The Complete Guide to AI Model Versioning in Production: Managing GPT-5.4 to GPT-5.6 Migrations Without Breaking Your Stack
Author: Markos Symeonides, ChatGPT AI Hub
Introduction: Model Versioning Is a Production Discipline, Not a Footnote
In production systems, upgrading an AI model is never just a library bump. It is a distributed change touching prompts, API clients, observability pipelines, cost envelopes, safety policies, routing, and customer experience. The tension is familiar to any DevOps or MLOps team: you want the accuracy, safety, and capability improvements of a new model release without jeopardizing latency SLOs, cost budgets, or behavior that downstream components rely upon.
As model families evolve—consider the GPT-5.x line with 5.4, 5.5, 5.5 Mini, and 5.6 variants like Sol, Terra, and Luna—you need a robust versioning strategy that keeps your stack stable while delivering incremental benefits. This guide provides a comprehensive, field-tested approach to version pinning, endpoint management, A/B migrations, regression harnesses, rollback and canary procedures, cost management, performance drift monitoring, CI/CD integration, and a practical case study. It also includes concrete code patterns for routing and failover, since your production reliability depends on code, not just policy.
Throughout, we will assume a neutral provider-agnostic approach while using the GPT-5.x sequence as a concrete example. All quantitative characteristics are indicative for planning; always consult your provider’s latest release notes and pricing tables before committing to production changes.
The GPT-5.x Version Landscape: 5.4, 5.5, 5.5 Mini, and 5.6 Sol/Terra/Luna
Model upgrades rarely come as a single monolithic option. Instead, a release train typically expands into a portfolio optimized for different objectives: long-context, low-latency, high-throughput, and cost-efficient variants. For the GPT-5.x sequence, you may encounter model identifiers like:
Access 40,000+ AI Prompts for ChatGPT, Claude & Codex — Free!
Subscribe to get instant access to our complete Notion Prompt Library — the largest curated collection of prompts for ChatGPT, Claude, OpenAI Codex, and other leading AI models. Optimized for real-world workflows across coding, research, content creation, and business.
- GPT-5.4 (baseline, widely deployed; stable behavior)
- GPT-5.5 (improved reasoning and tool use; modest cost/latency bump)
- GPT-5.5 Mini (cost-optimized, faster, smaller context window; best for low-stakes tasks)
- GPT-5.6 Sol (longest context, strong reasoning; higher cost and latency)
- GPT-5.6 Terra (balanced throughput and cost; general-purpose)
- GPT-5.6 Luna (low-latency variant; smaller responses, ideal for real-time UX)
While precise specs vary by provider, the following table illustrates common planning considerations. Treat it as a template for your internal documentation rather than authoritative values:
| Model | Indicative Context Window | Indicative p50 Latency (Tokens/sec or ms) | Relative Cost per 1K Tokens | Tool/Function Calling | Typical Use Cases |
|---|---|---|---|---|---|
| GPT-5.4 | 128k | Moderate | Baseline | Stable | Existing production apps valuing stability |
| GPT-5.5 | 200k | +10–20% vs 5.4 | +15–30% vs 5.4 | Improved tool accuracy | Complex reasoning, better tool integration |
| GPT-5.5 Mini | 64k | Fast | ~25–40% of 5.4 | Basic/limited | Low-stakes tasks, high-volume summarization |
| GPT-5.6 Sol | 256k+ | Slower than 5.5 | Higher than 5.5 | Advanced multi-tool | Long documents, complex chains, research |
| GPT-5.6 Terra | 160–200k | Similar to 5.5 | Comparable to 5.5 | Improved reliability | General workloads, balanced throughput |
| GPT-5.6 Luna | 32–80k | Lowest | Near 5.5 Mini | Fast tool calls | Real-time UX, chat assistants, latency-sensitive paths |
Note: Always verify capabilities and costs with official release notes. Maintain a living internal doc that maps model IDs to supported features, deprecations, and observed quirks.
Naming, Stability, and Deprecation
Two naming patterns appear in practice:
- Immutable IDs: e.g.,
gpt-5.5-2026-01-15. Provider guarantees frozen behavior for that hash/date. - Mutable tags: e.g.,
gpt-5.5. Provider may deliver silent improvements behind the same label.
In production, you should pin by immutable ID for deterministic behavior, then move to a new immutable ID deliberately. If your provider only offers mutable labels, front them with your own internal immutable aliases (e.g., model://core/[email protected]) to retain auditability and reproducibility.
Why Model Versioning Matters in Production Systems
Model versioning underpins reliability, quality, and governance:
- Determinism and Auditability: Pinning models by exact version ensures you can reproduce outputs for compliance and incident response.
- Behavioral Contracts: Downstream systems depend on output shape (e.g., JSON, function call schema). Version shifts can break implicit contracts.
- Cost Predictability: Different model versions vary in token efficiency and price. Versioning ensures budget adherence.
- Safety and Policy: Changes in refusal behavior or content filters may inadvertently degrade UX or safety. Version control lets you isolate effects.
- SLO Preservation: Rolling out new versions incrementally protects latency and availability guarantees.
Practically, versioning is not just a best practice; it’s a control point for risk. Your approach should combine static controls (pinning, configuration) with dynamic controls (routing, canarying, and rollback).
Version Pinning Strategies and API Endpoint Management
Stable model use starts with pinning. There are four robust patterns:
1) Pin by Immutable Model ID in Code
Hard-code the exact model version identifier where calls are made, then coordinate updates through a controlled release process. This is simple but creates code churn if you need to test multiple versions simultaneously. Use typed configuration to centralize the model identifier.
// TypeScript example: centralized model config
type ModelConfig = {
chat: string;
embedding: string;
};
export const MODELS: Record<'prod' | 'staging', ModelConfig> = {
prod: {
chat: 'gpt-5.4-2025-11-02',
embedding: 'text-embed-3-large-2025-10-01'
},
staging: {
chat: 'gpt-5.5-2026-01-15',
embedding: 'text-embed-3-large-2026-01-15'
}
};
// Usage
const env = process.env.APP_ENV as 'prod' | 'staging';
const modelId = MODELS[env].chat;
2) Pin via Environment-Driven Indirection
Expose model IDs as environment variables or configuration maps, isolating code from version changes. This pairs well with CI/CD and progressive delivery.
# Kubernetes ConfigMap for model pinning
apiVersion: v1
kind: ConfigMap
metadata:
name: model-config
data:
chat_model_id: gpt-5.4-2025-11-02
chat_model_id_canary: gpt-5.5-2026-01-15
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: chat-service
spec:
template:
spec:
containers:
- name: app
image: registry.example.com/chat-service:1.42.0
env:
- name: CHAT_MODEL_ID
valueFrom:
configMapKeyRef:
name: model-config
key: chat_model_id
- name: CHAT_MODEL_ID_CANARY
valueFrom:
configMapKeyRef:
name: model-config
key: chat_model_id_canary
3) Pin Behind an Internal Model Router
Introduce an internal service that maps an abstract capability to a concrete model version. This enables fleet-wide migrations by altering a single routing table, supports A/B, and provides centralized policy enforcement.
