25 GPT-5.5 Prompts for Software Architecture and System Design
In the rapidly evolving landscape of software engineering, mastering system design and architecture is paramount for developing scalable, maintainable, and high-performance applications. Architects today face multifaceted challenges, ranging from microservices orchestration and data consistency to security compliance and cost optimization. With the advent of GPT-5.5, engineers and architects can leverage advanced AI-driven reasoning to streamline complex design challenges, enabling more insightful decision-making and reducing iterative design cycles.
This comprehensive playbook introduces 25 meticulously crafted GPT-5.5 prompts tailored specifically for software architecture and system design, categorized into five critical domains: scalability, reliability, security, maintainability, and performance optimization. Each prompt is designed with explicit system instructions, contextual variables, and output schemas that align with real-world engineering workflows. For example, prompts guide the design of a real-time collaborative editor with conflict resolution mechanisms or architect a high-throughput, fault-tolerant payment gateway with multi-region deployment.
Why GPT-5.5 for System Design?
GPT-5.5 incorporates cutting-edge advancements in natural language understanding and contextual reasoning, enabling it to assist in generating detailed architectural blueprints, technology stack evaluations, and trade-off analyses. Unlike earlier models, GPT-5.5 can interpret nuanced system requirements, propose modular designs, and provide justifications grounded in established software engineering principles.
Key Capabilities Include:
- Contextual Awareness: Understands complex system requirements and constraints.
- Multi-turn Reasoning: Engages in iterative dialogue to refine design proposals.
- Schema-Driven Outputs: Produces structured JSON/YAML schemas for integration with CI/CD pipelines and architecture documentation tools.
- Code and Configuration Generation: Generates production-grade code snippets, deployment manifests, and infrastructure-as-code templates.
How to Use This Playbook
Each prompt in this collection includes:
- System Instructions: High-level guidance on what the prompt aims to achieve.
- Contextual Variables: Dynamic variables representing system parameters such as throughput, latency, user base size, or compliance requirements.
- Output Schema: Defines the expected format of the AI’s response, facilitating easy parsing and integration.
- Example Use Case: Demonstrations of prompt application with detailed walkthroughs, including code snippets, architectural diagrams, and deployment scripts.
Example: Designing a Real-Time Collaborative Editor
Consider a prompt designed to help architect a real-time collaborative text editor supporting thousands of concurrent users. GPT-5.5 can assist in generating:
- Event-driven architecture diagrams featuring Operational Transformation (OT) or Conflict-free Replicated Data Types (CRDTs).
- WebSocket-based communication protocols with fallback strategies.
- Scalable backend components, including distributed state synchronization and persistence layers.
- Sample code snippets in TypeScript demonstrating client-server synchronization logic.
interface DocumentChange {
userId: string;
timestamp: number;
operations: Operation[];
}
type Operation = Insert | Delete;
interface Insert {
type: 'insert';
position: number;
text: string;
}
interface Delete {
type: 'delete';
position: number;
length: number;
}
// Example function to apply an operation
function applyOperation(doc: string, op: Operation): string {
switch(op.type) {
case 'insert':
return doc.slice(0, op.position) + op.text + doc.slice(op.position);
case 'delete':
return doc.slice(0, op.position) + doc.slice(op.position + op.length);
}
}Example: Architecting a High-Throughput Payment Gateway
For a payment gateway handling millions of transactions per day, GPT-5.5 can generate detailed designs encompassing:
- Microservices for transaction processing, fraud detection, and settlement.
- Event sourcing and CQRS patterns for auditability and scalability.
- Infrastructure-as-Code (IaC) scripts for multi-region Kubernetes deployments on AWS EKS or Google GKE.
- Security best practices, including PCI-DSS compliance checklists and tokenization strategies.
apiVersion: apps/v1
kind: Deployment
metadata:
name: payment-processor
labels:
app: payment-gateway
spec:
replicas: 10
selector:
matchLabels:
app: payment-gateway
component: processor
template:
metadata:
labels:
app: payment-gateway
component: processor
spec:
containers:
- name: processor
image: payment-processor:v1.2.0
ports:
- containerPort: 8080
env:
- name: DATABASE_URL
valueFrom:
secretKeyRef:
name: payment-db-credentials
key: url
resources:
requests:
cpu: "500m"
memory: "1Gi"
limits:
cpu: "2"
memory: "4Gi"
livenessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 30
periodSeconds: 10
readinessProbe:
httpGet:
path: /readyz
port: 8080
initialDelaySeconds: 15
periodSeconds: 5
By integrating these prompts into your workflow, you can harness GPT-5.5’s capabilities to elevate your architectural decisions and accelerate system design processes significantly. This playbook not only serves as a starting point but also as a continuously extensible framework for evolving your design methodologies alongside emerging technological trends.
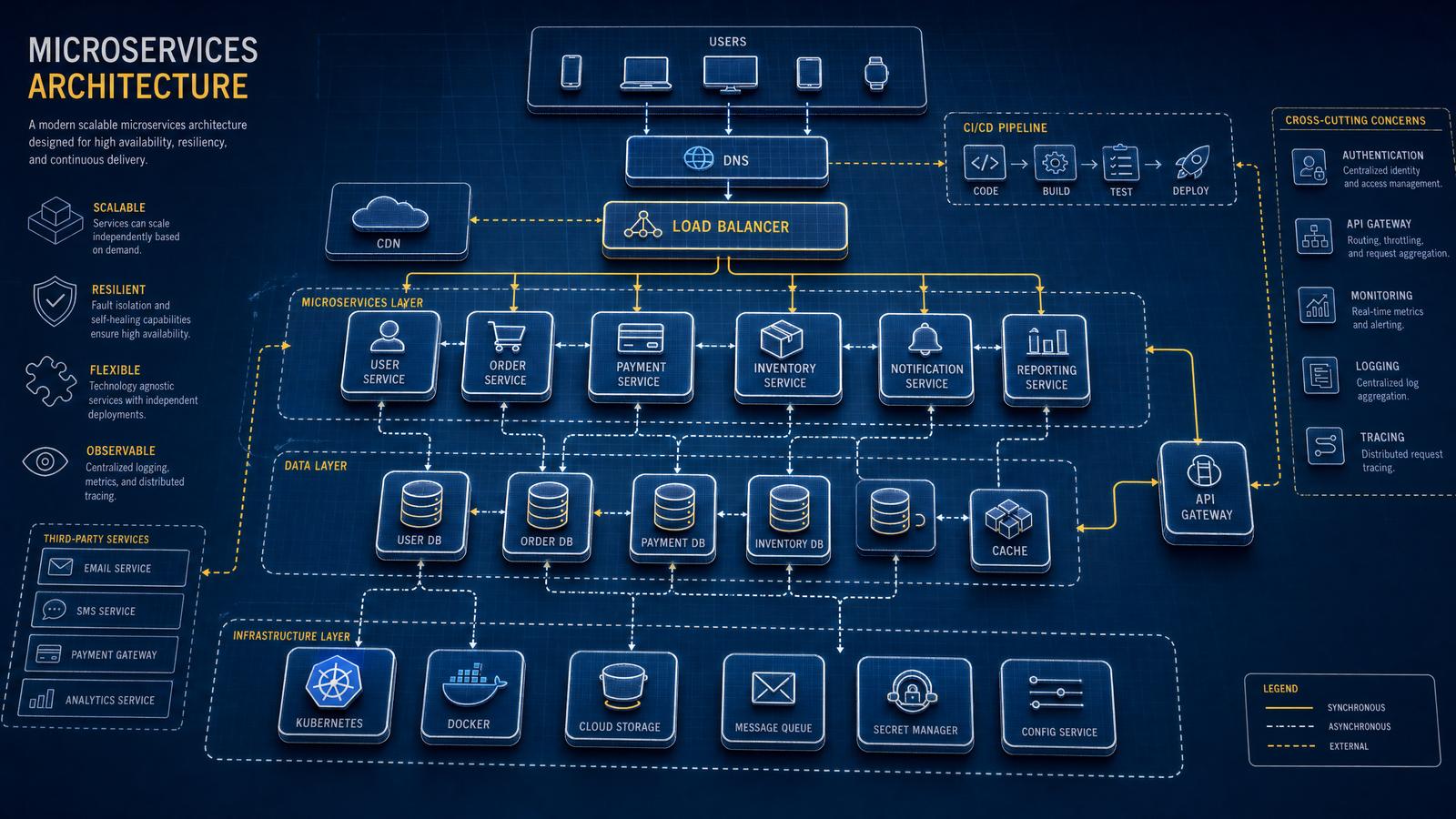
1. Microservices & Distributed Systems
Designing microservices and distributed systems demands a meticulous approach to separation of concerns, resilience engineering, and efficient inter-service communication patterns. These architectures must handle complex operational challenges such as fault tolerance, scalability, eventual consistency, and observability. Leveraging GPT-5.5’s advanced contextual understanding, architects can generate nuanced system designs that incorporate best practices, industry standards, and emerging patterns to maximize system robustness and responsiveness under diverse workloads.
