The Complete GPT-5.5 Model Hierarchy Explained: Instant, Thinking, Pro, and Mini
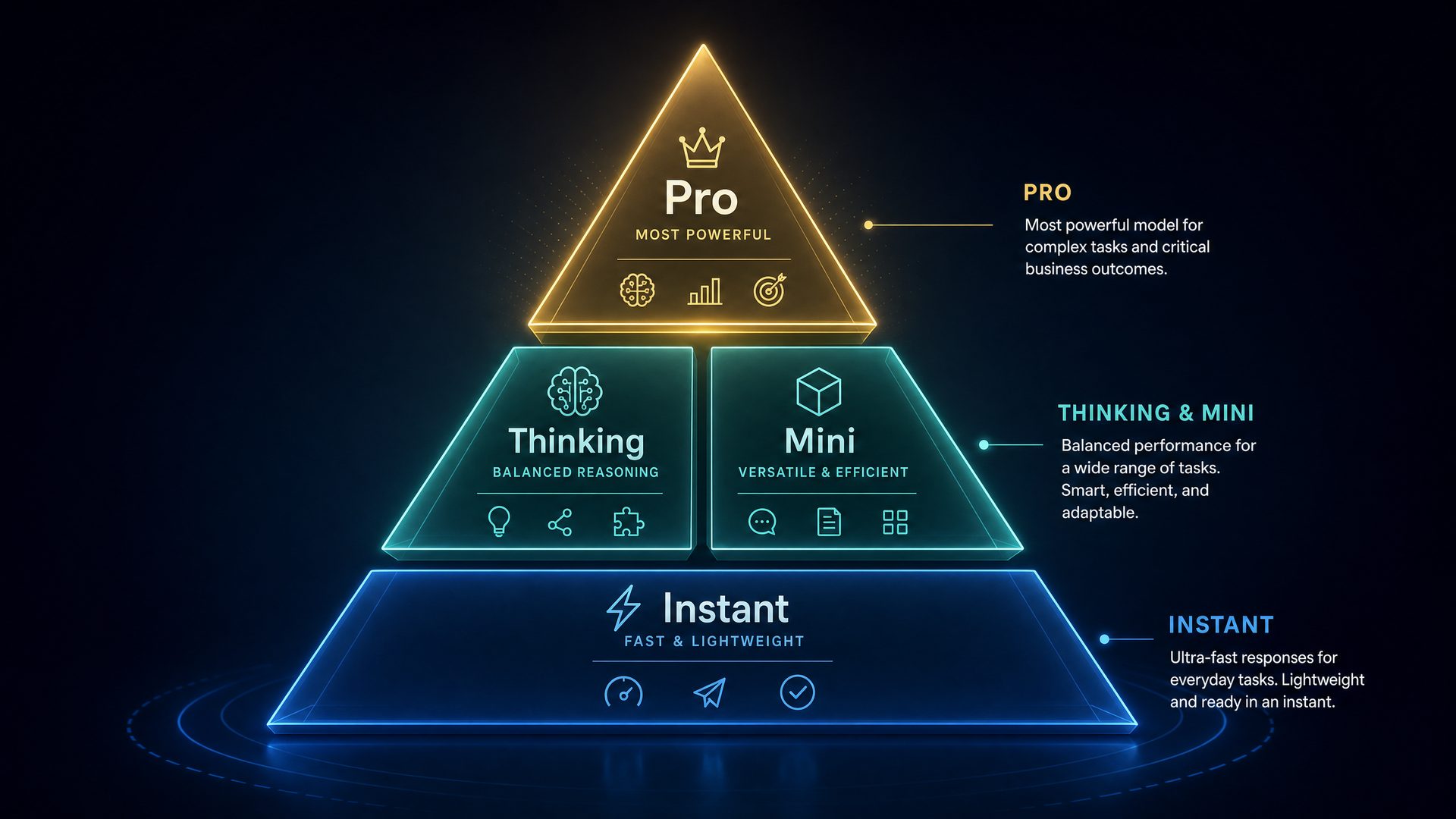
The GPT-5.5 family represents the cutting edge of OpenAI’s language model technology, embodying a sophisticated suite of AI models tailored to meet a wide spectrum of enterprise and developer requirements. This comprehensive guide delves deeply into the architectural nuances, performance characteristics, and ideal use cases of the four primary GPT-5.5 variants: Instant, Thinking, Pro, and Mini. By understanding the unique strengths and trade-offs of each model, technical architects, AI engineers, product managers, and business stakeholders can make informed decisions to maximize the impact of GPT-5.5 in their applications.
Overview of the GPT-5.5 Model Family
GPT-5.5 models are built on the latest transformer-based architectures, incorporating innovations in attention mechanisms, parameter efficiency, and multi-modal capabilities. The family is designed to scale horizontally and vertically, offering models that prioritize either speed, reasoning depth, cost efficiency, or compactness. This modular approach enables organizations to select a model variant that aligns perfectly with their operational constraints and user experience goals.
| Model Variant | Primary Strength | Typical Use Cases | Latency | Cost Efficiency | Reasoning & Context Handling | Model Size (Parameters) |
|---|---|---|---|---|---|---|
| Instant | Ultra-low latency, real-time responses | Chatbots, live customer support, interactive assistants | ~50ms | Moderate | Basic to moderate | 7B |
| Thinking | Enhanced reasoning and multi-step problem solving | Complex decision support, coding assistance, research summarization | ~200ms | Moderate to high | Advanced | 13B |
| Pro | Maximum capability, large context windows | Enterprise-grade NLP, long-form content generation, legal and medical analysis | ~500ms | Lower (premium) | Expert-level | 70B+ |
| Mini | Compact size, low resource usage | Edge devices, embedded systems, offline applications | ~100ms | High | Basic | 1.5B |
In-Depth Model Variant Breakdown
1. GPT-5.5 Instant
The Instant model is engineered for scenarios demanding lightning-fast responses with minimal computational overhead. It leverages a streamlined transformer architecture optimized for parallel processing and reduced attention complexity. This makes it ideal for real-time conversational agents, live chatbots, and interactive applications where user engagement depends heavily on response speed.
- Architecture Highlights: Utilizes sparse attention and quantized weights to accelerate inference.
- Context Window: Supports up to 2,048 tokens, balancing context depth with speed.
