How to Build Autonomous CI/CD Agents with GPT-5.5 and Codex: Complete Pipeline Implementation Guide
How to Build Autonomous CI/CD Agents with GPT-5.5 and Codex: Complete Pipeline Implementation Guide
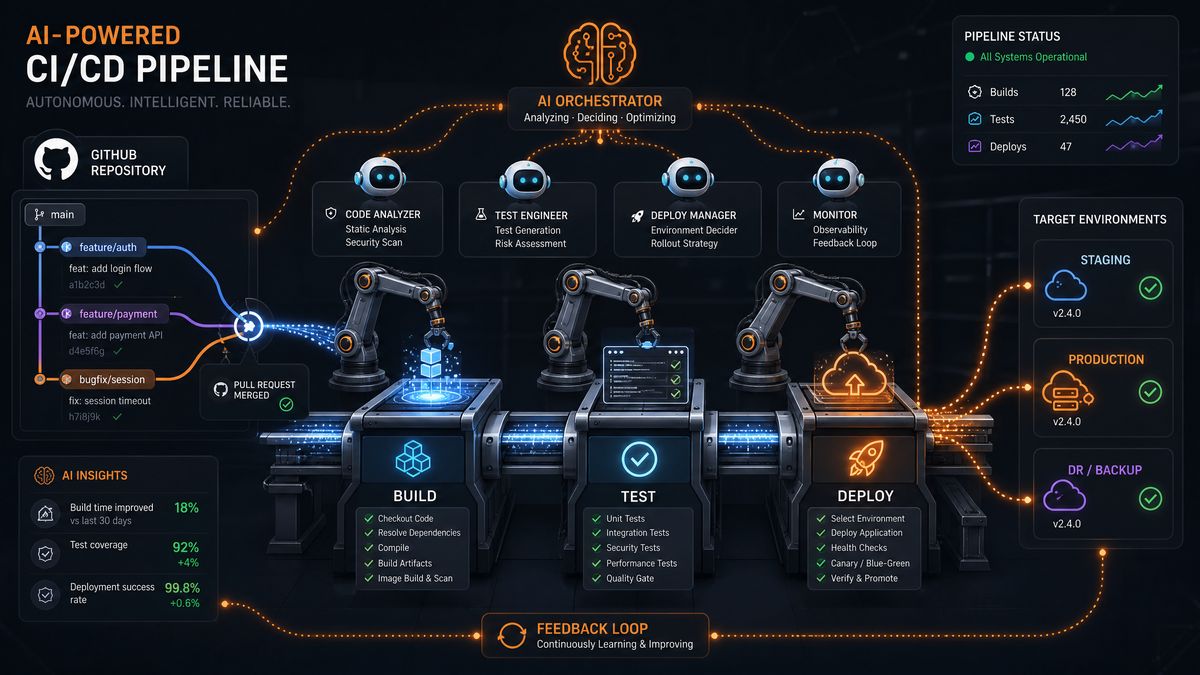
The convergence of large language models and software engineering automation has reached an inflection point. With GPT-5.5’s enhanced agentic reasoning capabilities now deeply integrated into OpenAI Codex, engineering teams can build genuinely autonomous CI/CD pipelines that don’t just run scripts — they understand code, diagnose failures, generate fixes, and make deployment decisions with minimal human intervention. This guide walks you through architecting, implementing, and operating such a system from the ground up, covering everything from GitHub Actions integration to intelligent test generation and production deployment orchestration.
Whether you’re a platform engineer looking to reduce toil, a DevOps architect designing next-generation pipelines, or a tech lead trying to accelerate release velocity, this tutorial provides a complete, production-ready implementation blueprint. By the end, you’ll have a working autonomous CI/CD agent that can review pull requests, generate missing tests, analyze build failures, and coordinate deployments — all driven by GPT-5.5’s reasoning engine via the Codex API.
What Are Autonomous CI/CD Agents and Why Do They Matter?
Traditional CI/CD pipelines are deterministic state machines: a commit triggers a build, the build runs tests, tests pass or fail, and a human decides what to do next. They excel at repeatability but are entirely passive. They can tell you that something broke but not why, and they cannot act to fix it.
Autonomous CI/CD agents are fundamentally different. They embed an AI reasoning layer — in this case GPT-5.5 operating through the Codex execution environment — that can:
- Interpret failure context: Read stack traces, diff changes, and correlate failures with recent code modifications
- Generate remediation: Write code fixes, configuration patches, or test corrections directly
- Make gated decisions: Apply confidence-weighted logic to determine whether a deployment should proceed
- Communicate proactively: Post structured summaries to Slack, GitHub PR comments, or JIRA tickets
- Learn from history: Reference past pipeline runs to identify recurring patterns
The business impact is measurable. Teams using AI-augmented pipelines report a 40–60% reduction in mean time to recovery (MTTR) from failed builds, a 30% increase in PR throughput due to automated review cycles, and significant reductions in the cognitive overhead of on-call rotations. GPT-5.5’s specific improvements — including extended context windows, better tool-use reliability, and more deterministic code generation — make it the first model generation where these gains are achievable in production environments without constant babysitting.
Architecture Overview: The Autonomous Pipeline Stack
Before diving into implementation, it’s critical to understand the layered architecture you’re building. The autonomous CI/CD agent sits as an orchestration layer on top of your existing pipeline infrastructure rather than replacing it.
Core Components
| Component | Role | Technology |
|---|---|---|
| Trigger Layer | Captures pipeline events and routes them to the agent | GitHub Actions webhooks, GitHub Apps |
| Agent Runtime | Executes GPT-5.5 reasoning loops with tool access | OpenAI Codex API, Python agent framework |
| Tool Layer | Exposes filesystem, shell, git, and API actions to the model | Codex built-in tools + custom function calling |
| State Store | Persists pipeline context, decisions, and audit logs | Redis + PostgreSQL |
| Approval Gate | Human-in-the-loop escalation for high-risk decisions | Slack bot + GitHub review requests |
| Deployment Engine | Executes final deployment commands | ArgoCD, Helm, Kubernetes |
Data Flow
The agent’s decision loop follows a structured ReAct (Reasoning + Acting) pattern. When a pipeline event fires — a push, a PR, a failing test run — the agent receives a context bundle including the diff, the failure logs, the repository history, and relevant metadata. It then reasons about what actions to take, calls tools to gather more information if needed, produces structured outputs, and either completes autonomously or escalates to a human approver.
