AI Prompting in 2026: Advanced Context Engineering Techniques for ChatGPT, Claude, and Codex

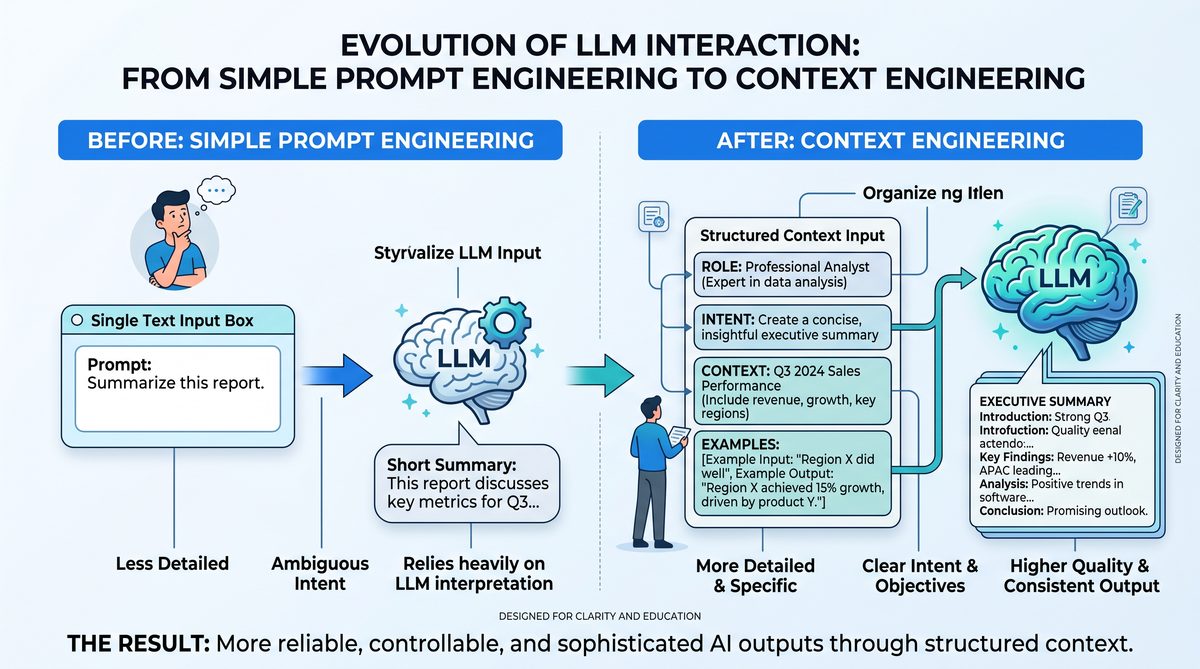
From Prompt Engineering to Context Engineering
As we advance into 2026, the landscape of AI interaction, particularly with large language models (LLMs) such as ChatGPT, Claude, and Codex, has undergone a fundamental transformation. Historically, the discipline of prompt engineering focused on designing individual prompts—carefully worded instructions or queries—to coax desired responses from AI models. These methods often relied on trial-and-error, leveraging specific linguistic tricks, token ordering, and carefully crafted phrasing to manipulate model behavior. However, this approach is rapidly becoming obsolete. The current generation of LLMs demonstrates a markedly improved ability to interpret and utilize extended context windows, which has given rise to the new paradigm of context engineering.
Context engineering represents a strategic shift from optimizing isolated prompts to orchestrating comprehensive, structured context environments that guide AI models more effectively. This section explores why 2026 models respond better to rich, well-organized context rather than clever prompt hacks, elucidates the principles underlying this shift, and provides actionable insights for developers and technical professionals aiming to harness the full potential of contemporary AI systems.
The Evolution from Prompt to Context Engineering
Prompt engineering in the early 2020s was inherently limited by the token window size and the models’ relative inability to maintain coherent understanding over long inputs. Developers learned to exploit prompt phrasing, token repetition, and even token encoding anomalies to “trick” models into producing specific outputs. For instance, chaining multiple questions within a single prompt or appending pseudo-code comments to influence Codex’s code generation were common tactics.