// Node.js Express model router: capability -> concrete model
import express from 'express';
const app = express();
app.use(express.json());
type RouteEntry = {
stable: string;
canary?: string;
canaryPct?: number; // 0..100
};
const routes: Record<string, RouteEntry> = {
'chat.core': { stable: 'gpt-5.4-2025-11-02', canary: 'gpt-5.5-2026-01-15', canaryPct: 10 },
'chat.lowlatency': { stable: 'gpt-5.6-luna-2026-02-10' },
'summary.bulk': { stable: 'gpt-5.5-mini-2026-01-10' }
};
app.post('/resolve', (req, res) => {
const { capability, userId } = req.body;
const entry = routes[capability];
if (!entry) return res.status(404).json({ error: 'Unknown capability' });
const shouldCanary =
entry.canary && typeof userId === 'string'
? (hash(userId) % 100) < (entry.canaryPct ?? 0)
: false;
res.json({ model: shouldCanary ? entry.canary : entry.stable });
});
function hash(s: string) { // simple deterministic hash
let h = 0;
for (let i = 0; i < s.length; i++) h = (h * 31 + s.charCodeAt(i)) & 0xffffffff;
return Math.abs(h);
}
app.listen(8080, () => console.log('Model router listening on 8080'));
4) Pin via API Gateway/Reverse Proxy
Use gateway logic to inject headers or rewrite endpoints based on route policies. This decouples clients from provider changes and allows traffic shifting without redeploying microservices.
# NGINX: route to different upstreams based on header or cookie
map $http_x_model_capability $upstream {
default chat_gpt_54;
"chat.core" chat_gpt_54;
"chat.core.canary" chat_gpt_55;
"summary.bulk" chat_gpt_55_mini;
}
upstream chat_gpt_54 { server provider.api:443; }
upstream chat_gpt_55 { server provider.api:443; }
upstream chat_gpt_55_mini { server provider.api:443; }
server {
listen 443 ssl;
server_name ai-gw.example.com;
location /v1/chat/completions {
proxy_set_header Host provider.api;
proxy_set_header X-Model-ID $model_id;
proxy_pass https://$upstream;
}
}
In all cases, document your pinning mechanism, centralize model IDs, and make updates observable with change management tooling and deployment annotations.
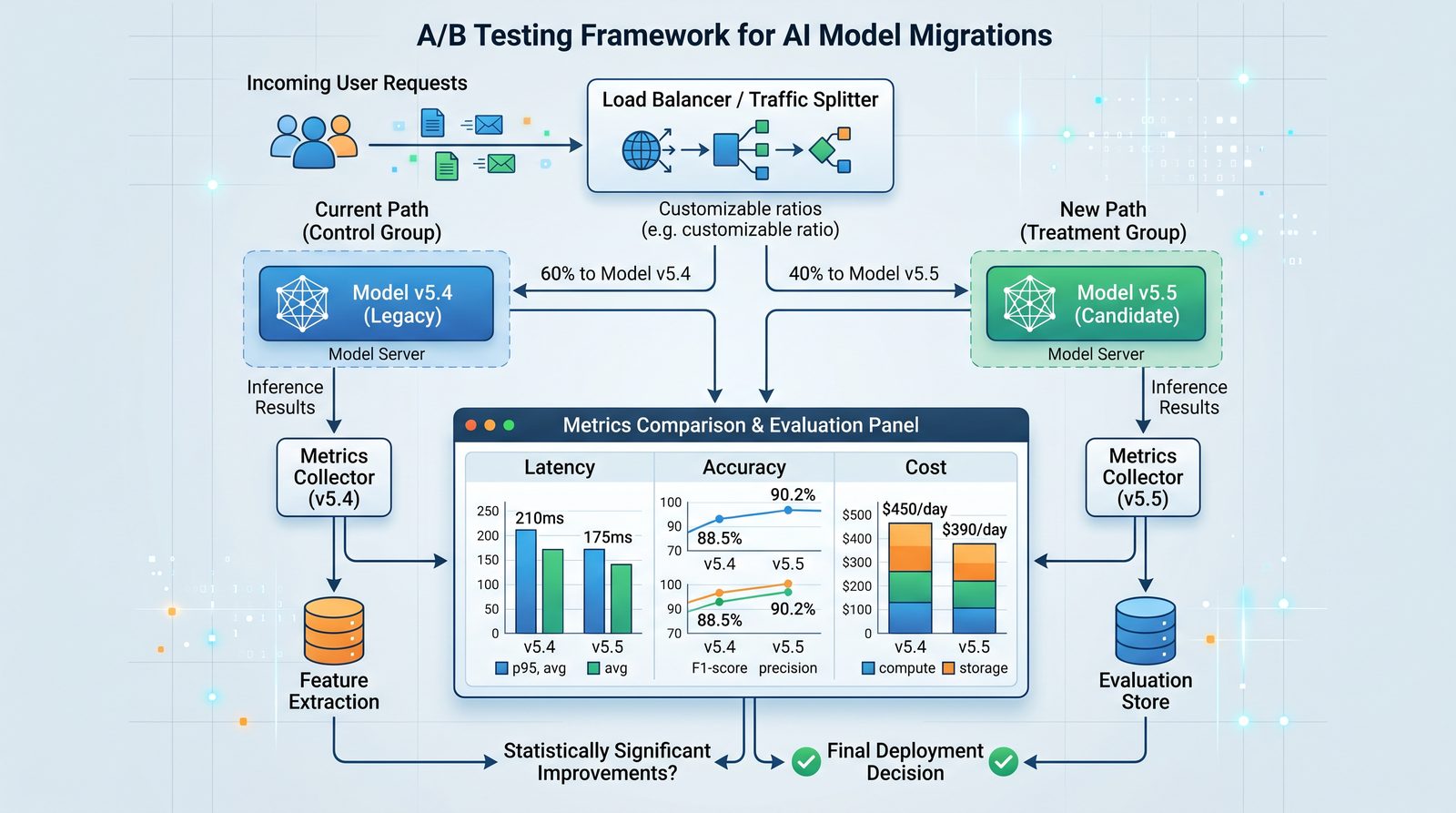
A/B Testing Framework for Model Migrations
An A/B (or A/B/n) framework de-risks upgrades by measuring impact on real traffic while isolating the test cohort. The key principles:
- Deterministic Bucketing: Hash on a stable identifier (user, account, tenant) to ensure consistent model assignment across sessions.
- Guardrails and Quotas: Cap exposure (e.g., 1–10%) and predefine automatic rollback criteria.
- Metric Instrumentation: Track quality KPIs (e.g., task success, acceptance), operational KPIs (latency, errors), and cost KPIs (tokens and spend).
- Statistical Power: Ensure sufficient sample size to detect meaningful differences; avoid premature conclusions.
- Ethical and Contractual Checks: Ensure cohorts don’t receive materially worse outcomes in regulated contexts without necessary consent or safeguards.
