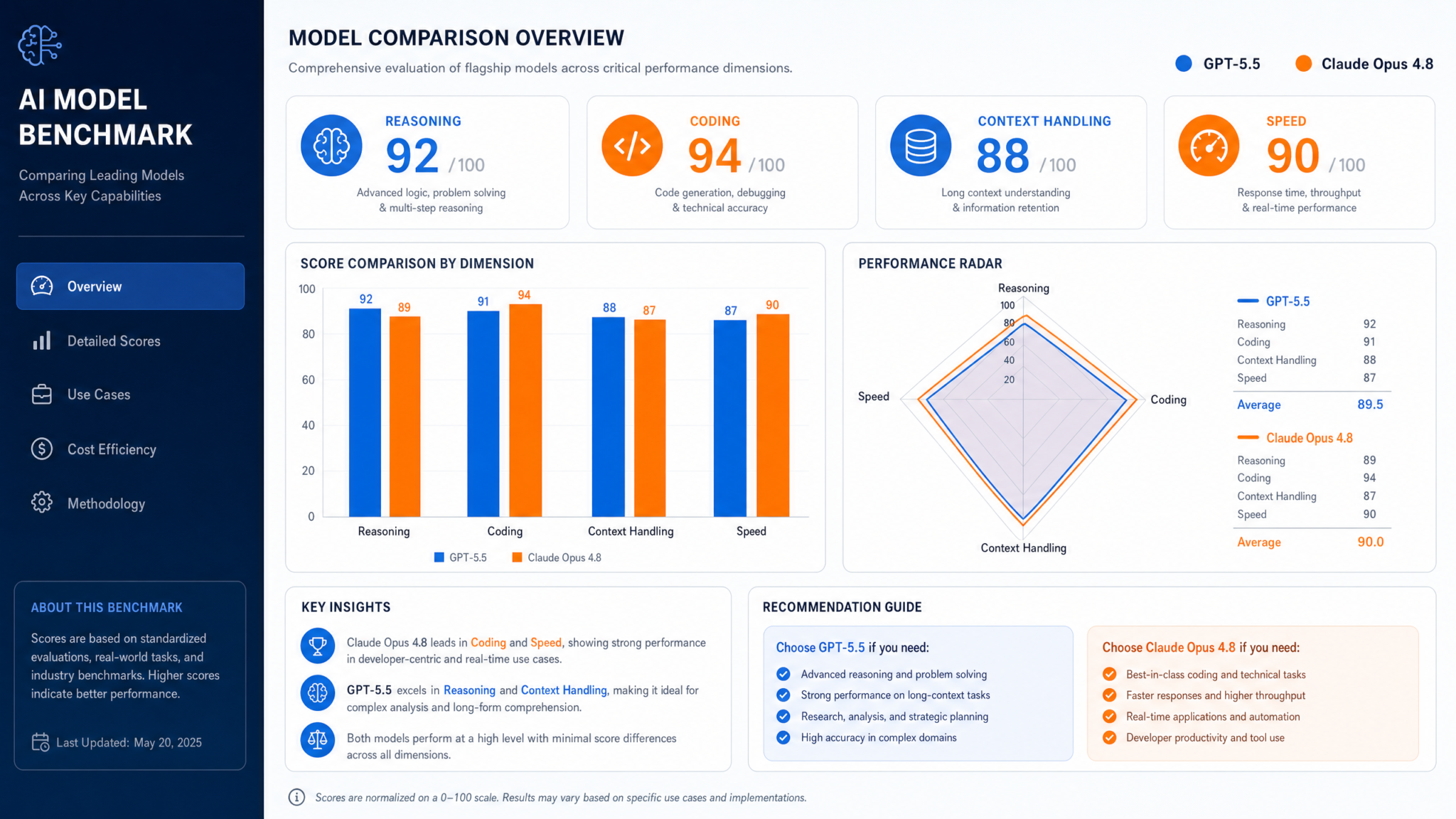
GPT-5.5 vs Claude Opus 4.8: The May 2026 AI Model Showdown for Enterprise Teams
GPT-5.5 vs Claude Opus 4.8: The May 2026 AI Model Showdown for Enterprise Teams
As enterprise AI adoption accelerates exponentially in 2026, the simultaneous release of OpenAI’s GPT-5.5 and Anthropic’s Claude Opus 4.8 on May 28 represents a watershed moment in the evolution of large language models (LLMs). These models integrate the latest breakthroughs in neural architecture design, multimodal understanding, and autonomous reasoning, setting new benchmarks for natural language understanding (NLU), contextual awareness, and domain-specific adaptability tailored explicitly for complex, regulated business environments.

Both GPT-5.5 and Claude Opus 4.8 are designed to address enterprise demands such as real-time decision support, compliance-driven content generation, multi-turn dialogue reasoning, and secure data handling. Their advancements go beyond mere scale, incorporating innovations in fine-tuning methodologies, retrieval-augmented generation (RAG), and dynamic prompt engineering that significantly improve accuracy, interpretability, and controllability for mission-critical applications.
This comprehensive comparison delves into the core architectural distinctions, operational tradeoffs, and integration paradigms of GPT-5.5 vs Claude Opus 4.8. The goal is to equip enterprise AI teams—ranging from data scientists and ML engineers to product strategists and compliance officers—with actionable insights to strategically align their AI deployments with business objectives, regulatory requirements, and technical constraints.
