50 GPT-5.5 Prompts for Data Engineers: ETL Pipelines, Data Quality, Warehouse Design, and Real-Time Streaming

50 GPT-5.5 Prompts for Data Engineers: ETL Pipelines, Data Quality, Warehouse Design, and Real-Time Streaming
Data engineering has entered a new era of accelerated development, and GPT-5.5 sits at the center of that transformation. For engineers responsible for moving, transforming, and serving data at scale, the model offers something genuinely powerful: the ability to reason through complex architectural decisions, generate production-grade code, and surface edge cases that would otherwise surface only in painful post-deployment incidents. Whether you are designing a multi-hop ingestion pipeline, debugging a slowly changing dimension strategy, or evaluating trade-offs between streaming frameworks, GPT-5.5 compresses hours of research and iteration into focused, actionable output.
The prompts collected in this guide are built for working data engineers, not theorists. Each one is engineered to deliver specific, contextually grounded responses by supplying GPT-5.5 with the constraints, stack details, and success criteria it needs to reason precisely. You will find prompts covering ETL pipeline design, data quality enforcement, warehouse schema optimization, and real-time streaming architecture. Every prompt is copy-paste ready and structured to minimize vague output. Used consistently, this collection will sharpen your delivery speed, reduce architectural debt, and help you build data systems that hold up under production pressure.
Section 1: ETL Pipeline Design and Automation
Pipeline design is where data engineering projects succeed or fail before a single row of data is ever processed. The prompts in this section help you leverage GPT-5.5 to architect robust, maintainable, and observable ETL systems using industry-standard tooling. From Airflow DAG structure to dbt model generation and migration automation, these prompts are designed to produce output you can bring directly into your development environment.
Prompt 1: Airflow DAG Architecture for Multi-Source Ingestion Pipelines
You are a senior data engineer with deep expertise in Apache Airflow 2.x and production pipeline design.
I need to build an Airflow DAG that ingests data from three sources: a PostgreSQL transactional database,
a REST API with OAuth2 authentication, and an S3 bucket containing partitioned Parquet files.
The pipeline must run on a daily schedule, enforce dependency ordering between source extractions and
downstream transformations, and include task-level retries with exponential backoff.
Generate the full DAG file in Python, including operator choices with justification, task group structure
for logical separation, and inline comments explaining every architectural decision.
Assume the target is a Snowflake data warehouse and the Airflow environment runs on Kubernetes with the
KubernetesExecutor.Prompt 2: dbt Model Generation for a Star Schema Transformation Layer
You are a dbt expert and analytics engineer specializing in dimensional modeling for cloud data warehouses.
I have raw source tables in BigQuery representing e-commerce transactions: raw_orders, raw_order_items,
raw_customers, raw_products, and raw_events.
Generate a complete set of dbt models that transform these raw tables into a star schema with a central
fact_orders table and dimension tables for customers, products, dates, and channels, following dbt best
practices for staging, intermediate, and mart layers.
Include model SQL files, schema.yml with column-level descriptions and tests (not_null, unique,
accepted_values, relationships), and a sources.yml file.
Explain the grain of each model, the join logic used, and any slowly changing dimension handling applied
to dim_customers using dbt snapshots.Prompt 3: Incremental Load Strategy Design for High-Volume Fact Tables
You are a data engineering architect with expertise in designing incremental ingestion patterns for
large-scale OLAP systems. I am building an incremental load pipeline for a fact table that receives
approximately 50 million new rows per day in Snowflake, sourced from a PostgreSQL operational database
that does not have reliable updated_at timestamps on all tables.
Design a comprehensive incremental load strategy that addresses watermark management, handling of
late-arriving data up to 72 hours after event time, deduplication logic, and upsert mechanics using
Snowflake MERGE statements.
Provide the full SQL for the merge pattern, a Python orchestration wrapper using the Snowflake connector,
and a decision framework for choosing between append-only, upsert, and delete-reload patterns based on
table characteristics.
Include specific guidance on how to handle the absence of reliable change timestamps using sequence-based
or hash-based change detection.Prompt 4: Error Handling and Dead Letter Queue Patterns for ETL Pipelines
You are a senior data reliability engineer with expertise in building fault-tolerant data pipelines.
I need a comprehensive error handling framework for an ETL pipeline built on Apache Airflow that processes
financial transaction data where data loss is unacceptable and every failed record must be recoverable
without reprocessing the entire batch.
Design a dead letter queue pattern using an S3-backed error store, including the Python code for
capturing failed records with full error context (source, timestamp, error type, raw payload, stack trace),
a retry mechanism that distinguishes between transient and permanent failures, and an alerting integration
with PagerDuty via webhook.
Provide Airflow callback functions for on_failure_callback and on_retry_callback, a schema for the error
metadata store, and a reprocessing DAG that can replay dead letter records after manual inspection.
Include guidance on error categorization taxonomy for financial data pipelines specifically.Prompt 5: Schema Evolution Management for Production Data Pipelines
You are a data platform engineer specializing in schema registry systems and backward-compatible pipeline
design. I operate a data pipeline that ingests JSON payloads from 12 upstream microservices into a
Kafka topic before landing in Snowflake, and upstream teams frequently add, rename, or remove fields
without advance notice, causing pipeline failures.
Design a schema evolution management system using Confluent Schema Registry with Avro, including
compatibility mode recommendations for each evolution scenario (backward, forward, full), Python code
for schema registration and validation at ingestion time, and an automated schema diff alerting mechanism.
Provide a decision matrix for handling breaking versus non-breaking changes, SQL migration scripts for
propagating schema changes to the Snowflake target table using ALTER TABLE patterns, and a governance
workflow for schema change approval that integrates with a GitHub pull request process.
Include specific handling for nested JSON structures and arrays that frequently cause schema drift issues.Prompt 6: Change Data Capture Implementation with Debezium and Kafka
You are a CDC specialist and streaming data engineer with production experience implementing Debezium
connectors at scale. I need to implement Change Data Capture from a PostgreSQL 14 database with
approximately 200 tables, capturing additions, updates, and deletes and streaming them into Apache Kafka
before materializing changes into a Snowflake data warehouse for near-real-time analytics.
Provide a complete Debezium connector configuration for PostgreSQL using logical replication with the
pgoutput plugin, including slot management, heartbeat configuration, and handling for tables with and
without primary keys.
Generate the Kafka consumer code in Python that deserializes Debezium envelope messages, distinguishes
between operation types (c, u, d, r), and applies changes to Snowflake using an efficient MERGE pattern.
Include guidance on replication slot monitoring to prevent WAL bloat, connector offset management for
recovery after consumer downtime, and a table inclusion/exclusion filter strategy for the 200-table scope.Prompt 7: Data Validation Framework Design for ETL Quality Gates
You are a data quality engineer with expertise in building automated validation frameworks for enterprise
data pipelines. I need to design a comprehensive data validation framework that acts as a quality gate
between the extraction and loading stages of an ETL pipeline processing healthcare claims data, where
regulatory compliance requires documented validation results for every pipeline run.
Build a Python validation framework using Great Expectations that covers completeness checks (null rates
by column), referential integrity between claims and member tables, value range validation for monetary
fields, format validation for ICD-10 codes and NPI numbers, and statistical drift detection comparing
current batch distributions against a 30-day rolling baseline.
Generate the expectation suite definitions, a custom expectation class for ICD-10 code format validation,
a validation result serializer that writes structured JSON reports to S3, and an Airflow operator wrapper
that fails the DAG task when critical expectations are violated while logging warnings for non-critical ones.
Include a severity tiering model that distinguishes between pipeline-blocking failures and advisory warnings.Prompt 8: Orchestration Design for Dependency-Heavy Multi-Team Pipeline Ecosystems
You are a data platform architect with expertise in large-scale orchestration design across multiple
engineering teams. I am designing an orchestration architecture for a data platform where 6 independent
data engineering teams each own separate Airflow DAGs, but there are complex cross-team dependencies
where Team B's pipeline cannot start until Team A's pipeline completes successfully, and these
dependencies change frequently.
Design an orchestration pattern using Airflow's ExternalTaskSensor and dataset-aware scheduling
introduced in Airflow 2.4, including a cross-DAG dependency registry pattern using Airflow Variables
or a dedicated metadata table, and a visual dependency map generator using the Airflow REST API.
Provide Python code for a reusable dependency management utility that teams can import to declare
upstream dependencies without modifying other teams' DAGs, an SLA monitoring setup with escalation
logic, and a circuit breaker pattern that prevents downstream pipelines from running when upstream
data quality scores fall below a defined threshold.
Include recommendations for DAG versioning and deployment strategies in a multi-team GitOps workflow.Prompt 9: Pipeline Testing Strategy and Test Automation for ETL Systems
You are a data engineering quality assurance specialist with deep expertise in testing methodologies
for data pipelines. I need to build a comprehensive testing strategy and automated test suite for a
Python-based ETL pipeline that extracts from Salesforce, transforms customer and opportunity data,
and loads into Redshift, currently operating with zero test coverage and frequent production incidents.
Design a three-tier testing architecture covering unit tests for individual transformation functions
using pytest and pandas testing utilities, integration tests using a local Redshift-compatible
PostgreSQL environment with Docker Compose, and end-to-end contract tests that validate output schema
and row count expectations against known reference datasets.
Generate example test files for each tier including fixture definitions, parametrized test cases for
edge cases (empty source data, duplicate records, null primary keys, type mismatches), and mock
implementations for Salesforce API calls using responses or unittest.mock.
Include a CI/CD pipeline configuration for GitHub Actions that runs the full test suite on pull
requests, generates a coverage report, and enforces a minimum 80 percent coverage threshold before
merge is permitted.Prompt 10: Database Migration Automation from On-Premises to Cloud Data Warehouse
You are a cloud migration architect specializing in data warehouse modernization projects. I need to
migrate a 15TB on-premises SQL Server data warehouse with 340 tables, 200 stored procedures, and
approximately 150 SSIS packages to Snowflake, with a hard requirement of zero data loss, a maximum
acceptable downtime window of 4 hours for cutover, and the migration completing within a 6-month timeline.
