How to Build Multi-Agent Workflows with OpenAI Codex: Automating 8-Hour Tasks with Parallel Agent Orchestration
How to Build Multi-Agent Workflows with OpenAI Codex: Automating 8-Hour Tasks with Parallel Agent Orchestration
Ambitious, end-to-end automation projects often stall not because your model can’t write code, but because you don’t have a reliable way to coordinate multiple agents over hours of runtime, while staying on budget, recovering from transient failures, and proving progress. This tutorial walks through a practical, production-grade architecture for building “Codex-style” multi-agent workflows: a planner that decomposes a complex objective, specialist agents that work in parallel, a reviewer that protects quality, and an orchestrator that keeps everything moving. You will learn how to design the architecture, wire up parallel execution, implement token/credit budgeting, checkpoint long runs, monitor progress, and integrate with CI/CD pipelines—complete with Python code examples and command-line utilities you can drop into your own projects. The 2026 Prompt Library: 5 Templates for Prompt Engineering
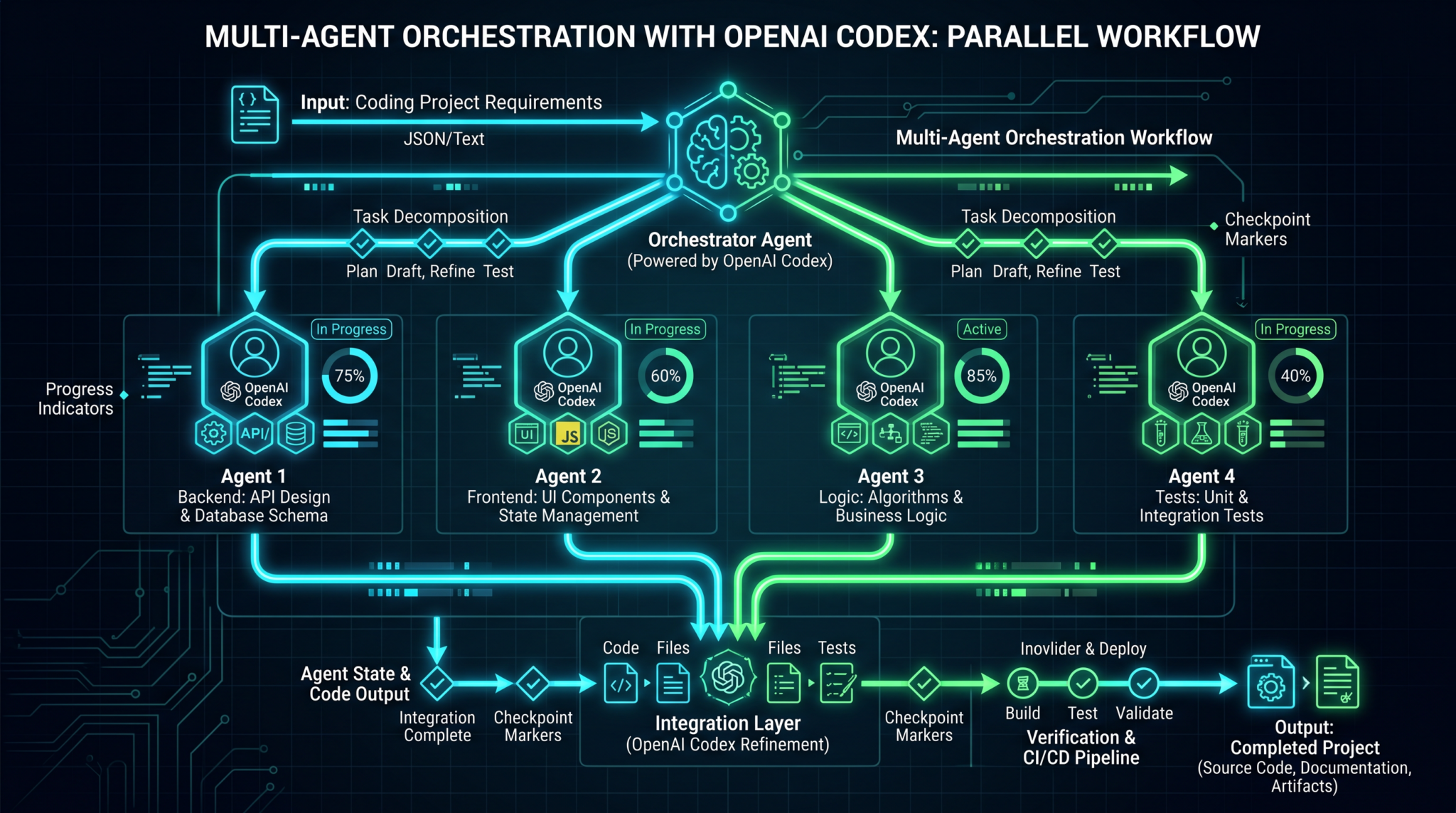
1. Introduction to Codex agent architecture
When people say “Codex agent,” they often mean a code-capable LLM paired with tools and guardrails, not just a single prompt. In a multi-agent architecture, we position the model inside a system that plans, executes, reviews, and monitors longer-running work. Think of it as a small, well-managed team: a planner breaks down the big goal into a DAG of tasks; multiple implementers (specialists) work in parallel; a reviewer or validator checks the outputs; and a coordinator handles orchestration, budgeting, retries, and checkpoints.
