How to Use OpenAI Codex for Automated Code Review: Setting Up PR Analysis, Security Scanning, and Performance Optimization Agents

How to Use OpenAI Codex for Automated Code Review: Setting Up PR Analysis, Security Scanning, and Performance Optimization Agents
Author: Markos Symeonides
Automated code review agents built on Codex-class models can catch defects earlier, enforce team standards consistently, and reduce reviewer fatigue on high-volume repositories. In this tutorial, you’ll build a production-ready workflow that uses OpenAI’s code-capable models (the Codex lineage embedded in modern GPT-4-class models) to analyze pull requests (PRs), perform security and performance scans, and integrate with GitHub/GitLab CI/CD. You’ll also learn how to craft robust prompts, manage cost, handle false positives, and embed your team’s rules. Real code examples are included in Node.js and Python with CI configurations for GitHub Actions and GitLab CI.
Table of Contents
- Overview and Architecture
- Setting Up a Codex-Class Review Agent
- Configuring PR Analysis and Prompt Design
- Security Scanning: OWASP Top 10, Secrets, and Dependencies
- Performance Optimization Checks
- Integrations with GitHub Actions and GitLab CI
- Custom Review Rules and Team Standards
- Handling False Positives and Tuning Sensitivity
- End-to-End Examples: Prompts and Outputs
- Cost Management for High-Volume Repositories
- Best Practices for Human-in-the-Loop Reviews
- Observability, Metrics, and Continuous Evaluation
- Next Steps
1) Overview and Architecture
Codex-class models excel at understanding and generating code. When embedded in a PR workflow, they can:
- Summarize PRs and highlight risks
- Detect security issues aligned to OWASP Top 10
- Spot performance anti-patterns and suggest optimizations
- Enforce team-specific conventions and quality gates
- Draft actionable, line-level review comments
The reference architecture below balances review accuracy, cost, and maintainability.
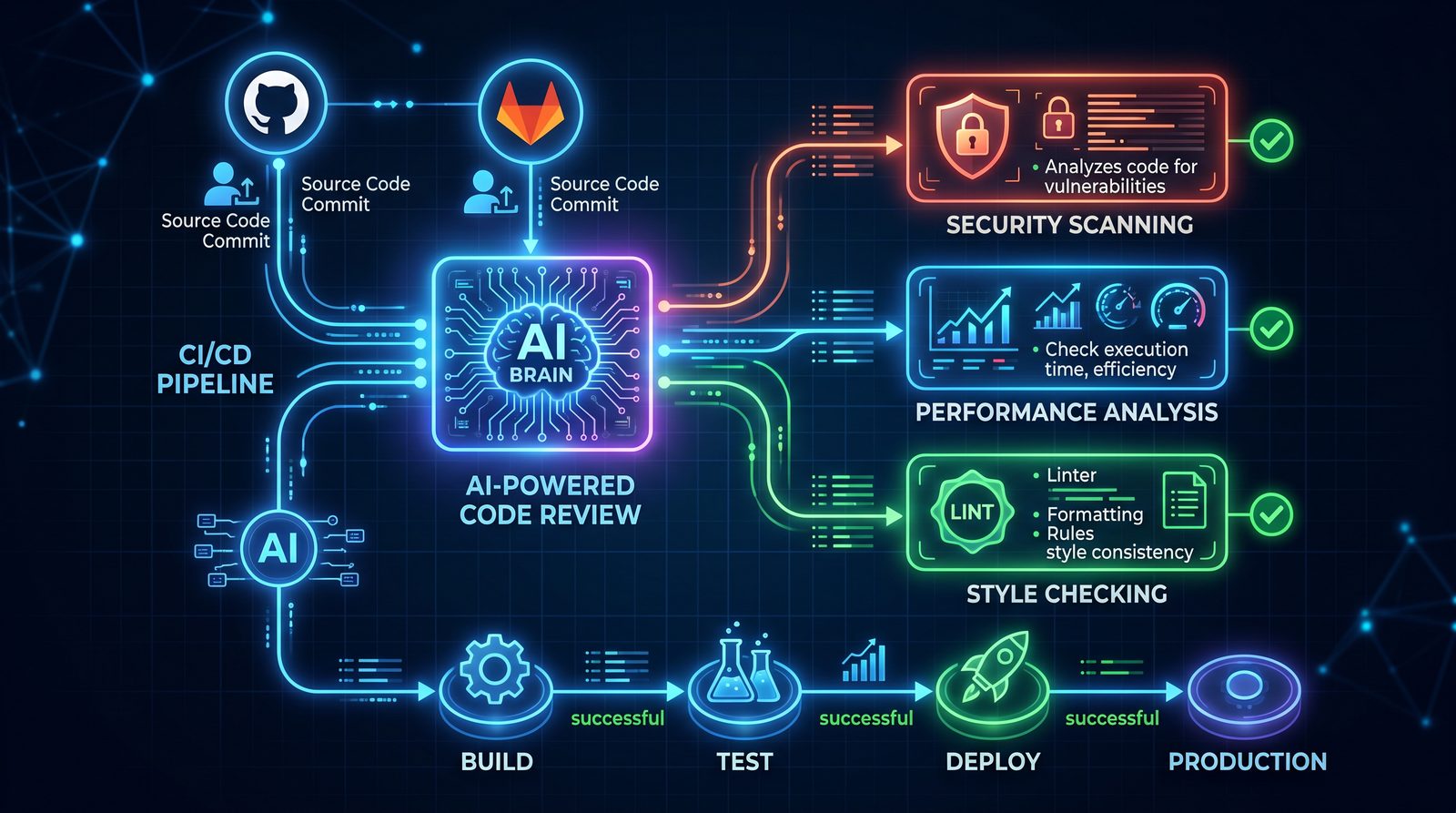
Core components
- Diff collector: Fetches the PR/MR diff, commit messages, and file metadata.
