The Codex Database Engineering Playbook: 20 Prompts for Schema Design, Query Optimization, Migration Scripts, and Data Pipeline Automation
The Codex Database Engineering Playbook: 20 Prompts for Schema Design, Query Optimization, Migration Scripts, and Data Pipeline Automation

This playbook provides twenty production-grade, copy-ready Codex prompts to accelerate high-impact database engineering tasks across schema design, query optimization, migration engineering, and data pipeline automation. Each prompt is structured with precise context, inputs, constraints, and expected deliverables so you can drop it directly into your workflow. The prompts are database-agnostic where possible and include vendor-specific tuning notes (PostgreSQL, MySQL, SQL Server, SQLite, BigQuery, Snowflake) as applicable.
These prompts assume familiarity with SQL, DDL/DML, query planners, version control for database schemas, and DevOps deployment strategies (blue/green, rolling migrations, and zero-downtime techniques). Where relevant, prompts provide input templates (YAML/JSON) to help you standardize invocation from CI/CD jobs or infra-as-code pipelines.
For complementary deep dives on adjacent topics, see For a deeper exploration of this topic, our comprehensive guide on The Big Model Comparisons Story: What July 03’s News Means for Developers provides detailed strategies and implementation frameworks that complement the approaches discussed in this section., For a deeper exploration of this topic, our comprehensive guide on 40 ChatGPT-5.5 Prompts for Academic Researchers: Literature Reviews, Hypothesis Generation, Data Interpretation, and Paper Writing provides detailed strategies and implementation frameworks that complement the approaches discussed in this section., and For a deeper exploration of this topic, our comprehensive guide on 10 Best AI Research Tools for data analysis Compared u2014 Features, Pricing, Use Cases provides detailed strategies and implementation frameworks that complement the approaches discussed in this section..
Table of Contents
- Schema Design (5 prompts)
- Query Optimization (5 prompts)
- Migration Scripts (5 prompts)
- Data Pipeline Automation (5 prompts)
Schema Design
These five prompts help you establish high-integrity, future-proof schemas that balance normalization with access patterns, apply targeted indexing, choose appropriate partitioning strategies, harden data quality with constraints, and plan for evolution with minimal downtime.
Prompt 1: Normalized schema generation
Design a normalized relational schema from raw domain requirements, while preserving query ergonomics through well-chosen surrogate keys and explicit relationship tables.
When to use
- Bootstrapping a new application domain from narratives, event flows, or API specs.
- Refactoring a denormalized or JSON-heavy prototype into a maintainable relational model.
- Preparing for multi-tenant and auditability requirements.
Copy-ready Codex prompt
Task: Generate a 3NF/BCNF-oriented relational schema from the provided domain description and access patterns. The design must minimize redundancy, maintain referential integrity, and support the specified high-frequency queries with predictable performance.
Context:
- Domain: <Insert domain summary; e.g., B2B SaaS subscriptions, usage-based billing, invoicing>
- Requirements:
- Entities, attributes, relationships (1:1, 1:N, M:N)
- Multitenancy: {none | schema-per-tenant | row-level tenancy key}
- Audit needs: created_at, updated_at, deleted_at (soft delete), change history options
- Compliance: PII columns, encryption at rest, data retention windows
- Estimated scale over 24 months:
- Tenants: ~<N>
- Peak write QPS: <N>
- Peak read QPS: <N>
- Largest table row count: ~<N>
- Primary DB engine: {PostgreSQL|MySQL|SQL Server|SQLite|Snowflake|BigQuery}
Constraints:
- Target at least 3NF; justify any intentional denormalization for performance hotspots.
- Favor surrogate primary keys (BIGINT/UUID v7) unless a stable natural key is superior.
- Define all FKs, unique constraints, and check constraints for domain invariants.
- Ensure tenant isolation strategy is explicit and index tenant_id when row-scoped.
- All timestamps are timezone-aware, immutable creation time; updated_at on mutation.
- Include soft delete design and how it interacts with unique constraints.
- Include named schemas/namespaces where supported (e.g., PostgreSQL).
- Document indexing essentials for primary access paths only (deep index strategy is a separate prompt).
- Provide canonical DDL and an entity-relationship overview.
Deliverables:
1) A concise ER narrative: entities, relationships, cardinalities.
2) DDL statements for all tables, constraints, and minimal essential indexes.
3) Example seed rows for at least 3 tables.
4) Notes on multitenancy and audit columns.
5) A list of the top 5 expected queries and how the schema supports them.
Input:
- domain_description: <text>
- access_patterns: list of query intents with filters/sorts
- tenancy_mode: <mode>
- compliance_notes: <text>
- db_engine: <engine>
Output format:
- Markdown-like sections are fine inside code fences; main artifact is SQL DDL with comments.
Now read the inputs and produce the schema.
---BEGIN INPUTS---
domain_description: <paste here>
access_patterns:
- <read/write query intent 1>
- <...>
tenancy_mode: <row-level|schema-per-tenant|none>
compliance_notes: <PII columns and retention notes>
db_engine: <PostgreSQL|MySQL|SQL Server|SQLite|Snowflake|BigQuery>
---END INPUTS---Verification checklist
- Every relationship has an explicit FK with ON DELETE/UPDATE rules.
- All uniqueness and domain invariants are enforced with unique/check constraints.
- Top 5 queries leverage covered or clustered indexes for their predicates/sorts.
- Soft-delete design does not break uniqueness or omit critical filters in queries.
Example starter DDL snippet
-- PostgreSQL example
CREATE TABLE tenant (
tenant_id BIGSERIAL PRIMARY KEY,
name TEXT NOT NULL,
created_at TIMESTAMPTZ NOT NULL DEFAULT now()
);
CREATE TABLE account (
account_id BIGSERIAL PRIMARY KEY,
tenant_id BIGINT NOT NULL REFERENCES tenant(tenant_id) ON DELETE CASCADE,
email CITEXT NOT NULL,
status TEXT NOT NULL CHECK (status IN ('active','suspended')),
created_at TIMESTAMPTZ NOT NULL DEFAULT now(),
updated_at TIMESTAMPTZ NOT NULL DEFAULT now(),
deleted_at TIMESTAMPTZ
);
CREATE UNIQUE INDEX account_tenant_email_uq
ON account (tenant_id, lower(email))
WHERE deleted_at IS NULL;Prompt 2: Index strategy
Derive a principled, workload-driven index plan that balances read acceleration, write overhead, and storage footprint, with explicit coverage for critical queries and guardrails against over-indexing.
When to use
- After normalizing your schema and enumerating key access patterns.
- When write throughput regresses due to index bloat or unnecessary indexes.
- To rationalize existing indexes before a high-traffic event or cost-reduction initiative.
Copy-ready Codex prompt
Task: Propose a minimal, high-impact index strategy from schema DDL and representative queries. Quantify expected benefits and write amplification. Recommend removal of redundant or low-value indexes.
