GPT-5.5 Mini Prompting Guide: Optimizing for Speed, Cost, and Edge Deployment

In the rapidly evolving landscape of large language models, OpenAI’s GPT-5.5 family introduces specialized variants tailored to diverse applications and deployment environments. Among these, GPT-5.5 Mini stands out as a highly efficient, 1.5 billion parameter model optimized for speed, cost-effectiveness, and edge deployment. This comprehensive guide aims to provide an in-depth understanding of GPT-5.5 Mini’s design philosophy, use cases, and advanced prompting techniques that unlock its full potential in real-world scenarios.
With the exponential growth of AI applications across industries, developers and enterprises face increasing demands for models that balance performance with resource constraints. GPT-5.5 Mini addresses these challenges by delivering a compact yet capable solution that can be deployed on resource-limited hardware such as edge devices, mobile platforms, and on-premises servers without compromising on responsiveness or accuracy.
Key Characteristics of GPT-5.5 Mini
- Parameter Count: Approximately 1.5 billion parameters, striking a balance between model complexity and computational efficiency.
- Architecture: Transformer-based model leveraging optimized attention mechanisms and quantization-aware training to reduce latency.
- Latency: Designed for sub-100 millisecond response times on modern edge GPUs (e.g., NVIDIA Jetson series) and inference accelerators.
- Cost Efficiency: Reduced operational costs through lower compute and memory demands, enabling cost-effective scaling in production environments.
- Compatibility: Supports standard ONNX and TensorRT formats for seamless integration into various deployment pipelines.
Design Philosophy: Speed, Cost, and Edge Deployment
GPT-5.5 Mini is engineered with a three-pronged design philosophy:
- Speed: Utilizing layer pruning, mixed-precision inference, and optimized kernel implementations, the model achieves rapid generation speeds essential for real-time applications such as conversational agents and interactive assistants.
- Cost-Effectiveness: By reducing parameter size and enabling efficient batching strategies, GPT-5.5 Mini lowers both cloud compute expenses and energy consumption for on-premises deployments.
- Edge-Friendliness: The model’s architecture supports quantized weights (INT8 and FP16) and leverages hardware-specific acceleration, making it deployable on devices ranging from edge servers to embedded systems.
Practical Use Cases
GPT-5.5 Mini’s versatility makes it suitable for a wide variety of applications including, but not limited to:
- Mobile Virtual Assistants: Providing responsive natural language understanding and generation on smartphones without reliance on cloud connectivity.
- IoT Device Command Processing: Enabling smart home devices and industrial IoT sensors to interpret and act on voice or text commands locally.
- Enterprise Knowledge Bases: Implementing on-premise query engines that respect data privacy regulations by avoiding external API calls.
- Interactive Chatbots: Deploying customer support bots on edge servers to reduce latency and improve user experience.
Advanced Prompting Techniques Covered in This Guide
To harness GPT-5.5 Mini’s capabilities effectively, this guide delves into sophisticated prompting strategies such as:
- Dynamic Prompt Engineering: Crafting context-aware prompts that adapt based on user input and session history to maintain conversational consistency.
- Few-Shot and Zero-Shot Learning: Leveraging minimal examples within prompts to achieve task-specific performance without fine-tuning.
- Prompt Compression: Techniques to reduce prompt length and complexity, optimizing inference speed and memory usage.
- Chain-of-Thought Prompting: Encouraging stepwise reasoning in generated outputs to improve the accuracy of complex tasks.
Step-by-Step Walkthrough: Deploying GPT-5.5 Mini on Edge Devices
- Model Conversion: Convert the pretrained GPT-5.5 Mini model to a hardware-optimized format using OpenAI’s conversion tools or third-party frameworks like ONNX Runtime.
- Deployment Setup: Prepare the edge device environment with necessary dependencies such as CUDA, cuDNN, and TensorRT.
- Inference Pipeline Implementation: Develop the inference service utilizing asynchronous batching and prompt caching for maximum throughput.
- Performance Monitoring: Integrate telemetry tools to track latency, memory usage, and throughput in real-time.
python convert_model.py --input gpt5_5_mini.pt --output gpt5_5_mini.onnx --quantize int8sudo apt-get install cuda-toolkit-11-7
pip install onnxruntime-gpu tensorrtimport onnxruntime as ort
session = ort.InferenceSession("gpt5_5_mini.onnx", providers=['TensorrtExecutionProvider'])
def generate_response(prompt):
inputs = preprocess(prompt)
outputs = session.run(None, inputs)
return postprocess(outputs)import psutil
import time
start = time.time()
response = generate_response("Hello, GPT-5.5 Mini!")
end = time.time()
print(f"Latency: {end - start} seconds")
print(f"Memory Usage: {psutil.virtual_memory().percent}%")Comparative Performance Table
| Model | Parameters | Latency (ms) | Cost per 1K queries (USD) | Deployment Target |
|---|---|---|---|---|
| GPT-5.5 XL | 13B | 450 | $2.50 | Cloud GPU |
| GPT-5.5 Mini | 1.5B | 90 | $0.35 | Edge Devices |
| GPT-5.5 Nano | 500M | 60 | $0.20 | Embedded Systems |
Understanding GPT-5.5 Mini: Design Philosophy and Model Characteristics
GPT-5.5 Mini is architected to balance performance with resource constraints, making it ideal for latency-sensitive and cost-sensitive applications. Its 1.5B parameter architecture is a deliberate reduction from larger siblings like GPT-5.5 Pro (175B parameters) or GPT-5.5 Thinking (30B+ parameters), trading off some raw capacity for improved efficiency.