- Chunker: Splits the diff into manageable, context-rich chunks by file/language.
- Prompt builder: Constructs structured prompts (system + user), with a JSON schema for outputs.
- Analyzer: Calls an OpenAI code-capable model with low temperature and structured output.
- Post-processor: Validates JSON, filters low-confidence findings, maps to OWASP/perf categories.
- Reporter: Posts review comments and a summary check to GitHub/GitLab, optionally fails on high severity.
- Cache/Cost guard: Skips unchanged chunks, deduplicates, and enforces per-run token budgets.
2) Setting Up a Codex-Class Review Agent
Prerequisites
- OpenAI API key in CI secrets (e.g., OPENAI_API_KEY)
- GitHub or GitLab token with repo/MR read and comment scopes
- Node.js 18+ or Python 3.9+
Model selection
Use a strong, code-capable GPT-4-class model for analysis and a lightweight model for pre-screens. For example:
- Primary analysis: a GPT-4-class “Codex lineage” model suited for code review
- Pre-screening: a cost-efficient mini model to flag files unlikely to need deep analysis
Set temperature to 0–0.2 for deterministic, audit-friendly results.
Security of secrets
- Store OPENAI_API_KEY and repo tokens in CI secrets, not in code.
- Scope tokens to read/write PRs only. Avoid full admin scopes.
- Log only non-sensitive metadata. Never log raw diffs with secrets or tokens.
Node.js reference implementation
The script below fetches a GitHub PR diff, chunks it, sends it to the model, and posts comments. It outputs a single review summary with optional line comments.
/**
* analyze-pr.js
* Node.js reference implementation for a Codex-class code review agent.
* Requires:
* - OPENAI_API_KEY (env)
* - GITHUB_TOKEN (env)
* - GITHUB_REPOSITORY (org/repo)
* - PR_NUMBER (number)
*/
import fs from "node:fs";
import path from "node:path";
import fetch from "node-fetch";
import { fileURLToPath } from "node:url";
import OpenAI from "openai";
const __filename = fileURLToPath(import.meta.url);
const __dirname = path.dirname(__filename);
const OPENAI_API_KEY = process.env.OPENAI_API_KEY;
const GITHUB_TOKEN = process.env.GITHUB_TOKEN;
const REPO = process.env.GITHUB_REPOSITORY; // "org/repo"
const PR_NUMBER = process.env.PR_NUMBER; // e.g., 123
if (!OPENAI_API_KEY || !GITHUB_TOKEN || !REPO || !PR_NUMBER) {
console.error("Missing required env vars: OPENAI_API_KEY, GITHUB_TOKEN, GITHUB_REPOSITORY, PR_NUMBER");
process.exit(1);
}
const openai = new OpenAI({ apiKey: OPENAI_API_KEY });
// Choose a code-capable model
const MODEL = "gpt-4o-mini"; // Codex-class successor suitable for code analysis
async function getPullRequestFiles() {
const url = `https://api.github.com/repos/${REPO}/pulls/${PR_NUMBER}/files`;
const res = await fetch(url, {
headers: {
"Authorization": `token ${GITHUB_TOKEN}`,
"Accept": "application/vnd.github+json"
}
});
if (!res.ok) {
throw new Error(`GitHub API error: ${res.status} ${await res.text()}`);
}
return await res.json();
}
function languageFromFilename(filename) {
const ext = filename.split(".").pop();
const map = {
js: "JavaScript", ts: "TypeScript", py: "Python", rb: "Ruby", java: "Java",
go: "Go", cs: "C#", php: "PHP", cpp: "C++", c: "C", rs: "Rust",
kt: "Kotlin", swift: "Swift", scala: "Scala", sh: "Shell", yaml: "YAML",
yml: "YAML", json: "JSON", md: "Markdown", sql: "SQL"
};
return map[ext] || "Unknown";
}
function buildSystemPrompt(config) {
return `
You are an autonomous senior code reviewer (Codex-class). Output MUST be valid JSON matching the schema:
{
"summary": { "overview": string, "risk_score": number, "categories": string[] },
"findings": [
{
"id": string,
"file": string,
"line": number | null,
"severity": "critical" | "high" | "medium" | "low" | "info",
"category": "security" | "performance" | "maintainability" | "style" | "dependency",
"title": string,
"description": string,
"evidence": string,
"owasp": string[] | [],
"tags": string[],
"suggestion": { "type": "explanation" | "patch", "content": string }
}
]
}
Strict requirements:
- Report only when evidence is strong. Avoid speculative findings.
- Use OWASP tags for security (e.g., "A01:2021-Broken Access Control").
- Point to specific lines when possible; otherwise line should be null.
- Group similar issues into one finding, not duplicates.
- Suggest minimal, safe changes. If unsure, ask for clarification in description.
- Follow team rules when provided.