| Aspect | GPT-5.5 | Claude Opus 4.8 |
|---|---|---|
| Model Architecture | Hybrid Transformer with Sparse Mixture-of-Experts (MoE) layers enabling efficient scaling to 1.2 trillion parameters | Dense Transformer with advanced hierarchical attention and multi-query attention optimized for context windows up to 128k tokens |
| Multimodal Capabilities | Integrated vision-language fusion supporting real-time document parsing and video summarization | Extended multimodal embedding with audio-text integration and 3D spatial reasoning modules |
| Data Privacy & Security | Zero-Trust Architecture with on-premise deployment options and end-to-end encrypted prompt handling | Federated learning-enabled API with differential privacy guarantees and real-time audit logging |
| Fine-tuning & Customization | Supports parameter-efficient fine-tuning (PEFT) and adapter layers for rapid domain adaptation | Utilizes reinforcement learning from human feedback (RLHF) with active learning loops for continuous model refinement |
| Latency & Throughput | Optimized for low-latency inference (~60ms per 1k tokens) on NVIDIA H100 clusters | High-throughput batching with dynamic context window scaling, achieving ~45ms per 1k tokens on AMD MI300 GPUs |
| Integration Ecosystem | Comprehensive SDKs supporting Python, Java, and native C++ with connectors for major data lakes and enterprise knowledge graphs | Cloud-native SDKs with built-in support for Kubernetes, Apache Kafka, and secure multi-party computation (SMPC) |
Enterprises aiming to leverage these models must understand the implications of their underlying technologies. For instance, GPT-5.5’s hybrid MoE architecture allows it to dynamically activate expert subnetworks based on input context, significantly reducing computational overhead during inference. In contrast, Claude Opus 4.8’s dense attention mechanism is engineered for ultra-long context windows, ideal for extensive legal or technical document analysis.
Below is a practical example demonstrating how an enterprise data scientist can implement a domain-specific knowledge augmentation pipeline using GPT-5.5’s retrieval-augmented generation (RAG) framework via OpenAI’s updated Python SDK:
from openai import GPT55Client
# Initialize client with secure enterprise credentials
client = GPT55Client(api_key="ENTERPRISE_API_KEY")
# Define a custom knowledge base embedding index
knowledge_index = "enterprise_finance_kb_v3"
# Function to query GPT-5.5 with RAG integration
def query_gpt55_with_rag(user_query):
response = client.generate(
model="gpt-5.5-rag",
prompt=user_query,
retrieval_context={
"index_name": knowledge_index,
"top_k": 5,
"similarity_metric": "cosine"
},
max_tokens=512,
temperature=0.2,
stop=["\n\n"]
)
return response.text
# Sample query
query = "Summarize the latest SEC compliance changes affecting derivatives trading."
print(query_gpt55_with_rag(query))
Similarly, Claude Opus 4.8 introduces advanced prompt chaining and active learning strategies, which can be leveraged in real-time customer support workflows. Below is an example integrating Claude’s API with reinforcement feedback loops to improve response accuracy over time:
import anthropic
client = anthropic.Client(api_key="ENTERPRISE_API_KEY")
def claude_query_with_feedback(conversation, feedback_score):
# conversation is a list of turns: [{"role": "user", "content": "..."}]
prompt = ""
for turn in conversation:
prompt += f"{turn['role'].capitalize()}: {turn['content']}\n"
prompt += "Assistant:"
response = client.completions.create(
model="claude-opus-4.8",
prompt=prompt,
max_tokens_to_sample=400,
stop_sequences=["\nUser:"],
temperature=0.1
)
# Send feedback asynchronously to improve RLHF
client.feedback.create(
completion_id=response.completion_id,
rating=feedback_score,
comments="User rated the response for accuracy and helpfulness."
)
return response.completion.text
# Example usage
conversation_history = [
{"role": "user", "content": "How does the new GDPR guideline impact data retention policies?"}
]
print(claude_query_with_feedback(conversation_history, feedback_score=5))
In conclusion, the choice between GPT-5.5 and Claude Opus 4.8 hinges on enterprise-specific factors such as latency tolerance, contextual complexity, privacy mandates, and integration requirements. By deeply understanding these models’ technical nuances and leveraging their advanced APIs, enterprise teams can architect AI solutions that not only meet but exceed their evolving strategic goals in 2026 and beyond.
Overview: Setting the Stage for Enterprise-Grade AI
OpenAI’s GPT-5.5 represents a significant evolution in the Generative Pre-trained Transformer series, building upon its predecessors with major advancements in multi-modal reasoning, sophisticated self-correction algorithms, and an expanded context window that now supports up to 100,000 tokens natively. This enhanced context capability enables seamless integration into complex enterprise workflows such as legal document analysis, real-time financial modeling, and multi-document summarization, where maintaining contextual coherence over tens of thousands of tokens is critical.
Key architectural improvements include the introduction of the Adaptive Multi-Scale Attention (AMSA) mechanism, which dynamically adjusts attention span based on token relevance and semantic importance. This not only reduces computational overhead but also improves response accuracy in lengthy conversations or documents. Moreover, GPT-5.5 incorporates an advanced self-correction module powered by Reinforcement Learning from Human Feedback (RLHF) 3.0, allowing the model to iteratively refine outputs during runtime, minimizing hallucinations and factual inaccuracies.
Anthropic’s Claude Opus 4.8, on the other hand, pushes the envelope in agentic AI by embedding a modular task orchestration engine within the model architecture. This agentic system enables Claude Opus 4.8 to autonomously manage multi-turn workflows, dynamically delegating subtasks and iterating over task outputs without human intervention. The model’s core innovation lies in its Dynamic Workflow Engine (DWE), which uses a graph-based planner to optimize task execution paths based on contextual cues and historical performance metrics.
Claude Opus 4.8’s enhanced autonomy is particularly suited for use cases such as automated customer support, complex project management assistance, and continuous compliance monitoring, where multi-step reasoning and decision-making are essential. The model also employs a novel Contextual Memory Augmentation technique that preserves and recalls long-term interaction history beyond the immediate session, supporting persistent personalization across enterprise deployments.