This design strategy reflects a growing industry trend toward specialized, lightweight models that can operate effectively on limited hardware without sacrificing essential language understanding. By focusing on a carefully optimized subset of parameters and architectural components, GPT-5.5 Mini delivers a compelling blend of speed, cost efficiency, and deployment flexibility.
In practice, GPT-5.5 Mini targets use cases such as mobile assistants, IoT devices, and embedded systems, where computational resources and power budgets are constrained, yet responsiveness and language comprehension remain critical.
Key Attributes of GPT-5.5 Mini
- Extreme Efficiency: The model’s parameter count and architecture are optimized for rapid inference on edge devices, including mobile CPUs, embedded GPUs, and specialized AI accelerators. This includes support for quantization schemes such as INT8 and FP16 to further reduce memory footprint and computational load while maintaining acceptable accuracy.
- Low Latency: By minimizing model size and computational overhead, Mini achieves sub-100ms response times on optimized hardware, enabling real-time applications such as voice assistants and interactive chatbots. Benchmarking on devices like the Qualcomm Snapdragon 8cx Gen 3 and NVIDIA Jetson Xavier NX demonstrates consistent throughput improvements over larger models.
- Cost-Effective Deployment: Reduced computational requirements translate directly into lower operational costs, making Mini suitable for high-volume, budget-conscious scenarios such as large-scale customer support automation and embedded AI in consumer electronics. This cost-efficiency is further enhanced by compatibility with containerized deployment frameworks like Docker and Kubernetes, allowing scalable orchestration.
- Edge and Offline Ready: Mini supports lightweight runtime environments such as ONNX Runtime and TensorRT, enabling deployment on-premises or on devices without continuous internet connectivity, which enhances privacy and control. Offline capability is critical for sectors like healthcare and defense, where data sovereignty and latency are paramount.
Architectural Considerations
Mini leverages a transformer architecture similar to its larger siblings but with strategically pruned layers and attention heads. This pruning is guided by extensive knowledge distillation from the full-sized model, ensuring Mini retains core language understanding capabilities despite its smaller size.
Specifically, the architecture comprises:
- 12 Transformer layers: Reduced from 48+ layers in GPT-5.5 Pro, each layer maintains the core self-attention and feed-forward submodules but with fewer parameters.
- Attention Head Pruning: Attention heads are selectively pruned based on their contribution to model performance, identified through layer-wise relevance propagation (LRP) and sensitivity analysis, reducing overhead without significant accuracy degradation.
- Smaller Embedding Dimensions: The embedding size is scaled down to 768, compared to 12288 in GPT-5.5 Pro, balancing expressiveness with efficiency.
- Knowledge Distillation: A two-stage distillation process transfers knowledge from the large teacher model to the Mini student model, using both logits matching and intermediate feature map alignment to preserve semantic understanding.
Technical Deep Dive: Knowledge Distillation Workflow
- Teacher Model Inference: The large GPT-5.5 Pro generates soft targets (probability distributions over the vocabulary) for a curated dataset covering diverse domains.
- Student Model Training: The Mini model is trained to minimize a combined loss function consisting of cross-entropy with ground truth labels and Kullback-Leibler divergence against teacher soft targets.
- Intermediate Feature Matching: To retain internal representational fidelity, feature maps from key transformer layers of both models are aligned using mean squared error loss.
- Fine-Tuning: Post-distillation, Mini undergoes domain-specific fine-tuning to adapt to target application requirements, such as conversational AI or code generation.
Example: Pruned Transformer Layer Configuration
class MiniTransformerLayer(nn.Module):
def __init__(self, embed_dim=768, num_heads=12):
super(MiniTransformerLayer, self).__init__()
self.self_attn = nn.MultiheadAttention(embed_dim, num_heads)
self.linear1 = nn.Linear(embed_dim, embed_dim * 4)
self.dropout = nn.Dropout(0.1)
self.linear2 = nn.Linear(embed_dim * 4, embed_dim)
self.norm1 = nn.LayerNorm(embed_dim)
self.norm2 = nn.LayerNorm(embed_dim)
self.activation = nn.GELU()
def forward(self, src):
src2, _ = self.self_attn(src, src, src)
src = src + self.dropout(src2)
src = self.norm1(src)
src2 = self.linear2(self.dropout(self.activation(self.linear1(src))))
src = src + self.dropout(src2)
src = self.norm2(src)
return src
Performance Benchmarks on Representative Hardware
| Hardware | Model | Latency (ms) | Throughput (tokens/sec) | Memory Usage (MB) |
|---|---|---|---|---|
| Qualcomm Snapdragon 8cx Gen 3 | GPT-5.5 Mini (1.5B) | 85 | 250 | 1200 |
| NVIDIA Jetson Xavier NX | GPT-5.5 Mini (1.5B) | 90 | 270 | 1100 |
| Cloud CPU (16 vCPUs) | GPT-5.5 Mini (1.5B) | 60 | 320 | 1500 |
Deployment Configuration Example with ONNX Runtime
To deploy GPT-5.5 Mini efficiently on edge devices, ONNX Runtime provides a versatile inference platform with hardware acceleration. Below is an example configuration snippet optimizing for CPU with AVX2 support and enabling graph optimizations:
import onnxruntime as ort
session_options = ort.SessionOptions()
session_options.graph_optimization_level = ort.GraphOptimizationLevel.ORT_ENABLE_ALL
session_options.intra_op_num_threads = 4
session_options.execution_mode = ort.ExecutionMode.ORT_SEQUENTIAL
# Enable CPU execution provider with AVX2 optimizations
providers = ['CPUExecutionProvider']
session = ort.InferenceSession("gpt5_5_mini.onnx", sess_options=session_options, providers=providers)
def infer(input_ids):
inputs = {"input_ids": input_ids}
outputs = session.run(None, inputs)
return outputs
Summary
GPT-5.5 Mini exemplifies the state-of-the-art in compact transformer design, balancing the trade-offs between model size, performance, and deployment constraints. By leveraging pruning, distillation, and targeted architectural optimizations, it enables high-quality language understanding in environments where latency, cost, and hardware limitations are critical factors.