${config?.rulesNote ? `\nTeam rules: ${config.rulesNote}\n` : ""}
`;
}
function buildUserPrompt({ filename, language, patch, additions, deletions }, options) {
// Trim overly large patches to a cap (token/cost guard)
const MAX_CHARS = options?.maxChars || 12000;
let trimmedPatch = patch;
if (patch && patch.length > MAX_CHARS) {
trimmedPatch = patch.slice(0, MAX_CHARS) + "\n... [truncated]";
}
return `
Analyze the following ${language} diff and produce JSON per schema:
File: ${filename}
Changes: +${additions} / -${deletions}
Unified diff (git patch format):
${trimmedPatch}
Review modes enabled: ${options?.modes?.join(", ") || "security, performance, maintainability"}.
Focus:
- Security: OWASP Top 10 categories, injection, broken access control, insecure deserialization, SSRF, secrets.
- Performance: Hot-path allocations, N+1 queries, blocking I/O in async contexts, inefficient loops.
- Maintainability: Null handling, error handling contracts, confusing control flow, dead code.
- Dependency: Introduced/upgraded packages with known CVEs (if provided separately).
Constraints:
- If no issues, output an empty findings array with a clear summary.
- Be concise; avoid generic advice. Reference exact code snippets in evidence.
`;
}
async function analyzeChunk(chunk, config) {
const response = await openai.chat.completions.create({
model: MODEL,
temperature: 0.1,
response_format: { type: "json_object" },
messages: [
{ role: "system", content: buildSystemPrompt(config) },
{ role: "user", content: buildUserPrompt(chunk, { modes: config?.modes, maxChars: config?.maxChars }) }
],
});
const text = response.choices[0].message.content || "{}";
try {
return JSON.parse(text);
} catch (e) {
// Fallback parsing: attempt to recover JSON
const match = text.match(/\{[\s\S]*\}$/);
return match ? JSON.parse(match[0]) : { summary: { overview: "Parse error", risk_score: 0, categories: [] }, findings: [] };
}
}
function dedupeFindings(findings) {
const seen = new Set();
return findings.filter(f => {
const key = `${f.file}:${f.line || 0}:${(f.title || "").slice(0,50)}:${f.category}`;
if (seen.has(key)) return false;
seen.add(key);
return true;
});
}
async function postReviewSummary(body) {
const url = `https://api.github.com/repos/${REPO}/issues/${PR_NUMBER}/comments`;
const res = await fetch(url, {
method: "POST",
headers: {
"Authorization": `token ${GITHUB_TOKEN}`,
"Accept": "application/vnd.github+json",
"Content-Type": "application/json"
},
body: JSON.stringify({ body })
});
if (!res.ok) {
console.error(`Failed to post summary: ${res.status} ${await res.text()}`);
}
}
async function postReviewComment(file, line, body) {
// PR review comment API requires a commit_id and position for diff; for simplicity, post as issue comment with file context.
const formatted = `File: ${file}${line ? ` (line ${line})` : ""}\n\n${body}`;
await postReviewSummary(formatted);
}
function renderSummaryReport(allSummaries, combinedFindings) {
const total = combinedFindings.length;
const bySeverity = { critical: 0, high: 0, medium: 0, low: 0, info: 0 };
combinedFindings.forEach(f => { bySeverity[f.severity] = (bySeverity[f.severity] || 0) + 1; });
const topCategories = {};
combinedFindings.forEach(f => { topCategories[f.category] = (topCategories[f.category] || 0) + 1; });
const cats = Object.entries(topCategories).sort((a,b)=>b[1]-a[1]).slice(0,5).map(([k,v]) => `${k}(${v})`).join(", ");
return [
"Automated Codex-Class Review Summary",
"",
`Findings: ${total} (critical:${bySeverity.critical}, high:${bySeverity.high}, medium:${bySeverity.medium}, low:${bySeverity.low})`,
`Top categories: ${cats || "none"}`,
"",
...allSummaries.map((s, i)=>`Part ${i+1}: ${s.summary?.overview || ""}`)
].join("\n");
}
async function main() {
const files = await getPullRequestFiles();
const chunks = files
.filter(f => f.status !== "removed")
.filter(f => !/\.lock$/.test(f.filename)) // skip lockfiles to save cost (or handle separately)
.map(f => ({
filename: f.filename,
language: languageFromFilename(f.filename),
patch: f.patch || "",
additions: f.additions,
deletions: f.deletions
}))
.filter(f => f.patch);
const config = {
modes: ["security", "performance", "maintainability"],
maxChars: 24000,
rulesNote: "No secrets in code; enforce async I/O in Node; avoid raw SQL strings outside ORM; prefer parameterized queries."
};
const results = [];
for (const chunk of chunks) {
const result = await analyzeChunk(chunk, config);
results.push(result);
}
const allFindings = dedupeFindings(results.flatMap(r => r.findings || []));
const summary = renderSummaryReport(results, allFindings);
// Post summary
await postReviewSummary("```\n" + summary + "\n```");
// Optionally, post top N line comments
const top = allFindings
.filter(f => ["critical","high"].includes(f.severity))
.slice(0, 10);
for (const f of top) {
const body = [
`Severity: ${f.severity.toUpperCase()}`,
`Category: ${f.category}`,
`Title: ${f.title}`,
`Description: ${f.description}`,
f.owasp && f.owasp.length ? `OWASP: ${f.owasp.join(", ")}` : "",
`Evidence:\n${f.evidence}`,
`Suggestion (${f.suggestion.type}):\n${f.suggestion.content}`
].filter(Boolean).join("\n\n");
await postReviewComment(f.file, f.line || null, body);
}
// Optionally fail CI on criticals
const hasCritical = allFindings.some(f => f.severity === "critical");
if (hasCritical) {
console.error("Critical issues found by automated review.");
process.exit(2);
}
}
main().catch(err => {
console.error(err);
process.exit(1);
});
Why JSON output?
