Tree of Thoughts, Persona Prompting, and Meta-Prompts: The New Prompt Engineering Playbook
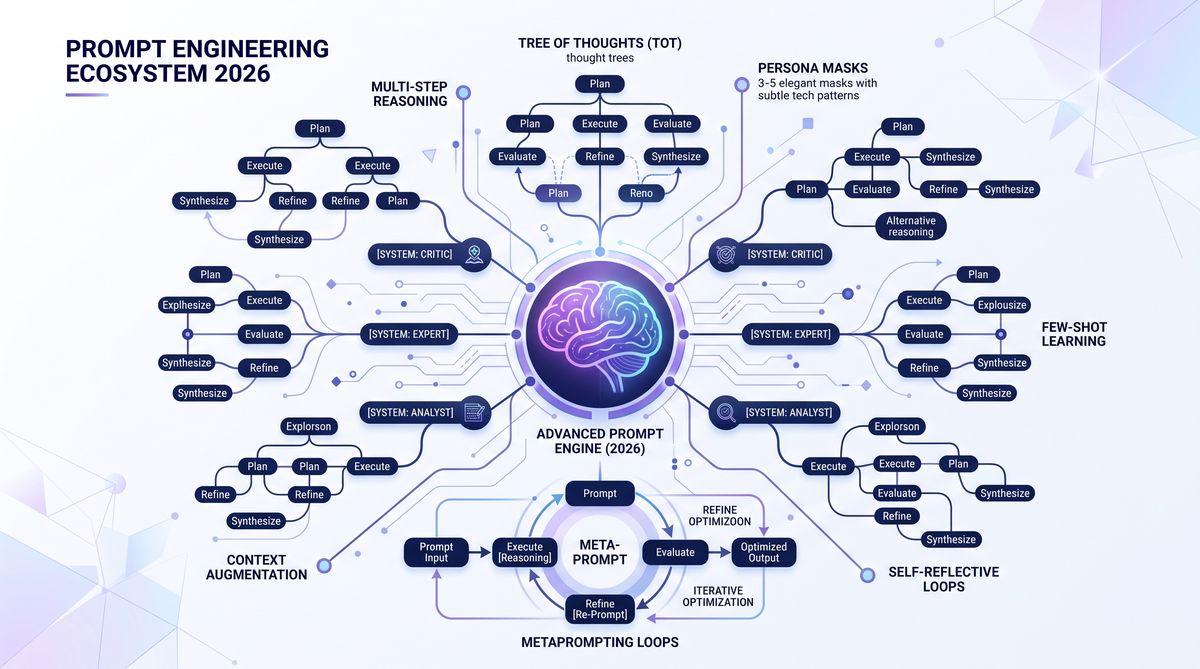
Since the inception of large language models (LLMs) such as OpenAI’s GPT series and Anthropic’s Claude, the art and science of prompt engineering have undergone profound transformations. What began as rudimentary textual instructions quickly evolved into a sophisticated discipline critical to harnessing the full potential of these generative AI systems. From 2020, when prompt engineering was largely experimental and limited to simple task instructions, to 2026, where we now leverage complex cognitive frameworks like Tree of Thoughts, persona-based prompting, and meta-prompting, the journey has been marked by significant breakthroughs, empirical insights, and cross-disciplinary innovations.
In the early days, prompt crafting was mostly heuristic-driven, relying on trial and error to coax desired responses from models. Developers and researchers experimented with varying prompt lengths, explicit task definitions, and keyword emphasis. However, as LLMs grew in size and complexity, these methods became insufficient to address nuanced requirements such as multi-step reasoning, context retention, and style adaptation. The introduction of Chain of Thought (CoT) prompting around 2022 was a pivotal moment. CoT demonstrated that guiding models to articulate intermediate reasoning steps led to substantial improvements in logical problem solving and complex question answering. This advancement sparked a wave of research into structured prompt designs and reasoning frameworks.
