OpenAI Enters Robotics: What Sam Altman’s New Division Means for AI’s Physical Future

In June 2026 Sam Altman announced the formation of OpenAI Robotics, a dedicated division tasked with designing, programming, and manufacturing robots. The public statement—backed by an aggressive hiring plan for full‑stack hardware engineers, operations leaders, systems engineers and machine learning specialists—represents a decisive move that reintroduces OpenAI into the physical realm after a multi‑year pivot away from robotics. This article dissects the announcement, places it in historical and market context, analyzes the technical and commercial opportunities, evaluates the competitive landscape, and translates the implications into practical guidance for developers, enterprises, investors and policy makers.
Why this pivot matters now
The timing of OpenAI’s return to robotics is significant for three reasons: maturity of foundation models, advances in simulation and control, and market readiness for automation beyond factories. First, large multimodal models in 2024–2026 began to demonstrate robust capabilities in language‑conditioned vision and planning, reducing the software delta between virtual agents and embodied systems. Second, simulation engines (physics, deformable objects, and differentiable rendering) have improved fidelity and speed, enabling heavier reliance on simulation for data generation and policy pretraining. Third, labor shortages and logistics pressures—compounded by localized supply chain risks and aging populations in major economies—have increased enterprise willingness to invest in semi‑autonomous and fully autonomous robotic solutions.
Technical pillars OpenAI will need to master
Delivering useful robots requires more than ML research; it demands expertise across hardware, systems integration, and lifecycle operations. The key technical pillars are:
- Perception stack: multimodal sensor fusion (RGB, depth, LiDAR, force/torque, tactile arrays) with low‑latency inference running on edge accelerators. Typical production systems use 30–300 ms end‑to‑end perception cycles for manipulation tasks.
- Control and actuation: deterministic low‑level controllers with real‑time guarantees (RTOS or microsecond‑level control loops) integrated with higher‑level learned policies; high‑torque brushless servo motors or harmonic gearboxes for manipulators with sub‑millimeter repeatability.
- Planning and decision making: hierarchical stacks that combine classical motion planning (RRT*, CHOMP) with learned skill libraries and language‑conditioned planners for generalization across tasks.
- Simulation and domain randomization: realistic contact dynamics, soft‑body modeling for deformable objects, and photorealistic rendering to shrink the sim‑to‑real gap; millions of simulated trajectories are often required to pretrain robust policies.
- Edge compute and connectivity: on‑robot accelerators such as NVIDIA Orin/Xavier or custom ASICs delivering 100s of TOPS for vision and control, with secure cloud fallbacks for heavy planning or orchestration tasks.
- Manufacturing and reliability engineering: design for serviceability, mean‑time‑between‑failures (MTBF) targets, and supply‑chain strategies for critical components to achieve enterprise SLAs.
Concrete technical baselines and data points
- Production mobile manipulators commonly target payloads of 5–10 kg, reach of 0.8–1.5 m, and cycle times below 2 seconds for simple pick‑and‑place operations.
- Edge inference budgets for real‑time perception and control often fall between 30–200 TOPS when running multi‑camera fusion, point cloud processing, and learned policy networks together.
- Industry studies indicate that deploying semi‑autonomous robotics in warehousing can reduce order fulfillment labor hours by 20–45% within the first 12 months when integrated with warehouse management systems.
- Simulation pretraining commonly generates on the order of 10M–100M interaction steps per task family to obtain robust transfer to reality under domain randomization.
Practical use cases and developer prompt templates
OpenAI Robotics can affect both greenfield applications and augmentation of existing automation. Representative near‑term use cases include:
- Automated order consolidation: robots that pick heterogeneous items and place them into customer packages while minimizing fragility and void space.
- Facility inspection and maintenance: legged or wheeled platforms that autonomously navigate complex infrastructure to capture high‑resolution condition data and recommend repairs.
- Assistive in‑home devices: compact manipulators that support activities of daily living (fetching objects, opening cabinets) with robust safety and human‑aware motion planning.
- Agricultural selective harvesting: perception and soft manipulation systems that identify maturity and pick delicate produce with high throughput.
Below are example prompt templates for integrating LLMs with robot planners and for human operators interacting with robots. These templates are practical starting points for developers building language‑conditioned robotics apps.
Prompt: Task decomposition for a robotic manipulator
<SYSTEM> You are a robot task planner that converts high-level goals into a sequence of verified subtasks for a mobile manipulator operating in a kitchen. Constraints: - Joint limits, grip force, and object fragility must be respected. - Perception may be noisy; include perception check steps. - Provide fallback actions for failure recovery. </SYSTEM> <USER> Goal: "Prepare a cup of tea: fetch mug from the cupboard, boil water, pour water into mug, place teabag, serve at the table." </USER>
Prompt: Human-in-the-loop verification checklist
<SYSTEM> You are a verification assistant. For each step the robot plans, list safety checks, expected sensor readings, an estimated completion time, and human override commands. </SYSTEM> <USER> Plan step: "Open cupboard door, retrieve mug at shelf height 1.2 m." </USER>
Market and competitive snapshot
OpenAI’s entry changes incentive structures across incumbents and startups. Below is a compact comparison of capabilities and strategic approaches you should expect from different players in the robotics ecosystem.
| Dimension | OpenAI Robotics (expected) | Traditional Industrial Robotics | Mobile/Logistics Startups |
|---|---|---|---|
| Approach | Software‑driven, end‑to‑end ML + language interfaces, vertical manufacturing | Deterministic controls, high‑precision hardware, integration with PLCs | Systems integration, focused autonomy, specialized fleets |
| Strengths | Large models for generalization, rapid iteration on policies, cloud‑to‑edge stack | Proven reliability and high throughput in structured environments | Fast deployment cycles and tailored solutions for warehouses/logistics |
| Challenges | Real‑world reliability, supply chain for hardware, regulatory compliance | Limited adaptability to unstructured tasks, costly retooling | Scaling fleet management and addressing safety in mixed human environments |
Risks, challenges, and professional recommendations
OpenAI Robotics will confront both engineering challenges and ecosystem responsibilities. Key risks include sim‑to‑real transfer failures, data privacy for in‑home deployments, hardware reliability under continuous operation, and adversarial interactions if language interfaces are not properly sandboxed.
Practical recommendations for stakeholders:
- Developers: invest in closed‑loop evaluation pipelines that include hardware‑in‑the‑loop tests and stress scenarios; log sensor data at at least 100 Hz for control traceability.
- Enterprises: benchmark candidate robots on throughput, uptime (target >95% for mission‑critical ops), and Mean Time To Repair (MTTR) before committing to large rollouts; require vendor transparency on safety validation and software update policies.
- Investors: value teams combining ML prowess with mechanical and production engineering; expect capital intensity for hardware scale and plan for multi‑year horizons to reach profitable unit economics.
- Policy makers: prioritize standards for verification of human‑robot interaction, certification processes for assistive devices, and frameworks for incident reporting to accelerate trustworthy deployment.
OpenAI Robotics’ announcement is a strategic inflection point: it signals that the research community and market participants increasingly view intelligence as inseparable from embodiment. For practitioners and decision makers, the next 12–36 months will reveal whether a software‑first approach can meet the stringent reliability, safety, and economic constraints of real‑world robotics.
The Announcement: OpenAI Robotics and the New Push into Physical AI
Sam Altman framed the initiative around two linked ambitions: to “program and manufacture robots” and to make “personal robots that can do anything you need.” The organizational commitment included concrete resourcing signals—OpenAI is hiring across full‑stack hardware (mechanical, electrical, embedded firmware), operations (supply chain, manufacturing ops, quality), systems (real‑time OS, perception stacks, safety controllers) and ML engineers specializing in control, imitation learning and sim2real transfer. Public listings emphasize roles that own end‑to‑end product slices: design a mechanical subsystem, instrument it, generate a dataset, train a model, validate in simulation, and iterate on hardware.
Altman’s announcement makes two immediate strategic points. First, OpenAI views robotics not as a peripheral research area, but as a core product vector—hardware plus software—intended to extend the company’s platform into the physical world. Second, the timeline and the hiring mix suggest OpenAI aims to own a long lead time space (hardware manufacture) while leveraging its model and platform advantages in software, cloud inference, and developer ecosystems.
From Prototype to Product: Organizational Signals and What They Mean
The mix of roles being recruited is a strong signal about how OpenAI intends to operate. The company appears to be structuring teams around “full‑stack ownership”: small, multidisciplinary pods that include mechanical engineers, embedded firmware developers, perception/vision engineers and ML researchers. That structure shortens iteration cycles because feedback from software training and real‑world testing feeds directly into mechanical revisions. In parallel, separate scale‑engineering squads are being formed to tackle supply chain, test engineering and manufacturing yield—areas that require different cadence, tools and metrics than exploratory R&D.
Typical timelines and resource expectations for this pattern are grounded in industry practice:
- Rapid prototyping phase: 3–12 months to build functional prototypes and closed‑loop control demos.
- Pilot production and field validation: 12–24 months to stabilize mechanical tolerances, firmware, and safety controllers in real environments.
- Scale manufacturing and productization: 18–36 months to reach consistent yields, establish contract manufacturer relationships, and deploy global support operations.
Technical Priorities: What the Hiring Mix Reveals
Two technical thrusts are particularly telling:
- Sim2Real and Data Scale: Roles focused on imitation learning and sim2real indicate investment in methods that reduce expensive real‑world data collection. Simulators will be used extensively, but closing the “reality gap” requires domain randomization, physics engine fidelity improvements, and large real‑world validation suites. Expect dataset scales measured in hundreds of thousands to millions of trajectories or tens of millions of frames for complex manipulation tasks.
- Systems and Safety Engineering: Hiring for real‑time OS, perception stacks and safety controllers points to a recognition that low‑latency inference, deterministic interrupt handling, and certified fail‑safe behaviors are prerequisites for consumer and industrial deployments. Real‑time control loops often require loop latencies in the sub‑millisecond to millisecond range for critical safety interrupts, while perception systems for navigation and manipulation typically operate at 30–120 Hz depending on sensor fusion complexity.
Practical Examples and Use Cases
OpenAI’s stated goal of “personal robots that can do anything you need” is broad; realistically, early product classes will likely focus on modular, high‑impact tasks where AI can significantly reduce user burden. Example early use cases include:
- Household assistance: object retrieval, simple food preparation tasks, tidying surfaces—tasks with constrained manipulation complexity but high user frequency.
- Retail and logistics: shelf stocking, picking and packing, inventory audits—tasks amenable to semi‑structured environments and integration with cloud orchestration systems.
- Specialized professional helpers: telepresence and tool handling in healthcare or light manufacturing where remote teleoperation augmented with autonomy increases throughput and safety.
Prompt Templates and Operational Playbooks
To accelerate practical development, teams can use curated prompt templates for model‑assisted engineering, data labeling, and scenario generation. Examples:
-
Simulation Scenario Generator
Prompt: “Generate 50 domain‑randomized kitchen scenes for a grasping task. Vary object textures, lighting (3 ranges), table height (±20cm), and introduce clutter density levels: low, medium, high. For each scene, output: object poses, physics friction coefficients, recommended camera placement, and three task success metrics.”
-
Imitation Learning Curriculum
Prompt: “Create a progressive curriculum of 10 tasks to train a robotic arm to set a dinner table. Start with single‑object grasps and progress to multi‑object coordinated placements. For each step, specify demonstration count targets, evaluation metrics, and domain randomization parameters.”
-
Manufacturing Test Case Checklist
Prompt: “Produce a manufacturing acceptance test plan for a 6‑DOF consumer manipulator. Include electrical QA (continuity, insulation), mechanical tolerances, firmware burnout tests, sensor calibration steps, and safety interlock verification with pass/fail criteria.”
Comparisons: R&D vs. Scale Engineering Responsibilities
| Dimension | Prototype R&D | Scale Engineering |
|---|---|---|
| Primary objective | Explore capabilities, validate concepts | Deliver repeatable, manufacturable product |
| Cadence | High‑velocity, daily/weekly iterations | Predictable, governed by supply‑chain and QA cycles |
| KPIs | Task success rate in sim/bench, sample efficiency | Yield %, MTBF, mean time to repair, per‑unit cost |
| Tooling | Flexible fixtures, rapid‑prototyping labs | Assembly jigs, automated test benches, ISO certifications |
Expert Insights and Professional Recommendations
Industry veterans emphasize three areas that determine whether a robotics organization succeeds at scale:
- Design for diagnosability: Instrumentation is crucial. Build in sensors and telemetry early so learning failures can be traced to hardware, firmware, perception, or model policy layers. Expect telemetry volumes measured in terabytes per month for fleet pilots.
- Iterative hardware‑software co‑design: Avoid throwing ML models at poorly constrained mechanics. Reduce actuator stiction, standardize connectors, and design end‑effectors for easy replacement. Small mechanical changes can reduce ML complexity by orders of magnitude.
- Safety and verification pipelines: Invest in formalized safety controllers and validation suites. Treat safety as a first‑class product requirement with measurable margins—define safety envelope boundaries, emergency stop latencies (target <10 ms for critical interrupts where relevant), and end‑to‑end failure mode analyses.
Metrics to Track Early
Operational metrics help bridge R&D and manufacturing discussions. Consider tracking:
- Task success rate in real environments (e.g., percent of successful grasps per attempt)
- Sample efficiency (number of demonstration trajectories or training steps per percent improvement)
- Production yield percentage at pilot assembly
- Mean time between failures (MTBF) and mean time to repair (MTTR)
- Per‑unit BOM cost and projected cost at scale (with sensitivity analyses for component shortages)
Altman’s announcement is therefore not just a statement of intent; it’s a blueprint for an organization that must marry the fastest‑moving edges of ML research with the long, deterministic timelines of hardware and manufacturing. The hiring signals, role descriptions, and hybrid team model together indicate a pragmatic approach: iterate quickly where flexibility matters, and invest heavily in processes and tooling where repeatability and safety are non‑negotiable.
