Codex API Integration Masterclass: 30 Production-Ready Prompts for Building Custom Endpoints, Webhook Handlers, Authentication Flows, and Rate-Limited Service Architectures

Codex API Integration Masterclass: 30 Production-Ready Prompts for Building Custom Endpoints, Webhook Handlers, Authentication Flows, and Rate-Limited Service Architectures
This masterclass is a dense, practical guide of 30 advanced prompts tailored for software engineers building production integrations with Codex. Each prompt is structured with a precise “Prompt”, a technical “Why this works” justification, “Expected inputs” for real implementation, and “Customization” notes for adapting to different architectures or privacy constraints. Where applicable, you will find code blocks, implementation patterns, and tables that compare alternatives. This is intentionally pragmatic: treat each prompt as a ready-to-run spec for safe, testable, and observable integrations.
Before diving into the prompts, a few guiding engineering principles for Codex integrations:
- Design for observability: traces, metrics, and structured logs around every Codex call.
- Isolate AI workloads: run model calls in separate worker processes or service tiers to control latency and QoS.
- Fail fast and degrade gracefully: provide cached fallbacks and user-friendly errors when model calls fail.
- Secure data at rest and in transit: encryptPD and redact PII before sending prompts.
Two internal resources that may complement this guide are
For a deeper exploration of related strategies and implementation patterns, our comprehensive guide on Codex Sites Masterclass: 30 Production-Ready Prompts for Building Interactive Dashboards, Client Portals, Data Visualizations, and Automated Reporting Apps provides detailed frameworks, step-by-step workflows, and production-ready templates that complement the approaches discussed in this section.
and
For a deeper exploration of related strategies and implementation patterns, our comprehensive guide on 50 GPT-5.5 Prompts for Operations Managers: Supply Chain Optimization, Process Automation, Resource Allocation, and Performance Dashboards provides detailed frameworks, step-by-step workflows, and production-ready templates that complement the approaches discussed in this section.
. Use those for cross-functional workflows and deployment templates.
Section A — Custom Endpoints (8 prompts)
Custom endpoints adapt Codex to domain-specific APIs, add preprocessing/postprocessing, and encapsulate versioning and schema validation. The prompts below are designed for engineers building REST or RPC endpoints that wrap Codex calls—typically as microservices behind API gateways.
Prompt A1 — “Schema-enforced Summarization Endpoint”
Prompt: Create an endpoint that accepts long-form domain documents and returns a JSON schema-compliant summary (title, 100–200 word abstract, key facts list, and normalized tags). Validate inputs and outputs against JSON Schema and include a deterministic hashing strategy to deduplicate repeated requests.
Why this works: Constraining Codex with an explicit schema reduces hallucination risk and improves downstream automation. Schema validation on both input and output ensures safe contract changes; the hashing enables cache hits and idempotent processing.
Expected inputs:
- document_id: string
- text: string (UTF-8)
- language: optional ISO-639 code
- schema_version: semantic version string
- max_tokens: optional integer to bound the model output
Customization: Swap JSON Schema for protobufs if you require binary efficiency. You can also add a “confidence_threshold” to decide whether to store the summary in primary DB or mark for human review.
// Example Node.js/Express skeleton (production should add rate limiting, auth, and retries)
const express = require('express');
const Ajv = require('ajv');
const ajv = new Ajv();
const summarySchema = { /* JSON Schema for response */ };
app.post('/v1/summarize', async (req, res) => {
const { document_id, text, language, schema_version } = req.body;
// Basic validation
if (!text || typeof text !== 'string') return res.status(400).send({ error: 'text required' });
// Compute hash for dedup
const hash = computeHash(text, schema_version);
const cached = await cache.get(hash);
if (cached) return res.json(cached);
// Call Codex (pseudo)
const prompt = `Summarize to schema_v${schema_version}: ${text}`;
const codexResponse = await codex.generate({ prompt });
// Validate output
const valid = ajv.validate(summarySchema, codexResponse);
if (!valid) return res.status(500).send({ error: 'model output failed validation', details: ajv.errors });
await cache.set(hash, codexResponse);
res.json(codexResponse);
});
Prompt A2 — “Transactional Transformation Endpoint (Idempotent)”
Prompt: Build a transactional endpoint that transforms a payload using Codex, stores the transformed result in a primary relational DB, and guarantees idempotency using a client-supplied operation_id and server-side dedup table. Provide rollback semantics if the DB persists fail after the model call.
Why this works: Idempotent operations are crucial for safe retries. Having Codex transform data before persistence allows controlled, auditable mutations. Implementing a write-ahead dedup table (operation_id → status) avoids duplicate side effects.
Expected inputs:
- operation_id: UUID (client-generated)
- payload: object
- transform_spec: optional instruction set (e.g., “normalize_dates”)
- user_id: authentication principal
Customization: Use distributed transactions (e.g., two-phase commit) only if you must update multiple databases; otherwise design compensating transactions. If supporting async processing, return 202 and provide a status endpoint for the operation_id.
