Advanced AI Prompting Techniques for 2026: Mastering the CTF (Context-Task-Format) Method
The rapid evolution of large language models (LLMs) such as ChatGPT, Claude, and Codex has transformed the landscape of artificial intelligence, enabling unprecedented capabilities in natural language understanding, generation, and reasoning. As these models become increasingly sophisticated, the art and science of prompt engineering have grown correspondingly complex and critical. In 2026, advanced prompting techniques are no longer optional but essential for harnessing the full potential of these AI systems across diverse applications.
✓ Instant access✓ No spam✓ Unsubscribe anytime
This comprehensive guide explores the cutting-edge paradigm known as the CTF method—Context, Task, Format—which structures prompts to maximize clarity, precision, and control. We will delve deeply into how to employ few-shot learning, chain-of-thought reasoning, persona assignment, and methods to mitigate hallucinations. We will also dissect complex multi-step workflows tailored for ChatGPT, Claude, and Codex, illustrating how to architect prompts that guide these systems through intricate reasoning and creative processes.
Whether you are a developer, AI researcher, or technical strategist, this guide offers a definitive resource for elevating your prompt engineering practice in 2026 and beyond.
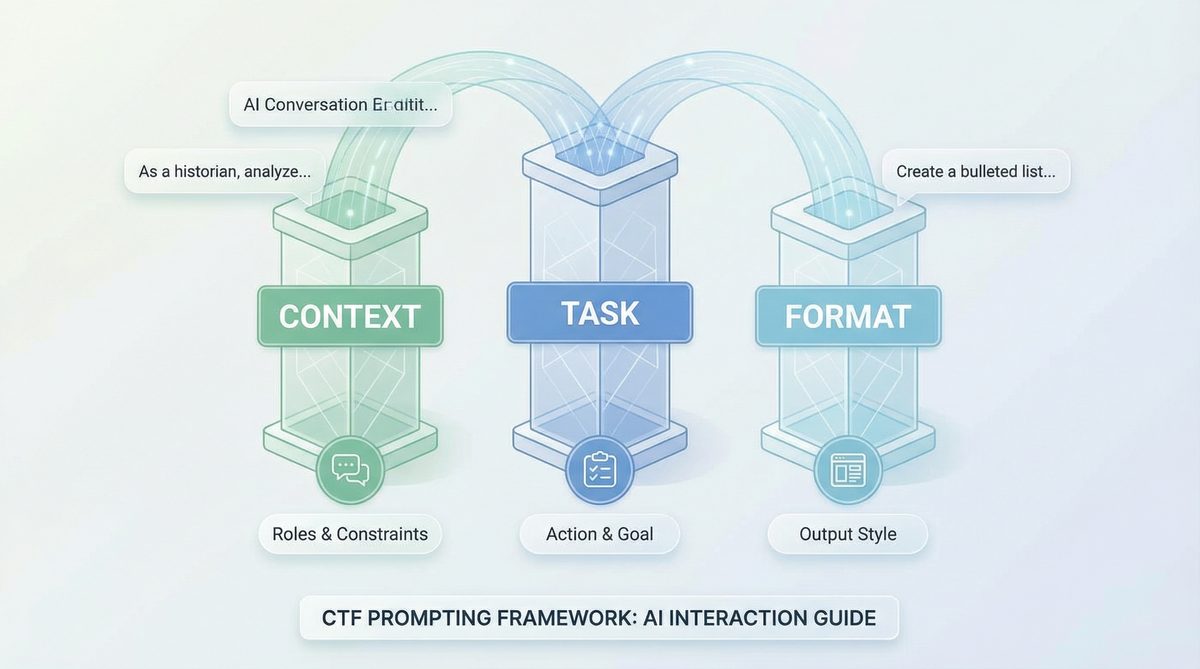
The Foundations of the CTF Method: Context, Task, and Format
At its core, the CTF method is a structured approach to prompt design that segments the prompt into three distinct components:
- Context: The background information, knowledge base, or situational details that the AI requires to understand the domain, constraints, or environment for the task.
- Task: The explicit instruction or objective the AI must achieve, typically articulated as a question, command, or problem statement.
- Format: The desired structure, style, or output constraints that define how the AI should present its response.
By disentangling these elements, prompt engineers can design prompts that are more interpretable, less ambiguous, and easier to adapt across models and domains. This modularity also facilitates advanced techniques such as few-shot learning and chain-of-thought reasoning by clearly specifying the role each piece of information plays.
