30 ChatGPT-5.5 Prompts for Product Managers: Roadmap Planning, User Research Synthesis, PRD Writing, and Stakeholder Communication

Author: Markos Symeonides, ChatGPT AI Hub
High-performing product managers increasingly use AI as an extension of their decision-making workflows, not a replacement. When prompting effectively, ChatGPT-5.5 can accelerate strategic planning, sharpen research synthesis, enforce PRD rigor, and streamline stakeholder communications. This masterclass delivers 30 production-ready prompts organized by core product management workflows. Each prompt is purpose-built with unambiguous instructions, strict output schemas, and variables you can swap to fit your context. Copy, paste, fill in your data, and run.
The prompts are structured to minimize ambiguity and maximize reproducibility. They emphasize the following principles:
- Explicit role and task: What the assistant is doing and why.
- Clear input contracts: What you will provide (e.g., transcripts, backlog CSV, OKRs, resource constraints).
- Deterministic output formats: JSON schemas, Gherkin, markdown tables, bullet hierarchies, or YAML, to ease import into PM tooling.
- Constraints and tie-break rules: So prioritization and synthesis decisions are explainable and auditable.
- Metrics-first mentality: Every plan includes measurable success criteria.
If you’re integrating these prompts into your stack (e.g., spreadsheets, Notion, Jira, or BI tools), standardize output formats across your team to ensure downstream automation remains stable. Consider saving reusable prompt variants per product line and retrofitting them with your taxonomy (e.g., initiative vs. epic vs. feature vs. sub-task).
For practitioners seeking deeper methods, see:
Product managers working with data-heavy features can accelerate their analysis workflows by leveraging AI-powered SQL generation and dashboard creation. Our collection of 35 ChatGPT-5.5 Prompts for Data Analysts includes ready-to-use templates for generating complex queries, building automated reporting pipelines, and creating stakeholder-ready visualizations from raw datasets.
Access 40,000+ AI Prompts for ChatGPT, Claude & Codex — Free!
Subscribe to get instant access to our complete Notion Prompt Library — the largest curated collection of prompts for ChatGPT, Claude, OpenAI Codex, and other leading AI models. Optimized for real-world workflows across coding, research, content creation, and business.
,
For product teams coordinating with non-technical stakeholders across legal, HR, and operations, having pre-built prompt templates eliminates the friction of translating business requirements into AI-ready instructions. Our guide to 40 ChatGPT-5.5 Prompts for Non-Technical Teams provides workflow-specific templates that replace manual processes in contract review, candidate screening, and operational reporting.
, and
For teams looking to expand their AI capabilities, our guide on The Complete GPT-5.5 and GPT-5.6 Model Selection Guide provides actionable frameworks for choosing between Sol, Terra, Luna, and GPT-5.5 models that complement the strategies discussed in this article.
.
Before You Start: Output Contracts and Reusable Schemas
Well-structured outputs make or break AI-assisted product workflows. Below are canonical schemas referenced throughout the prompts. Use them verbatim to keep your systems interoperable.
Canonical JSON Schemas
{
"initiative": {
"id": "string",
"title": "string",
"objective": "string",
"okr_alignment": {
"objective_id": "string",
"key_results": [
{
"kr_id": "string",
"kr_name": "string",
"impact_path": "string"
}
]
},
"priority_score": {
"method": "RICE|ICE|WSJF|custom",
"score_value": "number",
"inputs": {
"reach": "number",
"impact": "number",
"confidence": "number",
"effort": "number",
"other": "object"
}
},
"dependencies": [
{
"type": "upstream|downstream|external",
"on": "id or system name",
"risk": "low|med|high",
"mitigation": "string"
}
],
"resources": {
"eng_person_months": "number",
"design_weeks": "number",
"data_weeks": "number",
"other": "object"
},
"timeline": {
"start": "YYYY-MM-DD",
"end": "YYYY-MM-DD",
"milestones": [
{
"name": "string",
"date": "YYYY-MM-DD",
"exit_criteria": "string"
}
]
},
"success_metrics": [
{
"metric": "string",
"target": "number|string",
"measurement": "SQL|event|definition",
"frequency": "daily|weekly|monthly",
"owner": "string"
}
],
"notes": "string"
}
}RICE, ICE, and WSJF at a Glance
| Method | Formula | Best for | Common Pitfalls | Calibration Tips |
|---|---|---|---|---|
| RICE | (Reach × Impact × Confidence) ÷ Effort | Feature backlogs with uncertain outcomes and variable effort | Overstating impact; inconsistent effort estimates | Define discrete impact bands; enforce effort t-shirt sizing rules |
| ICE | (Impact × Confidence) ÷ Effort | Quick tests and growth experiments | Ignoring reach can bias toward niche wins | Use ICE only for experiments where reach is controlled/known |
| WSJF | (Cost of Delay) ÷ Job Size | Scaled agile, scheduling complex epics | Subjective cost-of-delay inputs; inconsistent sizing | Centralize CoD factors (user/business/risk) and review quarterly |
Example Calculation Snippets
# Python pseudo-code for RICE
def rice(reach, impact, confidence, effort):
return (reach * impact * confidence) / effort
# Impact banding convention:
# 3 = massive, 2 = high, 1 = medium, 0.5 = low, 0.25 = minimal
# Example
score = rice(reach=5000, impact=2, confidence=0.7, effort=8) # -> 875.0Roadmap Planning: 7 Prompts
Roadmaps are commitments to measurable outcomes. The prompts in this section emphasize alignment, prioritization transparency, and feasible delivery under constraints.
Prompt 1: Quarterly Planning Synthesis
Generate a cross-functional, constraint-aware quarterly plan grounded in OKRs, capacity limits, and historical velocity.
Role: Expert product operations analyst and roadmap planner.
Task: Build a quarterly plan that maximizes OKR impact within capacity and dependency constraints.
Inputs you will paste:
- Company OKRs for the quarter (structured or bullets)
- Candidate initiatives backlog (CSV or table with: id, title, objective, reach, impact_band, confidence_pct, effort_pm, dependencies, notes)
- Team capacity by function (Eng PMs, Eng person-months, Design weeks, Data weeks)
- Historic velocity and carryover (if any)
- Non-negotiables (compliance, contractual)
- Timeline constraints (holidays, code freeze windows)
Instructions:
1) Normalize inputs: convert impact_band → numeric (3,2,1,0.5,0.25); confidence_pct → 0-1; effort_pm as-is.
2) Compute RICE for each initiative: RICE = (reach × impact × confidence) ÷ effort.
3) Create dependency graph; flag initiatives blocked by non-negotiables or upstream items. Include mitigation proposals.
4) Fit initiatives into quarterly capacity using a greedy but explainable heuristic:
- Sort by RICE, then by OKR criticality, then by lower resource intensity.
- Reserve capacity for non-negotiables first.
- Cap risk: no more than {{MAX_CONCURRENT_RISKY}} high-risk initiatives in parallel.
5) Propose a milestone schedule (start/end dates, major reviews) respecting code freeze windows.
