Codex Security Prompts Masterclass: 30 Production-Ready Prompts for Automated Threat Modeling, Code Auditing, and Vulnerability Remediation
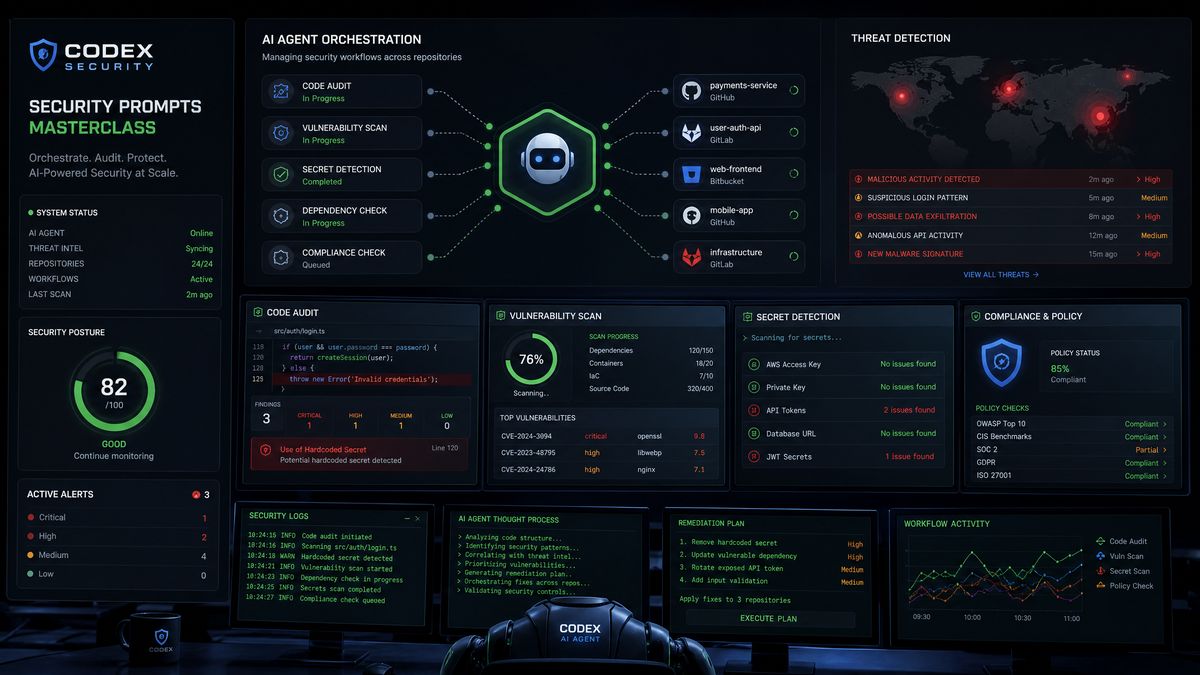
Codex Security Prompts Masterclass: 30 Production-Ready Prompts for Automated Threat Modeling, Code Auditing, and Vulnerability Remediation
Security engineering has entered a new era. With OpenAI Codex now deeply integrated into enterprise development workflows, security teams have access to an AI-powered assistant capable of performing sophisticated threat modeling, conducting systematic code audits, and automating vulnerability remediation at a scale that was previously impossible without large, specialized teams. But the quality of Codex’s security output is only as good as the prompts driving it. Poorly constructed prompts yield generic, surface-level findings. Precisely engineered prompts unlock deep, context-aware security analysis that rivals senior penetration testers and application security engineers.
This masterclass presents 30 production-ready prompts organized across five critical security engineering domains: threat modeling, static application security testing (SAST), dynamic analysis support, dependency and supply chain security, and automated remediation workflows. Each prompt includes full text, context for use, expected output characteristics, and practical implementation notes. Whether you are securing a microservices architecture, auditing legacy monoliths, or building a fully automated security pipeline, these prompts will transform how your team uses Codex as a security tool.
Why Codex Is a Game-Changer for Security Engineering
Traditional security tooling operates on static rule sets and signature databases. SAST tools like SonarQube, Semgrep, and Checkmarx scan for known vulnerability patterns, but they struggle with business logic flaws, complex authentication bypasses, and context-dependent security issues. Codex approaches security differently — it understands code semantics, can reason about data flow across multiple files, and can generate contextually appropriate fixes rather than simply flagging issues.
The key differentiators for Codex in security contexts include its ability to understand the intent behind code, not just its syntax. When you ask Codex to analyze an authentication flow, it does not simply check for the absence of rate limiting — it traces the entire authentication path, considers edge cases, and evaluates whether the implementation matches the security requirements of the business context. This semantic understanding enables a class of security analysis that pure pattern-matching tools simply cannot achieve.
For security engineers, this means Codex can serve as a force multiplier across the entire security development lifecycle (SDLC). From threat modeling during architecture reviews to generating remediation pull requests after a penetration test, Codex can accelerate and deepen every security touchpoint. The prompts in this masterclass are engineered to extract maximum value from these capabilities across real production scenarios.
How to Use This Masterclass
Each prompt in this guide follows a consistent structure. The prompt title describes the security objective. The full prompt text is presented exactly as you would enter it into a Codex-enabled environment. Implementation notes explain how to provide the right context, what output to expect, and how to integrate the results into your workflow. Many prompts include template variables in angle brackets — replace these with your actual codebase details, technology stack, or specific vulnerability context.
For best results, use these prompts with Codex in an environment where it has access to your codebase. Tools like GitHub Copilot Enterprise, the OpenAI API with file context, or IDE plugins configured with workspace-level context will yield significantly better results than prompts submitted without code context. When working with sensitive codebases, ensure you have reviewed your organization’s data handling policies before submitting code to external AI services.
It is also worth noting that Codex security analysis works best iteratively. Use the initial prompt to get a high-level threat assessment, then follow up with targeted prompts drilling into specific concerns. The prompts in this guide are designed to support this iterative workflow — several are explicitly designed as follow-up prompts to deepen earlier analysis.
Part 1: Threat Modeling Prompts (Prompts 1–7)
Threat modeling is the foundation of proactive security engineering. These prompts help security teams systematically identify threats during architecture reviews, design phases, and ongoing assessments of existing systems. They are designed to produce structured, actionable threat models aligned with industry frameworks including STRIDE, PASTA, and MITRE ATT&CK.
