Inside OpenAI’s Agentic AI Research Paper: 5 Key Findings That Reveal How AI Work Is Evolving from Chat to Autonomous Execution
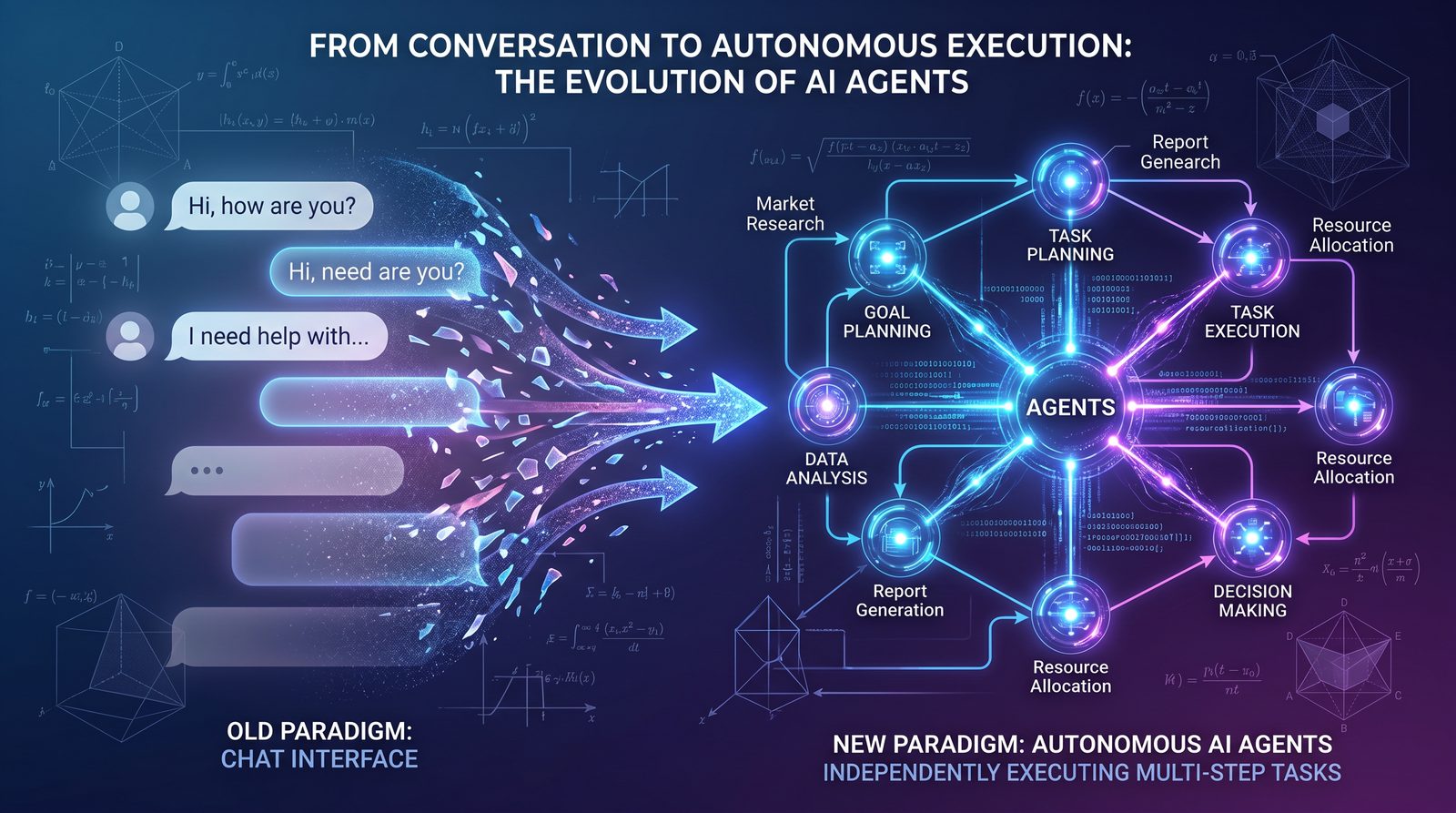
Inside OpenAI’s Agentic AI Research Paper: 5 Key Findings That Reveal How AI Work Is Evolving from Chat to Autonomous Execution
Author: Markos Symeonides, ChatGPT AI Hub
Executive Summary
OpenAI’s June 25, 2026 research paper, “The Shift to Agentic AI: Evidence from Codex,” documents a decisive move away from traditional chat-based AI usage toward agentic workflows—systems that plan, act, and verify across multi-step tasks with minimal human intervention. According to the paper, OpenAI’s internal platform, Codex, replaced ad-hoc chat with agent-driven execution for almost all AI-mediated work, reaching 97.9% adoption among internal users. The study reports that users are delegating more complex, hours-long tasks to agents and shifting their interaction style from conversational prompting to delegational briefs. The authors further analyze productivity impacts—quality, speed, and stability—along with broad implications for roles, operating models, and enterprise adoption.
