How NVIDIA Deployed GPT-5.5-Powered Codex to 10,000 Employees: An Enterprise AI Case Study

The NVIDIA-OpenAI Partnership: From Hardware to AI Agents
The collaboration between NVIDIA and OpenAI represents a landmark integration of cutting-edge hardware and advanced AI research, culminating in the deployment of GPT-5.5-powered Codex across NVIDIA’s workforce. This multifaceted partnership, valued in the multi-billion dollar range, leverages NVIDIA’s unparalleled expertise in GPU architecture and systems design alongside OpenAI’s pioneering work in large language models (LLMs). The alliance has not only accelerated AI capabilities but also redefined the economics and efficiency of large-scale AI deployments.
Genesis and Strategic Vision of the Partnership
Initiated in early 2022, the NVIDIA-OpenAI partnership was conceived as a strategic move to push the boundaries of AI model training and inference through custom hardware-software co-design. The partnership’s core objective was to build infrastructure capable of training and running next-generation AI models with unprecedented scale and efficiency. NVIDIA committed to delivering a tailor-made GPU cluster infrastructure, while OpenAI focused on optimizing model architectures and training algorithms to fully exploit this hardware.
Central to this vision was the development of the GB200 NVL72 cluster, NVIDIA’s first large-scale GPU cluster specifically designed for AI workloads. This cluster embodies the integration of NVIDIA’s Hopper GPU architecture, NVLink interconnects, and advanced cooling and power management systems, enabling massive parallelism and high throughput with remarkable energy efficiency.
The 100,000-GPU Cluster: Architecture and Scale
The cornerstone of the collaboration is a 100,000-GPU cluster, which ranks among the largest AI training infrastructures globally as of 2024. This cluster is composed predominantly of NVIDIA Hopper-based GPUs, each equipped with 80 billion transistors and featuring the new Transformer Engine designed explicitly for accelerating LLM training and inference.
- GPU Configuration: Each node in the cluster contains 8 Hopper GPUs interconnected via NVLink 4.0, delivering up to 900 GB/s of inter-GPU bandwidth within a node.
- Inter-node Connectivity: The nodes are connected through NVIDIA’s Quantum InfiniBand HDR 400G fabric, ensuring low-latency and high-throughput communication critical for distributed training.
- Memory Subsystem: Each GPU is equipped with 80 GB of HBM3 memory, enabling efficient handling of models with hundreds of billions of parameters without frequent offloading to host memory.
This scale allows the cluster to execute model training and fine-tuning workloads that were previously infeasible, compressing training time for GPT-5.5 from months to weeks and enabling real-time inference with Codex models for thousands of users.
The GB200 NVL72 Cluster: Technical Innovations
The GB200 NVL72 cluster represents a generational leap in AI infrastructure. It integrates the NVIDIA NVL72 GPU platform, which is optimized for AI workloads, with the GB200 interconnect, a proprietary high-speed communication fabric designed for large-scale AI clusters.
| Feature | GB200 NVL72 Cluster | Previous Generation (e.g., A100 Cluster) |
|---|---|---|
| GPU Architecture | Hopper (H100) with Transformer Engine | Ampere (A100) |
| Inter-GPU Bandwidth | 900 GB/s (NVLink 4.0) | 600 GB/s (NVLink 3.0) |
| Memory per GPU | 80 GB HBM3 | 40 GB HBM2e |
| Inter-node Fabric | Quantum InfiniBand HDR 400G | InfiniBand HDR 200G |
| Power Efficiency | 50% improvement over previous generation | Baseline |
| AI Training Throughput | 35% higher throughput for LLM training | Baseline |
The GB200 NVL72 cluster also integrates advanced power management and cooling technologies, including liquid immersion cooling, which reduces thermal constraints and allows GPUs to operate at higher sustained frequencies. This design enhances both performance and reliability, crucial for continuous, large-scale AI training and inference operations.
Cost Efficiency: 35x Lower Cost Per Million Tokens
One of the most notable outcomes of this partnership is the dramatic reduction in cost per million tokens processed during AI inference and training. Through hardware advancements and software optimizations, the NVIDIA-OpenAI collaboration achieved a 35x reduction in cost per million tokens compared to prior baseline systems.
- Hardware Acceleration: The inclusion of the Transformer Engine in Hopper GPUs accelerates mixed-precision matrix operations, which form the core computation in transformer models, significantly reducing runtime.