Context: Providing the Right Foundation
Context is arguably the most critical aspect of the CTF method. Large language models rely heavily on the information embedded in the prompt to ground their responses accurately. The context can include:
- Domain-specific knowledge or glossaries
- Relevant facts or data points
- Historical or situational background
- Previous conversation turns or user preferences
For example, when querying ChatGPT for a medical diagnosis, the context might include patient symptoms, medical history, and lab results. For a coding task in Codex, the context could be the existing codebase, function definitions, and API documentation.
Effective context provision requires a balance. Too little context leads to vague or hallucinated answers, while too much can overwhelm the model or introduce irrelevant details. Techniques such as context window optimization, selective summarization, and embedded knowledge graphs can enhance context delivery.
Task: Defining the Objective with Precision
The task section directs the AI to perform a specific operation. Clarity and specificity here reduce ambiguity and improve output quality. Tasks can be framed as:
- Direct commands (“Translate the following text from English to German.”)
- Questions (“What are the main causes of climate change?”)
- Problem statements (“Debug the following Python function that fails on edge cases.”)
- Creative prompts (“Compose a poem in the style of Shakespeare about AI.”)
Including constraints or requirements in the task statement—such as word limits, tone, or level of detail—further guides the model. For instance, “Explain in simple terms suitable for a 10-year-old” or “Provide a detailed technical analysis with references.”
Format: Structuring the Output for Usability
Format instructions ensure that the AI’s output is usable directly or easily post-processed. This includes specifying:
- Output style (bullet points, numbered lists, paragraphs)
- Language or dialect
- Data formats (JSON, CSV, code snippets)
- Length constraints
- Inclusion of meta-information (citations, explanations)
For example, when requesting a JSON-formatted API response example from Codex, the format instruction might be: “Return the code snippet as a JSON object with keys ‘endpoint’, ‘method’, and ‘parameters’.”
By explicitly defining the format, prompt engineers minimize the need for extensive post-processing and ensure smoother integration into pipelines or user interfaces.
Integrating Context, Task, and Format
Combining these three components effectively enables nuanced prompting. Consider this example prompt for Claude tasked with generating a concise technical summary:
Context: The document below is a research paper on quantum computing algorithms, focusing on error correction techniques.
Task: Summarize the key findings and implications of the paper in no more than 150 words.
Format: Provide the summary as a bullet-point list, using clear technical language suitable for an audience of computer scientists.This prompt clearly demarcates what the model needs to understand, what it must do, and how it must present the output, resulting in a focused and relevant response.
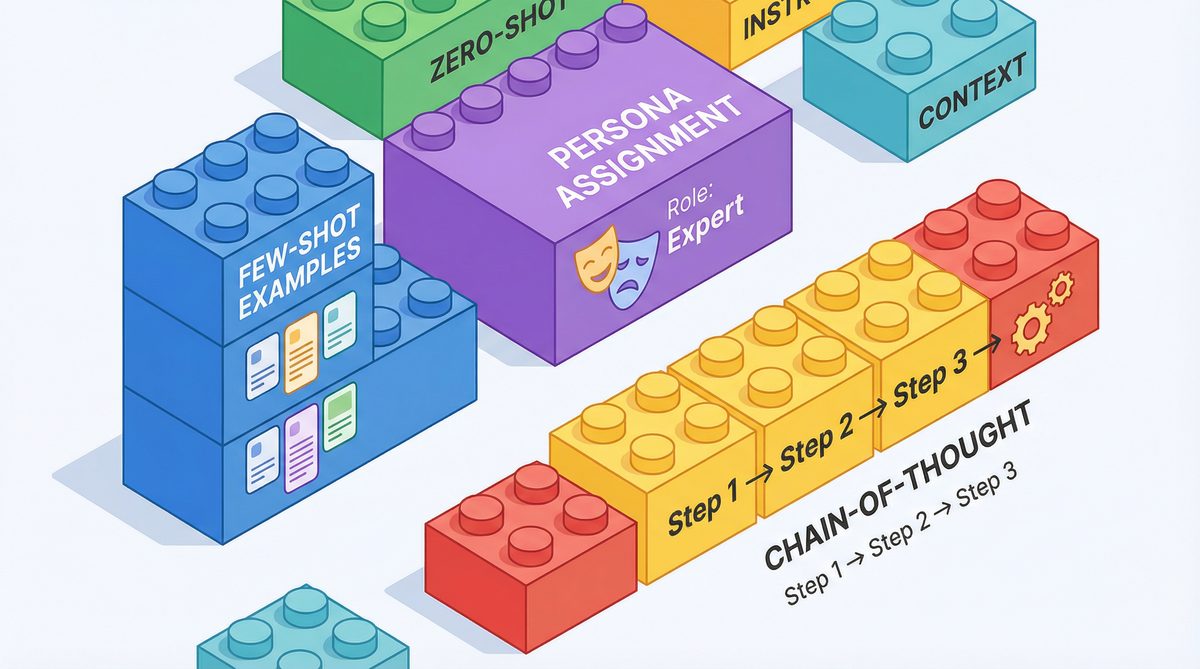
Leveraging Few-Shot Learning Within the CTF Framework
Few-shot learning is a transformative technique that allows models to generalize new tasks from a limited number of examples embedded directly in the prompt. Unlike fine-tuning, which requires extensive retraining, few-shot prompting offers a lightweight, flexible method to adapt LLMs to specialized tasks on-the-fly.