// Pseudo-logic for transactional idempotent endpoint
BEGIN TRANSACTION
if (exists_in_dedup(operation_id)) {
return SELECT persisted_result FROM results WHERE operation_id = operation_id;
}
mark_dedup(operation_id, 'in_progress');
response = callCodexTransform(payload, transform_spec);
try {
insert results (operation_id, response, user_id);
update dedup set status='done' where operation_id=operation_id;
COMMIT;
} catch (err) {
update dedup set status='failed' where operation_id=operation_id;
ROLLBACK;
// Optionally: publish compensating event
throw err;
}
Prompt A3 — “Adaptive Prompt Router Endpoint”
Prompt: Create an endpoint that routes incoming requests to specialized Codex prompt templates based on detected domain and task type. Use a first-stage lightweight classifier followed by template selection, with fallback logic to a general-purpose template.
Why this works: Routing to specialized templates improves semantic accuracy and reduces token usage. A lightweight classifier (rule-based or tiny model) provides low-latency routing, while fallback ensures coverage.
Expected inputs:
- input_text: string
- task_hint: optional explicit user hint (e.g., “summarize”, “rewrite”)
- priority: optional (low/normal/high)
Customization: Replace the classifier with an embedding-based similarity lookup when you have many templates. Use context-aware routing by including user history in the decision logic.
// Router pseudocode
if (task_hint) selectedTemplate = templates[task_hint];
else {
classification = lightweightClassifier.predict(input_text); // rule or tiny model
selectedTemplate = templates[classification.task] || templates['general'];
}
codexPrompt = renderTemplate(selectedTemplate, { input_text });
result = codex.generate({ prompt: codexPrompt });
Prompt A4 — “Multi-Model Orchestration Endpoint”
Prompt: Design an endpoint that orchestrates multiple Codex model calls—one for semantic extraction, one for rendering, and one for verification—composing results into a final response. Include retry policies and cost-aware model selection.
Why this works: Multi-stage orchestration lets you split responsibilities: cheaper models handle extraction, expensive models refine language. Verification steps help catch hallucinations and enforce constraints.
Expected inputs:
- resource_text: string
- orchestration_plan: optional (e.g., “extract→render→verify”)
- budget_limit: optional numeric cap
Customization: Add an asynchronous orchestration workflow (e.g., using durable functions or a task queue) for long-running multi-step work. Use a policy engine to choose models based on remaining budget and time-to-live (TTL).
// Pseudocode orchestration
extraction = callModel('codex-small', extractPrompt(resource_text));
rendering = callModel('codex-large', renderPrompt(extraction));
verification = callModel('codex-medium', verifyPrompt(rendering, extraction));
if (verification.passed) return rendering;
else if (verification.suggested_edits) apply edits and re-run render;
Prompt A5 — “Schema-mapped CRUD Endpoint (OpenAPI + Codex Auto-mapper)”
Prompt: Implement a CRUD endpoint that maps external JSON fields to internal DB schema automatically using Codex for field mapping and type coercion. Output an OpenAPI-compatible response and produce the mapping as a structured artifact to store for future requests.
Why this works: Codex excels at transform tasks like field mapping and type normalization when given examples and constraints. Producing a stored mapping artifact makes subsequent requests deterministic and reduces model usage.
Expected inputs:
- external_payload: object
- source_schema_hint: optional
- target_schema_version: required
Customization: Add a “review_required” flag to route mappings through a human-in-the-loop approval system for high-risk domains (finance, healthcare). Persist mappings in a versioned schema registry.
Prompt A6 — “Batch Enrichment Endpoint with Chunking and Backpressure”
Prompt: Craft an endpoint that performs batch enrichment: accept N items, chunk them into smaller payloads for Codex, support backpressure, and report partial success/failure details in a structured manner.
Why this works: Chunking controls token limits and latency; backpressure avoids overwhelming downstream systems. Explicit partial success reporting allows clients to handle retries per item rather than re-sending everything.
Expected inputs:
- items: array of objects
- chunk_size: optional int (default 10)
- response_mode: choice of “aggregate” or “stream”
Customization: Support streaming responses for low-latency user experiences using Server-Sent Events (SSE) or HTTP/2 streams. Use a work-queue for long-running enrichments and expose status endpoints.
// Batch chunking
chunks = split(items, chunk_size);
for (chunk of chunks) {
await rateLimiter.acquire();
codexResp = await codex.generate({ prompt: buildEnrichmentPrompt(chunk) });
storeResults(codexResp);
}
return aggregateStatus();
Prompt A7 — “Controlled Vocabulary Mapping Endpoint”
Prompt: Build an endpoint that maps free-text inputs to a controlled vocabulary with confidence scores. Include a mechanism to expand the vocabulary via an admin-approved pipeline and provide an audit trail of mapping decisions.
Why this works: Controlled vocabularies enable standardized downstream analytics. Confidence scores and audit logs allow human reviewers to tune mappings and address ambiguous entries.
Expected inputs:
- text: string
- vocabulary_id: string
- threshold: float (0.0–1.0)
Customization: If your domain requires strict determinism, perform exact dictionary matching first, and use Codex only for fallback fuzzy mapping. Provide an “explain” payload that includes the prompt and model rationalization.