Strict JSON lets you parse, deduplicate, and enforce policies deterministically. You can convert JSON findings to PR comments, dashboards, and metrics without brittle string parsing.
Python reference (GitLab/MR-friendly)
# review_mr.py
# Python example for GitLab merge requests using a Codex-class model.
import os
import json
import requests
from openai import OpenAI
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")
GITLAB_TOKEN = os.getenv("GITLAB_TOKEN")
PROJECT_ID = os.getenv("CI_PROJECT_ID")
MR_IID = os.getenv("CI_MERGE_REQUEST_IID")
GITLAB_API = os.getenv("CI_API_V4_URL", "https://gitlab.com/api/v4")
if not (OPENAI_API_KEY and GITLAB_TOKEN and PROJECT_ID and MR_IID):
raise SystemExit("Missing OPENAI_API_KEY, GITLAB_TOKEN, CI_PROJECT_ID, CI_MERGE_REQUEST_IID")
client = OpenAI(api_key=OPENAI_API_KEY)
MODEL = "gpt-4o-mini"
def get_mr_changes():
url = f"{GITLAB_API}/projects/{PROJECT_ID}/merge_requests/{MR_IID}/changes"
r = requests.get(url, headers={"PRIVATE-TOKEN": GITLAB_TOKEN})
r.raise_for_status()
return r.json()["changes"]
def language_from_filename(filename):
ext = filename.split(".")[-1]
return {
"js":"JavaScript","ts":"TypeScript","py":"Python","rb":"Ruby","java":"Java","go":"Go",
"cs":"C#","php":"PHP","cpp":"C++","c":"C","rs":"Rust","kt":"Kotlin","swift":"Swift",
"scala":"Scala","sh":"Shell","yaml":"YAML","yml":"YAML","json":"JSON","md":"Markdown","sql":"SQL"
}.get(ext, "Unknown")
def build_system_prompt():
return """
You are a Codex-class autonomous reviewer. Output strict JSON:
{"summary":{"overview":string,"risk_score":number,"categories":string[]},"findings":[{"id":string,"file":string,"line":number|null,"severity":"critical"|"high"|"medium"|"low"|"info","category":"security"|"performance"|"maintainability"|"style"|"dependency","title":string,"description":string,"evidence":string,"owasp":string[],"tags":string[],"suggestion":{"type":"explanation"|"patch","content":string}}]}
Only report with strong evidence. Group duplicates. Use OWASP tags for security findings. Keep responses concise.
"""
def build_user_prompt(change):
patch = change.get("diff") or ""
if len(patch) > 24000:
patch = patch[:24000] + "\n... [truncated]"
return f"""
Analyze the following {language_from_filename(change["new_path"])} diff and produce JSON per schema:
File: {change["new_path"]}
Unified diff:
{patch}
Focus: security (OWASP), performance, maintainability. Only emit findings with evidence.
"""
def post_mr_note(body):
url = f"{GITLAB_API}/projects/{PROJECT_ID}/merge_requests/{MR_IID}/notes"
r = requests.post(url, headers={"PRIVATE-TOKEN": GITLAB_TOKEN}, json={"body": body})
r.raise_for_status()
def main():
changes = get_mr_changes()
all_findings = []
summaries = []
for ch in changes:
if ch.get("new_file") and not ch.get("diff"):
continue
messages = [
{"role": "system", "content": build_system_prompt()},
{"role": "user", "content": build_user_prompt(ch)}
]
resp = client.chat.completions.create(
model=MODEL, temperature=0.1, response_format={"type":"json_object"}, messages=messages
)
text = resp.choices[0].message.content
try:
data = json.loads(text)
except Exception:
continue
summaries.append(data.get("summary", {}))
all_findings.extend(data.get("findings", []))
sev_order = {"critical":5,"high":4,"medium":3,"low":2,"info":1}
all_findings.sort(key=lambda f: sev_order.get(f.get("severity","info"),1), reverse=True)
lines = []
by_sev = { "critical":0,"high":0,"medium":0,"low":0,"info":0}
for f in all_findings:
by_sev[f["severity"]] = by_sev.get(f["severity"],0)+1
lines.append(f"Automated Codex-Class Review: {len(all_findings)} findings")
lines.append(f"By severity: {by_sev}")
for f in all_findings[:15]:
lines.append(f"- [{f['severity'].upper()}] {f['file']}:{f.get('line') or '?'} - {f['title']}")
post_mr_note("```\n" + "\n".join(lines) + "\n```")
# Optional: fail pipeline if critical findings exist
if any(f.get("severity") == "critical" for f in all_findings):
raise SystemExit("Critical issues found")
if __name__ == "__main__":
main()
3) Configuring PR Analysis and Prompt Design
What to review in a PR
- Security: input validation, authz/authn boundaries, injection risks, secret exposure
- Performance: algorithmic complexity, hot-path allocations, blocking I/O, N+1 queries
- Correctness: null handling, error propagation, concurrency hazards
- Maintainability: readability, modularity, dead code, excessive nesting
- Style: lint rules not auto-fixable, team conventions
- Dependencies: new/updated packages and known vulnerabilities
Prompt structure
Use a system message to set strict behavior and a user message per file/diff. Embed a JSON schema explicitly, specifying fields like severity, category, and suggestion. Keep temperature low and require evidence quotes.