This article synthesizes the paper’s five key findings and provides practical guidance for leaders pivoting toward agentic AI. We explore the underlying methodology as reported, unpack interaction design patterns, compare OpenAI’s approach to Anthropic and Google offerings, critique limitations, and offer an actionable roadmap for enterprise teams. You’ll also find code examples, architecture templates, and metrics checklists to guide implementation.
Paper Overview and Methodology
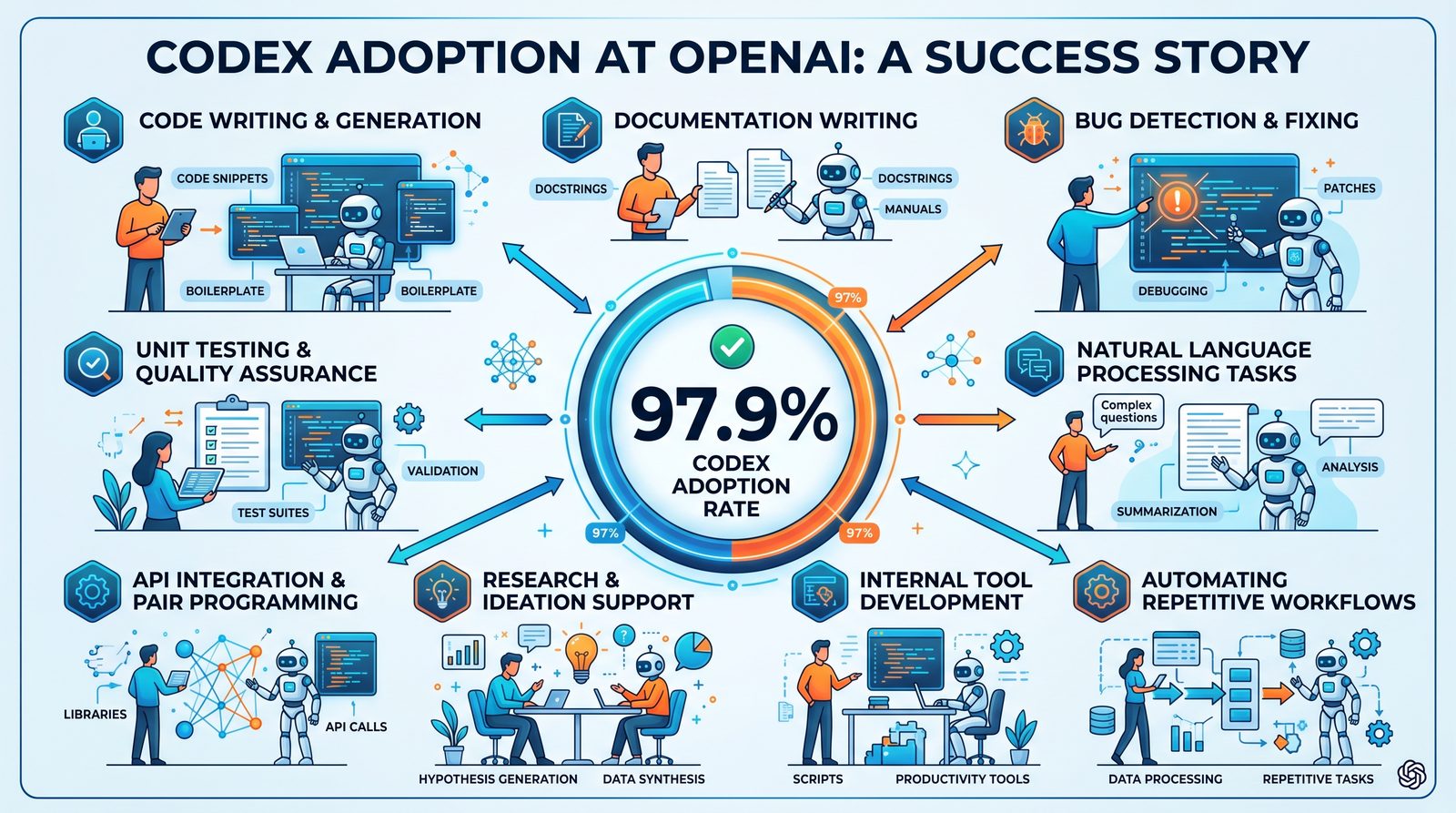
What OpenAI Studied
The paper examines the evolution of AI usage patterns within OpenAI’s own workflows after deploying “Codex,” described as an internal agentic platform for executing multi-step tasks. The central thesis is that agentic AI shifts AI’s role from a conversational aide to an autonomous executor that can plan subtasks, invoke tools, coordinate workflows, and deliver outcomes with less human micromanagement.
Methodology at a Glance
As reported by the paper, the authors employed a multi-method approach to characterize the shift:
- Usage telemetry of Codex versus chat-based tools, including tool-invocation and workflow-run data.
- Task-level annotations that captured complexity (e.g., number of steps, external tool calls), duration, and handoff patterns between humans and agents.
- Human evaluations of output quality using blind rubrics for specific domains (e.g., engineering, support, analytics).
- Time-to-completion and throughput measures for representative task categories.
- Safety and stability metrics (e.g., variance in outputs, failure escalation rate, intervention frequency).
Crucially, the paper defines “agentic” not as a monolithic agent but as a design pattern: planning and execution loops with explicit steps, tools, and verification gates. This reframing helps separate the idea of “agents” from any specific vendor implementation, focusing on outcomes and task dynamics.
Key Definitions
- Agentic AI: AI systems that can break down goals into steps, select and invoke tools, execute plans, and validate results, often with minimal human supervision.
- Delegational interaction: Users provide constraints, resources, and acceptance criteria (e.g., a brief or job ticket) and the agent handles execution end-to-end.
- Complex task: Work that spans multiple steps, tools, and context sources, typically measured in hours rather than minutes.
With these definitions in place, the paper proceeds to present five findings that, collectively, describe a new human-AI operating model.
Finding 1: Codex Replaced Chat-Based Workflows (97.9% Adoption)
What the Paper Reports
The most striking result is the internal adoption rate: 97.9% of OpenAI employees reportedly used Codex as their primary AI work interface, displacing direct chat interactions except for quick, exploratory tasks. Adoption was broad across functions—engineering, product, research ops, support, marketing—and correlates with the presence of reusable workflows and tool integrations.
Why Adoption Took Off
- Repeatability: Teams could package successful prompt chains, tools, and checklists into reusable “runs.”
- Observability: Instrumented steps and logs made outcomes auditable—essential for quality and compliance.
- Tooling: Integrated code execution, data access, and vendor APIs closed the loop from instruction to action.
- Out-of-the-box controls: Constraints, guardrails, and human escalation points made agentic workflows safer for production use.
What This Means for Human-AI Workflows
Chat remains valuable for ideation and “first drafts,” but production work gravitates to agents: workflows that are consistently measurable, improvable, and shareable. Organizations adopting AI should treat chat as an incubator for workflows, not as the main production surface.
Practical Example: Wrapping a Successful Chat Flow into an Agent
Suppose your team uses a prompt to summarize product feedback and file Jira tickets. In a chat, this is manual and error-prone. As an agentic workflow:
- Define inputs: a feedback dataset and a Jira project mapping.
- Plan: cluster feedback, extract themes, draft tickets, validate duplicates.
- Execute tools: semantic clustering, text generation, Jira API.
- Verify: enforce acceptance criteria (ticket quality rubric), escalate edge cases.
- Log: persist steps, artifacts, and metrics to observability dashboards.
# Pseudo-Python: codifying a “feedback-to-Jira” agentic workflow
from typing import List, Dict, Any, Optional
import time
class ToolResult(Exception):
pass
class Tools:
def cluster_feedback(self, items: List[str]) -> List[Dict[str, Any]]:
# Returns clusters with representative comments
...
def dedupe_tickets(self, tickets: List[Dict[str, str]]) -> List[Dict[str, str]]:
...
def create_jira_issue(self, project_key: str, summary: str, description: str) -> str:
...
class Rubrics:
def ticket_quality(self, ticket: Dict[str, str]) -> Dict[str, Any]:
# Returns {score: float, reasons: List[str]}
...
class FeedbackToJiraAgent:
def __init__(self, llm, tools: Tools, rubrics: Rubrics, project_key: str):
self.llm = llm
self.tools = tools
self.rubrics = rubrics
self.project_key = project_key
self.logs = []
def plan(self, feedback: List[str]) -> List[Dict[str, Any]]:
# Ask LLM to propose a stepwise plan with tool calls
prompt = f"Propose steps to cluster {len(feedback)} feedback items, " \
"draft high-quality Jira tickets (summary+description), " \
"dedupe, and enforce acceptance criteria. Include tool calls."
return self.llm.generate_plan(prompt)
def run(self, feedback: List[str]) -> Dict[str, Any]:
start = time.time()
plan = self.plan(feedback)
clusters = self.tools.cluster_feedback(feedback)
draft_tickets = []
for cluster in clusters:
ticket = self.llm.write_ticket(cluster)
quality = self.rubrics.ticket_quality(ticket)
if quality["score"] < 0.8:
ticket = self.llm.revise_ticket(ticket, quality["reasons"])
draft_tickets.append(ticket)
final = self.tools.dedupe_tickets(draft_tickets)
created = []
for t in final:
issue_key = self.tools.create_jira_issue(self.project_key, t["summary"], t["description"])
created.append(issue_key)
end = time.time()
return {"issues": created, "duration_sec": end - start, "steps": plan, "clusters": clusters}
# Usage: FeedbackToJiraAgent(llm, tools, rubrics, "PROJ").run(feedback_items)
The difference from chat is explicit planning, tool orchestration, and rubrics-based verification—hallmarks of the agentic pattern described in the paper.
Finding 2: Task Complexity Is Increasing—Delegating Multi-Step, Hours-Long Work
What the Paper Reports
OpenAI’s data indicates a marked shift toward delegating longer, more complex tasks to Codex. Instead of requesting quick answers, users are offloading entire workflows: data analysis with reporting, code refactors with tests and rollouts, support case triage with multi-channel follow-up, and more. The signature of this shift is the growth in agent-run duration and step counts, alongside increasing tool diversity per run.
Why Complexity Moved to Agents
- Planning is native: Agents create subgoals and reorder steps.
- Tool availability: With APIs and internal tools integrated, agents can fetch data, create artifacts, and push changes.
- Verification layers: Rubrics, validators, unit tests, and gates reduce the risk of long-run failures.
Design Pattern: DAG-Based Agentic Execution
For hours-long tasks, Directed Acyclic Graphs (DAGs) help manage parallelism, retries, and observability. Each node is a step with inputs, a tool call or LLM action, and output schemas. A planner generates the DAG; an orchestrator coordinates execution with backoff and checkpoints.
// TypeScript pseudo-implementation: DAG agent orchestrator
type StepId = string;
type Artifact = any;
interface Step {
id: StepId;
name: string;
requires: StepId[];
run: (ctx: Record<string, Artifact>) => Promise<Artifact>;
retry?: { max: number; backoffMs: number };
verifier?: (artifact: Artifact) => Promise<{ ok: boolean; reasons?: string[] }>;
}
class DAGAgent {
private steps: Map<StepId, Step> = new Map();
private artifacts: Map<StepId, Artifact> = new Map();
addStep(step: Step) {
this.steps.set(step.id, step);
}
async execute() {
const pending = new Set(this.steps.keys());
while (pending.size > 0) {
let progressed = false;
for (const id of Array.from(pending)) {
const step = this.steps.get(id)!;
const ready = step.requires.every(dep => this.artifacts.has(dep));
if (!ready) continue;
progressed = true;
try {
const ctx: Record<string, Artifact> = {};
for (const dep of step.requires) ctx[dep] = this.artifacts.get(dep);
let attempts = 0;
const max = step.retry?.max ?? 1;
let success = false;
let artifact: Artifact | null = null;
while (attempts <= max && !success) {
try {
artifact = await step.run(ctx);
if (step.verifier) {
const v = await step.verifier(artifact);
if (!v.ok) throw new Error(`Verifier failed: ${v.reasons?.join(", ")}`);
}
success = true;
} catch (e) {
attempts++;
if (attempts <= max) await new Promise(r => setTimeout(r, step.retry?.backoffMs ?? 500));
else throw e;
}
}
this.artifacts.set(id, artifact);
pending.delete(id);
} catch (e) {
console.error(`Step ${id} failed:`, e);
throw e; // or escalate to human
}
}
if (!progressed) throw new Error("Deadlock detected or missing dependencies");
}
return this.artifacts;
}
}
// Example: multi-hour analytics run
const agent = new DAGAgent();
agent.addStep({
id: "ingest",
name: "Ingest raw events",
requires: [],
run: async () => fetch("https://data/api/events").then(r => r.json()),
});
agent.addStep({
id: "clean",
name: "Clean & normalize",
requires: ["ingest"],
run: async (ctx) => normalize(ctx["ingest"]),
verifier: async (data) => ({ ok: data.length > 1000 })
});
agent.addStep({
id: "analysis",
name: "LLM-assisted cohort analysis",
requires: ["clean"],
run: async (ctx) => llmAnalyze(ctx["clean"]),
});
agent.addStep({
id: "report",
name: "Generate report + charts",
requires: ["analysis"],
run: async (ctx) => renderReport(ctx["analysis"]),
});
agent.execute().then(res => console.log("Artifacts:", res));
Operational Safeguards for Complex Runs
- Budgeting: Cap tokens, time, and API costs per run; require approvals for exceeding limits.
- Checkpoints: Persist intermediate artifacts for resuming after failures.
- Human-in-the-loop: Escalation hooks for ambiguous steps and high-impact decisions.
- Verification-first: Fail fast when rubrics signal weak outputs; prioritize re-planning over blind retries.
Finding 3: From Conversation to Delegation—A New Interaction Pattern
What the Paper Reports
The paper describes a shift from conversational prompting (“ask-and-answer”) to delegational briefs that look more like job tickets or work orders. Instead of incremental chat exchanges, users specify objectives, constraints, resources, and acceptance criteria up front. The agent plans and executes, reporting status and requesting clarifications as needed.
Delegational Brief Template
Below is a practical template for transitioning from chat-style prompts to agent-ready briefs:
Title: Refactor Search Service and Improve Latency SLOs
Objective:
- Refactor the search service to reduce P95 latency from 450ms to under 250ms.
Scope:
- Services: search-api, indexer.
- Environments: staging, prod (deploy behind feature flag).
- Do NOT modify auth flows.
Resources:
- Repos: org/search-api, org/indexer
- Dashboards: Grafana: search-latency, error-rate
- Docs: Confluence: search-arch, indexer-protocol
Constraints:
- Maintain backward compatibility for v1 clients.
- Budget: 8 hours compute, 2 code reviewers.
- Tests must cover hot paths (autocomplete, facet filtering).
Acceptance Criteria:
- P95 <= 250ms over 24h canary in prod.
- 0 regression in error rate above 0.1%.
- Approved PRs, green CI, changelog updated.
Deliverables:
- PRs for search-api and indexer with benchmarks.
- Runbook entries updated.
- Canary rollout plan documented.
Escalation:
- Pause and request review if latency goals conflict with availability or breaking changes are required.
Interaction Modes: Conversational vs Delegational
| Dimension | Conversational Chat | Delegational Agent |
|---|---|---|
| User input style | Open-ended prompts, incremental adjustments | Structured briefs with objectives, constraints, resources, criteria |
| System behavior | Responds turn-by-turn | Plans, executes, verifies, and reports progress |
| Observability | Chat transcript | Step logs, artifacts, metrics, and audit trail |
| Failure handling | User backtracks and re-prompts | Automated retries, re-planning, escalation |
| Reuse | Hard to package and share | Reusable workflows with parameters |
Bridging the Gap with Prompt-to-Brief
If your organization is entrenched in chat, start by introducing a “prompt-to-brief” meta-pattern—an agent that takes a rough prompt and returns a structured brief, then asks for confirmation before running the plan.
# Python pseudo: prompt-to-brief agent
class PromptToBrief:
TEMPLATE = """Transform the user's rough request into a structured brief:
- Objective
- Scope
- Resources
- Constraints
- Acceptance Criteria
- Deliverables
- Escalation
Ask exactly 3 clarification questions if information is missing.
"""
def __init__(self, llm):
self.llm = llm
def draft(self, prompt: str) -> dict:
raw = self.llm.generate(self.TEMPLATE + "\n\nUser Request:\n" + prompt)
return self.parse_brief(raw)
def parse_brief(self, raw: str) -> dict:
# Extract sections with heuristics/regex
...
def confirm(self, brief: dict) -> bool:
# Present brief to user for confirmation
...
def run(self, prompt: str):
brief = self.draft(prompt)
if not self.confirm(brief):
return "Aborted by user"
return brief # hand off to execution agent
Training users to think in briefs is the fastest way to unlock agentic leverage while retaining control and clarity.
Finding 4: Productivity Metrics—Quality, Speed, and Stability Under Agentic AI
What the Paper Reports
The paper examines how agentic AI affects output quality, speed, and stability across common tasks. Rather than focusing on a single aggregate metric, the authors discuss domain-specific rubrics and time-to-completion, alongside stability indicators such as variance across runs and escalation rates. The picture that emerges is nuanced: agents often complete more work faster with higher consistency, but gains depend on the strength of verification gates, tool maturity, and the predictability of the domain.
Measuring What Matters
- Quality: Use blind human evaluations with domain rubrics, plus automated checks (tests, linting, schema validators).
- Speed: Measure end-to-end time-to-completion, not just model latency.
- Stability: Track variance in outcomes across runs, rate of human escalations, and rollback frequency.
- Cost: Include tokens, API charges, and internal compute—budget agents like any service.
Example: Engineering Productivity Metrics
| Metric | Definition | Collection Method |
|---|---|---|
| Lead time to PR | Time from brief approval to PR opened | Workflow logs + GitHub API |
| PR acceptance rate | PRs merged without significant rework | PR metadata + review labels |
| Test coverage delta | Change in coverage for touched modules | CI coverage reports |
| Rollback ratio | Rollbacks per 100 deployments involving agents | Deploy logs |
| Variance across runs | Std dev of key outputs across replayed runs | Replay harness |
Harness for Reproducibility and Replays
# Python pseudo: record-replay harness for agent runs
import json, time, uuid
from dataclasses import dataclass, asdict
from typing import Any, Callable, Dict, List
@dataclass
class Event:
ts: float
kind: str
data: Dict[str, Any]
class Recorder:
def __init__(self):
self.events: List[Event] = []
self.run_id = str(uuid.uuid4())
def log(self, kind: str, data: Dict[str, Any]):
self.events.append(Event(time.time(), kind, data))
def dump(self, path: str):
with open(path, "w") as f:
json.dump({"run_id": self.run_id, "events": [asdict(e) for e in self.events]}, f, indent=2)
class AgentRunner:
def __init__(self, planner: Callable, executor: Callable, verifier: Callable):
self.planner = planner
self.executor = executor
self.verifier = verifier
self.rec = Recorder()
def run(self, brief: Dict[str, Any]):
self.rec.log("brief", brief)
plan = self.planner(brief)
self.rec.log("plan", {"steps": plan})
artifacts = []
for step in plan:
out = self.executor(step)
self.rec.log("step", {"id": step["id"], "out": out})
ok = self.verifier(step, out)
self.rec.log("verify", {"id": step["id"], "ok": ok})
if not ok: raise ValueError(f"Verification failed for {step['id']}")
artifacts.append(out)
self.rec.log("complete", {"artifacts": artifacts})
return artifacts, self.rec
# Later: load the log and replay to measure variance
By focusing on end-to-end metrics with strong verification and replay capabilities, teams can achieve the stability gains described in the paper and build confidence for broader adoption.