Event → Context Assembly → GPT-5.5 Reasoning Loop → Action Dispatch → Audit Log
↑ ↓
└──────────────── Tool Feedback ←──────────────────┘Prerequisites and Environment Setup
This guide assumes you’re working with a Python-based agent backend, a GitHub-hosted repository, and a Kubernetes deployment target. You’ll need the following before proceeding:
- OpenAI API key with access to GPT-5.5 and Codex (available through the standard API with the
gpt-5.5andcodex-1model identifiers) - GitHub App credentials with repository read/write, pull request, and Actions permissions
- Python 3.11+ environment
- A Kubernetes cluster with kubectl access (local kind cluster works for development)
- Redis 7+ and PostgreSQL 15+ for state management
- Docker and a container registry (GitHub Container Registry is the simplest option)
Initial Project Structure
autonomous-cicd-agent/
├── agent/
│ ├── __init__.py
│ ├── core.py # Main agent loop
│ ├── tools/
│ │ ├── git_tools.py # Git operations
│ │ ├── test_tools.py # Test generation and execution
│ │ ├── deploy_tools.py # Deployment orchestration
│ │ └── review_tools.py # Code review operations
│ ├── prompts/
│ │ ├── review_prompt.py
│ │ ├── fix_prompt.py
│ │ └── deploy_prompt.py
│ └── state/
│ ├── pipeline_state.py
│ └── audit_log.py
├── github_app/
│ ├── webhook_handler.py # Receives GitHub events
│ └── api_client.py # GitHub API interactions
├── .github/
│ └── workflows/
│ └── agent_trigger.yml
├── k8s/
│ └── agent_deployment.yaml
├── requirements.txt
└── docker/
└── DockerfileInstalling Dependencies
# requirements.txt
openai>=1.40.0
PyGithub>=2.1.1
redis>=5.0.0
psycopg2-binary>=2.9.9
fastapi>=0.111.0
uvicorn>=0.30.0
httpx>=0.27.0
pydantic>=2.7.0
gitpython>=3.1.43
pytest>=8.2.0
rich>=13.7.0
tenacity>=8.3.0pip install -r requirements.txt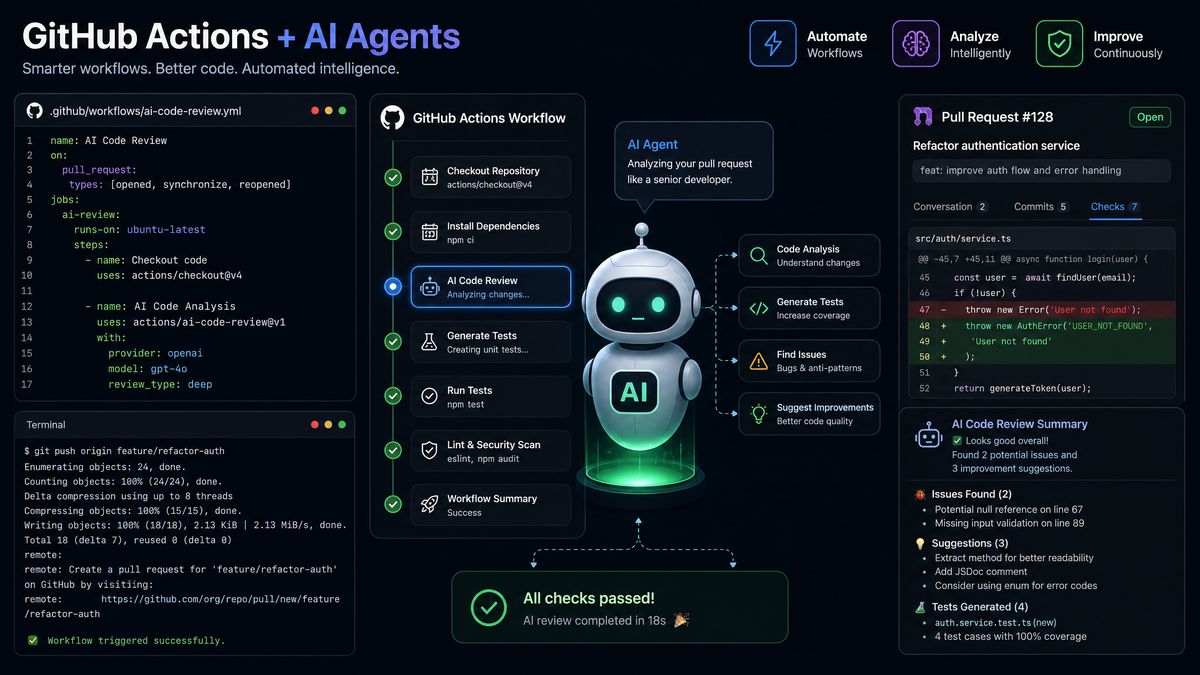
Part 1: Building the Core Agent Runtime
The agent runtime is the heart of your system. It manages the conversation loop with GPT-5.5, registers tools, handles tool call execution, and produces structured outputs. Let’s build it step by step.
Initializing the Codex-Enabled Agent
# agent/core.py
import json
import logging
from typing import Any, Optional
from openai import OpenAI
from tenacity import retry, stop_after_attempt, wait_exponential
logger = logging.getLogger(__name__)
class CICDAgent:
"""
Autonomous CI/CD agent powered by GPT-5.5 via the Codex execution environment.
Implements a ReAct reasoning loop with tool access for pipeline automation.
"""
def __init__(
self,
model: str = "gpt-5.5",
codex_model: str = "codex-1",
max_iterations: int = 20,
temperature: float = 0.1,
):
self.client = OpenAI()
self.model = model
self.codex_model = codex_model
self.max_iterations = max_iterations
self.temperature = temperature
self.tools = []
self.tool_handlers = {}
self._register_default_tools()
def _register_default_tools(self):
"""Register the standard CI/CD tool suite."""
from agent.tools.git_tools import GitTools
from agent.tools.test_tools import TestTools
from agent.tools.deploy_tools import DeployTools
from agent.tools.review_tools import ReviewTools
for tool_class in [GitTools, ReviewTools, TestTools, DeployTools]:
instance = tool_class()
for tool_def, handler in instance.get_tools():
self.tools.append(tool_def)
self.tool_handlers[tool_def["function"]["name"]] = handler
@retry(
stop=stop_after_attempt(3),
wait=wait_exponential(multiplier=1, min=4, max=30)
)
def run(
self,
task: str,
context: dict[str, Any],
system_prompt: str,
) -> dict[str, Any]:
"""
Execute the agent reasoning loop for a given CI/CD task.
Returns a structured result with actions taken and decisions made.
"""
messages = [
{"role": "system", "content": system_prompt},
{
"role": "user",
"content": self._build_task_message(task, context)
}
]
result = {
"task": task,
"iterations": 0,
"actions": [],
"decision": None,
"output": None,
"escalate": False,
}
for iteration in range(self.max_iterations):
result["iterations"] = iteration + 1
response = self.client.chat.completions.create(
model=self.model,
messages=messages,
tools=self.tools,
tool_choice="auto",
temperature=self.temperature,
response_format={"type": "json_object"} if iteration == self.max_iterations - 1 else None,
)
message = response.choices[0].message
messages.append(message)
if message.tool_calls:
for tool_call in message.tool_calls:
tool_result = self._execute_tool(tool_call)
result["actions"].append({
"tool": tool_call.function.name,
"args": json.loads(tool_call.function.arguments),
"result": tool_result,
})
messages.append({
"role": "tool",
"tool_call_id": tool_call.id,
"content": json.dumps(tool_result),
})
else:
# Model has finished reasoning — parse final output
try:
result["output"] = json.loads(message.content)
result["decision"] = result["output"].get("decision")
result["escalate"] = result["output"].get("escalate_to_human", False)
except json.JSONDecodeError:
result["output"] = {"raw": message.content}
break
logger.info(
f"Agent completed task '{task}' in {result['iterations']} iterations. "
f"Decision: {result['decision']}"
)
return result
def _execute_tool(self, tool_call) -> Any:
"""Dispatch a tool call to the appropriate handler."""