Prompt A8 — “Versioned Endpoint with Canary Releases”
Prompt: Implement a versioned endpoint pattern that supports canary releases. Route a configurable percentage of traffic to a new Codex prompt template or model version, collect A/B metrics (latency, accuracy, cost), and facilitate safe rollbacks.
Why this works: Canarying reduces deployment risk for changes in prompt or model version. Capturing A/B metrics enables data-driven rollouts and automated rollback triggers based on error budgets.
Expected inputs:
- request_payload
- traffic_allocation: percentage
- metrics_tags: optional
Customization: Integrate with feature flagging systems (e.g., LaunchDarkly) or service mesh routing to centralize traffic routing. Use adaptive canary allocation that increases the share when metrics meet SLOs.
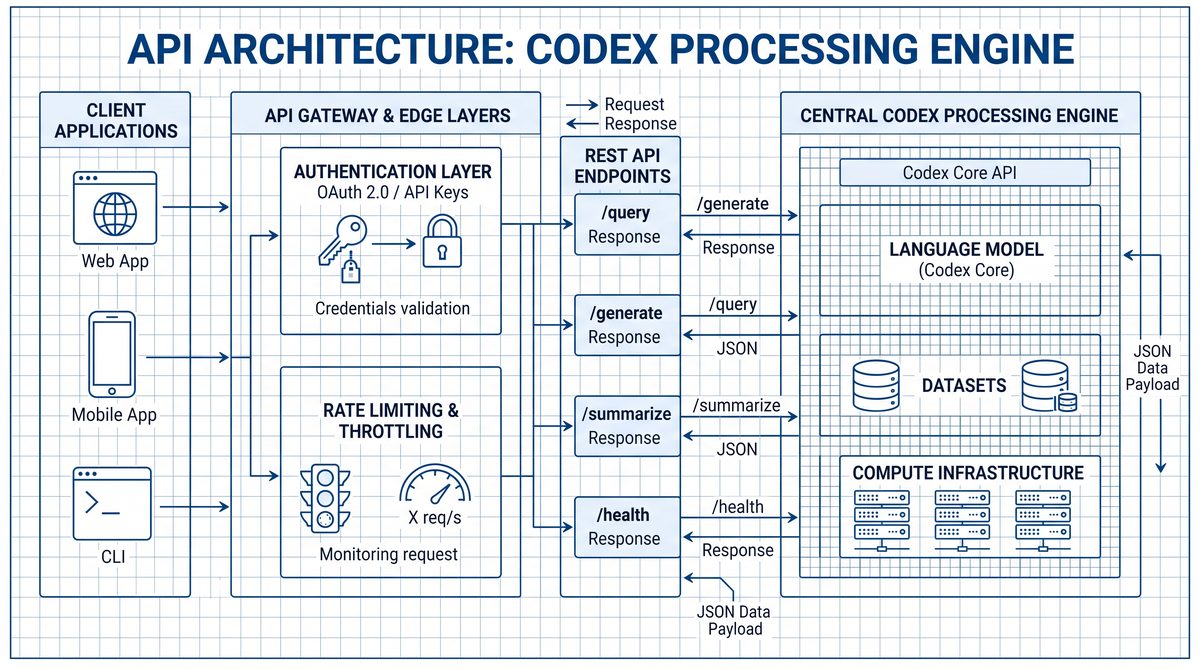
Section B — Webhook Handlers (8 prompts)
Webhook handlers receive asynchronous events and often trigger downstream Codex calls for enrichment or classification. Key concerns include signature verification, idempotency, retry semantics, and secure processing of webhook payloads.
Prompt B1 — “Secure Webhook Receiver with Signature Verification”
Prompt: Create a webhook receiver that verifies incoming requests using HMAC signatures, timestamps to mitigate replay attacks, and explicit error codes for mismatches. Include a fallback for legacy clients and a mechanism to rotate secrets without losing delivery.
Why this works: HMAC + timestamp prevents forgery and replay. Secret rotation without delivery loss requires a dual-key verification phase where signatures are checked against both old and new keys.
Expected inputs (HTTP headers/body):
- X-Signature: HMAC hex signature
- X-Timestamp: epoch seconds
- body: JSON payload
Customization: For stronger guarantees, use asymmetric signatures (RSA/ECDSA) so providers can sign with private keys; your service validates with a stored public key. Also consider mutual TLS (mTLS) in enterprise environments.
// Signature verify
const computed = hmac_sha256(secret, timestamp + '.' + body);
if (!constantTimeEquals(computed, receivedSignature)) {
return res.status(401).send({ error: 'invalid signature' });
}
if (Math.abs(now - timestamp) > 300) {
return res.status(400).send({ error: 'timestamp out of range' });
}
Prompt B2 — “Idempotent Webhook Handler with Event Dedup Table”
Prompt: Build a webhook handler that guarantees idempotency by checking an event_id against a deduplication store (e.g., Redis or relational DB). The handler must support transactional processing of events that trigger Codex calls and persist both input and output for auditability.
