The Ultimate Guide to AI Agent Infrastructure in 2026: Architecture, Tools, and Best Practices
The Ultimate Guide to AI Agent Infrastructure in 2026
As artificial intelligence continues to evolve at a breakneck pace, 2026 stands as a pivotal year in the transformation of AI agent infrastructure. The landscape has shifted dramatically from previous eras dominated by intelligence bottlenecks—where the primary challenge was developing more capable AI models—to a new paradigm defined by infrastructure bottlenecks. This shift underscores the immense complexity involved in scaling, orchestrating, and optimizing AI agents that power everything from conversational assistants to autonomous systems.
In this comprehensive guide, we explore the critical aspects of building resilient, efficient, and scalable AI agent infrastructure in 2026. We delve into the underlying causes of infrastructure bottlenecks, unveil innovative strategies such as the Advisor Strategy featuring Haiku and Opus frameworks, and dissect advanced caching techniques inspired by industry leaders like GitHub, which achieves an astonishing 94% cache hit rate.
Whether you are a developer, architect, or technical decision-maker, understanding these concepts is crucial to navigating the evolving AI ecosystem and building the next generation of intelligent systems. This guide is the first part of a multi-section series designed to provide exhaustive insights and practical knowledge to empower your AI infrastructure projects.
From Intelligence Bottlenecks to Infrastructure Bottlenecks: Understanding the Paradigm Shift
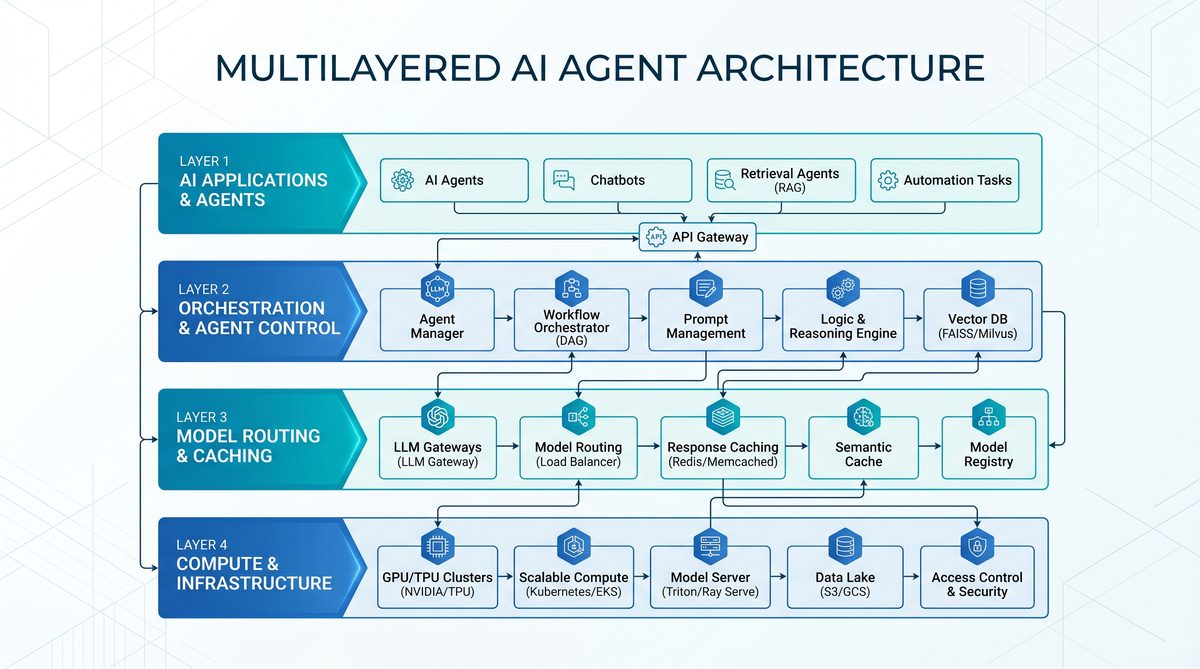
In the early days of AI development, the primary constraint was intelligence bottlenecks. These bottlenecks referred to the computational and algorithmic limits on the intelligence or capabilities of AI models themselves. Developers and researchers focused heavily on improving model architectures, increasing the size of training datasets, and enhancing the quality of data to push the boundaries of AI cognition.