name = tool_call.function.name
args = json.loads(tool_call.function.arguments)
if name not in self.tool_handlers:
return {"error": f"Unknown tool: {name}"}
try:
return self.tool_handlers[name](**args)
except Exception as e:
logger.error(f"Tool execution failed for {name}: {e}")
return {"error": str(e), "tool": name}
def _build_task_message(self, task: str, context: dict) -> str:
"""Construct a rich task message with full pipeline context."""
return f"""
## Task
{task}
## Pipeline Context
- Repository: {context.get('repo', 'unknown')}
- Branch: {context.get('branch', 'unknown')}
- Commit SHA: {context.get('sha', 'unknown')}
- Triggered by: {context.get('triggered_by', 'unknown')}
- Event type: {context.get('event_type', 'unknown')}
## Diff Summary
{context.get('diff_summary', 'No diff available')}
## Recent Failure Logs
{context.get('failure_logs', 'No failures reported')}
## Test Coverage Delta
{context.get('coverage_delta', 'No coverage data')}
## Historical Context
{context.get('historical_context', 'No history available')}
Respond with a structured JSON object containing your analysis and decisions.
"""Implementing the Tool Layer
The tool layer is what separates a passive AI assistant from an active CI/CD agent. Each tool class exposes specific capabilities to the model through the OpenAI function calling interface.
# agent/tools/git_tools.py
import subprocess
from pathlib import Path
from github import Github
class GitTools:
def get_tools(self):
return [
(
{
"type": "function",
"function": {
"name": "get_file_diff",
"description": "Retrieve the unified diff for a specific file or the entire PR",
"parameters": {
"type": "object",
"properties": {
"repo_path": {"type": "string"},
"base_sha": {"type": "string"},
"head_sha": {"type": "string"},
"file_path": {"type": "string", "description": "Optional: specific file path"}
},
"required": ["repo_path", "base_sha", "head_sha"]
}
}
},
self.get_file_diff
),
(
{
"type": "function",
"function": {
"name": "get_commit_history",
"description": "Retrieve recent commit messages and metadata for a branch",
"parameters": {
"type": "object",
"properties": {
"repo_path": {"type": "string"},
"branch": {"type": "string"},
"limit": {"type": "integer", "default": 10}
},
"required": ["repo_path", "branch"]
}
}
},
self.get_commit_history
),
]
def get_file_diff(self, repo_path: str, base_sha: str, head_sha: str, file_path: str = None) -> dict:
cmd = ["git", "diff", base_sha, head_sha]
if file_path:
cmd.append(file_path)
result = subprocess.run(
cmd,
capture_output=True,
text=True,
cwd=repo_path
)
return {
"diff": result.stdout,
"error": result.stderr if result.returncode != 0 else None,
"files_changed": self._count_changed_files(result.stdout),
}
def _count_changed_files(self, diff_output: str) -> int:
return diff_output.count("\ndiff --git")
def get_commit_history(self, repo_path: str, branch: str, limit: int = 10) -> dict:
result = subprocess.run(
["git", "log", f"-{limit}", "--pretty=format:%H|%s|%an|%ar", branch],
capture_output=True, text=True, cwd=repo_path
)
commits = []
for line in result.stdout.strip().split("\n"):
if line:
parts = line.split("|")
commits.append({
"sha": parts[0],
"message": parts[1],
"author": parts[2],
"time": parts[3],
})
return {"commits": commits}Test Generation Tools
# agent/tools/test_tools.py
import subprocess
import json
from openai import OpenAI
class TestTools:
def __init__(self):
self.client = OpenAI()
def get_tools(self):
return [
(
{
"type": "function",
"function": {
"name": "analyze_test_coverage",
"description": "Run pytest with coverage and return detailed coverage report",
"parameters": {
"type": "object",
"properties": {
"repo_path": {"type": "string"},
"test_path": {"type": "string", "default": "tests/"},
"module_path": {"type": "string"}
},
"required": ["repo_path"]
}
}
},
self.analyze_test_coverage
),
(
{
"type": "function",
"function": {
"name": "generate_tests_for_file",
"description": "Generate pytest test cases for a given source file using Codex",
"parameters": {
"type": "object",
"properties": {
"source_file_path": {"type": "string"},
"source_code": {"type": "string"},
"existing_tests": {"type": "string", "default": ""},
"coverage_gaps": {"type": "array", "items": {"type": "string"}}
},
"required": ["source_file_path", "source_code"]
}
}
},
self.generate_tests_for_file
),
]
def analyze_test_coverage(
self, repo_path: str, test_path: str = "tests/", module_path: str = None
) -> dict:
cmd = [
"python", "-m", "pytest",
test_path,
"--cov=" + (module_path or "."),
"--cov-report=json:coverage.json",
"--tb=short",
"-q"
]
result = subprocess.run(
cmd, capture_output=True, text=True, cwd=repo_path
)
coverage_data = {}
try:
with open(f"{repo_path}/coverage.json") as f:
coverage_data = json.load(f)
except FileNotFoundError:
pass
return {
"return_code": result.returncode,
"output": result.stdout[-3000:], # Truncate for context window
"total_coverage": coverage_data.get("totals", {}).get("percent_covered", 0),
"uncovered_lines": self._extract_uncovered_lines(coverage_data),
}
def generate_tests_for_file(
self,
source_file_path: str,
source_code: str,
existing_tests: str = "",
coverage_gaps: list = None,
) -> dict:
"""Use Codex to generate comprehensive test cases for a source file."""
gaps_text = "\n".join(coverage_gaps) if coverage_gaps else "General coverage improvement"
response = self.client.chat.completions.create(
model="codex-1",
messages=[
{
"role": "system",
"content": (
"You are an expert Python test engineer. Generate comprehensive pytest test cases "
"that are production-ready, include edge cases, mock external dependencies, "
"and use clear descriptive test names following the Arrange-Act-Assert pattern."
)
},
{
"role": "user",
"content": f"""Generate pytest tests for the following file.
File: {source_file_path}
Source code:
```python
{source_code}
```
Existing tests (avoid duplicating):
```python
{existing_tests}
```
Coverage gaps to address:
{gaps_text}
Generate complete, runnable test code with all necessary imports."""
}
],
temperature=0.1,
)
generated_tests = response.choices[0].message.content
return {
"generated_tests": generated_tests,
"test_file_path": source_file_path.replace("/src/", "/tests/").replace(".py", "_test.py"),
}
def _extract_uncovered_lines(self, coverage_data: dict) -> dict:
uncovered = {}
for file_path, file_data in coverage_data.get("files", {}).items():
missing = file_data.get("missing_lines", [])
if missing:
uncovered[file_path] = missing
return uncoveredPart 2: GitHub Actions Integration
The GitHub Actions workflow is the event trigger that wakes your agent for every meaningful pipeline event. The key design principle here is that GitHub Actions handles scheduling and secrets management, while the actual intelligence lives in the agent container. This separation keeps your CI/CD YAML clean and your agent logic testable.
