The Complete GPT-5.5 and GPT-5.6 Model Selection Guide: Choosing Between Sol, Terra, Luna, and GPT-5.5 for Every Use Case
The GPT-5.6 and GPT-5.5 model families give teams a full spectrum of options—from elite reasoning and domain specialization to cost-optimized throughput and low-latency serving. This guide provides an end-to-end, technically grounded framework for choosing among GPT-5.6 Sol, GPT-5.6 Terra, GPT-5.6 Luna, GPT-5.5, and GPT-5.5 Mini across diverse workloads. You will find comparative analysis, decision criteria, budgeting methods, latency planning, context window strategies, and concrete recommendations for coding, content operations, analytics, customer service, and scientific research.
Table of Contents
- GPT-5.6 and GPT-5.5 Model Lineup at a Glance
- A Practical Model-Selection Framework
- Cost Modeling, Budgeting, and Optimization
- Latency Planning and Throughput Engineering
- Context Windows and Long-Context Strategies
- Use-Case Playbooks and Model Recommendations
- Evaluation, Benchmarks, and Acceptance Criteria
- Architecture Patterns: Routing, Fallbacks, and Caching
- Security, Compliance, and Governance
- Migration Guidance and Change Management
- Frequently Asked Questions
- Key Takeaways
GPT-5.6 and GPT-5.5 Model Lineup at a Glance
Selecting the right model begins with understanding each option’s purpose and sweet spot. The GPT-5.6 series covers the top end of capability with tiers that trade off quality and price; GPT-5.5 models provide powerful general-purpose capacity, long context, and lightweight throughput options.
GPT-5.6 Sol: Flagship intelligence for the hardest problems
Profile: GPT-5.6 Sol is the flagship model, strongest in coding, biology, and cybersecurity. It is built to maximize problem-solving depth, cross-domain reasoning, and robustness on complex, multi-step tasks where precision matters.
- Strengths: Advanced code synthesis and refactoring; scientific reasoning with domain-context grounding; cybersecurity analysis and exploit reasoning.
- Benchmark note: Outperforms Anthropic Mythos on Terminal-Bench 2.1 per the brief, reflecting leadership on terminal- and tool-centric workflows.
- Best fit scenarios: Complex codebase modifications; secure coding audits; literature-grounded biological protocols; cybersecurity threat modeling; high-stakes decision support.
- Trade-offs: As a flagship, Sol will typically have a higher per-token cost than lower tiers; it may exhibit higher latency under the same throughput settings compared to smaller models.
GPT-5.6 Terra: Balanced performance for daily work
Profile: GPT-5.6 Terra optimizes for day-to-day productivity—strong quality across a wide range of tasks with a balance of cost and latency.
- Strengths: Reliable reasoning for general coding tasks, structured writing, data summarization, content planning, and customer experience workflows.
- Best fit scenarios: Product documentation; marketing drafts; code reviews and unit test scaffolding; triage bots; lightweight analytics and report generation.
- Trade-offs: Not as deep as Sol on frontier reasoning or advanced scientific/cybersecurity tasks, but more cost-efficient for routine workloads.
GPT-5.6 Luna: Cost-optimized, high-throughput option
Profile: GPT-5.6 Luna focuses on affordability and throughput, delivering consistent quality for standardized tasks while keeping costs low for large-scale deployments.
- Strengths: Batch processing of templated content; classification and tagging; routine customer support replies; scalable QA pipelines.
- Best fit scenarios: High-volume chat triage; content localization; metadata generation; programmatic copy refinement with templates.
- Trade-offs: May not match Terra or Sol on nuanced, multi-step reasoning; optimal when prompts and outputs follow predictable patterns.
GPT-5.5: General-purpose powerhouse with 400K context
Profile: GPT-5.5 offers strong general-purpose capabilities with a standout feature: a large 400K-token context window. Priced at $5 per million input tokens and $30 per million output tokens, it enables long-context operations such as whole-repository analysis, large-document synthesis, and complex prompt chains without aggressive chunking.
- Strengths: Long-context reasoning and synthesis; multi-document analysis; complex orchestration without frequent summarization.
- Best fit scenarios: Legal or policy analysis across book-length materials; research literature reviews; codebase-wide refactoring plans; long-thread customer support workflows.
- Trade-offs: While highly capable, the absolute frontier performance in coding/biology/cybersecurity is led by GPT-5.6 Sol per the brief.
GPT-5.5 Mini: Lightweight, fast inference
Profile: GPT-5.5 Mini is a lightweight variant designed for low-latency and efficient serving. It is ideal for latency-sensitive micro-interactions and high-frequency tasks where milliseconds matter.
- Strengths: Fast responses; efficient token usage; excellent candidate for pre-screening or routing tasks.
- Best fit scenarios: Autocomplete-style features in code editors; classification and intent detection; basic summarization; first-pass content filtering; routing to stronger models on demand.
- Trade-offs: Not intended for the most complex reasoning or domain-specific deep dives.
