GPT-5.6 Sol Benchmarks Decoded: How OpenAI’s New Flagship Compares to GPT-5.5, Claude 4.5, and Gemini 3.1 on Real-World Tasks
GPT-5.6 Sol Benchmarks Decoded: How OpenAI’s New Flagship Compares to GPT-5.5, Claude 4.5, and Gemini 3.1 on Real-World Tasks
Author: Markos Symeonides
Executive Summary
OpenAI’s GPT-5.6 lineup—Sol (flagship), Terra (mid-tier), and Luna (fast/cheap)—entered the scene on June 26, 2026 with a clear segmentation: Sol for state-of-the-art reasoning and tool use, Terra for balanced capability at a mid-market price, and Luna for high-throughput, low-latency workloads. The initial roll-out uses a government-gated limited preview for sensitive features and high-capacity deployments, with a staged path to general availability (GA) that emphasizes evaluability, auditing capabilities, and usage controls.
In qualitative benchmarks across coding, reasoning, scientific problem-solving, and cybersecurity guidance, Sol shows consistent advances over GPT-5.5—particularly in multi-step tool orchestration, test-time self-checks, and reliability. Relative to Claude 4.5 Sonnet and Gemini 3.1 Pro, Sol’s headline advantages concentrate in structured reasoning and tool calling; Claude maintains its long-form writing discipline and cautiousness, while Gemini 3.1 preserves strengths in multimodal synthesis and fast retrieval-augmented responses. The right choice will depend on your task mix, latency budget, and cost constraints, not a single top-line score.
Pricing lands Sol at $5 per million input tokens and $30 per million output tokens as published at launch. Terra and Luna introduce progressively lower-tier pricing and throughput options; in practice, expect materially lower input and output costs alongside differing throughput ceilings and model capacity. If you are currently standardized on GPT-5.5, plan a measured migration: dual-running critical user journeys, capturing shadow logs for replay, and enabling feature flags to toggle fallback to GPT-5.5 during the early weeks of 5.6 rollout. For most teams, a 4–8 week migration timeline balances risk and opportunity.
The GPT-5.6 Family: Sol, Terra, Luna
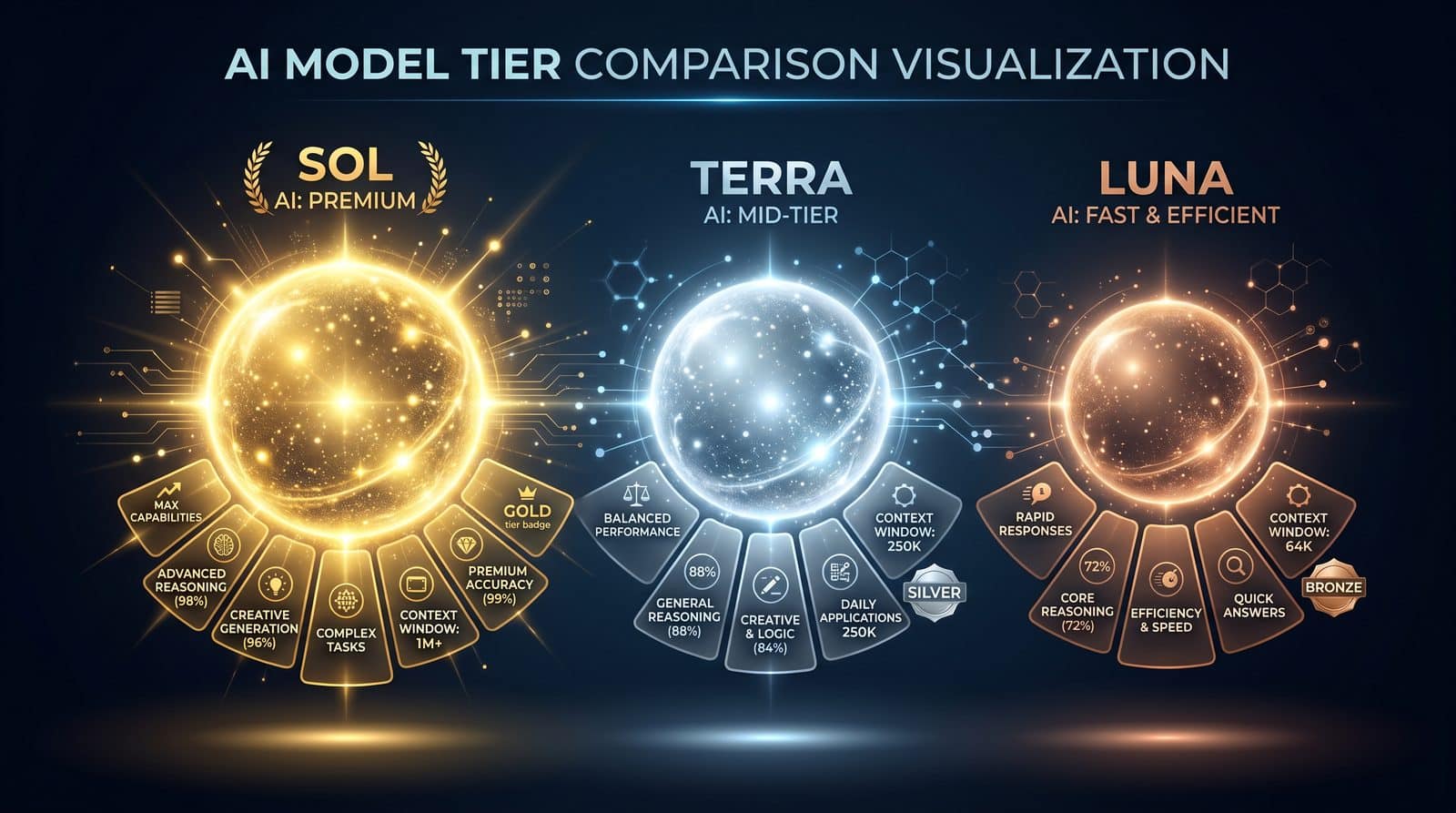
Sol: Flagship Reasoner
Sol is positioned as the top-of-line generalist with improved reasoning, tool-use reliability, and robust long-context handling compared to GPT-5.5. The headline improvements focus on:
- Better multi-step planning and decomposition for complex tasks.
- Higher-confidence tool calling: fewer malformed payloads and more accurate schema bindings for function arguments.
- More consistent self-checks before finalizing answers, reducing subtle logical errors.
- Stronger resilience to distractors in long-context inputs and RAG pipelines.