Microservices architecture breaks down monolithic applications into independently deployable services, each encapsulating a specific business capability. Distributed systems extend this concept across networked nodes, emphasizing scalability, availability, and partition tolerance. Key design principles include defining clear service boundaries, selecting appropriate communication protocols, implementing fault isolation, and enabling seamless scalability.
Core Design Considerations
- Service Boundaries: Define services around business capabilities or bounded contexts to minimize coupling.
- Communication Patterns: Choose synchronous (REST, gRPC) or asynchronous (messaging, event-driven) communication based on latency and consistency needs.
- Fault Tolerance: Implement circuit breakers, retries with exponential backoff, bulkheads, and failover mechanisms to ensure resilience.
- Data Management: Use eventual consistency, distributed transactions, or sagas to maintain data integrity across services.
- Observability: Integrate centralized logging, metrics, tracing (e.g., OpenTelemetry) for monitoring and diagnostics.
- Security: Enforce authentication, authorization, and secure communication channels (TLS, mTLS).
Production-Grade Infrastructure Components
- Service Mesh: Tools like Istio or Linkerd provide advanced traffic management, observability, and security features.
- API Gateway: Centralized entry point for routing, authentication, rate-limiting, and request aggregation.
- Message Brokers: Kafka, RabbitMQ, or AWS SNS/SQS enable reliable asynchronous communication.
- Container Orchestration: Kubernetes for automated deployment, scaling, and management.
- Configuration Management: Use tools like Consul or Vault for dynamic configuration and secrets management.
-
Prompt: Designing a Scalable Microservices Architecture for an E-commerce Platform
System Instructions: “Generate a detailed microservices architecture for a global e-commerce platform supporting user accounts, product catalogs, order processing, and payment handling. Emphasize service boundaries, inter-service communication, and fault tolerance.”
Context Variables:
userBaseSize: 10 million monthly active userspeakRequestRate: 50,000 requests per secondpaymentProviders: Stripe, PayPalregions: US, EU, APAC
Output Schema:
{ "services": [ {"name": "UserService", "responsibilities": "Manage user profiles and authentication", "communication": "REST API"}, {"name": "CatalogService", "responsibilities": "Product listings and inventory", "communication": "gRPC"}, {"name": "OrderService", "responsibilities": "Order lifecycle management", "communication": "Event-driven via message queue"}, {"name": "PaymentService", "responsibilities": "Process payments with external providers", "communication": "REST API with retries"} ], "communicationPatterns": ["Synchronous REST between UserService and CatalogService", "Asynchronous events between OrderService and PaymentService"], "scalabilityStrategies": ["Auto-scaling groups per service", "Regional failover", "Circuit breaker for payment calls"] }Detailed Architecture Analysis
The platform consists of four core microservices, each optimized for its domain:
- UserService: Handles user registration, authentication (OAuth2/JWT), profile management. Exposes RESTful endpoints secured with TLS and rate-limiting.
- CatalogService: Maintains product data, inventory counts, and search indexes. Uses gRPC for high-performance, low-latency RPC calls, enabling synchronous queries from UserService and frontend APIs.
- OrderService: Manages order creation, updates, and status tracking through event-driven mechanisms (e.g., Kafka or AWS Kinesis). This decouples order processing from synchronous requests, improving throughput and fault isolation.
- PaymentService: Integrates with external payment gateways (Stripe, PayPal) via REST APIs. Implements retry policies, circuit breakers (e.g., Hystrix or Resilience4j), and idempotency keys to prevent double charges.
Production-Grade Configuration Example (Kubernetes Deployment Snippet)
apiVersion: apps/v1 kind: Deployment metadata: name: payment-service labels: app: payment-service spec: replicas: 5 selector: matchLabels: app: payment-service template: metadata: labels: app: payment-service spec: containers: - name: payment-service image: company/payment-service:1.2.0 ports: - containerPort: 8080 env: - name: STRIPE_API_KEY valueFrom: secretKeyRef: name: payment-secrets key: stripeApiKey - name: PAYPAL_CLIENT_ID valueFrom: secretKeyRef: name: payment-secrets key: paypalClientId readinessProbe: httpGet: path: /health port: 8080 initialDelaySeconds: 10 periodSeconds: 15 livenessProbe: httpGet: path: /health port: 8080 initialDelaySeconds: 30 periodSeconds: 30 resources: requests: cpu: "500m" memory: "512Mi" limits: cpu: "2" memory: "2Gi" # Circuit breaker and retry implemented in service code using resilience4j or similarInter-Service Communication Patterns
Communication Type Source Service Destination Service Protocol Purpose Fault-Tolerance Mechanism Synchronous UserService CatalogService gRPC Retrieve product details for user browsing Timeouts, retries with exponential backoff Asynchronous OrderService PaymentService Message Queue (e.g., Kafka) Trigger payment processing after order placement Message retries, dead-letter queues, circuit breakers -
Prompt: Fault-Tolerant Distributed System for Real-Time Collaborative Editor
System Instructions: “Design a distributed system architecture enabling real-time collaboration on documents with low latency and conflict resolution.”
Context Variables:
concurrentUsersPerDocument: 1000latencyRequirement: <100msconflictResolutionStrategy: Operational Transformation (OT) or CRDTspersistence: Event sourcing with CQRS
Output Schema:
{ "components": [ {"name": "CollaborationService", "protocol": "WebSockets", "function": "Broadcast real-time changes"}, {"name": "ConflictResolutionEngine", "algorithm": "CRDT", "function": "Merge concurrent edits"}, {"name": "PersistenceLayer", "pattern": "Event Sourcing", "function": "Store all edit events"}, {"name": "QueryService", "pattern": "CQRS", "function": "Serve read requests efficiently"} ], "dataFlow": ["Client <-> CollaborationService <-> ConflictResolutionEngine <-> PersistenceLayer"], "faultTolerance": ["Automatic reconnection", "Event replay for recovery", "Conflict-free merges"] }Architecture Breakdown
- CollaborationService: Uses WebSocket connections for bidirectional, low-latency communication. Implements presence and session management to track active users.
- ConflictResolutionEngine: Applies CRDT algorithms (e.g., RGA, LWW-Element-Set) which enable commutative and idempotent merges ensuring eventual consistency without locking.
- PersistenceLayer: Event sourcing stores immutable edit events in an append-only log, facilitating auditability and temporal queries.
- QueryService: Implements CQRS pattern separating write operations (events) from read models optimized for fast UI queries, updated asynchronously.
Technology Stack Recommendations
- WebSocket Framework: Use frameworks like Socket.IO (Node.js), SignalR (.NET), or Phoenix Channels (Elixir) for real-time communication.
