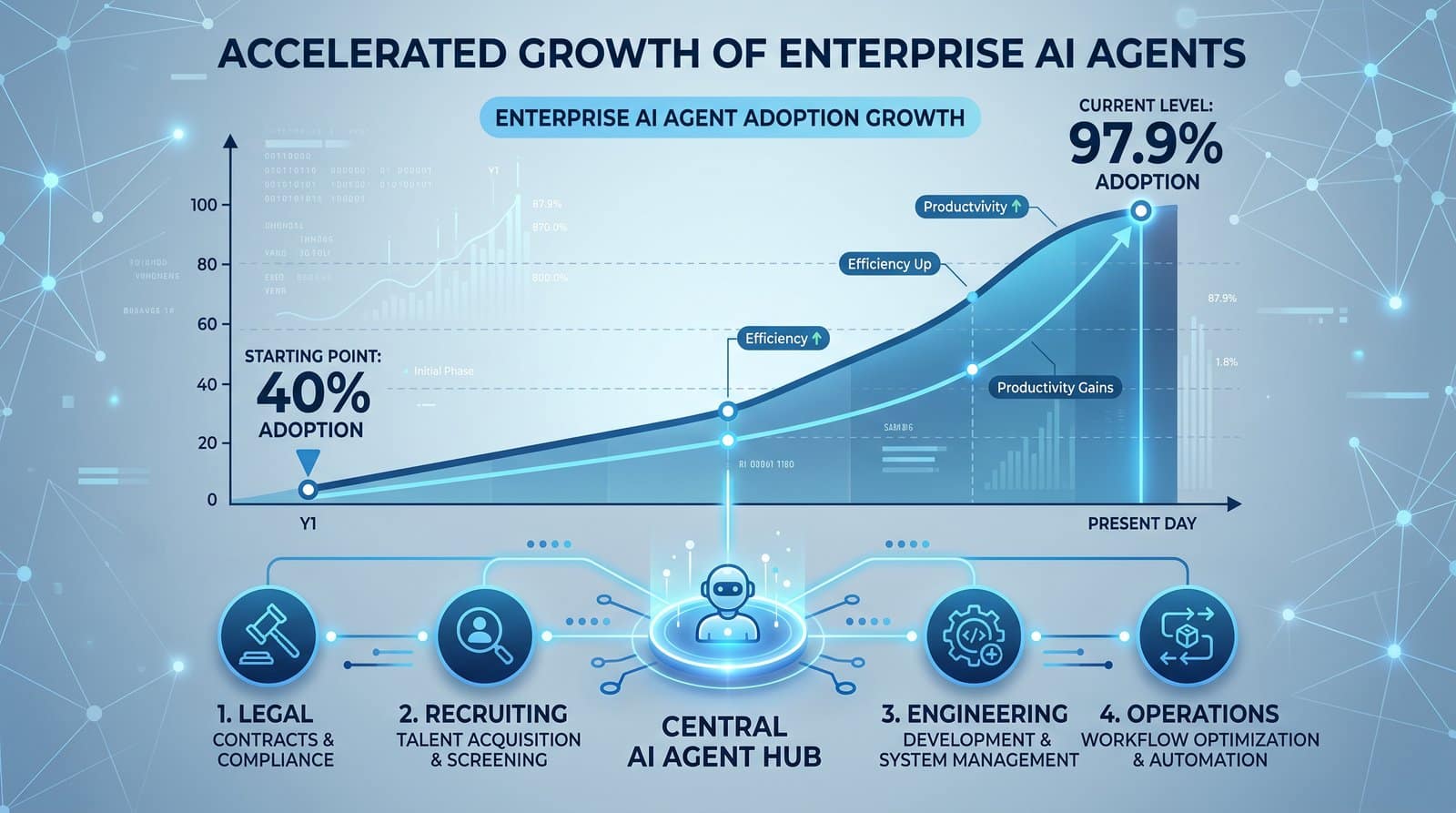
OpenAI’s Shift from Chat to Agents: How 97.9% Internal Codex Adoption Is Reshaping Enterprise AI Strategy

OpenAI is undergoing a decisive shift in how its people and platforms get work done, moving from conversational prompts in ChatGPT to autonomous, multi-step Codex agents that execute jobs end‑to‑end. The company reports that 97.9% of employees now use Codex—up from 40% in August 2025—while non‑developer usage has exploded (137x growth for individuals and 189x for organizations). Inside the company, the depth of engagement is changing as well: users submitting 8‑plus‑hour tasks have increased nearly tenfold since the start of 2026, and active agentic AI users grew 5x in H1 2026. The legal team alone generated 13x more monthly output tokens in June 2026 than in November 2025, underscoring that this is not just a tooling update—it is a new operating model. Externally, adoption remains early but notable: organization‑level usage stands at 17.3% and individual usage at 0.7%. Codex’s pricing moved from message‑based plans to token‑based credits in 2026, aligning costs with the computational intensity of continuously running agents rather than single messages. Together, these signals point to one conclusion: enterprise AI strategy is pivoting from one‑off prompts to orchestrated agents designed to deliver measurable outcomes.