For a comprehensive guide on prompt engineering techniques tailored to GPT-5.5 Mini, see the GPT-5.5 Mini Prompting Guide.
When to Use GPT-5.5 Mini vs. Other GPT-5.5 Variants

Choosing the optimal GPT-5.5 variant is a critical decision that hinges on multiple factors, including your application’s computational complexity, latency requirements, throughput demands, and the constraints imposed by your deployment environment. The GPT-5.5 family offers a spectrum of model sizes and capabilities designed to fit diverse use cases, from lightweight edge inference to heavyweight cloud-based AI services.
Each variant balances trade-offs between model size, inference speed, cost-efficiency, and reasoning power. Understanding these trade-offs enables developers and system architects to optimize for performance and budget simultaneously.
- Mini (1.5B parameters): A compact and highly efficient model optimized for low-latency inference on resource-constrained hardware, such as edge devices or on-device AI. Ideal for tasks that require rapid responses without extensive contextual understanding.
- Instant (6B parameters): A mid-tier model that strikes a balance between speed and reasoning capability, suitable for real-time chatbots, content generation, and applications requiring moderate contextual awareness.
- Thinking (30B+ parameters): A large-scale model designed to handle complex problem-solving, multi-turn dialogues, and advanced code generation. This variant supports extended context windows and deeper reasoning chains.
- Pro (175B parameters): The flagship, full-capacity model delivering state-of-the-art performance in creativity, nuanced understanding, and comprehensive knowledge synthesis. Best suited for intensive natural language understanding and generation tasks in cloud environments.
Use Case Matrix
| Model Variant | Best For | Latency | Cost | Deployment | Complexity Handling |
|---|---|---|---|---|---|
| Mini (1.5B) | Simple Q&A, classification, summarization, edge AI | Very Low (<100ms) | Lowest | Edge, On-device, Offline | Simple to Moderate |
| Instant (6B) | Chatbots, content generation, moderate reasoning | Low (~200ms) | Low | Cloud, Edge (Powerful devices) | Moderate |
| Thinking (30B+) | Complex reasoning, multi-turn dialogue, code generation | Medium (~500ms+) | Medium | Cloud | High |
| Pro (175B) | Creative writing, advanced research, nuanced understanding | High (1s+) | High | Cloud | Very High |
Detailed Performance and Deployment Considerations
Below are key technical considerations to guide the selection of GPT-5.5 variants in production-grade environments:
Latency Sensitivity
Applications demanding sub-100ms response times, such as real-time voice assistants or AR/VR interactive systems, benefit most from the Mini variant. Leveraging model quantization techniques and optimized inference runtimes (e.g., ONNX Runtime, TensorRT) can further reduce latency.
# Example: Loading GPT-5.5 Mini model with optimized ONNX Runtime for edge inference
import onnxruntime as ort
session = ort.InferenceSession("gpt5_5_mini_quantized.onnx", providers=['CPUExecutionProvider'])
def generate_response(input_tokens):
outputs = session.run(None, {"input_ids": input_tokens})
return outputs[0]
Cost Efficiency
Mini and Instant variants provide substantial savings on cloud compute costs, especially when deployed at scale. For instance, running Mini on ARM-based edge CPUs or mobile NPUs can eliminate cloud inference expenses altogether. The cost per token scales roughly linearly with parameter count, so smaller models drastically reduce operational expenditure.
Context Window and Complexity Handling
Thinking and Pro variants support extended context windows (e.g., 16K tokens or more) enabling sophisticated multi-turn conversations and chain-of-thought reasoning. These are critical for applications like legal document analysis, technical support chatbots, or code generation workflows requiring contextual awareness across lengthy inputs.
Deployment Environments
- Edge & On-device: Mini excels due to minimal memory footprint (~3GB RAM) and compatibility with mobile accelerators (e.g., Apple Neural Engine, Qualcomm Hexagon DSP).
- Cloud: Instant, Thinking, and Pro variants typically require GPU or TPU infrastructure. Auto-scaling clusters with GPU pools (e.g., NVIDIA A100, Google TPU v4) can handle variable loads and improve throughput.
Step-by-Step Variant Selection Workflow
- Define Application Requirements: Identify latency targets, expected input complexity, and deployment constraints.
- Estimate Throughput & Budget: Calculate expected queries per second and per-query cost ceilings.
- Prototype and Benchmark: Run comparative inference benchmarks using sample workloads on candidate variants.
- Optimize Deployment: Apply model compression, pruning, quantization, or distillation as needed to meet latency and cost goals.
- Monitor in Production: Continuously track latency, error rates, and resource utilization to inform dynamic routing between variants if applicable.