A/B Routing Code Example
// TypeScript middleware for deterministic bucketing
import { Request, Response, NextFunction } from 'express';
const CANARY_PCT = parseInt(process.env.CANARY_PCT || '10', 10);
const CANARY_MODEL = process.env.CANARY_MODEL || 'gpt-5.5-2026-01-15';
const STABLE_MODEL = process.env.STABLE_MODEL || 'gpt-5.4-2025-11-02';
export function assignModel(req: Request, _res: Response, next: NextFunction) {
const userId = (req.headers['x-user-id'] as string) || 'anonymous';
const bucket = hash(userId) % 100;
const variant = bucket < CANARY_PCT ? 'canary' : 'stable';
(req as any).modelId = variant === 'canary' ? CANARY_MODEL : STABLE_MODEL;
(req as any).variant = variant;
next();
}
function hash(s: string) {
let h = 0;
for (let i = 0; i < s.length; i++) h = ((h << 5) - h + s.charCodeAt(i)) | 0;
return Math.abs(h);
}
Metrics and Event Schema
Log structured events for each request to measure outcomes per variant. A minimal schema:
{
"ts": "2026-02-14T12:34:56.789Z",
"request_id": "uuid-...",
"user_id": "acct_123",
"variant": "stable|canary",
"model_id": "gpt-5.4-2025-11-02",
"tokens_prompt": 321,
"tokens_completion": 177,
"latency_ms": 842,
"error": null,
"task": "answer_question",
"success": true,
"quality_score": 0.92
}
Compute aggregate metrics per variant over identical time windows. Consider sequential testing corrections if running multiple overlapping experiments.
Regression Testing: Building Evaluation Harnesses
Offline regression tests prevent surprises by comparing model outputs on a representative evaluation set. Your harness should:
- Store a curated test set with inputs and expected outputs (or evaluation rubric) under version control.
- Support dual-run comparisons: baseline model vs candidate model.
- Implement automatic scorers for structured tasks (exact match, F1, JSON schema validation) and human-in-the-loop for subjective tasks.
- Produce a diff report with win/loss/neutral breakdown and highlight high-severity regressions.
- Block promotion if critical regressions exceed thresholds.
Python Evaluation Harness (Pytest)
# tests/test_regression.py
import json
import os
import time
import uuid
from typing import Dict, Any
import httpx
import pytest
BASELINE = os.getenv("BASELINE_MODEL", "gpt-5.4-2025-11-02")
CANDIDATE = os.getenv("CANDIDATE_MODEL", "gpt-5.5-2026-01-15")
API_URL = os.getenv("API_URL", "https://ai-gw.example.com/v1/chat/completions")
API_KEY = os.getenv("API_KEY")
with open("tests/fixtures/eval_set.json") as f:
EVAL_SET = json.load(f)
def call(model: str, messages):
headers = {"Authorization": f"Bearer {API_KEY}"}
payload = {"model": model, "messages": messages, "response_format": {"type": "json_object"}}
t0 = time.time()
r = httpx.post(API_URL, headers=headers, json=payload, timeout=60)
r.raise_for_status()
latency_ms = int((time.time() - t0) * 1000)
obj = r.json()
return obj["choices"][0]["message"]["content"], latency_ms
def score(task: Dict[str, Any], output: str) -> float:
# Example: JSON field correctness with simple rubric
try:
data = json.loads(output)
except json.JSONDecodeError:
return 0.0
correct = 0
total = 0
for k, v in task["expected"].items():
total += 1
if data.get(k) == v:
correct += 1
return correct / total if total else 0.0
@pytest.mark.parametrize("task", EVAL_SET)
def test_candidate_not_regressing(task):
baseline_out, baseline_lat = call(BASELINE, task["messages"])
candidate_out, candidate_lat = call(CANDIDATE, task["messages"])
s_base = score(task, baseline_out)
s_cand = score(task, candidate_out)
# Record results for reporting
print(json.dumps({
"task_id": task["id"],
"baseline": {"score": s_base, "latency_ms": baseline_lat},
"candidate": {"score": s_cand, "latency_ms": candidate_lat}
}))
# Example gating: candidate must not be >=5% worse per task
assert s_cand + 0.05 >= s_base
Golden Set Management
Maintain a diverse, evolving golden set including edge cases: long-context prompts, multi-turn tool calls, and prompts activating safety filters. Tag tasks by severity so that a regression in a high-severity task blocks release, while a minor drop in a low-severity task may be acceptable if the overall win rate improves.
Human Review and Rubrics
For subjective outputs (e.g., creative generation), integrate a human review workflow. Use a rubric with Likert scoring and blind comparisons (A vs B) to reduce bias. Store reviewer decisions and inter-rater agreement metrics to ensure reliability.
Prompt Compatibility Across Versions: What Breaks and How to Protect Yourself
Model upgrades can change how prompts are interpreted. Common breakage categories:
- Function/Tool Calling: Argument coercion changes, stricter JSON schema enforcement, or modified tool selection behavior.
- System Prompt Sensitivity: Slight changes in instruction following may alter tone or verbosity.
- Sampling and Determinism: Changes in default temperature, top-p, or nucleus sampling can shift output distribution.
- Tokenization Changes: Edge cases in token counting may push prompts over limits, causing truncation or errors.
- Safety Refusals: Evolved safety policy models may refuse previously allowed content or vice versa.
Compatibility Strategies
- Explicit Response Formats: Use
response_formatand JSON schema with strict validation to force structured output. - Tool Contracts: Version your tool schema and validate arguments server-side. Reject or adapt to missing/extra fields.
- Prompt Preambles: Reduce reliance on brittle phrasings; prefer explicit constraints and examples.
- Sampling Control: Set explicit
temperature,top_p, andfrequency_penaltyvalues. - Token Budgets: Proactively measure prompt tokenization and enforce budgets to avoid overflow when tokenizer changes.
Example: Strict JSON Output with Schema Validation
// Node.js: enforce JSON schema post-response
import Ajv from 'ajv';
import { postCompletion } from './client';
const schema = {
type: 'object',
properties: {
title: { type: 'string' },
priority: { type: 'string', enum: ['low', 'medium', 'high'] },
due: { type: 'string', format: 'date' }
},
required: ['title', 'priority'],
additionalProperties: false
};
const ajv = new Ajv({ allErrors: true });
export async function generateTask(modelId: string, messages: any[]) {
const res = await postCompletion({ model: modelId, messages, response_format: { type: 'json_object' }});
const content = res.choices[0].message.content;
let obj;
try {
obj = JSON.parse(content);
} catch {
throw new Error('Non-JSON response');
}
const valid = ajv.validate(schema, obj);
if (!valid) throw new Error(`Schema error: ${ajv.errorsText()}`);
return obj;
}
Guardrail Prompts and Fallback
Introduce a guardrail step when high-stakes outputs are involved: re-validate the answer with a secondary check (e.g., consistency checker prompt) or route to a more reliable (possibly higher-cost) model when validation fails. This pattern reduces risk when switching versions.
