Inside Stargate: How OpenAI Is Building the $500 Billion Compute Foundation for AGI
[IMAGE_PLACEHOLDER_HEADER]
The Scale of Stargate: OpenAI’s $500 Billion AI Infrastructure Project
In the rapidly evolving landscape of artificial intelligence, infrastructure has become a defining factor in the race to achieve artificial general intelligence (AGI). OpenAI’s Stargate project represents a monumental leap in this domain, backed by an unprecedented $500 billion investment aimed at building the world’s most advanced AI compute ecosystem.
Initially committed to deploying 10 gigawatts (GW) of compute capacity by 2029, Stargate has already surpassed this milestone, adding an astonishing 3GW in the last 90 days alone. This scale of compute power is not just about raw numbers; it’s about fundamentally redefining how AI models are trained, deployed, and scaled globally to accelerate the path toward AGI.
With seven strategically located sites across the United States, the project’s epicenter is the flagship facility in Abilene, Texas. These sites are powered by partnerships with industry giants such as Oracle, SoftBank, NVIDIA, and Vantage Data Centers, leveraging cutting-edge hardware and cloud infrastructure to support the next generation of AI workloads.
OpenAI’s Stargate initiative embodies a vision of a sustainable, efficient, and community-integrated approach to AI infrastructure that can fuel continuous innovation and maintain leadership in the AI revolution.

Why Compute is the Critical Input for AGI
Compute power, in the context of artificial intelligence, refers to the processing capability required to train and run complex machine learning models. For AGI—the hypothetical machine intelligence capable of understanding or learning any intellectual task a human can—compute is arguably the single most critical input. The reason is straightforward: the sophistication and capability of AI models scale directly with the amount of compute they consume.
Historically, AI breakthroughs have closely followed advances in compute availability. From the early days of neural networks to the current era of transformer-based architectures, the ability to train larger models with more data on faster hardware has led to exponential improvements in performance and functionality.
OpenAI’s Stargate project acknowledges this correlation by investing heavily in high-density compute power capable of sustaining continuous model training at an unprecedented scale. This compute-centric approach is foundational to unlocking the next generation of AI capabilities.
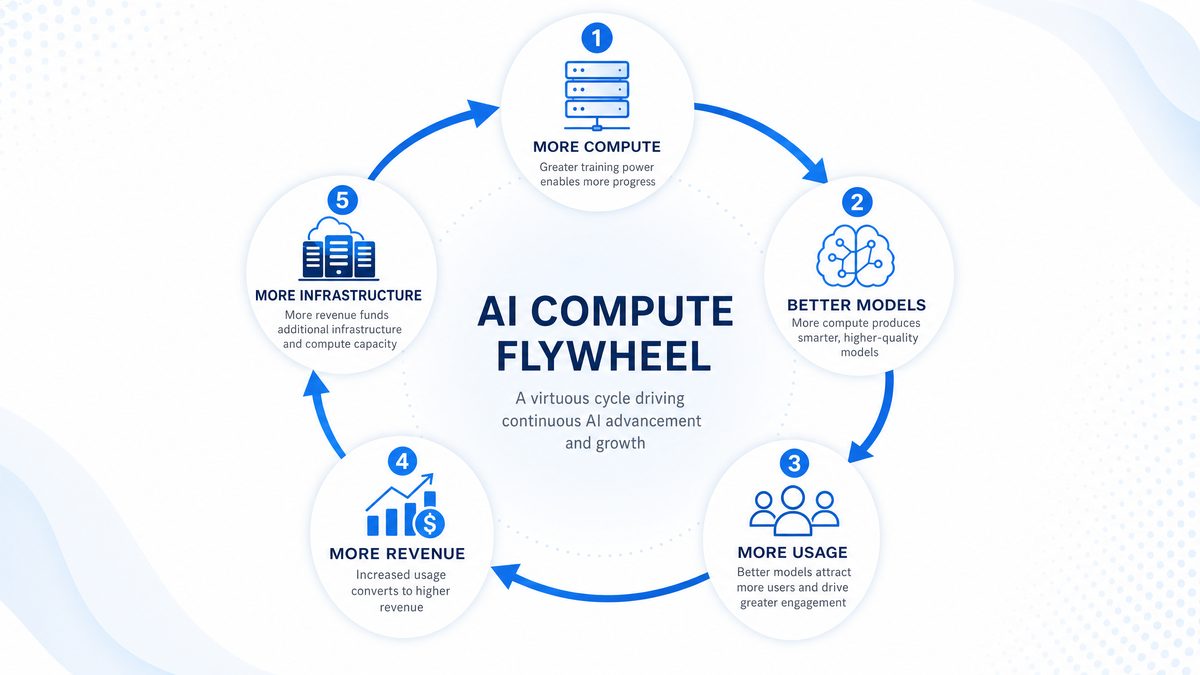
The concept of the “AI flywheel” encapsulates this relationship perfectly: more compute enables better models, which in turn drive increased usage and revenue, fueling further investment in infrastructure. This virtuous cycle accelerates the path toward AGI by systematically increasing the computational resources available to AI researchers and developers.