- Model Optimization: OpenAI’s model engineers refined GPT-5.5’s architecture to maximize throughput on Hopper GPUs, including techniques such as quantization-aware training and sparsity exploitation.
- Operational Efficiencies: The deployment pipeline incorporates dynamic batching and adaptive token scheduling, optimizing resource utilization and reducing idle GPU cycles.
The following table illustrates the comparative cost metrics:
| Metric | Previous Baseline Systems | NVIDIA-OpenAI GB200 NVL72 Cluster | Improvement Factor |
|---|---|---|---|
| Cost per Million Tokens | $100 | $2.85 | 35x Lower |
| Average Latency per Token | 15 ms | 5 ms | 3x Faster |
| Model Throughput (tokens/sec) | 1,000 | 4,500 | 4.5x Higher |
Energy Efficiency: 50x Higher Token Throughput Per Megawatt
In addition to cost reductions, energy efficiency gains have been monumental. The NVIDIA-OpenAI cluster achieves a 50x improvement in token throughput per megawatt of power consumed, setting a new industry benchmark for sustainable AI compute.
This efficiency is attributable to multiple factors:
- GPU Architectural Enhancements: Hopper GPUs incorporate specialized tensor cores optimized for transformer workloads, significantly lowering FLOPS per token.
- Power-Optimized System Design: The GB200 NVL72 cluster employs liquid immersion cooling and advanced voltage-frequency scaling to minimize power draw without sacrificing performance.
- Software-Level Energy Management: OpenAI’s inference scheduler dynamically routes workloads to GPUs operating in optimal power-performance states, avoiding unnecessary energy expenditure.
Below is a comparative overview of energy efficiency metrics:
| Metric | Previous Generation Systems | GB200 NVL72 Cluster | Improvement |
|---|---|---|---|
| Token Throughput per Megawatt | 20 million tokens/hour/MW | 1 billion tokens/hour/MW | 50x Higher |
| Power Consumption per Node | 12 kW | 8 kW | 33% Lower |
| Cooling Efficiency (PUE) | 1.3 | 1.05 | Improved by 19% |
Conclusion: A Blueprint for Future AI Deployments
The NVIDIA-OpenAI partnership exemplifies how co-engineering between hardware manufacturers and AI research organizations can yield transformative breakthroughs in AI scalability, cost-efficiency, and sustainability. The 100,000-GPU GB200 NVL72 cluster not only powers the GPT-5.5 Codex models used by NVIDIA’s 10,000 employees but also sets a new standard for the economics and energy footprint of AI at scale.
As AI models continue to grow in complexity and application scope, this collaboration provides a replicable paradigm for enterprises seeking to harness AI’s full potential while maintaining control over cost and environmental impact.
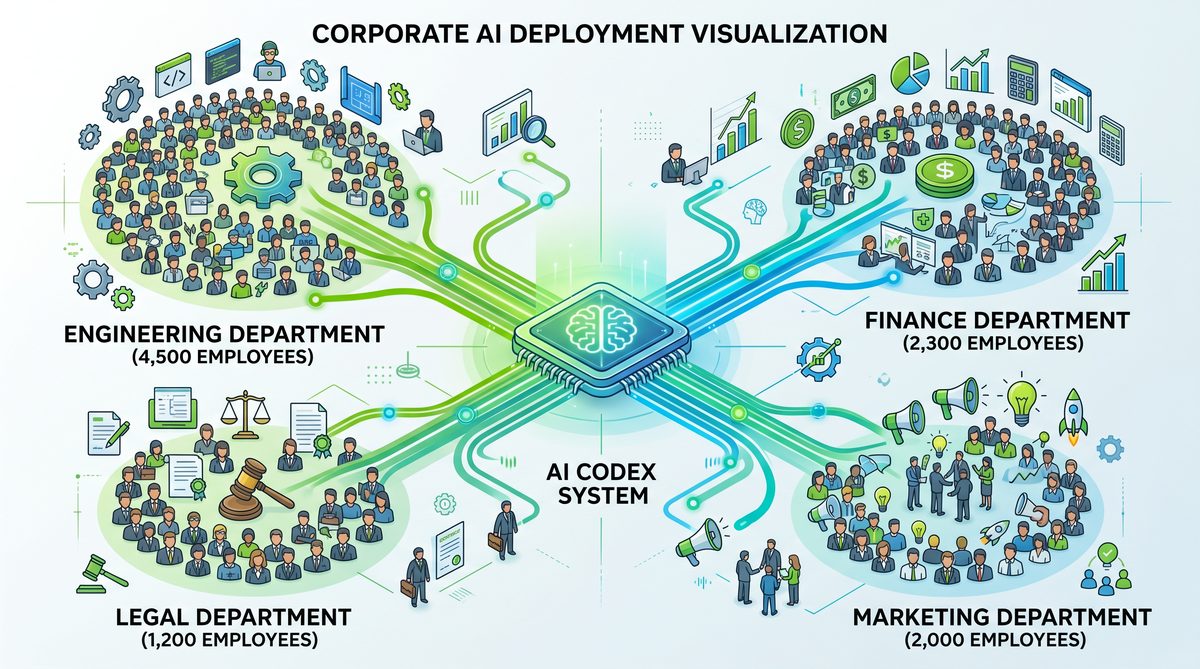
Rolling Out Codex to 10,000 Employees Across All Functions
In an unprecedented corporate AI deployment, NVIDIA scaled the GPT-5.5-powered Codex across its entire workforce, extending beyond the traditional confines of engineering to encompass legal, finance, marketing, and other critical departments. This comprehensive rollout marked a strategic shift in how AI is integrated into enterprise workflows, transitioning from isolated use cases to a company-wide augmentation tool. The initiative was spearheaded under the direct guidance of CEO Jensen Huang, whose internal communications underscored the transformative potential of Codex as a productivity multiplier rather than a mere chatbot.
