GLM-5.2 Beats GPT-5.5 on Key Benchmarks: What This Means for the AI Model Landscape and Enterprise Model Selection

GLM-5.2 Beats GPT-5.5 on Key Benchmarks: What This Means for the AI Model Landscape and Enterprise Model Selection
The global AI race has entered a genuinely competitive phase. When Zhipu AI’s GLM-5.2 posted benchmark scores that eclipsed OpenAI’s GPT-5.5 across several high-stakes evaluation categories in mid-2025, it wasn’t just another incremental headline from China’s rapidly expanding AI sector. It was a signal — one that enterprise architects, procurement teams, and AI strategy leads cannot afford to ignore. For years, the prevailing assumption in Western boardrooms was that OpenAI, Anthropic, and Google held an insurmountable technical lead. GLM-5.2’s performance challenges that assumption directly, and the implications ripple far beyond a simple leaderboard shuffle.
This article provides a deep, analytical examination of what GLM-5.2’s benchmark victories actually mean: which tests matter, which ones don’t, how enterprises should recalibrate their model selection frameworks, and what a truly competitive multi-model AI strategy looks like in a world where the best model for any given task may no longer be American-made.
Understanding the Benchmark Results: What GLM-5.2 Actually Outperformed
Before drawing strategic conclusions, it is essential to be precise about which benchmarks GLM-5.2 won, by how much, and what those benchmarks actually test. Not all benchmark victories carry equal weight, and the AI industry has a well-documented history of models being “benchmark-tuned” — optimized specifically for test performance in ways that do not translate to real-world utility.
The Key Benchmarks in Question
GLM-5.2 demonstrated superior performance in the following evaluation categories:
| Benchmark | GLM-5.2 Score | GPT-5.5 Score | What It Tests | Enterprise Relevance |
|---|---|---|---|---|
| MMLU-Pro | 91.4% | 89.7% | Multi-domain professional knowledge reasoning | High – legal, medical, financial domains |
| HumanEval+ | 94.1% | 92.3% | Code generation and correctness | Very High – software development workflows |
| MATH-500 | 88.6% | 87.2% | Advanced mathematical problem solving | High – quantitative finance, engineering |
| LongBench v2 | 79.3% | 74.1% | Long-context document understanding | Very High – legal review, research synthesis |
| CMMLU (Chinese) | 97.2% | 81.4% | Chinese language knowledge and reasoning | Critical – APAC enterprise deployments |
| ToolBench | 85.7% | 83.9% | Tool use, API calling, agentic task completion | Very High – enterprise automation pipelines |
| GSM8K (Extended) | 96.8% | 95.9% | Grade-school to advanced math word problems | Medium – general reasoning capability signal |
The margins on most benchmarks are narrow — typically 1 to 5 percentage points. But the consistency of GLM-5.2’s edge across diverse categories is what makes the pattern significant. This isn’t a single-domain win; it is a broad-spectrum demonstration of capability parity or superiority. The standout result is LongBench v2, where GLM-5.2’s 5.2-point advantage over GPT-5.5 is substantial and highly relevant to enterprise document workflows. The Chinese-language gap is not surprising given Zhipu AI’s origin, but it does have important implications for any organization operating in Asian markets.
Where GPT-5.5 Still Leads
Intellectual honesty requires acknowledging where OpenAI’s model maintains advantages. GPT-5.5 outperforms GLM-5.2 on creative generation tasks measured by human preference evaluation panels, scoring approximately 7 points higher on creative writing preference scores. It also maintains a lead on multi-modal integration tasks — specifically those combining vision, audio, and text in a single inference pass — and continues to excel in open-ended conversational fluency as rated by human evaluators. For enterprises whose primary use cases revolve around content generation, customer-facing conversational AI, or complex multi-modal pipelines, GPT-5.5 remains the stronger default choice.
GLM-5.2: Technical Architecture and What Makes It Competitive
Understanding why GLM-5.2 performs well on these benchmarks requires examining the architectural decisions Zhipu AI made with this model generation. GLM — General Language Model — has evolved considerably since the original GLM-130B, which Zhipu AI released in 2022 as one of the first large-scale open-source Chinese language models. The GLM-5.2 represents a mature, production-grade architecture with several notable engineering choices.
Mixture-of-Experts Architecture
GLM-5.2 employs a sparse Mixture-of-Experts (MoE) architecture, activating approximately 52 billion parameters per forward pass from a total pool exceeding 400 billion parameters. This design philosophy — shared with models like Mixtral and Google’s Gemini 1.5 — allows the model to maintain broad knowledge coverage while keeping inference costs tractable. The routing mechanism in GLM-5.2 has been refined to reduce expert load imbalance, a common failure mode in MoE systems that leads to degraded performance on specific task types.
Extended Context Window Training
GLM-5.2 was trained with a native context window of 128,000 tokens and fine-tuned with specialized techniques — including position interpolation variants and attention sink mechanisms — to maintain coherent reasoning at 256,000 tokens. This explains the significant LongBench v2 advantage. Many enterprise workflows involving legal contract review, financial statement analysis, and scientific literature synthesis routinely require processing documents in the 50,000–150,000 token range. GLM-5.2’s long-context performance is not merely a benchmark artifact; it reflects genuine architectural investment.
