Codex Workspace Agents Masterclass: 35 Production-Ready Prompts for Building, Deploying, and Managing Enterprise AI Agents
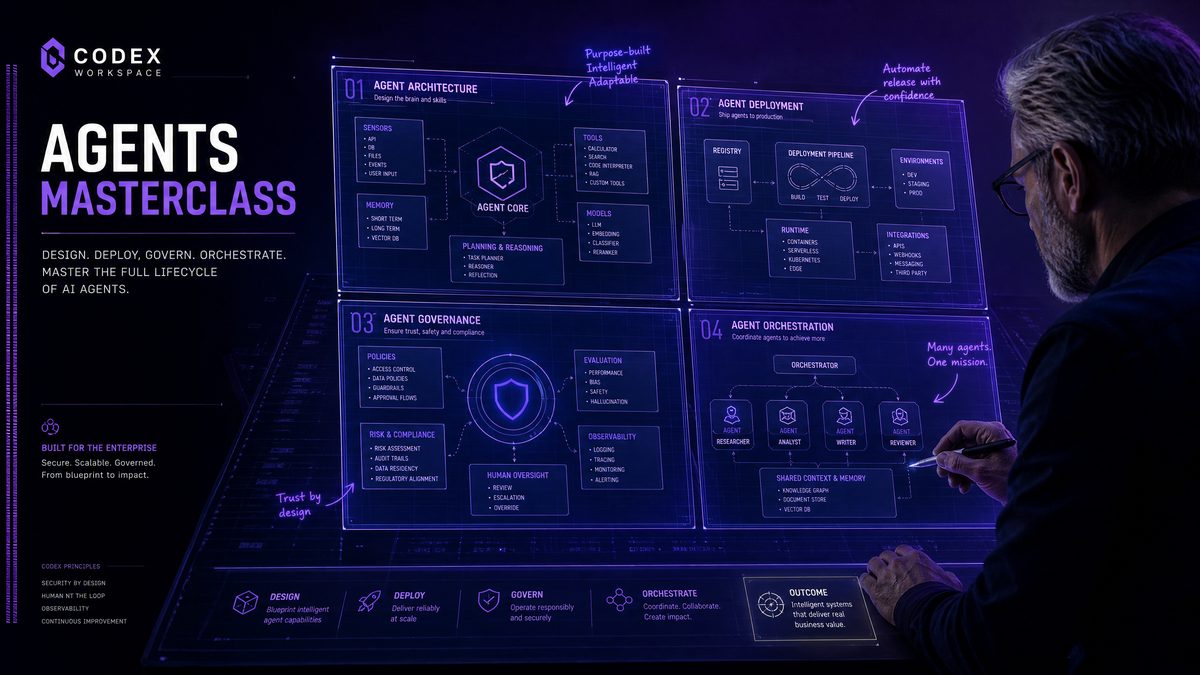
Codex Workspace Agents Masterclass: 35 Production-Ready Prompts for Building, Deploying, and Managing Enterprise AI Agents
Enterprise automation has entered a new era. OpenAI’s Codex, when applied to Workspace Agent development, gives engineering teams a powerful collaborative partner capable of generating production-grade code, structured specifications, deployment configurations, and operational runbooks at a pace that fundamentally changes what small teams can accomplish. Workspace Agents — autonomous AI systems embedded within enterprise toolchains like Slack, Microsoft Teams, Jira, Salesforce, and internal APIs — require careful architectural thinking, rigorous testing, and thoughtful governance. Getting these systems right means navigating capability boundaries, managing context at scale, handling failures gracefully, and ensuring agents behave predictably across thousands of interactions per day.
This masterclass delivers 35 production-ready prompts engineered specifically for Codex, covering the complete lifecycle of enterprise Workspace Agents: from initial architecture and design through deployment pipelines, monitoring, security hardening, and long-term operational management. Each prompt is structured with precise context, concrete constraints, and explicit output expectations so that Codex generates artifacts you can carry directly into sprint planning, code review, or infrastructure provisioning. Whether you are building your first agent or scaling a fleet of specialized agents across a global organization, these prompts will accelerate your delivery and raise the quality bar at every stage of the process.
Section 1: Agent Architecture and Design (Prompts 1–10)
Sound architecture is the foundation of every reliable enterprise agent. The prompts in this section guide Codex through the most consequential design decisions: what the agent can and cannot do, how it reasons across multiple turns, how it manages memory and context, and how it presents itself to end users. Investing time here prevents costly rework during deployment and operations.
Prompt 1: Generating a Comprehensive Agent Specification Document
You are a senior AI systems architect at a Fortune 500 financial services company preparing to deploy a Workspace Agent inside Microsoft Teams for the corporate IT helpdesk team.
Generate a complete Agent Specification Document for an agent named "Helios" that handles employee IT support requests including password resets, software provisioning, VPN troubleshooting, and hardware ticket escalation.
The document must include: an executive summary, a detailed purpose and scope statement, a list of supported intents with example utterances for each, a list of explicitly out-of-scope capabilities, integration touchpoints (Active Directory, ServiceNow, Okta), compliance requirements (SOC 2 Type II, GDPR), escalation paths to human agents, and a versioning strategy.
Format the output as a structured technical specification with numbered sections, suitable for review by both engineering leadership and a compliance officer, and flag any design decisions that require stakeholder sign-off before development begins.
Prompt 2: Defining Capability Boundaries with Guardrail Logic

You are designing the capability boundary layer for an enterprise Workspace Agent that operates inside a legal department's document management system, where unauthorized actions could create regulatory liability.
Write a detailed capability boundary definition document that categorizes every agent action into one of four tiers: fully autonomous (no human approval required), supervised autonomous (executes but logs for review), human-in-the-loop (requires explicit approval before execution), and prohibited (hard-blocked regardless of instruction).
For each tier, provide five concrete example actions relevant to a legal document management context, the technical enforcement mechanism (prompt-level restriction, API permission scope, or runtime policy check), and the audit logging requirement.
Include a decision tree in pseudocode that the agent runtime can use to classify an incoming request against the correct tier before any tool call is initiated, and annotate each branch with the compliance rationale driving that boundary.
Prompt 3: Designing a Production-Grade Tool Schema for Agent Function Calling
You are a backend engineer building the tool layer for a Workspace Agent integrated with a B2B SaaS company's internal data platform, which exposes endpoints for querying customer health scores, updating account records, triggering onboarding workflows, and generating renewal forecasts.
Generate a complete OpenAI function-calling tool schema in valid JSON for all four tool categories, where each tool definition includes a precise name following snake_case convention, a detailed description written specifically to guide the language model's tool selection reasoning, a fully typed parameters object with required and optional fields, enum constraints where applicable, and a clear description of what a successful response payload looks like.
Ensure that destructive operations (record updates, workflow triggers) include a dry_run boolean parameter that defaults to true, so the agent can preview effects before committing changes.
After the JSON schema, write a 200-word prose explanation of the tool naming and description conventions you applied, explaining why precise tool descriptions reduce hallucinated tool calls in production environments.
Prompt 4: Architecting a Multi-Step Conversation Flow for Complex Enterprise Workflows
You are architecting the conversation flow for a Workspace Agent that guides HR managers through a six-step employee offboarding process inside Slack, where each step must be completed in sequence and some steps require data from previous steps to proceed.
Design a complete conversation flow architecture document that maps every state in the offboarding process as a named node, defines the valid transitions between nodes including the triggering conditions (user confirmation, API success response, timeout), specifies what data the agent must carry forward in its session context at each transition, and identifies the three most likely failure points where the conversation could stall or branch unexpectedly.
Include a Mermaid.js state diagram representing the full flow, followed by a JSON schema for the session context object that persists across turns, with field-level annotations explaining why each piece of data is necessary for downstream steps.
Conclude with a list of five edge cases — such as a manager abandoning the flow midway or an API returning a partial success — and specify exactly how the agent should handle each one to avoid leaving offboarding tasks in an incomplete state.
