Why ChatGPT’s Futures Class of 2026 Signals OpenAI’s Pivot to Developer Education — And What It Means for the AI Talent Pipeline
Why ChatGPT’s Futures Class of 2026 Signals OpenAI’s Pivot to Developer Education — And What It Means for the AI Talent Pipeline

For years, OpenAI’s strategy was straightforward: ship increasingly capable models, wrap them in a stable API, and let the developer ecosystem do the rest. In 2026, that center of gravity appears to be moving. The “ChatGPT Futures Class of 2026” — framed as a next-generation builders program based in San Francisco — suggests a significant bet on developer education, community incubation, and human capital. If this is OpenAI’s new north star, the implications for the AI talent pipeline, enterprise adoption, and platform competition are profound.
While specific program details may evolve, the trajectory is clear enough to analyze. The shift from an API-first to an education-first posture is not just marketing; it is the start of a different operating model for how AI capability is distributed: deliberately, with curricula, standards, and shared practices that compress the learning curve and reduce failure rates at scale. This article breaks down what the Futures program likely entails, why it exists now, how it compares to established developer communities, and what it signals for developers, teams, and the broader AI ecosystem.
Executive summary
OpenAI’s prospective ChatGPT Futures Class of 2026 represents a deliberate bet that the next tranche of AI value will be unlocked not by raw model capability alone, but by compressing the distance between capability and competent application. The program’s focus on hands-on building, peer learning, and reproducible best practices is a strong indicator of an education-first platform strategy. This mirrors a broader industry pivot: AI companies are racing to grow skilled developer communities that can implement repeatable patterns—RAG, tool calling, multimodal pipelines, eval-first development—while controlling for safety, compliance, and cost.
Key signals and implications:
- The center of platform power is shifting from “who has the best model” to “who produces the most productive, safety-aware builders.”
- Programs like Futures will prioritize applied skills: evaluation frameworks, retrieval quality, agentic workflows, cost-performance optimization, and production-grade safety controls.
- Compared to classic evangelism programs (GDG, MVP, AWS Heroes), Futures emphasizes build-sprints, measurable outcomes, and curriculum-backed mastery over pure advocacy.
- Enterprises should expect a tighter feedback loop between vendor curricula and internal enablement, with new credentials and job ladders aligned to AI application lifecycle roles (Prompt Engineer → AI Applications Engineer → LLMOps/AI Reliability → AI Product Architect).
- For developers: get fluent in evaluation, RAG diagnostics, tool orchestration, streaming UX, and incident response for AI systems. Build a portfolio that demonstrates reliability, not just demos.
What is the ChatGPT Futures Class of 2026?
For the purposes of this analysis, “ChatGPT Futures Class of 2026” refers to a next-generation builders cohort centered in San Francisco that OpenAI has signaled or would plausibly organize to accelerate high-impact applications built on top of its platform. Exact logistics, selection criteria, and benefits may change or may be announced incrementally; the contours below reflect a synthesis of standard program mechanics used in the industry, adapted to AI application development.
Program intent
- Compress time-to-proficiency for building production-grade AI applications.
- Establish a “shared language” for AI app patterns—evaluation-first development, retrieval correctness, safe tool use, privacy-preserving data flows, and observability.
- Create a visible cohort of practitioners who become multipliers in their local ecosystems.
- Feed structured feedback from advanced builders directly into the product roadmap.
Likely structure
- Duration: 8–16 weeks, split into themed sprints (RAG, agents and tool use, multimodal UX, evals and safety, deployment and cost control).
- Format: Hybrid in-person sessions in San Francisco with remote-friendly components, emphasizing hands-on labs and design reviews.
- Deliverables: At least two production-quality reference implementations per participant with public write-ups, reproducible repos, and evaluation reports.
- Mentorship: Pairings with domain mentors (AI product, LLMOps, security, data engineering) and structured office hours with platform engineers.
- Curriculum artifacts: Playbooks, rubrics, coding templates, and canonical evaluation harnesses.
Participant profile
- Applied engineers and product builders with 2–8 years experience shipping software; bonus for prior ML, data engineering, or SRE exposure.
- Early-stage founders or internal product leads chartered to ship AI functionality within 3–6 months.
- Security/compliance-minded practitioners tasked with operationalizing AI under regulated constraints.
Output expectations
- Reference-quality projects that demonstrate measurable reliability (e.g., target retrieval recall ≥ 0.85 on domain evals; task success rate ≥ 0.9 under controlled adversarial prompts).
- Open educational assets: guides, lab notebooks, and teardown posts that the community can reuse.