- CRDT Libraries: Automerge, Yjs for JavaScript clients; delta-crdts for backend implementations.
- Event Store: Apache Kafka, EventStoreDB, or cloud services like AWS Kinesis for reliable event persistence.
- Database for Read Models: NoSQL databases such as MongoDB or Elasticsearch optimized for read-heavy loads.
Code Snippet: Implementing CRDT-based Merge
import Automerge from 'automerge'; // Initialize document let doc1 = Automerge.init(); doc1 = Automerge.change(doc1, doc => { doc.text = new Automerge.Text(); doc.text.insertAt(0, ...'Hello'); }); // Simulate concurrent edit on doc2 let doc2 = Automerge.clone(doc1); doc2 = Automerge.change(doc2, doc => { doc.text.insertAt(0, 'A'); }); // Merge changes let merged = Automerge.merge(doc1, doc2); console.log(merged.text.toString()); // Output: "AHello"Fault Tolerance and Recovery Strategies
- Automatic Reconnection: Clients automatically reconnect to CollaborationService with exponential backoff on connection loss.
- Event Replay: Upon reconnection or service restart, missed events are replayed from the event store to synchronize client state.
- Conflict-Free Merges: CRDT algorithms ensure that concurrent edits merge deterministically without user intervention.
-
Prompt: Partitioning Strategy for High-Volume Distributed Messaging System
System Instructions: “Recommend an optimal partitioning and sharding strategy for a distributed messaging system processing billions of messages daily.”
Context Variables:
messageSizeAvg: 2KBretentionPeriod: 30 daysconsumersCount: 5000throughputRequirement: 100,000 messages per second
Output Schema:
{ "partitionStrategy": "Topic-based partitioning with key hashing", "shardCount": 256, "replicationFactor": 3, "loadBalancing": "Round-robin among consumer groups", "dataPlacement": "Geo-distributed clusters with latency-aware routing" }Comprehensive Partitioning and Sharding Strategy
For a system ingesting billions of messages daily at an average size of 2KB, the partitioning strategy must optimize throughput, minimize latency, and support fault tolerance:
- Topic-Based Partitioning: Messages are categorized into topics representing logical streams (e.g., user activity, transactions). Each topic is divided into multiple partitions to parallelize consumption.
- Key Hashing: Within each topic, messages are assigned to partitions based on a hash of their key (e.g., userID, sessionID). This maintains message order per key while distributing load evenly.
- Shard Count: A shard count of 256 partitions balances parallelism and management overhead. This number should be chosen based on expected throughput and cluster capacity.
- Replication Factor: A replication factor of 3 ensures data durability and availability during node failures.
- Load Balancing: Consumers are grouped logically, with round-robin assignment to partitions, ensuring balanced processing and scalability.
- Geo-Distributed Clusters: Deploy clusters across multiple geographic regions with latency-aware routing to serve consumers closer to their location, reducing end-to-end latency.
Example Kafka Topic Configuration
apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaTopic metadata: name: user-activity labels: strimzi.io/cluster: my-cluster spec: partitions: 256 replicas: 3 config: retention.ms: 2592000000 # 30 days in milliseconds segment.bytes: 1073741824 # 1 GB segment size for optimal log compaction cleanup.policy: deleteConsumer Group Load Balancing Example (Java)
Properties props = new Properties(); props.put("bootstrap.servers", "broker1:9092,broker2:9092"); props.put("group.id", "consumer-group-1"); props.put("enable.auto.commit", "false"); props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); props.put("value.deserializer", "org.apache.kafka.common.serialization.ByteArrayDeserializer"); KafkaConsumerLatency-Aware Geo-Distribution Strategy
Implementing geo-distributed clusters requires:
- Multi-region Kafka clusters with MirrorMaker 2.0 for cross-region replication.
- Routing clients to nearest cluster endpoints using DNS-based load balancing or Anycast IP.
- Latency monitoring to dynamically adjust routing policies.
- Consistent hashing to ensure messages with the same key route to the same partition across clusters, preserving ordering.
Summary Table: Partitioning Strategy Parameters
Parameter Value Description Partition Strategy Topic-based with Key Hashing Ensures ordered processing per key and balanced load Shard Count 256 Number of partitions per topic for parallelism Replication Factor 3 Number of replicas to ensure durability and availability Load Balancing Round-robin among consumer groups Distributes message processing evenly Data Placement Geo-distributed clusters Reduces latency via proximity routing and replication
2. API Design & Integration
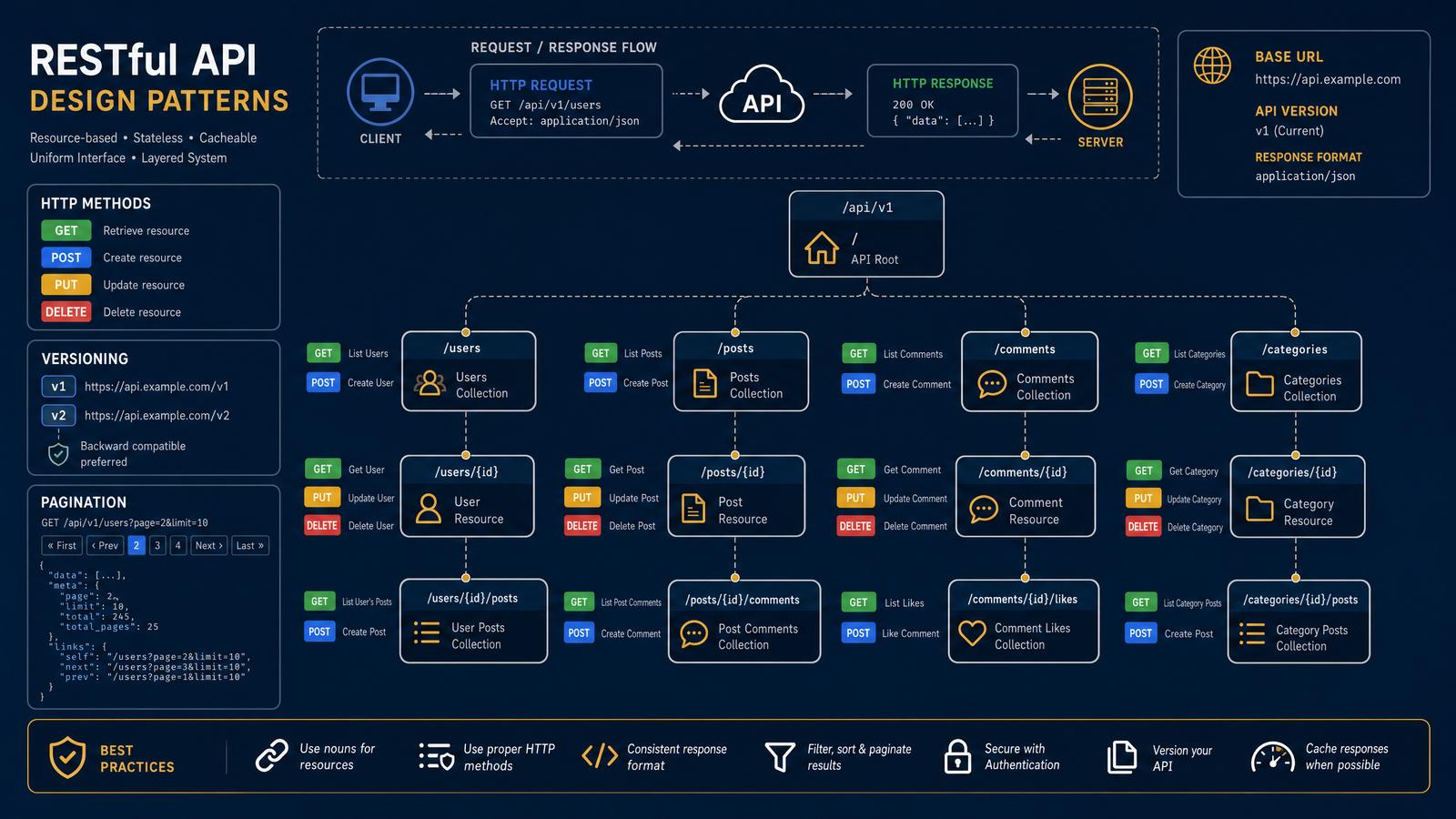
API design is fundamental to creating modular, scalable, and maintainable system architectures. A well-designed API not only enables seamless communication between components and services but also enforces clear contracts that reduce integration errors and simplify future enhancements. Leveraging GPT-5.5 can dramatically accelerate the process of defining precise, consistent, and extensible API contracts, while also supporting robust integration strategies that align with best practices in modern software engineering.