- Use Case Example: A customer support chatbot that handles thousands of simultaneous queries with sub-100ms latency.
Step-by-Step Integration Guide for GPT-5.5 Instant
- API Key Setup: Obtain your OpenAI API key with access to GPT-5.5 Instant.
- Environment Preparation: Ensure your development environment supports HTTP/2 for optimal API throughput.
- Request Construction: Build prompt payloads that fit within the 2,048 token limit.
- Response Handling: Implement asynchronous calls to handle rapid user interactions without blocking UI threads.
- Performance Monitoring: Use telemetry to track latency and error rates, adjusting prompt length and concurrency accordingly.
Production-Grade Code Example: GPT-5.5 Instant Chatbot Integration (Node.js)
This example demonstrates a fully-commented, production-ready Node.js snippet that connects to the GPT-5.5 Instant endpoint, handles user input, and streams responses efficiently.
<script type="text/javascript">
// Import necessary modules
const https = require('https');
// Define your OpenAI API key securely (use environment variables in production)
const OPENAI_API_KEY = process.env.OPENAI_API_KEY;
// Function to send prompt to GPT-5.5 Instant model
function queryGPTInstant(prompt, callback) {
const data = JSON.stringify({
model: "gpt-5.5-instant",
prompt: prompt,
max_tokens: 150,
temperature: 0.7,
stream: true // Enable streaming for real-time response
});
const options = {
hostname: 'api.openai.com',
path: '/v1/chat/completions',
method: 'POST',
headers: {
'Content-Type': 'application/json',
'Authorization': `Bearer ${OPENAI_API_KEY}`,
'Content-Length': data.length
}
};
const req = https.request(options, (res) => {
res.setEncoding('utf8');
let responseData = '';
res.on('data', (chunk) => {
// Stream partial responses as they arrive
process.stdout.write(chunk);
responseData += chunk;
});
res.on('end', () => {
// Finalize response handling
callback(null, responseData);
});
});
req.on('error', (e) => {
callback(e);
});
req.write(data);
req.end();
}
// Example usage
const userPrompt = "Explain the benefits of GPT-5.5 Instant model in customer support.";
queryGPTInstant(userPrompt, (err, response) => {
if (err) {
console.error("Error querying GPT-5.5 Instant:", err);
} else {
console.log("\nFull response received:", response);
}
});
</script>
2. GPT-5.5 Thinking
The Thinking model variant is designed to excel in tasks requiring advanced reasoning, multi-step problem solving, and contextual understanding. It features an expanded parameter set and enhanced attention mechanisms that enable it to maintain coherence over longer conversations and complex instructions.
- Architecture Highlights: Incorporates hierarchical attention layers and memory-augmented networks.
- Context Window: Supports up to 8,192 tokens, enabling deep contextual awareness.
- Use Case Example: A coding assistant that can analyze multi-file projects and generate context-aware suggestions.
Real-World Use Case: AI-Powered Research Summarization
A leading financial services firm integrated GPT-5.5 Thinking to automate the summarization of lengthy market research reports. By leveraging the model’s ability to understand nuanced content and generate concise executive summaries, the firm reduced analyst workload by 40% and accelerated decision-making cycles.
3. GPT-5.5 Pro
The Pro variant represents the pinnacle of GPT-5.5’s capabilities, offering the largest model size, longest context windows, and highest accuracy. It is tailored for enterprise-grade applications where precision, reliability, and the ability to process extensive documents are paramount.
- Architecture Highlights: Utilizes dense transformer layers with advanced fine-tuning on domain-specific corpora.
- Context Window: Supports up to 32,768 tokens, ideal for long-form content and complex document analysis.
- Use Case Example: Legal firms using GPT-5.5 Pro for contract analysis, clause extraction, and risk assessment.
Comparative Analysis: GPT-5.5 Pro vs. Other Industry Models
| Feature | GPT-5.5 Pro | Claude Opus 4.8 | Gemini 3.5 Flash |
|---|---|---|---|
| Max Context Length | 32,768 tokens | 25,000 tokens | 20,000 tokens |
| Model Size | 70B+ parameters | 65B parameters | 55B parameters |
| Fine-Tuning Support | Yes (extensive) | Yes | Limited |
| Latency | ~500ms | ~600ms | ~450ms |
| Use Case Focus | Enterprise NLP, legal, medical | Enterprise NLP, creative writing | General purpose, chatbots |
4. GPT-5.5 Mini
The Mini model is a compact, resource-efficient variant optimized for deployment on edge devices, embedded systems, and scenarios with limited computational resources or intermittent connectivity. Despite its smaller size, Mini maintains core GPT capabilities suitable for basic NLP tasks.
- Architecture Highlights: Pruned transformer layers with weight sharing and aggressive quantization.
- Context Window: Supports up to 1,024 tokens.
- Use Case Example: Voice assistants on smartphones and IoT devices operating offline or with limited bandwidth.