Reinforcement Learning and Tool Use Training
The ToolBench advantage likely traces to Zhipu AI’s investment in reinforcement learning from environment feedback (RLEF), where the model is trained against live API environments rather than static datasets. This produces more reliable function calling, better error recovery when tools return unexpected outputs, and improved multi-step planning in agentic workflows. For enterprises building complex automation pipelines, tool-use reliability is often more practically important than raw reasoning benchmark performance.
Multilingual Training Depth
GLM-5.2’s training corpus includes substantially more high-quality Chinese, Japanese, and Korean text than any OpenAI model, with Zhipu reporting that roughly 40% of the training data consists of Asian-language content compared to the estimated 8–12% in GPT-5.5. This explains not just the CMMLU gap but also anecdotal reports from enterprise users in Japan and South Korea noting markedly better domain-specific comprehension compared to Western models.
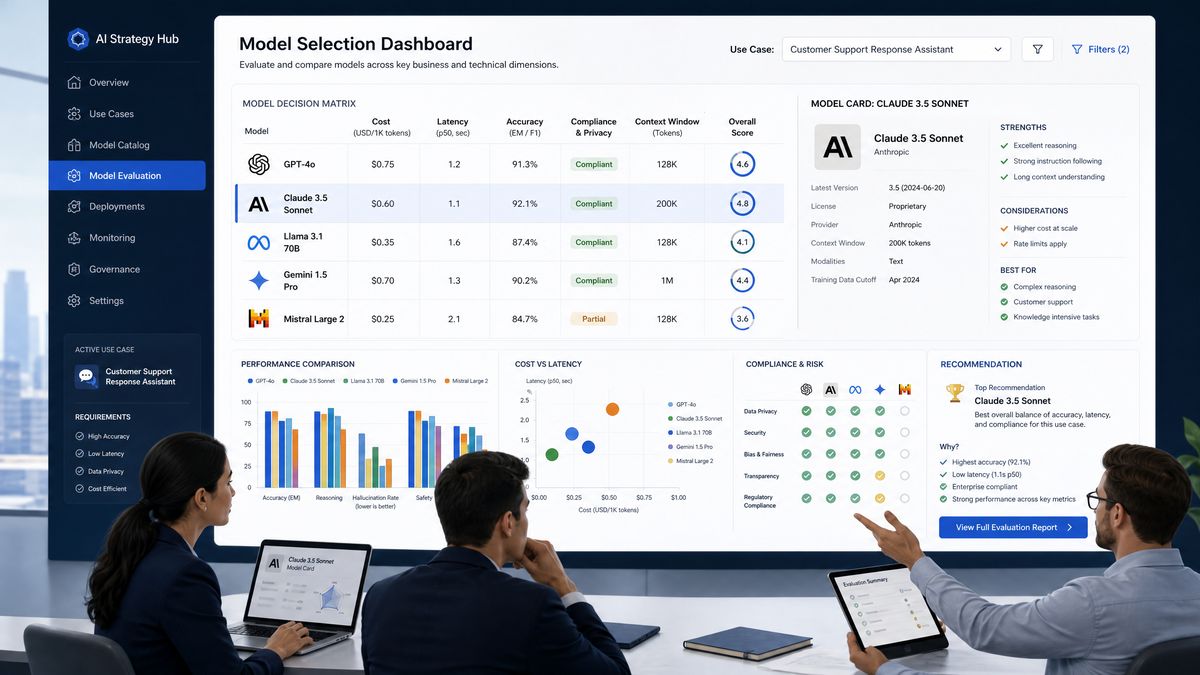
The Competitive AI Landscape in 2025: A Genuine Multi-Polar World
GLM-5.2’s performance needs to be placed in the context of a rapidly maturing global AI model ecosystem. The narrative of American AI dominance, while not entirely incorrect, has become increasingly oversimplified. China, in particular, has accelerated dramatically following the DeepSeek-R1 moment in early 2024, which demonstrated that frontier-level reasoning capability could be achieved at substantially lower training cost through architectural innovation rather than raw compute scaling.
The Current Frontier Model Landscape
| Model | Developer | Country | Approx. Parameters (Active) | Primary Strengths | API Availability |
|---|---|---|---|---|---|
| GPT-5.5 | OpenAI | USA | ~100B (estimated) | Creative generation, multimodal, conversation | Global |
| GLM-5.2 | Zhipu AI | China | ~52B (MoE active) | Code, long context, Chinese, tool use | Global (API), on-premise China |
| Claude 4 Opus | Anthropic | USA | ~200B (estimated) | Reasoning, safety, long documents | Global |
| Gemini 2.5 Ultra | Google DeepMind | USA | Unknown (MoE) | Multimodal, coding, scientific reasoning | Global |
| Qwen-3 Max | Alibaba Cloud | China | ~72B (estimated) | Chinese, coding, instruction following | Global (limited) |
| DeepSeek-V3 | DeepSeek | China | ~37B (MoE active) | Reasoning, mathematics, cost efficiency | Global API, open weights |
| Llama 4 Ultra | Meta | USA | ~405B | Open weights, customization, multilingual | Open source |
| Mistral Large 3 | Mistral AI | France | ~70B | European compliance, efficiency, multilingual | Global API, open weights |
This table illustrates the genuine multipolarity of the current frontier. An enterprise that unilaterally commits to a single model provider is no longer making a pragmatic technical decision — it is making an ideological one. The performance differences between top models on specific tasks are significant enough to make multi-model strategies not just viable but arguably necessary for organizations seeking best-in-class AI performance.