Prompt 5: Building a Robust Error Handling and Recovery Strategy
You are a reliability engineer responsible for ensuring that a customer-facing Workspace Agent integrated with an e-commerce platform's order management system handles failures gracefully without exposing internal system details or leaving customers in unresolved states.
Write a comprehensive error handling strategy document covering five categories of failure: transient API errors (5xx responses), authentication failures (401/403), data validation errors (malformed input from the user), downstream service timeouts, and unexpected model output that fails business logic validation.
For each failure category, specify the detection mechanism, the immediate agent response to the user (including exact sample language that is empathetic and actionable), the internal retry or fallback logic with maximum retry counts and backoff intervals, the escalation trigger if recovery fails, and the structured log entry format the agent should emit for each error event.
Format the strategy as an engineering runbook that an on-call engineer unfamiliar with the agent's codebase could use to diagnose and resolve incidents at 2 a.m., and include a summary table mapping error category to mean time to resolution targets.
Prompt 6: Designing a Context Window Management Strategy for Long-Running Agent Sessions
You are a machine learning engineer optimizing a Workspace Agent that supports long-running project management sessions inside Jira, where conversations can span dozens of turns and involve large amounts of ticket data, comment threads, and user instructions that collectively exceed the model's context window limit.
Design a complete context window management strategy that addresses four specific challenges: deciding which historical turns to retain versus summarize versus evict as the conversation grows, handling large tool response payloads (such as a Jira sprint board with 80 tickets) without consuming the entire available context, preserving the most decision-critical information across a session that may last several hours, and ensuring the agent can accurately answer questions about earlier parts of the conversation even after summarization has occurred.
For each challenge, provide a concrete algorithm or heuristic written in Python pseudocode, a worked example showing how the strategy applies to a realistic Jira session transcript, and a metric you would track in production to verify the strategy is working correctly.
Conclude with a recommendation on whether this agent should use a sliding window, hierarchical summarization, or retrieval-augmented memory approach, with a quantitative justification based on the session characteristics you have described.
Prompt 7: Implementing Memory Patterns for Personalized Agent Experiences
You are building the memory subsystem for a Workspace Agent deployed inside a professional services firm's internal knowledge portal, where the agent must remember individual consultant preferences, past project contexts, frequently accessed knowledge domains, and previously resolved queries to deliver increasingly personalized assistance over time.
Design a three-tier memory architecture that separates in-session working memory (ephemeral, context window resident), short-term episodic memory (persisted for 30 days, queryable by session ID and user ID), and long-term semantic memory (permanent, stored as vector embeddings in a dedicated memory store).
For each memory tier, specify the data schema, the write trigger (when does the agent decide to persist something to this tier), the read strategy (how does the agent decide to retrieve from this tier before responding), the privacy controls required under GDPR Article 17 right-to-erasure provisions, and the estimated storage cost per active user per month.
Provide a Python class skeleton for a MemoryManager that exposes a unified interface across all three tiers, with method signatures, docstrings, and inline comments explaining the routing logic that determines which tier a given memory operation targets.
Prompt 8: Designing Multi-Turn Reasoning Logic for Complex Decision Support
You are designing the reasoning architecture for a Workspace Agent that assists procurement managers in evaluating vendor proposals, a task that requires synthesizing information gathered across multiple conversation turns, applying weighted scoring criteria, identifying missing information, and producing a final recommendation with a documented rationale.
Write a detailed multi-turn reasoning logic specification that defines how the agent maintains a structured reasoning state object across turns, how it identifies when it has gathered sufficient information to proceed to the next reasoning phase versus when it must ask a clarifying question, how it handles contradictory information provided by the user in different turns, and how it generates a final recommendation that traces every conclusion back to specific evidence gathered during the conversation.
Include a concrete example trace showing a five-turn procurement evaluation conversation, annotating each turn with the agent's internal reasoning state before and after processing the user's message.
Conclude with a chain-of-thought prompt template the agent should use internally when synthesizing its final vendor recommendation, designed to minimize hallucinated justifications by anchoring every claim to a specific data point collected during the session.
Prompt 9: Crafting Persona and Tone Design Guidelines for Enterprise Agents
You are a conversational design specialist creating the persona and tone guidelines for a Workspace Agent named "Meridian" that will serve as the primary interface between employees and a global logistics company's internal operations platform, interacting with users ranging from warehouse floor supervisors to C-suite executives across 14 countries.
Produce a comprehensive persona and tone design document that defines Meridian's core personality attributes (select exactly five and justify each choice based on the user population and business context), communication style guidelines for three distinct user segments (frontline operational staff, mid-level managers, and senior leadership), explicit rules for adapting formality, technical depth, and response length based on detected user context, and a list of 10 prohibited communication patterns (such as dismissive language, excessive hedging, or false certainty) with an example of each pattern and its preferred alternative.
Include a set of 15 sample exchanges demonstrating Meridian's voice across different scenarios: delivering bad news about a shipment delay, explaining a complex API integration status, onboarding a new user, and de-escalating a frustrated employee.
Conclude with a quality rubric containing five measurable criteria that human reviewers can use to score any agent response for persona consistency during QA testing.
Prompt 10: Creating a Comprehensive Agent Testing Framework
You are a QA engineering lead responsible for defining the testing strategy for a Workspace Agent that handles sensitive employee benefits inquiries inside a healthcare company's HR platform, where incorrect responses could have legal, financial, and wellbeing consequences for employees.
Design a complete agent testing framework that covers five testing layers: unit tests for individual tool call logic, integration tests for end-to-end conversation flows against a staging environment, adversarial tests specifically designed to probe the agent's guardrails and refusal behaviors, regression tests that run automatically on every model or prompt update, and a human evaluation protocol for subjective quality dimensions that automated tests cannot capture.
For each testing layer, specify the tooling stack, the minimum coverage requirements before a release can proceed to production, five concrete test case examples written in a structured Given-When-Then format, and the acceptance criteria that determine pass or fail.
Provide a CI/CD pipeline configuration in YAML that orchestrates all five testing layers in the correct sequence, with appropriate parallelization for speed, and include a test reporting schema that aggregates results across layers into a single release readiness scorecard visible to both engineering and compliance stakeholders.
Section 2: Deployment and API Integration (Prompts 11-20)
Once your Codex agent is built and tested, moving it from a prototype into a production-grade system requires careful attention to infrastructure, authentication, and scalability. The following ten prompts cover every critical deployment concern, from the first API call to long-term capacity planning. Each prompt is designed to extract actionable configuration guidance, code scaffolding, and architectural decisions that engineering teams can implement immediately.
Prompt 11: API Trigger Configuration for Codex Agents
Configuring API triggers correctly determines how reliably external systems can invoke your Codex agent. This prompt helps you generate a complete trigger configuration blueprint, including endpoint structure, payload schemas, authentication headers, and error response contracts.
You are a senior backend engineer specializing in AI agent infrastructure. I need a comprehensive API trigger configuration guide for a Codex agent that will be invoked by multiple upstream services.
Context:
- Agent purpose: [DESCRIBE YOUR AGENT'S FUNCTION]
- Expected callers: [LIST UPSTREAM SERVICES, e.g., CRM, CI/CD pipeline, mobile app]
- Invocation frequency: [ESTIMATED CALLS PER MINUTE/HOUR]
- Payload complexity: [SIMPLE KEY-VALUE / NESTED JSON / MULTIPART]
Please produce:
1. A recommended REST endpoint structure with versioning conventions (e.g., /v1/agents/codex/invoke)
2. A complete JSON payload schema with required and optional fields, data types, and validation rules
3. HTTP header requirements including Content-Type, Authorization format, and any custom headers for tracing
4. Synchronous vs. asynchronous invocation patterns — when to use each and how to implement both
5. A response contract covering success (200/202), client error (400/422), and server error (500/503) shapes
6. Timeout configuration recommendations based on agent complexity
7. A sample cURL command and a Python requests snippet demonstrating a correctly formed API call
8. Idempotency key implementation to prevent duplicate executions on retry
Format the output as a technical specification document suitable for sharing with a backend engineering team.Prompt 12: Webhook Setup and Validation for Agent Callbacks
Webhooks allow your Codex agent to push results back to external systems asynchronously. This prompt generates everything needed to set up a secure, reliable webhook pipeline, including signature verification to prevent spoofed payloads.