Prompt 1: Full STRIDE Threat Model Generation
Prompt:
“Analyze the following system architecture and generate a comprehensive STRIDE threat model. For each STRIDE category (Spoofing, Tampering, Repudiation, Information Disclosure, Denial of Service, Elevation of Privilege), identify at least three specific threats relevant to this architecture. For each threat, provide: (1) a threat ID, (2) the affected component or data flow, (3) the attack vector, (4) the potential business impact rated as Critical/High/Medium/Low, (5) existing mitigations if any, and (6) recommended security controls. Format the output as a structured threat register table. Architecture description: [PASTE ARCHITECTURE DESCRIPTION OR SYSTEM DESIGN DOCUMENT]”
Implementation Notes: Provide Codex with an architecture description that includes all components, data flows, trust boundaries, and external integrations. A well-written architecture decision record (ADR) or C4 model description works excellently as input. The output threat register can be directly imported into security tracking tools like Jira, Azure DevOps, or Archer. For microservices architectures, run this prompt separately for each service boundary to maintain appropriate granularity.
Prompt 2: Data Flow Diagram Security Analysis
Prompt:
“Review the following data flow diagram description and identify all trust boundary crossings, sensitive data exposure points, and authentication gaps. For each issue found: describe the data flow segment at risk, explain the specific security concern, identify whether this represents a design flaw or implementation risk, and suggest architectural controls to address it. Also identify any data flows that lack encryption, any places where PII or sensitive business data is unnecessarily duplicated or cached, and any flows that do not have corresponding audit logging. DFD description: [PASTE DFD DESCRIPTION OR DATA FLOW SPECIFICATION]”
Implementation Notes: Export your DFD from tools like Microsoft Threat Modeling Tool, OWASP Threat Dragon, or IriusRisk and use the textual description as input. This prompt is particularly valuable during architecture reviews before code is written, when architectural changes are cheapest to implement.
Prompt 3: MITRE ATT&CK Mapping for Application Threats
Prompt:
“Map the attack surface of the following application to relevant MITRE ATT&CK for Enterprise techniques. For each attack surface element identified, provide the corresponding ATT&CK technique ID and name, the specific way the technique would manifest in this application context, the likelihood of exploitation given the described environment (High/Medium/Low), and the detection opportunity. Focus particularly on Initial Access, Execution, Persistence, Privilege Escalation, Defense Evasion, Credential Access, and Exfiltration tactics. Application description: [PASTE APPLICATION DESCRIPTION INCLUDING TECHNOLOGY STACK, AUTHENTICATION MECHANISMS, AND DEPLOYMENT ENVIRONMENT]”
Implementation Notes: The output of this prompt integrates directly with SIEM correlation rules and detection engineering workflows. Use the ATT&CK technique IDs to search for existing detection rules in your SIEM platform and identify coverage gaps. This prompt is especially valuable for red team planning and purple team exercises.
Prompt 4: API Threat Modeling
Prompt:
“Perform a comprehensive threat model for the following REST/GraphQL API specification. Analyze each endpoint for: broken object-level authorization (BOLA/IDOR), broken function-level authorization, mass assignment vulnerabilities, excessive data exposure, lack of rate limiting and resource throttling, injection vulnerabilities in parameters, broken authentication flows, and security misconfiguration. For each identified threat, provide the specific endpoint affected, the OWASP API Security Top 10 category, the attack scenario, the risk rating using CVSS base score criteria, and specific remediation guidance. API specification: [PASTE OPENAPI/SWAGGER SPEC OR API ROUTE DEFINITIONS]”
Implementation Notes: Paste your OpenAPI specification YAML or JSON directly into the prompt. This works exceptionally well with OpenAPI 3.0 specs that include request/response schemas — Codex can reason about data exposure by examining response schemas against the OWASP API Security Top 10. Consider running this as part of your API design review process, before implementation begins.
Prompt 5: Cloud Infrastructure Threat Assessment
Prompt:
“Analyze the following cloud infrastructure configuration (AWS/Azure/GCP) and produce a threat assessment covering: IAM privilege escalation paths, network exposure and lateral movement opportunities, data exfiltration risks from storage services, logging and monitoring gaps, cryptographic key management weaknesses, and container/serverless-specific threats. For each finding, map to the relevant CIS Benchmark control, provide the risk severity, describe the exploitation scenario, and recommend the specific configuration change with example CLI commands or IaC code to remediate. Infrastructure configuration: [PASTE TERRAFORM/CLOUDFORMATION/ARM TEMPLATE OR IaC CONFIGURATION]”
Implementation Notes: This prompt works best with Terraform HCL or CloudFormation YAML as input. The specific remediation with CLI commands output makes this particularly actionable for DevOps and cloud security teams. For large infrastructure configurations, focus each prompt run on a single service or resource group.
Prompt 6: Microservices Inter-Service Communication Threat Model
Prompt:
“Evaluate the following microservices architecture for threats specific to service-to-service communication. Analyze: mutual TLS configuration and certificate management risks, service mesh security policy gaps, message queue and event bus security including poisoned message attacks, service account and workload identity risks, API gateway bypass scenarios, sidecar proxy misconfiguration risks, and secrets management across service instances. For each threat identified, explain the blast radius if the threat is realized, the detection difficulty, and provide specific mitigation steps including code snippets or configuration examples where applicable. Microservices architecture: [PASTE SERVICE TOPOLOGY, COMMUNICATION PATTERNS, AND TECHNOLOGY STACK DETAILS]”
Implementation Notes: Include details about your service mesh (Istio, Linkerd, Consul Connect), message brokers (Kafka, RabbitMQ, AWS SQS), and secrets management solution (Vault, AWS Secrets Manager) in the architecture description for maximally specific output.
Prompt 7: Threat Model Delta Analysis
Prompt:
“Compare the following two versions of a system design document and identify all new threats introduced by the architectural changes. For each new threat: identify which specific change introduced it, explain why this change creates a new attack surface or weakens an existing control, rate the urgency of addressing this threat (Immediate/High/Medium/Low), and provide specific security requirements that the implementation team must satisfy to ship this change safely. Also identify any threats from the original design that may have been inadvertently resolved by the new design. Original design: [PASTE ORIGINAL DESIGN] New design: [PASTE NEW DESIGN]”
Implementation Notes: This is ideal for security review of architecture change proposals (ACPs) or significant refactoring efforts. Running this prompt as part of your architecture review board process helps ensure security implications of changes are captured before implementation.