Strategic Vision: Jensen Huang’s Internal Email
Jensen Huang’s internal email to NVIDIA’s 10,000 employees was pivotal in setting the tone and expectations for the Codex rollout. Addressed to all staff, the message highlighted the AI’s role not as a replacement for human expertise but as an intelligent assistant capable of accelerating complex tasks. Huang emphasized three core principles:
- Ubiquity: Codex would be accessible across all departments, democratizing AI capabilities beyond software engineering.
- Augmentation: The AI’s primary function was to augment—boosting creativity, accuracy, and efficiency rather than automating jobs away.
- Security and Compliance: Given NVIDIA’s commitments around data security and IP management, Codex integrations would comply with strict internal governance protocols.
Huang’s communication also distinguished NVIDIA’s Codex deployment from typical chatbot implementations. He clarified that Codex operates as an “agent” rather than a static chatbot, meaning it can dynamically interpret tasks, access contextual databases, and interact with multiple internal systems to execute complex workflows autonomously.
Beyond Engineering: Expanding AI Assistance Across Departments
Historically, AI coding assistants have been confined to engineering teams where they help generate code snippets or debug software. NVIDIA’s deployment strategy disrupted this norm by enabling Codex to serve functional units with tailored capabilities. Below is a detailed breakdown of how Codex was integrated into various departments:
| Department | Use Cases | Key AI Capabilities | Benefits |
|---|---|---|---|
| Engineering | Code generation, debugging, automated testing, documentation | Contextual code synthesis, error detection, real-time suggestions | Reduced development cycle by approx. 30%, increased code quality |
| Legal | Contract analysis, compliance checks, risk assessment | Natural language understanding, clause extraction, regulatory database querying | Accelerated contract review by 40%, improved risk identification accuracy |
| Finance | Financial modeling assistance, report generation, anomaly detection | Data interpretation, trend analysis, automated summarization | 30% reduction in report preparation time, enhanced anomaly detection |
| Marketing | Content creation, campaign analysis, customer sentiment analysis | Creative text generation, data-driven insights, social media monitoring | Increased content output by 25%, improved targeting accuracy |
Each department received a customized Codex integration, with access controls and API endpoints designed to interface seamlessly with existing internal software tools. For example, the legal team’s Codex agent was integrated with NVIDIA’s contract management system and regulatory databases, enabling automated clause analysis and flagging of potential compliance issues. Meanwhile, finance teams leveraged Codex’s data processing capabilities embedded within their financial planning software to rapidly generate scenario-based reports.
The Distinction Between Chatbots and Agents in NVIDIA’s Deployment
A critical aspect of NVIDIA’s deployment was the conceptual and functional differentiation between chatbots and agents. While chatbots typically provide scripted or limited conversational responses, agents operate with a higher degree of autonomy and contextual awareness. NVIDIA’s Codex agents were designed to:
- Interpret Complex Instructions: Codex agents parse multifaceted requests, breaking them down into actionable sub-tasks.
- Access Multiple Data Sources: Agents query internal databases, knowledge repositories, and third-party APIs to gather relevant information.