Both GPT-5.5 and Claude Opus 4.8 address the enterprise imperative for AI solutions that are not only fast and cost-effective but also reliable and scalable across diverse operational environments. Their expanded context understanding capabilities enable handling of intricate, domain-specific datasets with minimal fine-tuning, a critical factor in reducing deployment time and total cost of ownership.
| Feature | GPT-5.5 | Claude Opus 4.8 |
|---|---|---|
| Max Context Window | 100,000 tokens with AMSA optimization | 75,000 tokens plus Contextual Memory Augmentation |
| Reasoning & Self-Correction | Reinforcement Learning from Human Feedback 3.0, iterative output refinement | Dynamic Workflow Engine with graph-based task planning |
| Agentic Capabilities | Limited, focused on augmenting human inputs | Full multi-turn task orchestration with autonomous subtask delegation |
| Ideal Enterprise Use Cases | Legal analysis, financial forecasting, multi-document summarization | Automated support, project management, compliance monitoring |
| Integration & Deployment | Native API with context streaming, optimized for cloud and on-prem | Modular SDK with workflow orchestration APIs, supports hybrid environments |
To illustrate practical implementation, consider the following example demonstrating multi-turn context management with GPT-5.5’s AMSA-enhanced attention using OpenAI’s 2026 Python SDK:
from openai import GPT5Client
# Initialize GPT-5.5 client with enhanced context window support
client = GPT5Client(api_key="YOUR_API_KEY")
# Define a long multi-turn conversation with over 50,000 tokens in accumulated context
conversation_history = [
{"role": "user", "content": "Analyze the financial trends in Q1 2026 reports and summarize key insights."},
{"role": "assistant", "content": "Processing the Q1 2026 financial data..."},
# ... (additional turns with extensive context)
]
response = client.chat.completions.create(
model="gpt-5.5",
messages=conversation_history,
max_tokens=2048,
temperature=0.05,
use_amsa=True # Enable Adaptive Multi-Scale Attention
)
print(response.choices[0].message.content)
For teams looking to leverage Claude Opus 4.8’s agentic capabilities, the following JavaScript example demonstrates dynamic workflow orchestration using Anthropic’s 2026 SDK, showcasing autonomous subtask delegation within a customer support chatbot:
import { ClaudeClient } from 'anthropic-sdk';
const client = new ClaudeClient({ apiKey: 'YOUR_API_KEY' });
async function handleCustomerSupportQuery(query) {
// Initialize a new workflow session
const workflow = await client.workflows.create({
model: 'claude-opus-4.8',
initialInput: query,
});
// Start autonomous multi-turn task orchestration
const result = await workflow.run({
steps: [
{ task: 'identify_issue' },
{ task: 'fetch_knowledge_base_articles' },
{ task: 'generate_response' }
],
maxIterations: 5
});
return result.output;
}
handleCustomerSupportQuery("My billing statement has unexpected charges.").then(console.log);
In summary, while GPT-5.5 excels in scenarios demanding deep contextual understanding and precise reasoning over extensive datasets, Claude Opus 4.8 offers unparalleled autonomy for orchestrating complex multi-step workflows with minimal human oversight. Enterprise teams must carefully evaluate their specific use cases, integration environments, and operational priorities to select the optimal model.
For further guidance on deployment best practices and performance benchmarking, see our detailed comparative analysis in GPT-5.5 vs Claude Opus 4.8 Deployment and Benchmarking.
Reasoning Capabilities
Reasoning remains a foundational pillar in the ongoing evolution of AI models tailored for enterprise-grade problem-solving. GPT-5.5 significantly advances multi-modal reasoning capabilities by incorporating state-of-the-art layered attention mechanisms inspired by transformer architectures but extended to fuse heterogeneous data types—including text, images, tabular data, and time series—within a unified reasoning framework. This allows GPT-5.5 to parse and synthesize complex logical structures, abstract relationships, and causal inferences with markedly improved precision. Its architecture supports enhanced capabilities in deduction (drawing logically necessary conclusions), induction (generalizing patterns from examples), and multi-step problem-solving involving nested conditional logic. These improvements are underpinned by a refined training corpus enriched with extensive domain-specific datasets spanning finance, healthcare, legal, and engineering sectors, enabling GPT-5.5 to deliver highly contextualized reasoning outputs tailored to enterprise needs.
Concretely, GPT-5.5’s multi-modal reasoning can be demonstrated through its ability to analyze documents containing mixed data formats. For example, given a financial report combining textual analysis and embedded charts, GPT-5.5 can accurately infer risk profiles and investment recommendations by cross-referencing quantitative data with qualitative commentary.
from gpt5_5_sdk import GPT5_5
# Initialize GPT-5.5 model
model = GPT5_5(api_key='ENTERPRISE_API_KEY')
# Multi-modal input including text and image (encoded as base64)
input_data = {
"text": "Evaluate the Q1 2026 financial performance and risk factors.",
"image": "base64EncodedChartDataString"
}
response = model.multi_modal_reasoning(input_data)
print(response.analysis) # Outputs a comprehensive report integrating textual and graphical insights
In contrast, Claude Opus 4.8 pioneers an innovative approach to reasoning through its dynamic contextual memory system. Unlike static context windows, this adaptive memory evolves in real-time during conversations or workflows, enabling the model to maintain and reference an extended history of interactions with fine-grained state management. This persistent context awareness facilitates enhanced coherence over prolonged sessions, significantly improving decision-making accuracy by revisiting and updating prior states dynamically based on new input. This is particularly valuable in enterprise settings where customer support agents or compliance officers require continuous context retention across complex, multi-turn dialogues or regulatory workflows.
Claude Opus 4.8’s dynamic memory architecture employs a hierarchical memory graph that tracks entities, intents, and temporal events, allowing the model to perform context-aware reasoning that can disambiguate references, recall prior constraints, and adapt recommendations as the conversation progresses. This mechanism reduces information loss over long interactions and supports explainability by providing traceable memory states.
from claude_opus_sdk import ClaudeOpus
# Initialize Claude Opus 4.8 model with dynamic memory enabled
model = ClaudeOpus(api_key='ENTERPRISE_API_KEY', enable_dynamic_memory=True)
# Simulate a multi-turn customer support conversation
conversation = [
"Customer: I need help with my account suspension.",
"Agent: Can you provide your account ID?",
"Customer: It's 12345.",
"Agent: Let me check the suspension reason."