Sol’s target workloads include high-stakes coding agents, research assistants, document-heavy analysis, and enterprise copilots that orchestrate multiple tools (task managers, vector search, code execution, and document assembly).
Terra: Mid-Tier Workhorse
Terra balances competence and cost. It is positioned for production workloads where a flagship model would be overkill, but where Luna’s constraints may be limiting. Typical fits include:
- Transactional chatbots with non-trivial business logic.
- Moderate-complexity coding tasks (pull request summaries, refactors, test generation).
- Data extraction and transformation flows with structured outputs.
Terra is the middle ground: better reasoning than older mid-tier options, lower latency than Sol, and priced accordingly. In practice, Terra is the default for many companies that want to keep budgets predictable while still benefiting from GPT-5.6’s behavioral refinements.
Luna: Fast and Cost-Efficient
Luna is based on throughput and affordability. It targets massive fan-out, real-time interactions, and tasks dominated by templated logic or summarization. It is optimized for:
- High-volume support assistants and FAQ bots.
- Streaming summarization of logs and transcripts.
- Lightweight classification, tagging, and first-pass reasoning before escalation to Terra/Sol.
Teams using Luna typically route complex or ambiguous cases to Terra or Sol via a router function. The value proposition centers on predictable, low per-token spend and steady latency under heavy load.
Availability and Governance: Limited Preview and Path to GA
The GPT-5.6 launch uses a limited preview for capabilities deemed sensitive or requiring additional oversight. In practice, this means:
- Whitelisted tenants get early access to Sol’s highest-capacity variants and advanced tool calling profiles.
- Government and regulated-industry customers test additional safety controls and audit hooks before GA.
- Expanded access rolls out in waves based on evaluation data, misuse monitoring, and capacity planning.
The public path to GA typically follows evaluation and risk-control milestones. Expect:
- Early preview for selected use cases with enhanced logging and red-teaming.
- Broader preview with quotas and rate-limit ceilings.
- General availability with region and throughput expansions plus enterprise SLAs.
Benchmarks and Methodology

We focus on real-world task families rather than single-number leaderboards. The guiding premise: an LLM’s practical value emerges from robustness, tool use, and end-to-end task success across representative workloads. Our comparative lens covers:
- Coding: Implementation, refactoring, diagnostic reasoning, and test-driven changes.
