Advanced Prompt Engineering Frameworks for 2026: RTF, CREATE, Chain-of-Thought, ReAct, and DSPy
Advanced Prompt Engineering Frameworks for 2026: A Comprehensive Guide
As artificial intelligence language models continue to evolve rapidly, advanced prompt engineering frameworks have become indispensable tools for maximizing their potential. By 2026, frameworks such as RTF, CREATE, Chain-of-Thought, ReAct, and DSPy have emerged as industry standards for designing effective prompts that unlock complex reasoning, multi-step problem-solving, and dynamic interactions across leading AI platforms including ChatGPT, Claude, and Codex.
This guide provides a deep technical dive into these advanced frameworks, exploring their fundamental principles, operational mechanics, and practical implementation strategies. It also offers comparative insights into how these frameworks perform across different large language models (LLMs), enabling AI practitioners to tailor their prompt engineering approaches according to the target system.
Furthermore, we explore the evolution of prompt engineering from simple template-based instructions to sophisticated, modular, and adaptive frameworks that integrate reasoning, action, and evaluation. These frameworks not only improve output quality but also enhance model interpretability, robustness, and adaptability, which are critical for deploying AI safely and effectively in real-world applications.
Understanding Core Frameworks: RTF and CREATE
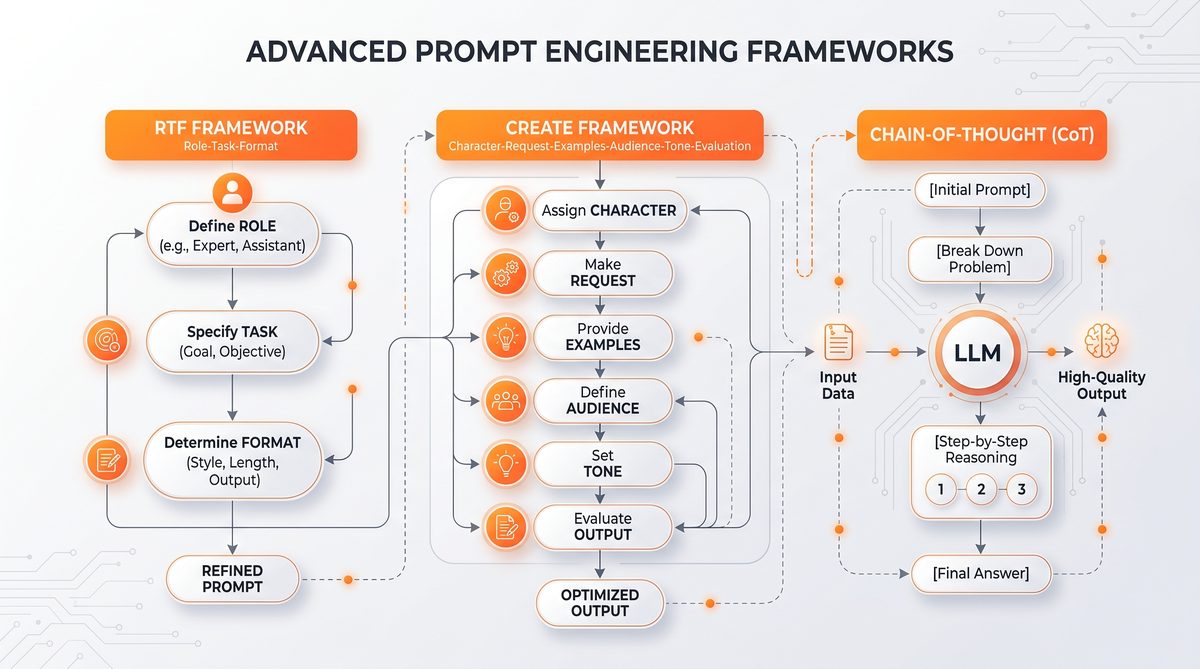
RTF (Read, Think, Formulate) Framework
The RTF framework is designed to guide language models through a structured cognitive process that mirrors human analytical reasoning. It divides prompt interaction into three distinct phases:
- Read: The model ingests and parses the input context, focusing on key information extraction.
- Think: The model engages in internal reasoning, drawing inferences and evaluating possible solutions or interpretations.
- Formulate: The model composes a final, coherent response based on the reasoning process.