Quick comparison table
| Model | Primary Strengths | Typical Use Cases | Context Window | Cost Tier | Latency Tier | Not Ideal For |
|---|---|---|---|---|---|---|
| GPT-5.6 Sol | Frontier reasoning; coding, biology, cybersecurity; robust multi-step analysis | Secure refactoring, threat modeling, scientific protocol synthesis, complex planning | Large (verify exact limits per API docs) | Premium | Higher than smaller models | Ultra-high-volume templated tasks if cost is primary constraint |
| GPT-5.6 Terra | Balanced quality-cost; strong generalist | Docs, marketing content, code review, analytics summaries, support | Large (verify exact limits per API docs) | Mid | Moderate | Frontier-grade deep scientific or security reasoning |
| GPT-5.6 Luna | Cost efficiency; high throughput; stable quality on standardized tasks | Bulk content, tagging, triage bots, localization, programmatic copy | Large (verify exact limits per API docs) | Lower | Lower | Highly nuanced, multi-step reasoning under tight accuracy constraints |
| GPT-5.5 | General-purpose; 400K-token long context; reliable synthesis | Long-document analysis, codebase-wide tasks, research reviews | 400K tokens | Published: $5/M input, $30/M output | Moderate | Frontier-grade top-1 accuracy on the hardest domain problems |
| GPT-5.5 Mini | Low latency; lightweight throughput; fast retries | Autocomplete, intent classification, routing, basic summaries | Smaller than GPT-5.5 (verify exact limits) | Lower | Lowest | Complex multi-step scientific/cybersecurity reasoning |
A Practical Model-Selection Framework
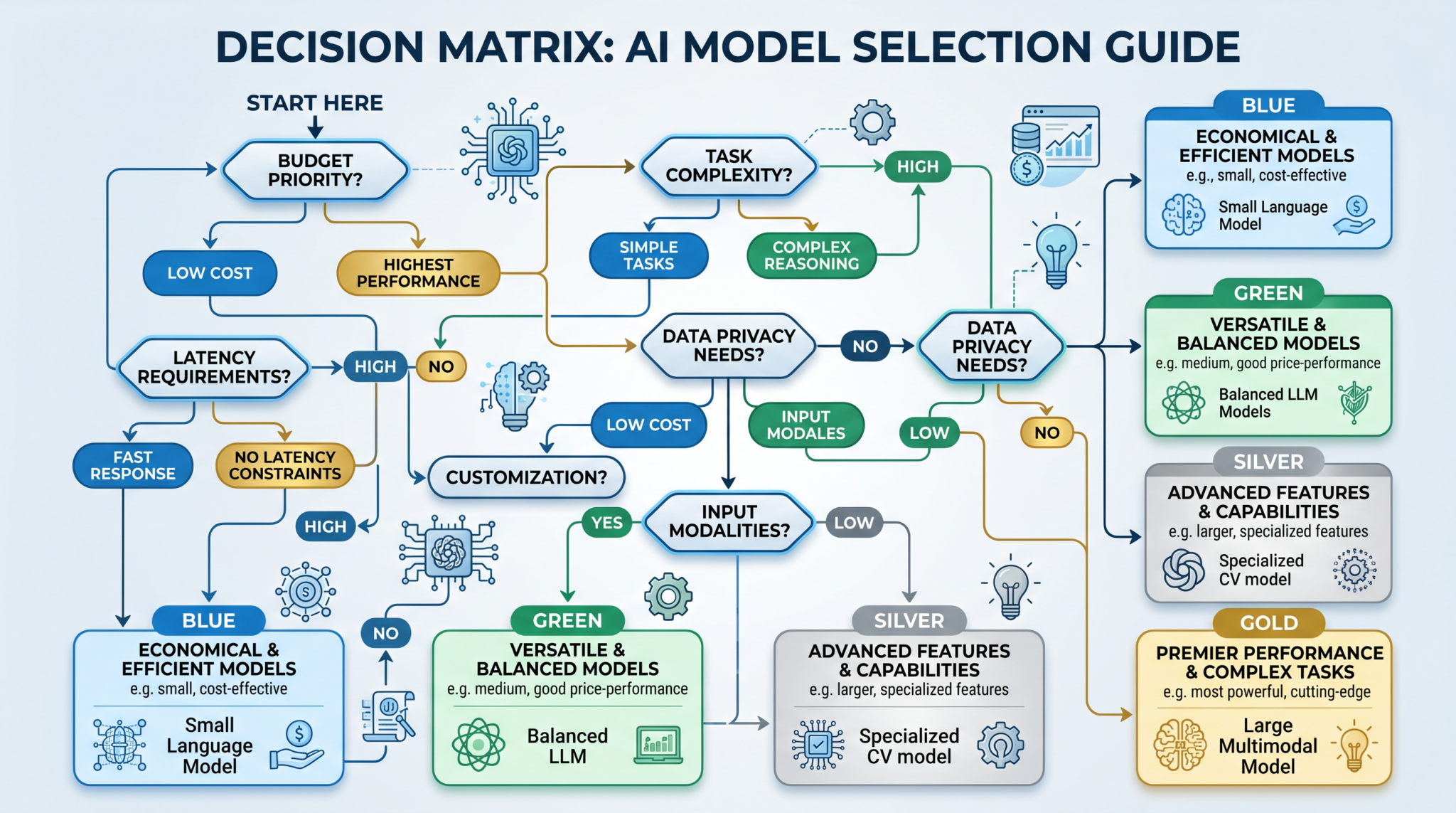
Model selection is about matching a capability and cost envelope to your operational constraints and quality bar. Use this framework to standardize decisions across teams and avoid ad hoc one-off choices that bloat costs or risk quality.