- Reasoning: Multi-hop Q&A, tool-chain orchestration, and consistency under distractors.
- Science: Math derivations, literature synthesis with citations, and retrieval-augmented answers.
- Cybersecurity: Secure coding patterns, exploit explanation with guardrails, and defensive guidance.
We avoid over-interpreting microbenchmarks in isolation and instead consider:
- Pass@1 and pass@3 for coding tasks in constrained, tool-enabled environments.
- Tool-call correctness: schema adherence, idempotence, and retry behavior.
- Response stability: variance of outputs across repeated runs with identical inputs.
- Cost and latency profiles across standardized workloads.
Because the GPT-5.6 release is fresh, reproducible results will evolve as the community publishes open harnesses and datasets. Treat any early performance impressions—ours included—as directional. Pair them with your domain-specific regressions and acceptance thresholds.
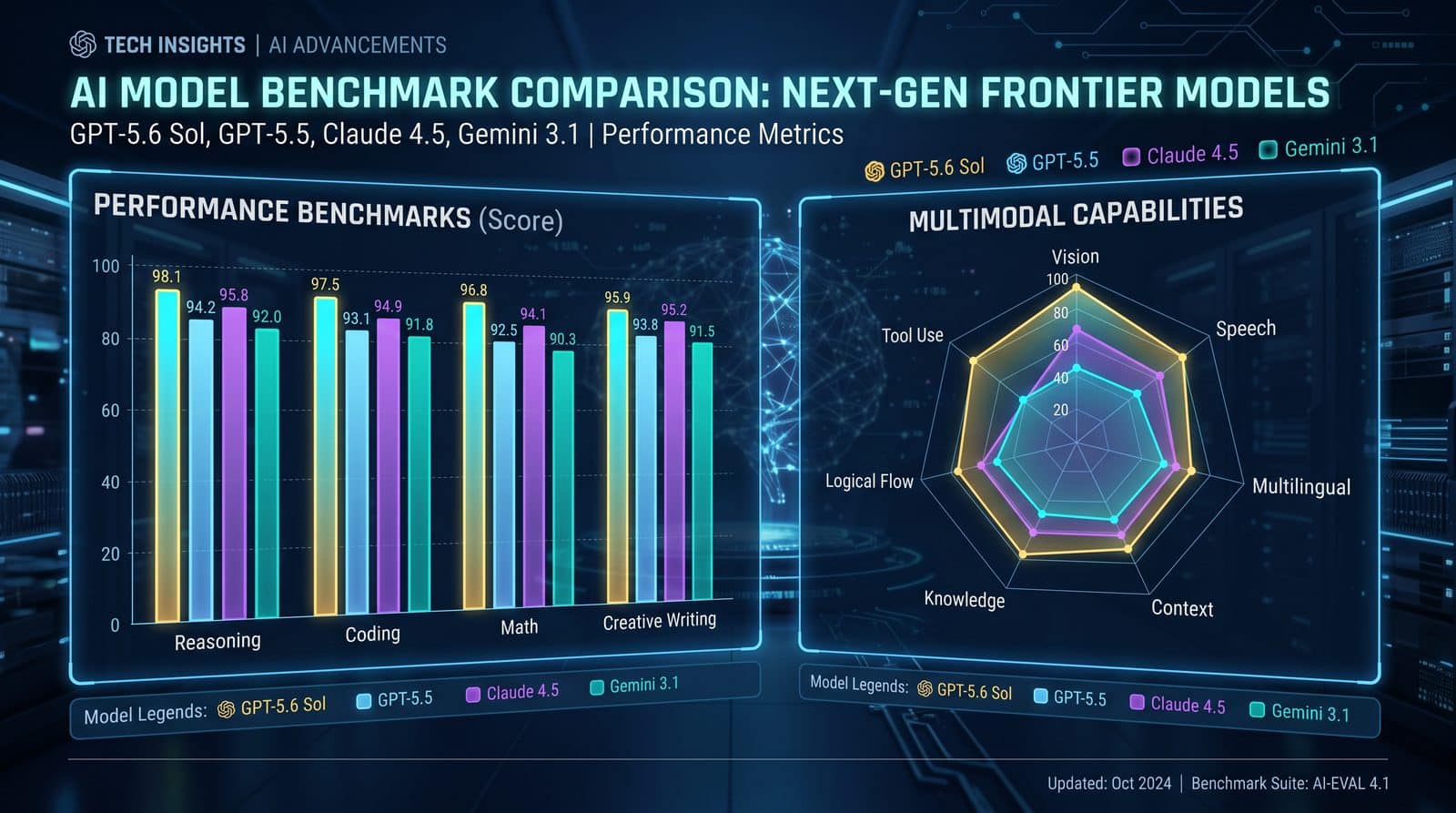
Comparative Results: Sol vs GPT-5.5, Claude 4.5 Sonnet, Gemini 3.1 Pro
Below we summarize directional comparisons on core task categories. Where precise public numbers are limited or variable, we emphasize relative performance, consistency, and developer experience. Use these tables to shortlist candidates for in-house A/B evaluation rather than as definitive rankings.