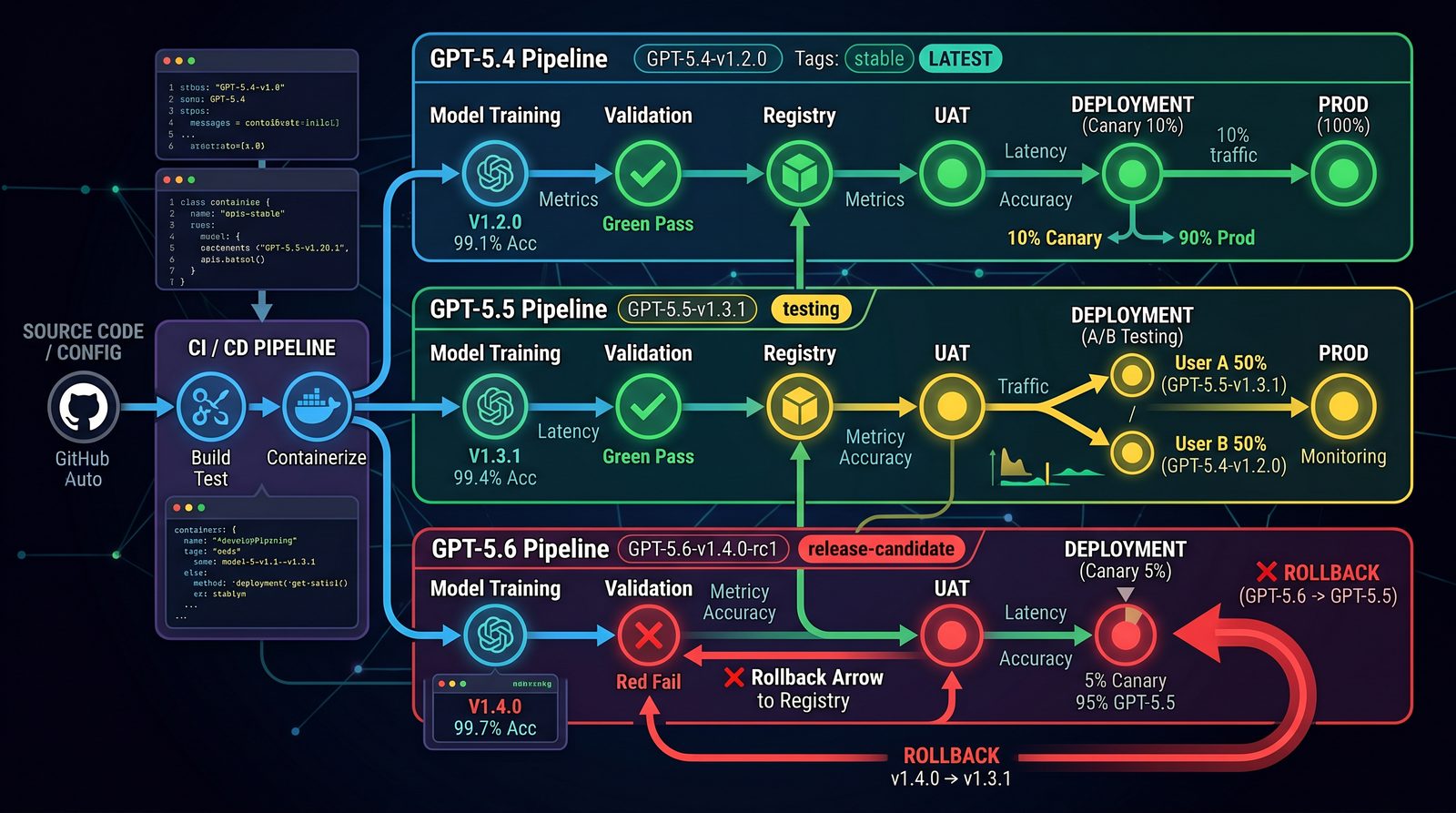
Rollback Procedures and Canary Deployments
Upgrades should be fully reversible. A robust rollout plan includes:
- Canary Deployments: Expose 1–10% of traffic to the new model, monitor metrics, then gradually increase.
- Automated Rollback: Define SLO/SLA breach conditions and revert automatically if exceeded.
- Feature Flags: Gate model usage behind flags for rapid toggling across services.
- Release Annotations: Tag deployments with model version metadata for precise auditing.
Istio VirtualService for Canary Routing
# istio VirtualService to shift traffic between stable and canary model routers
apiVersion: networking.istio.io/v1beta1
kind: VirtualService
metadata:
name: model-router
spec:
hosts:
- model-router.svc.cluster.local
http:
- route:
- destination:
host: model-router
subset: stable
weight: 90
- destination:
host: model-router
subset: canary
weight: 10
Argo Rollouts Example with Automated Rollback
# argo-rollouts.yaml
apiVersion: argoproj.io/v1alpha1
kind: Rollout
metadata:
name: chat-service
spec:
strategy:
canary:
steps:
- setWeight: 10
- pause: { duration: 600 } # 10 minutes for metrics
- setWeight: 25
- pause: { duration: 1800 }
- setWeight: 50
analysis:
templates:
- templateName: latency-check
- templateName: error-rate-check
rollbackWindow:
revisions: 2
replicas: 6
selector:
matchLabels:
app: chat-service
template:
metadata:
labels:
app: chat-service
model.version: "gpt-5.5-2026-01-15"
spec:
containers:
- name: app
image: registry.example.com/chat-service:1.43.0
env:
- name: CHAT_MODEL_ID
value: gpt-5.5-2026-01-15
Operational Runbook
Document a step-by-step runbook: how to toggle flags, revert config maps, and validate rollback success. Include contact escalation, dashboard links, and data snapshots that confirm state restoration.
Cost Implications of Version Upgrades
Newer models frequently increase per-token costs and may require more tokens to achieve the same task. Conversely, better reasoning can reduce retries and post-processing. Evaluate cost at the workflow level, not just per request.
Cost Model
Define the effective cost per task (ECPT):
ECPT = (avg_prompt_tokens + avg_completion_tokens) * unit_cost
+ retry_rate * (avg_tokens_per_retry * unit_cost)
+ post_processing_costs
Comparative Cost Table (Illustrative)
| Model | Unit Cost (relative) | Tokens per Task (avg) | Retry Rate | ECPT (relative) | Notes |
|---|---|---|---|---|---|
| GPT-5.4 | 1.0x | 1.0x | 5% | 1.05x | Stable baseline |
| GPT-5.5 | 1.2x | 0.95x | 3% | 1.16x | Fewer retries offset higher unit cost |
| GPT-5.5 Mini | 0.4x | 1.1x | 8% | 0.87x | Great for non-critical tasks |
| GPT-5.6 Sol | 1.5x | 0.9x | 2% | 1.38x | High quality, higher spend |
Mixed-Model Routing for Cost Control
Route by task criticality and latency budget:
- High stakes or complex:
5.5or5.6 Sol - Medium stakes:
5.6 Terra - Low stakes, bulk:
5.5 Minior5.6 Luna
Implement policy-based routing in your model router so you can shift traffic rapidly in response to budget signals.
