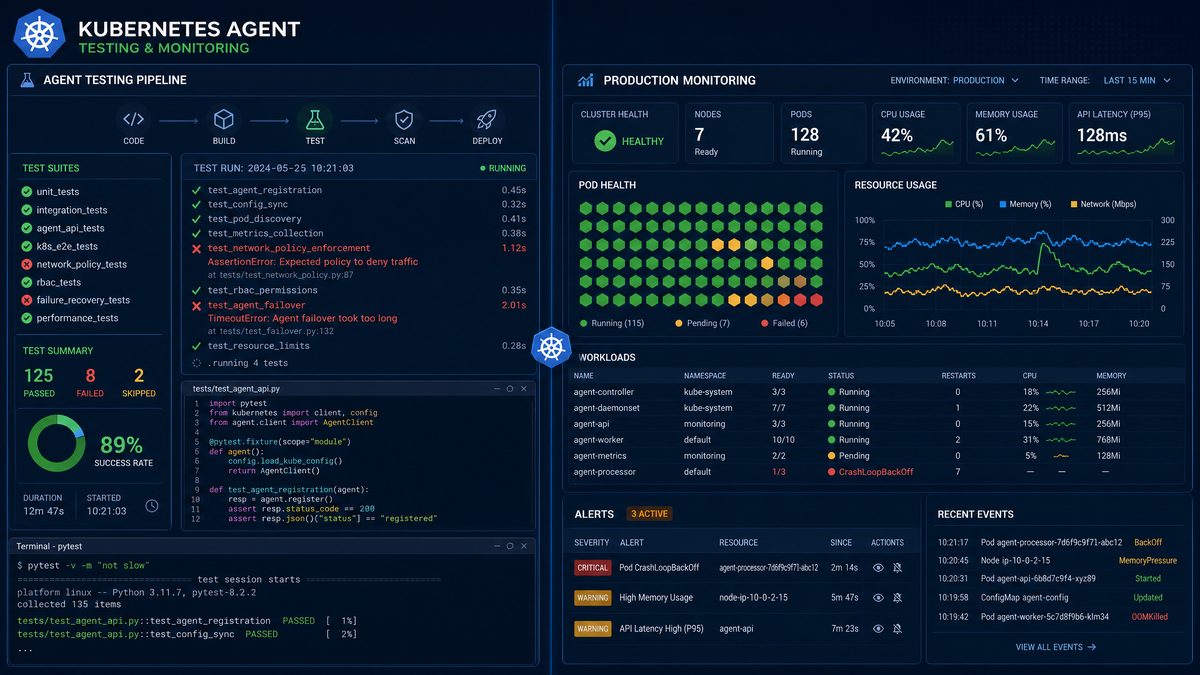
Testing a Kubernetes agent requires three distinct testing strategies. Unit tests verify that individual components behave correctly in isolation. Integration tests verify that the full pipeline produces correct Kubernetes API calls against a real cluster. Chaos tests verify that the agent behaves safely when the cluster is in an unexpected state.
Unit Testing the Intent Classifier
import pytest
from unittest.mock import MagicMock, patch
import json
class TestIntentClassifier:
@pytest.fixture
def mock_openai_client(self):
client = MagicMock()
return client
@pytest.fixture
def classifier(self, mock_openai_client):
return IntentClassifier(
client=mock_openai_client,
cluster_context={
"cluster_name": "test-cluster",
"namespaces": ["production", "staging", "development"],
"production_namespaces": ["production"]
}
)
def _make_mock_response(self, intent: KubernetesIntent):
mock_response = MagicMock()
mock_response.choices[0].message.parsed = intent
return mock_response
def test_scale_intent_classification(self, classifier, mock_openai_client):
expected_intent = KubernetesIntent(
original_request="Scale the api-server deployment to 5 replicas in production",
operations=[
KubernetesOperation(
operation_type=OperationType.SCALE,
resource_type=ResourceType.DEPLOYMENT,
resource_name="api-server",
namespace="production",
parameters=ScaleParameters(replicas=5),
reason="Scale api-server deployment to 5 replicas as requested",
requires_confirmation=True
)
],
estimated_risk_level="medium",
summary="Scale api-server to 5 replicas in production"
)
mock_openai_client.beta.chat.completions.parse.return_value = (
self._make_mock_response(expected_intent)
)
result = classifier.classify(
"Scale the api-server deployment to 5 replicas in production"
)
assert len(result.operations) == 1
assert result.operations[0].operation_type == OperationType.SCALE
assert isinstance(result.operations[0].parameters, ScaleParameters)
assert result.operations[0].parameters.replicas == 5
assert result.operations[0].requires_confirmation == True
class TestKubernetesOperationValidator:
@pytest.fixture
def mock_apps_v1(self):
mock = MagicMock()
deployment = MagicMock()
deployment.spec.replicas = 3
mock.read_namespaced_deployment.return_value = deployment
return mock
@pytest.fixture
def validator(self, mock_apps_v1):
validator = KubernetesOperationValidator.__new__(
KubernetesOperationValidator
)
validator.apps_v1 = mock_apps_v1
validator.core_v1 = MagicMock()
validator.allowed_namespaces = {"production", "staging", "development"}
validator.dry_run = True
return validator
def test_blocks_protected_namespace(self, validator):
operation = KubernetesOperation(
operation_type=OperationType.SCALE,
resource_type=ResourceType.DEPLOYMENT,
resource_name="coredns",
namespace="kube-system",
parameters=ScaleParameters(replicas=3),
reason="Test operation",
requires_confirmation=True
)
result = validator._validate_operation(operation, MagicMock())
assert result is not None
assert "protected" in result.lower()
def test_blocks_excessive_scale_factor(self, validator, mock_apps_v1):
# Current replicas = 3, target = 15 (5x, exceeds 3x limit)
operation = KubernetesOperation(
operation_type=OperationType.SCALE,
resource_type=ResourceType.DEPLOYMENT,
resource_name="api-server",
namespace="production",
parameters=ScaleParameters(replicas=15),
reason="Test scale operation",
requires_confirmation=True
)
result = validator._validate_operation(operation, MagicMock())
assert result is not None
assert "scale factor" in result.lower()
def test_blocks_latest_tag_in_production(self, validator):
operation = KubernetesOperation(
operation_type=OperationType.UPDATE_IMAGE,
resource_type=ResourceType.DEPLOYMENT,
resource_name="api-server",
namespace="production",
parameters=UpdateImageParameters(
container_name="api",
image="gcr.io/my-project/api-server",
tag="latest"
),
reason="Update to latest",
requires_confirmation=True
)