This phased approach reduces hallucinations and improves answer accuracy by compelling the model to articulate intermediate reasoning steps explicitly. When applied to ChatGPT, RTF prompts often include instructions such as “First, identify the key facts, then reason through possible outcomes, and finally provide the answer.” In contrast, Claude benefits from more open-ended cues that stimulate exploratory thinking in the “Think” phase. Codex, optimized for code generation, leverages RTF by integrating problem analysis and stepwise code formulation.
For example, when tasked with analyzing a complex legal document, an RTF prompt might explicitly instruct the model to first extract relevant clauses (“Read”), then assess their implications under specific legal standards (“Think”), before finally synthesizing a summary or verdict (“Formulate”). This encourages transparency and allows users to audit intermediate steps, reducing risks of misinterpretation.
Advanced RTF implementations incorporate meta-prompts that dynamically adjust the depth of each phase based on task complexity or user feedback. For instance, in technical troubleshooting scenarios, the “Think” phase can be extended to systematically enumerate possible root causes before “Formulate” constructs a prioritized action plan. Such adaptive prompting enhances model flexibility and reliability across domains.
Moreover, RTF supports modular prompt design, where each phase is encapsulated as a reusable prompt block, enabling developers to mix-and-match or chain reasoning patterns across diverse tasks. This modularity facilitates maintainability and scalability in enterprise AI systems.
CREATE (Contextual Reasoning and Elaborate Answering Technique)
CREATE is an advanced framework emphasizing the generation of context-aware and elaborated responses, which is critical for tasks requiring nuanced understanding and detailed explanations.
- Contextualization: The model is prompted to deeply incorporate the context, including implicit cues and domain-specific knowledge.
- Reasoning: The model performs layered reasoning, often instructed to explore multiple perspectives or hypotheses.
- Elaboration: The final output is expected to be comprehensive, with justifications, examples, and clarifications.
- Answering: The concluding segment is a concise, precise answer synthesized from the previous steps.
- Transparency: The model is encouraged to show its thought process openly.
- Evaluation: The model self-evaluates its answer for completeness and correctness.
- Iteration: If necessary, the model refines its answer based on the evaluation step.
When used with ChatGPT, CREATE prompts can explicitly request the model to “consider alternative explanations” and “validate the answer before concluding.” Claude’s architecture, which supports reflective reasoning, aligns well with CREATE’s iterative evaluation and refinement phases. Codex can utilize CREATE by embedding detailed problem statements and requesting stepwise code commenting and testing within the prompt.
For instance, in a scientific research assistant application, CREATE enables the model to first deeply analyze experimental data (Contextualization), then hypothesize multiple interpretations (Reasoning), followed by elaborating on potential mechanisms with supporting literature references (Elaboration). The model then synthesizes a concise hypothesis statement (Answering), transparently exposes its reasoning, evaluates the confidence level, and iteratively refines the hypothesis if inconsistencies or gaps are detected.
This iterative self-evaluation is particularly valuable for mitigating model biases and maintaining accuracy in complex scenarios requiring domain expertise.
Technically, CREATE prompts often incorporate explicit checkpoint tokens or delimiters that signal transition between phases, allowing developers to capture and analyze intermediate outputs for debugging or auditing purposes. Advanced implementations also integrate feedback from external validation tools (e.g., fact-checkers, code linters) into the evaluation and iteration loop, further enhancing response quality.
Both RTF and CREATE emphasize transparency in reasoning, but CREATE extends the process by integrating self-evaluation and iterative refinement, which improves robustness in complex scenarios. CREATE’s richer phase structure also supports multi-turn dialogues where each interaction builds upon previous outputs, enabling cumulative knowledge building and nuanced user engagement.