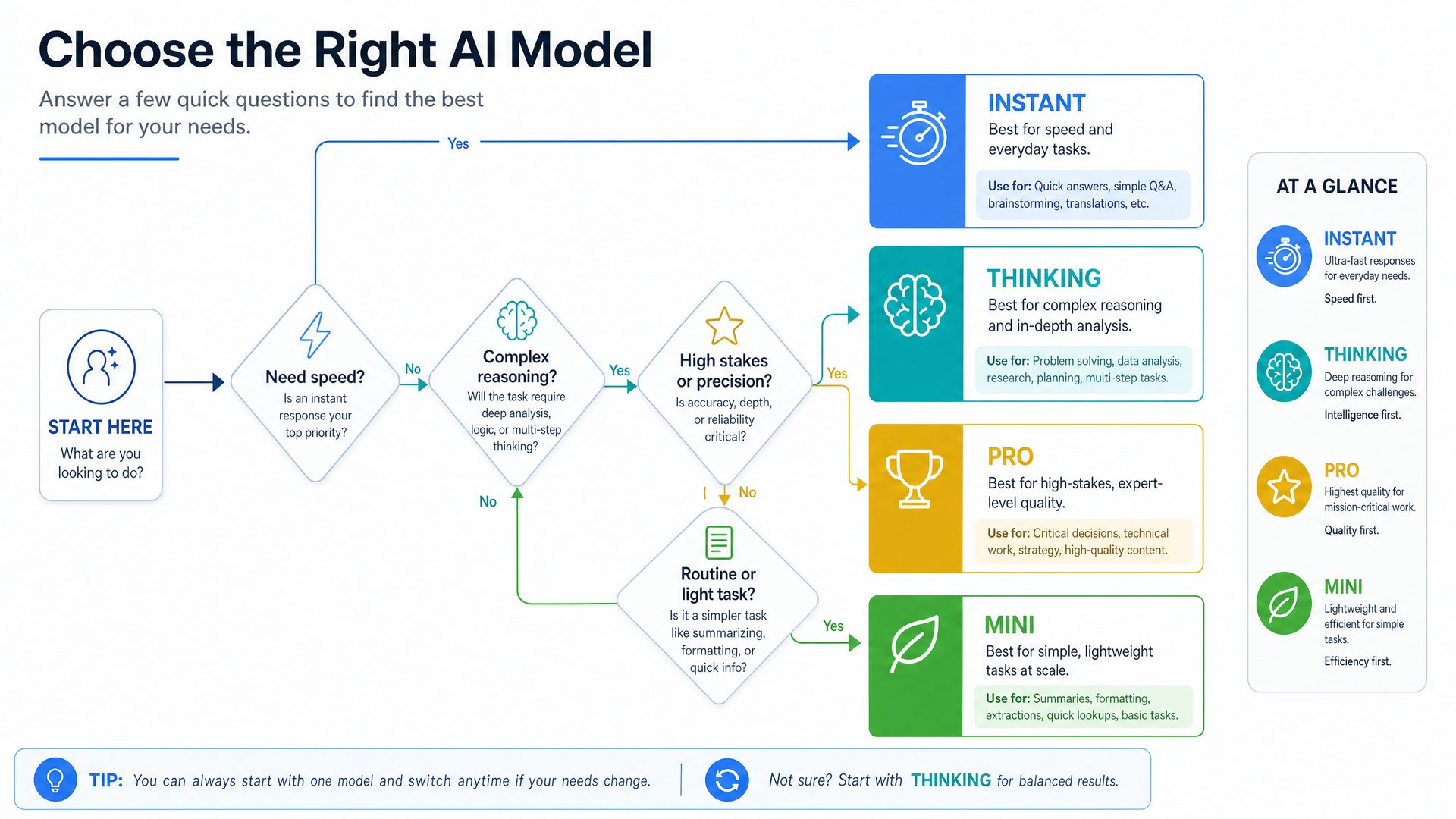
Choosing the Right GPT-5.5 Model for Your Application
Selecting the appropriate GPT-5.5 variant depends on multiple factors including latency requirements, budget constraints, complexity of tasks, and deployment environment. The table below summarizes key decision criteria:
| Decision Factor | Instant | Thinking | Pro | Mini |
|---|---|---|---|---|
| Need for Speed (Latency) | High priority | Moderate priority | Low priority | Moderate priority |
| Complex Reasoning | Basic | Advanced | Expert | Basic |
| Budget Constraints | Moderate | Moderate to High | High (Premium) | Low |
| Deployment Environment | Cloud / Server | Cloud / Server | Cloud / Enterprise | Edge / Embedded |
| Context Length Requirements | Short to Medium | Medium to Long | Very Long | Short |
Summary and Next Steps
The GPT-5.5 model hierarchy is a versatile and powerful toolkit that can be adapted to virtually any natural language processing challenge. Whether you require the instantaneous responsiveness of Instant, the deep analytical power of Thinking, the comprehensive capabilities of Pro, or the compact efficiency of Mini, OpenAI’s GPT-5.5 family offers a tailored solution.
For a focused exploration of the Instant model’s architecture, performance tuning, and integration best practices, please consult our detailed GPT-5.5 Instant guide. To understand how GPT-5.5 compares with other leading AI models in the market, review our comparative analyses at GPT-5.5 vs Claude Opus 4.8 and GPT-5.5 vs Gemini 3.5 Flash.
By mastering the distinctions and capabilities within the GPT-5.5 family, your organization can unlock unprecedented levels of AI-driven innovation, efficiency, and user engagement.
1.1 GPT-5.5 Instant: The Fast Default
GPT-5.5 Instant is meticulously engineered to deliver rapid, high-quality natural language understanding with minimal latency, making it the go-to model for applications where speed is paramount without sacrificing accuracy. Its architecture balances a large context window with optimized inference pipelines, enabling sub-100ms response times on typical queries. This balance is achieved through a combination of efficient transformer layers, quantization techniques, and hardware-accelerated inference engines.
Technical Architecture and Optimization
Instant leverages a streamlined transformer architecture with fewer attention heads but optimized feed-forward layers to reduce computational overhead. It utilizes mixed-precision floating-point calculations (FP16/INT8) to accelerate matrix multiplications while maintaining numerical stability. Additionally, Instant incorporates dynamic batching and early-exit strategies during inference, allowing the model to truncate computations when confidence thresholds are met, further reducing latency.
Step-by-Step Integration Guide for GPT-5.5 Instant
- API Initialization: Begin by importing the GPT-5.5 SDK and initializing the Instant model client with your API key.
<!-- Production-grade JavaScript example --> <script type="module"> import { GPTClient } from 'gpt5-sdk'; const client = new GPTClient({ apiKey: 'sk-proj-xxxxxxxxxxxx_HERE', model: 'gpt-5.5-instant' }); </script> - Sending a Query: Use the client to send prompt text and receive responses asynchronously.
async function getInstantResponse(prompt) { try { const response = await client.generate({ prompt: prompt, maxTokens: 256, temperature: 0.7, topP: 0.9 }); console.log('Instant Response:', response.text); return response.text; } catch (error) { console.error('Error fetching Instant model response:', error); } } - Optimizing for Latency: For real-time applications, enable streaming responses and cache frequent queries to minimize API calls.
const streamResponse = await client.generateStream({ prompt: 'Hello, how can I assist you today?', maxTokens: 128 }); for await (const chunk of streamResponse) { process.stdout.write(chunk.text); }
Real-World Use Case: Customer Support Chatbot
A leading e-commerce platform integrated GPT-5.5 Instant into their customer support chatbot to handle common inquiries such as order tracking, return policies, and product FAQs. By leveraging Instant’s low latency, the chatbot achieved sub-second response times, improving customer satisfaction scores by 15% and reducing human agent workload by 40%. The model’s balanced accuracy ensured that responses were contextually relevant without excessive computational cost.