1) Define objective, stakes, and target quality
- Objective clarity: State the target outcome (e.g., “securely refactor cryptographic functions,” “generate customer-ready product descriptions,” “triage tickets by intent and priority”).
- Stakes and risk tolerance: If misclassification or hallucinations carry high cost (e.g., security advisories, clinical research notes), prefer Sol or Terra with rigorous guardrails. If stakes are low and volume is high, Luna or 5.5 Mini may be appropriate.
- Acceptance criteria: Define metrics upfront: exactness (factual accuracy), completeness (coverage), consistency (format adherence), and timeliness (SLA compliance).
2) Quantify constraints: budget, latency, and context
- Budget: Establish per-request and monthly limits. For GPT-5.5, you can directly compute spend with $5/M input and $30/M output; for 5.6 models, compare relative costs and size workloads to meet budget targets.
- Latency: Identify max response time per UX and back-end SLA. Map to model tiers: Mini/Luna for fastest, Terra moderate, Sol higher latency due to complexity.
- Context: If you routinely exceed 100K tokens of prompt+context, GPT-5.5’s 400K context is a strong default. Otherwise, verify 5.6 context limits and choose based on needed window size.
3) Choose a starting tier and design fallbacks
- Frontier tasks: Start with Sol for safety-critical and highly specialized scenarios (security audits, scientific synthesis). Add a Terra fallback for cost-control if output passes a validator.
- General productivity: Start with Terra; auto-fallback to Sol only when validator detects ambiguity or low confidence.
- High-volume standardized work: Start with Luna or 5.5 Mini; escalate to Terra for flagged items or complex edge cases.
- Long-context synthesis: Start with GPT-5.5 when inputs are lengthy and summarization is costly or risky.
4) Build a small benchmark harness
Codify 20–50 representative tasks per workflow and capture inputs, expected patterns, and scoring methods. Run head-to-head comparisons across candidate models with the same prompts. If you already maintain prompt suites, add automated checks for format, key facts, and banned content. Integrate both deterministic checks (schema validation) and human annotations for quality judgments on a statistically meaningful sample.
5) Iterate prompts and system messages
Within each model tier, quality can vary drastically with prompt structure, instruction hierarchy, and examples. Use few-shot or chain-of-thought patterns when needed, but remember they inflate input tokens; consider concise rationales for cost-efficient transparency. For repetitive formats, codify exact schemas and enforce them with a validator.
6) Formalize routing logic
- Confidence gating: Use regressors/classifiers to estimate response confidence; reroute to a higher-tier model when confidence falls below a threshold.
- Cost guardrails: If token estimates exceed a limit, switch to models with larger context windows or enforce chunking strategies.
- Latency guardrails: Route latency-sensitive interactions to Mini/Luna; route research-heavy or complex tasks to Terra/Sol.
7) Continuously monitor outcomes
Add dashboards for cost per request, latency percentiles, pass rates against acceptance criteria, and escalation rates between tiers. Adjust routing thresholds and prompts based on drift in data distribution or seasonal variation in content types.
Cost Modeling, Budgeting, and Optimization
Costs scale with input and output tokens, concurrency, and re-try logic. You’ll need a simple accounting model to forecast spend, compare model tiers, and plan guardrails. Below is a concrete template you can adapt, with a numeric example for GPT-5.5 and symbolic variables for the 5.6 family so you can plug in your prices.
Token accounting fundamentals
Let tokens_in be input tokens, tokens_out be output tokens per request. Billing is based on per-million token rates for input and output. For GPT-5.5, rates are given; for 5.6, insert the current API prices.
# Cost per request
cost_request = (tokens_in / 1_000_000) * price_in + (tokens_out / 1_000_000) * price_out
# Monthly cost
monthly_cost = requests_per_month * cost_request
# Example (GPT-5.5): price_in = $5/M, price_out = $30/M
# Suppose tokens_in = 8,000; tokens_out = 2,000
cost_request = (8_000/1_000_000)*5 + (2_000/1_000_000)*30
= $0.04 + $0.06
= $0.10 per request
monthly_cost (100k reqs) = $10,000
Scenario planning with variable pricing
Define pricing variables for 5.6 models to compare scenarios without hard-coding numbers. This approach preserves flexibility and avoids surprises if prices change.