- Feedback loops: structured issue reports and feature requests informing SDKs, APIs, tooling, and docs.
Regardless of format specifics, the program’s core signal is unambiguous: platform advantage increasingly flows through education, not only through model releases. Education here means rigorous, repeatable practice—codified as patterns, guardrails, and shared evaluation criteria—so builders stop rediscovering the same mistakes.
Why OpenAI is investing in developer education now
Three forces make an education-first strategy timely and strategically necessary:
1) Capability outpaced operational understanding
Base model advancements have outrun common operational knowledge. Many teams can wire up a chat interface, but far fewer can:
- Design a retrieval system with measurable coverage, freshness, and latency budgets.
- Instrument agentic workflows with safe tool invocation and rollback semantics.
- Build robust evaluation loops that catch drift, regressions, and adversarial behavior before incidents reach users.
Education compresses this knowledge gap and reduces the long tail of production failures that erode trust.
2) Safety, compliance, and cost are the new competitive frontiers
As enterprises scale AI usage, success hinges on guardrails, observability, and cost control. These are not solved by model quality alone. They require shared practices: red-team playbooks, eval benchmarks, data governance patterns, rate-limit aware UX, and incident response. Education programs can align practitioners to these norms faster than documentation alone.
3) Ecosystem defensibility
Models are converging in capabilities across vendors. What becomes hard to copy is a thriving, productive, safety-aware developer community with canonical patterns and a pipeline of certified expertise. Education is a moat: it elevates developer lifetime value, entrenches platform knowledge, and strengthens feedback cycles into the core product.
Strategic payoffs
- Higher activation and retention: builders reach “first reliable feature” faster.
- Lower support burden: shared curricula reduce repetitive troubleshooting.
- Better product-market fit: embedded cohorts surface real-world edge cases early.
- Reputation and trust: visible investment in safety and reliability training signals maturity to enterprises and regulators.
From API-first to education-first: the strategic pivot
API-first platforms rely on docs, SDKs, and evangelism to attract builders. That was sufficient when the primary challenge was access to capability. In AI, access is no longer the bottleneck—operational mastery is. An education-first strategy reorganizes the platform stack around accelerating competent application.
An education-first stack
- Canonical patterns: formalize reference architectures (RAG, agents, multimodal pipelines) with production-ready templates.
- Evaluation-first development: ship harnesses, datasets, and rubrics that quantify task reliability and safety.
- Workflow-aware SDKs: primitives that make the right thing the easy thing (e.g., safe tool schemas, retry budgets, streaming-first idioms).
- Role-based curricula: hands-on labs for AI Application Engineers, LLMOps/AI Reliability, Security/Privacy, Product Managers.
- Credentials and community: verifiable assessments, cohort-based learning, and active peer networks.
How this differs from classic evangelism
- Measured outcomes over activity: badges for shipped, evaluated projects rather than talk volume.
- Deep collaboration with product/infra: cohorts as structured feedback conduits, not just advocacy channels.
- Safety as a first-class learning objective, not an afterthought.
What participants are building: patterns, architectures, and example blueprints
If you gather advanced builders for a focused program, what actually gets produced? Expect a portfolio across four dominant patterns with measurable outcomes.
1) Retrieval-Augmented Generation (RAG) with evaluation-first rigor
RAG remains the most reliable way to inject proprietary knowledge without fine-tuning. But naive RAG yields brittle results. Futures-style curricula would enforce:
- Corpus curation: chunking strategies, semantic vs. structural signals, document freshness, and deduplication.
- Index quality: hybrid search (BM25 + dense), safeguards against semantic drift, and zero-shot lexical fallbacks.
- Query planning: intent classification, multi-query expansion, and metadata filters.
- Context policy: window budgeting, citation discipline, and retrieval diversity constraints.
- Evaluation harness: retrieval recall@k, nDCG, groundedness, and answer faithfulness with adversarial probes.