Design a phased migration automation framework including a schema conversion utility that maps SQL Server
data types to Snowflake equivalents, flags unsupported features, and generates DDL scripts with documented
manual intervention points.
Provide a bulk data migration strategy using Snowflake's COPY INTO command with staged files in Azure
Blob Storage, including the Python orchestration code for parallel table extraction using BCP,
compression, upload, and load with row count reconciliation at each stage.
Generate a migration validation report template that captures source versus target row counts, checksum
comparisons for critical tables, and a rollback procedure that can restore operations to SQL Server
within the 4-hour cutover window if critical validation checks fail.Section 2: Data Quality and Governance
Maintaining trustworthy data across an organization requires systematic frameworks, automated checks, and clear ownership boundaries. The following prompts address the full spectrum of data quality and governance challenges, from designing foundational frameworks to implementing real-time freshness monitoring. Each prompt is crafted to extract structured, production-ready guidance from AI systems, helping data engineers and governance teams build robust, auditable data ecosystems.
Prompt 11: Designing a Comprehensive Data Quality Framework
You are a senior data architect with expertise in enterprise data governance. Design a comprehensive data quality framework for a mid-sized financial services company with 50+ data sources, including transactional databases, third-party APIs, and streaming event pipelines.
Your framework must cover:
1. The six dimensions of data quality: completeness, accuracy, consistency, timeliness, validity, and uniqueness — with measurable definitions for each
2. A tiered classification system (Critical, High, Medium, Low) for datasets based on business impact
3. Scoring methodology: how to calculate a composite Data Quality Score (DQS) per dataset and per domain
4. Ownership and accountability model: who owns quality for each tier, escalation paths, and RACI matrix
5. Tooling recommendations for both open-source (Great Expectations, Soda Core, dbt tests) and enterprise options
6. Integration points with the data catalog, metadata layer, and observability platform
7. Governance committee structure: meeting cadence, decision rights, and KPI review process
8. A phased 12-month implementation roadmap with milestones, resource estimates, and success criteria
Output the framework as a structured document with numbered sections, example scoring formulas, and a sample RACI matrix in table format.Prompt 12: Building Anomaly Detection Rules for Data Pipelines
You are a data reliability engineer specializing in pipeline observability. Create a detailed specification for an anomaly detection rule engine that monitors data pipelines in a retail analytics platform processing 10 million rows daily across 200 tables.
Include the following in your specification:
1. Rule taxonomy: categorize anomaly types (volume anomalies, schema drift, distribution shift, null rate spikes, referential integrity violations, statistical outliers) with detection logic for each
2. Threshold-setting strategies: static thresholds vs. dynamic baselines using rolling averages, z-scores, and interquartile range methods — provide SQL and Python examples for each
3. Seasonality handling: how to adjust thresholds for weekly, monthly, and holiday-driven patterns in retail data
4. Rule authoring interface: YAML-based rule definition schema with field-level, table-level, and cross-table rule examples
5. Severity classification: P1/P2/P3/P4 severity levels with response SLAs and auto-remediation triggers
6. Alert routing: integration with PagerDuty, Slack, and Jira for different severity levels
7. False positive reduction: feedback loops, snooze mechanisms, and rule tuning workflows
8. Performance considerations: how to run 500+ rules efficiently without degrading pipeline performance
Provide complete YAML rule examples, Python detection functions, and a sample alert payload in JSON format.Prompt 13: Implementing End-to-End Data Lineage Tracking
You are a data governance engineer with deep expertise in metadata management. Design and implement an end-to-end data lineage tracking system for a healthcare organization that must satisfy HIPAA audit requirements and support impact analysis across a complex dbt + Spark + Airflow stack.
Address these requirements:
1. Lineage capture strategy: column-level vs. table-level lineage, the trade-offs, and when to use each in a healthcare context
2. Automatic lineage extraction: how to parse dbt manifest.json, Spark query plans, and Airflow DAG dependencies to build a unified lineage graph
3. Metadata storage: graph database schema (using Neo4j or Apache Atlas) for representing lineage nodes (datasets, transformations, jobs, users) and edges (produces, consumes, transforms)
4. API design: REST endpoints for querying upstream lineage, downstream impact, and full provenance chains — include OpenAPI specification snippets
5. UI requirements: lineage visualization features needed for data stewards vs. engineers vs. compliance officers
6. PHI (Protected Health Information) tagging: how lineage integrates with sensitivity labels to auto-generate data flow maps for HIPAA compliance
7. Change detection: alerting when lineage breaks due to schema changes or pipeline modifications
8. Integration with OpenLineage standard: how to emit and consume OpenLineage events across tools
Provide a Neo4j Cypher query for extracting a full provenance chain, a Python script for parsing dbt manifest.json into lineage edges, and a sample OpenLineage event payload.Prompt 14: Designing SLA Monitoring for Data Pipelines
You are a data platform engineer responsible for pipeline reliability. Create a complete SLA monitoring system for a B2B SaaS company where downstream customers depend on data being available in their dashboards by specific times each day.
Your design must include:
1. SLA definition framework: how to formalize SLAs with business stakeholders — include a template for capturing SLA terms (expected arrival time, acceptable delay window, data completeness threshold, escalation contacts)
2. SLA types to monitor: arrival SLAs (data lands by time X), freshness SLAs (data is no older than X hours), completeness SLAs (at least X% of expected records present), and quality SLAs (error rate below X%)
3. Monitoring architecture: how to implement SLA tracking using Apache Airflow sensors, dbt exposures, or a custom metadata service — provide architecture diagram in text/ASCII format
4. Breach detection logic: Python code for a SLA checker that queries pipeline metadata and raises alerts when SLAs are at risk (warning at 80% of time window elapsed) or breached
5. Customer-facing SLA reporting: how to generate automated reports showing SLA adherence rates per customer, per pipeline, and per time period
6. SLA breach runbook: step-by-step incident response procedure when a customer-facing SLA is breached
7. SLA negotiation data: how to use historical pipeline performance data to set realistic, defensible SLAs
8. Integration with billing and customer success: how SLA breach data flows into customer health scores and credit calculations
Include a complete Python SLA checker class, a sample SLA definition YAML file, and an ASCII architecture diagram.Prompt 15: Establishing Data Contracts Between Teams
You are a principal data engineer advocating for data mesh principles. Design a comprehensive data contract system for a large e-commerce company where 15 independent domain teams produce data consumed by 30+ downstream teams, and where breaking changes currently cause frequent, costly pipeline failures.
Your data contract system must cover:
1. Data contract anatomy: define all required fields — schema definition, semantic meaning, quality SLAs, versioning policy, ownership, support channels, deprecation notice period, and example data
2. Contract specification format: provide a complete YAML-based data contract schema with annotations, and a filled-in example for an "orders" domain dataset
3. Contract enforcement mechanisms: how to validate contracts at ingestion time using Schema Registry (Confluent or AWS Glue), dbt schema tests, and CI pipeline checks
4. Versioning and breaking change policy: semantic versioning for data contracts, what constitutes a breaking vs. non-breaking change, and the required notice and migration period for each
5. Contract negotiation workflow: the process for a new consumer team to request a contract, negotiate terms with the producer team, and get approval from a governance board
6. Automated contract testing: how to generate and run contract tests automatically when a producer deploys changes — include a GitHub Actions workflow
7. Contract registry: architecture for a centralized contract registry service with search, discovery, and subscription notification features
8. Consequences of contract violations: how to handle producers who break contracts — monitoring, alerting, and escalation procedures
Provide a complete YAML data contract example for an orders dataset, a GitHub Actions workflow for contract validation, and a Python contract validation script.Prompt 16: Automating Data Profiling at Scale
You are a data quality engineer building automation tooling. Design an automated data profiling system that runs continuously across a data lakehouse containing 5,000+ tables in Delta Lake format, generating statistical profiles used for anomaly detection, documentation, and governance.
Include these components:
1. Profiling metrics catalogue: for each column type (numeric, string, date, boolean, complex/JSON), define the full set of statistics to compute — include formulas and business justification for each metric
2. Intelligent sampling strategy: how to determine optimal sample sizes for profiling large tables (100M+ rows) while maintaining statistical accuracy — provide the sampling formula and confidence interval calculations
3. Incremental profiling: how to profile only new/changed data using Delta Lake change data feed rather than full table scans, with Python/PySpark implementation
4. Profile storage schema: database schema for storing profile results with versioning, enabling trend analysis and drift detection over time
5. Profile scheduling: how to prioritize profiling jobs based on table criticality, update frequency, and downstream usage — include a priority scoring algorithm
6. Automated insight generation: how to use profile results to automatically generate human-readable data quality observations (e.g., "Column 'email' has 3.2% null rate, up from 0.1% last week")
7. Integration with data catalog: how profiles automatically enrich catalog entries with statistics, quality scores, and freshness indicators
8. Cost optimization: strategies to minimize compute costs for profiling jobs on cloud platforms (Databricks, AWS EMR, Google Dataproc)
Provide a complete PySpark profiling function for a numeric column, the profile storage schema in SQL DDL, and a Python priority scoring algorithm.Prompt 17: Building Data Quality Remediation Workflows
You are a data operations engineer designing self-healing data systems. Create a comprehensive remediation workflow system that automatically detects, triages, and resolves data quality issues in a financial reporting pipeline where data errors have regulatory consequences.