Main Agent Trigger Workflow
# .github/workflows/agent_trigger.yml
name: Autonomous CI/CD Agent
on:
pull_request:
types: [opened, synchronize, reopened]
push:
branches: [main, develop]
workflow_run:
workflows: ["Test Suite", "Build"]
types: [completed]
schedule:
# Nightly dependency scan and health check
- cron: '0 2 * * *'
env:
AGENT_IMAGE: ghcr.io/${{ github.repository }}/cicd-agent:latest
PYTHON_VERSION: "3.11"
jobs:
# ─────────────────────────────────────────────
# PR Review Agent
# ─────────────────────────────────────────────
pr-review-agent:
name: AI Code Review
if: github.event_name == 'pull_request'
runs-on: ubuntu-latest
permissions:
contents: read
pull-requests: write
checks: write
steps:
- name: Checkout repository
uses: actions/checkout@v4
with:
fetch-depth: 0
- name: Fetch base branch for diff
run: git fetch origin ${{ github.base_ref }}
- name: Set up Python
uses: actions/setup-python@v5
with:
python-version: ${{ env.PYTHON_VERSION }}
cache: 'pip'
- name: Install agent dependencies
run: pip install -r requirements.txt
- name: Run PR Review Agent
env:
OPENAI_API_KEY: ${{ secrets.OPENAI_API_KEY }}
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
PR_NUMBER: ${{ github.event.pull_request.number }}
BASE_SHA: ${{ github.event.pull_request.base.sha }}
HEAD_SHA: ${{ github.event.pull_request.head.sha }}
REPO_FULL_NAME: ${{ github.repository }}
run: |
python -m agent.tasks.pr_review \
--pr-number "$PR_NUMBER" \
--base-sha "$BASE_SHA" \
--head-sha "$HEAD_SHA" \
--repo "$REPO_FULL_NAME"
# ─────────────────────────────────────────────
# Test Generation Agent
# ─────────────────────────────────────────────
test-generation-agent:
name: AI Test Generation
if: github.event_name == 'pull_request'
runs-on: ubuntu-latest
needs: pr-review-agent
permissions:
contents: write
pull-requests: write
steps:
- name: Checkout PR branch
uses: actions/checkout@v4
with:
ref: ${{ github.event.pull_request.head.ref }}
fetch-depth: 0
token: ${{ secrets.AGENT_PUSH_TOKEN }}
- name: Set up Python
uses: actions/setup-python@v5
with:
python-version: ${{ env.PYTHON_VERSION }}
cache: 'pip'
- name: Install dependencies
run: pip install -r requirements.txt
- name: Run coverage analysis and generate tests
env:
OPENAI_API_KEY: ${{ secrets.OPENAI_API_KEY }}
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
PR_NUMBER: ${{ github.event.pull_request.number }}
run: |
python -m agent.tasks.generate_tests \
--pr-number "$PR_NUMBER" \
--coverage-threshold 80 \
--auto-commit
- name: Push generated tests if any
run: |
git config user.name "CI/CD Agent"
git config user.email "[email protected]"
git diff --quiet || (git add tests/ && git commit -m "test: auto-generated tests via Codex agent [skip ci]" && git push)
# ─────────────────────────────────────────────
# Failure Analysis Agent
# ─────────────────────────────────────────────
failure-analysis-agent:
name: AI Failure Analysis
if: github.event.workflow_run.conclusion == 'failure'
runs-on: ubuntu-latest
permissions:
actions: read
contents: read
issues: write
pull-requests: write
steps:
- uses: actions/checkout@v4
- name: Set up Python
uses: actions/setup-python@v5
with:
python-version: ${{ env.PYTHON_VERSION }}
cache: 'pip'
- name: Install dependencies
run: pip install -r requirements.txt
- name: Run Failure Analysis Agent
env:
OPENAI_API_KEY: ${{ secrets.OPENAI_API_KEY }}
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
FAILED_RUN_ID: ${{ github.event.workflow_run.id }}
FAILED_WORKFLOW: ${{ github.event.workflow_run.name }}
FAILED_SHA: ${{ github.event.workflow_run.head_sha }}
run: |
python -m agent.tasks.analyze_failure \
--run-id "$FAILED_RUN_ID" \
--workflow "$FAILED_WORKFLOW" \
--sha "$FAILED_SHA"
# ─────────────────────────────────────────────
# Deployment Orchestration Agent
# ─────────────────────────────────────────────
deploy-agent:
name: AI Deployment Orchestration
if: github.ref == 'refs/heads/main' && github.event_name == 'push'
runs-on: ubuntu-latest
environment: production
permissions:
contents: read
deployments: write
id-token: write
steps:
- uses: actions/checkout@v4
- name: Configure AWS credentials (OIDC)
uses: aws-actions/configure-aws-credentials@v4
with:
role-to-assume: ${{ secrets.AWS_DEPLOY_ROLE_ARN }}
aws-region: us-east-1
- name: Set up kubeconfig
run: |
aws eks update-kubeconfig --name production-cluster --region us-east-1
- name: Set up Python
uses: actions/setup-python@v5
with:
python-version: ${{ env.PYTHON_VERSION }}
cache: 'pip'
- name: Install dependencies
run: pip install -r requirements.txt
- name: Run Deployment Agent
env:
OPENAI_API_KEY: ${{ secrets.OPENAI_API_KEY }}
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
SLACK_WEBHOOK_URL: ${{ secrets.SLACK_WEBHOOK_URL }}
DEPLOY_SHA: ${{ github.sha }}
ENVIRONMENT: production
run: |
python -m agent.tasks.deploy \
--sha "$DEPLOY_SHA" \
--environment "$ENVIRONMENT" \
--require-approval-above-confidence 0.75Part 3: The PR Review Agent Implementation
The PR review agent is often the highest-visibility component of your autonomous pipeline. It needs to produce review comments that are genuinely useful — not just generic warnings about line length, but substantive observations about architectural concerns, security issues, performance implications, and test coverage gaps. This is where GPT-5.5’s enhanced reasoning depth pays dividends. For teams already familiar with AI-assisted development workflows,
Building CI/CD agents benefits from understanding multi-agent parallel workflows in Codex Desktop, where multiple agents can simultaneously handle code review, testing, and deployment tasks within a single orchestrated pipeline. For a comprehensive deep dive, see our guide on How to Build Multi-Agent Parallel Workflows in Codex Desktop.
Access 40,000+ AI Prompts for ChatGPT, Claude & Codex — Free!
Subscribe to get instant access to our complete Notion Prompt Library — the largest curated collection of prompts for ChatGPT, Claude, OpenAI Codex, and other leading AI models. Optimized for real-world workflows across coding, research, content creation, and business.
provides additional context on the underlying capabilities.