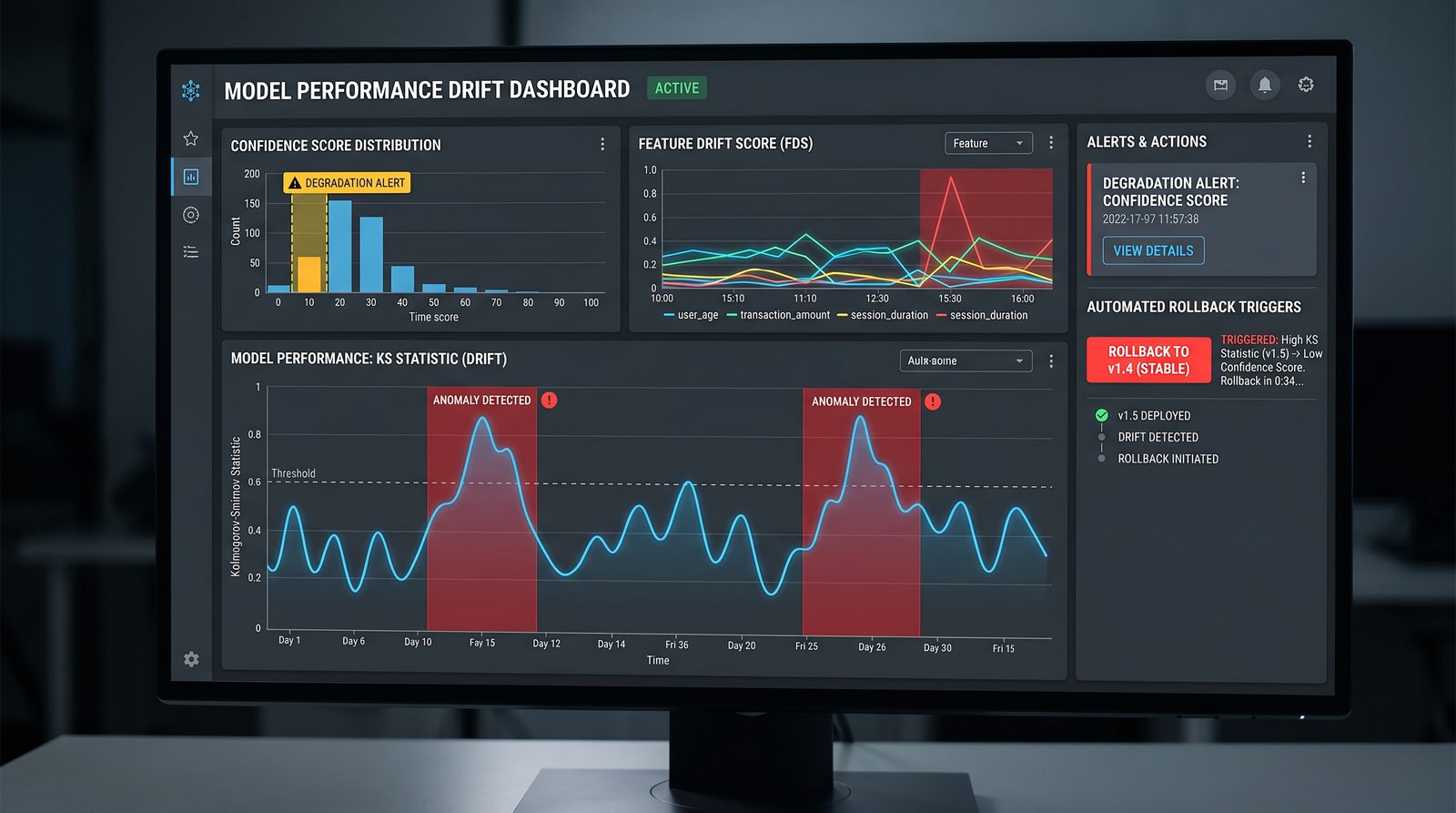
Monitoring Model Performance Drift
Even without an upgrade, model performance can drift due to input distribution changes, upstream data shifts, or silent provider updates (if using mutable tags). Monitor both offline and online signals:
- Quality: Task success rate, user satisfaction, human-rubric scores.
- Operational: Latency percentiles, error rates, token consumption, rate-limit events.
- Safety/Compliance: Refusal rates, false positive/negative flags, policy violation counts.
Observability Pipeline
Adopt a standardized event schema for all model interactions to enable cross-version comparisons. Emit to a centralized lake or warehouse with near-real-time dashboards. At minimum, include model ID, request/response tokens, latencies, and outcome metrics.
Online Scoring and Shadow Testing
Shadow mode (dual inference) runs a candidate model in parallel without affecting user-visible outputs. This provides unbiased online metrics. Be mindful of cost and data governance concerns when duplicating requests.
// Python: shadow call with async task
import asyncio
import os
import httpx
API_URL = os.getenv("API_URL")
API_KEY = os.getenv("API_KEY")
async def main():
messages = [{"role": "user", "content": "Summarize the following..." }]
async with httpx.AsyncClient(timeout=20) as client:
# primary request
primary = client.post(API_URL, headers={"Authorization": f"Bearer {API_KEY}"},
json={"model": "gpt-5.4-2025-11-02", "messages": messages})
# shadow request
shadow = client.post(API_URL, headers={"Authorization": f"Bearer {API_KEY}"},
json={"model": "gpt-5.5-2026-01-15", "messages": messages,
"metadata": {"shadow": True}})
r1, r2 = await asyncio.gather(primary, shadow)
print("Primary:", r1.status_code)
print("Shadow:", r2.status_code)
if __name__ == "__main__":
asyncio.run(main())
Drift Alerts
Set SLO-aligned alerts with budgets (e.g., 99th percentile latency, 5xx error bursts, or success rate drops). Include model ID as a label so alerts are scoped and actionable.
CI/CD Pipeline Integration for Model Updates
Treat model upgrades as code. Incorporate into CI/CD with gates that enforce testing standards before production exposure.
GitHub Actions Example
# .github/workflows/model-upgrade.yaml
name: Model Upgrade Pipeline
on:
workflow_dispatch:
inputs:
candidate_model:
description: 'Candidate model ID'
required: true
baseline_model:
description: 'Baseline model ID'
required: true
jobs:
evaluate:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Setup Python
uses: actions/setup-python@v5
with:
python-version: '3.11'
- name: Install deps
run: pip install -r requirements.txt
- name: Run regression harness
env:
API_URL: https://ai-gw.example.com/v1/chat/completions
API_KEY: ${{ secrets.API_KEY }}
BASELINE_MODEL: ${{ github.event.inputs.baseline_model }}
CANDIDATE_MODEL: ${{ github.event.inputs.candidate_model }}
run: pytest -q --maxfail=1 --disable-warnings
deploy_canary:
needs: evaluate
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Patch ConfigMap
run: |
yq -i '.data.chat_model_id_canary = "${{ github.event.inputs.candidate_model }}"' k8s/model-config.yaml
- name: Apply K8s
uses: azure/k8s-deploy@v4
with:
manifests: |
k8s/model-config.yaml
images: |
registry.example.com/chat-service:${{ github.sha }}
ramp_up:
needs: deploy_canary
runs-on: ubuntu-latest
steps:
- name: Increase canary percentage
run: |
# Update router config or service mesh weights
echo "Ramping canary to 25%..."