Design the following workflow components:
1. Issue classification engine: how to automatically classify detected quality issues by type (fixable vs. unfixable), root cause category (source system, transformation logic, infrastructure, upstream dependency), and remediation complexity
2. Automated remediation playbooks: define 10 specific automated remediation actions (e.g., re-trigger failed pipeline, apply deduplication logic, backfill missing records from source, quarantine invalid records) with the conditions that trigger each
3. Human-in-the-loop escalation: decision logic for when automated remediation is insufficient and human review is required — include a decision tree diagram in ASCII format
4. Quarantine zone architecture: how to design a data quarantine system that isolates bad records, tracks their status, and manages their eventual reprocessing or rejection
5. Remediation tracking: database schema and API for tracking every quality issue from detection through resolution, including audit trail for regulatory purposes
6. Root cause analysis automation: how to use issue history and pipeline metadata to automatically suggest probable root causes and link to relevant runbooks
7. Remediation SLAs: how to set and monitor time-to-resolve SLAs by issue severity, with escalation triggers
8. Post-remediation validation: automated checks to confirm that remediation actions actually resolved the issue and did not introduce new problems
Provide a Python remediation orchestration class, an ASCII decision tree for escalation logic, and a SQL schema for the issue tracking database.Prompt 18: Generating Automated Compliance Reports
You are a data governance specialist with expertise in regulatory compliance. Design an automated compliance reporting system for a multinational company subject to GDPR, CCPA, SOX, and PCI-DSS regulations, where compliance reports are currently produced manually and take two weeks per quarter.
Your automated system must address:
1. Regulatory requirement mapping: create a structured mapping of each regulation's data-related requirements to specific technical controls and monitoring metrics — provide a table for GDPR Article 30 (Records of Processing Activities) as an example
2. Data inventory automation: how to automatically maintain a complete inventory of personal data, sensitive financial data, and cardholder data across all systems using catalog metadata and classification tags
3. Report templates: define the structure and required content for each regulation's primary compliance report, with field-level mapping to data sources
4. Evidence collection automation: how to automatically gather evidence (access logs, encryption status, retention policy adherence, consent records) from infrastructure APIs and data platform metadata
5. Anomaly flagging: how to automatically identify and flag potential compliance violations (e.g., PII data found outside approved systems, data retained beyond policy period) for human review
6. Report generation pipeline: an Airflow DAG that orchestrates evidence collection, validation, report generation, and distribution on a scheduled basis
7. Audit trail: how to make the report generation process itself auditable — version control for report definitions, immutable evidence storage, and digital signing
8. Regulatory change management: process for updating report templates and controls when regulations change
Provide a complete Airflow DAG for quarterly GDPR report generation, a sample GDPR Article 30 mapping table, and a Python evidence collection function for data retention compliance.Prompt 19: Enriching a Data Catalog with Automated Metadata
You are a data catalog engineer working with Apache Atlas or DataHub. Design an automated metadata enrichment pipeline that continuously populates and maintains a data catalog for an organization with 3,000+ datasets, reducing manual documentation effort by 80% while improving catalog completeness from 30% to 90%.
Your enrichment pipeline must cover:
1. Metadata source inventory: catalog all available metadata sources (database system tables, dbt docs, Spark query history, BI tool metadata, data profiling results, lineage graphs, access logs) and what each contributes
2. Automated description generation: how to use LLMs to generate column and table descriptions from schema names, sample data, and query context — include a prompt template and quality validation approach
3. Business glossary linking: automated matching of technical column names to business glossary terms using fuzzy matching and embedding-based similarity — provide a Python implementation
4. Tag propagation: how sensitivity tags (PII, financial, confidential) automatically propagate through the lineage graph from tagged source columns to all derived datasets
5. Ownership inference: how to infer dataset ownership from git history, query logs, and pipeline authorship when explicit ownership is not set
6. Usage statistics enrichment: how to pull query frequency, unique user counts, and last-accessed timestamps from query logs and surface them in catalog entries
7. Freshness and quality badge system: how to compute and display freshness indicators and quality scores on catalog entries, with automated updates
8. Catalog completeness scoring: a scoring model that measures catalog completeness per dataset and generates a prioritized list of enrichment tasks
Provide a Python script for LLM-based description generation with validation, a business glossary matching function using sentence transformers, and a DataHub metadata ingestion recipe in YAML.Prompt 20: Implementing Data Freshness Monitoring
You are a data observability engineer. Design a comprehensive data freshness monitoring system for a real-time analytics platform where stale data directly impacts business decisions in areas including inventory management, fraud detection, and customer personalization.
Your monitoring system must include:
1. Freshness definition framework: how to define freshness requirements for different data archetypes — streaming (sub-minute), near-real-time (minutes), batch (hours), and reference data (days) — with business justification for each tier
2. Freshness measurement methods: four distinct technical approaches to measuring data freshness (watermark columns, metadata timestamps, record count velocity, heartbeat records) — when to use each, with SQL and Python implementations
3. Expected update interval learning: how to automatically learn normal update patterns for each table using historical metadata, accounting for business hours, weekends, and known batch windows
4. Multi-layer monitoring: how to monitor freshness at the source system layer, ingestion layer, transformation layer, and serving layer independently, and how to correlate failures across layers
5. Freshness SLA dashboard: specification for a real-time dashboard showing freshness status across all monitored datasets, with RAG (Red/Amber/Green) status indicators and drill-down capability
6. Proactive alerting: how to predict freshness SLA breaches before they occur based on current pipeline velocity and remaining time window — include the prediction formula
7. Consumer notification system: how to automatically notify downstream dashboard users and API consumers when data they depend on is stale, with estimated restoration time
8. Freshness in the data contract: how freshness guarantees are expressed in data contracts and enforced through automated testing
Provide a Python freshness monitoring class with methods for each measurement approach, a SQL query for detecting stale tables across a data warehouse, and a sample freshness SLA configuration in YAML format.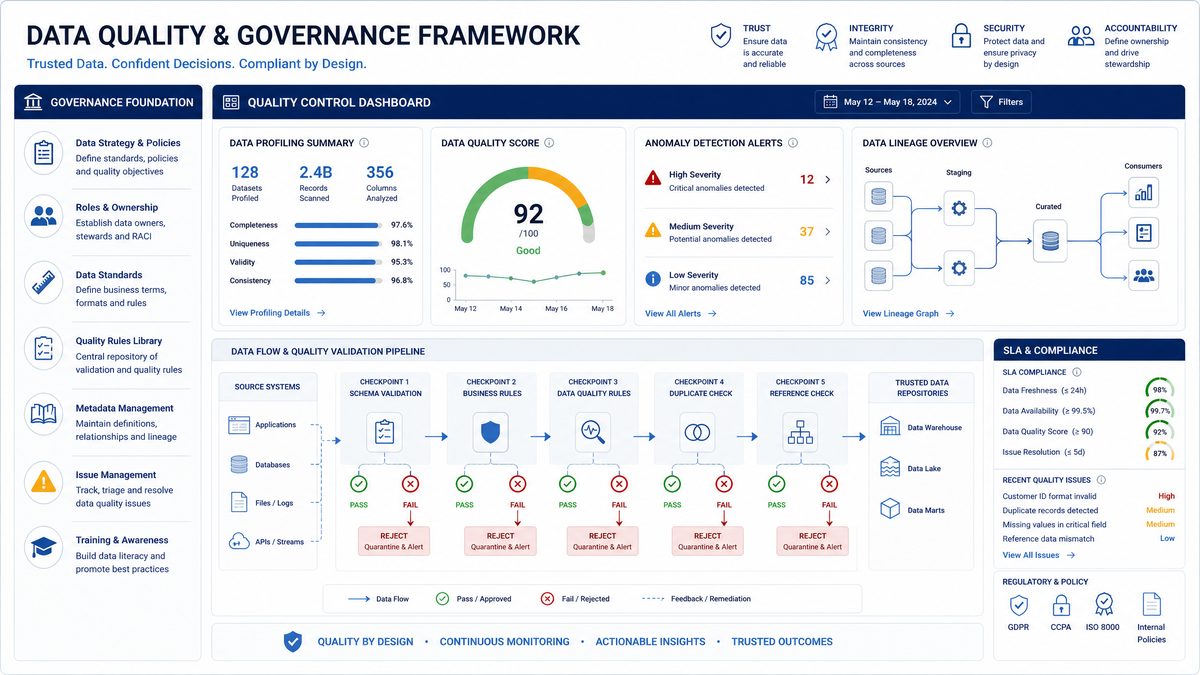
The automation patterns embedded in these data quality workflows share deep architectural DNA with modern software delivery practices. Data quality checks — from contract validation to anomaly detection rule deployment — are increasingly treated as first-class citizens in deployment pipelines, triggering gate conditions that prevent bad data from reaching production just as unit tests prevent broken code from shipping. Teams implementing these governance frameworks frequently
Section 3: Data Warehouse and Lakehouse Architecture
Modern data warehouses and lakehouses demand precise architectural decisions that balance performance, cost, and scalability. The following prompts help data engineers, architects, and analysts extract deep, actionable guidance from AI systems when designing, optimizing, and migrating warehouse and lakehouse environments. Each prompt is crafted to produce structured, implementation-ready responses.
For teams looking to extend these capabilities further, our detailed guide on 50 GPT-5.5 Prompts for DevOps Engineers: CI/CD Pipelines, Infrastructure as Code, Monitoring, and Incident Response provides the implementation patterns and configuration steps needed to build production-grade workflows that scale across enterprise environments.
For teams looking to extend these capabilities further, our detailed guide on Codex MCP Integration Masterclass: 30 Production-Ready Prompts for Building Enterprise Connectors and Tool Orchestration provides the implementation patterns and configuration steps needed to build production-grade workflows that scale across enterprise environments.
Access 40,000+ AI Prompts for ChatGPT, Claude & Codex — Free!
Subscribe to get instant access to our complete Notion Prompt Library — the largest curated collection of prompts for ChatGPT, Claude, OpenAI Codex, and other leading AI models. Optimized for real-world workflows across coding, research, content creation, and business.
