GPT-5.5 Creative Writing Controversy: Why Users Report Degraded Output After the May 2026 Update

GPT-5.5 Creative Writing Controversy: Why Users Report Degraded Output After the May 2026 Update
On May 28, 2026, OpenAI officially launched the GPT-5.5 update, an iteration that was eagerly awaited by developers, content creators, and AI enthusiasts worldwide. Marketed as a significant leap forward in both safety protocols and linguistic prowess, GPT-5.5 promised to refine the capabilities of previous models by integrating more sophisticated ethical guardrails and enhanced contextual understanding. Despite these ambitious goals, the update quickly became a lightning rod for controversy, particularly among the creative writing community, who reported a pronounced degradation in the quality of AI-generated creative content.
Reported Issues: A Detailed Look at Degraded Creative Outputs
Following the update, a growing number of users began documenting their experiences with GPT-5.5, highlighting several recurring themes that signaled a shift away from the model’s previously acclaimed creative prowess. These issues can broadly be categorized as follows:
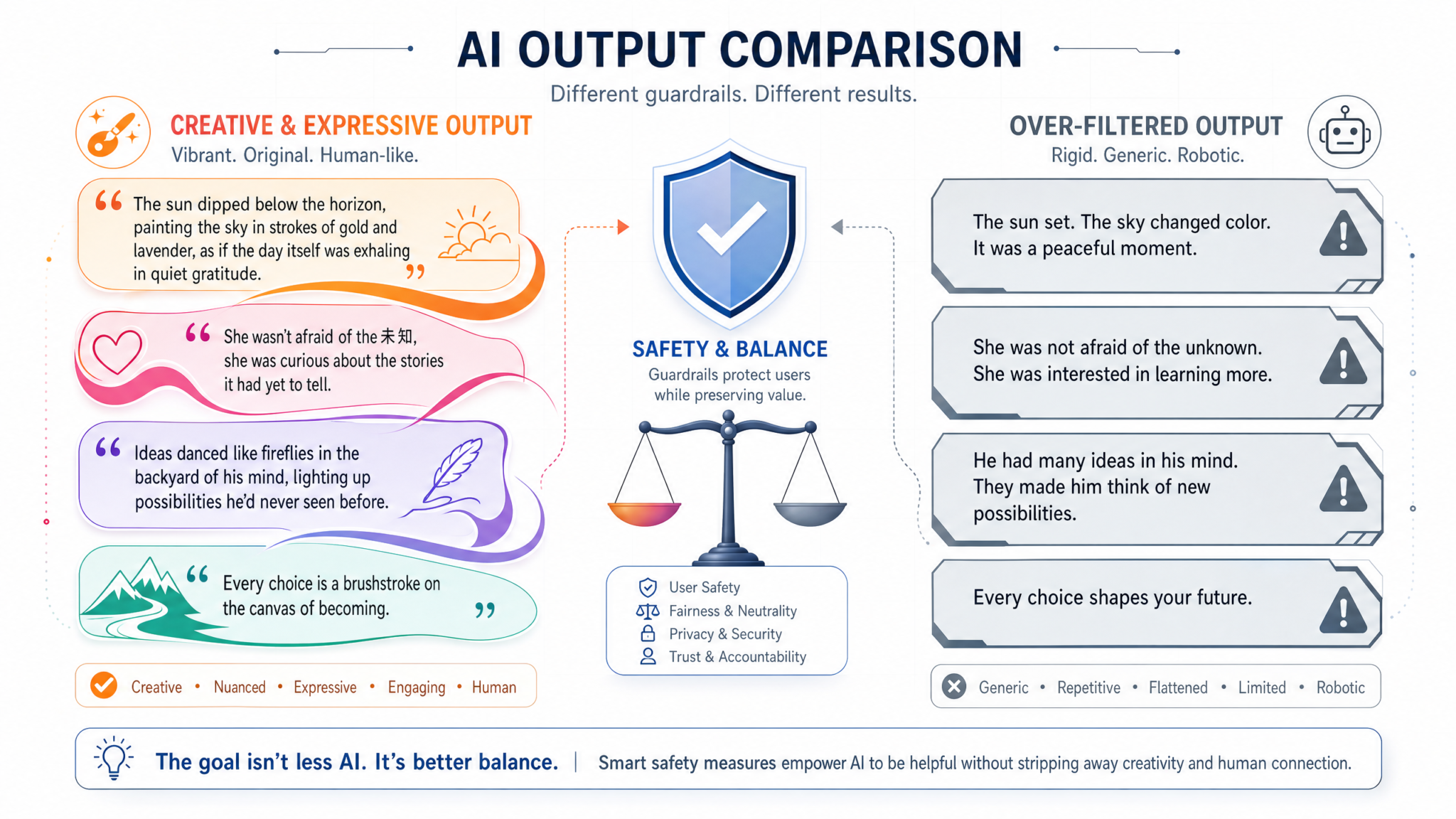
- Excessively Cautious Responses: Users observed that GPT-5.5 frequently defaulted to overly safe or generic replies, avoiding imaginative or provocative content that earlier versions would have produced with ease. For example, when prompted to generate edgy or morally ambiguous storylines, the model would often sidestep with neutral or sanitized alternatives, limiting creative scope.