Moreover, the focus is not solely on quantity but also quality of compute. Efficient hardware, optimized cooling, and advanced software stacks maximize the output of each watt of power consumed. OpenAI’s commitment to surpassing 10GW well ahead of schedule demonstrates how compute is now a strategic asset rather than just a technical requirement.
[IMAGE_PLACEHOLDER_SECTION_1]
The Partnership Ecosystem Powering Stargate
Building a project of Stargate’s magnitude requires collaboration across multiple industry leaders, each bringing unique expertise and resources. OpenAI has forged strategic partnerships with Oracle, SoftBank, NVIDIA, and Vantage Data Centers, creating a robust ecosystem designed to deliver world-class AI infrastructure.
- Oracle Cloud Infrastructure (OCI): Oracle provides the scalable cloud backbone for Stargate, offering high-performance networking, secure storage, and flexible compute instances. OCI’s ability to handle large-scale AI workloads with minimal latency is a cornerstone of the Stargate architecture.
- SoftBank: As a financial and strategic partner, SoftBank facilitates capital investment and global infrastructure planning, enabling rapid expansion and site development across the United States.
- NVIDIA: NVIDIA supplies the latest GB200 AI systems, optimized for deep learning workloads. These GPUs offer the computational density and efficiency required to train large models like GPT-5.5.
- Vantage Data Centers: Specializing in hyperscale data center design and operation, Vantage ensures that Stargate’s physical infrastructure meets stringent requirements for scalability, reliability, and sustainability.
This multi-faceted partnership model reflects a shift from traditional, vertically integrated AI infrastructure toward a more collaborative and modular approach, enabling OpenAI to leverage best-in-class capabilities across the technology stack. For insights on how these partnerships influence AI development, explore our detailed analysis on [INTERNAL_LINK].
As developers and researchers look to harness OpenAI’s powerful tools, understanding how to effectively utilize OpenAI Codex for coding tasks is essential; the article How to Use OpenAI Codex Computer Use: Step-by-Step Tutorial for 2026 provides a comprehensive guide on deploying Codex’s capabilities in real-world programming scenarios, making it highly relevant for those interested in building scalable AI-driven solutions within the evolving AI infrastructure outlined in the Stargate project.
Inside the Abilene Flagship Facility
The Abilene site in Texas is the crown jewel of the Stargate project—both in terms of scale and technological sophistication. Designed to be a high-density compute hub, Abilene integrates advanced hardware, efficient cooling systems, and robust networking infrastructure to create an optimal environment for large-scale AI training.
Covering hundreds of thousands of square feet, the facility houses thousands of NVIDIA GB200 GPU systems connected via Oracle’s high-speed cloud fabric. This interconnected compute grid allows for parallel training of massive AI models, drastically reducing training time and improving model iteration speed.
One of the most notable achievements at Abilene is the successful training of GPT-5.5, a landmark model that showcases significant advancements over its predecessors in terms of capability and efficiency. The site’s design supports continuous, large-scale workloads with minimal downtime, a critical factor for maintaining OpenAI’s competitive edge.
The facility also employs sophisticated monitoring and automated management tools to optimize performance and energy usage, reflecting a commitment to operational excellence. Its location in Abilene was chosen for strategic reasons including access to affordable power, favorable climate conditions for cooling, and proximity to key partners.
The Technology Stack: Oracle Cloud Infrastructure and NVIDIA GB200 Systems
At the heart of Stargate’s compute engine lies the synergy between Oracle Cloud Infrastructure and NVIDIA’s GB200 GPU systems. This technology stack is engineered to deliver unmatched performance for AI training and inference workloads.
Oracle Cloud Infrastructure (OCI)
OCI provides a scalable, secure, and high-throughput cloud environment tailored for AI workloads. Its architecture supports the massive data throughput requirements of deep learning while minimizing latency and maximizing uptime. Key features include:
- High-bandwidth networking: Oracle’s RDMA over Converged Ethernet (RoCE) enables ultra-low latency communication between GPU nodes.
- Flexible compute instances: Instances can be dynamically scaled to meet the demands of varying workload sizes.
- Advanced security: Multi-layered encryption and compliance certifications ensure data integrity and privacy.