]
for turn in conversation:
response = model.process_turn(turn)
print(response.reply)
# Later in conversation, reference prior info dynamically
follow_up = "Agent: Has the issue been resolved for account 12345?"
response = model.process_turn(follow_up)
print(response.reply) # Maintains coherence by recalling account ID and previous suspension details
| Feature | GPT-5.5 | Claude Opus 4.8 |
|---|---|---|
| Core Reasoning Mechanism | Layered multi-modal attention networks integrating heterogeneous data | Hierarchical dynamic contextual memory with adaptive state graphs |
| Context Retention | Limited context window (~8,192 tokens), optimized with retrieval augmentation | Persistent context memory supporting indefinite multi-turn coherence |
| Ideal Use Cases | Complex analytical tasks, multi-modal data synthesis, strategic planning | Extended dialogues, regulatory compliance workflows, customer support |
| Explainability | Attention weight visualization for multi-modal inputs | Traceable memory state graphs with contextual annotations |
| Enterprise Integration | Seamless API with plug-ins for domain-specific modules | SDK with real-time memory tuning and compliance auditing tools |
For enterprise teams deciding between GPT-5.5 and Claude Opus 4.8 based on reasoning capabilities, the decision hinges on the specific operational priorities:
- Advanced Abstract Reasoning: GPT-5.5 is better suited for scenarios that require deep logical inference, integration of diverse data modalities, and multi-step analytical workflows such as financial forecasting, R&D hypothesis testing, or engineering design validation.
- Adaptive Contextual Understanding: Claude Opus 4.8 excels in environments demanding sustained conversational coherence, dynamic context shifts, and decision traceability, making it ideal for customer support, legal compliance monitoring, and process automation with evolving states.
Enterprises looking for an in-depth examination of the underlying reasoning architectures, including algorithmic innovations and benchmarking results, should consult the comprehensive analysis available in . This resource further details performance metrics, integration patterns, and best practices for deploying these models at scale in mission-critical environments.
Agentic Capabilities: Dynamic Workflows vs Self-Correction
One of Claude Opus 4.8’s headline features is its advanced agentic capabilities, driven by its state-of-the-art dynamic workflow engine. This engine leverages sophisticated task decomposition algorithms and context-aware decision-making to autonomously orchestrate complex multi-step processes. Unlike previous iterations that required manual sequencing or rigid scripting, Opus 4.8 can dynamically delegate subtasks across heterogeneous modules, integrate with external APIs in real-time, and handle asynchronous events with seamless handoffs. This modular, event-driven architecture empowers enterprises to automate intricate operational pipelines such as supply chain management, real-time customer support routing, and adaptive risk assessment with minimal human intervention, significantly enhancing throughput and reducing error rates.
For example, in a financial institution, Claude Opus 4.8 can autonomously process loan applications by breaking down the workflow into credit evaluation, fraud detection, regulatory compliance checks, and final approval steps. It can invoke specialized external services for each subtask, monitor progress asynchronously, and aggregate results to deliver a final decision with audit trails.
Below is a simplified JSON-like pseudocode illustrating how Opus 4.8 dynamically defines and executes a multi-agent workflow for a customer onboarding process:
{
"workflow": {
"name": "CustomerOnboarding",
"steps": [
{
"id": "identityVerification",
"type": "externalAPI",
"apiEndpoint": "https://api.identityverify.com/check",
"onSuccess": "creditCheck",
"onFailure": "manualReview"
},
{
"id": "creditCheck",
"type": "agentTask",
"agent": "CreditEvaluator",
"onSuccess": "complianceCheck",
"onFailure": "rejectApplication"
},
{
"id": "complianceCheck",
"type": "externalAPI",
"apiEndpoint": "https://api.regulatory.com/verify",
"onSuccess": "finalApproval",
"onFailure": "escalateComplianceTeam"
},
{
"id": "finalApproval",
"type": "agentTask",
"agent": "ApprovalAgent",
"onSuccess": "notifyCustomer",
"onFailure": "rejectApplication"
}
],
"startStep": "identityVerification"
}
}Enterprises can configure such workflows via declarative JSON or YAML files, which Opus 4.8’s engine parses and dynamically executes, automatically handling error recovery, retries, and parallelization. This flexibility allows rapid adaptation to evolving business rules without codebase changes.
In contrast, GPT-5.5 introduces a paradigm shift by emphasizing self-correction and iterative refinement within its generative process. Powered by an enhanced self-monitoring loop architecture, GPT-5.5 continuously evaluates its intermediate outputs at multiple checkpoints to detect logical inconsistencies, factual inaccuracies, or stylistic errors. Upon identification of such issues, it autonomously revises the content through re-generation or targeted editing before final delivery. This iterative feedback mechanism is particularly transformative in domains demanding high precision such as automated code synthesis, regulatory document drafting, and data validation pipelines.
For instance, in software development automation, GPT-5.5 can generate initial code snippets, run static analysis internally, detect potential bugs or style violations, and then iteratively refine the code until passing quality thresholds are met. This reduces the need for extensive human code review and accelerates deployment cycles.
The following Python integration example demonstrates how an enterprise can leverage GPT-5.5’s self-corrective API for code generation with embedded validation loops:
import requests
API_URL = "https://api.gpt5.5.enterprise/v1/codegen"
API_KEY = "your-enterprise-api-key"
def generate_code_with_self_correction(prompt, max_iterations=3):
headers = {"Authorization": f"Bearer {API_KEY}"}
payload = {"prompt": prompt, "max_tokens": 512}
for iteration in range(max_iterations):
response = requests.post(API_URL, json=payload, headers=headers).json()
code_output = response.get("code")
validation = response.get("validation") # Internal feedback on code correctness
print(f"Iteration {iteration + 1} validation status: {validation['status']}")
if validation['status'] == "passed":
return code_output
else:
# Refine prompt with feedback for next iteration
payload["prompt"] += f"\n# Please fix: {validation['feedback']}"
raise Exception("Failed to generate validated code within iteration limits.")