Dynamic Reasoning and Action Frameworks: Chain-of-Thought and ReAct
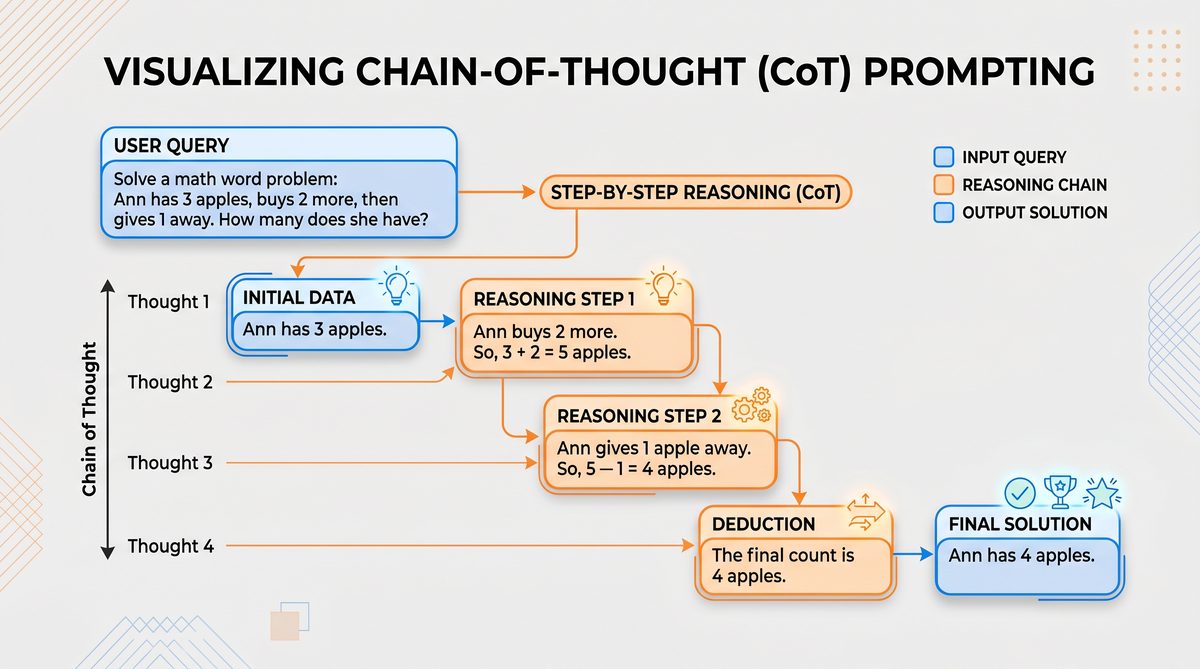
Chain-of-Thought (CoT) Prompting
Chain-of-Thought prompting is a transformative technique that encourages the model to generate intermediate reasoning steps explicitly before arriving at a final answer. Unlike straightforward question-answering prompts, CoT guides the model to “think aloud,” which enhances multi-step problem solving, especially for mathematical, logical, and commonsense reasoning tasks.
CoT prompts typically involve instructions or examples that demonstrate stepwise reasoning, such as:
“Let’s think step-by-step.”
This approach has proven to be highly effective across ChatGPT, Claude, and Codex. For ChatGPT, CoT prompts improve the correctness of answers by reducing premature conclusions. Claude’s design, which inherently supports reflective reasoning, benefits from CoT by producing more detailed and coherent chains of logic. Codex uses CoT for generating multi-step code solutions, breaking down complex algorithms into manageable segments.
In practice, CoT can be applied to a wide range of challenges, from solving complex algebraic equations and logic puzzles to generating detailed plans or narratives. For example, when asked to solve a mathematical word problem, the model is instructed to explicitly write out each step of the solution, which can be parsed and verified independently for correctness.
Recent research has shown that CoT prompting significantly boosts model performance on benchmark datasets such as GSM8K for math reasoning and Big-Bench Hard (BBH) for commonsense tasks. These improvements are attributed to the model’s ability to decompose complex tasks into simpler subproblems, which aligns well with human problem-solving strategies.
Developers can enhance CoT effectiveness by combining it with few-shot learning, providing exemplar stepwise reasoning demonstrations that guide the model’s output style and depth. Additionally, dynamically adjusting the granularity of reasoning steps based on user feedback or task difficulty can optimize performance and response latency.
Technically, CoT can be integrated with external verification tools, such as symbolic math solvers or logic checkers, to validate intermediate reasoning steps, thereby increasing trustworthiness in critical applications.
ReAct (Reasoning + Acting) Framework
ReAct is an innovative prompting framework that combines reasoning with action-oriented responses. The core idea is to interleave thought processes (“Reasoning”) with task executions (“Acting”) dynamically, enabling models to interact with external tools, APIs, or environments while reasoning internally. This hybrid approach is particularly valuable for applications requiring decision-making, data retrieval, or code execution on the fly.
- Reasoning: The model deliberates about the problem, plans the next steps, and determines what action to take.
- Acting: The model performs actions such as querying a database, invoking an API, or generating code snippets.
