How GPT-5.5 Powers OpenAI Codex: Architecture, Sandboxing, and Real-World Agent Workflows
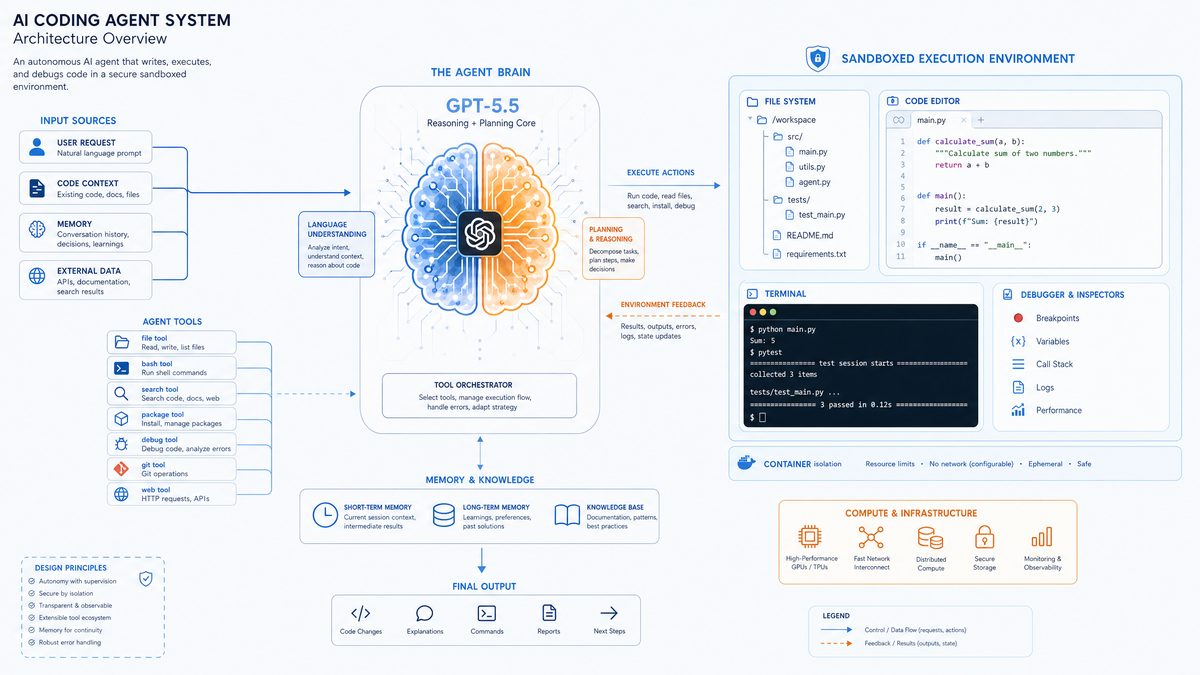
The intersection of cutting-edge language models and software development tools has led to transformative changes in the way developers write, debug, and maintain code. At the forefront of this evolution is OpenAI’s Codex agent, a specialized AI system architected around the advanced GPT-5.5 model. Unlike earlier iterations, Codex seamlessly integrates GPT-5.5’s expansive reasoning power with secure sandboxed execution environments, enabling sophisticated autonomous programming workflows. These capabilities have reshaped the landscape of intelligent coding assistants, offering unprecedented support for multi-file project comprehension, automated debugging, optimized test generation, and intelligent code refactoring. In this comprehensive article, we dissect the technical framework of OpenAI Codex, spotlighting how GPT-5.5’s enhancements specifically power agent-driven software engineering and detailing the synergistic infrastructure designed for real-world developer demands.
1. The Core Architecture of OpenAI Codex Powered by GPT-5.5
OpenAI Codex is an advanced AI agent specifically tailored for programming assistance, functioning as an intelligent partner capable of interpreting, generating, and manipulating complex software codebases at scale. At its core, Codex harnesses GPT-5.5, an iteration built on the transformer architecture but fine-tuned and optimized explicitly for source code understanding and generation. This section elucidates the underlying architectural principles that govern Codex, focusing on how GPT-5.5’s novel features unlock profound advancements in code comprehension, contextual reasoning, and developer interaction.
