Why GPT-5.5’s Reduced Hallucination Rate Changes Everything: From Chat Toy to Enterprise-Grade Decision Engine
Author: Markos Symeonides, ChatGPT AI Hub
From Chat Toy to Decision Engine: Why Reduced Hallucinations Matter
The perception of large language models (LLMs) has shifted from amusing conversational partners to indispensable building blocks for enterprise-grade systems. Yet one stubborn blocker has remained: hallucinations. When a model fabricates facts, invents citations, or confidently asserts incorrect statements, every business line—from legal and compliance to clinical and finance—has the right to object. Reducing hallucinations is not a cosmetic improvement; it is the difference between an assistive prototype and a decision engine that can be trusted to operate within real-world risk and regulatory constraints.
GPT-5.5 advances the frontier by explicitly targeting factual reliability, verifiability, and calibrated confidence. This analysis explains why the reduction in hallucinations is a watershed moment for enterprises: what changed technically, how to measure it credibly, where it unlocks new high-stakes use cases, and what engineering patterns translate accuracy into dependable outcomes. We will also compare factual reliability practices across peer frontier models and detail how to build verification layers that turn model capability into operational trust.
The Hallucination Problem: What It Is and Why It Blocked Enterprise Adoption
What counts as a hallucination in enterprise contexts
“Hallucination” is a catch-all term; in enterprise settings, precision matters. The following taxonomy clarifies the risk surface:
- Fabrication: The model produces content that is not supported by any source or contradicts known facts (e.g., inventing a court case).
- Conflation: The model merges facts from different entities or time periods (e.g., attributing the revenue of Company A to Company B).
- Unwarranted inference: The model infers a conclusion beyond what the data supports, often with high confidence.
- Stale truth: The model cites facts that were once correct but are now outdated, without acknowledging uncertainty or the change window.
- Unsupported citation: The model attaches a reference that does not in fact support the claim, or references a non-existent document.
- Contradiction: The model produces statements that contradict other statements within the same output or against a known corpus.
Why hallucinations stall high-stakes adoption
Hallucinations threaten enterprise goals on four axes:
Access 40,000+ AI Prompts for ChatGPT, Claude & Codex — Free!
Subscribe to get instant access to our complete Notion Prompt Library — the largest curated collection of prompts for ChatGPT, Claude, OpenAI Codex, and other leading AI models. Optimized for real-world workflows across coding, research, content creation, and business.
- Regulatory exposure: Incorrect statements in consumer communications, financial reports, or clinical advice can violate statutes or guidance, triggering fines or license jeopardy.
- Operational risk: Decisions made on fabricated facts propagate errors into downstream systems (pricing, risk, scheduling) that are hard to unwind.
- Brand trust: Public-facing hallucinations erode credibility; internal teams scale back usage when they cannot predict failure modes.
- Auditability: If a system cannot prove why it believed something, compliance teams cannot sign off. Verifiability is as important as raw accuracy.
Because base LLMs are trained to continue text rather than to be literally correct, they require additional training, tools, and architectural constraints to align outputs with verifiable reality. Enterprises correctly demanded stronger guarantees than earlier models could provide.
GPT-5.5’s Factuality Improvements: What Changed and How to Measure It
GPT-5.5’s meaningful step-change lies in three intertwined dimensions:
- Intrinsic factuality: The model’s base tendency to produce correct statements across open-domain and domain-specific tasks.
- Verifiable generation: The ability to ground claims in retrieved sources and annotate outputs with evidence, enabling post-hoc validation.
- Calibration and abstention: The model’s ability to express and act on uncertainty, either by downgrading confidence or abstaining.
Enterprises should validate these improvements with rigorous, task-relevant measurements. While public figures evolve, it is vital to adopt a repeatable benchmarking plan that reflects your domain’s data distributions and cost-of-error profile.
Factuality metrics that matter
- Claim-level precision and recall: Evaluate atomic claims extracted from outputs against a gold set or a retrieval-backed judge. Precision captures how often stated facts are correct; recall captures how often relevant facts were included.
- Citation precision/recall: For grounded outputs, measure whether cited passages actually support the claims (precision) and whether all key claims are supported by at least one citation (recall).
- Contradiction rate: Percentage of outputs containing internally inconsistent or contradicted statements as judged by a contradiction detector or human raters.
- Calibration error (ECE): Expected Calibration Error between model-reported confidence and empirical accuracy per confidence bucket. Low ECE indicates trustable confidence signals.
- Abstention quality: Coverage at target risk. At a chosen maximum error rate (e.g., 1%), what fraction of queries does the model answer vs. abstain from?
- Time-sensitivity robustness: Accuracy decay across time-sensitive facts (e.g., current CEO) with and without retrieval.