# Define published or current prices for each model (example variables)
P_SOL_IN, P_SOL_OUT = price_in_sol, price_out_sol
P_TERRA_IN, P_TERRA_OUT = price_in_terra, price_out_terra
P_LUNA_IN, P_LUNA_OUT = price_in_luna, price_out_luna
P_55_IN, P_55_OUT = 5.0, 30.0 # GPT-5.5 from brief
def estimate_cost(tokens_in, tokens_out, price_in, price_out, requests):
return (tokens_in/1_000_000)*price_in * requests + (tokens_out/1_000_000)*price_out * requests
# Compare monthly spend for two routing plans
# Plan A: All Terra
monthly_terra = estimate_cost(6000, 1500, P_TERRA_IN, P_TERRA_OUT, 50_000)
# Plan B: 60% Luna, 30% Terra, 10% Sol
monthly_luna = estimate_cost(4500, 1200, P_LUNA_IN, P_LUNA_OUT, 30_000)
monthly_terra_b = estimate_cost(6000, 1500, P_TERRA_IN, P_TERRA_OUT, 15_000)
monthly_sol = estimate_cost(7000, 1700, P_SOL_IN, P_SOL_OUT, 5_000)
monthly_plan_b = monthly_luna + monthly_terra_b + monthly_sol
Cost levers that matter
- Prompt compression: Condense system instructions and examples without reducing clarity; pay attention to verbose few-shot demonstrations that inflate tokens-in.
- Schema control: Force structured outputs (e.g., JSON) and parse with strict validators to reduce retries and regeneration costs.
- Tiered routing: Serve the majority of routine traffic via Luna or Mini; reserve Terra/Sol for ambiguous or high-stakes items.
- Caching: Cache deterministic transformations and repeated prompts; a single cache hit can save both cost and latency across high-traffic endpoints.
- Context pruning: For long-context tasks, prefer sparse retrieval over monolithic prompts where feasible; or use GPT-5.5 specifically when long-context is essential to avoid expensive chunk management cycles.
Budgeting checklists for procurement
- Top-down allocation: Define monthly budget envelope per product area; map to token quotas rather than request quotas to preserve flexibility.
- Alert thresholds: Monitor spend at 50/75/90% of budget to trigger prompt tightening, caching, or tier shifts.
- Granular reporting: Break down spend by endpoint and use-case; compute cost-per-success for more truthful ROI vs. raw cost-per-request.
Worked example: research synthesis with GPT-5.5
Suppose an analyst tool assembles 15 short articles into a single 70,000-token prompt (including instructions and citations). The required essay is 2,500 tokens.
# GPT-5.5 pricing: $5/M in, $30/M out
tokens_in = 70_000
tokens_out = 2_500
cost = (70_000/1_000_000)*5 + (2_500/1_000_000)*30
= $0.35 + $0.075
= $0.425 per synthesis
With 10,000 such requests per month, budget about $4,250. This is often significantly simpler operationally compared to chunk-based RAG assembly with multiple calls, provided the 400K window is sufficient.
Latency Planning and Throughput Engineering
Latency depends on model size, server-side queuing, request length, and decoding parameters. While exact milliseconds vary by infrastructure and load, you can reliably plan by tier and usage pattern.
Expectations by model tier
- GPT-5.5 Mini: Best when sub-second interactions matter (autocomplete, intent detection). Low server compute and smaller outputs enable quick turnarounds.
- GPT-5.6 Luna: Generally faster than Terra/Sol given similar input sizes; suited for chat triage, programmatic content operations.
- GPT-5.6 Terra: Balanced latency suitable for most user-facing applications, including back-office tooling where 1–3 second responses are acceptable.
- GPT-5.6 Sol: Expect higher latencies, especially with large prompts or complex reasoning. Employ streaming to deliver early tokens and preserve UX fluidity.
Key engineering tactics
- Streaming outputs: For long responses, stream tokens to the client; users can begin reading while generation continues.
- Parallel retrieval: For RAG, fetch documents concurrently; prefetch likely-needed items to hide network latency.
- Prompt shaping: Front-load decisive instructions and include compact examples; avoid verbose story-like context that contributes little to task performance.
- Concurrency control: Use async batching where possible; throttle upstream calls to avoid rate-limit backoffs that elongate tail latencies.
- Timeout policies: Enforce sensible timeouts; escalate to faster tiers or serve partial answers with transparent disclaimers when deadlines hit.
Latency-aware routing example
def route_by_latency(task, max_latency_ms):
if task.type in ["autocomplete", "intent_detect", "tagging"] and max_latency_ms <= 400:
return "gpt-5.5-mini"
if task.type in ["triage", "templated_reply"] and max_latency_ms <= 1000:
return "gpt-5.6-luna"
if task.type in ["docs", "code_review", "analytics_summary"] and max_latency_ms <= 3000:
return "gpt-5.6-terra"
return "gpt-5.6-sol" # default for complex
Context Windows and Long-Context Strategies
Context windows set the maximum combined size of prompts, instructions, and retrieved materials. A careful plan here often saves both cost and complexity.