- Observation: The model evaluates the outcomes of its actions and integrates this feedback into subsequent reasoning steps.
ReAct prompts typically include markers or tokens that separate reasoning and acting phases, for example:
Reasoning: I need to find the current weather in Paris.
Action: query_weather_api("Paris")
Observation: The temperature is 18°C with clear skies.
Reasoning: Given the weather, the best time to visit is in the afternoon.
ChatGPT supports ReAct by allowing conversational interleaving of reasoning and external API calls through plugins or custom integrations. Claude’s architecture is well-suited for ReAct due to its ability to maintain context across multiple reasoning-action cycles. Codex leverages ReAct by generating code that can both reason about the task and execute commands, making it ideal for autonomous coding agents.
One compelling use case of ReAct is in autonomous agents tasked with complex workflows such as booking travel itineraries, managing calendars, or performing data analysis. The model can reason about user preferences, call external APIs to retrieve flight or hotel information, observe responses, and iteratively refine recommendations.
From a technical perspective, ReAct frameworks require robust context management to maintain state across reasoning-action-observation loops. This is often implemented via memory buffers or structured prompt state representations. Additionally, error handling and fallback mechanisms are critical to ensure graceful recovery from failed actions or unexpected API responses.
Recent advances have extended ReAct to multi-agent systems where several specialized models perform distinct reasoning or action roles, communicating via defined protocols. This modularity enhances scalability and enables complex collaborative AI applications.
Furthermore, ReAct’s ability to integrate with external tools positions it as a cornerstone for the emerging paradigm of AI-augmented workflows, where language models complement human expertise with automated data retrieval, computation, and decision support.
DSPy: Deep Structured Prompting in Python for Complex Tasks
Introduction to DSPy
DSPy represents a paradigm shift in prompt engineering by integrating deep structured prompting within a Python environment. It enables developers to construct, manipulate, and execute complex prompt pipelines programmatically, thereby enhancing reproducibility, modularity, and scalability of prompt designs.
DSPy provides an API that abstracts prompt components into Python objects such as:
- Prompt Blocks: Reusable prompt templates with variable insertion slots.
- Logic Nodes: Conditional branching, loops, and state management within prompts.
- Integration Hooks: Interfaces for invoking external APIs, databases, or AI models.
- Evaluation Metrics: Automated scoring and feedback loops embedded in the prompt flow.
This structured approach allows for advanced prompt engineering workflows that can adapt dynamically to user inputs and intermediate model outputs.
For example, a DSPy pipeline for a customer support chatbot might include conditional logic to escalate unresolved issues, integrate API calls to retrieve user account data, and incorporate self-evaluation steps to measure response quality. Such pipelines can be version-controlled, unit-tested, and deployed as part of larger AI services.
DSPy also supports advanced debugging features, such as step-by-step prompt execution tracing and modular prompt component visualization, which help developers identify bottlenecks and optimize prompt design efficiently.
How DSPy Operates Across ChatGPT, Claude, and Codex
DSPy’s Python-centric design aligns naturally with Codex, which excels at code generation and execution. Developers can use DSPy to script complex prompt sequences that generate, test, and debug code snippets dynamically, effectively creating autonomous coding assistants.
When interfacing with ChatGPT through DSPy, prompts can be programmatically constructed to incorporate RTF, CREATE, or CoT methodologies, enhancing interaction quality and enabling multi-turn dialogue management. Claude’s flexible API and emphasis on safety and interpretability make it an ideal backend for deploying DSPy-driven prompting pipelines that require transparency and iterative refinement.
Through DSPy, prompt engineering becomes a software engineering practice, where prompt logic and content are version-controlled, tested, and optimized systematically. This reduces manual prompt crafting errors and facilitates collaborative development of complex AI applications. AI Prompting in 2026: Advanced Context Engineering Techniques for ChatGPT, Claude, and Codex
Moreover, DSPy supports integration with modern MLOps tools and platforms, enabling seamless deployment pipelines, monitoring, and continuous integration/continuous deployment (CI/CD) of prompt workflows. This industrial-grade tooling elevates prompt engineering from ad-hoc experimentation to robust production systems.
Case studies have shown that DSPy-driven prompt engineering significantly reduces time-to-market for AI-powered products, improves maintainability, and enhances cross-team collaboration by providing a common, code-based framework for prompt development.