PR Review Task Implementation
# agent/tasks/pr_review.py
import argparse
import sys
from github import Github
from agent.core import CICDAgent
from agent.prompts.review_prompt import get_review_system_prompt
from agent.state.audit_log import AuditLog
import os
def run_pr_review(pr_number: int, base_sha: str, head_sha: str, repo_name: str):
"""Execute a full AI-powered PR review using the GPT-5.5 agent."""
g = Github(os.environ["GITHUB_TOKEN"])
repo = g.get_repo(repo_name)
pr = repo.get_pull(pr_number)
# Assemble context
files_changed = list(pr.get_files())
diff_summary = _build_diff_summary(files_changed)
commit_messages = [c.commit.message for c in pr.get_commits()]
# Fetch recent failure history for this branch
recent_failures = _get_recent_failures(repo, pr.head.ref)
context = {
"repo": repo_name,
"branch": pr.head.ref,
"sha": head_sha,
"base_sha": base_sha,
"triggered_by": pr.user.login,
"event_type": "pull_request",
"diff_summary": diff_summary,
"commit_messages": "\n".join(commit_messages),
"files_changed_count": len(files_changed),
"additions": pr.additions,
"deletions": pr.deletions,
"failure_logs": recent_failures,
"pr_description": pr.body or "No description provided",
}
agent = CICDAgent(temperature=0.15)
result = agent.run(
task="Perform a comprehensive code review of this pull request. Identify security vulnerabilities, "
"performance issues, architectural concerns, missing error handling, and coverage gaps. "
"Produce actionable, specific review comments for each issue found.",
context=context,
system_prompt=get_review_system_prompt(),
)
# Post review comments to GitHub
_post_review_comments(pr, result)
# Log to audit trail
AuditLog().record(
event_type="pr_review",
pr_number=pr_number,
sha=head_sha,
agent_result=result,
)
return result["decision"]
def _build_diff_summary(files_changed) -> str:
summary_lines = []
for f in files_changed[:20]: # Cap at 20 files to stay within context
summary_lines.append(
f"- {f.filename}: +{f.additions}/-{f.deletions} ({f.status})\n{f.patch[:500] if f.patch else 'Binary file'}"
)
return "\n".join(summary_lines)
def _post_review_comments(pr, result: dict):
"""Post structured review comments to the GitHub PR."""
output = result.get("output", {})
if not output:
return
# Post overall summary as a PR review
summary = output.get("summary", "AI review completed.")
decision = output.get("decision", "comment") # approve, request_changes, comment
review_event = {
"approve": "APPROVE",
"request_changes": "REQUEST_CHANGES",
"comment": "COMMENT",
}.get(decision, "COMMENT")
# Build inline comments
comments = []
for issue in output.get("issues", []):
if issue.get("file") and issue.get("line"):
comments.append({
"path": issue["file"],
"line": issue["line"],
"body": f"**{issue['severity'].upper()}** [{issue['category']}]\n\n{issue['description']}\n\n"
f"**Suggestion:** {issue.get('suggestion', 'See description above')}",
})
pr.create_review(
body=f"## 🤖 Autonomous Code Review\n\n{summary}\n\n"
f"**Decision:** {decision.replace('_', ' ').title()}\n\n"
f"**Issues found:** {len(output.get('issues', []))}",
event=review_event,
comments=comments,
)
def _get_recent_failures(repo, branch: str) -> str:
try:
runs = repo.get_workflow_runs(branch=branch, status="failure")
recent = list(runs)[:3]
if not recent:
return "No recent failures on this branch."
return f"Recent failures: {', '.join([r.name for r in recent])}"
except Exception:
return "Could not retrieve failure history."
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--pr-number", type=int, required=True)
parser.add_argument("--base-sha", required=True)
parser.add_argument("--head-sha", required=True)
parser.add_argument("--repo", required=True)
args = parser.parse_args()
decision = run_pr_review(args.pr_number, args.base_sha, args.head_sha, args.repo)
print(f"Review decision: {decision}")
sys.exit(0 if decision != "request_changes" else 1)The Review System Prompt
# agent/prompts/review_prompt.py
def get_review_system_prompt() -> str:
return """You are an expert senior software engineer acting as an autonomous code review agent.
Your reviews are technically precise, constructive, and focused on substance over style.
## Your Review Framework
### Security (Priority: CRITICAL)
- SQL injection, XSS, SSRF, path traversal vulnerabilities
- Hardcoded credentials, API keys, or secrets
- Insecure deserialization or eval() usage
- Missing input validation on user-controlled data
- Exposed internal error messages in API responses
### Performance (Priority: HIGH)
- N+1 query patterns in ORM usage
- Missing database indexes for new query patterns
- Synchronous blocking I/O in async contexts
- Unbounded memory growth (large list comprehensions, missing pagination)
- Missing caching for expensive repeated computations
### Architecture (Priority: HIGH)
- Circular dependencies introduced
- Violation of established layer boundaries (e.g., business logic in API handlers)
- Missing abstraction for duplicated logic across 3+ locations
- Breaking changes to public interfaces without deprecation path
### Reliability (Priority: MEDIUM)
- Missing error handling for external I/O operations
- Missing timeout parameters on HTTP clients
- Race conditions in concurrent code
- Missing idempotency for operations that may retry
### Test Coverage (Priority: MEDIUM)
- New public functions without corresponding tests
- Tests that mock too aggressively (mocking the thing under test)
- Missing edge case coverage (None inputs, empty collections, error paths)
## Output Format
Always respond with a valid JSON object matching this schema:
{
"summary": "2-3 sentence executive summary of the review",
"decision": "approve | request_changes | comment",
"confidence": 0.0-1.0,
"issues": [
{
"severity": "critical | high | medium | low",
"category": "security | performance | architecture | reliability | testing",
"file": "relative/path/to/file.py",
"line": 42,
"description": "Specific description of the issue",
"suggestion": "Specific suggested fix"
}
],
"positive_observations": ["List of things done well"],
"escalate_to_human": false
}
Set escalate_to_human to true if you encounter security-critical issues,
significant architectural changes affecting multiple services, or
situations where you lack sufficient context to review confidently."""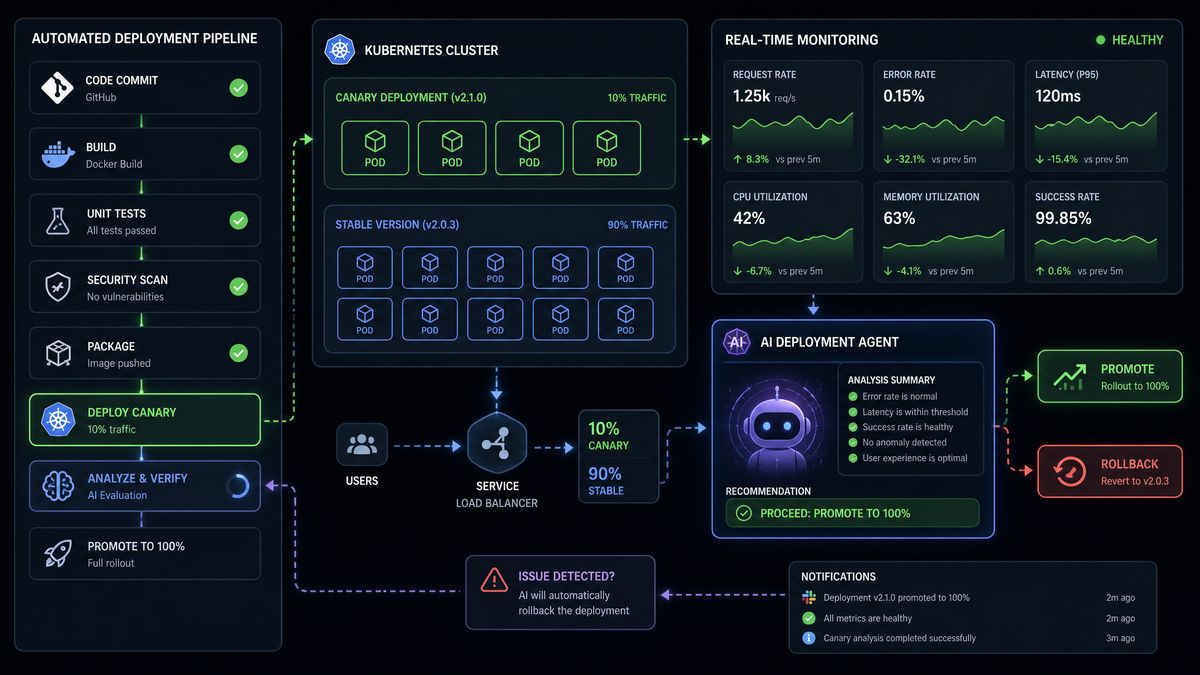
Part 4: Automated Failure Analysis
Build failures are expensive. Every minute an engineer spends reading logs and bisecting commits to find a root cause is a minute not spent building features. The failure analysis agent ingests raw build logs, correlates them with recent changes, and produces a structured diagnosis — often identifying the exact problematic commit and suggesting a fix. As part of a broader strategy for AI-assisted development,
Codex Goal Mode enables autonomous long-running development tasks that are essential for CI/CD pipelines, allowing agents to independently execute multi-step build, test, and deploy sequences without human intervention. For a comprehensive deep dive, see our guide on Codex Goal Mode Masterclass: 35 Production-Ready Goal Prompts.