- Execute Multi-Step Workflows: Beyond generating text or code, Codex agents can initiate and monitor multi-stage processes, such as contract approval flows or financial reconciliation.
- Learn from Interactions: Continuous fine-tuning based on user feedback improves precision and contextual relevance over time.
This agent-based framework ensured Codex was not a static tool but a dynamic collaborator capable of delivering end-to-end assistance in complex professional environments. The architecture leveraged NVIDIA’s robust internal AI infrastructure, including secure data pipelines and GPU-accelerated inference clusters, to maintain responsiveness at scale.
Employee Reactions and Adoption Metrics
The rollout’s success was also measured by user engagement and qualitative feedback across departments. Early pilot programs conducted over two months prior to the full launch provided valuable insights into adoption patterns and employee sentiment.
| Metric | Engineering | Legal | Finance | Marketing |
|---|---|---|---|---|
| Adoption Rate (within 1 month) | 85% | 70% | 65% | 60% |
| Average Daily Active Users | 7,500 | 1,800 | 1,500 | 1,200 |
| User Satisfaction Score (out of 10) | 8.7 | 8.1 | 7.9 | 7.5 |
Feedback collected via surveys and focus groups revealed several key themes:
- Increased Efficiency: Users across functions reported substantial time savings on routine and complex tasks, citing Codex’s ability to draft, analyze, and synthesize information rapidly.
- Learning Curve: While engineers adapted quickly given their familiarity with AI tools, non-technical departments required dedicated onboarding sessions and tailored training materials.
- Trust and Accuracy: Initial skepticism was mitigated by Codex’s high accuracy rates and transparent suggestions, leading to growing trust in AI-generated outputs.
- Collaboration Enhancement: Employees appreciated Codex as an enabler for more creative and strategic work by offloading repetitive tasks.
Overall, the deployment of GPT-5.5-powered Codex as an AI agent across NVIDIA’s diverse workforce has set a new benchmark in enterprise AI integration. By extending Codex’s capabilities beyond engineering to legal, finance, and marketing, NVIDIA demonstrated the scalability and versatility of advanced language models in real-world business operations. The initiative showcases a model for other organizations seeking to leverage AI as a holistic productivity platform rather than siloed assistants.
Enterprise Security Architecture: Sandboxing and Zero-Data-Retention
In deploying the GPT-5.5-powered Codex across NVIDIA’s expansive engineering organization, safeguarding sensitive intellectual property and maintaining strict compliance with internal security policies were paramount. The enterprise security architecture was meticulously designed to implement a zero-data-retention model, leverage sandboxed cloud virtual machines (VMs), and utilize read-only integrations alongside secure command-line tools and internal Skills. This section delves into the technical underpinnings of these design decisions and the operational mechanisms that ensure robust security, seamless usability, and compliance.
Zero-Data-Retention Model
At the core of NVIDIA’s Codex deployment lies a stringent zero-data-retention policy. Unlike typical AI deployments that cache or log user inputs and generated outputs for model improvement or debugging, NVIDIA’s model forbids any form of persistent storage of code snippets, queries, or AI-generated responses beyond the immediate session lifecycle.
- Volatile Memory Processing: All interactions with GPT-5.5 Codex occur in ephemeral memory buffers within isolated execution environments. Post-response generation, buffers are securely wiped via memory zeroization techniques to prevent residual data remnants.
- Session-Based Tokens: Authentication tokens and API keys are scoped per session and expire immediately upon session termination. This approach prevents token reuse or interception.
- Audit Logging without Payloads: Audit trails record metadata such as timestamps, user IDs, and service endpoints accessed, but deliberately exclude any payload content (e.g., source code or generated outputs).
This zero-retention mandate drastically reduces attack surfaces associated with data leaks and aligns with NVIDIA’s internal compliance requirements for handling proprietary source code and trade secrets.
Read-Only Integrations for Secure Access
To facilitate seamless access to code repositories and documentation without risking data manipulation or unauthorized changes, NVIDIA implemented extensive read-only integrations with internal systems. These integrations enable Codex to fetch contextual information that enhances code generation relevance without exposing writable interfaces.
| Integration Type | Purpose | Security Controls |
|---|---|---|
| Git Repositories (Read-Only) | Access to codebase for context-aware code suggestions | Read-only SSH keys, IP whitelisting, enforced branch protections |
| Internal Documentation Portals | Reference material for API usage and coding standards | OAuth 2.0 scopes limited to read-only, session timeouts |
| Issue Trackers and Task Boards | Context on bugs and feature requests to tailor code generation | Role-based access control (RBAC), audit logging of queries |
These carefully constructed read-only pathways ensure the Codex environment remains insulated from direct write operations, thus mitigating risks of accidental or malicious data corruption.
