Advanced Prompt Engineering for ChatGPT, Claude, and Codex in 2026
As AI language models continue to evolve rapidly, the art and science of prompt engineering have become pivotal for unlocking their full potential. In 2026, advanced prompt engineering techniques for models such as ChatGPT, Claude, and Codex have matured into sophisticated methodologies that enable developers and AI practitioners to extract highly accurate, contextually rich, and production-grade outputs. This comprehensive guide explores state-of-the-art prompting strategies including zero-shot, few-shot, and chain-of-thought prompting, structured frameworks, and specialized approaches for coding agents.
✓ Instant access✓ No spam✓ Unsubscribe anytime
By understanding how to design prompts strategically, separate extraction layers, and harness multi-turn conversational flows, you can optimize model performance across diverse applications—from natural language processing and decision support to complex code generation and debugging. This article delves deep into these techniques and frameworks, providing practical insights and examples to elevate your AI workflows.
Zero-shot, Few-shot, and Chain-of-Thought Prompting Techniques
Prompting techniques have evolved significantly since the early days of language models. The core approaches, zero-shot and few-shot prompting, combined with the recent surge of chain-of-thought prompting, form the foundation of effective interactions with ChatGPT, Claude, and Codex.
Zero-shot Prompting
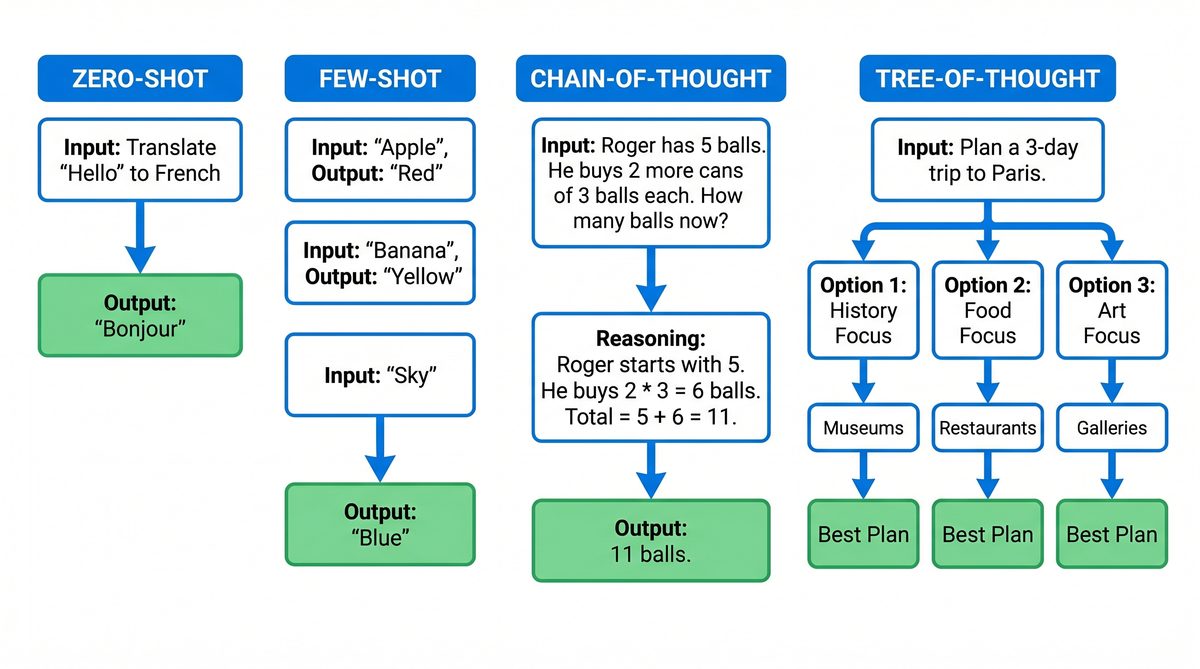
Zero-shot prompting involves instructing a model to perform a task without providing any examples. This technique relies on the model’s pre-trained knowledge and its ability to generalize based on the prompt’s instructions alone. Zero-shot is particularly useful for rapid prototyping and scenarios where example generation is impractical.
For instance, consider the zero-shot prompt:
“Summarize the following article in three sentences.”
The model generates a summary based solely on this instruction and the input text, without any demonstration of summarization styles or formats.
Advantages of zero-shot prompting include:
- Minimal prompt engineering effort
- Flexibility across various tasks without retraining
- Fast iteration cycles
However, zero-shot performance can be inconsistent on complex or ambiguous tasks, often benefiting from augmented context or examples.
