The Codex Debugging Playbook: 20 Prompts for Systematic Bug Isolation, Root Cause Analysis, and Automated Fix Generation

Author: Markos Symeonides, ChatGPT AI Hub
The Codex Debugging Playbook: 20 Prompts for Systematic Bug Isolation, Root Cause Analysis, and Automated Fix Generation
Reliable debugging with large codebases requires repeatable procedures and precise instructions for the assistant. This article presents a practical, field-tested playbook of 20 prompts designed for OpenAI Codex-style agents that can read repositories, reason over execution traces, and generate validated patches. Each prompt includes full text you can paste into your agent, the expected behavior, example output, and customization tips. The prompts are organized across three phases: Bug Isolation, Root Cause Analysis, and Automated Fix Generation.
These prompts assume your agent has access to the repository content (through a file loader or context retrieval), can run your test suite and sample commands in a sandbox, and can produce diffs and test artifacts. When appropriate, they use structured placeholders (like {{repo_path}} or {{test_cmd}}) to adapt to different environments. If your toolchain supports functions or tools (e.g., “run_command”, “read_file”, “write_file”, “git_diff”), attach them to the agent for best results. Where live execution isn’t permitted, prompts instead guide static analysis and hypothetical execution reasoning.
Prerequisites and Setup Considerations
- Ensure the agent can read files (source, config, tests) and optionally execute commands in a sandboxed environment.
- Provide the agent a concise, authoritative context: the primary language(s), framework, build system, test runner, and top-level goals.
- Limit the scope of each run to the relevant modules; use codebase indexers or chunked retrieval to avoid token exhaustion.
- Grant the agent read-only access at first; enable write capability (patches) only once you trust its plan.
- Prefer unified diffs and incremental changes; always require tests and rollback instructions.
- When logs or traces are large, summarize in slices and request hierarchical reasoning.
Playbook Map
| # | Category | Prompt Name | Primary Goal |
|---|---|---|---|
| 1 | Bug Isolation | Binary Search on Execution Path | Divide failing flow into checkpoints to locate fault |
| 2 | Bug Isolation | Structured Log Analysis | Convert logs into timeline and anomaly map |
| 3 | Bug Isolation | State Inspection at Failure | Capture and compare runtime state snapshots |
| 4 | Bug Isolation | Minimal Reproduction Builder | Create deterministic reproducer |
| 5 | Bug Isolation | Environment Comparison | Diff runtime environment (dev vs prod) |
| 6 | Bug Isolation | Dependency Conflict Detector | Identify version mismatches and API breakages |
| 7 | Root Cause Analysis | Stack Trace Decomposition | Identify point-of-failure and causality chain |
| 8 | Root Cause Analysis | Race Condition Reasoner | Concurrency timeline and hazard detection |
| 9 | Root Cause Analysis | Memory Leak Locator | Lifecycle and reference analysis |
| 10 | Root Cause Analysis | Performance Bottleneck Profiler | Hotspot identification and hypothesis |
| 11 | Root Cause Analysis | Data Flow Tracer | Path tracing of inputs to outputs |
| 12 | Root Cause Analysis | Configuration Drift Auditor | Diff configs across tiers and versions |
| 13 | Root Cause Analysis | Regression Bisection | Find offending commit via test bisection |
| 14 | Automated Fix Generation | Patch + Test Generator | Create minimal fix with tests and diff |
| 15 | Automated Fix Generation | Refactoring Stabilizer | Restructure code for clarity and resilience |
| 16 | Automated Fix Generation | Error Handling Hardening | Introduce guards, retries, and safe fallbacks |
| 17 | Automated Fix Generation | Performance Improvement Patch | Optimize critical path without regressions |
| 18 | Automated Fix Generation | Security Patch Composer | Eliminate injection, deserialization, and unsafe patterns |
| 19 | Automated Fix Generation | Backward-Compatible Fix | Feature flags and deprecation mitigation |
| 20 | Automated Fix Generation | Documentation Sync | Update README, docs, changelogs, examples |
Effective debugging with AI agents requires breaking complex problems into discrete, verifiable subtasks that can be executed in parallel. Our Codex Task Decomposition Playbook provides a systematic framework for splitting any complex project into agent-ready subtasks, including dependency mapping and verification checkpoints that ensure each subtask produces correct intermediate results.
Access 40,000+ AI Prompts for ChatGPT, Claude & Codex — Free!
Subscribe to get instant access to our complete Notion Prompt Library — the largest curated collection of prompts for ChatGPT, Claude, OpenAI Codex, and other leading AI models. Optimized for real-world workflows across coding, research, content creation, and business.
Using Codex Agents Effectively for Debugging
- Scope control: Provide the agent links to only the relevant directories (services, modules) via {{file_globs}}. Avoid dumping the entire monorepo at once.
- Artifacts first: Ask for a plan and a checklist the agent will follow before it changes code. Require a diff and tests for any patch.
- Determinism: Favor reproducible environments—containerized, pinned dependencies, and recorded seeds for randomized code paths.
- Observability scaffolding: Allow the agent to inject temporary logging around suspected hotspots, then collect and reason about the logs.
- Guardrails: Explicitly forbid sweeping refactors without tests; prefer minimal diffs and measurable outcomes (failing tests turned green, performance counters improved).