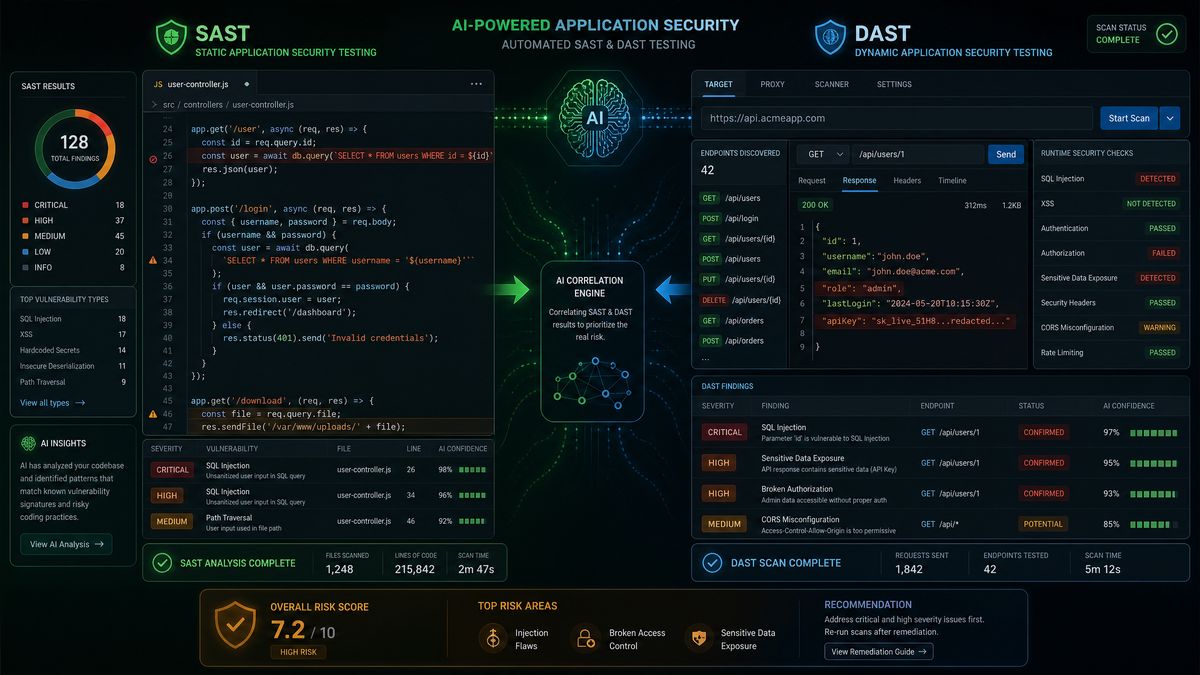
Part 2: Code Auditing and SAST Prompts (Prompts 8–16)
Static application security testing with Codex goes beyond traditional pattern matching. These prompts leverage Codex’s semantic code understanding to find vulnerabilities that rule-based SAST tools routinely miss, including business logic flaws, complex injection vectors, and subtle authentication bypasses. For security engineers who want to understand more about how Codex integrates with existing security workflows,
Security engineers running long-running code audits benefit from Codex Chronicle’s screen-context memory system, which maintains persistent awareness of previously identified vulnerabilities and remediation patterns across extended scanning sessions. For a comprehensive deep dive, see our guide on Codex Chronicle: Screen-Context Memory System.
provides a detailed walkthrough of tool configuration and API usage patterns.
Prompt 8: Comprehensive Security Code Review
Prompt:
“Perform a comprehensive security-focused code review of the following code. Identify all security vulnerabilities, categorized by the OWASP Top 10 and CWE taxonomy. For each vulnerability found: provide the exact file location and line numbers, write a clear explanation of why this is a vulnerability and how it could be exploited, provide a proof-of-concept attack payload or scenario, rate the CVSS v3.1 score with vector string, and provide a complete, safe replacement code snippet. Do not stop after finding the first vulnerability — exhaustively analyze the entire code for all security issues including subtle logic flaws, race conditions, and cryptographic weaknesses. Code to review: [PASTE CODE HERE]”
Implementation Notes: For large codebases, prioritize high-risk files: authentication modules, authorization middleware, input parsing functions, and cryptographic implementations. The CVSS vector string output enables direct integration with vulnerability management platforms like Tenable, Qualys, or ServiceNow VR.
Prompt 9: SQL Injection Deep Dive Audit
Prompt:
“Analyze the following code for all forms of SQL injection vulnerabilities including: classic string concatenation injection, second-order SQL injection where user input is stored and later used in queries, blind SQL injection vectors, time-based blind injection points, out-of-band injection possibilities, ORM misuse that bypasses parameterization, and stored procedure injection. For each finding: show the vulnerable code, demonstrate the injection payload that would exploit it, explain the database-specific exploitation path (assuming [DATABASE TYPE]), and provide the parameterized or ORM-safe replacement. Also check for any SQL error messages that could be returned to users, which would aid attacker enumeration. Code: [PASTE CODE]”
Implementation Notes: Replace [DATABASE TYPE] with MySQL, PostgreSQL, MSSQL, Oracle, or SQLite as appropriate. The second-order injection analysis is particularly valuable — these vulnerabilities are frequently missed by automated tools because the injection and execution occur in different code paths. This prompt works well on data access layer files.
Prompt 10: Authentication and Session Management Audit
Prompt:
“Conduct an exhaustive security audit of the following authentication and session management implementation. Check for: password hashing algorithm strength and proper salt usage, timing attack vulnerabilities in credential comparison, session token entropy and predictability, session fixation vulnerabilities, missing session invalidation on privilege changes, JWT implementation flaws including algorithm confusion attacks (RS256 to HS256 downgrade), ‘none’ algorithm acceptance, missing signature verification, insecure token storage, refresh token rotation implementation, multi-factor authentication bypass opportunities, account enumeration through differential error messages or timing, brute force protection effectiveness, and password reset flow security. Provide specific exploit code where relevant to demonstrate each vulnerability. Code: [PASTE AUTHENTICATION CODE]”
Implementation Notes: JWT algorithm confusion attacks are frequently overlooked by developers but are trivially exploitable. The proof-of-concept exploit code output from this prompt can be used directly in security awareness training to demonstrate the real-world impact of these issues to development teams.
Prompt 11: Authorization and Access Control Audit
Prompt:
“Analyze the following code for authorization and access control vulnerabilities. Specifically look for: insecure direct object references (IDOR) where user-supplied IDs access resources without ownership verification, missing function-level access control on sensitive operations, privilege escalation paths through parameter manipulation, horizontal privilege escalation between users of the same role, authorization checks that rely on client-supplied data, path traversal in file access operations, GraphQL authorization gaps including introspection abuse and field-level authorization missing, and any features where authorization logic is implemented inconsistently across different code paths for the same resource. For each finding, provide a test case that demonstrates the authorization bypass and the correct server-side enforcement code. Code: [PASTE CODE]”
Implementation Notes: This prompt is particularly effective when applied to route handlers, controller methods, and service layer functions. The test case output can be converted directly into automated security regression tests to prevent authorization regressions in future releases.