System prompt template (reusable)
{
"role": "system",
"content": "You are a Codex-class autonomous reviewer. Output strict JSON with fields: summary (overview, risk_score, categories), findings (id, file, line, severity, category, title, description, evidence, owasp, tags, suggestion). Report only with strong evidence; avoid duplicates; use OWASP tags where applicable."
}
User prompt template (diff-focused)
{
"role": "user",
"content": "Analyze the following <LANGUAGE> diff for security, performance, and maintainability. Provide JSON findings with line numbers and minimal safe suggestions. Unified diff:\\n<PATCH>"
}
Chunking strategy
- Chunk by file, never across languages. Maintain per-file context.
- Trim patches beyond a safe size and mark as truncated. Add a second pass for large files if needed.
- Skip known generated files (e.g., .snap, .lock, yarn.lock) unless dependency scanning is enabled.
- Pass metadata: file path, language, additions/deletions, previous review history if available.
Deterministic parsing and validation
- Use response_format: json_object to enforce JSON when supported.
- Fallback with robust JSON extraction to handle occasional format drift.
- Validate each finding: file exists, line is within changed range, severity is allowed.
- Normalize categories and tags to a controlled vocabulary.
4) Security Scanning: OWASP Top 10, Secrets, and Dependencies
Codex-class models augment static scanners by reasoning about context and intent. Combine them with deterministic tools for best coverage.
Coverage map (selected OWASP Top 10)
| OWASP Category | What to Ask the Model to Detect | Signal Examples |
|---|---|---|
| A01:2021 Broken Access Control | Missing authz checks on sensitive paths, direct object references, role bypass | Routes with admin operations but no role checks; exposed IDs used directly in DB queries |
| A03:2021 Injection | String-concatenated SQL, command injection, template injection | Raw SQL with user input; shell execution of user-supplied args |
| A05:2021 Security Misconfiguration | Disabling HTTPS checks, permissive CORS, verbose error leaks | CORS “*”, stack traces returned in API |
| A07:2021 Identification and Authentication Failures | Weak password checks, missing MFA enforcement, session fixation | Passwords logged or compared insecurely |
| A08:2021 Software and Data Integrity Failures | Unpinned dependencies, unsigned plugin loading, unsafe deserialization | Dynamic import of untrusted packages, pickle.loads on user input |
| A09:2021 Security Logging and Monitoring Failures | Missing audit logs for critical actions | No logging on privilege changes |
| A10:2021 Server-Side Request Forgery (SSRF) | External fetch of user-provided URLs without allowlists | HTTP clients invoked with unchecked URLs |
Secrets scanning via prompt + regex pre-pass
- Pre-scan diffs with lightweight regex for API keys, tokens, credentials.
- Pass matches to the model to confirm if they are real secrets or test fixtures.
- Require evidence and a redaction plan in suggestions.
// secret_scan.js (pre-pass example)
const SECRET_PATTERNS = [
/AKIA[0-9A-Z]{16}/g, // AWS Access Key ID
/aws_secret_access_key\s*=\s*["'][A-Za-z0-9\/+=]{40}["']/gi,
/xox[baprs]-[0-9A-Za-z-]{10,48}/g, // Slack tokens
/-----BEGIN (RSA|DSA|EC|PGP) PRIVATE KEY-----/g
];
export function findPotentialSecrets(patch) {
const hits = [];
SECRET_PATTERNS.forEach(rx => {
const m = patch.match(rx);
if (m) hits.push(...m);
});
return Array.from(new Set(hits));
}
Dependency vulnerability checks (OSV integration)
When the diff includes package manifests (package.json, requirements.txt, go.mod, pom.xml), gather new/updated dependencies and query a vulnerability database such as OSV. Feed any flagged CVEs into the model as evidence for a dependency-category finding.
Access 40,000+ AI Prompts for ChatGPT, Claude & Codex — Free!
Subscribe to get instant access to our complete Notion Prompt Library — the largest curated collection of prompts for ChatGPT, Claude, OpenAI Codex, and other leading AI models. Optimized for real-world workflows across coding, research, content creation, and business.
// osv_check.js
import fetch from "node-fetch";
export async function queryOSV(packageName, ecosystem, version) {
// https://osv.dev schema
const res = await fetch("https://api.osv.dev/v1/query", {
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify({ package: { name: packageName, ecosystem }, version })
});
if (!res.ok) return [];
const data = await res.json();
return data.vulns || [];
}
Feeding dependency issues to the model
function buildDependencyPrompt(depFindings) {
return `
Evaluate the following updated dependencies. For any with known CVEs, generate 'dependency' findings with severity (high if exploitable), and suggestions (pin safe versions).
Dependencies with CVEs:
${JSON.stringify(depFindings, null, 2)}
`;
}
Security-focused prompt augmentations
- Require OWASP tags for security findings.
- Ask for exploitability conditions and remediation steps as evidence and suggestion.
- Enforce “no speculation” by asking for exact code references and conditions.
5) Performance Optimization Checks
Codex-class analysis is powerful at surfacing performance anti-patterns with context-based suggestions. Calibrate your prompt to target your stack’s hot paths.