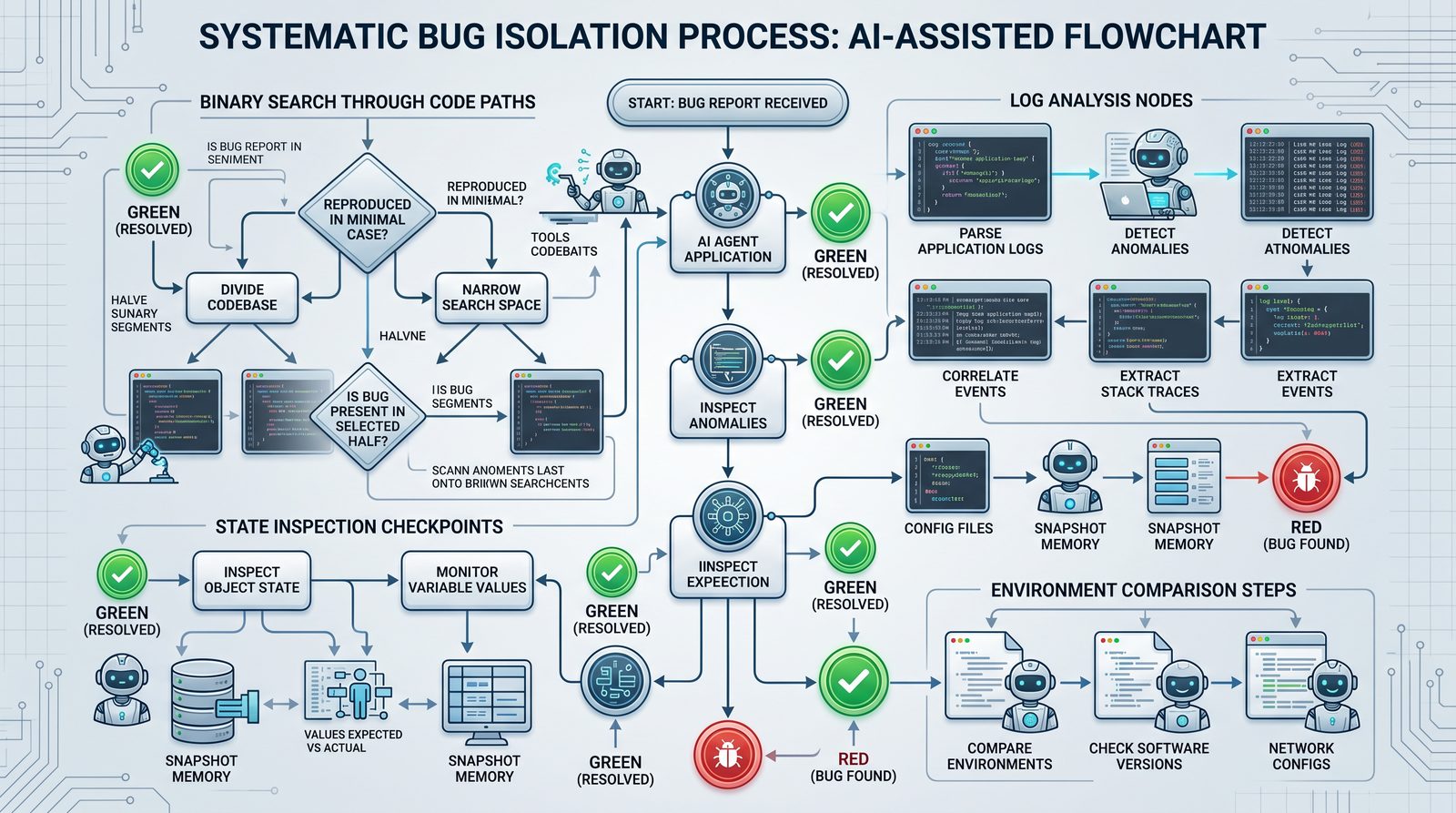
Bug Isolation Prompts
The first six prompts systematically narrow the search space to a small set of files, functions, or configuration entries. They rely on checkpoints, logs, state snapshots, controlled reproductions, environment diffs, and dependency analysis.
Prompt 1: Binary Search on Execution Path
This prompt guides the agent to instrument intermediate checkpoints in the failing flow (e.g., request handlers, service layers, database calls) and perform a binary search across the path to find the earliest point of divergence.
System Goal:
Perform binary search over the failing execution path to isolate where the observed behavior deviates from the expected.
Instructions:
1) Read repository files matching {{file_globs}} and focus on the flow invoked by {{entry_point}} with args {{args}}.
2) Identify a linearized sequence of checkpoints (function/method calls, IO boundaries, external API calls).
3) Insert temporary logging at midpoints and run {{repro_cmd}} to collect logs (or simulate if execution is unavailable).
4) Use binary search: narrow the segment where expected vs actual diverges.
5) Summarize the earliest deviation with code refs and candidate root causes.
6) Output:
- Checkpoint plan
- Collected/simulated logs
- Deviating checkpoint and hypothesis
- Next-step instrumentation suggestions
- No code changes committed; propose a minimal patch if needed
Inputs:
- {{repo_path}}, {{file_globs}}, {{entry_point}}, {{args}}, {{repro_cmd}}
Constraints:
- Keep logging diff minimal and removable
- Annotate line numbers and file paths
- Avoid refactors; logging only
Expected Behavior
- Derives 6–10 checkpoints that cover the core path.
- Runs a controlled binary search: halves the path iteratively until the deviating point is found.
- Produces compact logs showing agreement before the midpoint and divergence after.
- Recommends a specific function and line range to inspect next.
Example Output
Checkpoint Plan:
1. http_handler() - api/server.py:112
2. parse_request() - api/parsers.py:48
3. validate_payload() - api/validators.py:73
4. dispatch() - core/router.py:201
5. process_order() - services/orders.py:141
6. commit_txn() - db/transactions.py:89
Binary Search Iteration 1:
Midpoint: validate_payload() - OK
Logs: [validator] payload keys: ["user_id", "items", "discount_code"]
Iteration 2:
Midpoint between dispatch() and commit_txn(): process_order() - DIVERGENCE
Logs show discounted_total negative after promotional rule "BOGO-2024" applied
Earliest deviation:
services/orders.py:160 in apply_promotions(): negative discounted_total
Hypothesis:
Promotion rule "BOGO-2024" double-applies for multi-item orders when a bundle is present.
Next steps:
Add guard condition for bundle promotions and instrument apply_promotions() lines 158–172.
Customization Tips
- For event-driven or async flows, define “checkpoint” as queued event boundaries and message handlers.
- For CLI tools, use subcommand boundaries (parse, validate, execute, report).
- Limit logs to structured JSON to ease machine parsing.
Prompt 2: Structured Log Analysis
Transform verbose logs into a timeline of events, error clusters, and anomaly indicators. The agent extracts fields, normalizes timestamps, and correlates with code locations.
System Goal:
Convert raw logs from {{log_files_glob}} into a structured timeline, detect anomalies, and map them to code locations.
Instructions:
1) Parse logs (JSON, text) into structured entries with fields: ts, level, component, message, event_id, request_id.
2) Build a timeline for each request_id and a global time series of error rates.
3) Identify bursts, outliers, and missing events; correlate with code regions.
4) Output:
- Per-request timelines with key transitions
- Error/latency heatmap summary
- Anomaly list with probable code references
- Suggested probes or counters to add
Inputs:
- {{log_files_glob}}, optional {{code_map}} dictionary of component-to-file mapping
Constraints:
- Avoid speculative code changes; propose minimal instrumentation only
- If timestamps skewed, derive relative ordering
Expected Behavior
- Produces a per-request timeline with status changes, latency spikes, and missing events.
- Builds aggregate plots (lists) of error rates per minute and by component.
- Maps anomalies back to functions and files using component tags.
Example Output
Anomaly Summary:
- Component: "payment" (payments/processor.py): 420 errors in 5 min, spike at 12:04–12:09 UTC.
- Missing event: "refund_issued" after "charge_failed"; handler likely not invoked in payments/refunds.py.
- Outlier latency: db.save_order() jumped from p95 30ms to 220ms coincident with version 2.4.1 roll-out.
Suggested Probes:
- Add event_id "refund_issued" log in refunds.issue_refund().
- Wrap db.save_order() with latency timer and log payload size.
Customization Tips
- Feed logs in batches; the agent can summarize by time windows to keep context manageable.
- Provide a component-to-file mapping to improve code correlation.