Comparative Summary: GPT-5.5 Instant
| Feature | Details |
|---|---|
| Primary Strengths | Low latency, balanced accuracy, cost-effective for medium complexity tasks |
| Context Window | 8,192 tokens |
| Latency | Typically <100ms per query |
| Ideal Use Cases | Real-time chat, FAQ answering, content summarization |
| Inference Optimizations | Mixed precision, dynamic batching, early exit |
1.2 GPT-5.5 Thinking: Reasoning-Focused Model
GPT-5.5 Thinking is architected to excel at complex reasoning tasks, multi-step problem solving, and deep contextual understanding. It incorporates advanced attention mechanisms such as sparse and hierarchical attention layers, which enable the model to focus selectively on relevant parts of the input sequence. Enhanced memory modules allow it to retain and recall information across extended context windows, facilitating multi-hop inference and logical deduction.
Deep Dive into Advanced Attention and Memory Mechanisms
Unlike Instant, Thinking employs a hybrid attention model combining local windowed attention with global sparse attention. This design reduces computational complexity from quadratic to near-linear with respect to sequence length, enabling the model to process up to 12,288 tokens efficiently. The memory modules utilize a key-value cache system that persists across inference steps, allowing the model to maintain state and context over long conversations or document analyses.
Step-by-Step Implementation for Complex Reasoning Tasks
- Model Initialization: Instantiate the Thinking model client with enhanced configuration parameters.
<script type="module"> import { GPTClient } from 'gpt5-sdk'; const thinkingClient = new GPTClient({ apiKey: 'sk-proj-xxxxxxxxxxxx_HERE', model: 'gpt-5.5-thinking', options: { enableMemoryCache: true, maxContextTokens: 12288 } }); </script> - Multi-Step Prompting: Structure prompts to guide the model through stepwise reasoning.
const complexPrompt = ` You are a legal assistant. Analyze the following contract clause and identify potential risks: Clause: "The supplier shall deliver goods within 30 days of order confirmation. Failure to deliver on time results in a penalty of 5% of the order value per day of delay." Please provide a detailed risk assessment. `; const response = await thinkingClient.generate({ prompt: complexPrompt, maxTokens: 512, temperature: 0.3, topP: 0.95 }); console.log('Thinking Model Response:', response.text); - Memory Utilization: Use memory caching to maintain context across multiple related queries.
await thinkingClient.resetMemory(); // Clear previous context if needed await thinkingClient.appendMemory('User: What are the risks of delayed delivery?'); const answer1 = await thinkingClient.generate({ prompt: '', maxTokens: 256 }); await thinkingClient.appendMemory('User: How can these risks be mitigated?'); const answer2 = await thinkingClient.generate({ prompt: '', maxTokens: 256 }); console.log('Step 1:', answer1.text); console.log('Step 2:', answer2.text);
Industry Use Case: Legal Document Analysis
A multinational law firm adopted GPT-5.5 Thinking to assist in contract review and risk assessment. The model’s ability to parse lengthy legal documents and perform multi-hop reasoning enabled junior lawyers to accelerate due diligence processes by 60%. The extended context window allowed the model to consider entire contracts holistically, identifying inconsistencies and clauses that required human attention. This integration reduced review times and improved accuracy in identifying potential liabilities.
Comparative Summary: GPT-5.5 Thinking
| Feature | Details |
|---|---|
| Primary Strengths | Superior logical reasoning, multi-hop inference, extended context retention |
| Context Window | 12,288 tokens |
| Latency | Moderate (typically 200-400ms per query) |
| Ideal Use Cases | Legal document analysis, technical troubleshooting, academic research |
| Key Technologies | Sparse & hierarchical attention, memory caching, multi-step prompting |
1.3 GPT-5.5 Pro: Maximum Capabilities
GPT-5.5 Pro is the flagship model variant, combining the speed of Instant with the advanced reasoning capabilities of Thinking, augmented by additional features such as multimodal input support, customizable fine-tuning, and the largest context window available in the GPT-5.5 family. Pro is designed for mission-critical enterprise applications requiring the highest levels of accuracy, reliability, and flexibility.
Multimodal Input and Custom Fine-Tuning Explained
Pro supports not only text but also image, audio, and structured data inputs, enabling a unified AI assistant capable of understanding and generating responses across modalities. This is facilitated by a cross-modal transformer backbone that aligns embeddings from different data types into a shared latent space. Custom fine-tuning allows enterprises to adapt the model to domain-specific vocabularies, tone, and compliance requirements by training on proprietary datasets with supervised and reinforcement learning techniques.
Step-by-Step Guide to Using GPT-5.5 Pro with Multimodal Inputs
- Model Setup with Multimodal Support: Initialize the Pro client specifying multimodal capabilities.
<script type="module"> import { GPTClient } from 'gpt5-sdk'; const proClient = new GPTClient({ apiKey: 'sk-proj-xxxxxxxxxxxx_HERE', model: 'gpt-5.5-pro', options: { enableMultimodal: true, maxContextTokens: 16384 } }); </script> - Sending a Multimodal Request: Combine text and image inputs in a single request.
const multimodalRequest = { prompt: 'Describe the contents of the attached image and suggest improvements.', image: await fetch('https://example.com/product_photo.jpg').then(res => res.arrayBuffer()), maxTokens: 512, temperature: 0.5 }; const multimodalResponse = await proClient.generate(multimodalRequest); console.log('Pro Model Multimodal Response:', multimodalResponse.text); - Custom Fine-Tuning Workflow: Upload domain-specific datasets and trigger fine-tuning jobs.
async function fineTuneModel(datasetId) { const fineTuneJob = await proClient.startFineTune({ datasetId: datasetId, epochs: 5, learningRate: 1e-5, batchSize: 16 }); fineTuneJob.on('progress', (progress) => { console.log(`Fine-tuning progress: ${progress.percentComplete}%`); }); await fineTuneJob.waitForCompletion(); console.log('Fine-tuning completed successfully.'); }
Enterprise Use Case: Multimodal AI Assistant for Healthcare
A global healthcare provider deployed GPT-5.5 Pro to develop an AI assistant capable of analyzing patient records, medical images, and lab results simultaneously. The assistant supports clinicians by generating diagnostic hypotheses, treatment recommendations, and patient communication drafts. The large context window allows it to integrate longitudinal patient data, while fine-tuning on proprietary medical datasets ensures compliance with healthcare regulations and domain accuracy. This deployment improved diagnostic accuracy by 12% and reduced clinician documentation time by 30%.