In this section, we explore advanced prompts tailored to generate comprehensive API designs, covering RESTful and GraphQL specifications, as well as API Gateway architectures for hybrid cloud environments. Each prompt is enriched with contextual variables and detailed output schemas, catering to real-world complexities such as multi-tenancy, role-based access control, audit logging, real-time data streaming, and security observability.
Key Considerations for API Design & Integration
- Consistency: Uniform naming conventions, data formats, and error handling mechanisms across all endpoints.
- Security: Authentication, authorization, and encryption strategies that protect data in transit and at rest.
- Scalability: Design for horizontal scaling, rate limiting, and efficient pagination to handle growing user bases.
- Extensibility: Versioning schemes and extensible schemas to accommodate evolving business requirements.
- Observability: Integration of logging, metrics, and distributed tracing to monitor API health and performance.
-
Prompt: Defining RESTful API Specification for a Multi-Tenant SaaS Application
System Instructions: “Generate a RESTful API specification for a SaaS application that supports multi-tenancy with role-based access control and audit logging.”
Context Variables:
tenancyModel: Isolated databases per tenantroles: Admin, User, AuditorloggingRequired: True
Output Schema:
{ "endpoints": [ { "path": "/tenants/{tenantId}/users", "methods": ["GET", "POST"], "rolesAllowed": ["Admin"], "description": "Retrieve or create users within the specified tenant." }, { "path": "/tenants/{tenantId}/users/{userId}", "methods": ["GET", "PUT", "DELETE"], "rolesAllowed": ["Admin", "User"], "description": "Retrieve, update, or delete a specific user. Users can access their own profile." }, { "path": "/tenants/{tenantId}/audit-logs", "methods": ["GET"], "rolesAllowed": ["Auditor"], "description": "Access audit logs for the specified tenant for compliance and monitoring." } ], "authentication": "OAuth 2.0 with JWT tokens issued per tenant", "rateLimiting": "1000 requests per minute per tenant", "responseFormat": "JSON API standard", "errorHandling": { "standardErrors": { "400": "Bad Request - Invalid input data", "401": "Unauthorized - Invalid or missing token", "403": "Forbidden - Insufficient permissions", "404": "Not Found - Resource does not exist", "429": "Too Many Requests - Rate limit exceeded", "500": "Internal Server Error - Unexpected error" } }, "auditLogging": { "enabled": true, "logFields": ["timestamp", "userId", "tenantId", "action", "resource", "statusCode", "ipAddress"], "storage": "Encrypted, append-only logs stored in a secure data lake" } }Detailed Walkthrough
This API design supports a multi-tenant SaaS system where each tenant operates in an isolated database environment, enhancing data security and reducing cross-tenant interference.
Role-based access control (RBAC) enforces strict permissions:
- Admin: Full user management within the tenant scope.
- User: Access only to their own profile for reading and updating.
- Auditor: Read-only access to audit logs for compliance monitoring.
Authentication employs OAuth 2.0 with JWT tokens that include tenant claims to ensure tenant isolation at the token validation stage.
Example: OpenAPI 3.0 Snippet for User Endpoints
openapi: 3.0.3 info: title: Multi-Tenant SaaS API version: 1.0.0 servers: - url: https://api.saasapp.com paths: /tenants/{tenantId}/users: get: summary: List users in a tenant security: - oauth2: [admin] parameters: - name: tenantId in: path required: true schema: type: string responses: '200': description: A list of users content: application/vnd.api+json: schema: type: array items: $ref: '#/components/schemas/User' '401': $ref: '#/components/responses/Unauthorized' post: summary: Create a new user in a tenant security: - oauth2: [admin] requestBody: required: true content: application/vnd.api+json: schema: $ref: '#/components/schemas/NewUser' responses: '201': description: User created '400': $ref: '#/components/responses/BadRequest' /tenants/{tenantId}/users/{userId}: get: summary: Get user by ID security: - oauth2: [admin, user] parameters: - name: tenantId in: path required: true schema: type: string - name: userId in: path required: true schema: type: string responses: '200': description: User details content: application/vnd.api+json: schema: $ref: '#/components/schemas/User' '403': $ref: '#/components/responses/Forbidden' components: schemas: User: type: object properties: id: type: string username: type: string email: type: string role: type: string enum: [Admin, User, Auditor] NewUser: type: object required: - username - email properties: username: type: string email: type: string role: type: string enum: [Admin, User, Auditor] securitySchemes: oauth2: type: oauth2 flows: clientCredentials: tokenUrl: https://auth.saasapp.com/token scopes: admin: Full admin access user: Basic user access auditor: Read-only audit access responses: Unauthorized: description: Unauthorized access BadRequest: description: Invalid request parameters or payload Forbidden: description: Insufficient permissionsThis OpenAPI definition enforces role-based scopes and includes detailed request and response schemas following the JSON API standard.
-
Prompt: Designing GraphQL API for a Social Media Platform
System Instructions: “Create a GraphQL schema that supports user profiles, posts, comments, and real-time notifications.”
Context Variables:
subscriptionsRequired: TruepaginationStyle: Cursor-basedauthorizationModel: Role-based with field-level permissions
Output Schema:
{ "types": [ { "name": "User", "fields": [ {"name": "id", "type": "ID!"}, {"name": "name", "type": "String!"}, {"name": "email", "type": "String!"}, {"name": "profilePicture", "type": "String"}, {"name": "friends", "type": "[User!]!"} ], "description": "Represents a user profile with personal information and social connections." }, { "name": "Post", "fields": [ {"name": "id", "type": "ID!"}, {"name": "author", "type": "User!"}, {"name": "content", "type": "String!"}, {"name": "comments", "type": "[Comment!]!"}, {"name": "createdAt", "type": "DateTime!"} ], "description": "A social media post made by a user." }, { "name": "Comment", "fields": [ {"name": "id", "type": "ID!"}, {"name": "author", "type": "User!"}, {"name": "content", "type": "String!"}, {"name": "createdAt", "type": "DateTime!"} ], "description": "A comment made on a post." }, { "name": "Notification", "fields": [ {"name": "id", "type": "ID!"}, {"name": "type", "type": "String!"}, {"name": "message", "type": "String!"}, {"name": "read", "type": "Boolean!"} ], "description": "Real-time notifications sent to users." } ], "queries": [ {"name": "getUser", "args": {"id": "ID!"}, "returnType": "User"}, {"name": "getPosts", "args": {"cursor": "String", "limit": "Int"}, "returnType": "[Post!]!"} ], "mutations": [ {"name": "createPost", "args": {"content": "String!"}, "returnType": "Post"}, {"name": "addComment", "args": {"postId": "ID!", "content": "String!"}, "returnType": "Comment"} ], "subscriptions": [ {"name": "onNewNotification", "args": {"userId": "ID!"}, "returnType": "Notification"} ], "authorization": { "model": "role-based", "fieldLevelPermissions": true, "roles": ["Admin", "User", "Guest"] }, "pagination": { "style": "cursor-based", "defaultLimit": 20, "maxLimit": 100 } }Schema Definition Example (SDL)
scalar DateTime type User { id: ID! name: String! email: String! profilePicture: String friends: [User!]! } type Post { id: ID! author: User! content: String! comments: [Comment!]! createdAt: DateTime! } type Comment { id: ID! author: User! content: String! createdAt: DateTime! } type Notification { id: ID! type: String! message: String! read: Boolean! } type Query { getUser(id: ID!): User getPosts(cursor: String, limit: Int = 20): [Post!]! } type Mutation { createPost(content: String!): Post addComment(postId: ID!, content: String!): Comment } type Subscription { onNewNotification(userId: ID!): Notification }Authorization Strategy
Field-level permissions are enforced dynamically at runtime via middleware or resolver wrappers. For example, the
emailfield onUsertype might only be visible toAdminand the user themselves, whilefriendslist is public to all authenticated users.Cursor-Based Pagination Implementation
This approach uses opaque cursors to paginate through posts efficiently, preventing issues with offset-based pagination such as inconsistent results on data changes. Example query:
query GetPosts($cursor: String, $limit: Int) { getPosts(cursor: $cursor, limit: $limit) { id content createdAt } }Real-Time Notifications with Subscriptions
Subscriptions utilize WebSocket connections to push real-time updates to clients. The
onNewNotificationsubscription filters notifications byuserId, ensuring users receive only their own notifications.Example Resolver Snippet (Node.js with Apollo Server)
const { PubSub, withFilter } = require('apollo-server'); const pubsub = new PubSub(); const NOTIFICATION_TOPIC = 'NEW_NOTIFICATION'; const resolvers = { Subscription: { onNewNotification: { subscribe: withFilter( () => pubsub.asyncIterator([NOTIFICATION_TOPIC]), (payload, variables, context) => { return payload.userId === context.user.id; } ) } }, Mutation: { createPost: async (_, { content }, { user }) => { // Save post logic here return createdPost; }, addComment: async (_, { postId, content }, { user }) => { // Save comment logic here return createdComment; } } }; -
Prompt: API Gateway Design for Hybrid Cloud Integration
System Instructions: “Develop an API Gateway architecture that integrates on-premise legacy systems with cloud-native microservices, ensuring security and observability.”