result = validator._validate_operation(operation, MagicMock())
assert result is not None
assert "latest" in result.lower()
def test_allows_valid_scale_within_limits(self, validator, mock_apps_v1):
# Current = 3, target = 6 (2x, within 3x limit)
operation = KubernetesOperation(
operation_type=OperationType.SCALE,
resource_type=ResourceType.DEPLOYMENT,
resource_name="api-server",
namespace="production",
parameters=ScaleParameters(replicas=6),
reason="Scale up for increased traffic",
requires_confirmation=True
)
result = validator._validate_operation(operation, MagicMock())
assert result is None
Integration Testing with a Real Cluster
Integration tests run against a dedicated test namespace in a non-production cluster. They verify the full pipeline including actual Kubernetes API calls, and they clean up after themselves using pytest fixtures with guaranteed teardown.
import pytest
from kubernetes import client as k8s_client, config as k8s_config
@pytest.fixture(scope="session")
def k8s_test_namespace():
k8s_config.load_kube_config(context="test-cluster")
core_v1 = k8s_client.CoreV1Api()
namespace_name = f"agent-test-{uuid.uuid4().hex[:8]}"
namespace = k8s_client.V1Namespace(
metadata=k8s_client.V1ObjectMeta(name=namespace_name)
)
core_v1.create_namespace(namespace)
yield namespace_name
core_v1.delete_namespace(namespace_name)
@pytest.fixture(scope="session")
def test_deployment(k8s_test_namespace):
k8s_config.load_kube_config(context="test-cluster")
apps_v1 = k8s_client.AppsV1Api()
deployment = k8s_client.V1Deployment(
metadata=k8s_client.V1ObjectMeta(
name="test-nginx",
namespace=k8s_test_namespace
),
spec=k8s_client.V1DeploymentSpec(
replicas=2,
selector=k8s_client.V1LabelSelector(
match_labels={"app": "test-nginx"}
),
template=k8s_client.V1PodTemplateSpec(
metadata=k8s_client.V1ObjectMeta(
labels={"app": "test-nginx"}
),
spec=k8s_client.V1PodSpec(
containers=[k8s_client.V1Container(
name="nginx",
image="nginx:1.25.0",
resources=k8s_client.V1ResourceRequirements(
limits={"cpu": "100m", "memory": "128Mi"},
requests={"cpu": "50m", "memory": "64Mi"}
)
)]
)
)
)
)
apps_v1.create_namespaced_deployment(
namespace=k8s_test_namespace,
body=deployment
)
yield "test-nginx"
apps_v1.delete_namespaced_deployment(
name="test-nginx",
namespace=k8s_test_namespace
)
@pytest.mark.integration
class TestScaleIntegration:
def test_scale_and_rollback(
self, k8s_test_namespace, test_deployment
):
k8s_config.load_kube_config(context="test-cluster")
apps_v1 = k8s_client.AppsV1Api()
core_v1 = k8s_client.CoreV1Api()
state_store = StateStore(db_path="/tmp/test-state.db")
event_emitter = MagicMock()
executor = KubernetesExecutor(
apps_v1=apps_v1,
core_v1=core_v1,
state_store=state_store,
event_emitter=event_emitter,
dry_run=False
)
rollback_engine = RollbackEngine(
executor=executor,
state_store=state_store,
apps_v1=apps_v1,
core_v1=core_v1
)
scale_op = KubernetesOperation(
operation_type=OperationType.SCALE,
resource_type=ResourceType.DEPLOYMENT,
resource_name=test_deployment,
namespace=k8s_test_namespace,
parameters=ScaleParameters(replicas=4),
reason="Integration test scale operation",
requires_confirmation=False
)
success, result, error = executor.execute_operation(scale_op)
assert success, f"Scale failed: {error}"
# Verify the scale took effect
deployment = apps_v1.read_namespaced_deployment(
name=test_deployment,
namespace=k8s_test_namespace
)
assert deployment.spec.replicas == 4
# Now rollback
rb_success, rb_message = rollback_engine.rollback_resource(
namespace=k8s_test_namespace,
resource_type=ResourceType.DEPLOYMENT,
resource_name=test_deployment
)
assert rb_success, f"Rollback failed: {rb_message}"
# Verify rollback restored original replicas
deployment = apps_v1.read_namespaced_deployment(
name=test_deployment,
namespace=k8s_test_namespace
)
assert deployment.spec.replicas == 2
Monitoring and Observability for the Agent