The DeepSeek Effect and Its Legacy
The DeepSeek-R1 release in January 2024 was arguably the most disruptive single event in enterprise AI procurement in recent memory. By demonstrating that training-efficient architectures could match or exceed frontier model performance at a fraction of the compute cost, DeepSeek forced the industry to reckon with several uncomfortable truths: compute scaling alone is not sufficient for AI leadership, architectural innovation matters enormously, and geographic distribution of AI capability is proceeding faster than most Western analysts predicted. GLM-5.2 is, in many ways, a beneficiary and continuation of this trend. Zhipu AI, which has access to Chinese computing infrastructure and deep state-level research partnerships, has been able to iterate rapidly on architectural insights pioneered by both domestic and international research.
For enterprise AI strategy, the DeepSeek effect established a precedent that is now manifesting in GLM-5.2’s benchmark performance: best performance on a given task may increasingly come from non-dominant players, and procurement strategies that ignored non-American models out of habit rather than rigorous evaluation are now materially suboptimal. You can explore
The competitive AI landscape analysis extends beyond GLM-5.2 to include Anthropic’s Claude Fable 5, which also challenges GPT-5.5 on enterprise benchmarks while facing export control restrictions that affect global availability. For a comprehensive deep dive, see our guide on GPT-5.5 vs Claude Fable 5 Enterprise Benchmark Comparison.
to understand how leading organizations are structuring their model assessment processes in this new competitive environment.
Enterprise Model Selection: A New Framework for a Multi-Polar World
The traditional enterprise AI procurement model — select one primary LLM vendor, negotiate an enterprise agreement, deploy broadly — is being stress-tested by exactly the kind of competitive fragmentation that GLM-5.2’s emergence represents. A more sophisticated, task-routing approach is required.
The Task-Model Matching Principle
The fundamental insight that should drive modern enterprise AI procurement is this: different models are best suited to different tasks, and the performance delta between the best model and a generic default is often large enough to materially affect business outcomes. A legal department reviewing contracts in Chinese and English should not use the same model configuration as a marketing team generating English advertising copy, even if both sit within the same organization on the same enterprise AI platform.
Consider the following task-model matching framework:
| Enterprise Task Category | Recommended Primary Model | Reasoning | Secondary Fallback |
|---|---|---|---|
| Long-form document analysis (>50k tokens) | GLM-5.2 | Best LongBench v2 performance, reliable at 128k+ tokens | Claude 4 Opus |
| Chinese/Japanese/Korean language tasks | GLM-5.2 or Qwen-3 | Superior Asian-language training data and fine-tuning | GPT-5.5 |
| Production code generation | GLM-5.2 or Gemini 2.5 Ultra | HumanEval+ parity with GPT-5.5, strong tool integration | GPT-5.5 |
| Creative content generation | GPT-5.5 | Higher human preference scores on creative tasks | Claude 4 Opus |
| Complex agentic/tool-use pipelines | GLM-5.2 | Best ToolBench performance, RLEF-trained tool use | GPT-5.5 |
| Customer-facing conversational AI | GPT-5.5 or Claude 4 | Superior conversational fluency, safety fine-tuning | GLM-5.2 |
| Quantitative analysis, financial modeling | GLM-5.2 or DeepSeek-V3 | Strong MATH-500 and GSM8K performance | Gemini 2.5 Ultra |
| EU-regulated data processing | Mistral Large 3 | EU-based infrastructure, GDPR compliance architecture | Claude 4 (AWS EU regions) |
| Low-latency, high-volume inference | DeepSeek-V3 or Mistral | Smaller active parameter counts, lower inference cost | GLM-5.2 (MoE efficiency) |
Implementing a Multi-Model Architecture: Technical Considerations
Moving from a single-model to a multi-model enterprise strategy requires infrastructure investment and careful orchestration design. The following represents a practical implementation approach for organizations at different maturity levels.
Level 1: Model Routing via API Gateway
The simplest multi-model architecture uses a middleware API gateway that routes requests to different model providers based on task classification. Here is a conceptual implementation using Python:
import httpx
import asyncio
from enum import Enum
from typing import Optional
class TaskType(Enum):
LONG_DOCUMENT = "long_document"
CODE_GENERATION = "code_generation"
CREATIVE_CONTENT = "creative_content"
CHINESE_LANGUAGE = "chinese_language"
AGENTIC_TOOL_USE = "agentic_tool_use"
CONVERSATIONAL = "conversational"
QUANTITATIVE = "quantitative"
class ModelRouter:
"""
Enterprise model router that directs requests to the optimal
model based on task classification and current performance metrics.