Few-shot Prompting
Few-shot prompting improves task performance by including one or more examples embedded directly within the prompt. This approach guides the model by demonstrating the desired input-output behavior, thereby reducing ambiguity and improving output reliability.
Example of a few-shot prompt for sentiment analysis:
Review: "The movie was thrilling and kept me on the edge of my seat." Sentiment: Positive Review: "I found the plot dull and the characters underdeveloped." Sentiment: Negative Review: "An absolute masterpiece with stunning visuals." Sentiment:
Here, the model can infer the task and produce a sentiment classification for the last review based on the examples.
Few-shot prompting benefits include:
- Improved accuracy on specialized or nuanced tasks
- Ability to customize style and output formatting
- Useful when annotated data is limited but some exemplars exist
The major challenge is prompt length constraints, as embedding many examples can exhaust token limits, especially for complex tasks.
Chain-of-Thought Prompting
Chain-of-thought (CoT) prompting, a technique that gained prominence in recent years, encourages the model to generate intermediate reasoning steps before providing a final answer. This is particularly effective for complex reasoning, multi-step problems, and logical inference tasks.
Consider a math word problem:
Question: If a train travels 60 miles in 1.5 hours, what is its average speed? Answer:
A chain-of-thought prompt guides the model to reason step-by-step:
Step 1: Distance = 60 miles Step 2: Time = 1.5 hours Step 3: Speed = Distance / Time = 60 / 1.5 Step 4: Speed = 40 miles per hour Answer: 40 miles per hour
By explicitly asking the model to “think aloud,” CoT prompting reduces errors caused by skipping intermediate reasoning. This technique enhances interpretability and reliability, especially in domains like mathematics, coding logic, and complex question answering.
Implementing CoT prompting can be done via explicit instructions (e.g., “Explain your reasoning step by step”) or by including exemplars that demonstrate the reasoning process in few-shot settings.
Combining these three prompting techniques enables practitioners to tailor model outputs precisely based on task complexity, domain specificity, and desired output style.
Production-Grade Prompting Techniques and Structured Frameworks
Get Free Access to 40,000+ AI Prompts
Join 40,000+ AI professionals. Get instant access to our curated Notion Prompt Library with prompts for ChatGPT, Claude, Codex, Gemini, and more — completely free.
Get Free Access Now →No spam. Instant access. Unsubscribe anytime.
While zero-shot, few-shot, and chain-of-thought techniques provide foundational approaches, deploying AI models in production requires robust prompting frameworks that ensure consistency, reliability, and maintainability. This section explores production-grade prompting best practices, including prompt modularization, extraction layer separation, and golden test sets.
Prompt Modularization and Reusability
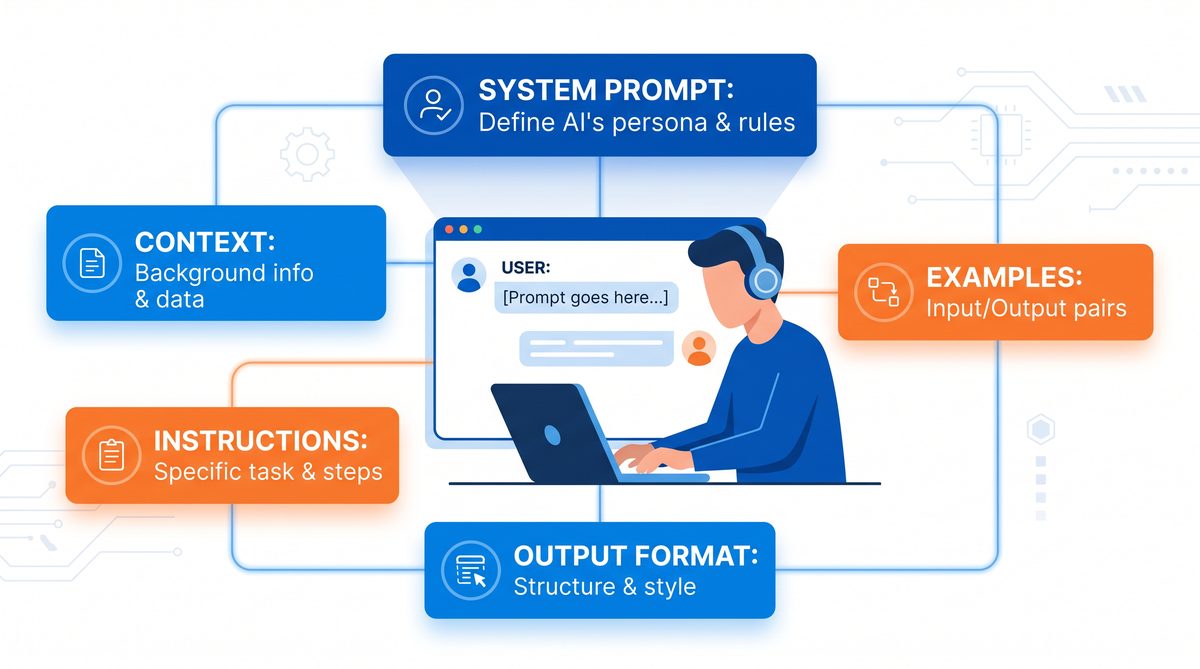
In production environments, prompts often grow complex and require frequent updates. Modularizing prompts into reusable components improves maintainability and scalability. This can be achieved by separating prompt elements such as instructions, examples, formatting guidelines, and context into distinct modules that can be dynamically combined.