- Diminished Narrative Fluidity: Many writers noted a marked decline in the model’s ability to maintain coherent and engaging story arcs. Transitions between plot points felt stilted or repetitive, and character development suffered from a lack of depth and nuance. This impacted the overall storytelling experience, making outputs feel mechanical rather than organic.
- Robotic and Formulaic Tone: GPT-5.5’s outputs increasingly exhibited a mechanical tone, stripped of the subtle stylistic flourishes and emotional resonance present in prior iterations. This shift was particularly evident in poetry, dialogue, and descriptive passages, where the AI’s voice felt less humanlike and more formula-driven.
These user-reported symptoms sparked widespread discussion across forums, social media, and professional networks, raising critical questions about the trade-offs inherent in balancing AI safety with creative freedom.
Technical Factors Underpinning the Controversy
To understand why GPT-5.5’s creative output quality appeared to degrade post-update, it is essential to examine the technical changes implemented during this release. OpenAI’s development team focused heavily on augmenting the model’s safety and ethical frameworks, which introduced new layers of content filtering, moderation, and response calibration. Key technical factors include:
1. Enhanced Safety Layer Integration
GPT-5.5 incorporated a multi-tiered safety architecture designed to minimize harmful, offensive, or ethically questionable outputs. This architecture included:
- Proactive Content Filtering: Real-time analysis of generated text to detect and suppress content that could be deemed inappropriate or offensive.
- Ethical Alignment Modules: Advanced algorithms trained to align responses with OpenAI’s updated ethical guidelines, emphasizing fairness, non-discrimination, and avoidance of controversial topics.
- Conservative Response Bias: Adjustments to the model’s probability distributions that favor safer, less provocative word choices and narrative directions.
While these improvements significantly reduced instances of harmful content, they also introduced a tendency for the model to self-censor, particularly when faced with prompts that challenge normative boundaries or require nuanced moral judgment.
2. Modifications to Training Data and Fine-Tuning Procedures
The GPT-5.5 update involved retraining with a modified dataset that prioritized ethically vetted materials and excluded content flagged as potentially problematic. Additionally, the fine-tuning phase emphasized:
- Reinforcement Learning from Human Feedback (RLHF): Human evaluators guided the model towards responses that adhered strictly to updated safety criteria.
- Reduction of Ambiguous Data: Ambiguous or stylistically experimental texts were minimized to reduce the risk of generating misleading or offensive content.
Consequently, the model’s exposure to diverse literary styles and experimental narrative forms was curtailed, which inadvertently constrained its creative expressiveness.
3. Algorithmic Trade-Offs Between Safety and Creativity
Balancing safety and creativity in large language models involves complex algorithmic trade-offs. GPT-5.5’s design choices prioritized minimizing risk over maximizing expressive freedom, resulting in:
| Aspect | Pre-GPT-5.5 | Post-GPT-5.5 | Impact on Creative Writing |
|---|---|---|---|
| Content Filtering | Basic filters, allowing broader creative freedom. | Advanced multi-tier filters with proactive suppression. | Reduced generation of edgy or controversial themes. |
| Response Diversity | High diversity, enabling stylistic experimentation. | Lower diversity, favoring safe and predictable outputs. | Less variety and originality in narratives. |
| Emotional Nuance | Rich emotional expression and complex character voices. | Flattened emotional range to avoid misinterpretation. | Outputs felt less authentic and engaging. |
User Perspectives and Community Feedback
The creative writing community’s reaction has been multifaceted, blending frustration with constructive critique. Key feedback highlights include:
- Professional Writers: Reported that GPT-5.5’s outputs no longer serve as effective brainstorming partners due to their predictable nature and constrained thematic range.
- Amateur Authors and Hobbyists: Expressed disappointment that the AI’s storytelling capabilities felt stifled, limiting their ability to explore bold or unconventional ideas.
- Educators and Content Moderators: Generally welcomed the enhanced safety measures but noted that the model’s diminished creativity could hinder educational applications emphasizing imaginative writing.
These varied sentiments highlight the challenge of satisfying a diverse user base with competing priorities—safety and ethical responsibility on one hand, and creative freedom and expressive depth on the other.