Promotion Gates
Define promotion criteria in code: minimum win rate, maximum regression per critical task, and operational SLO adherence. Automate the decision but require human approval for high-severity changes.
Case Study: Migrating a Production App from GPT-5.4 to GPT-5.5
Consider a content summarization and recommendation system currently on GPT-5.4. The goals: improve summarization coherence and reduce tool call errors, while keeping latency within p95 < 1.5s and cost increase < 20%.
Step 1: Inventory and Scope
Identify all services calling the model: chat-service, summarizer, rec-engine, back-office tools. Map their prompt templates, tool schemas, and success metrics. Annotate high-stakes paths (customer-facing recommendations) versus low-stakes paths (internal reports).
Step 2: Build and Run Offline Regression
Create/refresh the evaluation set emphasizing long documents, multi-step tool invocations, and failure-prone prompts. Run the Pytest harness baseline (5.4) vs candidate (5.5). Results (illustrative):
- Summarization quality score +7%
- Tool call argument errors -40%
- JSON schema violations -60%
- Latency +12%
- Token usage -5%
All critical tasks pass thresholds. Proceed to shadow testing.
Step 3: Shadow Test in Staging, Then Production
Enable shadow mode for 10% of production traffic on summarizer only. Verify no personal data policy violations. Observe that 5.5 yields similar or improved outputs with slightly higher latency. No safety regressions detected.
Step 4: Canary Rollout
Use the gateway to route 5% of chat.core traffic to GPT-5.5. Monitor KPIs for 24h. Then ramp to 15%, 30%, 50% over several days. Guardrails: rollback if p95 latency > 1.8s, error rate > 1%, or success rate drops > 2%.
Step 5: Prompt Adjustments
In early canary, a subset of prompts exhibit verbose tone that breaks UI truncation. Add a system instruction: “Limit each response to 300 words unless specified.” For tool calls, tighten the schema and validate arguments to reduce rare mismatches.
Step 6: Cost Analysis
Costs increase 14% due to unit price but are partially offset by reduced retries. Overall ECPT +9%, within budget. Bulk summarization migrates to 5.5 Mini for cost control, while user-facing chat remains on 5.5.
Step 7: Full Promotion and Post-Deployment Review
After two weeks at 50–75% exposure without guardrail triggers, promote GPT-5.5 to stable. Maintain GPT-5.4 as fallback for two additional release cycles. Document lessons learned and update the golden set with new edge cases discovered during rollout.
Version Routing and Fallback Patterns: Code Recipes
Pattern 1: Circuit Breaker with Fallback
// Go: circuit breaker around model call with fallback to previous version
package modelclient
import (
"context"
"errors"
"net/http"
"time"
)
type Client struct {
PrimaryModel string
FallbackModel string
HTTP *http.Client
Failures int
OpenUntil time.Time
}
func (c *Client) Call(ctx context.Context, messages []Message) (Response, error) {
if time.Now().Before(c.OpenUntil) {
return c.callModel(ctx, c.FallbackModel, messages)
}
resp, err := c.callModel(ctx, c.PrimaryModel, messages)
if err != nil {
c.Failures++
if c.Failures >= 3 {
c.OpenUntil = time.Now().Add(2 * time.Minute)
}
// Attempt fallback immediately
fb, fbErr := c.callModel(ctx, c.FallbackModel, messages)
if fbErr == nil {
return fb, nil
}
return Response{}, err
}
c.Failures = 0
return resp, nil
}
func (c *Client) callModel(ctx context.Context, model string, messages []Message) (Response, error) {
// Implement HTTP call to gateway with model override header
// Return parsed response or error
return Response{}, errors.New("not implemented")
}
Pattern 2: Hedged Requests for Tail Latency
Fire a second request to a faster model if the first exceeds a threshold. Cancel the loser on first success.
// Python: hedged request to reduce tail latency
import asyncio
import os
import httpx
API_URL = os.getenv("API_URL")
API_KEY = os.getenv("API_KEY")
async def query(model, messages):
async with httpx.AsyncClient() as client:
r = await client.post(API_URL, headers={"Authorization": f"Bearer {API_KEY}"},
json={"model": model, "messages": messages})
r.raise_for_status()
return r.json()
async def hedged(messages, slow_model, fast_model, hedge_delay_ms=200):
slow = asyncio.create_task(query(slow_model, messages))
await asyncio.sleep(hedge_delay_ms/1000)
fast = asyncio.create_task(query(fast_model, messages))
done, pending = await asyncio.wait({slow, fast}, return_when=asyncio.FIRST_COMPLETED)
for p in pending: p.cancel()
for d in done: return d.result()
# Usage:
# result = asyncio.run(hedged(messages, "gpt-5.6-sol-2026-02-10", "gpt-5.6-luna-2026-02-10"))
Pattern 3: Capability-Based Routing
Map business capabilities to models with policy evaluation (latency, cost, compliance):
// TypeScript: policy-driven router
type Policy = {
maxLatencyMs?: number;
maxCostPer1k?: number; // relative index mapped internally
requireLongContext?: boolean;
};
const catalog = {
"gpt-5.4-2025-11-02": { cost: 1.0, latency: 1200, ctx: 128000 },
"gpt-5.5-2026-01-15": { cost: 1.2, latency: 1350, ctx: 200000 },
"gpt-5.5-mini-2026-01-10": { cost: 0.4, latency: 800, ctx: 64000 },
"gpt-5.6-sol-2026-02-10": { cost: 1.5, latency: 1600, ctx: 256000 },
"gpt-5.6-luna-2026-02-10": { cost: 0.5, latency: 600, ctx: 32000 }
} as const;
function route(policy: Policy) {
const candidates = Object.entries(catalog).filter(([_, v]) => {
if (policy.maxLatencyMs && v.latency > policy.maxLatencyMs) return false;
if (policy.maxCostPer1k && v.cost > policy.maxCostPer1k) return false;
if (policy.requireLongContext && v.ctx < 160000) return false;
return true;
});
// Pick highest context within constraints as example
candidates.sort((a, b) => b[1].ctx - a[1].ctx);
return candidates[0]?.[0] || "gpt-5.4-2025-11-02";
}
API Endpoint Management: Forward Compatibility
Your API surface should de-risk provider changes by standardizing request and response envelopes. Introduce an internal “AI gateway” that abstracts provider differences.