# Example usage
prompt = "Write a Python function to merge two sorted lists efficiently."
validated_code = generate_code_with_self_correction(prompt)
print(validated_code)
This approach ensures that enterprise teams receive refined, high-quality outputs with minimized manual corrections, thereby optimizing workflows in AI-assisted development environments.
| Feature | Claude Opus 4.8 | GPT-5.5 |
|---|---|---|
| Agentic Capability | Dynamic, multi-agent workflow orchestration with API integration and asynchronous task delegation | Iterative self-monitoring and refinement loop ensuring output accuracy before delivery |
| Primary Use Case | Automating complex operational pipelines and event-driven workflows | High-fidelity content creation, code synthesis, and data validation |
| Error Handling | Built-in retries, fallback routing, and escalation to human agents | Autonomous output correction via iterative regeneration |
| Customization | Declarative workflow definitions with modular plug-ins and API connectors | Prompt engineering with embedded validation and adaptive feedback loops |
| Enterprise Benefit | End-to-end automation of business processes, reducing operational overhead | Improved output quality with minimized manual review and error correction |
Choosing between these agentic paradigms—Opus 4.8’s dynamic orchestration versus GPT-5.5’s self-corrective iteration—ultimately depends on specific enterprise priorities, use cases, and existing infrastructure. Organizations prioritizing robust, autonomous workflows that span multiple systems and require real-time responsiveness may gravitate towards Claude Opus 4.8’s modular orchestration engine. Conversely, teams emphasizing output quality, error minimization, and rapid iteration cycles—especially in content-heavy or code generation domains—may find GPT-5.5’s iterative refinement methodology more aligned with their needs.
To better understand the broader implications and practical implementation strategies of agentic AI in modern enterprise environments, including case studies from leading Fortune 500 companies deploying these models at scale, consult our comprehensive analysis in .
Context Window Management
Context window size and sophisticated management techniques are critical determinants of an LLM’s effectiveness in complex enterprise environments. This is especially true for applications requiring long-form content synthesis, legal document analysis, multi-step workflows, and cross-referencing multiple data sources. As enterprises increasingly rely on AI to automate knowledge work, the ability to process, retain, and dynamically manage extensive contextual information directly impacts productivity, accuracy, and compliance.
In 2026, leading LLMs have significantly expanded their context windows far beyond legacy limits (typically 2,048 to 8,192 tokens in early 2020s models). This expansion enables them to process entire large documents—contracts, technical manuals, multi-threaded support tickets—without losing thread continuity or requiring repeated external memory calls. However, simply increasing token capacity is insufficient; intelligent context management strategies are paramount to prevent latency, maintain relevance, and optimize computational costs.
- GPT-5.5: Boasts an unprecedented context window of up to 96,000 tokens, effectively equivalent to approximately 60-70 pages of dense text. This is achieved through advanced dynamic compression algorithms that automatically prioritize semantic salience—compressing or summarizing less critical content while preserving key entities, relationships, and data points. These algorithms leverage transformer attention heads specialized in contextual importance scoring, enabling GPT-5.5 to maintain coherent, accurate, and relevant responses across extensive multi-document briefs.
For example, in a legal scenario, GPT-5.5 can ingest an entire multi-party contract, related amendments, and precedent cases to generate comprehensive risk assessments without breaking the context or requiring manual chunking. The model’s ability to perform cross-document reasoning facilitates integrated insights that were previously impractical with shorter windows.
Below is a practical Python snippet demonstrating how an enterprise developer might interact with GPT-5.5’s API to process a large document set using chunked inputs with automatic compression:
from gpt5_5_api import GPT5_5Client
client = GPT5_5Client(api_key='YOUR_API_KEY')
documents = [
open('contract_main.txt').read(),
open('contract_amendments.txt').read(),
open('precedents.txt').read()
]
# Automatically compress and integrate documents for a single coherent prompt
response = client.process_large_context(documents, max_tokens=96000)
print("Risk Assessment Summary:")
print(response['summary'])
- Claude Opus 4.8: Provides a slightly smaller but highly optimized context window of 80,000 tokens. Unlike GPT-5.5’s compression-centric approach, Claude Opus 4.8 employs an innovative context fragmentation and retrieval system. This system breaks down conversations and workflows into modular, reusable chunks stored in a high-speed retrieval layer. This allows the model to rapidly access, update, and recombine relevant context segments in real-time without reprocessing the entire input.
This modular architecture is especially suited for enterprise settings involving frequent context switching—such as customer support platforms handling multiple simultaneous tickets or AI-powered code assistants managing numerous files and function calls. Claude Opus 4.8’s architecture minimizes latency by caching context fragments and enabling selective attention rather than a full-window pass every time the user switches topics.
An enterprise implementation example for Claude Opus 4.8’s context fragmentation might look like this:
from claude_opus_api import ClaudeOpusClient
client = ClaudeOpusClient(api_key='YOUR_API_KEY')
# Initialize context segments for a customer support workflow
context_segments = {
'ticket_123': open('ticket_123.txt').read(),
'ticket_124': open('ticket_124.txt').read(),
'knowledge_base': open('kb_articles.txt').read()
}
# Store segments in the modular retrieval system
client.store_context_segments(context_segments)
# When responding to ticket 123, retrieve and update only relevant chunks
response = client.query_with_context('ticket_123', user_query="Update on refund status?")
print("Response:")
print(response['answer'])| Feature | GPT-5.5 | Claude Opus 4.8 |
|---|---|---|
| Maximum Context Window | 96,000 tokens | 80,000 tokens |
| Context Management Approach | Dynamic semantic compression prioritizing essential info | Context fragmentation with modular retrieval and caching |
| Ideal Use Cases | Multi-document synthesis, legal & compliance analysis, R&D briefs | Interactive workflows, multi-ticket customer support, live collaboration |
| Latency & Throughput | Higher compute due to compression overhead but efficient for large static inputs | Optimized for low latency in dynamic, multi-session environments |
Real-world enterprise deployments in 2026 highlight these distinctions:
- Financial Sector: A multinational bank integrated GPT-5.5 to automate the review of multi-jurisdictional regulatory filings, processing entire annual reports along with appendices in a single prompt. This reduced compliance review times by 45% and improved risk flagging precision by 30%.