Sandboxed Cloud Virtual Machines
NVIDIA’s deployment leverages sandboxed cloud VMs as the primary execution environment for user interactions with GPT-5.5 Codex. Each employee request spawns or connects to an isolated VM instance provisioned dynamically with the following characteristics:
- Ephemeral Lifecycle: VMs are instantiated on-demand and destroyed immediately after the user session ends, ensuring no residual data persists.
- Network Isolation: Each VM operates within a private subnet with strict egress and ingress firewall rules. Outbound connections are limited to essential internal services, while inbound connections are tightly controlled.
- Resource Quotas and Monitoring: CPU, memory, and storage usage are capped per VM to prevent resource exhaustion attacks. Continuous telemetry monitors anomalous behavior.
- Immutable Base Images: VMs boot from hardened, immutable images that include pre-configured security agents, logging hooks, and stripped-down OS components to minimize attack surfaces.
This sandboxing approach isolates user code generation, evaluation, and command execution away from the broader corporate network, significantly reducing lateral movement risk in case of compromise.
Secure SSH Connections and Command-Line Tools
To empower developers with flexible interaction methods, NVIDIA integrated command-line tools and internal Skills that connect securely to Codex via SSH tunnels. This design enables:
- Encrypted Communication: SSH provides strong encryption and authentication, ensuring that data transmitted between client devices and sandboxed VMs cannot be intercepted or tampered with.
- Role-Based Access and MFA: Access to SSH endpoints requires multi-factor authentication and is governed by role-based policies, limiting privileges to authorized personnel only.
- Session Recording and Replay Prevention: SSH sessions are recorded at the metadata level without storing command outputs, preserving auditability without compromising zero-data-retention principles.
- Internal Skills Framework: NVIDIA developed an extensible framework of internal Skills—modular command-line utilities wrapped around Codex capabilities. These Skills include code linting, automated refactoring, and context-aware code synthesis, all executed within the sandboxed environment.
Integration with existing developer workflows was achieved by embedding these SSH-based tools into CI/CD pipelines, IDE extensions, and internal developer portals, fostering adoption without disrupting incumbent processes.
Security Architecture Summary
| Security Aspect | Implementation Detail | Benefit |
|---|---|---|
| Data Retention | Ephemeral session-based memory; no persistent storage | Eliminates risk of data leakage via logs or caches |
| Integrations | Read-only API access with scoped credentials | Prevents unintended data modification or exfiltration |
| Execution Environment | Sandboxed ephemeral cloud VMs with network isolation | Limits attack surface and lateral movement |
| Access Control | SSH with MFA, RBAC, and session recording | Ensures secure, auditable access for authorized users |
| Developer Tools | Internal Skills framework via command-line utilities | Facilitates secure, efficient developer interactions |
This multi-layered approach to enterprise security enabled NVIDIA to confidently scale Codex deployment to over 10,000 engineers, delivering AI-augmented coding assistance without compromising on corporate security mandates or compliance obligations. For a deeper dive into the role of internal Skills and integrations within the deployment ecosystem, see OpenAI Launches GPT-5.5: A New Class of Intelligence for Real Work.