However, as foundational models matured and AI capabilities surged, the paradigm shifted. Today, the dominant challenge lies not in the intelligence of models but in the infrastructure required to support deploying, scaling, and managing AI agents in complex, real-world environments. This transition marks the movement from a focus on model-centric challenges to infrastructure-centric challenges.
The Nature of Infrastructure Bottlenecks
Infrastructure bottlenecks encompass several intertwined technical constraints that limit AI agent performance and scalability:
- Compute Resource Allocation: Efficiently distributing and managing compute resources across diverse AI workloads to avoid over-provisioning or underutilization.
- Latency and Throughput: Ensuring that AI agents respond rapidly and can handle high volumes of concurrent requests without degradation in performance.
- Data Management: Handling the inflow and outflow of data for training, inference, and feedback loops, including versioning, privacy, and compliance.
- Agent Orchestration: Coordinating multiple agents and sub-agents to work collaboratively, including task delegation, conflict resolution, and state synchronization.
- Scalability and Reliability: Building systems that can scale horizontally and vertically while maintaining uptime and fault tolerance.
In practice, these bottlenecks manifest as challenges in system design and operations. For example, an AI-driven customer support system might have highly intelligent language models but fail to deliver timely responses due to inadequate backend infrastructure or poor caching strategies. Similarly, autonomous vehicle fleets may face critical delays in decision-making if the orchestration infrastructure cannot keep pace with sensor data inflow and agent coordination demands.
Key Drivers Behind the Shift
The shift from intelligence to infrastructure bottlenecks is driven by several macro trends in the AI ecosystem:
- Explosion of AI Agent Use Cases: The proliferation of AI agents across industries—from healthcare and finance to manufacturing and entertainment—has exponentially increased the demand for scalable infrastructure.
- Multi-Agent Systems Complexity: Modern AI solutions increasingly rely on ensembles of agents working in concert, which elevates orchestration complexity and resource contention.
- Cloud-Native and Edge Deployments: The hybridization of cloud and edge computing demands flexible infrastructure capable of balancing workloads across heterogeneous environments.
- Real-Time Interaction Requirements: Many AI applications require near-instantaneous feedback loops, pushing infrastructure to minimize latency.
- Cost and Sustainability Pressures: Rising energy costs and environmental concerns have intensified the need for infrastructure efficiency and optimization.
Implications for AI Infrastructure Architects
For architects and developers, this evolution necessitates a shift in mindset and tooling. Traditional AI infrastructure focused primarily on supporting model training and inference pipelines. In contrast, modern AI agent infrastructure demands a holistic approach that integrates:
- Advanced orchestration frameworks capable of dynamic agent coordination and lifecycle management.
- Intelligent caching and data retrieval systems to minimize redundant computations and accelerate response times.
- Robust monitoring and observability tools to detect and mitigate infrastructure bottlenecks in real time.
- Scalable storage solutions optimized for AI workloads, including specialized databases and distributed file systems.
- Security and compliance layers tailored to AI-specific privacy and governance requirements.
This comprehensive understanding of infrastructure bottlenecks sets the stage for exploring innovative strategies designed to overcome these challenges. The following section introduces the Advisor Strategy, leveraging Haiku and Opus, which exemplifies a forward-looking approach to AI agent orchestration and infrastructure optimization.