Context Variables:
legacyProtocols: SOAP, JMScloudServices: RESTful microservices with OAuth 2.0securityRequirements: TLS termination, JWT validationobservabilityTools: Distributed tracing, metrics aggregation
Output Schema:
{ "gatewayComponents": [ { "name": "ProtocolTranslator", "function": "Convert SOAP/JMS to REST", "details": "Provides adapters that transform legacy SOAP requests into RESTful JSON APIs and vice versa, leveraging XML parsers and JMS clients." }, { "name": "SecurityModule", "function": "TLS termination, JWT validation", "details": "Handles SSL/TLS termination, verifies JWT tokens against the identity provider, and enforces scopes for API access." }, { "name": "RoutingModule", "function": "Dynamic routing based on service registry", "details": "Uses a service discovery mechanism (e.g., Consul, Eureka) to route requests to appropriate microservices or legacy endpoints." }, { "name": "ObservabilityModule", "function": "Integrate tracing and metrics", "details": "Implements distributed tracing (e.g., OpenTelemetry), aggregates Prometheus metrics, and exports logs to centralized systems." } ], "deploymentModel": "High-availability cluster with autoscaling", "failoverStrategy": "Circuit breaker and fallback endpoints", "additionalFeatures": { "rateLimiting": "Configured per client and tenant", "caching": "Response caching with Redis", "requestValidation": "Schema validation for inbound requests" } }Architecture Diagram Description
The API Gateway acts as a centralized ingress point, bridging legacy on-premise systems and modern cloud-native microservices. The
ProtocolTranslatorenables seamless interoperability by converting SOAP/XML and JMS messages into RESTful calls and JSON payloads.The
SecurityModulemanages secure communications by terminating TLS sessions and validating JWTs issued by a centralized Identity and Access Management (IAM) system, ensuring only authenticated and authorized requests proceed.The
RoutingModuledynamically routes requests based on the service registry, providing resilience and scalability. It supports canary deployments and blue-green releases by tagging services accordingly.The
ObservabilityModuleintegrates distributed tracing (using OpenTelemetry), aggregates metrics via Prometheus exporters, and forwards logs to ELK or similar platforms, enabling comprehensive monitoring and troubleshooting.Example: Kubernetes Deployment YAML Snippet with API Gateway
apiVersion: apps/v1 kind: Deployment metadata: name: hybrid-api-gateway labels: app: api-gateway spec: replicas: 3 selector: matchLabels: app: api-gateway template: metadata: labels: app: api-gateway spec: containers: - name: api-gateway image: company/api-gateway:latest ports: - containerPort: 8080 env: - name: PROTOCOL_TRANSLATOR_ENABLED3. Database Schema & Query Optimization
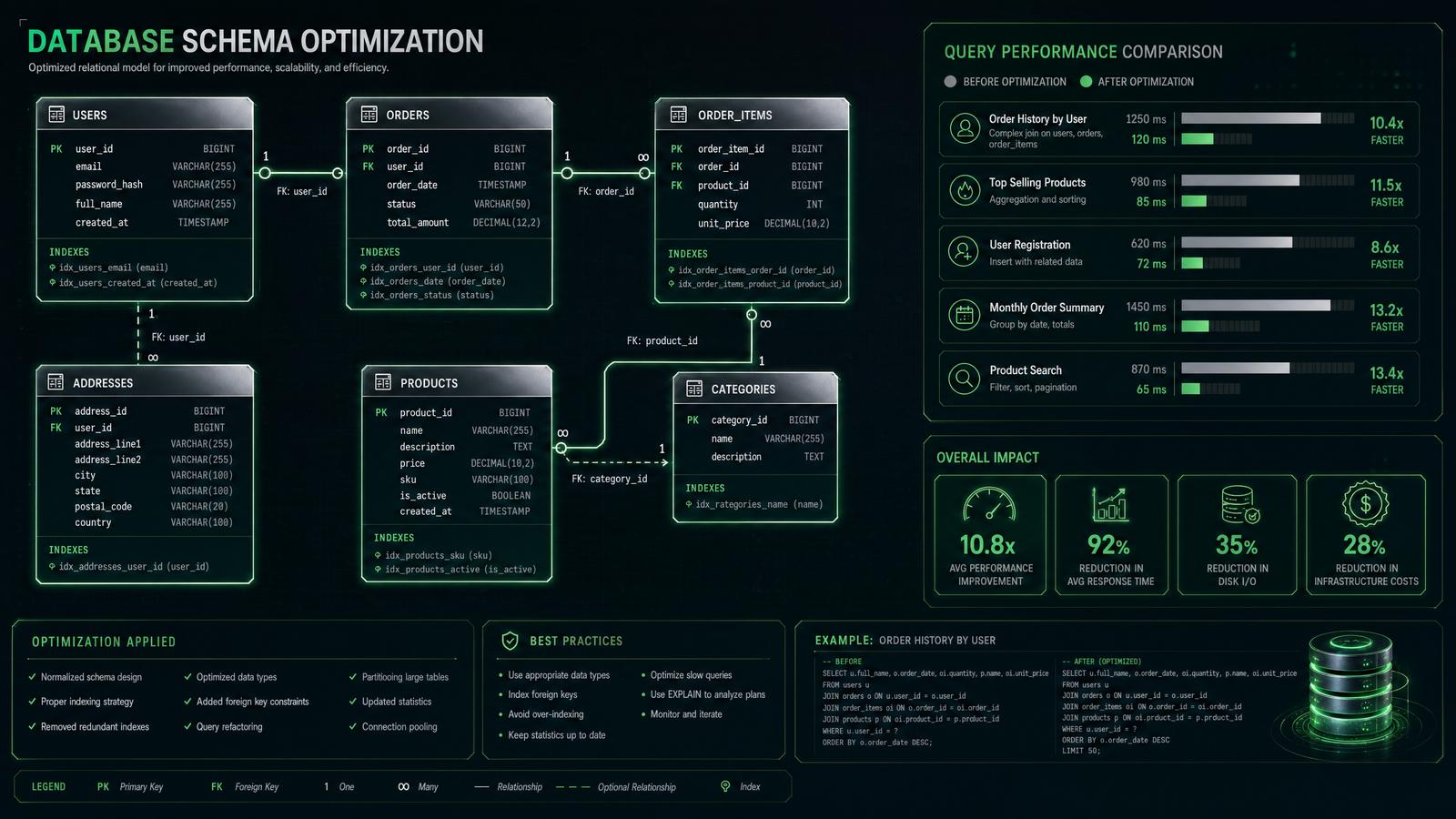
Effective database design and query optimization are foundational to achieving high system performance, scalability, and maintainability in any software architecture. In modern systems, databases handle vast volumes of data with diverse workload patterns, requiring a deep understanding of relational and NoSQL schema design principles, normalization forms, indexing strategies, and query execution plans. GPT-5.5 excels in generating highly normalized schemas aligned with business domains, suggesting optimal indexes tailored to workload characteristics, and producing performant query rewrites that reduce latency and resource consumption.