Table of Contents
- The Headline Numbers and Why They Matter
- From Chat to Agents: What’s Actually Changing
- Implications for Enterprise AI Strategy
- Workforce Planning and Operating Model
- Pricing, Token Credits, and Cost Modeling
- Implementation Blueprint: A 90‑Day Plan
- Governance, Security, and Compliance for Agents
- Technical Deep Dive: Building Agentic Systems
- Benchmarks and KPIs that Matter
- Case Vignettes from Early Internal Patterns
- Risks and Failure Modes to Anticipate
- Market Landscape and Competitive Signals
- What to Do Now: Priority Actions and Resources
- Key Takeaways
The Headline Numbers and Why They Matter
Data emerging from OpenAI’s internal rollout of Codex agents sketches a clear trajectory from chat‑style interactions to job‑level automation:
- 97.9% of OpenAI employees are now active Codex users, up from 40% in August 2025.
- Non‑developer usage has exploded, with individual use cases increasing 137x and organizational use cases up 189x.
- The number of users submitting 8‑plus‑hour tasks climbed nearly tenfold since the start of 2026, indicating greater trust in agents handling long‑running, multi‑step workflows.
- Active agentic AI users grew 5x in the first half of 2026.
- OpenAI’s legal team produced 13x more monthly output tokens in June 2026 than in November 2025, highlighting non‑technical teams’ ability to harness agents for substantive, sustained work.
- External organization adoption stands at 17.3%, with individual external adoption at 0.7%—a gap that suggests boards and CTOs are endorsing pilots even while individual contributors lag.
- Codex shifted from message‑based plans to token‑based credits in 2026, a pricing model better aligned to continuously running, tool‑invoking, data‑retrieving agents.
While adoption statistics can be noisy during platform transitions, the direction of travel is unmistakable. Internal usage saturating at ~98% signals that agent workflows are not confined to engineering or research. Legal’s 13x output token growth points toward document‑heavy, revision‑intensive processes finding leverage through automated drafting and review. The surge in 8‑hour tasks implies a move from “assistive” interactions to “autonomous” execution: agents are being entrusted to run for a workday, integrate multiple tools, and return outputs that meet standards without constant human oversight.
These numbers matter for enterprise decision‑makers in three ways:
- Operating model shift: The unit of work is changing—from messages and chats to jobs with SLAs, guardrails, and measurable outcomes.
- Budgeting and governance realignment: Token‑based credits and sustained runtimes require new cost controls, scheduling discipline, and observability.
- Workforce transformation: Non‑developers are rapidly becoming “agent composers,” assembling tools, data sources, and policies into reusable automations.
| Metric | Before | After | Implication |
|---|---|---|---|
| Internal Codex usage | 40% (Aug 2025) | 97.9% (mid‑2026) | Near‑universal internal adoption; agents are mainstream workflow |
| Non‑developer usage (individual) | Baseline | +137x | Agent skills spreading beyond engineering |
| Non‑developer usage (organizational) | Baseline | +189x | Teams formalizing agent‑based processes |
| 8+ hour tasks submitted | Baseline (Jan 2026) | ~10x | Higher autonomy and job‑level confidence |
| Active agentic AI users | Baseline (H2 2025) | 5x (H1 2026) | Broader behavioral shift to agents |
| Legal team monthly output tokens | Nov 2025 baseline | 13x (June 2026) | Material productivity in text‑heavy functions |
| External organizations adopting | — | 17.3% | Enterprise pilots gaining traction |
| External individual users | — | 0.7% | Top‑down deployment outpacing bottom‑up |
| Pricing model | Message‑based | Token‑based credits (2026) | Costs correlate to runtime and output size |
For leaders tracking inflection points, the jump from 40% to 97.9% internal adoption in under a year is less about a single product feature and more about fit: agents suit the way organizations create value—through repeatable, multi‑tool workflows—far more than freeform chat. Codex’s token‑based pricing also signals that OpenAI is aligning economics with compute intensity and real workloads, not convenience messaging.