Yet, by 2024, it became apparent that CoT had limitations, particularly when dealing with tasks requiring branching reasoning paths, iterative hypothesis testing, or dynamic context adjustments. This realization gave rise to the “Tree of Thoughts” paradigm, a systematic expansion of CoT where the model explores multiple reasoning trajectories in a search tree, enhancing exploration and solution quality. Concurrently, researchers recognized the importance of embedding distinct personas into prompts—tailoring model outputs to specific roles, expertise levels, or emotional tones—giving birth to persona-based prompting. This approach not only improved output relevance but also unlocked new applications in creative writing, data analysis, and coding assistance.
Meta-prompting further pushed the boundaries by enabling recursive prompt generation and self-reflective reasoning loops. Models began to evaluate and refine their own prompts or outputs dynamically, leading to emergent behaviors akin to self-improvement and adaptive learning. This technique has become central to developing robust, context-aware AI assistants capable of managing complex workflows and multi-turn interactions in real time.
In parallel, the growing reliance on LLMs in critical applications exposed vulnerabilities such as prompt injection attacks—where malicious inputs manipulate model behavior. This spurred the development of advanced security frameworks and defensive prompt engineering strategies, ensuring safe and trustworthy deployments. Additionally, the field has matured with the introduction of rigorous evaluation metrics tailored to prompt performance, moving beyond subjective assessments to data-driven validation techniques employing BLEU, ROUGE, and novel LLM-as-a-judge methodologies.
As we stand in 2026, prompt engineering is no longer a peripheral skill but a foundational competency for AI developers and researchers. This comprehensive guide delves into the most advanced techniques shaping modern prompt engineering, offering practical insights, theoretical foundations, and actionable examples. Whether you are designing intelligent agents, automating creative workflows, or securing AI systems, mastering these methods will be indispensable for leveraging the next generation of LLM capabilities.
Tree of Thoughts: Expanding Reasoning Horizons
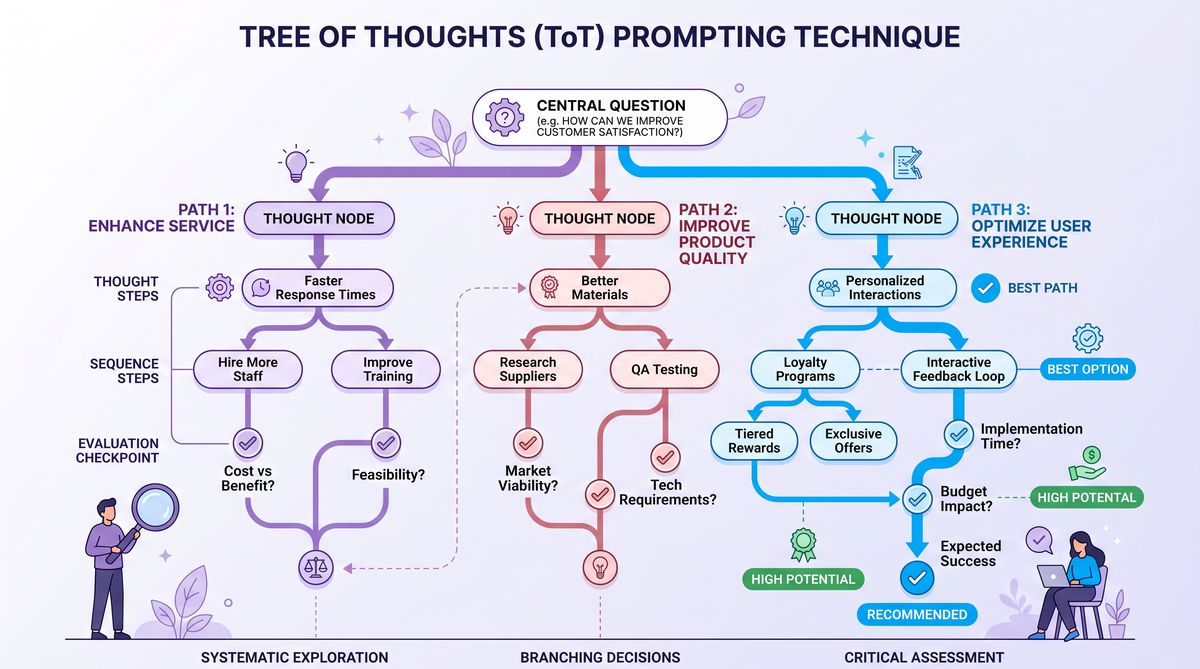
The Tree of Thoughts (ToT) framework represents a paradigm shift in prompt engineering aimed at enhancing the reasoning capabilities of large language models. While Chain of Thought (CoT) prompting encourages sequential stepwise reasoning, ToT models the reasoning process as a search over a tree structure of possible thought sequences. This approach enables the exploration of multiple reasoning paths concurrently, allowing the model to backtrack, prune suboptimal branches, and select the most promising solution trajectory.