Prompt 12: Cryptographic Implementation Audit
Prompt:
“Review the following code for cryptographic vulnerabilities and weaknesses. Analyze: use of deprecated or broken algorithms (MD5, SHA1, DES, RC4, ECB mode), inadequate key lengths, hardcoded cryptographic keys or salts, improper IV/nonce reuse or predictability, missing authenticated encryption (use of encryption without integrity protection), insecure random number generation using non-cryptographic PRNGs, improper certificate validation including disabled hostname verification, use of custom cryptographic implementations instead of vetted libraries, TLS configuration weaknesses including protocol version and cipher suite choices, and improper key storage. For each issue: explain the cryptographic weakness in technical detail, describe the practical attack that exploits it, and provide the corrected implementation using current best practice libraries. Code: [PASTE CODE]”
Implementation Notes: Pay particular attention to the IV/nonce reuse analysis — this is a subtle but catastrophic vulnerability in CBC and CTR mode encryption that many developers do not understand. The practical attack explanation output is invaluable for developer security training.
Prompt 13: Injection Vulnerability Comprehensive Scan
Prompt:
“Scan the following code for all injection vulnerability classes beyond SQL injection. Include analysis for: OS command injection including indirect injection through file names or environment variables, LDAP injection in directory service queries, XPath injection in XML processing, NoSQL injection for MongoDB, Redis, and Elasticsearch, XML external entity (XXE) injection including blind XXE, Server-Side Template Injection (SSTI) for all template engines present, expression language injection (EL/OGNL/SpEL), HTTP header injection including response splitting, SMTP header injection in email functions, and code injection through dynamic evaluation functions (eval, exec, Function constructor). For each finding provide the injection vector, a working payload, the impact, and the sanitization or parameterization approach required. Code: [PASTE CODE]”
Implementation Notes: SSTI and XXE are consistently underdetected by traditional SAST tools, making this prompt especially valuable for filling coverage gaps. When Codex identifies SSTI, request a follow-up analysis of the specific template engine being used for the most accurate remediation guidance.
Prompt 14: Race Condition and Concurrency Security Audit
Prompt:
“Analyze the following code for security-relevant race conditions and concurrency issues. Look for: Time-of-Check Time-of-Use (TOCTOU) vulnerabilities in file system operations, database read-modify-write race conditions that could allow double-spending, coupon/discount code race conditions, account balance manipulation through concurrent requests, session handling race conditions, authentication bypass through concurrent login attempts, file upload race conditions, and distributed system race conditions in microservices contexts. For each finding: describe the exploitation scenario with specific timing requirements, estimate the exploitability under real-world network conditions, demonstrate with pseudocode how the race would be triggered, and provide the atomic operation or locking mechanism needed to eliminate the race. Code: [PASTE CODE]”
Implementation Notes: Race conditions in financial transaction processing, coupon redemption, and account creation flows are frequently exploited in the wild. Include any database transaction handling code alongside the application code for complete analysis.
Prompt 15: XSS and Client-Side Security Audit
Prompt:
“Perform a comprehensive client-side security audit of the following code. Identify: reflected, stored, and DOM-based XSS vulnerabilities including mutation XSS and XSS in SVG or CSS contexts, Content Security Policy bypass opportunities, clickjacking vulnerabilities, cross-origin resource sharing (CORS) misconfiguration, postMessage security issues, prototype pollution vulnerabilities in JavaScript, client-side template injection, sensitive data exposure in localStorage, sessionStorage, or browser history, dangerouslySetInnerHTML or equivalent unsafe rendering in React/Vue/Angular, and subresource integrity missing on external scripts. For each vulnerability: provide the attack payload, describe the impact including data theft or account takeover scenarios, and provide the safe rendering or sanitization code. Code: [PASTE FRONTEND CODE]”
Implementation Notes: DOM-based XSS and prototype pollution are significantly underdetected by traditional SAST tools but are effectively identified by Codex’s semantic analysis. This prompt works well for React, Vue, Angular, and vanilla JavaScript codebases. Always provide the full component or module for context.
Prompt 16: Business Logic Security Analysis
Prompt:
“Analyze the following business logic implementation for security vulnerabilities that would not be detected by standard SAST tools. Look for: negative value exploits in financial calculations, integer overflow in quantity or pricing logic, workflow state machine bypass — ways to skip required steps or reach invalid states, feature flag or A/B test security implications, coupon/promotion stacking vulnerabilities, referral fraud opportunities, data validation inconsistencies between client and server, insecure deserialization in business object processing, mass assignment vulnerabilities allowing modification of fields that should be read-only, and any implicit trust assumptions about the order or completeness of operations. For each finding: describe the business impact in monetary or data integrity terms, the technical exploitation method, and the specific validation or state management fix required. Code: [PASTE BUSINESS LOGIC CODE]”
Implementation Notes: This prompt requires the most business context to be effective. Include comments about what the business rules should be alongside the code. Business logic vulnerabilities are the hardest to detect with automated tools and represent some of the highest business impact findings from penetration tests.
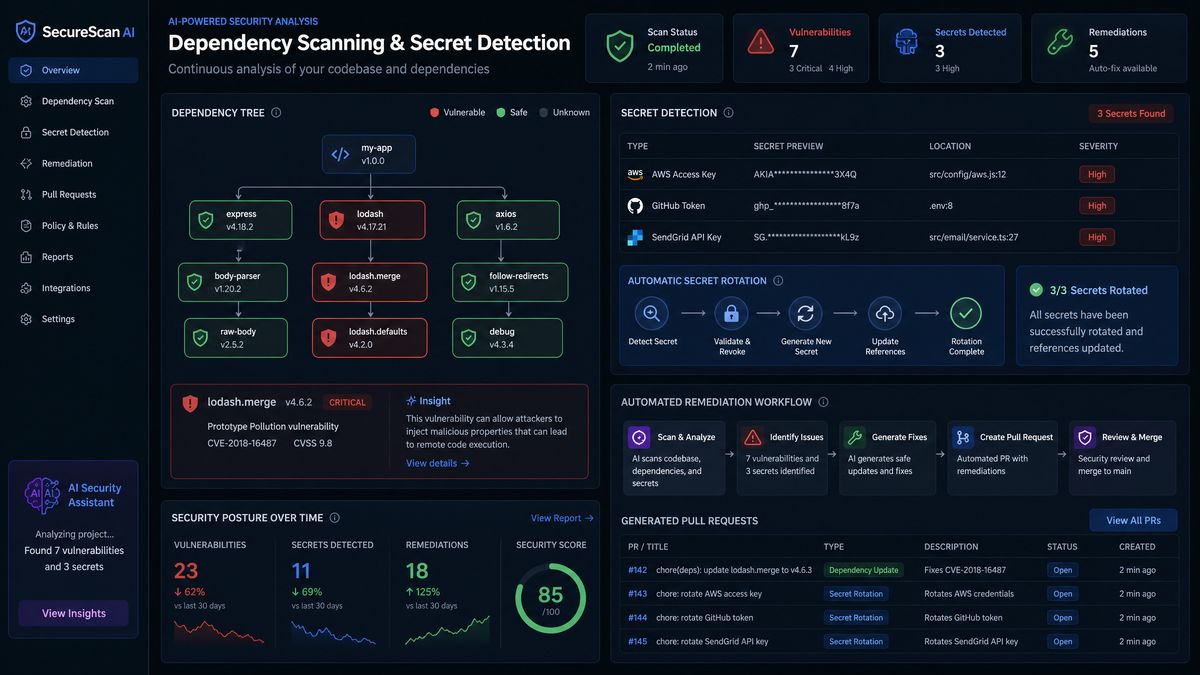
Part 3: Secret Detection and Supply Chain Security Prompts (Prompts 17–21)
Modern applications are increasingly vulnerable through their dependencies and configuration management rather than their first-party code. These prompts address the growing threat surface of software supply chain attacks, hardcoded secrets, and insecure dependency usage. Security teams building comprehensive vulnerability management programs should also review
Automated security scanning with Codex requires robust data loss prevention policies to ensure that vulnerability findings, secret detections, and remediation recommendations don’t inadvertently expose sensitive information through AI-generated reports. For a comprehensive deep dive, see our guide on Enterprise DLP Policies for ChatGPT and Codex.