Why this works: Delivery systems may retry webhooks for network failures. Deduplication ensures that repeated deliveries do not cause duplicate side effects. Persisting both inputs and outputs aids debugging and lineage tracing.
Expected inputs:
- event_id: string (from webhook)
- event_type
- payload
Customization: Use distributed locks to prevent parallel processors acting on the same event_id. If strict fast-path dedup is necessary, store event signatures in a bloom filter for quick rejects, but maintain canonical DB for full verification.
Prompt B3 — “Webhook-to-Task Queue Adapter (Backpressure Friendly)”
Prompt: Implement a webhook handler that immediately enqueues incoming events to a durable work queue and returns HTTP 202 to the sender. Include metadata for tracing and a lightweight synchronous path for low-latency needs (e.g., schema validation responses).
Why this works: Enqueuing decouples webhook processing from event reception, preventing the sender from being blocked by long Codex calls and reducing the risk of timeouts. Durable queues support rate-limited workers.
Expected inputs:
- webhook_body
- headers
- optional ack_mode: “sync” or “async”
Customization: For high-throughput scenarios, use partitioned queues keyed by resource_id to maintain ordering. Provide a diagnostic endpoint for queue depth and worker health.
Prompt B4 — “Webhook Processor with Contextual Enrichment”
Prompt: Design a webhook processor that enriches the event payload using external data (DB lookups, caches) before calling Codex to classify or synthesize a response. Include circuit breakers to prevent cascading failures when external services are down.
Why this works: Enrichment adds domain context that significantly improves model accuracy. Circuit breakers protect availability and allow fallback behaviors when dependencies are unavailable.
Expected inputs:
- event
- enrichment_keys: list of DB keys to fetch
- fallback_policy
Customization: Cache frequently-used enrichment payloads with TTLs and use stale-while-revalidate strategies. For critical events, require a human-in-the-loop if enrichment fails.
Prompt B5 — “Secure File Attachment Webhook Handler”
Prompt: Implement a handler to receive webhook events that include URLs to file attachments. The flow must securely download, scan (malware/PDF anomalies), store in blob storage, and then pass a sanitized prompt to Codex for analysis, ensuring PII redaction where necessary.
Why this works: File attachments increase attack surface. Scanning and sanitization before model ingestion mitigate risks and comply with data governance rules. Storing sanitized copies supports audits.
Expected inputs:
- attachment_url
- attachment_type: mime
- event_metadata
Customization: For performance, parallelize downloads with size limits, and reject oversized files. Integrate with DLP tools for PII detection and redaction rules configurable by tenant.
Prompt B6 — “Event-Sourced Webhook Consumer (Immutable Log + Replay)”
Prompt: Build a webhook consumer that writes raw events into an immutable event log (e.g., Kafka, Pulsar) for replayability. The consumer should support replaying historical events into updated Codex pipelines and track replay progress.
Why this works: Immutable logs allow safe reprocessing when prompts evolve or when you need to backfill features. Replay tracking prevents double processing and supports versioned replays.
Expected inputs:
- raw_event
- topic
- partition_key (optional)
Customization: For multitenant workloads, separate topics per tenant, or use tenant-aware keys. Implement log compaction policies to remove redundant events while preserving necessary audit information.
Prompt B7 — “Webhook Handler with Adaptive Retry and Exponential Backoff”
Prompt: Implement a robust retry mechanism for transient failures invoking Codex from a webhook: use exponential backoff with jitter, a maximum retry cap, and circuit breaker integration. Include retry metadata in logs for observability.
Why this works: Exponential backoff and jitter reduce thundering herd problems; circuit breakers avoid retry storms when the downstream is degraded. Logging retry attempts aids root cause analysis.
Expected inputs:
- event_payload
- retry_policy_config
Customization: Make retry policies tenant-configurable, e.g., aggressive for premium customers. For critical real-time events, escalate to an alternative pathway if retries fail.
Prompt B8 — “Webhook Contract Validator with Versioned Schemas”
Prompt: Author a webhook contract validator service that enforces versioned schemas, auto-notifies senders of mismatches, and provides a compatibility matrix for schema evolution. Integrate with a developer portal to publish schema changes.
Why this works: Schema enforcement reduces integration friction and prevents unknown payload shapes causing runtime errors. A published compatibility matrix helps requesters migrate safely.
Expected inputs:
- webhook_body
- schema_version_header
Customization: Implement a “compatibility mode” where unknown optional fields are ignored but logged; enforce strict mode for breaking changes. Auto-generate example webhook payloads and test harnesses for integrators.
Section C — Authentication Flows (OAuth2) (7 prompts)
Authentication flows secure access to Codex-powered endpoints. OAuth2 remains the de facto standard for delegated authorization in web and mobile contexts. These prompts target secure implementation of standard OAuth2 patterns and common extensions like PKCE, device flow, and token introspection.
Prompt C1 — “OAuth2 Authorization Code Flow with PKCE and Token Storage”
Prompt: Implement a secure authorization code flow with Proof Key for Code Exchange (PKCE) for single-page applications (SPAs) and mobile apps. Exchange the code for access and refresh tokens, store refresh tokens in an encrypted server-side store, and issue short-lived session cookies for the SPA.