Example: Dynamic Routing Based on Query Complexity
In production, a hybrid approach can improve cost-efficiency by routing simple queries to Mini and complex ones to Thinking or Pro. Below is an example Python snippet implementing runtime routing based on input length and keyword heuristics:
def route_query(input_text):
complexity_threshold = 100 # token count threshold
keywords = ['legal', 'contract', 'research', 'code', 'algorithm']
token_count = len(tokenize(input_text))
if token_count < complexity_threshold and not any(k in input_text.lower() for k in keywords):
return "Mini" # Low complexity - use Mini
elif token_count < 500:
return "Instant" # Moderate complexity
else:
return "Thinking" # High complexity
# Example usage
query = "Explain the implications of the new data privacy law."
model_choice = route_query(query)
print(f"Routing query to {model_choice} variant.")
Summary
To summarize, the GPT-5.5 Mini variant is the go-to choice for latency-critical, resource-constrained applications with relatively straightforward NLP tasks. It empowers edge deployments and offline scenarios with minimal infrastructure overhead.
For tasks demanding richer contextual understanding or more sophisticated reasoning, the Instant and Thinking variants provide progressively greater capacity at the cost of increased latency and compute requirements.
The Pro variant remains the preferred solution for the most demanding workloads requiring maximal creativity, subtlety, and knowledge depth, typically hosted in cloud environments with ample GPU resources.
By carefully matching GPT-5.5 variants to your application’s unique profile, you can optimize speed, cost, and deployment flexibility effectively.
Advanced Prompting Techniques Tailored for GPT-5.5 Mini
Due to its smaller size and optimized architecture, GPT-5.5 Mini requires carefully crafted prompts that maximize model effectiveness while maintaining efficiency. Unlike larger models with vast context windows and greater parameter counts, Mini’s performance hinges on prompt precision, token economy, and strategic context management. Below, we delve into advanced prompting techniques designed to leverage GPT-5.5 Mini’s strengths and mitigate its limitations, thereby optimizing for speed, cost-efficiency, and edge deployment.
Stay Ahead of the AI Curve
Get weekly insights on ChatGPT, OpenAI, and AI tools delivered to your inbox.
1. Few-Shot Learning Optimization
GPT-5.5 Mini has a more constrained context window and limited capacity to internalize extensive context compared to larger siblings like GPT-5.5 Base or GPT-5.5 XL. Consequently, few-shot prompting must be concise yet representative to guide the model effectively without overwhelming its memory.
Key Principles:
- Prioritize quality over quantity: Use fewer, but highly relevant and diverse examples that cover edge cases and typical inputs.
- Maintain strict format consistency: Uniform input-output patterns reduce the model’s ambiguity and improve generalization.
- Place few-shot examples at the prompt’s start: This ensures maximum visibility within the truncated context window.
- Leverage domain-specific vocabulary and phrasing to align model expectations.
Consider the following production-grade example for customer feedback classification:
prompt = """
You are a helpful assistant that classifies customer feedback into categories: Bug Report, Positive Feedback, or Negative Feedback.
Example 1:
Input: "The app crashes when I try to open it."
Output: Bug Report
Example 2:
Input: "I love the new dark mode feature!"
Output: Positive Feedback
Now classify the following input:
Input: "The login process is very slow."
Output:
"""In this example:
- Two examples are sufficient to establish classification categories without overloading the context window.
- The format is rigid: each example clearly separates Input and Output fields.
- The task is explicitly stated to reduce model confusion.
Additional Tips:
- Dynamic example selection: When deploying at scale, dynamically select few-shot examples most similar to the user input using semantic similarity metrics (e.g., cosine similarity on embeddings) to improve relevance.
- Example diversity: Include positive, negative, and edge-case samples to prevent bias.
- Prompt length management: Use token counting utilities (e.g., OpenAI’s tokenizer or tiktoken) to ensure examples and instructions fit within Mini’s context window (typically ~512 tokens).
2. Prompt Compression and Token Efficiency
Reducing prompt length is critical for optimizing inference speed and cost, especially when deploying GPT-5.5 Mini at the edge or under strict latency budgets. Token efficiency can be achieved by compressing natural language instructions, eliminating redundancy, and using structured data formats.
Strategies for Compression:
- Abbreviations & Symbols: Replace verbose phrases with standardized abbreviations or symbols. For example, use “→” for “maps to” or “classify as”.
- Structured formats: Use JSON, YAML, or CSV snippets in the prompt to convey instructions more succinctly than prose.
- Remove redundant instructions: If certain behaviors are consistent across requests, encode them in the prompt template rather than repeating.
- Use shorthand labels: Instead of “Bug Report” use “Bug”, or “Positive Feedback” use “Positive” if the model understands these labels.
Example of a compressed prompt optimized for GPT-5.5 Mini:
prompt = """
Classify feedback as: Bug, Positive, Negative.
Examples:
1) "App crashes on start." → Bug
2) "Love dark mode." → Positive
Input: "Login very slow."
Output:
"""This compressed prompt reduces token count from over 80 tokens in the verbose example to under 50 tokens, significantly speeding up inference and reducing cost.
Production Considerations:
- Use tokenizers like
tiktokento measure token impact of prompt variants. - Benchmark latency and cost by A/B testing verbose vs compressed prompts in your deployment environment.
- Balance compression with clarity — overly compressed prompts might reduce accuracy.