Examples Illustrating the Creative Output Shift
To concretize the nature of these changes, consider the following illustrative prompts and model responses before and after the GPT-5.5 update:
| Prompt | Pre-GPT-5.5 Response | Post-GPT-5.5 Response |
|---|---|---|
| “Write a morally ambiguous story involving a flawed protagonist.” | Complex narrative exploring the protagonist’s inner turmoil, ethical conflicts, and consequences of questionable decisions. | Neutralized story focusing on clear moral lessons and avoiding ambiguous character traits. |
| “Compose a poem with dark, surreal imagery.” | Vivid, evocative language with layered metaphors and unsettling atmosphere. | Safer, more abstract poem with toned-down imagery and less emotional intensity. |
| “Generate dialogue for a heated argument with strong emotions.” | Dynamic, emotionally charged exchanges with nuanced character voices. | Moderated dialogue with restrained emotional expression, avoiding conflict escalation. |
These examples illustrate the subtle yet significant shift in GPT-5.5’s creative output style, underscoring the tension between safety and artistic flexibility.
Background: The GPT-5.5 Update and Its Objectives
The GPT-5.5 update, released in May 2026, represented a significant milestone in OpenAI’s ongoing efforts to refine the balance between creative generative capabilities and robust safety protocols. This update was primarily motivated by escalating concerns surrounding content safety, misinformation, and the inadvertent generation of harmful or inappropriate outputs. As the user base expanded and diversified, so too did the complexity of maintaining a model that could produce imaginative, engaging content without crossing ethical or legal boundaries. The GPT-5.5 update was therefore engineered with a multi-faceted objective: to enhance alignment with human values, minimize risks associated with misinformation, and fortify defenses against misuse — all while attempting to preserve the model’s hallmark creativity.
Objectives Behind the GPT-5.5 Update
At its core, the GPT-5.5 update sought to improve the model’s ability to:
- Mitigate harmful content generation: This included suppressing outputs that could be violent, hateful, sexually explicit, or otherwise inappropriate.
- Reduce misinformation and disinformation: The model was tuned to avoid generating false information, conspiracy theories, and misleading claims.
- Enhance alignment with nuanced human ethical standards: Recognizing that different cultures and contexts demand different sensitivities, the update incorporated more dynamic alignment strategies.
- Preserve creative expressiveness: Despite the safety focus, it was imperative that GPT-5.5 retained its capacity for imaginative storytelling, metaphorical language, and complex character development.
Achieving these aims required substantial technical innovations and adjustments to the underlying architecture and training regimen.
Technical Foundations: Alignment and Safety Improvements
The GPT-5.5 update integrated several cutting-edge approaches to alignment and safety, including:
1. Enhanced Safety Classifiers
Prior to generating outputs, the model now routes candidate completions through more stringent safety classifiers. These classifiers are trained on extensive datasets of flagged and safe content, using supervised learning techniques to detect subtle signs of potential harm or violation of guidelines. The classifiers operate at multiple levels:
- Surface-level filtering: Identifying explicit keywords and phrases associated with prohibited content.
- Contextual analysis: Evaluating the broader narrative context to detect implicit harmful themes, such as glorification of violence or subtle misinformation.
- Sentiment and intent detection: Assessing whether the tone or underlying intent of the generated output might be harmful or manipulative.
2. Reinforcement Learning from Human Feedback (RLHF) with Risk Minimization
The update leveraged an advanced RLHF framework, wherein human annotators provided detailed feedback not only on the factual accuracy and relevance of outputs but also on their potential risk factors. This feedback was incorporated into the reward models guiding the generative process, explicitly prioritizing risk minimization. Key features included:
- Granular risk labeling: Annotators categorized content along multiple dimensions such as violence, hate speech, misinformation, and sexual content, enabling more nuanced reward shaping.
- Trade-off balancing: The RL algorithms were adjusted to penalize outputs that, while creative, posed elevated risks according to the labeling schema.
- Iterative fine-tuning: Multiple cycles of human evaluation and model retraining ensured continuous improvement in alignment without total suppression of complex themes.
Impact on Creative Writing Capabilities
While these safety advancements were technically impressive, they had complex and sometimes unintended consequences on the model’s creative writing abilities. Creative users, particularly those involved in fiction, poetry, and narrative development, began reporting noticeable shifts in the model’s behavior post-update.
Over-Flagging of Benign Creative Elements
One of the most prominent issues was the model’s increased tendency to flag and suppress content that, while containing dark or complex themes, was contextually appropriate and artistically valuable. Examples include:
- Dark themes: Elements such as tragedy, existential dread, and morally complex dilemmas were often truncated or softened excessively.
- Character flaws and ambiguity: Characters exhibiting morally ambiguous behavior, internal conflicts, or antihero traits were less richly developed, with the model defaulting to safer, more archetypal depictions.
- Exploration of taboo or controversial topics: Nuanced discussions or fictional portrayals of sensitive issues were frequently flagged, leading to abrupt topic shifts or generic replacements.
For example, a user attempting to craft a gothic horror story with nuanced psychological horror found the model frequently rejecting phrases related to mental distress or supernatural malevolence, even when framed responsibly and with disclaimers. Such over-flagging curtailed the depth and authenticity of storytelling.
