Multi-Agent Prompting with Claude 4.6 Sonnet: Building AI Code Review Pipelines That Actually Work
Multi-Agent Prompting with Claude 4.6 Sonnet: Building AI Code Review Pipelines That Actually Work
[IMAGE_PLACEHOLDER_HEADER]
1. Introduction: Why Multi-Agent Beats Single-Agent for Code Review
In the rapidly evolving landscape of AI-assisted software development, the complexity of code review demands more than just a single AI agent attempting to cover every aspect. The multifaceted nature of code review—encompassing security audits, style consistency, bug detection, and concise summarization—requires specialized expertise that a single monolithic AI model often cannot deliver efficiently or accurately.
Multi-agent AI architectures, exemplified by the Claude 4.6 Sonnet and Opus 4.6/4.7 models, embrace this challenge by deploying a team of specialized agents, each fine-tuned for a specific review domain. This approach mirrors human code review workflows where different experts focus on security, code quality, or documentation.
For example, Opus 4.7 excels at security-sensitive reviews, detecting vulnerabilities and PII leaks with high accuracy, while Claude 4.6 Sonnet specializes in generating clear technical summaries and enforcing coding style. This division of labor not only enhances review quality but also optimizes resource allocation, reduces latency, and simplifies maintenance.
The success of this methodology is demonstrated by industry leaders like Uber, who have adopted multi-agent AI pipelines to the extent that nearly 11% of their live backend updates are AI-generated, achieving unprecedented throughput and reliability.
For a deeper dive into effective agent prompting strategies, see our Advanced Prompting for AI Desktop Agents: The 2026 Mastery Guide, which explores best practices in managing complex workflows and autonomous AI agent interactions.
[INTERNAL_LINK]
2. The Multi-Agent Architecture Explained
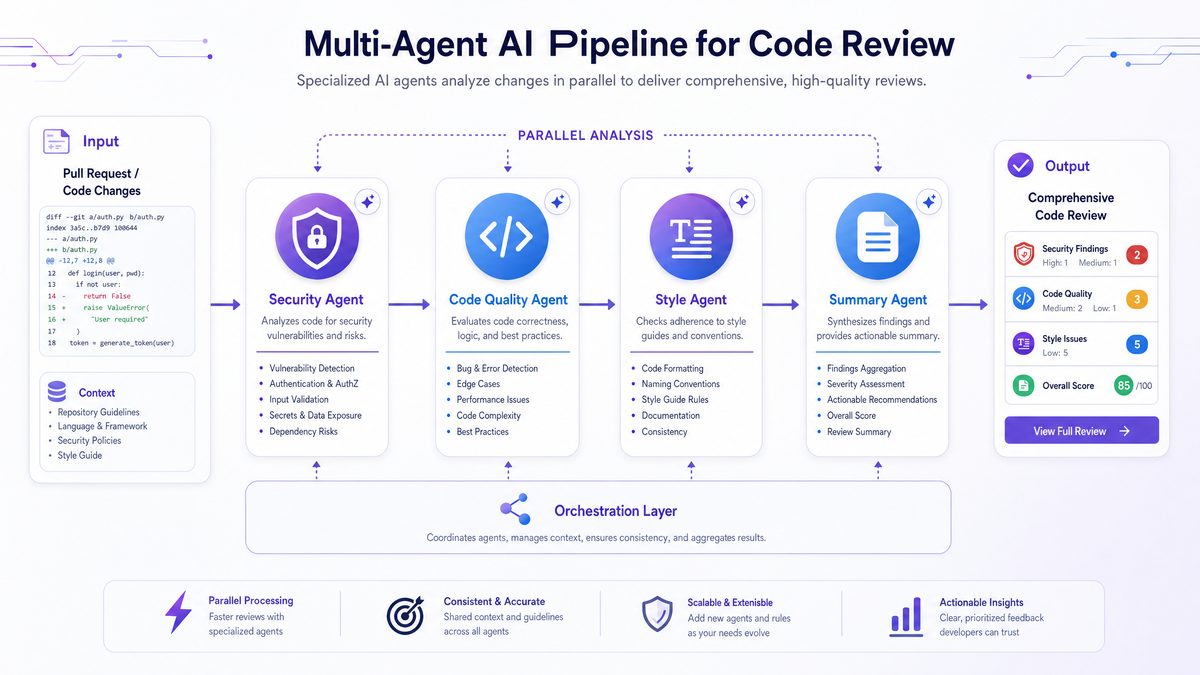
The foundation of a multi-agent AI code review pipeline is a well-orchestrated system where several specialized agents, each running a variant of Claude or Opus, analyze different facets of a single Pull Request (PR). This modular architecture enables parallel processing and focused expertise, delivering comprehensive and actionable feedback.