Stay Ahead of the AI Curve
Get weekly insights on ChatGPT, OpenAI, and AI tools delivered to your inbox.
Subscribe to Our NewsletterBeyond basic schema generation, GPT-5.5 can produce detailed explanations of normalization stages, identify potential bottlenecks in query plans, and recommend partitioning or sharding strategies for distributed databases. It can also tailor recommendations to specific database engines (e.g., PostgreSQL, MySQL, MongoDB), hardware configurations, and operational constraints. This section explores advanced prompt engineering for database schema design and query optimization with real-world examples and best practices.
-
Prompt: Designing a Normalized Database Schema for a Subscription Billing System
System Instructions: "Create a normalized relational schema to support customer subscriptions, plan tiers, usage tracking, and invoicing."
Detailed Context Variables
- subscriptionPlans: Basic, Pro, Enterprise — representing multiple pricing tiers with varying feature sets and pricing.
- billingCycle: Monthly and yearly billing options, affecting invoice generation frequency and proration logic.
- usageMetrics: Tracking API calls and storage usage to enable metered billing and overage charges.
Normalized Schema Design Explanation
The schema is designed to satisfy Third Normal Form (3NF), ensuring elimination of transitive dependencies and redundant data storage. Each entity represents a single concept, and foreign key constraints enforce referential integrity. This design facilitates flexibility in subscription management, accurate usage tracking, and detailed invoicing.
Output Schema
{ "tables": [ {"name": "Customers", "columns": [ "CustomerID SERIAL PRIMARY KEY", "Name VARCHAR(255) NOT NULL", "Email VARCHAR(255) UNIQUE NOT NULL", "CreatedAt TIMESTAMP DEFAULT CURRENT_TIMESTAMP" ]}, {"name": "SubscriptionPlans", "columns": [ "PlanID SERIAL PRIMARY KEY", "Name VARCHAR(50) NOT NULL", "Price DECIMAL(10, 2) NOT NULL", "BillingCycle VARCHAR(10) CHECK (BillingCycle IN ('Monthly', 'Yearly')) NOT NULL" ]}, {"name": "Subscriptions", "columns": [ "SubscriptionID SERIAL PRIMARY KEY", "CustomerID INT NOT NULL REFERENCES Customers(CustomerID)", "PlanID INT NOT NULL REFERENCES SubscriptionPlans(PlanID)", "StartDate DATE NOT NULL", "EndDate DATE" ]}, {"name": "UsageRecords", "columns": [ "UsageID SERIAL PRIMARY KEY", "SubscriptionID INT NOT NULL REFERENCES Subscriptions(SubscriptionID)", "Metric VARCHAR(50) NOT NULL CHECK (Metric IN ('API Calls', 'Storage Used'))", "Amount NUMERIC(15, 4) NOT NULL", "Date DATE NOT NULL" ]}, {"name": "Invoices", "columns": [ "InvoiceID SERIAL PRIMARY KEY", "SubscriptionID INT NOT NULL REFERENCES Subscriptions(SubscriptionID)", "AmountDue DECIMAL(12, 2) NOT NULL", "DueDate DATE NOT NULL", "Status VARCHAR(20) CHECK (Status IN ('Pending', 'Paid', 'Overdue')) NOT NULL" ]} ], "relationships": [ {"from": "Subscriptions.CustomerID", "to": "Customers.CustomerID"}, {"from": "Subscriptions.PlanID", "to": "SubscriptionPlans.PlanID"}, {"from": "UsageRecords.SubscriptionID", "to": "Subscriptions.SubscriptionID"}, {"from": "Invoices.SubscriptionID", "to": "Subscriptions.SubscriptionID"} ], "normalization": "3NF" }Production-Grade SQL Table Creation Example (PostgreSQL)
CREATE TABLE Customers ( CustomerID SERIAL PRIMARY KEY, Name VARCHAR(255) NOT NULL, Email VARCHAR(255) UNIQUE NOT NULL, CreatedAt TIMESTAMP DEFAULT CURRENT_TIMESTAMP ); CREATE TABLE SubscriptionPlans ( PlanID SERIAL PRIMARY KEY, Name VARCHAR(50) NOT NULL, Price DECIMAL(10, 2) NOT NULL, BillingCycle VARCHAR(10) CHECK (BillingCycle IN ('Monthly', 'Yearly')) NOT NULL ); CREATE TABLE Subscriptions ( SubscriptionID SERIAL PRIMARY KEY, CustomerID INT NOT NULL REFERENCES Customers(CustomerID) ON DELETE CASCADE, PlanID INT NOT NULL REFERENCES SubscriptionPlans(PlanID), StartDate DATE NOT NULL, EndDate DATE ); CREATE TABLE UsageRecords ( UsageID SERIAL PRIMARY KEY, SubscriptionID INT NOT NULL REFERENCES Subscriptions(SubscriptionID) ON DELETE CASCADE, Metric VARCHAR(50) NOT NULL CHECK (Metric IN ('API Calls', 'Storage Used')), Amount NUMERIC(15,4) NOT NULL, Date DATE NOT NULL ); CREATE TABLE Invoices ( InvoiceID SERIAL PRIMARY KEY, SubscriptionID INT NOT NULL REFERENCES Subscriptions(SubscriptionID), AmountDue DECIMAL(12, 2) NOT NULL, DueDate DATE NOT NULL, Status VARCHAR(20) CHECK (Status IN ('Pending', 'Paid', 'Overdue')) NOT NULL );Additional Design Considerations
- Indexing: Add indexes on foreign key columns (e.g.,
Subscriptions.CustomerID) to speed up joins. - Partitioning: For large UsageRecords, consider partitioning by date to improve query performance.
- Proration Logic: Implement stored procedures or application logic to handle billing proration on subscription plan changes.
- Audit Trails: Optionally add audit tables or use triggers to track subscription changes.
-
Prompt: Query Optimization for High-Throughput Financial Transactions
System Instructions: "Analyze and optimize SQL queries for a payment processing system handling 10,000 transactions per second."