Why this works: PKCE prevents authorization code injection when clients cannot safely store client secrets. Storing refresh tokens server-side reduces exposure to token theft. Short-lived cookies mitigate the risk of session hijacking.
Expected inputs:
- code: authorization code
- code_verifier: from PKCE
- redirect_uri
Customization: For mobile native apps, use OS-native secure storage for session tokens. Add refresh token rotation and revoke old refresh tokens on each refresh request.
// Exchange flow pseudocode
POST /oauth/token
grant_type=authorization_code
code=...
redirect_uri=...
code_verifier=...
// On server, verify and store refresh token in encrypted DB
Prompt C2 — “OAuth2 Client Credentials Flow with Fine-Grained Scopes”
Prompt: Build a client credentials grant implementation for server-to-server integrations. Define and enforce fine-grained scopes (e.g., codex:generate:text, codex:read:history). Add telemetry so each token use is logged with scope, client_id, and resource path.
Why this works: Fine-grained scopes enable least-privilege authorization and reduce blast radius if a token is leaked. Telemetry facilitates audits and anomaly detection.
Expected inputs:
- client_id, client_secret
- requested_scopes
Customization: Support scope escalation requests that require human approval. Implement token introspection endpoints for resource servers to verify token validity and scopes.
Prompt C3 — “Device Authorization Flow for Headless or Limited-Input Devices”
Prompt: Implement the OAuth2 device flow to authorize smart devices or CLI tools. Include a self-service polling endpoint and an admin UI to approve or revoke device authorizations. Add rate limiting to prevent excessive polling.
Why this works: Device flow allows out-of-band authorization where the client cannot perform browser-based redirects securely. Polling must be rate limited to avoid DDOS-like behavior.
Expected inputs:
- device_code
- user_code
- client_id
Customization: For frictionless UX, allow QR code deep links to accelerate approval and provide device naming for easier admin audits.
Prompt C4 — “Refresh Token Rotation and Detection of Replay”
Prompt: Implement refresh token rotation where each refresh request invalidates the previous refresh token and issues a new one. Detect and respond to replay by revoking all tokens for the associated user/client and alerting security teams.
Why this works: Rotation reduces the window of usefulness for stolen refresh tokens. Replay detection indicates token leakage and requires immediate remediation to block further compromise.
Expected inputs:
- refresh_token
- client_id
Customization: Tie refresh tokens to a bound device fingerprint or client certificate. On detection of replay, provide automated rollback of sessions and force re-authentication across devices.
// Rotation logic sketch
verify(refresh_token);
if (refresh_token.used) {
// possible replay
revokeAllTokensForUser(user_id);
alertSecurity();
}
issueNewRefreshToken();
markOldAsUsed();
Prompt C5 — “Token Introspection and Audience Restriction”
Prompt: Provide a token introspection endpoint that resource servers can call to verify token validity, scopes, expiry, and audience (aud) claim. Reject tokens where the audience does not match the resource server’s identifier.
Why this works: Audience restriction prevents token reuse across services and is a critical defense when multiple resource types are present. Introspection centralizes policy enforcement.
Expected inputs:
- token_to_introspect
- resource_server_id
Customization: Expose additional attributes like tenant_id and token_issue_origin for richer access control decisions. Cache introspection responses with TTL to reduce latency.
Prompt C6 — “Short-Lived Access Tokens with Fine-Grained Delegation”
Prompt: Design an access token issuance strategy that favors very short-lived access tokens (e.g., 1–5 minutes) and delegates session continuity to securely stored refresh tokens or ephemeral session tickets. Make tokens audience-limited and scope-trimmed.
Why this works: Short-lived tokens reduce risk from token leakage and simplify scaling of authentication systems. Delegation via refresh reduces friction for long-lived sessions without long-lived attack vectors.
Expected inputs:
- initial_auth (e.g., code exchange)
- requested_lifespan
Customization: Consider rotating signing keys frequently and enabling continuous key rollover to further harden the environment. For mobile, combine with native secure storage.
Prompt C7 — “Delegated OAuth2 for Third-Party Extensions with Consent UI”
Prompt: Create an OAuth2-based extension model where third-party apps request delegated access to user resources. Provide a consent UI that explains scopes and optional selective granting, and implement revocation via a developer dashboard.
Why this works: User trust requires transparent consent and easy revocation. Providing selective grants reduces over-privileged third-party apps.
Expected inputs:
- client_id
- requested_scopes
- redirect_uri
Customization: Provide pre-approved scopes for verified apps, and introduce an approval workflow for enterprise tenants requiring admin consent. Integrate with your audit logs for compliance reporting.
Access 40,000+ AI Prompts for ChatGPT, Claude & Codex — Free!