# Example: Python RAG pipeline with evaluation hooks
from typing import List, Dict, Any
from uuid import uuid4
import time
import os
# Pseudocode utilities (replace with your stack: OpenAI SDK, vector DB, BM25)
class Retriever:
def __init__(self, dense_index, bm25_index):
self.dense = dense_index
self.lex = bm25_index
def hybrid_search(self, query: str, k_dense=8, k_bm25=8) -> List[Dict[str, Any]]:
d = self.dense.search(query, k=k_dense)
l = self.lex.search(query, k=k_bm25)
# simple reciprocal rank fusion
by_id = {}
for rank, doc in enumerate(d):
by_id.setdefault(doc["id"], {"score": 0, "doc": doc})["score"] += 1/(rank+1)
for rank, doc in enumerate(l):
by_id.setdefault(doc["id"], {"score": 0, "doc": doc})["score"] += 1/(rank+1)
return [v["doc"] for _, v in sorted(by_id.items(), key=lambda x: x[1]["score"], reverse=True)]
def build_context(docs: List[Dict[str, Any]], max_tokens=1200) -> str:
ctx = []
token_budget = 0
for d in docs:
t = d["text"]
# assume cheap token estimator
est = len(t) // 3
if token_budget + est > max_tokens:
break
token_budget += est
ctx.append(f"[{d['id']}] {t}")
return "\n\n".join(ctx)
def grounded_generation(openai_client, query: str, ctx: str) -> str:
prompt = f"""
You must answer using ONLY the provided context.
Cite sources explicitly using [doc_id] brackets.
If the answer cannot be found, say "I don't know" and suggest next steps.
Context:
{ctx}
Question: {query}
"""
# Replace with your chat/completions call; stream in production
resp = openai_client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role":"user","content":prompt}],
temperature=0.1
)
return resp.choices[0].message.content
def eval_recall(gold_docs: List[str], retrieved_docs: List[Dict[str, Any]], k=10) -> float:
topk = {d["id"] for d in retrieved_docs[:k]}
hits = sum(1 for g in gold_docs if g in topk)
return hits / max(1, len(gold_docs))
def answer_groundedness(answer: str, allowed_ids: List[str]) -> float:
# naive: require at least one citation per fact line
lines = [l for l in answer.split("\n") if l.strip()]
citations = sum(1 for l in lines if any(f"[{i}]" in l for i in allowed_ids))
return citations / max(1, len(lines))
def rag_pipeline(openai_client, retriever: Retriever, query: str, gold: Dict[str, Any]):
run_id = str(uuid4())
start = time.time()
candidates = retriever.hybrid_search(query)
ctx = build_context(candidates)
answer = grounded_generation(openai_client, query, ctx)
metrics = {
"run_id": run_id,
"latency_ms": (time.time() - start) * 1000,
"retrieval_recall@10": eval_recall(gold["doc_ids"], candidates, k=10),
"groundedness": answer_groundedness(answer, [d["id"] for d in candidates]),
"tokens_ctx_est": len(ctx) // 3
}
return answer, metrics
Beyond code, a Futures cohort would enforce measurement discipline: every change to chunking, embedding model, or reranker must move recall or nDCG positively on a held-out set. Builders would learn to publish evaluation cards with their demos. See also: For a deeper exploration of this topic, our comprehensive guide on The Big Model Comparisons Story: What July 03’s News Means for Developers provides detailed strategies and implementation frameworks that complement the approaches discussed in this section.
2) Agentic workflows and safe tool use
Agents are tools orchestrators, not oracles. The core competency is designing robust tool schemas, state transitions, and recovery paths. Futures would likely center on:
- Declarative tool schemas with strict type validation.
- Planner-executor separation to bound exploration and enable auditing.
- Rate-limit aware retries and exponential backoff across tool calls.
- Safety policies: deny-lists, allow-lists, and “tripwires” that escalate to human review.
// Example: Type-safe tool schema and guarded execution in TypeScript (pseudo)
type ToolResponse = { ok: true, data: any } | { ok: false, error: string };
interface ToolSpec {
name: string;
description: string;
inputSchema: any; // JSON Schema
handler: (input: any) => Promise<ToolResponse>;
guard?: (input: any) => Promise<boolean>; // return false to block execution
}
const tools: Record<string, ToolSpec> = {
"searchTickets": {
name: "searchTickets",
description: "Search support tickets by keyword and customer_id",
inputSchema: {
type: "object",
properties: { q: { type: "string" }, customer_id: { type: "string" } },
required: ["q"], additionalProperties: false
},
guard: async (input) => {
// prevent exfiltration-like patterns
const risky = /password|ssn|token/i.test(input.q);
return !risky;
},
handler: async (input) => {
try {
const res = await fetch(`https://api.example.com/tickets?q=${encodeURIComponent(input.q)}&cid=${input.customer_id||""}`, { headers: { "Authorization": `Bearer ${process.env.API_KEY}` }});
if (!res.ok) return { ok: false, error: `HTTP ${res.status}` };
const data = await res.json();
return { ok: true, data };
} catch (e) {
return { ok: false, error: String(e) };
}
}
}
};
// Planner-executor sketch
async function runAgentStep(model, state, observation) {
const toolCatalog = Object.values(tools).map(t => ({
name: t.name, description: t.description, schema: t.inputSchema
}));
const plan = await model.plan({ state, observation, tools: toolCatalog });
if (!plan.tool) return { state, observation: "No action taken" };
const spec = tools[plan.tool.name];
if (!spec) return { state, observation: `Unknown tool ${plan.tool.name}` };
// Validate input against schema, then guard
const valid = validateAgainstSchema(plan.tool.input, spec.inputSchema);
if (!valid) return { state, observation: "Invalid tool input" };
if (spec.guard && !(await spec.guard(plan.tool.input))) {
return { state, observation: "Blocked by policy guard" };
}
const res = await spec.handler(plan.tool.input);
const next = await model.observe({ state, toolResult: res });
return { state: next.state, observation: next.summary };
}
The educational thrust: no tool execution without schema validation, policy checks, and explicit observability. Builders learn to log each decision with reasons, enabling reproducible audits and safer autonomy.