Context:
- DB engine: {PostgreSQL|MySQL|SQL Server|SQLite|Snowflake|BigQuery}
- Schema DDL: <paste>
- Representative queries: <paste top 20 queries with frequency and typical predicate values>
- Workload profile:
- Read/write ratio: <R:W>
- Top filters (columns + selectivity estimates)
- Sort/group-by patterns
- Join keys and cardinalities
- Hot partition keys (if partitioned)
- Storage constraints: <GB budget>
Constraints:
- For each query class, specify index access path (index-only, bitmap, skip scan, covering).
- In Postgres, consider partial indexes, BRIN for append-only large tables, and multicolumn order.
- In MySQL/InnoDB, mind leftmost prefix and clustered PK implications.
- In SQL Server, include filter indexes and included columns.
- Avoid over-indexing; each index must map to query evidence.
- Note maintenance cost: additional write IOPS and vacuum/reorg overhead.
- Provide safe drop list for unused/overlapping indexes with a monitor-first plan.
Deliverables:
1) Index proposals: DDL and rationale mapped to queries.
2) Coverage matrix: queries x indexes with expected planner usage.
3) Drop candidates with risk assessment.
4) Ongoing measurement plan (pg_stat_statements/Performance Schema/DMVs).
5) Post-deploy verification steps and rollback.
Inputs:
- ddl: <text>
- queries: <text or structured JSON capturing frequency, latency, predicate selectivity>
- engine: <text>
- constraints: <space/storage priorities>
Output:
- SQL DDL for CREATE INDEX (and include/partial/filter syntax as applicable).
- A concise textual matrix and measurement plan.Heuristics to encode in outputs
- Sort key appears last in multicolumn B-tree; equality predicates lead ordering.
- Low-selectivity columns alone should not be indexed unless used with high-selectivity companions.
- Cover frequent paginated lookups with composite indexes aligned to WHERE + ORDER BY.
- Use partial indexes for “active” subsets (e.g., deleted_at IS NULL).
- Prefer BRIN for massive, monotonically increasing timestamped tables in Postgres.
Example
-- Postgres: paginated invoice lookups by tenant, status, due_date desc
CREATE INDEX inv_tenant_status_due_idx
ON invoice (tenant_id, status, due_date DESC)
INCLUDE (invoice_id, total_amount)
WHERE deleted_at IS NULL;Prompt 3: Partitioning decisions
Select an optimal partitioning scheme and retention policy that minimizes query latency and storage costs, while keeping operational tasks (vacuum, reindex, archiving) safe and bounded.
When to use
- Large append-mostly tables with time-based access patterns.
- Multi-tenant workloads requiring isolation and scalable maintenance windows.
- Cloud data warehouses with cost-containment and pruning benefits.
Copy-ready Codex prompt
Task: Recommend a partitioning strategy and retention/archival plan for the provided large tables and their query patterns. Provide DDL and operational runbooks.
Context:
- Engine: {PostgreSQL|MySQL 8+|SQL Server|BigQuery|Snowflake}
- Tables: <list name, estimated row counts, daily growth, skew profile>
- Queries: top filters, time windows, joins, and aggregations
- SLA: p95 latency targets, maintenance windows
- Retention: online window (e.g., 13 months), cold storage rules
- Constraints: multi-tenant keys, small-db limits, cloud storage cost targets
Constraints:
- Choose between range/list/hash partitioning and justify the choice.
- Detail partition key(s), granularity (daily/weekly/monthly), and expected partition count growth.
- Provide DDL and attach indexes at partitioned level where supported.
- Provide automation scripts for new partition creation and dropping expired partitions.
- Consider local vs global indexes (where supported) and implications.
- Document vacuum/analyze/reclustering cadence.
Deliverables:
1) Partitioning DDL and example child partitions for the next 3 intervals.
2) Archival and drop policy jobs with safety checks.
3) Query routing notes for partition pruning.
4) Risk notes: data skew, hot partitions, and mitigation (subpartitioning, hash on tenant_id).
5) Monitoring queries for orphan partitions and bloat.
Inputs:
- table_profiles: <json with table sizes, growth rates>
- workload: <json with filters and time windows>
- retention_policy: <text>
- engine: <text>
Output:
- SQL and runbook text. Include cron/k8s CronJob/Cloud Scheduler examples as appropriate.PostgreSQL example
-- Parent table
CREATE TABLE event_log (
tenant_id BIGINT NOT NULL,
occurred_at TIMESTAMPTZ NOT NULL,
event_type TEXT NOT NULL,
payload JSONB NOT NULL,
PRIMARY KEY (tenant_id, occurred_at, event_type)
) PARTITION BY RANGE (occurred_at);
-- Next three monthly partitions
CREATE TABLE event_log_2025_01 PARTITION OF event_log
FOR VALUES FROM ('2025-01-01') TO ('2025-02-01');
CREATE TABLE event_log_2025_02 PARTITION OF event_log
FOR VALUES FROM ('2025-02-01') TO ('2025-03-01');
CREATE TABLE event_log_2025_03 PARTITION OF event_log
FOR VALUES FROM ('2025-03-01') TO ('2025-04-01');
-- Partial index on 'active' 90-day window
CREATE INDEX ON event_log_2025_03 (tenant_id, event_type, occurred_at);
-- Repeat per hot partition via template job.
-- Rotation script (psql + bash): create next partition + drop expired
-- Include existence checks, transaction safety, and alerts.Prompt 4: Constraint design
Codify domain invariants via primary keys, foreign keys, unique and exclusion constraints, and check constraints, supplemented by trigger-based guards only where strictly necessary.
When to use
- Hardening data quality guarantees beyond application-layer validation.
- Supporting regulatory audit requirements with provable invariants.
- Avoiding race conditions that cause duplicate rows or invalid state transitions.
Copy-ready Codex prompt
Task: From the schema and domain rules, produce a complete constraint suite that enforces business invariants at the database layer. Include checks, unique keys, FKs, and (if supported) exclusion constraints. Provide minimal triggers for invariants not expressible via declarative constraints.
Context:
- Engine: {PostgreSQL|MySQL|SQL Server|SQLite}
- Existing DDL: <paste>
- Invariants:
- <rule 1: e.g., 'a user cannot have two active subscriptions'>
- <rule 2: e.g., 'invoice total must equal sum(line_items) +/- rounding'>
- <rule 3: e.g., 'promotion period must not overlap for same tenant'>
- Soft delete behavior: <column>, null means active
- Multi-tenant: tenant_id grouping semantics
Constraints:
- Prefer declarative constraints; triggers only for cross-row aggregations if unavoidable.
- All constraints must be multitenancy-aware (scoped by tenant_id where relevant).
- Include deferrable constraints for transactional batching where necessary (Postgres).
- Ensure online addition where engine supports it (e.g., NOT VALID then VALIDATE in Postgres).
Deliverables:
1) Constraint DDL with comments referencing the invariant each enforces.
2) If triggers are required, provide trigger function/procedure with idempotency and deterministic behavior.
3) Safe rollout plan: lock minimization, backfill/validation steps.
4) Negative test cases that should fail.