Subscribe to get instant access to our complete Notion Prompt Library — the largest curated collection of prompts for ChatGPT, Claude, OpenAI Codex, and other leading AI models. Optimized for real-world workflows across coding, research, content creation, and business.
| Flow | Best Use Case | Security Trade-offs |
|---|---|---|
| Authorization Code + PKCE | SPAs, mobile apps | High security, no client secret needed |
| Client Credentials | Server-to-server | Client secret required; best for trusted servers |
| Device Flow | Devices without browsers | Out-of-band authorization; polling vulnerability if unthrottled |
| Implicit (deprecated) | Legacy SPAs | High token exposure risk; avoid |
Section D — Rate-Limited Service Architectures (7 prompts)
Rate limiting and service architecture design ensure predictable costs, fair use, and reliability when integrating Codex. These prompts emphasize best practices for rate limiting, token bucket algorithms, priority queues, circuit breakers, and observability for throttled systems.
Prompt D1 — “Centralized Rate Limiter with Token Bucket and Multi-Tenant Quotas”
Prompt: Implement a centralized rate limiter service employing token buckets per tenant and global token bucket for the Codex API calls. Provide dynamic quota scaling, fair sharing, and per-tenant burst capacity. Emit metrics for token consumption and throttling events.
Why this works: Centralized control ensures global visibility and consistent enforcement across services. Token buckets provide a smooth rate-limiting mechanism allowing bursts while preserving long-term throughput constraints.
Expected inputs:
- tenant_id
- requested_tokens (e.g., tokens proportional to prompt tokens)
- priority
Customization: For high-scale, partition the rate limiter by tenant hash and use a distributed in-memory store (e.g., Redis with Lua scripts) for atomic updates. Offer emergency override for critical tenants.
// Token bucket pseudocode (atomic in Redis)
current = GET(bucket_key)
if (current < requested_tokens) return REJECT
DECRBY(bucket_key, requested_tokens)
proceed
Prompt D2 — “Client-side Backpressure Signals and Throttling Advice”
Prompt: Design a protocol where the server returns structured backpressure signals (Retry-After, estimated queue position, recommended delay) and the client implements an exponential backoff with jitter. Include a machine-readable error code namespace for automated client policies.
Why this works: Cooperative backpressure avoids wasteful retries and improves client resiliency. Structured advisory data allows clients to adapt their behavior programmatically.
Expected inputs/responses:
- HTTP 429 with headers: Retry-After, X-Queue-Position, X-Estimated-Wait
- Body: { error_code, message, recommended_delay_ms }
Customization: Offer a “bulk” endpoint for queued batch work with SLA tiers, where clients can choose slower-but-cheaper processing. Provide SDK helper functions for standardized retry strategies.
Prompt D3 — “Priority Queue with SLA Tiers and Preemption”
Prompt: Implement a priority queuing system that exposes heterogeneous SLAs (e.g., real-time, standard, best-effort). The queue should support preemption of lower-priority jobs when high-priority jobs arrive and maintain fairness over time.
Why this works: Priority queues let you support premium customers with tighter SLOs while maintaining cost-efficient processing for background workloads. Preemption ensures critical tasks are addressed promptly.
Expected inputs:
- job_payload
- priority_level
- max_wait_time
Customization: Use aging policies to prevent starvation of best-effort jobs. For multi-tenant fairness, combine per-tenant quotas with priority classes.
Prompt D4 — “Adaptive Rate Limiting with Cost-Awareness”
Prompt: Create an adaptive rate limiter that adjusts token consumption rates based on model cost-per-token, current cloud spend, and business rules. During high-cost periods, reduce per-tenant budgets and notify owners. Provide “cost tokens” that map to monetary cost instead of request count.
Why this works: Model usage drives cloud spend—adaptive control maintains budgets while preventing unexpected bills. Mapping to cost units aligns technical throttling with finance objectives.
Expected inputs:
- request_cost_estimate
- tenant_budget_remaining
- current_spend_rate
Customization: Incorporate predictive spend models based on historical usage to proactively throttle or raise alerts. Implement pre-commit costing for large asynchronous jobs.
Prompt D5 — “Local and Global Rate Limiting Hybrid”
Prompt: Implement a hybrid strategy combining local (client-side or edge) and global (centralized) rate limiting. Allow clients to enforce local soft limits for responsiveness while central authority enforces hard global quotas.
Why this works: Hybrid systems reduce central coordination overhead, lower latency on local checks, and still provide consistent global constraints. This reduces throttle events perceived by clients.
Expected inputs:
- client_rate_config
- global_quota_state
Customization: Provide SDKs that implement client-side token buckets and fallback to central checks when local buckets are drained or uncertain. Use edge caches to serve short-lived global quota snapshots.
Prompt D6 — “Circuit Breaker for Downstream Model Availability”
Prompt: Build a circuit breaker component around Codex calls that trips when error thresholds or latency SLOs are breached. When open, fall back to cached results or a lower-tier model. Include half-open probing logic and a cooldown window.
Why this works: Circuit breakers prevent cascading failures and protect the service from expensive retries against a degraded model. Fallbacks preserve user experience in read-only or degraded modes.
Expected inputs/config:
- failure_threshold
- timeout_window_ms
- fallback_strategy
Customization: Add adaptive thresholds based on traffic patterns—higher thresholds during low-load windows. Maintain telemetry of circuit state transitions for postmortems.