3) Multimodal UX with streaming-first patterns
Real-world human-computer interaction is streaming and multimodal. Futures-style training emphasizes:
- Stable partial rendering across tokens: optimistic UI that degrades gracefully under backpressure.
- Latency budgets and fallbacks: content-aware truncation, server-sent events, and speculative decoding if supported.
- Voice and image I/O: state synchronization between audio, text, and tool events.
// Streaming UX sketch with Server-Sent Events (SSE)
app.get("/chat", async (req, res) => {
res.writeHead(200, {
"Content-Type": "text/event-stream",
"Cache-Control": "no-cache, no-transform",
"Connection": "keep-alive",
});
const stream = await openai.chat.completions.create({
model: "gpt-4o-mini",
stream: true,
messages: req.query.history,
});
for await (const event of stream) {
if (event.choices?.[0]?.delta?.content) {
const token = event.choices[0].delta.content;
res.write(`data: ${JSON.stringify({ token })}\n\n`);
}
}
res.end();
});
Streaming is not just a UX improvement; it’s a reliability practice. It exposes rate-limit pressure early, creates room for progressive disclosure, and supports fallback prompts if generation stalls.
4) Evaluation, safety, and AI reliability as first-class disciplines
Beyond functional evals, Futures-style curricula would institutionalize:
- Safety probes: jailbreak attempts, prompt overflow, tool abuse, and data exfiltration simulations.
- Drift detection: longitudinal tracking of answer consistency on anchor tasks.
- Cost-performance tradeoffs: budget-aware routing, including early exit, compression, and selective use of higher-capability models.
# Evaluation harness sketch (Python)
from typing import Callable, Dict, Any, List
import statistics as stats
class EvalCase:
def __init__(self, name: str, input: Dict[str, Any], expected: Any, tags: List[str]):
self.name = name
self.input = input
self.expected = expected
self.tags = tags
class Evaluator:
def __init__(self, runner: Callable[[Dict[str, Any]], Dict[str, Any]]):
self.runner = runner
def run(self, cases: List[EvalCase]) -> Dict[str, Any]:
results = []
for c in cases:
out = self.runner(c.input)
results.append({
"name": c.name,
"ok": self._judge(out, c.expected),
"latency_ms": out["latency_ms"],
"cost_usd": out.get("cost_usd", 0.0),
"tags": c.tags
})
lat = [r["latency_ms"] for r in results]
return {
"count": len(results),
"pass_rate": sum(1 for r in results if r["ok"]) / max(1, len(results)),
"p95_latency_ms": sorted(lat)[int(0.95*len(lat))-1] if lat else 0,
"by_tag": self._by_tag(results),
"cases": results
}
def _judge(self, out: Dict[str, Any], expected: Any) -> bool:
# Plug in semantic similarity or rule-based checks
return out.get("ok", False)
def _by_tag(self, results) -> Dict[str, Any]:
tags = {}
for r in results:
for t in r["tags"]:
tags.setdefault(t, []).append(r)
return { t: {"pass_rate": sum(1 for r in rs if r["ok"])/max(1,len(rs))} for t, rs in tags.items() }
In short, participants don’t just build; they measure and publish the reliability profile of what they build.