The Advisor Strategy: Leveraging Haiku and Opus for Scalable AI Agent Orchestration
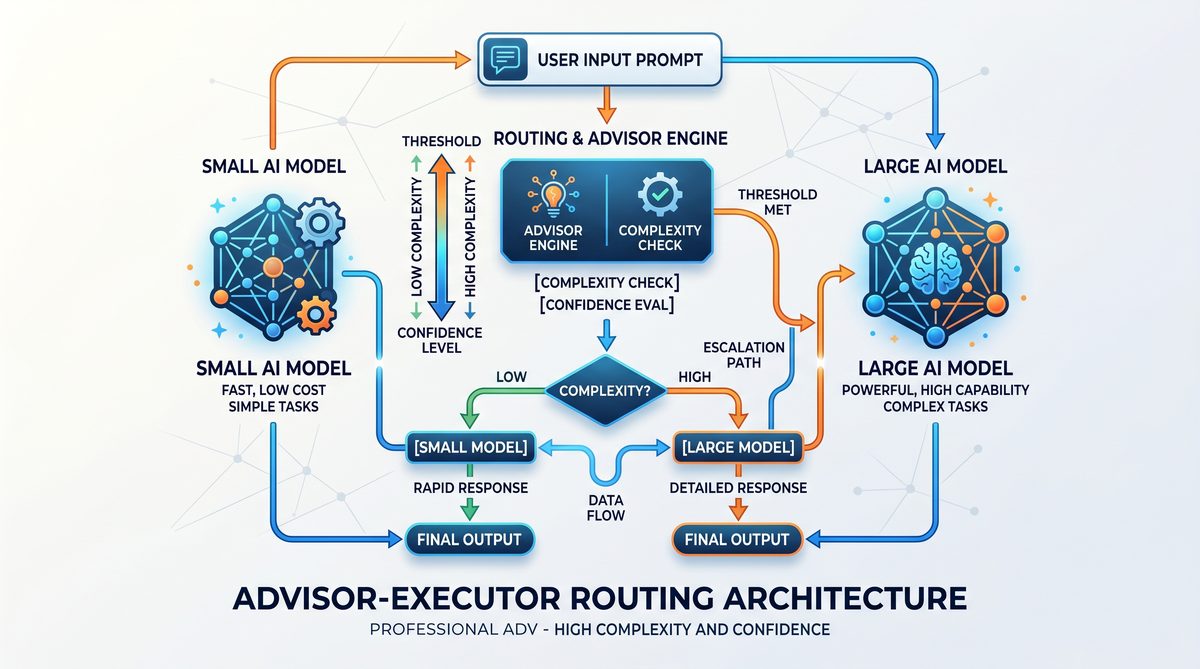
As AI agent systems grow in complexity, traditional monolithic architectures become untenable. The Advisor Strategy emerges as a modular and scalable framework that orchestrates AI agents by separating concerns between advisory and operational layers. Central to this strategy are two key components: Haiku and Opus.
The Advisor Strategy addresses critical challenges in agent orchestration, including dynamic task allocation, contextual memory management, and fault-tolerant agent collaboration. By dissecting Haiku and Opus individually, we can understand how they contribute to a resilient, performant AI agent infrastructure.
Haiku: The Advisor Layer
Haiku functions as the advisory brain behind AI agent orchestration. It is designed to provide contextual guidance, strategic decision-making, and meta-level reasoning that directs the behavior of subordinate operational agents. Key features of Haiku include:
- Contextual Awareness: Haiku maintains a holistic understanding of the system state, historical interactions, and external environment inputs.
- Policy-Driven Decision Making: Implements adaptive policies that govern agent task prioritization, resource allocation, and escalation procedures.
- Learning and Adaptation: Continuously refines advisory strategies based on feedback loops, performance metrics, and anomaly detection.
- Inter-Agent Communication: Mediates communication and synchronization among multiple agents, ensuring coherent collective behavior.
Technically, Haiku leverages state-of-the-art language models combined with symbolic reasoning modules to balance flexibility and precision. It functions as the “brain” that advises when and how operational agents should act, optimizing system-wide outcomes rather than isolated agent objectives.
Opus: The Operational Layer
While Haiku provides strategic oversight, Opus embodies the operational execution of tasks. Opus is a flexible, microservice-based framework that hosts individual AI agents, each specialized for specific functions such as natural language understanding, knowledge retrieval, or decision execution. Key characteristics of Opus include:
- Modularity: Each agent in Opus is a loosely coupled service with clearly defined interfaces and responsibilities.
- Scalability: Opus supports horizontal scaling of agents based on demand, enabling elastic resource utilization.
- Fault Isolation: Individual agents operate independently, so failures are contained without cascading effects.
- Interoperability: Agents communicate via standardized protocols and message brokers, facilitating seamless integration.
Opus agents are optimized for low-latency execution and can be deployed across cloud and edge environments, providing the operational backbone for AI applications with stringent performance requirements.