Theoretical Foundations and Evolution
Few-shot prompting emerged prominently with OpenAI’s GPT-3, which demonstrated that providing a handful of input-output pairs within the prompt significantly improved performance on novel tasks. The underlying mechanism involves the model pattern-matching the examples and extrapolating to new inputs based on learned analogies.
This method is particularly effective when the task is complex or uncommon enough that the model’s pretrained knowledge alone is insufficient. By embedding examples in the context, the model gains immediate reference points guiding its reasoning and generation.
Constructing Effective Few-Shot Prompts
Within the CTF method, few-shot learning manifests primarily in the Context segment, where exemplar input-output pairs are included. The general structure is:
Context:
Example 1:
Input: <input_1>
Output: <output_1>
Example 2:
Input: <input_2>
Output: <output_2>
...
Task:
Input: <new_input>
Output:Key considerations when designing few-shot prompts include:
- Relevance: Examples should closely match the target task.
- Diversity: Provide varied examples to cover edge cases and different input types.
- Clarity: Format examples consistently and unambiguously to avoid confusing the model.
- Number of Shots: Typically between 3 to 10 examples, balancing model context window constraints and diminishing returns.
Example: Few-Shot Prompt for Sentiment Analysis with ChatGPT
Context:
Example 1:
Input: "I love this product! It works perfectly."
Output: Positive
Example 2:
Input: "The service was terrible and slow."
Output: Negative
Example 3:
Input: "Average experience, nothing special."
Output: Neutral
Task:
Input: "The movie had stunning visuals but a weak plot."
Output:This prompt guides ChatGPT to classify sentiment based on the pattern demonstrated in examples. The model then completes the output with the appropriate sentiment label.
Few-Shot Learning in Codex for Programming Tasks
Few-shot prompting is especially powerful with Codex for code generation, debugging, and transformation tasks. Embedding multiple input-output pairs of code snippets and their explanations enables Codex to learn complex patterns such as API usage or specific coding styles.
Example prompt snippet:
Context:
Example 1:
Input: Python function to convert Fahrenheit to Celsius.
Output:
def fahrenheit_to_celsius(f):
return (f - 32) * 5 / 9
Example 2:
Input: Python function to check if a number is prime.
Output:
def is_prime(n):
if n < 2:
return False
for i in range(2, int(n**0.5) + 1):
if n % i == 0:
return False
return True
Task:
Input: Python function to calculate the factorial of a number.
Output:Codex extrapolates from the provided examples to generate the factorial function with the expected style and correctness.
Challenges and Best Practices
Despite its power, few-shot prompting faces challenges such as:
- Context Window Limitations: Models have finite token windows; large few-shot examples can exhaust capacity.
- Example Selection Bias: Poorly chosen examples may mislead the model.
- Example Ordering: The sequence of examples can influence the model’s interpretation.
To mitigate these, developers use techniques like example pruning, dynamic example retrieval, and prompt chaining (
For a deeper understanding of how these concepts apply in practice, our comprehensive analysis in Advanced Prompting Techniques for ChatGPT and Claude in 2026: A Practitioner’s Handbook provides detailed insights and actionable strategies that complement the topics discussed in this article.
) to maintain efficiency and accuracy.Chain-of-Thought Reasoning: Unlocking Deeper Model Cognition
Chain-of-thought (CoT) prompting is a paradigm that encourages models to articulate intermediate reasoning steps explicitly, rather than generating direct answers. This method improves performance on tasks requiring logical deduction, multi-step calculations, or complex problem solving.