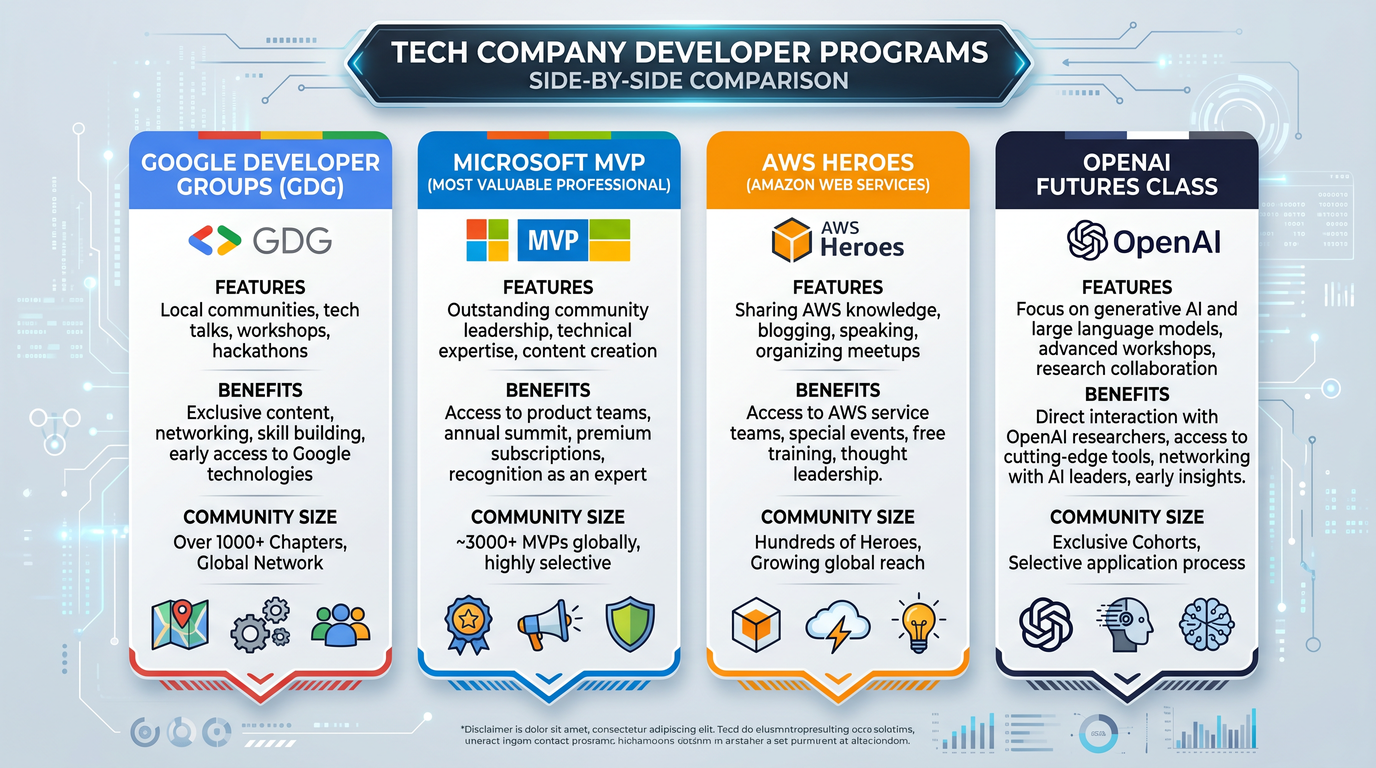
How it compares to Google Developer Groups, Microsoft MVP, and AWS Heroes
Developer community programs vary along four axes: intent, selection, incentives, and outputs. Futures appears to emphasize production outcomes, safety, and reproducibility over general advocacy. The table below contextualizes the likely differences.
| Program | Primary intent | Selection focus | Incentives | Outputs emphasized | Curriculum depth |
|---|---|---|---|---|---|
| ChatGPT Futures (2026) | Accelerate reliable AI app building; codify patterns and evals | Builders with proof of shipping and appetite for measurement | Mentorship, visibility, early tooling access, structured feedback loop | Reference implementations with evaluation cards; safety tooling | High: cohort-based labs, rubrics, role-based tracks |
| Google Developer Groups (GDG) | Community growth and advocacy for Google technologies | Community organizers and contributors | Community support, event resources, recognition | Meetups, talks, community projects | Medium: workshops and codelabs, less emphasis on production evals |
| Microsoft MVP | Recognize community experts and advocates | Demonstrated expertise and contributions | Recognition, access, NDA briefings, product team connects | Blogs, talks, OSS contributions, technical guidance | Medium-High in areas; less standardized across AI app lifecycle |
| AWS Heroes | Evangelize AWS services; showcase builders | Deep expertise and community impact | Recognition, platform access, co-marketing | Content, OSS, architectures on AWS | Medium: strong architecture guidance; eval-first AI is nascent |
The distinctive Futures elements are cohort structure, evaluation-first deliverables, and safety instrumentation as part of the curriculum and outputs. It is less about evangelism breadth and more about operational excellence depth.