Common patterns to flag
- N+1 DB queries in loops
- Blocking I/O on async/event loops
- Excessive intermediate allocations/copies
- Inefficient regex/combinatorial parsing
- Quadratic loops over large collections
- Unbounded concurrency/fan-out without backpressure
- String concatenation in tight loops (favor builders/joins)
Prompt snippet for performance emphasis
Performance focus:
- Identify hot-path risks (loops, handlers, middleware).
- Highlight blocking calls in async contexts and propose non-blocking alternatives.
- For DB code, detect per-item queries and suggest bulk operations or joins.
- Provide minimal diff-ready patches when safe.
Example: Node.js event loop blocking
diff --git a/server.js b/server.js
index 123..456 100644
--- a/server.js
+++ b/server.js
@@ -42,7 +42,13 @@ app.get("/report", async (req, res) => {
- const data = fs.readFileSync("./large.json", "utf8"); // blocking on event loop
+ const data = await fs.promises.readFile("./large.json", "utf8"); // non-blocking
const report = JSON.parse(data);
res.json(report);
});
Expected model finding (excerpt)
{
"id": "perf-node-blocking-001",
"file": "server.js",
"line": 43,
"severity": "high",
"category": "performance",
"title": "Blocking file read on event loop",
"description": "fs.readFileSync blocks the Node.js event loop under load.",
"evidence": "Found fs.readFileSync(...) in a request handler.",
"owasp": [],
"tags": ["nodejs","event-loop","io"],
"suggestion": { "type": "patch", "content": "Replace readFileSync with await fs.promises.readFile(...)" }
}
Example: Python N+1 query
diff --git a/views.py b/views.py
--- a/views.py
+++ b/views.py
@@ -20,7 +20,11 @@ def list_users():
- users = User.query.all()
- return [{"name": u.name, "posts": [p.title for p in u.posts]} for u in users]
+ users = User.query.options(selectinload(User.posts)).all()
+ return [{"name": u.name, "posts": [p.title for p in u.posts]} for u in users]
Expected model finding (excerpt)
{
"id": "perf-nplus1-002",
"file": "views.py",
"line": 21,
"severity": "medium",
"category": "performance",
"title": "Potential N+1 query mitigated by eager loading",
"description": "Original code risked N+1 queries; change introduces selectinload, which is recommended.",
"evidence": "Accessing u.posts in a list comprehension over users.",
"owasp": [],
"tags": ["sqlalchemy","n+1","eager-loading"],
"suggestion": { "type": "explanation", "content": "Retain selectinload; if list is large, paginate results." }
}
6) Integrations with GitHub Actions and GitLab CI
GitHub Actions
# .github/workflows/codex-review.yml
name: Codex-Class Automated Review
on:
pull_request:
types: [opened, synchronize, reopened, ready_for_review]
jobs:
review:
runs-on: ubuntu-latest
permissions:
pull-requests: write
contents: read
steps:
- name: Checkout
uses: actions/checkout@v4
- name: Setup Node
uses: actions/setup-node@v4
with:
node-version: "20"
- name: Install deps
run: npm ci
if: ${{ hashFiles('**/package-lock.json') != '' }}
- name: Analyze PR
env:
OPENAI_API_KEY: ${{ secrets.OPENAI_API_KEY }}
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
GITHUB_REPOSITORY: ${{ github.repository }}
PR_NUMBER: ${{ github.event.number }}
run: node scripts/analyze-pr.js
- name: Post status
if: failure()
run: echo "Critical issues identified by Codex-class reviewer."
GitLab CI
# .gitlab-ci.yml
stages: [review]
codex_review:
stage: review
image: python:3.11
variables:
PIP_DISABLE_PIP_VERSION_CHECK: "1"
before_script:
- pip install openai requests
script:
- python scripts/review_mr.py
rules:
- if: $CI_PIPELINE_SOURCE == "merge_request_event"
artifacts:
when: always
reports:
junit: report.xml
allow_failure: false
Mapping findings to checks
- GitHub: post a summary comment and optional line comments; fail the job on criticals to block merge (optional).
- GitLab: post MR notes; optionally output JUnit-format to integrate with merge request widgets.
7) Custom Review Rules and Team Standards
Codex-class agents become significantly more valuable when they encode your team’s conventions and risk appetite. Externalize rules in a versioned repo file (e.g., .codex-review.yml) and feed them into prompts.
Rules config example (.codex-review.yml)
modes:
- security
- performance
- maintainability
severity_thresholds:
block_merge: ["critical"] # fail CI when these severities appear
notify_only: ["low","info"] # do not fail CI
language_policies:
JavaScript:
- rule: "No blocking I/O in HTTP handlers"
evidence_hint: "fs.readFileSync, child_process.execSync"
severity: "high"
- rule: "Use parameterized queries"
evidence_hint: "raw SQL string concatenation"
severity: "critical"
Python:
- rule: "Avoid unsafe deserialization"
evidence_hint: "pickle.loads on variable input"
severity: "high"
dependency_policies:
allowed_licenses: ["MIT","Apache-2.0","BSD-3-Clause"]
ban_packages: ["left-pad@*"]
require_pins: true
file_exclusions:
- "dist/**"
- "**/*.snap"
- "**/*.lock"
style_conventions:
max_function_length: 80
max_cyclomatic_complexity: 10
Injecting rules into prompts
Summarize rules into a concise note (rulesNote) and include in your system message. Provide evidence hints to improve precision.
Team-specific examples
- Security baseline: require authz on routes under /admin and /billing.