Prompt 3: State Inspection at Failure
Capture runtime state snapshots at the point-of-failure: variable values, cache contents, db query results, and object lifecycles. The agent compares failing vs passing runs.
System Goal:
Inspect runtime state at failure; compare to a control (passing run) to isolate misconfigured or mutated values.
Instructions:
1) Identify critical state variables along the path {{entry_point}} -> {{failure_point}}.
2) If instrumentation permitted, add temporary dumps: locals(), selected globals, cache keys, db query result counts.
3) Run failing scenario {{repro_cmd}} and control scenario {{control_cmd}}.
4) Compute diffs of state snapshots; rank differences by impact.
5) Output:
- Snapshot diff table
- Suspicious variables and provenance (where set/mutated)
- Proposed next checks (e.g., trace setters)
Inputs:
- {{entry_point}}, {{failure_point}}, {{repro_cmd}}, {{control_cmd}}, {{snapshot_spec}}
Constraints:
- Do not persist sensitive data in logs; redact secrets (tokens, passwords)
- Avoid side effects beyond logging
Expected Behavior
- Produces a ranked list of variables whose values differ across runs.
- Locates where a variable is mutated and whether mutation is expected.
- Illustrates the cascade from state difference to failure.
Example Output
Snapshot Diff:
- user.region: failing="EU", control="US" (impacts VAT calculation)
- discounts.active_rules: failing=["BOGO-2024", "EU-VAT-REDUCE"], control=["BOGO-2024"]
- cart.items_total: failing=0 due to overflow in parse_items()
Provenance:
- discounts.load_rules() applied EU-VAT-REDUCE based on env var REGION="EU" set in prod only.
- parse_items() integer overflow for quantity >= 2^31.
Next checks:
- Guard parse_items() against int overflow and constrain REGION to supported values.
Customization Tips
- Define {{snapshot_spec}} to avoid dumping large collections; sample, summarize, and hash.
- Use structured serialization (JSON) for diffs to ease machine parsing.
Prompt 4: Minimal Reproduction Builder
Ask the agent to construct a deterministic reproduction: a small script or test case that triggers the bug with fixed seeds and controlled inputs, runnable in CI.
System Goal:
Create a minimal, deterministic reproducer for the failure, suitable for CI and isolation.
Instructions:
1) Read the failing behavior description and input samples from {{failure_notes}}.
2) Extract the essential API calls and dependencies into a small script/test.
3) Pin versions, set seeds, and fix environment variables.
4) Validate that the reproducer fails in the same way as the original scenario.
5) Output:
- Script/test file content
- Run instructions for CI
- Notes on variability and how to stabilize
Inputs:
- {{failure_notes}}, {{api_entrypoint}}, {{ci_env}}, {{seed}}
Constraints:
- Keep reproducer minimal: single file if possible
- Require deterministic failure messages or exit codes
Expected Behavior
- Produces a small reproducible script/test.
- Documents commands to run and expected outputs.
- Pins versions to avoid flakiness.
Example Output
Reproducer Script (Python):
import os
import random
random.seed(42)
os.environ["REGION"] = "EU"
from app.orders import process_order
def main():
payload = {
"user_id": "u-1234",
"items": [{"sku": "BUNDLE-9", "qty": 2147483647}],
"discount_code": "BOGO-2024"
}
result = process_order(payload)
assert result["discounted_total"] >= 0, "negative total bug reproduced"
if __name__ == "__main__":
main()
Run:
python -m venv .venv && source .venv/bin/activate
pip install -r requirements.txt
python reproducer.py # AssertionError expected
Customization Tips
- When external APIs are involved, stub them with fixed responses using a local fake server or mock library.
- For non-deterministic concurrency bugs, capture seeds and enforce single-threaded execution to reproduce at least one failure mode deterministically.
Prompt 5: Environment Comparison (Dev vs Prod)
Identify and explain behavioral differences between environments by comparing configuration, runtime flags, resource limits, and build artifacts.
System Goal:
Compare dev vs prod environments; identify drift that explains the failure.
Instructions:
1) Collect environment artifacts: env vars, config files, docker images, JVM/python versions, resource limits.
2) Build a diff with impact assessment on the failing flow.
3) Prioritize differences likely to influence observed behavior (e.g., REGION, feature flags, CPU arch).
4) Output:
- Diff table (name, dev, prod, impact)
- Hypotheses linking drift to symptoms
- Validation plan (temporary overrides)
Inputs:
- {{dev_env_dump}}, {{prod_env_dump}}, {{config_paths}}, {{build_info}}
Constraints:
- Redact secrets
- Limit to differences relevant to {{entry_point}}
Expected Behavior
- Produces a clear diff of environment parameters.
- Names specific flags/configs that likely caused the behavior change.
- Suggests harmless overrides to validate hypotheses.
Example Output
Environment Diff:
- REGION: dev="US", prod="EU" → VAT rules activated in prod only.
- PYTHON_VERSION: dev=3.10.4, prod=3.11.3 → Possible stdlib change affecting json serialization.
- FEATURE_FLAG_PROMO_STACKING: dev="false", prod="true" → Promo rules stacking enabled.
Hypotheses:
- Promo stacking in prod creates double-discount scenario causing negative totals.
Validation Plan:
- Override FEATURE_FLAG_PROMO_STACKING=false in prod canary; confirm totals non-negative.
Customization Tips
- Provide container image digests and OS/kernel versions when native libraries differ.
- Include build metadata (compiler flags, optimization levels) for performance-related issues.
Prompt 6: Dependency Conflict Detector
Search for conflicts across dependency trees, mismatched versions, and breaking changes in transitive libraries.
System Goal:
Detect dependency conflicts (version mismatches, ABI/API breaks) that may cause failures.
Instructions:
1) Parse dependency manifests (e.g., requirements.txt, package.json, pom.xml) and lock files.
2) Build a version graph; detect multiple versions of the same package and known breaking ranges.
3) Cross-reference changelogs or advisory DB if available.
4) Output:
- Conflict list with impacted modules/files
- Suggested resolution (pin/upgrade/downgrade)
- Validation plan (local overrides)
Inputs:
- {{manifest_paths}}, {{lock_files}}, {{advisories_db}}
Constraints:
- Prefer smallest change that resolves conflict
- Maintain backward compatibility with existing code and tests
Expected Behavior
- Enumerates conflicts with actionable resolutions.
- Explains which modules break due to API changes.
- Provides a minimal plan to confirm the fix.
Example Output
Conflicts:
- "fastjson" 2.x required by analytics, 1.x pinned in core → parse behavior differences
- "requests" 2.32.0 changed SSL defaults → breaks custom cert handling in http/client.py
Resolution:
- Pin "fastjson" to 1.5.2 uniformly or refactor analytics import path to 2.x API.
- Set requests[security] and configure SSL context via certifi bundle; add compat wrapper.
Validation:
- Run tests with uniform pin; verify parsing and SSL behaviors.