GPT-5.5’s 400K-token window
GPT-5.5 supports a 400K-token context window, making it ideal for long-form synthesis, whole-repo analysis, policy/legal reviews, and multi-document research without aggressive chunking. If your tasks regularly exceed 100K tokens, starting with GPT-5.5 simplifies architecture and reduces error-prone chunk management.
GPT-5.6 family context considerations
The GPT-5.6 family supports large context windows appropriate for long-form tasks; verify exact token limits per model in the API documentation. When your inputs are not extremely long, Terra and Luna may be more cost-effective than over-provisioning for a window you don’t need. For frontier tasks with heavy reasoning and moderate context, Sol often delivers best results without requiring extreme context sizes.
Long-context strategies
- Selective retrieval: Use sparse retrieval or embeddings search to include only the most relevant chunks. Balance recall and precision.
- Hierarchical summaries: For very large corpora, build cluster summaries, then refine with GPT-5.5 when you must combine many clusters.
- Sliding windows: On temporal or ordered data (meeting transcripts, logs), use sliding windows with overlap to maintain coherence while keeping tokens manageable.
- Schema prompts: When assembling long prompts, define a strict document structure with section headers so the model can anchor its attention more effectively.
- Auditability: Keep a record of all included chunks and references. For compliance-heavy workloads, this trail is as important as the final answer.
Use-Case Playbooks and Model Recommendations
Below are concrete playbooks mapping workloads to best-fit models. Each includes strengths, tactical prompts, and operational tips.
Coding and software engineering
When to choose GPT-5.6 Sol
- Complex refactoring: Large-scale codebase migrations, API transitions, or security hygiene sweeps. Sol’s frontier reasoning is advantageous where there are many cross-file dependencies and sensitive logic.
- Security-focused coding: Threat modeling, exploit chain analysis, and remediation guidance. Per the brief, Sol outperforms Anthropic Mythos on Terminal-Bench 2.1, highlighting its strength in terminal- and tool-centric coding workflows.
- Advanced code synthesis: Generation guided by spec documents, with strict output schemas and test harness integration.
When to choose GPT-5.6 Terra
- Daily code review: Readability suggestions, docstring updates, and unit test scaffolding with a balanced cost/latency profile.
- Developer onboarding: Summarize module architecture and generate starter tasks with consistent quality.
When to choose GPT-5.6 Luna
- Style normalization: Enforce lint rules or docstring patterns across many files at scale.
- Template-driven snippets: Repetitive boilerplate generation for CRUD operations or config files.
When to choose GPT-5.5
- Whole-repository analysis: Use the 400K window to provide a large subset of the repo for architectural insights or migration plans.
- Monorepo documentation: Cross-reference many files and generate high-level overviews or dependency maps without heavy chunking.
When to choose GPT-5.5 Mini
- Autocomplete and intent: Method name suggestions, quick doc lookups, and routing (e.g., whether to escalate to Terra or Sol).
Prompt pattern example
System: You are a senior software engineer. Prioritize security and clarity.
User: You will receive a module and its tests. Identify security issues, propose fixes,
and generate updated code snippets with inline comments. Output JSON with fields:
{"issues":[...], "recommendations":[...], "patches":[...]}.
Content operations (marketing, docs, localization)
When to choose GPT-5.6 Terra
- Marketing drafts: Balanced tone, structure, and specificity for product pages, email campaigns, and social content calendars.
- Technical documentation: Reliable and coherent content that adheres to style guides and glossary terms.
When to choose GPT-5.6 Luna
- High-volume localization: Translate and adapt content to different markets with style-checked templates.
- Bulk refreshes: Update product descriptions or FAQs programmatically with standardized quality bars.
When to choose GPT-5.6 Sol
- Complex positioning: Highly nuanced messaging for expert audiences (e.g., cybersecurity buyers) where topic mastery is required.
When to choose GPT-5.5
- Long-form synthesis: Create whitepapers or guides merging many sources into a consistent narrative.
When to choose GPT-5.5 Mini
- Style checks and routing: Quick tone/format classification, then route to Terra or Luna based on requirements.
Operational tip
Maintain a centralized glossary and style guide snippet. Insert it at the top of every content prompt to standardize voice across models and reduce editorial cycles. For high-volume runs, generate a small batch, review, adjust prompts, and then proceed.
Analytics and decision support
When to choose GPT-5.6 Terra
- Summary analytics: Generate executive summaries from dashboards and metrics exports; Terra balances quality with cost.
When to choose GPT-5.6 Sol
- Complex reasoning: Multi-layered inference, scenario planning, and potential risk analysis where errors are costly.
When to choose GPT-5.6 Luna
- Bulk pattern labeling: Classify and tag events or tickets for downstream modeling at scale.