Prompt D7 — “Observability-First Throttling: Metrics, Tracing, and Alerts”
Prompt: Implement an observability-first throttling system that emits detailed metrics (tokens_consumed, requests_throttled, queue_length), traces the lifecycle of queued jobs, and triggers alert policies when throttling exceeds thresholds. Provide dashboards for business and platform engineers.
Why this works: Without comprehensive telemetry, throttling policies become opaque and cause churn. Observability enables SLOs, capacity planning, and effective incident response.
Expected inputs/outputs:
- metrics: counters and histograms
- traces: start/end/timestamps with span tags
- alerts: configured on key signals
Customization: Provide multi-dimensional metrics by tenant, region, and model. Offer automated runbooks that are triggered by specific alert types.
| Strategy | Latency Impact | Implementation Complexity | Best For |
|---|---|---|---|
| Central Token Bucket | Moderate | Medium | Global quota enforcement |
| Local Soft Limits | Low | Low | Fast client-side control |
| Priority Queues | Variable | High | SLA differentiation |
| Adaptive Cost-Aware | Low to Moderate | High | Budget-sensitive workloads |
Appendix — Cross-Cutting Concerns and Patterns
Below are implementation details, examples, and patterns that repeatedly appear across the prompts. These are practical blueprints that you can copy-paste and adapt to reduce development time.
Telemetry and Observability Pattern
Standardize your telemetry payload for all Codex interactions. At minimum, capture the following fields:
- request_id (UUID)
- tenant_id
- model (e.g., codex-4)
- prompt_token_count
- response_token_count
- latency_ms
- outcome (success/partial/failure)
- error_code
Emit both high-cardinality logs for troubleshooting and aggregated metrics for dashboards. Use distributed tracing to connect Codex calls with upstream user actions.
Redaction and Privacy-first Prompting
Before sending user content to Codex, run deterministic PII redaction and hashing pipeline. Example steps:
- Identify PII via deterministic regex and ML-based detectors.
- Replace with tokens: <EMAIL_HASH:sha256>, <PHONE_HASH>.
- Store mapping in secure vault if reversible mapping is required (rare).
- Include a consent flag in the prompt metadata and the generated outputs.
Design prompts to ask for “safe_mode” output if PII removal reduces context—allowing human verification of sensitive transformations.
Prompt Engineering Best Practices
Use the following tactical prompt engineering strategies across the endpoints:
- System-level instructions at the top of the prompt that define style and output format (e.g., “Return JSON only”).
- Provide explicit examples (few-shot) for mapping tasks to reduce ambiguity.
- Constrain length and define explicit tokens to mark sections (e.g., START/END markers).
- Use a verification step where the model outputs both the content and a checksum/sign-off that can be validated by a verifier model.
Example: Verification Step Pattern
// High-level pattern for verify-and-apply
primary = callCodex(primaryPrompt);
verifyPrompt = `Verify the following output is consistent with constraints: ${primary.output}`;
verification = callCodex(verifyPrompt);
if (!verification.passed) {
// escalate to human or retry with modified prompt
}
apply(primary.output);
Security Checklist for Production Codex Integrations
- Use secure model credentials; rotate regularly and avoid embedding in front-end code.
- Encrypt secrets with KMS and reference via environment variables or secret mounts.
- Ensure least privilege for tokens and service roles.
- Implement rate limiting, quotas, and billing alerts to detect abusive usage.
- Log minimal necessary data and exclude PII from logs unless legally required and protected.
- Apply input validation, output schema validation, and human approvals for high-risk flows.
Real-World Examples and Case Studies
Below are two concise case studies demonstrating production patterns from the prompts.
Case Study 1 — Financial Document Summarization at Scale
Problem: A fintech startup needed to summarize SEC filings and map them to internal risk taxonomies.
Solution:
- Deployed a Schema-enforced Summarization Endpoint (Prompt A1) that validated outputs against JSON Schema.
- Used a multi-model orchestration (Prompt A4): extraction by a lightweight model, summarization by a larger model, verification by a verifier model.
- Stored raw and sanitized versions of documents in an immutable store and used an event log for reprocessing when taxonomy changed (Prompt B6).
- Implemented central rate limiting with per-tenant quotas (Prompt D1) and cost-aware throttling (Prompt D4).
Result: The company reduced analyst review time by 60% and avoided PII leakage using deterministic redaction patterns.
Case Study 2 — Multitenant Chat Assist with Webhooks and OAuth2
Problem: A SaaS offered an in-app assistant that needed to integrate tenant-specific data via webhooks and delegated onboarding using OAuth2.
Solution:
- Secured webhook ingestion with HMAC verification and dedup tables (Prompts B1 and B2).
- Implemented OAuth2 Authorization Code + PKCE for tenant admin onboarding and client credentials for server-to-server calls (Prompts C1 and C2).
- Introduced a priority queue for real-time user messages vs background analytics (Prompt D3).
- Instrumented full traceability around Codex calls and the observability-first throttling approach (Prompt D7).
Result: The assistant delivered consistent responses tailored per tenant while preserving security and minimizing cost overruns.