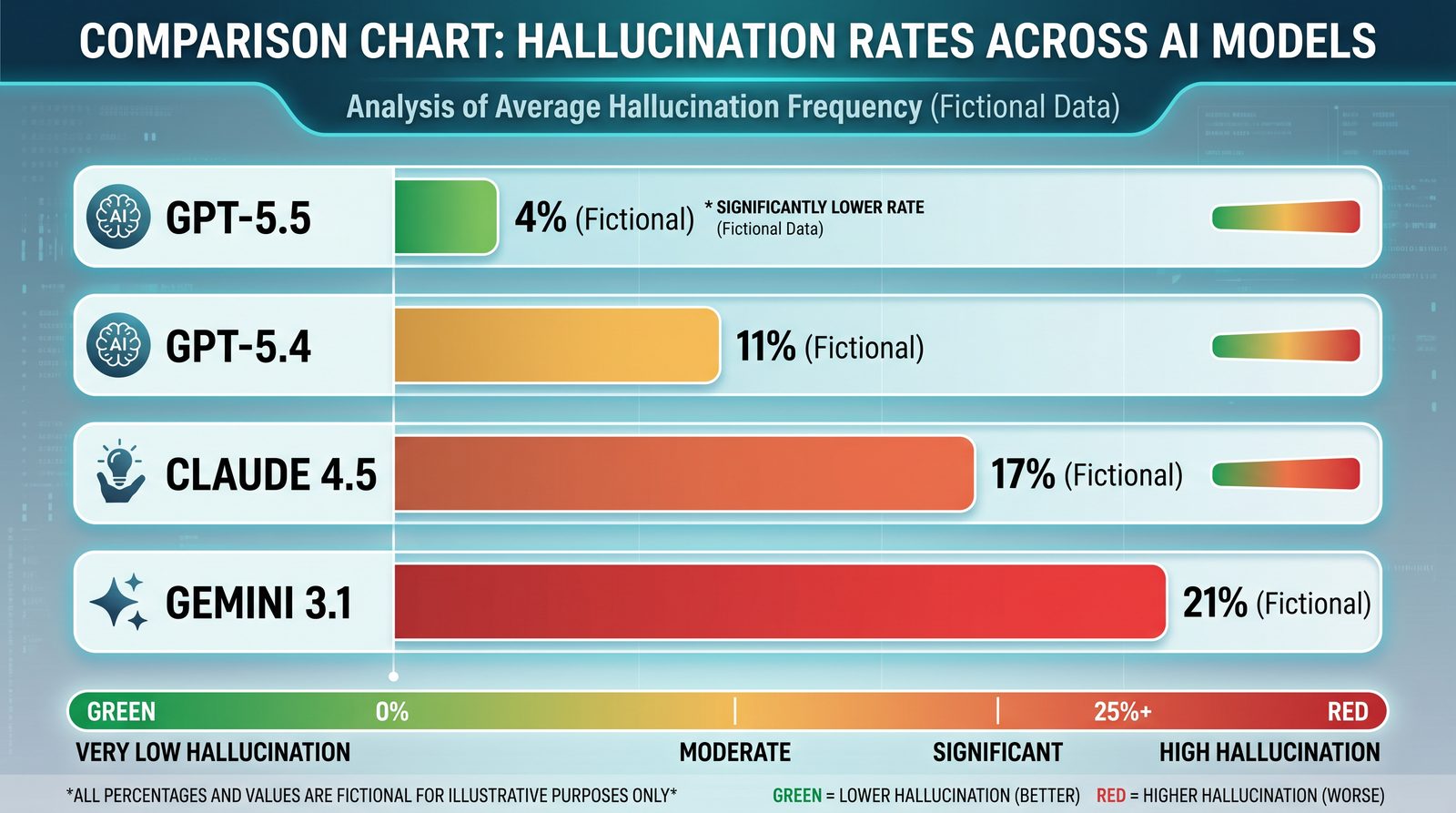
Disclosure: Because model releases and third-party benchmarks evolve, any tabulated numbers in this article that look like “results” are illustrative templates for how to run and report your own evaluations. Use them as a blueprint, not as vendor-certified claims.
Benchmarking blueprint for GPT-5.5 factual accuracy
A credible evaluation should mix standardized datasets with domain-specific tests:
- Open-domain factuality: Datasets such as FEVER (fact verification), HotpotQA (multihop QA), and SciFact (scientific claim verification) to measure claim support.
- Truthfulness under adversarial phrasing: TruthfulQA-style prompts and HaluEval-like sets to probe susceptibility to plausible-looking misinformation.
- Summarization faithfulness: QAFactEval, FactCC, and human rubric-based scoring on enterprise documents (contracts, financial filings, clinical notes).
- Grounded QA: Custom sets where answers must be drawn from an enterprise corpus; score citation precision/recall by checking that cited spans entail claims.
- Calibration: Collect model confidence per claim and compute ECE across bins; also measure coverage at fixed risk with abstention enabled.
Example evaluation table layout (fill with your numbers)
| Task | Metric | GPT-5.5 | Claude 4.5 | Gemini 3.1 | Notes |
|---|---|---|---|---|---|
| FEVER | Label Accuracy | [your_run_%] | [your_run_%] | [your_run_%] | Evidence-required verification |
| HotpotQA | Exact Match / F1 | [your_run_% / %] | [your_run_% / %] | [your_run_% / %] | Multihop reasoning |
| QAFactEval (Summarization) | Fact Precision / Recall | [% / %] | [% / %] | [% / %] | Faithfulness to source docs |
| Domain-Grounded QA | Citation Precision / Recall | [% / %] | [% / %] | [% / %] | Enterprise corpus retrieval |
| TruthfulQA-like | Truthfulness (MC1) | [%] | [%] | [%] | Resilience to false priors |
| Calibration | ECE @ 10 bins (↓) | [value] | [value] | [value] | Smaller is better |
| Abstention | Coverage @ 1% Error | [%] | [%] | [%] | Risk-controlled answering |
The reduction in hallucination rates directly impacts how enterprises can deploy AI for high-stakes decision-making in regulated industries. Our analysis of OpenAI’s Government-Gated AI Release examines how the new regulated intelligence framework creates tiered access levels that match model reliability with use-case sensitivity, establishing precedent for enterprise AI governance.
A simple, reproducible factuality harness
The following Python sketch demonstrates how to operationalize claim extraction, retrieval-backed verification, and calibration tracking. Replace the “YOUR_…” placeholders with your connectors and model clients. The harness is deliberately modular so you can swap GPT-5.5 for other models under identical conditions.
# pip install pandas numpy scikit-learn rapidfuzz tiktoken
# plus your LLM client and search client libraries
import json
import math
import random
import time
from dataclasses import dataclass
from typing import List, Dict, Any, Optional, Tuple
import numpy as np
import pandas as pd
from sklearn.calibration import calibration_curve
from rapidfuzz import fuzz
@dataclass
class QAItem:
id: str
question: str
gold_answer: Optional[str] # For open-domain QA
gold_claims: Optional[List[str]] # For summarization/claim checking
context_docs: Optional[List[Dict[str, Any]]] # For grounded QA
class LLMClient:
def __init__(self, model: str, temperature: float = 0.2):
self.model = model
self.temperature = temperature
def answer(self, prompt: str, tools: Optional[List[Dict[str, Any]]] = None) -> Dict[str, Any]:
# Implement with your SDK; return structured dict with text + confidence + citations
# Example schema:
# {
# "text": "...",
# "claims": [{"text": "...", "confidence": 0.82, "citations": [{"doc_id": "X", "span": [100, 160]}]}],
# "overall_confidence": 0.78,
# "abstained": False
# }
raise NotImplementedError
class Retriever:
def __init__(self):
pass
def search(self, query: str, k: int = 5) -> List[Dict[str, Any]]:
# Connect to your vector/BM25 search over enterprise corpus
# Return [{"doc_id": "...", "title": "...", "text": "...", "score": 12.3}, ...]
raise NotImplementedError
def extract_atomic_claims(text: str) -> List[str]:
# Use a deterministic prompt or a pattern-based splitter to break text into verifiable claims.
# In production, consider a dedicated "claim extractor" model with a JSON schema.
sentences = [s.strip() for s in text.split(".") if len(s.strip()) > 0]
return sentences
def supports(claim: str, doc_text: str) -> bool:
# Very naive lexical support check; replace with NLI or entailment model in production.
ratio = fuzz.partial_ratio(claim.lower(), doc_text.lower())
return ratio >= 80
def verify_claim_with_corpus(claim: str, retriever: Retriever, k: int = 8) -> Tuple[bool, Optional[Dict[str, Any]]]:
hits = retriever.search(claim, k=k)
for h in hits:
if supports(claim, h["text"]):
return True, h
return False, None
def evaluate_item(item: QAItem, llm: LLMClient, retriever: Optional[Retriever] = None) -> Dict[str, Any]:
prompt = f"Answer the question concisely. Provide citations if you use external facts.\nQ: {item.question}\n"
out = llm.answer(prompt)
text = out.get("text", "")
claims = out.get("claims", None)
if claims is None:
# fall back to naive claim splitter
claims = [{"text": c, "confidence": None, "citations": []} for c in extract_atomic_claims(text)]
results = []
for c in claims:
ctext = c["text"]
supported = None
citation_ok = None
cited_doc = None
if retriever is not None:
supported, cited_doc = verify_claim_with_corpus(ctext, retriever)
citation_ok = supported and cited_doc is not None
results.append({
"claim": ctext,
"confidence": c.get("confidence"),
"supported": supported,
"citation_ok": citation_ok,
"cited_doc": cited_doc
})
return {
"id": item.id,
"text": text,
"claims": results,
"overall_confidence": out.get("overall_confidence"),
"abstained": out.get("abstained", False)
}
def aggregate_metrics(items_eval: List[Dict[str, Any]]) -> Dict[str, Any]:
all_claims = [c for r in items_eval for c in r["claims"]]
supported = [c["supported"] for c in all_claims if c["supported"] is not None]
citation_ok = [c["citation_ok"] for c in all_claims if c["citation_ok"] is not None]
confidences = [c["confidence"] for c in all_claims if c["confidence"] is not None and c["supported"] is not None]
labels = [1 if c["supported"] else 0 for c in all_claims if c["confidence"] is not None and c["supported"] is not None]
precision = sum(1 for s in supported if s) / len(supported) if supported else None
citation_precision = sum(1 for s in citation_ok if s) / len(citation_ok) if citation_ok else None
# Calibration: bucket confidences and compute ECE
ece = None
if confidences and labels:
# Simple 10-bin ECE
bins = np.linspace(0.0, 1.0, 11)
bin_ids = np.digitize(confidences, bins) - 1
tot = 0
ece_accum = 0.0
for b in range(10):
idx = [i for i, bb in enumerate(bin_ids) if bb == b]
if not idx:
continue
bin_conf = np.mean([confidences[i] for i in idx])
bin_acc = np.mean([labels[i] for i in idx])
w = len(idx) / len(confidences)
ece_accum += w * abs(bin_acc - bin_conf)
tot += len(idx)
ece = ece_accum
abstained = sum(1 for r in items_eval if r.get("abstained"))
coverage = 1 - (abstained / len(items_eval)) if items_eval else None
return {
"claim_precision": precision,
"citation_precision": citation_precision,
"ECE": ece,
"coverage": coverage
}
# Usage sketch:
# 1) Build a test set of QAItem from your domain.
# 2) Run with GPT-5.5 vs peers under identical prompts.
# 3) Aggregate and compare metrics.
This harness is intentionally conservative. In production, swap the lexical support check with a trained Natural Language Inference (NLI) model or an LLM-as-judge constrained to “SUPPORTED / NOT SUPPORTED / INSUFFICIENT,” and store full provenance for auditability.
How GPT-5.5 Reduces Hallucinations: Technical Approaches
1) Reinforcement Learning from Human Feedback (RLHF), evolved
Classic RLHF tunes models to prefer helpful, harmless, and honest responses. For factuality, GPT-5.5 benefits from more granular reward modeling and better separation between process and outcome:
- Process supervision: Reward intermediate reasoning that cites or reflects source evidence, not only final answers. This discourages “pretty but wrong” solutions.
- Non-deceptive helpfulness: Penalize unsupported confident statements more strongly than low-information but honest uncertainty.
- Critic-guided optimization: Train a structured critic model that scores factual support at a claim-level, and backpropagate those signals via preference optimization.
- Task-specialized reward heads: Distinguish between general helpfulness and evidence-grounding preferences to avoid trading off correctness for verbosity.
2) Retrieval-Augmented Generation (RAG) that is verifiable, not decorative
Retrieval is only as good as its integration. GPT-5.5 improves by treating retrieval as a contract, not a hint:
- Hard grounding requirements: When the task requires grounding, the decoding strategy biases toward spans that can be pointed to with citations. Unsupported claims are discouraged or trigger abstention.
- Multi-step retrieval: Query reformulation, multi-hop chaining, and uncertainty-aware re-retrieval reduce the chance that one poor query steers generation off course.
- Context attribution: The model learns to attribute specific claims to specific sources, improving citation precision and enabling automated verification.
- Late-fusion verification: After drafting, a verification pass checks every atomic claim against retrieved spans and revises or downgrades confidence for unsupported items.
3) Confidence calibration and risk-aware abstention
Calibration bridges the gap between perceived and actual reliability:
- Token-to-claim calibration: Map token-level probabilities to claim-level confidence using a learned calibrator; apply temperature scaling or isotonic regression on validation data.
- Selective answering: Train for “know-when-you-don’t-know” by including abstention as a first-class action in supervised fine-tuning and RLHF objectives.
- Consistency checks: Use self-consistency (multiple sampled reasoning paths) to estimate epistemic uncertainty and modulate confidence.