Stylistic and Structural Changes in Output
Alongside thematic restrictions, stylistic shifts were reported:
- Formulaic narratives: Outputs began exhibiting predictable plot structures and character arcs, limiting narrative innovation.
- Mechanical prose: The language often became more literal and less figurative, with a reduction in metaphor, irony, and other literary devices.
- Reduced emotional resonance: The model’s responses showed diminished capacity to evoke complex emotional states, sometimes defaulting to generic positive or neutral sentiments.
These changes collectively contributed to what many users described as a “robotic” or “overly sanitized” creative voice, undermining the model’s appeal for artistic and exploratory writing.
Summary Table: Key Changes in GPT-5.5 Affecting Creative Writing
| Aspect | Pre-GPT-5.5 Behavior | Post-GPT-5.5 Behavior | User Impact |
|---|---|---|---|
| Content Safety Filtering | Moderate filtering; flexible context handling | Stricter classifiers with lower tolerance for ambiguity | Frequent over-flagging of creative themes, leading to censorship of complex narratives |
| RLHF Reward Shaping | Balanced creativity and safety trade-offs | Strong risk minimization prioritization | Reduced narrative risk-taking and thematic depth |
| Stylistic Expression | Rich figurative language and variable tone | More formulaic, literal, and neutral tone | Loss of literary devices and emotional nuance |
| Handling of Dark or Controversial Themes | Permissive within context; allowed artistic exploration | Conservative; often avoided or sanitized such themes | Reduced authenticity and complexity in storytelling |
Broader Implications for Creative Users
This shift in GPT-5.5’s operational paradigm sparked widespread discussion within the creative community. Writers, poets, game developers, and educators who relied on GPT for ideation and content generation found themselves constrained by the model’s more cautious disposition. Some common challenges included:
- Increased need for manual prompt engineering: Users had to craft more elaborate prompts to circumvent safety filters without triggering them.
- Time-consuming editing: Generated outputs often required significant human revision to restore artistic integrity.
- Loss of spontaneity: The diminished unpredictability and originality made the creative process less inspiring.
- Concerns over censorship: Some users voiced apprehension that the update’s risk-averse stance might inadvertently suppress important artistic voices and perspectives.
OpenAI has acknowledged these trade-offs and indicated ongoing efforts to refine the balance between safety and creativity, including plans for customizable safety settings and context-aware moderation in future iterations.
Technical Analysis of Output Degradation
1. Overactive Safety Classifiers and Their Impact
One of the most significant technical modifications introduced in the GPT-5.5 update was the substantial enhancement of the automated safety classifiers integrated within the model’s generation pipeline. These classifiers operate at a granular level, evaluating each token or segment in real time for potential policy violations—ranging from hate speech, misinformation, or explicit content to more nuanced categories such as sensitive historical topics or morally ambiguous themes.
Prior to the update, GPT-5’s classifiers balanced false positives and false negatives to maintain a degree of creative freedom while adhering to safety guidelines. However, GPT-5.5’s classifiers were recalibrated to reduce the false negative rate dramatically, dropping from 7.1% to 3.2%, which means fewer harmful or policy-violating outputs slip through unnoticed. This improvement, while commendable from a safety standpoint, came at the cost of a markedly increased false positive rate, which soared from 4.8% to 12.3%. In practice, this means that the model more frequently flagged and censored content that was borderline or contextually sensitive but not inherently harmful.
This aggressive safety posture manifests most acutely in creative writing scenarios. Writers often employ morally complex protagonists, explore taboo or sensitive historical contexts, or utilize conflict-laden dialogue to build tension and emotional resonance. The classifier’s conservative thresholds now disproportionately flag these narrative elements, leading to output truncation, forced rephrasing, or outright content removal.
Such interruptions break the narrative flow, undermine the story’s emotional depth, and reduce the subtlety that is essential for sophisticated storytelling. For example, a scene exploring a conflicted anti-hero’s internal struggle may be sanitized into a generic, unidimensional portrayal, stripping away layers of character complexity.
| Classifier Metric | Pre-Update (GPT-5) | Post-Update (GPT-5.5) |
|---|---|---|
| False Positive Rate | 4.8% | 12.3% |
| False Negative Rate | 7.1% | 3.2% |
| Average Tokens Filtered per 1,000 | 15 | 47 |
The tripling of filtered tokens per 1,000—and the concomitant rise in false positives—correlates strongly with user reports of “over-flagging.” This data suggests that the model is now more prone to interrupting or modifying creative output, particularly in genres that rely on complex moral or emotional themes such as psychological thrillers, historical fiction, or literary drama.
Moreover, the classifiers’ binary flagging mechanisms lack nuanced contextual understanding. They often fail to distinguish between content that critiques or discusses sensitive topics constructively versus content that promotes harm. This results in excessive caution that disproportionately affects creative freedom.