for guidance on integrating these prompts into CI/CD pipeline security gates.
Prompt 17: Hardcoded Secret Detection and Classification
Prompt:
“Scan the following codebase files for hardcoded secrets, credentials, and sensitive configuration values. Identify: API keys and tokens (AWS, GCP, Azure, Stripe, Twilio, SendGrid, GitHub, etc.), database connection strings with credentials, private cryptographic keys and certificates, OAuth client secrets, hardcoded passwords in any form including environment variable defaults, JWT signing secrets, internal service URLs that should not be in source code, and any encoded strings that when decoded reveal sensitive values (Base64, hex). For each finding: identify the secret type, assess whether it appears to be a real credential or a test value, estimate the potential impact if the secret is valid and exposed, and provide the specific environment variable pattern or secrets manager integration code to replace it. Do not include the actual secret values in your response — reference them by location only. Files: [PASTE FILE CONTENTS]”
Implementation Notes: The instruction to not repeat secret values in the output is important for preventing sensitive information from appearing in AI interaction logs. This prompt works well as a pre-commit hook or PR review step. For comprehensive coverage, combine with tools like Trufflehog and GitLeaks, using Codex to triage and contextualize findings.
Prompt 18: Dependency Security Analysis
Prompt:
“Analyze the following dependency manifest file for security risks. For each dependency listed: identify any known CVEs or security advisories (reference the CVE ID and severity where known), flag packages with known histories of supply chain compromise or typosquatting risk, identify dependencies that have been abandoned or have no recent security maintenance, assess version pinning practices and the risk of unpinned dependencies, identify overly broad dependency permissions in the package manifest, look for dependencies that include postinstall scripts which could execute malicious code, flag packages with unusually large numbers of transitive dependencies that increase attack surface, and identify any packages that duplicate functionality of more security-maintained alternatives. Provide a prioritized remediation plan. Dependency manifest: [PASTE package.json, requirements.txt, go.mod, pom.xml, OR Gemfile]”
Implementation Notes: While Codex’s training data has a knowledge cutoff, it can reason about dependency security hygiene, version pinning, and structural risks effectively. Always cross-reference specific CVE findings with current databases like OSV.dev, Snyk, or GitHub Advisory Database before acting on them.
Prompt 19: Container Image Security Analysis
Prompt:
“Review the following Dockerfile and container configuration for security vulnerabilities and misconfigurations. Check for: use of privileged containers or dangerous capabilities (SYS_ADMIN, NET_ADMIN), running as root user, use of latest or mutable image tags instead of pinned digest hashes, secrets passed as build arguments that appear in image layers, unnecessary packages installed that increase attack surface, missing security scanning in CI/CD build steps, COPY or ADD instructions that include sensitive files, exposed ports that should not be accessible, missing read-only filesystem configuration, health check absence, use of deprecated base images, and distroless or hardened base image opportunities. Also analyze any docker-compose or Kubernetes manifest files provided for pod security context misconfigurations. Provide specific remediated Dockerfile/manifest snippets for each finding. Dockerfile/manifest: [PASTE DOCKERFILE AND ASSOCIATED MANIFESTS]”
Implementation Notes: Include your docker-compose.yml or Kubernetes deployment manifests alongside the Dockerfile for comprehensive coverage. The specific remediated snippet output is particularly valuable for developers who may not be familiar with container security hardening practices.
Prompt 20: CI/CD Pipeline Security Audit
Prompt:
“Analyze the following CI/CD pipeline configuration for security vulnerabilities and supply chain attack vectors. Look for: GitHub Actions, GitLab CI, or Jenkins pipeline configurations that reference third-party actions or plugins without SHA pinning, secrets exposure through environment variables in log output, missing OIDC/federated identity and over-reliance on long-lived credentials, pull request trigger configurations that could allow untrusted code to access secrets, missing approval gates for production deployments, artifact integrity verification absence (SLSA compliance gaps), build environment isolation issues, dependency caching configurations that could be poisoned, overly permissive GITHUB_TOKEN permissions, and pipeline-as-code injection through user-controlled inputs. For each finding, provide the remediated pipeline configuration snippet. Pipeline configuration: [PASTE CI/CD CONFIGURATION FILE]”
Implementation Notes: GitHub Actions SHA pinning for third-party actions is one of the most consistently missed security controls in modern CI/CD pipelines and one of the highest-impact supply chain attack vectors. The remediated snippet output makes it straightforward to generate a PR fixing each finding.
Prompt 21: Infrastructure as Code Security Scan
Prompt:
“Perform a security analysis of the following Infrastructure as Code configuration. Map every finding to the relevant CIS Benchmark control, AWS Well-Architected security pillar, or Azure/GCP security baseline as appropriate. Identify: publicly exposed resources that should be private (S3 buckets, storage accounts, database instances), overly permissive IAM roles and policies including wildcard permissions and the confused deputy problem, missing encryption at rest and in transit, disabled logging and monitoring, network security group rules that allow unrestricted ingress, missing MFA enforcement on privileged accounts, resource tags missing for compliance tracking, hardcoded account IDs or ARNs that create coupling risks, and missing deletion protection on critical resources. Provide Terraform/Pulumi/CDK remediation code for each finding, not just descriptions. IaC configuration: [PASTE TERRAFORM, CDK, OR PULUMI CODE]”
Implementation Notes: The explicit request for remediation code rather than descriptions is critical for this prompt. IaC security findings have a direct, testable fix — always demand the specific code change rather than advisory text. This output can be directly committed as a security hardening PR.