An agent that operates on production infrastructure without comprehensive observability is a liability. The monitoring strategy covers three dimensions: operational metrics (what the agent is doing), safety metrics (what the agent is preventing), and performance metrics (how quickly the agent responds). All three are essential for building operator confidence in the system.
For organizations scaling their Codex implementation, understanding the full platform ecosystem is essential. Our detailed walkthrough in How to Build and Deploy an iOS App With Codex in 2026: Complete Step-by-Step Guide covers the architectural patterns and best practices that enterprise teams need when building production-grade AI agent systems.
from prometheus_client import Counter, Histogram, Gauge, start_http_server
import structlog
from opentelemetry import trace
from opentelemetry.sdk.trace import TracerProvider
from opentelemetry.sdk.trace.export import BatchSpanProcessor
from opentelemetry.exporter.otlp.proto.grpc.trace_exporter import OTLPSpanExporter
# Prometheus metrics
OPERATIONS_TOTAL = Counter(
'k8s_agent_operations_total',
'Total number of operations processed',
['operation_type', 'resource_type', 'namespace', 'status']
)
OPERATIONS_BLOCKED = Counter(
'k8s_agent_operations_blocked_total',
'Operations blocked by safety guardrails',
['operation_type', 'block_reason']
)
INTENT_CLASSIFICATION_DURATION = Histogram(
'k8s_agent_intent_classification_duration_seconds',
'Time spent on intent classification',
buckets=[0.1, 0.5, 1.0, 2.0, 5.0, 10.0]
)
ROLLBACKS_TOTAL = Counter(
'k8s_agent_rollbacks_total',
'Total rollback operations',
['trigger', 'success']
)
ACTIVE_SNAPSHOTS = Gauge(
'k8s_agent_active_snapshots',
'Number of active rollback snapshots in state store'
)
RISK_LEVEL_DISTRIBUTION = Counter(
'k8s_agent_risk_level_total',
'Distribution of risk levels across intents',
['risk_level']
)
class ObservableAgentPipeline:
def __init__(
self,
classifier: IntentClassifier,
validator: KubernetesOperationValidator,
executor: KubernetesExecutor,
rollback_engine: RollbackEngine,
otlp_endpoint: str = "http://localhost:4317"
):
self.classifier = classifier
self.validator = validator
self.executor = executor
self.rollback_engine = rollback_engine
# Configure structured logging
structlog.configure(
processors=[
structlog.processors.TimeStamper(fmt="iso"),
structlog.stdlib.add_log_level,
structlog.processors.StackInfoRenderer(),
structlog.processors.format_exc_info,
structlog.processors.JSONRenderer()
]
)
self.log = structlog.get_logger()
# Configure OpenTelemetry tracing
provider = TracerProvider()
provider.add_span_processor(
BatchSpanProcessor(OTLPSpanExporter(endpoint=otlp_endpoint))
)
trace.set_tracer_provider(provider)
self.tracer = trace.get_tracer("k8s-agent")
def process_request(
self,
request: str,
operator_id: str,
auto_confirm: bool = False
) -> dict:
with self.tracer.start_as_current_span("process_request") as span:
span.set_attribute("operator.id", operator_id)
span.set_attribute("request.length", len(request))
self.log.info(
"processing_request",
operator_id=operator_id,
request_preview=request[:100]
)
# Intent classification with timing
with self.tracer.start_as_current_span("classify_intent"):
with INTENT_CLASSIFICATION_DURATION.time():
intent = self.classifier.classify(request)
RISK_LEVEL_DISTRIBUTION.labels(
risk_level=intent.estimated_risk_level
).inc()
span.set_attribute("intent.risk_level", intent.estimated_risk_level)
span.set_attribute("intent.operation_count", len(intent.operations))
# Validation
with self.tracer.start_as_current_span("validate_intent"):
validation = self.validator.validate_intent(intent)
for op, reason in validation.rejected_operations:
OPERATIONS_BLOCKED.labels(
operation_type=op.operation_type.value,
block_reason=self._categorize_block_reason(reason)
).inc()
self.log.warning(
"operation_blocked",
operation_type=op.operation_type.value,
resource=f"{op.resource_type}/{op.resource_name}",
namespace=op.namespace,
reason=reason
)
if not validation.is_valid:
return {
"status": "rejected",