Typical agents in such a pipeline include:
- Security Reviewer (Opus 4.7): Focuses on identifying PII leaks, prompt injection vulnerabilities, and insecure API usage.
- Static Analyzer (Sonnet 4.6): Detects bugs, code smells, and architectural flaws through deep static analysis.
- Style Enforcer (Sonnet 4.6): Ensures adherence to coding standards, formatting, and naming conventions.
- Summary Generator (Sonnet 4.6): Produces concise, human-readable summaries of PR changes for efficient stakeholder communication.
Each agent operates under a carefully crafted system prompt tailored to maximize output quality in its domain. The agents communicate indirectly via a central orchestrator responsible for input sanitation, coordinating execution (parallel or sequential), aggregating results, resolving conflicting feedback, and producing a unified review report.
This architecture offers flexibility to swap or upgrade individual agents without disrupting the entire pipeline, allowing teams to adapt to evolving codebase needs and AI model improvements.
[IMAGE_PLACEHOLDER_SECTION_1]
3. Detailed Agent Roles and Prompt Templates
3.1 Security Reviewer (Opus 4.7)
The Security Reviewer serves as the gatekeeper against vulnerabilities that could compromise the codebase or downstream AI systems. Utilizing Opus 4.7’s enhanced semantic understanding and security training, it performs a thorough inspection of code diffs to detect:
- Exposure of Personally Identifiable Information (PII) such as passwords, API keys, tokens, or user data.
- Prompt injection attacks that could manipulate AI behavior.
- Insecure cryptographic patterns or unsafe use of authentication APIs.
System prompt template:
System:
You are a highly specialized AI security auditor based on Opus 4.7, tasked with scanning the provided code diff for any potential security vulnerabilities. Your focus areas include:
- Detection of Personally Identifiable Information (PII) leaks such as passwords, API keys, tokens, or user data.
- Identification of prompt injection vulnerabilities that might compromise AI systems.
- Inspection of cryptographic and authentication-related code for insecure patterns.
Instructions:
- Analyze the code changes carefully and highlight exact lines with issues.
- Provide a detailed explanation of the vulnerability and potential impact.
- Suggest actionable remediation steps.
- Maintain a professional and precise tone suitable for engineering teams.
Code Diff:
{insert code diff here}This focused prompt ensures the agent’s attention remains on security aspects, leveraging Opus 4.7’s specialized training to surface subtle and complex vulnerabilities.
3.2 Static Analyzer (Sonnet 4.6)
The Static Analyzer agent detects bugs and architectural issues beyond the capabilities of traditional static analysis tools. It leverages Sonnet 4.6’s deep understanding of programming languages to:
- Identify common bug patterns such as null dereferences, race conditions, and off-by-one errors.
- Assess code complexity and highlight areas for simplification.
- Spot architectural anti-patterns that could impair maintainability or scalability.
System prompt template:
System:
You are an expert AI static code analyzer built on Claude 4.6 Sonnet. Your goal is to review the provided code changes for correctness, bug detection, and architectural soundness.
Instructions:
- Identify any potential bugs or logical errors in the code.
- Highlight sections with excessive complexity or technical debt.
- Provide clear explanations for your findings.
- Suggest improvements or refactorings where applicable.
- Avoid comments on style or formatting; focus solely on code correctness.
Code Diff:
{insert code diff here}This agent’s natural language explanations make its feedback highly actionable and easier to understand than raw static analysis reports.
3.3 Style Enforcer (Sonnet 4.6)
Consistency in code style is vital for readability and maintainability. The Style Enforcer focuses exclusively on enforcing coding standards, such as PEP8 or Google Style Guide, by:
- Checking naming conventions, indentation, spacing, and comment formats.