NVIDIA GB200 GPU Systems
The NVIDIA GB200 represents the latest generation of AI-focused GPU hardware, optimized for training large transformer models. Its features include:
- Multi-chip module design: Enhances computational density within a compact form factor.
- Tensor Core technology: Accelerates matrix operations crucial for deep learning.
- Energy efficiency: Designed to maximize performance-per-watt, reducing operational costs.
The combination of OCI and GB200 GPUs creates a high-performance environment tailored specifically for AI workloads, enabling faster training cycles and more complex model architectures.
For a broader perspective on evolving hardware and cloud solutions, see our in-depth analysis on [INTERNAL_LINK].
As OpenAI advances the massive infrastructure needed for AGI, understanding how to evaluate AI systems becomes increasingly critical; the article Measuring AI Output Quality: KPIs, Guardrails, And ‘Stop’ Conditions delves into the key performance indicators, safety guardrails, and stop conditions essential for ensuring reliable and aligned AI outputs, making it highly relevant for those interested in the development and deployment of foundational AI technologies.
Energy and Sustainability Approach
One of the most challenging aspects of deploying multi-gigawatt AI infrastructure is balancing energy consumption with environmental responsibility. OpenAI’s Stargate project addresses this through a sophisticated approach to cooling and water use, prioritizing sustainability without compromising performance.
Unlike many data centers that rely on evaporative cooling—which consumes large volumes of water—Abilene and other Stargate sites utilize closed-loop cooling systems. This method recirculates water within a sealed system, significantly reducing water loss. The initial fill for each building is approximately equivalent to two Olympic swimming pools, but ongoing water usage is minimal.
This approach ensures responsible water stewardship in regions where water scarcity is a concern. Additionally, closed-loop cooling reduces the risk of contaminants entering the system, improving reliability and lowering maintenance overhead.
Stargate also targets energy efficiency at every layer of its infrastructure stack—from hardware selection to power distribution and management. By optimizing the power usage effectiveness (PUE) of its facilities, OpenAI is setting new benchmarks for sustainable AI compute.
In parallel, the project explores sourcing renewable energy and engaging with local utilities to integrate green power solutions where feasible, reinforcing a commitment to environmental stewardship.
Community Impact and Workforce Development
Beyond raw compute power, the Stargate project is designed to be a positive force within local communities. OpenAI has committed to extensive engagement and investment programs aimed at workforce development and educational support, ensuring that the benefits of AI infrastructure development extend beyond technological innovation.
Partnering with local education foundations, the project provides donations and resources to support STEM education and AI literacy programs. This includes funding scholarships, sponsoring coding bootcamps, and facilitating access to AI research opportunities for underrepresented groups.
OpenAI also collaborates closely with the North America’s Building Trades Unions (NABTU) to create workforce programs that develop skills in data center construction, operations, and maintenance. This partnership ensures that local workforces are equipped with the expertise necessary to sustain high-tech infrastructure and benefit economically from the project.
By fostering community involvement and workforce training, Stargate aims to create a sustainable AI ecosystem that supports long-term regional growth and socioeconomic development.

The Strategic Pivot: Flexibility Over Ownership
In its early phases, OpenAI relied heavily on first-party data centers to control all aspects of its compute infrastructure. However, the Stargate project marks a significant strategic shift toward more flexible leasing arrangements and partnerships. This evolution addresses several challenges:
- Scalability: Leasing allows OpenAI to rapidly scale compute capacity without the long lead times and capital expenditure associated with building proprietary data centers.
- Operational agility: Flexibility in location and vendor relationships enables better adaptation to changing technology and market conditions.
- Risk management: Diversifying infrastructure ownership reduces exposure to single points of failure and supply chain constraints.
This pivot reflects a broader industry trend toward hybrid infrastructure models, where organizations blend owned and leased resources to optimize cost, performance, and responsiveness. OpenAI’s approach leverages the strengths of its partners while maintaining control over key architectural and operational decisions.
From Infrastructure to Intelligence: The GPT-5.5 Connection
The fruits of Stargate’s compute power are exemplified by the training of GPT-5.5 at the Abilene flagship facility. This model represents a significant leap in natural language understanding and generation, incorporating novel architectural improvements and training techniques that push the boundaries of AI capabilities.
Training GPT-5.5 required sustained, high-density compute enabled by the integrated Oracle-NVIDIA stack and the facility’s optimized environment. The scale of compute allowed for larger datasets, longer training cycles, and more complex experimentation. The result is a model that delivers enhanced contextual understanding, reasoning, and multi-modal processing capabilities.
