Complete Guide to Claude Managed Agents: Dreaming, Outcomes, and Multiagent Orchestration
[IMAGE_PLACEHOLDER_HEADER]
What Are Claude Managed Agents?
[IMAGE_PLACEHOLDER_SECTION_1]
Claude Managed Agents represent a groundbreaking leap in AI-driven autonomous agents, engineered by Anthropic to deliver highly efficient, customizable, and scalable AI workflows. These agents operate autonomously while remaining fully manageable through intuitive interfaces and powerful APIs, empowering developers, product managers, and AI practitioners to deploy intelligent assistants tailored for complex real-world challenges.
As artificial intelligence integrates deeper into industries such as healthcare, finance, customer service, and software development, the need for autonomous agents that balance raw cognitive power with safe, practical usability has grown exponentially. Claude Managed Agents meet this demand by providing a platform where AI agents can be created, monitored, and iteratively improved without sacrificing transparency or control.
The managed nature of these agents ensures enterprise-grade reliability, addressing critical concerns including ethical compliance, operational consistency, and seamless integration with existing systems.
Definition and Background of Claude Managed Agents
At their core, Claude Managed Agents are autonomous AI entities built on Anthropic’s Claude family of large language models (LLMs), optimized for autonomous task execution, decision-making, and continuous learning within defined operational parameters. Unlike traditional AI models that require manual inputs for every single action, managed agents independently interpret instructions, manage multi-step workflows, and adapt dynamically to changing contexts.
The evolution of Claude Managed Agents traces back to early autonomous AI experiments with scripted agents. However, initial versions lacked flexibility and required extensive human oversight. Advances in LLM technology, especially the Claude series, enabled Anthropic to introduce managed agents capable of sophisticated natural language understanding, reasoning, planning, and self-correction within rigorous safety guardrails.
Since their debut, Claude Managed Agents have found applications across customer support automation, data analysis, creative content generation, and software development assistance. Their design philosophy balances powerful AI capabilities with robust control mechanisms to ensure predictable, safe, and effective behavior.
Recent enhancements have expanded integration capabilities to include enterprise data warehouses, CRM systems, and cloud-native tools. This enables managed agents to operate in dynamic, data-rich environments, extending their utility to domains like healthcare diagnostics, financial risk assessment, and legal document review.
Core Functionalities Before the May 2026 Update
- Task Autonomy: Agents executed multi-step tasks independently, such as scheduling meetings by accessing calendars, proposing times, and confirming appointments without constant human input.
- Human-in-the-Loop Controls: Developers could monitor, pause, or override agents to maintain output quality and safety, including corrective prompting and decision overrides.
- Context Awareness: Session-level memory enabled agents to maintain coherent interactions across multiple exchanges, preserving task continuity.
- Basic Feedback Integration: Agents adjusted responses within sessions based on limited feedback, correcting misunderstandings dynamically.
While these features established a strong foundation, the May 2026 update introduced transformative capabilities that significantly enhance agent self-improvement, success measurement, and collaborative operation.
Use Cases and Applications
Claude Managed Agents have been successfully deployed across various industries, demonstrating versatility and robust performance:
- Customer Service: Automating ticket triaging and resolution using natural language understanding to classify issues, diagnose problems via knowledge bases, and guide users through troubleshooting steps—significantly reducing human agent load and accelerating response times.
- Enterprise Workflow Automation: Managing document processing, scheduling, and internal communications. Agents extract actionable insights from meeting transcripts, generate follow-up tasks, and coordinate cross-departmental workflows seamlessly.
- Content Creation: Assisting marketing teams with drafting, editing, brainstorming, and SEO optimization—generating multiple copy variants rapidly to boost productivity and creativity.
- Data Analysis: Parsing unstructured data to identify trends and generate tailored reports, enabling informed decision-making for stakeholders.
- Software Development Assistance: Supporting developers by generating code snippets, reviewing pull requests, and suggesting optimizations aligned with coding standards and best practices.
These use cases highlight the scalability and flexibility of Claude Managed Agents in augmenting human workflows and delivering measurable business value.