- Flagging deviations and recommending automated linting fixes.
- Separating style feedback from functional or security reviews to reduce noise.
System prompt template:
System:
You are an AI style enforcement specialist using Claude 4.6 Sonnet. Your task is to review the code diff with a focus on style and formatting.
Instructions:
- Assess compliance with the specified style guide: {insert relevant style guide}.
- Identify any deviations in naming, indentation, spacing, or comment styles.
- Suggest concrete formatting changes or linting rules to apply.
- Do not comment on code correctness or security.
- Provide feedback in clear, constructive language.
Code Diff:
{insert code diff here}3.4 Summary Generator (Sonnet 4.6)
The Summary Generator synthesizes complex code changes into clear, concise summaries that facilitate rapid understanding for both engineers and non-technical stakeholders:
- Extracts the purpose and scope of the PR.
- Highlights key functional modifications and affected components.
- Notes potential risks or required follow-ups.
System prompt template:
System:
You are an AI-powered technical summarizer running on Claude 4.6 Sonnet. Your role is to generate a clear, concise summary of the provided code changes.
Instructions:
- Describe the purpose and scope of the changes.
- Highlight key functional modifications and affected components.
- Mention any potential issues or required follow-ups.
- Write in professional language suitable for engineering teams and product managers.
- Keep the summary under 200 words.
Code Diff:
{insert code diff here}By integrating this agent, teams reduce review cycle times and improve communication across roles.
[IMAGE_PLACEHOLDER_SECTION_2]
[INTERNAL_LINK]
4. Orchestration and Pipeline Management
Multi-agent AI pipelines require robust orchestration mechanisms to coordinate agent execution, manage inputs and outputs, and produce coherent review reports. Key orchestration tasks include:
- Execution strategy: Decide between parallel and sequential agent runs. For example, running the Security Reviewer first can block unsafe merges early, while other agents may run concurrently to save time.
- Input sanitation: Prepare consistent, sanitized code diffs for each agent, handling token limits and data formatting.
- Result aggregation: Merge heterogeneous outputs into a unified review, prioritizing critical security issues and reconciling conflicting feedback.
- Conflict resolution: Apply rule-based weighting or escalate ambiguous cases to human reviewers to maintain trust and accuracy.
This modular orchestration enables flexible pipeline customization, allowing teams to introduce new agents or adjust workflows based on project requirements.
[INTERNAL_LINK]
5. Cost, Performance, and Accuracy Considerations
Running multiple AI agents per PR naturally raises concerns about cost and latency. It is essential to understand the trade-offs between Claude 4.6 Sonnet and Opus 4.6/4.7 in various agent roles.
| Agent Role | Model | Cost per 1,000 tokens (USD) | Latency | Accuracy/Focus | Recommended Usage |
|---|---|---|---|---|---|
| Security Reviewer | Opus 4.7 | Higher ($0.12) | Medium | High (security-focused) | Critical security checks, PII detection |
| Static Analyzer | Sonnet 4.6 | Moderate ($0.08) | Low | High (code correctness) | Bug detection, architectural review |
| Style Enforcer | Sonnet 4.6 | Moderate ($0.08) | Low | Medium (style-focused) | Code style and formatting |
| Summary Generator | Sonnet 4.6 | Moderate ($0.08) | Low | High (natural language) | PR summaries and explanations |
To optimize costs while maintaining quality, teams can apply strategies such as:
- Batching style enforcement checks for multiple PRs.
- Using Opus 4.7 selectively for high-risk or security-critical PRs.
- Caching common prompt completions when applicable.
- Monitoring token usage and API calls with automated analytics dashboards.
These measures help sustain scalable AI-assisted code review without excessive budget overruns.
6. Advanced Techniques for Enhancing Multi-Agent Pipelines
Beyond basic prompt design and orchestration, several advanced strategies can significantly improve multi-agent code review pipelines:
6.1 Adaptive Agent Invocation Based on Code Context
Not every PR requires all agents. Implementing dynamic invocation based on PR characteristics conserves resources:
- Contextual triggers: Skip the Security Reviewer for documentation-only changes or Static Analyzer for non-code assets.
- Incremental reviews: Break large PRs into smaller chunks assigned selectively to agents.