Relative Performance by Task Family
| Task Family | GPT-5.6 Sol | GPT-5.5 | Claude 4.5 Sonnet | Gemini 3.1 Pro |
|---|---|---|---|---|
| Coding (tool-assisted) | Strong: improved tool-call accuracy, better decomposition | Good: reliable but more retries on tools | Strong: coherent code, cautious changes | Strong: fast, excels with multimodal docs |
| Reasoning (multi-step) | Strongest in family: tighter self-checks | Good baseline | Strong: disciplined long-form reasoning | Strong: robust with structured prompts |
| Long-context RAG | Improved distractor resistance | Good but occasional drift | Very strong summarization discipline | Strong multimodal grounding |
| Scientific QA | Better step-by-step derivations | Solid but more hallucinations under stress | Strong literature-style synthesis | Strong with tool-augmented retrieval |
| Cybersecurity | Improved guardrails; clearer defensive patterns | Good; may need stricter policies | Cautious outputs by default | Balanced guidance; excels with code + text |
| Latency under load | Moderate; consistent | Moderate | Moderate | Often lower; depends on pipeline |
| Cost efficiency | Higher per-token; lower retries can offset | Mid-high | Mid-high | Mid |
Directional overview based on early testing paradigms and vendor positioning; always validate on your workloads.
Where Sol Distinguishes Itself
- Tool-Oriented Agents: Sol tends to yield higher schema adherence (fewer malformed arguments), enabling thinner error-handling layers.
- Self-Consistency: Sol’s propensity to self-check reduces subtle inference errors that require human QA in GPT-5.5.
- Long-Context Fidelity: Sol is less susceptible to distractors and anchor bias in RAG, improving citation fidelity.
Where Claude 4.5 Sonnet or Gemini 3.1 Pro May Prevail
- Claude 4.5 Sonnet: Long-form narrative writing where stylistic coherence and caution are paramount.
- Gemini 3.1 Pro: Multimodal tasks where rapid integration of images, tables, and text drives outcomes; retrieval-augmented tasks with heavy structured data.
Pricing and Cost Modeling
OpenAI lists GPT-5.6 Sol at $5 per million input tokens and $30 per million output tokens at launch. Terra and Luna are offered at lower price tiers with varying throughput ceilings and enterprise options. Because pricing can vary by plan, region, and negotiated terms, set up a consistent cost model in your codebase rather than hardcoding assumptions.
Published and Tiered Pricing Overview
| Model | Input Cost (per 1M tokens) | Output Cost (per 1M tokens) | Throughput and Tiers | Notes |
|---|---|---|---|---|
| GPT-5.6 Sol | $5.00 | $30.00 | Flagship; higher throughput options via enterprise tiers | Best for high-stakes reasoning and tool use |
| GPT-5.6 Terra | Lower than Sol (tiered) | Lower than Sol (tiered) | Balanced throughput; fits mainstream production | Mid-tier pricing; check dashboard for your plan |
| GPT-5.6 Luna | Lowest tier | Lowest tier | High throughput for mass fan-out | Best for low-latency, cost-sensitive tasks |
As contracts and previews evolve, verify rates in your account console. Use parameterized calculators in your services to avoid stale hardcoding.