Gateway Request Contract
{
"model": "string (internal model ID or capability)",
"messages": [{"role":"system|user|assistant","content":"..."}],
"tools": [{"name":"...","parameters":{}}],
"tool_choice": "auto|name",
"response_format": {"type":"text|json_object"},
"metadata": {"shadow": true, "experiment_id": "exp-123"}
}
Normalize provider responses into a consistent schema. Add visibility fields: model_id, usage.tokens, latency, tool_calls, and errors. This decouples clients from provider churn and model upgrades.
Prompt Templates as Versioned Artifacts
Prompts should be versioned alongside code. Consider semantic versioning for prompts and maintain backward-compatible changes when possible.
# prompts/summary/1.2.0.md
# System
You are a concise summarizer. Restrict output to <= 180 words.
# Instructions
- Extract key points
- Avoid speculation
- Use bullet points if input > 500 words
Track which prompt version is used with which model in telemetry for reproducing behavior.
Decision Framework: When to Upgrade vs. Stay
Use a structured decision process balancing quality, cost, risk, and roadmap:
- Define Objectives: What concrete outcomes do you seek (e.g., reduce tool errors by 30%)?
- Estimate Impact: From release notes and small-scale tests, forecast quality/cost changes.
- Run Offline Tests: If candidate fails critical tasks or requires extensive prompt rewrites, defer.
- Shadow and Canary: If online metrics show net benefit and no SLO breach, continue.
- Evaluate Cost Envelope: Ensure budget capacity. If near limits, consider mixed-model routing.
- Fallback Readiness: If rollback is easy and safe, risk is lower; proceed.
Stay on your current version if:
- Critical workflow fails with no quick remediation.
- Latency budgets are exceeded and hedging is impractical.
- Cost increases outpace value gains.
- Compliance revalidation is non-trivial and unplanned.
Upgrade if:
- Offline and online tests demonstrate quality gains in critical tasks.
- Tool/function call reliability measurably improves.
- Cost per task remains within budget, especially after retry reduction.
- Rollback is proven and automated.
Prompt Compatibility Details by Version Family (Illustrative)
| Version | Prompt Sensitivity | Tool Calls | JSON Strictness | Notes |
|---|---|---|---|---|
| GPT-5.4 | Low-moderate | Stable | Moderate | Well-known quirks, easy to maintain |
| GPT-5.5 | Moderate | Improved selection; stricter args | Higher | Better at following schema examples |
| GPT-5.5 Mini | Moderate | Basic | Moderate | May require clearer instructions for JSON |
| GPT-5.6 Sol | Moderate | Advanced multi-step | High | Excellent for long tool chains |
Safety and Compliance Regression Checks
Include safety prompts in your test suite. Measure changes in refusal rates, biased outputs, or policy violations. If compliance requires vendor recertification for new models, plan changes in advance and block deployment until approvals are complete.
End-to-End Example: Building a Model Router Service
Here is a condensed, full-stack example of a model router with telemetry, A/B, and fallback.
Router Service (Node.js)
// server.ts
import express from 'express';
import fetch from 'node-fetch';
const app = express();
app.use(express.json());
type Route = { stable: string; canary?: string; pct?: number; fallback?: string };
const routes: Record<string, Route> = {
'chat.core': { stable: 'gpt-5.4-2025-11-02', canary: 'gpt-5.5-2026-01-15', pct: 15, fallback: 'gpt-5.4-2025-11-02' },
'chat.lowlatency': { stable: 'gpt-5.6-luna-2026-02-10', fallback: 'gpt-5.5-mini-2026-01-10' }
};
app.post('/v1/chat/completions', async (req, res) => {
const { capability, messages, metadata } = req.body;
const userId = metadata?.user_id || 'anon';
const r = routes[capability];
if (!r) return res.status(400).json({ error: 'unknown capability' });
const bucket = Math.abs(hash(userId)) % 100;
const model = r.canary && (bucket < (r.pct || 0)) ? r.canary : r.stable;
try {
const out = await forward(model, messages, metadata);
recordTelemetry({ userId, capability, model, ok: true, out });
return res.json(out);
} catch (e) {
// Fallback
if (r.fallback && r.fallback !== model) {
try {
const fb = await forward(r.fallback, messages, { ...metadata, fallback: true });
recordTelemetry({ userId, capability, model: r.fallback, ok: true, out: fb, fallback: model });
return res.json(fb);
} catch (e2) {
recordTelemetry({ userId, capability, model, ok: false, error: String(e2) });
return res.status(502).json({ error: 'both primary and fallback failed' });
}
}
recordTelemetry({ userId, capability, model, ok: false, error: String(e) });
return res.status(502).json({ error: 'upstream failed' });
}
});
function hash(s: string) { let h=0; for (const c of s) h=(h*31 + c.charCodeAt(0))|0; return h; }
async function forward(model: string, messages: any[], metadata: any) {
const r = await fetch(process.env.PROVIDER_URL!, {
method: 'POST',
headers: { 'Authorization': `Bearer ${process.env.API_KEY}`, 'Content-Type':'application/json' },
body: JSON.stringify({ model, messages, response_format: { type: 'json_object' }, metadata })
});
if (!r.ok) throw new Error(`provider ${r.status}`);
return r.json();
}
function recordTelemetry(event: any) { /* send to kafka/datadog */ }
app.listen(8081, () => console.log('Router on 8081'));
Terraform for Router Secrets
# terraform variables and k8s secrets example
variable "api_key" { type = string }
resource "kubernetes_secret" "router" {
metadata { name = "router-secrets" }
data = {
PROVIDER_URL = "https://provider.example.com/v1/chat/completions"
API_KEY = var.api_key
}
}
Operational Playbook for GPT-5.6 Variants (Sol/Terra/Luna)
As portfolios expand, plan routing by scenario:
- Sol (long-context): Enable for document-heavy workflows. Protect latency SLOs with hedged requests to Luna for UX-critical paths.
- Terra (balanced): Default general-purpose engine when you need predictable throughput.
- Luna (low-latency): Prefer for short responses and interactive chat; cap max tokens to prevent overrun.
Add configuration toggles in your router to shift specific endpoints to Sol during research tasks and back to Terra for day-to-day operations.
Advanced A/B: CUPED and Sequential Testing Considerations
For high-volume apps, reduce variance with pre-experiment covariates (e.g., CUPED) to speed detection of small effects. If you run multiple experiments concurrently, apply sequential testing corrections to avoid inflated Type I error rates. Consider a centralized experimentation platform, or at minimum, store assignment logs for re-analysis.
Error Taxonomy and Retry Strategy
Version upgrades may change failure modes. Standardize error handling:
- 4xx (client): Fix prompts, schema, or inputs.
- 429 (rate limit): Backoff with jitter, observability on rate-limit budgets; consider token streaming to reduce spikes.
- 5xx (provider): Retry with exponential backoff; use fallback model after N failures.
// JavaScript retry with backoff
async function withRetry(fn, maxRetries=3, base=200) {
for (let i=0; i<=maxRetries; i++) {
try { return await fn(); }
catch (e) {
if (i === maxRetries) throw e;
await new Promise(r => setTimeout(r, base * 2**i + Math.random()*50));
}
}
}
Data Governance: PII and Shadow Mode
Before duplicating traffic in shadow tests, ensure data handling complies with contracts and regulations. Mask PII where feasible, or restrict shadowing to non-sensitive cohorts. Log model IDs and ensure data residency requirements are respected across providers and regions.