Context Variables
- databaseEngine: PostgreSQL 13+
- queries:
SELECT * FROM transactions WHERE status='pending' AND created_at > now() - interval '5 minutes' - indexesAvailable: Primary key on
transaction_id, non-clustered index onstatus - hardwareSpecs: 32-core CPU, 256GB RAM, NVMe SSD storage for low latency I/O
Analysis of Original Query
The original query uses a
WHEREclause filtering onstatusand a recentcreated_attimestamp. The existing index onstatusalone is insufficient to efficiently filter by both conditions, causing sequential scans or inefficient index scans. Fetching all columns withSELECT *further increases I/O and CPU usage, particularly under high concurrency.Optimized Query and Index Recommendations
{ "optimizedQuery": "SELECT transaction_id, amount, created_at FROM transactions WHERE status = 'pending' AND created_at > now() - interval '5 minutes'", "indexesSuggested": ["CREATE INDEX idx_status_created_at ON transactions (status, created_at DESC)"], "explainPlan": { "seqScan": false, "indexScan": true, "cost": "Low", "rowsEstimated": 5000 }, "additionalRecommendations": [ "Partition transactions table by time (e.g., monthly partitions) to limit data scanned", "Run VACUUM ANALYZE regularly to maintain index statistics", "Use prepared statements and connection pooling to reduce overhead", "Employ query parallelism if supported by the PostgreSQL version" ] }Example: Creating Composite Index in PostgreSQL
CREATE INDEX idx_status_created_at ON transactions (status, created_at DESC);Step-by-Step Query Execution Improvement Walkthrough
- Identify bottleneck: Use
EXPLAIN ANALYZEon the original query to confirm sequential scans and high cost. - Refine SELECT clause: Replace
SELECT *with only necessary columns to reduce I/O. - Create composite index: Index on
(status, created_at DESC)allows the database to efficiently filter and order data. - Partition data: Implement table partitioning by date ranges to reduce the dataset queried.
- Maintain statistics: Schedule regular VACUUM and ANALYZE commands to keep planner statistics current.
- Monitor performance: Continuously monitor query latency and adjust indexing or partitioning as data grows.
EXPLAIN Output Example for Optimized Query
Index Scan using idx_status_created_at on transactions (cost=0.42..15.67 rows=5000 width=48) Index Cond: ((status = 'pending'::text) AND (created_at > (now() - '00:05:00'::interval)))Additional Best Practices
- Leverage connection pooling (e.g., PgBouncer) to manage high concurrency.
- Use asynchronous processing for non-critical transaction steps.
- Consider using materialized views or caching layers for aggregated transaction metrics.
- Perform load testing with realistic transaction volumes to validate optimizations.
-
Prompt: NoSQL Data Modeling for a Location-Based Social Network
System Instructions: "Design a NoSQL document schema to support geo-queries, friend connections, and event feeds."
Context Variables
- databaseType: MongoDB 5.0+
- geoIndexRequired: True — support efficient geospatial queries near user locations.
- userConnections: Bidirectional friendships requiring fast lookup and updates.
- eventFeedUpdateFrequency: Real-time updates with high write throughput.
NoSQL Schema Design Principles
Unlike relational models, document databases favor denormalization for performance and scalability. The schema design should optimize for common query patterns such as fetching nearby users, retrieving friends lists, and streaming event feeds. MongoDB's support for GeoJSON and specialized geospatial indexes enables efficient location-based queries.
Output Schema
{ "collections": [ { "name": "Users", "fields": { "_id": "ObjectId", "name": "string", "location": {"type": "GeoJSON Point", "index": "2dsphere"}, "friends": "array of ObjectId (bidirectional references)", "lastActive": "timestamp" } }, { "name": "Events", "fields": { "_id": "ObjectId", "userId": "ObjectId", "content": "string", "createdAt": "timestamp", "location": {"type": "GeoJSON Point", "index": "2dsphere"} } } ], "indexes": ["2dsphere on location fields", "Index on userId in Events"] }MongoDB Schema Creation and Indexing Example
db.users.createIndex({ location: "2dsphere" }); db.users.createIndex({ lastActive: 1 }); db.events.createIndex({ location: "2dsphere" }); db.events.createIndex({ userId: 1 });Data Model Explanation and Trade-offs
- Users Collection: Stores user profile and geolocation data with a
2dsphereindex to enable queries like "find users within radius X". Thefriendsfield holds an array of ObjectIds for bidirectional friendship representation, allowing fast lookup but potentially growing large arrays for popular users. - Events Collection: Stores user-generated content with location metadata. The
2dsphereindex enables geo-filtering of events, while the index onuserIdsupports efficient retrieval of a user's event feed.
Example Geo-Query: Find Users Within 5km Radius
db.users.find({ location: { $nearSphere: { $geometry: { type: "Point", coordinates: [ -73.9667, 40.78 ] }, $maxDistance: 5000 } } });Handling Real-Time Event Feed Updates
- Use capped collections or change streams in MongoDB to push real-time updates.
- Consider denormalizing event data into user documents if feed read performance outweighs update complexity.
- Implement TTL indexes on events to automatically expire outdated data.
Scaling Considerations
- Sharding users and events collections by geographic region or user ID hash to distribute load.
- Use Redis or similar in-memory stores for caching hot friend lists and event feeds.
- Monitor index sizes and performance using MongoDB Atlas or equivalent monitoring tools.
Summary Table: Relational vs NoSQL Design Trade-offs
Aspect Relational (Normalized) NoSQL (Document) Schema Flexibility Rigid, predefined tables and relationships Flexible, schema-less or schema-on-read Query Complexity Supports complex joins and transactions Limited joins, favors denormalization Performance Optimal for ACID compliance and complex queries Optimized for high write/read throughput and horizontal scaling Scalability Vertical scaling, sharding complex Horizontal scaling and sharding native
4. Scalability & Performance Planning

Ensuring that software systems scale gracefully under increasing load and maintain optimal performance is a cornerstone of robust system design. This involves a deep understanding of workload characteristics, infrastructure limitations, and failure scenarios. GPT-5.5 can assist architects and engineers by generating detailed, actionable scalability and performance strategies tailored to specific system requirements and operational contexts.
In this section, we explore advanced prompt templates designed to elicit comprehensive plans addressing scalability, capacity planning, fault tolerance, and performance tuning for complex, high-demand systems. These prompts include precise context variables, expected output schemas, and are augmented with real-world code snippets, configuration examples, and architectural patterns.
-
Prompt: Scalability Plan for a High-Throughput Payment Gateway
System Instructions: "Develop a scalability and capacity planning strategy for a payment gateway processing 100,000 transactions per second globally."
Context Variables:
peakTPS: 100,000 transactions per secondlatencySLA: <50ms end-to-end latencyfailureTolerance: 99.999% uptime (5 nines)infrastructure: Kubernetes clusters deployed across 5 global regions
Detailed Scalability Approach:
The system must support horizontal scaling at both the application and infrastructure layers. Key techniques include:
- Horizontal Pod Autoscaling: Dynamically adjust the number of pods based on CPU/memory utilization and custom metrics like request rate.
- Regional Load Balancing: Use geo-aware load balancers (e.g., AWS Global Accelerator, GCP Traffic Director) to route traffic to the nearest healthy region.
- Message Queue Buffering: Introduce durable queues (e.g., Apache Kafka, AWS Kinesis) to smooth traffic spikes and decouple front-end from downstream processing.
Capacity Planning Calculations:
Estimate resource requirements based on peak TPS and latency constraints:
Metric Assumptions Calculated Need CPU Cores Assuming 50 µs per transaction per core 2000 cores (100,000 TPS × 50 µs = 5,000 ms of CPU time per second → 5 seconds CPU per second, so ~2000 cores) Memory 20 MB per core for JVM heap and buffers 4000 GB total (2000 cores × 2 GB) Network Bandwidth Assuming 1 KB per transaction payload 100 Gbps (100,000 TPS × 1 KB × 8 bits) Fault Tolerance Strategies:
- Multi-Region Failover: Active-active cluster deployments with cross-region replication to ensure zero downtime during regional outages.
- Circuit Breakers: Implement using libraries like
Netflix HystrixorResilience4jto prevent cascading failures. - Retry Policies with Exponential Backoff: Mitigate transient failures while avoiding overwhelming the system.
Monitoring and Observability Setup:
- Prometheus Metrics: Track custom application metrics such as transaction latency, error rates, and throughput.