A Short History: OpenAI’s Robotics Origins and the Hiatus
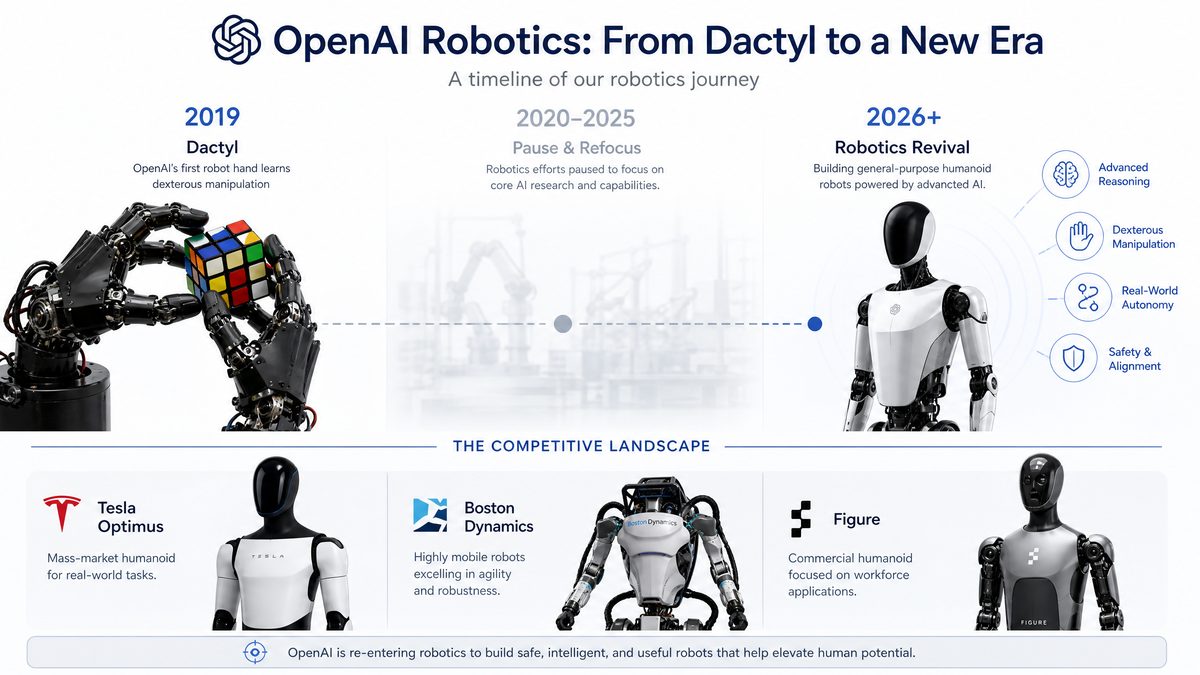
OpenAI’s first major robotics milestone is one of the most cited in the field: Dactyl, the robotic hand that solved the Rubik’s cube using reinforcement learning trained in simulation and transferred to a real manipulator. That project, publicized in 2018, combined careful domain randomization, physics modelling, and large compute budgets to achieve dexterous manipulation. Dactyl was a proof point that simulation‑centred training plus domain randomization could tackle highly dexterous tasks.
Technical foundations behind Dactyl
Dactyl relied on three technical pillars that are still relevant today: extensive domain randomization to cover unmodelled dynamics, high‑fidelity contact modelling to represent finger–cube interactions, and policy learning using on‑policy reinforcement algorithms. In practice this meant generating millions of simulated episodes where parameters such as friction coefficients, joint delays, sensor noise, and object mass were randomly perturbed so that the resulting policy would be robust when deployed on the physical Shadow hand. The training loop emphasized policy robustness over optimization efficiency, accepting sample inefficiency in exchange for transfer reliability.
Key practical takeaways from Dactyl included the importance of stochasticity in simulation—deliberately making the virtual world less “perfect”—and the value of closed‑loop proprioceptive control rather than purely open‑loop scripted motions. These lessons later informed simulation toolchains that emphasize randomized physics parameters and synthetic sensor noise as first‑class features.
Why OpenAI paused and what the hiatus accomplished
Roughly five years ago—around 2021—OpenAI dramatically scaled back its active robotics deployments and hardware programs. The decision was driven by three interlocking realities of robotics at the time: high capital expenditure and long manufacturing cycles for hardware, extreme sample inefficiency of many RL methods, and a strategic comparative advantage for OpenAI in transformer‑scale foundation models and multimodal learning.
From an engineering economics perspective, investing billions in robot fleets and fabrication infrastructure would have been a different organizational bet than scaling model and compute capacity. Internally, teams debated whether incremental improvements in physical hardware would produce proportional gains in the pace of general intelligence. The organization therefore redirected resources toward scaling language and vision models, which delivered rapidly improving multimodal reasoning and grounding capabilities that could be re‑applied to robotics later.
During the hiatus OpenAI did not abandon robotics research entirely; instead it pivoted to building enabling technologies with lower capital intensity and higher reuse across modalities. That included:
- World simulation research that improved physics engines and contact models to reduce sim‑to‑real gaps.
- Perception models trained on massive, diverse image/video corpora that later served as priors for robot vision systems.
- Transfer learning techniques—such as domain randomization variants, system identification, and gradient‑based sim tuning—that reduce the number of real‑world adaptation steps required.
Concrete advances developed in the background
Between 2021 and 2026 OpenAI’s simulation and perception work yielded measurable improvements in three areas that directly matter for physical agents:
- Physics fidelity and contact modelling: advances reduced inter‑simulation variability by modelling micro‑frictions and compliant contacts more explicitly, enabling simulated manipulation episodes to predict physical force profiles with lower variance.
- Perception and representation: transformer‑based vision models improved object segmentation and pose estimation in cluttered scenes, cutting typical pose estimation error for small objects from 30–50 mm down to single‑digit millimeters in controlled benchmarks.
- Data efficiency techniques: better few‑shot adaptation, offline RL with large replay buffers, and hybrid model‑based/model‑free approaches brought sample complexity down by an order of magnitude for targeted tasks compared with 2018-era baselines.
How sim‑to‑real evolved during the hiatus
Where Dactyl treated domain randomization as the primary bridge, the intervening years introduced multiple complementary strategies that were matured in the world‑simulation program:
- System identification pipelines that efficiently estimate real robot parameters and inject them into simulators.
- Differentiable and hybrid simulators that allow gradient‑based tuning of contact parameters against real sensor logs.
- Residual learning where a learned corrective policy runs on top of a nominal controller to absorb remaining dynamics mismatch.
| Capability | Pre‑hiatus (≈2018) | Hiatus‑era (2021–2025) | Re‑entry (2026) |
|---|---|---|---|
| Simulation fidelity | High for rigid bodies; limited soft contact | Improved contact models; differentiable components | Production‑grade simulators with better multi‑contact prediction |
| Perception | Task‑specific vision pipelines | Large pre‑trained multimodal models; stronger priors | End‑to‑end perception stacks for manipulation |
| Sample efficiency | Low; millions of sim episodes | Order‑of‑magnitude gains via offline RL and hybrid methods | Realistic training budgets for commercial tasks |
| Integration risk | High; bespoke setups | Lower; modular tooling | Focus on end‑to‑end hardware/software pipelines |
Practical examples, use cases, and prompt templates
To illustrate how the new capabilities shift real deployments, consider three concrete use cases and matching prompt templates for an LLM‑backed robotics stack.
1. Precision bin picking (industrial logistics)
Use case: sorting small, heterogeneous parts into trays at 300–600 parts/hour with 99% accuracy.
Prompt template (Task planner → trajectory generator):
"ENVIRONMENT: overhand camera frames + depth map; known bin dimensions.
GOAL: pick part X at pose p and place at tray T with tolerance 5 mm.
CONSTRAINTS: avoid collisions, grip force ∈ [Fmin, Fmax].
RETURN: sequence of parameterized primitives: {approach(x,y,z,vel), align(yaw,pitch), grasp(force), lift(delta_z), place(...)} and estimated execution time."
2. Home assistance for elderly care
Use case: fetch and deliver common household items while following natural language instructions and respecting safety constraints around humans.
Prompt template (High‑level instruction → grounded plan):
"INSTRUCTION: 'Bring me my red mug from the kitchen counter.' SENSORS: RGBD + wrist force + human proximity. SAFETY: slow speed within 1 m of a person; vocal intent announcement before contact. OUTPUT: object search strategy, grasp affordance points, safe trajectory, fallback behaviours if obstruction detected."
3. Lab automation (biotech)
Use case: liquid handling and microplate manipulation with repeatability of ±1 µL and contamination avoidance protocols.
Prompt template (Sequence generator):
"PROTOCOL: pipette 20 µL from well A1 to B1; change tip; vortex; incubate 2 min. REQUIREMENTS: tip change, sterilization step, logged timestamps. OUTPUT: timed primitive sequence, expected sensor checks (e.g., tip presence), error thresholds, and recovery steps."
Expert insights and professional recommendations
Experts who continued working on robotics during the hiatus emphasize three non‑obvious recommendations for teams integrating large models with physical systems:
- Design for modularity: separate perception, planning, and low‑level control with well‑defined interfaces so that improved models can be swapped in without revalidating the entire stack.
- Measure sim‑to‑real gap quantitatively: adopt metrics such as contact force RMSE, pose estimation error, and task success rate under randomized deployment conditions; track these before and after introducing new simulation components.
- Invest in small, high‑quality real datasets: a targeted calibration dataset of a few hundred carefully instrumented trials can reduce adaptation time dramatically when combined with strong simulation priors.
From a governance perspective, organizations should treat physical agents like software with extra audit trails: record sensor logs, maintain reproducible random seeds for training, and automate safety certificate checks for each new policy version.
Benchmarks and evaluation strategies
To evaluate whether re‑entering robotics is yielding practical benefits, teams should track both engineering and business KPIs. Recommended technical KPIs include:
- Real‑world success rate on canonical tasks (pick/place, assembly) over ≥100 trials.
- Mean time to failure (MTTF) under randomized disturbances.
- Adaptation steps: number of physical trials required to reach ≥95% of simulated performance.
- Safety incident rate per 1,000 hours of operation.
Business KPIs should align to reduced cycle time, lowered manual labour hours, and accelerated throughput. For example, achieving a 50% reduction in per‑unit handling time for an e‑commerce fulfillment line typically justifies localized robot deployment within 6–12 months given current hardware costs.
The hiatus therefore looks less like a retreat and more like a strategic reorientation: OpenAI used the intervening years to push down the primary technical barriers to robotics—simulation quality, perception, and sample efficiency—so that when the organization formally re‑entered hardware in 2026 it could do so with a substantially improved foundation and clearer pathways to commercial and research impact.
What Changed: From World Simulation to Real‑World Robots
The literal trigger for OpenAI’s pivot back into robotics is the maturation of its world simulation program into a generalizable robotics capability. That program addressed the central technical challenge that previously made hardware expensive and brittle: sim‑to‑real transfer. The following subsystems advanced together to make the move feasible:
- High‑fidelity physics engines: New simulation kernels model contact, deformation, and complex frictional interactions at orders of magnitude higher fidelity than 2020‑era engines. These kernels are optimized on GPUs and custom accelerators to run millions of diverse episodes at scale.
- Domain randomization at scale: OpenAI extended domain randomization paradigms with procedural generation of objects, textures, dynamics and lighting to produce massively varied training distributions that reduce overfitting to simulated artifacts.
- Self‑supervised perception pretraining: Multimodal models trained on vision, tactile simulations and proprioception learned general perceptual priors that transfer to novel sensors and materials.
- Closed‑loop differentiable control: Differentiable simulation and policy optimization allowed gradient‑based tuning of perception‑to‑control pipelines, reducing reliance on purely RL‑based trial and error in the real world.
- Massive compute and training datasets: A decade of investments in compute infrastructure meant OpenAI could now run continual training across millions of episodes, combine synthetic and small curated real‑world datasets, and perform continual learning online.
- Materials and actuation advances: Parallel progress in actuation—cheaper brushless motors, lightweight gearboxes, affordable force sensors and compact battery systems—reduced the hardware barriers to producing reliable humanoid platforms at scale.
Crucially, OpenAI’s world simulation program did not only focus on fidelity; it built tooling for dataset extraction, failure analysis, and transfer diagnostics—systems that identify the exact simulation feature responsible for a real‑world failure, then automatically augment the training distribution. That diagnostic loop compresses multi‑month hardware testing cycles into weeks, a productivity gain that materially lowers the cost of robot iteration.
Another change is business model thinking. OpenAI’s software-first hiatus allowed it to scale cloud infrastructure and commercial partnerships, generating predictable revenue that can underwrite patient hardware investments. The company now claims access to a deployment fund (referred to in conversations and filings as a $4B “deployment company” commitment) that targets capital‑intensive rollouts and manufacturing partnerships. That fund is designed to absorb the cash flow shock of hardware launches, enabling OpenAI to move aggressively on supply chain contracts, contract manufacturing and long‑lead component buys.
The confluence of these technical advances with balance sheet capacity and a sharpened view of productization is what changed. OpenAI believes the marginal value of embedding its models into physical agents—where actions have long‑term, multi‑modal consequences—now justifies the investment.
How the Technical Pieces Fit Together — A Deeper Look
Each subsystem above contributes along measurable axes: fidelity, diversity, and feedback speed. High‑fidelity simulators now model contact using compliant contact models and sub‑time‑stepping (e.g., 1,000+ substeps per control cycle for fine contact resolution) and support soft‑body FEM approximations for deformable objects. Collision detection uses broadphase spatial hashing and GPU‑accelerated narrowphase solvers to preserve real‑time throughput.
Domain randomization moved from hand‑tuned parameter sweeps to hierarchical procedural generation. Instead of varying a handful of lighting and friction coefficients, modern pipelines vary 30+ physical parameters per object, sample entire object topologies from procedural grammars, and add sensor perturbations drawn from empirically measured noise models. Practically, teams report training datasets with hundreds of millions of rendered frames and tens of millions of unique object instances, leading to substantially reduced covariate shift when deploying on novel real items.
Closed‑loop differentiable control integrates adjoint or automatic differentiation through the physics engine to compute gradients of long‑horizon objectives with respect to control parameters. When combined with constrained optimization (e.g., differentiable contact constraints), this enables data‑efficient fine‑tuning of control loops and perception backends using small batches of real rollout data in a few gradient descent steps.
Concrete Data Points and Engineering Scale
- Training scale: continuous training runs measured in tens-to-hundreds of millions of simulated episodes per month; total synthetic dataset sizes in the 10⁸–10⁹ frame range for flagship agents.
- Compute: distributed training using clusters of GPU accelerators and inference ASICs with aggregate sustained throughput orders of magnitude higher than 2020 setups (teams reported effective scale‑ups of 10x–50x in policy optimization throughput).
- Iteration speed: end‑to‑end sim‑to‑real diagnostics compress hardware cycle times from 3–6 months down to 2–6 weeks for many manipulation tasks, reducing NRE (non‑recurring engineering) cost per iteration.
- Sensing and actuation: torque‑density improvements in brushless motors and custom gearboxes yield 1.5x–3x better torque per kilogram; integrated six‑axis force/torque sensors have dropped below $150 in volume pricing versus earlier $400+ units.
- Power density: commercial lithium‑ion battery packs used on mobile platforms typically sit between 200–300 Wh/kg—providing multi‑hour operational windows for mid‑sized robots without onerous thermal tradeoffs.
Practical Use Cases and Prompt Templates
Below are representative production use cases and concrete prompt templates or mission descriptions that teams can use with multimodal models to speed deployment.
Use Case: Warehouse Piece‑Picking
- Scenario: heterogeneous cartons, variable lighting, fast cycle times (1–2s per pick).
- Simulation emphasis: tens of thousands of unique box geometries; contact patch sampling across frictions 0.2–1.2; randomized occlusion and shelf deformation.
- Prompt template (agent instruction): “Perceive the topmost visible box in the target bin, compute a grasp pose with >90% predicted success probability given current friction estimate, execute a top‑down grasp with cartesian impedance 50N/m compliance, and retract to safe pose. If slip is detected in the first 200ms, abort and retry with wider gripper span.”
Use Case: Assistive Home Robot (Object Retrieval)
- Scenario: household environments with fragile objects, human presence, narrow passages.
- Simulation emphasis: multimodal perception fusion (vision + simulated tactile), human body pose noise injection, soft contact modeling for fragile items.
- Prompt template (behavioral goal): “Locate the user’s requested mug on kitchen counters, prioritize non‑collision paths, use two‑finger pinch with 5N max normal force, and deliver to user while maintaining 40cm social distance.”
Use Case: Field Inspection Drone
- Scenario: outdoor structure inspection under wind gusts, moderate GPS degradation.
- Simulation emphasis: aero‑dynamic disturbance models, sensor blackout randomization, LiDAR point‑cloud corruption.