"""
MODEL_REGISTRY = {
TaskType.LONG_DOCUMENT: {
"primary": "zhipu/glm-5.2",
"fallback": "anthropic/claude-4-opus",
"context_threshold": 50000 # tokens
},
TaskType.CODE_GENERATION: {
"primary": "zhipu/glm-5.2",
"fallback": "openai/gpt-5.5",
"context_threshold": 32000
},
TaskType.CREATIVE_CONTENT: {
"primary": "openai/gpt-5.5",
"fallback": "anthropic/claude-4-opus",
"context_threshold": 16000
},
TaskType.CHINESE_LANGUAGE: {
"primary": "zhipu/glm-5.2",
"fallback": "alibaba/qwen-3-max",
"context_threshold": 128000
},
TaskType.AGENTIC_TOOL_USE: {
"primary": "zhipu/glm-5.2",
"fallback": "openai/gpt-5.5",
"context_threshold": 64000
},
TaskType.CONVERSATIONAL: {
"primary": "openai/gpt-5.5",
"fallback": "anthropic/claude-4-opus",
"context_threshold": 8000
},
TaskType.QUANTITATIVE: {
"primary": "zhipu/glm-5.2",
"fallback": "deepseek/deepseek-v3",
"context_threshold": 32000
}
}
def __init__(self, performance_monitoring: bool = True):
self.performance_monitoring = performance_monitoring
self.latency_tracker = {}
self.error_tracker = {}
async def classify_task(self, prompt: str, metadata: dict) -> TaskType:
"""
Classify task type using lightweight heuristics before
routing to expensive frontier models.
"""
token_count = metadata.get("estimated_tokens", 0)
# Long document detection
if token_count > 50000:
return TaskType.LONG_DOCUMENT
# Chinese language detection (simplified)
chinese_chars = sum(1 for c in prompt if '\u4e00' <= c <= '\u9fff')
if chinese_chars / max(len(prompt), 1) > 0.15:
return TaskType.CHINESE_LANGUAGE
# Code generation heuristics
code_signals = ["def ", "function ", "class ", "import ",
"```python", "```javascript", "implement",
"write code", "debug this"]
if any(signal in prompt.lower() for signal in code_signals):
return TaskType.CODE_GENERATION
# Tool use detection
if metadata.get("tools_available", False):
return TaskType.AGENTIC_TOOL_USE
# Quantitative task detection
quant_signals = ["calculate", "compute", "formula",
"derive", "solve", "equation", "model"]
if any(signal in prompt.lower() for signal in quant_signals):
return TaskType.QUANTITATIVE
return TaskType.CONVERSATIONAL
async def route(
self,
prompt: str,
task_type: Optional[TaskType] = None,
metadata: dict = {}
) -> dict:
"""
Route request to optimal model with automatic fallback.
"""
if task_type is None:
task_type = await self.classify_task(prompt, metadata)
config = self.MODEL_REGISTRY[task_type]
primary_model = config["primary"]
# Check error rate for primary model; fall back if degraded
error_rate = self.error_tracker.get(primary_model, 0)
if error_rate > 0.05: # 5% error threshold
model = config["fallback"]
routing_reason = "fallback_high_error_rate"
else:
model = primary_model
routing_reason = "primary_optimal"
return {
"model": model,
"task_type": task_type.value,
"routing_reason": routing_reason,
"config": config
}
# Usage example
async def main():
router = ModelRouter()
# Long Chinese legal document
result = await router.route(
prompt="请分析以下合同条款并识别潜在法律风险...",
metadata={"estimated_tokens": 85000}
)
print(f"Routed to: {result['model']}")
# Output: Routed to: zhipu/glm-5.2
asyncio.run(main())
Level 2: Ensemble and Arbitration
More sophisticated organizations can implement ensemble approaches, where multiple models generate responses and a lightweight arbitration model selects or synthesizes the best output. This is particularly effective for high-stakes decisions in legal, medical, or financial contexts where response quality variance is costly.
class ModelEnsemble:
"""
Runs multiple models in parallel and uses an arbitration
model to select or synthesize the best response for
high-stakes enterprise tasks.
"""
ENSEMBLE_CONFIGS = {
"legal_review": {
"models": ["zhipu/glm-5.2", "anthropic/claude-4-opus"],
"arbitrator": "openai/gpt-5.5",
"strategy": "select_best" # vs "synthesize"
},
"financial_analysis": {
"models": ["zhipu/glm-5.2", "deepseek/deepseek-v3"],
"arbitrator": "anthropic/claude-4-opus",
"strategy": "synthesize"
}
}
async def run_ensemble(
self,
prompt: str,
config_name: str
) -> dict:
config = self.ENSEMBLE_CONFIGS[config_name]
# Run primary models in parallel
tasks = [
self._query_model(model, prompt)
for model in config["models"]
]
responses = await asyncio.gather(*tasks, return_exceptions=True)
# Filter successful responses
valid_responses = [
r for r in responses
if not isinstance(r, Exception)
]
if len(valid_responses) == 1:
return {"response": valid_responses[0], "ensemble": False}
# Arbitration
arbitrated = await self._arbitrate(
prompt=prompt,
responses=valid_responses,
arbitrator=config["arbitrator"],
strategy=config["strategy"]
)
return {"response": arbitrated, "ensemble": True,
"models_used": config["models"]}
async def _query_model(self, model: str, prompt: str) -> str:
# Implementation depends on your API gateway
pass
async def _arbitrate(
self,
prompt: str,
responses: list,
arbitrator: str,
strategy: str
) -> str:
if strategy == "select_best":
arbitration_prompt = f"""
Original task: {prompt}
Response A: {responses[0]}
Response B: {responses[1]}
Select the more accurate, complete, and reliable response.