Mathematical Formulation of the Tree of Thoughts Search Space
Formally, consider the reasoning process as a search over a tree T defined by nodes representing partial thought states and edges representing transitions via generated thoughts. Let S be the set of all possible states (thought sequences) and A the action space of possible next thoughts. The search tree T = (S, E) where E ⊆ S × A × S captures edges from a current state to next states via actions.
At step t, the model is at state s_t ∈ S representing a sequence of thought tokens. The model generates a set of candidate next thoughts A_t = {a_{t,1}, a_{t,2}, …, a_{t,k}}. Each action leads to a new state s_{t+1} = s_t ⊕ a_{t,i}, where ⊕ denotes sequence concatenation. The goal is to find a path P = (s_0, s_1, …, s_T) maximizing a utility function U(P) that measures solution quality, such as logical correctness or task relevance.
The search algorithm explores multiple branches, expanding nodes based on heuristics or model-assigned confidence scores, and prunes low-utility paths. This approach can be conceptualized as a best-first search guided by learned heuristics embedded within the LLM’s scoring of candidate thoughts.
Comparison with Chain of Thought Prompting
| Aspect | Chain of Thought (CoT) | Tree of Thoughts (ToT) |
|---|---|---|
| Reasoning Structure | Linear sequence of intermediate steps | Branching tree of multiple thought sequences |
| Exploration Strategy | Deterministic or single-path generation | Multi-path search with backtracking and pruning |
| Handling Ambiguity | Limited; single hypothesis per step | Robust; explores multiple hypotheses simultaneously |
| Computational Cost | Lower; single pass reasoning | Higher; requires managing multiple branches |
| Performance on Complex Tasks | Good on sequential tasks | Superior on tasks requiring multi-path reasoning and decision making |
Python Implementation Examples
The following code snippets demonstrate a simplified Tree of Thoughts implementation using Python to illustrate core concepts. The example centers on solving a logical puzzle by exploring multiple reasoning paths.