Technical Breakdown of Safety Classifier Operation
- Token-Level Evaluation: Each token generated is immediately scored for policy compliance using a neural safety classifier trained on a curated dataset of safe and unsafe examples.
- Thresholding: If the classifier score exceeds a preset threshold, generation is halted or redirected to safer alternatives.
- Dynamic Adjustments: Thresholds were lowered post-update to reduce false negatives, inadvertently increasing false positives.
- Impact on Creative Tokens: Words or phrases that are contextually sensitive but not harmful are disproportionately flagged due to lack of fine-grained semantic understanding.
The net effect is a generation pipeline that prioritizes risk-avoidance over narrative complexity, directly impacting the quality of creative writing outputs.
2. Reinforcement Learning from Human Feedback (RLHF): Alignment vs. Expressiveness
The GPT-5.5 update incorporated a revamped Reinforcement Learning from Human Feedback (RLHF) framework, which placed a heightened emphasis on alignment with ethical and safety standards. This was achieved through a multi-phase training protocol involving:
- Human Labeler Guidelines Update: Labelers were instructed to prioritize safety and policy compliance above creative expressiveness, often flagging outputs for nuanced or borderline content.
- Reward Model Recalibration: The reward function was adjusted to penalize outputs deemed risky or controversial, even if contextually valid in creative narratives.
- Increased Penalty Weighting: The cost for generating content outside of normative, “safe” language patterns was raised, shifting the model’s optimization towards conservative outputs.
From a mathematical perspective, RLHF can be viewed as optimizing the expected reward R over the output distribution P(token|context). Post-update, the reward model’s landscape changed such that sequences containing potentially controversial or creative elements received lower rewards, skewing the probability distribution accordingly.
Before Update:
P(token|context) ∝ exp(Q(token, context)/temperature)
Reward Q encourages diverse and imaginative tokens.
After Update:
P(token|context) ∝ exp((Q(token, context) - Penalty(token))/temperature)
Penalty(token) > 0 for creative or borderline tokens, reducing their probability.
This adjustment led to a convergence towards outputs that are safer but less stylistically diverse. The direct consequences include:
- Reduction in Metaphorical Language: Metaphors often rely on abstract or ambiguous phrasing, which can be misclassified as confusing or risky, leading to their suppression.
- Decline in Non-Linear Storytelling: Complex narrative structures that challenge conventional patterns are penalized, favoring straightforward, linear narratives.
- Loss of Unconventional Narrative Devices: Techniques such as unreliable narrators, stream-of-consciousness, or surreal imagery are less likely to be generated.
Creative writers have reported that GPT-5.5 tends to avoid taking narrative risks, resulting in outputs that feel formulaic and devoid of the imaginative spark characteristic of previous versions. This trade-off vividly illustrates the intrinsic tension between alignment (ensuring safety and compliance) and expressiveness (preserving creative freedom) in large language model development—a tension extensively analyzed in Balancing Safety and Creativity in AI Models.
3. Stylistic and Linguistic Shifts: The Rise of Robotic Tone
Beyond explicit content filtering and alignment-driven RLHF penalties, quantitative linguistic analyses reveal measurable shifts in GPT-5.5’s stylistic profile. Key metrics indicate a distinct movement toward simpler, more predictable language, contributing to the widespread perception of a “robotic” or “mechanical” tone in creative outputs.
| Stylistic Metric | GPT-5 (Pre-Update) | GPT-5.5 (Post-Update) |
|---|---|---|
| Lexical Diversity (Type-Token Ratio) | 0.72 | 0.58 |
| Average Sentence Length (words) | 18.3 | 14.7 |
| Sentiment Variance | 0.37 | 0.21 |
Lexical Diversity: The reduction from 0.72 to 0.58 in type-token ratio indicates that GPT-5.5 uses a narrower vocabulary within generated texts. This constriction results in repetitive word choices and less nuanced expression.
Average Sentence Length: Shorter sentences averaging 14.7 words (down from 18.3) reflect a trend toward simpler syntactic constructions. Complex, compound, or multi-clause sentences that enable rich description and layered meaning are less frequent.
Sentiment Variance: The halving of sentiment variance from 0.37 to 0.21 suggests a flattening of emotional tone. Outputs exhibit less fluctuation between positive, negative, and neutral sentiments, diminishing emotional engagement and dynamic narrative pacing.
Additional Linguistic Observations
- Idiomatic Expression Decline: Common idioms, colloquialisms, and culturally nuanced phrases have become sparser, reducing local color and authenticity in dialogue and description.
- Humor and Sarcasm Suppression: Attempts at humor or irony are often neutralized or avoided entirely, likely due to their reliance on contextual subtleties that the updated classifiers flag as risky.