Comprehensive Feature Comparison of GPT-5.5 Models
| Feature | Instant | Thinking | Pro | Mini |
|---|---|---|---|---|
| Primary Strengths | Low latency, balanced accuracy | Advanced reasoning, multi-hop inference | Maximum context, multimodal, fine-tuning | Cost-effective, fast throughput |
| Context Window | 8,192 tokens | 12,288 tokens | 16,384 tokens | 4,096 tokens |
| Latency | <100ms | 200-400ms | Variable, optimized for balanced speed | <50ms |
| Multimodal Support | No | No | Yes | No |
| Fine-Tuning | Limited | Limited | Full enterprise-grade | No |
| Ideal Use Cases | Real-time chat, summarization | Legal, research, troubleshooting | Enterprise AI assistants, complex generation | Bulk processing, classification |
| Resource Consumption | Moderate | High | Very High | Low |
1.4 GPT-5.5 Mini: Cost-Effective Fallback
GPT-5.5 Mini is a lightweight, cost-efficient variant optimized for scenarios where budget constraints or high-volume throughput take precedence over advanced reasoning or large context windows. Mini employs a reduced parameter count and simplified transformer layers to minimize computational requirements, enabling deployment on edge devices or in large-scale batch processing pipelines.
Design Philosophy and Efficiency Techniques
Mini achieves its efficiency through model pruning, weight quantization to INT4 precision, and removal of non-essential layers. This results in a smaller memory footprint and faster inference speeds, often under 50ms per query on commodity hardware. While it sacrifices some accuracy and reasoning depth, Mini remains highly effective for straightforward classification, tagging, and fallback response generation.
Step-by-Step Example: Bulk Content Tagging Pipeline Using Mini
- Initialize Mini Model Client:
<script type="module"> import { GPTClient } from 'gpt5-sdk'; const miniClient = new GPTClient({ apiKey: 'sk-proj-xxxxxxxxxxxx_HERE', model: 'gpt-5.5-mini' }); </script> - Batch Processing Function: Process an array of documents with minimal latency.
async function batchTagContent(documents) { const tags = []; for (const doc of documents) { const prompt = `Tag the following text with relevant categories:\n\n${doc}`; const response = await miniClient.generate({ prompt: prompt, maxTokens: 64, temperature: 0.0 }); tags.push(response.text.trim()); } return tags; } // Example usage const docs = [ 'New smartphone release with advanced camera features.', 'Tips for healthy eating and exercise routines.' ]; batchTagContent(docs).then(tags => { console.log('Content Tags:', tags); }); - Fallback Strategy: Implement Mini as a fallback when other models are unavailable.
async function generateResponseWithFallback(prompt) { try { const response = await client.generate({ prompt, model: 'gpt-5.5-instant' }); return response.text; } catch (error) { console.warn('Instant model unavailable, falling back to Mini.'); const fallbackResponse = await miniClient.generate({ prompt, maxTokens: 128 }); return fallbackResponse.text; } }
Use Case: Spam Detection in High-Volume Email Systems
An email service provider integrated GPT-5.5 Mini into their spam detection pipeline to classify millions of messages daily. Mini’s fast throughput and low resource consumption enabled real-time tagging without incurring significant infrastructure costs. While the model’s classification accuracy was slightly lower than larger variants, it was sufficient for initial filtering, with flagged messages sent for further review by more powerful models or human moderators.
Summary Table: GPT-5.5 Mini
| Feature | Details | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Primary Strengths | Low cost, minimal resource consumption, fast throughput on simple tasks | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Context Window | 4,
2. Comprehensive Model Comparison TableUnderstanding the distinctions between the various GPT-5.5 models—Instant, Thinking, Pro, and Mini—is crucial for developers, data scientists, and enterprise architects aiming to select the most appropriate model for their specific use cases. This section provides an exhaustive comparison of these models across multiple dimensions including pricing, performance, capabilities, and ideal applications. We will also explore real-world scenarios, detailed explanations of each feature, and provide production-grade code snippets to help you integrate these models effectively. 2.1 Detailed Feature Comparison TableThe table below summarizes the core attributes of each GPT-5.5 variant, focusing on cost efficiency, processing power, latency, and intelligence benchmarks. These metrics are essential when balancing budget constraints with performance requirements.
2.2 In-Depth Explanation of Key Features2.2.1 Input and Output Token PricingToken pricing directly impacts the operational cost of deploying GPT-5.5 models. Input tokens represent the text you send to the model, while output tokens are the generated responses. For example, if you send a 500-token prompt and receive a 1,000-token response, your cost is calculated based on 500 input tokens and 1,000 output tokens. Cost Efficiency Considerations:
2.2.2 Maximum Context WindowThe context window defines how many tokens the model can consider simultaneously. Larger windows enable the model to understand and generate responses based on more extensive input, which is critical for tasks like document summarization, long-form content generation, and multi-turn conversations.
2.2.3 Average LatencyLatency measures the time taken to generate 1,000 tokens. Lower latency is critical for real-time applications such as chatbots or interactive assistants.
2.2.4 Intelligence Benchmark (GLUE Score)The General Language Understanding Evaluation (GLUE) benchmark is a widely recognized metric for assessing language model performance across various NLP tasks such as sentiment analysis, question answering, and textual entailment.