However, with the expansion of context windows—now routinely exceeding 64,000 tokens in state-of-the-art models such as GPT-4 Turbo and Claude Instant—these tricks have diminished in effectiveness. The models now excel at maintaining semantic coherence and long-term dependencies across extensive text sequences. Consequently, the single-prompt approach, while still relevant, is no longer sufficient or optimal for eliciting high-fidelity outputs.
Why 2026 Models Prefer Structured Context
Several architectural and training improvements underpin the superior performance of 2026 LLMs with structured contexts:
- Extended Context Windows: Modern transformer architectures incorporate sparse attention mechanisms, memory-augmented attention layers, and hierarchical positional embeddings, enabling effective processing of tens of thousands of tokens. This allows for embedding entire documents, codebases, or conversational histories within a single context window.
- Contextual Memory and Retrieval Augmentation: Integration with retrieval-augmented generation (RAG) systems and external vector databases means models can dynamically incorporate factual or domain-specific knowledge embedded in the context, improving accuracy and relevance.
- Fine-Grained Contextual Understanding: Advanced pretraining on diverse, multi-turn conversations and structured datasets has enhanced models’ ability to parse and reason over complex context structures, such as nested instructions, conditional logic, and multi-modal inputs.
- Hierarchical Reasoning Capabilities: New architectures support hierarchical token processing, allowing models to abstract and summarize context segments, enabling more effective long-range dependency tracking.
These advancements mean that the model’s “attention” is no longer easily fooled by isolated prompt wording; instead, it evaluates the entire context holistically, prioritizing logical consistency, relevance, and explicit structure.
Comparing Prompt Engineering and Context Engineering
| Aspect | Prompt Engineering (Pre-2025) | Context Engineering (2026 and Beyond) |
|---|---|---|
| Focus | Crafting a single, optimized prompt sentence or paragraph | Designing and curating a comprehensive, structured context environment spanning thousands of tokens |
| Techniques | Token placement tricks, keyword priming, prompt templates, few-shot examples embedded inline | Segmented context blocks, structured metadata, hierarchical information embedding, external knowledge integration |
| Model Interaction | Reactive and short-term; relies on immediate prompt phrasing | Proactive and long-term; builds upon layered context and multi-turn reasoning |
| Limitations | Restricted by small context windows (up to ~4,000 tokens), brittle to phrasing changes | Leverages massive context windows (up to ~100,000+ tokens), robust to input variations |
| Outcome Quality | Inconsistent; prone to hallucination and prompt sensitivity | Consistent, accurate, and contextually nuanced responses |
The Death of Prompt Hacks
Many of the “prompt hacks” that defined early prompt engineering, such as token injection, adversarial prompt chaining, or clever token boundary exploitation, have lost their efficacy. Models in 2026 possess enhanced robustness against such manipulations due to:
- Robust Training Regimens: Exposure to adversarial prompts during training and fine-tuning phases has hardened models against exploitative input patterns.
- Contextual Regularization: Mechanisms that penalize incoherent or out-of-context token generation mitigate the impact of trick prompts.
- Transparency and Interpretability Tools: Integrated interpretability frameworks allow developers to visualize and understand model attention, making it easier to design legitimate context rather than exploit loopholes.
As a result, the focus has shifted towards leveraging the model’s genuine strengths—comprehensive understanding and reasoning over large datasets—rather than exploiting superficial prompt vulnerabilities. This evolution demands a higher level of sophistication from developers, requiring expertise in data structuring, semantic segmentation, and context-aware design.
Practical Guidelines for Effective Context Engineering
To capitalize on this paradigm shift, practitioners should adopt the following best practices:
- Modular Context Construction: Break down input information into logically distinct segments, such as background knowledge, instructions, and examples. Use clear delimiters and formatting to help models parse segments efficiently.
- Metadata Embedding: Incorporate structured metadata tags (e.g., JSON-LD snippets, YAML front matter) within the context to specify roles, priorities, or data schemas, which models can leverage for precise interpretation.
- Progressive Context Refinement: Iteratively build context windows by layering additional relevant information and pruning outdated or redundant tokens to optimize token budget usage.
- Multi-Turn Context Management: Maintain persistent context states across interactions to facilitate continuity and cumulative reasoning, especially for complex workflows or coding assistance.
- Leverage External Knowledge Sources: Integrate retrieval systems to supply up-to-date factual data dynamically, ensuring the context remains current and authoritative.