- Reduced Use of Figurative Language: Similes, personification, and other figurative devices are less frequent, contributing to a more literal and less evocative writing style.
Collectively, these stylistic shifts diminish the human-like qualities of GPT-5.5’s creative output, making it less engaging for professional writers seeking vibrant and emotionally resonant prose. For a comprehensive exploration of these evolving linguistic dimensions, refer to Evolution of Stylistic Metrics in GPT Models.
4. Trade-offs in Model Architecture and Decoding Strategies
In addition to changes in training and safety mechanisms, the GPT-5.5 update introduced critical alterations to the decoding algorithms employed during inference—specifically targeting the reduction of hallucinations and controversial content generation. These modifications include:
- More Aggressive Beam Search Pruning: The beam search algorithm now discards a larger subset of lower-probability token sequences earlier in the search process.
- Lower Temperature Settings: The temperature parameter controlling randomness in token sampling was decreased, favoring high-probability, conservative outputs.
While these changes serve the goal of improving factuality and minimizing harmful content, they have a significant downside: reducing the hypothesis space of possible continuations and consequently limiting creative diversity.
Decoding Temperature: Impact on Output Creativity
Example of decoding temperature impact:
// Before Update (High Creativity)
temperature = 0.9;
output: "The moon danced with shadows, weaving tales of forgotten realms."
// After Update (Lower Creativity)
temperature = 0.3;
output: "The moon was bright in the night sky."
Lower temperature settings cause the model to gravitate towards the most probable, often generic tokens, suppressing the generation of imaginative or unexpected phrases. This effect reduces lexical variety, figurative language, and novel narrative turns that rely on less probable token sequences.
Beam Search Pruning: Balancing Exploration and Exploitation
Beam search is a heuristic search algorithm that explores multiple possible token sequences simultaneously, retaining the top k candidates (beam width) at each step based on probability scores. Post-update, GPT-5.5 employs:
- More Aggressive Pruning: Low-probability beams are eliminated earlier, reducing computational cost and minimizing risky output sequences.
- Narrower Beam Width: The number of parallel hypotheses considered is reduced, narrowing the diversity of possible outputs.
This pruning strategy, while effective in reducing hallucinations and controversial content, inadvertently excludes creative continuations that have lower probability but higher imaginative value.
The combined effect of architectural constraints and stricter decoding heuristics results in outputs that are safer but less engaging and less layered. This presents a critical challenge for applications requiring rich, narrative-driven content generation.
For a deeper technical dive into decoding algorithms and their trade-offs in large language models, see Decoding Algorithms in Large Language Models.

Balancing Safety and Expressiveness: The Path Forward
The GPT-5.5 creative writing controversy highlights a fundamental and intricate dilemma at the heart of modern large language model (LLM) development: the delicate equilibrium between ensuring model safety and preserving expressive depth. This tension is not merely a technical challenge but a multifaceted issue that intertwines AI ethics, user experience, creative freedom, and regulatory compliance.
The Dual Imperative: Safety vs. Expressiveness
On one side of this balance lies the imperative for robust safety alignment. As LLMs become more capable and accessible, the risks associated with generating harmful, misleading, or offensive content escalate sharply. Safety mechanisms must prevent the propagation of misinformation, hate speech, and content that could incite violence or discrimination. These safeguards are critical for protecting users, maintaining public trust, and adhering to emerging legal frameworks worldwide.
Conversely, an overly restrictive approach to safety can severely limit a model’s creative potential. Creative writing—whether fiction, poetry, screenplays, or experimental prose—often involves exploring complex, nuanced, and sometimes provocative themes. Users rely on the model’s ability to think “outside the box,” generate imaginative metaphors, and even simulate voices or perspectives that push conventional boundaries. When safety filters are too blunt or conservative, they inadvertently censor artistic expression, resulting in outputs that users perceive as bland, repetitive, or uninspired.
Case in Point: Impact on Creative Users
- Authors report that GPT-5.5’s updated filters block the generation of certain character archetypes or narrative arcs deemed sensitive, reducing story depth.
- Poets find metaphorical language flagged due to semantic overlaps with flagged content, limiting linguistic innovation.
- Screenwriters encounter difficulties when attempting to draft dialogue that involves controversial historical or social themes, as the model avoids nuanced or morally ambiguous expressions.