From Chat to Agents: What’s Actually Changing
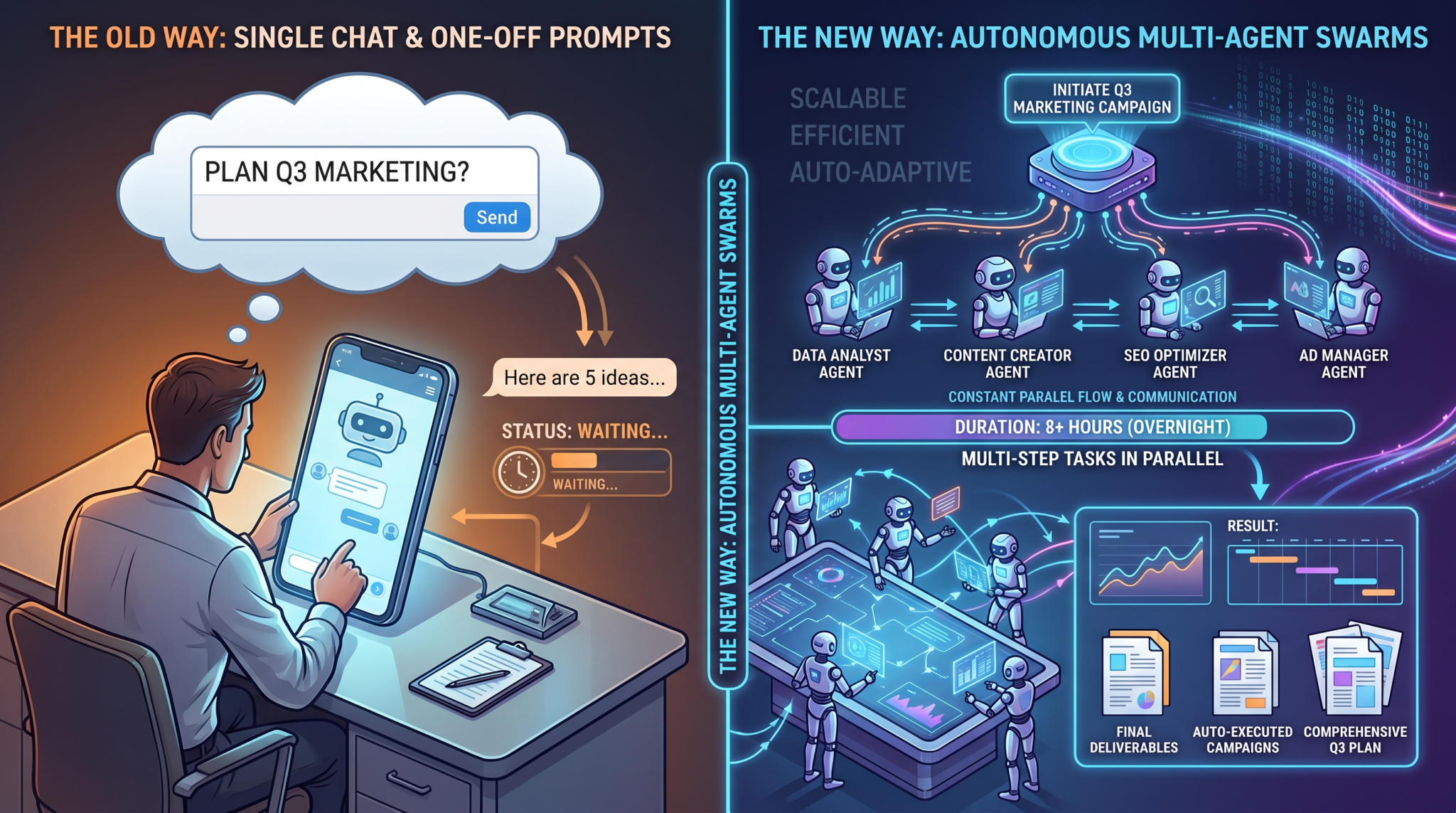
Agentic systems alter the “job architecture” of work. In a chat paradigm, a user prompts, evaluates, and iterates. In an agent paradigm, users define goals and constraints; the agent plans steps, invokes tools, calls APIs, retrieves data, and produces outcomes with minimal back‑and‑forth. The shift is less about “smarter” models and more about framing outcomes as autonomous jobs with orchestration, schedules, and guardrails.
From Messages to Jobs
Chat sessions are ephemeral, best suited to ideation, short analyses, and ad‑hoc tasks. Jobs are persistent, scheduled, and policy‑governed. When OpenAI reports a near tenfold increase in 8‑plus‑hour tasks, it indicates a critical design change: users are entrusting agents with time‑bounded, multi‑step objectives that span data fetching, tool execution, error handling, and result delivery.
- Input: Goals, constraints, SLAs (e.g., “Draft and validate a 40‑page policy compendium weekly; cite all sources; route for approval.”)
- Process: Planning, retrieval, tool invocation, iteration with self‑checks.
- Output: Artifacts delivered to systems of record with traceability and metrics.