Teams using Codex for automated code review can extend the same agents to handle bug detection and fix generation as part of their CI/CD pipeline. Our detailed tutorial on Using OpenAI Codex for Automated Code Review covers the setup process for PR analysis agents, security scanning configurations, and performance optimization workflows that catch issues before they reach production.
Root Cause Analysis Prompts
With the failing scope isolated, the next seven prompts focus on causality: reconstructing stack traces, reasoning about concurrency hazards, tracking memory lifecycles, locating performance hotspots, tracing data flows, auditing configuration drift, and bisecting regressions.
Prompt 7: Stack Trace Decomposition
Ask the agent to decode stack traces into a causal narrative and pinpoint the exact code line causing the failure. It correlates frames with source and explains exceptions and error propagation paths.
System Goal:
Decompose stack traces into causality and pinpoint the failure line and upstream contributing factors.
Instructions:
1) Ingest stack traces from {{trace_files}} or console output.
2) Map frames to source files and extract code snippets around each frame line.
3) Explain the exception category, conditions, and propagation path.
4) Identify the first failing expression and its inputs; propose repro inputs.
5) Output:
- Annotated stack trace
- Failure line with snippet
- Contributing upstream conditions
- Targeted hypothesis for fix
Inputs:
- {{trace_files}}, {{source_globs}}
Constraints:
- Avoid speculative refactors; limit to analysis
- If multiple traces, cluster by signature and analyze top clusters
Expected Behavior
- Produces annotated stack traces with source context.
- Names the line and expression that threw the exception or propagated the error.
- Explains how upstream inputs matured into failure conditions.
Example Output
Annotated Trace:
Traceback (most recent call last):
File "services/orders.py", line 160, in apply_promotions
discounted_total -= compute_bogo(items)
ValueError: negative total not allowed
Source Context (services/orders.py:156–162):
156: def apply_promotions(items, discounted_total):
157: if "BOGO-2024" in active_rules:
158: discounted_total -= compute_bogo(items)
159: # Missing guard: discounted_total must remain >= 0
160: return discounted_total
Upstream:
- active_rules includes "BOGO-2024" and "EU-VAT-REDUCE" → stacking double subtract.
Hypothesis:
- Add non-negative clamp or conditional check before subtracting BOGO on VAT-reduced totals.
Customization Tips
- Provide symbol maps for obfuscated/minified stacks.
- Include build IDs for mapping to exact source revisions.
Prompt 8: Race Condition Reasoner
Concurrency bugs often arise from out-of-order operations, missing locks, or non-atomic sequences. The agent creates a timeline of threads, tasks, or callbacks and locates hazards.
System Goal:
Detect race conditions by constructing a concurrency timeline and finding non-atomic sequences and missing synchronization.
Instructions:
1) Identify shared state variables accessed by concurrent threads/tasks.
2) Build an access timeline from logs or inferred from code (read/write operations).
3) Find non-atomic read-modify-write sequences and missing locks.
4) Output:
- Shared-state map (variables, owners, access points)
- Timing diagram of events
- Hazards and recommended synchronization strategies
- Minimal instrumentation to confirm
Inputs:
- {{concurrency_logs}}, {{source_globs}}, {{threads_info}}
Constraints:
- Prefer granular locks or lock-free patterns with CAS
- Avoid performance regressions; outline trade-offs
Expected Behavior
- Identifies shared variables and conflicting accesses.
- Shows a timeline where interleaving causes incorrect outcomes.
- Proposes locks, atomic ops, or message-passing alternatives.
Example Output
Shared State:
- inventory_cache[sku]: read/write by worker-1, worker-2
- promotion_applied[user_id]: read by thread-A, write by thread-B
Hazard:
- read-modify-write on inventory_cache without lock:
T1 reads qty=2, T2 reads qty=2
T1 computes qty-1 → writes 1
T2 computes qty-1 → writes 1 (lost update, should be 0)
Recommendation:
- Use atomic decrement or a per-sku lock; alternatively move to a single-writer queue.
Customization Tips
- Ask for thread-safe redesigns only after the agent proves the hazard with a minimal timeline.
- Include instrumentation hooks to record interleavings without excessive overhead.
Prompt 9: Memory Leak Locator
Analyze object lifecycles, references, and allocation trends to find leaks. The agent suggests where references persist unnecessarily and how to release them.
System Goal:
Locate memory leaks by tracing object lifecycles and reference retention.
Instructions:
1) Use allocation logs or profiler outputs {{mem_profiles}} to find steady growth in particular types.
2) Trace references from long-lived containers (caches, registries) to leaked objects.
3) Identify missing cleanup hooks or cycles preventing GC.
4) Output:
- Allocation trend summary
- Reference graph explanation
- Cleanup strategy and tests
Inputs:
- {{mem_profiles}}, {{source_globs}}, {{gc_settings}}
Constraints:
- Avoid global mutable refs where possible
- Propose cleanup with bounded overhead
Expected Behavior
- Reports allocations by type and a trend line.
- Explains which references keep objects alive.
- Suggests garbage collection strategies or explicit cleanup points.
Example Output
Allocations:
- OrderContext objects +7% per min without release.
- connections in db.pool grow without shrink after exceptions.
Reference Graph:
- OrderContext held by global "active_orders" dict; entries never removed on error.
Cleanup:
- Ensure remove_active_order(order_id) in exception paths; add finalizer in OrderContext.__del__ for logging.
Customization Tips
- Provide profiler snapshots across multiple intervals to confirm growth trends.
- Ask the agent to propose synthetic tests that simulate error paths to validate cleanup.
Prompt 10: Performance Bottleneck Profiler
Use profiler data to identify hotspots and propose targeted optimizations with measurable speed-ups, keeping correctness intact.
System Goal:
Analyze profiler outputs and propose optimizations with expected gains and validation tests.
Instructions:
1) Ingest {{cpu_profile}}, {{io_profile}}, and {{alloc_profile}}; extract top hotspots.
2) Map hotspots to code and reason about algorithmic complexity and IO patterns.
3) Propose minimally invasive optimizations with expected gain.
4) Output:
- Hotspot list
- Optimization proposals
- Micro-bench tests and validation plan
Inputs:
- {{cpu_profile}}, {{io_profile}}, {{alloc_profile}}, {{bench_cmd}}
Constraints:
- Maintain correctness; include regression tests
- Avoid speculative micro-optimizations without evidence
Expected Behavior
- Produces a ranked list of hotspots and concrete optimization steps.
- Estimates performance gains and explains risks.
- Provides micro-benchmarks to validate improvements.
Example Output
Hotspots:
- json.dumps(payload) 38% CPU; repeated per item.
- compute_bogo(items) O(n^2) due to nested scans.
Optimizations:
- Precompute payload templates and serialize once; reuse per item.
- Convert compute_bogo to O(n) with hashmap counts.
Tests:
- Benchmark scenario: 10k items, seed=42 → expect ~2.4x speed-up.