from typing import List, Tuple, Callable
# Define a Thought node representing a partial reasoning state
class ThoughtNode:
def __init__(self, state: List[str], score: float = 0.0):
self.state = state # Sequence of thoughts
self.score = score # Heuristic score
self.children = [] # Next possible thoughts
def add_child(self, child):
self.children.append(child)
# Hypothetical model scoring function
def model_score(thought_sequence: List[str]) -> float:
# Placeholder heuristic: longer sequences with 'valid' keyword score higher
score = len(thought_sequence)
if "valid" in thought_sequence[-1]:
score += 10
return score
# Generate candidate next thoughts
def generate_candidates(current_state: List[str]) -> List[str]:
# For illustration, fixed candidates
candidates = ["consider option A", "consider option B", "reject option"]
return candidates
# Tree of Thoughts Search Algorithm
def tree_of_thoughts_search(root_state: List[str], max_depth: int = 3) -> Tuple[List[str], float]:
root = ThoughtNode(root_state)
frontier = [root]
for depth in range(max_depth):
next_frontier = []
for node in frontier:
candidates = generate_candidates(node.state)
for c in candidates:
new_state = node.state + [c]
score = model_score(new_state)
child_node = ThoughtNode(new_state, score)
node.add_child(child_node)
next_frontier.append(child_node)
# Prune to top-k nodes by score
next_frontier.sort(key=lambda x: x.score, reverse=True)
frontier = next_frontier[:5] # Keep top 5 branches
# Select best path
best_node = max(frontier, key=lambda x: x.score)
return best_node.state, best_node.score
# Example usage
if __name__ == "__main__":
initial_state = ["start reasoning"]
best_path, best_score = tree_of_thoughts_search(initial_state)
print("Best reasoning path:", best_path)
print("Score:", best_score)
This example outlines a basic breadth-first search approach across thought sequences, scoring each path and pruning to maintain computational feasibility. In production systems, the candidate generation and scoring functions would be powered by LLMs, potentially with beam search or Monte Carlo Tree Search (MCTS) to further optimize exploration.
Applications and Practical Considerations
Tree of Thoughts has proven particularly effective in areas requiring complex decision trees such as multi-hop question answering, code synthesis with alternative implementations, and strategic game playing. By explicitly modeling alternative reasoning trajectories, ToT enables LLMs to avoid early commitment to suboptimal branches, mitigating common failure modes seen in linear CoT prompting.
However, the increased computational overhead and implementation complexity require careful management. Techniques such as heuristic pruning, dynamic branching factors, and hybrid CoT-ToT models are active areas of research aimed at balancing exploration quality with efficiency.
For developers looking to integrate Tree of Thoughts into their applications, understanding the underlying search principles and designing effective scoring heuristics are critical. Additionally, combining ToT with persona-based prompting or meta-prompting can amplify reasoning performance in domain-specific contexts. Schema-First ChatGPT Prompts for Data Analysis: The 2026 Pattern Library
Persona-Based Prompting: Psychological Foundations and Practical Use Cases
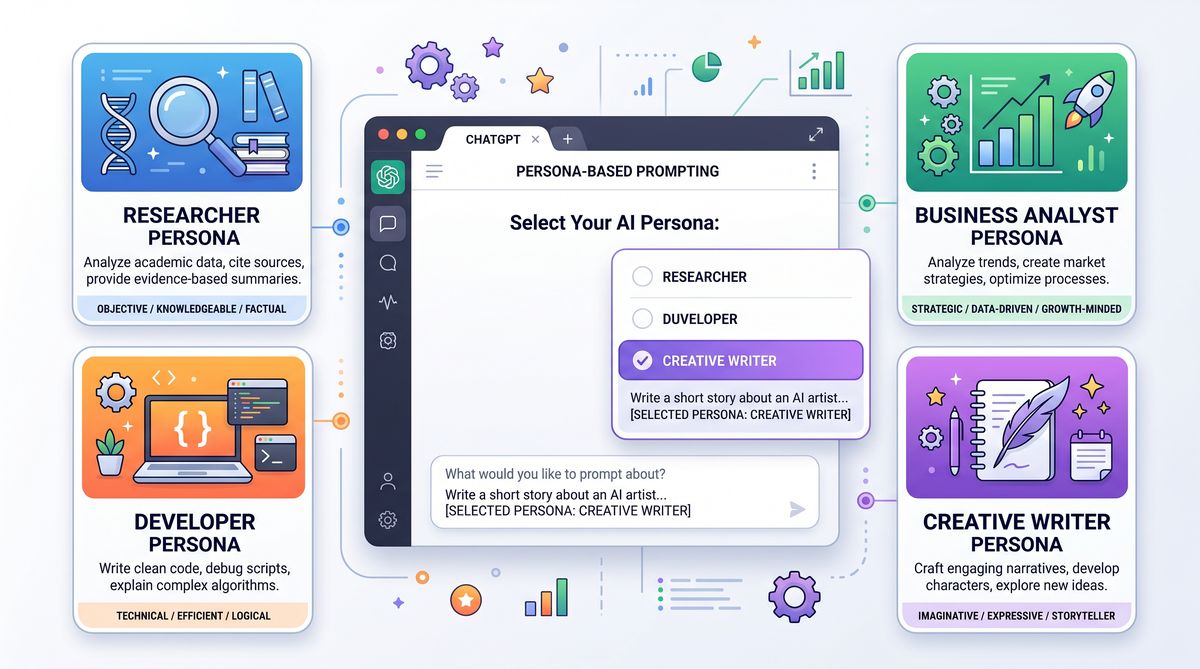
Persona-based prompting constitutes a sophisticated approach to tailoring large language model outputs by embedding distinct identities, roles, or emotional states into prompts. By invoking a persona, the model’s responses can align more closely with desired expertise levels, tones, or behavioral traits, thereby enhancing relevance, engagement, and usability. This section explores the psychological underpinnings of persona creation, system prompt engineering techniques, and detailed use cases to illustrate its transformative potential.