6) For each included initiative, map to OKRs and define 2-3 measurable success metrics with targets.
7) Produce a cutline for excluded initiatives with reason codes (capacity, dependency, low score, risk).
8) Highlight trade-offs and contingency plans.
Output format (markdown):
# Quarterly Plan Summary
- Quarter: {{YYYY-QX}}
- OKR coverage: {{percent_of_objectives_covered}}%
- Capacity utilization (Eng/Design/Data): {{x}}/{{y}}/{{z}}
## Included Initiatives (table)
| id | title | RICE | OKR objective | resources (Eng PM, Design wk, Data wk) | start | end | key milestones | risks | mitigations |
## Excluded / Deferred (table)
| id | title | reason | what would change the decision |
## Dependency Map (bullets)
- {{id}} depends on {{id}} (risk: {{low|med|high}}) – mitigation: {{text}}
## Metrics & Targets (bullets by initiative)
- {{id}}: {{metric}} target {{value}} by {{date}} (owner: {{name}})
## Trade-offs & Contingencies
- {{text}}
Now paste your data below and run:
- OKRs:
- Backlog:
- Capacity:
- Velocity/carryover:
- Non-negotiables:
- Timeline constraints:Prompt 2: Feature Prioritization with RICE/ICE
Score features consistently and output a ready-to-import ranking with transparent inputs and tie-breaks.
Role: Feature prioritization engine using RICE and ICE.
Task: Compute RICE and ICE, then produce a harmonized rank with tie-break logic and sensitivity flags.
Inputs:
- Features CSV/table with columns:
id, title, reach, impact_band (3,2,1,0.5,0.25), confidence_pct (0-100), effort_pm, category, strategic_tag
- Optional: use_ice_for = ["experiments","growth"] to apply ICE when category matches
Constraints & conventions:
- Confidence = confidence_pct / 100.
- If effort_pm = 0 → set to 0.25 to avoid division by zero.
- Tie-breaks: higher reach → lower effort → higher confidence → strategic_tag in {{STRATEGIC_TAGS}}.
- Sensitivity: flag items where a ±20% effort change alters rank by ≥3 positions.
Output format (markdown table):
| rank | id | title | method | RICE | ICE | reach | impact | confidence | effort_pm | category | strategic_tag | sensitivity_flag | notes |
Steps:
1) Convert all columns to numeric where relevant.
2) Compute:
- RICE = (reach × impact × confidence) ÷ effort_pm
- ICE = (impact × confidence) ÷ effort_pm
3) For each feature, choose "method":
- If category in use_ice_for → method=ICE
- Else method=RICE
4) Rank features by chosen method score; apply tie-break rules.
5) Sensitivity analysis: recompute with effort±20%, record if rank shift ≥3.
6) Output the table sorted by rank, including notes on any data anomalies.
Paste your data now:
- use_ice_for: {{["experiments","growth"]}}
- STRATEGIC_TAGS: {{["platform","retention","N:S"]}}
- Features:
Prompt 3: Dependency Mapping and Critical Path
Model upstream/downstream dependencies and identify the critical path with risk-weighted mitigation recommendations.
Role: Dependency analyst and critical path planner.
Task: Build a dependency graph and identify critical path for a set of initiatives.
Inputs:
- Initiatives with fields: id, title, duration_weeks, dependencies (list of ids with type upstream|external), risk (low|med|high), notes
- External blackout windows (dates)
- Team constraints (max parallel streams: {{N}})
Instructions:
1) Construct a directed acyclic graph (DAG). If cycles detected, report and propose break strategies.
2) Compute earliest start/finish using topological order and blackout windows.
3) Determine critical path (longest path duration).
4) Recommend mitigation for high-risk edges (supplier SLAs, internal alternatives, feature flags).
5) Propose a parallelization plan up to {{N}} streams without increasing critical path length.
Output format:
- Critical Path (ordered list): [id -> id -> id], total weeks: {{N}}
- Gantt-like schedule (markdown table):
| id | title | start | end | slack_weeks | risk | mitigation |
- Risks & Mitigations (bullets)
- Cycle or data issues (if any) with remediation plan
Paste your dataset:
Prompt 4: Resource Allocation Optimizer
Create an allocation that meets capacity limits and reserves buffers for interrupts, with rationale.
Role: Resource allocation optimizer.
Task: Assign resources across initiatives within capacity, risk buffers, and specialization constraints.
Inputs:
- Initiatives: id, eng_pm (person-months), design_weeks, data_weeks, skill_requirements (e.g., "iOS", "data-platform"), priority (numeric)
- Capacity: eng_pm_total, design_weeks_total, data_weeks_total
- Buffers: eng_interrupt_buffer_pct, design_buffer_pct, data_buffer_pct
- Specialization availability: skills → available_person_months
Rules:
- Respect buffers by reducing available capacity accordingly.
- Must not assign a skill beyond availability.
- If partial assignment required, document staged plan.
Output format (markdown):
## Allocation Summary
- Effective capacity (after buffers): Eng {{x}}, Design {{y}}, Data {{z}}
## Assignments (table)
| id | eng_pm_assigned | design_wk_assigned | data_wk_assigned | skill_assignments | shortfall | stage_plan |
## Unfunded Items (table)
| id | shortfall_reason | recommendation |
## Rationale & Trade-offs
- {{bulleted reasoning}}
Paste:
Prompt 5: OKR Alignment Matrix
Map initiatives to OKRs with explicit impact paths and detect gaps or over-coverage.
Role: OKR alignment auditor.
Task: Map each initiative to OKRs, define impact paths, and highlight gaps and over-coverage.
Inputs:
- OKRs: list of Objectives {id, text} and Key Results {id, objective_id, name, baseline, target}
- Initiatives: {id, title, hypothesis_of_impact, primary_metrics, secondary_metrics}
Instructions:
1) For each initiative, propose 1 primary Objective and up to 2 KRs it most directly influences.
2) Write a one-sentence "impact path" explaining how the initiative affects the KR.
3) Detect:
- Orphan OKRs (no initiatives)
- Orphan initiatives (no OKR fit)
- Over-coverage (≥3 initiatives on one KR)
4) Recommend rebalancing actions.
Output format (markdown):
## Alignment Table
| initiative_id | initiative_title | objective_id | kr_id | impact_path |
## Gaps and Risks
- Orphan OKRs: {{list}}
- Orphan initiatives: {{list}}
- Over-coverage KRs: {{list}}
## Rebalancing Recommendations
- {{bullets}}
Paste your OKRs and initiatives:
Prompt 6: Competitive Positioning Scanner
Benchmark roadmap bets against competitors and surface differentiation points tied to buyer value.
Role: Competitive intelligence analyst.
Task: Compare planned initiatives to competitor capabilities and identify differentiation opportunities.
Inputs:
- Planned initiatives (id, title, feature_summary, target_segment, expected_value_prop)
- Competitors: list with {name, capability_matrix (feature → strength 0-5), recent_announcements, pricing_notes}
- Buyer personas and selection criteria (weightings)
Instructions:
1) Build a comparison: for each initiative, map to competitor capabilities.