Conclusion
The transition from prompt engineering to context engineering marks a critical evolution in AI-human interaction. In 2026, the power of LLMs lies not in the art of crafting a single, clever prompt but in the science of constructing rich, structured, and persistent context environments that enable models to perform at their highest capability. For developers and technical professionals, mastering context engineering is essential to unlock the full potential of ChatGPT, Claude, Codex, and future generative AI systems.
Model-Specific Prompting: ChatGPT vs Claude vs Codex
As AI language models continue to evolve, understanding their unique architectures and operational nuances is critical for maximizing output quality and efficiency. In 2026, the leading models—OpenAI’s ChatGPT, Anthropic’s Claude, and OpenAI’s code-specialized Codex—exhibit distinct approaches to processing instructions. Each model’s design philosophy influences how it interprets prompts, manages context, and generates responses. Mastering model-specific prompting strategies is essential for developers and technical professionals aiming to leverage these systems effectively in complex, real-world applications.
ChatGPT: Memory, Personalization, and Conversational Depth
ChatGPT continues to set the standard for conversational AI with its robust memory capabilities and advanced personalization features. Unlike earlier iterations, the 2026 ChatGPT maintains a dynamic long-term memory across sessions, which can be fine-tuned or reset by the user. This memory system enables the model to accumulate contextual knowledge about user preferences, project specifics, and past interactions, greatly enhancing continuity and relevance in multi-turn dialogues.
Key technical aspects of ChatGPT’s prompting include:
- Context Window Expansion: ChatGPT supports an extended context window of up to 64,000 tokens, allowing it to process extensive documents or conversations in a single prompt. This capability is critical for tasks requiring detailed analysis or multi-document synthesis.
- Personalization Tokens: Developers can embed user-specific tokens or metadata within prompts, which the model uses to tailor tone, style, and domain-specific jargon. This results in outputs that align closely with organizational or individual branding.
- Hierarchical Prompting: ChatGPT effectively handles hierarchical instructions, where the prompt contains nested tasks or conditional logic. This is facilitated by its ability to parse and retain structured information across turns.
When prompting ChatGPT, it is advisable to:
- Explicitly define the scope and desired output format early in the prompt.
- Leverage system-level instructions to set global behavior for the session.
- Use chaining prompts to build upon previous answers, exploiting the long-term memory for coherent narrative progression.
Claude: Constitutional AI and Robust Instruction Following
Anthropic’s Claude distinguishes itself through its Constitutional AI framework, which embeds a set of ethical and operational principles directly into the model’s reasoning process. This architectural choice significantly impacts how Claude parses and executes instructions, emphasizing safety, fairness, and interpretability.
Technical highlights of Claude’s prompting paradigm include:
- Constitutional Prompt Layers: Claude applies layered constitutional checks at multiple stages of generation, ensuring outputs align with predefined ethical guidelines without sacrificing instruction compliance.
- Explicit Instruction Parsing: Claude excels at detailed and complex instruction parsing, supporting multi-step reasoning with minimal hallucination. This is achieved via specialized attention mechanisms that prioritize instruction tokens.
- Adaptive Response Calibration: The model can adjust its verbosity, formality, and assertiveness based on prompt cues, making it highly versatile for diverse applications ranging from customer support to technical documentation.
Effective prompting strategies for Claude involve:
- Incorporating clear, step-wise instructions to align with Claude’s multi-step reasoning strengths.
- Embedding ethical constraints or content boundaries directly into the prompt when sensitive topics are involved.
- Utilizing explicit role-playing cues (e.g., “You are a legal advisor…”) to trigger domain-specific constitutional checks and tailor responses accordingly.
Codex: Task-Oriented Precision and Code Generation Excellence
Codex remains the premier choice for code generation and task-oriented automation. It is architecturally optimized for understanding programming languages, APIs, and developer intent, making it uniquely suited for generating syntactically correct and semantically meaningful code snippets. Codex’s prompting mechanisms capitalize on its deep training in code repositories and technical documentation.
Notable technical characteristics of Codex include:
- Syntax-Aware Tokenization: Codex uses a tokenization scheme that aligns closely with programming language tokens rather than natural language tokens, allowing more precise parsing of code structures.
- Function Signature Recognition: It can recognize and complete function signatures, docstrings, and inline comments, enabling comprehensive code generation from minimal prompts.