Psychological Aspects of LLM Personas
Personas in human communication serve as mental models or social identities that influence language style, knowledge domain, and interaction patterns. Similarly, LLM personas are constructed by conditioning the model through prompts to simulate specific cognitive schemas and behavioral traits. This conditioning leverages the model’s extensive pretraining on diverse textual data, enabling role-play and contextual adaptation.
From a cognitive psychology standpoint, personas invoke schema theory, where activating a relevant schema facilitates contextually appropriate retrieval and generation of knowledge. For LLMs, persona prompts act as schemas that bias token prediction distributions towards particular linguistic registers, jargon, and reasoning patterns.
In addition, emotional and motivational aspects can be encoded to simulate empathy, assertiveness, or creativity, enhancing the user experience.
System Prompt Engineering for Persona Creation
Persona-based prompting typically involves crafting system-level prompts that define the model’s identity, expertise, and behavioral guidelines. These prompts precede user inputs and set the frame for subsequent interactions. Effective system prompt design includes:
- Role Specification: Clearly stating the persona’s role, e.g., “You are an expert Python programmer.”
- Behavioral Constraints: Defining tone, formality, and style, e.g., “Respond concisely with technical accuracy.”
- Knowledge Scope: Limiting or expanding domain knowledge, e.g., “Focus on data science methodologies.”
- Interaction Protocols: Guidelines for handling uncertainty, e.g., “If unsure, admit lack of knowledge.”
These elements coalesce into a comprehensive persona prompt that guides the LLM’s generation process effectively.
Use Case 1: Coding Assistant Persona
In software development, persona prompting enables the creation of expert coding assistants that adapt their responses to the developer’s skill level and project context. For example:
You are a senior software engineer with 15 years of experience in Python. Your responses must be clear, precise, and include code snippets with best practices. Explain complex concepts in simple terms where needed.This persona prompt encourages the model to provide high-quality code suggestions, debugging help, and architectural advice, fostering productive developer interactions. It can be further enhanced by including domain-specific jargon, preferred libraries, or coding standards.
Use Case 2: Creative Writing Persona
For creative content generation, persona prompts can instill distinct authorial voices or narrative styles. Example:
You are a Victorian-era novelist known for intricate character development and lush descriptive prose. Write all stories with poetic language, rich metaphors, and a melancholic tone.This directs the model to generate text that mimics the stylistic nuances of a particular literary figure or era, enabling tailored storytelling experiences.
Use Case 3: Data Analysis Expert Persona
In data-centric workflows, persona prompting can create analytical experts who interpret datasets and provide actionable insights:
You are a data analyst specialized in healthcare datasets. Provide thorough statistical explanations, interpret trends, and suggest data-driven recommendations with clarity and precision.This persona guides the model to focus on relevant domain knowledge and communicate findings effectively to both technical and non-technical stakeholders.