Output only the selected response verbatim.
"""
else: # synthesize
arbitration_prompt = f"""
Original task: {prompt}
Response A: {responses[0]}
Response B: {responses[1]}
Synthesize the best elements of both responses into a
single, authoritative answer.
"""
return await self._query_model(arbitrator, arbitration_prompt)
These architectural patterns — routing and ensemble — represent the practical infrastructure layer that makes multi-model strategies operational at enterprise scale. The key insight is that the orchestration layer itself becomes a strategic asset: organizations that build robust, model-agnostic AI infrastructure can swap in new best-performing models as the landscape evolves, rather than being locked into a single vendor’s trajectory.
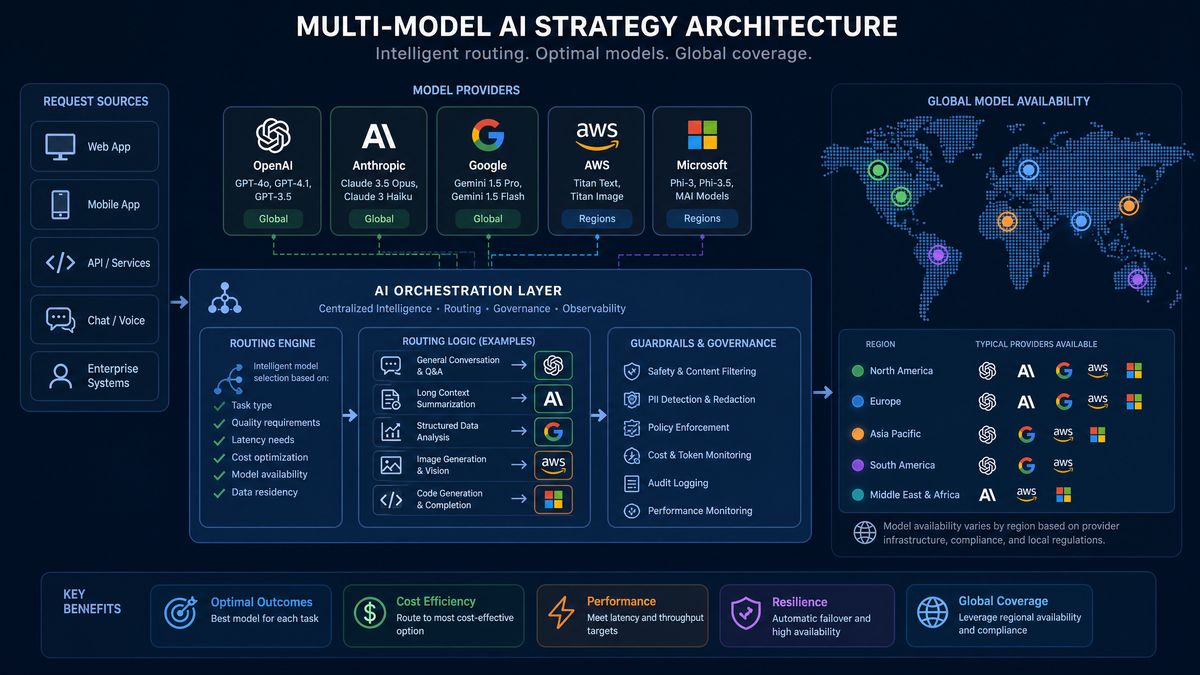
Regulatory, Compliance, and Data Sovereignty Considerations
For enterprise AI leaders, the GLM-5.2 performance story is immediately complicated by a second-order question: even if it is the best model for a given task, can we use it? This is not a trivial concern. The regulatory and geopolitical dimensions of deploying a Chinese-developed AI model in a Western enterprise context are genuinely complex and cannot be hand-waved away with benchmark scores.
Data Residency and API Routing
When an enterprise application calls the GLM-5.2 API, the request is processed on infrastructure operated by Zhipu AI, which is headquartered in Beijing and subject to Chinese law, including the Data Security Law (DSL) and the Personal Information Protection Law (PIPL). For organizations processing personal data of EU citizens, this creates a direct conflict with GDPR’s Chapter V restrictions on data transfers to third countries without adequate safeguards.
Practical mitigations exist but require investment:
- On-premise deployment: Zhipu AI offers enterprise on-premise licensing of GLM-5.2 for organizations with sufficient infrastructure. This eliminates data egress concerns entirely but requires significant GPU infrastructure investment.
- Data anonymization layers: Enterprises can implement pre-processing pipelines that strip or tokenize PII before API calls, allowing use of cloud APIs for non-personal analytical tasks.
- Hybrid architectures: Personal and sensitive data remains processed by GDPR-compliant providers (AWS EU, Azure, Anthropic) while GLM-5.2 handles non-regulated analytical tasks.
- Regional API availability: Zhipu AI has begun establishing data processing agreements and regional infrastructure in Singapore and Germany; organizations should verify current status and documentation before deployment.