"reason": "One or more operations failed validation",
"rejected": [
{"operation": op.dict(), "reason": reason}
for op, reason in validation.rejected_operations
]
}
# Confirmation check
if validation.requires_confirmation and not auto_confirm:
return {
"status": "pending_confirmation",
"summary": intent.summary,
"operations": [op.dict() for op in validation.approved_operations],
"risk_level": intent.estimated_risk_level
}
# Execution
results = []
with self.tracer.start_as_current_span("execute_operations"):
for operation in validation.approved_operations:
with self.tracer.start_as_current_span(
f"execute_{operation.operation_type.value}"
) as op_span:
op_span.set_attribute(
"operation.resource",
f"{operation.resource_type}/{operation.resource_name}"
)
op_span.set_attribute("operation.namespace", operation.namespace)
success, result, error = self.executor.execute_operation(
operation
)
OPERATIONS_TOTAL.labels(
operation_type=operation.operation_type.value,
resource_type=operation.resource_type.value,
namespace=operation.namespace,
status="success" if success else "failure"
).inc()
if not success:
self.log.error(
"operation_failed",
operation_type=operation.operation_type.value,
resource=f"{operation.resource_type}/{operation.resource_name}",
namespace=operation.namespace,
error=error
)
op_span.set_status(
trace.StatusCode.ERROR, error
)
results.append({
"operation": operation.dict(),
"success": success,
"result": result,
"error": error
})
return {
"status": "completed",
"results": results,
"summary": intent.summary
}
def _categorize_block_reason(self, reason: str) -> str:
reason_lower = reason.lower()
if "protected namespace" in reason_lower:
return "protected_namespace"
elif "scale factor" in reason_lower:
return "excessive_scale_factor"
elif "replica" in reason_lower and "maximum" in reason_lower:
return "replica_limit"
elif "registry" in reason_lower:
return "unapproved_registry"
elif "tag" in reason_lower and "production" in reason_lower:
return "mutable_tag_in_production"
elif "confirmation" in reason_lower:
return "requires_confirmation"
return "policy_violation"
Production Deployment Patterns and Access Control
Deploying the agent itself to Kubernetes requires careful attention to the principle of least privilege. The agent’s service account should have exactly the permissions it needs for its allowed operations, nothing more. Use Kubernetes RBAC to scope permissions to specific namespaces and resource types. Avoid cluster-admin bindings at all costs — if an attacker compromises the agent, a scoped service account limits the blast radius.
# rbac.yaml - Agent RBAC configuration
apiVersion: v1
kind: ServiceAccount
metadata:
name: k8s-agent
namespace: agent-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: k8s-agent-production-role
namespace: production
rules:
# Deployments: read and update (no delete)
- apiGroups: ["apps"]
resources: ["deployments", "deployments/scale"]
verbs: ["get", "list", "watch", "patch", "update"]
# StatefulSets: read only
- apiGroups: ["apps"]
resources: ["statefulsets"]
verbs: ["get", "list", "watch"]
# Pods: read and delete (for restart via pod deletion)
- apiGroups: [""]
resources: ["pods"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["pods/log"]
verbs: ["get"]
# ConfigMaps: read and update (no create, no delete)
- apiGroups: [""]
resources: ["configmaps"]
verbs: ["get", "list", "watch", "patch", "update"]
# Events: create (for audit trail)
- apiGroups: [""]
resources: ["events"]
verbs: ["create"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: k8s-agent-production-binding
namespace: production
subjects:
- kind: ServiceAccount
name: k8s-agent
namespace: agent-system
roleRef:
kind: Role
name: k8s-agent-production-role
apiGroup: rbac.authorization.k8s.io
# deployment.yaml - Agent deployment with security context
apiVersion: apps/v1
kind: Deployment
metadata:
name: k8s-agent
namespace: agent-system
spec:
replicas: 2
selector:
matchLabels:
app: k8s-agent
template:
metadata: