The Codex Task Decomposition Playbook: How to Break Complex Projects into Agent-Ready Subtasks for 10x Faster Delivery
The Codex Task Decomposition Playbook: How to Break Complex Projects into Agent-Ready Subtasks for 10x Faster Delivery
Author: Markos Symeonides
Table of Contents
- The art of task decomposition for AI agents
- Why Codex works best with well-scoped, independent tasks
- The DECOMPOSE framework
- Sizing tasks correctly: too big vs too small for Codex
- Dependency mapping and parallel execution strategies
- Managing state and context across subtasks
- Quality gates between subtask completions
- Real-world examples: full-stack app, data pipeline, content system
- Prompt templates for each decomposition stage
- Measuring velocity improvements
- Common decomposition anti-patterns and how to avoid them
- Case study: 40-hour project completed in 4 hours with proper decomposition
- Conclusion
The art of task decomposition for AI agents
Decomposition is the cornerstone of leveraging AI coding agents effectively. Humans handle ambiguity through intuition and context; AI agents excel when presented with clear, well-scoped, independently verifiable tasks. The difference is the difference between giving a junior developer a vague feature and assigning a seasoned engineer a crisp, testable unit of work.
The art lies in translating complex, multi-faceted projects into a set of modular, outcome-driven subtasks that:
- Are independent or have minimal, explicit dependencies
- Have a concrete definition of done and testable outputs
- Fit within context and token budgets without overloading the model
- Support parallel execution to maximize throughput
- Maintain high quality through gates and contracts
Agent-ready decomposition is not merely splitting work smaller. It’s crafting a directed acyclic graph (DAG) of tasks where each node produces an artifact (code, spec, data) with a contract, allowing upstream and downstream tasks to operate safely. This structure optimizes for Codex-style models by controlling context, reducing cross-talk, and enabling deterministic evaluation.
Related reading: Agent Orchestration Patterns, Prompt Engineering Blueprint
Why Codex works best with well-scoped, independent tasks
Codex-class code generation models are powerful pattern matchers with strong local reasoning under constraints. They reward you for sculpting tasks that are:
- Focused: One primary objective per task reduces prompt entropy and increases exactness.
- Context-bounded: Input and contract fit neatly into the model’s effective context window.
- Deterministically testable: Verifiable outcomes enable fast, automatic gating and feedback loops.
- Composable: Outputs are reusable and designed with clear interfaces to feed downstream tasks.
Benefits of well-scoped tasks
- Higher precision: Narrow prompts reduce failure modes and hallucination, targeting specific code transformations or template fits.
- Repeatability: Small tasks with stable prompts yield consistent results, enabling cache reuse and fine-tuning prompt parameters.
- Parallelism: Independent tasks allow you to scale throughput horizontally with multiple agent workers.
- Faster feedback: Shorter cycles mean faster test-run-fix loops, critical for both quality and speed.
Illustrative example: refactoring vs rewriting
Instead of asking an agent to “rewrite the entire authentication module,” decompose into tasks like:
- Extract user session interface from existing code
- Implement adapter for OAuth provider with contract tests
- Refactor middleware to use the new interface
- Add end-to-end tests for login and refresh flows
Each subtask can be precisely prompted, tested, and merged, allowing Codex-class models to operate within a known pattern for each unit of work.
The DECOMPOSE framework
The DECOMPOSE method is a systematic approach to carve complex projects into agent-ready subtasks that flow from definition to evaluation.
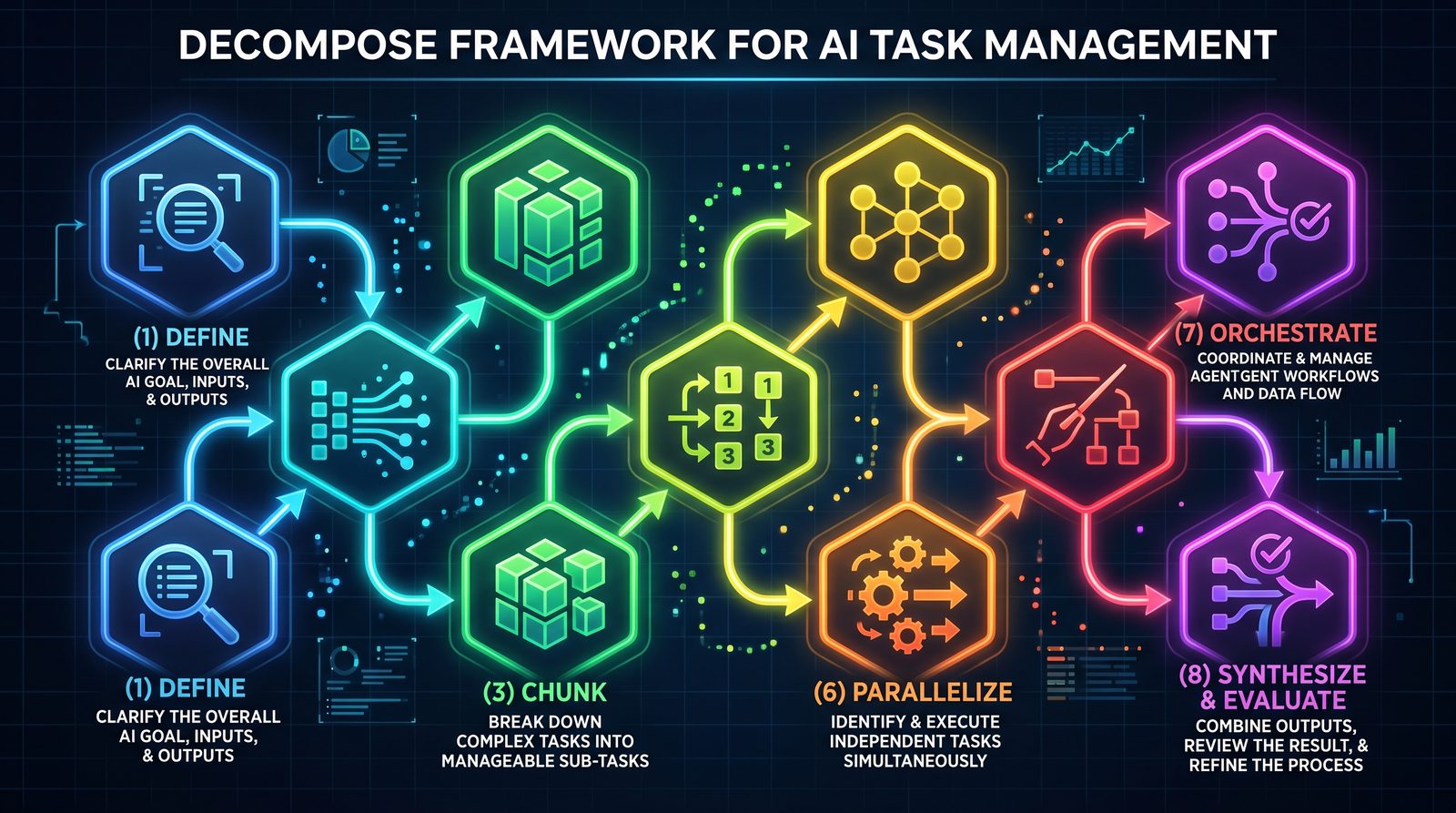
Overview
- Define: Set scope, goals, non-goals, constraints, and success metrics.
- Extract: Pull requirements, interfaces, and existing assets into structured briefs.
- Chunk: Split work into cohesive, testable units with contracts.
- Order: Sequence tasks and identify milestones.
- Map dependencies: Build the task DAG and critical path.
- Parallelize: Maximize concurrent execution within constraints.
- Orchestrate: Implement the pipelines, workers, and context passing.
- Synthesize: Integrate outputs, resolve conflicts, and harmonize styles.
- Evaluate: Enforce quality gates, measure outcomes, and learn.
D — Define
Purpose
Create a concise project charter with unambiguous objectives and a measurable definition of done (DoD).
Actions
- Write a one-paragraph problem statement and a bulleted DoD
- List constraints: performance, security, stack, deadlines
- Identify known unknowns and risks
- Establish metrics: coverage %, latency thresholds, acceptance tests
Artifacts
{
"project": "User subscriptions MVP",
"scope": [
"Stripe billing integration",
"Role-based access control (RBAC)",
"Basic admin dashboard"
],
"non_goals": ["Analytics pipeline", "Promotion engine"],
"constraints": {
"stack": ["Next.js", "Node", "Postgres", "Stripe"],
"security": ["OWASP Top 10"],
"performance": {"p95_latency_ms": 300}
},
"definition_of_done": [
"E2E tests for subscribe/cancel succeed",
"RBAC enforced on protected routes",
"Admin dashboard lists active subscriptions"
],
"metrics": {"test_coverage": 0.8}
}
Prompt template
System: You are a senior engineer and delivery lead.
User: Draft a project charter for <PROJECT> with:
- Scope (in), Non-goals (out)
- Constraints (stack, perf, security)
- Definition of Done (bullet list, testable)
- Risks and assumptions
Return valid JSON matching keys: project, scope, non_goals, constraints, definition_of_done, risks.
E — Extract
Purpose
Gather and normalize inputs: requirements, APIs, schemas, existing code segments, and domain rules into structured briefs.
Actions
- Scrape and summarize existing code interfaces
- Normalize requirements into user stories and acceptance criteria
- Create interface contracts for external systems (e.g., Stripe)
Artifacts
{
"stories": [
{"id": "SUB-1", "as_a": "user", "i_want": "subscribe", "so_that": "I can access premium",
"acceptance": ["can enter card", "see active status", "receive receipt email"] }
],
"interfaces": {
"stripe": {
"subscribe": {"input": {"plan_id": "string", "user_id": "uuid"}, "output": {"session_url": "url"}},
"webhooks": ["checkout.session.completed", "customer.subscription.deleted"]
}
}
}
Prompt template
System: You extract requirements and APIs into concise, testable briefs.
User: Given the following resources:
- Requirements doc (text)
- Existing code (snippets)
- External API doc (links or text)
Extract:
1) User stories with acceptance criteria
2) Interfaces (functions, endpoints) with input/output schemas
Return JSON with keys: stories, interfaces, constraints, open_questions.
C — Chunk
Purpose
Split the project into cohesive, independently testable tasks with clear contracts and outputs.
Actions
- Identify deliverable artifacts per task (file, module, doc)
- Define inputs, outputs, and acceptance tests per task
- Set size bounds (tokens, LOC, time budget)
Artifacts
tasks:
- id: API-STRIPE-ADAPTER
goal: "Implement Stripe adapter for subscriptions"
inputs: ["interfaces.stripe", "env.STRIPE_KEY"]
outputs: ["src/payments/stripeAdapter.ts"]
tests: ["tests/payments/stripeAdapter.spec.ts"]
size: {"tokens_max": 2000, "loc_max": 200}
- id: RBAC-MIDDLEWARE
goal: "RBAC middleware enforcing roles"
inputs: ["stories SUB-1", "db schema roles"]
outputs: ["src/middleware/rbac.ts"]
tests: ["tests/middleware/rbac.spec.ts"]
size: {"tokens_max": 1800, "loc_max": 120}
Prompt template
System: You design task breakdowns for AI agent execution.
User: Using the project charter and extracted briefs, propose a task list where each task:
- Has a single clear goal
- Declares inputs, outputs, tests
- Fits within 1,500-2,500 tokens and <= 200 LOC
Return YAML under key 'tasks' with id, goal, inputs, outputs, tests, size.
O — Order
Purpose
Sequence tasks from foundations to features, identifying milestones and critical path.
Actions
- Identify tasks that unblock others (e.g., contracts before implementations)
- Group related tasks into milestones
- Mark critical path items
Artifacts
milestones:
- id: M1-CONTRACTS
tasks: ["API-STRIPE-ADAPTER", "RBAC-CONTRACTS"]
- id: M2-IMPLEMENTATION
tasks: ["RBAC-MIDDLEWARE", "API-STRIPE-ADAPTER-TESTS"]
critical_path: ["RBAC-CONTRACTS", "RBAC-MIDDLEWARE", "E2E-SUBS"]
Prompt template
System: You create execution plans with milestones and critical path.
User: Given a YAML task list, produce:
- Milestones grouping 3-5 related tasks
- Critical path (list of task IDs)
- Suggested execution order
Ensure that contract tasks precede implementation tasks.
M — Map dependencies
Purpose
Construct the dependency graph (DAG), making upstream/downstream relationships explicit. This is the skeleton of parallel execution.
Actions
- Map task output to dependent task inputs
- Create a DAG structure with adjacency lists
- Identify cycles and break them with contracts
Artifacts
dag:
RBAC-CONTRACTS: []
API-STRIPE-ADAPTER: ["RBAC-CONTRACTS"]
RBAC-MIDDLEWARE: ["RBAC-CONTRACTS"]
E2E-SUBS: ["API-STRIPE-ADAPTER", "RBAC-MIDDLEWARE"]
Prompt template
System: You build dependency graphs for agent task orchestration.
User: From the task YAML, map dependencies by matching outputs to inputs and logical order.
Return a DAG as YAML: task_id: [dependency_ids].
Detect cycles; propose contract tasks to break them if found.
P — Parallelize
Purpose
Maximize concurrent work without violating contracts or overloading shared resources.
Actions
- Identify independent branches in the DAG
- Set worker pool sizes per capability (e.g., codegen vs testing)
- Use rate limits and quotas for external APIs
Artifacts
parallel_plan:
workers:
codegen: 6
review: 2
test: 3
batches:
- ["RBAC-CONTRACTS"]
- ["API-STRIPE-ADAPTER", "RBAC-MIDDLEWARE"]
- ["E2E-SUBS"]
Prompt template
System: You propose parallel execution batches under resource constraints.
User: Given a DAG and worker capacities, output batches of tasks that can run concurrently.
Respect dependencies and ensure high utilization.
O — Orchestrate
Purpose
Implement the runner that schedules tasks, manages prompts, passes context, and enforces quality gates.
Actions
- Build a controller to topologically sort tasks and dispatch to workers
- Define a context contract per task (minimal, precise)
- Persist artifacts and metadata for reproducibility
Example orchestrator (Python)
import asyncio, json, uuid
from collections import defaultdict, deque
class ArtifactStore:
def __init__(self):
self.blob = {} # artifact_id -> bytes
self.meta = {} # artifact_id -> metadata
def put(self, task_id, filename, content, meta):
aid = f"{task_id}:{filename}:{uuid.uuid4()}"
self.blob[aid] = content.encode()
self.meta[aid] = {**meta, "task_id": task_id, "filename": filename}
return aid
def get_latest(self, task_id, filename):
candidates = [(aid, m) for aid, m in self.meta.items()
if m["task_id"] == task_id and m["filename"] == filename]
if not candidates: return None
candidates.sort(key=lambda x: x[1].get("ts", 0))
return candidates[-1][0], self.blob[candidates[-1][0]].decode()
class Task:
def __init__(self, id, deps, run):
self.id = id
self.deps = deps
self.run = run
async def run_task(task, context, store):
try:
res = await task.run(context, store)
return task.id, "success", res
except Exception as e:
return task.id, "error", str(e)
async def orchestrate(tasks, dag, context):
indegree = defaultdict(int)
edges = defaultdict(list)
for t, deps in dag.items():
indegree[t] += 0
for d in deps:
edges[d].append(t)
indegree[t] += 1
q = deque([t for t in dag if indegree[t]==0])
store = ArtifactStore()
completed = set()
while q:
batch = list(q)
q.clear()
results = await asyncio.gather(*[run_task(tasks[b], context, store) for b in batch])
for tid, status, _ in results:
if status != "success":
raise RuntimeError(f"Task {tid} failed")
completed.add(tid)
for nxt in edges[tid]:
indegree[nxt] -= 1
if indegree[nxt] == 0:
q.append(nxt)
return store
# Example run functions would prompt Codex and write files/tests, then run gate checks.
Prompt template
System: You are an orchestration planner for AI agent workflows.
User: Create an execution plan and controller outline in <LANGUAGE> to:
- Run tasks in topological order with parallel batches
- Pass minimal context artifacts by ID
- Persist outputs with metadata (task_id, filename, checksum)
- Enforce per-task gates (lint, unit tests, contracts)
S — Synthesize
Purpose
Integrate and harmonize outputs: merge code, standardize styles, reconcile contracts, and ensure cross-module cohesion.
Actions
- Run formatters and linters across the repo
- Generate a unified API/Module index or README from code
- Resolve merge conflicts by regenerating localized diffs
Artifacts
{
"merge_report": {
"files_changed": 12,
"conflicts": ["src/app.ts", "src/middleware/rbac.ts"],
"actions": ["Regenerated rbac.ts using updated contracts"]
}
}
Prompt template
System: You are a code integration specialist.
User: Given these files and their diffs, resolve conflicts while honoring interfaces and tests.
- Return unified files
- Update imports and styles to match project conventions
- Do not modify unchanged logic
E — Evaluate
Purpose
Enforce quality gates, measure outcomes, collect learnings, and feed back improvements to prompts and patterns.
Actions
- Run unit, integration, and contract tests
- Collect metrics: pass rates, cycle times, token usage
- Perform post-mortem on failures and update templates
Artifacts
{
"metrics": {
"unit_pass_rate": 0.97,
"coverage": 0.84,
"mean_cycle_time_sec": 420,
"token_per_task_avg": 1800
},
"learnings": [
"Split RBAC middleware into authz and policy modules next time",
"Introduce schema types to reduce downstream type errors"
]
}
Prompt template
System: You assess deliverables against objective gates and produce improvement actions.
User: Evaluate the project against:
- Unit/integration test results
- Lint/format/security scan
- Definition of Done and metrics
Return: pass/fail summary, defects, suggested prompt/template updates.
Sizing tasks correctly: too big vs too small for Codex
Right-sized tasks maximize model effectiveness and orchestration throughput. Oversized tasks exceed context budgets and invite ambiguity; undersized tasks multiply overhead and coupling risk.
Heuristics for code tasks
- Target 800–2,200 tokens total prompt + expected output; cap at 3,000 unless necessary.
- Output 50–200 LOC per task; cap at 300 LOC for code generation.
- Include no more than 4–6 artifacts (files) per task. Prefer 1–3 artifacts.
- Context: Provide only relevant contracts, interfaces, and examples (1–2 screens worth).
- Time budget: Design for 5–20 minutes of wall-clock per task, including gates.
Heuristics for data/infra tasks
- Define clear I/O schemas (e.g., JSON Schema, Pydantic models).
- Provide 1–2 representative samples per data shape.
- Use stubbed endpoints for external services; swap secrets at runtime.
Detecting scope errors
| Symptom | Too Big | Too Small | Fix |
|---|---|---|---|
| Token usage | > 3,000, frequent truncation | < 400, frequent uncertainty | Split by interface boundaries or merge microtasks |
| Testability | Hard to define unit tests | Overhead dominating effort | Introduce contracts; batch similar tiny tasks |
| Coupling | Many implicit dependencies | Hidden duplicates across tasks | Refactor to modules; centralize shared utilities |
Practical example
Task “Build dashboard” is too big. Refactor to:
- Design dashboard routes and layouts (contracts, mock data)
- Implement data table component with pagination
- Hook component to API using typed client
Avoid splitting into “write single CSS class” level microtasks unless automated by a code mod pipeline.
Dependency mapping and parallel execution strategies
Dependency mapping and parallelism are the heart of acceleration. Build the DAG carefully, then execute wide where safe, narrow where necessary.
Building the DAG
Automated DAG building code (Python)
from typing import Dict, List, Set
def build_dag(tasks: List[dict]) -> Dict[str, Set[str]]:
outputs_to_task = {}
for t in tasks:
for out in t.get("outputs", []):
outputs_to_task[out] = t["id"]
dag = {}
for t in tasks:
deps = set()
for inp in t.get("inputs", []):
if inp in outputs_to_task:
deps.add(outputs_to_task[inp])
dag[t["id"]] = deps
# Sanity checks
def detect_cycle(dag):
temp, perm, order = set(), set(), []
def visit(n):
if n in perm: return
if n in temp: raise ValueError("Cycle detected")
temp.add(n)
for m in dag.get(n, []): visit(m)
temp.remove(n); perm.add(n); order.append(n)
for n in dag:
if n not in perm: visit(n)
return order[::-1]
order = detect_cycle(dag)
return dag
Parallel execution strategies
- Batch by level: Execute tasks with the same indegree (no pending deps) together.
- Worker specialization: Separate pools for codegen, testing, and integration to avoid bottlenecks.
- Chunky parallelism: Aim for batches of 2–6 tasks to balance overhead and utilization.
- Backpressure control: Limit in-flight tasks based on CPU, I/O, and API quotas. Use concurrency primitives (semaphores).
- Fail-fast for critical path: Prioritize critical tasks’ completion to reduce total risk.
Async executor example (Node.js)
import pLimit from 'p-limit';
type Task = {
id: string;
deps: string[];
run: () => Promise<void>;
};
export async function runBatches(tasks: Task[]) {
const byId = new Map(tasks.map(t => [t.id, t]));
const depsLeft = new Map(tasks.map(t => [t.id, new Set(t.deps)]));
const ready: string[] = tasks.filter(t => t.deps.length === 0).map(t => t.id);
const limit = pLimit(4);
const finished = new Set<string>();
while (ready.length) {
const batch = [...ready.splice(0)];
await Promise.all(batch.map(id => limit(async () => {
await byId.get(id)!.run();
finished.add(id);
for (const [tid, deps] of depsLeft.entries()) {
deps.delete(id);
if (deps.size === 0 && !finished.has(tid)) ready.push(tid);
}
})));
}
if (finished.size !== tasks.length) throw new Error('Deadlock suspected');
}
Resilience tactics
- Retries with exponential backoff for transient failures (e.g., API rate limits)
- Idempotent task design: repeated runs overwrite artifacts deterministically
- Checkpointing: persist intermediate outputs for resume-on-fail
Managing state and context across subtasks
Passing the right context—and only the right context—determines agent effectiveness. Excess context dilutes focus; missing context induces errors. Manage state explicitly with manifests and artifact registries.
Artifact manifest
{
"project_id": "subs-mvp-2026-06",
"artifacts": [
{
"artifact_id": "API-STRIPE-ADAPTER:src/payments/stripeAdapter.ts:8d5",
"task_id": "API-STRIPE-ADAPTER",
"type": "code",
"checksum": "sha256:...",
"schema": "typescript",
"tags": ["payments", "stripe"],
"created_at": 1719650000
}
]
}
Context contract per task
- Minimal inputs: Only interfaces, schemas, and direct dependencies
- Summarized upstream: Use text summaries of modules instead of full files when possible
- Stable identifiers: Refer to artifacts by IDs, not by file paths only
Example: context packer (Python)
def pack_context(task, store):
ctx = {"task_id": task["id"], "contracts": [], "examples": []}
for inp in task.get("inputs", []):
# Resolve from store. You can encode rules: if input ends with .schema.json, include full; else summarized.
aid_and_content = store.get_latest(*inp.split(":", 1)) if ":" in inp else None
if aid_and_content:
aid, content = aid_and_content
if inp.endswith(".schema.json"):
ctx["contracts"].append({"id": aid, "content": content})
else:
ctx["contracts"].append({"id": aid, "content": summarize(content)})
return ctx
def summarize(text, max_chars=1200):
# naive summarizer, replace with model-based chunked summarizer
return text[:max_chars] + ("..." if len(text) > max_chars else "")
Session memory and RAG
- Persist embeddings of code and interfaces for retrieval by similarity
- Use per-task system prompts to pin conventions (naming, logging, error handling)
- Keep a run log with prompts, responses, and gate results for traceability
Run log entry example
{
"task_id": "RBAC-MIDDLEWARE",
"prompt_id": "r1",
"system": "You are a senior TypeScript engineer. Follow project's ESLint/Prettier config. Use functional style.",
"user": "Implement RBAC middleware per contract: ...",
"response_hash": "sha256:abc...",
"gates": {"lint": "pass", "unit": "pass", "contract": "pass"}
}
Quality gates between subtask completions
Quality gates ensure that each subtask’s output meets standards before unblocking downstream tasks. They also provide early error signals, preserving throughput and integrity.
Gate types
- Static analysis: Linting, formatting, type checks
- Unit tests: Task-specific tests that assert local correctness
- Contract tests: Inputs/outputs match declared schemas or interfaces
- Security scans: Dependency vulnerabilities, basic SAST rules
- Performance smoke: p95 latency under small load for critical paths
Gate runner example (bash + Node)
# gates.sh
set -euo pipefail
echo "Running gates for $1"
case "$1" in
"lint")
npm run lint
;;
"type")
npm run typecheck
;;
"unit")
npm test -- --runInBand
;;
"contract")
node scripts/contract-check.js
;;
"security")
npm audit --audit-level=moderate
;;
*)
echo "Unknown gate $1"; exit 2;;
esac
Contract check script
// scripts/contract-check.js
import fs from 'fs';
import Ajv from 'ajv';
const ajv = new Ajv({allErrors: true});
const schema = JSON.parse(fs.readFileSync('contracts/stripe.subscribe.schema.json', 'utf8'));
const sample = JSON.parse(fs.readFileSync('samples/stripe.subscribe.sample.json', 'utf8'));
const validate = ajv.compile(schema);
if (!validate(sample)) {
console.error(validate.errors);
process.exit(1);
}
console.log('Contract check passed');
Gate configuration
gates:
RBAC-MIDDLEWARE: ["lint", "type", "unit", "contract"]
API-STRIPE-ADAPTER: ["lint", "unit", "contract", "security"]
Prompt template for gate-aware generation
System: You must produce code that passes these gates: <GATES>.
User: Implement <TASK> with:
- Follow ESLint/Prettier rules
- Types must pass tsc
- Unit tests in <TEST_FILE> must pass (write/update tests if listed)
- Conform to JSON schema <SCHEMA_FILE>
Return only changed files with clear file paths and contents.
Real-world examples: breaking down a full-stack app, a data pipeline, a content system
This section demonstrates full decompositions using the DECOMPOSE method, concrete tasks, prompts, and orchestration patterns.
Example 1: Full-stack app — Subscription-enabled Next.js app
Define
{
"project": "Subscription-enabled Next.js app",
"scope": ["Stripe subscriptions", "RBAC", "Admin dashboard (list users/subs)"],
"non_goals": ["Coupons", "Detailed analytics"],
"constraints": {"stack": ["Next.js 14", "TypeScript", "Prisma", "Postgres"], "security": ["OWASP Top 10"]},
"definition_of_done": ["Subscribe/cancel flow E2E passes", "RBAC enforced for premium routes", "Admin sees active subs"]
}
Extract
{
"stories": [
{"id":"SUB-1", "as_a":"user", "i_want":"subscribe", "acceptance":["pay with card", "immediate access", "receipt email"]},
{"id":"SUB-2", "as_a":"user", "i_want":"cancel", "acceptance":["no future charges", "grace until period end"]}
],
"interfaces": {
"stripe": {
"createCheckoutSession": {"input":{"priceId":"string", "customerId":"string"}, "output":{"url":"string"}},
"webhooks": ["checkout.session.completed", "customer.subscription.deleted"]
}
},
"constraints": {"pricing_model":"monthly", "regions":["US", "EU"]}
}
Chunk
tasks:
- id: DB-SCHEMA
goal: "Define Prisma models for User, Subscription, Role"
inputs: []
outputs: ["prisma/schema.prisma"]
tests: ["tests/db/schema.migration.spec.ts"]
size: {"tokens_max": 1400, "loc_max": 120}
- id: CONTRACTS-RBAC
goal: "RBAC contracts: roles enum, guards interface"
inputs: []
outputs: ["contracts/rbac.types.ts"]
tests: ["tests/contracts/rbac.spec.ts"]
- id: STRIPE-ADAPTER
goal: "Stripe adapter module"
inputs: ["interfaces.stripe", "env.STRIPE_KEY"]
outputs: ["src/payments/stripe.ts"]
tests: ["tests/payments/stripe.spec.ts"]
- id: API-ROUTES
goal: "Next.js API routes for subscribe/cancel/webhook"
inputs: ["contracts/rbac.types.ts", "src/payments/stripe.ts"]
outputs: ["src/app/api/subscribe/route.ts", "src/app/api/webhook/route.ts", "src/app/api/cancel/route.ts"]
tests: ["tests/api/subs.e2e.spec.ts"]
- id: RBAC-MIDDLEWARE
goal: "Middleware to enforce premium routes"
inputs: ["contracts/rbac.types.ts"]
outputs: ["src/middleware/rbac.ts"]
tests: ["tests/middleware/rbac.spec.ts"]
- id: ADMIN-DASHBOARD
goal: "Admin dashboard page"
inputs: ["prisma/schema.prisma", "contracts/rbac.types.ts"]
outputs: ["src/app/admin/page.tsx"]
tests: ["tests/ui/admin.spec.ts"]
- id: E2E-SUBS
goal: "Playwright tests for subscribe/cancel"
inputs: ["API-ROUTES", "RBAC-MIDDLEWARE", "ADMIN-DASHBOARD"]
outputs: ["tests/e2e/subs.spec.ts"]
tests: []
Order and map dependencies
dag:
DB-SCHEMA: []
CONTRACTS-RBAC: []
STRIPE-ADAPTER: []
API-ROUTES: ["STRIPE-ADAPTER", "CONTRACTS-RBAC"]
RBAC-MIDDLEWARE: ["CONTRACTS-RBAC"]
ADMIN-DASHBOARD: ["DB-SCHEMA", "CONTRACTS-RBAC"]
E2E-SUBS: ["API-ROUTES", "RBAC-MIDDLEWARE", "ADMIN-DASHBOARD"]
Parallelize
batches:
- ["DB-SCHEMA", "CONTRACTS-RBAC", "STRIPE-ADAPTER"]
- ["API-ROUTES", "RBAC-MIDDLEWARE", "ADMIN-DASHBOARD"]
- ["E2E-SUBS"]
Gate configuration
gates:
DB-SCHEMA: ["lint", "unit"]
CONTRACTS-RBAC: ["lint", "unit"]
STRIPE-ADAPTER: ["lint", "unit", "contract"]
API-ROUTES: ["lint", "unit", "contract"]
RBAC-MIDDLEWARE: ["lint", "type", "unit"]
ADMIN-DASHBOARD: ["lint", "unit"]
E2E-SUBS: ["unit"]
Representative task prompt
System: You are a senior Next.js + TypeScript engineer.
User: Implement Next.js API routes for subscribe, cancel, and Stripe webhooks.
Constraints:
- Use src/payments/stripe.ts adapter
- Enforce RBAC guards per contracts/rbac.types.ts
- Return only file updates to: src/app/api/subscribe/route.ts, src/app/api/cancel/route.ts, src/app/api/webhook/route.ts
- Include minimal happy-path unit tests in tests/api/subs.e2e.spec.ts stub
- Must pass lint and type checks
Orchestration notes
- Run first batch concurrently; as soon as contracts and adapter pass gates, trigger API-ROUTES and RBAC-MIDDLEWARE in parallel.
- Admin dashboard depends on schema; release it when DB-SCHEMA passes its gate.
- E2E tests run last, verifying workflow end-to-end.