- Performance baseline: ban synchronous FS/crypto within request lifecycles.
- Maintainability baseline: fail for new functions exceeding cyclomatic complexity 10.
8) Handling False Positives and Tuning Sensitivity
Practical strategies
- Evidence requirement: model must quote exact code lines and conditions. Discard findings without evidence.
- Severity gating: only block merges on critical/high; surface medium/low as comments.
- Cross-tool corroboration: only elevate if static tool (e.g., ESLint, Semgrep, Bandit) and model agree.
- Allowlist/waivers: support per-finding suppression IDs (e.g., codex-ignore: perf-nplus1-002) with expiry.
- Temperature/Top-p: keep temperature low (≤ 0.2) and avoid creative sampling for reviews.
- Feedback loop: track dismissed findings and feed patterns back into prompts (e.g., “Do not report XYZ in tests/benchmark files”).
Confidence scoring
Have the model self-assess confidence in evidence and only include findings above a threshold. You can optionally add a “confidence” field in your JSON schema and filter below a cutoff.
Deduplication and stability
- Dedupe by file:line:title:category key.
- Pin model version and temperature to maintain consistent outputs.
- Cache unchanged file analyses by commit hash to avoid re-analysis noise.
9) End-to-End Examples: Prompts and Outputs
Example: Insecure SQL construction (OWASP Injection)
diff --git a/userRepo.js b/userRepo.js
--- a/userRepo.js
+++ b/userRepo.js
@@ -33,7 +33,9 @@ export async function findUser(db, username) {
- const q = `SELECT * FROM users WHERE name = '${username}'`;
- return db.query(q);
+ // Use parameterized query to avoid SQL injection
+ const q = "SELECT * FROM users WHERE name = $1";
+ return db.query(q, [username]);
}
Model output (JSON excerpt)
{
"summary": {
"overview": "Replaced string-concatenated SQL with parameterized query to mitigate injection risk.",
"risk_score": 3,
"categories": ["security","maintainability"]
},
"findings": [
{
"id": "sec-sqlinj-001",
"file": "userRepo.js",
"line": 34,
"severity": "critical",
"category": "security",
"title": "SQL injection risk via string concatenation",
"description": "User input 'username' was embedded into a SQL string without parameterization.",
"evidence": "Original: `SELECT * FROM users WHERE name = '${username}'`",
"owasp": ["A03:2021-Injection"],
"tags": ["sql","node","db"],
"suggestion": {
"type": "patch",
"content": "Use parameterized query: db.query('SELECT * FROM users WHERE name = $1', [username])"
}
}
]
}
Example: Leaked secret in config
diff --git a/config.py b/config.py
--- a/config.py
+++ b/config.py
@@ -3,6 +3,7 @@
-API_KEY = "sk-live-1234567890abcdef"
+API_KEY = os.getenv("API_KEY")
Model output (JSON excerpt)
{
"findings": [
{
"id": "sec-secret-001",
"file": "config.py",
"line": 4,
"severity": "high",
"category": "security",
"title": "Hard-coded secret",
"description": "A live API key string was present in config. Moved to environment variable.",
"evidence": "Found pattern 'sk-live-********'",
"owasp": ["A02:2021-Cryptographic Failures"],
"tags": ["secret","config"],
"suggestion": {
"type": "patch",
"content": "Rotate the key and use environment variables or a secret manager. Ensure the old key is revoked."
}
}
]
}
Example: Maintainability (complex function)
diff --git a/utils.js b/utils.js
--- a/utils.js
+++ b/utils.js
@@ -10,7 +10,18 @@ export function process(items) {
- // 120-line function (omitted) with nested logic
+ // Consider splitting into smaller pure functions:
+ // - parseInput
+ // - transform
+ // - validate
+ // Improves testability and reduces cyclomatic complexity.
}
Model output (JSON excerpt)
{
"findings": [
{
"id": "maint-complexity-001",
"file": "utils.js",
"line": 12,
"severity": "low",
"category": "maintainability",
"title": "High cyclomatic complexity",
"description": "Function exceeds team complexity threshold; refactor into smaller units.",
"evidence": "Heuristics indicate >80 LOC and multiple nested branches.",
"owasp": [],
"tags": ["complexity","refactor"],
"suggestion": { "type":"explanation", "content":"Extract pure functions and add unit tests per unit." }
}
]
}
10) Cost Management for High-Volume Repositories
Token budgeting
- Cap per-diff characters: truncate long patches and perform targeted second passes only for risky files.
- Analyze only changed files; skip renames with no content change.
- Use a fast “pre-screen” model to tag likely-safe files; send risky files to a stronger model.
- Cache analyses by file content hash to avoid re-analyzing unchanged chunks across pushes.
Approximate token math
- Roughly 3–4 characters per token for English-like text; code can vary.
- Estimate tokens = (system + user prompt + diff chunk) / chars-per-token.
- Compute spend = tokens_in/1M * model_input_price + tokens_out/1M * model_output_price.
- Set a max budget per run and bail early if exceeded (e.g., ignore low-severity categories).
Practical cost controls
- File filters: exclude generated assets, snapshots, lockfiles from model passes; handle lockfiles with deterministic dependency scanners.
- Structured output: JSON is shorter than verbose prose; keeps output tokens low.
- Throttle concurrency to avoid spikes; pipeline runs can be serialized for large PRs.
- Use differential analysis: only analyze newly changed hunks since last commit.