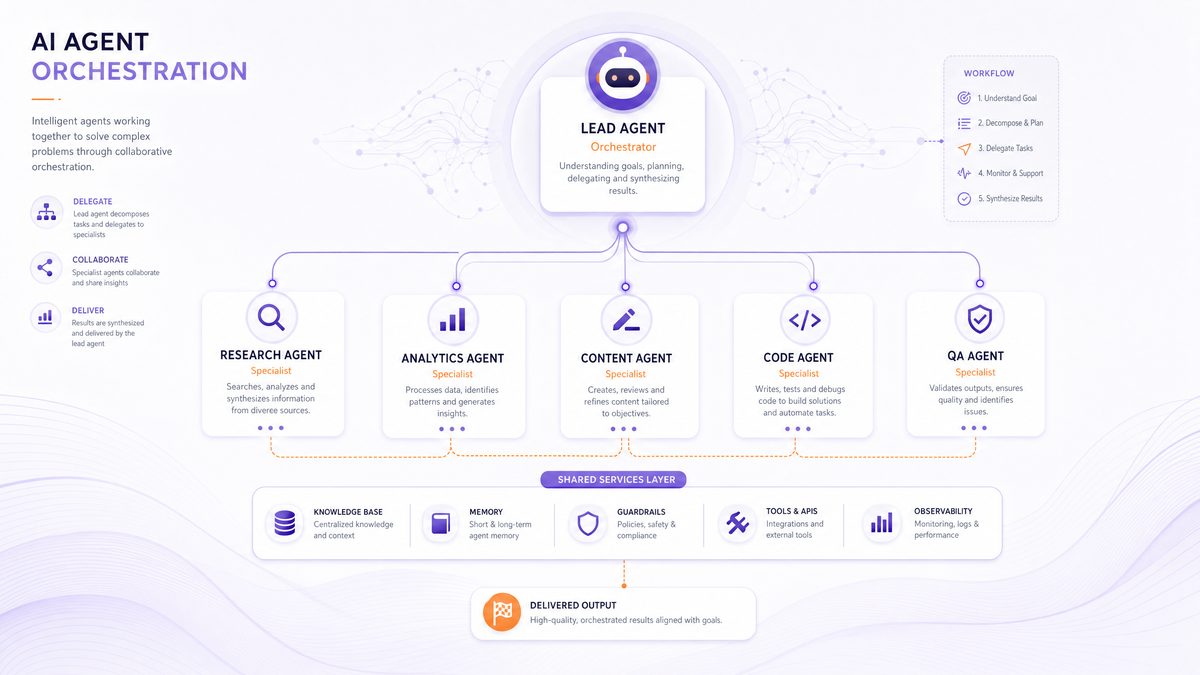
Architecture Overview: Single Agents vs Managed Agents
The Claude Managed Agents architecture distinguishes between standalone single agents and managed agents operating in a controlled, scalable environment:
| Aspect | Single Agent | Managed Agent |
|---|---|---|
| Control | Operates independently with limited oversight | Managed via Anthropic platform with centralized oversight and configuration |
| Scalability | Limited to individual use cases | Designed for multi-workflow, multi-team scaling |
| Customization | Basic prompt engineering | Advanced configuration including workflow orchestration and success criteria |
| Monitoring | Minimal tracking and diagnostics | Comprehensive monitoring, debugging, and analytics tools |
While single agents excel at rapid prototyping and simple automation, they lack the robustness and governance necessary for enterprise deployments. Managed agents embody a platform approach, facilitating agent lifecycle management, compliance, and performance auditing. Features such as session replay, rollback, and multi-tenant management are pivotal for large-scale operations.
Comparison with Other Managed Agent Frameworks
Compared to other managed agent frameworks like OpenAI’s agent toolkits or third-party orchestrators, Claude Managed Agents offer unique advantages:
- Deep Integration with Claude LLMs: Leveraging advanced, safety-focused language models ensures nuanced understanding, context retention, and reliable reasoning, particularly in sensitive domains.
- Built-in Safety and Ethical Guardrails: Robust constraints based on Anthropic’s constitutional AI principles reduce risks of bias, misinformation, and harmful content—outperforming many competitors.
- Flexible Multiagent Orchestration: Seamless coordination of specialized agents via a sophisticated orchestration framework enables modular, scalable workflows adaptable to evolving business needs.
- Extensible API and Developer Tooling: Rich SDKs and monitoring dashboards facilitate integration, debugging, and iterative enhancement, shortening development cycles.
- Enterprise-Grade Compliance: Features like audit trails, role-based access control, and data privacy safeguards meet stringent regulatory requirements.
These differentiators position Claude Managed Agents as a leading choice for enterprises demanding safe, scalable, and intelligent autonomous agents.
Developers interested in practical implementation and API references can consult [INTERNAL_LINK]. Additionally, the concept of “Dreaming”—a pivotal feature enabling agents to self-improve between sessions—is explored in detail at Claude Dreaming Explained: How Anthropic’s AI Agents Self-Improve Between Sessions.