- Risk scoring: Use historical bug densities or threat intelligence to prioritize security checks.
6.2 Context Enrichment Through External Metadata
Providing agents with enriched context improves feedback relevance:
- Dependency graphs: Information about affected modules helps in architectural impact analysis.
- Commit history: Recent changes and author patterns assist in detecting recurring issues.
- Security policies: Embedding internal compliance standards guides security-focused agents.
6.3 Feedback Loop Integration and Continuous Learning
Incorporating human feedback and analytics drives continuous pipeline improvement:
- Human-in-the-loop validation: Engineers review AI comments for false positives and gaps.
- Automated error analysis: Track precision, recall, and latency metrics per agent.
- Prompt tuning: Regularly refine system prompts to address weaknesses.
- Model fine-tuning: When feasible, adapt Claude or Opus models on internal code review datasets.
7. Practical Workflow Examples
7.1 Workflow A: Security-Critical Enterprise Application
- Orchestrator triggers Security Reviewer (Opus 4.7) first; flags critical vulnerabilities for immediate human review.
- Static Analyzer (Sonnet 4.6) assesses correctness and architecture.
- Style Enforcer (Sonnet 4.6) verifies compliance with style guides.
- Summary Generator (Sonnet 4.6) produces a comprehensive report for engineering managers.
This sequential pipeline is ideal for finance, healthcare, or other high-stakes domains where security is paramount.
7.2 Workflow B: Agile Startup with Rapid Feature Delivery
- All agents run in parallel to minimize review latency.
- Security Reviewer uses a reduced prompt scope focusing on critical vulnerabilities.
- Style enforcement is batched weekly, except for core UI changes.
- Summary outputs are integrated directly into PR comments for developer visibility.
This parallelized pipeline supports fast iteration without compromising essential quality checks.
8. Common Pitfalls and How to Avoid Them
- Overlapping responsibilities: Avoid duplicated or conflicting feedback by defining clear agent scopes and prompt boundaries.
- Prompt drift: Continuously monitor and update prompts to maintain effectiveness.
- Latency bottlenecks: Optimize for parallel execution and asynchronous processing.
- Cost overruns: Implement usage caps, selective agent invocation, and token management.
- Security risks: Handle sensitive code securely with data anonymization and compliance best practices.
9. Comparative Analysis: Multi-Agent vs Monolithic AI Code Review Systems
| Dimension | Multi-Agent Pipeline | Monolithic AI Review |
|---|---|---|
| Specialization | Agents specialized for security, style, bugs, summaries | Single model attempts to cover all aspects simultaneously |
| Scalability | Modular agents can be scaled or upgraded independently | Scaling requires retraining/upgrading a large monolithic model |
| Cost Efficiency | Potentially higher due to multiple calls; mitigated by selective invocation | Lower per PR call volume but risk of lower precision and increased false positives |
| Latency | Optimizable through parallel execution; may increase with sequential dependencies | Single call per review; generally lower latency but may sacrifice depth |
| Feedback Clarity | Clear, focused feedback aligned with agent roles | Mixed feedback that can be ambiguous or overwhelming |
| Maintenance | Agents updated individually, easier to test and validate | Complex updates needed for entire system; higher regression risk |
| Error Handling | Conflicts resolved by orchestrator rules or human escalation | Difficult to isolate error sources within monolithic output |
10. Best Practices for Monitoring and Observability
10.1 Comprehensive Logging
Log agent inputs, outputs, token usage, response times, and errors for root cause analysis and performance monitoring.
10.2 Metrics and Dashboards
- Accuracy: Track false positive/negative rates per agent.
- Latency: Monitor response times to identify bottlenecks.
- Cost: Analyze token consumption and API usage.
- Feedback volume: Detect prompt drift or over-reporting tendencies.
10.3 Alerting and Automated Remediation
Set thresholds and alerts for anomalies, triggering human review or pipeline adjustments as needed.
10.4 Continuous Improvement Cycles
Use monitoring insights to refine prompts, update models, and optimize pipeline configurations regularly.
11. Integration with Development Tools
11.1 Pull Request Platforms
Directly post review comments, summaries, and status checks to GitHub, GitLab, or Bitbucket to reduce context switching.
11.2 Continuous Integration (CI) Systems
Embed multi