Example: enforcing a run budget
let tokenBudget = 200_000; // Example tokens per run
for (const chunk of chunks) {
const est = (chunk.patch.length + 3000) / 4; // rough char-to-token
if (tokenBudget - est <= 0) { console.warn("Budget exceeded, skipping remaining files."); break; }
tokenBudget -= est;
await analyzeChunk(chunk, config);
}
11) Best Practices for Human-in-the-Loop Reviews
Workflow design
- Advisory by default: post comments without blocking merges, except for critical/high issues.
- Clear escalation: criticals require human validation; assign reviewers automatically (CODEOWNERS).
- Patch suggestions: when safe, have the model provide minimal patches; reviewers can accept or adjust.
- Decision log: post a summary comment listing accepted/rejected findings for traceability.
Reviewer ergonomics
- Aggregate summary at top; line comments for top-severity findings only.
- Labels/tags for quick triage: security, performance, maintainability.
- Suppressions with context: allow “codex-ignore:<id>” comments with rationale and expiry.
Blending with static tools
- Run ESLint/Flake8/Semgrep/Bandit/Snyk in parallel; combine signals to reduce noise.
- Let the model “explain” static tool outputs with code context and remediation steps.
- Only block on issues with corroboration or high-confidence, high-impact evidence.
12) Observability, Metrics, and Continuous Evaluation
What to measure
- Precision/recall proxy: ratio of accepted vs. dismissed findings by severity and category.
- Cost per PR: tokens consumed and spend per category.
- Latency: time from PR open to comments posted.
- Drift: changes in model outputs across versions.
Logging and storage
- Store prompt IDs, hashed diffs, model, temperature, and findings (without secrets) for audit.
- Keep a small corpus of “golden PRs” to regression-test prompts and model versions.
Automated evaluation loop
- Periodically re-run the agent on golden PRs; inspect deltas in findings.
- Fine-tune rules and evidence hints based on human feedback trends.
- Track false-positive patterns and encode suppressions or clarifications in prompts.
13) Next Steps
With the reference implementation in place, iterate towards a mature review assistant:
- Expand language support and specialized prompts (e.g., Terraform, Kubernetes manifests, mobile)
- Add auto-fix PRs for purely mechanical changes (e.g., sync I/O to async)
- Introduce a review dashboard aggregating findings across repos and sprints
- Set up a lightweight approval flow where reviewers can accept model-suggested patches directly
For deeper prompt design patterns and integrating with build systems, see:
Advanced Prompt Engineering for Code Review Automation,
GitHub Actions Integration with OpenAI Models,
and OWASP Top 10 Security Checks with LLMs.
Appendix: Robust Prompt Template (Drop-In)
System:
You are an autonomous senior code reviewer (Codex-class). Output strict JSON:
{
"summary": { "overview": string, "risk_score": number, "categories": string[] },
"findings": [
{
"id": string,
"file": string,
"line": number | null,
"severity": "critical" | "high" | "medium" | "low" | "info",
"category": "security" | "performance" | "maintainability" | "style" | "dependency",
"title": string,
"description": string,
"evidence": string,
"owasp": string[] | [],
"tags": string[],
"suggestion": { "type": "explanation" | "patch", "content": string }
}
]
}
Requirements:
- Report only with strong evidence (quote exact code).
- Use OWASP tags for security when applicable.
- Avoid duplicates. Group similar findings.
- Minimal safe patches for straightforward fixes.
- Respect team rules: <rulesNote>.
User:
Analyze this <LANGUAGE> unified diff and produce JSON per schema.
File: <FILENAME>
Changes: +<ADDS> / -<DELS>
<PATCH>
Focus: security (OWASP), performance, maintainability, dependency risks (if provided).
Constraints: concise findings; if none, return empty findings with a summary.
Appendix: Mapping JSON to PR Comments
function findingToComment(f) {
const header = `[${f.severity.toUpperCase()}][${f.category}] ${f.title}`;
const owasp = f.owasp?.length ? `OWASP: ${f.owasp.join(", ")}` : "";
const evidence = f.evidence ? `Evidence:\\n${f.evidence}` : "";
const suggestion = f.suggestion ? `Suggestion (${f.suggestion.type}):\\n${f.suggestion.content}` : "";
return `${header}\\n\\n${f.description}\\n\\n${owasp}\\n\\n${evidence}\\n\\n${suggestion}`;
}
Appendix: Semgrep + Codex-class Hybrid
# Run semgrep rules; then have the model explain and prioritize findings
semgrep --config p/owasp-top-ten --json > semgrep.json
// explain_semgrep.js
import fs from "node:fs";
import OpenAI from "openai";
const client = new OpenAI({ apiKey: process.env.OPENAI_API_KEY });
const semgrep = JSON.parse(fs.readFileSync("semgrep.json","utf8"));
const MODEL = "gpt-4o-mini";
const messages = [
{ role: "system", content:
"You are a Codex-class reviewer. Given Semgrep findings and code snippets, group duplicates, prioritize by exploitability, and output strict JSON with 'findings' including severity, title, description, evidence, owasp, suggestion." },
{ role: "user", content: JSON.stringify(semgrep) }
];
const resp = await client.chat.completions.create({
model: MODEL, temperature: 0.1, response_format: { type: "json_object" }, messages
});
console.log(resp.choices[0].message.content);
By combining deterministic scanners with Codex-class reasoning, you’ll achieve better signal-to-noise and more actionable reviews.