2) Score differentiation: Δ = our_expected_strength - competitor_strength (by persona weights).
3) Identify "table stakes" vs "differentiators".
4) Recommend messaging angles and roadmap adjustments.
Output format (markdown):
## Initiative vs Competitor Matrix
| initiative_id | competitor | our_strength_est | competitor_strength | delta | persona_weight | status (table-stakes|differentiator) | notes |
## Messaging & Roadmap Recommendations
- {{bullets per initiative}}
Paste data:
Prompt 7: Technical Debt Prioritization
Quantify tech debt by user pain, incident risk, velocity drag, and strategic alignment to produce an explainable ranking.
Role: Technical debt portfolio manager.
Task: Rank tech debt items by weighted criteria and propose remediation plans.
Inputs:
- Debt items: id, subsystem, description, user_pain (0-5), incident_risk (0-5), velocity_drag (0-5), remediation_effort_pm, strategic_alignment (0-5), notes
- Weights: {user_pain_w, incident_risk_w, velocity_drag_w, strategic_alignment_w}
- Constraints: available_eng_pm
Scoring:
- Score = (user_pain_w*user_pain + incident_risk_w*incident_risk + velocity_drag_w*velocity_drag + strategic_alignment_w*strategic_alignment) ÷ remediation_effort_pm
- Tie-break: higher incident_risk → lower effort → higher velocity_drag
Output format:
| rank | id | subsystem | score | user_pain | incident_risk | velocity_drag | alignment | effort_pm | recommendation | schedule_window |
Steps:
1) Compute scores and rank with tie-breaks.
2) Fit within available_eng_pm; propose schedule windows (between feature work, code-freeze windows).
3) Write a one-sentence "why now" justification per item.
Paste:
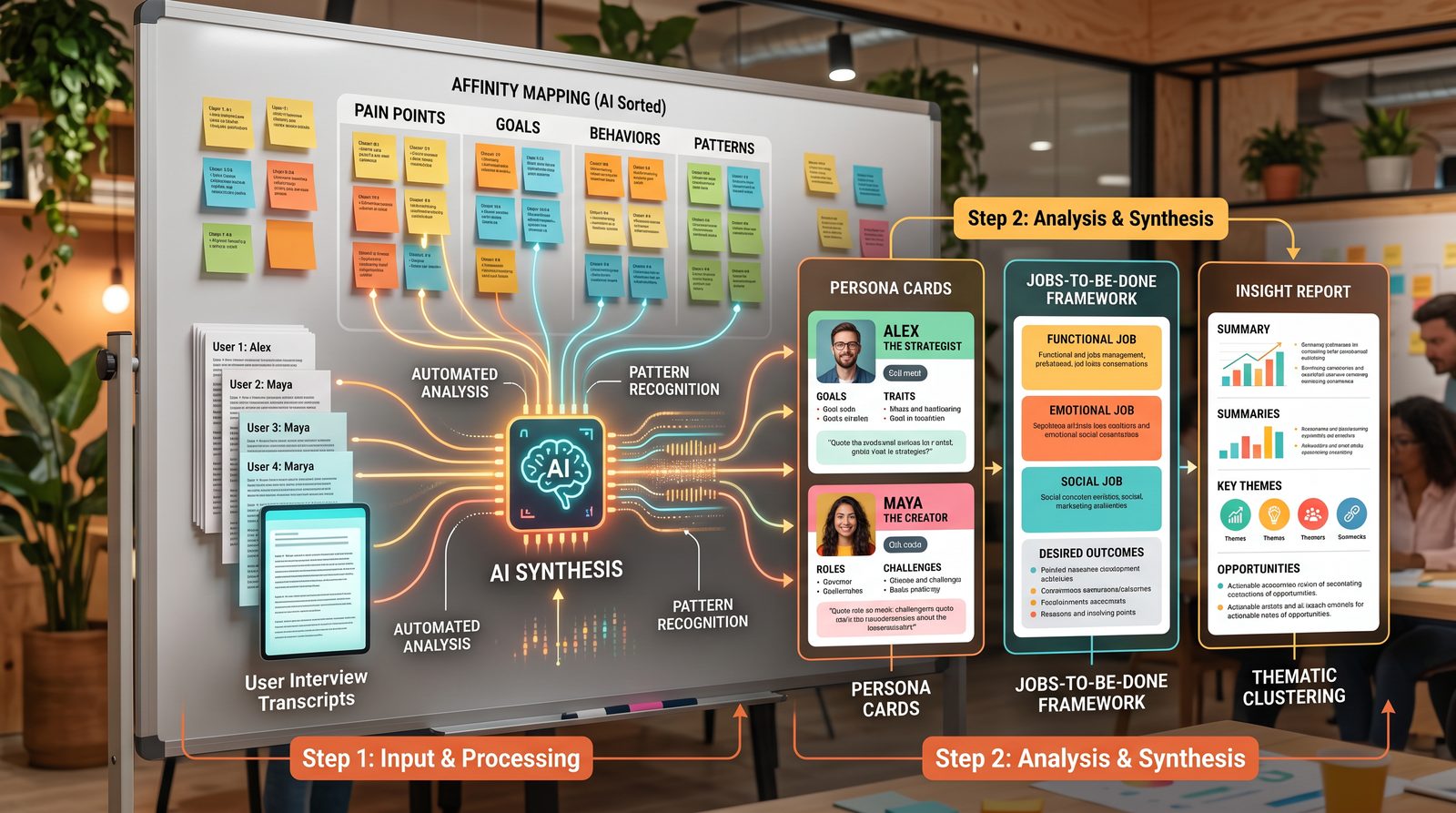
User Research Synthesis: 7 Prompts
Translate qualitative chaos into structured signals that drive strategy and design. The following prompts enforce repeatable synthesis and traceability to raw input.
Prompt 8: Interview Transcript Analysis
Extract pain points, tasks, and quotes from messy transcripts with confidence scoring and cross-interview frequency.
Role: Qualitative research synthesizer.
Task: Analyze interview transcripts to extract themes, tasks, pain points, and illustrative quotes.
Inputs:
- Transcripts: paste multiple interviews separated by "---- INTERVIEW ----", each with metadata header:
Participant: {{role/segment}}
Company size: {{N}}
Region: {{geo}}
Date: {{YYYY-MM-DD}}
Notes: {{optional}}
Instructions:
1) For each interview:
- Identify top 5 pain points, top 5 tasks (as verbs + objects), and top 3 unmet needs.
- Extract verbatim quotes (max 2 per theme) with timestamps (if available).
2) Across interviews:
- Aggregate themes with frequency counts by segment/region.
- Assign confidence (low/med/high) based on n and consistency.
3) Flag contradictions or segment-specific divergences.
4) Output a normalized JSON and a human-readable summary.