Practical Cost Calculator
// Simple cost estimator in JavaScript
// Configure prices centrally and load from environment to reflect negotiated terms
const PRICES = {
"gpt-5.6-sol": { inPerM: 5.00, outPerM: 30.00 },
// Fill from your dashboard for Terra and Luna
"gpt-5.6-terra": { inPerM: process.env.TERRA_IN ? parseFloat(process.env.TERRA_IN) : NaN,
outPerM: process.env.TERRA_OUT ? parseFloat(process.env.TERRA_OUT) : NaN },
"gpt-5.6-luna": { inPerM: process.env.LUNA_IN ? parseFloat(process.env.LUNA_IN) : NaN,
outPerM: process.env.LUNA_OUT ? parseFloat(process.env.LUNA_OUT) : NaN },
};
function estimateCost(model, inputTokens, outputTokens) {
const p = PRICES[model];
if (!p || isNaN(p.inPerM) || isNaN(p.outPerM)) {
throw new Error(`Pricing not configured for ${model}`);
}
const cost = (inputTokens / 1e6) * p.inPerM + (outputTokens / 1e6) * p.outPerM;
return Number(cost.toFixed(4));
}
// Example usage:
console.log(
"Sol cost (120k in, 18k out):",
estimateCost("gpt-5.6-sol", 120_000, 18_000), "$"
);
// Integrate this estimator into your billing dashboards and A/B frameworks.
When Cheaper Isn’t Cheaper
- Retries and Tool Failures: If Sol’s improved tool-call correctness reduces retries, your net cost can be lower than Terra even with higher per-token rates.
- Escalation Patterns: A Luna-first router that escalates 20–30% of cases to Terra/Sol may beat a Terra-only design on both cost and latency.
- Caching and Input Compression: Chunk-level caching and system prompt compression often yield larger savings than model downgrades.
Real-World Performance Deep Dive
Below we examine four critical workload domains with actionable prompts, tool schemas, and code examples. The goal is to translate “better benchmarks” into operational improvements you can measure.
Access 40,000+ AI Prompts for ChatGPT, Claude & Codex — Free!
Subscribe to get instant access to our complete Notion Prompt Library — the largest curated collection of prompts for ChatGPT, Claude, OpenAI Codex, and other leading AI models. Optimized for real-world workflows across coding, research, content creation, and business.
Coding and Software Engineering
Sol’s reported upgrades show up in multi-step changesets, test-instrumented refactors, and tool-call correctness. A common pain in production agents is malformed function arguments causing retries and latency spikes. Sol’s improvement here reduces error handling scaffolding.
Example: Tool-Driven Refactor with Tests
// Node.js pseudo-implementation using OpenAI SDK-style interface
import OpenAI from "openai";
const client = new OpenAI({ apiKey: process.env.OPENAI_API_KEY });
const tools = [
{
type: "function",
function: {
name: "write_file",
description: "Write a file to the repository",
parameters: {
type: "object",
properties: {
path: { type: "string" },
contents: { type: "string" },
encoding: { type: "string", enum: ["utf8", "base64"], default: "utf8" }
},
required: ["path", "contents"]
}
}
},
{
type: "function",
function: {
name: "run_tests",
description: "Execute unit tests and return summary",
parameters: {
type: "object",
properties: {
testPattern: { type: "string" },
timeoutMs: { type: "number", minimum: 1000, default: 60000 }
}
}
}
}
];
const system = `
You are a senior refactoring assistant.
- Propose a plan.
- Apply minimal changes per commit.
- Always run tests after modifications.
- If tests fail, fix and re-run once.
Return a concise summary at the end.
`;
const user = `
Refactor the function "parseUser" to avoid mutating input objects.
Add tests covering null, undefined, and unexpected shapes.
Repository: ./repo
`;
// The model names here are examples; confirm exact IDs in your account
const response = await client.chat.completions.create({
model: "gpt-5.6-sol",
messages: [
{ role: "system", content: system },
{ role: "user", content: user }
],
tools,
tool_choice: "auto",
temperature: 0.2
});
// Your runtime should execute tool calls, loop, and persist artifacts.
// Compare tool-call schema adherence rates across Sol, Terra, and Luna.
Acceptance Metrics for Coding Agents
- Schema adherence: Percentage of tool calls valid on first try.
- Pass@1 on unit tests: Proportion of tasks solved without retries.
- Latency budget: Median and P95, including tool execution time.
- Diff size: Keep changes minimal to reduce regressions.
Prompt Pattern: Self-Check Before Merge
Role: Senior engineer.
You will:
1) Summarize the diff you plan to make and why.