For example, a modular prompt structure might look like:
- Instruction module: Defines the task objective.
- Example module: Contains few-shot demonstrations.
- Context module: Provides domain-specific data or background.
- Formatting module: Specifies output constraints or styles.
This approach improves prompt clarity, reduces duplication, and facilitates automated prompt generation pipelines.
Extraction Layer Separation
One of the advanced strategies for production prompting involves separating the generation phase from the extraction phase. The idea is to first generate a rich, structured output and then extract relevant information through a dedicated extraction layer or parser.
For instance, in a document summarization workflow, the model might produce a detailed summary with labeled sections (e.g., “Key Points,” “Risks,” “Recommendations”), which is then parsed programmatically to populate structured databases or dashboards.
This separation has several advantages:
- Improved error handling: Extraction logic can validate and correct generation outputs.
- Flexibility: The generation model can be updated independently of extraction rules.
- Enhanced explainability: Structured outputs clarify how conclusions were derived.
Practically, extraction layers can be implemented using regex patterns, rule-based parsers, or even secondary AI models fine-tuned for extraction tasks.
Golden Test Sets and Prompt Validation
Ensuring prompt quality in production requires systematic validation. Golden test sets—carefully curated datasets with expected outputs—serve as benchmarks to test prompt effectiveness over model updates and prompt iterations.
Key practices include:
- Maintaining a diverse set of test cases covering edge conditions and common scenarios.
- Automating periodic prompt evaluation using these golden sets.
- Tracking performance metrics such as accuracy, output consistency, and runtime latency.
- Using test results to refine prompt phrasing, example selection, and formatting instructions.
Golden test sets are critical for monitoring prompt drift, mitigating model hallucinations, and ensuring that prompt changes do not degrade quality.
Structured Prompting Frameworks
Several prompting frameworks have emerged to bring discipline and repeatability to prompt engineering. These frameworks formalize prompt construction, validation, and deployment, often integrating with model APIs and developer tools.
Examples of structured prompting frameworks include:
- Prompt templates: Parameterized prompts with placeholders for dynamic content.
- Prompt chaining: Linking multiple prompts in sequence where outputs feed into subsequent prompts.
- Prompt scoring and ranking: Generating multiple candidate outputs and selecting the best based on heuristics or learned metrics.
- Interactive debugging tools: Visualizing prompt input-output flows and token-level attention.
Adopting these frameworks increases development velocity and reduces the risk of brittle prompt designs in complex production environments.
When implementing these advanced AI workflows, understanding the underlying model architecture is crucial. Our comprehensive analysis of From Prompts to AI Skills: How to Build Reusable Prompt Workflows for ChatGPT, Claude, and Codex explores how parameter scaling affects reasoning capabilities in modern LLMs.