Developers can combine persona-based prompting with dynamic context injection to create adaptive AI assistants that shift roles based on user needs or project phases, greatly enhancing flexibility. 20 Advanced Prompts for OpenAI Codex /goal: Master Autonomous Multi-Hour Coding Sessions
Meta-Prompting: Recursive and Self-Reflective Prompt Engineering
Meta-prompting advances prompt engineering by enabling large language models to reason about and generate their own prompts recursively. This technique introduces self-reflection loops where the model evaluates, refines, and adapts prompts or outputs dynamically, leading to emergent self-improvement and contextual awareness. Meta-prompting is foundational for building autonomous AI agents capable of managing complex tasks with minimal human intervention.
Recursive Prompt Generation
At its core, recursive prompt generation involves the model using an initial prompt to produce a sub-prompt that better frames or clarifies the user’s intent. This sub-prompt is then used to generate the final output. The process can iterate multiple times, with each recursion refining the prompt to optimize response quality.
For example, an initial vague instruction like “Explain quantum computing” can trigger the model to generate a clarifying sub-prompt such as “Explain quantum computing to a graduate-level physics student, emphasizing qubit superposition and entanglement.” This sub-prompt then guides a more targeted and informative response.
Self-Reflection Loops
Self-reflection loops extend recursive prompting by enabling the model to critique its own outputs, identify errors or ambiguities, and regenerate improved responses. This mimics a human editorial process and can be implemented as follows:
- Generate initial response based on prompt.
- Evaluate response quality using predefined criteria or heuristics.
- If deficiencies are detected, generate a refinement prompt to address issues.
- Produce a revised response based on the refinement prompt.
- Repeat as needed or until convergence.
This iterative mechanism significantly enhances output accuracy, coherence, and relevance, especially for complex or ambiguous tasks.
Architecture Diagram Description
The meta-prompting architecture can be conceptualized as a modular pipeline comprising the following components:
- Input Module: Receives the user’s initial prompt or query.
- Prompt Generator: Produces refined or recursive prompts based on the input and model feedback.
- Response Generator: Generates candidate responses from the current prompt.
- Evaluator: Assesses response quality using automated metrics or learned heuristics.
- Controller: Decides whether to accept the response or trigger another refinement cycle.
- Output Module: Delivers the final, polished response to the user.
Each component interacts in a feedback loop, enabling continuous prompt and output enhancement. This pipeline can be implemented via API orchestration layers, multi-stage prompt chains, or even integrated within a single prompt using advanced prompt templates.
Practical Implementation Example
Below is a pseudocode illustration of a meta-prompting loop integrating recursive prompt generation and self-reflection:
def meta_prompting_loop(user_input, max_iterations=3):
current_prompt = user_input
for i in range(max_iterations):
response = llm_generate(current_prompt)
evaluation = evaluate_response(response)
if evaluation == "acceptable":
return response
refinement_prompt = llm_generate_refinement_prompt(response, evaluation)
current_prompt = refinement_prompt
return response # Return best effort after max iterations
def llm_generate(prompt):
# Calls LLM API to generate output based on prompt
pass
def evaluate_response(response):
# Applies heuristics or LLM-as-a-judge to assess response quality
pass
def llm_generate_refinement_prompt(response, evaluation):
# Generates a new prompt aimed at correcting identified issues
passThis framework exemplifies how meta-prompting enables autonomous iterative improvement, making it invaluable for applications demanding high reliability and contextual sensitivity. Prompting Guide: How to Leverage GPT-5.5 Instant Memory Sources for Personalized AI Workflows
Security and Prompt Injection Mitigation
As prompt engineering techniques grow in complexity and deployment scale, so do security risks related to prompt injection attacks. Prompt injection involves adversaries crafting inputs that manipulate the model’s behavior, bypassing intended constraints or causing harmful outputs. Advanced prompt engineering must therefore incorporate robust mitigation strategies to safeguard AI systems.
Advanced Prompt Injection Attacks
Modern attacks include:
- Hidden Commands: Embedding instructions within seemingly benign inputs that override system prompts.