Act as a security-focused integration architect. I am building a webhook callback system so that my Codex agent can deliver completed task results to downstream services asynchronously.
Requirements:
- Downstream receivers: [LIST SYSTEMS, e.g., Slack, Jira, internal dashboard]
- Expected payload size: [SMALL <1KB / MEDIUM 1-10KB / LARGE >10KB]
- Delivery guarantees needed: [AT-LEAST-ONCE / EXACTLY-ONCE]
- Security sensitivity: [LOW / MEDIUM / HIGH — e.g., contains PII or financial data]
Generate the following:
1. A webhook registration flow — how downstream systems register their callback URLs with the agent platform
2. HMAC-SHA256 signature generation and verification code in Python and Node.js
3. A webhook payload envelope schema including event_type, timestamp, agent_id, correlation_id, and data fields
4. Retry logic specification: exponential backoff parameters, maximum retry attempts, and dead-letter queue handling
5. Delivery status tracking — how to record successful delivery, pending retries, and permanent failures
6. A checklist for validating webhook receiver endpoints before going live (latency, SSL certificate, response code expectations)
7. Sample webhook receiver implementation in Express.js that validates the signature and acknowledges receipt within 200ms
8. Monitoring alerts to trigger when webhook delivery failure rates exceed acceptable thresholds
Include inline comments in all code samples explaining security-critical lines.Prompt 13: OAuth Authentication Flows for Codex Agent Access
Securing your Codex agent behind a proper OAuth flow prevents unauthorized access and enables fine-grained permission scopes. This prompt produces a complete OAuth implementation guide tailored to the specific grant types your deployment scenario requires.
You are an identity and access management specialist. I need to implement OAuth 2.0 authentication to protect my Codex agent API endpoints and control which clients can invoke which agent capabilities.
Deployment context:
- Client types accessing the agent: [MACHINE-TO-MACHINE / USER-FACING WEB APP / MOBILE APP / ALL THREE]
- Identity provider: [e.g., Auth0, Okta, Azure AD, custom implementation]
- Required permission scopes: [e.g., agent:invoke, agent:read_history, agent:admin]
- Token lifetime requirements: [SHORT-LIVED 15min / STANDARD 1hr / LONG-LIVED with refresh]
Provide:
1. The recommended OAuth 2.0 grant type for each client type with justification (Client Credentials, Authorization Code + PKCE, Device Flow)
2. Scope definition schema — how to structure scopes to map to specific agent actions
3. Token validation middleware in Python (FastAPI) that verifies JWT signature, expiry, and required scopes
4. Refresh token rotation implementation to maintain security without forcing frequent re-authentication
5. A token introspection endpoint design for real-time revocation checking
6. Service account setup guide for machine-to-machine clients invoking the agent from CI/CD pipelines
7. A sequence diagram (described in text with ASCII art) showing the full Authorization Code + PKCE flow for a user-facing application
8. Common OAuth misconfiguration vulnerabilities specific to AI agent APIs and how to prevent each one
9. Audit logging requirements — what authentication events must be recorded for compliance
Structure the response as an implementation guide with a security review checklist at the end.Prompt 14: Rate Limiting Strategies to Protect Agent Infrastructure
Without proper rate limiting, a single misbehaving client or traffic spike can exhaust your Codex API quota and degrade service for all users. This prompt generates a multi-layered rate limiting architecture that balances protection with legitimate usage flexibility.
Act as a platform reliability engineer. I need to design and implement a comprehensive rate limiting strategy for a Codex agent API that serves multiple tenants with different usage tiers.
System parameters:
- Total Codex API budget per month: [YOUR TOKEN/CREDIT LIMIT]
- Number of tenants: [APPROXIMATE COUNT]
- Tenant tiers: [e.g., Free: 100 calls/day, Pro: 1000 calls/day, Enterprise: unlimited with fair-use]
- Traffic patterns: [STEADY / BURSTY / BATCH-HEAVY]
- Current infrastructure: [e.g., NGINX, AWS API Gateway, Kong, custom middleware]
Design and deliver:
1. A three-layer rate limiting architecture: per-IP, per-API-key, and per-tenant-tier limits with rationale for each layer
2. Algorithm selection guide comparing Token Bucket, Leaky Bucket, Fixed Window, and Sliding Window — recommend the best fit for AI agent workloads
3. Redis-based sliding window rate limiter implementation in Python with Lua scripting for atomic operations
4. HTTP 429 response structure including Retry-After header, rate limit headers (X-RateLimit-Limit, X-RateLimit-Remaining, X-RateLimit-Reset), and a human-readable error body
5. Burst allowance configuration — how to permit short bursts above the sustained rate without opening abuse vectors
6. Priority queue implementation so that high-tier tenants receive faster processing during congestion
7. Rate limit bypass mechanism for internal health checks and monitoring agents
8. Dashboard metrics to expose: current utilization per tenant, approaching-limit warnings, and throttled request counts
9. Graceful degradation behavior when the Codex API itself imposes upstream rate limits
Include a configuration file template (YAML format) that captures all rate limit rules in a human-readable, version-controllable format.Prompt 15: Credit Usage Optimization to Minimize Codex API Costs
Codex API costs scale directly with token consumption and the number of agent steps executed. Without deliberate optimization, production workloads can generate unexpectedly large bills. This prompt produces a systematic cost reduction strategy without sacrificing agent quality.
You are a FinOps engineer with deep expertise in LLM API cost optimization. My Codex agent is in production and I need to reduce token consumption and credit usage by at least 40% without degrading output quality or user experience.