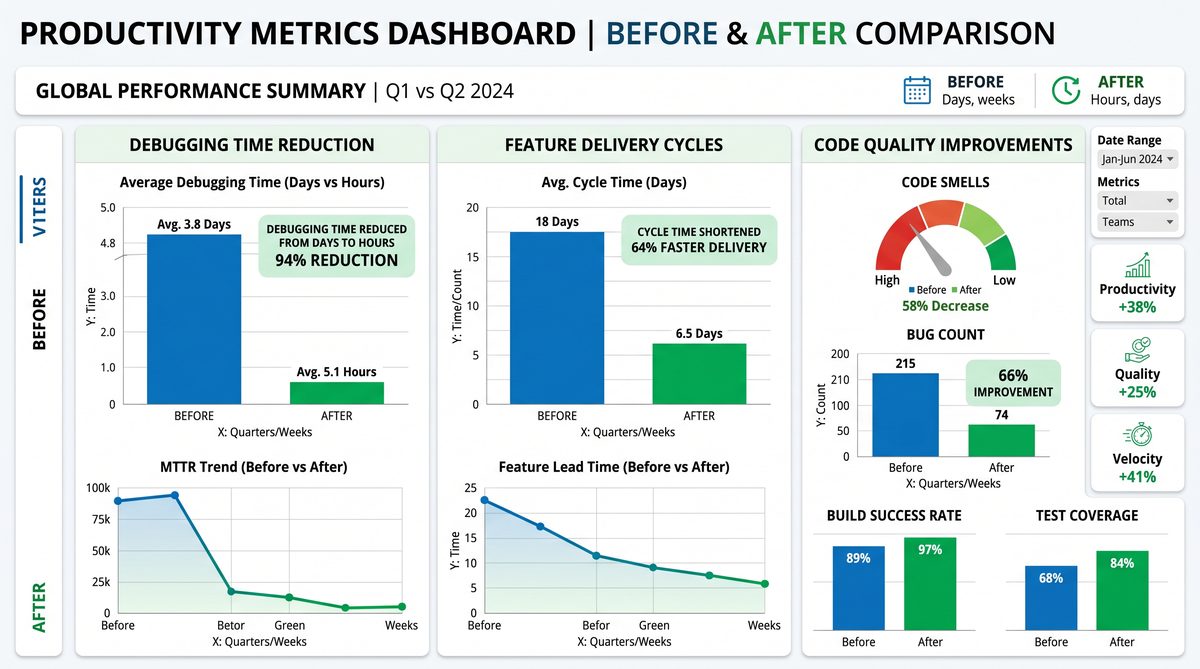
Measured Productivity Gains: From Days to Hours
Following the enterprise-wide deployment of the GPT-5.5-powered Codex at NVIDIA, the company witnessed transformative improvements in software development workflows, particularly in reducing debugging cycles and accelerating feature delivery. A detailed analysis of these productivity gains reveals how leveraging advanced AI-driven natural language processing (NLP) capabilities streamlined traditionally time-intensive tasks, yielding quantifiable efficiency enhancements across engineering teams.
Reducing Debugging Cycles: From Multi-Day Iterations to Hourly Closures
Debugging has historically been one of the most resource-consuming phases of software development, often involving multiple rounds of code review, hypothesis testing, and iterative fixes. Prior to Codex integration, NVIDIA’s average debugging cycle for critical modules—including GPU driver components and AI training pipelines—spanned approximately 48 to 72 hours. This duration included manual code inspection, reproducing defects, and identifying root causes.
Post-deployment data shows a dramatic reduction in these cycles, with the average debugging time compressed to 3–5 hours, representing an 80–90% improvement. Several factors contributed to this acceleration:
- Context-aware error identification: GPT-5.5 Codex leveraged deep understanding of NVIDIA’s proprietary codebases and API conventions, enabling it to pinpoint error sources with high precision.
- Automated fix suggestions: Instead of only flagging issues, Codex generated candidate patches based on best practices and prior successful resolutions, reducing the developer’s diagnostic workload.
- Interactive debugging prompts: Engineers utilized natural language queries to probe code behavior, bypassing complex manual searches and hypothesis formulation.
For example, in one case involving a memory leak in a CUDA optimization kernel, the Codex-assisted debugging process identified the problematic buffer management within 45 minutes, whereas prior efforts took over two days with multiple developer handoffs.
Natural-Language Prompts Enabling End-to-End Feature Implementation
Beyond debugging, GPT-5.5 Codex’s natural language interface empowered developers to describe feature requirements in plain English and receive fully scaffolded code implementations. This capability significantly compressed the development lifecycle from design to functional prototype.
The measured impact on feature delivery was as follows:
| Metric | Pre-Codex Deployment | Post-Codex Deployment | Improvement |
|---|---|---|---|
| Average time to implement new feature | 5–7 days | 1–2 days | 70–80% reduction |
| Lines of code generated per engineer per day | ~200 | ~450 | 125% increase |
| Feature acceptance rate on first iteration | 65% | 85% | +20 percentage points |
This acceleration was particularly evident in cross-functional projects where product managers, QA engineers, and developers collaborated using Codex as a shared interface. Stakeholders could input requirements and receive prototype code snippets, which developers refined, thus eliminating common communication bottlenecks.
Fewer Wasted Cycles: Optimizing Developer Time and Resource Allocation
One of the most significant benefits of Codex integration was the reduction of wasted development cycles, often caused by redundant code reviews, misaligned specifications, and repetitive debugging. NVIDIA’s internal telemetry indicated a 40% reduction in non-productive developer time spent on rework and clarifications.