3. Structured Output Forcing with JSON Schemas
Structured outputs are vital for reliable downstream processing in production applications. GPT-5.5 Mini can be explicitly conditioned to produce JSON-formatted outputs by including a detailed schema in the prompt. This approach reduces the need for complex post-processing and error handling.
Why Use JSON Schema Enforcement?
- Deterministic parsing: JSON outputs can be parsed programmatically with strict validators, ensuring data integrity.
- Integration: Easier to integrate model outputs with databases, APIs, or analytics pipelines.
- Error reduction: Structured output reduces ambiguity and inconsistent formats.
Example prompt with JSON schema enforcement:
prompt = """
You are an assistant that extracts entities from text.
Extracted data should be in JSON format:
{
"entities": [
{
"type": "PERSON",
"text": "..."
},
...
]
}
Text: "Alice and Bob went to the market."
Output:
"""Expected output:
{
"entities": [
{
"type": "PERSON",
"text": "Alice"
},
{
"type": "PERSON",
"text": "Bob"
}
]
}Enhancements for Robustness:
- Schema Validation: Use JSON schema validation libraries (e.g.,
jsonschemain Python) post-inference to verify output correctness. - Prompted Examples: Provide 1-2 few-shot examples illustrating the exact JSON structure to reinforce output format.
- Output Truncation Handling: Implement checks for incomplete JSON and retry with adjusted temperature or prompt tweaks.
4. Prompt-Based Routing Logic
Due to GPT-5.5 Mini’s resource constraints, it is prudent to design a routing architecture that dynamically delegates requests based on complexity. Simple queries that fit Mini’s capabilities are handled locally, while complex or ambiguous queries are escalated to larger, more powerful models. This hybrid approach optimizes throughput and cost.
Implementing Routing Logic:
- Keyword Detection: Define a set of keywords or patterns that signal query complexity. For example, queries with technical jargon or multi-part instructions may be flagged for escalation.
- Heuristic Rules: Use rule-based heuristics such as input length thresholds or presence of negations to infer query difficulty.
- Confidence Scores: Utilize model output confidence metrics (e.g., probability distributions over tokens or custom scoring) to detect uncertain responses that warrant escalation.
- Hybrid Prompt Engineering: Embed routing hints directly in the prompt to guide Mini’s behavior, e.g., “If uncertain, respond ‘escalate’.”
Example Routing Logic Pseudocode:
def route_query(input_text):
keywords = ['complex', 'detailed', 'multi-step', 'legal', 'medical']
if any(word in input_text.lower() for word in keywords):
return 'route_to_large_model'
response, confidence = query_gpt_5_5_mini(input_text)
if confidence < 0.7 or response == 'escalate':
return 'route_to_large_model'
return response
Production Deployment Tips:
- Implement routing as a microservice or middleware layer to abstract complexity from clients.
- Log routing decisions and outcomes for ongoing performance tuning.
- Continuously update heuristic rules based on error analysis and feedback loops.
Production-Grade Python Script: Dynamic Query Routing Between Mini and Thinking
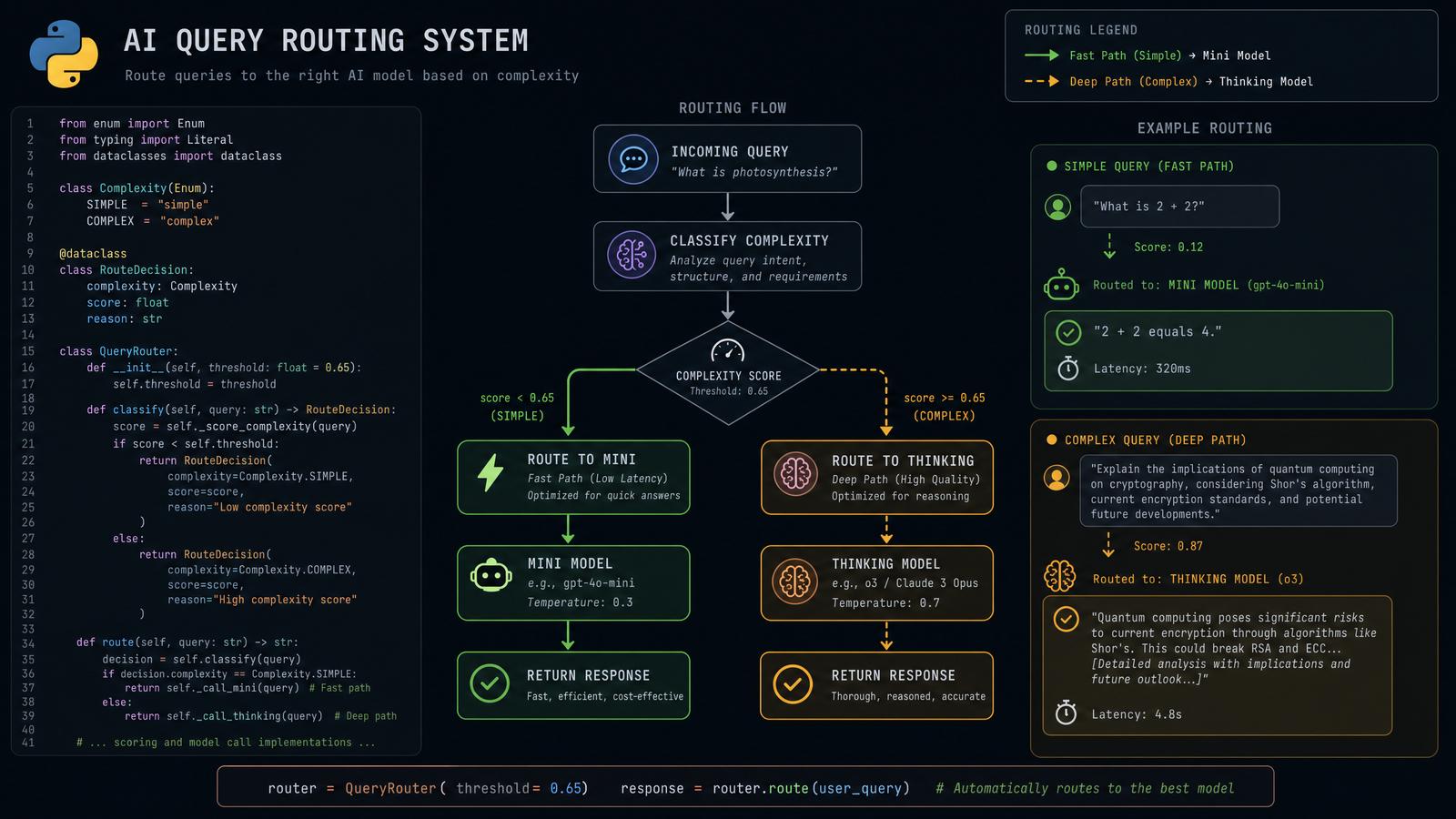
The following Python example demonstrates a scalable and production-grade approach to dynamically route user queries between GPT-5.5 Mini and GPT-5.5 Thinking models based on the complexity of the input. This hybrid system is designed to optimize key operational metrics such as latency, cost-efficiency, and output quality by leveraging the strengths of each model: the lightweight Mini for quick, straightforward queries, and the powerful Thinking for complex reasoning or code generation.
Overview of System Architecture and Goals