Customization Tips
- Provide real workload traces not just synthetic profiles to avoid optimizing irrelevant paths.
- Require the agent to prove correctness with equivalence tests.
Prompt 11: Data Flow Tracer
Trace how input data fields evolve as they traverse layers, to locate mis-transformations or schema mismatches.
System Goal:
Trace data from inputs to outputs; detect schema mismatches and incorrect transformations.
Instructions:
1) Select key fields (e.g., user_id, items_total, discounted_total).
2) For each layer (parser, validator, router, service, db), extract code that transforms these fields.
3) Build a flow diagram; identify incorrect transformations or missing validations.
4) Output:
- Flow steps with code references
- Diff between expected and actual transformations
- Fix hypotheses
Inputs:
- {{source_globs}}, {{schema_docs}}, {{input_samples}}
Constraints:
- Maintain up-to-date schema; do not introduce silent coercions
Expected Behavior
- Lists transformations with code locations and their expected outputs.
- Finds where data deviates from expected schema.
- Proposes schema-aligned fixes.
Example Output
Data Flow:
- parse_items(): qty parsed as signed 32-bit int → overflow on large qty
- validate_payload(): no upper bound set for qty
- apply_promotions(): assumes discounted_total non-negative
Fix Hypotheses:
- Parse qty as Python int (unbounded), enforce upper bounds at validation.
- Clamp discounted_total before finalization.
Customization Tips
- Include schema docs and contract tests to ensure fixes align with external API expectations.
- If multiple services, ask for cross-service flow tracing (producer-consumer) with message schemas.
Prompt 12: Configuration Drift Auditor
Audit configuration files and runtime flags across versions and environments to find drift responsible for misbehavior.
System Goal:
Audit configuration drift across versions/environments and relate to observed symptoms.
Instructions:
1) Gather config files across {{envs}} and versions: YAML, JSON, ENV files.
2) Normalize keys and compare values; detect additions/removals/changes.
3) Prioritize changes affecting the failing module(s).
4) Output:
- Drift report with impacted services
- Suggested remediations and rollout strategy
- Canary test plan
Inputs:
- {{config_paths}}, {{envs}}, {{module_targets}}
Constraints:
- Respect secrets; do not print sensitive values
- Propose reversible changes and staged rollouts
Expected Behavior
- Summarizes config differences with impact.
- Relates drift to failure symptoms.
- Proposes staged remediation with validation.
Example Output
Drift:
- promos.stack=true introduced in prod v2.4.1; default false in dev.
- db.write_consistency=eventual in prod; strong in dev.
Impact:
- Promo stacking combined with eventual consistency yields stale totals.
Remediation:
- Set promos.stack=false and db.write_consistency=strong for order totals path only; staged rollout 10% → 50% → 100%.
Customization Tips
- When configs are hierarchical, ask the agent to resolve inheritance and overrides before diffing.
- Provide module-target lists to focus the audit.
Prompt 13: Regression Bisection
Combine test automation and git bisection to locate the commit introducing the regression. The agent orchestrates the process with a deterministic test.
System Goal:
Perform regression bisection with a deterministic failing test to find the offending commit.
Instructions:
1) Use {{fail_test_cmd}} to determine pass/fail deterministically.
2) Run git bisection across {{branch}} with test results guiding the search.
3) Once the bad commit is identified, analyze the diff and produce a hypothesis.
4) Output:
- Bisection log
- Candidate commit and rationale
- Next-step validation plan
Inputs:
- {{repo_path}}, {{branch}}, {{fail_test_cmd}}
Constraints:
- Use shallow checkouts for speed
- If flaky, re-run test 3 times per commit and use majority result
Expected Behavior
- Logs the bisection process step-by-step.
- Finds the first bad commit deterministically.
- Explains how the commit diff relates to failure.
Example Output
Bisection Log:
- good: a1c2e3 (tests green)
- bad: f9e8d7 (tests red)
- midpoint: d4c3b2 → red
- midpoint: b5a6c7 → green
- midpoint: c7d8e9 → red
- Found first bad commit: c7d8e9
Diff Analysis:
- services/orders.py: applied promo stacking rule by default (promos.stack=true)
- validators: missing non-negative check
Hypothesis:
- c7d8e9 introduced promo stacking default causing negative totals.
Customization Tips
- Pin all dependencies during bisection to avoid unrelated failures.
- Save bisection artifacts to inspect later in CI.
For teams looking to expand their AI capabilities, our guide on How to Build Multi-Agent Workflows with OpenAI Codex provides actionable frameworks for building multi-agent workflows with parallel orchestration that complement the strategies discussed in this article.
Automated Fix Generation Prompts
With causes located, the final seven prompts produce validated changes: patches with tests, refactoring for clarity, error handling, performance improvements, security hardening, backward-compatible fixes via feature flags, and documentation updates. Require diffs, test coverage, and rollback paths.
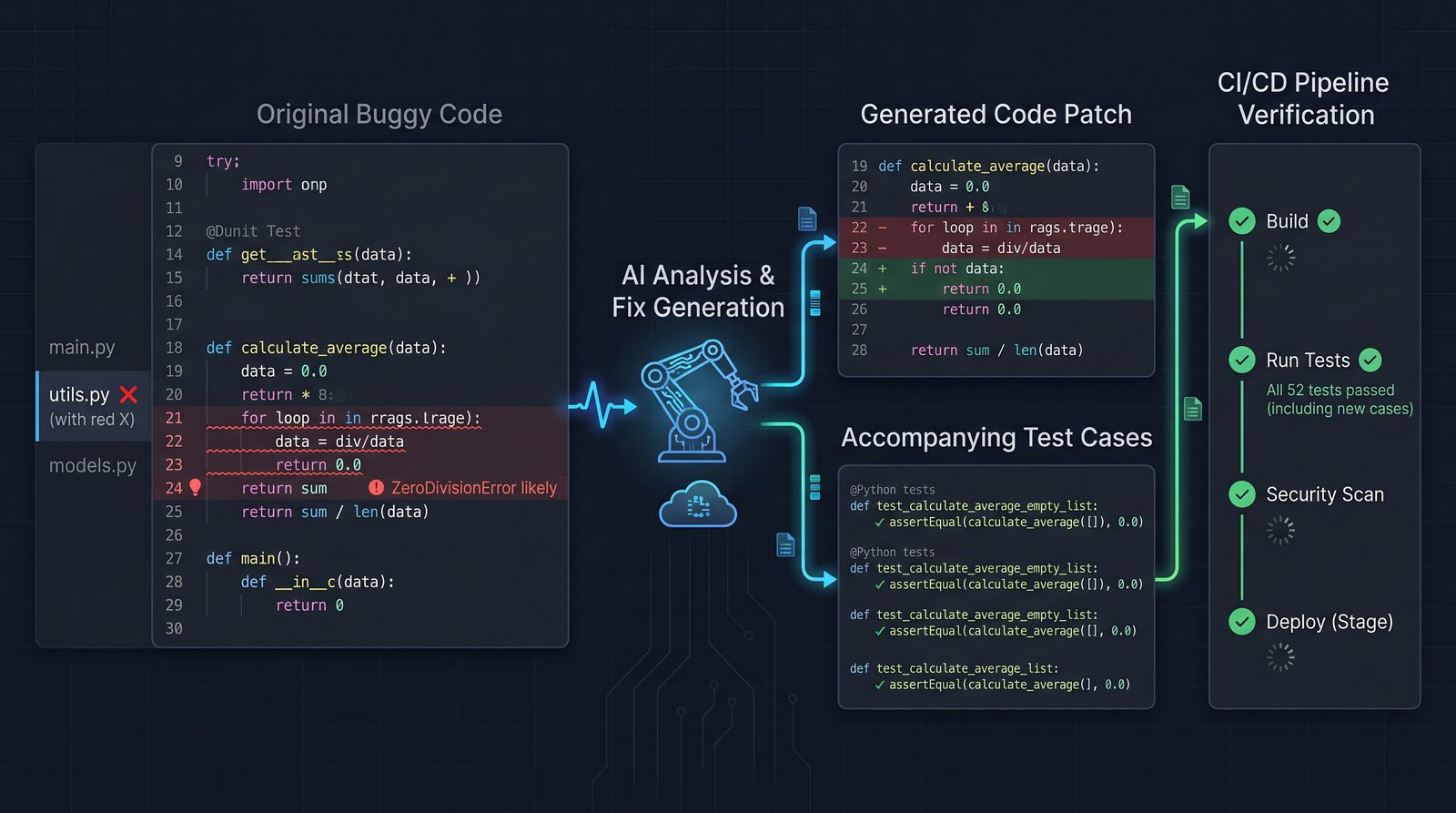
Prompt 14: Patch + Test Generator
Generate a minimal patch that fixes the bug and companion tests proving the fix. The agent provides unified diffs, test files, and instructions to run them.