Historical Context and Motivation
Early LLM outputs often suffered from shallow or incorrect reasoning, especially on tasks demanding multi-hop inference. Researchers discovered that prompting models to “think aloud” via stepwise explanations significantly enhanced accuracy. CoT effectively leverages the model’s latent reasoning capabilities by making the reasoning process explicit in the output.
Implementing Chain-of-Thought in the CTF Framework
CoT reasoning can be integrated into the Format and Task components, instructing the model to provide detailed stepwise reasoning before the final answer. For example:
Context: You are an expert mathematician.
Task: Solve the following problem and explain your reasoning step-by-step.
Format: Provide a detailed chain of thought, enumerating each inference or calculation step, concluding with the final answer.
Problem: A store sells pencils at $0.50 each and erasers at $0.75 each. If a customer buys 3 pencils and 2 erasers, what is the total cost?This prompt encourages the model to break down the problem logically, enhancing transparency and correctness.
Example: Chain-of-Thought Prompt for Logical Reasoning with Claude
Context: You are a logic expert.
Task: Determine who owns the red car based on the clues below.
Format: Explain your reasoning step-by-step, then provide a final conclusion.
Clues:
1. The person who owns the blue car lives next to the person who owns the red car.
2. Alice lives to the left of Bob.
3. The green car owner is not Bob.
Question: Who owns the red car?Claude would generate a detailed reasoning path, considering each clue sequentially before deducing the answer.
Chain-of-Thought with Few-Shot Examples
Combining CoT with few-shot learning amplifies performance. Including exemplars demonstrating stepwise reasoning primes the model to replicate that approach on novel inputs. For instance:
Context:
Example 1:
Question: If a train travels at 60 mph for 2 hours, how far does it go?
Answer:
Step 1: Speed = 60 mph
Step 2: Time = 2 hours
Step 3: Distance = Speed × Time = 60 × 2 = 120 miles
Final Answer: 120 miles
Task:
Question: A car travels at 45 mph for 3 hours. How far does it go?
Answer:The model will follow the pattern, breaking down the problem stepwise.
Technical Insights: How CoT Enhances Model Reasoning
From a technical perspective, CoT prompts activate latent variables within the transformer architecture that align with reasoning patterns. By explicitly encouraging intermediate steps, the model’s attention weights distribute over logical subcomponents, reducing hallucinations and surface-level guesswork.
Moreover, CoT facilitates debugging and interpretability by exposing the model’s thought process, allowing developers to identify reasoning errors or gaps. This is especially valuable in high-stakes domains such as medical diagnosis or legal interpretation.
Persona Assignment: Tailoring AI Responses Through Role-Playing
Persona assignment is an advanced prompting technique where the model adopts a specific identity or role to shape tone, knowledge scope, and behavioral tendencies. This method enhances user experience, contextual appropriateness, and domain specialization.
Why Persona Matters in AI Communication
LLMs are inherently neutral and can simulate multiple styles and knowledge bases. However, explicitly assigning a persona yields:
- Consistency: Uniform tone and style across interactions.
- Authority: Enhances credibility when role is domain-expert (e.g., doctor, lawyer).
- Engagement: More relatable and context-aware conversations.
- Bias Mitigation: Controlled behavior reduces inappropriate responses.
Persona Specification in CTF Prompts
Persona is typically embedded in the Context, setting behavioral constraints and knowledge boundaries. For example:
Context: You are a cybersecurity expert with 10 years of experience specializing in penetration testing and vulnerability assessment.
Task: Explain the concept of SQL injection attacks to a novice audience.
Format: Provide a clear, jargon-free explanation with examples.This guides the model to adopt the voice and knowledge domain of a cybersecurity expert, shaping terminology, depth, and tone accordingly.
Advanced Persona Techniques: Dynamic and Composite Personas
Beyond static personas, advanced prompting in 2026 supports dynamic persona switching and composite role assignments. For instance, a prompt might specify:
- Hybrid persona combining domain expertise with empathy (e.g., a doctor who is also a counselor).
- Temporal personas that evolve during a conversation (starting as a tutor, then as an examiner).
- Persona with constraints on ethics and compliance (e.g., strictly adhering to GDPR in data discussions).
Example multi-persona prompt:
Context: You are both a legal advisor and a technical AI ethicist.
Task: Review the following AI deployment plan for compliance and ethical risks.