In real-world deployments, balancing performance and cost is crucial. Lightweight models reduce inference time and API costs but may struggle with nuanced or multi-step reasoning. Conversely, larger models provide high-quality responses at a higher cost and latency. The dynamic router addresses this by:
- Automatically classifying queries by complexity using heuristic and regex-based analysis.
- Routing simple factual or short queries to
GPT-5.5 Minifor fast, low-cost responses. - Routing complex, multi-step, or programming-related queries to
GPT-5.5 Thinkingfor detailed and accurate responses.
This approach enables scalable deployments where cost and speed are balanced without sacrificing the user experience.
Expanded Python Script with Production-Grade Enhancements
The following code includes improvements such as robust error handling, configurable parameters, detailed logging, asynchronous API calls for scalability, and modular design for extensibility.
import openai
import re
import logging
import asyncio
import os
from typing import Optional
# Configure logging for monitoring and debugging
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s [%(levelname)s] %(message)s',
handlers=[
logging.FileHandler("query_router.log"),
logging.StreamHandler()
]
)
# Retrieve API key from environment variables for security best practices
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")
if not OPENAI_API_KEY:
logging.error("OpenAI API key not found. Please set the OPENAI_API_KEY environment variable.")
raise EnvironmentError("Missing OpenAI API key")
openai.api_key = OPENAI_API_KEY
# Model constants - configurable for future upgrades or A/B testing
MODEL_MINI = "gpt-5.5-mini-1.5b"
MODEL_THINKING = "gpt-5.5-thinking-30b"
# Tuning parameters for each model
MODEL_CONFIGS = {
MODEL_MINI: {"max_tokens": 100, "temperature": 0.5, "top_p": 0.9},
MODEL_THINKING: {"max_tokens": 300, "temperature": 0.7, "top_p": 0.95},
}
def is_complex_query(query: str) -> bool:
"""
Heuristic function to determine if the query is complex.
Criteria include:
- Presence of multi-step reasoning or request keywords.
- Requests for code snippets or programming help.
- Query length threshold to catch verbose questions.
This function can be extended with NLP techniques or ML models for better accuracy.
"""
complex_keywords = [
r"\bexplain\b",
r"\bhow\b",
r"\bwhy\b",
r"\bcode\b",
r"\bimplement\b",
r"\bsummarize\b",
r"\banalyze\b",
r"\bcompare\b",
r"\bsolve\b",
r"\bcalculate\b",
r"\bfunction\b",
r"\balgorithm\b",
r"\bdesign\b",
r"\bexample\b",
]
length_threshold = 100 # characters
if len(query) > length_threshold:
logging.debug(f"Query length {len(query)} exceeds threshold {length_threshold}. Marking as complex.")
return True
for pattern in complex_keywords:
if re.search(pattern, query, re.IGNORECASE):
logging.debug(f"Query matches complex keyword pattern: {pattern}")
return True
return False
async def query_gpt_async(model: str, prompt: str, max_tokens: int, temperature: float, top_p: float) -> Optional[str]:
"""
Asynchronous call to OpenAI Completion API.
Implements retry logic for transient errors and rate limits.
"""
max_retries = 3
for attempt in range(max_retries):
try:
logging.info(f"Sending request to model {model} (Attempt {attempt + 1})")
response = await openai.Completion.acreate(
engine=model,
prompt=prompt,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
n=1,
stop=None,
)
text = response.choices[0].text.strip()
logging.info(f"Received response from model {model}")
return text
except openai.error.RateLimitError as e:
logging.warning(f"Rate limit exceeded on attempt {attempt + 1}: {e}")
await asyncio.sleep(2 ** attempt) # Exponential backoff
except openai.error.OpenAIError as e:
logging.error(f"OpenAI API error on attempt {attempt + 1}: {e}")
break
logging.error(f"Failed to get response from model {model} after {max_retries} attempts")
return None
async def dynamic_router_async(query: str) -> Optional[str]:
"""
Asynchronous router that sends the query to the appropriate model.