Introducing Dreaming: Self-Improvement through Session Review
[IMAGE_PLACEHOLDER_SECTION_2]
What is Dreaming?
Dreaming is an innovative feature introduced in the May 2026 update that empowers Claude Managed Agents to self-analyze past interactions to identify strengths, weaknesses, and patterns for improvement. By autonomously reviewing previous sessions, agents generate insights that inform behavioral and decision-making enhancements, enabling continuous self-improvement without human intervention.
Unlike traditional static AI models requiring periodic retraining on curated datasets, Dreaming facilitates dynamic, ongoing reflection akin to human introspection. Agents proactively detect latent errors, optimize strategies, and refine task approaches—shifting AI autonomy from reactive adjustments to anticipatory learning.
Motivations Behind Introducing Dreaming
Traditional AI improvement relies heavily on external feedback loops or developer interventions, often slow and resource-intensive. Dreaming addresses these limitations by enabling agents to independently:
- Detect recurring errors or misunderstandings, such as misinterpreting ambiguous queries or missing procedural steps.
- Recognize and reinforce successful strategies for future tasks without explicit programming.
- Adapt dynamically to evolving user needs, terminology shifts, emerging trends, and novel task requirements.
This self-reflective mechanism reduces manual retraining needs, expedites agent evolution, lowers operational overhead, and accelerates deployment.
How Dreaming Works: Reviewing Past Sessions
Data Collection Methods from Sessions
Dreaming relies on rich, high-fidelity session data captured by agents, including:
- User inputs and queries capturing linguistic nuances and intent variations.
- Agent responses and actions, including confidence scores and decision rationales.
- Contextual metadata like timestamps, environmental parameters, and task-specific variables.
- Feedback or correction signals, both explicit (user ratings) and implicit (behavioral cues).
Comprehensive data capture ensures Dreaming can detect subtle patterns and correlations essential for meaningful self-assessment.
Pattern Recognition Techniques
Using advanced machine learning methods—such as unsupervised clustering, sequence analysis, dimensionality reduction, and anomaly detection—Dreaming identifies:
- Common failure modes (e.g., misclassification, logic errors, misunderstanding question types).
- Success factors (e.g., effective phrasing, optimal workflow steps, preferred contextual cues).
- Workflow inefficiencies like redundant steps, unnecessary API calls, or latency spikes.
- Emergent behavioral trends indicating drift or concept shifts in user interactions.
Pattern detection is optimized for scale, enabling efficient processing of large session datasets.
Self-Improvement Adjustments Based on Insights
Insights from Dreaming translate into actionable agent adjustments, including:
- Refined prompt templates and response strategies to reduce misunderstandings and improve clarity.
- Updated heuristics and decision thresholds to better align with observed user behavior.
- Reprioritized task execution flows to maximize success and reduce latency, such as eliminating redundant steps or parallelizing operations.
- Incorporation of newly detected contextual cues to enhance situational awareness.
This continuous feedback loop fosters incremental, autonomous performance enhancement, driving perpetual learning cycles.
Benefits of Dreaming for Agent Performance
- Improved Accuracy: Reduction in repeated errors and enhanced response correctness, leading to higher task success rates.
- Adaptability: Increased resilience to novel inputs and shifting user expectations, maintaining robustness in dynamic environments.
- Efficiency Gains: Streamlined workflows reduce resource consumption and response times, optimizing operational costs and user satisfaction.
- Reduced Maintenance: Lower dependence on manual retraining frees developer teams to focus on innovation.
- Scalability: Systematic propagation of improvements supports scaling agent deployments with confidence.
Practical Examples and Case Studies Demonstrating Dreaming in Action
Consider a customer support agent initially struggling with ambiguous technical inquiries. Through Dreaming, it identifies terminology frequently misunderstood, adjusts parsing heuristics, and updates its knowledge base, resulting in a 25% reduction in failed resolutions. The agent also begins proactively requesting clarifications, improving communication clarity.
In content creation, a writing assistant recognizes that concise executive summaries enhance user satisfaction. It adapts outputs to include summaries by default, increasing positive feedback by 15%. Additionally, Dreaming enables dynamic tone adjustments based on audience, improving stylistic consistency.
In financial analysis, an agent detects parsing errors caused by inconsistent document formatting. It implements enhanced validation and parsing methods, reducing error rates by 30%, significantly boosting report reliability.
Best Practices for Integrating Dreaming into Workflows
- Schedule regular Dreaming cycles aligned with operational rhythms (e.g., nightly, weekly) for timely insights incorporation.