Prompting for Coding Agents: Codex and Claude Code
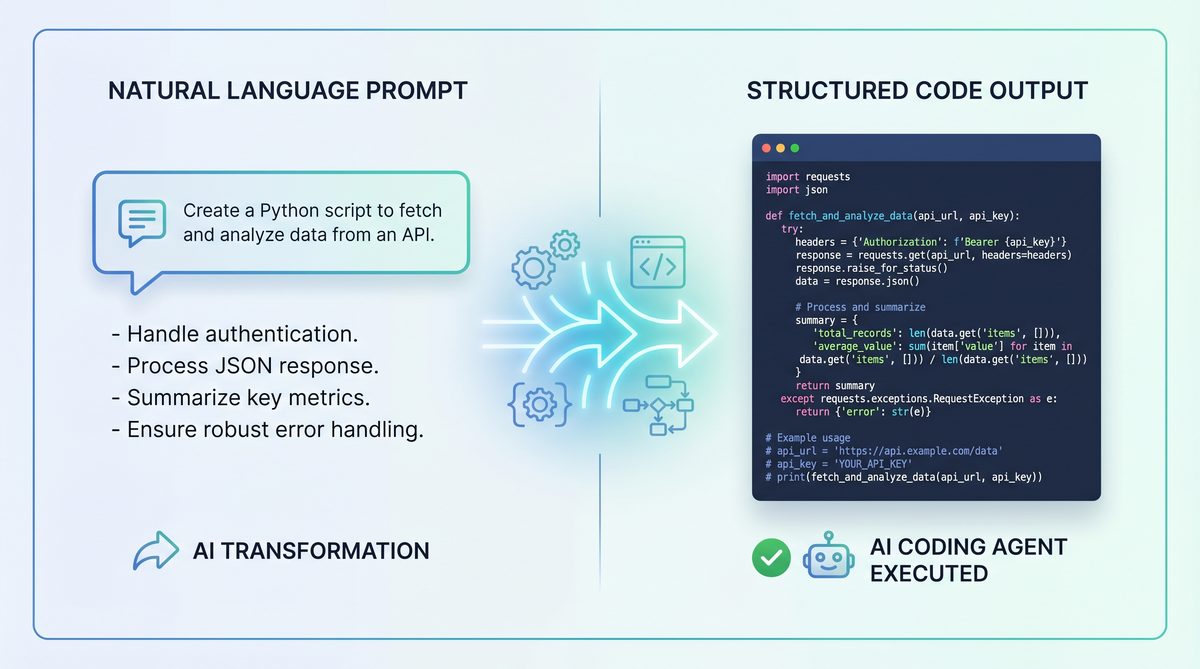
In 2026, AI-assisted coding agents such as OpenAI’s Codex and Anthropic’s Claude Code have revolutionized software development workflows. However, effective prompt engineering for coding models requires domain-specific strategies that differ from natural language prompting.
Key Considerations for Coding Prompts
- Precise task description: Clearly specifying the desired function, input-output format, and constraints.
- Contextual code snippets: Providing relevant codebase excerpts or API documentation as context.
- Style and idiomatic preferences: Indicating coding conventions, language versions, and commenting styles.
- Error handling instructions: Requesting the model to include validation or exception management.
For example, a prompt to generate a Python function might be:
# Write a Python function that calculates the factorial of a number using recursion. # Include input validation to handle negative numbers. def factorial(n):
Codex or Claude Code will typically continue the function implementation following these instructions.
Few-shot and Chain-of-Thought in Code Generation
Few-shot prompting is highly effective for coding agents, where including example function implementations or test cases can guide the model toward desired solutions. In addition, chain-of-thought prompting can be adapted as “chain-of-logic” prompting, where the model is encouraged to reason through algorithmic steps before coding.
Example of chain-of-logic prompt:
# To solve this problem, first check if the input is valid. # Then, apply a recursive approach by multiplying the current number by factorial of (n-1). # Finally, return the computed value. def factorial(n):
This helps reduce common coding errors and improves code readability.
Multi-turn Debugging and Code Refinement
Multi-turn conversation strategies are essential for iterative code development. Users can provide feedback on generated code, request optimizations, or ask for explanations in successive prompt turns. Effective multi-turn prompting involves:
- Referencing previous code snippets or responses explicitly.
- Maintaining stateful context to ensure continuity.
- Using clarifying questions to refine ambiguous requirements.
For instance, after receiving generated code, a user might prompt:
“The function works well, but can you optimize it for tail recursion? Also, add inline comments explaining each step.”
Such iterative prompting fosters collaborative AI-assisted programming environments.
To master multi-turn prompt management and state tracking with coding agents, our detailed walkthrough of How to Use OpenAI Codex CLI for Automated Data Pipelines: A Step-by-Step Tutorial provides a robust methodology for session design and context window optimization.
Multi-Turn Conversation Strategies for ChatGPT and Claude
Multi-turn conversations with AI models like ChatGPT and Claude have become the norm for complex query handling, decision support, and interactive applications. Effective multi-turn prompting relies on managing dialogue context, user intent shifts, and output consistency.