- Environment Context Integration: Codex supports embedding environment metadata (e.g., programming language version, framework specifics) within prompts to tailor outputs accurately.
Best practices when prompting Codex include:
- Providing concise, unambiguous instructions with clear input/output examples.
- Using inline comments within prompts to guide the model’s output style and code organization.
- Specifying the target programming language and environment details explicitly to avoid compatibility issues.
Comparative Overview of Model-Specific Prompting Attributes
| Feature | ChatGPT | Claude | Codex |
|---|---|---|---|
| Primary Use Case | Conversational AI, multi-turn dialogue, content generation | Ethical instruction following, multi-step reasoning | Code generation, task automation, API synthesis |
| Context Window | Up to 64,000 tokens | Up to 100,000 tokens (optimized for instruction complexity) | Up to 8,192 tokens (focused on code snippets) |
| Instruction Processing | Hierarchical, dynamic memory-aware | Constitutional-guided, step-wise parsing | Syntax-aware, example-driven |
| Safety Mechanisms | Moderation filters, user-resettable memory | Built-in constitutional layers enforcing ethical constraints | Limited; relies on prompt engineering for safety |
| Personalization | Extensive via memory and tokens | Moderate, guided by ethical principles | Minimal; focused on task precision |
Tailoring Prompts for Optimal Model Performance
Understanding the intrinsic biases and operational frameworks of ChatGPT, Claude, and Codex is essential for crafting effective prompts. Below are tailored recommendations for maximizing each model’s potential:
- ChatGPT: Leverage its memory by building progressive dialogues, embedding user-specific context, and specifying output formats early. Utilize system prompts to define the session’s scope and preferred communication style.
- Claude: Focus on clear, ethically bounded instructions with explicit role definitions. Break down complex tasks into sequential steps to utilize Claude’s constitutional reasoning effectively, ensuring responses align with compliance requirements.
- Codex: Provide minimal but precise code-related prompts, including example inputs and outputs. Annotate code snippets with comments to guide syntax and logic generation. Explicitly define environment parameters such as programming language and execution context.
In conclusion, the evolution of AI models into specialized domains and frameworks necessitates an equally sophisticated approach to prompting. Developers who invest in understanding the subtle differences in instruction processing, memory management, and ethical constraints across ChatGPT, Claude, and Codex will unlock unprecedented capabilities in their AI-driven workflows.
Structured Intent: The Framework for Reliable AI Outputs
In 2026, the landscape of AI prompting has evolved beyond basic command-and-response paradigms into a sophisticated discipline grounded in structured intent. This shift is crucial for developers and AI practitioners aiming to harness the full potential of leading large language models (LLMs) such as ChatGPT (now at version 5.5), Claude, and Codex. Structured intent refers to the deliberate and explicit formulation of prompts that clearly define what the AI should do, why it should do it, and how it should approach the task. This framework increases reliability, reduces ambiguity, and optimizes output quality.
At the core of this methodology is the RICE framework—an acronym standing for Role, Intent, Context, and Examples. Together, these components create a robust prompt architecture, adaptable across different AI engines and use cases. Below, we break down each element and illustrate practical implementations for Claude, GPT-5.5, and Codex.
The RICE Framework Explained
| Component | Description | Purpose |
|---|---|---|
| Role | Defines the persona or capacity the AI should assume (e.g., “You are a cybersecurity expert”). | Guides the model’s tone, knowledge scope, and style of reasoning. |
| Intent | Specifies the primary goal or task (e.g., “Analyze the vulnerability report for critical risks”). | Focuses the AI’s output toward the desired objective. |
| Context | Provides relevant background information, constraints, or parameters (e.g., “The report covers software version 3.2.1”). | Ensures accuracy and relevance by narrowing the AI’s knowledge scope. |
| Examples | Includes sample inputs and desired outputs to demonstrate the expected format or style. | Reduces ambiguity and improves output consistency. |
Implementing RICE in Claude via XML Tags
Anthropic’s Claude has embraced XML-like tagging as a formalized mechanism for encoding structured intent within prompts. This approach enables developers to explicitly delineate the RICE components, improving interpretability and response consistency. The use of XML tags also facilitates programmatic prompt generation and validation, which is essential for large-scale or mission-critical deployments.