This architecture doesn’t require any specific model name. You can use a code-capable model in the OpenAI ecosystem (for example, a GPT-4-class model) to achieve Codex-like behavior. The architectural patterns below remain the same regardless of the exact model: planner, parallel workers, reviewer, and orchestrator.
Main roles and responsibilities
- Planner (decomposer): Reads a high-level spec and produces a DAG of tasks—each with a definition, dependencies, acceptance criteria, and rough budget. Optionally assigns tasks to specialized agent types (e.g., “data_extraction,” “refactor,” “test_scaffold”).
- Implementers (specialist agents): Execute the subtasks (writing code, running tools, reading docs, or transforming data). Each has a clear interface: task in, artifact(s) out, plus logs and usage.
- Reviewer (quality gate): Checks outputs against acceptance criteria; can request fixes or escalate issues back to the planner.
- Orchestrator (controller): Schedules tasks based on dependencies and budgets, handles concurrency limits, manages retries and backoff, persists checkpoints, and provides observability.
| Component | Inputs | Outputs | Key Concerns |
|---|---|---|---|
| Planner | Goal spec, constraints | DAG: tasks + deps + budgets | Granularity, ordering, budget allocation |
| Implementers | Task spec, resources | Artifacts, logs | Token usage, determinism, retryability |
| Reviewer | Artifacts, criteria | Pass/fail, fixes | Quality, consistency |
| Orchestrator | DAG, budgets | Schedule, metrics, checkpoints | Parallelism, error handling, observability |
The rest of this tutorial builds a skeleton system you can extend. We’ll start with parallel execution, then add decomposition, budgeting, checkpointing, and monitoring. By the end, you will have an end-to-end script that can run for hours while keeping your spend predictable and your results traceable. How to Build a a Research Assistant with Claude Code in 2026: Step-by-Step
2. Setting up parallel agent orchestration
Parallelism is what turns an 8-hour serial task into a 2-hour workflow. The orchestrator’s job is to keep a pipeline of ready tasks flowing into worker agents while respecting dependency order, per-agent budgets, and concurrency limits. In Python, the simplest robust way to do this is with asyncio: a semaphore to constrain concurrency, asyncio.gather for batches, and a task scheduler that yields tasks whose dependencies are satisfied.
Design decisions
- Async-first: Use asyncio to control concurrency. Avoid CPU-bound work in the event loop; offload it to threads or processes if needed.
- Idempotency: Tag each API call with an idempotency key so retries don’t duplicate work.
- Backpressure: Bound concurrency with a semaphore to prevent resource exhaustion or rate-limit breaches.
- Dependency-aware scheduling: Use a DAG and only schedule tasks whose prerequisites are complete and successful.
Core orchestration scaffold
Below is a minimal coordinator that pulls tasks from a ready queue, dispatches to agents asynchronously, records results, and respects a concurrency cap. We’ll stub a fake planner and implementer here, then replace them with real LLM-backed logic in later sections.
# orchestrator.py
import asyncio
from dataclasses import dataclass, field
from typing import List, Dict, Optional, Any
import time
import uuid
@dataclass
class Task:
id: str
name: str
description: str
deps: List[str] = field(default_factory=list)
budget_credits: int = 100 # internal credit abstraction
agent_type: str = "general"
status: str = "PENDING"
result: Optional[str] = None
error: Optional[str] = None
attempts: int = 0
@dataclass
class RunConfig:
max_concurrency: int = 4
max_retries: int = 3
retry_backoff: float = 2.0
run_id: str = field(default_factory=lambda: str(uuid.uuid4()))
class Orchestrator:
def __init__(self, tasks: List[Task], config: RunConfig) -> None:
self.tasks: Dict[str, Task] = {t.id: t for t in tasks}
self.config = config
self.sem = asyncio.Semaphore(config.max_concurrency)
self.start_time = time.time()
def ready_tasks(self) -> List[Task]:
ready = []
for t in self.tasks.values():
if t.status == "PENDING":
if all(self.tasks[d].status == "DONE" for d in t.deps):
ready.append(t)
return ready
async def run(self) -> None:
while True:
# If all tasks are terminal, break
states = [t.status for t in self.tasks.values()]
if all(s in {"DONE", "FAILED"} for s in states):
break
# Schedule ready tasks
batch = self.ready_tasks()
if not batch:
await asyncio.sleep(0.2)
continue
await asyncio.gather(*(self._run_one(t) for t in batch))
duration = time.time() - self.start_time
successes = sum(1 for t in self.tasks.values() if t.status == "DONE")
failures = sum(1 for t in self.tasks.values() if t.status == "FAILED")
print(f"Run {self.config.run_id} finished in {duration:.1f}s: "
f"{successes} success, {failures} failed.")