1.1 Understanding GPT-5.5’s Expanded Context Window
One of the most transformative shifts in GPT-5.5, as leveraged by Codex, is the model’s dramatically enlarged context window, capable of processing up to 64,000 tokens in a single pass. To put this into perspective, previous GPT models typically operated with context windows in the range of 4,000 to 6,000 tokens, which constrained their ability to reason about large or multi-file projects cohesively. This tenfold increase fundamentally alters Codex’s approach to software engineering tasks, allowing it to:
- Multi-File Reasoning: Modern software projects often span hundreds or thousands of lines of code distributed across numerous source files and modules. With its extended context, Codex can simultaneously ingest multiple files, parse their interdependencies, and construct a holistic mental model of the entire codebase. For example, understanding how a change in a utility function within a shared library affects the behavior of various application components is now feasible without artificially concatenating or summarizing files.
- Stateful Interaction and Continuous Dialogue: Unlike stateless completion models, Codex maintains a running understanding of ongoing development sessions, factoring in prior code edits, user instructions, and feedback from sandbox test results. This persistent statefulness enables the agent to sustain lengthy, meaningful interactions with developers, adapting outputs and suggestions based on the evolving coding context without losing track of preceding dialogue or code states.
- Enhanced Syntax and Semantic Awareness: By processing larger blocks of code within a single context, GPT-5.5 preserves syntactic structures such as function definitions, class hierarchies, and control flows intact across file boundaries. Semantically, the agent captures relationships such as inheritance, polymorphism, or API usage patterns more accurately, leading to more precise code completions, error predictions, and intent inference.
Consider a scenario where a developer is refactoring a complex web application consisting of frontend React components, backend API handlers, and shared data models. Codex, with its extended context window, can analyze the entire relevant code segment in one pass—grasping how frontend event handlers interact with backend endpoints and adapting code suggestions to maintain consistency across layers. This is a substantial leap beyond linear, single-file-focused AI coding assistants.
1.2 Tokenization and Embedding Optimizations for Code
GPT-5.5’s architecture incorporates advanced tokenization and embedding techniques fine-tuned for programming languages and their unique syntax. Typical textual tokenizers split input based on word boundaries and punctuation, which can be suboptimal for code, where the semantic unit often correlates with identifiers, operators, or language-specific syntax tokens.
Key innovations in this area include:
- Language-Specific Tokenization: The tokenizer utilizes heuristic and learned rules to segment code into meaningful tokens that align with language grammar—e.g., recognizing multi-character operators in C++, JSX tags in JavaScript, or indentation in Python. This reduction in token fragmentation improves processing efficiency and semantic clarity.
- Domain-Adapted Embeddings: By training embedding layers on vast repositories of open-source and proprietary code, GPT-5.5 learns dense vector representations that cluster semantically similar constructs and idiomatic patterns. For instance, synonymous function names or commonly used design patterns reside near each other in embedding space, aiding inference and error detection during generation.
- Error Pattern Detection: The embeddings capture subtle syntactic or stylistic irregularities that often characterize faulty code. When these anomaly vectors are fed into downstream generation layers, Codex can preemptively flag potential errors or inconsistencies while proposing completions, enhancing the agent’s overall code quality output.
By optimizing token representation and embedding semantics specifically for code, GPT-5.5 significantly reduces ambiguity during code generation and helps maintain idiomatic accuracy across diverse programming languages and ecosystems.
1.3 Integration with Development Environments
OpenAI Codex is designed to fit organically within developers’ existing workflows. Its architecture exposes robust APIs and plugins that integrate seamlessly with popular Integrated Development Environments (IDEs) such as Visual Studio Code, JetBrains products, and cloud-based IDE platforms.
This integration hinges on several architectural decisions:
- Context Streaming and Incremental Updates: Rather than forcing full file reloads for each user edit, Codex’s interface supports streaming partial changes and incremental context updates, ensuring minimal latency and efficient use of the expanded context window.