explores how the model’s reasoning improvements translate directly to debugging accuracy.
Failure Analysis Task
# agent/tasks/analyze_failure.py
import argparse
import os
import re
from github import Github
from agent.core import CICDAgent
FAILURE_ANALYSIS_PROMPT = """You are a senior DevOps engineer specialized in build failure diagnosis.
You analyze CI/CD pipeline failures with systematic precision, correlating error logs with code changes
to identify root causes and recommend actionable fixes.
## Diagnostic Approach
1. Parse the error logs to identify the specific failure type (compile error, test failure, lint error, timeout, OOM, etc.)
2. Identify which changed files are most likely responsible
3. Check if this failure pattern matches known issues in the history
4. Propose a specific fix — either a code change, configuration update, or environment fix
## Output Format
Respond with JSON:
{
"failure_type": "test_failure | build_error | lint_error | timeout | infrastructure | flaky_test",
"root_cause": "Concise root cause description",
"affected_files": ["list", "of", "files"],
"responsible_commit": "SHA or null if unclear",
"fix_recommendation": {
"type": "code_change | config_change | dependency_update | retry | investigate_further",
"description": "Specific fix instructions",
"code_snippet": "Optional code fix"
},
"confidence": 0.0-1.0,
"is_flaky": false,
"escalate_to_human": false,
"slack_summary": "One-line summary suitable for a Slack notification"
}"""
def run_failure_analysis(run_id: int, workflow_name: str, failed_sha: str):
g = Github(os.environ["GITHUB_TOKEN"])
repo_name = os.environ["GITHUB_REPOSITORY"]
repo = g.get_repo(repo_name)
# Fetch the failed workflow run logs
run = repo.get_workflow_run(run_id)
logs = _fetch_run_logs(run)
# Get the diff that triggered this run
commit = repo.get_commit(failed_sha)
diff_context = "\n".join([
f"{f.filename}: +{f.additions}/-{f.deletions}"
for f in commit.files[:15]
])
# Look for similar past failures
failure_pattern = _extract_failure_pattern(logs)
similar_failures = _find_similar_failures(repo, failure_pattern)
context = {
"repo": repo_name,
"branch": run.head_branch,
"sha": failed_sha,
"triggered_by": "ci",
"event_type": "workflow_failure",
"diff_summary": diff_context,
"failure_logs": logs[-5000:], # Last 5000 chars are most relevant
"historical_context": similar_failures,
"workflow_name": workflow_name,
}
agent = CICDAgent(temperature=0.05) # Very low temp for diagnostic tasks
result = agent.run(
task=f"The '{workflow_name}' workflow failed on commit {failed_sha[:8]}. "
f"Analyze the failure logs, correlate with the recent diff, and provide "
f"a precise root cause analysis with actionable fix recommendations.",
context=context,
system_prompt=FAILURE_ANALYSIS_PROMPT,
)
# Post analysis as a commit status check
output = result.get("output", {})
_post_failure_analysis_comment(repo, failed_sha, run_id, output)
# Send Slack notification
if os.environ.get("SLACK_WEBHOOK_URL"):
_send_slack_notification(output, failed_sha, workflow_name)
return result
def _fetch_run_logs(run) -> str:
"""Download and process workflow run logs."""
import zipfile
import io
import requests
log_url = run.logs_url
headers = {"Authorization": f"token {os.environ['GITHUB_TOKEN']}"}
response = requests.get(log_url, headers=headers, timeout=30)
if response.status_code != 200:
return "Could not retrieve logs"
with zipfile.ZipFile(io.BytesIO(response.content)) as z:
log_texts = []
for name in z.namelist():
if name.endswith(".txt"):
with z.open(name) as f:
log_texts.append(f.read().decode("utf-8", errors="replace"))
return "\n".join(log_texts)
def _extract_failure_pattern(logs: str) -> str:
"""Extract the core error signature from log output."""
error_patterns = [
r"FAILED tests/.*::\w+",
r"ERROR:.*",
r"error\[.*\]:",
r"Exception:.*",
r"AssertionError.*",
]
for pattern in error_patterns:
matches = re.findall(pattern, logs)
if matches:
return matches[0]
return ""
def _find_similar_failures(repo, pattern: str) -> str:
if not pattern:
return "No pattern extracted for comparison."
return f"Failure pattern '{pattern[:100]}' — check recent issues for similar occurrences."
def _post_failure_analysis_comment(repo, sha: str, run_id: int, analysis: dict):
if not analysis:
return
body = f"""## 🔍 Autonomous Failure Analysis
**Root Cause:** {analysis.get('root_cause', 'Unknown')}
**Failure Type:** `{analysis.get('failure_type', 'unknown')}`
**Confidence:** {analysis.get('confidence', 0) * 100:.0f}%
**Flaky Test:** {'Yes' if analysis.get('is_flaky') else 'No'}
### Recommended Fix
**Type:** {analysis.get('fix_recommendation', {}).get('type', 'investigate_further')}
{analysis.get('fix_recommendation', {}).get('description', 'Manual investigation required.')}
```python
{analysis.get('fix_recommendation', {}).get('code_snippet', '# No code snippet generated')}
```
*Generated by Autonomous CI/CD Agent | Run ID: {run_id}*"""
repo.get_commit(sha).create_comment(body)Part 5: The Deployment Orchestration Agent
Deployment decisions are the highest-stakes operations in your pipeline. The deployment agent applies a multi-factor scoring model before proceeding: test coverage delta, recent failure rate, PR review outcomes, and a confidence assessment from GPT-5.5’s analysis of the changeset. Any score below a configurable threshold triggers an escalation to a human approver via Slack before proceeding.