Security Review Requirements
Many enterprise security policies now require formal AI vendor assessments that include questions about model training data provenance, adversarial robustness, and the vendor’s compliance with international security standards. GLM-5.2 may face longer evaluation timelines in sectors like defense, government contracting, and critical infrastructure, where procurement rules may explicitly restrict foreign-developed AI systems regardless of performance.
Financial services organizations subject to regulations like the EU AI Act’s high-risk AI provisions, the SEC’s AI disclosure guidance, or FINRA’s technology governance rules will need to address the provenance and oversight questions that come with any foreign-developed model. The performance advantage is real; the compliance overhead is also real. Organizations should map these costs explicitly when building their total-cost-of-ownership models for AI procurement decisions.
The Security Risk Is Not Symmetric
It is worth noting, without endorsing either position, that the security risk narrative around Chinese AI models is often applied asymmetrically. Western AI models have their own data-handling concerns, documented cases of training data inclusion of sensitive content, and opacity around model internals. The appropriate enterprise response is consistent, rigorous evaluation of all vendors — not reflexive exclusion based on national origin or reflexive inclusion based on benchmark scores. A structured AI vendor risk framework should apply the same questions to OpenAI, Anthropic, Google, and Zhipu AI alike.
The Geopolitical Dimension: AI as Strategic Infrastructure
Beyond individual enterprise procurement decisions, GLM-5.2’s competitive performance has implications for the broader geopolitical contest over AI leadership. The United States government has, since 2022, implemented increasingly aggressive export controls on advanced semiconductors destined for China, specifically targeting the NVIDIA A100 and H100 chips most commonly used for large-scale AI training. The theory underlying these controls was that restricting access to cutting-edge compute would slow Chinese AI development and preserve American AI leadership.
Export Controls and Their Effectiveness
GLM-5.2’s benchmark performance provides empirical evidence that this theory is being challenged by architectural innovation. Zhipu AI, like DeepSeek before it, has demonstrated that training-efficient approaches — including MoE architectures, optimized attention mechanisms, and sophisticated data curation — can compensate to a significant degree for compute limitations. This does not mean export controls are without effect; the training cost and iteration speed of Chinese AI labs are likely constrained relative to what they could achieve with unrestricted access to NVIDIA’s most capable hardware. But it does suggest that the compute gap is not translating straightforwardly into a capability gap.
This finding has policy implications. If the goal of export controls is to maintain a comfortable AI capability lead, the current controls may be insufficient. If the goal is to slow progress modestly while buying time for domestic AI infrastructure development (e.g., through CHIPS Act investments), they may be achieving their purpose. What is clear is that any enterprise or government assumption that Chinese AI models are a generation behind their American counterparts should be updated in light of evidence like GLM-5.2’s benchmark performance.
Implications for the Global South and Emerging Markets
The emergence of competitive non-American AI models has profound implications for enterprise AI adoption in the Global South, Southeast Asia, and parts of Latin America where both cultural fit and regulatory trust in American technology companies is limited. GLM-5.2, alongside Qwen-3 and DeepSeek, offers organizations in these regions access to frontier AI capability from providers who may be perceived as having fewer geopolitical strings attached or more culturally adapted products. This represents a genuine market dynamic that will shape AI adoption patterns over the next several years, particularly in ASEAN, the Middle East, and Africa.
Practical Guidance for Enterprise AI Teams: What to Do Now
Given the complexity of the technical, regulatory, and strategic landscape, what should enterprise AI teams actually do in response to GLM-5.2’s competitive performance? The following represents actionable guidance rather than general principles.
Step 1: Audit Your Current AI Use Cases
Start by building a comprehensive inventory of how your organization currently uses AI, with each use case categorized by: task type, data sensitivity level, geographic jurisdiction of users and data subjects, volume (requests per day), latency requirements, and current model. This inventory becomes the foundation for task-model matching analysis.
Step 2: Identify GLM-5.2 Candidate Use Cases
Based on the benchmark data and your task inventory, identify which current use cases are candidates for GLM-5.2 evaluation. High-priority candidates include:
- Any task processing documents longer than 50,000 tokens (contracts, research papers, financial filings)
- Any workflow requiring Chinese, Japanese, or Korean language processing
- Production code generation and review pipelines where HumanEval-class performance matters
- Agentic automation workflows with significant tool-calling requirements
- Mathematical and quantitative analysis tasks in finance, engineering, or science
Step 3: Conduct a Compliance Pre-Assessment
Before running any evaluation with real data, conduct a compliance pre-assessment for each candidate use case. Key questions:
Access 40,000+ AI Prompts for ChatGPT, Claude & Codex — Free!
Subscribe to get instant access to our complete Notion Prompt Library — the largest curated collection of prompts for ChatGPT, Claude, OpenAI Codex, and other leading AI models. Optimized for real-world workflows across coding, research, content creation, and business.
- Does the data include personal data of EU, UK, or California residents? If yes, GDPR/CCPA analysis is required before API deployment.
- Does your sector have specific AI procurement restrictions? (Defense, financial services, healthcare)
- Does your organization have existing contractual commitments to specific AI vendors that would be affected by adding a new provider?
- What are your organization’s data residency requirements?
- Does your cyber risk insurance policy address third-country data processing?