What Agents Need That Chats Don’t
- Tooling: Integration with internal APIs, RPA, data warehouses, vector stores, and SaaS apps.
- Memory: Short‑term working memory for plans and long‑term stores for reusable knowledge.
- Policies: Guardrails that constrain scope, actions, and data access.
- Observability: Run IDs, logs, spans, and metrics for audit and debugging.
- Scheduling: Triggers, cron, and event‑driven starts.
- Cost Controls: Budgets per job, token caps, and throttling.
Why Non‑Developers Are Driving Growth
The 137x and 189x non‑developer adoption surges underscore that agent platforms abstract away code. Business users can compose workflows from building blocks: prompts, policies, connectors, and checklists. Legal’s 13x token output growth illustrates how functions that revolve around documents, compliance, and review are a natural fit for agentic automation. The work of drafting, redlining, assembling citations, and packaging deliverables is algorithmically decomposable—even if domain oversight remains critical.
Agentic AI changes who gets to automate. It moves automation from scripts and RPA specialists to the domain experts themselves.
How Pricing Reflects the Shift
Message‑based plans were built for conversational use. Token‑based credits, introduced for Codex in 2026, map more cleanly to real costs: planning steps, tool calls, longer context windows, retrieval, and large outputs consume more tokens. Enterprises can now think in “job budgets” rather than “message quotas,” which aligns governance and procurement with the actual unit of value delivered.
Implications for Enterprise AI Strategy
OpenAI’s internal usage patterns provide a roadmap for enterprises: when adoption saturates internally and non‑tech teams scale usage, the concern shifts from “should we use AI?” to “how do we operate AI at job scale?” The answers cross architecture, budgeting, risk, and change management.
1) Design for Jobs, Not Conversations
Define AI value in terms of recurring jobs with owners, inputs, outputs, SLAs, and budgets. This ends the ambiguity of chat and moves organizations toward outcome‑based thinking. For instance, a “report‑generation” job might run every Monday, consolidate approved data sources, generate narrative analysis, and ship a PDF to a knowledge portal—without ad‑hoc user intervention.
2) Invest in Tooling and Connectors
Agentic value scales with integrations. Prioritize connectors to ERP, CRM, CMS, data warehouses, identity systems, and document repositories. Establish a pattern library for common actions (e.g., “fetch policy,” “submit ticket,” “post knowledge base article”) that non‑developers can drag into workflows.
3) Implement Observability as a First‑Class Requirement
Metrics designed for chat (e.g., user satisfaction per conversation) are insufficient. For agents, track job completion rates, token spend per outcome, tool error rates, re‑attempt frequency, latency, and policy violations. Each run should be traceable with a stable run ID and comprehensive logs.
4) Align Cost Controls with Token Budgets
With token‑based credits, enterprises must allocate budgets per job, not per user. Configure hard caps, soft alerts, and progressive throttles. Expose budget telemetry to job owners daily. Tie exceptions to approval workflows, like raising a cost ceiling for quarter‑end runs.
5) Separate Composition from Execution
Non‑developers will compose jobs; platform teams should own execution runtime and policy enforcement. This separation ensures that business users can innovate within guardrails, while platform teams manage reliability, security, and cost.
6) Plan for a Multi‑Role Workforce
- Agent composer: Designs jobs, writes specifications, and tests outcomes.
- Agent operator: Monitors runs, triages failures, and manages schedules.
- Guardrail engineer: Crafts policies, redaction rules, and safe tool use.
- Data steward: Curates sources, metadata, and lineage for agent access.
- LLMOps engineer: Manages fine‑tuning, evaluation sets, and deployment.
7) Govern with Evidence, Not Guesswork
Define a minimum viable governance framework that focuses on measurable risks: data leakage, unauthorized actions, hallucinatory citations, and uncontrolled spend. Require test suites and reproducible runs before promoting a job to production. Scale oversight with automation—policy checks and approval gates—rather than manual review for every run.
Workforce Planning and Operating Model
The move to agents compels organizations to revisit headcount planning, job descriptions, and training. The reported 5x growth in active agentic users and near‑universal internal adoption point to a model where a critical mass of employees becomes fluent in agent composition, not just usage.
Role Design
- Agent Program Lead (APL): Owns the roadmap for department‑level agent deployments, budget forecasts, and outcome KPIs.
- Agent Composer: Domain expert who designs workflows, defines inputs/outputs, and prototypes within guardrails.
- Guardrail Engineer: Implements policy constraints, PII handling rules, and action whitelists.
- LLMOps Engineer: Builds evaluation suites, manages model versions, tracks drift, and enforces service levels.
- Agent Operator: Monitors runs, responds to failures, tunes schedules, and manages escalations.
Competency Model
- Business decomposition: Breaking objectives into agent‑executed steps.