Prompt 21: Star Schema Design for Analytical Workloads
You are a senior data warehouse architect with 15+ years of experience designing analytical systems
for enterprise environments. I need comprehensive guidance on designing a star schema for the
following business domain:
Business Domain: [SPECIFY DOMAIN - e.g., e-commerce, healthcare, financial services]
Primary Business Process: [SPECIFY PROCESS - e.g., sales transactions, patient encounters, trades]
Reporting Grain: [SPECIFY GRAIN - e.g., daily sales by product and region]
Expected Fact Table Row Count: [SPECIFY VOLUME - e.g., 500 million rows per year]
Target Platform: [SPECIFY PLATFORM - e.g., Snowflake, BigQuery, Redshift, Databricks]
Please provide:
1. FACT TABLE DESIGN
- Identify all measurable facts (additive, semi-additive, non-additive)
- Define the grain statement precisely
- List all foreign keys to dimension tables
- Recommend degenerate dimensions where appropriate
- Specify numeric data types optimized for the target platform
- Address factless fact tables if applicable to this domain
2. DIMENSION TABLE DESIGN
- Identify all descriptive dimensions (minimum 6-8 dimensions for this domain)
- For each dimension provide:
* Natural key vs surrogate key strategy
* Attribute list with recommended data types
* Cardinality estimates
* Hierarchy definitions (e.g., Product > Category > Department)
* Role-playing dimension opportunities
- Design a date dimension with 25+ attributes including fiscal calendar support
3. SCHEMA DIAGRAM DESCRIPTION
- Describe the complete entity-relationship structure
- Identify any snowflaking that may be appropriate
- Flag any many-to-many relationships requiring bridge tables
4. CONFORMED DIMENSIONS
- Identify which dimensions should be shared across multiple fact tables
- Provide a data bus matrix showing fact tables vs dimensions
- Explain governance implications of conformed dimensions
5. PERFORMANCE CONSIDERATIONS
- Clustering/sort key recommendations for the target platform
- Distribution key strategy (for MPP systems)
- Partitioning recommendations
- Indexing strategy where applicable
6. COMMON DESIGN PITFALLS
- List 5 specific anti-patterns to avoid for this business domain
- Provide corrective design patterns for each
Deliver the response as a structured technical specification that a data engineer can use
directly to begin implementation. Include SQL DDL examples for at least the central fact table
and two key dimension tables on the specified target platform.
Prompt 22: Slowly Changing Dimensions Implementation Strategy
You are a data warehousing expert specializing in dimensional modeling and historical data
management. I need a complete implementation guide for slowly changing dimensions (SCDs)
in my warehouse environment.
Current Environment:
- Warehouse Platform: [SPECIFY PLATFORM]
- Source System: [SPECIFY SOURCE - e.g., Salesforce CRM, SAP ERP, custom OLTP]
- Dimension in Question: [SPECIFY DIMENSION - e.g., Customer, Employee, Product]
- Key Attributes Subject to Change: [SPECIFY ATTRIBUTES - e.g., address, department, price tier]
- Historical Reporting Requirement: [YES/NO - do reports need point-in-time accuracy?]
- Data Volume: [SPECIFY - e.g., 10 million customer records, 5,000 changes per day]
- ETL/ELT Tool: [SPECIFY TOOL - e.g., dbt, Apache Spark, Informatica, Azure Data Factory]
Provide a comprehensive SCD implementation guide covering:
1. SCD TYPE SELECTION ANALYSIS
- Evaluate SCD Type 0 (retain original) - when and why to use it
- Evaluate SCD Type 1 (overwrite) - business scenarios where this is appropriate
- Evaluate SCD Type 2 (add new row) - full implementation with effective dating
- Evaluate SCD Type 3 (add new column) - limited history use cases
- Evaluate SCD Type 4 (mini-dimension) - high-volatility attribute separation
- Evaluate SCD Type 6 (hybrid 1+2+3) - combined approach benefits
- Recommend the optimal type(s) for the specified dimension and justify your choice
2. SCD TYPE 2 COMPLETE IMPLEMENTATION
- Surrogate key generation strategy (sequences, UUIDs, hashes)
- Effective date and expiry date column design
- Current row flag implementation and maintenance
- Row hash for change detection
- Source system natural key preservation
- Handling of late-arriving data and out-of-order changes
3. SQL IMPLEMENTATION
Provide complete, executable SQL for the target platform covering:
- Dimension table DDL with all SCD columns
- Initial load procedure
- Incremental merge/upsert logic using MERGE statement or equivalent
- Change detection query using hash comparison
- Current record lookup view
- Point-in-time lookup function or query pattern
4. dbt IMPLEMENTATION (if dbt is the specified tool)
- dbt snapshot configuration with strategy settings
- snapshot YAML configuration
- Downstream model referencing snapshot tables
- Testing strategies for SCD correctness
5. OPERATIONAL CONSIDERATIONS
- Impact on fact table joins (current vs historical lookups)
- Storage growth projections over 3 years
- Purging strategy for expired rows
- Impact on BI tool query patterns
- Handling deletions in the source system
6. DATA QUALITY CHECKS
- List 8 specific data quality tests to validate SCD implementation
- Provide SQL for each test
- Define acceptable thresholds and alerting criteria
Format the response as a technical runbook with numbered steps, executable code,
and decision trees where multiple implementation paths exist.
Prompt 23: Partitioning Strategy for Large-Scale Warehouse Tables
You are a database performance engineer specializing in large-scale analytical systems.
I need an expert-level partitioning strategy for warehouse tables experiencing performance
and cost challenges.
System Context:
- Platform: [SPECIFY PLATFORM - e.g., BigQuery, Snowflake, Azure Synapse, Databricks Delta]
- Table Type: [SPECIFY - e.g., fact table, event log, sensor data, transaction history]
- Current Table Size: [SPECIFY - e.g., 8 TB, 200 billion rows]
- Daily Data Growth: [SPECIFY - e.g., 50 GB/day, 500 million rows/day]
- Primary Query Patterns: [SPECIFY - e.g., last 30 days by region, range scans by date]
- Current Performance Issues: [SPECIFY - e.g., full table scans, slow query response, high costs]
- Retention Requirement: [SPECIFY - e.g., 7 years hot, 3 years warm, archive after 10 years]
Provide a complete partitioning strategy including:
1. PARTITIONING APPROACH SELECTION
- Range partitioning on date/timestamp columns - pros, cons, implementation
- List partitioning on categorical columns - when to use, cardinality limits
- Hash partitioning for even distribution - use cases and limitations
- Composite partitioning (multi-level) - when complexity is justified
- Platform-specific partitioning features:
* BigQuery: partition by ingestion time vs column, partition expiration
* Snowflake: micro-partitioning behavior, clustering keys vs explicit partitioning
* Databricks Delta: ZORDER vs partitioning, liquid clustering
* Synapse: distribution + partition interaction
- Recommend the optimal strategy for the specified context with justification
2. PARTITION COLUMN SELECTION
- Criteria for selecting the partition column
- Cardinality analysis guidelines (minimum and maximum partition counts)
- Avoiding partition skew - detection and remediation
- Date/time granularity selection (year, month, day, hour) based on query patterns
- Secondary clustering column recommendations
3. IMPLEMENTATION SQL
Provide complete DDL and DML for:
- Creating the partitioned table on the specified platform
- Migrating existing data into the partitioned structure
- Partition pruning verification queries (EXPLAIN plan analysis)
- Partition metadata inspection queries
- Automated partition management procedures
4. PARTITION MAINTENANCE
- Automated partition creation for future periods
- Partition archival and deletion procedures
- Handling late-arriving data in closed partitions
- Partition statistics refresh strategy
- Monitoring partition health and skew over time
5. QUERY OPTIMIZATION FOR PARTITIONED TABLES
- Query patterns that guarantee partition pruning
- Anti-patterns that cause full partition scans
- Rewriting queries to leverage partition elimination
- Partition-aware join strategies
- Dynamic partition pruning in distributed query engines
6. COST-BENEFIT ANALYSIS
- Estimated query performance improvement (provide methodology)
- Storage cost impact of partition overhead
- Compute cost reduction through partition pruning
- Break-even analysis for migration effort
- Ongoing maintenance cost considerations
7. TESTING AND VALIDATION
- Before/after performance benchmarking methodology
- Partition pruning validation test suite
- Data completeness verification after migration
- Rollback plan if partitioning causes regressions
Include platform-specific code examples and explain any platform limitations
that affect the recommended approach.
Prompt 24: Materialized Views Design and Refresh Strategy
You are a query optimization specialist with deep expertise in materialized view design
for analytical databases. I need a comprehensive strategy for implementing materialized
views to accelerate query performance and reduce compute costs.