- Version Control System Hooks: Codex connects with Git and other version control systems to access code history and diffs, enabling context-aware suggestions especially useful when reviewing pull requests or performing code merges.
- Adaptive Response Generation: The model dynamically modulates output length, verbosity, and complexity based on IDE context, developer preferences, and project conventions, reducing noise and aligning suggestions with team coding standards.
The result is an AI-powered coding assistant that complements developer workflows naturally, empowering them with rich contextual understanding without disrupting existing practices. For a broader comparative analysis of similar AI models and their integration scopes in software development, visit
The Codex agent architecture discussed here extends to mobile platforms, where developers can initiate and monitor autonomous coding tasks from their phones, leveraging the same GPT-5.5 powered sandbox environment remotely. OpenAI Codex Goes Mobile.
.
2. Sandboxed Execution Environment: Safe and Effective Code Testing
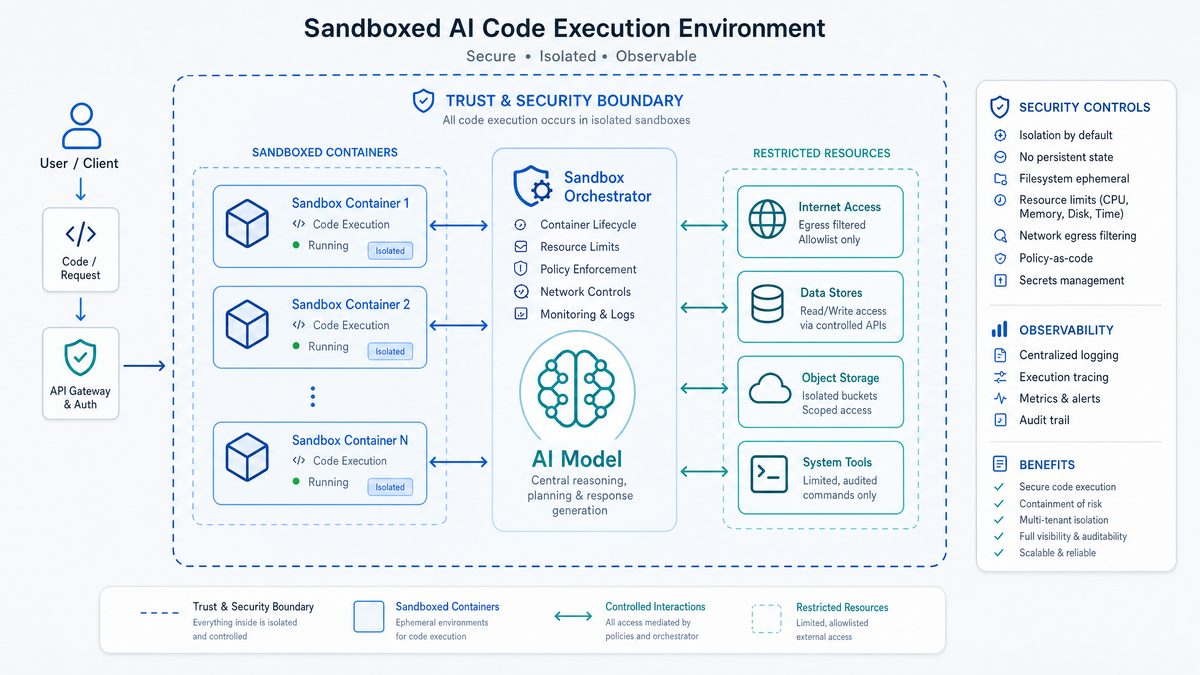
An essential pillar of OpenAI Codex’s architecture is its tightly integrated sandboxed execution environment. Unlike basic code completion tools, Codex is distinguished by its ability to run generated or modified code snippets instantly in a controlled, secure environment. This live execution is fundamental to supporting autonomous workflows such as debugging, test validation, and real-time performance monitoring.