- Alertmanager Alerts: Configure alerts for SLA breaches, resource exhaustion, and anomalous patterns.
- Distributed Tracing: Use
Jaegerto trace transaction flow across microservices, identify bottlenecks, and latency hotspots.
Example Kubernetes Horizontal Pod Autoscaler Configuration:
apiVersion: autoscaling/v2beta2 kind: HorizontalPodAutoscaler metadata: name: payment-gateway-hpa namespace: payments spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: payment-gateway minReplicas: 50 maxReplicas: 1000 metrics: - type: Resource resource: name: cpu target: type: Utilization averageUtilization: 70 - type: Pods pods: metric: name: transactions_per_second target: type: AverageValue averageValue: 5000Sample Kafka Configuration for Message Queuing:
kafka-topics.sh --create --topic payment-transactions --partitions 500 --replication-factor 3 --config retention.ms=604800000This command creates a Kafka topic with 500 partitions to ensure high throughput and replication factor 3 for durability.
Summary Output Schema:
{ "scalingApproach": [ "Horizontal pod autoscaling", "Regional load balancing", "Message queue buffering" ], "capacityPlanning": { "cpuCoresRequired": 2000, "memoryGBRequired": 4000, "networkBandwidthGbps": 100 }, "faultTolerance": [ "Multi-region failover", "Circuit breakers", "Retry policies with exponential backoff" ], "monitoringSetup": [ "Prometheus metrics", "Alertmanager alerts", "Distributed tracing with Jaeger" ] } -
Prompt: Performance Tuning Strategy for Real-Time Analytics Platform
System Instructions: "Produce a performance tuning plan for a real-time analytics platform ingesting streaming data and providing sub-second query responses."
Context Variables:
dataIngestionRate: 1 million events per secondqueryLatencyTarget: <500msstorageType: Columnar OLAP database (e.g., Apache Druid, ClickHouse)computeModel: Serverless functions with autoscaling (e.g., AWS Lambda, Azure Functions)
Optimization Techniques:
- Data Pre-Aggregation: Compute rollups and summaries at ingestion time to reduce query complexity.
- Materialized Views: Maintain pre-computed views to serve frequent queries rapidly.
- Efficient Partition Pruning: Design partition keys to enable the query engine to skip irrelevant data segments, reducing I/O.
Resource Allocation Strategies:
- Dynamic Scaling: Serverless functions auto-scale based on incoming event rate and query concurrency.
- In-Memory Caching: Use Redis or Memcached to cache hot query results and metadata.
Bottleneck Mitigation:
- Backpressure Handling: Implement mechanisms to slow data ingestion when downstream systems are overwhelmed, such as Kafka’s flow control or reactive streams.
- Query Concurrency Limits: Throttle queries during peak load to maintain SLA.
Monitoring Setup:
- Latency Histograms: Track distribution of query response times to detect tail latency issues.
- Error Rate Tracking: Monitor ingestion failures, query errors, and system exceptions.
- Resource Utilization Dashboards: Visualize CPU, memory, and network usage in real-time.
Example Apache Druid Tuning Snippet for Ingestion:
{ "type" : "index_parallel", "spec": { "dataSchema": { "granularitySpec": { "type": "uniform", "segmentGranularity": "HOUR", "queryGranularity": "MINUTE" }, "metricsSpec": [ {"type":"count","name":"count"}, {"type":"doubleSum","name":"total_revenue","fieldName":"revenue"} ], "dimensionsSpec": { "dimensions": ["user_id", "product_id", "region"] } }, "ioConfig": { "type": "index_parallel", "inputSource": {"type": "kafka", "topic": "events-topic"}, "inputFormat": {"type": "json"} }, "tuningConfig": { "type": "index_parallel", "maxRowsPerSegment": 5000000, "maxTotalRows": 100000000, "partitionsSpec": { "type": "hashed", "targetPartitionSize": 500000 } } } }Serverless Autoscaling Example with AWS Lambda (Node.js):
exports.handler = async (event) => { // Process streaming event // Ensure idempotency and minimal cold start latency by keeping dependencies lightweight return { statusCode: 200, body: JSON.stringify('Processed event successfully'), }; };Summary Output Schema:
{ "optimizationTechniques": [ "Data pre-aggregation", "Materialized views", "Efficient partition pruning" ], "resourceAllocation": [ "Dynamic scaling of compute nodes", "In-memory caching for hot data" ], "bottleneckMitigation": [ "Backpressure handling on ingestion", "Query concurrency limits" ], "monitoring": [ "Latency histograms", "Error rate tracking", "Resource utilization dashboards" ] } -
Prompt: Load Balancing Strategy for Global Video Streaming Service
System Instructions: "Design a load balancing strategy for a video streaming service with millions of concurrent viewers worldwide."
Context Variables:
concurrentViewers: 5 millioncontentDeliveryNetwork: Integrated CDN usage (e.g., Cloudflare, Akamai)latencyTarget: <200ms startup timefailoverMechanism: Automatic rerouting on node failure
Comprehensive Load Balancing Strategy:
To efficiently serve a massive global audience with low startup latency, the system must leverage multi-layered load balancing and edge caching:
- Global DNS-Based Routing: Use a DNS provider with latency-based routing (e.g., AWS Route 53 latency routing) to direct users to the closest regional cluster.
- Regional Application Load Balancers: Within each region, application load balancers distribute incoming streaming requests across multiple backend streaming servers.
- Edge Caching via CDN: Leverage CDN edge nodes to cache video segments near users, reducing origin server load and decreasing startup latency.
Advanced Routing Policies:
- Latency-Aware Routing: Continuously measure user-to-region latency and route traffic dynamically to minimize startup delay.
- Health Checks with Automatic Failover: Employ active health monitoring to detect failing nodes and automatically reroute traffic to healthy endpoints.
Scaling Model:
The system should implement auto-scaling based on concurrent viewer metrics using cloud-native autoscaling groups or Kubernetes Horizontal Pod Autoscalers, combined with pre-warming strategies during anticipated peak hours.
Example: Route 53 Latency-Based Routing Configuration:
resource "aws_route53_record" "video_streaming_latency_routing" { zone_id = aws_route53_zone.primary.zone_id name = "streaming.example.com" type = "A" alias { name = aws_lb.region1.dns_name zone_id = aws_lb.region1.zone_id evaluate_target_health = true } set_identifier = "region1" latency_routing_policy { region = "us-east-1" } } resource "aws_route53_record" "video_streaming_latency_routing_region2" { zone_id = aws_route53_zone.primary.zone_id name = "streaming.example.com" type = "A" alias { name = aws_lb.region2.dns_name zone_id = aws_lb.region2.zone_id evaluate_target_health = true } set_identifier = "region2" latency_routing_policy { region = "eu-west-1" } }Sample NGINX Configuration Snippet for Regional Load Balancer:
http { upstream backend { server backend1.example.com max_fails=3 fail_timeout=30s; server backend2.example.com max_fails=3 fail_timeout=30s; server backend3.example.com max_fails=3 fail_timeout=30s; } server { listen 80; location / { proxy_pass http://backend; proxy_next_upstream error timeout invalid_header http_500 http_503; proxy_connect_timeout 5s; proxy_read_timeout 30s; } } }CDN Edge Caching Best Practices:
- Cache video segments with appropriate
Cache-Controlheaders to maximize hit ratios. - Use HTTP/2 or HTTP/3 protocols for faster multiplexing.
- Implement token-based authentication on CDN requests to secure content.
Summary Output Schema:
{ "loadBalancers": [ "Global DNS-based routing", "Regional application load balancers", "Edge caching via CDN" ], "routingPolicies": [ "Latency-aware routing", "Health checks with automatic failover" ], "scalingModel": [ "Auto-scaling based on concurrent viewers", "Pre-warming during peak hours" ], "monitoring": [ "Real-time viewer metrics", "Load balancer health dashboards", "CDN cache hit ratio tracking" ] }