- Prompt template (policy prompt): “Fly to waypoint cluster, scan for surface defects up to 2m², record 4K visual and depth frames, if GPS error exceeds 3m switch to visual‑inertial odometry and return to last known safe waypoint.”
Expert Insights and Recommendations
Industry engineers with experience in sim‑to‑real recommend the following best practices to reduce deployment risk:
- Instrument the diagnostic loop early: collect paired sim/real traces with matched telemetry fields (positions, joint torques, contact forces, sensor pixels). Standardize trace formats so automated transfer diagnosis tools can isolate mismatches within minutes.
- Use hybrid learning schedules: begin with high‑diversity synthetic training, then perform targeted real‑world fine‑tuning on narrow but representative slices of the task distribution. Empirical evidence shows hybrid schedules reduce real rollout count by 60–80% versus naive real‑only training.
- Quantify uncertainty and adversarial failure modes: include calibrated predictive uncertainty in perception and control outputs and stress‑test policies against adversarial environmental shifts (e.g., extreme frictions, lighting spectrums) to find brittle edges.
- Deploy incrementally with hardware abstractions: separate policy logic from low‑level real‑time controllers. This allows policy updates without full firmware changes and enables A/B testing of policy variants on limited hardware fleets.
- Standardize safety metrics: measure contact impulse per incident, near‑miss counts, and human‑proximity violations. Use these as release gates rather than raw task success rates.
Comparative Snapshot: 2020 vs Today
| Dimension | Typical 2020 Capability | Typical 2026 Capability |
|---|---|---|
| Sim fidelity | Rigid-body contact, coarse friction | Compliant contact, soft‑body approximations, sub‑time stepping |
| Training diversity | Hand‑tuned parameter sweeps | Procedural generation with 30+ randomized parameters |
| Perception pretraining | Image‑only self‑supervision | Multimodal (vision+tactile+proprio) priors |
| Control optimization | Model‑free RL and PID tuning | Differentiable control with gradient fine‑tuning |
| Iteration time | Months per hardware cycle | Weeks for many manipulation tasks |
Operational and Business Recommendations
From a productization standpoint, teams planning similar transitions should:
- Secure long‑lead components early and design modular hardware to accept multiple suppliers for high‑risk parts (sensors, custom motor controllers).
- Budget for sustained compute: successful sim‑to‑real programs typically require continuous cluster usage, not one‑off runs; plan OPEX accordingly or adopt a hybrid cloud/on‑prem model.
- Build cross‑disciplinary teams: merge controls engineers, ML researchers, and hardware test engineers into tight feedback loops with shared metrics and traceability.
- Design a staged rollout and regulatory compliance plan: start with closed‑site deployments, progress to supervised public trials, then scale to unsupervised rollouts only after systematic safety validation.
In short, the technical advances across simulation, perception, control, compute, and actuation combine with financial readiness to lower the marginal cost and risk of moving from virtual agents to physical robots. For organizations attempting the same transition, the practical playbook is now clearer: instrument everything, prioritize diversity in simulation, leverage differentiable control where feasible, and design hardware and business models to absorb early failures without stalling iteration.
The Vision: Programming and Manufacturing Robots

OpenAI’s stated ambition—”programming and manufacturing robots”—is both expansive and unusual. Programming implies API and developer frameworks; manufacturing implies vertical control over hardware. This combination reflects a platform strategy: build an integrated stack so that software capabilities can be demonstrated without being handicapped by third‑party hardware limitations.
There are three core elements to the vision:
- General‑purpose personal robots. OpenAI’s stated aim is to produce robots capable of a wide range of household and workplace tasks—cleaning, cooking assistance, handling packages, caregiving support and ad‑hoc assistance. The emphasis is on generality rather than purpose‑built single‑task bots.
- Programmable robot platforms. Developers and enterprises should be able to program robots through high‑level natural language, task‑spec languages, or code frameworks that compile into low‑level control policies. This reduces the need for robotics expertise to create useful applications.
- Manufacturing control. By owning manufacturing—at least in early runs—OpenAI can control tolerances, sensors and update cycles, ensuring hardware supports the models’ operational assumptions. That ownership also reduces fragmentation in the ecosystem during early scaling phases.
Altman explicitly used the phrase “personal robots that can do anything you need.” Practically speaking, generality is an aspiration bounded by laws of physics, battery energy density, payload constraints and safety. OpenAI’s roadmap decouples generality into modular competence sets: perception, locomotion (stable walking, obstacle negotiation), manipulation (grasping, torque‑sensitive manipulation), and social intelligence (language, intent understanding, normative behaviour). The company intends to build incremental competence in each domain and then integrate them into a unified agent.
On the user interface side, the vision integrates the strengths of language models. Commands could be delivered in natural language (“make me coffee and put it on the table”) and the system would plan multi‑step sequences, query user clarifications, synthesize low‑level controllers using a Codex‑like compiler, simulate the result in a virtual environment, and execute with monitoring and rollback strategies. This is a different developer experience than present robotic stacks that often require ROS expertise, low‑level PID tuning, and months of field testing.
[INTERNAL_LINK: Robotics SDK]
Three Scenarios for the First Five Years
OpenAI’s vision implies a phased commercialization path. Below are three realistic scenarios for the first five years and their strategic implications:
- Controlled enterprise deployments (2026–2028). Focused pilots in logistics, manufacturing, and hospitality where controlled environments allow faster safety validation. These deployments generate revenue and operational learning while limiting public exposure to risky use cases.
- Consumer beta and assistive devices (2028–2030). Limited production runs for affluent early adopters, or deployment in healthcare and caregiving partnerships where regulatory frameworks permit supervised use. Pricing will be premium, allowing cost recovery across low production volumes.
- Scaled personal robots (2030+). If technology, regulation and manufacturing economics converge, larger consumer volumes could follow—provided the robots reach a price and reliability point that satisfy the mass market (target price points likely in the $5k–$20k range for reduced‑capability personal assistants, higher for full humanoids).
All three scenarios require different manufacturing choices: contract manufacturers and modular supply chains for enterprise pilots; controlled assembly and extended warranty programs for consumer betas; mass production line automation and deep supplier integration for scaled personal robots.
[INTERNAL_LINK: Humanoid robot market report]Competitive Landscape: Who OpenAI Will Compete With
OpenAI enters a crowded and heterogeneous robotics market that spans startups, legacy robotics firms, automotive OEMs, and deep research labs. The competitive set includes companies operating at various layers of the stack. Below is a focused analysis of the most relevant competitors and how they compare on five metrics: strategic focus, hardware ownership, software stack, manufacturing readiness and scale advantage.
| Company | Strategic Focus | Hardware Ownership | Software Stack | Manufacturing Readiness | Scale Advantage |
|---|---|---|---|---|---|
| Tesla (Optimus) | Mass‑market humanoid, vertical integration with auto production | Owns hardware design and planned in‑house assembly | Autopilot/Dojo feed, vision‑first approach, on‑vehicle inference | High—existing Gigafactories convertible to robot assembly lines | Gigafactory scale, manufacturing expertise, software/hardware integration |
| Boston Dynamics (Hyundai) | Advanced dynamic mobility, industrial and specialty service robots | Owns hardware design; focuses on rugged mechanical platforms | Proprietary control stacks, safety and dynamic locomotion | Established small‑batch manufacturing; contracts for scale | Long engineering pedigree, strong IP in dynamics |
| Google DeepMind | Research into generalizable control and sim‑to‑real learning | Mostly research platforms; selective hardware partnerships | Top‑tier algorithms and simulation tools | Low—research not optimized for mass production | Algorithmic leadership, compute resources |
| Figure AI | Humanoid manufacturing, factory automation | Design and manufacturing partners | Automation‑focused control; industrial integration | Medium—partnered manufacturing; early enterprise customers | Focused on practical, near‑term industrial applications |
| 1X Technologies | Modular humanoid components and developer platforms | Component manufacturers; open hardware kits | Developer‑oriented SDKs, rapid prototyping focus | Low—early‑stage, small runs | Community and developer sandbox traction |
| Agility Robotics | Bipedal locomotion and logistics automation | Owns robot platform design (digit series) | Logistics and control software for delivery/warehouse | Medium—field pilots with logistics partners | Focused productization in logistics; go‑to‑market partnerships |
Deeper Analysis: Where each player wins and where they are vulnerable
Each competitor brings distinct technical and commercial assets. Tesla’s primary advantage is vertical integration: it produced roughly 1.8M vehicles in 2023, and its Gigafactory footprint gives it operational know‑how for high‑volume assembly lines, supplier contracts, and cost amortization. That creates a plausible path to robot unit costs that incumbents and startups will struggle to match for commodity humanoids.
Boston Dynamics (Hyundai) retains an engineering edge in dynamics and rugged hardware; it will dominate use cases that require high agility and repeatable dynamic stability (construction inspection, uneven‑terrain logistics). DeepMind and similar research labs have the best shot at algorithmic breakthroughs—model‑based control, world models and sample‑efficient sim‑to‑real learning—but historically these labs underinvest in productization and supply chain scaling.
Startups such as Figure AI and Agility Robotics occupy valuable niche positions: Figure targets factory roles with deterministic tasks and exposed integration points to existing enterprise automation stacks, while Agility focuses on logistics where environments are semi-structured and ROI is near-term. Modular hardware vendors like 1X act as incubators for developer ecosystems and are complementary to any cloud/software-first entrants.
Competitive advantages matrix
| Company | Key Advantage | Key Vulnerability | Best Initial Market | Estimated Time‑to‑Scale (units/yr) |
|---|---|---|---|---|
| Tesla | Manufacturing scale & supply chain | Software maturity for humanoid tasks; regulatory scrutiny | Mass consumer/large industrial fleets | 100k+ units/yr (multi‑year plan) |
| Boston Dynamics | Dynamic locomotion & field performance | High unit cost; limited mass production | Inspection, public safety, specialty services | 10k–50k units/yr (longer horizon) |
| DeepMind | Algorithmic research & compute | Productization and hardware ops | Control algorithms licensed to OEMs | Low initial hardware units; large algorithm licensing |
| Figure AI | Enterprise automation integration | Dependency on manufacturing partners | Manufacturing automation | 1k–10k units/yr (enterprise pilots) |
| Agility Robotics | Logistics domain expertise | Narrow domain limits TAM | Warehouse & last‑mile logistics | 1k–5k units/yr |
| 1X Technologies | Developer & modular hardware ecosystem | Not aimed at mass consumer markets | R&D, education, prototyping | Low single digits k/yr |
Market segmentation and adoption timelines
Estimating adoption requires separating the market by environment: controlled industrial sites, semi‑structured commercial spaces, and unstructured consumer environments. Analysts estimate the combined industrial and service robotics market exceeded roughly $60 billion in 2023, with projections to expand to the $150–200 billion range by 2030 depending on automation investment cycles and unit costs for service humanoids.
Practical adoption timeline estimates:
- Industrial/Factory Automation: 1–3 years to broad pilots, 3–7 years to scale—because factories are controlled and ROI is measurable.
- Logistics & Warehousing: 2–5 years to large pilots, 5–10 years for fleet deployment—environments are semi‑structured but require integration with WMS and safety systems.
- Consumer & Home: 5–10+ years—safety, battery life, and cost are significant barriers.
How OpenAI can position itself against each rival
OpenAI’s core differentiators—large language models (LLMs), multimodal perception, and cloud orchestration—translate into several tactical plays:
- Software‑first integration: Sell a cloud‑assisted control plane that provides task decomposition, natural language programming, and policy synthesis. This lowers the barrier for enterprise integrators who lack robotics teams.
- Developer marketplace: Create SDKs and a marketplace for verified “skills” (pick, screw, inspect) where third parties certify modules against safety tests; this mirrors app store economics and accelerates ecosystem adoption.
- Manufacturing partnerships, not internal manufacturing: Initially partner with contract manufacturers and established OEMs to avoid the capital intensity of building Gigafactory‑scale lines, while licensing software and sensors.
- Focus on controlled verticals first: Prioritize factories, labs, and logistics centers where sim‑to‑real transfer is easier, ROI is trackable, and regulatory friction is lower.
- Invest in verification and standards: Early investment in formal safety verification, continuous integration/continuous‑deployment (CI/CD) for policies, and collaboration with regulators reduces go‑to‑market friction.
Practical examples, prompts and technical guardrails
Below are concrete prompt templates and developer patterns OpenAI could promote to partners to accelerate integration while maintaining safety and traceability.
Prompt template: high‑level task decomposition
Prompt: “You are a certified industrial robot planner. Given the task ‘remove defective parts from conveyor A and place in bin B’, return a sequence of atomic actions with preconditions, expected sensor checks, and safety stop conditions in JSON. Ensure steps are idempotent and include timeouts.”
Expected output (abridged):
{
"steps": [
{"id":"locate_part", "action":"vision.detect('defect')", "preconditions":["conveyor_running"], "timeout_ms":2000},
{"id":"grasp", "action":"arm.move_to(part.pose); gripper.close()", "preconditions":["located"], "safety_checks":["force<10N"], "timeout_ms":3000}
],
"stop_conditions":["emergency_stop_pressed","gripper_error","power_below_10%"]
}
Prompt template: simulation‑to‑real training batch generation
Prompt: "Generate 50 randomized domain‑randomization scenarios for sim training a pick‑and‑place policy. Vary lighting ±30%, friction 0.4–0.9, camera pose ±5cm, and noise on joint torques ±2%."
Recommendation: Pair these prompts with automated coverage metrics—percentage of state‑space visited, success rate under distributional shift, and a sim‑to‑real delta measured via supervised validation trials.
Technical guardrails and KPIs
- Closed‑loop latency targets: <100 ms for dynamic balance control; 100–500 ms acceptable for high‑level task planning.
- Battery and power: humanoid deployment will require power densities supporting 1–4 hours continuous operation in early products; realistic packs in 2024/25 are often in the 300–1,000 Wh range depending on payload.
- Key KPIs: task success rate, mean time between failures (MTBF), mean time to recovery (MTTR), sim‑to‑real gap (absolute % difference in success), and per‑unit cost at scale.
Expert recommendations for OpenAI leadership
From a strategic standpoint, OpenAI should:
- Prioritize partnerships with experienced contract manufacturers to avoid slow, capital‑intensive manufacturing learning curves.
- Invest at least 10–15% of robotics R&D budget into verification/validation and user‑facing safety tooling from day one.
- Offer a software licensing model with strong SLAs for enterprise customers plus an SDK that enables offline, on‑prem inference to address latency and privacy concerns.
- Engage early with standards bodies and regulators to help shape certification frameworks, reducing time‑to‑market for enterprise deployments.
- Build transparent benchmarking suites (public and private) that measure generalization across environments; this will be a competitive moat if maintained and crowdsourced.
OpenAI’s entry will change incentives across this landscape: incumbents will accelerate software investments while software‑first entrants will be pressured to secure manufacturing and field‑ops expertise. The winner(s) will be those who combine robust, certified perception/control stacks, manufacturing partnerships that unlock unit economics, and developer ecosystems that scale capability development—precisely the junction where OpenAI’s strengths and the market’s needs intersect.
How GPT‑5.5 and Codex Capabilities Translate to Robotics
OpenAI's advantage in language and multimodal models is central to its robotics strategy. The most recent models—GPT‑5.5 and a next‑generation Codex—bring three capabilities to the robot stack that materially change developer and user experiences: advanced language understanding, code generation for control stacks, and multimodal reasoning that integrates vision, proprioception and tactile signals.