Implications for the AI talent pipeline
Education-driven programs reshape both supply and demand.
A new role taxonomy
- AI Application Engineer: Focus on product integration, prompt strategy as code, tool schemas, and streaming UX.
- LLMOps/AI Reliability Engineer: Owns evaluation harnesses, regression tests, model routing, telemetry, and incident response.
- Data/Retrieval Engineer: Manages corpora, chunking, indexing, query planning, and quality metrics.
- AI Product Architect: End-to-end system design, safety boundaries, cost-performance envelopes, and roadmap trade-offs.
Credentialing and signals
Cohort-based programs will popularize verifiable credentials for demonstrated competencies: “RAG Reliability I,” “Agentic Tool Use,” “Evals and Safety Fundamentals.” Employers increasingly screen for these badges plus a portfolio that includes evaluation cards and post-incident reviews, not just glossy demos.
Geographic concentration and diffusion
San Francisco-centric cohorts accelerate local network effects: faster iteration, in-person design reviews, and investor attention. Over time, satellite cohorts, remote tracks, and partner institutions diffuse the playbook globally.
Compensation and hiring shifts
- Premiums for reliability and evaluation fluency; pay bands reflect on-call readiness for AI incidents and compliance maturity.
- Teams rebalance: fewer “prompt-only” roles, more hybrid engineers with data, infra, and product instincts.
- Vendors and consultancies scale enablement practices; internal platform teams formalize AI guilds with rubrics derived from vendor curricula.
What skills are being prioritized (and how to learn them)
Futures emphasizes skills that translate directly into production reliability and safety. Below: the skill map and concrete steps to develop mastery.

| Skill | Why it matters | Core techniques | Proof of competence |
|---|---|---|---|
| Evaluation-first development | Prevents regressions and quantifies reliability | Task suites, adversarial probes, drift monitors, CI gates | Eval repo with pass-rate targets and p95 latency budgets |
| RAG quality engineering | Grounds answers, minimizes hallucinations | Hybrid search, reranking, chunk policies, nDCG/recall@k | Retrieval dashboard hitting ≥0.85 recall on held-out set |
| Safe tool orchestration | Enables automation without unsafe actions | Typed schemas, guards, planner-executor split, rollback | Traceable tool logs; 0 critical policy violations in tests |
| Streaming and multimodal UX | Improves latency, trust, and accessibility | SSE/WebSocket, partial rendering, timeouts and fallbacks | Stable streaming demo under synthetic backpressure |
| Cost-performance optimization | Controls unit economics and scale | Model routing, prompt compression, caching, early exit | Cost per task cut ≥30% without accuracy loss |
| Security and privacy controls | Meets compliance and user trust requirements | PII redaction, data residency, least-privilege tools | Passing red-team suite; audit-ready data-flow maps |
Learning paths
- Build a minimal RAG system with a strong evaluation harness; iterate until metrics surpass baseline. Publish your eval card. See: For a deeper exploration of this topic, our comprehensive guide on The Big Model Comparisons Story: What July 03’s News Means for Developers provides detailed strategies and implementation frameworks that complement the approaches discussed in this section.
- Implement a two-tool agent with typed schemas, policy guards, and rollback. Instrument end-to-end traces and produce a safety incident playbook.
- Refactor your chat UI to use streaming; measure perceived latency improvements and error recovery behavior under induced throttling.
- Add cost loggers to your pipeline; experiment with routing and caching policies; quantify savings and accuracy impact.
- Document your data flows; add PII redaction and access controls; run a basic red-team suite and capture findings.
Canonical project rubric
When you ship a portfolio project, ensure it meets a reproducible rubric:
- Repository includes: infra setup, data preparation, evaluation harness, and a one-click way to run tests.
- Evaluation card with task descriptions, datasets, metrics (recall@k, groundedness, pass-rate), and cost/latency budgets.
- Safety section: tool policies, red-team findings, mitigations, and residual risks.
- Observability: trace samples, log schema, anonymized incident postmortems if applicable.
Effects on the broader AI ecosystem and community
An education-first pivot by a leading AI platform exerts system-wide pressure and creates positive externalities.
Standardization of patterns and metrics
When a dominant vendor publishes curricula and rubrics, those become de facto standards. Expect convergence on:
- Common evaluation terms and thresholds (e.g., groundedness scoring, retrieval recall targets).
- Shared OSS harnesses, datasets, and incident taxonomy (e.g., jailbreak classes, tool-abuse typologies).
- Design templates for RAG, agents, and streaming UX incorporated into popular frameworks.