Example prompt structure for Claude using RICE:
<role>You are a data engineer specializing in ETL pipelines.</role> <intent>Generate a Python script to extract data from an API and load it into a PostgreSQL database.</intent> <context>The API returns JSON data with nested objects. The database schema includes tables for users, transactions, and metadata.</context> <examples> Input: API returns user_id, transaction_id, and amount. Output: Python code snippet using requests and psycopg2 libraries. </examples>
This explicit markup not only guides Claude’s internal parsing mechanisms but also supports debugging and prompt version control. By segmenting the prompt into these logical blocks, developers can isolate which part of the instruction might be causing unexpected outputs and iterate efficiently.
System Prompts for GPT-5.5: Orchestrating Complex Conversations
OpenAI’s GPT-5.5 leverages system-level prompts to establish structured intent at the outset of an interaction. Unlike user prompts that may vary dynamically, system prompts are persistent instructions that set the foundational behavior and constraints for the AI throughout a session.
Using the RICE framework in system prompts involves embedding Role, Intent, and Context as static, high-priority directives. Examples are often provided via user inputs or fine-tuning data. The advantage is that the model maintains a coherent persona and task orientation, resulting in consistent and reliable outputs across multiple exchanges.
For instance, a system prompt for a legal assistant GPT-5.5 instance might look like this:
You are a legal expert specializing in intellectual property law (Role). Your task is to analyze patent documents and summarize potential infringement risks (Intent). Focus on U.S. patent law and recent case precedents from 2020 to 2026 (Context).
Developers can embed such system prompts programmatically via API parameters, ensuring every interaction aligns with the predefined structured intent. This is especially critical in enterprise applications where compliance and accuracy are non-negotiable.
Task Decomposition with Codex: Structured Intent in Code Generation
Codex, OpenAI’s code-focused LLM, benefits significantly from structured intent by incorporating task decomposition strategies. Instead of issuing monolithic, vague instructions, developers break down complex coding requests into smaller, well-defined sub-tasks, each framed with clear Role, Intent, Context, and Examples.
This approach leverages Codex’s strength in understanding modular instructions and producing syntactically and semantically correct code snippets that can be combined programmatically.
Consider a prompt for automating a data pipeline:
- Role: “You are a Python developer with expertise in API integration and database interactions.”
- Intent: “Write a function to authenticate to the API.”
- Context: “The API requires OAuth2 with client credentials.”
- Examples: “Provide a function using the requests_oauthlib library.”
After receiving the first function, the developer follows up with a similarly structured prompt for subsequent functions such as data extraction, transformation, and loading. This decomposition enables incremental validation, debugging, and reuse of code components, dramatically improving reliability.
Comparative Summary of Structured Intent Implementation Across Models
| Feature | Claude | GPT-5.5 | Codex |
|---|---|---|---|
| Structured Intent Encoding | XML-like tags explicitly mark RICE components | System prompts embed Role, Intent, Context persistently | Task decomposition with modular prompts |
| Role Specification | Explicit <role> tag | Defined in system prompt preamble | Specified per sub-task prompt |
| Intent Clarity | Structured <intent> tag guidance | Included in system prompt | Focused per sub-task |
| Contextual Constraints | <context> tag for background info | Static context in system prompt | Context provided for each function |
| Use of Examples | <examples> tag with input/output pairs | Examples often provided dynamically in conversation | Examples included in each sub-task prompt |
By adopting structured intent and the RICE framework, developers can greatly improve the predictability and quality of AI outputs. This is especially vital as the complexity of AI-assisted workflows increases and as models become integrated into critical systems requiring high degrees of accuracy and contextual awareness.
For a deeper dive into prompt engineering best practices and their application to these techniques, see our comprehensive guide on From Prompt Engineering to Context Engineering: The Essential 2026 Transition Guide for AI Power Users.
Multi-Agent Prompting Strategies
In 2026, the increasing sophistication of AI agents like OpenAI’s Codex, Anthropic’s Claude, and GPT models has ushered in a new era of multi-agent prompting strategies. These techniques enable developers to orchestrate collaborative workflows where multiple AI agents interact, specialize, and complement each other’s strengths. Multi-agent prompting not only enhances task efficiency but also expands the range of applications, from complex software development pipelines to strategic planning and execution in business processes.