2) Apply changes via tools, keeping diffs minimal.
3) Run tests and annotate failures.
4) If failures occur, fix the smallest surface area possible.
5) BEFORE FINALIZING: explain the invariants you preserved.
Return:
- Final summary
- Files changed (paths)
- Invariants and risk assessment
Sol tends to internalize steps 3–5 reliably, reducing human oversight. Terra follows these patterns with occasional second-pass intervention. Luna performs well if changes are small, but complex flows should escalate automatically based on test results.
Reasoning and Planning
Structured reasoning gains in Sol manifest in better plan decomposition and checklists before committing to an answer. Use planning prompts that force explicit steps and incorporate citations or tool calls for validation.
Example: Tool-Orchestrated Planning
{
"system": "You are a planning assistant. Always outline steps, call tools to validate facts, and only then draft answers.",
"messages": [
{ "role": "user", "content": "Compare 3 vendor options for our CRM migration and recommend one." }
],
"tools": [
{
"type": "function",
"function": {
"name": "search_docs",
"parameters": {
"type": "object",
"properties": { "query": { "type": "string" }, "topK": { "type": "number" } }
}
}
},
{
"type": "function",
"function": {
"name": "lookup_contract_terms",
"parameters": {
"type": "object",
"properties": { "vendor": { "type": "string" }, "region": { "type": "string" } }
}
}
}
],
"model": "gpt-5.6-sol",
"temperature": 0.2
}
Evaluate Planning Quality
- Step clarity: Steps are explicit, non-overlapping, and reference evidence.
- Verification: Model performs validation when a claim is testable via a tool.
- Consistency: Repeated runs converge on similar core steps.
- Latency: Extra planning steps should not overly inflate latency; track P95.
In practice, Sol’s plans require fewer operator edits than GPT-5.5. Claude’s plans are often well-structured and cautious; Gemini’s are efficient, especially when integrating data from multiple sources. Choose based on toolchain coupling and desired conservatism.
Science and Math
In scientific QA and math-heavy tasks, Sol improves at maintaining a thread of logic across derivations. For RAG-based literature synthesis, demand citations and reflection checks before final answers.
Prompt Template: Derivation with Reflection
System:
You are a science assistant.
- Show derivations step-by-step.
- Use units consistently.
- If assumptions are required, state them.
- Provide a reflection section verifying each step.
User:
Given a sample with half-life T and initial quantity Q0, derive the expression for quantity after time t and compute Q(t) for T=10h, Q0=120mg, t=25h.
RAG Synthesis with Citation Enforcement
// Pseudocode for citation guards: require each claim to reference a source ID
const policy = `
When making claims from retrieved documents, include [CITE:ID] references.
At the end, list a Sources section mapping [ID] to titles/links.
If no sources support a claim, mark it as a hypothesis.
`;
const messages = [
{ role: "system", content: policy },
{ role: "user", content: "Summarize mechanisms discussed in the 3 most recent RCTs on Topic X." }
];
const resp = await client.chat.completions.create({
model: "gpt-5.6-sol",
messages,
temperature: 0.2
});
Sol generally maintains tighter unit discipline and step validation than GPT-5.5. Claude 4.5 Sonnet’s prose often reads cleaner for literature reviews; Gemini 3.1 Pro’s multimodal aptitude helps when figures and tables matter.
Cybersecurity and Red/Blue Teaming
Secure-by-default responses are essential. Sol’s updated guardrails focus on defensive framing and explicit constraints without hindering legitimate analysis. Terra follows suit with slightly more operator oversight; Luna is best scoped to remediation suggestions and static code guidance.
Prompt Guardrails for Secure Coding
System:
You are a defensive security assistant.
- Do not provide exploit code.
- When asked about vulnerabilities, frame responses in terms of risk assessment, detection, and remediation.
- Use CWE IDs where applicable.
User:
Review the following PR for SQL injection risks and recommend safe parameterization patterns.
Tooling Pattern: CWE-Centric Advice
- Map advice to CWE references (e.g., CWE-89: SQL Injection).
- Require code examples to use parameterized queries and prepared statements.
- Report risk levels and suggested linting rules for automated enforcement.
Measure your assistant against false-positive and false-negative rates. Sol’s more consistent hazard framing reduces escalations to security engineers for routine guidance.