Context Preservation and Management
Maintaining relevant conversation history is vital for coherent multi-turn interactions. Developers often use one or more of the following techniques:
- Windowed context: Including only the most recent or relevant turns within the model’s token limit.
- Summarization: Using the model itself or external tools to generate concise summaries of earlier dialogue to include as context.
- State variables: Storing structured metadata or intent flags outside the model prompt to reduce token usage.
These methods help balance context richness and prompt length constraints while preserving conversational coherence.
Handling User Corrections and Clarifications
Users often revise their queries or provide clarifications mid-conversation. Prompt engineering can account for this by:
- Explicitly acknowledging corrections to maintain rapport and clarity.
- Reframing ambiguous queries based on prior dialogue.
- Using instructive prompts that encourage the model to ask clarifying questions if inputs are unclear.
Example prompt for clarification:
“I’m not sure I fully understand. Could you please clarify what you mean by ‘optimize’ in this context?”
Such strategies improve user experience and output relevance.
Session Initialization and Closing
Starting and ending conversations with clear framing prompts can set expectations and improve task focus.
Session initialization prompts might include:
- Defining the assistant’s role and capabilities.
- Specifying output formats or verbosity levels.
- Setting conversational goals or limitations.
Session closing can prompt for feedback or summarize key points to ensure satisfactory user outcomes.
Advanced multi-turn strategies also integrate with external knowledge bases, APIs, and user profiles to dynamically adapt responses—a frontier explored in our article on How to Use OpenAI Codex as Your AI Coding Agent: Complete Setup and Workflow Guide covering AI context augmentation techniques.
Comparative Overview of Prompting Techniques Across Models
| Technique | ChatGPT (GPT-4+) | Claude (v3+) | Codex/Claude Code |
|---|---|---|---|
| Zero-shot Prompting | Strong generalization; excels in natural language tasks. | High factual accuracy; excels in safety-sensitive tasks. | Limited for complex code without examples; best for simple snippets. |
| Few-shot Prompting | Improves style adaptation and domain specificity. | Effective for nuanced instructions; better handling of ambiguity. | Critical for guiding code style and API usage. |
| Chain-of-Thought Prompting | Highly effective for reasoning and complex Q&A. | Strong at stepwise reasoning with enhanced safety mitigations. | Adapted as chain-of-logic for code reasoning and debugging. |
| Multi-turn Conversation | Stateful dialogue support with memory window constraints. | Focus on interpretability and user correction integration. | Supports iterative code refinement and debugging workflows. |
| Production-grade Prompting | Supports modular templates and extraction layer separation. | Emphasizes robust prompt validation and safety filters. | Specialized prompt frameworks for code generation and validation. |
Future Trends in Prompt Engineering
As we look beyond 2026, prompt engineering will continue to evolve in response to expanding AI capabilities and deployment scenarios. Anticipated trends include:
- Automated prompt synthesis: AI-generated prompts that optimize themselves through reinforcement learning or evolutionary algorithms.
- Multi-modal prompt integration: Combining text, code, images, and audio inputs in unified prompting frameworks.
- Personalized prompting: Adapting prompts dynamically based on user profiles, preferences, and real-time feedback.
- Hierarchical prompting: Layered prompts that orchestrate multiple specialized models for complex workflows.
- Explainability-by-design: Embedding transparent reasoning steps and output provenance within prompts.
These advancements will deepen the symbiosis between humans and AI, making prompt engineering an increasingly strategic skill for AI-driven innovation.
Useful Links
- OpenAI Prompting Guide
- Anthropic Claude Official Documentation
- OpenAI Cookbook on GitHub
- Chain-of-Thought Prompting Paper (Wei et al.)
- Microsoft Prompt Engineering Guide
- OpenAI Codex Model Documentation
- Hugging Face: A Guide to Prompt Engineering
- Survey on Prompt Engineering Techniques (2023)
Useful Links and Resources
Here are some valuable resources to help you explore the topics covered in this article:
- OpenAI Prompt Engineering Guide
- Anthropic Prompt Library
- Learn Prompting
- Prompt Engineering Institute
- OpenAI Cookbook
- Chain-of-Thought Prompting Paper
🕐 Instant∞ Unlimited🎁 Free
Get Free Access to 40,000+ AI Prompts
Join 40,000+ AI professionals. Get instant access to our curated Notion Prompt Library with prompts for ChatGPT, Claude, Codex, Gemini, and more — completely free.
Get Free Access Now →No spam. Instant access. Unsubscribe anytime.