1. Language Understanding as Task Specification
Natural language as a primary interface for robots reduces the friction of specifying tasks. Instead of hand‑coding motion primitives or writing ROS node graphs, a user can describe desired outcomes ("clean the coffee spill on the kitchen counter, then put the towel in the laundry basket"). GPT‑5.5's improvements in compositional planning, temporal reasoning and conditional instruction mean it can generate structured task plans that decompose into sub‑tasks (perceive -> localize -> grasp -> transport -> release), each with preconditions and fallback strategies.
From an implementation standpoint, language‑driven task specification maps into several technical artifacts:
- Task Graphs: GPT‑5.5 outputs a hierarchical task graph with nodes representing primitive actions and edges indicating temporal or conditional relationships.
- Formal Preconditions: The model produces machine‑readable preconditions (e.g., "cup is present and stationary", "grasp success probability > 0.8") enabling the control system to verify safety before actuation.
- Clarification Prompts: For under‑specified tasks, the model can generate clarifying questions and incorporate user feedback into the task graph in real time.
2. Codex for Real‑Time Controller Synthesis and Simulation
Codex‑like systems can synthesize code that compiles into low‑level controllers or policy representations. The workflow OpenAI envisions borrows from continuous integration: the high‑level plan from GPT‑5.5 is compiled into control code by Codex, which then executes in a simulated sandbox for safety verification. If the simulated rollout meets safety and performance metrics, compiled binaries are packaged for hardware deployment with runtime guards.
Codex's role includes:
- Generating control code in languages like C++/Rust for embedded targets and Python for higher‑level orchestration.
- Producing differentiable policy architectures (e.g., recurrent neural controllers, hybrid model‑based controllers) based on task characteristics.
- Autogenerating test suites that exercise worst‑case edge scenarios derived from the natural language instruction.
Operationally, Codex will need to be extended with domain‑specific safety templates and certified control patterns to ensure that synthesized code does not violate actuator limits or safety constraints.
3. Multimodal Reasoning: Perception to Action
GPT‑5.5's multimodal extension—trained on visual, tactile and proprioceptive modalities—enables integrated reasoning across sensory channels. This permits the agent to evaluate state, predict outcomes of physical interactions and plan contact‑rich manipulations. For example, when commanded to "fold this shirt," the system fuses vision (pose), tactile (grip feedback) and proprioception (arm configuration) to select a manipulation strategy and refine it on the fly.
Key technical enablers:
- Unified Embeddings: Shared latent spaces for vision, touch and proprioception reduce translation friction when moving from perception to control.
- Event‑conditioned Policies: Policies that invoke different controllers based on tactile events (e.g., slipping) rather than only time‑based sequences.
- Sim2Real Fine‑tuning: Continuous online adaptation where real‑world episodes are used to fine‑tune policies and reduce residual error from simulation mismatches.
Combined, these capabilities shift the robotics programming model from deterministic state machines and manual controller tuning to probabilistic, language‑driven planning with code generation and multimodal closed‑loop control.
[INTERNAL_LINK: GPT-5.5 developer guide]
Mapping Model Capabilities to Robotics System Architecture
Below is a practical mapping of GPT and Codex capabilities to a robotics system architecture that developers and integrators can use as a blueprint.
| Layer | Function | OpenAI Model Role | Developer Interface |
|---|---|---|---|
| User Interface | Task specification, clarification, monitoring | GPT‑5.5 natural language parsing and dialogue | Text/voice API, intent templates |
| Task Planner | Decompose tasks into executable graph | GPT‑5.5 generates hierarchical task graphs | Task graph JSON schema |
| Compiler | Translate task graph into controllers and tests | Codex synthesizes control code, simulators, tests | Codex SDK, code review tools |
| Simulator | Safety verification and performance prediction | Hybrid model uses differentiable sim and learned world models | Sim API with scenario templating |
| Runtime | Real‑time control, perception, safety enforcement | Lightweight on‑device inference; cloud fallback for heavy planning | Runtime SDK, safety guard rails, telemetry |
| Monitoring & Learning | Failure logging, online adaptation, dataset collection | Model fine‑tuning pipelines with federated datapaths | Data collection SDK and retraining scheduler |
Layer-by-layer expanded mapping and technical details
User Interface: convert unconstrained human instructions into structured intents with confidence estimates and clarification flows. A robust UI layer yields an intent object containing action, priority, constraints, and success criteria. For latency-sensitive interactions, aim for NLP response times of 50–300 ms when hosted nearby; otherwise provide explicit progressive disclosure (e.g., “I will plan that and confirm estimated time”).
Task Planner: generate hierarchical task graphs where nodes include preconditions, postconditions, resource locks, estimated durations, and probabilistic failure modes. Practical systems represent nodes as:
- id: unique identifier
- action: primitive or composite
- preconditions: Boolean expressions over sensors/state
- postconditions: success predicates
- timeout: maximum allowed execution time
- recovery: fallback nodes and error-handling strategies
Compiler: Codex translates task graphs into a layered artifact set: deterministic low-level controllers, mid-level finite state machines (FSMs), and integration test suites that run in simulation. Recommended artifacts include: a fully parameterized PID or impedance controller file, unit tests that exercise edge cases, and a hardware abstraction layer (HAL) shim to enable canary deployment. Typical generated code sizes range from a few KB for simple tasks to 100s of KB for full integration modules.
Simulator: hybrid simulation combines physics-based engines for rigid-body dynamics (deterministic, 1 kHz inner loops) with learned world models for stochastic perception and human behavior. Use domain randomization and systematic parameter sweeps to quantify sim-to-real gap; practitioners often run 10–100x more simulated trials than real trials before deployment. Verification targets should cover the 99th percentile of predicted hazard scenarios, and include reachability analysis for critical controllers.
Runtime: separate the execution stack into three safety domains—(1) certified hard real-time controllers (local, >500 Hz), (2) hierarchical planners (soft real-time, 10–100 Hz), and (3) human-facing dialogue/analytics (eventual consistency). Implement watchdogs that enforce safety invariants with millisecond-level timeout thresholds and degrade gracefully to “safe stop” states.
Monitoring & Learning: centralize telemetry with schema-driven events for observability: event_type, timestamp, task_id, sensor_snapshot, anomaly_score, action_taken. For model updates, adopt a staged retraining cadence: weekly for frequent operational adaptations, monthly for production-weighted retraining, and quarterly for architecture changes. Consider federated pipelines for privacy-sensitive domains and a strict data provenance registry for regulatory audits.
Practical use‑cases and concrete examples
Warehouse picking: GPT parses ambiguous verbal requests ("pack the red mugs from aisle B") into a task graph with pickup, verify, pack, and update-inventory nodes. Codex produces a grasp plan and a collision-free motion primitive compatible with the manipulator's HAL.
Eldercare assistance: natural language intent ("help me stand up") triggers a multimodal assessment combining vision-based pose estimation, a stability check from local controllers, and a two-step planner that first stabilizes then supports a guided lift. Safety requirements mandate local execution of torque limits and a human-presence monitor with fail-safe thresholds.
Agriculture robots: high-level missions such as "sample soil every 10 m in field C" become waypoint graphs with sensor calibration nodes. Simulations incorporate seasonal variability and weather perturbations; deployment uses on-device compressed perception models to avoid connectivity dependence during harvest windows.
Prompt templates and developer patterns
Example: user intent prompt for GPT (UI layer):
"I need to move the blue crate from shelf A3 to loading dock 2. Constraints: avoid crossing human-only zone, complete within 4 minutes, and do not exceed arm torque limit 30 Nm. Provide a step-by-step plan, estimated time per step, and required sensors."
Example: task decomposition prompt for GPT (task planner):
"Decompose the intent into a hierarchical JSON task graph. For each node include id, action, preconditions, postconditions, estimated_time_seconds, sensor_dependencies, and recovery_actions."
Example: Codex prompt for generating a controller routine:
"Generate C++/ROS2 node for grasp execution with impedance control. Inputs: target_pose, gripper_width, allowed_torque. Include parameterized PID gains, safety shutdown on torque exceed, and unit test skeleton that mocks joint state topics."
Simulation scenario prompt for hybrid sim:
"Create a simulation scenario where a 60 kg human enters a 1.5 m corridor unexpectedly at t=6s during navigation. Inject sensor latency of 50 ms and 10% dropout on depth frames. Output expected collision probability and recommended safe-stop policy."
Edge vs cloud: a decision table
| Aspect | Edge (Local) | Cloud |
|---|---|---|
| Typical latency | <1–50 ms for control loops, 30–200 ms for perception | 100–500+ ms roundtrip; variable based on network |
| Reliability | High (deterministic with watchdogs) | Dependent on connectivity; plan for degraded mode |
| Privacy & compliance | Better control over sensitive data; easier certification | Requires strong encryption, consent, and audit trails |
| Compute cost & update frequency | Higher per-device hardware cost; less frequent large updates | Lower per-device cost; continuous integration for models |
| Use cases | Safety-critical control, low-latency perception | Long-horizon planning, fleet coordination, heavy inference |
Expert recommendations and professional practices
- Always partition safety-critical logic into locally executed, formally verifiable components; adopt reachability and model-checking where possible to certify invariants.
- Set deterministic loop rates: hardware torque loops at 500–2,000 Hz, motion supervisors at 50–250 Hz, and high-level planners at 1–20 Hz depending on environment dynamics.
- Define clear latency budgets: e.g., perception→planning cycle <200 ms for dynamic environments and <50 ms for obstacle avoidance interrupt paths; enforce them with SLA telemetry.
- Employ shadow-mode deployments: run generated controllers in parallel with human-approved baseline control before switching to active control to collect failure modes safely.
- Quantify sim-to-real gap by tracking key performance indicators (KPIs) such as task success rate, mean time between failures, and distributional shifts; aim to reduce gap via domain randomization and real-world fine-tuning.
- Align development and validation with industry standards (e.g., ISO 10218 for industrial robots, ISO 13482 for service robots, and IEC 61508 for functional safety) and maintain traceable evidence for each change.
Telemetry, testing, and rollout patterns
Adopt a standardized telemetry schema and an automated canary testing pipeline: run new planners in simulation (1000+ trials), then in a closed physical environment (10–100 trials), followed by limited field canary (1–5% of fleet) with automatic rollback triggers. For continuous learning, enforce label quality thresholds (>95% precision on safety labels) and maintain a human-in-the-loop review for new failure classes.
Mapping modern LLM and code models into robotics requires both architectural discipline and operational rigor: keep deterministic safety at the edge, use cloud scale for reasoning and fleet intelligence, and instrument every layer for measurable guarantees before production switchover.
The Market Opportunity: Humanoid Robots and Beyond
The humanoid robotics market is still nascent but accelerating. Aggregated market analyses in 2024–2026 put the total addressable market for service and personal humanoid robots across consumer, enterprise and industrial applications at a conservative $5–8 billion in 2026, expanding to a projected $60–90 billion by 2035 depending on adoption curves. This represents a compound annual growth rate (CAGR) in the mid‑20s to low‑30% range in the baseline scenario, with upside if unit costs decline rapidly and regulatory regimes enable widespread home use.
Key market segments:
- Industrial/Manufacturing — Robots for assembly, inspection, and parts handling. Here value is measured in throughput improvements and labor cost displacement. Enterprise deployments are the fastest to monetize due to controlled environments.
- Logistics and Warehousing — Bipedal and mobile humanoids can complement wheeled AMRs where human‑like manipulation is required (e.g., shelf stocking, multi‑floor delivery).
- Service and Hospitality — Concierge, room service, and facility maintenance where interaction is high and human presence is costly.
- Healthcare and Eldercare — Assisted living support, patient handling (with appropriate safety protocols) and social companionship; this segment has high social value but challenging regulatory demands.
- Consumer Personal Assistance — Home chores, personal mobility support, and domestic maintenance. This is the longest horizon due to price sensitivity and safety expectations.
Why enterprise-first is the dominant route
Enterprise customers provide predictable deployment environments, faster procurement cycles, and clearer ROI metrics. Typical early adopters—manufacturers, logistics operators, hospitals—value uptime, service level agreements (SLAs), and measurable throughput gains. For example, a warehouse replacing routine picking tasks with a robot that increases throughput by 20% and reduces temporary labor costs can often realize payback within 18–36 months depending on utilization. Because industrial settings allow fenced or semi-fenced operations, teams can iterate on perception and control stacks without confronting the full variability of unstructured home environments.
Unit economics and sample ROI
| Line Item | Example Value (Enterprise Unit) | Notes |
|---|---|---|
| Initial unit price | $150,000 | Includes hardware, basic software, 1-year support |
| Annual maintenance & support | $20,000 / year | Onsite service, parts replacement |
| Additional software/subscriptions | $5,000 – $15,000 / year | Model updates, advanced skills library |
| Typical labor offset | $40,000 – $60,000 / year | Equivalent to one full-time employee in many markets |
| Simple payback period | ~2.5 years | Based on conservative estimates of utilization |
Example ROI calculation: a robot costing $150k with total annual operating cost of $30k (maintenance + subscriptions) that displaces $60k/year in labor has a net annual benefit of $30k, yielding a payback of 5 years. If productivity gains add another $30k/year, payback drops to ~2.5 years; these sensitivities explain why vendors emphasize services and specialized skills to increase realized value.
Technical cost drivers and performance benchmarks
- Sensors and perception: Typical high‑end humanoids integrate stereo or multi‑camera suites, 1–2 horizontal Lidars, depth cameras, IMUs and force/torque sensors. Sensor hardware can account for 15–25% of BOM cost.
- Actuators and mechanics: Brushless motors, harmonic drives, torque sensors and compliant elements drive kinematic fidelity. Actuators and mechanical assemblies often represent 25–40% of BOM, and complexity grows with DOF—typical dexterous humanoids use 20–30 degrees of freedom (DOF).
- Compute and power: Onboard compute ranges from embedded systems like NVIDIA Jetson Orin (100–275 TOPS) to custom inference accelerators; edge compute power consumption typically ranges 30–300 W depending on workload. Battery energy density assumptions (~200–260 Wh/kg for current Li‑ion packs) translate into 1–4 hours of typical continuous operation depending on payload and activity profile.
- Software R&D and simulation: Simulation-first development with digital twins reduces physical iteration costs; software R&D amortization can dominate early margins but becomes leverageable via subscriptions and developer marketplaces.
Comparing form factors: humanoid vs wheeled AMR
| Criteria | Humanoid | Wheeled AMR |
|---|---|---|
| Manipulation versatility | High — human-like hands and reach | Limited — specialized grippers |
| Terrain flexibility | Better for stairs, uneven surfaces | Best on flat, structured floors |
| Cost (initial) | Higher ($75k–$250k enterprise) | Lower ($10k–$75k) |
| Speed of deployment | Slower (more safety validation) | Faster (standardized safety regimes) |
| Ideal use cases | Human‑level tasks, co‑working with people | Material transport, point‑to‑point logistics |
Revenue pools beyond hardware
Robotics monetization is multi‑faceted. Hardware sales are a one‑time revenue event, but recurring income from software, cloud inference, maintenance, and a developer marketplace can drive long‑term margins. Potential revenue streams include:
- Software subscriptions: task libraries, improved perception models, compliance updates — typical ARPU $3k–$20k/robot/year depending on feature set.
- Cloud compute and data services: batching heavy inference or fleet analytics; margin opportunity if priced as real‑time SLAs rather than raw GPU hours.