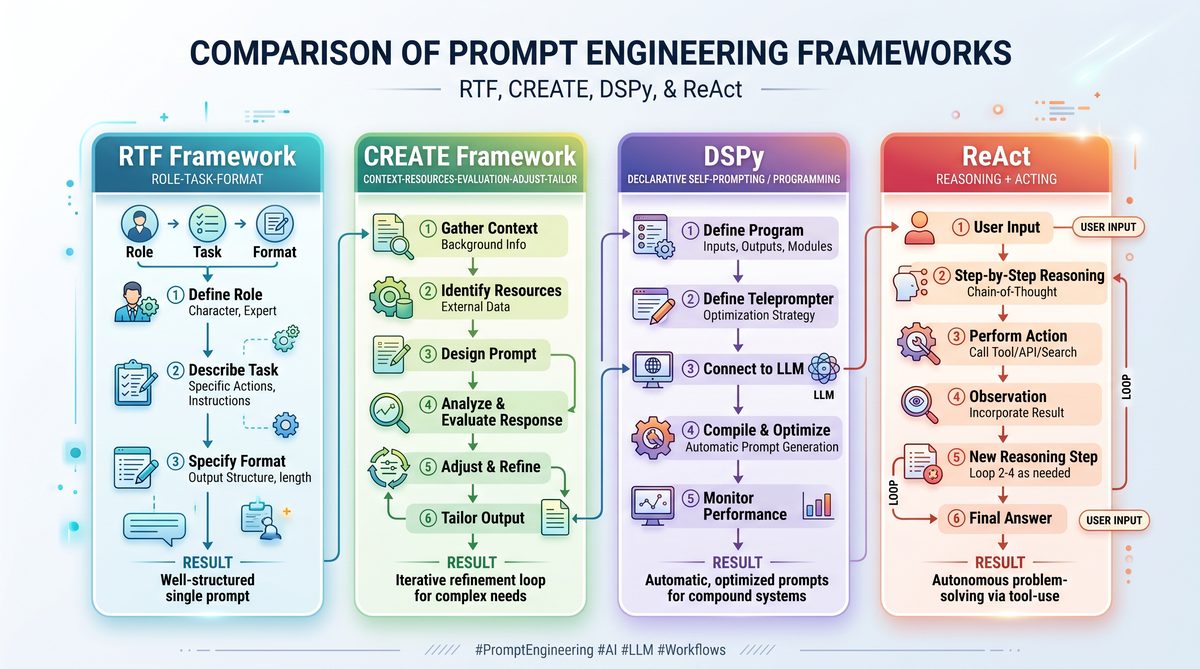
Comparative Summary of Framework Characteristics
| Framework | Primary Focus | Key Mechanisms | Best Use Cases | Compatibility Highlights |
|---|---|---|---|---|
| RTF | Structured reasoning phases | Read → Think → Formulate | Analytical Q&A, fact extraction | ChatGPT: Direct instructions; Claude: Exploratory cues; Codex: Stepwise code development |
| CREATE | Contextual elaboration and iteration | Context → Reason → Elaborate → Answer → Transparency → Evaluate → Iterate | Complex explanations, iterative refinement | ChatGPT: Iterative prompts; Claude: Reflective reasoning; Codex: Detailed code commentary |
| Chain-of-Thought | Explicit multi-step reasoning | Stepwise logical decomposition | Math, logic puzzles, stepwise problem solving | High effectiveness on all three models with stepwise instructions |
| ReAct | Interleaved reasoning and action | Reasoning → Action → Observation loop | Decision-making, API/tool integration, autonomous agents | ChatGPT: Plugin integration; Claude: Context maintenance; Codex: Autonomous code execution |
| DSPy | Deep structured prompting via Python | Modular prompt blocks + logic nodes + API hooks | Complex pipelines, scalable prompt engineering | Codex: Native code synergy; ChatGPT & Claude: API-driven prompt orchestration |
Implementing Advanced Frameworks: Practical Considerations and Strategies
Framework Selection Based on Task Requirements
Choosing an appropriate prompting framework hinges on the nature of the task, desired output quality, and model capabilities. For high-stakes analytical tasks requiring transparency and accuracy, RTF and CREATE are preferred due to their structured and iterative reasoning processes. For problems that demand explicit multi-step logic, Chain-of-Thought remains the go-to approach.