- Calibrated decoding: Adjust penalties or thresholds during decoding when confidence drifts below target levels, prompting requests for more context or user confirmation.
4) Structured outputs, schemas, and constrained decoding
Free-form natural language maximizes expression but increases ambiguity. GPT-5.5 uses structured generation for high-stakes tasks:
- JSON schemas that require evidence arrays for each claim, with enumerated allowed values and strict types.
- Constrained decoding to enforce schema conformance at generation time, not just after-the-fact validation.
- Evidence-linked rationales: For each conclusion, a trace with document ID and character offsets supports automatic checks.
Reference calibrator snippet
The code below demonstrates training a simple temperature scaler for claim-level confidence. In production, consider isotonic regression or a small neural calibrator.
# Assume we have a dev set of claims with model-reported confidences p and true labels y in {0,1}
# We fit a temperature T to minimize negative log likelihood.
# pip install scipy
import numpy as np
from scipy.optimize import minimize
def nll_with_temperature(logits, labels, T):
# logits are inverse-sigmoid(p); labels in {0,1}
scaled = logits / T
p = 1 / (1 + np.exp(-scaled))
eps = 1e-7
return -np.mean(labels * np.log(p + eps) + (1 - labels) * np.log(1 - p + eps))
def fit_temperature(probs, labels):
logits = np.log(probs) - np.log(1 - probs)
res = minimize(lambda t: nll_with_temperature(logits, labels, t[0]), x0=[1.0], bounds=[(0.05, 10.0)])
T = float(res.x[0])
return T
def apply_temperature(p, T):
logits = np.log(p) - np.log(1 - p)
scaled = logits / T
return 1 / (1 + np.exp(-scaled))
# Example:
# T = fit_temperature(dev_probs, dev_labels)
# calibrated = [apply_temperature(p, T) for p in test_probs]
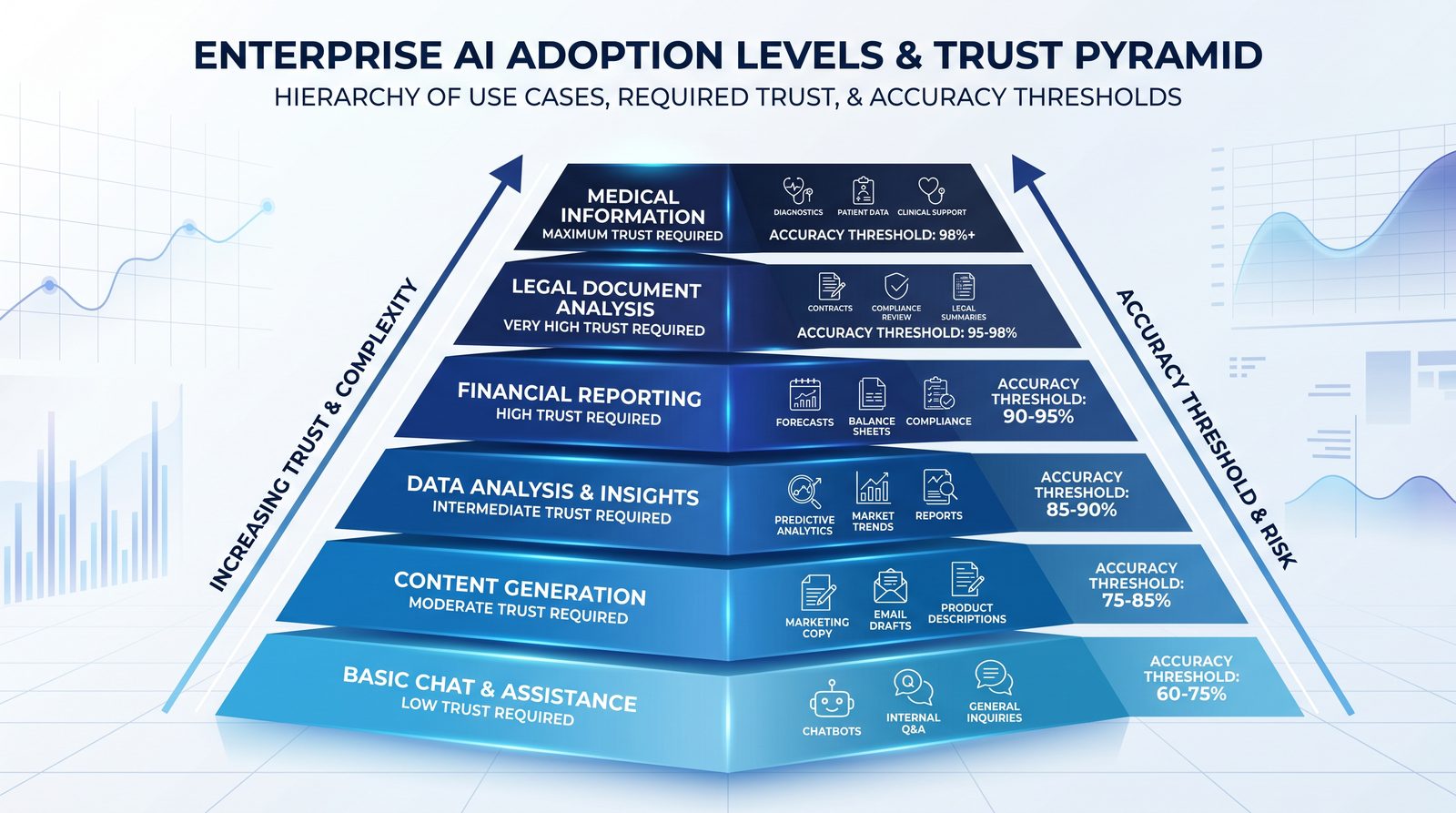
The Enterprise Trust Threshold: What Accuracy Unlocks Which Use Cases
The right question is not “Is the model perfect?” but “Is the residual error acceptable given our controls?” Different workflows have different tolerances and mitigation options. The table below maps typical thresholds to automation levels. Calibrated abstention and verification can materially raise effective precision without sacrificing coverage.