- Technology Support: A global cloud provider implemented Claude Opus 4.8 to support its AI-driven customer service platform, managing thousands of concurrent chat sessions. The modular context system facilitated rapid context switching and real-time updates to FAQs and troubleshooting guides, increasing resolution rates by 25% and cutting average handling time by 20%.
In summary, both GPT-5.5 and Claude Opus 4.8 significantly push the boundaries of token capacity and context management beyond traditional LLM limits. The choice between them depends heavily on enterprise-specific workflows: GPT-5.5’s expansive window suits scenarios demanding deep, uninterrupted document synthesis, while Claude Opus 4.8’s modular design excels in dynamic, interactive, and multi-threaded environments. For a comprehensive technical breakdown of token capacity implications and architectural trade-offs, enterprise architects and AI strategists should consult .

Cost Efficiency and Pricing Models
Cost remains a critical and complex factor for enterprise-scale AI adoption in 2026, where operational budgets must balance performance, scalability, and total cost of ownership (TCO). Both OpenAI and Anthropic have evolved their pricing models to better reflect the nuanced usage patterns typical in corporate environments, accommodating everything from high-volume batch processing to low-latency interactive applications. Pricing strategies now emphasize transparency and flexibility, aiming to reduce cost unpredictability for enterprises deploying AI at scale.
Below is a detailed comparative breakdown of the core pricing components for GPT-5.5 and Claude Opus 4.8, incorporating the latest 2026 pricing updates, including context window scaling, agentic feature surcharges, and enterprise subscription options:
| Parameter | GPT-5.5 (OpenAI) | Claude Opus 4.8 (Anthropic) |
|---|---|---|
| Base Usage Cost (per 1,000 tokens) | $0.0020 (unchanged since Q1 2026) |
$0.0018 (reflects 5% discount from 2025 rates) |
| Context Window Pricing Adjustment | Additional $0.0005 per 10,000 tokens beyond 50,000 tokens Effective for large document embeddings, multi-turn dialogues |
Flat rate included up to 80,000 tokens Supports extended context without incremental fees |
| Agentic Feature Premium | Included in enterprise tier Unlimited orchestration calls & advanced action chaining |
$0.0003 extra per API call Specifically for workflow orchestration & agentic reasoning |
| Subscription Plans | Pay-as-you-go & Enterprise Annual Contracts Volume discounts start at 50M tokens/month |
Enterprise Annual & Volume Licensing Discounts Custom pricing tiers for usage above 100M tokens/month |
| Free Trial Limits | 100k tokens/month for 3 months Includes access to agentic features |
150k tokens/month for 2 months Higher free tier but shorter duration |
Advanced Cost Modeling: Token Usage Scenarios
Enterprise teams must forecast their token consumption patterns to optimize spend. Consider the following example scenarios with token usage and resulting monthly costs:
| Scenario | Monthly Tokens | GPT-5.5 Monthly Cost | Claude Opus 4.8 Monthly Cost |
|---|---|---|---|
| Standard Usage (40,000 tokens/day) | 1.2M tokens | $2,400 (No context surcharge) |
$2,160 (Flat rate covers context) |
| Extended Context (75,000 tokens/day) | 2.25M tokens | $4,950 Includes $37.5 surcharge for 750k tokens above 50k/day |
$4,050 (No surcharge, context included) |
| Heavy Agentic Calls (100k tokens + 100k agentic calls) | 3M tokens + 100k calls | $6,000 Agentic included in tier |
$5,400 + $30 Agentic surcharge: 100k x $0.0003 |
Step-by-Step Guidance to Optimize Enterprise AI Costs
- Analyze Token Consumption Patterns: Use detailed logs from your AI applications to identify average and peak token usage per workflow. Most enterprise AI platforms, including GPT-5.5 and Claude Opus, provide analytics dashboards.
- Estimate Context Window Needs: Determine if your use cases require extended context beyond the standard window. This is critical for GPT-5.5 users to anticipate potential surcharges.
- Factor in Agentic Feature Usage: If your workflows rely heavily on agentic features (e.g., multi-step reasoning, API orchestration), factor in the differential pricing between platforms.
- Simulate Monthly Costs: Build a cost model spreadsheet incorporating base token costs, surcharges, and call fees. Adjust for volume discounts or enterprise contract terms.
- Leverage Free Trials and PoCs: Utilize the free trial tiers to test real-world scenarios and validate cost assumptions. Pay close attention to token consumption metrics during pilot runs.
- Negotiate Enterprise Agreements: Engage with vendor sales teams to explore volume licensing discounts, custom SLAs, and bundled feature pricing tailored to your organizational scale.
Practical Example: Calculating Monthly Cost with GPT-5.5 Pricing API
The following Python snippet demonstrates how an enterprise can programmatically estimate their monthly cost using the GPT-5.5 pricing model, including context window surcharges:
import math
def gpt55_monthly_cost(tokens_used, context_tokens=50000):
base_rate = 0.0020 / 1000 # per token
surcharge_rate = 0.0005 / 10000 # per token beyond context window
surcharge_threshold = context_tokens
base_cost = tokens_used * base_rate
surcharge_tokens = max(0, tokens_used - surcharge_threshold)
surcharge_cost = surcharge_tokens * surcharge_rate
total_cost = base_cost + surcharge_cost
return round(total_cost, 2)
# Example usage
monthly_tokens = 2_250_000 # 75k tokens/day * 30 days
cost = gpt55_monthly_cost(monthly_tokens)
print(f"Estimated GPT-5.5 monthly cost: ${cost}")
Real-World Case Study: FinTech Enterprise Deploying AI Chatbots
Company: FinSecure Technologies
Use Case: Customer support chatbot with dynamic multi-turn conversations and document retrieval
Monthly Token Volume: ~3 million tokens
Context Window: Extended context for 70,000 tokens per conversation
Agentic Calls: Limited orchestration features for transaction verification workflows
Findings:
- GPT-5.5’s surcharge for context window above 50,000 tokens increased monthly costs by approximately 8%. However, agentic features were fully included, simplifying budgeting.
- Claude Opus 4.8’s flat context window pricing avoided surcharges, but agentic call fees added a 2% overhead to total spend.