Access 40,000+ AI Prompts for ChatGPT, Claude & Codex — Free!
Subscribe to get instant access to our complete Notion Prompt Library — the largest curated collection of prompts for ChatGPT, Claude, OpenAI Codex, and other leading AI models. Optimized for real-world workflows across coding, research, content creation, and business.
Finding 5: Implications for Knowledge Work and Job Roles
What the Paper Reports
The shift to agents reshapes roles: from prompt authors to workflow designers, from individual contributors executing steps to reviewers and curators overseeing agent outputs, and from ad-hoc tool users to platform stewards who manage templates, policies, and integrations. The paper frames this not as displacement of expertise but redistribution: humans spend less time on repetitive execution and more on defining objectives, constraints, and acceptance criteria—plus troubleshooting ambiguous cases.
Emerging Roles
- Agent Workflow Designer: Translates domain knowledge into reusable workflows with planning and verification steps.
- AI Platform Engineer: Manages agent runtime, tools, observability, and governance.
- AI QA/Reviewer: Applies rubrics, reviews high-impact outputs, and curates datasets for continuous improvement.
- Domain Steward: Owns acceptance criteria and ensures outputs meet regulatory and business standards.
Career Pathways
Agentic AI elevates skills in systems thinking, product sense, and risk management. Organizations should provide upskilling tracks that combine domain expertise with workflow design and verification practices.
What This Means for Enterprises Adopting AI
From Chat Pilots to Agentic Platforms
If your AI program centers on chat pilots and a few productivity wins, the paper suggests you’re leaving disproportionate value on the table. Agentic platforms capture leverage by:
- Codifying repeatable workflows with observability and SLAs.
- Embedding verification and human oversight.
- Integrating tools and data to close the loop from instruction to action.
Architecture Reference: Minimal Agentic Stack
- Planner: Converts briefs into plans (DAGs) with step metadata and tool bindings.
- Executor: Runs steps with retries, backoff, and resource budgeting.
- Tooling Layer: APIs, code sandboxes, vector and SQL stores, SaaS integrations.
- Verifier: Rubrics, tests, schema checkers, policy engines.
- Observability: Step logs, metrics, artifacts, replay harnesses.
- Governance: RBAC, approvals, audit trails, PII policies.
Data and Security Considerations
- Minimize data exposure via scoped tokens, environment segmentation, and per-run credentials.
- Instrument PII/tag propagation; apply masking strategies at the tool boundary.
- Adopt policy-as-code to enforce redaction, network access, and model selection rules.
Cost and Capacity Planning
- Track unit economics per workflow and per step.
- Use budget-aware planning: the planner proposes a plan and an estimated budget before execution.
- Run canaries and shadow mode before scaling to production volumes.
How to Prepare Your Team for the Agentic AI Transition
90-Day Enablement Plan
- Weeks 1–3: Identify top 3 repeatable tasks per function that consume >10% capacity. Create delegational briefs and acceptance criteria.
- Weeks 4–6: Build MVP workflows with planning, tool calls, and verification. Add observability and cost budgets.
- Weeks 7–9: Run pilots in shadow mode; measure quality, speed, stability; instrument replay-variance harness.
- Weeks 10–12: Productionize with approvals, RBAC, PII safeguards, and on-call escalation. Document runbooks.
Training Curriculum
- Writing effective briefs and acceptance criteria.
- Designing verification rubrics and tests.
- Tool integration basics (APIs, auth, error handling).
- Observability and incident response for agentic workflows.
Playbooks for High-Value Functions
- Engineering: Code changes with unit/integration tests, canary deploys, rollout monitoring.
- Analytics: Data extraction, cleaning, analysis, and report generation with dataset versioning.
- Support: Triage, response drafting, KB updates, escalation to human agents.
- Marketing: Campaign briefs, content production, compliance checks, A/B launch orchestration.