Inputs:
- schema: <text>
- invariants: <bulleted list>
- engine: <text>
Output:
- SQL DDL and test queries to validate constraints post-deploy.PostgreSQL example: non-overlapping promotions per tenant
-- Exclusion constraint using range types
ALTER TABLE promotion
ADD CONSTRAINT promotion_no_overlap
EXCLUDE USING gist
(tenant_id WITH =, tstzrange(start_at, end_at, '[)') WITH &&)
WHERE (deleted_at IS NULL)
DEFERRABLE INITIALLY IMMEDIATE;
-- Test cases
-- Should fail: overlapping window for same tenant_id
INSERT INTO promotion (tenant_id, start_at, end_at) VALUES (1, '2025-01-01', '2025-02-01');
INSERT INTO promotion (tenant_id, start_at, end_at) VALUES (1, '2025-01-15', '2025-01-25');Prompt 5: Schema evolution planning
Plan forward-compatible, low-risk schema changes with feature flags, dual-write/dual-read phases, and clear cutover criteria, suitable for high-availability systems.
When to use
- Introducing new columns with backfills, renaming columns/tables, or reshaping relationships.
- Migrating from strings to enums, or JSON to structured columns.
- Refactoring IDs (e.g., INT to BIGINT) with minimal downtime.
Copy-ready Codex prompt
Task: Produce a phased schema evolution plan that avoids breaking reads/writes during rollout. Include DDL, backfill strategy, toggles, and monitoring gates for each phase.
Context:
- Engine: {PostgreSQL|MySQL|SQL Server}
- Current DDL: <paste>
- Target shape: <describe desired schema changes>
- Traffic profile: peak QPS, write amplification, long-running transactions
- Constraints: zero/minimal downtime, backward compatibility for N releases
- Observability: available metrics, logs, and error tracking
Constraints:
- Use additive-first changes: add nullable columns; avoid renames until last cutover.
- Provide dual-write (application-level) and dual-read (fallback) periods where needed.
- Include chunked backfill with idempotent batches and progress markers.
- Provide kill-switch/feature flags and clear rollback steps.
- Ensure index builds are concurrent/online where supported.
- Document expected lock levels and how to avoid table rewrites.
Deliverables:
1) Phased plan with precise steps and verification checks per phase.
2) DDL/DML/DDL-concurrent scripts.
3) Backfill job (SQL or app code) with resume capability.
4) Metrics and error thresholds for go/no-go gates.
5) Final cleanup plan (drop old columns/indexes) after stabilization.
Inputs:
- current_schema: <text>
- target_changes: <text>
- traffic: <text>
- engine: <text>
Output:
- A step-by-step runbook and accompanying scripts.Example outline
Phase 0: Prepare
- Add nullable new_column, create concurrent index, deploy app reading old field.
Phase 1: Dual-write
- App writes both old_column and new_column; verify parity via sampling.
Phase 2: Backfill
- Batch update with LIMIT/OFFSET or keyset pagination; throttle on replication lag.
Phase 3: Dual-read
- Read from new_column; fallback to old if null; assert error rate < 0.01%.
Phase 4: Cutover
- Stop dual-write; freeze backfill; lock and promote new_column, remove old references.
Phase 5: Cleanup
- Drop old_column after retention window; remove feature flags.Query Optimization
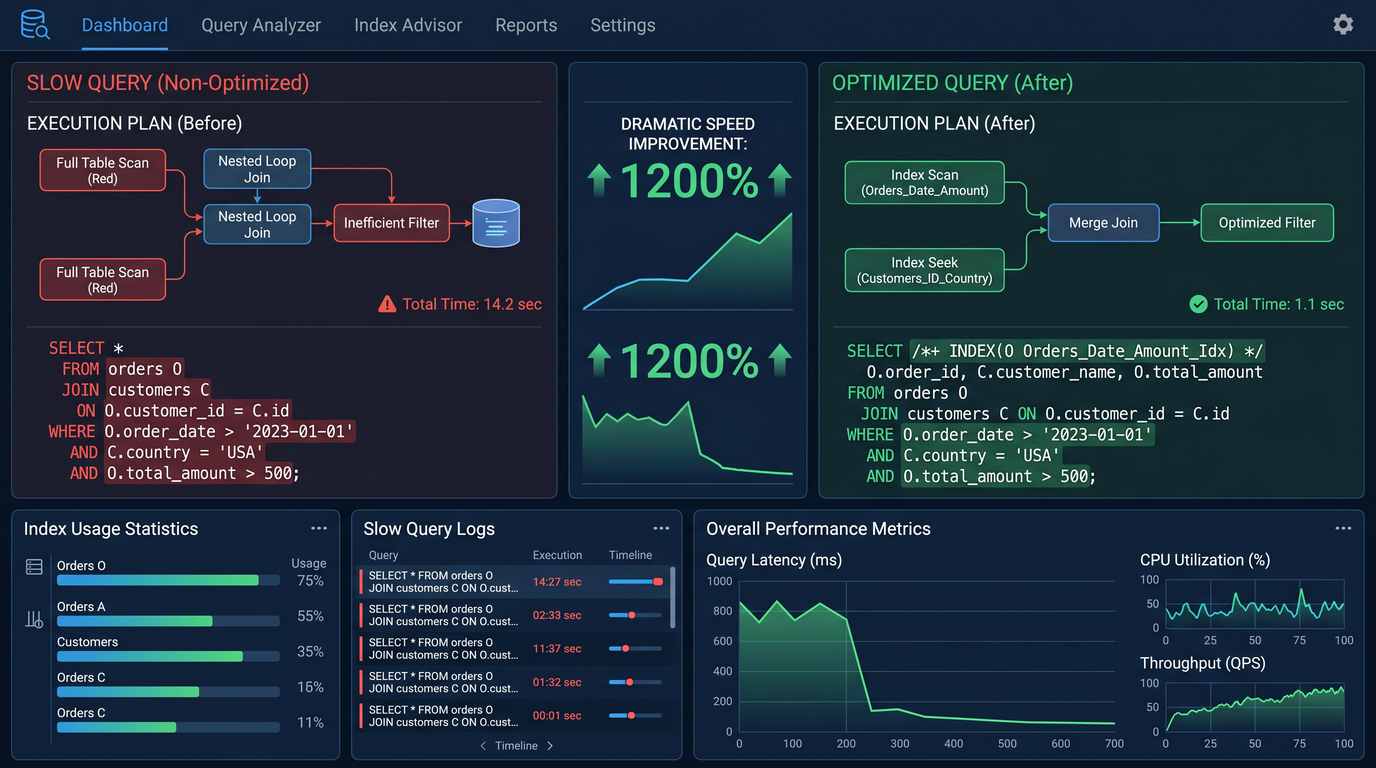
These prompts transform slow, high-variance queries into robust, predictable performers. They guide you through targeted plan analysis, index-based acceleration, safe rewrites, and batch processing improvements for BI and OLTP contexts.
Prompt 6: Slow query analysis
Diagnose top latency offenders from logs or query statistics, identifying actionable root causes and providing quick-win mitigations and long-term fixes.