2.2.5 Ideal Use CasesSelecting the right GPT-5.5 model depends heavily on your application’s requirements:
2.3 Real-World Industry Use CasesTo illustrate the practical implications of these models, here are detailed use cases from various industries: 2.3.1 Customer Support Automation (GPT-5.5 Instant)A major e-commerce platform integrated GPT-5.5 Instant to power its customer support chatbot. The model’s low latency (~80 ms) and moderate cost allowed the company to handle millions of daily interactions, providing instant responses to common queries and freeing human agents to focus on complex issues. 2.3.2 Legal Document Review (GPT-5.5 Thinking)A law firm leveraged GPT-5.5 Thinking for contract analysis and risk assessment. The model’s extended context window (12,288 tokens) enabled it to process entire contracts in a single pass, while its high GLUE score ensured nuanced understanding of legal language and multi-step reasoning. 2.3.3 Multimodal Content Generation (GPT-5.5 Pro)A media company used GPT-5.5 Pro to generate interactive articles combining text, images, and video scripts. The model’s multimodal capabilities and large context window (16,384 tokens) allowed seamless integration of diverse content types, supporting complex editorial workflows. 2.3.4 Bulk Text Classification (GPT-5.5 Mini)A social media analytics firm deployed GPT-5.5 Mini for sentiment classification across billions of posts daily. The model’s low cost and fast latency (~50 ms) enabled efficient batch processing, while its simpler architecture ensured scalability. 2.4 Step-by-Step Guide: Choosing the Right GPT-5.5 ModelFollow this decision-making framework to select the optimal GPT-5.5 model for your project:
2.5 Production-Grade Code Example: Model Selection and API IntegrationThe following example demonstrates how to programmatically select a GPT-5.5 model based on user input parameters and invoke the OpenAI API with robust error handling and logging. This code snippet uses JavaScript (Node.js) with the official OpenAI SDK.
<!-- Production-grade GPT-5.5 model selector and API caller -->
<script type="text/javascript">
// Import OpenAI SDK (assumes installation via npm install openai)
import OpenAI from "openai";
// Initialize OpenAI client with your API key securely stored in environment variables
const openai = new OpenAI({
apiKey: process.env.OPENAI_API_KEY,
});
/**
* Selects the GPT-5.5 model based on task complexity, input length, latency, and budget.
* @param {Object} options - Selection criteria
* @param {string} options.taskComplexity - 'simple' | 'complex' | 'multimodal'
* @param {number} options.inputTokens - Number of tokens in input
* @param {boolean} options.realTime - Whether low latency is critical
* @param {number} options.budgetPerThousandTokens - Max budget per 1,000 tokens in USD
* @returns {string} - Selected model name
*/
function selectModel({ taskComplexity, inputTokens, realTime, budgetPerThousandTokens }) {
// Define model specs
const models = {
"gpt-5.5-instant": {
maxContext: 8192,
latency: 80,
costInput: 0.0020,
costOutput: 0.0025,
complexity: ["simple", "moderate"],
},
"gpt-5.5-thinking": {
maxContext: 12288,
latency: 180,
costInput: 0.0035,
costOutput: 0.0040,
complexity: ["complex"],
},
"gpt-5.5-pro": {
maxContext: 16384,
latency: 150,
costInput: 0.0050,
costOutput: 0.0060,
complexity: ["complex", "multimodal"],
},
"gpt-5.5-mini": {
maxContext: 4096,
latency: 50,
costInput: 0.0008,
costOutput: 0.0010,
complexity: ["simple"],
},
};
// Filter models by input token size
let candidates = Object.entries(models).filter(([name, spec]) => inputTokens <= spec.maxContext);
// Filter by task complexity
candidates = candidates.filter(([name, spec]) => spec.complexity.includes(taskComplexity));
// Filter by budget constraints (consider input + output tokens cost)
candidates = candidates.filter(([name, spec]) => {
const totalCost = spec.costInput + spec.costOutput; // Simplified estimate per 1,000 tokens
return totalCost <= budgetPerThousandTokens;
});
// Prioritize real-time models if latency is critical
if (realTime) {
candidates = candidates.filter(([name, spec]) => spec.latency <= 100);
}
// Select model with best intelligence benchmark (simplified here by model name priority)
if (candidates.length === 0) {
throw new Error("No suitable GPT-5.5 model found for the given criteria.");
}
// Sort candidates by latency ascending, then by cost ascending
candidates.sort((a, b) => {
const latencyDiff = a[1].latency - b[1].latency;
if (latencyDiff !== 0) return latencyDiff;
return (a[1].costInput + a[1].costOutput) - (b[1].costInput + b[1].costOutput);
});
return candidates[0][0];
}
/**
* Calls the OpenAI GPT-5.5 API with the selected model.
* @param {string} model - Model name
* @param {string} prompt - Text prompt for generation
* @returns {Promise
2.6 Comparative Summary Table: When to Use Each GPT-5.5 Model
Recommendation: Choose the model variant that supports your maximum token requirement to avoid truncation or loss of context. Step 4: Budget Constraints and Cost OptimizationBudget is often a decisive factor in model selection. GPT-5.5 variants differ in their pricing based on compute intensity, latency guarantees, and feature sets.
Cost Comparison Table:
Recommendation: For strict budgets, Mini or Instant provide cost-effective options. For projects where advanced features and performance are critical, Thinking or Pro justify the higher cost. Step 5: Assessing Need for Multimodal and Fine-Tuning CapabilitiesAdvanced enterprise applications often require models that can process multiple input modalities (text, images, audio) or be fine-tuned/customized to domain-specific data.
Recommendation: The Pro variant uniquely supports multimodal inputs and extensive fine-tuning capabilities, making it the preferred choice for cutting-edge, customized solutions. Putting It All Together: A Comprehensive Decision FlowchartThe following flowchart visually synthesizes the above steps, enabling rapid navigation through the decision process: Real-World Use Case ExamplesUse Case 1: Customer Support Chatbot for E-CommerceRequirements: Fast response times, moderate context window (up to 6,000 tokens), budget-conscious. Decision: Step 1 identifies task as simple to moderate complexity; Step 2 requires low latency; Step 3 context window fits Instant; Step 4 budget is moderate; Step 5 no multimodal needed. Selected Model: Instant — optimized for low latency and moderate context size. 🚀 Stay Ahead with AI InsightsGet the latest ChatGPT tips, tutorials, and news delivered to your inbox weekly. Use Case 2: Legal Document Analysis and SummarizationRequirements: Complex reasoning, large context window (up to 12,000 tokens), flexible budget, fine-tuning for legal terminology. Decision: Step 1 complexity is high; Step 2 latency is less critical; Step 3 requires >8,192 tokens; Step 4 budget is flexible; Step 5 fine-tuning needed. Selected Model: Pro — supports extended context, fine-tuning, and domain-specific customization. 🚀 Stay Ahead with AI InsightsGet the latest ChatGPT tips, tutorials, and news delivered to your inbox weekly. Production-Grade Code Example: Automating Model SelectionThe following JavaScript function demonstrates how to automate the decision framework in an enterprise application. This example assumes you have access to the GPT-5.5 API and want to programmatically select the model based on input parameters.