"""
if is_complex_query(query):
logging.info("Routing to Thinking model for complex query.")
prompt = f"Answer the following complex question thoroughly:\n\n{query}\n\nAnswer:"
config = MODEL_CONFIGS[MODEL_THINKING]
return await query_gpt_async(MODEL_THINKING, prompt, **config)
else:
logging.info("Routing to Mini model for simple query.")
prompt = f"Answer the following question concisely:\n\n{query}\n\nAnswer:"
config = MODEL_CONFIGS[MODEL_MINI]
return await query_gpt_async(MODEL_MINI, prompt, **config)
def run_sync(coro):
"""
Helper function to run async function synchronously for CLI usage.
"""
return asyncio.get_event_loop().run_until_complete(coro)
if __name__ == "__main__":
test_queries = [
"What is the capital of France?",
"Explain the benefits of using transformers in natural language processing.",
"Write a Python function to reverse a linked list.",
"List three symptoms of the common cold.",
"How do you calculate the eigenvalues of a matrix?",
"Compare the HTTP and HTTPS protocols.",
"Solve the following math problem: Integrate x^2 dx from 0 to 3.",
"Provide an example of a decorator function in Python.",
]
for q in test_queries:
logging.info(f"Processing query: {q}")
response = run_sync(dynamic_router_async(q))
if response:
print(f"Query: {q}\nResponse:\n{response}\n{'='*60}\n")
else:
print(f"Query: {q}\nResponse: Failed to get answer.\n{'='*60}\n")
Technical Breakdown and Production Considerations
- Async API Calls: Using
asyncioenables concurrent processing of multiple queries in real-time applications, improving throughput and reducing latency. - Robust Error Handling: The retry logic with exponential backoff handles transient rate limits and network errors gracefully, which is critical for production stability.
- Configurable Parameters: Temperature,
max_tokens, and model names are abstracted into dictionaries to enable easy tuning and experimentation. - Logging: Detailed logs facilitate monitoring usage patterns, debugging, and auditing. Logs include timestamps, log levels, and messages written to both console and file.
- Security: API keys are loaded from environment variables to avoid accidental leaks in source code repositories.
- Extensibility: The heuristic function can be extended or replaced with a machine learning-based query classifier for higher accuracy.
Model Routing Decision Table
| Query Characteristic | Routing Decision | Model | Max Tokens | Temperature | Use Case |
|---|---|---|---|---|---|
| Short, factual questions (e.g., "What is the capital of France?") | Simple | GPT-5.5 Mini | 100 | 0.5 | Fast, cost-effective responses |
| Multi-step reasoning or explanation requests (e.g., "Explain transformers") | Complex | GPT-5.5 Thinking | 300 | 0.7 | Detailed, high-quality outputs |
| Programming/code generation queries (e.g., "Write a Python function") | Complex | GPT-5.5 Thinking | 300 | 0.7 | Accurate code generation and explanations |
Step-by-Step Walkthrough of Query Routing
- Receive user query: The system accepts a raw text query from the end-user or application.
- Complexity classification: The
is_complex_queryfunction uses regex patterns and length thresholds to classify the query. - Route to model: Based on classification, the query is sent to either the Mini or Thinking model with an appropriate prompt template and parameters.
- Handle API response: The system awaits the response asynchronously, applies retry logic if necessary, and extracts the text result.
- Return to caller: The final answer is returned to the user-facing application or UI component.
Extending the Complexity Classifier with NLP Techniques
For production systems with high query volumes and diverse inputs, heuristic regex-based classification may not suffice. Consider integrating lightweight NLP models or embeddings-based similarity classifiers to detect complexity more reliably.
- Use
spaCyorNLTKto extract syntactic features and named entities. - Leverage sentence embeddings (e.g.,
sentence-transformers) to cluster queries by semantic complexity. - Train a supervised classifier on labeled query datasets to predict complexity with higher precision.
Example: Improved Complexity Classifier Using Sentence Transformers
from sentence_transformers import SentenceTransformer
from sklearn.metrics.pairwise import cosine_similarity
import numpy as np
# Predefined embeddings for example complex queries
model = SentenceTransformer('all-MiniLM-L6-v2')
complex_examples = [
"Explain how transformers work in NLP.",
"Write a function to reverse a linked list.",
"Compare HTTP and HTTPS protocols.",
]
complex_embeddings = model.encode(complex_examples)
def semantic_complexity_check(query: str, threshold: float = 0.7) -> bool:
query_embedding = model.encode([query])
similarities = cosine_similarity(query_embedding, complex_embeddings)
max_sim = np.max(similarities)
return max_sim > threshold
This function can be integrated alongside or instead of regex heuristics for a more nuanced routing decision.
Summary
The dynamic routing script provided combines practical heuristics, asynchronous API calls, and robust error handling to create a scalable and cost-efficient system that intelligently balances speed and quality by leveraging the complementary strengths of GPT-5.5 Mini and Thinking models. This pattern is extensible and forms a strong foundation for deploying GPT models in production environments where latency, cost, and output fidelity are paramount.