Output format:
JSON:
{
"interviews": [
{
"participant_role": "...",
"segment": "...",
"region": "...",
"date": "...",
"themes": [
{"theme": "string", "type": "pain_point|task|need", "quotes": ["...","..."]}
]
}
],
"aggregate": {
"themes": [
{"theme": "string", "type": "pain_point|task|need", "count": N, "segments": {"SMB":N1,"Enterprise":N2}, "regions": {"NA":N,"EU":N}, "confidence": "low|med|high"}
],
"contradictions": [{"description":"string","segments":["..."],"regions":["..."]}]
}
}
Summary (markdown):
## Key Themes
- {{theme}} ({{type}}): count {{N}}, confidence {{...}} — segments: {{...}}
## Quotes
- "{{quote}}" — {{participant_role}}, {{segment}}
Paste transcripts:
Prompt 9: Persona Creation from Research
Derive actionable personas grounded in behaviors, not fluff, with anti-persona where relevant.
Role: Persona synthesizer.
Task: Generate 2-5 personas (and optional anti-persona) from research notes and usage data.
Inputs:
- Research findings (themes, tasks, JTBD, usage metrics by segment)
- Product domain context and constraints
Instructions:
1) Cluster behaviors and goals to form personas; avoid demographic proxies unless directly relevant.
2) For each persona, include:
- Name, shorthand label
- Core JTBD (top 3)
- Success metrics (what they value)
- Behaviors (tools, workflows, channels)
- Pain points
- Buying triggers and objections
- Feature priorities (top 5)
- Adoption playbook (activation, aha moment, expansion path)
3) Define an anti-persona if a segment is misaligned with product strategy.
Output format (markdown):
## Persona: {{Name}} ({{Label}})
- JTBD: {{1}}, {{2}}, {{3}}
- Values: {{metrics}}
- Behaviors: {{bullets}}
- Pain points: {{bullets}}
- Triggers/Objections: {{bullets}}
- Feature priorities: {{bullets}}
- Adoption playbook: {{bullets}}
## Anti-Persona (if any)
- {{summary}}
Paste inputs:
Prompt 10: Jobs-to-Be-Done Extraction
Parse interviews into JTBD structure: situation, motivation, desired outcome, anxieties, and habits.
Role: JTBD analyst.
Task: Convert qualitative inputs into structured JTBD statements with forces diagram.
Inputs:
- Interview notes or transcripts
- Context of product usage
- Segmentation (if known)
Instructions:
1) Identify JTBD using standardized schema:
- When I {{situation}}, I want to {{motivation}}, so I can {{desired_outcome}}.
2) For each JTBD, capture forces:
- Push (current pain), Pull (attraction to solution), Anxiety (risks), Habit (status quo)
3) Map JTBD to candidate features and metrics.
Output format (markdown + JSON):
## JTBD Statements
- When I {{situation}}, I want to {{motivation}}, so I can {{desired_outcome}}.
### Forces (table)
| JTBD | Push | Pull | Anxiety | Habit |
### Feature Mapping (table)
| JTBD | Feature | Measurable metric | North Star linkage |
JSON:
{
"jtbd": [
{
"statement": "When I ...",
"forces": {"push":"...", "pull":"...", "anxiety":"...", "habit":"..."},
"features": [{"name":"...","metric":"...","north_star":"..."}]
}
]
}
Paste data:
Prompt 11: Sentiment and Topic Analysis
Blend rule-based and model-based sentiment detection to track trends by cohort and feature.
Role: Sentiment and topic analyst.
Task: Analyze user feedback for sentiment (compound score), topic clusters, and trend lines.
Inputs:
- Feedback records CSV/table: id, date, segment, region, channel (support|reviews|NPS|sales), feature_tag, text
Instructions:
1) Use a hybrid approach:
- Rule-based lexicon for domain terms (append below).
- Model-based classification for overall sentiment (neg/neu/pos) and compound score -1..1.
2) Group by feature_tag and segment; compute average sentiment and volume trends by week.
3) Extract top 10 topics per feature (keyphrases) and their sentiment deltas.
4) Flag anomalies (sudden sentiment drop >= 0.3 or volume spike >= 2x).
5) Output structured JSON and a markdown summary.
Domain lexicon (extend as needed):
- "crash","timeout","data loss" → strong negative
- "fast","reliable","intuitive" → positive
Output JSON:
{
"by_feature": {
"feature_tag": {
"weekly": [{"week":"YYYY-WW","avg_sentiment":0.12,"count":123}],
"topics": [{"phrase":"...","sentiment":-0.4,"supporting_ids":[...]}],
"anomalies": [{"week":"YYYY-WW","type":"drop|spike","detail":"..."}]
}
}
}
Markdown Summary:
## Sentiment by Feature (table)
| feature_tag | avg_sentiment | 4w_trend | anomalies |
## Topics & Quotes
- {{feature}}: "{{phrase}}" (sent: {{score}}) — examples: {{ids}}
Paste feedback:
Prompt 12: Feature Request Clustering
Group long-tail requests into coherent themes, link to personas, and estimate demand impact.
Role: Feature request clustering analyst.
Task: Cluster feature requests and map to personas and demand proxies.
Inputs:
- Requests CSV/table: id, date, segment, persona (if known), text, demand_proxy (e.g., ARR at-risk, #accounts, MQLs), effort_estimate_tshirt (S|M|L|XL)
Instructions:
1) Preprocess: normalize text, remove duplicates (Levenshtein threshold 0.85), keep canonical id linkage.
2) Embed and cluster requests (target 8-15 clusters); label clusters with concise names.
3) For each cluster, compute:
- Count, segments distribution, demand proxy totals, implied reach.
- Representative examples (3-5).
- Estimated impact band relative to product goals.
4) Suggest top 5 clusters to pursue with rationale and effort notes.
Output format:
| cluster_id | name | count | segments | demand_proxy_total | impact_band | implied_reach | effort_mix | representative_ids | notes |
Paste requests:
Prompt 13: User Journey Mapping
Build end-to-end journeys by persona, overlay friction points, and quantify drop-offs.
Role: Journey mapper.
Task: Create user journeys with stages, intents, friction points, and metrics.
Inputs:
- Personas (or segments)
- Stages list (e.g., Discover → Evaluate → Activate → Engage → Retain → Expand)
- Quant data (funnel conversion %, time on task, CSAT) by stage
- Qual notes (pain points, quotes)
Instructions:
1) For each persona/segment, define the canonical journey stages.
2) For each stage:
- Intent, primary tasks, UX surfaces, success metric, drop-off %, time to complete.
- Friction points and root-cause hypotheses.
3) Recommend the 3 highest ROI fixes per persona with expected metric lift.
Output format (markdown):
## Persona: {{Name}} — Journey Map
| Stage | Intent | Tasks | Surfaces | Success Metric | Drop-off | Time | Frictions | Hypotheses | Fixes |
Paste inputs:
Prompt 14: Insight Report Generator
Produce a stakeholder-ready insight report with executive summary, methods, and prioritized recommendations linked to metrics.
Role: Research insight reporter.
Task: Generate a structured insight report from qualitative and quantitative inputs.