Synergizing Haiku and Opus
The Advisor Strategy’s power stems from the synergy between Haiku and Opus. Haiku guides the overall system by interpreting high-level goals and constraints, while Opus executes the detailed operational steps. This separation of concerns enables:
- Dynamic Task Delegation: Haiku assigns tasks to the most appropriate Opus agents based on context, availability, and expertise.
- Adaptive Resource Management: Haiku monitors agent workloads and adjusts resource allocation to optimize throughput and responsiveness.
- Robust Error Handling: Haiku detects operational anomalies in Opus agents and triggers recovery or fallback strategies.
- Incremental Learning: Feedback from Opus agents informs Haiku’s policy updates, fostering continuous system improvement.
Implementing the Advisor Strategy requires integrating sophisticated communication layers, real-time telemetry, and AI-driven policy engines. The architecture is inherently extensible, allowing organizations to customize Haiku and Opus components to their domain-specific needs.
Comparative Overview of Haiku and Opus Components
| Feature | Haiku (Advisor Layer) | Opus (Operational Layer) |
|---|---|---|
| Primary Role | Strategic guidance and decision-making | Task execution and operational processing |
| Architecture | Monolithic advisory engine with integrated reasoning modules | Microservices-based modular agents |
| Scalability | Scaled mainly vertically with policy complexity | Horizontally scalable agent instances |
| Communication | Coordinates inter-agent messaging and synchronization | Communicates via APIs and message brokers |
| Fault Tolerance | Monitors and handles systemic faults | Isolates agent-level failures |
| Learning | Continuous policy refinement based on telemetry | Operates based on predefined algorithms and real-time data |
This layered model of AI agent infrastructure is particularly effective for complex applications that require both high-level strategic control and robust, scalable execution. It represents a best practice for overcoming the emerging infrastructure bottlenecks by clearly delineating responsibilities and optimizing each layer for its specific function.
As we continue, the next crucial facet of AI agent infrastructure involves caching strategies. Effective caching minimizes redundant computations, reduces latency, and conserves compute resources—key factors in achieving operational excellence. GitHub’s reported 94% cache hit rate provides valuable insights
Understanding how production-grade AI agents are architected requires examining real implementations. The architecture behind OpenAI Codex, including its sandboxing approach and real-world agent workflows, provides a concrete reference implementation for the infrastructure patterns discussed in this guide.
into how advanced caching can transform AI systems. We will explore these strategies in detail in the subsequent parts of this guide.
From Intelligence Bottlenecks to Infrastructure Bottlenecks: Navigating the Paradigm Shift
In the formative years of AI agent development, the primary challenges revolved around intelligence bottlenecks. These bottlenecks stemmed from limitations in model architectures, training data scarcity, and computational power. However, as foundational models have evolved exponentially, achieving unprecedented levels of cognitive capability and contextual understanding, the bottleneck has shifted from intelligence itself to the underlying infrastructure that supports these agents.
Understanding the Transition
The early AI landscape focused heavily on improving algorithmic intelligence—making models smarter, faster, and more context-aware. However, as models like GPT-5 and beyond have demonstrated near-human levels of understanding and reasoning, the bottleneck transitioned. Today’s AI challenges are less about making models smarter and more about how to architect and scale the infrastructure that supports these intelligent agents effectively and efficiently.
This shift is driven by several critical factors:
- Model Scale and Complexity: State-of-the-art agents now incorporate trillions of parameters, multi-modal data inputs, and layered reasoning modules, requiring robust infrastructure to host and serve them at scale.
- Latency Sensitivity: Real-time decision-making environments demand ultra-low latency responses, placing stringent requirements on data pipelines, network architecture, and compute distribution.
- Multi-agent Coordination: Modern systems utilize ensembles or swarms of agents working in concert, necessitating sophisticated orchestration and communication layers.
- Data Bandwidth and Storage: Large-scale agents generate and consume vast quantities of data, challenging existing storage and caching mechanisms.