Environment Details:
- Database Platform: [SPECIFY PLATFORM]
- Workload Type: [SPECIFY - e.g., BI dashboards, ad-hoc analytics, scheduled reports, ML feature store]
- Slow Query Examples: [SPECIFY 2-3 example query patterns or descriptions]
- Current Query Response Time: [SPECIFY - e.g., 45 seconds average for dashboard queries]
- Target Response Time: [SPECIFY - e.g., under 3 seconds]
- Refresh Tolerance: [SPECIFY - e.g., data can be 1 hour stale, must be real-time, daily refresh acceptable]
- Underlying Table Size: [SPECIFY - e.g., 500 GB fact table, 10 million row dimension]
- Concurrent Users: [SPECIFY - e.g., 200 BI users, 50 data scientists]
Provide a complete materialized view implementation guide:
1. MATERIALIZED VIEW CANDIDATE IDENTIFICATION
- Criteria for identifying good materialized view candidates
- Query pattern analysis methodology (frequency, cost, similarity)
- Aggregation patterns that benefit most from materialization
- Join patterns suitable for pre-computation
- Anti-patterns: queries that do NOT benefit from materialized views
- Overlap analysis to avoid redundant materialized views
- Cost-benefit threshold: when materialization is justified
2. DESIGN PATTERNS FOR ANALYTICAL WORKLOADS
- Pre-aggregated summary tables (daily, weekly, monthly rollups)
- Pre-joined denormalized views for star schema acceleration
- Filtered subsets for frequently accessed data segments
- Window function pre-computation patterns
- Cross-database/cross-schema materialized views
- Incremental vs complete refresh design trade-offs
3. PLATFORM-SPECIFIC IMPLEMENTATION
Provide complete SQL for each of the following platforms relevant to your environment:
SNOWFLAKE:
- Dynamic tables with target lag configuration
- Automatic query rewrite behavior and limitations
- Clustering on materialized views
- Cost implications of dynamic table compute
BIGQUERY:
- Materialized view DDL with partition and cluster settings
- Automatic refresh scheduling and staleness tolerance
- Query rewrite eligibility requirements
- Authorized views vs materialized views trade-offs
DATABRICKS:
- Delta Live Tables for streaming materialization
- REFRESH MATERIALIZED VIEW syntax
- Photon acceleration for materialized view queries
REDSHIFT:
- CREATE MATERIALIZED VIEW with distribution and sort keys
- Auto refresh configuration
- Query rewrite prerequisites
4. REFRESH STRATEGY DESIGN
- Complete refresh: when to use, implementation, scheduling
- Incremental refresh: requirements, limitations, SQL patterns
- Streaming/continuous refresh: tools and latency trade-offs
- Refresh dependency chains: ordering when views depend on views
- Refresh failure handling and alerting
- Stale data detection and user notification strategy
5. QUERY REWRITE AND TRANSPARENCY
- How to verify automatic query rewrite is occurring
- Explicit materialized view hints when auto-rewrite fails
- BI tool configuration for materialized view awareness
- Testing query rewrite with EXPLAIN plans
6. MAINTENANCE AND GOVERNANCE
- Staleness monitoring queries
- Usage tracking to identify underutilized materialized views
- Dependency tracking when underlying tables change
- Schema evolution impact on materialized views
- Documentation and catalog registration requirements
7. PERFORMANCE VALIDATION
- Benchmark framework for measuring improvement
- A/B testing approach with and without materialized views
- Dashboard load time measurement methodology
- Cost per query comparison metrics
Provide executable SQL for at least 3 materialized view examples relevant to
the specified workload type, with refresh procedures and monitoring queries.
Prompt 25: Data Warehouse Cost Optimization Framework
You are a cloud cost optimization architect specializing in data warehouse platforms.
I need a systematic framework for reducing warehouse costs without degrading performance
or data availability for business users.
Current Environment:
- Platform: [SPECIFY - e.g., Snowflake, BigQuery, Redshift, Azure Synapse, Databricks]
- Current Monthly Cost: [SPECIFY - e.g., $45,000/month]
- Cost Breakdown: [SPECIFY - e.g., 60% compute, 30% storage, 10% data transfer]
- Primary Cost Drivers: [SPECIFY - e.g., always-on warehouses, full table scans, data duplication]
- Team Size: [SPECIFY - e.g., 15 data engineers, 80 BI users, 10 data scientists]
- SLA Requirements: [SPECIFY - e.g., dashboards must load in under 5 seconds, ETL must complete by 6 AM]
- Target Cost Reduction: [SPECIFY - e.g., 30% reduction within 90 days]
Deliver a comprehensive cost optimization framework:
1. COST AUDIT AND BASELINE MEASUREMENT
- Platform-specific queries to identify top cost-consuming queries
- Warehouse/cluster utilization analysis queries
- Storage cost breakdown by database, schema, and table
- Data scanning cost analysis (bytes billed per query)
- Idle resource identification methodology
- Cost attribution by team, project, and use case
- Baseline metric dashboard definition
2. COMPUTE OPTIMIZATION STRATEGIES
For Snowflake:
- Virtual warehouse right-sizing methodology
- Auto-suspend and auto-resume configuration by workload type
- Multi-cluster warehouse scaling policies
- Query acceleration service evaluation
- Warehouse scheduling for batch vs interactive workloads
- Resource monitors with budget alerts and query limits
For BigQuery:
- On-demand vs capacity pricing decision framework
- Slot reservation sizing and commitment strategy
- Query cost estimation before execution
- BI Engine reservation for dashboard acceleration
- Flex slots for burst workloads
For Databricks:
- Cluster policies and auto-termination settings
- Spot/preemptible instance strategy for batch workloads
- Photon enablement ROI calculation
- SQL warehouse sizing and auto-stop configuration
- Job cluster vs all-purpose cluster cost comparison
3. STORAGE OPTIMIZATION STRATEGIES
- Compression analysis and format optimization (Parquet, ORC, AVRO)
- Duplicate data identification and elimination
- Time travel and fail-safe cost management (Snowflake)
- Partition expiration for time-series data
- Tiered storage implementation (hot/warm/cold)
- Clone and zero-copy clone usage governance
- Transient vs permanent table strategy
4. QUERY OPTIMIZATION FOR COST REDUCTION
- Top 10 query anti-patterns that drive unnecessary costs
- SELECT * elimination: governance and tooling approach
- Predicate pushdown verification
- Result cache utilization analysis
- Query queuing and
Section 4: Real-Time Streaming and Event Processing
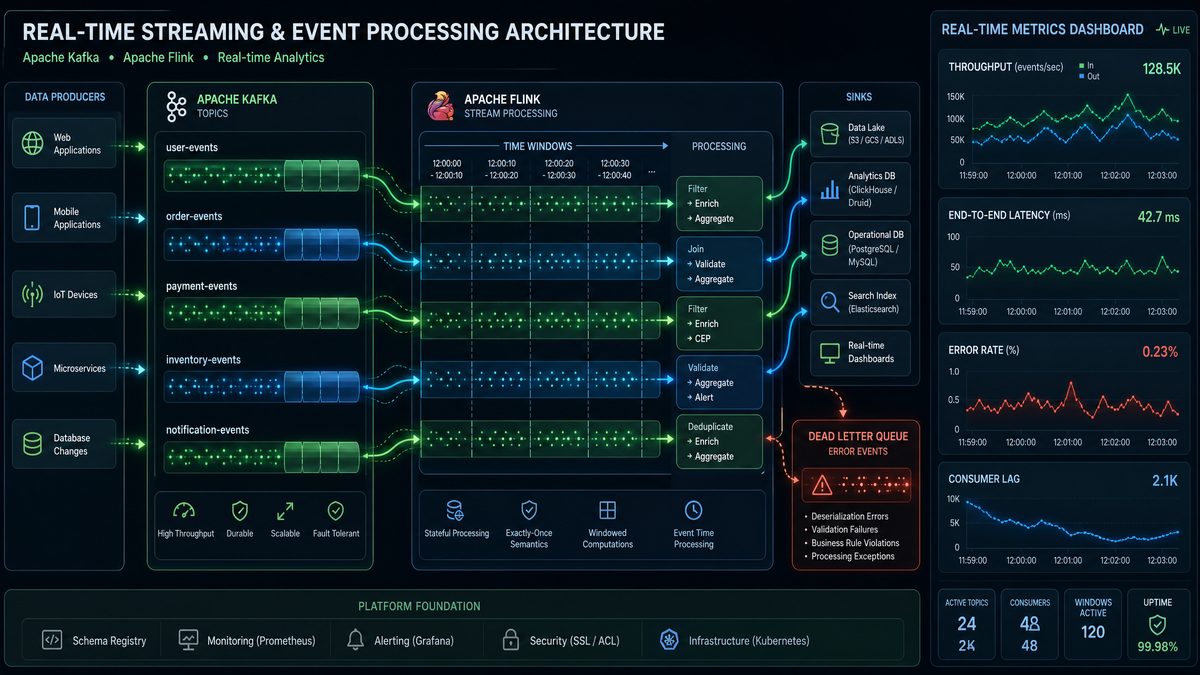
Real-time streaming systems demand precision in both architecture and implementation. The prompts in this section are engineered to extract deep, production-grade guidance from AI models on the most challenging aspects of stream processing — from Kafka topology design to Flink job orchestration, windowing semantics, and operational monitoring. Use these prompts when building or scaling event-driven pipelines that must handle high throughput, fault tolerance, and exactly-once guarantees.
Prompt 31: Kafka Pipeline Design for High-Throughput Microservices
You are a senior distributed systems architect with 12+ years of experience designing
Kafka-based event streaming platforms for Fortune 500 companies.
Design a production-grade Kafka pipeline for the following scenario:
SYSTEM CONTEXT:
- 150 microservices producing events across 3 data centers
- Peak throughput: 2.5 million events per second
- Event sizes: 500 bytes to 50 KB (mixed payload types)
- Consumers include: real-time dashboards, ML feature stores, data warehouses, and audit systems
- SLA: end-to-end latency under 200ms for 99th percentile
DESIGN REQUIREMENTS:
Provide a complete architectural blueprint covering:
1. TOPIC DESIGN STRATEGY
- Naming conventions and namespace organization
- Partition count calculations with justification formulas
- Replication factor recommendations per criticality tier
- Compaction vs. retention policies for different event types
- Topic configuration parameters (segment.bytes, retention.ms, min.insync.replicas)
2. PRODUCER CONFIGURATION
- Batching parameters (batch.size, linger.ms) optimized for throughput vs. latency tradeoffs
- Compression codec selection (gzip vs. snappy vs. lz4 vs. zstd) with benchmark rationale
- Idempotent producer configuration
- Retry logic and backoff strategies
- Producer interceptors for observability
3. BROKER CLUSTER TOPOLOGY
- Rack-aware replica assignment strategy
- Controller quorum configuration (KRaft mode)
- Log segment configuration for SSD vs. HDD storage tiers
- Network thread and I/O thread tuning
- JVM heap and GC configuration recommendations
4. CONSUMER GROUP ARCHITECTURE
- Consumer group segmentation by downstream system type
- Offset management strategy (auto vs. manual commit)
- Partition assignment strategies (RangeAssignor vs. CooperativeStickyAssignor)
- Rebalance minimization techniques
- Consumer lag alerting thresholds
5. CROSS-DATA-CENTER REPLICATION
- MirrorMaker 2 topology (active-active vs. active-passive)
- Consumer offset translation across clusters
- Failover and failback procedures
- Replication lag monitoring
6. SECURITY CONFIGURATION
- SASL/SCRAM vs. mTLS authentication recommendation
- ACL design for producer/consumer isolation
- Encryption at rest and in transit
For each configuration parameter you recommend, explain WHY that specific value is appropriate
for this workload. Include a sample topic configuration file and producer configuration snippet
in Java. Flag any tradeoffs explicitly.