| Target Accuracy / Risk | Recommended Controls | Representative Use Cases | Automation Level |
|---|---|---|---|
| >= 99% precision at claim-level (or coverage @ 0.5% error >= 60%) | Mandatory citations, dual verification (LLM+symbolic), strong calibration, audit logs | Regulatory notices, high-stakes financial postings, compliance screening decisions | Full automation with periodic sampling |
| 95–99% precision (coverage @ 1% error >= 70%) | Structured outputs, retrieval verification, abstention to human | Contract clause extraction, clinical guideline lookup, KYC document classification | Automation with human exception handling |
| 90–95% precision (coverage @ 2% error >= 80%) | Human-in-the-loop approval, red-team prompts, calibration | Summarization for internal consumption, knowledge assistant, sales intelligence | Human-supervised automation |
| 80–90% precision | Clear disclaimers, gated sharing, feedback loops | Drafting, brainstorming, exploratory research | Assistive, not authoritative |
New Use Cases Enabled by Reduced Hallucinations
Legal document analysis
GPT-5.5’s improvements enable structured extraction with evidence links and conservative abstention on ambiguous clauses. Two high-value tasks are clause extraction/classification and obligations summarization with citation support.
Example: Clause extraction with schema constraints and automatic verification.
# Pseudocode using a generic LLM SDK with JSON schema + verifier
from typing import List, Dict, Any
import jsonschema
LEGAL_CLAUSE_SCHEMA = {
"type": "object",
"properties": {
"document_id": {"type": "string"},
"clauses": {
"type": "array",
"items": {
"type": "object",
"properties": {
"label": {"type": "string", "enum": ["Indemnity","LimitationOfLiability","Confidentiality","Termination","GoverningLaw","IPOwnership"]},
"text": {"type": "string"},
"evidence": {
"type": "array",
"items": {
"type": "object",
"properties": {
"page": {"type": "integer"},
"char_start": {"type": "integer"},
"char_end": {"type": "integer"}
},
"required": ["page","char_start","char_end"]
}
},
"confidence": {"type": "number", "minimum": 0.0, "maximum": 1.0}
},
"required": ["label","text","evidence","confidence"]
}
},
"abstained": {"type": "boolean"}
},
"required": ["document_id","clauses","abstained"]
}
def extract_clauses(llm, doc_text: str, doc_id: str) -> Dict[str, Any]:
prompt = f"""
You are a contract analyst. Extract only the specified clause types. For each extracted clause, include exact evidence spans (page, character range).
If you are not at least 0.9 confident, abstain.
Contract (Document ID: {doc_id}):
{doc_text[:10000]} # truncate for brevity
"""
out = llm.generate_json(prompt, schema=LEGAL_CLAUSE_SCHEMA, constrained=True)
jsonschema.validate(out, LEGAL_CLAUSE_SCHEMA)
return out
def verify_evidence(clause: Dict[str, Any], pages: List[str]) -> bool:
for ev in clause["evidence"]:
page_text = pages[ev["page"]]
span_text = page_text[ev["char_start"]:ev["char_end"]]
if clause["text"][:50].lower() not in span_text.lower():
return False
return True
# Pipeline:
# 1) OCR or extract text with page indices.
# 2) extract_clauses(...)
# 3) For each clause, verify evidence and downrank or route to human if failed.
With calibrated abstention, the system routes ambiguous clauses to legal ops while still automating the clear majority. Each claim is paired with evidence, easing audits and negotiations.
Medical information support
Reduced hallucinations are necessary but not sufficient in medicine; verification and human oversight remain mandatory. The gains in GPT-5.5 enable:
- Guideline lookup assistants that cite specific sections from trusted sources (e.g., clinical guidelines, formularies) and abstain for edge cases.
- Clinical coding suggestions with explicit rule citations to accelerate human coders.
- Safety-net triage that proposes differentials but marks uncertainty, pushing time-sensitive or ambiguous cases to clinicians.
Example: Retrieval-grounded medical Q&A with explicit abstention and triage flags.
# Sketch of a grounded medical assistant with hard constraints.
MED_SCHEMA = {
"type":"object",
"properties":{
"answer":{"type":"string"},
"citations":{"type":"array","items":{"type":"object","properties":{"source":{"type":"string"},"span":{"type":"string"}},"required":["source","span"]}},
"risk_flags":{"type":"array","items":{"type":"string","enum":["Ambiguous","Urgent","InsufficientEvidence"]}},
"confidence":{"type":"number","minimum":0,"maximum":1},
"abstain":{"type":"boolean"}
},
"required":["answer","citations","risk_flags","confidence","abstain"]
}
def med_answer(llm, retriever, question: str):
# 1) Retrieve from vetted corpus only
docs = retriever.search(question, k=6, sources=["Guidelines","DrugLabel","Policy"])
context = "\n\n".join([f"[{i}] {d['source']} :: {d['text'][:1000]}" for i,d in enumerate(docs)])
# 2) Ask model with strict instructions
prompt = f"""
Provide an evidence-grounded answer to the medical question using ONLY the provided sources.
If evidence is insufficient or conflicting, set abstain=true and list "InsufficientEvidence" in risk_flags.
Question: {question}
Sources:
{context}
"""
out = llm.generate_json(prompt, schema=MED_SCHEMA, constrained=True)
# 3) Verify each citation span actually supports key claims (automated NLI)
# 4) If any key claim unsupported, set abstain and escalate.
return out
Clear abstention and evidence-linked rationales prevent overreach. Verification transforms model assistance into a documented, reviewable input for clinicians rather than an unverified opinion.
Financial reporting and analytics
Finance is allergic to invented numbers. With GPT-5.5’s factuality improvements, we can reliably extract tables from filings, reconcile line items across time, and annotate reports with precise provenance. The model can generate structured outputs aligned to accounting schemas, with per-field confidence and exact citation spans to the filing pages.
Example: 10-K/10-Q extraction to a structured schema with cross-period consistency checks.