- Context Manipulation: Injecting misleading context or credentials that alter model assumptions.
- Chain-of-Thought Hijacking: Exploiting multi-step reasoning prompts to introduce malicious reasoning paths.
- Persona Subversion: Altering persona prompts to produce biased or inappropriate responses.
These attacks can compromise confidentiality, integrity, and safety of AI-driven applications.
Defensive Prompt Engineering Strategies
Key mitigation techniques include:
- Input Sanitization: Filtering and normalizing user inputs to remove suspicious tokens or commands.
- Prompt Hardening: Designing system prompts that explicitly restrict override possibilities and include safety checks.
- Context Isolation: Separating sensitive system-level prompts from user inputs to prevent contamination.
- Red Teaming: Conducting adversarial testing to identify injection vectors and reinforce defenses.
- Dynamic Monitoring: Utilizing anomaly detection on model outputs to flag and respond to suspicious behavior.
Combining these strategies with ongoing research into provably robust prompt designs forms the cornerstone of secure AI deployments.
Evaluating Prompt Performance: Metrics and Methodologies
Rigorous evaluation of prompt effectiveness is essential for iterative improvement and benchmarking. Traditional NLP metrics and novel LLM-specific techniques provide quantitative and qualitative insights into prompt performance.
BLEU and ROUGE Metrics
BLEU (Bilingual Evaluation Understudy) and ROUGE (Recall-Oriented Understudy for Gisting Evaluation) are classical metrics originally developed for machine translation and summarization respectively. They measure n-gram overlap between generated outputs and reference texts, providing precision- and recall-oriented performance scores.
- BLEU: Focuses on precision of n-gram matches, penalizing outputs that are too short or diverge lexically.
- ROUGE: Emphasizes recall, capturing how much of the reference content is covered by the generated text.
While useful, these metrics have limitations for open-ended generation tasks where multiple valid outputs exist. Therefore, they must be supplemented by other evaluation strategies.
LLM-as-a-Judge Methodology
Recent advances enable using large language models themselves as evaluators of generated content. This approach involves prompting an LLM to assess output quality based on criteria such as coherence, factual accuracy, relevance, and creativity. Advantages include:
- Flexibility to evaluate diverse tasks and subjective qualities.
- Ability to provide detailed feedback and scoring.
- Reduced reliance on reference texts.
Example prompt for LLM evaluation:
Evaluate the following response for factual accuracy, clarity, and completeness. Provide a score from 1 to 10 and explain your reasoning.
Response: [MODEL_OUTPUT]This method can be integrated into automated prompt tuning loops, enabling continuous refinement based on model-generated feedback.
Composite Evaluation Framework
Developers and researchers often combine multiple metrics and human judgments to gain a holistic understanding of prompt performance. A composite framework may include:
- Automated n-gram metrics (BLEU, ROUGE)
- Model-based evaluation (LLM-as-a-judge)
- Task-specific accuracy measures (e.g., code correctness, factual consistency)
- User satisfaction surveys and real-world usage analytics
Such comprehensive evaluation facilitates data-driven prompt engineering, allowing objective comparison of techniques like Tree of Thoughts, persona-based prompting, and meta-prompting in diverse contexts.
Useful Links
- Tree of Thoughts: Deliberate Problem Solving with Large Language Models – arXiv
- Introducing ChatGPT: OpenAI’s Language Model for Dialogue
- Claude by Anthropic – AI Assistant with Safety Focus
- Prompt Injection Attacks and Mitigation Strategies – arXiv
- Evaluating Prompt Performance in LLMs – ChatGPT AI Hub
Access 40,000+ AI Prompts for ChatGPT, Claude & Codex — Free!
Subscribe to get instant access to our complete Notion Prompt Library — the largest curated collection of prompts for ChatGPT, Claude, OpenAI Codex, and other leading AI models. Optimized for real-world workflows across coding, research, content creation, and business.