Example 2: Data pipeline — Log ingestion to analytics
Define
{
"project": "Server log analytics pipeline",
"scope": ["Ingest logs", "Normalize schema", "Aggregate metrics", "Expose metrics API"],
"constraints": {"stack": ["Python", "Airflow", "DuckDB", "FastAPI"], "perf": {"throughput_lps": 5000}}
}
Extract
{
"schemas": {
"raw_log": {"timestamp":"string","level":"string","service":"string","message":"string","meta":"object"},
"norm_log": {"ts":"int64","sev":"enum[DEBUG,INFO,WARN,ERROR]","svc":"string","msg":"string","meta":"json"}
},
"interfaces": {
"kafka": {"topic":"logs", "brokers":["..."]},
"api_metrics": {"get:/metrics?svc=&from=&to=": {"output": {"p95": "float", "error_rate":"float"}}}
}
}
Chunk
tasks:
- id: INGEST-CONSUMER
goal: "Kafka consumer to write raw logs to object storage"
inputs: ["schemas.raw_log"]
outputs: ["ingest/consumer.py"]
tests: ["tests/ingest/consumer_test.py"]
- id: NORMALIZE-ETL
goal: "ETL to convert raw to normalized DuckDB"
inputs: ["schemas.raw_log", "schemas.norm_log"]
outputs: ["etl/normalize.py", "sql/norm_schema.sql"]
tests: ["tests/etl/normalize_test.py"]
- id: AGG-METRICS
goal: "Daily aggregation job for p95 latency and error rates"
inputs: ["sql/norm_schema.sql"]
outputs: ["etl/aggregate.py", "sql/agg_metrics.sql"]
tests: ["tests/etl/aggregate_test.py"]
- id: API-METRICS
goal: "FastAPI endpoint for metrics"
inputs: ["sql/agg_metrics.sql"]
outputs: ["api/main.py"]
tests: ["tests/api/metrics_test.py"]
- id: AIRFLOW-DAG
goal: "Airflow DAG to orchestrate ETL and aggregations"
inputs: ["etl/normalize.py", "etl/aggregate.py"]
outputs: ["dags/logs_pipeline.py"]
tests: ["tests/dags/pipeline_test.py"]
Dependencies and batches
dag:
INGEST-CONSUMER: []
NORMALIZE-ETL: ["INGEST-CONSUMER"]
AGG-METRICS: ["NORMALIZE-ETL"]
API-METRICS: ["AGG-METRICS"]
AIRFLOW-DAG: ["NORMALIZE-ETL", "AGG-METRICS"]
batches:
- ["INGEST-CONSUMER"]
- ["NORMALIZE-ETL"]
- ["AGG-METRICS", "AIRFLOW-DAG"]
- ["API-METRICS"]
Gate examples
- Unit tests with small sample logs
- Contract validation of schemas (Pydantic)
- Performance smoke: process 100k logs under 60s in CI
Sample code: Pydantic schema and ETL skeleton
# etl/models.py
from pydantic import BaseModel
from typing import Optional, Dict
class RawLog(BaseModel):
timestamp: str
level: str
service: str
message: str
meta: Optional[Dict] = None
class NormLog(BaseModel):
ts: int
sev: str
svc: str
msg: str
meta: Optional[Dict] = None
# etl/normalize.py
import duckdb, json
from models import RawLog, NormLog
def normalize(input_path: str, output_db: str):
con = duckdb.connect(output_db)
con.execute("CREATE TABLE IF NOT EXISTS logs (ts BIGINT, sev VARCHAR, svc VARCHAR, msg VARCHAR, meta JSON)")
with open(input_path) as f:
for line in f:
raw = RawLog(**json.loads(line))
norm = NormLog(ts=to_epoch(raw.timestamp), sev=map_level(raw.level),
svc=raw.service, msg=raw.message, meta=raw.meta)
con.execute("INSERT INTO logs VALUES (?, ?, ?, ?, ?)", [norm.ts, norm.sev, norm.svc, norm.msg, json.dumps(norm.meta or {})])
con.close()
Example 3: Content system — Multi-channel content engine
Define
{
"project": "Content engine for blog, newsletter, and social",
"scope": ["Topic research", "Outline", "Drafting", "Editing", "Channel formatting"],
"constraints": {"style_guide": "Tech-journal, concise", "plagiarism": "< 10% overlap", "tone": "expert"}
}
Extract
{
"guidelines": {
"voice": "authoritative, accessible",
"structure": ["hook", "thesis", "evidence", "examples", "CTA"]
},
"channels": ["blog", "newsletter", "LinkedIn", "X"]
}
Chunk
tasks:
- id: RESEARCH-BRIEF
goal: "Research sources and produce bullet brief"
inputs: ["topic"]
outputs: ["briefs/<topic>.md"]
tests: ["checks/plagiarism.md"]
- id: OUTLINE
goal: "Produce detailed outline with sections and key points"
inputs: ["briefs/<topic>.md", "guidelines"]
outputs: ["outlines/<topic>.md"]
tests: ["checks/outline-structure.md"]
- id: DRAFT
goal: "Write first draft with evidence and examples"
inputs: ["outlines/<topic>.md"]
outputs: ["drafts/<topic>.md"]
tests: ["checks/style-lint.md"]
- id: EDIT
goal: "Edit for clarity, consistency, and plagiarism"
inputs: ["drafts/<topic>.md"]
outputs: ["final/<topic>.md"]
tests: ["checks/plagiarism.md", "checks/grade-level.md"]
- id: FORMAT-CHANNELS
goal: "Produce channel-specific variants"
inputs: ["final/<topic>.md"]
outputs: ["channels/<topic>_blog.md", "channels/<topic>_newsletter.md", "channels/<topic>_linkedin.txt", "channels/<topic>_x.txt"]
tests: ["checks/channel-limits.md"]
Dependencies and parallelization
dag:
RESEARCH-BRIEF: []
OUTLINE: ["RESEARCH-BRIEF"]
DRAFT: ["OUTLINE"]
EDIT: ["DRAFT"]
FORMAT-CHANNELS: ["EDIT"]
batches:
- ["RESEARCH-BRIEF"]
- ["OUTLINE"]
- ["DRAFT"]
- ["EDIT"]
- ["FORMAT-CHANNELS"]
Quality gates
- Plagiarism scan and style lint
- Readability score bounds
- Channel char limits and hashtag policy
Related: AI Content Production Pipeline
Prompt templates for each decomposition stage
Use these templates to standardize prompts and reduce variance across runs.
Define
System: Delivery lead. Optimize for clarity and testability.