Current state:
- Average tokens per agent run: [YOUR CURRENT AVERAGE]
- Monthly API spend: [CURRENT MONTHLY COST]
- Most expensive agent tasks by token count: [LIST TOP 3 TASK TYPES]
- Current model in use: [e.g., codex-mini, full Codex model]
- Caching infrastructure available: [REDIS / MEMCACHED / NONE]
Produce a complete optimization playbook covering:
1. Prompt compression techniques — how to reduce system prompt length by 30-50% without losing behavioral fidelity, with before/after examples
2. Response length control — system prompt instructions and API parameters (max_tokens, stop sequences) to prevent verbose outputs
3. Semantic caching implementation — how to cache agent responses for semantically similar inputs using embedding similarity thresholds
4. Model routing strategy — when to route simple subtasks to a cheaper model and escalate to full Codex only for complex reasoning
5. Context window management — techniques for summarizing conversation history to prevent unbounded context growth
6. Batching strategies for non-real-time workloads that aggregate multiple requests into fewer API calls
7. Token counting implementation to measure and log consumption per task type before costs are incurred
8. A cost attribution dashboard design that breaks down spend by tenant, task type, and time period
9. Anomaly detection rules to alert when a single agent run exceeds a configurable token budget threshold
10. ROI calculation framework to measure quality impact of each optimization against cost savings
Format as a prioritized action plan with estimated savings percentage for each technique.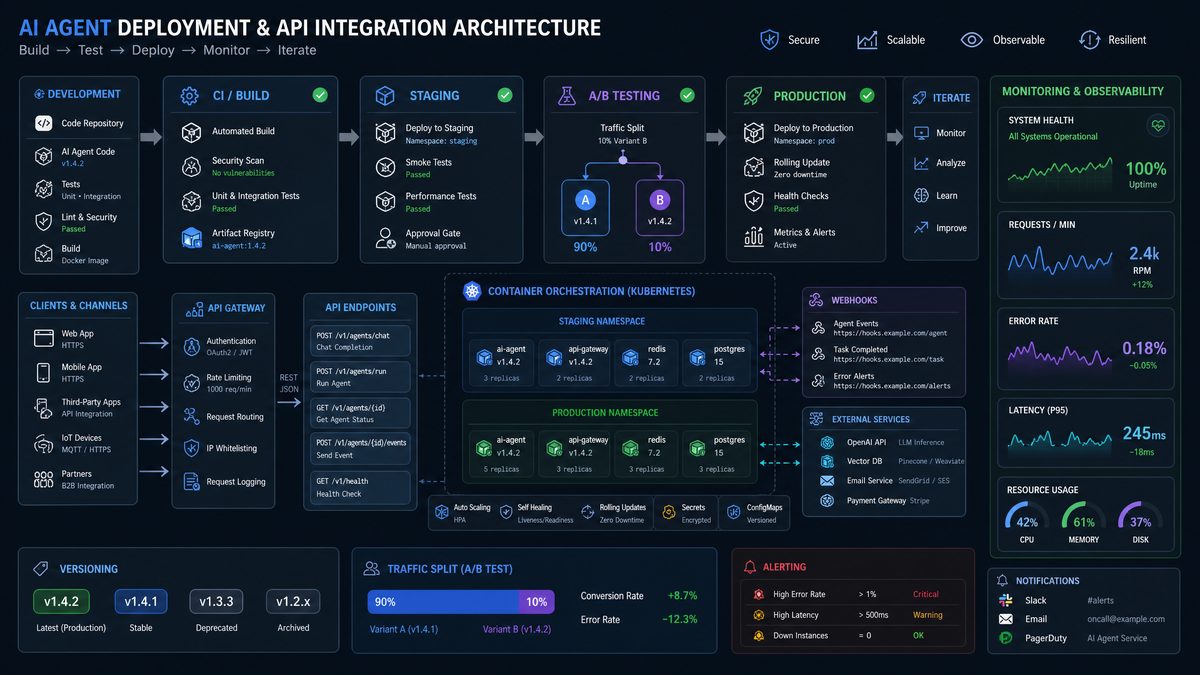
The deployment architecture you establish for your Codex agent does not exist in isolation — it becomes the foundation upon which tool integrations are layered. Understanding Codex MCP integration for enterprise connectors is essential at this stage because the Model Context Protocol defines how your deployed agent discovers, authenticates against, and orchestrates external tools at runtime. When your API trigger configuration, OAuth flows, and rate limiting policies are properly established, MCP tool calls inherit those same security boundaries and operational constraints automatically. This means that scaling decisions, health monitoring configurations, and version rollback procedures you define in the following prompts will apply uniformly across both direct API invocations and MCP-mediated tool executions, giving your operations team a single coherent surface to manage rather than two parallel systems with divergent behaviors.
Prompt 16: Horizontal Scaling Patterns for High-Availability Agent Deployments
A single-instance Codex agent deployment cannot meet enterprise availability or throughput requirements. This prompt generates a complete horizontal scaling architecture that distributes load, eliminates single points of failure, and maintains stateless agent execution across multiple nodes.
Act as a distributed systems architect. I need to design a horizontally scalable deployment architecture for a Codex agent that must handle peak loads of [YOUR PEAK REQUESTS PER SECOND] with 99.9% uptime SLA.
Infrastructure context:
- Cloud provider: [AWS / GCP / Azure / on-premises Kubernetes]
- Container orchestration: [Kubernetes / ECS / Docker Swarm / none]
- Current single-instance capacity: [MAX CONCURRENT REQUESTS IT CAN HANDLE]
- State management needs: [STATELESS / SESSION STATE / LONG-RUNNING TASK STATE]
- Database backend: [e.g., PostgreSQL, DynamoDB, MongoDB]
Design the complete scaling architecture including:
1. Stateless agent design principles — how to externalize all session state so any instance can handle any request
2. Kubernetes deployment manifest with Horizontal Pod Autoscaler (HPA) configuration targeting CPU and custom metrics (queue depth, active agent sessions)
3. Load balancer configuration for intelligent request routing — least connections vs. round-robin vs. weighted routing for agent workloads
4. Session affinity strategy for long-running agent tasks that span multiple API calls
5. Shared state backend design using Redis Cluster for agent context, task queues, and distributed locks
6. Database connection pooling configuration to prevent connection exhaustion during scale-out events
7. Graceful shutdown procedure ensuring in-flight agent tasks complete before a pod terminates
8. Auto-scaling trigger thresholds and cooldown periods tuned specifically for LLM API latency characteristics
9. Multi-region deployment considerations including data residency, latency routing, and failover automation
10. Chaos engineering test scenarios to validate that the scaled architecture handles node failures without task loss
Provide all Kubernetes manifests as complete YAML files with explanatory comments on every non-obvious configuration value.Prompt 17: Health Monitoring Dashboards for Production Codex Agents
Comprehensive observability is what separates a production-grade agent deployment from a best-effort prototype. This prompt generates a full monitoring stack specification, from metric collection through alerting, giving your operations team complete visibility into agent health and performance.
For teams looking to extend these capabilities further, our detailed guide on How to Build Custom Codex Plugins for Your Team: A Complete Developer Guide provides the implementation patterns and configuration steps needed to build production-grade workflows that scale across enterprise environments.
For teams looking to extend these capabilities further, our detailed guide on OpenAI Rolls Out MCP Support for ChatGPT Enterprise: What Model Context Protocol Means for Your Organization provides the implementation patterns and configuration steps needed to build production-grade workflows that scale across enterprise environments.
Access 40,000+ AI Prompts for ChatGPT, Claude & Codex — Free!
Subscribe to get instant access to our complete Notion Prompt Library — the largest curated collection of prompts for ChatGPT, Claude, OpenAI Codex, and other leading AI models. Optimized for real-world workflows across coding, research, content creation, and business.
You are a site reliability engineer building a comprehensive observability stack for a production Codex agent deployment. I need health monitoring that covers the agent application layer, the Codex API dependency, and the underlying infrastructure.
Current observability tools:
- Metrics: [Prometheus / Datadog / CloudWatch / New Relic]
- Logging: [ELK Stack / Loki / Splunk / CloudWatch Logs]
- Tracing: [Jaeger / Zipkin / AWS X-Ray / Datadog APM]
- Alerting: [PagerDuty / OpsGenie / Slack / email]
Design and deliver:
1. A complete metrics taxonomy organized into four tiers: infrastructure metrics, application metrics, Codex API metrics, and business metrics (task completion rates, user satisfaction proxies)
2. Prometheus metrics definitions (metric names, types, labels) for: request latency histograms, token consumption counters, agent task duration summaries, error rate gauges, and queue depth gauges
3. A Grafana dashboard JSON structure (described in detail) with panels for: real-time request throughput, p50/p95/p99 latency, error rate by error type, Codex API quota utilization, active agent sessions, and cost per hour
4. Structured logging schema for agent events — what fields every log line must contain for effective querying and correlation
5. Distributed tracing instrumentation guide — how to propagate trace context through the agent's tool calls and API requests
6. Alert rule definitions with thresholds, evaluation windows, and severity levels for: high error rate, latency degradation, quota exhaustion approaching, and instance health failures
7. Runbook template for each alert — what to check first, escalation path, and resolution steps
8. Synthetic monitoring setup — how to run scheduled test agent invocations to detect availability issues before real users encounter them
9. SLO definition framework: how to set and measure availability, latency, and correctness SLOs for an AI agent
Output the Prometheus alert rules in valid YAML format and the structured log schema as a JSON Schema document.Prompt 18: Version Management and Rollback Strategies for Agent Updates
Updating a Codex agent in production — whether changing the system prompt, modifying tool configurations, or upgrading the underlying model — carries risk. This prompt produces a version management framework that enables safe deployments and rapid rollback when regressions are detected.
Act as a DevOps engineer specializing in AI system deployments. I need a robust version management and rollback strategy for a Codex agent where changes to prompts, tools, model parameters, or application code can independently affect agent behavior.