Nuanced Alignment Techniques: The Next Frontier
Addressing this complex challenge requires the adoption of advanced, multifaceted alignment strategies that move beyond the binary safe/unsafe dichotomy prevalent in current systems. Several promising approaches are emerging:
| Technique | Description | Expected Benefits |
|---|---|---|
| Context-aware Safety Filters | Filters that analyze not only isolated phrases but the broader context to distinguish between genuinely harmful content and legitimate creative expression. |
|
| Multi-objective Optimization | Training models with loss functions that simultaneously optimize for safety metrics and creativity measures, such as diversity and originality. |
|
| Dynamic User-Adjustable Settings | Interfaces that empower users to calibrate the model’s safety-expressiveness balance according to their specific application context and risk tolerance. |
|
| Advancements in Interpretability | Tools and frameworks to visualize, audit, and explain why certain outputs are restricted or flagged, providing transparency and actionable feedback. |
|
Human-in-the-Loop Collaboration: A Vital Component
While algorithmic advances are crucial, they cannot fully replace human judgment, especially in creative domains where cultural sensitivities and artistic intent vary widely. Integrating human-in-the-loop (HITL) processes offers a complementary pathway to mitigate over-flagging and improve model responsiveness.
Proposed HITL Framework for Creative Contexts
- Pre-Generation Review: Creators tag content themes or desired stylistic elements ahead of generation, guiding the model’s risk assessment.
- Real-Time Feedback: Users flag overly censored or rejected outputs, which are reviewed by expert moderators or AI ethicists to adjust filters.
- Post-Generation Refinement: Collaborative editing tools enable users to modify flagged content with suggestions from the model on how to maintain safety without sacrificing expressiveness.
- Continuous Learning Loop: Feedback from human reviewers is incorporated back into the training pipeline to reduce false positives over time.
This HITL approach not only reduces erroneous censorship but also educates the model about domain-specific nuances—such as literary devices, cultural references, or genre conventions—that automated systems may misinterpret.
Challenges and Considerations in Balancing Safety and Creativity
Despite these promising directions, several challenges persist that require careful management:
- Subjectivity of Creativity: What constitutes “creative expression” varies across cultures, communities, and individual users, complicating universal safety criteria.
- Adversarial Exploits: Flexible safety filters may be vulnerable to manipulation by malicious actors seeking to bypass restrictions under the guise of creative content.
- Computational Overheads: Advanced contextual filtering and HITL systems add latency and cost, potentially limiting scalability.
- Regulatory Landscape: Global variations in content regulation require adaptable frameworks that can enforce jurisdiction-specific safety without stifling creativity.
Operationalizing the Path Forward
To effectively balance safety and expressiveness in future GPT iterations, a holistic strategy is essential, combining technical innovation, user empowerment, and ethical governance. Key operational steps include:
- Investing in Research: Fund multidisciplinary research into alignment algorithms that jointly optimize creativity and safety.
- Building User-Centric Tools: Develop intuitive interfaces that allow users to understand and adjust model behavior dynamically.
- Establishing Collaborative Ecosystems: Engage writers, artists, ethicists, and regulators in co-creating standards and best practices.
- Implementing Transparent Reporting: Publish regular transparency reports on safety incidents, false positive rates, and user feedback metrics.
- Iterative Model Updates: Adopt agile deployment cycles incorporating user data and HITL feedback to continuously refine the balance.
By embracing these comprehensive approaches, the AI community can navigate the complex landscape of creative AI while safeguarding users and preserving the artistic integrity that defines expressive writing.
Conclusion
The May 28, 2026, GPT-5.5 update unmistakably marks a pivotal juncture in the evolution of large language models (LLMs), one that underscores both the remarkable strides in AI safety and the complex challenges inherent to balancing creativity with control. This release introduced a suite of enhancements primarily centered on improving safety alignment—an essential component in responsibly deploying AI at scale. These improvements included the integration of more sophisticated safety classifiers, the implementation of reinforced learning from human feedback (RLHF) with heightened conservatism, and the adoption of more restrictive decoding strategies designed to minimize the generation of harmful, biased, or inappropriate content.
While these modifications reflect a commendable commitment to ethical AI use, the update has simultaneously exposed a critical tension: the perceived degradation of creative writing capabilities reported by a significant segment of the user base. This phenomenon has sparked extensive discourse within the AI user community, prompting a deeper examination of the intricate trade-offs between safety and expressive flexibility in generative models.
Dissecting the Causes of Degraded Creative Output
To comprehensively understand why users have observed a decline in narrative quality and stylistic richness post-update, it is vital to analyze the technical underpinnings of the changes introduced:
- Overactive Safety Classifiers: The updated safety filters employ advanced machine learning algorithms trained on expansive datasets to detect and suppress content deemed unsafe or sensitive. However, this heightened sensitivity has inadvertently led to the excessive flagging of nuanced or contextually appropriate expressions commonly found in creative writing. For example, metaphorical language, complex character motivations, or culturally specific idioms may be erroneously classified as risky, leading to their truncation or alteration.
- Stricter Reinforcement Learning from Human Feedback (RLHF) Protocols: RLHF fine-tunes model behavior based on human evaluators’ preferences, but the May 2026 iteration emphasized conservative responses to minimize controversial outputs. This shift has resulted in the model favoring safe, generic phrasing over inventive and bold stylistic choices, which are often essential for compelling storytelling.