Tasks involving real-time data access or integration with external systems benefit from ReAct’s hybrid reasoning-action cycle. DSPy is ideal for scenarios demanding complex prompt orchestration, such as multi-turn dialogue management, autonomous coding agents, or large-scale AI workflows. Understanding the synergy between the framework and target model is critical; for example, leveraging Codex’s programming strengths with DSPy yields powerful autonomous agents, while ChatGPT’s conversational finesse pairs well with RTF and CREATE.
Industry case studies highlight that selecting a mismatched framework can degrade performance or increase latency. For example, applying Chain-of-Thought prompting on open-ended creative tasks may result in verbose or meandering outputs, whereas ReAct’s integration with external tools may be overkill for simple fact retrieval. Thus, task analysis and pilot testing are vital steps before large-scale deployment.
Additionally, hybrid approaches that combine elements from multiple frameworks are gaining traction. For instance, a pipeline might use RTF for initial fact extraction, Chain-of-Thought for detailed reasoning, and ReAct for executing actions based on conclusions. DSPy facilitates such hybridization by providing modular building blocks and flexible control flow constructs.
Prompt Design Best Practices
- Explicit Instructions: Clearly specify each phase or step in the prompt, especially for RTF and CoT frameworks, to reduce ambiguity.
- Examples and Demonstrations: Provide sample reasoning chains or actions to guide the model’s output format and style.
- Context Management: For iterative frameworks like CREATE and ReAct, maintain context carefully to avoid information loss or drift over multi-turn interactions.
- Incremental Complexity: Start with simple prompts and progressively introduce advanced reasoning or action steps to ensure stability.
- Evaluation and Feedback Loops: Use self-evaluation steps (as in CREATE) or external validation to refine prompt effectiveness continuously.
- Model-Specific Tuning: Adapt prompt wording and structure to leverage the unique strengths and API constraints of ChatGPT, Claude, or Codex.
For example, when designing prompts for Codex, it is beneficial to include explicit code comments and inline instructions to guide code generation and debugging. In contrast, ChatGPT benefits from natural language cues and conversational context to maintain coherence.
Moreover, employing prompt templates with variable insertion slots for dynamic content improves reusability and reduces manual errors. Incorporating safety filters and fallback prompts is also recommended to handle unexpected or harmful outputs.
Finally, iterative prompt refinement, supported by user testing and quantitative metrics, is essential to optimize performance over time.
Integration with External Systems and APIs
Advanced prompting frameworks increasingly rely on real-time data and tool usage, necessitating robust integration methods:
- ChatGPT: Utilize plugin infrastructure and function calling features to connect with external APIs within ReAct prompts.
- Claude: Leverage its API to maintain conversational state and inject external knowledge dynamically during CREATE or ReAct prompting.
- Codex: Harness its code generation and execution capabilities combined with DSPy’s programmatic prompt construction to automate complex workflows.
Designing prompts that seamlessly incorporate external inputs while preserving internal reasoning coherence is a critical skill for 2026 prompt engineers. The 2026 ChatGPT Prompt Engineering Best Practices Guide
For instance, in financial services, ReAct can enable models to fetch real-time market data, perform risk assessments, and generate actionable reports dynamically. Similarly, in healthcare applications, integrating medical databases and clinical decision support tools via ReAct ensures up-to-date and evidence-based recommendations.
Technical challenges include managing latency, ensuring data privacy and security, and maintaining synchronization between model state and external system responses. Frameworks like DSPy provide abstractions and best practices to address these challenges effectively.
Evaluation Metrics and Continuous Improvement
To ensure that advanced prompting frameworks yield consistent, reliable results, rigorous evaluation metrics must be applied:
- Accuracy and Correctness: Measure the factual and logical validity of model outputs.
- Coherence and Clarity: Assess the fluency and understandability of reasoning steps and final answers.
- Efficiency: Evaluate the number of reasoning or action iterations needed to reach a satisfactory response.
- User Satisfaction: Incorporate feedback from end-users or human evaluators to fine-tune prompt designs.
Frameworks like CREATE and DSPy facilitate embedding evaluation stages directly within prompt pipelines, enabling automated feedback loops and iterative prompt refinement. This approach is essential for scaling prompt engineering efforts in complex enterprise AI deployments. Advanced Prompt Engineering Techniques for 2026: Master ChatGPT, Claude, and Beyond
Additionally, emerging metrics such as faithfulness (alignment of model reasoning with true evidence), robustness (consistency across input variations), and safety (avoidance of harmful content) are gaining importance.