Prompt 32: Apache Flink Job Architecture for Complex Event Processing
You are an Apache Flink expert who has architected streaming jobs processing petabytes
of data monthly in financial services and e-commerce environments.
Design a complete Flink job architecture for the following use case:
USE CASE: Real-time fraud detection for a payment processing platform
- Input streams: transaction events, user behavior events, merchant risk scores
- Required outputs: fraud alerts (sub-100ms), risk score updates, audit trail
- State requirements: per-user transaction history (30-day window), merchant profiles
- Scale: 800,000 transactions per minute at peak
ARCHITECTURE DESIGN — provide exhaustive detail on:
1. JOB GRAPH DESIGN
- Source operator configuration (Kafka connector settings, watermark strategies)
- Transformation operator chain design
- Operator parallelism assignment strategy
- KeyBy partitioning key selection rationale
- Operator chaining vs. slot sharing group decisions
- Async I/O operator usage for external enrichment calls
2. STATE BACKEND SELECTION AND CONFIGURATION
- RocksDB vs. HashMapStateBackend decision matrix for this use case
- RocksDB tuning parameters (block cache size, write buffer count, compaction style)
- State TTL configuration for different state types
- Incremental checkpointing configuration
- State migration strategy for schema evolution
3. WINDOWING IMPLEMENTATION
- Window type selection (tumbling, sliding, session) for each detection pattern
- Window trigger and evictor custom implementations
- Late data handling strategy (allowed lateness + side outputs)
- Window state cleanup configuration
4. CHECKPOINTING AND RECOVERY
- Checkpoint interval calculation based on recovery time objective
- Checkpoint storage configuration (S3 vs. HDFS vs. local)
- Savepoint strategy for planned maintenance
- Restart strategy configuration (fixed-delay vs. failure-rate)
- Exactly-once sink configuration
5. PERFORMANCE TUNING
- Network buffer configuration
- Managed memory fraction tuning
- Object reuse optimization
- Serialization framework selection (Kryo vs. Avro vs. Protobuf)
6. DEPLOYMENT CONFIGURATION
- TaskManager and JobManager resource sizing
- Kubernetes deployment with FLINK_CONF_DIR customization
- Reactive scaling configuration
Provide annotated Java/Scala code snippets for the core job topology, state descriptor
declarations, and checkpoint configuration. Include a resource estimation formula for
TaskManager sizing based on state size and parallelism.
Prompt 33: Exactly-Once Semantics Implementation Across Distributed Systems
You are a distributed systems engineer specializing in transactional guarantees and
consistency models across heterogeneous streaming and storage systems.
Provide a comprehensive technical guide on implementing exactly-once semantics (EOS)
in a streaming pipeline with the following components:
PIPELINE COMPONENTS:
- Source: Apache Kafka (transactional producer upstream)
- Processing: Apache Flink with stateful operators
- Sinks: PostgreSQL (JDBC), Apache Iceberg (data lake), Redis (cache),
external REST API (non-idempotent)
ADDRESS EACH OF THE FOLLOWING IN DEPTH:
1. THEORETICAL FOUNDATIONS
- Distinguish between at-most-once, at-least-once, and exactly-once with
failure scenario diagrams described in text
- Explain the two-phase commit (2PC) protocol as implemented in Flink
- Describe the relationship between Flink checkpoints and Kafka transactions
- Explain idempotency vs. transactionality as complementary strategies
2. KAFKA TRANSACTIONAL PRODUCER CONFIGURATION
- transactional.id assignment strategy for multi-instance producers
- transaction.timeout.ms tuning
- Zombie fencing mechanism explanation
- isolation.level configuration on consumers (read_committed implications)
- Performance overhead quantification and mitigation
3. FLINK EOS CONFIGURATION
- CheckpointingMode.EXACTLY_ONCE configuration
- TwoPhaseCommitSinkFunction implementation pattern
- FlinkKafkaProducer EOS mode configuration
- Semantic.EXACTLY_ONCE vs. Semantic.AT_LEAST_ONCE tradeoff analysis
4. SINK-SPECIFIC EOS STRATEGIES
For PostgreSQL:
- Upsert pattern with conflict resolution
- Transaction boundary alignment with Flink checkpoints
- Connection pool management during 2PC
For Apache Iceberg:
- Atomic commit protocol
- Snapshot isolation and concurrent writer handling
- Compaction interaction with streaming writes
For Redis:
- Why true EOS is impossible and mitigation strategies
- Lua script atomicity for conditional updates
- Idempotency key pattern implementation
For non-idempotent REST APIs:
- Deduplication layer design
- Idempotency key generation and storage
- Retry budget management
5. FAILURE SCENARIO ANALYSIS
- Producer failure mid-transaction
- Flink job failure between pre-commit and commit
- Network partition during 2PC
- Duplicate detection after recovery
6. TESTING EXACTLY-ONCE GUARANTEES
- Chaos engineering test scenarios
- Validation methodology using record counting and checksums
Provide code examples for the TwoPhaseCommitSinkFunction implementation for PostgreSQL
and explain every configuration parameter's role in maintaining EOS guarantees.
Prompt 34: Advanced Windowing Strategies for Stream Analytics
You are a stream processing architect with deep expertise in temporal analytics,
time-series aggregation, and windowing semantics across Apache Flink and Kafka Streams.
Provide an exhaustive technical reference on windowing strategies for the following
analytical requirements:
BUSINESS REQUIREMENTS:
- E-commerce platform needing: rolling 5-minute revenue totals, session-based
cart abandonment detection, sliding 1-hour conversion rate windows,
irregular event-time gap detection, and cross-stream join windows
COVER EACH WINDOWING PATTERN IN DEPTH:
1. TUMBLING WINDOWS
- Implementation in Flink (event time vs. processing time)
- Watermark interaction and completeness guarantees
- Early firing triggers for low-latency partial results
- State size implications and cleanup
- Use case: 5-minute revenue aggregation with late data handling
- Code example with custom trigger for early results
2. SLIDING WINDOWS
- Memory cost formula: (window_size / slide_size) × state_per_key
- Optimization techniques for large window-to-slide ratios
- Incremental aggregation with AggregateFunction vs. ProcessWindowFunction
- Use case: 1-hour sliding conversion rate with 1-minute slides
- Performance comparison: sliding vs. multiple tumbling windows approach
3. SESSION WINDOWS
- Dynamic gap detection implementation
- Session window merger logic
- State accumulation during active sessions
- Maximum session duration enforcement
- Use case: cart abandonment detection with 30-minute inactivity gap
- Handling out-of-order events within sessions
4. GLOBAL WINDOWS WITH CUSTOM TRIGGERS
- When to use global windows over bounded windows
- Count-based trigger implementation
- Delta trigger for value-change-based firing
- Purging triggers vs. non-purging triggers
- Use case: trigger aggregation after every 1000 transactions per merchant
5. INTERVAL JOINS (STREAM-STREAM TEMPORAL JOINS)
- Time-bounded join implementation
- Buffer management for both streams
- Handling asymmetric event rates
- Use case: joining click events with purchase events within 30-minute window
6. WATERMARK STRATEGIES
- BoundedOutOfOrdernessWatermarkStrategy configuration
- Custom WatermarkGenerator for irregular event sources
- Watermark propagation in multi-source topologies
- Idle source handling to prevent watermark stalling
- Watermark alignment across parallel subtasks
7. LATE DATA HANDLING FRAMEWORK
- Allowed lateness configuration tradeoffs
- Side output collection for late records
- Reprocessing late data through separate pipeline
- Metrics for late data arrival rate monitoring
For each pattern, provide: Flink Java/Python code implementation, state size estimation
formula, latency vs. completeness tradeoff analysis, and recommended production settings.
Prompt 35: Dead Letter Queue Design and Poison Pill Management
You are a platform reliability engineer specializing in fault-tolerant messaging
systems and error handling patterns for high-volume event streaming pipelines.