Inputs:
- Top themes (from prior prompts)
- Key metrics (NPS, activation rate, retention cohorts)
- Representative quotes and examples
- Business context (OKRs)
Instructions:
1) Executive summary: 5-7 bullets with quantified impact.
2) Methods: sample sizes, segments, channels, timeframe.
3) Findings: 3-5 sections with data-backed evidence and quotes.
4) Recommendations: prioritized with expected metric lift and effort range.
5) Risks & unknowns: what additional data is needed.
Output format (markdown):
# Executive Summary
- {{bullets}}
# Methods
- {{details}}
# Findings
## Finding {{n}}: {{title}}
- Evidence: {{data}}
- Quotes: "{{q1}}", "{{q2}}"
# Recommendations (table)
| priority | recommendation | metric impact | effort | owner | next step |
# Risks & Unknowns
- {{bullets}}
Paste your inputs:
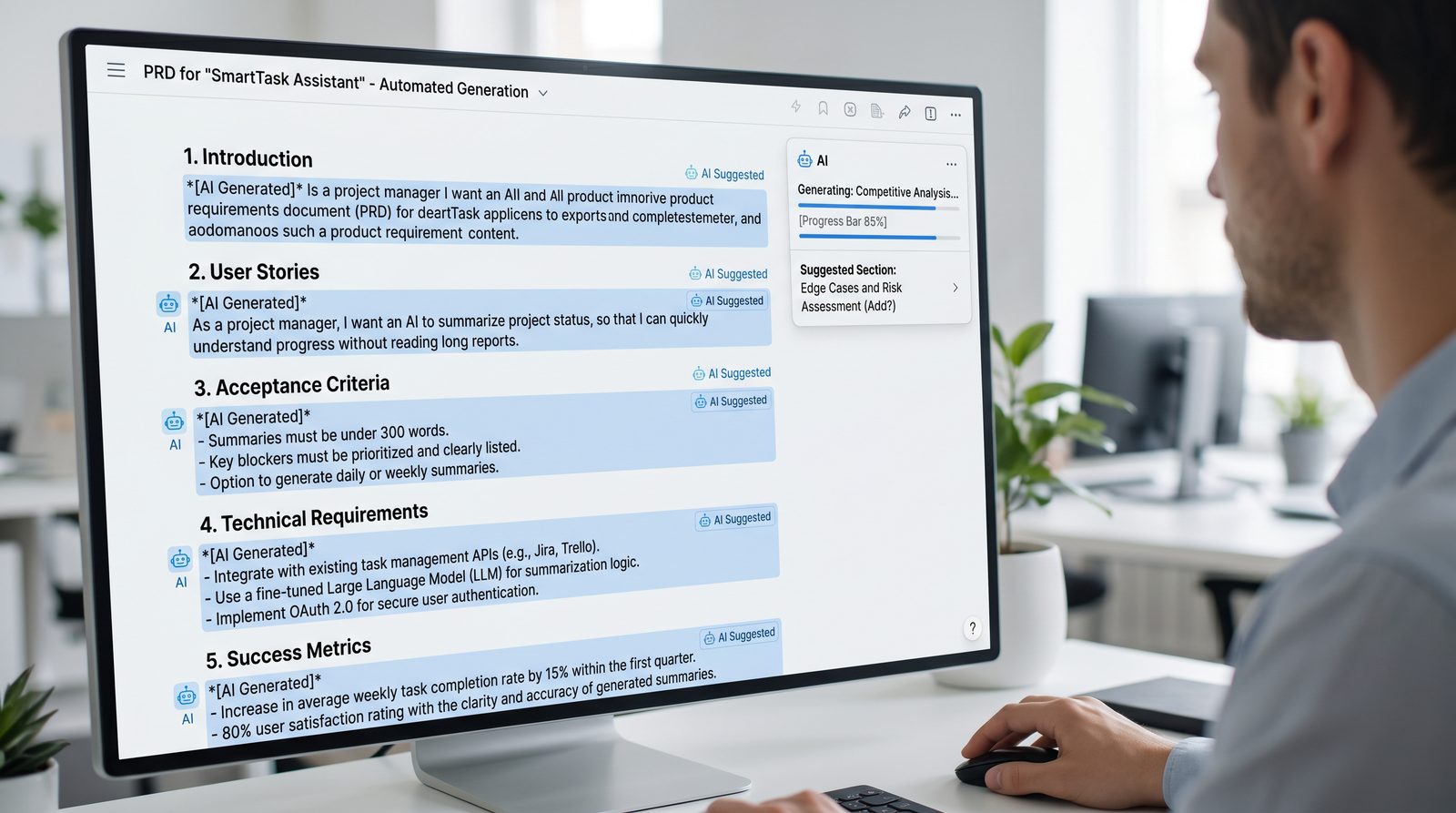
PRD Writing: 8 Prompts
PRDs must be precise, testable, and implementable. These prompts standardize PRD artifacts with schemas engineering and QA can act on immediately.
Prompt 15: PRD Template Generator
Create a tailored PRD template that reflects your organization’s vocabulary and processes.
Role: PRD template architect.
Task: Generate a PRD template calibrated to your team’s process.
Inputs:
- Product domain and audience
- Internal taxonomy (initiative/epic/feature/story)
- Release cadence and gating (e.g., design review, security review)
- Non-functional standards (performance, accessibility, compliance)
- Analytics stack (events, dashboards)
Output: A markdown PRD template with instructional placeholders.
Template:
# Context
- Problem statement:
- Background & research:
- Target personas:
- JTBD:
- Success metrics (primary/guardrail):
# Scope
- In scope:
- Out of scope:
- Dependencies:
- Assumptions:
- Constraints:
# Requirements
## User Stories (table)
| id | as a | I want | so that | acceptance criteria (link to Gherkin) |
## Functional Specifications
- {{feature_1}}:
- description:
- states & flows:
- error handling:
- analytics events:
## Non-Functional Requirements
- Performance:
- Security:
- Accessibility (WCAG):
- Reliability (SLO/SLA):
- Legal/compliance:
# Design
- Wireframes/prototypes:
- Content guidelines:
# Technical
- Architecture overview:
- API changes (link/OpenAPI):
- Data model:
- Feature flags & rollout:
# Analytics & Telemetry
- Events (table):
| event_name | properties | triggered_when | owner |
- Dashboards:
# Risks & Mitigations
- {{bullets}}
# Launch Plan
- Pre-launch checklist:
- Rollout plan:
- Support & training:
- Observability plan:
# Appendix
- Glossary:
- Prior art:
- Open questions:
Now describe your context:
Prompt 16: User Story Writer
Generate high-quality user stories with INVEST properties and direct links to acceptance criteria.
Role: User story writer.
Task: Draft user stories and attach acceptance criteria stubs.
Inputs:
- Feature brief
- Target personas
- Constraints and assumptions
Instructions:
1) Create 5-15 user stories using INVEST.