- Negotiated volume discounts of 12% with both vendors reduced effective costs significantly.
- Final decision favored GPT-5.5 due to predictable cost structure and integrated agentic features, which reduced operational complexity.
In conclusion, enterprise CFOs and technical leads should combine detailed usage analytics with vendor pricing nuances to develop a tailored, optimized cost strategy. The choice between GPT-5.5 and Claude Opus 4.8 depends heavily on specific workload characteristics, especially around context window sizes and agentic feature utilization.
Speed and Latency
Speed of response and latency are critical parameters in the deployment of AI models for real-time enterprise applications such as live customer support, dynamic data querying, and interactive conversational bots. In 2026, as demand for instantaneous engagement increases, minimizing latency while maintaining high throughput has become a cornerstone in AI service delivery.
GPT-5.5 Performance and Optimization
GPT-5.5 leverages next-generation hardware acceleration, including custom tensor processing units (TPUs) designed for 7nm process nodes and beyond, combined with optimized parallel query processing pipelines across multi-GPU clusters. This hardware-software co-design enables GPT-5.5 to deliver average latencies ranging from 150 to 250 milliseconds for standard prompt requests under typical enterprise loads (10,000+ concurrent users). Its architecture supports asynchronous processing for batch tasks and intelligently balances speed with throughput by dynamically allocating compute resources based on request priority and complexity.
In addition, GPT-5.5 incorporates advanced memory management techniques such as dynamic context window pruning and token caching, which reduce redundant computations during dialogue sessions. This results in faster response times without compromising the contextual relevance of interactions. Below is a practical example of how enterprise developers can implement asynchronous batch processing with GPT-5.5’s API to optimize latency and throughput:
import asyncio
from gpt55_sdk import GPT55Client
client = GPT55Client(api_key='YOUR_API_KEY')
async def process_batch(prompts):
tasks = [client.generate_text_async(prompt) for prompt in prompts]
responses = await asyncio.gather(*tasks)
return responses
async def main():
batch_prompts = [
"Generate a summary of Q1 financial results.",
"Provide troubleshooting steps for login errors.",
"Create a personalized greeting for customer ID 12345."
]
results = await process_batch(batch_prompts)
for res in results:
print(res)
if __name__ == "__main__":
asyncio.run(main())Claude Opus 4.8’s Low-Latency Distributed Architecture
Claude Opus 4.8 adopts a distributed microservice architecture explicitly engineered for ultra-low latency. By decomposing AI tasks into granular microservices and orchestrating them with a dynamic workflow engine, Claude Opus can execute parallel subtasks concurrently, minimizing bottlenecks typical in complex, multi-step operations. This architecture yields average response times approximately 120 to 200 milliseconds in production environments with high concurrency, making it particularly suited for latency-sensitive applications such as high-frequency trading bots and real-time customer engagement platforms.
The dynamic workflow engine also supports adaptive load balancing and real-time scaling, ensuring consistent performance even during peak traffic intervals. For example, a multi-turn dialogue system using Claude Opus 4.8 can process intent detection, entity extraction, and response generation as parallel subtasks rather than sequential steps, dramatically reducing end-to-end latency.
from claude_opus_sdk import ClaudeOpusClient
client = ClaudeOpusClient(api_key='YOUR_API_KEY')
def handle_user_query(query):
# Step 1: Intent detection microservice
intent = client.intent_detection(query)
# Step 2: Entity extraction microservice (runs in parallel)
entities = client.entity_extraction(query)
# Step 3: Response generation microservice
response = client.generate_response(intent, entities)
return response
# Example usage
user_input = "Schedule a meeting with the marketing team next Tuesday."
bot_response = handle_user_query(user_input)
print(bot_response)| Feature | GPT-5.5 | Claude Opus 4.8 |
|---|---|---|
| Average Latency | 150-250 ms | 120-200 ms |
| Architecture | Monolithic with hardware acceleration | Distributed microservices |
| Parallel Processing | Optimized parallel queries & async batch | Parallel subtasks via workflow engine |
| Scalability | High-volume scaling via mature infra | Dynamic load balancing & real-time scaling |
| Ideal Use Cases | Large-scale batch processing, high throughput Interactive chatbots with complex context |
Latency-sensitive workflows, real-time event processing Multi-step conversational AI |
Advanced Strategies for Latency Optimization
Enterprise teams seeking to optimize latency in their AI deployments can leverage several advanced strategies tailored to each model’s strengths:
- For GPT-5.5:
- Implement asynchronous batch requests to maximize GPU utilization and reduce idle time.
- Use context window pruning to shorten input sequences dynamically without losing essential information.
- Leverage token caching for repetitive query patterns to avoid redundant computation.
- Deploy on dedicated hardware clusters with direct GPU interconnects for reduced communication overhead.
- For Claude Opus 4.8:
- Design workflows with parallel microservices to split complex queries into concurrent subtasks.
- Use dynamic load balancing to distribute requests evenly across microservice instances.
- Integrate event-driven triggers to pre-emptively warm up microservices during peak periods.
- Monitor and fine-tune workflow dependencies to minimize serialization delays.
For enterprise engineers interested in a deep dive into practical optimization techniques and benchmarking methodologies, we recommend consulting our comprehensive guide in Latency Optimization for AI Models in Enterprise Environments.
Related Articles You Might Enjoy
Final Considerations for Enterprise Teams
When evaluating GPT-5.5 vs Claude Opus 4.8, enterprises must conduct a nuanced analysis tailored to their specific operational requirements, infrastructure capabilities, and long-term AI integration strategies. Each model offers distinct advantages rooted in their architectural innovations and training paradigms, which can significantly impact deployment outcomes in complex enterprise environments.
-
Advanced reasoning and self-correcting content generation:
GPT-5.5 leads the market with its highly refined transformer architecture enhanced by an adaptive error mitigation framework that incorporates feedback loops during inference. This system enables the model to detect inconsistencies and logical fallacies mid-generation, improving factual accuracy and coherence in complex scenarios such as legal document drafting or scientific research summarization.Technical highlight: GPT-5.5 integrates an on-the-fly chain-of-thought verifier module that dynamically re-evaluates output segments, reducing hallucination rates by up to 35% compared to previous versions.