async def _run_one(self, task: Task) -> None:
if task.status != "PENDING":
return
task.status = "RUNNING"
await self.sem.acquire()
try:
for attempt in range(1, self.config.max_retries + 1):
task.attempts = attempt
try:
# placeholder implementation; we replace with LLM-backed agent later
task.result = await self._fake_agent(task)
task.status = "DONE"
break
except Exception as e:
task.error = str(e)
if attempt >= self.config.max_retries:
task.status = "FAILED"
break
await asyncio.sleep(self.config.retry_backoff ** attempt)
finally:
self.sem.release()
async def _fake_agent(self, task: Task) -> str:
# Simulate variable time and occasional errors
await asyncio.sleep(0.2)
if "fail" in task.name.lower():
raise RuntimeError("simulated transient error")
return f"completed {task.name}"
Run this with a few tasks and dependencies to verify the flow. Next we’ll replace the fake agent with a real LLM-backed worker that calls the OpenAI Responses API and tracks usage details to manage budgets.
3. Breaking down complex tasks into subtasks
The planner transforms a single objective into an actionable DAG of subtasks with explicit dependencies and budgets. Good planning is the difference between a single, oversized prompt and a pipeline that can progress even when some tasks are blocked. We’ll prompt the model to return strict JSON and parse it into our Task objects. Later, we’ll enforce acceptance criteria and budget allocations.
Planner prompts and JSON schemas
A reliable way to get structured output is to provide a schema and ask the model to produce JSON that fits it. We’ll use the Responses API with a JSON schema response format to request a list of tasks. The model will name tasks, describe them, estimate effort, and propose dependencies. Then we’ll transform that result into our internal Task representation, assigning budgets based on estimated effort and a global budget.
# planner.py
from typing import List
from dataclasses import dataclass
from openai import OpenAI
from orchestrator import Task
client = OpenAI()
TASK_SCHEMA = {
"name": "TaskPlan",
"schema": {
"type": "object",
"properties": {
"tasks": {
"type": "array",
"items": {
"type": "object",
"properties": {
"id": {"type": "string"},
"name": {"type": "string"},
"description": {"type": "string"},
"deps": {"type": "array", "items": {"type": "string"}},
"agent_type": {"type": "string"},
"effort_estimate": {"type": "integer"} # 1..5
},
"required": ["id", "name", "description", "deps", "agent_type", "effort_estimate"],
"additionalProperties": False
}
}
},
"required": ["tasks"],
"additionalProperties": False
}
}
def make_planner_prompt(goal: str, constraints: str) -> List[dict]:
return [{
"role": "system",
"content": [
{"type": "text", "text":
"You are a senior project planner. Decompose goals into tasks. "
"Return strictly valid JSON matching the schema."}
]
}, {
"role": "user",
"content": [
{"type": "text", "text": f"High-level goal:\n{goal}\n\nConstraints:\n{constraints}\n"}
]
}]
def plan_tasks(goal: str, constraints: str, total_budget_credits: int = 1000) -> List[Task]:
resp = client.responses.create(
model="gpt-4.1-mini",
input=make_planner_prompt(goal, constraints),
response_format={
"type": "json_schema",
"json_schema": TASK_SCHEMA
},
metadata={"component": "planner"}
)
# Extract JSON
plan = resp.output[0].content[0].text # output_text can also be used in SDKs that provide it
import json
data = json.loads(plan)
tasks_raw = data["tasks"]
total_effort = sum(max(1, int(t.get("effort_estimate", 1))) for t in tasks_raw) or 1
tasks: List[Task] = []
for t in tasks_raw:
effort = max(1, int(t.get("effort_estimate", 1)))
budget = max(50, int(total_budget_credits * (effort / total_effort)))
tasks.append(Task(
id=t["id"],
name=t["name"],
description=t["description"],
deps=t.get("deps", []),
agent_type=t.get("agent_type", "general"),
budget_credits=budget
))
return tasks
You can tune the schema to capture acceptance criteria, required artifacts, test strategies, or review gates per task. When planning, keep tasks small enough to finish under a few iterations of your retry policy. Larger tasks can block downstream progress and increase the cost of mistakes. The Complete Guide to ChatGPT’s New Custom GPTs Interface: How the Updated Plugin Menu, MCP Connectors, and Action Icons Transform Enterprise AI Workflows
4. Token budget management with credit-based pricing
OpenAI APIs are priced per token, but it’s often useful to introduce an internal “credit” layer in your system. This lets you allocate budgets to agents and tasks independent of model choice, and enforce spend limits per project or CI run. The idea: convert token usage to credits via a configurable rate, and decrement per-task budgets as agents make calls. If a task runs out of credits, pause or escalate.