When to use
- When p95/p99 latencies regress unexpectedly after a deploy or data growth event.
- Before major campaigns that will spike read/write workloads.
- When costs balloon in serverless warehouses due to inefficient scans.
Copy-ready Codex prompt
Task: Analyze slow queries and propose prioritized remediations with quantified impact. Include hypotheses, supporting evidence from plans/stats, and safe experiments.
Context:
- Engine: {PostgreSQL|MySQL|SQL Server|Snowflake|BigQuery}
- Slow query samples (text + anonymized literals) with avg/p95/p99 latency, rows, calls
- EXPLAIN/EXPLAIN ANALYZE or profile outputs (where available)
- Schema fragments and index inventory for referenced tables
- Workload notes: cardinalities, skew, time filters, joins
- Change history: recent deploys, index changes, data volume shifts
Constraints:
- Classify issues: missing/ineffective indexes, filter/join misorder, type mismatch, parameter sniffing, stale stats, dead tuples/bloat, row vs column store inefficiency.
- Provide immediate mitigations (index hints, STATISTICS target bump, ANALYZE) and robust fixes (new indexes, rewrite, partitioning).
- Quantify expected improvement ranges and justify with selectivity math.
- Include rollout and measurement steps; avoid speculative risky changes.
Deliverables:
1) A ranked list of root causes with evidence.
2) Recommended changes (DDL/DML/query rewrite) with risk and effort estimate.
3) Measurement plan: sampling, baselines, and abort thresholds.
4) Post-change verification checklist.
Inputs:
- slow_queries: <text or JSON list with metrics>
- explains: <text>
- schema_and_indexes: <text>
- engine: <text>
Output:
- Structured analysis followed by actionable steps and scripts.Example diagnostic checklist
- Check mismatched data types in join predicates and filters.
- Identify functions on indexed columns that prevent index usage.
- Confirm stats freshness and histogram skew; increase STATISTICS target if needed.
- Look for wide SELECT lists preventing index-only scans.
- Validate parameter sniffing symptoms (SQL Server) and consider OPTION (RECOMPILE) for outliers.
Prompt 7: Execution plan interpretation
Turn raw EXPLAIN/ANALYZE outputs into human-readable diagnostics, linking plan nodes to known anti-patterns and pointing to the minimal change that yields maximum gain.
When to use
- Developers struggle to connect plan nodes to actual code smells and data distribution.
- Need to accelerate code reviews or PRs that modify critical SQL.
- Establish a common vocabulary for DB and application teams.
Copy-ready Codex prompt
Task: Interpret the provided execution plans and produce a concise diagnosis per query. Explain the role and cost of each dominant node, what triggered it, and how to avoid it if harmful.
Context:
- Engine: {PostgreSQL|MySQL|SQL Server|Snowflake|BigQuery}
- Inputs: EXPLAIN/EXPLAIN ANALYZE outputs in text or JSON format
- Associated SQL statements
- Relevant table/index stats and row estimates if available
Constraints:
- Call out red flags: seq scans on huge tables with selective predicates, nested loop on large join without index, misestimates leading to bad join order, recheck conditions on partial indexes, spills to disk, repartitions on distributed systems.
- Where estimates vs actuals diverge, propose stats fixes or rewrite to stabilize.
- Tie each recommendation to a specific plan node with an anticipated impact.
- Keep explanations actionable and vendor-specific where needed.
Deliverables:
1) Annotated plan: node-by-node reasoning with cost drivers.
2) Shortlist of changes: indexes, rewrites, or table distribution changes.
3) How to re-measure: exact EXPLAIN commands and expected deltas.
Inputs:
- plan_outputs: <text/json>
- sql_statements: <text>
- stats: <optional text>
- engine: <text>
Output:
- Structured findings and SQL snippets to test proposals.Example: PostgreSQL analyzer hints
-- Re-check for bitmap index scan indicates low correlation; consider CLUSTER or BRIN
-- Misestimate: actual rows 1.2M vs estimate 10K; increase stats target for predicate columns
-- Hash join spilling to disk: increase work_mem for this session or reduce row width via SELECT listPrompt 8: Index recommendations
Given workload traces and schema metadata, produce precise index recommendations with expected usage, memory cost, and interactions, avoiding noisy suggestions.
When to use
- During performance regression triage to target high-ROI indexes first.
- As a guardrail to keep ad-hoc index creation from fragmenting write performance.
Copy-ready Codex prompt
Task: Recommend a targeted set of indexes to materially improve the given workload. Each index must include: columns, order, include list (where supported), predicates for partial indexes, and mapped queries.
Context:
- Engine: {PostgreSQL|MySQL|SQL Server}
- Inputs:
- Top queries with frequencies, average/95th latency, and predicates
- Current index inventory
- Table schema (column types, nullability, data skew notes)
- Constraints: write cost ceiling, storage budget, and avoidance of redundant overlaps
Constraints:
- Rank proposals by benefit/cost with a one-sentence rationale.
- Prefer composite indexes that align with equality filters then ordering.
- Consider filtered/partial indexes for active subsets.
- Use INCLUDE columns to enable covering scans (where supported).
- Detect and flag overlapping/redundant indexes for consolidation.
Deliverables:
1) CREATE INDEX statements annotated with mapped query IDs.
2) A benefit/cost table and short rollout plan (concurrent/online build).
3) Post-deploy validation queries and safe-drop candidates.
Inputs:
- queries: <json or text with signature, frequency, latency, predicates>
- schema: <text>
- indexes: <text>
- engine: <text>
- constraints: <text>
Output:
- SQL DDL and a compact coverage matrix.Example output fragment
-- Query Q17: /invoices?tenant=...&status=...&order=due_date desc
CREATE INDEX CONCURRENTLY inv_tenant_status_due_idx
ON invoice (tenant_id, status, due_date DESC)
INCLUDE (invoice_id, total_amount)
WHERE deleted_at IS NULL;
-- Rationale: equality on (tenant_id,status) + sort; enables index-only on common projection.Prompt 9: Query rewriting
Rewrite problematic SQL to reduce planning ambiguity, minimize intermediate cardinalities, and exploit existing indexes, while preserving semantics and numerical accuracy.
When to use
- Planners pick unstable or expensive plans due to complex views/CTEs or implicit casts.
- Large aggregations spill to disk or cross partitions unnecessarily.
- You need to constrain row widths and avoid function calls blocking index usage.
Copy-ready Codex prompt
Task: Rewrite the provided SQL to improve performance and stability. Preserve exact results and edge-case semantics. Explain the trade-offs of each rewrite.
Context:
- Engine: {PostgreSQL|MySQL|SQL Server|Snowflake|BigQuery}
- Inputs: original SQL, view/CTE definitions, referenced table schemas, indexes
- Known issues: latency, plan flapping, high memory, excessive scans
Constraints:
- Remove unnecessary SELECT *; project only needed columns.
- Push down predicates; avoid functions on indexed columns (rewrite to sargable forms).
- Replace correlated subqueries with joins or window functions when appropriate.