2.1 Architecture of the Sandboxed Environment
The sandboxing solution is architected as a multi-layered, containerized runtime that isolates code execution from the host system, mitigating risks of security breaches or unintended side effects. Key architectural features include:
- Resource Limiting: Each sandbox instance is provisioned with strict quotas governing CPU cycles, allocated memory, disk I/O, and network bandwidth. These constraints prevent runaway processes or denial-of-service scenarios caused by inefficient or malicious code.
- Filesystem Virtualization: The sandbox employs a virtual file system overlay that presents only permitted directories and mock dependencies to the executing code. This layer delivers necessary resources—such as versioned libraries or test datasets—without exposing sensitive host filesystem contents.
- Network Controls: Outbound network access is heavily restricted or sandboxed using internal proxies and simulators. This provides a safe way to execute API interaction tests or simulate distributed system calls without exposing the environment to external attack surfaces.
Together, these mechanisms ensure that code under test runs predictably, securely, and within well-defined operational parameters. Additionally, the container orchestration system provisions fresh sandboxes per request to prevent state leakage or cross-session contamination.
2.2 Runtime Languages and Interpreters
The Codex sandbox supports multiple programming languages widely used in modern development ecosystems to accommodate diverse project needs. Languages currently supported include:
- Python: With standard interpreter environments plus popular scientific and web libraries.
- JavaScript/Node.js: Including support for ESNext features and commonly used npm packages.
- Go (Golang): With compile-to-binary run support, enabling fast execution cycles.
- Rust: Leveraging cargo build scripts and efficient binary runs.
- C#/.NET: Using runtime JIT compilation to test snippets in sandboxed CLR instances.
The sandbox employs lightweight language interpreters and Just-In-Time (JIT) compilation techniques to minimize overhead and maximize execution speed, ensuring that interactive coding sessions remain fluid and responsive even with complex codebases.
2.3 Feedback Loop Between GPT-5.5 and the Sandbox
A fundamental aspect of Codex’s autonomous capabilities is the iterative feedback loop connecting GPT-5.5 with its sandbox execution environment. This loop functions as follows:
- Code generated or modified by GPT-5.5 is dispatched dynamically to the sandbox for execution or testing.
- The sandbox captures detailed metadata during execution, including success/failure states, exception traces, runtime error messages, performance profiles, and resource usage.
- This execution feedback is reformatted into structured data and natural language summaries, then fed back into the GPT-5.5 model as augmented context for the next generation cycle.
- GPT-5.5 analyzes failure modes or performance regressions, generating refined code patches or test cases designed to resolve or optimize the observed issues.
Through this tight coupling, Codex attains a sophisticated understanding of code correctness and behavior, far beyond static pattern matching or heuristic completion. For example, during automated debugging, the agent can interpret stack traces, correlate them with source code, and synthesize corrective edits that are re-validated in real time. This capability elevates Codex from a passive assistant to an autonomous coding agent.
2.4 Ensuring Security and Reliability
The power to generate and execute arbitrary code introduces inherent security risks, and Codex’s sandbox architecture mitigates these through comprehensive safety measures, including:
- Multi-Tenant Isolation: Each sandbox operates entirely independently, using containerization and namespace separation techniques to prevent cross-session data leakage.
- Audit Logging and Monitoring: All code executions are logged with detailed timestamps, input/output states, and user context to facilitate post-mortem analysis and detect anomalous patterns.
- Runtime Anomaly Detection: The environment uses heuristic and machine learning-based detectors to identify suspicious behaviors such as infinite loops, resource exhaustion attempts, or unauthorized system calls, triggering immediate sandbox termination.
Through these layered protections, OpenAI ensures that the power and flexibility of Codex’s runtime capabilities does not come at the cost of security or stability. Detailed insights into secure code execution practices and sandbox technologies are available in our dedicated analysis
Developers looking to integrate Codex into their browser-based workflow can leverage the Chrome DevTools integration, which provides a direct interface to the sandboxed execution environment for real-time debugging and code inspection. How to Use OpenAI Codex with Chrome DevTools.
.