User: Define the project charter for <PROJECT> with:
- In-scope / Out-of-scope
- Constraints (stack, security, performance)
- Definition of Done (testable bullets)
- Risks and assumptions
Return JSON keys: project, scope, non_goals, constraints, definition_of_done, risks.
Extract
System: Requirements engineer.
User: Extract user stories, acceptance criteria, and interface contracts from the following materials:
<PASTE MATERIALS>
Return JSON: stories, interfaces, constraints, open_questions.
Chunk
System: Task designer.
User: Propose a task list such that each task:
- Has one clear goal and single primary artifact
- Declares inputs, outputs, tests
- Fits within tokens_max and loc_max
Return YAML under key 'tasks'.
Order
System: Planner.
User: Group tasks into milestones and label critical path. Ensure contracts precede implementations.
Return: milestones, critical_path, suggested_order.
Map dependencies
System: Dependency mapper.
User: Build a DAG: task_id: [dependencies]. Match outputs to downstream inputs and logic. Detect cycles; propose contract tasks when needed.
Parallelize
System: Scheduler.
User: Given DAG and resources (codegen=6, review=2, test=3), propose concurrent batches that maximize throughput.
Return: batches and notes on backpressure.
Orchestrate
System: Orchestration engineer.
User: Outline a controller that:
- Topologically schedules tasks with parallel batches
- Passes minimal context (artifact IDs)
- Persists outputs and metadata
- Applies gates per task
Return skeleton code in <LANGUAGE>.
Synthesize
System: Integrator.
User: Merge these files and resolve conflicts respecting contracts and tests. Conform to style and import conventions.
Evaluate
System: QA lead.
User: Evaluate deliverables against gates, DoD, and metrics. Summarize defects and propose prompt/template improvements.
Measuring velocity improvements
You cannot improve what you cannot measure. Instrument your pipeline to track throughput, cycle time, pass rates, and token budgets.
Key metrics
- Throughput: tasks completed per hour/day
- Cycle time: time from task ready to gate pass
- First pass yield (FPY): percent of tasks passing gates on first try
- Rework rate: average retries per task
- Token efficiency: tokens per LOC or artifact
Logging schema
{
"task_id": "API-ROUTES",
"status": "pass",
"started_at": 1719640000,
"ended_at": 1719640320,
"tokens_in": 1200,
"tokens_out": 800,
"retries": 1,
"gates": {"lint": "pass", "unit": "pass", "contract": "pass"}
}
SQL for metrics (DuckDB/Postgres)
-- Throughput by hour
SELECT date_trunc('hour', to_timestamp(ended_at)) AS hour, count(*) AS tasks_done
FROM run_logs WHERE status = 'pass'
GROUP BY 1 ORDER BY 1;
-- Cycle time stats
SELECT percentile_cont(0.5) WITHIN GROUP (ORDER BY ended_at - started_at) AS p50,
percentile_cont(0.95) WITHIN GROUP (ORDER BY ended_at - started_at) AS p95
FROM run_logs WHERE status = 'pass';
-- First pass yield
SELECT 1.0 * sum(CASE WHEN retries = 0 THEN 1 ELSE 0 END) / count(*) AS fpy
FROM run_logs WHERE status = 'pass';
-- Token efficiency
SELECT avg(tokens_in + tokens_out) / NULLIF(avg(loc_changed), 0) AS tokens_per_loc
FROM run_logs WHERE status = 'pass';
Visualization tips
- Plot cumulative flow (tasks in progress vs completed) to spot bottlenecks
- Track FPY over time; rising FPY indicates better prompts and chunking
- Monitor token per task; spikes indicate scope creep
Experiment design
- Baseline: Run a project with coarse tasks sequentially
- Treatment: Run with DECOMPOSE, parallel batches, and gates
- Hold constant: codebase, team, target DoD, and quality gates
- Compare: total lead time, FPY, defects found post-merge
Common decomposition anti-patterns and how to avoid them
1) The Mega-Prompt
Symptom: One enormous prompt asking the agent to build a whole feature end-to-end.
Risk: Context overflow, incoherent outputs, untestable artifacts.
Fix: Apply Chunk and Map dependencies. Insert contracts and tests early.
2) Hidden Coupling
Symptom: Tasks depend on implicit conventions or global state.
Risk: Non-reproducible runs; downstream instability.
Fix: Explicit contracts, artifact manifests, and minimal context packs.
3) Oscillating Scope
Symptom: Tasks expand and shrink mid-execution due to unclear DoD.
Risk: Rework and schedule slip.
Fix: Strong Define step; gate on written DoD; do not accept outputs without meeting acceptance criteria.
4) Excessive Microtasks
Symptom: Dozens of tiny tasks each changing one line.
Access 40,000+ AI Prompts for ChatGPT, Claude & Codex — Free!
Subscribe to get instant access to our complete Notion Prompt Library — the largest curated collection of prompts for ChatGPT, Claude, OpenAI Codex, and other leading AI models. Optimized for real-world workflows across coding, research, content creation, and business.
Risk: Orchestration overhead and merge conflicts.
Fix: Batch micro-changes into cohesive code mods; use code transformation scripts.
5) Serial Everything
Symptom: Unnecessary serialization of independent tasks.
Risk: Underutilized agents; long lead times.
Fix: Build a DAG; batch by level; set worker pools.
6) Missing Gates
Symptom: Outputs pass through without lint/tests.
Risk: Cascading failures; difficult debugging.
Fix: Enforce gates per task with fail-fast and retry loops.
7) Context Firehose
Symptom: Dumping entire repos into prompts.
Risk: Token waste; reduced precision.
Fix: Summarize, select, and reference artifacts by ID; adopt retrieval for on-demand context.
8) Unversioned Artifacts
Symptom: Overwriting files without metadata.
Risk: Non-reproducibility; hard to roll back.
Fix: Artifact registry with IDs, checksums, timestamps; per-task logs.
9) No Feedback Loop
Symptom: Repeating failures without improving prompts/templates.
Risk: Flat or declining FPY.
Fix: Evaluate step must capture learnings and update prompt libraries.
10) Ignoring Critical Path
Symptom: Non-critical tasks occupy agent capacity while critical ones wait.
Risk: Deadline misses despite high activity.
Fix: Prioritize critical path tasks in the scheduler and expand gates for them.