System Goal:
Create a minimal patch and tests for the identified bug; ensure tests fail without the patch and pass with it.
Instructions:
1) Summarize the failure and the smallest change that resolves it.
2) Produce unified diff(s) for affected files; avoid refactors.
3) Add tests: unit or integration as needed; include edge cases.
4) Provide run instructions and expected output.
5) Output:
- Diffs
- New/updated test files
- Commands to run tests
- Risk notes and rollback
Inputs:
- {{source_globs}}, {{test_globs}}, {{fail_description}}, {{fix_strategy}}, {{test_cmd}}
Constraints:
- Keep patch minimal; measure impact
- Cover failure paths with tests
Expected Behavior
- Produces a small diff with direct fix.
- Includes tests that fail before and pass after the patch.
- Documents risk and rollback steps.
Example Output
Diff (services/orders.py):
@@ def apply_promotions(items, discounted_total):
- discounted_total -= compute_bogo(items)
+ bogo_delta = compute_bogo(items)
+ if bogo_delta > discounted_total:
+ bogo_delta = discounted_total
+ discounted_total -= bogo_delta
return discounted_total
New Test (tests/test_promotions.py):
import pytest
from services.orders import apply_promotions
def test_bogo_never_negative():
items = [{"sku": "BUNDLE-9", "qty": 2147483647}]
assert apply_promotions(items, 10) >= 0
Customization Tips
- Ask for parameterized tests to cover multiple inputs.
- Require the agent to compute mutation score or branch coverage if the tooling is available.
Prompt 15: Refactoring Stabilizer
Refactor code to improve readability and reduce error surface while keeping behavior identical. The agent provides a plan, diffs, and tests for invariance.
System Goal:
Refactor problematic areas to clarify intent and reduce defects without changing behavior.
Instructions:
1) Identify functions with high complexity, duplicate logic, or unclear invariants.
2) Propose a refactoring plan: extract functions, name improvements, reduce branching.
3) Produce diffs, and invariance tests to ensure behavior unchanged.
4) Output:
- Plan
- Diffs
- Invariance tests
- Rollback plan
Inputs:
- {{source_globs}}, {{complexity_report}}, {{test_cmd}}
Constraints:
- Preserve behavior; no feature changes
- Provide migration notes if public APIs move
Expected Behavior
- Generates a coherent refactor plan.
- Shows diffs and invariance tests.
- Reduces complexity and error risk.
Example Output
Plan:
- Extract compute_bogo(items) from apply_promotions()
- Document invariants: discounted_total never negative
Diff (services/promos.py):
@@
-def apply_promotions(items, discounted_total):
- ...
+def compute_bogo_delta(items):
+ # Single responsibility: compute eligible free items delta
+ ...
Invariance Tests:
- For 100 random payloads (seed=42), old vs new outputs identical within 1e-9.
Customization Tips
- Request cyclomatic complexity metrics pre/post refactor.
- Ask for dependency inversion or interface extraction if too many modules import each other.
Prompt 16: Error Handling Hardening
Introduce robust error handling: guards, retries, timeouts, and fallback behaviors. Require precise scope and tests for each failure mode.
System Goal:
Harden error handling in critical paths with tests for each mode (timeout, transient error, invalid input).
Instructions:
1) Identify critical IO calls and failure points.
2) Add timeouts, retries with backoff, and distinguish transient vs fatal errors.
3) Validate with tests simulating failures.
4) Output:
- Diffs with guards and retry logic
- Tests per failure mode
- Observability hooks
Inputs:
- {{source_globs}}, {{io_endpoints}}, {{test_cmd}}
Constraints:
- Avoid infinite retries; cap attempts
- Log context for diagnosis without leaking sensitive data
Expected Behavior
- Implements timeouts, retries, and correct error categorization.
- Provides tests covering each mode.
- Adds lightweight observability.
Example Output
Patch (payments/processor.py):
@@
- resp = http.post(url, json=payload)
+ resp = http.post(url, json=payload, timeout=3.0)
+ if resp.status_code >= 500:
+ return retry_with_backoff(lambda: http.post(url, json=payload, timeout=3.0), attempts=3)
+ elif resp.status_code == 408:
+ raise TimeoutError("payment gateway timed out")
Tests:
- Simulate 500 → expect 3 retries with jitter.
- Simulate 408 → expect TimeoutError.
Customization Tips
- Ask for idempotent retry semantics and unique request IDs to prevent duplicates.
- Require metrics counters: retries_count, timeouts_count, error_rate.
Prompt 17: Performance Improvement Patch
Implement targeted performance improvements in the identified bottlenecks, with micro-bench tests demonstrating gains.
System Goal:
Apply minimal code changes to improve performance on hotspots without changing functionality.
Instructions:
1) Select top hotspots from prior analysis.
2) Replace O(n^2) with O(n) where possible; cache repeated computations.
3) Provide micro-bench and integration tests.