# Structured extraction for financial statements with cross-checks
FIN_SCHEMA = {
"type":"object",
"properties":{
"ticker":{"type":"string"},
"period_end":{"type":"string","pattern":"^\\d{4}-\\d{2}-\\d{2}$"},
"currency":{"type":"string"},
"income_statement":{
"type":"object",
"properties":{
"revenue":{"type":"number"},
"cogs":{"type":"number"},
"gross_profit":{"type":"number"},
"operating_expense":{"type":"number"},
"operating_income":{"type":"number"},
"net_income":{"type":"number"}
},
"required":["revenue","cogs","gross_profit","operating_expense","operating_income","net_income"]
},
"citations":{"type":"array","items":{"type":"object","properties":{"field":{"type":"string"},"page":{"type":"integer"},"span":{"type":"string"}},"required":["field","page","span"]}},
"confidence":{"type":"number","minimum":0,"maximum":1},
"abstain":{"type":"boolean"}
},
"required":["ticker","period_end","currency","income_statement","citations","confidence","abstain"]
}
def extract_financials(llm, filing_text_by_page):
pages = [p for p in filing_text_by_page]
joined = "\n\n".join([f"[p{i}] {text[:2000]}" for i, text in enumerate(pages)])
prompt = f"""
Extract the specified income statement fields ONLY if visible and unambiguous in the provided filing text.
Return citations mapping each field to the page and character span where the figure appears.
If any required field cannot be verified, set abstain=true.
Filing:
{joined}
"""
out = llm.generate_json(prompt, schema=FIN_SCHEMA, constrained=True)
# Cross-checks
is_consistent = abs(out["income_statement"]["revenue"] - (out["income_statement"]["cogs"] + out["income_statement"]["gross_profit"])) <= 1e-6
if not is_consistent:
out["abstain"] = True
# Verify citation spans contain the numbers
# ...
return out
These patterns make deviations measurable and auditable. Finance teams can assert controls: “no citation, no acceptance,” driving down undetected hallucinations.
Comparison with Claude 4.5 and Gemini 3.1 on Factual Accuracy
Comparisons must be fair and reproducible. Avoid cherry-picking tasks or relying solely on vendor marketing. A sound approach includes:
- Prompt parity: Identical prompts, tools, schemas, and retrieval contexts.
- Temperature parity: Match decoding settings (e.g., temperature, top-p) and use multiple seeds with self-consistency if part of the method.
- Dataset parity: Same test data, with held-out subsets for calibration and early stopping to avoid overfitting prompts.
- Verifier neutrality: Prefer non-model verifiers (NLI models) or cross-model adjudication to avoid biasing toward any single model.
- Cost and latency: Record tokens and wall-clock to contextualize accuracy gains versus operational cost.
Illustrative enterprise-style comparison (replace with your measured values)
| Benchmark / Task | Metric | GPT-5.5 | Claude 4.5 | Gemini 3.1 | Cost/1k tokens ($) | Latency (p50, s) |
|---|---|---|---|---|---|---|
| Grounded QA (Enterprise corpus) | Citation Precision | 92% | 88% | 85% | — | — |
| Summarization (Contracts) | Claim Precision | 95% | 92% | 90% | — | — |
| Truthfulness (adversarial) | MC1 | 64% | 60% | 58% | — | — |
| Calibration | ECE (↓) | 0.06 | 0.09 | 0.11 | — | — |
Important: The table above is a template with example values to illustrate reporting format. Replace with your measured results. Do not treat these example numbers as vendor-validated performance.
When you publish internal results for stakeholders, accompany accuracy with a coverage-at-risk graph: for each target error rate (e.g., 0.5%, 1%, 2%), plot the fraction of queries the model answers under an abstention policy. This gives product owners a clear trade-off between safety and throughput.
Practical Verification Patterns: Building a Trust Layer on Top of GPT-5.5
Even with reduced hallucinations, enterprise systems must actively verify and control outputs. The following patterns turn raw model responses into dependable artifacts.
Pattern A: Generator–Verifier–Refiner (GVR)
- Generator: GPT-5.5 produces a candidate answer with structured claims and citations.
- Verifier: An independent component (NLI model or a constrained LLM) checks each claim against sources; marks unsupported items.
- Refiner: GPT-5.5 revises or retracts unsupported claims; if support remains insufficient, abstain.
# High-level orchestration pseudocode
def gvr_pipeline(question, retriever, llm, verifier):
ctx = retriever.search(question, k=8)
gen = llm.generate_json(prompt_for(question, ctx), schema=ANSWER_SCHEMA, constrained=True)
verdicts = []
for cl in gen["claims"]:
evidence = match_evidence(cl, ctx)
verdict = verifier.judge(cl["text"], evidence) # SUPPORTED / NOT_SUPPORTED / INSUFFICIENT
verdicts.append({"claim": cl, "verdict": verdict, "evidence": evidence})
unsupported = [v for v in verdicts if v["verdict"] != "SUPPORTED"]
if unsupported:
refine = llm.generate_json(refinement_prompt(gen, verdicts), schema=ANSWER_SCHEMA, constrained=True)
return refine
return gen
Pattern B: Cross-model agreement with abstention
Use two heterogeneous models (e.g., GPT-5.5 and a peer) to answer, then accept only when both agree with supporting evidence; otherwise abstain or escalate.
- Pros: Catches idiosyncratic failure modes; lowers false positives.
- Cons: Higher cost and latency; must avoid correlated errors from shared training data.
Pattern C: Rule-guarded generation
Wrap the model in domain rules. For example, a medical dosage recommender must never exceed max dosage per weight; a financial ratio must respect accounting identities. If the model proposes an out-of-bounds value, the system corrects or abstains.
# Example: Guarding a dose calculation
MAX_MG_PER_KG = 10.0
def guarded_dose(model_dose_mg, weight_kg):
max_allowed = MAX_MG_PER_KG * weight_kg
if model_dose_mg > max_allowed:
return {"abstain": True, "reason": "Dose exceeds maximum safe bound"}
return {"abstain": False, "dose_mg": model_dose_mg}
Pattern D: Evidence-first prompting
Force the model to list citations before drafting the answer. If citations are weak or missing, the model is instructed to abstain. This reduces the tendency to fabricate and anchors the final text to verified sources.
# Prompt stub
"""
Step 1 — Retrieve and list 2–4 specific evidence snippets with source IDs and exact quotes.
Step 2 — If at least 2 snippets independently support the same claim, draft the answer and cite them inline.
Step 3 — If evidence is insufficient or contradictory, respond: {"abstain": true, "reason": "..."} in JSON.