Designing the BudgetManager
- Credits: Arbitrary unit that maps to token cost via a configurable factor. Example: 1 credit per 1,000 tokens estimate, or 1 credit per $0.01 of spend—use what makes sense in your org.
- Per-task budgets: Planner sets initial budgets. Orchestrator enforces them, allowing limited overage or top-ups with approval.
- Usage accounting: Track input/output tokens and convert to credits. Use the API response’s usage fields to get exact counts.
# budget.py
from dataclasses import dataclass
@dataclass
class Budget:
total_credits: int
used_credits: int = 0
@property
def remaining(self) -> int:
return max(0, self.total_credits - self.used_credits)
class BudgetManager:
def __init__(self, credit_per_1k_tokens: float = 1.0) -> None:
# Example: 1 credit for each 1,000 tokens
self.credit_per_1k_tokens = credit_per_1k_tokens
def tokens_to_credits(self, input_tokens: int, output_tokens: int) -> int:
# convert to credits; round up to keep safe
total_tokens = max(0, input_tokens) + max(0, output_tokens)
credits = int(((total_tokens / 1000.0) * self.credit_per_1k_tokens) + 0.9999)
return max(1, credits) if total_tokens > 0 else 0
def charge(self, budget: Budget, input_tokens: int, output_tokens: int) -> None:
c = self.tokens_to_credits(input_tokens, output_tokens)
if c > budget.remaining:
raise RuntimeError(f"Budget exceeded: need {c}, have {budget.remaining}")
budget.used_credits += c
We’ll integrate this into the implementer so that every LLM call checks against the task’s budget. If a task needs a top-up, the orchestrator can approve it or fail early with a clear reason. This keeps long runs predictable and auditable.
5. Error handling and checkpoints for long-running agents
A long-running workflow (hours or days) must survive transient API errors, network blips, process restarts, and partial failures. Checkpointing ensures you never repeat completed work. Combined with idempotency keys and retries with exponential backoff, you can deliver robust automations that confidently resume where they left off.
Key patterns
- Idempotency keys: Include a unique key per task-attempt when calling the API. If a retry sends the same request, the server returns the previous result.
- Exponential backoff with jitter: Retry predictable transient failures with increasing delays.
- Checkpoint store: Persist task states (PENDING, RUNNING, DONE, FAILED), attempts, artifacts, and usage. A small SQLite DB is perfect for local runs and CI.
- Heartbeats: Periodically write “I’m alive” updates so a supervisor or dashboard knows the run hasn’t frozen.
# checkpoints.py
import sqlite3
from dataclasses import dataclass
from typing import Optional, Dict, Any
import json
import time
from pathlib import Path
SCHEMA_SQL = """
CREATE TABLE IF NOT EXISTS tasks (
id TEXT PRIMARY KEY,
name TEXT,
status TEXT,
attempts INTEGER,
result TEXT,
error TEXT,
usage_json TEXT,
updated_at REAL
);
CREATE TABLE IF NOT EXISTS runs (
run_id TEXT PRIMARY KEY,
started_at REAL,
completed_at REAL,
meta_json TEXT
);
"""
class CheckpointStore:
def __init__(self, db_path: str = "checkpoints.sqlite") -> None:
self.db_path = db_path
Path(db_path).touch(exist_ok=True)
self._init_db()
def _init_db(self) -> None:
with sqlite3.connect(self.db_path) as conn:
conn.executescript(SCHEMA_SQL)
conn.commit()
def upsert_task(self, task_id: str, name: str, status: str, attempts: int,
result: Optional[str], error: Optional[str],
usage: Optional[Dict[str, Any]]) -> None:
with sqlite3.connect(self.db_path) as conn:
conn.execute(
"""
INSERT INTO tasks (id, name, status, attempts, result, error, usage_json, updated_at)
VALUES (?, ?, ?, ?, ?, ?, ?, ?)
ON CONFLICT(id) DO UPDATE SET
status=excluded.status,
attempts=excluded.attempts,
result=excluded.result,
error=excluded.error,
usage_json=excluded.usage_json,
updated_at=excluded.updated_at
""",
(task_id, name, status, attempts, result, error,
json.dumps(usage or {}), time.time())
)
conn.commit()
def set_run_start(self, run_id: str, meta: Optional[Dict[str, Any]] = None) -> None:
with sqlite3.connect(self.db_path) as conn:
conn.execute(
"""
INSERT INTO runs (run_id, started_at, completed_at, meta_json)
VALUES (?, ?, NULL, ?)