- Ensure comprehensive session data capture, balancing detail richness with privacy and compliance requirements.
- Combine Dreaming insights with human expert reviews for critical applications to validate and contextualize adjustments.
- Continuously monitor performance metrics to confirm improvements and detect regressions promptly.
- Iteratively refine Dreaming parameters (analysis scope, sensitivity) to tailor self-improvement to specific use cases.
Following these guidelines maximizes Dreaming’s benefits while maintaining control and transparency.
For detailed API usage and configuration examples related to Dreaming, visit [INTERNAL_LINK].
Outcomes: Defining Success with a Separate Grader
Overview of the Outcomes Feature
The Outcomes feature introduces a robust framework for defining and measuring agent task success through explicit rubrics and an independent grading agent. This approach decouples success evaluation from task execution, enabling objective, consistent, and transparent assessment of agent outputs.
Separating grading from execution prevents bias and conflation of responsibilities, enhancing quality assurance. The Outcomes framework supports both quantitative and qualitative metrics, aligning evaluations with diverse organizational goals.
Why Define Clear Success Rubrics?
Clear success criteria are essential to:
- Align agents with business goals and user expectations by codifying desired outcomes.
- Provide measurable benchmarks for data-driven performance optimization.
- Facilitate accountability and auditability, critical for compliance and stakeholder trust.
- Support collaboration by providing transparent, shared definitions of success.
Codifying “success” concretely enables effective monitoring and refinement of agent behavior.
Anatomy of an Outcomes Framework
Defining Clear, Measurable Success Criteria
Success rubrics specify quantifiable indicators such as:
- Accuracy thresholds (e.g., classification accuracy above 90%)
- Response time limits ensuring efficiency
- User satisfaction scores derived from feedback
- Compliance with regulatory or ethical standards
- Completeness and coherence in multi-step tasks
Criteria can be customized per domain and weighted to balance priorities.
The Role of the Separate Grading Agent
The grading agent operates independently from task-performing agents, evaluating outputs against defined rubrics. This impartiality reinforces trustworthy assessments.
Grading can occur synchronously for real-time feedback or asynchronously for post-task evaluation, feeding results back into agent learning and organizational dashboards.
Advanced graders combine rule-based checks, model-based evaluations, and human-in-the-loop annotations to maximize accuracy and reliability.
How Grading Influences Agent Learning and Task Completion
- Performance Tracking: Monitoring trends for proactive interventions.
- Reward Signals: Informing reinforcement learning to guide policy updates.
- Quality Assurance: Triggering alerts or human oversight upon failure detection.
- Compliance Reporting: Generating audit trails for regulatory reviews.
This feedback loop enhances reliability and maintains high execution standards.
Setting Up and Customizing Success Rubrics
Anthropic provides an intuitive interface and API to define and manage rubrics, enabling:
- Multi-dimensional criteria with weighted importance
- Integration of domain-specific metrics and external data
- Versioning and iterative refinement
- Scenario-based configurations for diverse workflows
This flexibility supports industries from healthcare to financial auditing.
Examples of Rubric Use Cases in Various Industries
| Industry | Success Criteria | Grading Metrics |
|---|---|---|
| Healthcare | Accurate diagnosis support, adherence to clinical guidelines | Diagnostic accuracy %, compliance rate, patient safety incidents, time-to-diagnosis |
| Finance | Risk assessment precision, regulatory compliance | False positive/negative rates, audit scorecards, anomaly detection rates |
| Customer Service | Resolution time, customer satisfaction | Average handling time, CSAT scores, first contact resolution rate |
| Legal | Contract clause accuracy, policy compliance | Clause detection accuracy, compliance violation counts |
Impact of Outcomes on Agent Reliability and Accountability
The Outcomes framework elevates Claude Managed Agents’ trustworthiness by providing:
- Transparent Metrics: Stakeholders access grading results to understand efficacy, fostering trust.
- Automated Quality Control: Maintains standards with consistent evaluations, reducing human workload.
- Regulatory Compliance: Documents adherence to industry standards, essential for regulated sectors.
- Continuous Improvement: Enables data-driven refinement cycles aligning outputs with evolving priorities.
This fosters confidence for mission-critical deployments and wider integration.
Developers can explore rubric configuration and grading workflows at [INTERNAL_LINK]. Effective prompt engineering is critical for maximizing multiagent system outcomes; advanced techniques are discussed in Mastering Multi-Agent Prompts: Advanced Techniques for Codex and Claude Code Orchestration.