Overview of Multi-Agent Prompting
Multi-agent prompting involves designing prompts that coordinate several AI agents simultaneously or sequentially to solve problems that exceed the capacity of individual models. This strategy leverages the unique capabilities of each model by assigning roles, such as planning, coding, reviewing, or reasoning, to different agents and ensuring smooth communication between them. For example, Claude’s advanced reasoning and contextual understanding can be used for high-level planning, while GPT or Codex can handle code generation and execution tasks.
This approach is particularly valuable when working with multiple Codex threads or blending Claude’s planning prowess with GPT’s execution capabilities. The goal is to create a seamless “chain-of-thought” that spans agent boundaries, making the entire process more coherent and robust.
Architectural Patterns for Multi-Agent Workflows
Effective multi-agent prompting requires a clear architectural pattern that orchestrates agent interaction. Common patterns include:
- Sequential Orchestration: Agents work in a pipeline fashion, where one agent’s output becomes the input for the next. For example, Claude may generate a project roadmap, which is then passed to Codex threads for modular code generation. Subsequent GPT agents might perform testing and documentation.
- Parallel Collaboration: Multiple agents work asynchronously on different sub-tasks within a larger goal. Coordination is managed externally, and results are later aggregated. This pattern is useful for distributed codebase generation or multi-domain data analysis.
- Feedback Loops: Agents iteratively refine outputs by exchanging feedback. For instance, GPT can generate code, Claude can review and suggest improvements, and Codex can implement the corrections, cycling until the solution meets the required criteria.
These patterns can be combined or adapted depending on the complexity of the task and the strengths of the models involved.
Orchestrating Multiple Codex Threads
OpenAI’s Codex models excel at code generation and understanding, especially when prompted with detailed specifications. However, large-scale software engineering tasks often require division into smaller, manageable components. Multi-threading Codex agents allows for parallel development of code modules, unit tests, and documentation snippets.
Key considerations for orchestrating multiple Codex threads include:
- Task Decomposition: Using a planning agent (such as Claude) to break down the project into discrete tasks with clear input/output specifications.
- State Management: Maintaining a shared state or context repository where each Codex thread can read dependencies and update progress to prevent conflicts and duplication.
- Inter-thread Communication: Implementing prompt-based protocols where one Codex thread can query another’s output or status to ensure integration consistency.
For example, a multi-module web application can be split into frontend components, backend APIs, and database schema generation, each handled by separate Codex threads running concurrently. A central coordinator agent (Claude or GPT) monitors progress, aggregates outputs, and triggers integration tests.
Using Claude for Planning and GPT for Execution
One of the most effective multi-agent prompting strategies in 2026 is to leverage Claude’s strategic planning and reasoning capabilities alongside GPT’s flexible generative abilities for execution. Claude models, designed with enhanced safety and interpretability, are ideal for creating comprehensive plans, setting priorities, and generating structured outlines.
Typical workflow:
- Planning Phase (Claude): Claude ingests the high-level goal and generates a detailed plan with subtasks, timelines, and resource allocation. This plan is outputted in a structured format like JSON or markdown tables.
- Execution Phase (GPT): GPT receives the structured plan and generates the necessary outputs—such as code, documentation, or communication drafts—according to the specifications.
- Validation and Feedback: Claude reviews the GPT outputs, flags inconsistencies or deviations, and iteratively refines the plan or prompts for re-execution, creating a closed-loop system.
This division of labor exploits Claude’s strength in logical coherence and GPT’s generative versatility, streamlining complex project workflows. It also reduces the risk of hallucinations or logical errors by embedding continuous validation steps.
Cross-Agent Chain-of-Thought Reasoning
Chain-of-thought prompting is a technique where the AI is guided to reason step-by-step to reach a conclusion. Extending this concept across agent boundaries is a powerful strategy in multi-agent setups. Rather than confining reasoning to a single model, each agent contributes a portion of the reasoning process, building on the previous agent’s output.
Example implementation:
- Step 1 (Claude): Generate an initial hypothesis or problem decomposition.
- Step 2 (GPT): Expand the hypothesis with detailed sub-steps, intermediate calculations, or code snippets.
- Step 3 (Codex): Translate the sub-steps into executable code or formal specifications.
- Step 4 (Claude): Analyze execution results or outputs, providing critique and suggesting refinements.
This cross-agent chain-of-thought ensures that reasoning remains transparent and modular, with each agent specializing in a specific cognitive role. It also facilitates debugging and auditability since each reasoning step is explicitly documented across agents.