Comparison with Anthropic and Google’s Agentic Approaches
Landscape Overview
OpenAI’s paper centers on Codex as an internal agentic platform and its impact on work. While the paper does not aim to benchmark competitors, it’s useful to contextualize agentic design patterns across providers. Below is a high-level comparison focusing on patterns—planning, tool use, verification, and platform integration.
| Aspect | OpenAI (Codex pattern) | Anthropic (Claude-based patterns) | Google (Gemini/Vertex patterns) |
|---|---|---|---|
| Core interaction | Delegational briefs to plans and runs | Structured prompts with tool use and artifacts | Agents/workflows in Vertex with tool orchestration |
| Planning | Planner generates steps/DAG; re-planning on failures | System prompts for decomposition; tool selection via function calling | Workflow graphs with event-driven orchestration |
| Tooling | APIs, code execution, data stores integrated into runs | Tool use with safety-focused constraints | Cloud-native tools (BigQuery, GCS, Workflows, Cloud Functions) |
| Verification | Rubrics, tests, policy engines; gate-based approvals | Constitutional-style critique loops with human review | Validators in pipelines; policy controls via IAM and org policies |
| Observability | Step logs, artifacts, replay harness | Logging and evaluations within app scaffolds | Cloud logs/metrics; lineage in data and ML pipelines |
| Ecosystem | Internal reuse of workflows/templates | Focus on safety and UI-assisted workflows | Enterprise integration across Google Cloud services |
Choosing a Path
Enterprises can realize agentic gains with any of the major providers by adopting planner-executor-verifier patterns, tool integration, and observability. The crucial differentiators are governance fit, integration costs, and your team’s familiarity with the ecosystem.
Critical Analysis: Limitations of the Paper and Open Questions
Limitations
- Internal context bias: An internal platform with strong executive sponsorship, integrated tools, and ML expertise may not generalize to less mature environments.
- Selection bias: Teams predisposed to AI may adopt agents faster, skewing metrics.
- Task framing: Defining and annotating “complexity” and “quality” is inherently subjective, even with rubrics.
- Compute and cost: Productivity metrics should be juxtaposed with cost curves; without unit economics, ROI may be unclear.
- Safety reporting: While guardrails are discussed, long-run safety and failure modes in adversarial or edge cases merit deeper quantification.
Open Questions
- How do agentic systems behave under distributional shift (e.g., new tools, changing schemas)?
- What are the best practices for human escalation thresholds across domains?
- How does agentic performance evolve over time with feedback loops versus static prompts?
- Which organizational structures produce the best results (centralized platform vs. federated ownership)?
What We’d Like to See Next
- Cross-organization studies to validate generalizability.
- Transparent unit economics and cost-per-outcome models.
- Benchmarks for stability (variance) and reproducibility across replays.
- Safety incident taxonomies with mitigation efficacy metrics.
Actionable Recommendations for CTOs and Engineering Leaders
1) Establish an Agentic Platform Charter
- Define agentic work as a first-class capability with SLAs, budgets, and observability.
- Create platform guardrails: approved tools, data scopes, and model policies.
- Designate ownership: platform team, domain stewards, and on-call rotations.
2) Migrate from Chat Pilots to Reusable Workflows
- Harvest successful prompts from chat; convert to briefs with acceptance criteria.
- Instrument planning, execution, and verification; add replays and runbooks.
- Gate production rollout via canaries and review steps.
3) Invest in Verification and Testing
- Standardize rubrics per domain; encode as code where possible.
- Create golden datasets and replay suites to measure variance.
- Automate policy checks (PII, compliance) at the tool boundary.
4) Align Incentives and Metrics
- Measure outcomes holistically: quality, speed, stability, and cost.
- Reward creation of reusable workflows and improvements in acceptance rates.
- Track rollback ratios to guard against superficial speed gains.
5) Build Skills and Roles
- Upskill ICs on briefs, verification, and observability; cross-train with platform engineers.
- Appoint domain stewards to own acceptance criteria and compliance.
- Fund time for workflow hardening and documentation.
6) Run a 6-Month Roadmap
- Q1: Platform setup, top-5 workflows per function, canary deployment.
- Q2: Expand integrations, unify governance, roll out replay harness and cost dashboards.
Design Patterns and Code Examples for Agentic Workflows
Pattern 1: Planner–Executor–Verifier (PEV)
PEV is the backbone of agentic systems: separate responsibilities for planning, running, and validating work. This separation improves observability and makes failures easier to diagnose.