Related Reading
Conclusion
GPT-5.5 Mini is a purpose-built model designed specifically for environments where efficiency, low latency, and edge deployment are critical. Unlike its larger counterparts, Mini achieves these goals without sacrificing the fundamental capabilities of natural language understanding and generation. This balance is realized through architectural optimizations and a set of advanced prompting strategies that allow developers to tailor the model's behavior precisely to their application needs.
Key Advanced Prompting Techniques
To unlock the full potential of GPT-5.5 Mini, it's essential to employ a variety of sophisticated prompting methodologies:
- Few-shot Learning: Incorporate a handful of relevant examples within the prompt to guide the model towards the desired output format and semantics, minimizing the need for extensive fine-tuning.
- Prompt Compression: Use techniques such as token pruning and semantic summarization to reduce prompt length without losing critical context, thus optimizing token consumption and latency.
- Structured Output Enforcement: Define explicit output schemas via prompt engineering or specialized tokens, ensuring consistent and machine-readable responses suitable for downstream processing.
- Intelligent Routing: Implement logic that dynamically selects between GPT-5.5 Mini and larger GPT-5.5 variants based on task complexity, available resources, and latency requirements.
Example: Few-shot Prompting for Data Extraction
prompt = """
Extract the following fields from the text:
- Name
- Date of Birth
- Email
Example:
Text: "John Doe was born on January 5, 1985. Contact: [email protected]"
Output:
Name: John Doe
Date of Birth: January 5, 1985
Email: [email protected]
Text: "Alice Smith, born 12th March 1990, email [email protected]"
Output:
"""This prompt guides GPT-5.5 Mini to produce structured outputs efficiently, reducing ambiguity and post-processing overhead.
Dynamic Routing: Balancing Cost, Speed, and Performance
Integrating GPT-5.5 Mini within a dynamic routing framework can further optimize AI deployments. Below is an expanded Python example illustrating how to route queries based on complexity analysis and latency constraints:
import time
def estimate_complexity(query: str) -> int:
# Simple heuristic: longer queries or those with technical keywords are complex
keywords = ['analysis', 'synthesis', 'optimization', 'code', 'data']
score = len(query.split()) + sum(word in query.lower() for word in keywords) * 5
return score
def call_gpt_mini(prompt: str) -> str:
# Simulate GPT-5.5 Mini call (replace with actual API integration)
time.sleep(0.1) # Simulated low latency
return "Mini response for: " + prompt[:50]
def call_gpt_large(prompt: str) -> str:
# Simulate GPT-5.5 Large call (replace with actual API integration)
time.sleep(0.5) # Higher latency due to model size
return "Large GPT response for: " + prompt[:50]
def route_request(query: str, max_latency_ms: int = 300) -> str:
complexity = estimate_complexity(query)
print(f"Estimated complexity: {complexity}")
if complexity < 20 and max_latency_ms >= 200:
# Route to Mini for simple queries with latency budget
return call_gpt_mini(query)
else:
# Route to Large for complex queries or strict latency
return call_gpt_large(query)
# Example usage
user_query = "Generate a summary of the latest financial report and suggest optimizations."
response = route_request(user_query)
print(response)
This routing logic exemplifies how GPT-5.5 Mini can be leveraged to handle straightforward tasks rapidly and cost-effectively, while deferring more demanding workloads to the full-scale GPT-5.5 model.
Production-Grade Deployment Considerations
When deploying GPT-5.5 Mini at scale, consider the following best practices to ensure robustness and maintainability:
- Containerization and Orchestration: Use Docker containers combined with Kubernetes or similar orchestration tools for scalable edge deployments, ensuring consistent environments and easy rollbacks.
- Latency Monitoring: Implement end-to-end monitoring with tools like Prometheus and Grafana to track inference latency, throughput, and error rates, enabling proactive scaling and debugging.
- Cost Management: Integrate usage analytics and budget alerts to optimize token usage and API calls, balancing cost against performance requirements.
- Security and Privacy: Employ secure communication protocols (TLS), API key management, and data anonymization techniques, especially when handling sensitive user data at the edge.
Example Kubernetes Deployment Snippet for GPT-5.5 Mini
apiVersion: apps/v1
kind: Deployment
metadata:
name: gpt-5-5-mini
spec:
replicas: 3
selector:
matchLabels:
app: gpt-mini
template:
metadata:
labels:
app: gpt-mini
spec:
containers:
- name: gpt-mini-container
image: your-registry/gpt-5-5-mini:latest
resources:
limits:
memory: "2Gi"
cpu: "1"
requests:
memory: "1Gi"
cpu: "0.5"
ports:
- containerPort: 8080
env:
- name: OPENAI_API_KEY
valueFrom:
secretKeyRef:
name: openai-credentials
key: api-key
readinessProbe:
httpGet:
path: /health
port: 8080
initialDelaySeconds: 5
periodSeconds: 10
Summary
Combined, these techniques and deployment strategies position GPT-5.5 Mini as a versatile and powerful AI component tailored for modern applications constrained by latency, cost, and hardware limitations. By mastering Mini's prompting and routing paradigms, developers can architect AI solutions that scale efficiently, adapt dynamically, and deliver outstanding user experiences across a wide array of edge and cloud environments.
For more detailed information on advanced GPT-5.5 prompting techniques and deployment strategies, explore our related guides:
-
OpenAI Codex vs Claude Code 2026: The AI Coding War — Gartner Leaders Compared
-
15 Production-Ready ChatGPT System Prompts for Software Development Teams
-
How to Use OpenAI Codex Goal Mode for End-to-End Project Automation