Key Infrastructure Bottlenecks Identified
| Bottleneck Category | Description | Impact on AI Agent Performance | Typical Mitigation Strategies |
|---|---|---|---|
| Compute Resource Saturation | Insufficient GPU/TPU availability and inefficient utilization. | Increased response latency; degraded throughput; failure to scale multi-agent deployments. | Dynamic provisioning; workload balancing; heterogeneous compute architectures. |
| Network Bandwidth Constraints | Limited inter-node bandwidth causing slow data transfer and synchronization delays. | Increases agent coordination latency; limits real-time multi-agent collaboration. | High-speed interconnects; data compression; edge caching. |
| Storage I/O Bottlenecks | Slow read/write speeds for large datasets and model checkpoints. | Delays in model loading, checkpointing, and data retrieval. | NVMe SSDs; tiered storage; intelligent caching (e.g., GitHub’s caching strategies). |
| Orchestration and Scheduling Complexity | Challenges in managing dependencies and resource allocation among multiple agents. | Underutilized resources; increased task queuing times; degraded system reliability. | Kubernetes, custom schedulers; priority queues; predictive scaling. |
Infrastructure Bottlenecks: Why They Matter More Than Ever
Because AI agents increasingly serve as integral components in critical applications—autonomous vehicles, real-time financial analytics, personalized healthcare—any infrastructural delays or failures can cascade into significant operational risks. Moreover, as organizations deploy large-scale multi-agent systems, the ability to maintain consistent performance across heterogeneous and distributed environments becomes paramount.
Addressing these bottlenecks requires a holistic approach combining hardware innovation, software orchestration, and novel system design patterns. This includes embracing edge and cloud hybrid models, investing in faster interconnects (such as NVLink and Infiniband), and leveraging AI-native infrastructure management tools capable of predictive resource allocation.
For more on system orchestration and scheduling in AI agent environments, see
The infrastructure patterns described in this guide are already being deployed at scale across industries. Our collection of enterprise AI automation case studies from 2026 documents how organizations have implemented these exact caching, routing, and orchestration strategies to achieve measurable operational improvements.
.
The Advisor Strategy: Haiku and Opus – Architecting Collaborative AI Agent Frameworks
As the complexity of AI agents grows, a single monolithic model often becomes insufficient. The Advisor Strategy, prominently exemplified by frameworks such as Haiku and Opus, offers a modular, collaborative approach that leverages multiple specialized agents working in synergy to augment decision-making and problem-solving capabilities.
What is the Advisor Strategy?
The Advisor Strategy involves deploying a core “primary” AI agent that consults multiple “advisor” agents, each specializing in discrete domains or functions. This architecture enhances robustness, interpretability, and adaptability by breaking down complex tasks into manageable sub-tasks handled by domain-specific advisors.
Haiku: The Core Framework
Haiku acts as the central orchestrator in this architecture, managing communication, consensus-building, and decision integration among advisor agents. Key features include:
- Contextual Query Routing: Haiku intelligently routes sub-queries to advisors based on their expertise, optimizing response relevance and speed.
- Adaptive Weighting: Utilizing reinforcement learning, Haiku dynamically adjusts the influence of each advisor’s input based on historical accuracy and current context.
- Explainability Module: Generates interpretable summaries of how advisor inputs contributed to the final decision, enhancing transparency.
Opus: Specialized Advisor Agents
Opus represents the family of specialized advisor agents within this framework. Each Opus advisor is trained on domain-specific datasets or equipped with unique capabilities:
- Technical Advisor: Handles complex programming and algorithmic queries, adept at code synthesis and debugging.
- Compliance Advisor: Ensures outputs adhere to regulatory and ethical standards.
- Data Advisor: Focuses on data integrity, anomaly detection, and pre-processing recommendations.
- Creative Advisor: Provides generative suggestions for creative tasks such as design, writing, or ideation.
Operational Workflow
| Step | Description | Haiku Role | Opus Advisor Role |
|---|---|---|---|
| 1. Input Reception | User submits a complex multi-domain query. | Receives and parses query, identifying sub-domains. | NA |
| 2. Sub-query Dispatch | Distributed sub-queries sent to relevant advisors. | Routes and manages query flow. | Processes specific sub-queries within domain. |
| 3. Response Aggregation | Collects advisor outputs. | Integrates and weighs inputs for consensus. | Generates domain-specific output. |
| 4. Final Synthesis | Combines all inputs into cohesive response. | Produces final user response with explainability. | NA |
Advantages of the Advisor Strategy
- Scalability: Modular design enables seamless integration of new advisors without retraining the entire system.