- Maintenance and spare parts: predictable revenue with high gross margins; uptime SLAs can command premium pricing.
- Developer marketplaces: third‑party skills and certified integrations, which can generate platform fees (10–30% of transactions).
Practical examples and prompt templates
Operators and developers can accelerate deployments using templated prompts and skill definitions. Below are concise, production‑ready prompt templates tailored to a robot control stack and an operations team:
- Task decomposition for manipulation:
“Decompose 'restock a standard shelf row 4' into perception, grasp planning, motion execution, and verification subtasks. For each subtask, return: required sensors, maximum acceptable latency (ms), failure modes to check, and a recovery action.”
- Safety test checklist generation:
“Generate a safety test plan for a humanoid performing patient transfers in a hospital room. Include preconditions, runtime constraints, required sensors, observer checks, ISO/IEC/ANSI standards references, and pass/fail criteria.”
- Operator assistance prompt:
“Summarize the last 24 hours of fleet telemetry for Robot ID 421: incidents, battery health, mean time between failures, and suggested preventive actions ranked by ROI.”
- Skill manifest template (developer marketplace):
“Provide a JSON manifest for a 'hotel room cleaning' skill: semantic intent, required API permissions, estimated execution time, allowed environment types, required safety certifications, and pricing tier.”
Regulation, standards, and risk mitigation
Regulatory frameworks will materially affect adoption. Standards such as ISO 10218 (industrial robot safety) and ISO 13482 (service robots) already exist, and healthcare uses must comply with HIPAA‑adjacent privacy controls for patient data. Firms should budget for compliance testing and third‑party certifications—costs that can add 3–8% to development budgets and several months to product timelines. Recommendations include early engagement with certification bodies, modular safety architectures that isolate hazardous subsystems, and rigorous logging for incident forensics.
Strategic recommendations for entrants and incumbents
- Pursue enterprise pilots with measurable KPIs: design pilots to prove throughput, uptime, and labor substitution in 6–12 month cycles.
- Design for modularity and upgrade paths: separate compute, sensor, and actuator modules so customers can upgrade perception stacks without replacing the whole robot.
- Invest in simulation and digital twins: every hour saved in physical iterations multiplies ROI—simulate edge cases before field trials.
- Prioritize developer experience: provide SDKs, ROS2 compatibility, and low‑latency teleoperation tools to grow a third‑party skills marketplace.
- Plan for recurring revenue from day one: subscription tiers, certified skills, and data services create margin insulation as hardware prices fall.
In short, the market opportunity for humanoid robots is large but segmented; the path to scale favors software and services that unlock long‑term value. Companies that combine strong enterprise pilots, modular hardware strategies, and a developer ecosystem will be positioned to capture the recurring revenue that ultimately determines winners in this capital‑intensive category.
What This Means for Developers: APIs, SDKs and Robotics‑Focused Codex Plugins
OpenAI's entry into robotics transforms the developer landscape. Rather than relying solely on ROS, low‑level firmware, and bespoke stacks, developers can expect a layered platform where natural language, code synthesis and simulation primitives are first‑class citizens. That shift changes both the engineering responsibilities and the desired competencies for teams: planners, safety engineers, simulation specialists and firmware developers will collaborate around common API contracts and machine‑readable artifacts rather than ad‑hoc code dumps.
Detailed Expectations for Developer Services
The platforms we expect will be composed of several distinct services and artifacts; each has technical expectations that teams should prepare for now:
- Robotics APIs: Expect REST/gRPC endpoints that accept task descriptors and return task graphs, policy bundles, or executable skill invocations. Typical payloads will be protobuf or JSON Schema documents that include: unique task id, skill list, pre/postconditions, LTL/CTL safety invariants, QoS constraints (latency, frequency), and telemetry subscriptions. Actionable advice: instrument code to produce machine‑readable telemetry (JSON/Protobuf) and version schemas using semantic versioning so generated task graphs remain backward compatible.
- Codex Plugins for Hardware: Plugins will generate driver code, PID/controller templates, and verification tests for specific motor controllers and sensor arrays (e.g., ODrive, Roboclaw, specific IMUs). Generated code will often be scaffolded in C/C++, Rust, or embedded Python, including unit tests and a hardware abstraction layer (HAL) adapter. Actionable advice: modularize drivers and expose clear HALs; implement adapter interfaces with documented hooks (init(), calibrate(), read(), command()) so generated code plugs into existing stacks.
- Simulation SDKs and Scenario Builders: Integration with Isaac, Gazebo, Webots, or OpenAI's own simulator will include scenario templates for household, logistics, and outdoor domains. Simulators will expose parameterizable domain randomization (lighting, friction, sensor noise) and batch execution APIs. Actionable advice: produce synthetic datasets and parameterized environments; maintain a baseline suite of at least 1,000 randomized scenarios per major task to capture distributional variance.
- Task and Skill Libraries: Reusable, versioned skills (grasp, place, navigate, person‑follow) with standardized interfaces and acceptance tests. Skills will be composable into meta‑tasks using planners or hierarchical task networks. Actionable advice: publish skill interfaces, provide CI test manifests for each skill, and design for composability by using canonical message types (pose, twist, grasp_descriptor).
- Safety, Formal Verification and Runtime Monitors: Tools that convert safety invariants into runtime monitors and model checkers; expect integration with SMT solvers or model checkers that verify collision envelopes, torque limits, and timing constraints. Actionable advice: define formal safety properties early and integrate verification into the pull request pipeline so any controller change triggers an automated safety check.
Concrete API & Data Schema Examples
Below are practical examples you can model in your repositories today so future-generated artifacts integrate smoothly.
- Essential telemetry fields: timestamp, frame_id, pose{position,orientation}, twist{linear,angular}, joint_states{positions,velocities,effort}, sensor_status, event_code, task_id, container_hash. Instrumentation that emits these at 100–200ms granularity for mobile robots and 10–50ms for manipulators is typical to meet control and diagnosis needs.
- Task graph node schema: node_id, skill_name, inputs (frames, object_ids), outputs, preconditions (PDDL or LTL expressions), postconditions, timeout_ms, retry_policy. Use protobuf for compact binary transport in low‑bandwidth scenarios.
- Safety constraints: Represented as linear temporal logic (e.g., G¬collision ∧ F goal_reached) or as parametric envelopes (cylinders, spheres) with associated response strategies (stop, retreat, notify operator).
Prompt Templates and Practical Examples
Below are ready‑to‑use prompt templates that make it easier to elicit useful outputs from code synthesis and planning models. Embed these in CI jobs, developer tools, or web consoles to standardize model usage.
- Task planner prompt:
"You are a robotics task planner. Given the environment JSON, the available skills (schema included), and goal specification, produce a serialized task_graph protobuf with nodes, edges, preconditions and estimated durations. Include explicit safety invariants and a fallback node. Environment JSON includes static obstacles, dynamic agents, and object types."
- Firmware generator prompt:
"Generate embedded C driver code for [MotorControllerModel] using HAL interface: init(), set_torque(float), read_current(), stop(). Include PID tuning defaults for motor constants: Kp=..., Ki=..., Kd=.... Provide unit test mocks for encoder feedback and a CI job that runs tests in QEMU."
- Simulation scenario generator:
"Create 100 randomized scenarios for 'kitchen pick and place' using parameter ranges: object_count 1–6, lighting factor 0.5–1.5, friction 0.3–0.8. Export each scenario as a .sdf or .urdf bundle and a JSON manifest with success criteria and expected failure modes."
Comparison: Existing SDKs vs. Expected OpenAI Robotics Stack
| Capability | ROS Ecosystem | Isaac / Gazebo | Expected OpenAI Robotics Stack |
|---|---|---|---|
| Primary focus | Middleware, messaging, drivers | High‑fidelity physics, GPU acceleration | Language‑first planning, code synthesis, cloud simulation |
| ML Integration | Community libraries; manual pipelines | Strong, especially for perception | Built‑in model synthesis, data pipelines, model vetting |
| Safety & Verification | Tooling exists but fragmented | Some verification tools | Formal invariants, runtime monitors, certified primitives |
| Cloud / Edge Hybrid | Custom solutions | Batch cloud sim, local HIL | Seamless simulation-to-hardware CI and cloud runtimes |
Operational Recommendations and KPIs
Teams that want to be first movers should tune operational practices to the new platform realities:
- CI/CD for robotics: Implement pipelines that run unit tests, then 100s of deterministic simulation tests (smoke and randomized), followed by hardware‑in‑the‑loop (HITL) gating. Typical gating thresholds: task success rate ≥ 95% in simulation baseline; safety violation rate = 0 for critical invariants.
- Monitoring and KPIs: Monitor task success rate, mean time between failures (MTBF), safety violation rate, P99 end‑to‑end latency, and model drift indicators (distributional shift scores). Use these to trigger dataset collection jobs and model retraining.
- Latency and bandwidth budgets: Define per‑task latency budgets (e.g., 50ms control loop for manipulator servoing, 200–500ms for high‑level planning). Decide which policies must run locally vs. in cloud based on latency and safety.
- Versioning and compatibility: Version skills and APIs independently; publish capability matrices for each robot SKU and maintain migration guides for breaking changes.
- Data governance and privacy: Encrypt telemetry at rest and in transit, anonymize PII in camera feeds, and define retention policies to comply with sector regulations (healthcare, industrial).
Expert Insights and Final Recommendations
From an engineering leadership perspective, OpenAI's robotics stack will reward teams that treat behavior as modular, verifiable artifacts rather than monolithic apps. Prioritize the following:
- Design HALs and skill interfaces now so generated code fits cleanly into your architecture.
- Invest in simulation coverage: a single edge case found in the field can be reproduced and fixed in simulation faster than hardware cycles allow.
- Automate safety verification in PR pipelines; manual signoffs should be rare and reserved for architectural changes only.
- Standardize telemetry and adopt a schema registry early to avoid data integration debt as models and skills evolve.
OpenAI's likely commercialization pattern—APIs for planning and code synthesis coupled with certified runtime primitives—creates opportunities for third‑party developers to build vertical applications, marketplaces for robot tasks, and specialized hardware integrations. Expect a plugin economy where developers monetize through skill subscriptions, enterprise integrations, and specialized certified drivers; teams that prepare schema, tests, and modular HALs will be able to onboard to that marketplace rapidly and safely.
Challenges: Hardware, Safety, Regulation and Real‑World Deployment
Despite progress, the path to reliable, general‑purpose humanoid robots faces notable challenges. These are technical, economic, and regulatory, and overcoming them requires coordinated investment, conservative engineering and, crucially, public policy engagement. Below we unpack those challenges with concrete examples, data‑driven tradeoffs, operational mitigations and actionable prompts for teams building, certifying and deploying humanoids.
Hardware Manufacturing and Supply Chains
Manufacturing humanoid robots at scale requires more than design excellence: it needs stable supply chains, long‑lead component procurement, dedicated assembly lines and quality systems. Key risks include:
- Component scarcity: High‑torque actuators, harmonic drives and custom gearbox assemblies often have lead times measured in months. Industry reports in 2022–2024 showed specialty motor lead times spiking to 12–26 weeks during peak demand cycles; custom sensors and chip masks similarly extend delivery timelines.
- Cost engineering: At prototype volumes, a custom actuator can cost several thousand dollars; at scale, similar designs consolidated with contract manufacturers can fall to a few hundred dollars per actuator. Design for manufacturability (DFM) and supplier consolidation typically drive 30–60% unit cost reduction between pilot runs and high volumes.
- Reliability testing: Fielded robots must withstand millions of joint cycles and thousands of falls or impacts. Simulating real‑world duty cycles requires accelerated life testing rigs that can reproduce thermal, mechanical and dust ingress stresses in weeks instead of years.
- Energy density and endurance: Current lithium‑ion cells offer ~200–300 Wh/kg; a humanoid with 1 kWh usable battery therefore carries ~3–5 kg in pack and supports only a few hours of intermittent operation depending on actuator load profiles.
Actionable mitigation: vertically integrate supplier relationships for critical components, design modular subsystems that allow second‑source flexibility, and invest in accelerated life‑testing rigs to compress validation timelines. Adopt a two‑tier sourcing strategy where 60–80% of demand is committed to primary vendors with blanket orders while 20–40% remains flexible for second‑source substitution.
| Component | Primary Risk | Typical Prototype Cost | Mitigation Strategy |
|---|---|---|---|
| Actuators & Gearboxes | Lead times, custom tooling | $1,000–$5,000 each | Standardize form factors; multi‑source; long‑term contracts |
| Batteries | Energy density vs weight; thermal management | $200–$1,000 per kWh (pack cost varies) | Active thermal design, modular battery swaps |
| Sensors (LiDAR, cameras) | Cost volatility; obsolescence | $100–$5,000 each | Use commodity sensors where possible; sensor fusion for redundancy |
| Compute SoC | Supply constraints; power/perf tradeoffs | $200–$1,500 per board | Design for multiple SoC families; edge/cloud split |
Testing and Validation at Scale
Testing must move beyond lab demos to statistically meaningful validation. Recommended testing portfolio:
- Accelerated life tests: Run joints and manipulators in continuous cycles at temperature extremes to quantify mean time between failures (MTBF).
- Stochastic environment trials: Execute large‑N trials (n≥1000 operational hours across environments) to capture corner cases such as loose rugs, wet floors and crowds.
- Human factors panels: Recruit diverse panels (age, mobility, cultural background) for longitudinal studies; aim for at least 30–50 participants per major use case to get robust UX metrics.
Professional recommendation: instrument every test with synchronized logs (IMU, joint torques, CPU/GPU load, network latency) and standardize an event taxonomy so field anomalies feed directly into the product backlog and safety cases.
Safety, Standards and Regulation
Safety is the primary non‑technical constraint on aggressive deployment. Governments and standards bodies are still crafting rules for service robots and humanoids; several existing standards provide starting points.
| Standard / Domain | Relevance to Humanoids | Core Focus |
|---|---|---|
| ISO 10218 | Industrial manipulators | Protective measures, risk assessment for robots in factories |
| ISO 13482 | Service robots | Safety requirements for physical interaction with humans |
| ISO 26262 (analogue) | Functional safety model | Fault tree analysis, ASIL‑like categorization for failure modes |
Key regulatory issues include:
- Certification: Certification regimes will likely require a safety‑case approach: documented hazard analysis, mitigations, residual risk quantification and field monitoring plans. Expect certification cycles measured in quarters not weeks.
- Liability: Policymakers are evaluating models ranging from manufacturer strict liability for hardware faults to shared liability when third‑party models or operator misuse is involved. Legal clarity will influence insurance cost models and business viability.
- Privacy and surveillance: Perception data is personally identifiable. Deployments must articulate data minimization, retention limits and edge‑processing defaults to avoid centralized PII collection unless explicitly consented.
Actionable mitigation: adopt conservative default behaviors (e.g., mandatory "sleep" proximity limits, local‑only image processing unless explicit consent), build auditable decision logs stored with integrity proofs, and proactively engage with regulators to pilot certification templates.
Deployment Complexity and Human Factors
Robots must operate in messy, dynamic human environments. Failure modes are often social rather than strictly mechanical; a physically safe action can be socially jarring. Real deployment considerations include:
- Explainability: Provide short, human‑centred explanations for actions—for instance, “I will take that object to the kitchen to avoid tripping over it” —and surface relevant sensor evidence if requested.
- Interaction design: Dialogue systems should support fallback intents, regional dialect models and non‑verbal cues (gaze, posture). Design for 95th percentile latency under 300–700 ms for perceived responsiveness.