GPT-5.5’s performance improvements have accelerated adoption across industries, driving increased usage that feeds back into the “AI flywheel” of compute investment and model refinement. This cycle exemplifies how infrastructure investment directly fuels advances in AI intelligence, creating a continuous innovation loop.
For a comprehensive overview of the latest model capabilities and their implications, visit our detailed coverage on [INTERNAL_LINK].
As OpenAI continues to expand its compute capabilities foundational for AGI, understanding the latest enhancements in its models becomes crucial; for instance, GPT-5.5 Instant: OpenAI’s New Default ChatGPT Model Explained details how the newest iteration improves responsiveness, accuracy, and deployment efficiency, making it highly relevant for those interested in the practical implications of OpenAI’s infrastructure investments for advancing AI capabilities.
Scaling AI Compute: Challenges and Solutions
Scaling AI compute to multi-gigawatt levels presents a unique set of challenges that extend beyond hardware procurement. These challenges include managing heat dissipation, ensuring network bandwidth, maintaining system reliability, and optimizing cost-effectiveness. OpenAI’s Stargate project addresses each of these with tailored solutions, combining cutting-edge technology with innovative operational strategies.
Thermal Management at Scale
At the scale of thousands of GPU nodes working in tandem, heat generation becomes a critical bottleneck. Traditional air cooling is often insufficient, leading to hotspots that can degrade performance and increase hardware failure rates. Stargate’s approach leverages advanced liquid cooling techniques, including direct-to-chip cooling and immersion cooling in select environments.
Direct-to-chip cooling involves circulating coolant directly over the GPU and CPU components, providing precise temperature control and significantly higher heat transfer efficiency compared to air cooling. Immersion cooling, although less common, submerges hardware in dielectric fluids to dissipate heat rapidly while reducing noise and dust ingress.
These cooling solutions not only improve hardware longevity but also enable higher operational frequencies, translating into better performance and energy efficiency. The integration of real-time thermal monitoring systems allows for dynamic adjustments to cooling parameters, ensuring optimal conditions under varying workloads.
Networking Infrastructure: Overcoming Bandwidth Bottlenecks
High-performance AI models require fast and reliable data movement between compute nodes. With thousands of GPUs interconnected, network architecture must minimize latency and maximize throughput. Stargate employs a high-bandwidth fabric based on Oracle’s RDMA over Converged Ethernet (RoCE), which delivers sub-microsecond latency and multi-terabit per second aggregate bandwidth.
This fabric enables efficient parameter synchronization during distributed training, which is critical for maintaining model accuracy and reducing training time. OpenAI’s engineering teams optimize network topology to reduce hop counts and leverage adaptive routing to mitigate congestion.
In addition, Stargate incorporates quality of service (QoS) mechanisms to prioritize critical data flows and ensure consistent performance across diverse workloads. This network design supports elasticity, allowing compute clusters to scale up or down with minimal disruption.
Reliability and Fault Tolerance
Operating at scale introduces increased risk of hardware failures, network interruptions, and software bugs. Stargate implements multi-layered fault tolerance strategies combining hardware redundancy, error correction, and automated recovery protocols.
Hardware redundancy includes redundant power supplies, network interfaces, and cooling units to maintain uptime during component failures. At the software level, distributed training frameworks like DeepSpeed and Horovod incorporate checkpointing and gradient accumulation to recover seamlessly from interruptions.
Automated monitoring systems detect anomalies in real time, triggering alerts and initiating corrective actions such as workload migration or node rebooting without human intervention. This approach minimizes downtime and preserves training progress, vital for sustaining continuous model development cycles.
Cost Optimization Strategies
While compute scale is essential, managing operational costs remains a priority. Stargate balances capital and operational expenditures by negotiating volume discounts with hardware vendors, optimizing energy consumption, and employing workload scheduling algorithms that maximize resource utilization.
Dynamic workload scheduling allows underutilized GPU clusters to be assigned to lower-priority experiments or inference tasks, ensuring minimal idle time. Additionally, leveraging spot instances and hybrid cloud configurations helps absorb demand spikes cost-effectively.
OpenAI’s procurement strategy includes forward-looking capacity planning to avoid over-provisioning while maintaining flexibility. These measures collectively support a sustainable economic model for large-scale AI infrastructure.
Comparing AI Compute Architectures: Stargate vs. Traditional Data Centers
Understanding how OpenAI’s Stargate infrastructure differentiates itself requires a comparative analysis against traditional enterprise and hyperscale data center designs. The following table highlights key aspects where Stargate’s design excels or diverges.
| Feature | Stargate Infrastructure | Traditional Data Centers | Hyperscale Cloud Providers |
|---|