- Consider pre-aggregations or materialized views for heavy BI queries.
- Maintain numeric precision; handle NULLs explicitly.
Deliverables:
1) Rewritten SQL variants with rationale.
2) Expected planner changes and memory/I/O impacts.
3) Test plan: row-count and checksum equality on sample and full data.
4) Optional: hint usage or configuration toggles, engine-specific.
Inputs:
- sql: <text>
- schemas: <text>
- indexes: <text>
- engine: <text>
Output:
- Side-by-side original vs optimized SQL with commentary.Example transformation
-- Anti-pattern: function on column prevents index usage
WHERE date_trunc('day', occurred_at) = '2025-01-01'::date
-- Rewrite to sargable range
WHERE occurred_at >= '2025-01-01'::date AND occurred_at < '2025-01-02'::datePrompt 10: Batch processing optimization
Optimize ETL/ELT batch workloads for throughput, memory use, and checkpointing, ensuring predictable windows and resumability in case of failures.
When to use
- Nightly or hourly jobs exceed SLAs or fail under load growth.
- Bulk data movement causes replication lag or locks user-facing tables.
- Warehouse transformation costs spiral due to inefficient joins/scans.
Copy-ready Codex prompt
Task: Optimize batch jobs to minimize wall time, resource spikes, and failure blast radius. Provide chunking, concurrency, and checkpoint strategies, plus SQL rewrites and index/temp table usage.
Context:
- Engine: {PostgreSQL|MySQL|SQL Server|Snowflake|BigQuery}
- Job description: <text>
- Current SQL scripts or pipeline code
- Input/output table sizes, partitioning, and indexes
- SLAs: Start/end windows; retries; allowed staleness
- Infra: available parallelism; memory budgets; I/O constraints
Constraints:
- Use keyset or range-based chunking by PK/partition; avoid OFFSET for large scans.
- Bound transaction sizes; commit frequently to reduce lock contention.
- Stage data in temp tables with necessary indexes to accelerate joins.
- Prefer MERGE/UPSERT with deterministic conflict handling.
- Provide idempotency and resume markers.
- Verify correctness with row counts and checksums per chunk.
Deliverables:
1) Revised SQL/ETL code with chunking and staging tables.
2) Concurrency plan and resource tuning notes (work_mem, tempdb, warehouse size).
3) Checkpointing and resume logic.
4) Verification queries and metrics to track.
Inputs:
- job: <text>
- scripts: <text>
- sizes: <json>
- engine: <text>
Output:
- Optimized code and runbook including failure handling.Example: Postgres chunked upsert
-- Process in ID ranges of ~100k
WITH batch AS (
SELECT * FROM staging_events
WHERE id >= :min_id AND id < :max_id
)
INSERT INTO events AS e (id, tenant_id, occurred_at, payload)
SELECT id, tenant_id, occurred_at, payload FROM batch
ON CONFLICT (id) DO UPDATE
SET payload = EXCLUDED.payload, occurred_at = EXCLUDED.occurred_at
WHERE e.payload IS DISTINCT FROM EXCLUDED.payload;Migration Scripts
These prompts focus on safe, observable changesets and reversible operations. They cover zero-downtime patterns, reliable backfills, version control strategies, and rollback designs that reduce operational risk.
Prompt 11: Zero-downtime migrations
Craft migrations that avoid blocking writes and minimize read disruption, with explicit locks, concurrent index builds, and application coordination patterns.
When to use
- Adding columns with defaults, adding indexes, backfilling data on hot tables.
- Renames and type changes that otherwise require table rewrites.
- Blue/green or rolling deploys across multiple app instances.
Copy-ready Codex prompt
Task: Produce zero/minimal downtime migration scripts with phase gates and monitoring hooks. Avoid blocking operations and plan concurrent alternatives where available.
Context:
- Engine: {PostgreSQL|MySQL|SQL Server}
- Current schema: <paste>
- Target change: <describe>
- RTO/RPO: <targets>
- App deploy model: {rolling|blue-green|canary}
- Observability: metrics, slow query logs, error tracking
Constraints:
- Separate DDL into small, lock-safe steps (e.g., add column NULL, backfill, add NOT NULL).
- Use concurrent/online index creation (CREATE INDEX CONCURRENTLY, ONLINE=ON).
- For defaults, avoid table rewrite (add column NULL, backfill, then add DEFAULT).
- For renames, use dual-column + app toggles; defer actual rename to maintenance window.
- Thoroughly document lock levels and expected durations.
Deliverables:
1) Migration scripts per phase with comments.
2) App coordination notes (dual-write/read, flags).
3) Monitoring and abort conditions.
4) Rollback stubs for each phase.
Inputs:
- current_schema: <text>
- change: <text>
- engine: <text>
- deploy_model: <text>
Output:
- Ordered, idempotent scripts and runbook.PostgreSQL example: NOT NULL with default
-- Phase 1: Add nullable column, no default (fast)
ALTER TABLE account ADD COLUMN status TEXT;
-- Phase 2: Backfill in batches
UPDATE account SET status = 'active' WHERE status IS NULL AND account_id BETWEEN :min AND :max;
-- Phase 3: Add default and not null (metadata-only)
ALTER TABLE account ALTER COLUMN status SET DEFAULT 'active';
ALTER TABLE account ALTER COLUMN status SET NOT NULL;Prompt 12: Data backfill scripts
Generate safe, resumable backfill jobs that avoid long locks, account for replication lag, and provide correctness checks at chunk-level granularity.
When to use
- Populating new columns or tables from historical data.
- Recomputing derived fields while serving live traffic.
Copy-ready Codex prompt
Task: Create an idempotent, throttled backfill job with chunking, retry, and verification. Include stop/resume markers and replication-safety considerations.
Context:
- Engine: {PostgreSQL|MySQL|SQL Server}
- Source and target tables/columns with transformations
- Expected data volume and skew
- Production constraints: replication lag threshold, lock limits, maintenance window
Constraints:
- Use keyset pagination (PK ranges) or time buckets; avoid OFFSET.
- Small transactions; sleep/throttle if replication lag exceeds threshold.
- Idempotency: WHERE target IS NULL or checksum mismatch.
- Verification: per-chunk counts, checksums, and sample content equality.
- Observability: emit metrics/log lines for progress.
Deliverables:
1) SQL script or application pseudo-code with chunk loop.
2) Verification queries and metrics design.
3) Resume-from checkpoint procedure.
4) Safety notes for locking and deadlocks.
Inputs:
- mapping: <json mapping from source to target with transformations>
- sizes: <json>
- engine: <text>
Output:
- Backfill implementation and runbook.Example: SQL + pseudo-code
-- Verification checksum
SELECT tenant_id, COUNT(*) cnt, SUM(CRC32(CONCAT_WS('|', col1, col2))) cks
FROM source
WHERE id BETWEEN :min AND :max
GROUP BY tenant_id;
-- Pseudo-code loop
for (min_id=1; min_id<=max_id; min_id+=step) {
max_id = min_id + step - 1
BEGIN
INSERT ... ON CONFLICT DO UPDATE ...