2) For each, include:
- Story (As a {{persona}}, I want {{capability}}, so that {{benefit}})
- Rationale
- Dependencies
- Acceptance criteria link anchor (#story-{{id}})
Output format:
| id | user story | rationale | dependencies | acceptance_criteria_anchor |
Paste inputs:
Prompt 17: Acceptance Criteria (Gherkin)
Produce testable acceptance criteria in Gherkin syntax mapped to each user story.
Role: QA specification author.
Task: Write Gherkin acceptance criteria per user story.
Inputs:
- User stories table with ids
- Edge cases and constraints
Instructions:
1) For each story id, produce a feature file section with:
- Feature: {{story title}}
- Background: preconditions
- Scenarios (happy path + 3-5 edge cases)
2) Use consistent tags for automation (e.g., @smoke, @regression)
Output:
```gherkin
# story-{{id}}
Feature: {{title}}
Background:
Given {{precondition}}
@smoke
Scenario: {{happy path}}
Given {{...}}
When {{...}}
Then {{...}}
@regression
Scenario: {{edge case 1}}
Given {{...}}
When {{...}}
Then {{...}}
```
Paste user stories and constraints:
Prompt 18: Technical Requirements and Architecture Notes
Enumerate functional and non-functional requirements with architecture considerations and trade-offs.
Role: Systems requirements engineer.
Task: Produce a technical requirements document aligned with the PRD.
Inputs:
- PRD draft
- Existing architecture components
- SLAs/SLOs
- Security/compliance mandates
Instructions:
1) Functional requirements: enumerate APIs, state changes, data flows.
2) Non-functional: latency targets, throughput, availability, durability, privacy.
3) Trade-offs: CAP considerations, consistency models, caching strategies.
4) Observability: logs, metrics, traces, alerts; SLO error budgets.
5) Backward compatibility & migration plan.
Output format (markdown):
# Functional Requirements
- {{FR-1}}: ...
# Non-Functional Requirements
- Latency (P95): {{ms}}
- Availability: {{%}}
- Data retention: {{...}}
# Architecture
- Components diagram (describe)
- Data flows:
- Consistency model:
# Observability
- Metrics:
- Logs:
- Alerts:
# Security & Compliance
- Threat model:
- Controls:
- Data classification:
# Migration & Rollback
- Plan:
- Feature flags:
Paste inputs:
Prompt 19: Edge Case Identification
Systematically enumerate edge cases by state, input, concurrency, and failure modes.
Role: Edge case enumerator.
Task: Identify edge cases across the feature lifecycle.
Inputs:
- Feature description and flows
- External integrations
- Data schemas
Instructions:
1) Consider categories:
- Input validation (range, type, locale)
- State transitions (invalid states)
- Concurrency/race conditions
- Network/timeouts/retries
- Permissions/roles
- Data integrity (duplicates, missing)
- Third-party failures
2) For each, output scenario title, steps, expected behavior, severity.
Output table:
| category | scenario | steps | expected | severity | monitoring |
Paste feature details:
Prompt 20: API Specification Draft (OpenAPI)
Create a first-pass OpenAPI spec aligned to the PRD, including error models and examples.
Role: API spec drafter.
Task: Produce an OpenAPI 3.0 YAML draft for proposed endpoints.
Inputs:
- Endpoint list (methods, paths)
- Request/response models
- Auth model
- Error taxonomy
Instructions:
1) Define components/schemas for all payloads with examples.
2) Standardize error response model: {"code":"string","message":"string","details":{}}
3) Include pagination, filtering, and idempotency conventions where relevant.
Output (YAML):
openapi: 3.0.3
info:
title: {{API Name}}
version: 0.1.0
servers:
- url: https://api.example.com
paths:
/{{resource}}:
get:
summary: List {{resource}}
parameters:
- in: query
name: page
schema: { type: integer, minimum: 1 }
- in: query
name: page_size
schema: { type: integer, minimum: 1, maximum: 100 }
responses:
'200':
description: OK
content:
application/json:
schema:
$ref: '#/components/schemas/{{ResourceList}}'
'400':
$ref: '#/components/responses/Error'
components:
responses:
Error:
description: Error
content:
application/json:
schema:
$ref: '#/components/schemas/Error'
schemas:
Error:
type: object
required: [code, message]
properties:
code: { type: string }
message: { type: string }
details: { type: object }
Paste endpoint details and models:
Prompt 21: Success Metrics Definition
Define primary and guardrail metrics with precise measurements and data quality checks.
Role: Product analytics architect.
Task: Specify success metrics and measurement plans.
Inputs:
- PRD objectives and hypotheses
- Available events and data sources
- Constraints (latency, attribution windows)
Instructions:
1) For each objective, define:
- Primary metric (formula, query stub)
- Guardrails (latency, error rates, support load)
- Instrumentation plan (events/properties)
- Ownership and review cadence
2) Include data quality checks (duplication, missingness thresholds).
Output (markdown + SQL snippets):
## Objective: {{name}}
- Primary Metric: {{definition}}
- Guardrails: {{list}}
- Event Instrumentation:
| event | properties | trigger |
- Ownership: {{team}}; Review: {{cadence}}
SQL stub:
```sql
-- Replace {{...}} with schema names
SELECT
DATE_TRUNC('week', event_time) AS wk,
COUNT(DISTINCT user_id) FILTER (WHERE event_name = '{{success_event}}')::float
/ NULLIF(COUNT(DISTINCT user_id) FILTER (WHERE event_name = '{{exposure_event}}'),0) AS rate
FROM {{events_table}}
WHERE event_time BETWEEN {{start}} AND {{end}}
GROUP BY 1
ORDER BY 1;
```
Paste objectives and events:
Prompt 22: Launch Checklist Builder
Assemble a tailored pre-launch, launch, and post-launch checklist with owners and deadlines.
Role: Launch program manager.
Task: Create a launch checklist with owners, deadlines, and dependencies.
Inputs:
- PRD scope and risk level
- Release date
- Teams involved (Eng, Design, QA, Legal, Support, Sales, Marketing)
- Regional/legal considerations
Output (markdown table):
| phase | task | owner | due | dependency | status | notes |
- Pre-Launch: security review, privacy review, perf test, docs, training, experiment config, feature flags
- Launch: comms, enablement, support runbook, incident plan, observability checks
- Post-Launch: metrics review, bug triage, cleanup, learnings
Paste details:
Stakeholder Communication: 8 Prompts
Clarity and confidence are the currency of influence. These prompts format information to match the expectations of executives, cross-functional partners, and boards.
Prompt 23: Executive Summary Writer
Condense complex proposals into crisp exec-ready summaries tied to business outcomes.
Role: Executive summary writer.
Task: Produce a one-page executive summary for a product initiative.