ON CONFLICT(run_id) DO UPDATE SET
started_at=excluded.started_at,
meta_json=excluded.meta_json
""",
(run_id, time.time(), json.dumps(meta or {}))
)
conn.commit()
def set_run_complete(self, run_id: str) -> None:
with sqlite3.connect(self.db_path) as conn:
conn.execute(
"UPDATE runs SET completed_at = ? WHERE run_id = ?",
(time.time(), run_id)
)
conn.commit()
We will call this store inside the orchestrator at every status change. On restart, the orchestrator can load tasks from the DB and skip those that are already DONE. You can also use Redis or a cloud database for distributed runs.
6. Python code examples for API calls and task decomposition
Now let’s wire up the implementer agent to call the OpenAI Responses API for code generation or transformation tasks, track usage to enforce budgets, and write checkpoints after each attempt. We’ll combine the orchestrator, planner, budget manager, and checkpoint store into an executable script.
Implementer agent
# agent.py
from typing import Dict, Any, Optional
from openai import OpenAI
from budget import Budget, BudgetManager
client = OpenAI()
class ImplementerAgent:
def __init__(self, agent_type: str, budget: Budget, budget_manager: BudgetManager) -> None:
self.agent_type = agent_type
self.budget = budget
self.budget_manager = budget_manager
def _system_instructions(self) -> str:
if self.agent_type == "refactor":
return ("You are a precise code-refactoring assistant. Provide diffs or patch-style outputs, "
"preserve behavior, and include a summary of changes.")
elif self.agent_type == "test_scaffold":
return ("You write unit tests with clear arrange/act/assert phases. "
"Target high-value paths and edge cases.")
else:
return ("You are a pragmatic software assistant. Generate code and explanations with "
"clear, runnable examples and minimal dependencies.")
def _idempotency_key(self, task_id: str, attempt: int) -> str:
return f"task:{task_id}:agent:{self.agent_type}:attempt:{attempt}"
def run(self, task_id: str, description: str, attempt: int) -> Dict[str, Any]:
# Prepare request following your budget constraints
system_text = self._system_instructions()
prompt_user = f"Task description:\n{description}\n\nProduce the required code and a short rationale."
# For retries, use idempotency_key to avoid duplicating charges/work if the server already processed it
resp = client.responses.create(
model="gpt-4.1-mini",
input=[
{"role": "system", "content": [{"type": "text", "text": system_text}]},
{"role": "user", "content": [{"type": "text", "text": prompt_user}]}
],
metadata={"component": "implementer", "task_id": task_id, "agent_type": self.agent_type},
idempotency_key=self._idempotency_key(task_id, attempt)
)
# Extract output and usage safely
try:
text = resp.output_text
except Exception:
# Fallback parsing when SDK attributes differ
text = resp.output[0].content[0].text
usage = {}
# SDKs typically provide usage fields; handle variations defensively
if hasattr(resp, "usage") and resp.usage is not None:
usage = {
"input_tokens": getattr(resp.usage, "input_tokens", getattr(resp.usage, "prompt_tokens", 0)),
"output_tokens": getattr(resp.usage, "output_tokens", getattr(resp.usage, "completion_tokens", 0)),
"total_tokens": getattr(resp.usage, "total_tokens", None)
}
input_tokens = usage.get("input_tokens", 0) or 0
output_tokens = usage.get("output_tokens", 0) or 0
# Charge budget based on tokens
self.budget_manager.charge(self.budget, input_tokens, output_tokens)
return {
"content": text,
"usage": usage
}
Integrating with the orchestrator
We’ll now integrate the implementer, planner, budget manager, and checkpoint store. This script creates a plan from a goal, spins up tasks with budgets, runs them in parallel, checkpoints progress, and prints a summary.