COMMIT
if (replication_lag() >= threshold) sleep(500ms)
}Prompt 13: Schema version control
Define a disciplined schema versioning approach with migration ordering, repeatable scripts, environment drift detection, and automated checks in CI.
When to use
- You need to standardize teams on a tool (Flyway, Liquibase, Rails migrations, Alembic).
- Preventing drift between staging and production.
Copy-ready Codex prompt
Task: Establish a schema version control policy and scaffolding for the chosen migration tool. Include naming conventions, checks, and CI integration.
Context:
- Tool: {Flyway|Liquibase|Alembic|Rails|DBMate|Sqitch}
- Environments: dev, staging, prod
- Requirements: approvals, code review, rollback strategy, seed data handling
- Existing repo structure: <paths>
Constraints:
- Timestamped and monotonic versioning for ordered migrations.
- Repeatable migrations for views/functions that can change frequently.
- Verify checksums/hashes; fail CI on drift.
- Pre- and post-conditions for safety checks (e.g., table exists, column missing).
- Generate environment-specific configs via templates/secrets.
Deliverables:
1) Directory structure proposal and example migration files.
2) CI steps: validate, migrate dry-run, drift detection.
3) Roll-forward vs rollback guidelines.
4) Example PR checklist.
Inputs:
- tool: <text>
- repo: <text>
- policy: <text>
Output:
- Concrete folder tree, config files, and sample migrations.Example: Flyway layout
sql/
V2025_01_15_1200__add_invoices_table.sql
V2025_01_16_0900__add_invoice_indexes.sql
R__views_and_functions.sql
conf/
flyway.conf # placeholders for JDBC URL, user, password via env
ci/
flyway-validate.sh
flyway-migrate-dry-run.shPrompt 14: Rollback procedures
Create reversible migrations and robust rollback playbooks with data safety guarantees, ensuring you can back out quickly under pressure.
When to use
- High-risk changes to critical tables or storage engines.
- Deploy windows with limited observability or uncertain workload impacts.
Copy-ready Codex prompt
Task: Provide rollback scripts and decision criteria for the associated forward migration. Ensure data integrity in both forward and reverse directions.
Context:
- Engine: {PostgreSQL|MySQL|SQL Server}
- Forward migration description and scripts
- Data shape changes: added columns, drops, type changes, indexes
- Backup/restore capabilities and RPO/RTO
- Read replicas: yes/no
Constraints:
- Prefer roll-forward; but include rollback path where feasible.
- If dropping data/columns, require a grace period with shadow copies.
- For type changes, keep original column until parity confirmed.
- Ensure rollback scripts are idempotent and safe to re-run.
- Define abort thresholds and who can authorize rollback.
Deliverables:
1) Rollback SQL scripts or procedures.
2) Decision tree with metrics-based gates and time bounds.
3) Verification steps after rollback.
4) Postmortem data collection checklist.
Inputs:
- forward_migration: <text>
- engine: <text>
- constraints: <text>
Output:
- A tested, time-bounded rollback playbook.Example pattern
-- Shadow table before destructive change
CREATE TABLE account_shadow AS TABLE account WITH NO DATA;
INSERT INTO account_shadow SELECT * FROM account;
-- Rollback uses account_shadow to restore rows/columns within T+24h window.Prompt 15: Cross-database migrations
Plan and script migrations between heterogeneous databases or storage tiers with schema translation, type compatibility, and minimal downtime cutovers.
When to use
- Moving OLTP workloads between PostgreSQL/MySQL/SQL Server.
- Offloading analytical workloads to BigQuery/Snowflake/Redshift.
- Replatforming to managed services or multi-region setups.
Copy-ready Codex prompt
Task: Produce a cross-database migration plan with schema translation, data movement, validation, and cutover/rollback. Include a pilot runbook.
Context:
- Source: {PostgreSQL|MySQL|SQL Server|SQLite|Oracle|MongoDB}
- Target: {PostgreSQL|MySQL|SQL Server|Snowflake|BigQuery|Redshift}
- Data footprint: tables, sizes, LOBs, sequences/identity, constraints
- Traffic profile: read/write rates, acceptable downtime
- Tooling: {DMS|Debezium|Sqoop|Custom ETL|Vendor tools}
- Security/compliance: PII handling, encryption, data masking
Constraints:
- Map types precisely; document lossy conversions and mitigations.
- Preserve PK/FK/unique constraints; emulate if target lacks features.
- Strategy: full load + CDC catch-up; quantify lag and cutover criteria.
- Validate row counts and checksums per table; sample deep comparisons.
- Backout plan: reversible DNS/connection switch or dual-write pause.
Deliverables:
1) Schema translation DDL with notes.
2) Data migration scripts/jobs (full + CDC).
3) Validation plan and tooling commands.
4) Cutover runbook and rollback options.
5) Pilot test plan with success metrics.
Inputs:
- source_inventory: <json>
- target_requirements: <text>
- tooling: <text>
Output:
- A complete, operator-friendly migration kit.Example: Full load + CDC outline
Phase A: Full load
- Parallel table copy in priority tiers; disable non-critical FKs; build essential indexes last.
Phase B: CDC
- Stream changes via Debezium/DMS; apply in order; monitor replication lag metric.