Inputs:
- Initiative overview
- OKR alignment
- Business impact model (revenue, cost, risk reduction)
- Risks and mitigations
- Asks (resources, decisions)
Output (one page markdown):
# Proposal: {{title}}
- Problem/Opportunity:
- Customer & Market Evidence:
- Proposed Solution:
- Expected Impact: {{revenue/cost/risk}} with assumptions
- Timeline & Milestones:
- Risks & Mitigations:
- Alternatives Considered:
- Asks: {{resources/decisions}}
- Success Metrics:
- Next Steps (decision date):
Paste inputs:
Prompt 24: Sprint Review Narrative
Tell the story of the sprint: goals, outcomes, demo highlights, and next sprint focus.
Role: Sprint review narrator.
Task: Write a structured sprint review narrative.
Inputs:
- Sprint goal(s)
- Completed work (linked to stories)
- Demo highlights (screenshots/links)
- Metrics deltas
- Blockers and learnings
- Next sprint plan
Output (markdown):
# Sprint {{n}} Review
- Goal(s): {{...}}
- What we committed vs delivered: {{%}}
- Highlights:
- {{demo item}} (link)
- Metrics:
- {{metric}}: {{before}} → {{after}} (Δ {{value}})
- Blockers & Resolutions:
- Learnings:
- Next Sprint Focus:
- Risks Carryover:
Paste details:
Prompt 25: Cross-Functional Update
Deliver weekly updates formatted for Eng, Design, GTM, and Support with tailored highlights and asks.
Role: Cross-functional update author.
Task: Produce a weekly update segmented by audience.
Inputs:
- Status by workstream
- Key blockers/dependencies
- Release timelines
- GTM needs (content, training)
- Support readiness
Output (markdown):
# Week of {{date}} — Product Update
## TL;DR (3 bullets)
- {{...}}
## Engineering
- Status:
- Risks:
- Next steps:
- Asks:
## Design
- Status:
- Decisions needed:
- Next steps:
## GTM
- Launch assets:
- Training:
- Enablement gaps:
- Asks:
## Support
- Runbook status:
- Known issues:
- Asks:
## Timeline
- Milestones (table):
| name | date | status |
Paste inputs:
Prompt 26: Decision Document (ADR)
Document decisions with context, alternatives, pros/cons, and decision rationale.
Role: Decision record author.
Task: Write an ADR (Architecture/Approach Decision Record).
Inputs:
- Context and problem statement
- Options considered
- Constraints and goals
- Data/evidence
- Decision and rationale
- Consequences and follow-ups
Output (markdown):
# ADR: {{title}}
- Date: {{YYYY-MM-DD}}
- Status: Proposed | Accepted | Deprecated
- Context:
- Decision:
- Options:
- Option A: {{desc}} — Pros/Cons
- Option B: {{desc}} — Pros/Cons
- Rationale:
- Consequences:
- Follow-ups:
- Owners:
Paste inputs:
Prompt 27: Trade-off Analysis Presentation
Create a structured trade-off analysis ready for slides, including cost/benefit and risk scoring.
Role: Trade-off analyst.
Task: Present trade-offs for 2-4 options.
Inputs:
- Options with: description, estimated impact (revenue/cost/risk), effort, time-to-value, dependencies, risks
- Scoring weights (impact, time-to-value, risk, strategic fit)
Instructions:
1) Normalize scores 0-5, compute weighted score.
2) Plot matrix concept (Impact vs Effort).
3) Provide recommendation and sensitivity to assumptions.
Output (markdown):
## Options (table)
| option | impact | effort | ttv | risk | strategic_fit | weighted_score | notes |
## Analysis
- Assumptions:
- Sensitivity:
- Recommendation:
- Next steps:
Paste options and weights:
Prompt 28: Roadmap Change Communication
Communicate roadmap changes with clear rationale and stakeholder-specific implications.
Role: Change communication author.
Task: Draft a roadmap change announcement.
Inputs:
- Original plan (items affected)
- Change (additions, removals, delays)
- Rationale (data, constraints)
- Stakeholder impacts (customers, sales, support, eng)
- Mitigations and alternatives
- Updated timelines
Output (markdown):
# Roadmap Update — {{date}}
- What changed:
- {{item}}: {{change}}
- Why:
- {{data-backed rationale}}
- Impact by stakeholder:
- Customers: {{...}}
- Sales: {{...}}
- Support: {{...}}
- Engineering: {{...}}
- Mitigations/Alternatives:
- Updated Timeline (table):
| item | old date | new date | status |
- FAQ:
- Q: {{...}}
- A: {{...}}
Paste inputs:
Prompt 29: Metrics Dashboard Narrative
Turn dashboards into narratives: what happened, why, and what we’ll do next.
Role: Metrics storyteller.
Task: Write a narrative around current dashboard metrics.
Inputs:
- Snapshot of KPIs (growth, retention, monetization, quality)
- Anomalies or noteworthy deltas
- Hypotheses and experiments in flight
- External factors (seasonality, pricing changes)
Instructions:
1) Summarize KPI movements (topline, by segment, by cohort).
2) Attribute causes with evidence; flag what’s speculative.
3) Outline actions with expected metric moves and timelines.
Output (markdown):
# KPI Narrative — Week {{YYYY-WW}}
- Topline: {{metric}} up/down {{x%}} — drivers: {{...}}
- Segment/Cohort Highlights:
- Quality & Reliability:
- Experiments:
- Risks & Watchlist:
- Actions & Owners:
- Next check-in:
Paste inputs:
Prompt 30: Board-Ready Product Update
Provide a concise, outcome-led board update with clear asks and risk posture.
Role: Board update writer.
Task: Create a board-ready product update.
Inputs:
- Quarterly objectives and outcomes
- Key wins and misses with metrics
- Strategic bets and progress
- Risks and mitigations
- Near-term priorities
- Asks (budget, headcount, strategic decisions)
Output (markdown):
# Product Update — Board Pack {{Quarter}}
- Objectives & Outcomes (table):
| Objective | Target | Actual | Status | Commentary |
- Strategic Bets:
- {{bet}} — status: {{on track/at risk}}; next milestone: {{date}}
- Product Velocity:
- Throughput: {{...}}; Lead time: {{...}}; Quality: {{...}}
- Customer Impact:
- NPS: {{...}}; Retention: {{...}}; ARR influenced: {{...}}
- Risks & Mitigations:
- {{risk}} — {{mitigation}}
- Priorities Next Quarter:
- {{bullets}}
- Asks:
- {{bullets}}
Paste inputs:
Putting It All Together: A Cohesive Workflow
To maximize value, chain these prompts into a repeatable monthly and quarterly operating rhythm. A suggested cadence:
- Monthly: Run Prompts 11–13 to keep a rolling read on sentiment, topics, and journeys. Feed clusters (Prompt 12) into your backlog for prioritization (Prompt 2).
- Quarterly: Kick off with OKR alignment (Prompt 5), capacity planning (Prompt 4), and dependency mapping (Prompt 3). Synthesize a quarterly plan (Prompt 1) and produce exec summaries (Prompt 23) and ADRs (Prompt 26) for key decisions.
- Before build: Finalize PRD artifacts (Prompts 15–22), ensuring QA coverage (Prompt 17) and API contracts (Prompt 20).