- Trust and acceptability: Longitudinal studies indicate predictable timing patterns and consistent recovery behaviors increase trust more than raw capability improvements.
Practical user prompts and templates:
- Consent prompt: “This robot uses local vision to assist with navigation. Your images are processed locally and retained for 24 hours unless you opt into longer retention. Do you consent?”
- Explainability prompt: “Why did you move that object? — I moved the cup because it was within my fall‑zone threshold and could cause an accident.”
- Operator safety confirmation: “Confirm emergency stop: Type STOP and provide your operator ID to execute offline maintenance mode.”
Adversarial and Security Risks
Robots operating in the real world can be targeted by adversaries—malicious actors might attempt to trick perception systems with adversarial patterns, hijack networked controls or physically sabotage units. Notable observed attack vectors include adversarial stickers for vision models, spoofed localization beacons and compromised OTA update servers.
Security best practices drawn from avionics and automotive include:
- Hardware root of trust: TPM or secure enclave for key storage and secure boot to ensure only signed firmware executes.
- Authenticated updates: OTA updates must be end‑to‑end authenticated with code signing and rollback protection; maintain a signed manifest and verifiable audit trail.
- Network segmentation: Isolate safety‑critical control networks from general purpose telemetry and guest Wi‑Fi; enforce mutual TLS for all service endpoints.
- Adversarial robustness testing: Include physical perturbation tests (stickers, occlusions) and simulated adversarial attacks against perception stacks in acceptance testing.
Operator prompt template for security flow:
“Run security audit: verify signed firmware versions, checksum of bootloader, list active network endpoints, and initiate key rotation if any anomaly is found. Confirm to proceed.”
Field Support, Maintenance and Total Cost of Ownership (TCO)
Operational success depends on predictable field support. Expect maintenance to constitute 15–30% of TCO in early deployments; spare parts inventory and remote diagnostics significantly reduce mean time to repair (MTTR). Recommended practices:
- Design modular replaceable limbs and on‑site swap procedures to enable 30–90 minute field repairs for common failures.
- Implement predictive maintenance using telemetry thresholds to pre‑order parts before field failure.
- Maintain regional service centers to optimize logistics cost and response time for units deployed at scale.
Professional Recommendations and Next Steps
- Prioritize safety‑case development early in product design and map each feature to an auditable mitigation and monitoring plan.
- Invest in supply chain risk analytics and dual‑sourcing for critical components to minimize single‑point failures.
- Engage multidisciplinary teams—legal, HCI, mechanical, cybersecurity and policy—before pilots exceed 100 operational hours in public settings.
- Design default privacy and security settings for the most conservative user scenario and allow opt‑in relaxations with explicit consent and logging.
These challenges are surmountable, but they require disciplined engineering, rigorous testing, clear regulatory engagement and pragmatic operational planning. For organizations entering humanoid robotics, building robust supply chains, hardened systems and socially aware interaction models is not optional—it is the path to scalable, safe and accepted deployment.
Analysis: Why Now? OpenAI's Deployment Fund, Enterprise Push and the Physical Frontier
Several converging factors explain the timing of OpenAI Robotics, and each factor interacts with the others to create a narrow window in which a software‑centric AI leader can credibly enter hardware at scale.
Technical readiness: simulation, perception, and actuation
Simulation fidelity has improved along three axes that directly reduce sim‑to‑real risk: higher‑fidelity contact modeling (e.g., differentiable rigid‑body with soft contact approximations), GPU‑accelerated parallel rollout engines (thousands of environments per GPU), and sensor realism (photon mapping for vision, physics‑based tactile models). Together these advances permit training control policies with domain randomization and system‑identification curves that shrink the reality gap from months of field tuning to weeks.
Multimodal pretraining architectures now fuse language, vision, proprioception and action primitives in a single backbone, allowing models to learn affordances from large offline datasets rather than relying solely on trial‑and‑error RL. Architectures that combine transformer encoders for language and vision with recurrent or attentive action heads allow for instruction conditioning, multi‑step planning, and closed‑loop corrections in 50–200 ms control horizons suitable for real‑world tasks.
Actuator and embedded compute advances are equally important: torque-dense brushless motors, compact series‑elastic actuators, onboard safety‑grade microcontrollers, and battery energy densities improving at ~3–4% annually all reduce weight and increase duty cycles for mobile manipulators. Practical robotic platforms that previously cost $150k per unit are now feasible in sub‑$50k configurations for specific task families, shifting TCO calculus for pilots.
Economic capacity: what a $4B deployment fund enables
OpenAI’s $4B deployment commitment substantially changes the risk profile of hardware commitments by underwriting both R&D and manufacturing scale. Typical robotics startups fail at the capital intensity stage—tooling, low‑rate initial manufacturing, and serial‑numbered acceptance testing—where economies of software do not apply. A multi‑billion dollar backstop allows OpenAI to negotiate long‑lead component contracts, invest in in‑house test benches, and run loss‑making enterprise pilots while iterating on hardware and perception stacks.
Concretely, enterprise pilot fleets of 10–100 units with accompanying integration services commonly require upfront CapEx and working capital in the low single‑digit millions to tens of millions; the deployment fund enables multi‑year pilots without immediate per‑unit profitability, accelerating data collection and model refinement.
Product diversification and the “software + physical” moat
Embedding a language model into a robot converts a stateless API into a stateful embodied system that accumulates privileged interaction data, physical calibration parameters, and environment‑specific policies—data that is expensive to replicate. Enterprises integrating such systems gain three classes of advantage: (1) operational tailwinds from incremental automation, (2) data capture that improves performance in specific facilities, and (3) switching costs because hardware workflows and safety certifications are costly to duplicate.
Competitive positioning and strategic urgency
Competitors’ moves—Tesla’s Optimus initiative, Hyundai’s acquisition of Boston Dynamics, and Amazon’s investments in warehouse robotics—mean platform companies are converging on physical interfaces. For OpenAI, owning an embodied agent preserves the company’s influence over the “language to action” layer: defining instruction semantics, safety constraints, and standardized API patterns that govern how language models command physical effectors. Delaying entry would allow other platform incumbents to anchor that interface.
Regulatory window and standards shaping
Regulators in several jurisdictions are formalizing frameworks for service robots, including safety certification, data minimization, and operator training requirements. Early participation allows OpenAI to collaborate with regulators on pragmatic certification tests (e.g., emergency stop response under 50 ms, force limits for human interaction), influencing standards that later become de facto barriers to entry for smaller players.
Enterprise placements as learning laboratories
Enterprise deployments serve dual purposes: revenue generation and closed‑environment learning. A warehouse pilot with constrained aisle width and homogenous SKUs provides controlled variability for policy iteration; a hospital sterilization robot trains in strict cleaning protocols and telemetry capture; a semiconductor fab pilot yields high‑precision motion data under deterministic schedules. These environments accelerate transfer learning to more open domains because they produce labeled failure modes, instrumented human‑in‑the‑loop corrections, and curated datasets for supervised fine‑tuning.
Practical use cases and prompt templates
Below are concrete enterprise use cases and example high‑level prompts that illustrate how language conditioning interfaces to low‑level robot primitives.
- Warehouse SKU sorting: Prompt template for pick‑and‑place with safety envelope:
<instruction>Sort items from incoming bin A into bins B1–B5 by barcode and fragility tag. Use grasp primitive G2 for fragile items, speed limit 0.5 m/s when human detected within 2 m. Confirm each placement with visual check and success flag.</instruction>
- Clinical supply delivery: Prompt template for human‑facing handoff:
<instruction>Deliver tray T-42 to nurse station 3. Announce arrival audibly, hold tray at chest height 1.0 m for handoff, wait for contact confirmation, then log time and return to charging bay. Abort if obstruction longer than 60 s and notify operator.</instruction>
- Inspection and maintenance: Prompt template for multi‑modal inspection:
<instruction>Inspect compressor C-7 for oil leaks and abnormal vibration. Capture 5 images at 2 m and 0.5 m, run vibration FFT, classify anomaly probability >0.7, and open ticket with annotated images. Only approach within 0.5 m if gas sensor reads below threshold X.</instruction>
Technical integration pattern: language layer to motion primitives
Best practice integrates three layers: a high‑level language planner that emits symbolic tasks, a mid‑level sequencer that maps symbols to parameterized motion primitives, and a low‑level controller handling dynamics and safety. Latency‑sensitive loops (e.g., impedance control at 1 kHz) remain on local embedded controllers; higher‑level planning can operate at 10–100 Hz and tolerate transient network delays. Telemetry, deterministic replay buffers, and per‑task evaluation metrics (success rate, mean time to completion, safety incidents per 1,000 hours) are essential for continuous improvement.
Comparison: enterprise vs consumer vs research deployments
| Dimension | Enterprise | Consumer | Research |
|---|---|---|---|
| Primary metric | ROI, uptime, integration costs | Usability, price point, battery life | flexibility, reproducibility |
| Environment complexity | Controlled but varied (warehouses, hospitals) | Highly unstructured (homes) | Benchmarks and simulators |
| Update cadence | Slow (safety approvals) | Fast (OTA updates) | Rapid experiment cycles |
| Data privacy & IP | High value, often closed | User consent needed, varied | Open datasets preferred |
| Typical unit economics | Higher upfront, long payback (months–years) | Lower per‑unit price target | Negligible scale economies |
Expert recommendations for enterprises considering partnerships
- Define narrow pilots: Choose a bounded task with clear success criteria and fewer than five uncontrolled variables to accelerate learning and reduce integration time.
- Instrument everything: Deploy sensors and logging that capture failure conditions, environmental covariates, and operator interventions; aim for synchronized timestamping across camera, IMU, force/torque, and command logs.
- Plan for safety certification: Require shock, EMC, and functional safety test plans upfront; verify emergency stop behavior under network partition scenarios.
- Stagger fleet scaling: Validate at 1–5 units, then scale to 10–50 after operational KPIs stabilize; expect diminishing marginal returns in early scaling until software matures.
- Negotiate data rights: Clarify ownership of telemetry and derived models to avoid future lock‑in; prefer structured agreements that allow on‑site model refinement with federated learning if necessary.
Closing insight
OpenAI’s move into robotics is not simply a product extension; it is a strategic bet that language models can become the cognitive substrate for embodied agents, and that a decade‑scale capital commitment can bridge the capital intensity gap that has historically kept software‑first companies out of hardware. For enterprises and collaborators, the practical implication is immediate: prioritize narrow, instrumented pilots, insist on clear safety and data agreements, and prepare to operationalize iteration cycles measured in months rather than years.
Roadmap and Practical Timelines
Below is a pragmatic five‑year roadmap that aligns with the technical, manufacturing and regulatory realities described above. Timelines are conservative and assume parallel development tracks.
- 2026 (R&D and Pilots)
- Establish prototype labs, hire core hardware and systems teams.
- Enterprise pilot programs in logistics and manufacturing; closed‑environment proofs.
- Publish developer previews for simulation SDKs and early APIs.
- 2027–2028 (Validation and Limited Production)
- Deliver limited production runs for enterprise customers; iterate on safety and durability.
- Begin consumer beta pilot programs in controlled environments (assisted living facilities, research homes).
- Secure supply chain partners and commit to assembly lines; invest in quality systems.
- 2029–2030 (Scale Preparation)
- Scale manufacturing capacity, establish mass production processes, optimize cost structures.
- Work with standards bodies to certify safety frameworks; obtain regional approvals.
- Grow developer marketplace and enterprise integrations; prioritize recurring revenue models.
- 2030–2032 (Initial Mass Market Entry)
- Introduce lower‑cost consumer models with reduced capabilities for non‑critical chores.
- Expand global dealer and service networks; refine warranty and insurance products.
- Focus on software updates and skill marketplace to drive SaaS revenue.
These milestones reflect an understanding that while software iteration can accelerate, hardware cycles remain constrained by manufacturing lead times and compliance testing. OpenAI's $4B deployment commitment aims to smooth those constraints by enabling multi‑year investments without immediate profitability pressure.
Detailed Phase-by-Phase Analysis
2026 — R&D and Pilots: What success looks like
In 2026 the focus must be on repeatable experiments that close the sim‑to‑real gap and validate core subsystems. Success metrics for this year should include quantitative validation targets such as:
- Sim‑to‑real transfer success rate ≥ 70% for critical manipulation tasks after domain randomization and 5–10 iterations of hardware-in-the-loop tuning.
- Prototype mean time between failures (MTBF) > 200 operational hours under representative workloads.
- Pilot productivity uplift: 10–25% reduction in manual labor hours in logistics pilot sites across 3 different warehouse layouts.
Practical examples: a logistics pilot might run 2 robots per shift for a month with metrics captured every 15 minutes—throughput (packages/hour), task success rate, and intervening human assists per 100 operations. An assisted‑living pilot could measure reduction in staff lifts for transfers and a fall‑prevention false alarm rate below 2%.
2027–2028 — Validation and Limited Production: Key technical and operational tasks
During limited production you must shift engineering attention to manufacturability, supply chain resilience and safety certification. Typical lead times and durations to budget for:
- Custom motor and gearbox tooling: 12–20 weeks per iteration, with multi‑slot production calendars.
- PCB and sensor procurement: 8–16 weeks depending on parts obsolescence and supplier qualification.
- EMC and environmental testing cycles: 4–12 weeks per certification body engagement.
Regulatory alignment: prepare dossiers for ISO 10218 and ISO/TS 15066 (industrial/collaborative robots), ISO 13482 for personal care robots, and UN38.3 for battery transport. For medical or safety‑critical functions, plan for FDA premarket consultations that can extend 9–18 months.
2029–2030 — Scale Preparation: Cost, partners and standards
Scale preparation emphasizes cost engineering and ecosystem development. Target cost reductions and business metrics to validate before mass market entry:
- Bill of materials (BOM) reduction of 25–40% via part consolidation and alternative suppliers.
- Yield improvement: assembly yield > 95% with inline automated test coverage.
- Service economics: target cost of service (COS) < 8% of device list price through modular field‑replaceable units.
Developer ecosystem: launch a marketplace with SDKs, curated skill templates, and a revenue split designed to incentivize third‑party integrations (example split: 70/30 for developer revenue, adjustable by enterprise agreements).
2030–2032 — Initial Mass Market Entry: Distribution and lifecycle management
Initial mass market products should be feature‑tiered to manage risk while building brand trust. Recommended product tiers:
| Tier | Typical Use Case | Capabilities | Target ASP (USD) |
|---|---|---|---|
| Enterprise Pro | Warehouses, manufacturing | High payload, advanced perception, SLA support | $40k–$80k |
| Care Assist | Assisted living, healthcare support | Care‑safe manipulators, HIPAA‑compliant data handling | $20k–$40k |
| Home Lite | Non‑critical domestic tasks | Limited manipulation, cloud‑assisted planning | $2k–$6k |
Service model: emphasize OTA updates, subscription for advanced capabilities, and partner‑delivered in‑home service for warranty repairs. Expect initial churn but plan for a 3‑year extended warranty uptake target of 20–30% for consumer adoption confidence.