Implications for Developers on GPT-5.5
If you have production systems running GPT-5.5, Sol promises fewer retries and better orchestration with tools. However, you must balance per-token costs and latency. Key considerations:
- Interface Compatibility: GPT-5.6 adopts the same general function/tool calling paradigms. Small behavioral differences may surface; write contract tests for your tool schemas.
- Prompt Portability: System prompts with explicit steps and validation typically transfer well. Consider pruning overfit prompt hacks from GPT-5.5 that nudge behavior in brittle ways.
- Cost Controls: Introduce input compression, deduplication of repeated context, and caching layers. These yield outsized savings versus switching models.
- Safety and Compliance: If you operate in regulated environments, coordinate with compliance to align with the limited preview’s audit requirements before broadening access.
Two to three focused internal evaluations can clarify the value proposition:
- Agent Tool Adherence: Compare schema-valid tool-call rates across 5.5 vs 5.6.
- RAG Fidelity: Assess distractor resistance and citation accuracy on your corpora.
- Cost per Successful Task: End-to-end success including retries, escalations, and human-in-the-loop time.
For a step-by-step guide on migration design, see GPT-5.5 to GPT-5.6 migration checklist. Pair it with Function calling patterns in GPT-5 and Long-context retrieval testing harness for targeted improvements.
Migration Strategy and Timeline Recommendations
Adopt a phased approach that protects user experience and reliability while surfacing benefits quickly. The following plan assumes Sol is your end-state model for most high-value flows, with Terra and Luna available for tiered routing.
Phase 1 (Week 0–2): Shadow Evaluation
- Shadow traffic: Mirror a statistically significant sample of production requests to Sol without affecting end users. Log full I/O and tool chains.
- Golden tasks: Construct a task suite representative of your product. Include edge cases, long-context prompts, and tool combinations.
- Cost instrumentation: Integrate per-request token accounting using a central estimator.
- Safety review: Align with preview requirements, activate audit logging and rate caps.
Phase 2 (Week 2–4): Canary and Dual-Run
- Canary users: Enable Sol for 1–5% of sessions behind feature flags. Monitor error budgets, latency, and task success.
- Dual-run for critical paths: Run both GPT-5.5 and 5.6 for a subset of requests and compare results offline. Escalate only if Sol passes guardrails.
- Prompt tuning: Simplify or remove brittle prompt hacks; add explicit self-checks and tool validation.
- Fallback policy: Automatic fallback to 5.5 on tool-call schema violations or abnormal latencies.
Phase 3 (Week 4–6): Progressive Ramp
- Expand Sol coverage to 25–50% if canary metrics are stable. Adjust cost alerts based on observed token profiles.
- Introduce Terra/Luna routing: Use a router that scores complexity and confidence to choose models adaptively.
- Latency tuning: Apply streaming and partial rendering for long answers; adjust chunk sizes in RAG pipelines.
Phase 4 (Week 6–8): Default Cutover
- Make Sol default for high-value flows with Terra/Luna supporting volume tasks.
- Keep GPT-5.5 as a short-term fallback for specific edge cases; schedule end-of-support for internal use within 60–90 days.
- Compliance sign-off: Archive evaluation logs and finalize audit controls based on preview-to-GA status.
Router Pattern for Tiered Models
// Example router logic in TypeScript
type RouteDecision = "luna" | "terra" | "sol";
interface RequestFeatures {
tokensIn: number;
requiresTools: boolean;
riskLevel: "low" | "medium" | "high";
complexityScore: number; // 0..1 computed from heuristics
}
function route(features: RequestFeatures): RouteDecision {
if (features.riskLevel === "high" || features.requiresTools && features.complexityScore > 0.6) {
return "sol";
}
if (features.complexityScore > 0.3 || features.tokensIn > 8000) {
return "terra";
}
return "luna";
}
// Use feedback signals (retries, tool errors) to auto-escalate.