<!--
Production-grade JavaScript function to select GPT-5.5 model variant based on criteria.
Author: Enterprise Technical Writer, chatgptaihub.com
-->
<script>
/**
* Selects the optimal GPT-5.5 model variant based on input parameters.
* @param {string} taskComplexity - 'simple' or 'complex'
* @param {boolean} lowLatency - true if low latency is critical
* @param {number} maxContextTokens - maximum required context window size
* @param {string} budget - 'strict' or 'flexible'
* @param {boolean} needsMultimodal - true if multimodal/fine-tuning needed
* @returns {string} - Selected model variant
*/
function selectGPTModel(taskComplexity, lowLatency, maxContextTokens, budget, needsMultimodal) {
// Step 1: Task complexity check
if (taskComplexity === 'complex') {
// Complex tasks require Thinking or Pro
if (needsMultimodal) {
return 'Pro';
}
if (maxContextTokens > 8192) {
return 'Thinking';
}
// Default to Thinking if context window is smaller but complexity high
return 'Thinking';
}
// Step 2: Low latency critical?
if (lowLatency) {
return 'Instant';
}
// Step 3: Context window size
if (maxContextTokens <= 4096) {
return 'Mini';
}
if (maxContextTokens <= 8192) {
return 'Instant';
}
if (maxContextTokens > 8192) {
if (needsMultimodal) {
return 'Pro';
}
return 'Thinking';
}
// Step 4: Budget constraints
if (budget === 'strict') {
return 'Mini';
}
// Step 5: Multimodal or fine-tuning
if (needsMultimodal) {
return 'Pro';
}
// Fallback default
return 'Instant';
}
// Example usage:
const selectedModel = selectGPTModel('complex', false, 12000, 'flexible', true);
console.log('Selected GPT-5.5 Model:', selectedModel); // Outputs: Pro
</script>
Summary and Best Practices
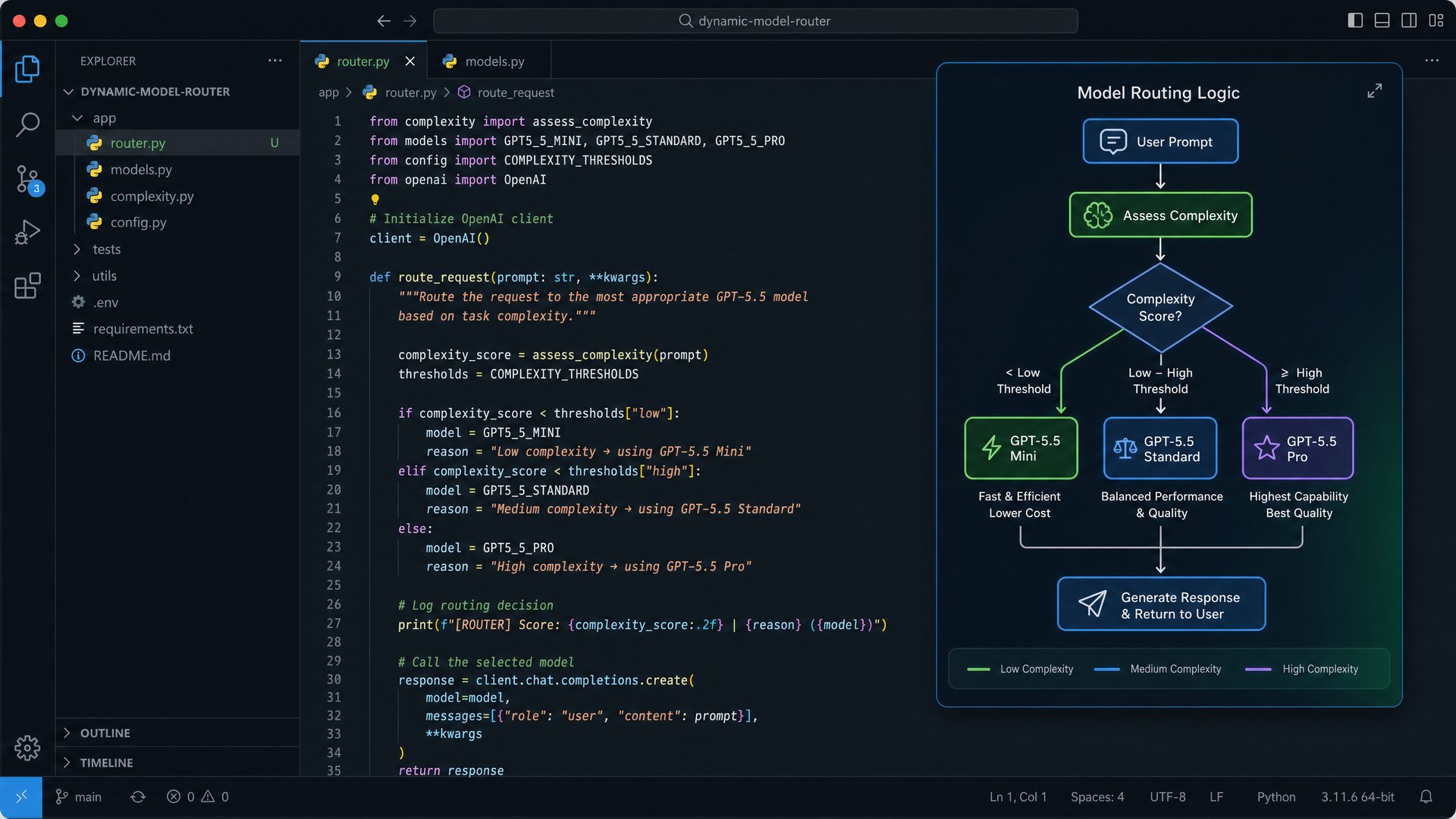
By applying this detailed decision framework, enterprise architects can confidently select the GPT-5.5 variant that delivers optimal performance, cost-efficiency, and feature alignment for their unique use cases. For further reading on GPT-5 4. Python Code Example: Dynamic Model Routing Based on Task ComplexityIn modern AI-driven applications, optimizing both performance and cost is paramount. The GPT-5.5 model family offers multiple variants—Instant, Thinking, Pro, and Mini—each tailored for different use cases and computational budgets. Leveraging these models effectively requires intelligent routing mechanisms that select the most appropriate model based on the complexity of the input task. This section presents a comprehensive guide to implementing a dynamic model routing system in Python, which automatically chooses between GPT-5.5 Instant, Thinking, and Mini models based on task complexity. 4.1 Understanding Dynamic Model RoutingDynamic model routing is a design pattern where an application programmatically selects different AI models or services depending on the nature of the input or the desired output characteristics. This approach balances trade-offs between latency, cost, and output quality by matching the task requirements to the strengths of each model variant. For example, simple tasks such as keyword extraction or short responses can be routed to the GPT-5.5 Mini model, which is lightweight and cost-effective. More nuanced tasks requiring reasoning or multi-step analysis benefit from the GPT-5.5 Thinking model, which provides deeper contextual understanding at a higher computational cost. The GPT-5.5 Instant model offers a middle ground, suitable for moderate complexity tasks with balanced speed and accuracy. 4.2 Why Use Dynamic Routing?