- Specialization: Advisors can evolve independently, allowing rapid domain-specific enhancements.
- Robustness: Redundant and complementary advisor inputs reduce single points of failure.
- Improved Explainability: Clear attribution of decisions to advisor inputs fosters trust and compliance.
Implementation Considerations
Deploying the Haiku + Opus framework requires thoughtful infrastructure design to handle multi-agent orchestration efficiently:
- Low-Latency Messaging: High-throughput, low-latency communication protocols (e.g., gRPC, ZeroMQ) are critical for real-time advisor exchanges.
- Scalable Orchestration: Kubernetes operators or custom orchestrators manage the dynamic scaling of advisor pods based on workload.
- State Synchronization: Shared context stores (such as Redis or distributed key-value stores) ensure consistent state across agents.
- Security and Isolation: Advisors handling sensitive data require sandboxing and strict access controls.
For a deeper dive into multi-agent communication protocols and orchestration tools, refer to
The infrastructure demands of AI coding assistants have driven much of the innovation in agent architecture. Our analysis of how AI coding assistants evolved throughout 2026 traces the direct relationship between model capability improvements and the infrastructure investments required to support them at scale.
.
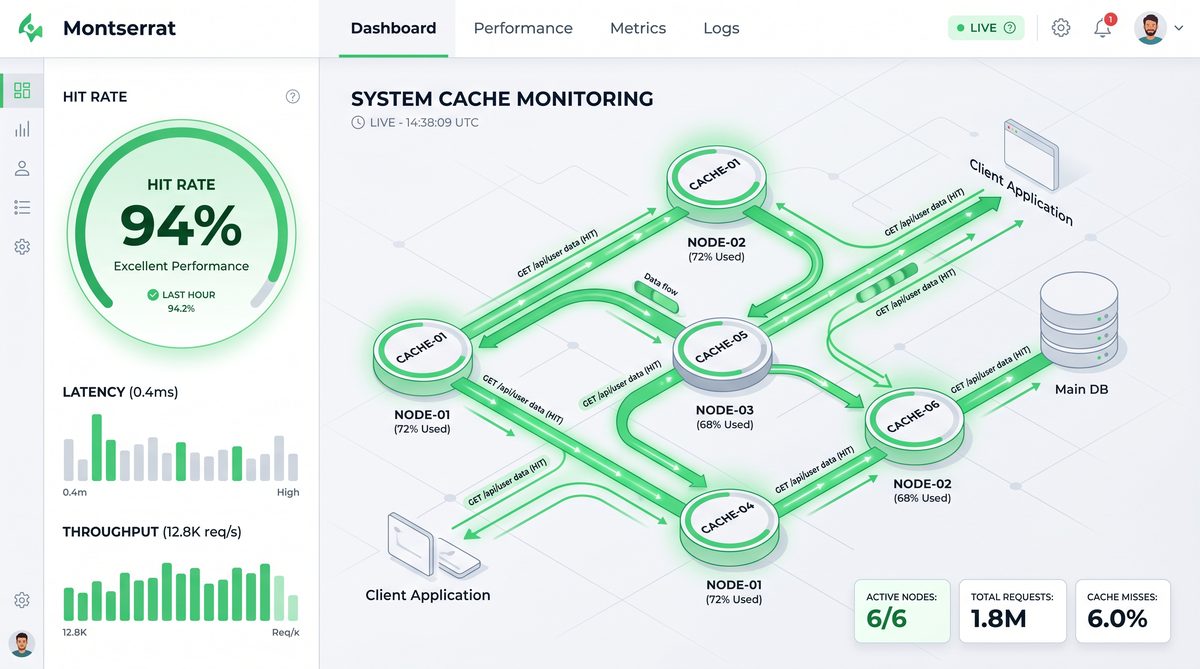
Caching Strategies for AI Agents: Lessons from GitHub’s 94% Hit Rate
Effective caching is a cornerstone of scalable AI agent infrastructure. GitHub’s recent achievement of a 94% cache hit rate in their AI-assisted code completion system exemplifies the power of advanced caching mechanisms in reducing latency, lowering compute costs, and improving user experience.