// JavaScript pseudo: PEV with budget-aware planning
type Brief = { objective: string; constraints: any; resources: any; criteria: any; budget: { tokens: number; dollars: number; hours: number } };
type Plan = { steps: any[]; est: { tokens: number; dollars: number; hours: number } };
type Artifact = any;
async function planner(brief: Brief): Promise<Plan> {
// Use an LLM to propose steps and estimate resource usage
const steps = await llmSuggestSteps(brief);
const est = await llmEstimate(steps, brief);
if (est.dollars > brief.budget.dollars) throw new Error("Budget exceeded");
return { steps, est };
}
async function executor(plan: Plan): Promise<Artifact[]> {
const artifacts: Artifact[] = [];
for (const s of plan.steps) {
const out = await dispatchToolOrLLM(s);
artifacts.push(out);
}
return artifacts;
}
async function verifier(artifacts: Artifact[], criteria: any): Promise<boolean> {
const results = await runRubricsAndTests(artifacts, criteria);
return results.every(r => r.ok);
}
async function run(brief: Brief) {
const plan = await planner(brief);
const arts = await executor(plan);
const ok = await verifier(arts, brief.criteria);
if (!ok) throw new Error("Verification failed");
return arts;
}
Pattern 2: Tool-First Agents
Agents should prefer tools for deterministic tasks (e.g., querying SQL, executing code, calling APIs) and reserve LLM reasoning for planning and interpretation. This reduces cost and variance.
# Python pseudo: tool-first policy
def dispatch(step, tools, llm):
if step["type"] == "sql":
return tools.sql(step["query"])
if step["type"] == "api":
return tools.http(step["method"], step["url"], step["body"])
if step["type"] == "code":
return tools.exec_code(step["language"], step["source"])
# Default to LLM only when no deterministic tool fits
return llm.generate(step["prompt"])
Pattern 3: Guardrails with Policy-as-Code
Policy engines can enforce data boundaries, tool whitelists, and model selection rules at runtime.
// Pseudo: policy check in executor
function policyCheck(step, context, policy) {
if (!policy.toolsAllowed.includes(step.tool)) throw new Error("Tool not allowed");
if (step.usesPII && !policy.piiScopes.includes(context.actor)) throw new Error("PII scope violation");
if (step.model && !policy.modelsAllowed.includes(step.model)) throw new Error("Model not allowed");
}
Pattern 4: Human-in-the-Loop Checkpoints
For high-impact steps, require approval before proceeding. Design UX to show artifacts, diffs, and rubric scores to speed reviews.
# Python pseudo: approval gate
def approval_gate(step_id, artifact, approver):
summary = summarize(artifact)
send_for_review(approver, step_id, summary, artifact)
decision = wait_for_decision(step_id)
if decision != "approved":
raise RuntimeError(f"Step {step_id} not approved: {decision}")
Pattern 5: Replay and Variance Control
To manage stability, regularly replay runs with fixed seeds and identical tool versions. Investigate variance signals before promoting workflows to Tier-1 usage.
Checklists, KPIs, and Governance Templates
Agentic Workflow Readiness Checklist
- Brief includes objective, scope, resources, constraints, acceptance criteria.
- Plan is explicit with step inputs/outputs and tool bindings.
- Verification includes automated checks and rubrics with pass thresholds.
- Budget is set for time, tokens, and external API costs.
- Observability captures step logs, artifacts, metrics, and lineage.
- PII and compliance policy checks enforced at tool boundaries.
- Human escalation points defined for ambiguous/high-impact decisions.
- Replay harness implemented; variance monitored over N replays.
Core KPIs
- Acceptance rate (outputs passing rubrics without rework).
- Lead time from brief to deliverable.
- Variance across replays (target downward trend over time).
- Rollback ratio (for deploy workflows).
- Cost per outcome (dollars per accepted deliverable).
Governance Template: Role-Based Access and Approvals
{
"roles": {
"platform-admin": ["approve-tools", "set-policies", "manage-rbac"],
"domain-steward": ["edit-criteria", "approve-high-impact"],
"contributor": ["run-workflows", "propose-changes"],
"auditor": ["view-logs", "download-artifacts"]
},
"approvals": {
"touching-prod": ["domain-steward"],
"using-pii": ["platform-admin", "domain-steward"],
"exceeding-budget": ["platform-admin"]
},
"policies": {
"modelsAllowed": ["providerA-modelX", "providerB-modelY"],
"toolsAllowed": ["sql", "http", "code", "email"],
"piiScopes": ["support-team", "analytics-team"]
}
}
Closing Thoughts
The June 25, 2026 paper from OpenAI portrays a clear inflection: when AI systems become agentic—planning, invoking tools, verifying, and learning from feedback—they cease to be mere chat companions and start acting like teammates. The reported 97.9% internal adoption of Codex as a primary work interface underscores that this is not only a technical evolution but an organizational one. Task complexity, delegation patterns, and productivity metrics all point toward a future in which teams orchestrate AI as a system of work, not a string of conversations.
For enterprises, the implications are immediate. Shift your center of gravity from chat to agentic workflows. Invest in verification, observability, and governance. Train your people to write briefs, not just prompts. Build a platform that treats agents like services with SLAs and budgets. And measure everything end-to-end. Done right, the move to agentic AI expands the frontier of feasible work—and does so with the safety, reliability, and accountability that modern organizations demand.