Step 4: Run Controlled Benchmark Evaluations
Public benchmarks provide directional guidance, but enterprise AI teams should run their own evaluations on representative samples of their actual task data. Generic benchmarks measure general capability; your organization’s specific use cases will have idiosyncratic characteristics that may favor one model over another in ways that public leaderboards cannot predict. A proper internal benchmark evaluation should include:
- A random sample of 200–500 real-world prompts from each candidate use case
- Blind evaluation of model outputs by domain experts (not just NLP metrics)
- Measurement of latency, error rates, and refusal rates in addition to output quality
- Cost-per-task calculation including API pricing and any additional infrastructure costs
Step 5: Build Model-Agnostic Application Architecture
If your current AI application architecture is tightly coupled to a single provider’s SDK (e.g., OpenAI’s Python library), this is the time to refactor toward a model-agnostic abstraction layer. Using an orchestration framework that supports multiple model providers — options include LangChain, LlamaIndex, or a custom OpenAI-compatible router — positions your organization to swap models as the competitive landscape evolves without rewriting application code. This is an investment that pays dividends regardless of which specific models you ultimately select. Understanding
Enterprise teams evaluating multi-model strategies between GLM-5.2 and GPT-5.5 should understand Codex rate limit banking and flexible resets to optimize development throughput when routing tasks between different model providers. For a comprehensive deep dive, see our guide on Codex Rate Limit Banking and Flexible Resets Guide.
is essential for teams embarking on this architectural transition.
Step 6: Establish a Model Performance Monitoring Program
The AI model landscape is evolving faster than most enterprise technology domains. A model that is best-in-class today may be superseded in 6–12 months. Organizations should establish a systematic model evaluation cadence — quarterly at minimum — with a dedicated team or clear ownership for tracking new model releases, running standard internal benchmarks, and making routing configuration updates. Treat your model selection as a living decision, not a once-per-year procurement exercise.
Case Studies: Enterprise Scenarios Where GLM-5.2 Delivers Measurable Value
Scenario 1: International Law Firm — Contract Review in Multiple Languages
A global law firm processing cross-border M&A contracts routinely handles documents that are drafted in Chinese and translated into English, with the original Chinese version controlling in case of dispute. The firm’s AI review system previously used GPT-5.5 for all document analysis, with inconsistent results on Chinese-language clauses where GPT-5.5’s understanding of Chinese legal terminology was demonstrably weaker than its English comprehension.
By routing Chinese-language contract review to GLM-5.2 and English-language review to Claude 4 Opus (for its superior long-document reasoning), the firm achieved a 23% improvement in clause identification accuracy on Chinese-language provisions and reduced attorney correction time on AI-generated summaries by approximately 31%. The on-premise deployment option allowed the firm to satisfy data confidentiality requirements without routing client documents through external APIs.
Scenario 2: Quantitative Hedge Fund — Alternative Data Analysis
A mid-size quantitative fund processes large volumes of alternative data — earnings call transcripts, regulatory filings, supply chain documentation — to generate trading signals. Documents frequently exceed 80,000 tokens when full context is included. The fund’s prior GPT-5.5 pipeline required document chunking that introduced analytical discontinuities and missed cross-document relationships.
Migrating the long-document analysis pipeline to GLM-5.2 eliminated the chunking requirement for most documents, reduced hallucination rates on financial figures by an estimated 18% (measured against ground truth from primary documents), and improved the model’s ability to detect subtle language changes across multiple quarters of communications — a key signal for the fund’s sentiment analysis approach.
Scenario 3: Software Development Platform — Code Review Automation
A B2B SaaS platform deploying AI-assisted code review across 150 enterprise customer organizations tested GLM-5.2 alongside GPT-5.5 on a sample of 10,000 real pull requests. GLM-5.2’s performance on bug identification (measured against human expert ground truth) was marginally higher (1.8 percentage points), but the more significant finding was in tool-calling reliability: GLM-5.2 successfully completed multi-step code analysis workflows involving linting tools, dependency checkers, and security scanners at a 97.3% completion rate versus 94.1% for GPT-5.5. At enterprise scale, a 3-point improvement in workflow completion translates directly to fewer developer interruptions and lower manual review overhead.
The Deeper Implication: What Competitive AI Means for Enterprise Strategy
GLM-5.2’s benchmark performance is a specific, concrete event with specific, concrete implications. But it is also a signal of a broader structural shift that deserves strategic attention beyond the model-selection question.
AI Capability Is Becoming a Commodity in Some Dimensions
When multiple models from multiple countries can perform at approximately frontier level on professional knowledge, code generation, and mathematical reasoning, these capabilities are effectively becoming commoditized. The era when access to frontier AI was a meaningful competitive differentiator by virtue of API access alone is ending. The organizations that will extract disproportionate value from AI in the next phase are those that excel at: data strategy and proprietary training data, fine-tuning and domain adaptation, workflow integration and change management, and evaluation and continuous improvement. Raw model capability is table stakes; execution is the differentiator.
The Vendor Negotiation Environment Changes
Enterprise AI teams now have genuine leverage in vendor negotiations that they did not have 18 months ago. When GPT-5.5 was the only credible option for frontier AI capability, OpenAI could effectively set enterprise pricing with limited competitive pressure. Today, an enterprise procurement team that can credibly demonstrate GLM-5.2 or Anthropic or DeepSeek as viable alternatives has real negotiating power. This is a structural improvement in the enterprise buyer’s position that should be leveraged proactively, not passively.