- Prompt and tool composition: Structuring prompts, attaching tools, and selecting data sources.
- Policy and risk awareness: Understanding guardrails and compliance obligations.
- Metrics literacy: Reading token budgets, run logs, and outcome dashboards.
- Continuous improvement: Iterating on jobs based on failure modes and feedback.
Training and Adoption Path
Internal usage at 97.9% suggests that at scale, training can’t be ad‑hoc. Enterprises should deploy a structured curriculum with progression:
- Foundation: Principles of agents vs chats, token budget basics, and safe data use.
- Composition: Hands‑on lab to assemble a two‑tool workflow (e.g., retrieve data, generate document, store artifact).
- Governed production: How to pass gates, write runbooks, and set budgets.
- Optimization: Reducing token spend, improving quality, creating reusable components.
Org Structures That Scale
Centralized platform teams should supply standards and runtime; federated business units should own job design and outcomes. Adopt a hub‑and‑spoke model: the hub provides connectors, security patterns, and evaluation; spokes tailor jobs to their processes, within defined guardrails.
Change Management
With non‑developer usage up 137x/189x across individuals and organizations, change programs should target domain users. Incentivize adoption with outcome‑based rewards: celebrate turnarounds where an agent reduces a weekly job from 10 person‑hours to 30 minutes and track that on scorecards. Equip managers to coach agent composition, not just approve tool requests.
Pricing, Token Credits, and Cost Modeling
Codex’s move to token‑based credits in 2026 aligns pricing with agent workloads. A single job might plan, fetch, analyze, draft, revise, and publish, consuming tokens at each stage. Enterprises should forecast costs in terms of tokens per outcome, not per user or per message.
Budgeting Framework
- Define outcome: e.g., “Generate weekly 20‑page compliance report.”
- Instrument tokens: Measure tokens used in planning, retrieval, generation, and tool calls.
- Set baseline: Run three pilot jobs; compute average tokens and variance.
- Cap and alert: Assign a token budget for the job (e.g., 95th percentile usage) with soft/hard limits.
- Optimize: Shrink contexts, cache retrievals, reuse summaries, and trim unnecessary steps.
Cost Control Mechanisms
- Per‑run budgets: Set max tokens/run and max tokens/day per job.
- Time caps: Limit job duration to avoid runaway processes.
- Retry policy: Limit retries and backoffs; fail fast with alerts when tools break.
- Caching: Reuse embeddings and summaries to cut retrieval costs.
- Data minimization: Truncate inputs and chunk intelligently.
Sample Cost Anatomy
While exact unit prices vary by plan and model, the anatomy remains consistent for agent jobs:
- Planning and coordination tokens
- Retrieval and embeddings tokens
- Generation tokens for drafts and revisions
- Tool call overhead and output parsing
| Stage | Token Drivers | Levers |
|---|---|---|
| Plan | Prompt size; planning depth | Use templates; constrain steps; short system prompts |
| Retrieve | Context length; chunk count | Chunk tuning; dedupe; caching; hybrid search |
| Generate | Draft length; revision cycles | Outline first; style guides; structured outputs |
| Tool | Action count; serialization | Batch operations; compact schemas; typed I/O |
Controlling Variance
Variance is the enemy of predictable budgets. Design jobs to be deterministic where possible: fixed templates, constrained outlines, and strict I/O schemas reduce rework and token bloat. Log tokens per step to pinpoint outliers (e.g., a retrieval spike after a connector change).
Implementation Blueprint: A 90‑Day Plan
Enterprises looking to pivot from chat tools to agents can de‑risk the journey with a staged, outcome‑centric approach. The goal is to create a repeatable pattern: identify one high‑value job, productionize it with guardrails, measure outcomes, and then scale.
Days 0–30: Foundation and First Job
- Governance basics: Define data access policies, action whitelists, and logging requirements.
- Connector quick wins: Implement read‑only connectors to key systems (document store, CRM, knowledge base).
- Choose a job: Select a document‑heavy, low‑risk workflow (e.g., assembling monthly internal reports).
- Instrument tokens: Set up per‑run token logging and budgets.
- Pilot run: Execute three runs end‑to‑end; capture completion time, accuracy, and token use.
Days 31–60: Productionize and Expand
- Add write actions: Enable controlled updates to knowledge bases and ticketing systems with approvals.
- Observability: Introduce run dashboards with success rate and spend per outcome.
- Guardrails: Apply PII redaction and citation enforcement; set job‑level SLAs.
- Training: Onboard agent composers with a hands‑on lab and style guides.
Days 61–90: Scale and Standardize
- Second job: Choose a higher‑stakes process (e.g., customer‑facing knowledge updates) with stricter approvals.
- Component library: Publish reusable policies, prompts, and tool wrappers.