4) Output:
- Diffs
- Bench results (before/after)
- Rollback plan
Inputs:
- {{source_globs}}, {{bench_cmd}}, {{perf_targets}}
Constraints:
- Prove correctness with equivalence tests
- Avoid hidden complexity that harms maintainability
Expected Behavior
- Applies small changes with significant gains.
- Demonstrates improvements with measured results.
- Preserves correctness.
Example Output
Patch (services/promos.py):
@@
- def compute_bogo(items):
- total = 0
- for i in items:
- for j in items:
- if i.sku == j.sku: total += 1
- return total // 2
+ def compute_bogo(items):
+ from collections import Counter
+ counts = Counter(i["sku"] for i in items)
+ return sum(c // 2 for c in counts.values())
Bench:
- Before: 10k items → 480ms
- After: 10k items → 120ms (~4x speed-up)
Customization Tips
- Ask for boundary tests proving behavior remains identical.
- Require constant-space or justify any increase in memory footprint.
Prompt 18: Security Patch Composer
Apply security fixes: guard against injection, enforce input validation, sanitize serialization, and restrict dangerous defaults.
System Goal:
Compose security patches targeting unsafe patterns (injection, deserialization, insecure defaults).
Instructions:
1) Identify code paths with dynamic SQL, shell calls, or unsafe deserialization.
2) Add parameterization, input validation, escaping, and safe defaults.
3) Provide security tests covering exploit attempts.
4) Output:
- Diffs
- Security test suite additions
- Risk assessment and advisories
Inputs:
- {{source_globs}}, {{security_findings}}, {{test_cmd}}
Constraints:
- No dynamic eval/exec for untrusted inputs
- Validate and sanitize all external inputs
Expected Behavior
- Eliminates unsafe patterns using standard secure techniques.
- Proves defenses with tests simulating attacks.
- Documents risks and residual limitations.
Example Output
Patch (db/queries.py):
@@
- sql = f"SELECT * FROM orders WHERE user_id = '{user_id}'"
- cursor.execute(sql)
+ sql = "SELECT * FROM orders WHERE user_id = %s"
+ cursor.execute(sql, (user_id,))
Security Tests:
- user_id = "'; DROP TABLE orders; --" → ensure harmless and error raised.
Advisory:
- Audit all dynamic SQL builders; standardize on parameterized queries.
Customization Tips
- Ask for safe defaults: HTTPS-only, secure cookies, CSRF tokens, content security policies.
- Require dependency upgrades if vulnerabilities found in libraries.
Prompt 19: Backward-Compatible Fix (Feature Flags)
Deliver fixes that maintain backward compatibility using feature flags, graceful deprecations, and versioned behavior toggles.
System Goal:
Implement a fix behind a feature flag; provide a migration path and compatibility tests.
Instructions:
1) Introduce a feature flag {{flag_name}} controlling the new behavior.
2) Default to old behavior; opt-in for canary environments.
3) Provide tests for both behaviors and rollout instructions.
4) Output:
- Diffs
- Flag docs
- Rollout strategy
Inputs:
- {{source_globs}}, {{flag_name}}, {{rollout_plan}}, {{test_cmd}}
Constraints:
- Avoid breaking existing clients
- Provide metrics to measure impact during rollout
Expected Behavior
- Implements the fix behind a feature flag.
- Provides tests for old vs new behavior.
- Documents rollout plan and metrics.
Example Output
Patch (services/promos.py):
@@
- def apply_promotions(items, total):
- return apply_promotions_v1(items, total)
+ def apply_promotions(items, total):
+ if flags.is_enabled("promos_v2"):
+ return apply_promotions_v2(items, total)
+ return apply_promotions_v1(items, total)
Docs:
- Flag "promos_v2": enabled in canary for 10% traffic; measure negative_total rate.
Tests:
- test_promos_v1_equivalence()
- test_promos_v2_non_negative_total()
Customization Tips
- Use server-side flags with audit logs to avoid client inconsistencies.
- Require rollback instructions and thresholds to auto-disable the flag upon anomaly.
Prompt 20: Documentation Sync
Update README, API docs, changelogs, and examples to align with fixes, new flags, and behavior changes. Documentation is integral to durable fixes.
System Goal:
Synchronize documentation with code changes; update README, API docs, examples, and changelog.
Instructions:
1) Summarize code changes from prior patches.
2) Update docs: README sections, API references, examples, config/flags info.
3) Add changelog entry with upgrade notes and links to tests.
4) Output:
- Doc diffs
- Examples updated
- Changelog entry
Inputs:
- {{docs_globs}}, {{source_globs}}, {{changes_summary}}
Constraints:
- Be precise; avoid ambiguous language
- Include version tags and dates
Expected Behavior
- Produces updated docs consistent with code changes.
- Includes examples that run and demonstrate new behavior.
- Adds changelog entries with upgrade guidance.
Example Output
README.md:
- Added section "Promotion Rules v2" with non-negative total guarantee.
API Docs:
- apply_promotions(items, total): noted flag "promos_v2" and behavior differences.
CHANGELOG.md:
- 2.4.2 — Fixed negative total bug, added "promos_v2" flag. See tests/test_promotions.py.
Concrete Code Examples for Several Prompts
The following code snippets illustrate how to integrate the playbook prompts with actual instrumentation and patches. Adjust details to your codebase and language.
Binary Search Instrumentation (Python)
# api/server.py
def http_handler(request):
log_event("checkpoint", step="http_handler", req_id=request.id)
payload = parse_request(request.body)
log_event("checkpoint", step="parse_request", req_id=request.id)
validate_payload(payload)
log_event("checkpoint", step="validate_payload", req_id=request.id)
response = dispatch(payload)
log_event("checkpoint", step="dispatch", req_id=request.id)
return response
# services/orders.py
def process_order(payload):
log_event("checkpoint", step="process_order_begin", user_id=payload["user_id"])
total = compute_total(payload["items"])
discounted_total = apply_promotions(payload["items"], total)
log_event("checkpoint", step="process_order_end", discounted_total=discounted_total)
return {"discounted_total": discounted_total}
Minimal Reproduction Test (JavaScript)
// tests/repro-bogo.test.js
const { applyPromotions } = require("../services/promos");
test("BOGO never yields negative totals", () => {
const items = Array(100).fill({ sku: "BUNDLE-9", qty: Number.MAX_SAFE_INTEGER });
const total = 10;
const out = applyPromotions(items, total);
expect(out).toBeGreaterThanOrEqual(0);
});
Performance Optimization Patch (Python)
# services/promos.py
from collections import Counter
def compute_bogo(items):
counts = Counter(i["sku"] for i in items)
return sum(c // 2 for c in counts.values())
def apply_promotions(items, total):
delta = compute_bogo(items)
return max(0, total - delta)
Security Patch (SQL Parameterization) (Python)
# db/queries.py
def get_orders_by_user(conn, user_id):
sql = "SELECT id, total FROM orders WHERE user_id = %s"
with conn.cursor() as cur:
cur.execute(sql, (user_id,))
return cur.fetchall()
Retry with Backoff (Python)
# utils/retry.py
import time
import random
def retry_with_backoff(fn, attempts=3, base=0.1, max_backoff=2.0):
for i in range(attempts):
try:
return fn()
except Exception as e:
if i == attempts - 1:
raise
sleep = min(max_backoff, base * (2 ** i) + random.random() * base)
time.sleep(sleep)
Advanced Customization Patterns
Codex agents become far more powerful when you supply structured artifacts, allow tool execution, and define explicit constraints. These patterns augment the prompts above.