Phase C: Cutover
- Freeze writes on source, drain CDC, verify checksums, switch traffic.Data Pipeline Automation
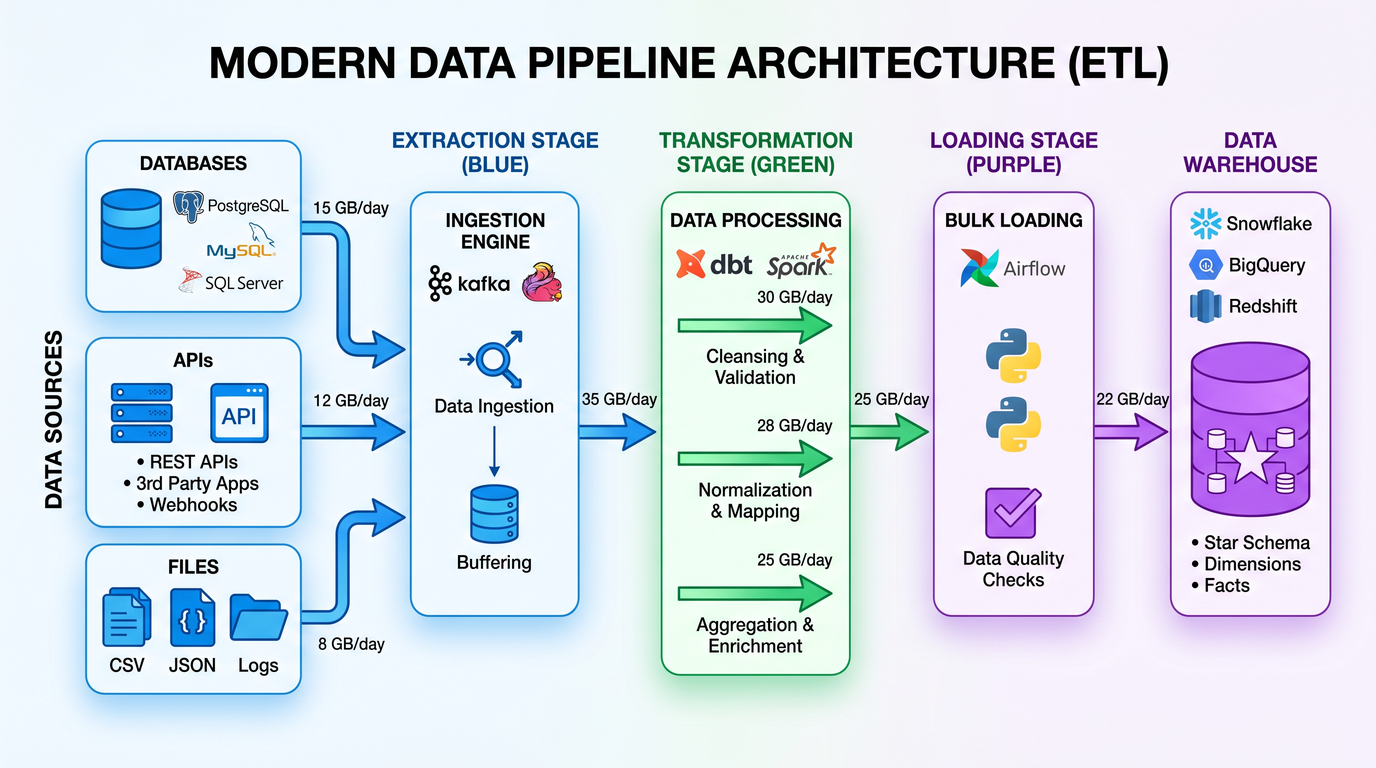
This final set of prompts helps you programmatically generate ETL pipelines, implement CDC, enforce data quality gates, instrument production with targeted monitors, and establish performance baselines you can defend.
Prompt 16: ETL pipeline generation
Generate end-to-end ETL/ELT pipelines from declarative specs, producing runnable code, infra as code hooks, and tests to ensure trust at first deploy.
When to use
- Bootstrapping new data products or feature stores.
- Standardizing pipeline conventions across teams.
- Reducing lead time from schema to data availability.
Copy-ready Codex prompt
Task: Generate a production-ready ETL/ELT pipeline from the provided declarative spec. Produce code, configuration, and tests.
Context:
- Orchestrator: {Airflow|Dagster|Prefect|Argo Workflows|dbt}
- Compute: {Spark|Flink|Pandas|SQL-only|Warehouse-native}
- Sources: relational, files, APIs with auth
- Targets: OLTP, data warehouse, object storage, feature store
- Non-functionals: SLAs, retries, idempotency, cost ceilings, lineage/metadata
Constraints:
- Parameterize environments (dev/staging/prod) via config files and secrets.
- Implement idempotent loads (MERGE/UPSERT) and deduplication keys.
- Include data quality checks and alerting hooks.
- Logging/metrics: structured logs and Prometheus/OpenTelemetry metrics.
- Tests: unit tests for transforms + end-to-end smoke test.
- Documentation: auto-generated README with DAG topology and schedules.
Deliverables:
1) Pipeline code (DAGs/jobs), configs, and secrets templates.
2) Deployment instructions (IaC snippets or CLI).
3) Data quality checks and alert wiring (Slack/PagerDuty).
4) Tests and sample fixtures.
5) Operational runbook (retry strategy, backfills).
Inputs:
- spec: <yaml/json with sources, transforms, targets, schedules, SLAs>
- platform: <text>
Output:
- A cohesive code bundle with comments and instructions.Example: Airflow + warehouse-native ELT
# dag.py: generate tasks for extract -> stage -> transform -> publish
# Use TaskFlow API, retries, and dataset-triggered schedules.
# Include dbt invocation for transform steps if applicable.Prompt 17: CDC implementation
Implement change data capture for reliable, near-real-time propagation of OLTP changes into analytics stores or downstream services, with exactly-once delivery semantics where feasible.
When to use
- Keeping data lakes or warehouses fresh without full reloads.
- Building event-driven integrations or microservice synchronization.
Copy-ready Codex prompt
Task: Design and implement a CDC pipeline with ordering guarantees, deduplication, and replay. Provide deployment and monitoring details.
Context:
- Source DB: {PostgreSQL|MySQL|SQL Server|Oracle}
- Capture method: logical decoding/binlog/CT/CDC tool (Debezium, DMS, GoldenGate)
- Transport: {Kafka|Kinesis|Pulsar|Pub/Sub}
- Sink: {Snowflake|BigQuery|Redshift|S3|Data Lake|Downstream service}
- Volume: change rate, peak bursts
- Constraints: ordering by PK, tenant boundaries, PII handling, latency SLO
Constraints:
- Define schema registry and event versioning.
- Use idempotent upsert/merge semantics at sink.
- Partition topics/streams to preserve key ordering; explain partition keys.
- Include dead-letter strategy and replay from checkpoints.
- End-to-end exactly-once or at-least-once semantics, documented.
- Backfill bootstrap with consistent snapshot + change stream catch-up.
Deliverables:
1) CDC architecture diagram (describe) and component configs.
2) Connector configurations and topic/stream definitions.
3) Sink merge/upsert SQL with dedup keys and late-arrival handling.
4) Monitoring: lag metrics, throughput, error rates, alert thresholds.
5) Runbook: bootstrap, reprocessing, schema change handling.
Inputs:
- source: <text>
- transport: <text>
- sink: <text>
- volume: <text>
Output:
- Configs, SQL, and operational guidance.Example: BigQuery MERGE from Kafka-landed staging
MERGE target t
USING (
SELECT *, ROW_NUMBER() OVER (PARTITION BY pk ORDER BY event_ts DESC) rn
FROM staging_changes
) s
ON t.pk = s.pk
WHEN MATCHED AND s.rn = 1 THEN
UPDATE SET ...
WHEN NOT MATCHED AND s.rn = 1 THEN
INSERT (...);Prompt 18: Data validation rules
Define and enforce data quality checks across pipelines with schema, semantic, and statistical validations that block bad data and surface clear diagnostics.
When to use
- Prevent corrupt or malformed data from polluting downstream models.
- Enforce SLAs on completeness, uniqueness, and referential integrity in analytics layers.
Copy-ready Codex prompt
Task: Generate a data validation suite with row-level, set-level, and statistical checks. Provide code/templates for execution in the chosen stack.
Context:
- Platform: {dbt tests|Great Expectations|Custom SQL|Spark}
- Datasets: staging and curated tables with schemas
- SLAs: nullability, uniqueness, referential integrity, value ranges, distribution drift
- Enforcement: fail pipeline vs warn-only thresholds
Constraints:
- Cover: schema conformity, null/empty handling, unique keys, FK checks, domain enums, regex, distribution bounds (mean/std/quantiles).
- Provide parametrized tests/templates to reuse across tables.