Acceleration of enterprise adoption
Enterprises benefit from lower enablement costs when vendor education is rigorous and aligned to real-world constraints. Internal AI guilds will remix vendor curricula into role-based training paths, reducing time from proof-of-concept to audited production.
Open-source interaction
Strong vendor curricula can catalyze OSS maturation by clarifying expectations for evaluation and reliability. Healthy interplay looks like:
- OSS libraries adopting vendor rubrics for evals and safety instrumentation.
- Vendor programs amplifying OSS components that meet production-grade standards.
- Community contributions back to datasets, adversarial probes, and tooling connectors.
Risk of vendor lock-in—mitigated by standards
Education tied too tightly to proprietary APIs risks lock-in. The antidote is to teach patterns that decouple application logic from model providers: adapters, well-defined data schemas, and evaluation harnesses that support multiple models. Expect curricula to acknowledge multi-model routing and portable evaluation, at least for advanced tracks.
Regulatory alignment and trust
Codified safety practices and transparent evaluation norms strengthen industry credibility. Programs that elevate incident response, auditing, and data governance make it easier for regulators and customers to assess risk and for vendors to demonstrate responsible deployment.
Predictions: how developer education will evolve over the next 24–36 months
- Credentials become currency. Verifiable micro-credentials for RAG reliability, eval engineering, and safe agent orchestration become common in job descriptions.
- Eval datasets go vertical. Industry consortia and vendors co-sponsor domain-specific evals (healthcare coding, legal summarization) with governance to minimize leakage and bias.
- Agentic benchmarks standardize. Reproducible tasks with tool restrictions and safety scoring emerge, enabling apples-to-apples comparison of agent stacks.
- Education shifts left. Curricula expand to data governance, privacy engineering, and procurement checks—before code is written.
- On-device and edge enter the syllabus. As capable on-device models proliferate, courses include bandwidth budgeting, privacy-by-default, and federated sync patterns.
- LLMOps formalizes. SRE-like duty cycles, error budgets for AI tasks, and post-incident review formats become standard. See: For a deeper exploration of this topic, our comprehensive guide on 10 Best AI Research Tools for data analysis Compared u2014 Features, Pricing, Use Cases provides detailed strategies and implementation frameworks that complement the approaches discussed in this section.
- Cohort-to-product loop tightens. Program outputs rapidly turn into first-class SDK features, templates, and built-in eval dashboards.
- Compute grants pair with education. Access to credits or reserved capacity is conditioned on demonstrable safety and efficiency practices learned in cohort programs.
Action plan: what developers should do now to position themselves
A focused 90-day plan can significantly raise your probability of selection for elite cohorts or equivalent roles—and more importantly, make your work production-ready.
Days 1–10: Establish your evaluation lab
- Pick a domain and assemble 100–300 question-answer pairs with source documents. Ensure coverage across entities, edge cases, and frequent failure modes.
- Implement an evaluation harness with:
- Retrieval metrics (recall@k, nDCG), answer groundedness, task success rate.
- Latency and cost logging; configure p95 targets.
- Adversarial probes (prompt overflow, conflicting context, toxic content).
- Automate your eval in CI; require pass-rate and groundedness thresholds to merge changes.
Days 11–30: Build a RAG baseline and measure
- Start with hybrid search (lexical + dense) and a simple reranker.
- Experiment with chunk sizes, overlap, and metadata. Record impacts on recall and latency.
- Publish your first evaluation card with a candid discussion of weaknesses and costs.
Days 31–50: Add safe tool orchestration
- Identify two tools (e.g., internal search and a ticketing API). Define strict JSON schemas and guards.
- Implement planner-executor with explicit logs and rollback on exception.
- Build a red-team suite targeting tool abuse; add policy tripwires and human-in-the-loop escalation.
Days 51–70: Upgrade UX and resilience
- Switch your UI to streaming; add optimistic rendering with graceful degradation on throttle.
- Introduce caching and early-exit for routine queries; monitor user-perceived latency.
- Add automated load tests with injected rate limit errors and network jitter.
Days 71–90: Optimize, document, and publish
- Implement cost-aware routing; quantify gains and guard against accuracy regressions.
- Write a full post with:
- Architecture diagram and data-flow map.
- Evaluation card (metrics, datasets, methodology).
- Safety section (red-team results, mitigations, residual risk).
- Operational runbook (alerts, incident response, rollback).
- Open-source your harness if feasible; invite replication and critique.
This plan not only raises your odds of acceptance into any cohort; it also functions as a portfolio that hiring managers and technical interviewers can assess rapidly. Consider pairing your write-up with a concise demo video and a repo that’s trivial to run locally or in a dev container.