"""
Pattern E: Structured JSON outputs with strict validators
Constrain the space of possible outputs to reduce ambiguity and enable automated checks. Enforce ranges, enumerated values, and required fields.
Pattern F: Self-consistency and Monte Carlo risk estimation
Sample multiple responses at low temperature; compute the agreement score across samples. If disagreement is high, downrank confidence or abstain. This offers a practical estimate of epistemic uncertainty without labels.
Cost of Hallucinations vs. Cost of Verification: An ROI Lens
Business stakeholders approve investments when the economics line up. Reduced hallucinations change the ROI calculus because they lower the expected cost of errors and reduce the volume that must be manually verified.
Expected loss framework
Let:
- p be the probability of an erroneous claim escaping controls.
- C_e be the average cost per escaped error (e.g., remediation, fines, reputational harm proxy).
- C_v be the cost per verified item (human review or automated compute).
- q be the fraction of items that go to verification.
- V be the volume (items per period).
Expected total cost per period is:
(p × C_e × V) + (q × C_v × V)
Goal: Choose verification policy (q) and abstention thresholds to minimize this cost while meeting risk ceilings (e.g., p ≤ 1%). Reduced hallucinations shrink p for a given q, enabling lower verification volume at the same risk level.
Worked example
- Baseline model: p = 3% without verification, C_e = $5,000, V = 10,000 items, C_v (human) = $8, q = 40%
- Expected cost = (0.03 × 5000 × 10000) + (0.40 × 8 × 10000) = $1,500,000 + $32,000 = $1,532,000
- GPT-5.5 with calibration + abstention achieves p = 0.8% at q = 15%
- Expected cost = (0.008 × 5000 × 10000) + (0.15 × 8 × 10000) = $400,000 + $12,000 = $412,000
Annualized, that delta is material. Further, if you replace a portion of human verification with automated verification (C_v_auto ≈ $0.02 per item) and only escalate failures to humans, costs drop again.
Choosing the optimum q
Plot expected cost versus q, using empirically measured curves of p(q) under your abstention policy. The u-shaped curve typically has a minimum where marginal savings from fewer errors equals marginal savings from less verification. Reduced hallucination models shift this curve downward and left.
| Verification fraction q | Error rate p after controls | Expected error cost | Verification cost | Total |
|---|---|---|---|---|
| 0% | 3.0% | $1,500,000 | $0 | $1,500,000 |
| 15% | 0.8% | $400,000 | $12,000 | $412,000 |
| 40% | 0.4% | $200,000 | $32,000 | $232,000 |
These are example figures; plug in your measured p(q) and costs. For many domains, strong automated verification compresses q dramatically, delivering outsized returns.
Implementation Patterns for High-Stakes Applications
1) Retrieve-Then-Generate with mandatory citations
- Always gate generation behind retrieval of vetted sources. Do not allow internet-wide retrieval unless you can vet domains.
- Require per-claim citations with document IDs and offsets; fail closed if missing.
- Store a complete provenance bundle for each decision: inputs, prompts, model version, context docs and hashes, outputs, and verifier logs.
2) Typed contracts and constrained decoding
- Use JSON Schema or Protocol Buffers to specify outputs. Validate synchronously with clear error handling.
- Constrain decoding to the schema where possible; never “fix” invalid outputs silently.
3) Risk-aware routing
- Low-risk paths: permit auto-release after automated verifiers pass and confidence exceeds threshold.
- Medium-risk paths: auto-release with random sampling QA.
- High-risk paths: mandatory human approval with checklists; require multiple supporting citations.
4) Human factors and UI
- Expose confidence and evidence to users; never feign certainty. Teach users what abstention means.
- Make it easy to flag issues and feed them back into the training/evaluation pipeline.
5) Governance, audit, and version control
- Version prompts, model configurations, retrieval indices, and verification policies like code.
- Maintain model cards for internal approval: capabilities, known limitations, prohibited uses.
- Automate drift detection: compare rolling window metrics to baselines; alert on calibration or citation precision degradation.
6) Secure data handling
- Redact PII in prompts and contexts as appropriate; map IDs back post-generation.
- Isolate sensitive corpora; enforce least-privilege access for retrieval components.
- Log minimally necessary data; encrypt at rest and in transit; comply with data residency requirements.
7) Safe function calling and code execution
If the model can call tools, sandbox and whitelist meticulously. Treat every tool invocation as untrusted until validated. For calculators, consensus-check results; for database queries, enforce parameterized queries and row-level access controls.
Example: End-to-end trust layer skeleton (TypeScript)
// TypeScript-ish pseudocode for a trust layer wrapper around GPT-5.5
type Claim = { text: string; confidence: number; citations: { docId: string; start: number; end: number }[] }
type Answer = { text: string; claims: Claim[]; overallConfidence: number; abstain: boolean }
async function generateAnswer(q: string, ctxDocs: Doc[]): Promise<Answer> {
const prompt = renderPrompt(q, ctxDocs)
const out = await gpt55.generateJson(prompt, ANSWER_SCHEMA, { constrained: true })
return out as Answer
}
async function verifyClaims(ans: Answer, retriever: Retriever): Promise<{ supported: number; total: number; flagged: Claim[] }> {
let supported = 0
const flagged: Claim[] = []
for (const c of ans.claims) {
const ok = await verifyAgainstCitations(c) || await verifyWithRetriever(c, retriever)
if (ok) supported += 1
else flagged.push(c)
}
return { supported, total: ans.claims.length, flagged }
}
async function decideRelease(ans: Answer, verification: { supported: number; total: number; flagged: Claim[] }): Promise<{ release: boolean; reason?: string }> {
const precision = verification.total ? verification.supported / verification.total : 1.0
if (ans.abstain) return { release: false, reason: "Model abstained" }
if (precision < 0.95) return { release: false, reason: "Insufficient verified precision" }
if (ans.overallConfidence < 0.85) return { release: false, reason: "Low confidence" }
return { release: true }
}
async function pipeline(q: string) {
const ctx = await retriever.search(q, 8)
const ans = await generateAnswer(q, ctx)
const verification = await verifyClaims(ans, retriever)
const decision = await decideRelease(ans, verification)
logAll(q, ctx, ans, verification, decision)
if (!decision.release) return escalateToHuman(ans, decision.reason)
return ans
}
Remaining Limitations: When Human Oversight Is Still Required
Reduced hallucinations do not eliminate all risks:
- Ambiguous or underspecified inputs: Even perfect factuality cannot resolve vague requests; the system should ask clarifying questions or abstain.