Part 4: DAST Support and Dynamic Analysis Prompts (Prompts 22–25)
While Codex operates on static code, it can dramatically accelerate and deepen dynamic testing by generating targeted test cases, attack payloads, and analysis frameworks based on code understanding. These prompts bridge the gap between static analysis and dynamic testing programs.
Prompt 22: Targeted Fuzzing Input Generation
Prompt:
“Based on the following input parsing and validation code, generate a comprehensive set of fuzzing inputs designed to trigger security vulnerabilities. Create inputs for each of these categories: boundary value attacks (maximum integer values, empty strings, null bytes, very long strings exceeding buffer allocations), encoding attacks (URL encoding, double URL encoding, Unicode normalization exploits, null byte injection), format string injection payloads, path traversal sequences adapted to the operating system context, XML/JSON/YAML deserialization attack payloads, regular expression denial of service (ReDoS) strings targeting any regex patterns in the code, and input combinations that could trigger logic errors based on the specific validation logic present. Format the output as a JSON array of test cases with: input value, targeted vulnerability class, expected behavior if vulnerable, and safe expected behavior. Code: [PASTE INPUT PARSING/VALIDATION CODE]”
Implementation Notes: The JSON array output format enables direct integration with testing frameworks like pytest, Jest, or custom fuzzing harnesses. Include the specific programming language and framework in your prompt for the most targeted payloads.
Access 40,000+ AI Prompts for ChatGPT, Claude & Codex — Free!
Subscribe to get instant access to our complete Notion Prompt Library — the largest curated collection of prompts for ChatGPT, Claude, OpenAI Codex, and other leading AI models. Optimized for real-world workflows across coding, research, content creation, and business.
Prompt 23: Burp Suite Test Plan Generation
Prompt:
“Based on the following API specification and application description, generate a comprehensive manual penetration testing plan optimized for execution with Burp Suite Professional. For each test area, provide: the specific Burp Suite feature or extension to use (Scanner, Intruder, Repeater, Sequencer, etc.), the exact HTTP request to capture and modify, the attack payloads or modifications to apply, the response indicators that confirm a vulnerability, and the Burp Suite configuration settings needed. Cover: authentication testing with session token analysis using Sequencer, authorization testing using Burp’s Autorize extension configuration, input validation testing with Intruder payload sets, business logic testing with specific request sequences, and rate limiting assessment. Include the specific Intruder payload positions and payload type configurations for each automated test. Application description and API spec: [PASTE DETAILS]”
Implementation Notes: This prompt produces a highly actionable penetration testing playbook. For teams less experienced with Burp Suite, the specific feature guidance is invaluable. The output can serve as a testing checklist for application security engineers performing assessments.
Prompt 24: Security Test Case Generation for Unit Testing
Prompt:
“Generate comprehensive security-focused unit and integration test cases for the following code. The tests should cover: authentication bypass attempts, authorization boundary testing for each user role, all injection vulnerability classes relevant to the code, boundary value and negative testing for all input validation, race condition testing for concurrent operation scenarios, error handling and exception security (ensuring errors don’t leak sensitive information), cryptographic function testing with known-good and known-bad inputs, and session management edge cases. Write the tests in [SPECIFY TEST FRAMEWORK: pytest/Jest/JUnit/RSpec] with realistic test data, clear assertion messages explaining what security property is being verified, and appropriate test isolation. Each test should include a comment explaining the security rationale and the vulnerability class it prevents. Code under test: [PASTE CODE]”
Implementation Notes: Security unit tests generated from this prompt serve as regression protection against vulnerability reintroduction. Integrate these tests into your CI pipeline as security regression gates. The security rationale comments are particularly valuable for developer education.
Prompt 25: Log Analysis and Anomaly Detection Rule Generation
Prompt:
“Analyze the following application log format and generate detection rules for security-relevant events and attack patterns. Create: (1) SIEM detection rules in Sigma format for common attack patterns including brute force, credential stuffing, account enumeration, SQL injection attempts, path traversal, and privilege escalation, (2) alerting thresholds with specific values justified for this application context, (3) correlation rules that detect multi-stage attack chains across multiple log sources, (4) a list of log enrichment fields that should be added to improve detection capability, and (5) baseline behavioral analytics queries to detect anomalous user behavior. For each rule, provide the false positive analysis and tuning recommendations. Log format sample: [PASTE LOG FORMAT AND SAMPLE LOG ENTRIES]”
Implementation Notes: Sigma format rules are tool-agnostic and can be converted to Splunk SPL, Elastic ESQL, Microsoft Sentinel KQL, or other SIEM query languages. The false positive analysis output is critical for operationalizing detection rules without alert fatigue.
Part 5: Automated Remediation Workflow Prompts (Prompts 26–30)
The highest-value application of Codex in security engineering is closing the loop from vulnerability discovery to verified remediation. These prompts are designed for automated remediation workflows where Codex generates production-quality fixes that can be reviewed and merged with minimal manual intervention.
Prompt 26: Vulnerability Remediation Code Generation
Prompt:
“Generate complete, production-ready remediation code for the following vulnerability finding. The fix must: (1) fully resolve the root cause, not just add superficial input validation, (2) maintain full backward compatibility with the existing API contract and behavior for valid inputs, (3) follow the coding conventions and patterns established in the surrounding code, (4) include inline comments explaining the security rationale for each change, (5) handle all edge cases and error conditions securely, (6) not introduce any new vulnerabilities, and (7) include the updated unit tests. After providing the fix, perform a second-pass security review of your own generated code to identify any remaining weaknesses. Vulnerability finding: [PASTE SAST/PENTEST FINDING WITH ORIGINAL CODE] Technology stack: [SPECIFY LANGUAGE AND FRAMEWORK]”
Implementation Notes: The self-review instruction in step 7 is critical and often overlooked — Codex can catch issues in its own generated code when explicitly asked to review it. This produces significantly higher quality remediations. The backward compatibility requirement prevents remediation-induced regressions.