Deployment environment:
- CI/CD platform: [GitHub Actions / GitLab CI / Jenkins / CircleCI]
- Container registry: [ECR / GCR / Docker Hub / Azure Container Registry]
- Deployment target: [Kubernetes / ECS / App Service / Cloud Run]
- Change frequency: [DAILY / WEEKLY / ON-DEMAND]
- Rollback time requirement: [TARGET TIME TO RESTORE PREVIOUS VERSION]
Produce a complete version management system covering:
1. Versioning scheme for all agent artifacts: application code, system prompts, tool configurations, and model selection — how to version each independently and track their combinations
2. GitOps workflow for agent configuration — how system prompts and tool configs are stored in Git, reviewed, and deployed through the same pipeline as code
3. Blue-green deployment implementation for zero-downtime agent updates with traffic cutover automation
4. Canary release strategy — how to route 5% of traffic to the new agent version, define success metrics, and automate promotion or rollback decisions
5. Automated regression test suite that runs against a new agent version before it
Section 3: Enterprise Governance and Security (Prompts 21-30)
Enterprise AI deployments demand rigorous governance frameworks that balance accessibility with security, compliance with usability, and innovation with risk management. The following ten prompts address the most critical governance and security challenges organizations face when deploying Claude at scale. Each prompt is engineered to extract comprehensive, actionable policy documents, configuration specifications, and operational frameworks that align with industry standards including SOC 2, ISO 27001, HIPAA, GDPR, and NIST guidelines.
Prompt 21: Access Control Policy Generation
Access control is the foundational layer of any enterprise AI governance strategy. This prompt generates a complete, role-based access control policy tailored to your organizational structure, ensuring that Claude API access is granted on a least-privilege basis with clearly defined escalation paths and review cycles.
You are an enterprise security architect specializing in AI governance frameworks. Generate a comprehensive Role-Based Access Control (RBAC) policy document for Claude API deployment across a mid-to-large enterprise environment.
The policy must include the following sections:
1. POLICY OVERVIEW AND SCOPE
- Define the purpose of this access control policy specific to Claude API usage
- Identify all systems, applications, and personnel covered by this policy
- State the effective date, version control requirements, and review cadence (minimum annual review)
- Reference applicable regulatory frameworks (SOC 2 Type II, ISO 27001, NIST SP 800-53)
2. ROLE DEFINITIONS AND PERMISSION MATRIX
Create a detailed permission matrix for the following roles:
- Executive Sponsor: Read-only access to usage dashboards and cost reports; no direct API access
- AI Platform Administrator: Full administrative access including API key management, model configuration, rate limit adjustments, and audit log access
- AI Developer (Senior): API access with elevated token limits (up to 100K tokens per request), ability to create and modify system prompts, access to all Claude model tiers including Claude 3 Opus
- AI Developer (Junior): API access with standard token limits (up to 32K tokens per request), read-only system prompt access, restricted to Claude 3 Haiku and Sonnet models only
- Business Analyst: Access only through approved internal applications built on Claude; no direct API key access; usage capped at 50 requests per hour
- End User: Access exclusively through approved front-end interfaces; zero direct API interaction; subject to content filtering and output review policies
- Security Auditor: Read-only access to all audit logs, usage metrics, and configuration settings; cannot modify any settings or initiate API calls
- External Contractor: Temporary API access with 30-day maximum duration, restricted to non-production environments, mandatory supervision by Senior Developer
3. AUTHENTICATION AND AUTHORIZATION REQUIREMENTS
- Specify multi-factor authentication (MFA) requirements for each role tier
- Define API key rotation schedules (recommended: 90-day rotation for production keys, 30-day for development)
- Describe OAuth 2.0 or SAML integration requirements for SSO-enabled environments
- Outline IP allowlisting requirements for production API access
- Define session timeout policies for web-based Claude interfaces
4. ACCESS PROVISIONING WORKFLOW
Provide a step-by-step workflow for:
a) New access requests: Required approvals, documentation, background check requirements
b) Access modifications: Change request process, dual-approval requirements for elevated access
c) Access revocation: Immediate revocation triggers, standard offboarding timeline (not to exceed 24 hours)
d) Temporary access grants: Maximum duration limits, monitoring requirements, automatic expiration enforcement
5. PRIVILEGED ACCESS MANAGEMENT (PAM)
- Define what constitutes privileged access in the context of Claude API deployment
- Specify just-in-time (JIT) access requirements for administrative functions
- Outline privileged session recording requirements
- Describe break-glass procedures for emergency access scenarios
6. ACCESS REVIEW AND RECERTIFICATION
- Define quarterly access review requirements for all privileged roles
- Specify annual recertification requirements for all roles
- Outline the process for identifying and remediating orphaned accounts
- Define escalation procedures for non-responsive recertification participants
7. POLICY VIOLATIONS AND ENFORCEMENT
- List specific violations and corresponding disciplinary actions
- Define the process for investigating suspected unauthorized access
- Specify mandatory reporting requirements for access control breaches
- Outline remediation requirements following policy violations
8. EXCEPTIONS MANAGEMENT
- Define the formal exception request process
- Specify maximum exception duration (not to exceed 90 days without executive approval)
- Require compensating controls documentation for all approved exceptions
- Mandate risk acceptance sign-off from CISO or designated authority
Format this as a formal policy document with numbered sections, a document control table (version, author, reviewer, approval date), and a sign-off page. Include template fields in [BRACKETS] for organization-specific values. The document should be immediately usable as a template for enterprise policy adoption.
Prompt 22: Audit Logging Configuration
Comprehensive audit logging is non-negotiable for regulated industries and security-conscious enterprises. This prompt produces a detailed technical specification for implementing audit logging across all Claude API interactions, ensuring complete traceability for compliance investigations, security incidents, and operational reviews.
You are a senior DevSecOps engineer with deep expertise in enterprise logging architectures and compliance requirements. Create a complete audit logging configuration specification for a production Claude API deployment serving 500+ internal users across multiple business units.