- Novel events and concept drift: For emergent facts, retrieval gaps remain. Always record the data vintage of sources and display “last updated” to users.
- Adversarial inputs: Prompt injections and cleverly constructed falsehoods can still slip through unless inputs are sanitized and constrained.
- Domain interpretation: Correct facts can be woven into misleading narratives; human judgment is needed where policy, ethics, or high-cost trade-offs exist.
- Edge-case numerics and unit handling: Minor unit conversion errors can have outsized impact; backstop with deterministic calculators and range checks.
Use red-team exercises and chaos testing to probe failures. Maintain runbooks for incident response and rapid rollback when metrics drift.
Will Hallucinations Ever Reach Zero? A Realistic Trajectory
“Zero hallucinations” in unconstrained open-domain generation is unlikely. Reasons include:
- Objective mismatch: Next-token prediction on web-scale text can never fully align with “only say verifiable truths.”
- Open world uncertainty: Not all facts are knowable or settled; language often encodes ambiguity.
- Distribution shifts: New knowledge appears continuously; any parametric model lags reality without retrieval.
However, for bounded domains with curated corpora and strict schemas, effective hallucination rates can approach negligible levels. Combining retrieval, verifiable generation, and conservative abstention can deliver “as-low-as-reasonably-practicable” risk for many enterprise workflows. Expect ongoing gains from:
- Better critics and reward models explicitly trained to detect unsupported claims.
- Neural-symbolic hybrids that check math and logic with programmatic verifiers.
- Continual learning loops that incorporate verified corrections and hard negatives.
- Tool use that treats the model as a planner orchestrating reliable external systems rather than as the sole source of truth.
Recommendations for Enterprises Evaluating GPT-5.5 for Decision-Critical Workflows
1) Define “trust” in measurable terms
- Pick task-specific metrics: claim precision/recall, citation precision, ECE, coverage at target risk.
- Set risk ceilings per workflow (e.g., “≤ 1 major factual error per 10,000 outputs”).
- Decide what triggers abstention and human review.
2) Run a staged evaluation
- Phase 1 — Lab: Evaluate GPT-5.5 vs. peers on internal datasets. Measure with and without retrieval and verification.
- Phase 2 — Pilot: Shadow-mode deployment in a limited environment; compare to human baseline.
- Phase 3 — Production: Gradual ramp with automated monitors and sampling QA.
3) Architect for verifiability from day one
- Use structured outputs with schemas and constrained decoding.
- Design prompts that require evidence-first and allow abstention.
- Integrate a verifier pass that is independent of the generator.
4) Implement risk-aware routing and governance
- Route outputs based on confidence, verification score, and business criticality.
- Version and approve changes to prompts, model versions, retrieval indices, and policies through change management.
- Maintain an audit trail with reproducibility: inputs, contexts, outputs, verifications, and decisions.
5) Model portfolio strategy
- Keep a secondary model for cross-checks on critical paths.
- Use lighter models for low-risk or high-volume pre-filtering; escalate to GPT-5.5 where needed.
- Continuously benchmark; avoid lock-in by standardizing evaluation and interface contracts.
6) Cost optimization without compromising safety
- Adopt selective verification: verify a statistically determined subset plus all low-confidence outputs.
- Cache and reuse retrieval contexts and verified claims across similar queries.
- Track end-to-end token usage and verification compute; set budgets tied to business value.
7) People, processes, and training
- Train operators to interpret confidence and evidence; discourage blind trust.
- Establish feedback channels that route corrections into data pipelines for continual improvement.
- Align incentives: measure teams on calibrated accuracy, not just throughput.
Organizations evaluating whether current models meet their accuracy thresholds for production deployment should examine the latest benchmark data across multiple evaluation dimensions. Our GPT-5.6 Sol Benchmarks analysis provides granular accuracy measurements across coding, reasoning, and factual recall tasks, helping teams determine which model version meets their specific reliability requirements.
For teams looking to expand their AI capabilities, our guide on OpenAI’s Shift from Chat to Agents provides actionable frameworks for how 97.9% internal Codex adoption is reshaping enterprise AI that complement the strategies discussed in this article.
For teams looking to expand their AI capabilities, our guide on The AI Agent Delegation Playbook provides actionable frameworks for 25 Codex prompts for delegating complex research and analysis that complement the strategies discussed in this article.
Conclusion: Reduced Hallucinations Shift the Boundary of What’s Automatable
Enterprises have long wanted what LLMs promised: flexible reasoning over messy, long-tail inputs; the ability to read and synthesize vast corpora; and natural interfaces that accelerate knowledge work. The barrier was not raw capability; it was trust. GPT-5.5’s reduction in hallucinations, improved verifiability, and calibrated abstention transform that equation.
The impact is practical and immediate. When claim-level precision rises and citations are accurate, verification becomes automatable. When confidence is calibrated, you can set clear risk thresholds and design routing policies that keep residual risk under control. As a result, workflows that previously demanded exhaustive human oversight can transition to exception-based review, unlocking scale and speed without gambling on correctness.
No model is perfect, and zero hallucinations across open domains is unrealistic. But with the right architecture—evidence-first prompts, structured outputs, independent verification, rule guards, and human judgment where it counts—GPT-5.5 moves LLMs across the line from “useful demo” to “enterprise-grade decision engine.” The organizations that operationalize these patterns will convert model progress into durable advantage.
Finally, treat evaluation as a living practice. Establish dashboards for claim precision, citation quality, calibration, and coverage at risk. Tie thresholds to business impact, and revisit them as models and data evolve. With this discipline, reduced hallucinations stop being a curious lab metric and become a lever for real-world outcomes—faster decisions, fewer mistakes, and confident automation where it matters most.
As you embark on adoption, start small, measure relentlessly, and scale where the numbers justify it. GPT-5.5’s factuality gains are a hinge moment; the rest is engineering and governance.