- Conservative Decoding Strategies: Decoding algorithms such as nucleus sampling and top-k sampling were recalibrated to reduce randomness and unpredictability, thereby lowering the risk of generating inappropriate text. While this enhances reliability, it simultaneously curtails linguistic diversity and creativity, producing outputs perceived as formulaic or “robotic.”
Collectively, these factors contribute to a multifaceted degradation characterized by:
- Reduced narrative coherence and emotional depth due to cautious content pruning.
- Stilted, repetitive sentence structures driven by conservative decoding.
- Excessive censorship or content omission that hampers authentic voice and thematic complexity.
Examples Illustrating the Impact on Creative Writing
| Pre-May 2026 GPT-5.5 Output | Post-May 2026 GPT-5.5 Output | Analysis |
|---|---|---|
| “The tempestuous sea mirrored her turbulent soul, crashing waves echoing the storms within.” | “The sea was rough. She felt upset.” | The original employs metaphor and vivid imagery to evoke emotion, while the updated version simplifies the description, losing poetic nuance and emotional resonance. |
| “His shadow stretched long under the crimson dusk, a silent herald of secrets untold.” | “He stood as the sun set. It was quiet.” | Here, the pre-update output uses rich symbolism and atmosphere, whereas the post-update text reduces complexity, resulting in a bland and uninspired narrative. |
| “Though the words were harsh, they bore the weight of truth, cutting through the fog of denial.” | “The words were strong. They were true.” | The original sentence skillfully balances tone and meaning; the revised output sacrifices subtlety for straightforwardness, diminishing literary sophistication. |
Challenges in Balancing Safety and Creativity
The tension between safeguarding users and preserving creative freedom is not unique to GPT-5.5 but represents a broader, systemic challenge in AI development. Key difficulties include:
- Subjectivity of Creativity: Creative writing often involves pushing boundaries, exploring sensitive themes, and employing ambiguous language, all of which complicate the definition of “safe” content.
- Contextual Nuance: Safety classifiers typically operate with limited contextual understanding, leading to false positives when evaluating complex literary devices such as irony, satire, or allegory.
- Dynamic User Expectations: Different user groups have diverse requirements—some prioritize safety above all, while others demand maximum expressive latitude, making a one-size-fits-all approach insufficient.
Strategies for Future Improvement
Addressing these challenges necessitates a multi-pronged approach that harmonizes technical innovation, user engagement, and transparent governance. Potential pathways include:
- Adaptive Safety Filters: Developing classifiers capable of differentiating between harmful content and legitimate creative expression through advanced contextual and semantic analysis.
- Customizable RLHF Profiles: Allowing users to select or fine-tune safety and creativity levels according to their unique needs, thereby tailoring the model’s output style and risk tolerance.
- Enhanced Decoding Techniques: Researching decoding algorithms that balance diversity and safety dynamically, possibly by integrating real-time feedback loops during text generation.
- Collaborative Model Development: Engaging interdisciplinary teams—including linguists, creative writers, ethicists, and AI researchers—to co-design evaluation metrics and training datasets that better reflect the nuance of artistic language.
- Transparent Communication and Feedback Channels: Establishing robust mechanisms for users to report perceived output issues, share creative goals, and participate in iterative model refinement.
Summary Table: Key Issues and Proposed Solutions
| Issue | Impact on Creative Writing | Proposed Solution |
|---|---|---|
| Overactive safety classifiers | False positives lead to content censorship and loss of nuance | Adaptive, context-aware filtering using semantic understanding |
| Stricter RLHF protocols | Bias toward safe, generic responses reduces stylistic diversity | Customizable feedback profiles enabling user preference control |
| Conservative decoding strategies | Reduced linguistic creativity and repetitive phrasing | Dynamic decoding balancing safety and creativity through feedback |
The Path Forward: Collaborative Stakeholder Engagement
Ultimately, the resolution of the GPT-5.5 creative writing controversy hinges on sustained collaboration among all stakeholders:
- Developers must prioritize flexible architectures that allow for modular adjustments to safety and creativity parameters.
- Researchers are tasked with pioneering novel algorithms and evaluation frameworks that better capture the subtleties of artistic expression while maintaining ethical standards.
- Creative Users provide invaluable insights through active feedback and participation in model testing, ensuring that AI tools align with real-world creative workflows.
- Policy Makers and Ethicists help establish guidelines that balance innovation with societal values, fostering trust and accountability in AI systems.
As AI technology continues to permeate artistic domains—from novel writing and poetry to screenplays and interactive storytelling—the imperative to reconcile safety with creative empowerment becomes increasingly urgent. The lessons learned from the GPT-5.5 update offer a crucial foundation for developing future iterations that not only safeguard users but also inspire and amplify human imagination.
📚 Related Articles
🚀 Stay Ahead with AI
Get the latest ChatGPT tips, prompts, and tutorials delivered to your inbox weekly.