Generate the following deliverables:
1. AUDIT LOG SCHEMA SPECIFICATION
Define the exact JSON schema for every Claude API audit log entry, including:
{
"log_entry": {
"event_id": "UUID v4 - unique identifier for each log entry",
"timestamp": "ISO 8601 format with millisecond precision and UTC timezone",
"session_id": "Persistent identifier linking related API calls within a user session",
"correlation_id": "Cross-system identifier for tracing requests through microservices",
"api_version": "Claude API version used for the request",
"model_id": "Specific Claude model invoked (e.g., claude-3-opus-20240229)",
"user_identity": {
"user_id": "Internal user identifier (never store email directly in log)",
"role": "User's assigned RBAC role at time of request",
"department": "Business unit or department code",
"application_id": "Identifier of the calling application or service"
},
"request_metadata": {
"request_timestamp": "When the request was initiated",
"token_count_input": "Number of input tokens consumed",
"token_count_output": "Number of output tokens generated",
"max_tokens_requested": "The max_tokens parameter value",
"temperature": "Temperature parameter value",
"system_prompt_hash": "SHA-256 hash of system prompt (never log raw system prompt)",
"has_tools": "Boolean indicating tool use",
"tool_names": "Array of tool names if tools were used",
"stream_enabled": "Boolean for streaming response"
},
"response_metadata": {
"response_timestamp": "When the response was completed",
"latency_ms": "Total request-to-response time in milliseconds",
"stop_reason": "Why the model stopped generating",
"finish_type": "Normal completion, max tokens, or safety stop"
},
"content_classification": {
"input_sensitivity_level": "Classification of input content: PUBLIC, INTERNAL, CONFIDENTIAL, RESTRICTED",
"output_sensitivity_level": "Classification of output content",
"pii_detected_input": "Boolean flag from PII scanner",
"pii_types_detected": "Array of PII categories detected (no actual PII values)",
"content_policy_flags": "Array of any content policy triggers"
},
"cost_tracking": {
"input_cost_usd": "Calculated cost for input tokens",
"output_cost_usd": "Calculated cost for output tokens",
"total_cost_usd": "Total request cost",
"cost_center": "Internal cost center code for chargeback",
"project_code": "Optional project code for granular cost allocation"
},
"security_context": {
"ip_address_hash": "Hashed IP address (preserve for security without storing raw IP)",
"user_agent": "Application or SDK identifier",
"tls_version": "TLS protocol version used",
"api_key_id": "Last 8 characters of API key used (never full key)",
"geographic_region": "Request origin region (country/region code only)"
},
"outcome": {
"status": "SUCCESS, FAILURE, PARTIAL, TIMEOUT",
"error_code": "Anthropic error code if applicable",
"error_category": "AUTHENTICATION, RATE_LIMIT, CONTENT_POLICY, NETWORK, SYSTEM",
"retry_count": "Number of retry attempts made"
}
}
}
2. LOG COLLECTION ARCHITECTURE
Provide infrastructure-as-code (Terraform or CloudFormation) configuration for:
- Log aggregation pipeline using either AWS CloudWatch, Azure Monitor, or Google Cloud Logging
- Real-time log streaming to SIEM (Splunk, Elastic, or Microsoft Sentinel)
- Log buffering and retry logic for high-availability deployments
- Dead letter queue configuration for failed log deliveries
3. LOG RETENTION AND LIFECYCLE POLICY
Define retention tiers with specific timeframes:
- Hot storage (immediate access): 90 days
- Warm storage (indexed, searchable): 1 year
- Cold storage (archived, retrievable within 24 hours): 7 years for regulated industries
- Specify immutability requirements (WORM storage) for compliance-sensitive logs
- Define secure deletion procedures for logs containing inadvertently captured sensitive data
4. LOG INTEGRITY AND TAMPER DETECTION
- Specify cryptographic signing requirements for log entries
- Define chain-of-custody requirements for audit evidence
- Describe log hash chaining implementation to detect tampering
- Outline procedures for log integrity verification during audits
5. ALERTING AND ANOMALY DETECTION RULES
Write specific alert rules for:
- Unusual API usage volume: Alert when a single user exceeds 3x their 30-day average within 1 hour
- Off-hours access: Alert on API calls between 10 PM and 6 AM local time for non-automated accounts
- Geographic anomaly: Alert when requests originate from unexpected geographic regions
- Repeated authentication failures: Alert after 5 consecutive authentication failures within 10 minutes
- Sensitive data exposure: Immediate alert when PII detection flags are triggered
- Cost spike detection: Alert when hourly costs exceed $500 or daily costs exceed $5,000
- Model downgrade attempts: Alert when users attempt to access model tiers above their authorization level
6. LOG ACCESS AND QUERY PROCEDURES
- Define who can query audit logs and under what circumstances
- Specify approved query interfaces and prohibited direct database access
- Outline log export procedures for legal holds and regulatory requests
- Describe the process for responding to law enforcement requests for log data
7. SAMPLE IMPLEMENTATION CODE
Provide Python code for a logging middleware class that:
- Intercepts all Claude API calls
- Captures all required fields from the schema above
- Implements async log shipping to prevent latency impact
- Handles failures gracefully without disrupting the primary API call
- Includes unit tests for critical logging functions
Include configuration examples for the three most common enterprise SIEM platforms and provide a compliance mapping table showing which log fields satisfy specific requirements under GDPR Article 30, HIPAA §164.312, and SOC 2 CC6.1.
Prompt 23: Data Classification Rules
Before any data enters a Claude API request, it must be properly classified to ensure appropriate handling, storage, and transmission controls. This prompt generates a complete data classification framework specifically designed for AI-assisted workflows, addressing the unique challenges of unstructured text inputs and AI-generated outputs.
You are a Chief Information Security Officer (CISO) with extensive experience implementing data governance programs at Fortune 500 companies. Develop a comprehensive data classification framework specifically designed for enterprise Claude API deployments where employees interact with the AI using company data.
This framework must address the unique challenge that AI inputs and outputs are unstructured text, making traditional structured data classification approaches insufficient.
PART 1: CLASSIFICATION TAXONOMY
Define four classification tiers with precise, unambiguous criteria:
TIER 1 - PUBLIC
Definition: Information explicitly approved for public distribution
Examples relevant to Claude usage: Marketing copy, public documentation, published research, press releases
Claude API handling requirements: No restrictions; standard logging applies
Retention: Standard corporate retention policy
Labeling requirement: No special labeling required
TIER 2 - INTERNAL USE ONLY
Definition: Non-sensitive business information not intended for external audiences
Examples relevant to Claude usage: Internal procedures, general business processes, non-sensitive project documentation, training materials without confidential content
Claude API handling requirements: Standard API calls permitted; logs retained 1 year; no special transmission controls
Retention: 3 years
Labeling requirement: "INTERNAL" header in system prompts when applicable
TIER 3 - CONFIDENTIAL
Definition: Sensitive business information where unauthorized disclosure could cause significant harm
Examples relevant to Claude usage: Financial projections, M&A discussions, personnel matters, unreleased product roadmaps, vendor contracts, customer lists without PII, proprietary methodologies
Claude API handling requirements:
- Mandatory system prompt classification declaration
- Enhanced logging with content hashing
- Restricted to authorized roles only
- No caching of prompts or responses
- TLS 1.3 minimum for all transmissions
- Geographic restriction to approved data centers
Retention: 5 years with access controls
Labeling requirement: "CONFIDENTIAL" marker required in all prompts and outputs
TIER 4 - RESTRICTED
Definition: Highest sensitivity information where unauthorized disclosure could cause severe legal, financial, or reputational harm
Examples relevant to Claude usage: PII, PHI, payment card data, authentication credentials, trade secrets, attorney-client privileged communications, regulated financial data
Claude API handling requirements:
- PROHIBITED from direct API submission without approved anonymization/tokenization
- Requires dedicated Claude deployment with zero data retention agreement
- Mandatory PII scrubbing before API submission
- Encrypted audit logs with HSM-protected keys
- Dual approval required for any exceptions
- Real-time monitoring and alerting
Retention: Per applicable regulation (GDPR: minimize; HIPAA: 6 years; PCI-DSS: 1 year post-transaction)
Labeling requirement: "RESTRICTED" marker plus specific regulation identifier (e.g., "RESTRICTED-PHI", "RESTRICTED-PII-GDPR")
PART 2: AUTOMATED CLASSIFICATION RULES
Provide regex patterns and keyword lists for automated pre-submission classification scanning:
For each of the following data types, provide:
a) Detection regex pattern (Python-compatible)
b) Confidence scoring approach (exact match vs. contextual)
c) Recommended classification tier
d) Recommended action (block, warn, allow with enhanced logging)
Data types to cover:
1. Social Security Numbers (US) and equivalent national identifiers (UK NI, Canadian SIN, EU national IDs)
2. Payment card numbers (all major networks, including masked formats)
3. Email addresses (distinguish between personal PII and business context)
4. Phone numbers (international formats)
5. Physical addresses (distinguish between business and residential)
6. Date of birth (various formats)
7. Medical record numbers and diagnosis codes (ICD-10)
8. IP addresses (distinguish between server logs and user tracking context)
9. Authentication credentials (passwords, API keys, tokens, certificates)
10. Financial account numbers (bank accounts, investment accounts)
11. Biometric descriptors
12. Legal case numbers and litigation references
13. M&A target company names (requires custom configuration)
14. Salary and compensation data
PART 3: CLASSIFICATION DECISION TREE
Create a detailed decision tree (describe as structured logic, not a visual diagram) that employees and automated systems can follow to determine the appropriate classification for any content they intend to submit to Claude. Include:
- Entry conditions and initial assessment questions
- Escalation paths for ambiguous content
- Default classification when uncertainty exists (always default to higher classification)
- Time limits for classification decisions (not to exceed 2 business days for manual review)
PART 4: EMPLOYEE GUIDANCE DOCUMENT
Write a plain-language guide (maximum 800 words, suitable for all technical levels) explaining:
- Why data classification matters for AI tools specifically
- How to quickly assess what classification applies to their work
- What to do when unsure
- Common mistakes to avoid
- Consequences of misclassification (disciplinary and regulatory)
PART 5: TECHNICAL IMPLEMENTATION SPECIFICATION
Provide a Python class implementation for a pre-submission content classifier that:
- Accepts raw text input intended for Claude API submission
- Applies all detection patterns from Part 2
- Returns a classification recommendation with confidence score
- Provides specific reasons for the classification
- Suggests redaction or anonymization actions where applicable
- Integrates with the audit logging schema from the previous prompt
- Processes text in under 100ms for strings up to 100,000 characters
Section 4: Multi-Agent Orchestration (Prompts 31-35)
Multi-agent orchestration represents the frontier of enterprise AI automation, where individual specialized agents collaborate, delegate, and coordinate to accomplish complex workflows that no single agent could handle alone. The prompts in this section address the architectural and operational challenges of building robust multi-agent systems using OpenAI Codex, covering everything from low-level communication protocols to high-level orchestration monitoring. Mastering these patterns transforms isolated automation scripts into cohesive, intelligent systems capable of handling enterprise-scale complexity with reliability and transparency.