KPIs and ROI: how orgs should measure an education-first strategy
Organizations investing in developer education—whether via vendor cohorts, internal academies, or both—should define success as improved time-to-reliable-feature, lower incident rates, and healthier unit economics. Suggested KPIs:
| Objective | KPI | Target | Measurement notes |
|---|---|---|---|
| Accelerate reliable delivery | Time-to-Reliable-Feature (TTRF) | Reduce by 30–50% | Start: story kickoff; End: pass eval suite + p95 latency budget met for 2 weeks |
| Raise baseline quality | Eval pass-rate on anchor tasks | ≥ 0.9 sustained | Anchor tasks stable across releases; detect drift |
| Improve retrieval grounding | Retrieval recall@k | ≥ 0.85 for targeted domains | Report per domain and freshness window |
| Control costs | Cost per successful task | -30% without quality loss | Account for caching/routing; monitor shadow traffic |
| Reduce incidents | Critical safety incidents per 10k sessions | <= baseline -70% | Requires standardized incident taxonomy and logging |
| Grow internal capability | Certified practitioners per role | 2–4 per squad | Role-aligned credentials; runbooks owned |
Program-level metrics for vendor cohorts
- Participant activation: % shipping at least one evaluated, production-ready feature within cohort period.
- Open artifacts: # of public guides, repos, and evaluation datasets generated.
- Downstream adoption: # enterprises adopting cohort-produced patterns or templates.
- Safety maturity: reduction in common incident categories across participant deployments.
Risks, trade-offs, and mitigation strategies
1) Overfitting to a single vendor
Risk: Curricula tightly coupled to proprietary APIs may limit portability and bargaining power.
Mitigation: Teach patterns first, APIs second. Use adapters, define evaluation harnesses that support multiple models, and document provider-agnostic designs. Encourage a “multi-model day 2” plan for critical workloads.
2) Curriculum drift vs. API change velocity
Risk: APIs and model behaviors change faster than curricula update, leading to stale guidance.
Mitigation: Ship versioned modules with explicit deprecation timelines and changelogs. Build curriculum review sprints each quarter with product team embeds.
3) Shallow credential inflation
Risk: Badges without rigorous assessment dilute signal.
Mitigation: Tie credentials to hands-on labs, proctored evals, and published artifacts. Random audits and renewal requirements aligned to current best practices.
4) Safety theater vs. real resilience
Risk: Checklists replace genuine stress testing; systems still fail under novel attacks.
Mitigation: Incorporate live-fire exercises, rotating red-team roles, and post-incident reviews with corrective actions baked into grading.
5) Equity and access
Risk: In-person, SF-centric programs concentrate opportunity.
Mitigation: Offer remote tracks, travel stipends, partner campuses, and open-source curricula with community mentors.
Conclusion
The Futures Class of 2026 is best read as a signal: OpenAI, like other leading AI companies, recognizes that the binding constraint on AI value is not access to models but access to mastery. Education—serious, measured, reproducible—scales that mastery. It is also a powerful moat: curricula, communities, and credentials are harder to copy than model weights alone.
For developers, the path is clear: become conversant in evaluation-first development, retrieval quality, safe tool use, and streaming UX; publish your work with rigorous metrics and safety disclosures. For organizations, align enablement to measurable outcomes: time-to-reliable-feature, pass rates on anchor tasks, controlled unit economics, and fewer critical incidents. For the ecosystem, demand interoperability and standards so education builds portable skill—and accelerates responsible AI across vendors and venues.
If there is a singular takeaway, it is this: the platforms that teach best will win—because they will create the builders who ship the most reliable value, the fastest. The Futures program is a preview of that reality. The sooner you orient your roadmap, hiring, and learning investments around education-first AI, the more compounding advantage you will accrue.
Pro tip: Wherever you are in the stack, instrument everything. If you can’t measure retrieval quality, groundedness, and task success end-to-end, you can’t improve them—or trust them. Your portfolio, SLAs, and incident reviews will speak louder than any demo.
Further reading and building resources: For a deeper exploration of this topic, our comprehensive guide on The Complete Guide to Google’s Agent2Agent Protocol and OpenAI Codex Interoperability: Building Cross-Platform AI Agent Systems provides detailed strategies and implementation frameworks that complement the approaches discussed in this section.
Access 40,000+ AI Prompts for ChatGPT, Claude & Codex — Free!
Subscribe to get instant access to our complete Notion Prompt Library — the largest curated collection of prompts for ChatGPT, Claude, OpenAI Codex, and other leading AI models. Optimized for real-world workflows across coding, research, content creation, and business.