Performance Engineering: Token Budgets and Caching
Optimize prompt length and reuse computations:
- Template Compression: Reduce verbosity in system prompts while preserving instructions.
- Retrieval Chunking: Tune chunk sizes for embeddings/context windows of the chosen model.
- Caching: Cache deterministic or near-deterministic responses (e.g., FAQs) by prompt hash and model ID to save tokens.
// Python: simple Redis cache keyed by model + prompt hash
import hashlib, json, os, redis, httpx
r = redis.Redis.from_url(os.getenv("REDIS_URL"))
def key(model, messages):
h = hashlib.sha256(json.dumps(messages, sort_keys=True).encode()).hexdigest()
return f"llm:{model}:{h}"
def ask(model, messages):
k = key(model, messages)
val = r.get(k)
if val: return json.loads(val)
resp = httpx.post(os.getenv("API_URL"), headers={"Authorization": f"Bearer {os.getenv('API_KEY')}"},
json={"model": model, "messages": messages}).json()
r.setex(k, 3600, json.dumps(resp))
return resp
Real-World Pitfalls and How to Avoid Them
- Silent Behavior Changes: Avoid mutable tags in production. If unavoidable, instrument canary alarms even for “no upgrade” periods.
- Prompt-UI Coupling: Changes in verbosity can break front-end layouts. Enforce max tokens and content length constraints.
- Schema Drift: Tool/JSON changes can cascade. Use strict validators and version tool schemas explicitly.
- Rate Limits: New models may have different limits. Update backoff and concurrency controls accordingly.
- Budget Surprises: Shadow and A/B can double or triple spend if unchecked. Set caps and monitor spend per experiment ID.
Security and Access Control for Model Upgrades
Control who can change model routing and versions. Use:
- RBAC on configuration stores and feature flags.
- Signed changes with code review for model router updates.
- Audit logs for all model version changes and exposure percentages.
Team Workflow: Product, Data Science, and Platform Collaboration
Successful upgrades require cross-functional alignment. Establish a recurring “model release council” involving platform, DS, and product leads to review metrics, propose upgrades, and plan rollouts. Capture decisions and outcomes in a changelog.
From 5.5 to 5.6: Planning Multi-Variant Adoption
As you consider 5.6 Sol/Terra/Luna, adopt a capability-centric migration:
- Map each endpoint to latency/quality requirements and context sizes.
- Pilot Sol on long-context workflows; hedge for latency-sensitive experiences.
- Use Luna for chat widgets and voice assistants; enforce small max_tokens and concise prompts.
- Evaluate Terra as the default for balanced cost and throughput once stability is confirmed.
Putting It All Together: A Minimal Migration Checklist
- Inventory all model call sites, prompts, and tools.
- Pin models by immutable IDs in all environments.
- Build/update evaluation harness and golden set.
- Run offline regression; remediate critical regressions.
- Prepare gateway/router with A/B and fallback.
- Shadow test in staging, then in production.
- Canary rollout with automated rollback triggers.
- Monitor quality, latency, cost; cap experiment spend.
- Document changes; update prompts, schemas, and runbooks.
- Promote to stable; keep fallback warm for at least two release cycles.
Frequently Asked Questions
How do I ensure reproducibility for audits?
Pin model IDs immutably, version prompts and tools, log all inputs/outputs with model IDs and configuration, and archive the evaluation set and metrics at the time of release.
How can I prevent prompt regressions across versions?
Write structurally robust prompts (explicit formats, example-driven), validate outputs, and maintain a regression harness. Avoid relying on model-specific quirks whenever possible.
What if a provider deprecates a model suddenly?
Maintain an internal abstraction with capability routing and fallback candidates. Keep at least one tested alternative model on standby and exercise the fallback path regularly to avoid bit-rot.
Appendix: Additional Implementation Snippets
Bash Load Test for Canary Stability
#!/usr/bin/env bash
URL="https://ai-gw.example.com/v1/chat/completions"
KEY="$API_KEY"
MODEL="${1:-gpt-5.5-2026-01-15}"
for i in {1..100}; do
BODY=$(jq -n --arg m "$MODEL" '{
model: $m,
messages: [{role:"user",content:"Say hello number '"$i"'"}]
}')
/usr/bin/time -f "%E" curl -s -o /dev/null -w "%{http_code}\n" \
-H "Authorization: Bearer $KEY" \
-H "Content-Type: application/json" \
-d "$BODY" "$URL"
done
Python Client with Version Header
import httpx, os
class AIClient:
def __init__(self, base_url, api_key):
self.base_url = base_url
self.api_key = api_key
def chat(self, messages, model=None, capability=None):
headers = {"Authorization": f"Bearer {self.api_key}"}
payload = {"messages": messages}
if model: payload["model"] = model
if capability: payload["capability"] = capability
r = httpx.post(f"{self.base_url}/v1/chat/completions", headers=headers, json=payload, timeout=30)
r.raise_for_status()
return r.json()
client = AIClient(os.getenv("GW_URL"), os.getenv("GW_KEY"))
res = client.chat([{"role":"user","content":"Status?"}], capability="chat.core")
print(res["model"])
Kubernetes Horizontal Pod Autoscaling for Latency Control
# autoscale router to handle increased load during canaries
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: model-router-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: model-router
minReplicas: 2
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70
Internal Links and Further Reading
Explore related topics in our library to strengthen your upgrade strategy:
-
Before migrating between model versions, teams should establish baseline performance metrics using structured evaluation frameworks. Our GPT-5.6 Sol Benchmarks analysis provides the specific benchmark data points you need to compare against your production workloads, including latency percentiles and accuracy scores across different task categories.
-
Organizations running multi-agent architectures face additional complexity during model migrations, as each agent may respond differently to version changes. Our tutorial on Building Multi-Agent Workflows with OpenAI Codex covers the orchestration patterns that support graceful model upgrades across parallel agent pipelines without disrupting active task execution.
-
For teams looking to expand their AI capabilities, our guide on GPT-5.6 Sol Benchmarks Decoded provides actionable frameworks for GPT-5.6 Sol benchmark comparisons across real-world tasks that complement the strategies discussed in this article.
Conclusion
Managing GPT-5.x migrations—from 5.4 to 5.5, or exploring 5.6 Sol/Terra/Luna—requires more than swapping a model ID. It calls for disciplined version pinning, robust A/B frameworks, offline regression harnesses, careful prompt engineering, canary and rollback mechanisms, cost governance, and comprehensive monitoring. With the patterns and code shown here, you can incrementally adopt new capabilities without breaking your stack, preserve auditability, and deliver measurable improvements to your users.
Make model upgrades a routine, observable, and reversible part of your DevOps lifecycle. When done well, you will unlock the benefits of advancing model families while maintaining the reliability your production systems demand.