- Budget management: Implement per‑department token quotas and automated alerts.
- Audit trails: Ensure every run has immutable logs and reproducible configuration snapshots.
Governance, Security, and Compliance for Agents
Agent deployments raise the stakes for governance because they can take actions on behalf of users and teams. The move to token‑based credits and long‑running tasks requires new controls that are job‑centric and continuous.
Policy Controls
- Action whitelists: Specify allowed tools and API endpoints per job.
- Data classification: Restrict access based on information sensitivity.
- PII and secrets handling: Redact sensitive fields; enforce vault‑backed secret access.
- Citation policies: For content generation, require source provenance with thresholds.
- Approval gates: For high‑impact actions, require human approvals before execution.
Runtime Safeguards
- Sandboxing: Isolate executions with scoped credentials and permissions.
- Rate limiting: Protect downstream systems from bursts and loops.
- Timeouts: Enforce maximum run durations to prevent cost blowouts.
- Kill switches: Allow operators to terminate jobs on anomaly detection.
Auditability
Every production run should be reproducible with an immutable record of:
- Model versions and prompts
- Tools invoked and parameters passed
- Data sources accessed
- Tokens consumed per step
- Outputs and their destinations
Compliance Alignment
Map controls to your regulatory obligations by job type. For example, a legal drafting job might require source citations in every section and a human sign‑off step. A support knowledge base job may require automatic rollback if metrics degrade.
Technical Deep Dive: Building Agentic Systems
Agents combine planning, tool use, retrieval, and long‑lived memory with strict I/O contracts. The following technical patterns help developers and platform teams build reliable, auditable, and cost‑efficient agents.
Core Architecture
- Planner: Decomposes goals into steps with a constrained schema.
- Tooling layer: Typed wrappers for APIs, RPA, and data access with idempotent behavior.
- Retrieval layer: Access to vector stores and structured data with caching.
- Policy engine: Enforces action scopes and data filters per run.
- Orchestrator: Schedules, monitors, and retries tasks with lineage.
- Observer: Logs tokens, spans, and metrics; emits alerts.
Constrained Planning
Favor structured planning over freeform text. Constrained schemas limit ambiguity and reduce token waste.
{
"goal": "Assemble monthly compliance report",
"constraints": ["Cite sources", "No external data"],
"plan": [
{"step": "retrieve_policies", "params": {"tags": ["compliance", "2026-06"]}},
{"step": "summarize_sections", "params": {"style": "formal"}},
{"step": "compile_citations", "params": {}},
{"step": "draft_report", "params": {"length_pages": 20}},
{"step": "validate", "params": {"checks": ["citations", "style"]}},
{"step": "publish", "params": {"dest": "knowledge_base"}}
]
}
Typed Tool Interfaces
Define tools with explicit input/output schemas. Reject or sanitize invalid inputs automatically.
interface RetrievePolicies {
input: { tags: string[]; date_range?: string }
output: { documents: Document[] }
}
interface DraftReport {
input: { sections: Section[]; style: "formal"|"plain"; length_pages: number }
output: { draft: string; citations: Citation[] }
}
Evaluation and Test Suites
Before a job goes to production, it should pass:
- Functional tests: Correctness on known inputs.
- Policy tests: Blocked data access and actions are refused.
- Cost tests: Token usage within budget under typical inputs.
- Resilience tests: Behavior under tool failures and timeouts.
Memory and Caching
- Working memory: Store plan state, decisions, and partial outputs.
- Long‑term memory: Persist validated facts and decisions for reuse.
- Caches: Reuse embeddings and summaries across runs to reduce tokens.
Observability and Telemetry
Instrument per‑step tokens, latency, and errors. Emit run‑level summaries:
{
"run_id": "run-2026-06-17-legal-042",
"job_name": "monthly_compliance_report",
"tokens": {
"plan": 1200,
"retrieve": 4500,
"generate": 9800,
"tool": 300
},
"latency_ms": 320000,
"tool_errors": 0,
"policy_violations": 0,
"status": "success"
}
Safety by Construction
Build policies into the code paths: deny tools by default, whitelist explicit actions, and verify outputs before publish. Require human approvals for actions that change external state.
Runtime Reliability
- Idempotency: Design tools to handle retries safely.
- Backpressure: Queue jobs and throttle based on downstream capacity.
- Graceful degradation: Fallback to read‑only or partial outputs when tools fail.
Benchmarks and KPIs that Matter
As organizations follow OpenAI’s trajectory—from chats to agents—new metrics define success. The emphasis shifts from user satisfaction per message to outcome quality per job and cost predictability.
Outcome Metrics
- Completion rate: Percentage of scheduled runs that complete successfully.
- Accuracy: Groundedness, citation completeness, and policy adherence.