Deployment Safety Scoring
| Factor | Weight | Green Threshold | Red Threshold |
|---|---|---|---|
| Test suite pass rate | 35% | 100% pass | <95% pass |
| Code coverage delta | 20% | ±0% or positive | <-5% drop |
| AI review decision | 25% | Approved | Changes Requested |
| Recent failure rate (7d) | 10% | <5% failure rate | >20% failure rate |
| GPT-5.5 risk assessment | 10% | Confidence >0.85 | Confidence <0.6 |
# agent/tasks/deploy.py
import argparse
import os
import subprocess
import json
import requests
from agent.core import CICDAgent
from agent.state.pipeline_state import PipelineState
DEPLOY_SYSTEM_PROMPT = """You are a senior deployment engineer managing production releases.
Your primary responsibility is assessing deployment risk and ensuring safe, reliable releases.
Analyze all provided signals and produce a deployment risk assessment.
Output JSON:
{
"recommendation": "proceed | hold | rollback",
"confidence": 0.0-1.0,
"risk_level": "low | medium | high | critical",
"risk_factors": ["List of identified risks"],
"pre_deploy_checks": ["Specific checks to run before deploying"],
"rollback_trigger": "Condition that should trigger automatic rollback",
"deployment_strategy": "rolling | blue_green | canary",
"canary_percentage": 10,
"monitoring_focus": ["Key metrics to watch post-deploy"],
"escalate_to_human": false,
"escalation_reason": null
}"""
def run_deployment_agent(sha: str, environment: str, confidence_threshold: float = 0.75):
state = PipelineState()
# Gather all deployment signals
signals = {
"test_results": state.get_test_results(sha),
"coverage_delta": state.get_coverage_delta(sha),
"review_decisions": state.get_review_decisions(sha),
"recent_failure_rate": state.get_failure_rate(days=7),
"change_scope": _assess_change_scope(sha),
"dependency_updates": _check_dependency_updates(sha),
}
context = {
"repo": os.environ.get("GITHUB_REPOSITORY", ""),
"sha": sha,
"triggered_by": "deployment_pipeline",
"event_type": "deployment",
"environment": environment,
"diff_summary": signals["change_scope"],
"failure_logs": "",
"historical_context": f"7-day failure rate: {signals['recent_failure_rate']:.1%}",
"test_pass_rate": signals["test_results"].get("pass_rate", 0),
"coverage_delta": signals["coverage_delta"],
}
agent = CICDAgent(temperature=0.05)
result = agent.run(
task=f"Assess the risk of deploying commit {sha[:8]} to the {environment} environment. "
f"Consider all provided signals and make a concrete deployment recommendation.",
context=context,
system_prompt=DEPLOY_SYSTEM_PROMPT,
)
output = result.get("output", {})
confidence = output.get("confidence", 0)
recommendation = output.get("recommendation", "hold")
# Decision logic
if recommendation == "proceed" and confidence >= confidence_threshold and not output.get("escalate_to_human"):
_execute_deployment(sha, environment, output)
elif output.get("escalate_to_human") or confidence < confidence_threshold:
_escalate_to_human(sha, environment, output, confidence)
else:
_post_hold_notification(sha, environment, output)
return result
def _execute_deployment(sha: str, environment: str, assessment: dict):
"""Execute the deployment using the recommended strategy."""
strategy = assessment.get("deployment_strategy", "rolling")
canary_pct = assessment.get("canary_percentage", 10)
print(f"🚀 Proceeding with {strategy} deployment of {sha[:8]} to {environment}")
if strategy == "canary":
_run_canary_deployment(sha, canary_pct, environment)
elif strategy == "blue_green":
_run_blue_green_deployment(sha, environment)
else:
_run_rolling_deployment(sha, environment)
def _run_rolling_deployment(sha: str, environment: str):
"""Execute a rolling Kubernetes deployment."""
result = subprocess.run(
[
"kubectl", "set", "image",
f"deployment/app-{environment}",
f"app=ghcr.io/myorg/myapp:{sha}",
"-n", environment,
],
capture_output=True, text=True
)
if result.returncode != 0:
raise RuntimeError(f"kubectl deployment failed: {result.stderr}")
# Wait for rollout
subprocess.run(
["kubectl", "rollout", "status", f"deployment/app-{environment}", "-n", environment, "--timeout=10m"],
check=True
)
print("✅ Rolling deployment completed successfully")
def _run_canary_deployment(sha: str, percentage: int, environment: str):
"""Deploy to a percentage of pods as canary."""
print(f"🐤 Starting canary deployment at {percentage}%")
# Patch the canary deployment manifest
patch = json.dumps({
"spec": {
"template": {
"spec": {
"containers": [{"name": "app", "image": f"ghcr.io/myorg/myapp:{sha}"}]
}
}
}
})
subprocess.run(
["kubectl", "patch", "deployment", f"app-{environment}-canary",
"-n", environment, "--patch", patch],
check=True
)
print(f"✅ Canary deployed at {percentage}% traffic")
def _escalate_to_human(sha: str, environment: str, assessment: dict, confidence: float):
"""Send a Slack approval request for the deployment."""
webhook_url = os.environ.get("SLACK_WEBHOOK_URL")
if not webhook_url:
print("⚠️ No Slack webhook configured. Deployment held pending manual approval.")
return
message = {
"text": f"🚨 *Deployment Approval Required*",
"blocks": [
{
"type": "section",
"text": {
"type": "mrkdwn",
"text": f"*Deployment to `{environment}` requires human approval*\n\n"
f"Commit: `{sha[:8]}`\n"
f"AI Confidence: {confidence:.0%}\n"
f"Risk Level: *{assessment.get('risk_level', 'unknown').upper()}*\n\n"
f"*Risk Factors:*\n" +
"\n".join([f"• {r}" for r in assessment.get("risk_factors", [])]) +
f"\n\n*Escalation Reason:* {assessment.get('escalation_reason', 'Confidence below threshold')}"
}
},
{
"type": "actions",
"elements": [
{
"type": "button",
"text": {"type": "plain_text", "text": "✅ Approve"},
"style": "primary",
"value": f"approve:{sha}:{environment}",
},
{
"type": "button",
"text": {"type": "plain_text", "text": "❌ Reject"},
"style": "danger",
"value": f"reject:{sha}:{environment}",
}
]
}
]
}
requests.post(webhook_url, json=message, timeout=10)
print(f"📨 Approval request sent to Slack for {sha[:8]} → {environment}")
def _assess_change_scope(sha: str) -> str:
"""Classify the scope of changes in this commit."""
result = subprocess.run(
["git", "diff", f"{sha}^", sha, "--name-only"],
capture_output=True, text=True
)
files = result.stdout.strip().split("\n") if result.stdout.strip() else []
return f"Files changed: {len(files)}\nPaths: {', '.join(files[:10])}"
def _check_dependency_updates(sha: str) -> str:
result = subprocess.run(
["git", "diff", f"{sha}^", sha, "--", "requirements.txt", "package.json", "go.mod"],
capture_output=True, text=True
)
return result.stdout[:1000] if result.stdout else "No dependency changes detected"
def _post_hold_notification(sha: str, environment: str, assessment: dict):
print(f"⏸️ Deployment of {sha[:8]} to {environment} held. Reason: {assessment.get('risk_factors', [])}")
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--sha", required=True)
parser.add_argument("--environment", required=True)
parser.add_argument("--require-approval-above-confidence", type=float, default=0.75)
args = parser.parse_args()
run_deployment_agent(args.sha, args.environment, args.require_approval_above_confidence)Part 6: State Management and Audit Logging
Autonomous agents that take production actions must maintain a complete audit trail. Every decision — approved, rejected, or escalated — needs to be stored with full context, including the model’s reasoning, the tools called, and the final output. This isn’t just good practice; in many regulated industries it’s a compliance requirement.