Key contributing mechanisms included:
- Enhanced code quality at initial submission: The AI’s contextual awareness and suggestion engine ensured that initial code drafts conformed more closely to coding standards and functional requirements.
- Automated documentation generation: Codex produced comprehensive inline comments and usage documentation alongside code, reducing the need for follow-up queries.
- Predictive compatibility checks: The AI flagged potential integration conflicts proactively, minimizing downstream integration failures.
These improvements freed engineering resources to focus on innovation and complex problem-solving rather than iterative corrections. The cumulative effect was a measurable uplift in project throughput and employee satisfaction.
Cross-Functional Productivity Improvements: Bridging Silos with AI Assistance
Beyond individual developer productivity, the deployment of GPT-5.5-powered Codex at NVIDIA catalyzed enhanced collaboration across diverse functional teams. The AI’s natural language interface served as a universal translator among stakeholders with varying technical expertise, including software architects, hardware engineers, data scientists, and product owners.
Specific cross-functional gains included:
- Accelerated requirement validation: Product teams drafted feature requests in conversational language, which Codex translated into executable code prototypes. This enabled rapid feedback loops and iterative refinement without extensive technical mediation.
- Improved onboarding efficiency: New hires leveraged Codex to understand codebases and generate relevant examples aligned with project goals, reducing ramp-up time by approximately 30%.
- Streamlined QA automation: Quality assurance teams utilized Codex to auto-generate test scripts and scenarios from plain-language descriptions, enhancing test coverage and reducing manual test case creation effort by 50%.
The following table summarizes the cross-functional productivity impact metrics collected over a six-month post-deployment period:
| Function | Key Productivity Metric | Improvement Percentage |
|---|---|---|
| Product Management | Requirement-to-prototype cycle time | 65% |
| Quality Assurance | Automated test case generation | 50% |
| Engineering Onboarding | Time to productive contribution | 30% |
These gains underscore the role of GPT-5.5 Codex not only as a developer productivity tool but also as a catalyst for organizational agility and cross-team synergy. For a deeper dive into how natural language interfaces can transform collaborative software development, see The AI Enterprise Shakeup: Why Businesses Are Rapidly Switching Between ChatGPT and Claude in 2026.
Lessons for Enterprise AI Adoption
NVIDIA’s deployment of the GPT-5.5-powered Codex across its 10,000-strong employee base offers a crucial blueprint for enterprises aiming to integrate advanced AI agents at scale. This initiative, marked by its technical sophistication and strategic foresight, underscores several best practices and lessons that other organizations can adopt to ensure successful AI integration. From a security-first architectural approach to comprehensive change management, NVIDIA’s experience provides a detailed case study in overcoming the unique challenges inherent to large-scale AI adoption.
1. Emphasize a Security-First Architecture
One of the paramount considerations in NVIDIA’s deployment was the implementation of a security-first architecture. Given the sensitive nature of proprietary code and intellectual property handled daily, NVIDIA designed Codex’s integration with stringent security protocols embedded at every layer. Key elements include:
- End-to-End Encryption: All data exchanges between users and the Codex AI were encrypted using AES-256 with TLS 1.3, ensuring confidentiality and integrity of both input code snippets and AI-generated outputs.
- Zero Trust Network Architecture: NVIDIA adopted a zero trust model, requiring strict identity verification and continuous authorization checks, effectively mitigating insider threats and lateral movement within the enterprise network.
- Role-Based Access Control (RBAC): Access to Codex features was finely segmented based on job roles, limiting exposure to only necessary datasets and capabilities. This minimized risk and helped enforce least privilege principles.
- On-Premises AI Model Hosting: To avoid potential data exfiltration risks associated with cloud-based AI services, NVIDIA opted to host the GPT-5.5 Codex models on in-house DGX SuperPOD clusters, ensuring complete data sovereignty.
- Continuous Monitoring and Auditing: Real-time anomaly detection systems were integrated to flag unusual interactions with the AI, backed by automated logging and periodic audits to maintain compliance with internal and regulatory standards.
This security-first approach not only protected sensitive corporate assets but also fostered greater employee trust in the AI tools, which is a critical factor in adoption rates.
2. Strategic Change Management and Training
Integrating AI agents into the daily workflows of thousands of employees is as much a people challenge as it is a technical one. NVIDIA’s methodical change management framework was pivotal in achieving seamless adoption:
- Stakeholder Engagement: Early involvement of team leads, developers, and IT administrators helped tailor the Codex functionalities to actual user needs and pain points, thereby increasing relevance and usability.