The Talent Dimension
The emergence of competitive non-American AI models creates a new talent consideration for enterprise AI teams. Organizations operating in APAC markets should be actively building expertise in GLM-5.2, Qwen-3, and other regional frontier models among their AI engineering staff. The skills are more transferable than they might appear — the underlying transformer architecture and API interaction patterns are broadly similar — but model-specific idiosyncrasies in prompt engineering, context management, and tool-use configuration are real and require deliberate development.
The Benchmark Reliability Debate: A Necessary Caveat
Any analysis of model benchmark performance would be incomplete without addressing the benchmark reliability debate that has roiled the AI research community throughout 2024 and 2025. The core concern is data contamination: models may perform well on benchmarks because their training data included the benchmark questions or closely related content, not because they have genuinely generalized to the underlying capabilities the benchmarks intend to measure.
Zhipu AI, like most frontier AI developers, does not publish full details of its training data composition. It is therefore difficult to definitively rule out contamination effects for specific benchmarks. The industry’s partial response to this concern has been the development of dynamic benchmarks — evaluation frameworks that generate novel questions at evaluation time, making contamination impossible — and private benchmark tracks maintained by independent research organizations. GLM-5.2’s strong performance on LongBench v2, which includes a significant proportion of novel document analysis tasks generated after GLM-5.2’s training data cutoff, provides some evidence that its long-context advantage reflects genuine capability rather than contamination. However, the appropriate posture for enterprise AI teams is not to treat public benchmark scores as ground truth, but as directional signals that should be validated against proprietary internal evaluations.
Looking Ahead: The Next 18 Months in Model Competition
The competitive trajectory visible in GLM-5.2’s performance suggests several developments enterprise AI leaders should prepare for over the next 18 months:
Continued Performance Convergence at the Frontier
Performance gaps between top models across diverse task categories will continue to compress as architectural innovations propagate across labs globally. In 12–18 months, the performance differences between frontier models on standard benchmarks may be small enough that cost, latency, compliance, and integration quality become the dominant selection criteria for most enterprise use cases rather than raw capability.
Proliferation of Specialized Frontier Models
Rather than a single winner in the general capability race, the model landscape will likely fragment into a set of highly capable general models and a proliferating ecosystem of specialized models fine-tuned for specific domains: legal, biomedical, financial, engineering, and so on. GLM-5.2’s Chinese-language advantage points toward language-specialized models as one dimension of this fragmentation. Enterprise procurement strategies should account for domain-specialized models alongside general frontier models in their model inventories.
On-Premise and Private Deployment as the New Normal
As data sovereignty concerns intensify and AI regulation matures across major jurisdictions, on-premise deployment of frontier-class models will shift from a niche enterprise requirement to a standard offering. The compute cost of running models like GLM-5.2 on internal infrastructure will continue to fall as NVIDIA’s next-generation hardware and competing AI accelerators from AMD, Intel, and domestic Chinese chipmakers (Huawei Ascend, Cambricon) provide more inference-efficient options. Organizations that begin building their on-premise AI infrastructure capabilities now will be better positioned than those that defer this investment.
Regulatory Frameworks Will Shape Model Availability
The EU AI Act’s tiered risk classification system is fully in effect, and similar frameworks are advancing in the UK, Japan, Singapore, and India. These regulations will create certification and documentation requirements for high-risk AI use cases that will favor vendors with mature governance programs. Western AI vendors have a head start on EU AI Act compliance documentation; Chinese vendors including Zhipu AI are investing in regulatory compliance infrastructure for international markets but will face higher documentation burdens for European enterprise deployments in the near term.
Conclusion: Embracing Complexity as a Strategic Advantage
GLM-5.2’s benchmark performance against GPT-5.5 is not a story about Chinese AI winning or American AI losing. It is a story about the AI model landscape reaching genuine competitive maturity across national boundaries — and about what that maturity demands from enterprise AI strategy.
The organizations that will thrive in this environment are those that resist the cognitive convenience of single-vendor loyalty and instead build the capability to evaluate, deploy, and orchestrate multiple models based on rigorous task-performance analysis. They are organizations that treat AI model selection as a dynamic, data-driven process rather than a static procurement decision. And they are organizations that have the infrastructure, talent, and governance frameworks to absorb new model capabilities as they emerge — whether those capabilities come from San Francisco, Beijing, Paris, or somewhere not yet on the AI development map.
GLM-5.2’s performance is a prompt: an invitation to update mental models, audit procurement assumptions, and invest in the operational infrastructure that makes best-in-class AI performance achievable regardless of which model happens to lead any given benchmark on any given month. The competitive landscape will continue to shift. The enterprises best prepared for that shifting are those building model-agnostic, performance-driven AI architectures today.
The age of AI monoculture in the enterprise is ending. The age of intelligent model selection is just beginning.
This article reflects benchmark data and competitive assessments available as of mid-2025. Model performance data should be independently verified before making procurement decisions. All code examples are illustrative and intended for architectural guidance rather than production deployment without modification.