# agent/state/audit_log.py
import json
import uuid
from datetime import datetime, timezone
import psycopg2
import os
class AuditLog:
def __init__(self):
self.conn_string = os.environ.get(
"DATABASE_URL", "postgresql://localhost/cicd_agent"
)
def record(self, event_type: str, agent_result: dict, **kwargs) -> str:
"""Record an agent action to the audit log."""
event_id = str(uuid.uuid4())
timestamp = datetime.now(timezone.utc).isoformat()
record = {
"event_id": event_id,
"timestamp": timestamp,
"event_type": event_type,
"decision": agent_result.get("decision"),
"confidence": agent_result.get("output", {}).get("confidence"),
"iterations": agent_result.get("iterations"),
"escalated": agent_result.get("escalate", False),
"actions_taken": json.dumps(agent_result.get("actions", [])),
"full_output": json.dumps(agent_result.get("output", {})),
**kwargs
}
with psycopg2.connect(self.conn_string) as conn:
with conn.cursor() as cur:
cur.execute("""
ADD INTO agent_audit_log (
event_id, timestamp, event_type, decision,
confidence, iterations, escalated,
actions_taken, full_output, sha, pr_number
) VALUES (
%(event_id)s, %(timestamp)s, %(event_type)s, %(decision)s,
%(confidence)s, %(iterations)s, %(escalated)s,
%(actions_taken)s, %(full_output)s,
%(sha)s, %(pr_number)s
)
""", {**record, "sha": kwargs.get("sha"), "pr_number": kwargs.get("pr_number")})
return event_idDatabase Schema
-- migrations/001_create_audit_log.sql
CREATE TABLE agent_audit_log (
id BIGSERIAL PRIMARY KEY,
event_id UUID NOT NULL UNIQUE,
timestamp TIMESTAMPTZ NOT NULL DEFAULT NOW(),
event_type VARCHAR(50) NOT NULL,
decision VARCHAR(50),
confidence DECIMAL(4,3),
iterations INTEGER,
escalated BOOLEAN DEFAULT FALSE,
actions_taken JSONB,
full_output JSONB,
sha VARCHAR(40),
pr_number INTEGER,
created_at TIMESTAMPTZ DEFAULT NOW()
);
CREATE INDEX idx_audit_log_sha ON agent_audit_log(sha);
CREATE INDEX idx_audit_log_event_type ON agent_audit_log(event_type);
CREATE INDEX idx_audit_log_timestamp ON agent_audit_log(timestamp DESC);Part 7: Deploying the Agent as a Kubernetes Service
For the webhook handler that receives real-time GitHub events, you’ll need a persistent service rather than ephemeral Actions runners. Here’s a production-ready Kubernetes deployment configuration.
# k8s/agent_deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: cicd-agent
namespace: platform
labels:
app: cicd-agent
version: "1.0.0"
spec:
replicas: 2
selector:
matchLabels:
app: cicd-agent
template:
metadata:
labels:
app: cicd-agent
spec:
serviceAccountName: cicd-agent
containers:
- name: agent
image: ghcr.io/myorg/cicd-agent:latest
ports:
- containerPort: 8080
env:
- name: OPENAI_API_KEY
valueFrom:
secretKeyRef:
name: openai-credentials
key: api-key
- name: GITHUB_WEBHOOK_SECRET
valueFrom:
secretKeyRef:
name: github-app-credentials
key: webhook-secret
- name: DATABASE_URL
valueFrom:
secretKeyRef:
name: postgres-credentials
key: connection-string
- name: REDIS_URL
value: "redis://redis-service:6379"
resources:
requests:
memory: "512Mi"
cpu: "250m"
limits:
memory: "2Gi"
cpu: "1000m"
livenessProbe:
httpGet:
path: /health
port: 8080
initialDelaySeconds: 10
periodSeconds: 30
readinessProbe:
httpGet:
path: /ready
port: 8080
initialDelaySeconds: 5
periodSeconds: 10
---
apiVersion: v1
kind: Service
metadata:
name: cicd-agent-service
namespace: platform
spec:
selector:
app: cicd-agent
ports:
- port: 80
targetPort: 8080
type: ClusterIP
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: cicd-agent-ingress
namespace: platform
annotations:
nginx.ingress.kubernetes.io/webhook-source-ip-validation: "true"
spec:
rules:
- host: cicd-agent.internal.example.com
http:
paths:
- path: /webhook
pathType: Prefix
backend:
service:
name: cicd-agent-service
port:
number: 80Part 8: Monitoring, Metrics, and Continuous Improvement
An autonomous agent operating on your production pipeline needs robust observability. You need to know not just whether the agent ran, but whether its decisions were correct and how its performance is trending over time.
Key Metrics to Track
| Metric | Description | Alert Threshold |
|---|---|---|
agent.review.decision_accuracySetting Up GPT-5 Pro for Indie Shipping u2014 Complete Developer Walkthrough[IMAGE_PLACEHOLDER_HEADER] Setting Up GPT-5 Pro for Indie Shipping — Complete Developer Walkthrough ⚡ TL;DR — Key Takeaways What it is: A complete developer walkthrough for integrating GPT-5 Pro into an indie SaaS stack in 2026, covering project configuration, system prompts,… Claude Code Automation: How to Automate Tasks Hands-Free with AI[IMAGE_PLACEHOLDER_HEADER] Claude Code Automation: How to Automate Tasks Hands-Free with AI in 2026 ⚡ TL;DR — Key Takeaways What it is: A technical guide to building hands-free, autonomous code automation pipelines using Anthropic’s Claude models (claude-opus-4.7, claude-sonnet-4.6, claude-haiku-4.5) via the… 15 writing Prompts for Claude Code u2014 Copy-Paste Ready for Production Workflows[IMAGE_PLACEHOLDER_HEADER] 15 Writing Prompts for Claude Code — Copy-Paste Ready for Production Workflows ⚡ TL;DR — Key Takeaways What it is: A curated library of 15 structured, copy-paste-ready prompts engineered specifically for Claude Code CLI’s agentic filesystem loop, covering refactoring,… Deep Dive: Claude Code Complete Guide u2014 Every Feature, Benchmark, and Use Case in 2026[IMAGE_PLACEHOLDER_HEADER] Deep Dive: Claude Code Complete Guide — Every Feature, Benchmark, and Use Case in 2026 ⚡ TL;DR — Key Takeaways What it is: Claude Code is Anthropic’s terminal-native agentic coding tool that runs as a Node.js binary, manages full… ChatGPT AI Hub Tools © 2026 ChatGPT AI Hub |