Why Caching Matters in AI Agent Infrastructure
AI agents frequently perform repetitive or similar computations, such as answering common queries, generating code snippets, or retrieving knowledge base entries. Without caching, these repetitive tasks cause unnecessary compute overhead, longer response times, and wasted bandwidth.
Proper caching leverages temporal and spatial locality, ensuring that previously computed results are reused when appropriate. This is especially critical in multi-agent systems where overlapping information needs arise across advisors and user interactions.
GitHub’s Caching Architecture Overview
GitHub’s caching strategy for their AI-powered code assistant consists of multiple layers designed to maximize hit rates and minimize latency:
- Client-Side Cache: Lightweight caches embedded within the IDE to store recent completions and suggestions.
- Edge Cache: Distributed caching nodes geographically close to end-users, reducing network round trips.
- Centralized Persistent Cache: A high-throughput backend cache storing precomputed embeddings, prompt templates, and partial inference results.
- Adaptive Cache Invalidation: Mechanisms to invalidate stale cache entries based on codebase changes or evolving user preferences.
Key Techniques for Achieving High Cache Hit Rates
| Technique | Description | Benefits | Challenges |
|---|---|---|---|
| Semantic Hashing | Generating hash keys based on semantic similarity rather than exact text matching. | Improves cache hits for paraphrased or similar queries; reduces false misses. | Requires sophisticated similarity functions; increased computational overhead. |
| Partial Response Caching | Caching intermediate computations such as token embeddings or partial decoder states. | Speeds up incremental generation; reduces full recomputation. | Complex cache management; increased storage requirements. |
| Context Window Segmentation | Segmenting input contexts to cache reusable segments independently. | Enables reusing common context fragments; reduces input processing time. | Requires advanced context modeling; possible cache fragmentation. |
| Adaptive Eviction Policies | Dynamic cache eviction based on usage patterns, relevance, and recency. | Optimizes cache resource utilization; keeps cache fresh. | Needs continuous monitoring; risk of evicting valuable entries. |
Implementing Caching in AI Agent Pipelines
Integrating caching effectively requires a multi-pronged approach:
- Identify Repetitive Workloads: Profile agent workloads to find opportunities where caching yields the most benefit.
- Design Cache Keys Thoughtfully: Keys should capture semantic intent and context to maximize hit rates.
- Leverage Distributed Caches: Use distributed caching systems such as Redis, Memcached, or custom-built solutions to scale horizontally.
- Ensure Cache Consistency: Implement robust invalidation and update mechanisms to maintain cache correctness.
- Monitor Cache Metrics: Continuously track hit/miss ratios, latency improvements, and resource savings to guide tuning.
Case Study: GitHub Copilot Caching Insights
GitHub’s AI assistant, Copilot, handles millions of code completion requests daily. Achieving a 94% cache hit rate translated to significant latency reductions and compute cost savings. Their strategy emphasized:
- Precomputing Embeddings: Frequently used code patterns were embedded and cached to avoid repeated model inference.
- Context-aware Suggestions: The system segmented code files and cached suggestions for reusable code blocks.
- Incremental Updates: As developers edited code, only affected cache segments were invalidated and refreshed.
These approaches underscore the importance of intelligent caching in modern AI infrastructure, especially as agents become more interactive and context-sensitive.
To explore caching strategies optimized for multi-agent environments and distributed systems, consult .
Access 40,000+ AI Prompts for ChatGPT, Claude & Codex — Free!
Subscribe to get instant access to our complete Notion Prompt Library — the largest curated collection of prompts for ChatGPT, Claude, OpenAI Codex, and other leading AI models. Optimized for real-world workflows across coding, research, content creation, and business.
Useful Links
- Arxiv: Scaling Laws for Neural Language Models
- Kubernetes – Container Orchestration System
- Redis Caching Strategies and Best Practices
- GitHub Blog: How Copilot Uses Caching
- OSDI 2020: Resource Management for AI Workloads
- OpenAI Research on Multi-agent Systems
- Microsoft Azure Caching Patterns
- IBM Developer: Architecting AI Infrastructure for Scale