Prompt 27: Security Patch Impact Analysis
Prompt:
“Analyze the following proposed security patch and assess its completeness and safety for deployment. Evaluate: (1) whether the fix fully addresses the root cause or only the reported symptom, (2) potential regression risks and which test cases would detect them, (3) performance implications of the security change, (4) whether the fix introduces any new security vulnerabilities (second-order effects), (5) edge cases not covered by the proposed fix, (6) whether similar vulnerable patterns exist elsewhere in the codebase that need the same fix applied, (7) the minimum required testing before deployment to production, and (8) whether a staged rollout or feature flag is advisable. Provide an overall deployment recommendation: Approved/Approved with Conditions/Requires Revision. Proposed patch: [PASTE DIFF OR UPDATED CODE] Original vulnerable code: [PASTE ORIGINAL CODE]”
Implementation Notes: This prompt is designed for use in a security review gate within your PR process. The structured approval recommendation output integrates well with GitHub branch protection rules or GitLab approval workflows. The identification of similar vulnerable patterns elsewhere is particularly valuable for preventing partial remediations.
Prompt 28: Security Debt Prioritization and Remediation Roadmap
Prompt:
“Given the following list of security findings from our security assessment program, generate a risk-based remediation roadmap. For each finding: calculate a composite risk score considering CVSS severity, exploitability in our environment, business impact, and remediation effort. Group findings into three horizons: Immediate (complete within 2 weeks — critical risks requiring emergency response), Short-term (complete within 90 days — high risks that should be in the next sprint), and Long-term (complete within 12 months — medium risks and architectural improvements). For the Immediate and Short-term items, provide a specific remediation task breakdown with estimated engineering hours. Identify any findings that share a root cause and can be resolved together for efficiency. Also identify any findings where compensating controls could temporarily reduce risk while permanent fixes are developed. Security findings list: [PASTE FINDINGS LIST WITH SEVERITY RATINGS]”
Implementation Notes: This prompt generates output that can be directly presented to engineering leadership to prioritize security investment. The shared root cause analysis often reveals that what appears to be dozens of separate findings can be resolved with a smaller number of targeted initiatives.
Prompt 29: Automated Security Comment Generation for Code Review
Prompt:
“Review the following code changes (pull request diff) from a security perspective and generate precise, actionable code review comments. For each security concern: write the comment in the format used by GitHub PR review (specify exact file and line number), clearly explain the vulnerability in terms a developer without deep security expertise can understand, provide a concrete example of how it could be exploited, include a specific code suggestion using GitHub’s suggestion syntax that the developer can apply with one click, reference the relevant security standard (OWASP, CWE, or language-specific security guide), and rate the severity as Blocking (must fix before merge), Important (should fix before merge), or Advisory (consider for future improvement). Focus only on security issues — do not comment on code style, performance, or non-security correctness issues. PR diff: [PASTE GIT DIFF OUTPUT]”
Implementation Notes: This prompt is designed for integration into automated PR security review tools. The GitHub suggestion syntax output allows developers to accept the security fix with a single click, dramatically reducing friction. The separation of blocking vs. advisory comments prevents security review from blocking every PR while still communicating risk.
Prompt 30: Security Runbook Generation for Incident Response
Prompt:
“Based on the following application architecture and the identified vulnerability, generate a comprehensive incident response runbook for the scenario where this vulnerability has been actively exploited. The runbook must cover: (1) Initial Detection — specific indicators of compromise (IOCs) and log queries to confirm exploitation, (2) Immediate Containment — specific actions to contain the breach without taking the entire application offline, with rollback decision criteria, (3) Evidence Preservation — what logs and artifacts to capture before they are overwritten, and how to preserve forensic integrity, (4) Root Cause Investigation — step-by-step forensic analysis process to determine the scope of compromise, (5) Notification and Communication — who to notify, when, and what information to include at each stage (including regulatory notification requirements for GDPR, CCPA, or HIPAA as applicable), (6) Remediation Steps — the exact code changes, configuration updates, and deployment steps to fix the vulnerability, (7) Post-Incident Verification — specific tests to confirm the vulnerability is resolved and exploitation has ceased, and (8) Post-Incident Review — lessons learned template. Application architecture: [PASTE ARCHITECTURE DETAILS] Vulnerability details: [PASTE VULNERABILITY DESCRIPTION]”
Implementation Notes: This prompt generates runbooks that can be stored in your incident response wiki and rehearsed in tabletop exercises before an actual incident occurs. The regulatory notification section is particularly valuable for ensuring compliance teams have the information they need during a high-pressure incident. Generate runbooks proactively for your highest-severity vulnerability classes.
Building a Codex-Powered Security Pipeline: Implementation Framework
Individual prompts provide significant value, but the transformational impact comes from integrating these prompts into an automated security pipeline that runs continuously. Here is a practical architecture for a Codex-powered security automation system.
Pipeline Architecture Overview
| Pipeline Stage | Trigger | Prompts Used | Output Destination | Automation Level |
|---|---|---|---|---|
| Architecture Review | Architecture Change Proposal submitted | Prompts 1, 2, 7 | Security review ticket | Semi-automated |
| Pre-commit Security Check | Git pre-commit hook | Prompts 17, 21 | Developer terminal | Fully automated |
| PR Security Review | Pull request opened | Prompts 8, 11, 15, 29 | PR review comments | Fully automated |
| CI/CD Security Gate | Pipeline execution | Prompts 18, 19, 20 | Pipeline pass/fail | Fully automated |
| Scheduled Deep Audit | Weekly scheduled run | Prompts 9, 10, 12, 13, 14 | Security backlog | Semi-automated |
| Penetration Test Support | Assessment engagement | Prompts 22, 23, 24 | Testing documentation | Manual trigger |
| Vulnerability Remediation | Finding confirmed | Prompts 26, 27, 28 | Remediation PR | Semi-automated |
| Incident Response | Security incident declared | Prompt 30 | Incident runbook | Manual trigger |
Integrating Prompts with the OpenAI API
For pipeline integration, these prompts should be called programmatically via the OpenAI API. Here is a reference implementation in Python demonstrating how to structure a code security review call with appropriate context:
import openai
import os
from pathlib import Path
def run_security_review(code_content: str, language: str, context: str = "") -> dict:
"""
Execute a security code review using Codex via OpenAI API.
Returns structured findings for pipeline integration.