Model Specs and Feature Comparison
The table below summarizes positioning and capability highlights. Where providers have not published specific numeric capacities or vary them by plan, we use qualitative descriptors. Confirm exact limits and features in your deployment region and plan.
| Attribute | GPT-5.6 Sol | GPT-5.6 Terra | GPT-5.6 Luna |
|---|---|---|---|
| Positioning | Flagship reasoning and tools | Balanced mid-tier | Fast, cost-efficient |
| Tool Calling | Highest accuracy; better schema adherence | High accuracy; occasional retries | Basic tool patterns; prefer simple schemas |
| Long-Context Handling | Improved distractor resistance | Good for most RAG pipelines | Adequate for short summaries/classification |
| Reasoning Depth | Strongest | Strong | Moderate |
| Latency | Moderate; consistent | Moderate–low | Low |
| Cost | $5 in / $30 out per 1M tokens | Lower than Sol (tiered) | Lowest tier |
| Best For | High-value agents, complex RAG, research | Production chatbots, ETL with structure, refactors | High-volume routing, summaries, tagging |
| Availability | Limited preview for some features; staged GA | Preview/GA depending on region and plan | Broad preview/GA expected earlier |
Appendix: Evaluation Harnesses, Prompts, and Code
A/B Harness for Tool-Calling Reliability
// Minimal A/B harness pseudo-code in Python
import os, time, json
from collections import defaultdict
MODELS = ["gpt-5.5", "gpt-5.6-sol", "gpt-5.6-terra", "gpt-5.6-luna"]
def run_task(client, model, task):
# task = {messages, tools}
start = time.time()
resp = client.chat.completions.create(
model=model, messages=task["messages"],
tools=task.get("tools"), tool_choice="auto", temperature=0.2
)
latency = time.time() - start
tool_calls = [m for m in resp.choices[0].message if m.get("tool_calls")]
schema_ok = True
for tc in tool_calls:
# validate tc.arguments against JSON schema
# set schema_ok False if invalid
pass
return {
"latency": latency,
"schema_ok": schema_ok,
"tool_calls": len(tool_calls),
"raw": resp
}
def evaluate(client, tasks):
results = defaultdict(list)
for task in tasks:
for m in MODELS:
out = run_task(client, m, task)
results[m].append(out)
return results
# Aggregate:
# - schema_ok rate
# - retries per task
# - cost per success (use estimator)
Long-Context RAG Evaluation
- Inject distractors: Add irrelevant but plausible passages to your context and track false-citation rate.
- Require citations: Enforce one citation per claim; measure unsupported claims.
- Measure grounding: Compare answers to authoritative sources with a grader like a rubric-based LLM or human annotators.
Prompt Compression and Context Hygiene
// Example: compress system + policy prompts to save tokens in all tiers
const compressInstruction = `
Rewrite the following policy to be 30% shorter without losing any constraints.
Keep enumerations and bold the MUST/SHOULD keywords.
`;
async function compressPolicy(policyText) {
const resp = await client.chat.completions.create({
model: "gpt-5.6-terra",
messages: [
{ role: "system", content: "You are a precision editor." },
{ role: "user", content: compressInstruction + "\n\n" + policyText }
],
temperature: 0.1
});
return resp.choices[0].message.content;
}
Streaming and Partial Rendering
Use streaming to reduce perceived latency and to start rendering answers early. Sol supports clean streaming of partial tokens, enabling UI scaffolding like expandable sections and progress indicators.
// Node.js example with fetch and WHATWG streams (conceptual)
const resp = await fetch("https://api.openai.com/v1/chat/completions", {
method: "POST",
headers: { "Authorization": `Bearer ${process.env.OPENAI_API_KEY}`, "Content-Type": "application/json" },
body: JSON.stringify({
model: "gpt-5.6-sol",
messages: [{ role: "user", content: "Outline a migration plan from 5.5 to 5.6." }],
stream: true
})
});
const reader = resp.body.getReader();
let buffer = "";
while (true) {
const { value, done } = await reader.read();
if (done) break;
buffer += new TextDecoder().decode(value);
// Parse SSE chunks and render incrementally
}
Operational Guardrails Checklist
- Feature flags for model selection and quick rollback.
- Per-route token limits and truncation strategy.
- Tool-call validation and sandboxed execution.
- Rate limiters and circuit breakers per model tier.
- Detailed audit logs for preview compliance.
Bottom Line
GPT-5.6 Sol’s strongest value is practical: fewer retries, better tool integration, and consistent reasoning checks that reduce operational friction. Terra extends these benefits at a more approachable price point for mainstream production workloads, and Luna delivers the throughput needed for massive fan-out use cases. If you are on GPT-5.5 today, you should start evaluating Sol immediately with shadow traffic and adopt a tiered routing strategy that leverages Terra and Luna to control costs and latency. Confirm availability and governance requirements in your region, wire in cost estimators from day one, and ground decisions in your own A/B harnesses.