# Example Python snippet using GPT-5.5's error mitigation API from gpt55_sdk import GPT55Client client = GPT55Client(api_key='YOUR_API_KEY') prompt = "Summarize the following legal case focusing on contract breaches and remedies." response = client.generate( prompt=prompt, enable_error_mitigation=True, # Activates self-correction during generation max_tokens=1024 ) print(response.text) -
Autonomous, agentic workflow management and dynamic task orchestration:
Claude Opus 4.8 excels with its modular agent architecture, designed to autonomously coordinate multi-step workflows within enterprise applications. This capability is essential for real-time decision-making systems in sectors like supply chain logistics, automated customer service, and DevOps automation. Claude Opus’s architecture allows deployment of specialized agents that communicate via an event-driven bus, enabling seamless orchestration of complex tasks without manual intervention.Practical implementation: Enterprises can chain agents for task decomposition, enabling dynamic re-prioritization based on contextual inputs.
# Sample workflow orchestration using Claude Opus 4.8 agents from claude_opus_sdk import AgentManager, TaskAgent def inventory_check(task_data): # Custom agent logic for inventory validation return f"Inventory status: {task_data['items']} checked." def reorder_agent(task_data): # Agent to initiate reorder if inventory low if task_data['inventory_level'] < 50: return "Triggering reorder process." return "Inventory sufficient." manager = AgentManager() manager.register_agent(TaskAgent(name="InventoryCheck", handler=inventory_check)) manager.register_agent(TaskAgent(name="ReorderAgent", handler=reorder_agent)) workflow_data = {'items': ['widgets', 'gadgets'], 'inventory_level': 45} result = manager.execute_workflow(workflow_data) print(result) -
Contextual comprehension:
GPT-5.5 offers a significantly expanded context window of up to 128k tokens, revolutionizing capabilities in large-document analysis, multi-source data synthesis, and comprehensive report generation. This is particularly advantageous for enterprises managing vast data repositories, such as financial institutions performing cross-quarter earnings analysis or healthcare systems integrating patient histories with genomic data.Claude Opus 4.8, conversely, employs a modular context management system optimized for interactive, real-time applications — including conversational AI and live data monitoring dashboards. Its dynamic context segmentation allows efficient memory usage and low-latency responses without sacrificing contextual depth.
Feature GPT-5.5 Claude Opus 4.8 Max Context Window 128,000 tokens 45,000 tokens with modular context switching Context Management Monolithic, long-span context retention Segmented, event-driven context updates Ideal Use Case Large document summarization, multi-source synthesis Real-time conversation agents, live data monitoring -
Cost and speed trade-offs:
Claude Opus 4.8 demonstrates superior efficiency in latency-critical environments due to its lightweight model variants and optimized inference pipelines leveraging hardware accelerators prevalent in 2026, such as next-gen TPU v6 and AI-dedicated ASICs. This results in average response times 20-30% faster than GPT-5.5 in comparable workloads, with pricing models tailored to usage bursts, favoring enterprises with fluctuating demand patterns.GPT-5.5, while marginally slower on average, remains highly competitive through scalable enterprise contracts, volume discounts, and integration with AI orchestration platforms that enable cost-effective load balancing and resource allocation.
Metric GPT-5.5 Claude Opus 4.8 Average Latency (ms) 180 ms 130 ms Cost per 1k tokens $0.035 (enterprise tier) $0.028 (on-demand pricing) Scaling Model Enterprise contracts with volume discounts Flexible pay-as-you-go with burst capacity
Ultimately, enterprise teams aiming to harness the full potential of AI in 2026 should consider hybrid deployment strategies that leverage the complementary strengths of GPT-5.5 and Claude Opus 4.8. For example:
- Utilize GPT-5.5 as the core engine for tasks requiring deep reasoning, high-fidelity content generation, and extensive document comprehension.
- Deploy Claude Opus 4.8 for autonomous workflow orchestration, real-time interaction, and latency-sensitive applications.
- Implement middleware layers to dynamically route requests between models based on task context, latency requirements, and cost considerations.
Step-by-step guidance for such hybrid deployments involves:
- Assessment: Analyze workload profiles and identify segments that benefit most from each model’s capabilities.
- Integration: Develop API gateways and orchestration middleware to abstract model selection and enable seamless switching.
- Monitoring: Establish telemetry and logging to continuously evaluate performance, cost, and accuracy metrics.
- Optimization: Iterate routing rules and fine-tune model parameters based on real-time analytics and user feedback.
Below is a conceptual example demonstrating dynamic routing logic in Python to balance requests between GPT-5.5 and Claude Opus 4.8 based on latency tolerance:
class AIModelRouter:
def __init__(self, gpt_client, claude_client):
self.gpt = gpt_client
self.claude = claude_client
def route_request(self, prompt, max_latency_ms):
# Simple heuristic: low latency tolerance routes to Claude Opus
if max_latency_ms < 150:
response = self.claude.generate(prompt)
source = "Claude Opus 4.8"
else:
response = self.gpt.generate(prompt, enable_error_mitigation=True)
source = "GPT-5.5"
return {'response': response, 'model_used': source}
# Usage example
router = AIModelRouter(gpt_client=GPT55Client(api_key='...'), claude_client=ClaudeOpusClient(api_key='...'))
result = router.route_request("Analyze quarterly sales data for anomalies.", max_latency_ms=140)
print(f"Response from {result['model_used']}: {result['response']}")
Cross-referencing these insights with your organization's operational goals, existing technical infrastructure, and compliance requirements will guide the optimal AI partnership and deployment framework.
For additional technical insights on deploying large-scale language models in enterprise ecosystems, refer to our comprehensive guides such as and .
Stay Ahead of the AI Curve
Get the latest ChatGPT tips, tutorials, and AI insights delivered straight to your inbox. Join thousands of professionals who trust ChatGPT AI Hub.