Continuous improvement pipelines often combine automated testing suites, user studies, and AI-driven prompt optimization tools to accelerate prompt refinement cycles. For example, reinforcement learning from human feedback (RLHF) can be integrated with prompt engineering workflows to align model outputs with desired behaviors.
Real-world deployments also benefit from monitoring frameworks that track prompt performance over time, alerting engineers to degradation or drift, and facilitating timely adaptation.
Future Directions and Innovations in Prompt Engineering Frameworks
Hybrid and Multi-Modal Prompting
The future of prompt engineering lies in hybrid frameworks that combine textual reasoning with multi-modal inputs such as images, code, and sensor data. Emerging models like Claude 3 and ChatGPT 5 support richer context embedding, enabling frameworks like RTF and ReAct to extend beyond text-only interactions to more interactive and multi-sensory AI experiences.
For example, in medical diagnostics, a hybrid prompt might integrate patient history (text), radiology images, and lab results, prompting the model to reason across modalities to generate differential diagnoses. Similarly, autonomous robots can leverage multi-modal prompting to synthesize visual, auditory, and textual data for real-time decision-making.
This evolution necessitates new prompt design paradigms that incorporate modality-specific processing, alignment, and fusion techniques. Frameworks will need to support dynamic modality switching and cross-modal reasoning seamlessly.
Automated Prompt Optimization
Machine learning-driven prompt tuning tools, integrated with frameworks like DSPy, will enable automated discovery of optimal prompt sequences and formats. These tools analyze model responses, identify weaknesses, and generate improved prompt variants, significantly reducing human effort in prompt design.
Techniques such as Bayesian optimization, genetic algorithms, and reinforcement learning are being applied to prompt tuning, often in conjunction with evaluation metrics to guide search towards high-performing prompt configurations. Additionally, meta-learning approaches are emerging, allowing models to generalize prompt strategies across tasks and domains.
Automated prompt optimization also includes dynamic prompt adaptation during inference, where the model or system adjusts prompt components on-the-fly based on intermediate outputs or external signals, enhancing responsiveness and robustness.
Explainability and Ethical Prompting
As AI systems become more autonomous, frameworks will increasingly incorporate ethical reasoning and explainability constraints. Enhanced transparency mechanisms, building on CREATE and RTF principles, will ensure that AI decisions can be audited, justified, and aligned with human values.
Future prompt engineering will embed ethical guidelines explicitly within reasoning steps, enforce bias detection and mitigation, and support user-controllable transparency levels. For example, prompts might require the model to disclose uncertainty, highlight assumptions, or flag potential ethical conflicts.
Research into causal reasoning and counterfactual explanations will inform prompt designs that facilitate deeper understanding of AI decisions, fostering trust and accountability. Regulatory frameworks and standards are also expected to shape prompt engineering best practices in this area.
Cross-Model Interoperability
Advanced prompt engineering will emphasize interoperability across diverse LLMs, enabling seamless transfer of prompting strategies between ChatGPT, Claude, Codex, and future models. Standardized prompt descriptors and APIs will facilitate this cross-platform synergy, allowing developers to write once and deploy everywhere with minimal adjustments.
Initiatives to develop universal prompt representation languages and tooling ecosystems are underway, aiming to abstract away model-specific idiosyncrasies. This will accelerate AI development cycles and foster a more vibrant ecosystem of shared prompt assets and repositories.
Interoperability also supports multi-model ensemble approaches, where complementary strengths of different LLMs are harnessed via coordinated prompting to improve overall system performance and resilience.
In conclusion, mastering advanced prompt engineering frameworks such as RTF, CREATE, Chain-of-Thought, ReAct, and DSPy will be crucial for AI practitioners in 2026 and beyond. By understanding their underlying mechanics and tailoring implementations to specific LLM architectures, professionals can unlock unprecedented capabilities in complex reasoning, autonomous decision-making, and scalable AI workflows.
Continued innovation and best practice dissemination in prompt engineering will empower the next generation of AI applications to be more intelligent, reliable, and aligned with human needs.
Access 40,000+ AI Prompts for ChatGPT, Claude & Codex — Free!
Subscribe to get instant access to our complete Notion Prompt Library — the largest curated collection of prompts for ChatGPT, Claude, OpenAI Codex, and other leading AI models. Optimized for real-world workflows across coding, research, content creation, and business.