3. Leveraging NVIDIA Infrastructure for Dedicated Compute at Scale
OpenAI Codex operates at a scale and responsiveness level that demands high-performance computational resources. These requirements are met through a close collaboration with NVIDIA, delivering a hardware foundation purpose-built to optimize the inference and runtime characteristics of GPT-5.5 within Codex.
3.1 High-Performance GPUs for Transformer Inference
The GPT-5.5 model powering Codex involves vast parameter counts and requires substantial parallelism to maintain latency targets compatible with interactive development. NVIDIA’s latest generation Tensor Core GPUs provide this capability through specialized hardware accelerators optimized for deep learning workloads.
- Massive Parallelism: Tensor Cores exploit mixed precision arithmetic to execute thousands of operations simultaneously, accelerating the matrix multiplications central to transformer architectures.
- Model Parallelism Strategies: Codex’s inference pipeline partitions the GPT-5.5 model across multiple GPUs, distributing memory load and computation. This is critical to handle the expanded 64,000-token context window without exceeding single-GPU memory constraints.
- Pipeline Parallelism: Incoming inference requests are segmented into pipeline stages that overlap computation and communication, maximizing throughput without increasing latency. This design supports tens of thousands of concurrent developer sessions.
3.2 Dedicated Compute Nodes for Agent Tasks
NVIDIA’s infrastructure provisions specialized compute nodes tailored exclusively for Codex operations, including sandbox management and inference processes. These nodes feature:
- Redundant power and cooling systems that ensure continuous operation and minimize downtime even under heavy load.
- High-speed NVMe storage arrays providing ultra-low latency access to cached project files, language runtimes, and dependencies required for sandbox execution and model context fetching.
- Low-latency, high-bandwidth networking technologies facilitating rapid data exchange between compute nodes, sandbox containers, and user client interfaces—critical for maintaining fluid, real-time sessions.
This robust hardware stack guarantees that Codex can deliver consistent, performant service despite the demanding inference and execution workload.
3.3 Adaptive Scheduling and Load Balancing
Codex employs intelligent scheduler algorithms that dynamically allocate workloads based on priority, session type, and resource availability. Real-time coding sessions with strict latency requirements are prioritized while batch processes—such as large static analysis or refactoring jobs—are farmed out to available GPU capacity during idle periods.
This balance ensures that interactive developer experiences remain responsive, while background agent tasks proceed efficiently without starving system resources.
3.4 Impact of Hardware on Codex Responsiveness
The synergy between GPT-5.5’s optimized architecture and NVIDIA’s leading-edge hardware culminates in benchmarks exhibiting unprecedented performance improvements. The table below summarizes key metrics comparing the current Codex system with prior GPT model deployments on CPU-based inference:
| Metric | GPT-5.5 + NVIDIA GPUs | Previous GPT Model + CPU | Improvement Factor |
|---|---|---|---|
| Maximum Context Window (tokens) | 64,000 | 6,000 | 10.7x |
| Average Inference Latency (ms) | 150 | 1000 | 6.7x faster |
| Concurrent Sessions Supported | 10,000 | 1,500 | 6.7x |
These performance gains enable Codex to offer instantaneous code completions, real-time sandbox feedback, and uninterrupted agent workflows that meet stringent developer expectations. For in-depth exploration of GPU-accelerated AI infrastructure, consult this comprehensive resource
The GPT-5.5 Instant model that powers the default Codex experience offers a balance between speed and capability, making it the recommended starting point for most development workflows before upgrading to Pro for complex multi-file refactoring tasks. GPT-5.5 Instant Explained.
.
4. Real-World Agent Workflows Enabled by GPT-5.5 and Codex
Moving beyond isolated features, Codex embodies a holistic AI agent capable of undertaking complex, autonomous software engineering workflows. Leveraging GPT-5.5’s extended reasoning and its sandbox feedback loop, the agent executes multi-phase tasks that have traditionally required intensive human labor. Below, we detail several illustrative workflows emblematic of this new paradigm.