- During delivery: Communicate via sprint narratives (Prompt 24), cross-functional updates (Prompt 25), and metrics narratives (Prompt 29). Document trade-offs (Prompt 27).
- When plans change: Use Prompt 28 to socialize roadmap changes with rationale and mitigations.
- End of quarter: Compile board-level updates (Prompt 30) with outcomes tied tightly to OKRs and metrics (Prompt 21).
Import Tips and Automation Hooks
- Tables to CSV: Most outputs are tables that paste cleanly into Google Sheets or Notion databases. Create a template sheet that matches the output columns for zero-friction ingestion.
- PRD to Jira: Use the story table (Prompt 16) with acceptance criteria anchors (Prompt 17) to generate Jira tickets via CSV import or API scripts.
- OpenAPI to Code: Feed the YAML from Prompt 20 into code generators for server stubs and client SDKs. Keep error models standardized.
- Metrics SQL: The stubs in Prompt 21 should be converted to saved queries in your BI tool. Parameterize date windows and segments.
Calibration Patterns for Reliable Results
Consistency across runs is achieved by standardizing inputs and documenting calibration choices.
- Impact Banding: Predefine numeric impact values for your product (e.g., 3=“North-Star moving”, 2=“Key driver”, 1=“Incremental”, 0.5=“Minor”, 0.25=“Marginal”). Educate teams to use them consistently.
- Effort Estimation: Use t-shirt sizes mapped to person-months (S=1, M=2, L=4, XL=8) for early stage planning. Convert to exact estimates only when needed.
- Confidence: Bind confidence to evidence types (A/B tests, historical analogs, expert judgment) and cap high confidence unless independently validated.
- Risk Buffers: Reserve capacity buffers for interrupts; track how often they are exceeded and refine buffer percentages.
- Persona-Centric Views: In synthesis prompts, always tag segment/persona to preserve the ability to slice insights for targeted planning.
Common Anti-Patterns and How to Avoid Them
| Anti-Pattern | Why it hurts | Fix |
|---|---|---|
| Ambiguous output formats | Breaks automation, yields inconsistent decisions | Use explicit schemas and tables as in each prompt |
| Uncalibrated scoring (RICE/ICE) | Inflated impact, misleading ranks | Adopt impact bands; run sensitivity analysis (Prompt 2) |
| Orphan OKRs | Effort wasted on areas without resourcing or accountability | Run OKR alignment (Prompt 5) and rebalance quarterly |
| PRDs without acceptance tests | Ambiguity in done-ness, rework during QA | Attach Gherkin criteria (Prompt 17) to each story |
| Insights with no actions | Research becomes shelf-ware | Generate insight reports with prioritized recommendations (Prompt 14) |
Security, Privacy, and Data Governance Considerations
When pasting real user data or internal metrics, ensure compliance with your data handling policies. Mask PII, aggregate where possible, and prefer de-identified IDs. For customer transcripts, obtain consent and remove sensitive data before analysis. Consider using a retrieval-augmented generation (RAG) approach with a governed document store to avoid pasting sensitive raw content directly; see
For teams looking to expand their AI capabilities, our guide on How to Build Multi-Agent Workflows with OpenAI Codex provides actionable frameworks for building multi-agent workflows with parallel orchestration that complement the strategies discussed in this article.
for patterns to keep data local while extracting insights.
Example End-to-End Flow
As an illustration, here’s how a PM might run the prompts in a single planning cycle for a B2B SaaS analytics product:
- Import three weeks of support tickets and NPS comments into Prompt 11 to get sentiment and topic deltas. Detect a sustained negative trend on “data freshness.”
- Run Prompt 12 on raw feature requests, revealing a strong cluster around “faster data ingestion” with high ARR at risk.
- Use Prompt 10 (JTBD) to frame the need: “When I prepare weekly reports Monday morning, I want fresh data by 7am so I can make decisions before standups.”
- Create an initial PRD with Prompt 15 focusing on “Fast Ingestion v1,” backed by acceptance criteria (Prompt 17) and API changes (Prompt 20).
- Score the work against other candidates with Prompt 2 (RICE) and fit it into the quarter with Prompt 1 (Quarterly Synthesis), honoring code freeze windows.
- Prepare exec summary (Prompt 23) highlighting expected churn reduction and cost avoidance from reduced support tickets, then run a trade-off analysis (Prompt 27) comparing “streaming ingest” vs “more frequent batch.”
- Socialize plan with cross-functional updates (Prompt 25) and capture an ADR (Prompt 26) for the architecture decision.
- After launch, write a metrics narrative (Prompt 29) with observed improvements and roll insights into the next iteration.
Additional Code Examples for Integration
Below are small snippets to help integrate AI outputs into your tools.
Parse Markdown Table to CSV (JavaScript)
function markdownTableToCSV(md) {
const lines = md.trim().split('\n').filter(l => l.trim() !== '');
const headerIdx = lines.findIndex(l => l.includes('|') && !l.includes('---'));
const headers = lines[headerIdx].split('|').map(s => s.trim()).filter(Boolean);
const rows = [];
for (let i = headerIdx + 2; i < lines.length; i++) {
if (!lines[i].includes('|')) continue;
const cols = lines[i].split('|').map(s => s.trim()).filter(Boolean);
if (cols.length === headers.length) rows.push(cols);
}
const csv = [headers.join(','), ...rows.map(r => r.map(c => `"${c.replace(/"/g, '""')}"`).join(','))].join('\n');
return csv;
}RICE Calculation in Sheets
# Assuming columns:
# Reach (B), Impact (C), Confidence % (D), Effort (E)
# RICE in F:
= (B2 * C2 * (D2/100)) / IF(E2=0, 0.25, E2)Gherkin to Test Case IDs Integration Hint
# Convention: scenario title becomes a slug
# story-ACCT-123 :: Scenario: user can export CSV
# Tooling can parse '# story-ACCT-123' to link to Jira ACCT-123Final Notes
The prompts above are optimized for ChatGPT-5.5’s reasoning and formatting capabilities. Tailor the variables (e.g., impact bands, buffers, risk caps) to your environment, and standardize them across teams for reproducibility. Remember that AI is a force multiplier; the best results come from rigorous inputs and disciplined follow-through. Bookmark this masterclass and integrate it into your PM operating system to compress cycles from weeks to days without sacrificing quality.
For deeper dives into adjacent topics, explore:
For teams looking to expand their AI capabilities, our guide on OpenAI’s Shift from Chat to Agents provides actionable frameworks for how 97.9% internal Codex adoption is reshaping enterprise AI that complement the strategies discussed in this article.
,
For teams looking to expand their AI capabilities, our guide on The AI Agent Delegation Playbook provides actionable frameworks for 25 Codex prompts for delegating complex research and analysis that complement the strategies discussed in this article.
, and
For teams looking to expand their AI capabilities, our guide on 40 ChatGPT-5.5 Prompts for Non-Technical Teams provides actionable frameworks for ChatGPT-5.5 prompts for legal, HR, recruiting, and operations that complement the strategies discussed in this article.
.