When to choose GPT-5.5
- Long time series narratives: If you need to embed lengthy logs or multi-quarter reports in a single prompt, GPT-5.5’s 400K context is ideal.
Data-to-text prompt template
System: You are an analytics assistant. Use precise language and cite figures.
User: Given the JSON metrics (kpis), produce a structured summary with sections:
"Highlights", "Risks", "Opportunities", "Next Actions". Use bullet points.
Strictly quote numbers with units and date ranges.
Customer service and support automation
When to choose GPT-5.6 Terra
- Agent assist: Provide real-time suggestions to human agents, summarize tickets, and prepare next-best actions.
When to choose GPT-5.6 Luna
- High-volume responses: Templated replies for common issues, prioritizing throughput and stable quality.
When to choose GPT-5.5
- Long-thread contexts: For escalations that reference long histories, the 400K window supports context-rich guidance.
When to choose GPT-5.5 Mini
- Intent classification: Route tickets by type, urgency, and persona; fast and economical.
Playbook tip
Design a confidence-based escalation: Luna answers first; if the answer fails a policy or format validator—or confidence is low—re-prompt with Terra; escalate to Sol for edge cases or sensitive topics.
Scientific research (biology focus) and cybersecurity
Why GPT-5.6 Sol stands out
Per the brief, Sol is strongest in biology and cybersecurity. When experiments, threat analyses, or protocol designs must be precise and deeply reasoned, it is the suggested first choice. The Terminal-Bench 2.1 outperformance vs. Anthropic Mythos indicates strength in terminal-style tool usage and problem solving, which aligns with secure coding and exploitation analysis tasks.
When to involve GPT-5.5
- Literature-rich synthesis: When many long documents must be considered, use GPT-5.5 to ingest the broader corpus; Sol can then refine specific sections with enhanced reasoning.
Operational guardrails
- Citation capture: Always request explicit citations and references with structured fields for auditability.
- Policy checks: Pass outputs through compliance filters and domain-specific validators before use in production or publication.
For a detailed step-by-step guide to formalizing prompt governance and ensuring deterministic outputs in regulated workflows, see our in-depth exploration in The 2026 Prompt Library: 5 Templates for AI Coding, which covers schema validation, audit logging, and escalation protocols.
Evaluation, Benchmarks, and Acceptance Criteria
A strong evaluation pipeline improves total cost of ownership by reducing uncertainty early and guiding routing thresholds. Combine standardized benchmarks with targeted, in-domain tests.
Public/standard benchmark alignment
- Terminal-Bench 2.1: Per the brief, GPT-5.6 Sol outperforms Anthropic Mythos. If your workloads parallel terminal-driven or tool-augmented tasks (coding, DevOps, security), include similar evaluations in your harness.
- Task-relevant subsets: Extend with domain-specific benchmarks in biology or security. Ensure tasks represent real decision contexts in your organization.
In-house evaluation harness
- Collect representative tasks: 20–50 per use-case with diversity in difficulty and input format.
- Define scoring rubrics: Objective checks (schemas, key facts), soft judgments (clarity, coherence), and risk metrics (hallucination rate).
- Blind review: Mix model outputs to avoid labeler bias; require rationale for scoring of borderline cases.
- Compute composite score: Weighted by importance (fact accuracy > style adherence, etc.).
- Perform sensitivity analysis: Assess performance at different prompt variants and temperature settings.
Acceptance criteria and gates
- Structured output validity: ≥98% JSON schema validity for automated pipelines.
- Factual accuracy: ≥95% correct facts on curated evaluation sets in moderate-stakes workflows; higher for safety-critical tasks.
- Latency: 95th percentile within SLA; escalate to faster tiers for outliers.
Continuous evaluation
Data drifts; model response patterns evolve with prompts and content. Re-run small, automated test suites weekly; run extended evaluations monthly or before large releases. Include “tripwire” cases that detect regressions in safety or compliance. For optimization strategies that reduce token use without sacrificing quality, our deep dive on How to Deploy GPT-5.5 on Amazon Bedrock for Multi-Cloud Enterprise AI: Complete Setup Guide with IAM Policies, Cost Controls, and Production Patterns provides formulas, dashboards, and governance tips for cost-aware teams.
Architecture Patterns: Routing, Fallbacks, and Caching
Production systems benefit from multi-model orchestration, balancing cost, latency, and quality. Below are core patterns that scale from early pilots to enterprise deployments.
Confidence-gated cascades
Start with a cost-efficient model; escalate only when needed. Use validators to check structure and a confidence estimator for semantic plausibility. If validation fails or confidence is low, pass the same prompt to a higher tier.
def cascade_inference(prompt):
out_luna = call("gpt-5.6-luna", prompt)
if is_valid(out_luna) and confidence(out_luna) >= 0.8:
return out_luna
out_terra = call("gpt-5.6-terra", prompt)
if is_valid(out_terra) and confidence(out_terra) >= 0.9:
return out_terra
return call("gpt-5.6-sol", prompt)
Long-context staging with GPT-5.5
Use GPT-5.5 to process long materials in a single pass (400K window), then feed compressed, structured summaries to Terra or Sol for focused reasoning. This approach reduces chunking overhead and errors while reserving top-tier compute for the hardest reasoning steps.