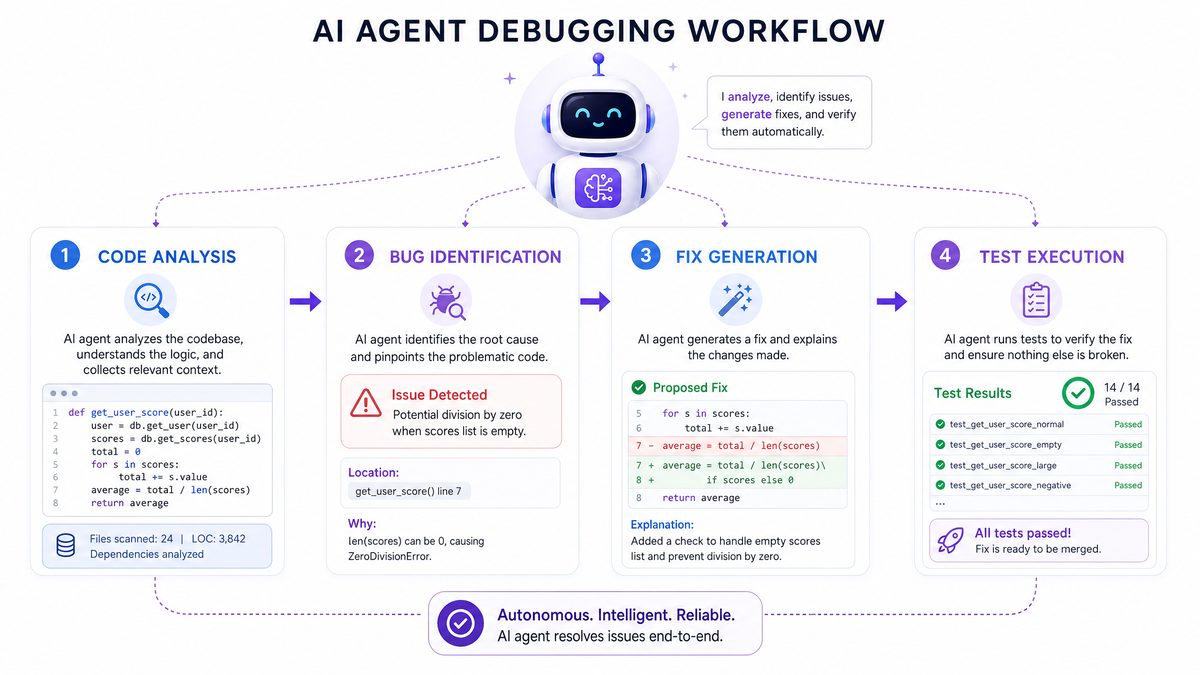
4.1 Autonomous Debugging
Debugging is often the most time-consuming phase of development, requiring careful examination of error logs, code inspection, and iterative patching. Codex transforms this process into an autonomous loop:
- Error Trace Parsing: Upon encountering runtime exceptions or failed test assertions executed within the sandbox, Codex parses detailed stack traces that may span multiple files. GPT-5.5’s multi-file reasoning allows it to pinpoint the probable fault location, even when the failure manifests indirectly due to intricate call chains.
- Patch Generation and Verification: Using its augmented context, the model generates tentative fixes, ranging from simple off-by-one error corrections to architectural changes like adding error handling or refactoring problematic code blocks. Each patch passes through immediate sandbox execution to validate the fix’s effectiveness.
- Iterative Refinement: If initial attempts fail, the agent synthesizes additional patches, explains its reasoning transparently in messages to the developer, and submits refined code variants until the problem is resolved or a threshold iteration count is reached.
For example, if a Python module throws a KeyError within a nested data parsing function, Codex can trace back across import dependencies, identify overlooked edge cases, and insert guard clauses validated through repeated sandbox test runs—all autonomously and within seconds.
4.2 Automated Test Generation and Validation
Maintaining robust test coverage is essential for software quality. Codex autonomously builds and refines test suites by:
- Extracting semantic information about function signatures, expected inputs, and output types from the analyzed codebase.