Comparison of Multi-Agent Prompting Roles
| Agent | Primary Strengths | Typical Roles in Multi-Agent Setup | Limitations |
|---|---|---|---|
| Claude | Logical reasoning, planning, safety, interpretability | Task decomposition, plan generation, output validation, critique | Less flexible in creative generation, slower in generating large text blocks |
| GPT | Flexible generative text, natural language understanding, versatility | Execution of plans, code generation, documentation, user communication | Prone to hallucination without validation, lacks deep planning |
| Codex | Code synthesis, code understanding, multi-language support | Parallel code generation, testing scripts, integration with IDEs | Limited natural language reasoning, requires structured prompts |
Best Practices for Multi-Agent Prompting
- Explicit Role Definition: Clearly define each agent’s responsibility in the prompt to reduce overlapping outputs and confusion.
- Structured Communication: Use machine-readable formats (JSON, XML, markdown) for inter-agent data exchange to ensure consistency and ease of parsing.
- Iterative Refinement: Incorporate feedback loops where planning agents validate generated outputs before moving forward.
- Context Management: Maintain a shared context repository or memory store accessible to all agents to synchronize state.
- Monitoring and Logging: Implement detailed logging of each agent’s outputs and decisions to facilitate debugging and audit trails.
For an in-depth exploration of related prompting techniques that enhance multi-agent workflows, see our section on Advanced Prompting Techniques for 2026: Moving from Simple Inputs to Structured Intent.
Adopting multi-agent prompting strategies is essential for leveraging the full potential of AI ecosystems in 2026. By orchestrating Claude, GPT, and Codex agents effectively, developers can build highly scalable, reliable, and intelligent systems capable of tackling complex, multi-faceted challenges.
Testing, Iterating, and Measuring Prompt Effectiveness
In the rapidly evolving landscape of AI prompting, especially when working with state-of-the-art large language models such as ChatGPT, Claude, and Codex, rigorous testing and iterative refinement of prompts is essential for achieving optimal performance. This process involves constructing systematic prompt test suites, employing A/B testing methodologies, quantifying output quality with robust evaluation frameworks, and establishing continuous improvement workflows. Additionally, meta-prompting emerges as a powerful technique to enhance prompt adaptability and effectiveness. This section delves deeply into these advanced strategies, providing developers and AI practitioners with actionable insights for maximizing the utility of their prompts in 2026 and beyond.
Building Prompt Test Suites
A prompt test suite is a curated collection of input scenarios designed to systematically evaluate the performance of prompts under diverse conditions. Effective test suites encompass a broad spectrum of use cases, edge cases, domain-specific queries, and varying complexity levels. The construction of such suites requires careful attention to coverage, representativeness, and scalability.
- Coverage and Diversity: Ensure the test suite includes inputs that span the expected operational domain, including typical, boundary, and adversarial examples. For instance, when designing prompts for Codex code generation, test cases should cover multiple programming languages, varying algorithmic complexity, and error-prone scenarios such as ambiguous requirements.
- Structured Input Variants: Incorporate paraphrased versions of the same query and inputs that involve synonym substitution or reordered instructions to assess prompt robustness against linguistic variations.
- Automated Execution: Integrate the test suite within automated pipelines that can execute prompt invocations across different model versions or configurations, capturing outputs and metadata for analysis.
By establishing a comprehensive test suite, prompt engineers can systematically identify weaknesses and monitor improvements over time.
A/B Testing Prompts
A/B testing remains a cornerstone technique for empirically comparing prompt designs. This controlled experimentation methodology involves randomly exposing the AI model to two or more prompt variants and measuring differential performance on key metrics.
- Define Clear Metrics: Before testing, establish quantifiable metrics such as correctness rate, response latency, token usage efficiency, or user satisfaction scores.
- Randomized Sampling: Ensure that input queries are randomly assigned to each prompt variant to mitigate selection bias.
- Statistical Significance: Collect sufficient sample size to apply statistical tests (e.g., t-test, chi-square) that confirm whether observed differences are meaningful.
- Multi-Variant Testing: Extend beyond binary comparisons to multi-armed bandit approaches for simultaneous evaluation of multiple prompts, optimizing for dynamic allocation towards better-performing variants.