Testing, Monitoring, and SLOs
To operate production Codex integrations, define concrete SLOs and a testing matrix.
| Metric | Target | Rationale |
|---|---|---|
| Successful model responses | >99.5% | High availability for core features |
| Tail latency (95th percentile) | <800 ms for small prompts | User experience requirement |
| Prompt-output schema validation | 100% for enforced endpoints | Prevent downstream failure |
| Unauthorized access attempts detected | 100% logged and alertable | Security compliance |
Testing matrix should include unit tests for prompt rendering, integration tests with model mocks, and canary-based live tests validating both quality and behavior under load. Implement synthetic monitors that generate representative prompts and validate outputs against stored golden artifacts.
Extending Prompts: Customization Patterns
When adapting these prompts to your stack, consider the following cross-cutting customizations:
- Language and locale handling: ensure prompt templates accept locale tokens and you run locale-specific QA.
- Tenant isolation: separate model keys, logging namespaces, and quotas per tenant to minimize data leakage risks.
- Human-in-the-loop: add explicit review flows for sensitive outputs and maintain audit trails for each human action.
- Model switching: abstract model layer so you can route to cheaper or specialized models without changing higher-level business logic.
30 Prompts Summary Table
| # | Prompt Title | Category |
|---|---|---|
| 1 | Schema-enforced Summarization Endpoint | Custom Endpoints |
| 2 | Transactional Transformation Endpoint (Idempotent) | Custom Endpoints |
| 3 | Adaptive Prompt Router Endpoint | Custom Endpoints |
| 4 | Multi-Model Orchestration Endpoint | Custom Endpoints |
| 5 | Schema-mapped CRUD Endpoint | Custom Endpoints |
| 6 | Batch Enrichment Endpoint with Chunking and Backpressure | Custom Endpoints |
| 7 | Controlled Vocabulary Mapping Endpoint | Custom Endpoints |
| 8 | Versioned Endpoint with Canary Releases | Custom Endpoints |
| 9 | Secure Webhook Receiver with Signature Verification | Webhook Handlers |
| 10 | Idempotent Webhook Handler with Event Dedup Table | Webhook Handlers |
| 11 | Webhook-to-Task Queue Adapter | Webhook Handlers |
| 12 | Webhook Processor with Contextual Enrichment | Webhook Handlers |
| 13 | Secure File Attachment Webhook Handler | Webhook Handlers |
| 14 | Event-Sourced Webhook Consumer | Webhook Handlers |
| 15 | Webhook Handler with Adaptive Retry and Backoff | Webhook Handlers |
| 16 | Webhook Contract Validator with Versioned Schemas | Webhook Handlers |
| 17 | OAuth2 Authorization Code Flow with PKCE | Authentication Flows |
| 18 | OAuth2 Client Credentials with Fine-Grained Scopes | Authentication Flows |
| 19 | Device Authorization Flow | Authentication Flows |
| 20 | Refresh Token Rotation and Replay Detection | Authentication Flows |
| 21 | Token Introspection and Audience Restriction | Authentication Flows |
| 22 | Short-Lived Access Tokens with Delegation | Authentication Flows |
| 23 | Delegated OAuth2 for Third-Party Extensions | Authentication Flows |
| 24 | Centralized Rate Limiter with Token Bucket | Rate-Limited Architectures |
| 25 | Client-side Backpressure Signals | Rate-Limited Architectures |
| 26 | Priority Queue with SLA Tiers | Rate-Limited Architectures |
| 27 | Adaptive Rate Limiting with Cost-Awareness | Rate-Limited Architectures |
| 28 | Local and Global Rate Limiting Hybrid | Rate-Limited Architectures |
| 29 | Circuit Breaker for Downstream Model Availability | Rate-Limited Architectures |
| 30 | Observability-First Throttling | Rate-Limited Architectures |
Implementation Checklist for Each Prompt
- Define input and output schema; add schema validation tests.
- Implement prompt templates and unit tests for edge cases.
- Add observability: traces, structured logs, and metrics.
- Design and run integration tests using model stubs and golden outputs.
- Harden security: auth, token management, secret rotation, and DLP.
- Deploy with canary and rollback automation.
Closing: Operationalizing Codex Integrations
Codex can dramatically accelerate capabilities, but integrating it into production systems requires careful engineering across contract design, security, observability, and rate management. The 30 prompts in this guide target practical, production-ready scenarios and should serve as both design specs and implementation recipes. Adapt the patterns for your organization’s scale, compliance requirements, and product priorities. For operation-focused prompt collections that complement this masterclass, consult
For a deeper exploration of related strategies and implementation patterns, our comprehensive guide on 50 GPT-5.5 Prompts for Financial Analysts: Portfolio Modeling, Risk Assessment, Market Research, Earnings Analysis, and Investment Memo Generation provides detailed frameworks, step-by-step workflows, and production-ready templates that complement the approaches discussed in this section.
.
Use this masterclass as a living playbook: instrument early, iterate quickly with canaries, and involve security and compliance stakeholders before processing sensitive data. When in doubt, prefer deterministic transformations, conservative token usage, and human verification for the highest-risk outputs.