Design a comprehensive Dead Letter Queue (DLQ) framework for a streaming platform with:
PLATFORM SPECIFICATIONS:
- 45 Kafka topics across 8 microservices
- Error categories: deserialization failures, business rule violations,
downstream system unavailability, schema incompatibility, processing timeouts
- Requirements: zero message loss, error observability, replay capability,
automated remediation for known error patterns
DESIGN THE COMPLETE DLQ FRAMEWORK:
1. DLQ TOPOLOGY DESIGN
- Topic naming convention: {original-topic}.{error-category}.dlq
- Partition strategy for DLQ topics (match source vs. fixed count)
- Retention policy per error category (deserialization: 30 days,
transient: 7 days, business rule: 90 days)
- Replication factor for DLQ topics
- Compaction considerations for idempotent replay
- Header enrichment schema for error metadata
2. ERROR CLASSIFICATION SYSTEM
Define handling strategy for each error type:
RETRIABLE ERRORS (network timeouts, rate limits, temporary unavailability):
- Exponential backoff with jitter implementation
- Maximum retry count per error type
- Retry topic design (topic.retry.1, topic.retry.2, topic.retry.3)
- Retry scheduling using Kafka timestamp headers
NON-RETRIABLE ERRORS (deserialization failures, schema violations):
- Immediate DLQ routing
- Raw bytes preservation strategy
- Original topic and partition metadata capture
BUSINESS RULE VIOLATIONS:
- Separate DLQ with extended retention
- Human review workflow integration
- Automated remediation rules engine
3. ERROR ENVELOPE SCHEMA
Design the complete error envelope Avro/Protobuf schema including:
- Original message bytes (raw, unmodified)
- Error timestamp, error type, error code
- Stack trace (truncated to 2KB)
- Processing attempt count and history
- Source topic, partition, offset
- Consumer group ID and host
- Correlation ID and trace ID for distributed tracing
4. REPLAY ARCHITECTURE
- Replay controller service design
- Selective replay by: time range, error type, correlation ID, partition
- Replay rate limiting to protect downstream systems
- Idempotency guarantee during replay
- Replay progress tracking and resumption
- Preventing replay loops (max replay count enforcement)
5. POISON PILL DETECTION AND ISOLATION
- Detecting messages that consistently fail across retries
- Automatic quarantine after N failures
- Alert escalation for quarantined messages
- Manual inspection tooling requirements
6. MONITORING AND ALERTING
- DLQ depth alerting thresholds per topic
- Error rate trend detection (spike vs. sustained elevation)
- Mean time to remediation (MTTR) tracking
- Dashboard design for DLQ operational visibility
7. IMPLEMENTATION CODE
Provide a complete Java implementation of:
- DLQ router using Kafka Streams
- Error envelope builder utility
- Retry scheduler consumer
Include Kafka topic configuration files and a decision flowchart described in text
for routing errors to the appropriate DLQ tier.
Prompt 36: Schema Registry Management and Schema Evolution Strategies
You are a data platform architect with deep expertise in schema management,
Confluent Schema Registry, and Avro/Protobuf/JSON Schema evolution patterns
for large-scale event streaming platforms.
Provide a complete schema governance framework for an enterprise streaming platform:
PLATFORM CONTEXT:
- 200+ event schema types across 15 producing teams
- Consumers include: stream processors, data warehouses, ML pipelines,
third-party integrations
- Schema registry: Confluent Schema Registry (or AWS Glue Schema Registry)
- Serialization formats: Avro (primary), Protobuf (gRPC integration),
JSON Schema (external partners)
DESIGN THE SCHEMA GOVERNANCE FRAMEWORK:
1. SCHEMA REGISTRY ARCHITECTURE
- Multi-environment setup (dev/staging/prod schema registries)
- Cross-datacenter replication configuration
- High availability configuration (ZooKeeper vs. Kafka-backed storage)
- Security: authentication, authorization, and audit logging
- Capacity planning: schema count limits and storage estimation
2. SUBJECT NAMING STRATEGY
- TopicNameStrategy vs. RecordNameStrategy vs. TopicRecordNameStrategy
- When to use each strategy with concrete examples
- Multi-event-type topic implications
- Subject naming for request-reply patterns
3. COMPATIBILITY MODES — DEEP DIVE
For each compatibility mode, provide:
- Exact definition and validation rules
- Allowed schema changes
- Prohibited schema changes
- Recommended use cases
Modes to cover: BACKWARD,
Section 5: Platform Engineering and DataOps
Platform engineering and DataOps represent the operational backbone of any mature data organization. The prompts in this section address the infrastructure, governance, and automation challenges that senior data engineers and platform teams face daily — from designing self-service environments that reduce bottlenecks to implementing robust disaster recovery strategies that protect critical data assets. GPT-5.5 excels at synthesizing cross-functional requirements across security, cost, reliability, and developer experience into actionable platform blueprints.
Prompt 41: Self-Service Data Platform Design
You are a senior platform engineer designing a self-service data platform for a 200-person data organization
spanning analysts, scientists, and engineers with varying technical skill levels.
Design a comprehensive self-service data platform that includes:
PLATFORM ARCHITECTURE:
- Portal design with role-based capability exposure
- Dataset discovery and catalog integration (Apache Atlas or DataHub)
- Compute provisioning (Spark clusters, notebooks, SQL warehouses)
- Automated environment provisioning with guardrails
- Data access request and approval workflows
USER EXPERIENCE TIERS:
- Tier 1 (Analysts): No-code/low-code SQL interfaces, pre-built dashboards
- Tier 2 (Data Scientists): Notebook environments, ML experiment tracking
- Tier 3 (Data Engineers): Full pipeline development, infrastructure provisioning
- Admin tier: Cost management, access governance, audit trails
GUARDRAILS AND GOVERNANCE:
- Automated PII detection before dataset exposure
- Budget caps per team and per user
- Resource quotas with automatic scaling limits
- Data retention policy enforcement
- Compliance tagging requirements
ONBOARDING AUTOMATION:
- New user provisioning workflow (< 4 hours from request to access)
- Team workspace creation with pre-configured templates
- Training module integration and certification tracking
- Sandbox environment with sample datasets
OPERATIONAL REQUIREMENTS:
- SLA definitions for platform availability (99.9% uptime target)
- Incident response playbooks for platform outages
- Change management process for platform updates
- Feedback collection and feature request prioritization
Provide architecture diagrams in ASCII, technology stack recommendations with justification,
implementation roadmap across 3 phases (0-3 months, 3-6 months, 6-12 months),
and success metrics for platform adoption.
Prompt 42: Cost Allocation and Chargeback Models for Data Infrastructure
You are a FinOps engineer responsible for implementing cost transparency and accountability
across a data platform running on AWS with monthly cloud spend of $2.3M.
Design a comprehensive cost allocation and chargeback model that covers:
COST CATEGORIZATION:
- Direct costs: Compute (EMR, Glue, Redshift), storage (S3, EBS), data transfer
- Shared costs: Networking, monitoring, security tooling, platform engineering overhead
- Amortized costs: Reserved instances, savings plans, committed use discounts
- Hidden costs: Data egress, API calls, support tiers
TAGGING STRATEGY:
- Mandatory tag taxonomy: team, project, environment, cost-center, data-classification
- Tag enforcement via AWS Config rules and SCPs
- Tag compliance reporting and remediation workflows
- Handling untaggable resources (data transfer, support)
ALLOCATION METHODOLOGIES:
- Direct allocation for clearly attributable workloads
- Proportional allocation for shared services (by usage metrics)
- Fixed allocation for platform overhead (by headcount or team size)
- Tiered showback vs. chargeback decision framework
REPORTING AND DASHBOARDS:
- Real-time cost dashboards per team, project, and environment
- Budget vs. actual tracking with anomaly detection
- Unit economics metrics (cost per pipeline run, cost per TB processed, cost per query)
- Forecasting models with 30/60/90-day projections
OPTIMIZATION RECOMMENDATIONS ENGINE:
- Automated identification of idle resources (> 7 days without activity)
- Right-sizing recommendations for compute clusters
- Storage lifecycle policy suggestions
- Reserved instance purchase recommendations based on usage patterns
GOVERNANCE PROCESS:
- Monthly cost review meeting templates and agenda
- Escalation thresholds and approval workflows for budget overruns
- Quarterly optimization targets per team
- Incentive structures for cost-conscious behavior
Provide SQL queries for cost analysis, Python scripts for automated reporting,
sample Terraform for tagging enforcement, and a cost allocation policy document template.
Prompt 43: Capacity Planning for Data Platforms
You are a data infrastructure architect performing capacity planning for a rapidly growing
data platform that has experienced 40% month-over-month growth in data volume over the past 6 months.
Develop a rigorous capacity planning framework that addresses:
CURRENT STATE ASSESSMENT:
- Inventory of all compute resources with current utilization metrics
- Storage growth trends by data domain and source system
- Network bandwidth utilization patterns
- Database connection pool saturation analysis
- Job queue depth and scheduling bottlenecks
DEMAND FORECASTING MODELS:
- Time series forecasting for storage growth (ARIMA, exponential smoothing)
- Compute demand modeling based on pipeline growth and business seasonality
- User growth projections and concurrent session modeling
- Data ingestion rate forecasting by source system
CAPACITY SCENARIOS:
- Base case: Linear continuation of current growth trends
- Optimistic case: Accelerated growth from new business initiatives
- Pessimistic case: Growth plateau with optimization opportunities
- Stress case: 3x spike scenarios (year-end processing, product launches)
SCALING STRATEGIES:
- Horizontal vs. vertical scaling decision matrix
- Auto-scaling policies with warm-up time considerations
- Pre-provisioning strategies for predictable peak periods
- Burst capacity via spot/preemptible instances
RESOURCE THRESHOLDS AND ALERTS:
- Warning thresholds (70% utilization) and critical thresholds (85% utilization)
- Automated capacity expansion triggers
- Runbook for manual capacity interventions
- Escalation procedures for unexpected capacity events
COST-CAPACITY TRADE-OFFS:
- Over-provisioning cost vs. performance degradation risk analysis
- Capacity reservation economics (1-year vs. 3-year commitments)
- Multi-tier storage strategy (hot/warm/cold) with migration policies
Provide Python code for automated capacity reporting, forecasting models with confidence intervals,
capacity planning spreadsheet templates, and quarterly review process documentation.
Prompt 44: Disaster Recovery for Data Pipelines and Warehouses
You are a data reliability engineer designing a comprehensive disaster recovery (DR) strategy
for a financial services company with strict RPO of 1 hour and RTO of 4 hours for critical data systems.