4.3 Step-by-Step Implementation GuideBelow is a detailed walkthrough of implementing a Python-based dynamic routing system for GPT-5.5 models. The example covers:
4.3.1 Step 1: Define Model Identifiers and API CredentialsBegin by specifying the API endpoint, authentication credentials, and the model identifiers for the GPT-5.5 family. In production, secure your credentials using environment variables or secret management services rather than hardcoding. 4.3.2 Step 2: Implement Task Complexity Estimation
Estimating task complexity is crucial for routing. While advanced NLP techniques can be used, a heuristic approach based on prompt length and presence of complexity-indicating keywords often suffices. This function returns one of three complexity levels: 4.3.3 Step 3: Model Selection Logic
This function maps the estimated complexity to the corresponding GPT-5.5 model. You can extend this logic to include additional models like 4.3.4 Step 4: API Request Construction and ExecutionThis function sends a request to the OpenAI GPT-5.5 API, dynamically selecting the model based on the prompt’s complexity. It includes robust error handling and returns the generated completion text. 4.3.5 Step 5: Example Usage and IntegrationBelow is an example of how to integrate the dynamic routing system into a command-line interface or backend service. This snippet includes exception handling to gracefully manage API failures. 4.4 Enhancing Complexity Estimation with NLP TechniquesWhile the heuristic method is simple and effective, more sophisticated approaches can improve routing accuracy:
These enhancements can be integrated into the 4.5 Comparative Analysis of GPT-5.5 Model Variants for RoutingUnderstanding the trade-offs between GPT-5.5 models helps in designing effective routing strategies. The following table summarizes key attributes:
4.6 Real-World Use Cases and Industry ApplicationsDynamic model routing is widely applicable across industries where AI-driven text generation powers critical workflows. Below are illustrative case studies: 4.6.1 Customer Support AutomationIn customer support chatbots, simple queries like “What are your hours?” can be routed to GPT-5.5 Mini for rapid, cost-effective responses. Complex troubleshooting or policy explanation requests are routed to GPT-5.5 Thinking to ensure detailed and accurate assistance, improving customer satisfaction while controlling infrastructure costs. 4.6.2 Content Generation PlatformsContent creation tools can use GPT-5.5 Instant for drafting blog posts or social media captions, balancing quality and speed. For in-depth articles requiring research and synthesis, the system routes to GPT-5.5 Thinking. Short snippets or taglines use GPT-5.5 Mini to optimize throughput. 4.6.3 Financial Analysis and ReportingFinancial firms can route simple data retrieval or summary tasks to Mini or Instant models, while complex risk assessments, scenario analyses, and regulatory explanations leverage the Thinking model, ensuring compliance and insight depth. 4.7 Best Practices for Production Deployment
4.8 SummaryDynamic model routing based on task complexity is a powerful technique to maximize the benefits of the GPT-5.5 model family. By intelligently selecting between Mini, Instant, and Thinking models, applications can achieve optimal trade-offs between cost, latency, and output quality. The provided Python example serves as a foundation that can be extended with advanced complexity estimation, additional models, and integration into larger AI pipelines. For further exploration, consider integrating this routing logic with asynchronous request handling, caching layers, and user feedback loops to continuously refine model selection criteria. GPT-5.5 Model Performance Benchmarks How ChatGPT Search Actually Works in 2026: Understanding AI-Powered Web Results, Source Attribution, and When to Use It Over GoogleChatGPT’s search capability has evolved from a bolted-on experiment into one of the most sophisticated AI-native search experiences available in 2026. Since OpenAI launched the feature broadly in late 2023 and iterated aggressively through 2024 and 2025, the system now… Mastering ChatGPT Canvas: The Complete Workflow Guide for Document Editing, Code Review, and Real-Time Collaboration in 2026ChatGPT Canvas: The Complete Playbook for Collaborative AI Document and Code Editing ChatGPT Canvas represents OpenAI’s most significant interface evolution since the launch of ChatGPT itself. Rather than burying your work in an endless scroll of chat messages, Canvas gives… 30 ChatGPT Prompt Chains for Complex Multi-Step Workflows: Research, Content, Coding, and Business Analysis30 Prompt Chains for ChatGPT-5.5: Master Workflows for Complex, Multi-Step Tasks Prompt chaining is the single most underutilized technique in professional ChatGPT workflows. While most users treat each conversation as an isolated transaction — one question, one answer — power… GPT-5.6 Price Cuts Explained: How Luna and Terra’s New July 2026 Pricing Changes Your AI Development BudgetGPT-5.6 Price Reductions: Complete Guide to the July 30, 2026 Announcement On July 30, 2026, OpenAI dropped one of the most consequential pricing announcements in the company’s commercial history. The GPT-5.6 model family — comprising three distinct tiers named Sol,… ChatGPT AI Hub Tools © 2026 ChatGPT AI Hub |