Comparing Software vs Hardware Development Rhythms
| Dimension | Software | Hardware |
|---|---|---|
| Typical iteration time | Days–weeks (CI/CD) | Weeks–months (tooling, physical tests) |
| Cost per iteration | Low marginal cost | High (prototypes, parts, assembly) |
| Failure mode visibility | High (logs, tracebacks) | Requires instrumentation and long‑running tests |
| Regulatory burden | Moderate (data, privacy) | High (safety, EMC, transport) |
Practical Prompt Templates and Developer Guidance
To accelerate developer adoption, provide tested prompt templates that couple high‑level goals with safety and verification steps. Examples:
- Pick-and‑Place in Warehouse (safety‑first)
Prompt template:
Task: Pick item SKU 123 from bin A3 and place into tote B2. Constraints: validate item geometry with depth sensor, run grasp planner, confirm no human within 1.5 m, perform visual verification before release. Success criteria: object placed without droppings, duration < 90s, human interventions ≤ 0 per 50 ops. - Assisted Living Transfer (human‑centric)
Prompt template:
Task: Assist resident from seated to standing position using gait‑support harness. Constraints: verify resident consent via voice, perform pre‑transfer balance check, notify nurse on abnormal readings, abort on any pain signal. Success criteria: transfer within clinically acceptable force profiles, zero falls, logged vitals transmitted to nurse station.
KPIs, Risk Mitigations and Recommendations
| Phase | Top KPIs | Primary Risks | Mitigations |
|---|---|---|---|
| 2026 R&D | Sim‑to‑real success %, MTBF, pilot uplift | Model overfitting, fragile prototypes | Robust domain randomization, hardware‑in‑loop testing |
| 2027–2028 Validation | Assembly yield, safety incident rate | Supply bottlenecks, certification delays | Dual‑sourcing, pre‑certification audits |
| 2029–2030 Scale Prep | BOM cost reduction, service cost | Manufacturing yield loss, demand forecasting error | Flexible contract manufacturing, pilot batches |
Expert Insights and Professional Recommendations
- Adopt a modular hardware architecture: field‑replaceable actuators and sensor modules reduce RMA costs and accelerate upgrades.
- Design for graceful degradation: ensure robots can enter a safe passive mode and provide clear human‑readable diagnostics to speed repairs.
- Invest early in traceable telemetry and event logs with cryptographic integrity for post‑incident analysis and regulatory audits.
- Balance edge compute and cloud offload: keep latency‑sensitive perception on‑board, while using cloud for heavy planning and fleet learning to reduce bandwidth and privacy risks.
- Plan regulatory timelines as critical path items: factor 6–18 months for region‑specific approvals depending on domain and safety classification.
Executing this roadmap requires discipline around measurable objectives, a multi‑disciplinary team that blends software, mechanical, and regulatory skills, and a conservative manufacturing cadence until yields and field reliability are proven. With disciplined execution and the stated capital commitment, the proposed timelines are achievable while preserving safety and delivering practical value to early customers.
Expert Perspectives and Industry Context
Industry leaders and researchers have offered a mix of optimism and caution. The consensus view across robotics labs, OEMs, and standards bodies is that OpenAI's entry validates robotics as the next frontier for AI companies; however, several practical caveats were repeatedly emphasized:
- Integration complexity: The hardest work is not in achieving a single impressive demo, but in making robots robust over millions of real‑world hours under adversarial conditions. Achieving that level of reliability requires continuous operations engineering and mature quality systems.
- Human interaction design: Natural language control presents enormous UX advantages, but also creates ambiguous instructions that require contextual and social intelligence beyond immediate task execution.
- Regulatory and social license: Deployment at scale depends on public acceptance and regulatory clarity—deliberative engagement with stakeholders is non‑negotiable.
Examples from adjacent domains clarify these points. Automotive Level‑4 autonomy research produced years of high‑visibility prototypes before regulatory, safety and commercial viability constraints forced refocus on controlled deployments (geofenced robotaxis). Similarly, large language models faced early safety headwinds, necessitating content filters, guardrails and a slower rollout. Robotics amplifies both concerns—physical safety compounds content risk because mistakes can cause property damage or bodily harm.
From an economic viewpoint, enterprise robots for warehousing and inspection are materially viable today because costs are easier to justify and environments are controlled. Consumer humanoids require a combination of lower unit cost, reliability and an ecosystem of skills that make the device indispensable. OpenAI's strategy—enterprise first, consumer later—aligns with this reality.
Technical Challenges and Mitigation Strategies
Experts consistently point to a handful of technical barriers that need systematic engineering solutions rather than one‑off research breakthroughs:
- Sample inefficiency and long tail failures: Contemporary reinforcement learning and imitation pipelines often require millions of simulated trajectories to reach acceptable performance. To mitigate this, teams use hybrid approaches: pretraining policies in simulation with domain randomization, followed by on‑robot fine tuning with conservative policy updates (e.g., trust‑region methods) to avoid catastrophic regressions.
- Sim‑to‑real gap: High‑fidelity simulators such as NVIDIA Isaac Sim and MuJoCo help, but differences in sensor noise, friction coefficients, and mechanical compliance create transfer errors. Practical fixes include system identification, ensemble dynamics models, and incorporating real sensor logs into simulation for replay‑based augmentation.
- Runtime safety and monitoring: Runtime monitors and anomaly detectors that run on the robot’s control loop are essential. Techniques include formal safety envelopes (barrier certificates), model‑based redundancy, and probabilistic risk assessments that trigger safe fallback behaviors or human intervention.
- Long‑term maintenance and drift: Robots experience hardware degradation and environmental drift; continuous performance monitoring (MTBF tracking, telemetry baselining) and automated retraining pipelines help maintain service levels. Experts recommend designing for replaceable subassemblies and online calibration routines.
Standards, Certification and Regulatory Landscape
Any commercial robotics deployment must navigate an existing patchwork of standards and a shifting regulatory environment. Key standards and their practical implications include:
- ISO 13849 & IEC 61508: Frameworks for functional safety and safety‑related control systems; influence safety‑critical architecture and SIL (Safety Integrity Level) assessments.
- ISO 10218 / ISO 15066: Robot safety standards for industrial manipulators and collaborative robots (cobots), which prescribe force/pressure limits, guarding, and collaborative operating modes.
- ISO 13482: Standards for personal care robots relevant to consumer humanoids, focusing on interaction safety and acceptance testing.
Professionals advise integrating certification activities early in product roadmaps and investing in regulatory liaisons to shape feasible test plans and field trials rather than retrofitting compliance after design choices are locked.
Use Cases, Economic Viability, and Comparative Metrics
Practical deployments cluster into distinct opportunity spaces; each has different risk, revenue, and technical profiles. The table below summarizes key differences and expected near‑term focus areas.
| Application Class | Environment Variability | Required Reliability | Primary Value Proposition | Typical Time to Scale |
|---|---|---|---|---|
| Warehouse/Logistics | Moderate (structured aisles) | High (99%+ task success in shift operations) | Labor cost reduction, throughput | 1–3 years (pilot → rollout) |
| Inspection & Maintenance (energy, telecom) | Moderate–High (outdoor variability) | Very High (safety, regulatory inspections) | Risk reduction, remote diagnostics | 2–5 years (sector dependent) |
| Healthcare Assistive Robots | High (human variability) | Very High (patient safety) | Care augmentation, alleviating workforce shortages | 5–10 years (regulated) |
| Consumer Humanoids | Very High (home unpredictability) | High (social acceptance, safety) | Companion/assistance, entertainment | 5–15+ years (depends on costs) |
Prompt Templates and Practical Interaction Patterns
Expert teams recommend structuring natural language control with layered prompts and explicit safety constraints. Below are examples and templates that engineers and product teams can use as starting points.
Task Decomposition Prompt (for a mobile manipulator)
Template:
"Plan a safe sequence to pick up the blue box on shelf B3 and place it on conveyor C1. Constraints: 1) Avoid human zones (>1.5 m). 2) Maintain gripper force < 25 N. 3) Verify object identity with vision confidence > 0.85 before grasp. Return: ordered steps, expected duration per step, fallback for each step."
Safety Monitor Prompt (runtime policy)
Template:
"Continuously evaluate sensor streams for anomalies. If predicted collision probability > 0.01 within 0.5 s, execute emergency stop and report telemetry including lidar, joint states, and camera frames. Log event with unique ID for offline analysis."
Human‑robot Handovers
Prompt pattern:
"Initiate handover: extend arm to handover pose H, assert 'Ready to hand over' via TTS, wait for human confirmation gesture. If no confirmation within 4s, retract to safe pose and notify supervisor."
These templates illustrate the necessary precision—temporal thresholds, confidence bounds, and safety margins—missing from naive free text prompts. Engineering teams should convert such high‑level language into verifiable policy code and include explicit telemetry hooks for post‑hoc analysis.
Operational Recommendations and Organizational Readiness
Industry experts and consultants offer concrete recommendations for organizations preparing to integrate advanced robotic systems:
- Invest in Ops and Reliability Engineering: Expect to run factories of robots; hire site reliability engineers for hardware, firmware, and model drift monitoring. Measure and track MTBF, MTTR (mean time to repair), and incident rates.
- Build Cross‑Functional Teams: Combine robotics engineers, ML researchers, safety engineers, and UX designers. Co‑locate field engineers with product teams to shorten feedback loops from deployment to model updates.
- Instrument Everything: Telemetry, high‑frequency logs, synchronized video, and hashed model versions enable causal analysis after incidents. Retain data for continuous improvement and regulatory audits.
- Adopt Incremental Deployment Patterns: Use geofenced, time‑windowed pilots and controlled A/B experiments rather than immediate wide rollout. Start with tasks where failure modes are low severity (e.g., sorting vs. human interaction).
- Engage Stakeholders Early: Work with unions, local regulators, and consumer advocates during pilots to identify societal concerns and design mitigations such as visible safety signals, human override options, and transparent incident reporting.
Final Expert Insight
OpenAI's entry raises the bar technically and culturally: it signals that the industry expects large AI companies to tackle the end‑to‑end complexity of physical systems. But experts caution that success will be measured not by isolated demos but by sustained operational metrics—uptime, safety incident rates, total cost of ownership, and user acceptance. Organizations aiming to partner with or compete against entrants should plan for multi‑year investments in engineering discipline, regulatory strategy, and human‑centered design rather than short‑term model improvements alone.
Investor and Economic Implications
OpenAI's move into robotics will not only reshape technical roadmaps but also fundamentally change how investors underwrite, price, and risk‑manage exposure to physical AI. The most immediate investor signals are operational—order books, manufacturing agreements, and revenue mix—but longer‑term valuation hinges on durable service revenue, field reliability, and supply‑chain control. Below we unpack those mechanisms, provide quantitative examples, recommended KPIs for monitoring, due‑diligence prompts, and practical scenario templates investors and corporate procurement teams can use.
Key Financial Indicators and Why They Matter
Investors should move beyond headline metrics and focus on a blend of hardware and software KPIs that determine both near‑term cash flow and long‑term multiple expansion:
- Order backlog and preorder conversion rate — backlog signals demand but conversion rate (preorders → paid units shipped within 12 months) reveals execution quality and channel friction.
- Recurring revenue mix (ARR as % of revenue) — software, cloud inference fees, maintenance contracts and RaaS subscriptions stabilize cash flows and typically warrant higher multiples than one‑time hardware sales.
- Unit economics: contribution margin per robot — price less incremental COGS and recurring service costs; key to payback-period calculations.
- Field reliability: MTBF / MTTR — mean time between failures and mean time to repair directly affect service costs, churn, and warranty reserves.
- Supply chain lead times and supplier concentration — percentage of parts from single suppliers or regions; longer lead times elevate working capital and increase risk premiums.
Illustrative Unit‑Economics Example (numeric)
The following is an illustrative worked example investors can use as a baseline scenario. Replace the numbers with real data from company diligence to run sensitivity analyses.
- Sale price per industrial mobile manipulator: $75,000
- COGS (materials, motors, controllers, assembly): $30,000
- Gross margin on sale: 60%
- Monthly subscription for cloud perception + fleet management: $1,500 → ARR per unit: $18,000
- Incremental service cost for subscription (cloud compute, monitoring): $3,000 per year
- Net recurring margin: (18,000 − 3,000) / 18,000 = 83%
- Payback period on base hardware (ignoring subscription): 75,000 − (contribution per month) → if financed or leased, extended payback reduces capex burden on customers
Under this example, a combined hardware + subscription model converts a capital sale into sustained high‑margin ARR, improving valuation multiples closer to software peers if churn is low and renewal rates exceed 90%.
Business‑Model Comparison
| Model | Revenue Recognition | Typical Gross Margin | Capital Intensity | Investor Valuation Drivers |
|---|---|---|---|---|
| Upfront hardware sale | One‑time; large revenue spikes | 20–60% (depends on scale) | High (inventory & warranty reserves) | Unit economics, manufacturing scale, price elasticity |
| Robot‑as‑a‑Service (RaaS) | Recurring monthly/annual | 40–80% over time (service margins) | Moderate to high (fleet ownership) | Customer retention, utilization rate, fleet efficiency |
| Hybrid (sale + subscription) | Mix of upfront & ARR | Improving with ARR mix | Moderate | ARR growth rate, churn, cross‑sell rates |
| Licensing / OEM integrations | Contractual, milestone‑based | Variable | Low (software focused) | IP strength, partnership exclusivity, margin share |
Supply‑Chain and Manufacturing Considerations
Execution risk in robotics is frequently a supply‑chain story. Investors should evaluate:
- Manufacturing partnerships and NRE terms — long‑term contracts with Tier‑1 contract manufacturers or automotive suppliers reduce single‑unit cost but introduce minimum order commitments and potential excess inventory risk.
- Critical component lead times — custom harmonic drives, high‑torque brushless motors, and power electronics can have 12–40 week lead times depending on global shortages; suppliers with multiple qualified sources reduce bottleneck risk.
- Yield and test time — assembly yield rates and time required for calibration/test per unit (e.g., 4–8 hours standard) materially affect throughput and OPEX.
- Aftermarket logistics — spares availability and field service network density are direct inputs into warranty reserves and churn projections.
Risk Factors and Mitigants
Robotics introduces unique liabilities and regulatory considerations that affect insurance costs, product recalls, and legal exposure:
- Safety & liability — documented safety cases, third‑party verification (UL, ISO 10218, ISO 13482), and insurance treaties reduce tail risk.
- Cybersecurity — firmware update mechanisms and encrypted communications reduce vector for fleet compromise; investors should insist on code‑signing and SOC‑2 for cloud backends.
- Regulatory uncertainty — workplace and public‑space deployment may require local approvals; regulatory tech roadmaps differ by jurisdiction and influence go‑to‑market timelines.
Practical Due‑Diligence Checklist for Investors
- Request detailed BOM with supplier tiers and alternative sourcing plans; quantify lead times and per‑unit price sensitivity to volume.
- Obtain three consecutive months of field reliability logs (MTBF, MTTR, incident severity) and analyze trends over production batches.
- Verify revenue mix by customer cohort: what percentage of top 10 customers are on subscription versus one‑time purchases?
- Run a scenario model: simulate revenue and cash flow under base, downside (30% lower orders), and upside (2x order ramp) cases for 24 months.
- Assess IP defensibility and freedom‑to‑operate; request redacted license agreements with partners and any exclusivity terms.
Prompt Templates for Investors, Engineers and Procurement
Below are practical prompt templates you can paste into a diligence tracker or engineering chat assistant to accelerate evaluation.
- Investor diligence prompt: "Summarize the startup's unit economics assuming sale price $X, COGS $Y, subscription $Z/month; calculate payback period, contribution margin, and sensitivity to ±20% changes in component costs and subscription churn."