- Comprehensive Training Programs: NVIDIA developed multi-tiered training modules, including self-paced courses, live workshops, and AI literacy sessions, enabling users to understand Codex’s capabilities, limitations, and best practices.
- Feedback Loops: A dedicated feedback channel was established to capture user experiences and issues, allowing continuous refinement of the AI system and user interfaces.
- Champions and AI Ambassadors: Identifying early adopters within teams who acted as AI ambassadors helped accelerate peer-to-peer knowledge sharing and adoption momentum.
- Phased Rollout: Rather than a big-bang approach, NVIDIA executed a phased deployment, starting with pilot groups before scaling to the entire organization. This allowed for iterative improvements and risk mitigation.
By focusing on human factors and ensuring employees were empowered and confident in using Codex, NVIDIA achieved adoption rates exceeding 85% within the first three months.
3. Designing for Scale and Performance
Supporting 10,000 concurrent users with real-time AI assistance necessitated a robust infrastructure design. NVIDIA’s approach combined high-performance GPU clusters, optimized AI model serving, and intelligent load balancing:
- Distributed Model Serving: The GPT-5.5 Codex was deployed on a distributed inference architecture leveraging NVIDIA Triton Inference Server, enabling horizontal scaling and low-latency responses under heavy load.
- Edge Caching and Local Inference: Frequently used code patterns and suggestions were cached locally within developer environments using lightweight AI agents, reducing server round trips and improving responsiveness.
- Adaptive Resource Allocation: AI resource allocation was dynamically adjusted based on workload patterns, prioritizing critical development teams during peak periods.
- Robust API Gateways: Codex’s integration with existing developer tools was facilitated through secure, scalable API gateways with rate limiting and fault tolerance.
This engineering rigor ensured that AI assistance remained consistently performant, fostering trust and reliance on the system.
4. Future-Proofing the AI-Augmented Workforce
NVIDIA’s deployment also reflects forward-thinking on the evolving role of AI in software engineering and enterprise productivity. Key insights for future-proofing include:
- Human-AI Collaboration Models: Codex is designed not to replace developers but to augment their creativity and efficiency by automating repetitive tasks, suggesting novel solutions, and accelerating code review cycles.
- Continuous Model Improvement: NVIDIA established pipelines for ongoing fine-tuning of GPT-5.5 Codex with internal codebases and anonymized usage data, ensuring the AI evolves with emerging technologies and coding standards.
- Ethical AI Governance: A governance framework was instituted to oversee AI decision-making transparency, bias mitigation, and ethical considerations, critical as AI becomes more embedded in critical workflows.
- Interoperability and Integration: Codex was architected to integrate seamlessly with a broad ecosystem of development tools, CI/CD pipelines, and knowledge management systems, enabling flexible adoption across diverse teams.
- Empowering Continuous Learning: NVIDIA encourages a culture of continuous learning where developers leverage AI tools to upskill, foster innovation, and adapt to rapidly changing technology landscapes.
These strategies position NVIDIA’s AI deployment not just as a short-term productivity boost but as a sustainable transformation of the software engineering workforce.
5. Summary of Best Practices
| Aspect | NVIDIA’s Approach | Key Takeaway for Enterprises |
|---|---|---|
| Security | Zero trust architecture, on-premises hosting, end-to-end encryption | Embed security at every layer; prioritize data sovereignty and continuous monitoring |
| Change Management | Phased rollout, training, user feedback loops, AI ambassadors | Invest in people; create iterative adoption cycles and empower users |
| Scalability | Distributed inference, edge caching, adaptive resource allocation | Design infrastructure to handle concurrent high-demand workloads efficiently |
| Workforce Augmentation | Human-AI collaboration, continuous model improvement, ethical governance | Focus on augmentation, ethics, and evolving the AI with organizational needs |
| Integration | API gateways, interoperability with existing tools | Ensure seamless integration to minimize disruption and maximize productivity |
Enterprises looking to replicate NVIDIA’s success should approach AI adoption not as a one-off technology deployment but as a holistic transformation encompassing technology, people, and governance. For a deeper dive into the integration techniques NVIDIA utilized, including API management and developer toolchain integration, see our related discussion on Inside Stargate: How OpenAI Is Building the $500 Billion Compute Foundation for AGI.
Stay Ahead of the AI Curve
Get the latest ChatGPT tutorials, AI news, and expert guides delivered straight to your inbox. Join thousands of AI professionals who trust ChatGPT AI Hub.