- Execution tools: Provide tools like run_command, read_file, write_file, git_diff, and test_runner. Instruct the agent to propose a plan before invoking tools.
- Sandboxing: Use ephemeral containers with pinned images to ensure reproducibility. The agent should log image digests and environment diffs for any execution results.
- Structured outputs: Ask the agent to emit JSON alongside natural language for logs, anomaly lists, and patch metadata. This is helpful for CI integrations.
- Observability templates: Predefine logging formats with standardized fields; the agent should use them when instrumenting checkpoints.
- Validation gates: Require failing tests before fixes and passing tests after. Enforce code review gates with a checklist derived from the agent’s plan.
Putting It All Together: A Workflow Example
The following end-to-end example integrates several prompts to resolve a negative total bug discovered after a production rollout.
- Use “Minimal Reproduction Builder” to create a deterministic failing test that asserts discounted_total never goes negative.
- Run “Structured Log Analysis” to detect anomalies coincident with rollout times and identify components involved (promotions, DB consistency).
- Apply “Binary Search on Execution Path” to instrument the path and isolate apply_promotions() as the earliest deviation.
- Run “Stack Trace Decomposition” to annotate the exception and pinpoint the exact line responsible.
- Invoke “Data Flow Tracer” to verify the input quantities and promotional deltas are mis-specified or overflowed.
- Audit “Configuration Drift” to find promos.stack=true in prod but false in dev.
- Execute “Regression Bisection” to identify the commit that introduced promo stacking by default.
- Generate “Patch + Test” to clamp totals and weaken stacking rules; provide unit tests ensuring non-negative totals under extreme values.
- Optionally apply “Feature Flag” pattern to roll out the new behavior safely.
- Run “Documentation Sync” to update README, API docs, and changelog.
CI/CD Integration
Integrate the prompts with your pipelines to automate analysis and patch validation, ensuring consistent quality.
- Jobs: Add a debug job that can run agent prompts for log parsing and bisection; a patch job that accepts agent diffs and runs tests; a docs job that confirms documentation updates.
- Artifacts: Persist agent plans, diffs, logs, and test outputs for review; compute coverage and performance metrics.
- Security: Restrict execution tools to pre-approved containers and readonly caches; collect audit logs for all agent actions.
Limitations and Mitigations
While Codex agents can reason and patch, they can hallucinate or drift without strong guidance. Mitigate risks by enforcing strict structure and validation.
- Require plans, checkpoints, and log-based validation before code changes.
- Constrain the scope: one module, one failing test per run.
- Measure outcomes: tests prove correctness, benchmarks prove performance improvements, security tests prove mitigations.
Prompts Reference Index
| Prompt | Inputs | Outputs | Primary Use |
|---|---|---|---|
| Binary Search on Execution Path | {{repo_path}}, {{entry_point}}, {{args}}, {{repro_cmd}} | Checkpoints, logs, deviation point | Earliest divergence isolation |
| Structured Log Analysis | {{log_files_glob}}, {{code_map}} | Anomalies, heatmaps, code references | Logs to actionable diagnostics |
| State Inspection at Failure | {{entry_point}}, {{failure_point}}, {{repro_cmd}} | Snapshot diffs, provenance | Variable/state divergence identification |
| Minimal Reproduction Builder | {{failure_notes}}, {{seed}}, {{ci_env}} | Repro script/test | Deterministic test generation |
| Environment Comparison | {{dev_env_dump}}, {{prod_env_dump}} | Diff table, validation plan | Dev/prod drift localization |
| Dependency Conflict Detector | {{manifest_paths}}, {{lock_files}} | Conflict list, resolution plan | Library version issues |
| Stack Trace Decomposition | {{trace_files}}, {{source_globs}} | Annotated traces, failure line | Failure pinpointing |
| Race Condition Reasoner | {{concurrency_logs}}, {{threads_info}} | Hazard map, synchronization plan | Concurrency bugs |
| Memory Leak Locator | {{mem_profiles}}, {{gc_settings}} | Allocation trends, cleanup strategy | Leaky lifecycles |
| Performance Bottleneck Profiler | {{cpu_profile}}, {{io_profile}} | Hotspots, optimization plan | Speed improvements |
| Data Flow Tracer | {{schema_docs}}, {{input_samples}} | Flow diagram, fix hypotheses | Mis-transformations |
| Configuration Drift Auditor | {{config_paths}}, {{envs}} | Drift report, remediation | Config misalignments |
| Regression Bisection | {{branch}}, {{fail_test_cmd}} | Bisection log, bad commit | Change provenance |
| Patch + Test Generator | {{fix_strategy}}, {{test_cmd}} | Diffs, tests | Validated bug fix |
| Refactoring Stabilizer | {{complexity_report}}, {{test_cmd}} | Plan, diffs, invariance tests | Reduce error surface |
| Error Handling Hardening | {{io_endpoints}}, {{test_cmd}} | Guards, retry logic, tests | Reliability improvements |
| Performance Improvement Patch | {{bench_cmd}}, {{perf_targets}} | Optimizations, benchmarks | Faster critical paths |
| Security Patch Composer | {{security_findings}}, {{test_cmd}} | Secure diffs, tests | Defense in depth |
| Backward-Compatible Fix | {{flag_name}}, {{rollout_plan}} | Flags, dual-behavior tests | Safe rollout |
| Documentation Sync | {{changes_summary}}, {{docs_globs}} | Doc diffs, examples, changelog | Developer alignment |
Final Notes
Debugging with Codex agents benefits immensely from structured prompts and strong validation. Use this playbook to systematically isolate failures, analyze causes, and deliver automated fixes with tests, metrics, and documentation. Keep changes minimal, rely on evidence, and preserve behavior unless explicitly toggled with feature flags. As you scale these workflows to larger teams and services, integrate the agent outputs into CI gates, maintain observability, and refine prompts with organization-specific conventions and safeguards.
For teams looking to expand their AI capabilities, our guide on OpenAI’s Shift from Chat to Agents provides actionable frameworks for how 97.9% internal Codex adoption is reshaping enterprise AI that complement the strategies discussed in this article.
All prompts in this playbook are intended to be copied verbatim and adapted via placeholders. Adjust the inputs to your agent tooling and repository conventions, and insist on measurable outcomes at every step—failing tests first, green tests after, and a documented trail of reasoning and changes.