- Cycle time: End‑to‑end runtime for a job.
- Rework rate: Fraction of runs requiring human correction.
Cost Metrics
- Tokens per outcome: Average and 95th percentile.
- Token variance: Standard deviation across runs.
- Budget adherence: Rate of runs within budget thresholds.
Reliability Metrics
- Tool error rate: Failures per tool invocation.
- Retry count: Retries per step and overall.
- Timeout rate: Percentage of runs exceeding time caps.
Adoption Metrics
- Active agent users: Growth month‑over‑month (OpenAI observed 5x H1 2026 growth internally).
- 8+ hour tasks: Indicator of autonomy and trust (near tenfold increase reported since early 2026 at OpenAI).
- Non‑developer share: Track the proportion of jobs composed by non‑dev teams.
Case Vignettes from Early Internal Patterns
While every enterprise’s portfolio will differ, OpenAI’s internal signals—especially legal’s 13x token output growth—suggest where value concentrates first.
Legal and Policy
Context: Document‑heavy drafting, citations, and version control make legal and policy functions a prime candidate for agents. The reported 13x increase in monthly output tokens from November 2025 to June 2026 implies sustained, long‑form generation and revision.
Agent Job: Draft, cite, and package policy documents weekly; route to counsel for approval; publish to a policy portal.
Value: Reduces manual drafting cycles, standardizes format, and ensures citation coverage. Human oversight remains essential, but agent pre‑work compresses time‑to‑draft significantly.
Knowledge Management
Context: Content consolidation and quality control benefit from agents that retrieve, de‑duplicate, and reformat documents.
Agent Job: Weekly sweep of knowledge repositories; update summaries; archive stale content; enforce taxonomy.
Value: Consistent knowledge hygiene without burdening specialists.
Back‑Office Operations
Context: Multi‑system workflows (e.g., reconciling entries, assembling reports) map well to agents.
Agent Job: Nightly reconciliation across finance systems; compile exceptions and draft tickets.
Value: Reduces manual effort and error rates; produces auditable logs.
Customer‑Facing Content
Context: Updating support articles and FAQs requires careful oversight.
Agent Job: Propose updates to high‑traffic articles using customer interaction signals; route for approvals; publish with rollback safeguards.
Value: Keeps content fresh and accurate while protecting brand and compliance.
Risks and Failure Modes to Anticipate
Agentic automation delivers leverage but introduces new failure modes. Anticipating these risks is core to responsible deployment.
Runaway Costs
Risk: Long‑running jobs with iterative drafts or retrieval loops can burst budgets under token‑based pricing.
Mitigation: Hard token caps, watchdogs for loop detection, and plan step limits.
Action Misfires
Risk: Incorrect tool parameters or misinterpretation can lead to unintended actions.
Mitigation: Strong typing, dry‑run modes, and approval gates for write operations.
Data Leakage
Risk: Unintended inclusion of sensitive data in prompts or outputs.
Mitigation: Redaction filters, strict data access policies, and logging of data flows.
Quality Drift
Risk: Over time, changes in data or tools degrade output quality.
Mitigation: Periodic evaluation suites, canary runs, and retraining prompts/templates.
Over‑automation
Risk: Automating processes that require nuanced judgment can backfire.
Mitigation: Keep humans‑in‑the‑loop where stakes are high; define clear handoff points.
Market Landscape and Competitive Signals
OpenAI’s internal adoption curve provides a bellwether for the broader enterprise market. Strong internal uptake—97.9% active users—suggests that agentic paradigms can scale across functions, not just in labs. External organization adoption at 17.3% and individual usage at 0.7% indicate a top‑down phase: leadership is greenlighting pilots before grassroots use matures. As procurement models follow token‑based credits, we should expect enterprise buyers to evaluate vendors on outcome cost predictability, observability, and governance fit, rather than just model benchmarks.
The net effect is a near‑term re‑segmentation of enterprise AI offerings into two camps:
- Chat‑centric tools: Lightweight productivity aids, good for ideation and ad‑hoc tasks.
- Agent‑centric platforms: Outcome engines for recurring, multi‑tool jobs with SLAs, budgets, and audits.
OpenAI’s shift toward agents and token‑based pricing is aligned to the latter, which is where enterprise budgets and strategic value will concentrate. Early adopters will differentiate not by raw model horsepower but by operationalizing agents with discipline—policies, connectors, and metrics that translate into reliable, auditable outcomes.
What to Do Now: Priority Actions and Resources
Enterprises do not need to boil the ocean to capitalize on the shift from chats to agents. The internal metrics released by OpenAI point to durable practices that any organization can adopt methodically.
Priority Actions
- Set the unit of value: Define top three jobs to automate in 90 days; write job specs with inputs, outputs, and SLAs.