# run_workflow.py
import asyncio
import os
from dataclasses import replace
from typing import Dict
from orchestrator import Orchestrator, Task, RunConfig
from planner import plan_tasks
from budget import Budget, BudgetManager
from checkpoints import CheckpointStore
from agent import ImplementerAgent
# Expect OPENAI_API_KEY in environment for the SDK
class LLMOrchestrator(Orchestrator):
def __init__(self, tasks, config, checkpoint_store, budget_manager):
super().__init__(tasks, config)
self.checkpoints = checkpoint_store
self.budget_manager = budget_manager
self.task_budgets: Dict[str, Budget] = {t.id: Budget(total_credits=t.budget_credits) for t in tasks}
async def run(self):
self.checkpoints.set_run_start(self.config.run_id, {"max_concurrency": self.config.max_concurrency})
await super().run()
self.checkpoints.set_run_complete(self.config.run_id)
async def _run_one(self, task: Task):
if task.status != "PENDING":
return
task.status = "RUNNING"
self.checkpoints.upsert_task(task.id, task.name, task.status, task.attempts, task.result, task.error, None)
await self.sem.acquire()
try:
for attempt in range(1, self.config.max_retries + 1):
task.attempts = attempt
agent = ImplementerAgent(task.agent_type, self.task_budgets[task.id], self.budget_manager)
try:
out = await asyncio.to_thread(agent.run, task.id, task.description, attempt)
task.result = out["content"]
usage = out.get("usage")
task.status = "DONE"
self.checkpoints.upsert_task(task.id, task.name, task.status, task.attempts, task.result, None, usage)
break
except Exception as e:
task.error = str(e)
self.checkpoints.upsert_task(task.id, task.name, "RUNNING", task.attempts, None, task.error, None)
if attempt >= self.config.max_retries:
task.status = "FAILED"
self.checkpoints.upsert_task(task.id, task.name, task.status, task.attempts, None, task.error, None)
break
await asyncio.sleep(self.config.retry_backoff ** attempt)
finally:
self.sem.release()
async def main():
goal = """Create a small CLI tool that downloads a CSV from a URL, validates a schema, computes summary stats, and writes a Markdown report."""
constraints = """Use Python 3.10+, standard libraries where possible, and write at least 3 unit tests. Provide a README."""
# Plan tasks
tasks = plan_tasks(goal, constraints, total_budget_credits=1200)
# Orchestrate
config = RunConfig(max_concurrency=3, max_retries=3, retry_backoff=2.0)
checkpoints = CheckpointStore("checkpoints.sqlite")
budget_manager = BudgetManager(credit_per_1k_tokens=1.2)
orch = LLMOrchestrator(tasks, config, checkpoints, budget_manager)
await orch.run()
if __name__ == "__main__":
asyncio.run(main())
This is a runnable backbone. You can now plug in a reviewer agent to check acceptance criteria, extend the planner schema to include tests, and add more agent types for specialized tasks (e.g., data ingestion, code synthesis, test generation). Notice that all token usage flows through the budget manager, and all state transitions are checkpointed.
7. Monitoring agent progress
When parallel agents run for hours, you need clear progress reporting. Monitoring should answer: Which tasks are running, blocked, or failed? How much budget did we consume? How many retries? What artifacts are available? Minimal monitoring requires structured logs and a progress file; more advanced setups push metrics to an observability stack (Prometheus, OpenTelemetry, or a managed APM).
Progress events
We’ll add a simple event logger that writes JSON lines to a file and prints summaries to stdout. Downstream tooling (e.g., a web UI) can tail this file for near-real-time dashboards. You can also emit OpenTelemetry traces for spans per task.
# progress.py
import json
import time
from threading import Lock
from typing import Dict, Any
class ProgressLogger:
def __init__(self, path: str = "progress.jsonl"):
self.path = path
self._lock = Lock()
def emit(self, event: Dict[str, Any]):
event["ts"] = time.time()
with self._lock:
with open(self.path, "a", encoding="utf-8") as f:
f.write(json.dumps(event, ensure_ascii=False) + "\n")
print(f"[progress] {event['type']}: {event.get('msg', '')}")
Integrate this into the orchestrator to emit events on task start, completion, failure, and budget updates.
# extend LLMOrchestrator in run_workflow.py
from progress import ProgressLogger
class LLMOrchestrator(Orchestrator):
def __init__(self, tasks, config, checkpoint_store, budget_manager):
super().__init__(tasks, config)
self.checkpoints = checkpoint_store
self.budget_manager = budget_manager
self.task_budgets = {t.id: Budget(total_credits=t.budget_credits) for t in tasks}
self.progress = ProgressLogger()
async def run(self):
self.checkpoints.set_run_start(self.config.run_id, {"max_concurrency": self.config.max_concurrency})
self.progress.emit({"type": "run.start", "run_id": self.config.run_id, "msg": "Run started"})
await super().run()
self.checkpoints.set_run_complete(self.config.run_id)
self.progress.emit({"type": "run.end", "run_id": self.config.run_id, "msg": "Run completed"})
async def _run_one(self, task: Task):
if task.status != "PENDING":
return
task.status = "RUNNING"
self.progress.emit({"type": "task.start", "task_id": task.id, "name": task.name})
self.checkpoints.upsert_task(task.id, task.name, task.status, task.attempts, task.result, task.error, None)
await self.sem.acquire()
try:
for attempt in range(1, self.config.max_retries + 1):
task.attempts = attempt
agent = ImplementerAgent(task.agent_type, self.task_budgets[task.id], self.budget_manager)
try:
out = await asyncio.to_thread(agent.run, task.id, task.description, attempt)
task.result = out["content"]
usage = out.get("usage")
task.status = "DONE"
self.checkpoints.upsert_task(task.id, task.name, task.status, task.attempts, task.result, None, usage)
self.progress.emit({"type": "task.done", "task_id": task.id, "usage": usage, "remaining_credits": self.task_budgets[task.id].remaining})
break
except Exception as e:
task.error = str(e)
self.checkpoints.upsert_task(task.id, task.name, "RUNNING", task.attempts, None, task.error, None)
self.progress.emit({"type": "task.retry", "task_id": task.id, "attempt": attempt, "msg": task.error})
if attempt >= self.config.max_retries:
task.status = "FAILED"
self.checkpoints.upsert_task(task.id, task.name, task.status, task.attempts, None, task.error, None)
self.progress.emit({"type": "task.failed", "task_id": task.id, "msg": task.error})
break
await asyncio.sleep(self.config.retry_backoff ** attempt)
finally:
self.sem.release()
Key metrics to track
| Metric | Description |
|---|---|
| Tasks completed/failed | High-level success/failure ratio |
| Average attempts per task | Health of prompts/tools; high means instability |
| Credits used per task | Budget adherence and overruns |
| Throughput (tasks/hour) | Parallelism effectiveness; identify bottlenecks |
| Latency per task type | Which agent types are slowest |
Start simple: JSON lines and a few summary prints can take you very far. For deeper visibility, export span events to an APM and annotate prompts, usage, and results with task IDs and run IDs so you can trace cause and effect across the system.
8. Integration with CI/CD pipelines
Automation is most impactful when it’s safe and repeatable. Connecting your multi-agent workflow to CI/CD lets you run planners and implementers on branch pushes, open pull requests with proposed changes, and run reviewer agents to annotate diffs. Guardrails ensure non-deterministic steps don’t break your pipeline, and budgets prevent runaway costs.
Common CI patterns
- Dry run vs live run: In PRs, run the planner and produce a plan and budget only. On main, allow implementers to apply code changes behind a flag.
- Artifact storage: Upload task outputs, logs, and progress files as CI artifacts for auditability.
- Budget gates: Fail the job if projected or actual credits exceed a threshold.
- Prompt/test snapshots: Keep prompt templates and sample inputs under version control; test with fixtures for stability.
GitHub Actions example
The YAML below runs the planner on every pull request to estimate budgets and generate a task plan, then runs a limited implementer job for safe tasks only. On merge to main, it executes the full workflow with a higher concurrency limit.
# .github/workflows/agents.yml
name: Agents
on:
pull_request:
branches: [ main ]
push:
branches: [ main ]
jobs:
plan:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: actions/setup-python@v5
with:
python-version: "3.11"
- name: Install deps
run: |
python -m pip install --upgrade pip
pip install openai tiktoken
- name: Plan tasks (dry run)
env:
OPENAI_API_KEY: ${{ secrets.OPENAI_API_KEY }}
run: |
python -c "from planner import plan_tasks; \
goal='Refactor data loaders and add unit tests'; \
constraints='Python 3.11. Use pandas only if necessary.'; \
tasks=plan_tasks(goal,constraints,total_budget_credits=600); \
print('Planned', len(tasks), 'tasks'); \
[print(t) for t in tasks]"
implement:
if: github.event_name == 'push'
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: actions/setup-python@v5
with:
python-version: "3.11"
- name: Install deps
run: |
python -m pip install --upgrade pip
pip install openai tiktoken
- name: Run workflow
env:
OPENAI_API_KEY: ${{ secrets.OPENAI_API_KEY }}
run: |
python run_workflow.py
- name: Upload artifacts
uses: actions/upload-artifact@v4
with:
name: agent-artifacts
path: |
checkpoints.sqlite
progress.jsonl
In more advanced pipelines, you might task a reviewer agent with evaluating diffs and leaving comments on PRs. A simple reviewer can run in CI with a read-only token and a low credit budget, summarizing issues and test coverage suggestions without making changes.
9. Key takeaways
- Architecture matters: A Codex-style system is more than a prompt—it’s planner, implementers, reviewer, and orchestrator working together. Clear roles allow parallelism and make long runs reliable.
- Parallelism compresses time: Async orchestration with dependency-aware scheduling turns day-long tasks into multi-hour runs without losing control.
- Budgeting keeps you honest: A credit layer enforces spend at the task level, using token usage from API responses. Allocate budgets during planning; enforce during execution.
- Checkpoints and retries are non-negotiable: Idempotency keys, exponential backoff, and a durable checkpoint store give you resilience across failures and restarts.
- Monitoring builds trust: Progress events and metrics help you see what’s happening and spot problems quickly. Start with JSONL; evolve to full tracing.
- CI/CD closes the loop: Running agents in your pipeline enables continuous refactoring, documentation generation, and test scaffolding—safely and repeatably.