Format: Provide a detailed analysis, highlighting legal compliance issues and ethical considerations.Such nuanced persona assignment enables richer, context-aware, and highly specialized AI outputs.
Persona in Multi-Modal and Multi-Agent Systems
Looking forward, emerging AI systems integrate multi-modal inputs (text, images, code) and multi-agent collaboration. Persona assignment extends to these scenarios, where different agents embody distinct roles, collaborating through prompts. For example, in a CTF prompt for a multi-agent workflow:
Context:
Agent 1 (Data Scientist): Analyze the dataset and extract features.
Agent 2 (AI Engineer): Use extracted features to train a model.
Agent 3 (Product Manager): Evaluate model performance and business impact.
Task: Coordinate the agents to optimize the AI product pipeline.
Format: Provide a sequence of interactions, specifying each agent's output and handoff.This exemplifies how persona and role assignment facilitate complex AI orchestration and workflow automation (
For a deeper understanding of how these concepts apply in practice, our comprehensive analysis in Advanced Prompting Techniques for ChatGPT (GPT-5.4) and Claude (Opus 4.6/Sonnet 4.6) in 2026 provides detailed insights and actionable strategies that complement the topics discussed in this article.
).
Mitigating Hallucinations: Ensuring Reliability in AI Outputs
Hallucinations—instances where AI generates plausible but incorrect or fabricated information—remain a significant challenge in deploying LLMs. Advanced prompt engineering incorporates multiple strategies to reduce hallucinations, improving trustworthiness and factual accuracy.
Understanding Hallucinations in Language Models
Hallucinations arise due to the probabilistic nature of language models, which generate tokens based on learned statistical patterns rather than grounded truth. Factors influencing hallucinations include:
- Ambiguous or insufficient context
- Open-ended or vague task instructions
- Model overconfidence
- Outdated or incomplete training data
For sensitive applications, mitigating hallucinations is paramount.
Prompt Engineering Techniques to Mitigate Hallucinations
Several advanced prompting strategies can reduce hallucinations:
- Explicit Verification Instructions: Direct the model to check facts or cite sources.
- Contextual Constraints: Provide authoritative, verified data in the context.
- Self-Consistency Checks: Ask the model to generate multiple reasoning paths and select consistent answers.
- Reinforcement via Chain-of-Thought: Encourage detailed reasoning to expose inconsistencies.
- Persona as Fact-Checker: Assign the model a persona of a meticulous fact-checker or editor.
Example: Prompt to Enforce Fact-Checking with ChatGPT
Context: You are an expert fact-checker with access to verified scientific databases.
Task: Provide a summary of the latest research on climate change impacts, including citations.
Format: Present the information as bullet points with inline citations using APA style.This prompt biases the model toward accuracy and verifiability, reducing hallucination risk.
Multi-Step Verification Workflows
For critical tasks, single-pass prompting is insufficient. Complex multi-step workflows incorporate verification loops:
- Initial generation with detailed reasoning.
- Automated or human-in-the-loop fact-checking of outputs.
- Regeneration or refinement prompts incorporating corrections.
- Final synthesis ensuring consistency and compliance.
For example, using Claude in a multi-turn conversation:
Turn 1: Generate a comprehensive report.
Turn 2: Cross-check each claim against authoritative sources.
Turn 3: Flag inconsistencies and regenerate flagged sections.
Turn 4: Summarize corrected report for final delivery.Such workflows are essential in domains like healthcare, legal advice, and scientific publication.
Technical Tools Complementing Prompting
Complementary to prompt engineering, external tools augment hallucination mitigation:
- Retrieval-Augmented Generation (RAG): Integrating external knowledge bases or search engines to ground responses.
- Verification Models: Secondary models trained to verify claims or detect inconsistencies.
- Prompt Chaining: Decomposing complex tasks into modular prompts with validation checkpoints.
Combining these with CTF-structured prompts creates robust pipelines that significantly elevate output reliability (
For a deeper understanding of how these concepts apply in practice, our comprehensive analysis in Wall of Context Prompting: The 2026 Technique That Is Replacing Long ChatGPT Prompts provides detailed insights and actionable strategies that complement the topics discussed in this article.
).Complex Multi-Step Workflows: Orchestrating Advanced Tasks Across Models
By 2026, AI prompting transcends simple single-turn instructions, evolving into orchestrated multi-step workflows that leverage the strengths of diverse LLMs like ChatGPT, Claude, and Codex. These workflows enable the synthesis of complex outputs involving reasoning, generation, verification, and adaptation.