- Stand up guardrails: Establish policies for data access, action whitelists, and approvals.
- Instrument costs: Implement token logging per step and cap budgets per run.
- Train composers: Certify a cohort of non‑developers to build within guardrails.
- Publish a component library: Templates, tool wrappers, prompts, and citation policies.
For teams designing autonomous workflows, a deep dive on best practices can shorten the learning curve. Our guide on The 2026 Prompt Library: 5 Templates for Prompt Engineering shows how to structure system prompts, planning schemas, and guardrails to minimize token waste and maximize reliability, complete with examples that map to multi‑tool jobs.
Moving agents into production is governance‑heavy. To accelerate readiness, review the OpenAI Acquires Ona: How Codex Will Integrate Survey Data Collection, Field Research, and Structured Data Pipelines for Enterprise Knowledge Management, which covers action whitelists, data classification, approval gates, audit logging, and role definitions aligned to agentic deployments.
Budget predictability is critical under token‑based credits. The How to Migrate from GPT-5.2 to GPT-5.5 in Production: Complete API Transition Guide with Prompt Compatibility Testing, Cost Optimization, and Rollback Strategies explains how to set per‑job budgets, track tokens per step, and reduce variance through caching, chunk tuning, and structured outputs—practices that map directly to Codex’s pricing model.
Key Takeaways
- OpenAI’s internal usage data shows a decisive pivot to agents: 97.9% of employees now use Codex, non‑developer usage is up 137x/189x, 8‑hour task submissions have grown nearly tenfold, and active agentic users are up 5x in H1 2026.
- Non‑developer momentum is real and material: the legal team produced 13x more monthly output tokens by June 2026 versus November 2025, demonstrating that document‑heavy, policy‑bound workflows benefit early.
- Codex’s move to token‑based credits in 2026 aligns costs with long‑running, multi‑tool jobs. Budgeting must shift from per‑message to per‑outcome with hard caps and telemetry.
- Enterprise AI strategy should prioritize job design, connectors, observability, and governance. Separate composition from execution: empower business users within platform‑enforced guardrails.
- A pragmatic 90‑day plan—governance basics, one high‑value job, productionization, and scaling with a component library—can deliver measurable value while de‑risking the transition.
Closing Analysis: From Experiments to an Operating System for Work
The story behind OpenAI’s internal numbers is not merely that people are using more AI; it’s that the fabric of work is changing. When nearly all employees engage with agents and non‑developers drive adoption, AI ceases to be a tool of convenience and becomes an operating system for recurring tasks. The steep growth in 8‑hour jobs and token generation for legal workflows signals a steady handover of routine, structured labor to autonomous systems that remain constrained by policy and overseen by humans. Enterprises that treat agents as outcome engines—and operationalize around jobs, budgets, and guardrails—will capture the productivity dividend first. Those that remain in a chat mindset will continue to see scattered wins without compounding value.
Access 40,000+ AI Prompts for ChatGPT, Claude & Codex — Free!
Subscribe to get instant access to our complete Notion Prompt Library — the largest curated collection of prompts for ChatGPT, Claude, OpenAI Codex, and other leading AI models. Optimized for real-world workflows across coding, research, content creation, and business.
Appendix: Sample Agent Job Runbook
Below is a concise runbook outline for a compliance report job, illustrating the operational details required to run agents responsibly at scale.
Job Overview
- Name: monthly_compliance_report
- Owner: Compliance APL
- SLA: Publish by first business Monday of each month, 10:00 AM
- Budget: Max 20,000 tokens/run; alert at 15,000
- Actions: Read policies, draft report, compile citations, publish to portal (approval required)
Policies
- Data sources: Internal policy repository only; no external browsing
- PII: Redact employee names; allow department names
- Citations: Every section requires at least two source citations
- Approvals: Publish requires human approval from compliance lead
Observability
- Logs: Retain 12 months; include tokens per step and tool parameters
- Alerts: Token threshold breached; tool errors; policy violation
- Reporting: Monthly dashboard with cost, success rate, and rework
Failure Handling
- Tool failure: Retry up to two times with exponential backoff; escalate on third failure
- Budget overrun: Halt generation and produce partial report with rationale
- Policy violation: Immediate halt and notify compliance lead
Versioning
- Prompts: Versioned in repository; change requires approval
- Tools: Semantic versioning; breaking changes gated behind canaries
- Rollbacks: Last known good configuration retained for fast revert
With this level of specificity and control, enterprises can translate OpenAI’s internal success metrics into operational practice: design jobs with clear goals and budgets, instrument every step for cost and quality, and empower non‑developers to compose within a strong guardrail framework. The result is a sustainable path from chat experiments to an agent‑driven operating model that delivers measurable, repeatable outcomes.