Prompt 31: Designing Agent-to-Agent Communication Protocols
You are an expert in distributed systems and multi-agent AI architectures. Design a comprehensive agent-to-agent communication protocol for an enterprise multi-agent system built on OpenAI Codex.
SYSTEM CONTEXT:
- Multiple specialized Codex agents operating within the same enterprise environment
- Agents include: DataFetchAgent, AnalysisAgent, ReportingAgent, NotificationAgent, ComplianceAgent
- Communication must be asynchronous, auditable, and fault-tolerant
- Infrastructure: message queue (RabbitMQ or AWS SQS), shared Redis cache, PostgreSQL for audit logs
PROTOCOL REQUIREMENTS:
Design a complete message protocol that includes:
1. MESSAGE ENVELOPE STRUCTURE
Define a standardized JSON schema for all inter-agent messages including:
- Unique message ID (UUID v4)
- Sender agent identity and version
- Recipient agent identity (direct or broadcast)
- Message type (REQUEST, RESPONSE, EVENT, HEARTBEAT, ERROR)
- Priority level (CRITICAL, HIGH, NORMAL, LOW)
- Payload with schema version
- Correlation ID for request-response tracking
- Timestamp, TTL, and retry metadata
- Digital signature for message authenticity
2. COMMUNICATION PATTERNS
Implement the following patterns with full code:
a) Request-Reply: Agent A sends a task request and awaits Agent B's response
b) Fire-and-Forget: Agent A delegates a task without waiting for confirmation
c) Publish-Subscribe: Agent A broadcasts an event to all subscribed agents
d) Streaming: Agent A sends a long-running task result in chunks to Agent B
3. SERIALIZATION AND TRANSPORT
- Use Protocol Buffers or MessagePack for high-throughput scenarios
- Implement JSON with compression for human-readable audit trails
- Handle binary payloads (files, images, large datasets) via pre-signed URLs
- Define maximum message size limits and chunking strategies
4. ERROR HANDLING IN COMMUNICATION
- Dead letter queues for undeliverable messages
- Exponential backoff with jitter for retries
- Circuit breaker pattern to prevent cascade failures
- Poison message detection and quarantine
5. SECURITY LAYER
- Mutual TLS between agents
- JWT-based agent identity tokens with short expiry
- Message-level encryption for sensitive payloads
- Rate limiting per agent to prevent resource exhaustion
DELIVERABLES:
- Complete Python implementation of the AgentCommunicationBus class
- Message schema definitions with Pydantic models
- Unit tests covering happy path and failure scenarios
- Performance benchmarks showing message throughput at scale
- Documentation explaining each protocol decision and trade-off
Provide production-ready code with comprehensive error handling, logging at each communication step, and inline comments explaining the reasoning behind architectural choices.
Prompt 32: Workflow Delegation and Handoff Patterns
You are a senior software architect specializing in enterprise workflow automation. Design and implement a sophisticated workflow delegation and handoff system for a multi-agent Codex environment.
BUSINESS SCENARIO:
An enterprise content operations pipeline where a MasterOrchestratorAgent receives high-level business tasks and must intelligently delegate subtasks to specialized agents, track progress, and reassemble results into coherent outputs.
DELEGATION ARCHITECTURE:
1. TASK DECOMPOSITION ENGINE
Build a TaskDecomposer class that:
- Accepts a high-level task description in natural language
- Uses Codex to analyze task complexity and identify required capabilities
- Breaks the task into a directed acyclic graph (DAG) of subtasks
- Assigns capability tags to each subtask (e.g., DATA_RETRIEVAL, NLP_ANALYSIS, CODE_GENERATION)
- Estimates execution time and resource requirements per subtask
- Identifies parallel vs. sequential execution opportunities
Example input: "Analyze last quarter's sales data, identify top-performing products, generate a Python visualization script, and email a summary to the regional managers."
Expected DAG output:
- Node 1: FetchSalesData (DataAgent) → parallel start
- Node 2: FetchManagerContacts (DirectoryAgent) → parallel start
- Node 3: AnalyzeSalesData (AnalysisAgent) → depends on Node 1
- Node 4: GenerateVisualization (CodeAgent) → depends on Node 3
- Node 5: ComposeEmail (CommunicationAgent) → depends on Node 3, Node 2
- Node 6: SendEmail (NotificationAgent) → depends on Node 4, Node 5
2. AGENT CAPABILITY REGISTRY
Implement an AgentRegistry that:
- Maintains a real-time catalog of available agents and their capabilities
- Tracks agent health, current load, and availability status
- Supports capability versioning (e.g., NLP_ANALYSIS_v2 vs. NLP_ANALYSIS_v3)
- Implements intelligent agent selection based on load balancing and specialization score
- Handles agent registration, deregistration, and capability updates dynamically
3. HANDOFF PROTOCOL
Design a formal handoff mechanism that ensures:
- Context preservation: all relevant state, intermediate results, and metadata transfer cleanly
- Handoff contracts: receiving agent acknowledges understanding of task requirements
- Partial result handoff: agent can pass incomplete work to another agent mid-task
- Rollback capability: if handoff fails, originating agent can resume or reassign
4. EXECUTION TRACKING
Build a WorkflowExecutionTracker that:
- Maintains real-time DAG execution state
- Provides percentage completion estimates
- Detects and handles stalled nodes (timeout, agent failure)
- Supports dynamic DAG modification (adding/removing nodes mid-execution)
- Generates execution timeline for post-mortem analysis
5. RESULT AGGREGATION
Implement a ResultAggregator that:
- Collects outputs from all leaf nodes
- Resolves conflicts when multiple agents produce overlapping results
- Applies merge strategies (LAST_WRITE_WINS, CONSENSUS, HUMAN_REVIEW)
- Validates aggregated results against the original task requirements
- Formats final output according to the requester's specified format
CODE REQUIREMENTS:
- Full Python implementation using asyncio for concurrent execution
- Integration with Apache Airflow or Prefect for DAG management (provide both options)
- Comprehensive logging with structured JSON log entries
- Unit tests with mock agents for each delegation pattern
- A working end-to-end example using the sales analysis scenario above
Include detailed comments explaining how each component handles edge cases such as agent unavailability, partial failures, and timeout scenarios.
Prompt 33: Conflict Resolution Between Agents
You are an expert in distributed systems consensus mechanisms and AI agent coordination. Design a comprehensive conflict resolution framework for a multi-agent Codex system where agents may produce contradictory outputs, compete for shared resources, or disagree on task ownership.
CONFLICT TAXONOMY:
First, define and categorize all conflict types this system must handle:
TYPE 1: DATA CONFLICTS
Scenario: Two agents retrieve and transform the same dataset independently, producing different cleaned versions.
- DataAgent_A removes outliers using IQR method → 4,823 records
- DataAgent_B removes outliers using Z-score method → 4,901 records
- AnalysisAgent needs one definitive dataset to proceed
TYPE 2: RESOURCE CONFLICTS
Scenario: Three agents simultaneously attempt to write to the same file, database record, or API endpoint.
- ReportAgent wants to update report_Q4_final.xlsx
- AuditAgent wants to append compliance notes to report_Q4_final.xlsx
- ArchiveAgent wants to move report_Q4_final.xlsx to cold storage
TYPE 3: TASK OWNERSHIP CONFLICTS
Scenario: Due to a routing ambiguity, two agents both begin executing the same task.