- Add drift detection using historical baselines, with skip windows for known seasonality.
- Results must be logged and surfaced to monitoring/alerting.
Deliverables:
1) Validation definitions (YAML/SQL/JSON) and reusable templates.
2) Execution snippets (dbt yml, Great Expectations suites, SQL).
3) Alert routes and severity mapping.
4) Runbook for triaging failures and temporary suppressions.
Inputs:
- datasets: <text>
- slas: <text>
- platform: <text>
Output:
- Validation artifacts and ops guide.Example: dbt tests YAML
models:
- name: fct_invoices
tests:
- unique:
column_name: invoice_id
- not_null:
column_name: tenant_id
- relationships:
to: dim_tenant
field: tenant_id
- accepted_values:
column_name: status
values: ['open','paid','void']
- expression_is_true:
expression: total_amount >= 0Prompt 19: Monitoring queries
Instrument your databases and pipelines with targeted monitoring queries and metrics that reveal performance regressions, data freshness issues, and operational risks early.
When to use
- Establishing SLOs and proactive alerting before incidents occur.
- Tuning capacity and scheduling windows based on live telemetry.
Copy-ready Codex prompt
Task: Produce a monitoring and alerting plan with concrete SQL queries/commands, metrics names, and thresholds. Focus on freshness, throughput, error rates, and performance headroom.
Context:
- Engine: {PostgreSQL|MySQL|SQL Server|Warehouse}
- Pipelines: <text>
- SLOs: latency, freshness, error budgets
- Observability stack: {Prometheus|Grafana|CloudWatch|Datadog|Stackdriver}
- Alert channels: Slack, PagerDuty
Constraints:
- Provide queries for lag/freshness, queue depths, p95 latencies, error counts.
- Include maintenance health: bloat, vacuum/analyze stats (Postgres), replication lag.
- Map each metric to alerts with severity and runbook link.
- Optimize queries themselves; avoid heavy scans.
Deliverables:
1) SQL monitoring queries or API calls.
2) Metric names, labels, and scrape intervals.
3) Alert rules with thresholds and durations.
4) Dashboard layout suggestions.
Inputs:
- services: <text>
- slos: <text>
- engine: <text>
Output:
- A practical, copy-pasteable monitoring kit.Examples
-- Postgres: replication lag (seconds)
SELECT EXTRACT(EPOCH FROM now() - pg_last_xact_replay_timestamp()) AS seconds_lag;
-- Table freshness by watermark column
SELECT max(updated_at) AS last_update FROM fct_invoices;
-- Bloat estimate (pg_stat_all_tables + pgstattuple extension recommended)Prompt 20: Performance benchmarks
Establish reproducible benchmarks for queries, migrations, and pipelines with dataset generation, seed scenarios, and result interpretation that guides capacity planning and cost control.
When to use
- Before major schema changes or index rollouts.
- To validate performance claims and guide hardware/warehouse sizing.
Copy-ready Codex prompt
Task: Create a benchmark plan and harness to measure performance of critical queries/pipelines under realistic data volumes and distributions. Provide scripts and guidance to interpret results.
Context:
- Engine/Platform: {PostgreSQL|MySQL|SQL Server|Snowflake|BigQuery|Spark}
- Workload: OLTP/OLAP mix, representative queries and transformations
- Data size targets: base volume + growth projections (e.g., 12-24 months)
- Environment: containerized local, staging, or ephemeral cloud instances
- Constraints: budget ceilings, runtime SLOs, concurrency levels
Constraints:
- Synthetic data generation preserving key distributions and correlations.
- Warmup runs and steady-state sampling; remove outliers by interquartile fences.
- Capture CPU, I/O, memory, and network metrics; warehouse credits where relevant.
- Report p50/p95/p99 latencies, error rates, and scalability curves.
- Automate via CI or on-demand job; archive results for trend analysis.
Deliverables:
1) Data generation scripts and seed fixtures.
2) Benchmark harness (scripts or notebooks) with parameterized scenarios.
3) Results schema and storage location for runs.
4) Reporting: charts/tables with interpretation and recommendations.
5) Change log for tested variants (schema changes, indexes, configs).
Inputs:
- workload: <text>
- scale: <text>
- engine: <text>
Output:
- A reproducible benchmark framework and analysis template.Example: PostgreSQL pgbench + custom queries
# 1) Initialize dataset with custom schema
# 2) Use pgbench for concurrency control
pgbench -c 64 -j 8 -T 300 -f query1.sql -f query2.sql --aggregate-interval=5
# 3) Collect EXPLAIN ANALYZE samples pre/post index changes and compare distributionsAppendix: Practical patterns and anti-patterns
Schema design patterns
- Use immutable append-only event logs for auditability; derive current state with materialized views where acceptable.
- Prefer enum reference tables over engine-specific enum types for portability across systems.
- Keep surrogate keys narrow for clustering efficiency; big UUIDs can impact cache density—consider UUID v7 or ULID with index-friendly ordering.
Indexing patterns
- For paginated UIs, align composite indexes with filters and sort order; use “seek then scan few” rather than “scan many then sort.”
- Use covering indexes for hot OLTP endpoints; measure write amplification carefully.
- Consolidate overlapping indexes; a single well-ordered composite often replaces several single-column indexes.
Query optimization patterns
- Convert non-sargable predicates into range checks; avoid wrapping indexed columns in functions.
- Replace correlated subqueries with joins or window functions to reduce repeated work.
- For warehouses, leverage clustering/partitioning columns to prune data; avoid unbounded cross joins.
Migration patterns
- Additive-first and dual-write/read patterns reduce risk during structural changes.
- Use shadow tables and copy-on-write strategies to derisk destructive operations.
- Precompute and validate data before flipping application toggles.
Pipeline patterns
- Design for idempotency at every stage: deduplication keys, MERGE targets, and retry-safe transformations.
- Surface data quality failures as first-class alerts with actionable diagnostics.
- Instrument with minimal yet sufficient metrics; avoid dashboards that hide the signal in noise.
How to operationalize these prompts
Adopt a standard input contract for each prompt type (YAML/JSON blocks) and store them alongside your infrastructure-as-code repository. Integrate prompt execution in CI to generate candidate DDL/SQL/scripts and diff them against the current baseline. Require code review for generated artifacts, and maintain a changelog of prompt inputs and outputs to trace rationale over time.
When rolling out index or query changes, always A/B test at low traffic tiers (canary) and monitor both latency and error budgets. For migrations, enforce checklists for preflight validation, runtime monitoring, and post-deploy verification to ensure reversibility windows remain intact.
Finally, create a small internal library of prompt presets adapted to your environment (engines, naming conventions, SLOs). This library will shorten iteration cycles and make improvements reproducible, auditable, and resilient to team changes.
Access 40,000+ AI Prompts for ChatGPT, Claude & Codex — Free!
Subscribe to get instant access to our complete Notion Prompt Library — the largest curated collection of prompts for ChatGPT, Claude, OpenAI Codex, and other leading AI models. Optimized for real-world workflows across coding, research, content creation, and business.