Case study: 40-hour project completed in 4 hours with proper decomposition
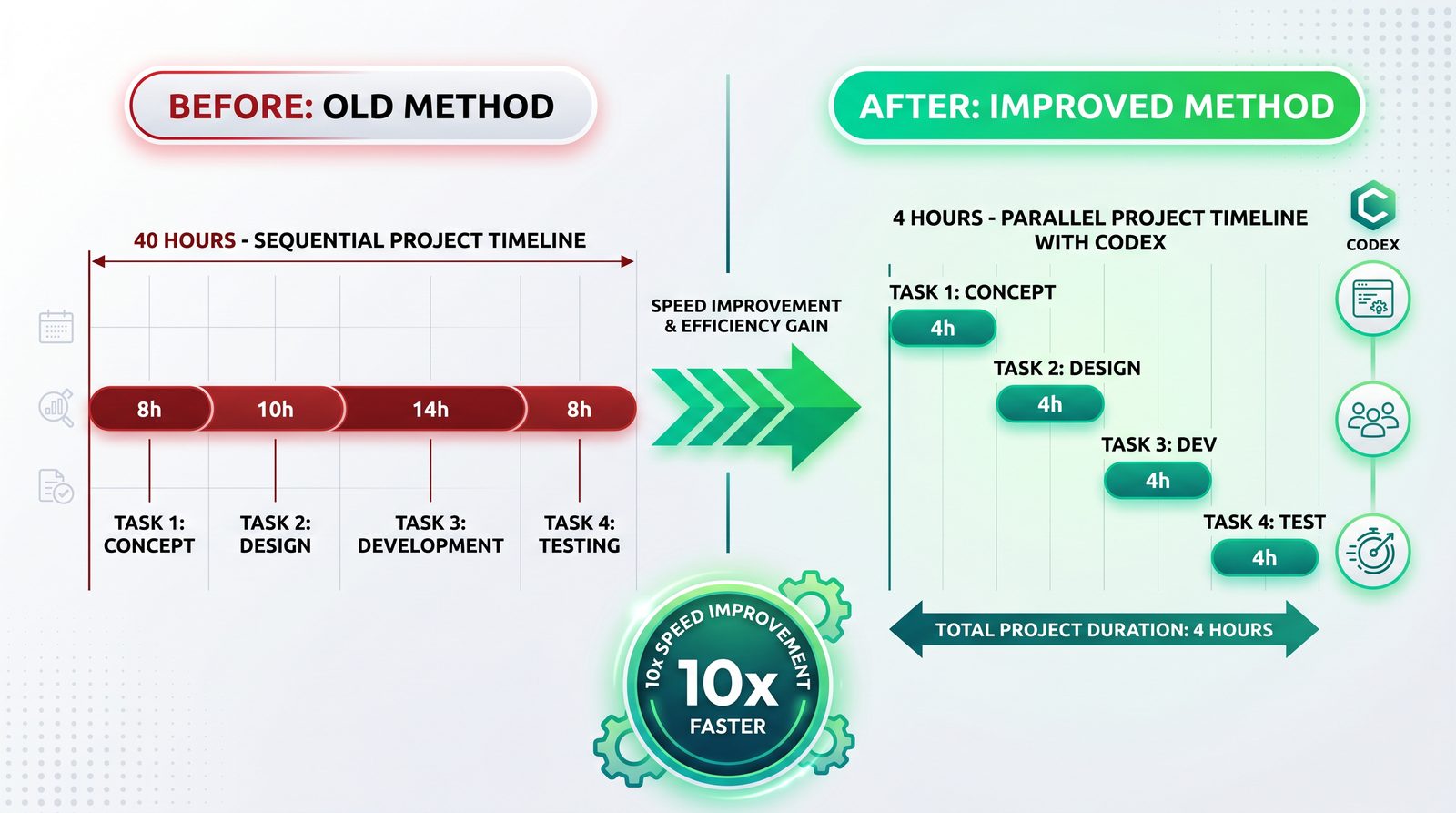
Context
A team needed to add subscription functionality to an existing SaaS product with Next.js and Stripe: backend adapters, API routes, RBAC, and an admin dashboard. Historically, similar efforts took 1 developer-week (≈40 hours) including testing and QA.
Approach using DECOMPOSE
Define and Extract (20 minutes)
- Drafted a charter with DoD and constraints
- Extracted user stories and Stripe interface contracts
Chunk and Order (25 minutes)
- Produced 7 tasks with tokens/LOC bounds
- Mapped DAG and milestones
Parallelize and Orchestrate (15 minutes)
- Configured 6 codegen workers, 2 review workers, 3 test workers
- Set up gate scripts (lint, unit, contract)
Execution timeline (3 hours)
| Time (hh:mm) | Batch | Tasks | Notes |
|---|---|---|---|
| 00:00–00:40 | Batch 1 | DB-SCHEMA, CONTRACTS-RBAC, STRIPE-ADAPTER | All pass gates; one retry for STRIPE-ADAPTER test stub |
| 00:40–02:10 | Batch 2 | API-ROUTES, RBAC-MIDDLEWARE, ADMIN-DASHBOARD | Parallel runs; two minor lint fixes auto-applied |
| 02:10–03:00 | Batch 3 | E2E-SUBS | Playwright tests implemented and passed on second run |
Outcomes
- Total lead time: 4 hours (incl. design and orchestration setup)
- FPY: 71% (5/7 tasks passed on first try)
- Coverage: 82% for relevant modules
- Defects post-merge: 0 in first week
Why it worked
- Tight contracts eliminated ambiguity between modules
- Batched parallel runs maximized agent utilization
- Gate automation caught issues early, avoiding downstream rework
- Strict context packs focused each agent on essentials
Lessons and reusables
- Keep a library of task templates with proven gates and prompts
- Establish common interfaces early to unlock parallel work
- Instrument runs; watch FPY and cycle time trends to improve prompts
Conclusion
Codex-class AI agents thrive on clarity, contracts, and composability. The DECOMPOSE method transforms complex initiatives into a disciplined sequence of small, powerful wins that scale across teams and projects. By defining crisp objectives, extracting actionable inputs, chunking into testable tasks, ordering and mapping dependencies, parallelizing aggressively but safely, orchestrating with explicit context and artifact management, synthesizing outputs thoughtfully, and rigorously evaluating outcomes, you unlock 10x delivery speed without sacrificing quality.
Adopt this playbook incrementally: start by adding contracts and gates to a single feature, then scale up to full DAG-driven orchestration. Build your prompt and task libraries. Instrument, measure, and iterate. The payoff is compounding: more reliable agents, faster cycles, higher FPY, and a team that spends more time on value and less on plumbing.
See also: System Prompt Design