With these patterns and the code above, you have a foundation for serious multi-agent automation. Expand the planner schema as your needs grow, add specialized agents for your domain, and refine prompts using your telemetry. The same infrastructure supports everything from codegen and test writing to data extraction and report generation. As you iterate, revisit the planner’s granularity, tighten budgets, and add more asserts to the reviewer to keep quality high. Codex Security Masterclass: 30 Production-Ready Prompts for Automated Vulnerability Scanning, Patch Generation, and Security Code Review
Access 40,000+ AI Prompts for ChatGPT, Claude & Codex — Free!
Subscribe to get instant access to our complete Notion Prompt Library — the largest curated collection of prompts for ChatGPT, Claude, OpenAI Codex, and other leading AI models. Optimized for real-world workflows across coding, research, content creation, and business.
Appendix: End-to-end example with task decomposition and reviews
To round things out, here’s a more complete example showing a reviewer agent and an extended planner schema. The reviewer checks outputs against acceptance criteria and either passes the task or requests a fix. In practice, the reviewer can annotate code diffs, scan for insecure patterns, or run quick static analysis prior to merging changes.
# reviewer.py
from typing import Dict, Any
from openai import OpenAI
client = OpenAI()
class ReviewerAgent:
def __init__(self, criteria: str, strict: bool = True) -> None:
self.criteria = criteria
self.strict = strict
def review(self, task_id: str, artifact: str) -> Dict[str, Any]:
prompt = f"""You are a code reviewer. Review the artifact below against the criteria.
Criteria:
{self.criteria}
Artifact:
{artifact}
Return a short verdict (PASS or FAIL) and concrete reasons. If FAIL, explain what to fix."""
resp = client.responses.create(
model="gpt-4.1-mini",
input=[
{"role": "system", "content": [{"type": "text", "text": "You are a rigorous reviewer. Be concise and specific."}]},
{"role": "user", "content": [{"type": "text", "text": prompt}]}
],
metadata={"component": "reviewer", "task_id": task_id}
)
text = resp.output_text
verdict = "PASS" if "PASS" in text[:100].upper() else "FAIL"
return {"verdict": verdict, "text": text}
Now let’s sketch how we might thread the reviewer into the orchestrator, making certain tasks subject to approval. For simplicity, we’ll assume all tasks have the same criteria; in a real system, each task in the planner schema would carry its own acceptance criteria.
# run_workflow_with_review.py (diff from run_workflow.py)
from reviewer import ReviewerAgent
class LLMOrchestratorWithReview(LLMOrchestrator):
def __init__(self, tasks, config, checkpoint_store, budget_manager, criteria: str):
super().__init__(tasks, config, checkpoint_store, budget_manager)
self.reviewer = ReviewerAgent(criteria=criteria)
async def _run_one(self, task: Task):
if task.status != "PENDING":
return
task.status = "RUNNING"
self.progress.emit({"type": "task.start", "task_id": task.id, "name": task.name})
self.checkpoints.upsert_task(task.id, task.name, task.status, task.attempts, task.result, task.error, None)
await self.sem.acquire()
try:
for attempt in range(1, self.config.max_retries + 1):
task.attempts = attempt
agent = ImplementerAgent(task.agent_type, self.task_budgets[task.id], self.budget_manager)
try:
out = await asyncio.to_thread(agent.run, task.id, task.description, attempt)
usage = out.get("usage")
review = await asyncio.to_thread(self.reviewer.review, task.id, out["content"])
if review["verdict"] == "PASS":
task.result = out["content"]
task.status = "DONE"
self.checkpoints.upsert_task(task.id, task.name, task.status, task.attempts, task.result, None, usage)
self.progress.emit({"type": "task.done", "task_id": task.id, "usage": usage, "review": "PASS"})
break
else:
self.progress.emit({"type": "task.review_fail", "task_id": task.id, "review": review["text"]})
raise RuntimeError("review failed")
except Exception as e:
task.error = str(e)
self.checkpoints.upsert_task(task.id, task.name, "RUNNING", task.attempts, None, task.error, None)
self.progress.emit({"type": "task.retry", "task_id": task.id, "attempt": attempt, "msg": task.error})
if attempt >= self.config.max_retries:
task.status = "FAILED"
self.checkpoints.upsert_task(task.id, task.name, task.status, task.attempts, None, task.error, None)
self.progress.emit({"type": "task.failed", "task_id": task.id, "msg": task.error})
break
await asyncio.sleep(self.config.retry_backoff ** attempt)
finally:
self.sem.release()
In production, pair this with guardrails: a whitelist of files an agent is allowed to change, test runs before marking tasks as DONE, and a reviewer agent that rejects outputs lacking tests or violating linters. This turns your multi-agent system into a dependable collaborator rather than a risky black box.