Architectural Overview of Multi-Step Prompting Workflows
Complex workflows typically involve:
- Decomposition: Breaking down a large task into smaller subtasks.
- Model Selection: Assigning subtasks to the most suitable model (e.g., Codex for code, Claude for reasoning).
- Prompt Chaining: Feeding outputs from one subtask as inputs to subsequent subtasks.
- Intermediate Verification: Incorporating checks and balances to ensure correctness.
- Final Synthesis: Aggregating and formatting the final output.
Example Workflow: Technical Documentation Generation
Consider generating comprehensive API documentation for a complex software library:
- Step 1 (Codex): Extract code signatures and comments from source files.
- Step 2 (Claude): Generate human-readable explanations for each function based on code and comments.
- Step 3 (ChatGPT): Compile explanations into coherent, structured documentation, adding usage examples.
- Step 4 (Claude): Review and fact-check documentation consistency and accuracy.
- Step 5 (ChatGPT): Format documentation in Markdown or HTML as required.
Each step uses a tailored prompt aligned with the CTF method, ensuring clarity and control throughout the pipeline.
Prompt Chaining Techniques
Prompt chaining involves linking outputs and inputs across multiple prompt invocations. There are two primary methods:
- Sequential Chaining: Simple linear progression where each prompt is fed the prior output.
- Recursive or Branching Chains: More complex flows involving conditional branching, loops, or parallel subtasks.
Example of sequential chaining for a legal contract analysis:
Prompt 1: Summarize the key obligations of Party A.
Prompt 2: Identify potential risks in those obligations.
Prompt 3: Suggest mitigation strategies for the identified risks.
Prompt 4: Compile a risk assessment report.Each prompt builds on the previous outputs, maintaining context and refining the final deliverable.
Multi-Model Collaboration
Each LLM has optimized capabilities:
- ChatGPT: Conversational fluency, creative generation, and general reasoning.
- Claude: Robust factual reasoning, ethical compliance, and summarization.
- Codex: Code understanding, generation, and debugging.
Advanced workflows strategically allocate tasks to these models, orchestrating their strengths for superior results. For instance, Codex handles code extraction and synthesis, while Claude performs fact-checking and analytical reasoning, and ChatGPT manages user interaction and formatting.
Case Study: AI-Assisted Software Development Pipeline
An AI-assisted development workflow for 2026 might include:
- Requirement Analysis (Claude): Interpret user stories and generate technical specifications.
- Code Generation (Codex): Write modular code components based on specs.
- Code Review (Claude): Analyze generated code for potential bugs or style issues.
- Documentation (ChatGPT): Create developer-friendly documentation and usage guides.
- Testing (Codex): Generate automated test suites based on requirements.
- Deployment Planning (Claude): Outline deployment strategies and risk assessments.
Each step is driven by carefully engineered CTF prompts ensuring clarity and consistency.
Best Practices for Designing Multi-Step Workflows
- Modular Prompt Design: Define clear CTF segments for each subtask to isolate concerns.
- Context Management: Efficiently manage context windows by summarizing or truncating irrelevant data.
- Error Handling: Design fallback prompts and error detection mechanisms.
- Logging and Auditing: Maintain detailed logs of intermediate outputs for traceability.
- Human-in-the-Loop Integration: Incorporate manual review steps where necessary.
Conclusion
Advanced AI prompting techniques in 2026, centered around the Context-Task-Format (CTF) method, represent a paradigm shift in how developers and researchers interact with powerful LLMs such as ChatGPT, Claude, and Codex. By structuring prompts with precise context, explicit tasks, and well-defined formats, practitioners unlock unprecedented capabilities in few-shot learning, chain-of-thought reasoning, persona assignment, hallucination mitigation, and complex multi-step workflows.
Mastering these techniques demands a deep understanding of model architectures, prompt dynamics, and application-specific requirements. The examples and frameworks outlined herein provide a foundation for building sophisticated AI applications that are reliable, interpretable, and highly effective.
As AI models continue to evolve, the art of prompt engineering will remain a critical skill, enabling the next generation of intelligent systems to deliver transformative outcomes across industries and disciplines.
🕐 Instant∞ Unlimited🎁 Free
Get Free Access to 40,000+ AI Prompts
Join 40,000+ AI professionals. Get instant access to our curated Notion Prompt Library with prompts for ChatGPT, Claude, Codex, Gemini, and more — completely free.
Get Free Access Now →No spam. Instant access. Unsubscribe anytime.