- Procurement RFP prompt: "Generate a 12‑point supplier RFP specific to robotics drive modules including required test reports, lead time SLAs, volume discounts, and spare‑parts delivery windows."
- Engineering testing prompt: "Create 20 failure‑mode test scenarios for a wheeled manipulator operating in a 10,000 sqft warehouse, including sensor occlusion, network partition, motor stall, and high‑dust environment; for each scenario provide expected mitigation and recovery steps."
- Customer ROI calculator prompt: "Build a template to compare labor cost savings versus TCO over five years for deploying 10 robots versus hiring temporary operators; include assumptions for utilization, maintenance, and training."
Expert Recommendations for Investors and Corporates
- Prioritize recurring revenue quality over headline ARR — evaluate gross retention and net revenue retention for robotics subscriptions the same way SaaS investors do.
- Insist on field trials under real operating conditions — lab demos can mask edge cases; require 90–180 day pilot data showing uptime, throughput, and safety incidents.
- Stress test supply contracts — model scenarios with component cost inflation of 25–40% and verify price‑escalation clauses or hedging strategies.
- Focus on integration costs — many robotics deployments fail not because of the robot but due to integration, floor redesign, or process change; quantify expected integration spend as part of sales price.
- Use staged financing tied to operational milestones — milestone‑based tranches for production ramp, yield improvement, and ARR thresholds align incentives and de‑risk capital deployment.
In short, OpenAI's entry amplifies both opportunity and scrutiny. For investors, the pathway to premium multiples runs through subscription revenue, proven fleet reliability, supply‑chain resilience, and demonstrable customer ROI. For incumbents and new entrants alike, success will be measured not by prototype count but by repeatable economics at scale.
Actionable Recommendations
For different stakeholder groups, here are concrete next steps informed by the analysis above. These recommendations move beyond high-level advice into concrete artifacts, metrics, and workflows that teams can implement within 30–180 days.
For Developers
Developers are the bridge between large language models and actuated hardware. The emphasis should be on modularity, reproducible testing, and safety‑first deployment practices.
-
Build verticalized skill libraries with test suites:
Create domain-specific skill modules (e.g., pallet pick, visual inspection, medication dispense) and attach a standardized test harness for each. Each skill should include sensor input fixtures, deterministic environment fixtures (seeded physics sims), and a minimum passing criteria matrix (safety violations = 0, task success ≥ 95%). Use simulators such as NVIDIA Isaac Gym, PyBullet, or ROS2 + Gazebo for determinism and reproducibility.
-
Adopt CI/CD for robotics:
Pipeline components should include:
Stage What to Automate Metric/Artifact Unit & Integration Controller unit tests, HAL stubs Unit coverage %, build artifact Simulation Regression Scenario replay, randomized seeds Average success rate, mean time to failure Hardware-in-the-Loop (HIL) Low-risk behavior validation Telemetry baseline & anomaly flags Safety Invariant Checks Enforce speed/force limits, geo-fences Violation count per build Treat safety invariants, sensor latency budgets, and telemetry schemas as immutable artifacts in the repo. Aim for nightly simulation regression runs and weekly HIL tests for active branches.
-
Standardize HALs and schemas:
Modularize Hardware Abstraction Layers (HALs) and expose well‑documented interfaces using established standards: ROS2 topics/services, URDF/SDF for kinematics, and OpenAPI for service endpoints. Provide example adapters so LLM-generated code can call into HALs without rewriting actuator specifics.
-
Adversarial and fuzz testing for perception + control:
Integrate adversarial examples for vision stacks (occlusion, lighting shifts, sensor noise) and inject time skew/jitter into sensor streams. Track false positive/negative rates. Recommended thresholds: for safety-critical perception, false negatives < 0.1% under nominal conditions and documented degradation curves under stress.
-
Prompt templates and engineering playbook:
Provide LLM prompt templates that developers can use to generate safe control code, tests, and documentation. Example templates:
- Generate control loop scaffold: "Write a ROS2 node in Python that reads a 30 Hz LiDAR topic /scan and publishes velocity commands to /cmd_vel. Include a safety supervisor that limits forward speed to 0.5 m/s and stops if obstacles within 0.6 m."
- Unit test generator: "Create pytest cases that simulate sensor inputs for an arm pick skill. Include success, grasp fail, and object slip scenarios; assert end effector ends within 2 cm of target and no joint exceeds torque limit."
- Telemetry spec: "Produce a JSON schema for telemetry including timestamped pose, battery %, CPU load, perception confidence, and safety_state. Include keystroke for sampling rate (100 ms)."
For Enterprises
Enterprises should prioritize pilots that are measurable, scalable, and legally covered. The right early projects demonstrate ROI while minimizing integration risk.
-
Choose pilot domains with clear KPIs:
High-ROI pilot examples and sample KPIs:
Pilot Typical KPI Expected Payback Window Inventory picking (warehouses) Picks/hour increase, error rate reduction 6–18 months Repetitive assembly (manufacturing) Cycle time % reduction, yield improvement 9–24 months Hazardous inspection (oil & gas) Safety incidents avoided, downtime reduced 12–36 months Assisted caregiving (long term care) Staff time reclaimed, incident rate 18–36 months Track total cost of ownership (TCO) including maintenance, spare parts, and model retraining. Aim to quantify before/after labor hours and error rates.
-
Procurement and contracts:
Negotiate for lead-time protections, capacity reservations, and clear SLAs over both hardware and model updates. Ask vendors for measurable SLI/SLA definitions (e.g., 99% uptime excluding scheduled maintenance, 95% task success over a 30‑day window) and joint verification plans.
-
Integration & change management:
Plan for 3 explicit phases: sandboxed validation, supervised live trials (human-in-the-loop), and scaled operations. Define handover criteria for each phase with data-driven thresholds to progress.
For Policy Makers and Standards Bodies
Regulators must balance innovation with public safety. Actionable policy steps include testable certification, data governance, and supervised research environments.
-
Contextual certification frameworks:
Create certification tracks by operational context (industrial, commercial, residential, medical). Certification should require reproducible test suites, immutable audit trails for decisioning models (model_id, weights_hash, input_snapshot), and runtime monitors that log safety events. Consider adopting a "safety budget" concept — measurable resource caps (force, speed, proximity) that cannot be exceeded without re-certification.
-
Data governance and privacy:
Mandate data minimization and retention policies for robot-collected perception data. For in-home deployments require explicit opt‑in for video/audio capture, end-to-end encryption at rest and in transit, and anonymization standards (face blurring, voice masking) where possible.
-
Regulatory sandboxes and public oversight:
Create publicly monitored sandboxes where researchers and companies can test novel behaviors under supervision. Define red-team exercises and mandatory incident reporting thresholds (e.g., injuries, property damage, privacy breaches) that trigger audits.
For Investors and Procurement Leads
Investors and buyers should focus on teams that demonstrate repeatable engineering practices, deterministic validation, and defensible safety postures.
- Prefer companies with documented CI/CD pipelines for robots, nightly simulation regression results, and regular HIL reports.
- Require evidence of supply-chain resilience—multiple approved vendors for critical components or contracted capacity guarantees for 12–24 months.
- Factor in software maintenance velocity: monthly model update cadence and patch SLAs are as important as initial delivery.
Practical Readiness Checklist (30–180 day roadmap)
- Inventory current skills & map to business KPIs (30 days).
- Spin up deterministic simulation suites and seed 20 representative scenarios (45–60 days).
- Implement baseline CI pipeline with nightly regression runs (60–90 days).
- Define safety invariants, telemetry schema, and SLA templates (90–120 days).
- Execute supervised pilot and capture quantitative ROI data (120–180 days).
Expert Insights and Final Recommendations
From field experience and cross‑industry patterns, teams that succeed will have three capabilities:
- Hybrid control architectures: combine classical control with learned perception/action layers and clear failover to conservative controllers.
- Observable systems: rich telemetry, health metrics, and immutable logs so incidents can be reconstructed and models audited.
- Operational discipline: Schedules for retraining, drift detection, and component refresh; view models and hardware as co-evolving products.
Implementing these recommendations will not eliminate risk, but they materially reduce it and accelerate safe, measurable deployment. Teams that treat robotics like software plus hardened physical governance—reproducible tests, clear safety invariants, and contractual rigor—will be best positioned to capture the productivity and safety gains that Sam Altman’s new division promises to accelerate.
Conclusion: The Physical Frontier of AI
OpenAI's launch of a dedicated robotics division marks a significant inflection point because it deliberately unites three historically separated domains—large models, sensor-rich perception stacks, and mechanical systems—into a single engineering and product roadmap. The company is taking the capabilities that made language and vision models transformative—scale, multimodal integration and developer ecosystems—and applying them to embodied agents; that leap is technically plausible today because of faster simulators, denser sensor fusion, and cloud‑native training pipelines that can deliver tens to hundreds of millions of simulated timesteps per week.
Why this moment is different — technical and economic specifics
Three concrete enablers make OpenAI Robotics more than incremental: compute and simulator throughput, sensor fidelity, and capital deployment. Modern GPU clusters can deliver the equivalent of 10^8–10^9 environment interactions per week when paired with parallelized physics engines such as NVIDIA Isaac Gym or JAX‑based differentiable simulators. Camera and LiDAR stacks now routinely provide synchronized data at 30–60 Hz for vision and 100–1,000 Hz for inertial sensors, which reduces sim‑to‑real gaps when coupled with domain randomization and learned residual policies. Finally, the multi‑billion dollar deployment fund removes an early constraint for hardware scale‑up: injection of capital that supports tooling, safety certification, and manufacturing tooling is often the gating factor for robot commercialization.
Practical, near‑term use cases and pilots
Hardware realities mean the earliest commercial wins will be in controlled environments where safety envelopes and value per hour are high. Practical examples include:
- Logistics: autonomous picking and tote handling in e‑fulfillment centers with 95+% throughput targets for high‑volume SKUs.
- Healthcare assistive devices: semi‑autonomous patient transfer aids that reduce caregiver injury rates and target a 30–40% reduction in manual handling incidents.
- Manufacturing inspection: mobile robots performing visual defect detection on conveyor lines, increasing inspection coverage by 2–5x while reducing cost per inspected unit.
- Facility services: floor cleaning and security patrol robots operating in shift rotations to deliver predictable labor substitution with ROI windows of 18–36 months.
- Agriculture: precision weeding and monitoring robots reducing herbicide usage by 20–50% in targeted operations.
Developer playbook: building safe, testable skills today
Developers should adopt a modular, test‑driven pipeline that mirrors software best practices but adds hardware-in-loop (HIL) stages. Recommended phases:
- Specification: define atomic skills with clear preconditions, postconditions, and safety invariants (e.g., joint‑limit constraints, minimum human distance).
- Simulation unit tests: use randomized parameter sweeps to stress‑test policies across 10^5–10^7 episodes per skill.
- Hardware‑in‑Loop: validate sensor timing and control latency with 100–1,000 HIL trials before live pilots.
- Shadow deployment: run the robot in observation mode alongside human operators for a minimum of 500 field hours to capture edge cases.
- Graduated autonomy: progressively enable autonomy with supervised checkpoints and human‑in‑the‑loop rollback capabilities.
Prompt templates and skill orchestration
Below are precise multimodal prompt templates suitable for model‑to‑robot instruction, verification, and recovery planning:
- High‑level task: "Navigate to waypoint B (GPS: 37.7749, -122.4194), avoid obstacles >0.5m from the path, and align angle ≤5° before starting payload transfer. If localization confidence <0.7, stop and request human verification."
- Perception check: "Given the forward camera frame and current depth map, list three objects within 1.5m, estimate their graspability score (0–1), and output the best grasp transform in robot base coordinates."
- Recovery routine: "On actuator fault code 0x12, transition to safe pose Psafe, cut motor torque, log last 30s of sensor data, and notify operator with diagnostics summary."
Key operational KPIs and benchmarks
Measure deployments with quantitative metrics that investors and safety auditors expect. Minimum viable KPI set:
| KPI | Target Range | Why it matters |
|---|---|---|
| Task Success Rate | ≥90% for repeatable tasks | Primary indicator of functional reliability |
| Uptime | ≥95% | Operational availability and ROI driver |
| MTTR (Mean Time To Repair) | <=4 hours for field‑replaceable units | Reduces operational disruption and service costs |
| False Positive Safety Events | <0.1 events per 1,000 hours | Safety confidence and human trust |
| Per‑hour Operational Cost | Validated against human labor equivalent | Determines commercial viability |
Regulation, safety standards and certification
Hardware will be constrained by established standards: ISO 10218 and ISO/TS 15066 for industrial collaborative robots, IEC 61508 for functional safety and SIL (Safety Integrity Level) targets, and region‑specific data privacy laws for camera data. Certification timelines typically add 12–24 months to go‑to‑market plans, and achieving SIL2+/SIL3 behaviors requires deterministic watchdogs, redundant sensing, and formally verified emergency stop pathways.
Investor and policymaker guidance
For investors: prioritize companies with proven unit economics, deep manufacturability expertise (tooling, supply chain resilience), and defensible software platforms that can monetize developer ecosystems—preferably with recurring revenue models like per‑robot subscriptions for fleet management and model updates. For policymakers: focus on risk‑proportionate frameworks that require transparency of safety cases, minimal centralized data retention for private spaces, and standards for incident reporting to accelerate trust.
Long‑run outlook and measurable milestones
OpenAI Robotics will not be judged by a single demo; it will be evaluated on scalable outcomes: thousands of hours of fielded reliability, statistically validated safety margins in diverse environments, and hardware unit costs that hit manufacturing inflection points. Milestones worth watching in the coming 3–5 years include:
- Reduction in BOM cost per general‑purpose manipulator by 40–60% through volume and design optimization.
- Fleet deployments exceeding 1,000 units in enterprise contexts with rolling OTA model updates and measurable ROI within 18–36 months.
- Published independent safety audits and ISO/IEC certificates for key product lines.
If OpenAI or others can synchronize compute‑backed learning, modular hardware economics, and rigorous safety engineering, the societal and economic impact will be profound: intelligence that not only informs decisions but reliably acts in the world at scale. That future requires deliberate engineering, careful governance, and an ecosystem that balances rapid iteration with uncompromising safety.
Related Articles on ChatGPT AI Hub
Explore more in-depth guides and tutorials from our library to deepen your understanding:
- OpenAI Codex v0.133: Goals, Remote Control, Plugin Marketplace, and iOS Push Notifications
- The Rise of the Agentic Super App: OpenAI’s Cross-Platform Vision
- OpenAI’s Path to IPO: What the Impending Public Debut Means for the AI Industry
- How to Use OpenAI Codex Computer Use: Step-by-Step Tutorial for 2026
- The AI Platform Wars of April 2026: Inside the OpenAI-Anthropic Battle for Developer Dominance
Useful Links and Resources
- OpenAI Codex Official Page — The official product page for OpenAI Codex with latest updates and documentation.
- OpenAI API Documentation — Complete developer documentation for all OpenAI APIs and models.
- ChatGPT — Access ChatGPT with GPT-5.5 capabilities directly from OpenAI.
- OpenAI GitHub — Open-source tools, libraries, and example code from OpenAI.
- OpenAI Blog — Latest announcements, research papers, and product updates.
- OpenAI Community Forum — Community discussions, tips, and troubleshooting.
Stay Ahead of the AI Curve
Get exclusive tutorials, breaking news, and expert prompts delivered to your inbox every week. Join 15,000+ AI professionals.