Hybrid retrieval
- Dense + sparse: Combine keyword search with vector embeddings to balance recall and precision.
- Pre-summarization: Summarize documents into compact, structured representations; store them for quick inclusion in prompts.
Caching and result re-use
- Deterministic tasks: Hash prompts (including system instructions and parameters) to cache outputs; set TTLs based on content volatility.
- Template variants: Cache at the template+data level where appropriate; prefer late binding of dynamic fields for better hit rates.
Model distillation to 5.5 Mini
For well-understood tasks, you can route most requests to GPT-5.5 Mini after refining prompts and validators. Keep a sampling policy that periodically rechecks with Terra or Sol to ensure quality drift is detected early.
Reference implementation snippets
Below is an illustrative pattern for a Node.js service that routes by task type and escalates on validation failure. Replace call() with your API client integration.
// Pseudocode for a routing service
async function generate(task) {
const prompt = buildPrompt(task);
if (task.type === "triage" || task.type === "tagging") {
const out = await call("gpt-5.5-mini", prompt);
if (valid(out)) return out;
}
if (task.type === "content" || task.type === "docs") {
const out = await call("gpt-5.6-luna", prompt);
if (conf(out) > 0.8 && valid(out)) return out;
}
if (task.type === "code_review" || task.type === "analysis") {
const out = await call("gpt-5.6-terra", prompt);
if (conf(out) > 0.9 && valid(out)) return out;
}
return await call("gpt-5.6-sol", prompt);
}
For more on advanced orchestration and guardrails, see our comprehensive tutorial on How to Deploy GPT-5.5 on Amazon Bedrock for Multi-Cloud Enterprise AI: Complete Setup Guide with IAM Policies, Cost Controls, and Production Patterns, which covers classifier gating, human-in-the-loop checkpoints, and telemetry-driven optimization.
Security, Compliance, and Governance
Strong governance practices are model-agnostic and ensure safe, auditable operations regardless of chosen tier.
Data handling
- Minimize PII exposure: Redact PII before sending to models when feasible. Implement allowlists/denylists for fields.
- Tenant isolation: Enforce strict separation of prompts/results across tenants. Tag logs with anonymized IDs.
- Retention policies: Align with legal requirements; apply TTLs to logs and caches. Ensure audit logs cannot be altered.
Policy and safety layers
- Pre-filtering: Block disallowed content categories before model invocation to reduce compliance risk.
- Post-validation: Validate outputs against schemas, knowledge bases, and policies; escalate for human review if uncertain.
Operational control
- Access management: Enforce role-based access for model keys and telemetry dashboards. Rotate keys regularly.
- Rate limiting: Protect systems from abuse and cost spikes; implement per-tenant caps with alerts.
- Incident response: Prepare playbooks for anomalous behaviors, including immediate tier downgrades or output suppression.
Migration Guidance and Change Management
Many teams will migrate from older architectures or single-model deployments to a multi-tier 5.6/5.5 approach. A deliberate plan reduces regressions and stakeholder friction.
From single-model to multi-tier
- Inventory use cases: Group by stakes, volume, latency, and context length.
- Define target tiers: Map high-stakes or complex tasks to Sol; general workflows to Terra; high-volume standardized tasks to Luna or 5.5 Mini; long-context to GPT-5.5.
- Build validators: For each workflow, codify output schemas and policy checks.
- Implement cascades: Add confidence-based escalation and report per-tier pass/fail rates.
- Iterate thresholds: Tune confidence and cost thresholds for optimal spend and quality.
From chunk-based RAG to long-context GPT-5.5
- Assess complexity: If chunking logic is complex and failure-prone, consider merging sources into a single 400K prompt.
- Pilot and compare: Measure quality and latency vs. your RAG pipeline; evaluate costs with the token accounting model.
- Hybrid approach: Keep retrieval for pre-filtering; still exploit the large context for simplified synthesis.
Stakeholder communication
- Transparent metrics: Share cost-per-success, latency percentiles, and acceptance rates by tier with product and finance teams.
- Runbooks: Document escalation, rollback, and manual review procedures.
- Change windows: Roll out in phases; avoid peak traffic for migrations; monitor carefully and be ready to revert.
Frequently Asked Questions
How should I think about quality vs. cost across the 5.6 family?
Use Sol when you need the highest reasoning depth and domain strength (coding, biology, cybersecurity). Use Terra for daily workflows where quality matters but does not justify premium cost on every call. Use Luna for high-volume, standardized tasks with predictable patterns. Then, layer routing to escalate to a higher tier only when necessary.
When is GPT-5.5 the better choice than a 5.6 model?