"""
client = openai.OpenAI(api_key=os.environ["OPENAI_API_KEY"])
system_prompt = """You are an expert application security engineer with 15 years of
experience in penetration testing and secure code review. You provide precise,
actionable security findings with CVSS scores, CWE mappings, and production-ready
remediation code. You never produce false positives without justification and always
consider the business context when rating severity."""
user_prompt = f"""Perform a comprehensive security code review of the following
{language} code. {context}
For each vulnerability found, provide a JSON object with these fields:
- vulnerability_id: sequential ID
- cwe_id: CWE identifier
- owasp_category: OWASP Top 10 category if applicable
- severity: Critical/High/Medium/Low/Informational
- cvss_score: CVSS v3.1 base score
- cvss_vector: full CVSS vector string
- description: clear description of the vulnerability
- location: file and line number if determinable
- exploit_scenario: how an attacker would exploit this
- remediation_code: complete fixed code snippet
- test_case: security test to verify the fix
Return a JSON array of all findings. Code to review:
{code_content}"""
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt}
],
temperature=0.1, # Low temperature for consistent, precise security analysis
max_tokens=4096,
response_format={"type": "json_object"}
)
return response.choices[0].message.content
def analyze_changed_files(diff_files: list[Path], language: str) -> list[dict]:
"""Process changed files from a PR for security analysis."""
all_findings = []
for file_path in diff_files:
code_content = file_path.read_text()
context = f"This file is part of a financial services application. Pay particular attention to authorization and input validation."
findings = run_security_review(code_content, language, context)
all_findings.extend(findings.get("findings", []))
# Filter to blocking findings for PR gate
blocking_findings = [f for f in all_findings if f["severity"] in ["Critical", "High"]]
return blocking_findings, all_findings
if __name__ == "__main__":
# Example: Run security review on all Python files changed in current PR
changed_files = [Path("src/auth/login.py"), Path("src/api/users.py")]
blocking, all_findings = analyze_changed_files(changed_files, "Python")
print(f"Total findings: {len(all_findings)}")
print(f"Blocking findings: {len(blocking)}")
if blocking:
print("PR blocked: Critical/High security findings require remediation")
for finding in blocking:
print(f" [{finding['severity']}] {finding['description']}")
exit(1) # Fail the pipeline
else:
print("Security gate passed — no blocking findings")
exit(0)
Prompt Engineering Best Practices for Security Contexts
After extensive testing of security prompts, several engineering principles consistently improve output quality. Setting a low temperature (0.1 to 0.2) produces more consistent, precise security findings and reduces the risk of hallucinated vulnerabilities. Higher temperatures are appropriate for creative tasks but work against security analysis, where accuracy is paramount.
Providing a detailed system prompt that establishes the security expert persona significantly improves output quality. The system prompt should specify the experience level, domain focus, and output standards expected. For security analysis, explicitly stating that false positives should be minimized and that each finding requires justification reduces noise.
Context richness is the single biggest determinant of analysis quality. The more context you provide about the application purpose, user roles, data sensitivity, and technology stack, the more targeted and accurate the security analysis becomes. A prompt that identifies the application as a healthcare platform handling PHI will produce qualitatively different and more relevant findings than the same code submitted without context.
Chain-of-thought instructions improve detection of complex vulnerabilities. For business logic and multi-step attack vectors, instruct Codex to reason through the attack chain step by step before providing its findings. This systematic reasoning approach significantly improves detection of vulnerabilities that require understanding sequences of operations rather than single code patterns.
Measuring Security Program Effectiveness
Implementing Codex security prompts requires tracking program effectiveness to demonstrate value and identify improvement opportunities. Here are the key metrics to instrument:
| Metric | Description | Target Benchmark | Measurement Method |
|---|---|---|---|
| Vulnerability Detection Rate | % of vulnerabilities found before production vs. total found | >85% pre-production detection | Track finding source (static/dynamic/production) in vuln tracker |
| Mean Time to Remediate (MTTR) | Average time from finding detection to verified fix | <7 days for Critical, <30 days for High | Jira/tracker date tracking |
| False Positive Rate | % of Codex findings confirmed as invalid upon review | <15% false positive rate | Manual review disposition tracking |
| Remediation Coverage | % of findings with Codex-generated remediation code used | >60% remediation code adoption | PR tracking and commit attribution |
| Recurrence Rate | % of vulnerability classes reappearing after remediation | <10% recurrence within 90 days | Pattern matching in subsequent reviews |
| Developer Security Score | Average security findings per developer per sprint | Decreasing trend over time | Findings attributed by code author |
Common Pitfalls and How to Avoid Them
Several recurring mistakes undermine the effectiveness of Codex-based security programs. The most common is treating Codex output as definitive without human verification. Codex is a powerful analysis tool, but it is not infallible. Every Critical and High finding should be verified by a human security engineer before being used to block releases or escalated to development teams. Low and Medium findings can be managed with lighter verification processes, but a sample should always be manually reviewed to calibrate accuracy.
Over-reliance on Codex for dynamic runtime vulnerabilities is another common pitfall. Codex excels at static analysis but cannot replace dynamic testing for vulnerabilities that only manifest at runtime, such as race conditions under production load, server-side request forgery in specific network topologies, or business logic flaws that require realistic data patterns to trigger. Use Codex to augment and guide dynamic testing, not replace it.
Context starvation is perhaps the most prevalent issue — submitting code without application context and expecting high-quality security analysis. The difference in output quality between a context-rich prompt and a bare code submission is dramatic. Invest time in crafting system prompts and context sections that accurately describe your application’s security posture, data sensitivity, and trust model.
Finally, treating security prompts as a one-time configuration rather than an iteratively improved asset leaves significant value on the table. The most effective security teams treat their Codex prompt library as a living asset, refining prompts based on false positive rates, adjusting severity calibrations based on business context, and adding new prompts as new threat vectors emerge. Schedule quarterly reviews of your prompt library to keep it aligned with your evolving attack surface.
Conclusion: Building a Codex-First Security Engineering Culture
The 30 prompts in this masterclass represent a comprehensive toolkit for security engineers looking to leverage Codex across the full spectrum of application security activities. From the architectural threat models in Part 1 that prevent vulnerabilities before code is written, through the deep code auditing prompts in Part 2 that find what traditional SAST misses, to the automated remediation workflows in Part 5 that close the loop from detection to fix — this prompt library addresses the complete security engineering lifecycle.
But prompts alone are not a security program. The transformative impact comes from systematically integrating these prompts into your development workflow: as pre-commit hooks, PR review automation, CI/CD security gates, and scheduled audit jobs. When Codex security analysis is embedded in the developer workflow rather than bolted on as an afterthought, it shifts security left in the most meaningful sense — making every developer a first-pass security reviewer with an expert AI partner.
The organizations seeing the greatest security benefits from Codex are those that have made it ubiquitous in their development process, trained their developers to work with AI-generated security findings, and built feedback loops that continuously improve prompt quality based on real-world accuracy data. The prompts in this guide give you the starting point. The commitment to continuous improvement of your Codex security practice is what will make it genuinely transformative for your organization’s security posture.
Start with the prompts most relevant to your current pain points — if secret management is your biggest challenge, implement Prompt 17 as a pre-commit hook this week. If your authentication layer is a known concern, run Prompt 10 against your auth module today. Security improvement is cumulative, and every vulnerability found and fixed before it reaches production represents real risk reduction. Codex, properly prompted, is one of the most powerful tools available for security engineers to accelerate that risk reduction at scale.