Design a DR framework covering:
SYSTEM CLASSIFICATION AND CRITICALITY:
- Tier 1 (Critical): Real-time trading data, regulatory reporting pipelines
- Tier 2 (Important): Customer analytics, operational dashboards
- Tier 3 (Standard): Historical analysis, ML training pipelines
- RPO/RTO targets per tier with business impact justification
BACKUP STRATEGIES:
- Incremental vs. full backup schedules per data tier
- Point-in-time recovery for transactional data stores
- Cross-region replication configuration for S3, RDS, and Redshift
- Backup encryption and key management in DR scenarios
- Backup validation and integrity checking automation
DATA PIPELINE DR:
- Pipeline state preservation (checkpointing strategies for Spark Streaming, Kafka)
- Dead letter queue management and replay mechanisms
- Idempotency requirements for pipeline reruns after recovery
- Dependency mapping for pipeline restoration sequencing
- Configuration and secrets backup for pipeline infrastructure
WAREHOUSE AND CATALOG DR:
- Redshift/Snowflake cross-region snapshot strategies
- Data catalog metadata backup and restoration procedures
- Schema registry backup for streaming pipelines
- dbt model and transformation logic version control as DR artifact
FAILOVER PROCEDURES:
- Automated failover triggers and health check definitions
- Manual failover runbooks with step-by-step procedures
- DNS and connection string update automation
- Downstream system notification procedures during failover
TESTING AND VALIDATION:
- Quarterly DR drill schedule and test scenarios
- Automated DR test framework with pass/fail criteria
- Recovery time measurement and reporting
- Post-drill retrospective template and improvement tracking
Provide Terraform for cross-region replication, Python scripts for backup validation,
DR runbook templates, and a DR testing scorecard.
Prompt 45: Multi-Cloud Data Strategy
You are a chief data architect developing a multi-cloud data strategy for an enterprise
that currently operates 70% on AWS and 30% on Azure, with a mandate to avoid vendor lock-in
while optimizing for cost and performance.
Design a comprehensive multi-cloud data strategy that addresses:
WORKLOAD PLACEMENT FRAMEWORK:
- Decision matrix for AWS vs. Azure vs. GCP workload placement
- Criteria: data gravity, latency requirements, cost, existing integrations, compliance
- Vendor-specific strengths mapping (AWS for ML scale, Azure for Microsoft ecosystem, GCP for analytics)
- Hybrid scenarios where workloads span multiple clouds
DATA PORTABILITY ARCHITECTURE:
- Open format strategy (Apache Parquet, Delta Lake, Apache Iceberg) for portability
- Avoiding proprietary format lock-in (Redshift Spectrum vs. open table formats)
- Metadata and catalog portability (Apache Atlas, open metadata standards)
- ETL/ELT tool selection favoring cloud-agnostic options (dbt, Airbyte, Apache Beam)
NETWORKING AND CONNECTIVITY:
- Cross-cloud data transfer cost analysis and optimization
- Direct interconnect options (AWS Direct Connect + Azure ExpressRoute)
- Data locality strategies to minimize egress costs
- Latency benchmarking for cross-cloud data access patterns
IDENTITY AND ACCESS MANAGEMENT:
- Federated identity across cloud providers
- Secrets management with multi-cloud support (HashiCorp Vault)
- Unified RBAC model across cloud platforms
- Audit logging aggregation from multiple cloud providers
OPERATIONAL UNIFIED LAYER:
- Single-pane-of-glass monitoring across clouds (Datadog, Grafana)
- Unified cost management and allocation
- Consistent CI/CD pipelines for multi-cloud deployments (Terraform)
- Incident management spanning multiple cloud environments
RISK AND COMPLIANCE:
- Data residency requirements across cloud regions
- Compliance certification mapping per cloud provider
- Vendor concentration risk assessment and mitigation
- Contract and SLA management across multiple providers
Provide architecture diagrams, TCO comparison models, migration sequencing recommendations,
and a vendor evaluation scorecard template.
Prompt 46: Secrets Management for Data Pipelines
You are a data security engineer implementing enterprise-grade secrets management
for a data platform with 500+ pipelines accessing 80+ external systems including databases,
APIs, cloud services, and third-party data providers.
Design a comprehensive secrets management solution covering:
SECRETS INVENTORY AND CLASSIFICATION:
- Audit all existing secret storage locations (hardcoded, environment variables, config files)
- Classification by sensitivity: database credentials, API keys, encryption keys, certificates
- Secret lifecycle mapping: creation, rotation, expiration, revocation
- Dependency mapping: which pipelines consume which secrets
SECRETS MANAGEMENT ARCHITECTURE:
- HashiCorp Vault deployment (HA configuration with auto-unseal)
- AWS Secrets Manager integration for AWS-native workloads
- Secret injection patterns: environment variables, sidecar containers, direct API calls
- Dynamic secrets for database credentials (auto-rotating PostgreSQL, MySQL credentials)
- PKI infrastructure for certificate management
PIPELINE INTEGRATION PATTERNS:
- Airflow integration: Connections backend using Vault or AWS Secrets Manager
- Spark/Databricks: Secret scopes and cluster-level secret injection
- dbt: Profile secrets management without hardcoding credentials
- Kubernetes: External Secrets Operator for pod-level secret injection
- CI/CD systems: GitHub Actions, GitLab CI secrets integration
ROTATION AND LIFECYCLE:
- Automated rotation schedules by secret type (API keys: 90 days, DB passwords: 30 days)
- Zero-downtime rotation patterns for active pipeline credentials
- Rotation failure detection and alerting
- Emergency rotation procedures for compromised credentials
AUDIT AND COMPLIANCE:
- Secret access audit logging with pipeline attribution
- Unused secret detection and cleanup workflows
- Compliance reporting for SOC2, PCI-DSS secret management requirements
- Secret scanning in git repositories (pre-commit hooks, CI scanning)
DEVELOPER EXPERIENCE:
- Local development secrets workflow without production access
- Secret request and approval process for new pipeline credentials
- Documentation standards for secret dependencies
- Onboarding guide for engineers new to the secrets management system
Provide Vault HCL configuration, Python integration examples for Airflow and Spark,
Kubernetes External Secrets manifests, and a secrets audit checklist.
Prompt 47: CI/CD for Data Pipelines
You are a DataOps engineer building a production-grade CI/CD system for a data engineering
team managing 200+ dbt models, 50 Airflow DAGs, and 30 custom Spark jobs across
development, staging, and production environments.
Design a comprehensive CI/CD framework that includes:
VERSION CONTROL STRATEGY:
- Git branching model for data pipelines (trunk-based vs. GitFlow trade-offs)
- Monorepo vs. polyrepo structure for data assets
- Commit conventions and PR templates for data changes
- Protected branch policies and required reviewers
TESTING PYRAMID FOR DATA:
- Unit tests: dbt model tests (not_null, unique, accepted_values, relationships)
- Integration tests: End-to-end pipeline tests with synthetic data
- Data quality tests: Great Expectations or Soda checks in CI
- Performance tests: Query execution time regression detection
- Schema change detection and backward compatibility validation
CI PIPELINE STAGES:
- Linting: SQL formatting (sqlfluff), Python linting (ruff, mypy), YAML validation
- Static analysis: dbt compile, DAG import checks, dependency graph validation
- Unit testing: dbt test, pytest for custom transforms
- Security scanning: Secrets detection, dependency vulnerability scanning
- Build: Docker image builds for custom operators, package publishing
CD PIPELINE STAGES:
- Staging deployment: Automated deployment to staging with smoke tests
- Data validation: Row count checks, statistical distribution comparisons
- Canary deployments: Gradual rollout for high-impact pipeline changes
- Production deployment: Automated or approval-gated based on change risk
- Post-deployment validation: Automated data quality checks in production
ROLLBACK STRATEGIES:
- Automatic rollback triggers based on data quality check failures
- Database migration rollback procedures (forward-only vs. reversible migrations)
- DAG version rollback in Airflow
- Blue-green deployment patterns for warehouse transformations
ENVIRONMENT MANAGEMENT:
- Environment parity strategies (dev/staging/prod data isolation)
- Ephemeral environments for feature branch testing
- Data subsetting for lower environments (privacy-preserving sampling)
Provide GitHub Actions workflow YAML files, dbt CI configuration,
Great Expectations checkpoint configurations, and a deployment runbook template.
Prompt 48: Observability Dashboards for Data Platforms
You are a data platform engineer building a comprehensive observability system for a data platform
processing 10TB daily across 300 pipelines, serving 150 internal users and 5 external data products.
Design an end-to-end observability framework covering:
OBSERVABILITY PILLARS FOR DATA:
- Metrics: Pipeline performance, data volume, latency, error rates, resource utilization
- Logs: Structured logging standards, log aggregation, search and analysis
- Traces: Distributed tracing for multi-step pipeline execution
- Data quality signals: Freshness, completeness, accuracy, consistency metrics
DASHBOARD ARCHITECTURE:
- Executive dashboard: SLA compliance, data product health, cost trends
- Operations dashboard: Real-time pipeline status, active incidents, queue depths
- Engineering dashboard: Performance trends, error rates, resource utilization
- Data quality dashboard: Quality scores by domain, anomaly detection alerts
- User experience dashboard: Query performance, self-service platform adoption
KEY METRICS AND SLIs:
- Pipeline SLIs: Success rate (target: 99.5%), p95 execution time, data freshness lag
- Warehouse SLIs: Query p50/p95/p99 latency, concurrency utilization, cache hit rates
- Ingestion SLIs: Records per second, schema error rate, deduplication effectiveness
- Storage SLIs: Growth rate, hot data access patterns, lifecycle policy effectiveness
ALERTING STRATEGY:
- Alert fatigue prevention: Severity levels (P1-P4) with escalation paths
- Symptom-based alerting vs. cause-based alerting
- Alert routing: PagerDuty for P1/P2, Slack for P3/P4
- Runbook links embedded in every alert
- Alert review cadence and cleanup process
TOOLING STACK:
- Metrics: Prometheus +