- Agent_A and Agent_B both receive "Generate monthly summary" task
- Both begin processing independently, consuming compute resources
- One must be designated the owner; the other must gracefully abort
TYPE 4: PRIORITY CONFLICTS
Scenario: A low-priority background task and a high-priority urgent task compete for the same agent's capacity.
- BackgroundIndexingAgent is mid-execution on a 2-hour indexing job
- UrgentComplianceAgent needs the same compute resources immediately
TYPE 5: SEMANTIC CONFLICTS
Scenario: Agents produce logically contradictory conclusions from the same data.
- RiskAgent concludes: "Portfolio risk is LOW based on volatility analysis"
- ComplianceAgent concludes: "Portfolio risk is HIGH based on regulatory thresholds"
- Both are technically correct within their respective frameworks
RESOLUTION FRAMEWORK:
1. CONFLICT DETECTION ENGINE
Build a ConflictDetector that:
- Monitors all agent outputs and resource access in real-time
- Identifies conflicts within 100ms of occurrence
- Classifies conflict type automatically using pattern matching
- Assigns conflict severity (BLOCKING, DEGRADING, INFORMATIONAL)
- Triggers appropriate resolution strategy based on type and severity
2. RESOLUTION STRATEGIES
Implement the following resolution algorithms:
a) VOTING CONSENSUS (for data and semantic conflicts)
- Collect outputs from N agents on the same question
- Apply weighted voting based on agent confidence scores and historical accuracy
- Require supermajority (>66%) for resolution; escalate ties to human review
- Log dissenting agent outputs for audit purposes
b) RESOURCE LOCKING WITH PRIORITY QUEUING (for resource conflicts)
- Implement optimistic locking with version vectors
- Priority queue ensures high-priority agents acquire locks first
- Deadlock detection using wait-for graph analysis
- Automatic lock release on agent timeout or failure
c) LEADER ELECTION (for task ownership conflicts)
- Implement Bully Algorithm or Raft-based leader election
- Elected leader takes task ownership; followers abort gracefully
- Re-election triggers automatically if leader fails mid-task
- Election results logged with full participant list
d) PREEMPTION WITH CHECKPOINTING (for priority conflicts)
- Low-priority agent saves execution checkpoint before yielding
- High-priority agent executes to completion
- Low-priority agent resumes from checkpoint afterward
- Checkpoint format must be agent-agnostic and serializable
e) MULTI-FRAMEWORK RECONCILIATION (for semantic conflicts)
- Each agent annotates output with its analytical framework and assumptions
- Reconciler identifies the specific divergence point in reasoning
- Generates a unified output that acknowledges multiple valid perspectives
- Flags cases requiring human expert judgment
3. ESCALATION PATHWAYS
Define clear escalation rules:
- Level 1: Automatic resolution (no human involvement, <5 seconds)
- Level 2: Supervisor agent arbitration (specialized conflict-resolution agent)
- Level 3: Human-in-the-loop review via Slack/Teams notification with context summary
- Level 4: Full workflow pause pending executive decision for business-critical conflicts
4. CONFLICT AUDIT TRAIL
Every conflict and resolution must be logged with:
- Conflict ID, type, severity, and timestamp
- All agents involved and their respective positions
- Resolution strategy applied and outcome
- Time-to-resolution metrics
- Whether resolution was correct (feedback loop from downstream results)
DELIVERABLES:
- Complete Python implementation of the ConflictResolutionFramework class
- Simulation script that artificially generates each conflict type for testing
- Resolution strategy performance benchmarks (resolution speed, accuracy rate)
- Decision tree diagram (as ASCII art or Mermaid syntax) showing resolution flow
- Integration guide for connecting the framework to an existing multi-agent system
Prompt 34: Shared State Management Across Agents
You are a distributed systems engineer with deep expertise in state management and consistency models. Design a production-grade shared state management system for a multi-agent Codex environment where multiple agents must read, write, and coordinate around shared data without introducing race conditions, stale reads, or data corruption.
SYSTEM REQUIREMENTS:
- Up to 50 concurrent agents accessing shared state simultaneously
- State includes: task queues, intermediate results, configuration, agent metadata, workflow status
- Consistency requirements vary by state type (some need strong consistency, others eventual)
- System must remain available during partial network partitions (CAP theorem trade-offs)
- Complete audit history of all state mutations required for compliance
SHARED STATE ARCHITECTURE:
1. STATE CLASSIFICATION SYSTEM
Define a state taxonomy with different consistency requirements:
TIER 1: CRITICAL STATE (Strong Consistency Required)
- Active task assignments and ownership records
- Financial transaction results and audit logs
- Compliance check outcomes and approval statuses
- Implementation: Synchronous writes to primary with read-your-writes guarantee
- Technology: PostgreSQL with serializable isolation or etcd
TIER 2: OPERATIONAL STATE (Sequential Consistency)
- Workflow execution progress and DAG node status
- Agent health metrics and availability flags
- Resource utilization and capacity data
- Implementation: Leader-follower replication with synchronous follower acknowledgment
- Technology: Redis Sentinel or Apache ZooKeeper
TIER 3: COLLABORATIVE STATE (Causal Consistency)
- Intermediate analysis results shared between agents
- Shared document drafts being iteratively improved by multiple agents
- Aggregated metrics and reporting data
- Implementation: Vector clocks for causal ordering; CRDTs for conflict-free merges
- Technology: Redis with Lua scripts or Riak
TIER 4: EPHEMERAL STATE (Eventual Consistency Acceptable)
- Agent activity logs and debug traces
- Performance telemetry and usage statistics
- Cache entries for frequently accessed reference data
- Implementation: Gossip protocol propagation; last-write-wins acceptable
- Technology: Redis Pub/Sub or Apache Kafka
2. STATE ACCESS LAYER
Build a UnifiedStateClient that abstracts all tiers:
class UnifiedStateClient:
- get(key, consistency_level) → returns value with version vector
- set(key, value, consistency_level, ttl=None) → returns success with new version
- compare_and_swap(key, expected_version, new_value) → atomic update
- watch(key_pattern, callback) → real-time change notifications
- transaction(operations_list) → atomic multi-key operations
- get_history(key, from_timestamp, to_timestamp) → full mutation history
Requirements:
- Automatic tier routing based on key namespace prefix
- Transparent retry logic with exponential backoff
- Connection pooling and circuit breakers per tier
- Metrics emission for all operations (latency, error rate, cache hit ratio)
3. CONFLICT-FREE REPLICATED DATA TYPES (CRDTs)
Implement the following CRDTs for collaborative agent state:
a) G-Counter: Track total tasks completed across all agents (increment only)
b) PN-Counter: Track net queue depth (agents add and remove tasks)
c) OR-Set: Maintain set of active agent IDs (add/remove with unique tags)
d) LWW-Register: Store latest configuration value with timestamp arbitration
e) RGA (Replicated Growable Array): Collaborative document editing by multiple agents
For each CRDT, provide:
- Full Python implementation
- Merge function that guarantees commutativity, associativity, and idempotency
- Serialization/deserialization for network transport
- Unit tests proving correctness under concurrent operations
4. DISTRIBUTED TRANSACTION SUPPORT
Implement Two-Phase Commit (2PC) for operations spanning multiple state tiers:
- Phase 1 (Prepare): All participating state stores lock resources and validate
- Phase 2 (Commit/Abort): Coordinator commits if all prepared; aborts on any failure
- Recovery protocol for coordinator failures mid-transaction
- Timeout handling to prevent indefinite lock holding
Also implement Saga pattern as an alternative for long-running transactions:
- Forward transactions with compensating rollback actions
- Choreography-based saga for simple linear workflows
- Orchestration-based saga for complex branching workflows
5. STATE SYNCHRONIZATION FOR AGENT ONBOARDING
When a new agent joins the system mid-workflow:
- State snapshot generation: consistent point-in-