- Generating varied test inputs informed by usage patterns and code behavior heuristics, including edge cases and invalid inputs to exercise error handling.
- Executing generated tests immediately in the sandbox environment, assessing code coverage and discovering untested branches or conditions.
- Suggesting optimizations such as redundant test removal, input mutation strategies, or mocking techniques to enhance test efficiency and accuracy.
In continuous integration workflows, Codex can dynamically augment existing test suites to mitigate regressions introduced by code changes, drastically reducing manual test development effort.
4.3 Intelligent Code Refactoring and Optimization
Technical debt accumulates across projects, impacting maintainability and performance. Codex addresses this by offering intelligent refactorings that preserve original behavior while enhancing code quality:
- It detects code smells, anti-patterns, and redundant implementations scattered across multiple files, using GPT-5.5’s global context understanding to identify widespread opportunities.
- The agent proposes restructurings such as modularization, function inlining, dead code elimination, or API standardization, generating annotated diffs that developers can review.
- Before submitting changes, Codex profiles the refactored code within the sandbox to benchmark performance against baseline metrics—ensuring optimizations translate into measurable gains.
This workflow helps keep large codebases clean and performant, translating to reduced maintenance costs and accelerated feature development.
4.4 Collaborative Developer-AI Interaction
Codex is more than an autonomous agent; it functions as a collaborative partner in the software lifecycle. Through continuous interaction, the agent adapts to developer preferences, coding conventions, and team styles by:
- Incorporating direct feedback on code suggestions, style adjustments, and verbosity to tailor its outputs.
- Learning project-specific idioms, naming conventions, and architecture patterns from accessing repository histories and prior interactions.
- Engaging in natural language dialogues that explain code decisions, solicit clarifications, and incorporate incremental instructions seamlessly.
This personalized assistance differs significantly from static, rule-based code completion tools by embodying an adaptive intelligence capable of evolving with the developer and project.
4.5 Pipeline Integration and Continuous Development
To maximize productivity gains, Codex integrates deeply with modern DevOps toolchains. It automates routine CI/CD tasks by:
- Automatically generating pull requests with suggested feature additions, bug fixes, or refactorings along with detailed change explanations.
- Producing comprehensive code review summaries highlighting key modifications and risks, facilitating team collaboration.
- Monitoring continuous integration builds and test runs to detect flakiness, regressions, or performance anomalies in real time and proposing mitigations.
This tight coupling ensures swift feedback loops and continuous improvement cycles, accelerating development velocity substantially. Explore how these autonomous agent workflows redefine modern software engineering in our comprehensive AI development lifecycle feature .
Conclusion
OpenAI Codex, architected around the powerful GPT-5.5 model, represents a paradigm shift in AI-assisted software development. By leveraging GPT-5.5’s monumental context window expansion, Codex attains unparalleled multi-file reasoning aptitudes, enabling the understanding of complex software projects with human-like depth. Its embedded sandboxed execution environment facilitates the safe and efficient running of arbitrary code, closing the gap between code generation and validation through real-time feedback loops. Empowered by NVIDIA’s cutting-edge GPU compute infrastructure, Codex scales effortlessly to support thousands of concurrent interactive sessions with sub-second latency—a fundamental prerequisite for practical use in live development contexts. Further, the agent’s suite of autonomous workflows, including debugging, test generation, and code refactoring, showcases the transformative potential of AI to not just assist but actively participate in and accelerate the software engineering lifecycle.
This confluence of advanced model design, secure runtime capabilities, dedicated hardware, and intelligent agent workflows sets OpenAI Codex apart as the new gold standard in AI-driven programming tools. As these technologies evolve, the collaborative synergy between human engineers and AI agents promises to unlock unprecedented engineering achievements, streamlining software creation while maintaining the highest standards of code quality and security.
Access 40,000+ AI Prompts for ChatGPT, Claude & Codex — Free!
Subscribe to get instant access to our complete Notion Prompt Library — the largest curated collection of prompts for ChatGPT, Claude, OpenAI Codex, and other leading AI models. Optimized for real-world workflows across coding, research, content creation, and business.