Whenever your inputs are long enough that chunking would introduce complexity or risk losing critical context. GPT-5.5’s 400K window allows monolithic prompts with many documents or repository segments, improving coherence and simplifying both the code and the QA pipeline.
What’s the role of GPT-5.5 Mini in sophisticated systems?
Mini is excellent for front-line classification, routing decisions, and autocomplete experiences. It also works well as a “first-pass” model that filters easy cases before escalating to Terra or Sol.
How do I forecast spend reliably?
Instrument token counts in development and staging. Apply the token accounting formulas, using known prices for GPT-5.5 and current prices for 5.6 models. Plan for a buffer (e.g., 15%) to accommodate retry logic and unexpected traffic spikes.
What if my outputs must be strictly structured?
Enforce JSON schemas and unit tests for outputs. Reject non-conforming outputs and re-prompt with clearer instructions. It’s common to require ≥98% schema validity before considering a model/tier viable for automation.
Do I need streaming?
If users benefit from seeing partial results quickly—yes. Streaming particularly improves UX for Sol and Terra on lengthy outputs; for Luna and Mini, it can still help but matters less given shorter outputs and lower latency.
How do I pick between Terra and Luna for content operations?
If the content is templated and high volume, Luna usually wins on cost. If the content needs stronger reasoning, varied tone, or stricter adherence to complex style guides, Terra is a safer default.
What benchmarks should I trust?
Use a combination. Terminal-Bench 2.1 is relevant for coding and tool-centric workflows; per the brief, Sol outperforms Anthropic Mythos there. But the most persuasive benchmarks are your in-house, task-specific evaluations with acceptance criteria that match production requirements.
Key Takeaways
- Match model to task: Use Sol for the most complex reasoning (coding/biology/cybersecurity), Terra for daily balanced work, Luna for high-volume standardized tasks, GPT-5.5 for long-context synthesis, and 5.5 Mini for low-latency micro-tasks.
- Route intelligently: Start with lower-cost models, validate, then escalate to higher tiers on low confidence or policy failures.
- Control costs systematically: Apply token accounting, prompt compression, schema validation, caching, and tiered routing.
- Plan for latency: Stream outputs, parallelize retrieval, and apply concurrency controls. Reserve Sol for tasks that truly need frontier reasoning.
- Exploit long context when it helps: GPT-5.5’s 400K window simplifies complex synthesis and reduces chunking overhead.
- Evaluate continuously: Combine public benchmarks with in-house suites; enforce acceptance criteria and monitor drift.
- Govern responsibly: Redact sensitive data, validate outputs, and maintain strong audit trails for compliance.
Appendix: Prompt, Policy, and Telemetry Templates
Prompt scaffolding for structured outputs
System: You are a domain expert. Follow the JSON schema exactly.
User: Task: <task description>
Schema:
{
"type": "object",
"properties": {
"summary": {"type":"string"},
"risks": {"type":"array", "items":{"type":"string"}},
"actions": {"type":"array", "items":{"type":"string"}}
},
"required": ["summary", "actions"]
}
Rules:
1) Do not include keys not defined in Schema.
2) Keep "summary" under 120 words.
3) Use concise language and cite sources inline when applicable.
Validation and retry policy
def generate_with_validation(model, prompt):
out = call(model, prompt)
if not is_json(out):
# Re-prompt with stricter instructions once
out = call(model, prompt + "\nReminder: Output must be valid JSON per the schema.")
if not schema_valid(out):
# Escalate to higher tier
out = call("gpt-5.6-terra" if model!="gpt-5.6-terra" else "gpt-5.6-sol", prompt)
return out
Telemetry fields to log
- Tokens in/out per request; cumulative per endpoint.
- Latency percentiles (P50, P90, P95) and error rates.
- Validation outcomes (pass/fail, reason code) and escalation rates.
- Cost-per-success by workflow and tier.
- Data sensitivity labels to ensure compliance reporting.
Access 40,000+ AI Prompts for ChatGPT, Claude & Codex — Free!
Subscribe to get instant access to our complete Notion Prompt Library — the largest curated collection of prompts for ChatGPT, Claude, OpenAI Codex, and other leading AI models. Optimized for real-world workflows across coding, research, content creation, and business.
Putting It All Together
Operational excellence comes from treating model choice as an engineering discipline. Use GPT-5.6 Sol when the cost of error is high and specialized reasoning is essential, particularly in coding, biology, and cybersecurity contexts. Adopt GPT-5.6 Terra as the daily driver for general productivity with a healthy balance of quality and cost. Deploy GPT-5.6 Luna for high-volume, standardized tasks where throughput dominates. Choose GPT-5.5 when your workloads depend on long-context synthesis at scale. And reserve GPT-5.5 Mini for low-latency micro-interactions, routing, and first-pass classification.
With a consistent decision framework, token accounting, latency-aware routing, and well-designed validations, you can meet SLAs, control budgets, and increase delivery speed—all while improving the quality and reliability of AI-assisted workflows across your organization.