For example, when optimizing ChatGPT prompts for customer support automation, A/B testing can reveal which prompt phrasing yields higher resolution accuracy or reduces follow-up queries, enabling data-driven prompt refinement.
Measuring Output Quality
Measuring the quality of outputs generated by AI models in response to prompts is a multifaceted challenge that combines quantitative and qualitative approaches. Key dimensions include accuracy, coherence, relevance, and creativity. Various evaluation frameworks have emerged to standardize this process:
| Evaluation Framework | Focus Area | Methodology | Applicable Models |
|---|---|---|---|
| BLEU / ROUGE / METEOR | Text similarity and overlap | Compare AI output with reference texts using n-gram overlap metrics | ChatGPT, Claude (text generation) |
| CodeBLEU | Code generation accuracy | Extends BLEU with code syntax and semantics awareness | Codex, Code LLMs |
| Human-in-the-Loop (HITL) | Subjective quality and usability | Expert review and annotation of outputs | All models, especially for creative or ambiguous tasks |
| Automated Eval Suites (e.g., OpenAI evals) | Task-specific performance | Modular tests aligned to domain benchmarks | ChatGPT, Claude, Codex |
Combining automated metrics with human evaluation often yields the most comprehensive insights. For instance, in code generation scenarios, CodeBLEU metrics can detect syntactical correctness, while expert developers assess semantic accuracy and maintainability.
Using Eval Frameworks for Continuous Improvement
Eval frameworks provide standardized environments for prompt testing that facilitate continuous integration and deployment (CI/CD) workflows in AI prompting. These frameworks enable systematic tracking of prompt performance over time, regression testing, and rapid iteration.
- OpenAI Evals: A modular, open-source framework supporting customizable evaluation pipelines that can run diverse tests on ChatGPT and Codex outputs, capturing granular performance metrics.
- Claude Eval Tools: Anthropic provides internal and partner-accessible tools that automate evaluation on safety, factuality, and alignment metrics tailored to Claude’s architecture.
- Custom Benchmarks: Organizations often build proprietary eval suites aligned with their domain-specific needs, integrating automated scoring with manual review workflows.
Integrating these frameworks into CI/CD pipelines enables prompt developers to detect performance regressions early, prioritize prompt optimizations based on quantitative data, and deploy updates with confidence.
When to Use Meta-Prompting
Meta-prompting refers to the technique of crafting prompts that instruct the AI model to reason about or improve its own output, often by requesting self-evaluation, step-by-step explanation, or iterative refinement. Employing meta-prompts can significantly enhance output quality, particularly for complex or ambiguous tasks.
Use Cases for Meta-Prompting:
- Complex Multi-Step Reasoning: When tasks require logical sequencing or problem decomposition (e.g., mathematical proofs, code debugging), meta-prompts can guide the model to generate intermediate reasoning steps, improving accuracy.
- Self-Critique and Correction: Prompting the model to review its own response and identify potential errors enables iterative refinement without human intervention.
- Adaptive Output Formatting: Meta-prompts can instruct the model to adjust tone, style, or detail level dynamically based on user feedback or context.
- Prompt Engineering at Scale: Meta-prompting facilitates automated prompt generation and tuning by having the model evaluate and propose prompt variants, accelerating the development of effective prompts.
However, meta-prompting introduces additional computational overhead and can increase response latency. Therefore, it is best employed selectively in scenarios where the marginal gains in output quality justify the cost.
For an in-depth exploration of advanced prompting strategies including meta-prompting, refer to our detailed guide on The 2026 AI Coding Agents Production Playbook.
Summary
Testing, iterating, and measuring prompt effectiveness is a critical discipline for AI developers seeking to harness the full potential of ChatGPT, Claude, and Codex. By building comprehensive prompt test suites, leveraging A/B testing methodologies, applying rigorous output quality metrics, and integrating eval frameworks into continuous workflows, teams can achieve systematic and data-driven prompt optimization. Meta-prompting further enriches this toolkit, enabling AI models to self-improve and adapt in real-time. Together, these advanced techniques form the backbone of prompt engineering best practices in 2026 and beyond.
Stay Ahead of the AI Curve
Get the latest ChatGPT tutorials, AI news, and expert guides delivered straight to your inbox. Join thousands of AI professionals who trust ChatGPT AI Hub.